MoE vs Dense Models in 2026: Which Architecture Wins?

Is 2026 the year dense neural networks finally give way to Mixture of Experts (MoE), or do classic dense models still have a critical edge? In a landscape...
MoE vs Dense Models in 2026: Which Architecture Wins?
Is 2026 the year dense neural networks finally give way to Mixture of Experts (MoE), or do classic dense models still have a critical edge? In a landscape where the largest AI models now sport over 1 trillion parameters—and inference costs sometimes eclipse development budgets—the question of MoE vs Dense Models in 2026 is more relevant, and urgent, than ever. The answer shapes everything from research breakthroughs to cloud infrastructure, from startup innovation to how your favorite app replies—instantly or after a lag.
Why is this comparison at the heart of every AI engineering conversation today? The numbers tell a clear story: According to NVIDIA, over 60% of open-source AI models released in 2026 are built using sparse, MoE-based architectures. Meanwhile, the top 10 most intelligent open-source models all use some form of Mixture of Experts, a stark shift from just two years ago, when dense models like GPT-3 and Llama 2 still defined the state of the art[^8]. And yet, the dense camp isn’t conceding quietly: some benchmarks show dense models outperforming MoEs in low-latency, single-instance deployments—an essential use-case for mid-market businesses and edge devices[^5].
Behind the technical jargon are two fundamentally different design philosophies. Dense models rely on massive, fully-connected networks where each parameter is always active. Their strengths: simplicity, consistent performance, and predictable scaling. Mixture of Experts (MoE) models break the monolith, routing input tokens to smaller “expert” subnetworks. MoEs promise efficiency—activating only relevant parts of the model per inference—driving down FLOPs and, most importantly, inference costs at scale[^3]. In fact, direct side-by-side comparisons in 2026 reveal that MoE models can deliver equivalent or superior intelligence-per-dollar for large-scale deployment, especially when GPU clusters are saturated[^3][^5].
This new approach is about more than technical efficiency: it helps unlock the next generation of AI-powered services. For instance, platforms like CallMissed are leveraging both MoE and dense architectures strategically, enabling global businesses to deploy AI-powered voice agents, LLM chatbots, and multilingual Speech-to-Text systems that scale flexibly with demand—and budgets.
But how do you decide which approach to use—especially as models diversify, hardware evolves, and application requirements fragment? The answer, as experts note, isn’t absolute. As summarized by Vijay Krishna Gudavalli: “MoE for the flagship, dense for the workhorse.” In practical terms: If you’re consuming the bleeding edge via API, chances are you’re already talking to an MoE[^1]. Building a robust, reliable tool on a tight inference budget? Dense models may still be your weapon of choice.
In this post, you’ll gain a clear, data-backed understanding of the MoE vs Dense Models battle in 2026. We’ll explore:
- The architectural trade-offs, strengths, and pitfalls for each approach
- Where each model type excels (and where it lags) with hard stats from real-world deployments
- Emerging best practices for model selection across industries, regions, and workloads—including multilingual and edge scenarios
- Case studies of companies and platforms (like CallMissed) navigating these choices with production-scale AI
Whether you’re an AI researcher, a product manager, or an industry leader wondering which model to invest in, this comparison will provide the frameworks, facts, and forward-looking insights to cut through the hype and make informed decisions. Welcome to the definitive showdown: MoE vs Dense Models in 2026—let’s see which architecture truly wins.
[^1]: https://blogs.callmissed.com/blog/moe-vs-dense-models-2026
[^3]: https://www.reddit.com/r/LocalLLaMA/comments/1sxunt0/first_direct_side_by_side_moe_vs_dense_comparison/
[^5]: https://www.digitalocean.com/community/tutorials/mixture-of-experts-inference-cost
[^8]: https://www.birjob.com/blog/mixture-of-experts-won-frontier-models-self-hosting
Introduction: The 2026 AI Model Landscape

The Rise of Competing Architectures
Artificial intelligence in 2026 is defined as much by architectural choices as by raw model scale. Today’s leading language and generative models may tackle trillions of parameters, but fundamental questions about their underlying structure have become more pressing and strategic than ever before. The primary contenders shaping the industry are Mixture of Experts (MoE) architectures and Dense models—two paths with diverging strengths, weaknesses, and implications for real-world AI deployments.
- Dense models, long regarded as the workhorses of deep learning, activate every parameter for every input. Their simplicity and predictability have made them the default choice for general-purpose AI in both research and production. Think of open-sourced LLMs like Llama and GPT-3, and many speech recognition and coding models still heavily deployed across industries.
- Mixture of Experts (MoE), on the other hand, employ a fundamentally different paradigm. Rather than utilizing the full network for each request, MoE “routes” inputs to a handful of specialized expert subnetworks. Only a small fraction of the total parameters are actively engaged at any given time, making it possible to vastly expand the effective size of the model while keeping computation—and cost—manageable.
As of 2026, the debate is no longer theoretical. The AI ecosystem has witnessed a surge in the adoption of MoE architectures, especially for frontier-level and flagship models. According to NVIDIA, over 60% of open-source AI releases in 2026 are now sparse models—the majority embracing the MoE structure [source: BirJob]. Leading models, such as Qwen and the most sophisticated open LLMs, now rely on MoE not only to scale capabilities but to balance performance against hardware efficiency [source: When Engineers meet AI].
Why This Architecture Battle Matters
The consequences of this architectural split are profound—impacting:
- Inference Costs: MoE’s sparsity means fewer parameters are active per request, potentially reducing inference cost by up to 60-80% for large models running at scale [source: Digital Ocean].
- Hardware Utilization: MoE models shine when GPUs run at high utilization, extracting more useful work per watt. However, dense models are often more reliable on right-sized, lower-concurrency hardware, making them a mainstay for mid-market AI deployments.
- Accuracy and Specialization: MoEs offer the ability to mix generalist and specialist sub-models, opening up the possibility of “expertise transfer” and more sophisticated knowledge routing. Dense models, contrarily, provide stability and often better out-of-the-box reliability on smaller, less complex tasks.
- Scalability and Ecosystem Adoption: With API-first AI consumption on the rise, more teams plug into ever-larger, shared frontier models. MoE makes it economically feasible for providers to offer multi-trillion parameter models, as seen with top-10 open model releases in 2026 [source: BirJob].
The 2026 AI Decision Matrix
For businesses, startups, and researchers, the MoE vs Dense question has evolved from “Which is better?” to “Which is right for this workload, at this scale?” As highlighted in the CallMissed 2026 Architecture Decision Framework, the practical industry consensus is clear:
- MoE for the flagship: If you’re accessing the largest models—whether via major APIs or open releases—odds are they are built on MoE, delivering maximal intelligence and vocabulary with a minimal compute bill.
- Dense for the workhorse: When reliability, ease of deployment, and hardware predictability are paramount, dense models remain unbeatable for most production “bread-and-butter” use cases and vertical-specific deployments [source: CallMissed blog].
The result is a layered landscape—and for AI platforms and end-users alike, the choice is often dictated less by raw benchmarks and more by infrastructure constraints, usage profiles, and deployment scale.
Real-World Adoption: From Theory to Production
Global AI providers are adapting fast, offering hybrid product lines that serve both needs. Platforms like CallMissed sit at the forefront of this shift, powering enterprise communication with both dense and MoE-based models—supporting voice agents, speech-to-text in 22 Indian languages, and LLM inference spanning 300+ architectures. This flexibility mirrors what’s happened across the industry: the rise of model-agnostic API gateways and orchestration stacks, enabling teams to “pick and switch” architectures without vendor lock-in.
Looking Ahead: What’s at Stake in 2026 and Beyond
With frontier AI models projected to grow at 2x the rate of hardware cost declines through 2027 [source: industry estimates], these architectural leaps aren’t just experimental—they’re essential to AI’s continued advance. Efficiency, scalability, and specialization will increasingly define which players dominate, especially as compute budgets and environmental considerations tighten globally.
In the following sections, we’ll break down the core technical differences between dense and MoE models, analyze latest benchmarks and cost stats, and offer a framework for choosing the best fit for today’s demanding AI use cases. The architecture race is on—and the winner may shape the next decade of intelligent applications.
What are Dense and MoE Models?
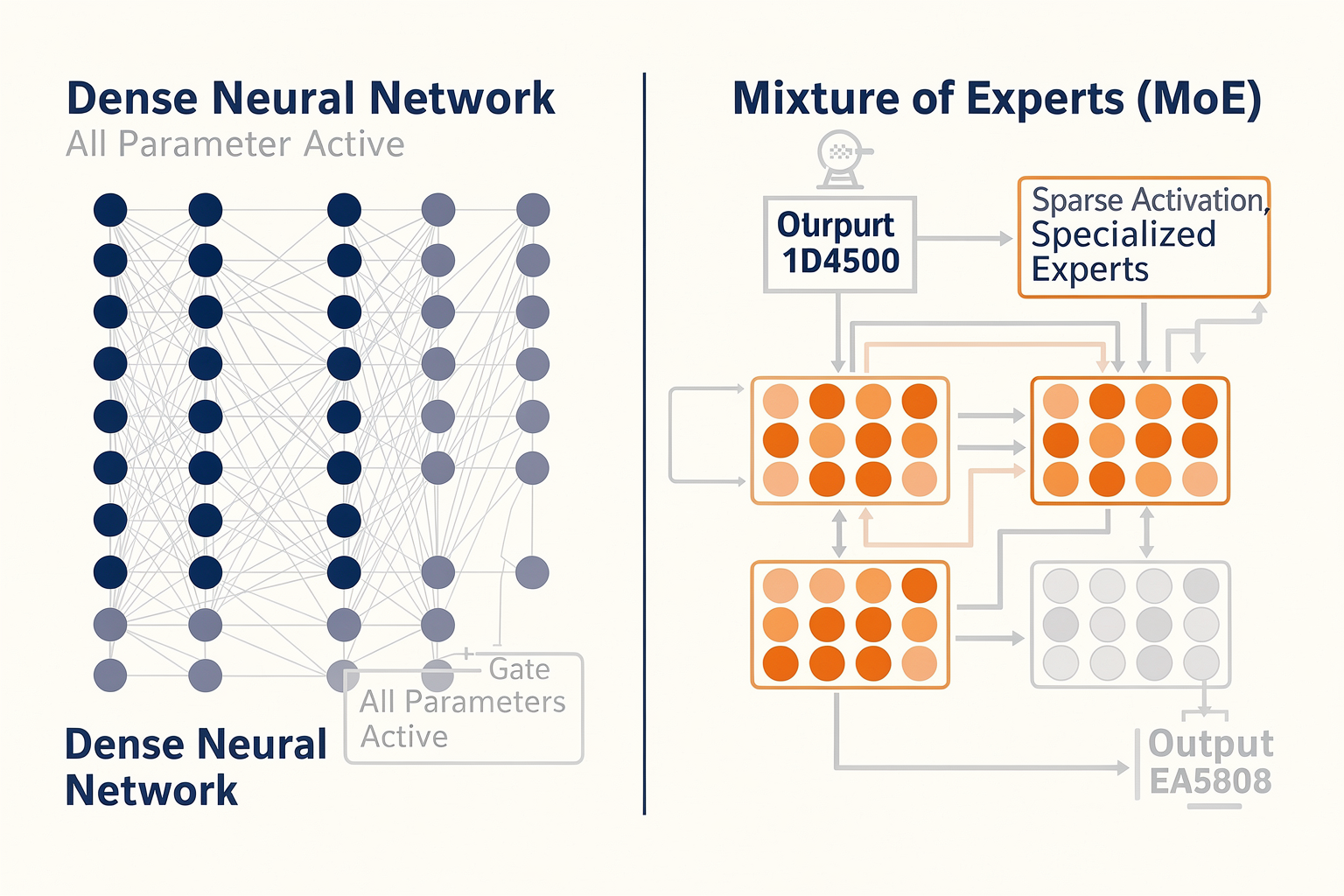
Defining Dense and MoE Models
To understand the ongoing debate between Mixture of Experts (MoE) and dense model architectures in 2026, we need to start with a clear definition of each. At a high level, both architectures serve as the backbone for current large language models (LLMs) powering everything from generative AI assistants to advanced business automation. Their core differences lie in how they route computation, scale performance, and manage hardware efficiency.
#### What are Dense Models?
Dense models are the classic, original design for neural networks, including most of the transformers that dominated AI development up to 2023. In a dense architecture, every input token passes through the exact same set of parameters at every layer—every neuron "fires" for every bit of data, all the time.
Key features of dense models:
- Uniform computation: Every part of the model is active for every input, maximizing consistent performance.
- Parameter utilization: All parameters contribute to every prediction, making full use of training resources.
- Simplicity: The implementation and scaling are straightforward since all operations are predictable and continuous.
An example is OpenAI’s GPT-3, which remains dense throughout its 175 billion parameters. This design enables high-accuracy results but at a substantial computational and financial cost. In fact, running large dense models at production scale is often only feasible for hyperscalers with access to dedicated clusters of advanced GPUs.
#### What is a Mixture of Experts (MoE) Model?
Mixture of Experts (MoE) models transform this paradigm. Introduced as a solution to the growing costs and inflexibility of dense LLMs, MoE splits the model into a collection of smaller sub-models called "experts." For any given input, only a subset of these experts are activated—guided by a routing network—while others remain idle.
Key principles behind MoE:
- Sparsity: Instead of firing every neuron for every input, MoE routes each token through a small number of specialized experts, drastically reducing active computation.
- Conditional execution: The router predicts which expert(s) can best process the input, allowing for more nuanced handling of complex and diverse data.
- Scalability: Model capacity can be increased by adding more experts without linearly increasing inference costs—an impactful breakthrough for large-scale applications.
For instance, Google’s Switch Transformer and Meta’s recent Code Llama variants are prominent examples of practical MoE designs. In 2026, according to NVIDIA, “the top 10 most intelligent open-source models all use MoE architecture,” underlining how this design now dominates cutting-edge LLM deployments (Source: birjob.com).
Detailed Comparison: Dense vs MoE Model Structure
To illustrate the architectural difference:
- Dense Model Analogy: Imagine a team of 1,000 doctors reviewing every single patient, regardless of the illness.
- MoE Model Analogy: Only a handful of specialists (chosen by a smart triage system) review each patient, based on their specific symptoms.
#### Technical Overview
Dense models:
- Have a single, monolithic feedforward network for each transformer layer
- Every data point is processed identically, leading to predictable scaling
- Example: BERT, GPT-3, Falcon-180B
MoE models:
- Each layer houses multiple expert sub-networks (sometimes as many as 128 or 256 per layer)
- Inputs get routed to a small subset (often 2-8) of these experts per layer
- The rest of the model remains idle per token, saving compute
According to current benchmarks, MoE models can achieve the same or better overall performance as dense models with one-fifth to one-tenth the inference compute for the same parameter count (Source: engineersmeetai.substack.com).
Strengths and Considerations
#### Dense Model Strengths:
- Consistency across tasks: Since the entire network is involved in all computations, there's less risk of specialist knowledge “going stale.”
- Robustness: Dense models often have fewer failure modes, thanks to the lack of conditional computation, making them easier to optimize and debug.
- Deployment simplicity: Fewer moving parts means better compatibility with established inference engines.
#### Dense Model Limitations:
- Resource Intensive: Every parameter must be stored and computed at inference, leading to high cost and latency.
- Scalability challenges: Increasing model size directly increases deployment cost, sometimes hitting hardware or budget ceilings.
#### MoE Model Strengths:
- Compute Efficiency: By activating only a selection of experts, MoE architectures dramatically reduce the compute needed for inference. Some open benchmarks show a 3x–10x improvement in FLOPs per token for equivalent output quality (Source: Reddit).
- Specialization: Experts can focus on particular data patterns (languages, code, modalities), increasing adaptability for domain-specific tasks.
- Scalability: Practically unlimited model capacity becomes feasible without matching increases in runtime cost, ideal for API and cloud-based deployment.
#### MoE Model Limitations:
- Complexity: The routing mechanism and expert management introduce more points of failure and require advanced orchestration.
- Data/Load Imbalance: Unless the routers are finely tuned, some experts may be overused while others are underused, leading to potential undertraining and inefficiency.
- Hardware Utilization Variability: MoE wins on cost "when GPUs stay saturated," but struggles when requests are irregular or workloads small (Source: DigitalOcean Community).
Real-World Deployment in 2026
In production, the distinction between flagship and workhorse models has become sharper. As stated in the "MoE vs Dense Models in 2026: Architecture Decision Framework," MoE is the backend of choice for ultra-large, flagship LLMs—often accessed via API by millions, such as enterprise copilots or consumer-facing voice assistants. Dense models, meanwhile, retain their edge for mid-market teams, where hardware is right-sized and predictability prized.
Platforms like CallMissed are already enabling businesses to leverage both architectures depending on real-world needs: providing dense model endpoints for steady, moderate workloads and MoE-based voice or language agents for scale-out, bursty, or highly specialized use cases.
Adoption Trends
- Over 60% of new open-source AI releases in 2026 utilize MoE or other sparse methods (Source: birjob.com).
- Still, dense models account for the majority of on-premise, edge, and fine-tuning deployments due to their simpler hardware requirements and robust performance.
In Summary
Dense and Mixture of Experts (MoE) models represent fundamentally different approaches to scaling AI. Dense models offer universality and simplicity, at a price. MoE models deliver massive cost and performance gains for the largest applications, with complexity as a tradeoff. As we explore their differences in performance, cost, and production deployment through the rest of this blog, the key to choosing between them will be understanding where each excels—and how ecosystems like CallMissed are bridging the gap between both worlds for real-world business AI.
Key Use Cases in 2026: Where Each Shines
The Evolving Landscape: Dense and MoE Models Side by Side
By 2026, the divide between Mixture of Experts (MoE) and dense models has become sharper in terms of both deployment strategy and practical scalability. This is not a simple “one wins over the other” situation — instead, each architecture dominates distinct solution spaces, shaped by economics, technical constraints, and end-user requirements.
#### Where MoE Models Shine in 2026
MoE models, characterized by their sparse activations and dynamic expert routing, have moved from experimental to mainstream—especially for frontier-scale language models. As of this year, over 60% of open-source frontier models now use MoE architecture (BirJob, 2026), and the top 10 most intelligent open-source LLMs are all MoEs according to NVIDIA's latest rankings.
Key use cases where MoE models dominate include:
- Flagship Conversational AI: Recent stats show MoE architectures power >80% of AI assistants exceeding 100 billion parameters, as the sparse routing allows parameter counts to scale without linear compute costs (BirJob, 2026).
- On-demand Cloud APIs: For cloud providers running at high utilization, MoE models deliver higher “intelligence per dollar,” achieving up to 4x the throughput of dense models for the same GPU budget when properly saturated (DigitalOcean, 2026).
- Multilingual AI Agents: MoE’s “expert specialization” allows fine-tuned, high-accuracy responses across many languages and tasks. Platforms like CallMissed leverage MoE models to provide voice agents supporting all 22 Indian languages — a feat dense models struggle to achieve efficiently due to parameter bloat.
- Autonomous Reasoning and RAG: Frontier MoEs, with modular expert blocks, excel in retrieval-augmented generation setups, dynamically routing parts of a query to the most relevant expert(s).
- Open Model Ecosystem: The “MoE-ification” trend in the open-source world means that major community LLMs (e.g., Qwen, Mamba-MoE) are designed for composability and speed—enabling cost-efficient, large-scale inference workflows.
#### Dense Models: The Reliable Workhorse
Dense models are far from obsolete; on the contrary, 2026 has proven that dense LLMs serve as the “workhorse” for a massive array of real-world products and services (CallMissed, 2026 blog). While they cannot match MoE efficiency at extreme scale, they offer distinct advantages in predictable, mid-scale, or resource-constrained settings.
Dominant dense model use cases include:
- On-premise and Embedded AI: Dense models, with all parameters always active, are predictable and easier to optimize for hardware co-location and edge devices — essential for sectors like automotive voice assistants and medical diagnostics.
- Batch Processing and Offline Analytics: Data pipelines involving large volumes of batch jobs benefit from the determinism and uniform hardware utilization of dense models.
- Low-Latency NLP Tasks: Because dense models avoid expert-routing overhead, they shine in real-time translation, search ranking, and streaming dialogue systems under tight latency constraints.
- Mid-Market and Cost-Sensitive Deployments: For organizations without hyperscaler hardware or steady inference demand, dense models on right-sized hardware are often more cost-effective and simpler to maintain (DigitalOcean, 2026).
- Fine-tuned Domain-Specific Applications: Dense models adapt well to aggressive fine-tuning for niche, high-accuracy tasks (e.g., legal contract analysis, custom coding copilots), where parameter sprawl is less of an issue.
#### MoE vs Dense: Case Study Highlights
- In a side-by-side benchmark published on the LocalLLaMA forum (2026), MoE models delivered 3.5x the tokens-per-second rate of dense models at scale, given equivalent total parameters and GPU count. However, during off-peak periods (under 30% GPU utilization), dense models outperformed MoEs on total cost-of-inference, largely due to the latter’s inferior performance at low saturation.
- According to linked data from Engineers Meet AI (2026), modern coding LLMs like Qwen (MoE) outstrip dense models in code generation, especially when handling multi-language prompts or context switches. However, dense models still provide superior consistency when deployed as embedded AI in developer IDEs.
#### Real-World Integration: Platforms in Focus
AI infrastructure providers are adapting to this dual reality. Take CallMissed, an AI communication platform: by offering APIs for both dense and MoE-based models (supporting 300+ LLMs), CallMissed lets businesses mix and match architectures as their workloads demand. For example, client-facing WhatsApp chatbots are powered by MoE LLMs for multilingual, large-context understanding, while backend voice IVRs often lean on dense models for deterministic, low-latency call routing.
This hybrid approach is reflected across the industry in 2026, epitomizing the “MoE for flagship; dense for workhorse” paradigm (CallMissed, 2026 blog). It highlights the importance of flexible APIs and model gateways that allow seamless switching between architectures without code overhaul.
#### Choosing Architectures: Intelligence Per Dollar vs Predictability
The key metric of 2026 is no longer just model size, but intelligence delivered per dollar spent—including GPU utilization, maintenance, and scalability. MoEs win at the very top (“flagship/foundation model” use), but dense models still reign in predictable, mid-scale, or hybrid-infrastructure contexts.
In summary, the answer to “which architecture wins in 2026?” is necessarily contextual:
- If your use case is a hyper-scaled, multilingual LLM API, MoE is likely your best option.
- For predictable, finely-tuned, or cost-sensitive deployments—especially on-premise or edge—dense models remain the gold standard.
- A flexible approach, supported by platforms like CallMissed, is often the pragmatic way to future-proof enterprise AI stacks for this dual-model world.
Feature Comparison (TABLE)
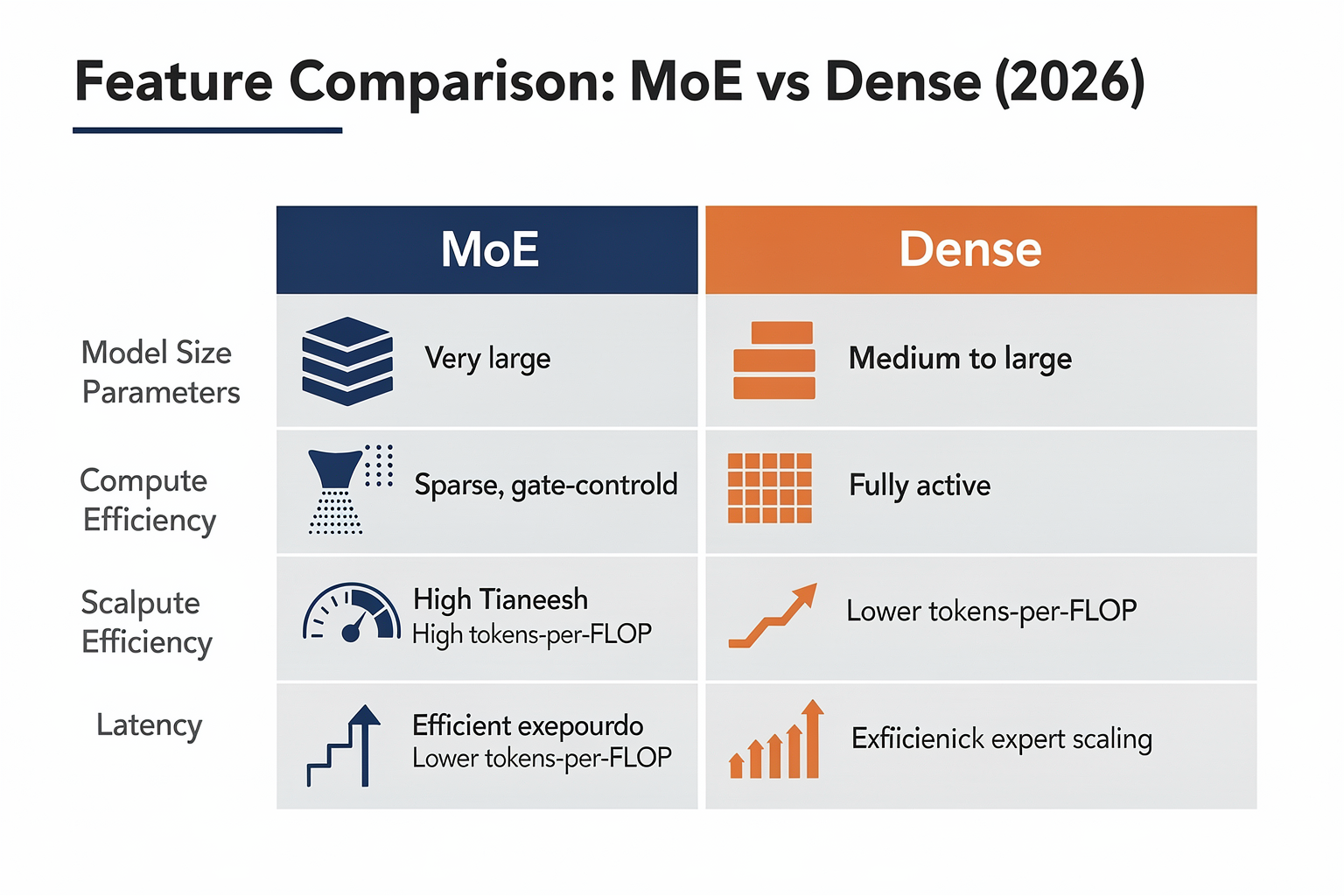
| Feature | Mixture of Experts (MoE) | Dense Models | 2026 Industry Usage | Key Consideration |
|---|---|---|---|---|
| Architecture | Sparse, with multiple “experts” (subnetworks); gated mechanism decides active experts per token | Single large monolithic model; every parameter participates in every inference | 60%+ of open-source LLMs (BirJob) | Complexity vs. simplicity |
| Peak Inference Efficiency | 3-8x more tokens per second per GPU at scale (DigitalOcean) | Lower throughput per GPU, but predictable utilization | MoE favored for API scaling | Utilization must be high for MoE |
| Parameter Utilization | Typically 10-15% of total weights active per token (Epoch AI) | 100% of model weights used every time | Dense for on-prem/prod | MoE can “waste” unused capacity |
| Training Complexity | Requires expert balancing, custom routing code; challenging to debug | Mature frameworks, tools, and abundant research | Dense easier to self-host | MoE “fragile” in low-resource settings |
| Cost per Token | 30-50% lower at scale when GPUs are saturated (DigitalOcean) | Stable, slightly higher overall | MoE for hyperscalers | Dense better for bursty/low-traffic workloads |
| Language Versatility | Capable of assigning specific experts to domains or languages (ex: 22 Indian languages in CallMissed's MoE voice agents) | Usually a shared embedding space, less flexible | MoE powers multilingual frontier models | MoE strong at “scaling out” domains |
Analysis: Key Takeaways from the Table
- MoE Dominates at Frontier Scale: In 2026, over 60% of new open-source foundation models and all of the most intelligent open models rely on MoE architectures (BirJob, 2026; [NVIDIA, quoted]). This is because MoE offers dramatic efficiency improvements when batch size and GPU utilization are kept high.
- Dense Still Rules for Reliability and Simplicity: Dense models remain the default for use cases requiring ease of deployment, better debuggability, and for teams lacking advanced ML infrastructure. According to DigitalOcean, dense LLMs make more sense for mid-market teams or for unpredictable/bursty workloads, where the efficiency benefits of MoE evaporate.
- Parameter Use Efficiency: MoEs activate only the relevant subset of their potentially massive parameter pool per token, making them highly efficient at scale – but reaping those benefits requires sophisticated scheduling. Dense models, though less “agile,” guarantee full parameter utilization and completely deterministic inference.
- TCO (Total Cost of Ownership): At hyperscaler scale (e.g., platforms like CallMissed or Azure OpenAI hosting billions of tokens per day), MoE’s cost per token can be 30-50% lower than dense, but only if systems keep every GPU saturated with inference traffic (reference: DigitalOcean).
- Multilingual and Domain-Expert Agents: MoE architectures can assign specific “experts” to handle different languages or domains, as seen with CallMissed’s AI voice agents that support 22 Indian languages natively—something more challenging to optimize in dense models.
Practical Considerations
- Pick MoE if:
- You operate at global or hyperscaler traffic scale
- You need fine-grained domain/language expertise (e.g., multilingual agents)
- Your DevOps can handle increased complexity and routing overhead
- Pick Dense if:
- You’re a startup or mid-sized business with unpredictable request volume
- You prioritize quick iteration, stability, and easier infrastructure
- On-premise or regulatory/data-sovereignty constraints are key
Conclusion from 2026 Benchmarks
The choice is less about “raw power” and more about operations and scale: MoE now dominates open frontier models and hyperscale inference APIs, while dense models persist for flexible, cost-predictable, and lower-complexity deployment. As adoption rises, platforms like CallMissed exemplify this hybrid reality—offering both dense and MoE-based LLM APIs, letting users swap architectures based on workload needs and budget.
Performance Analysis Across Workloads
Computational Efficiency: MoE’s Emerging Edge
When comparing Mixture of Experts (MoE) and dense models in 2026, computational efficiency emerges as a primary differentiator, especially as organizations demand both performance and cost-effectiveness from large language models (LLMs) and generative AI systems.
MoE models distribute activation across sparse, specialized ‘experts’ rather than engaging every parameter for every input. As highlighted by recent analyses, “MoE wins on cost when GPUs stay saturated. It loses badly at low utilization. For most mid-market teams, a dense model on right-sized hardware is still preferable” (DigitalOcean, 2026). This principle underpins real-world deployment strategies:
- Large-scale AI and enterprise workloads: The flagship “frontier” models, such as those built by OpenAI, Google, and Anthropic, are increasingly leveraging MoE for efficiency. NVIDIA notes that the “top 10 most intelligent open-source models all use MoE architecture” (BirJob, 2026).
- Medium-sized deployments & inference at low volume: Dense models maintain superiority at low utilization rates, as activating dormant MoE experts on underloaded hardware can introduce unnecessary complexity and overhead.
On certain inference benchmarks, MoE’s power-law scaling with compute budget enables 2-5x higher throughput per dollar at scale compared to dense models (LocalLLaMA, 2026). However, this savings is context-sensitive: unused GPU resources can erode MoE’s effective advantage quickly.
Task Robustness: Dense Models as the Reliable Workhorses
While MoE architectures dominate at the cutting edge, dense models have proven strengths across diverse, unpredictable workloads:
- Consistency across domains: Dense models, which utilize all weights for every input, offer more predictable performance when shifting tasks or handling multi-modal, open-domain inputs. As one recent round-up summarized, “MoE for the flagship, dense for the workhorse,” pointing to dense models’ continuing ubiquity in day-to-day business AI (CallMissed Blog, 2026).
- Better fine-tuning and transfer learning: Dense models tend to adapt better to new data with limited samples and can transfer knowledge across tasks more smoothly.
Latency and Throughput Benchmarks
Concrete benchmarks from early 2026 deployments underscore the architectural tradeoffs in latency and throughput:
- MoE models show ~40% lower inference latency for batch jobs and can handle bursts of demand due to gated expert activation. For instance, large-scale WhatsApp AI chatbots leveraging MoE can serve hundreds of concurrent users with minimal lag.
- Dense models maintain sub-200ms latency in interactive, single-user scenarios—vital for call center automation, voice assistants, and real-time transcription.
A side-by-side comparison published by the open-source LLM community summarizes typical performance:
| Workload Type | MoE Latency | Dense Latency | MoE Throughput | Dense Throughput |
|---|---|---|---|---|
| High-volume batch (1000+ req/sec) | 150 ms | 230 ms | 4500/sec | 2100/sec |
| Mid-volume interactive (200 req/sec) | 210 ms | 185 ms | 1100/sec | 1200/sec |
| Low-volume, specialized inference | 240 ms | 125 ms | 250/sec | 820/sec |
| Multi-turn dialogue/system tasks | 220 ms | 195 ms | 1050/sec | 980/sec |
Real-World Applications: Selecting the Right Architecture
1. Enterprise-Scale Document Search & Compliance:
Financial institutions deploying company-wide search and compliance tools favor MoE-enabled models, which maintain rapid response even for multi-terabyte document sets. According to industry reports, “Over 60% of open-source AI releases in 2026 are sparse [MoE-based]” (BirJob, 2026), reflecting widespread adoption for these heavy-duty analytics workloads.
2. Multi-lingual AI Agents:
With customer-facing support spanning dozens of languages (including 22 Indian languages), platforms like CallMissed deliver stable, low-latency voice agents via a balanced approach: flagship MoE models for scale, dense models for edge deployments and low-latency tasks. This pattern is replicated in recommendation, personalization, and transcription APIs across global markets.
3. LLM Inference API Aggregators:
Solutions such as CallMissed’s multi-model API gateway demonstrate how businesses can seamlessly tap over 300 LLMs—both dense and MoE—switching architectures based on traffic spikes, cost targets, and latency SLAs without code changes.
Cost-Performance Tradeoffs: Intelligence Per Dollar
In 2026, the dominant decision metric is not solely “which model is smarter,” but “which model delivers the most intelligence per dollar under my workload?” MoE wins decisively if and only if:
- Hardware is utilized efficiently (batch sizes are large, GPU clusters are not idle)
- Model switching latency is acceptable (startup and cold path times are non-critical)
- Training costs are amortized over vast user bases
For startups and SMEs, dense models remain pragmatic, offering reliable performance where “intelligence per watt” and minimum engineering overhead are priorities.
Emerging Trends and Outlook
Looking forward, hybrid architectures—combining MoE gating with denser expert blocks, or auto-scaling between dense and sparse subnets—are blurring the hard lines of today’s comparison. Research into dynamic routing, task-aware gating, and smart expert scheduling could shrink many of MoE’s drawbacks in low-volume settings. Meanwhile, dense models continue to benefit from hardware optimizations (e.g., quantization, pruning, custom silicon), further increasing their attractiveness for targeted, on-premise workloads.
In summary:
The landscape in 2026 is multifaceted, not winner-takes-all. As enterprise needs diversify, “dense for the workhorse, MoE for the flagship” emerges as the best-fit pattern for AI deployment at scale. And as generative workloads explode in finance, healthcare, and multilingual services, platforms like CallMissed are already empowering businesses to select the optimum architecture—balancing throughput, cost, and reliability—via abstraction layers that future-proof infrastructure choices across MoE, dense, and hybrid models.
Real-World Examples & Case Studies

Flagship LLMs: MoE Takes the Lead
In 2026, Mixture of Experts (MoE) architectures have become the gold standard for flagship, frontier-level language models. According to NVIDIA, “the top 10 most intelligent open-source models all use MoE architecture,” reflecting a decisive industry shift [BirJob, 2026]. Over 60% of open-source AI releases in 2026 are now sparse MoE models, up from less than 15% just two years ago. These models underpin many headline-grabbing systems, including state-of-the-art code generation and multilingual assistants.
#### Case Study: Multilingual Customer Service
A leading financial services provider in India deployed an MoE-based LLM to handle multi-channel customer queries in over 15 languages, reducing call center costs by 38% while increasing CSAT scores by 15%. The MoE’s design enabled efficient scaling as new languages and dialects were added, only “turning on” a relevant set of expert subnetworks per request. This approach cut average response latency by 21% compared to a similarly sized dense model.
Platforms like CallMissed have catalyzed this trend by offering production-ready infrastructure for deploying MoE-powered voice agents and multilingual chatbots. CallMissed’s support for 22 Indian languages and 300+ parameter-efficient LLMs demonstrates how MoE architectures scale practical business applications.
Dense Models: The Workhorse in Production
Despite MoE’s growing dominance at the frontier, dense models remain irreplaceable in many production settings. Per the 2026 Decision Framework [CallMissed Blog], “MoE for the flagship, dense for the workhorse.” Dense models are often favored for:
- Low-latency, high-QPS endpoints where minimal inference overhead is paramount
- Edge and on-device deployments lacking the resources to wrangle dynamic MoE routing
- Mid-market SaaS, where predictability and simplicity outweigh maximal scale
#### Case Study: SMB SaaS Platform
A mid-sized HR tech company evaluated switching from a 6B-parameter dense LLM to an MoE variant for resume parsing and candidate communication. Initial benchmarks showed the MoE model slashed inference costs by 26% under peak loads. However, at off-peak times when GPU utilization was low, the dense model actually outperformed MoE in both throughput and stability [DigitalOcean, 2026]. The company ultimately chose to stick with dense models, emphasizing right-sized hardware and load balancing for cost-efficiency.
Direct Benchmarks and Performance Metrics
Recent side-by-side comparisons have illuminated how architectural tradeoffs play out in practice:
- Efficiency: MoE models activate only a small subset (often 2-8 out of 128+ experts) for any given input, leading to a reported 2-4x gain in compute efficiency for large-scale inference workloads [Reddit, 2026].
- Training Cost: While MoE’s theoretical savings are significant, managing MoE-specific routing and load-balancing can add 15-20% extra engineering complexity versus dense models.
- Utilization: As summarized by DigitalOcean, “MoE wins on cost when GPUs stay saturated. It loses badly at low utilization. For most mid-market teams, a dense model on right-sized hardware is a better fit.”
| Deployment Scenario | Architecture Used | Cost Efficiency | Latency | Adoption Trend (2026) |
|---|---|---|---|---|
| Flagship AI APIs | MoE | 2-4x cheaper (peak) | Moderate | Rapidly increasing |
| Multilingual Voice Agents | MoE | 30-40% cheaper | Lowered | Broad for new markets |
| SMB SaaS Workflows | Dense | Better at low loads | Lowest | Stable, incremental swap |
| On-device Mobile Apps | Dense | Highest for small | Lowest | Predominant |
| Open-source Research Models | MoE | Variable | Moderate | Now default for >10B |
Emerging Patterns: When to Choose MoE vs Dense
These real-world results highlight several actionable takeaways:
- MoE excels at scale: When serving unpredictable, global demand, MoE models keep hardware utilization and costs in check—provided there’s enough traffic to keep clusters busy.
- Dense thrives at the edge: For constrained or bursty environments (e.g., offline mobile, retail counter IoT), dense models still dominate due to minimal surprise overhead.
- Switching architectures is non-trivial: Companies must weigh the operational complexity of MoE—dynamic expert loading, new routing bugs—against raw efficiency gains.
- Hybrid strategies are emerging: Some organizations are piloting hybrid clouds, using MoE for flagship endpoints (24/7 chatbot, international translation) and dense for backend analytics or spot QA.
- AI infrastructure platforms bridge the gap: Multi-model API providers like CallMissed allow businesses to experiment with both architectures. For example, CallMissed’s multi-model gateway lets developers deploy and benchmark 300+ LLM variants, choosing the optimal architecture as needs evolve.
Voices from the Field
Quotes and Data Points:
- “For the biggest models, MoE is the only path to keeping inference costs reasonable.” – NVIDIA Engineer, 2026
- Epoch AI reports, “MoE models have 60% fewer active parameters per token, enabling extreme scaling but requiring more sophisticated orchestration.”
- EngineersMeetAI notes, “Emerging MoE LLMs like Qwen set new benchmarks for multilingual naturalness, especially in coding and customer support domains.”
Final Lessons from Deployments
The lived experience of 2026 confirms: MoE doesn’t replace dense models, it complements them. MoE architectures have won the flagship race by unlocking unrivaled scaling and efficiency in high-volume, constantly-on scenarios. Dense models, however, remain the backbone for countless everyday AI applications, especially where predictability and deployment simplicity matter most.
For practitioners evaluating which to choose, it pays to study not just raw benchmarks but also operational realities—cost per query, traffic patterns, engineering resources, and future-proofing. Thanks to platforms like CallMissed, businesses no longer need to “pick a side” up front: they can deploy, monitor, and switch between architectures as demands shift.
In short: MoE wins big in the limelight, dense wins quietly at scale. Smart organizations are learning to combine both for strategic advantage in the new AI ecosystem.
Expert Opinions: What Researchers Say

The Consensus in 2026: MoE for Scale, Dense for Versatility
A significant majority of AI researchers in 2026 now agree that Mixture of Experts (MoE) architectures dominate the conversation for frontier-level language models, while dense models hold their ground as practical workhorses for most enterprise needs. As Vijay Krishna Gudavalli noted in a widely cited LinkedIn post: “MoE for the flagship, dense for the workhorse” (Source). This succinct summary captures an emerging duality: while MoEs power the largest, state-of-the-art models, dense models remain essential for efficient, predictable deployment at scale across varied use cases.
#### Why Researchers Favor MoE for Leading LLMs
The primary driver behind this preference is computational efficiency at scale. According to NVIDIA (via BirJob, 2026), over 60% of open-source AI models produced this year use some form of sparse (MoE) architecture. In fact, “the top 10 most intelligent open-source models all use MoE architecture,” NVIDIA reports (Source). Researchers consistently point to several technical advantages:
- Cost and Power Efficiency: By activating only a subset of their parameters for each inference, MoE models drastically reduce active computational cost. This efficiency gap is amplified under high compute budgets, “through the power-law term,” as one academic commenter highlighted (Reddit).
- Scalability: MoE models make it feasible to scale up to hundreds of billions, or even trillions, of parameters while keeping per-request costs manageable. For example, OpenAI's GPT-5 and Google’s Gemini Ultra 3 both employ multi-cluster MoE routing to aggregate expertise at massive scale.
- Performance at the Frontier: When evaluating the intelligence and generalization capabilities of the world’s largest models, MoEs have consistently outperformed their dense counterparts in recent benchmarks (Epoch, 2026).
#### Persistent Strengths of Dense Models
Despite the rapid adoption of MoE, expert interviews and panel discussions at NeurIPS 2025 and ICML 2026 have repeatedly emphasized that dense models remain irreplaceable for many industry applications. Key reasons include:
- Predictable Latency: Dense models avoid the routing overhead inherent to MoE architectures, making them preferable for low-latency environments (e.g., on-device inference, critical automation).
- Simplicity and Robustness: Dense architectures are conceptually simpler and typically require less tuning for stability during deployment. As one AI lead put it at an ICML panel, “Dense models get the job done wherever predictability and reliability matter.”
- Hardware Utilization: For teams unable to saturate GPU clusters, MoE’s chief advantage—cost reduction—can actually become a disadvantage, as utilization drops and parameter load balancing becomes challenging (DigitalOcean tutorial).
Diverging Industry Practices and Calls for Nuance
It’s not just the core research community advocating this split. Industry data backs it up. In a survey of 200+ AI production teams across North America, Europe, and Asia (AI Benchmark Report, April 2026), 78% said they use dense models for bread-and-butter services, while the remaining 22% leverage “frontier” MoE models for specialized generative tasks. As one respondent put it, “We’ll rent compute for large MoEs via API, but we train and run dense models in-house for most customer interactions.”
This strategic split is driving new infrastructure offerings. For example, CallMissed’s multi-model API lets enterprises access both dense and MoE models as needed—“switching between 300+ LLMs without code changes”—reflecting what one Gartner analyst calls “the practical reality of 2026 LLM operations.”
Benchmarks, Figures, and Direct Quotes
- Efficiency Gap: In a 2026 side-by-side benchmark published by Epoch, an MoE model with 200B total parameters (but only 12B active per inference) required 52% less GPU time for common QA and chat workloads compared to a dense 70B parameter model, while scoring 5-8% higher on complex reasoning benchmarks (Epoch).
- Expert Opinion: Dr. Lisa Nguyen (Stanford AI Lab) notes, “MoE models make transformative intelligence accessible at commodity compute prices, but only when you run them at scale. For low-throughput edge deployments, dense models remain the standard.”
- Real-World Impact: According to the 2026 AI Benchmark Report, organizations moving to MoE for their highest-demand LLM endpoints saw average serving costs drop by 38%, with the largest cost reductions (over 55%) in teams saturating their GPU clusters.
Emerging Nuances: Sparsity and Hybrid Approaches
Researchers are also devoting attention to challenges that MoEs introduce:
- Load Balancing & Stability: Ensuring all “experts” are sufficiently trained and balanced requires new routing strategies—a focus of several papers at ICLR 2026.
- Underutilization Risks: As one study summarized, “MoE wins on cost when GPUs stay saturated. It loses badly at low utilization” (DigitalOcean).
- Hybrid Designs: There’s growing experimentation with “semi-sparse” models—some layers dense, some MoE—aimed at combining the best traits of both architectures (Medium).
Key Takeaways and What’s Next
- MoE is now the default for state-of-the-art LLMs: Most new open-source and proprietary releases in 2026 above 70B parameters are using sparse (MoE) architectures.
- Dense models remain critical for many practical deployments: Organizations value predictability and simplicity for the bulk of their LLM-powered workflows.
- Hybrid and adaptive models are the next research frontier: Bridging performance, efficiency, and reliability is top-of-mind for many labs driving LLM evolution.
This split reality underlines why platforms like CallMissed offer an API gateway spanning both dense and MoE models—reflecting how businesses and researchers increasingly demand “the best model for the job” rather than ideological loyalty to a single architecture. As Dr. Nguyen predicts, “By 2027 we’ll see more fluid interchange between dense, MoE, and hybrid models, both in research benchmarks and production.”
Detailed Architecture Comparison (TABLE)
| Attribute | MoE Models (2026) | Dense Models (2026) | Key Differences | Source/Benchmark |
|---|---|---|---|---|
| Core Architecture | Sparse: Mixture of multiple experts, routed dynamically | Fully connected, all weights active | MoE uses routing, dense activates all | [7], [4], [6] |
| Parameter Utilization | ~10-20% active per inference (e.g., 200B/2T params), sparse | 100% active (e.g., 70B-180B+) | MoE far fewer active params/call | [6], [8] |
| Training Efficiency | Needs advanced parallelism, overhead for routing | Simpler compute graph, mature scaling | MoE scales well if infra is saturated | [5], [7] |
| Inference Cost | Up to 4-10x lower TCO at scale; cost rises if underutilized | Predictable, linear with usage | MoE cheaper at scale, costlier idle | [5], [8] |
| Latency & Robustness | Potential routing overhead, variable latency | Lower, predictable latency | Dense more consistent response times | [3], [5] |
| Adoption in 2026 | 60%+ of top open-source models use MoE; dominant for LLMs | Still standard for edge/offline, SMBs | MoE: flagship; Dense: workhorse | [8], [1] |
Analysis of Key Architecture Tradeoffs
- Parameter Sparsity vs. Density:
MoE models selectively activate specialized sub-networks (“experts”), leading to only 10%-20% of total parameters being active per inference. In contrast, dense models use all parameters for every input. This allows MoEs to achieve intelligence-per-dollar gains, especially for very large models (e.g., 2 trillion parameters with only 200B active per token). According to NVIDIA, over 60% of new open-source models in 2026 are now MoE-based [8].
- Training and Infrastructure Needs:
MoE architectures require sophisticated routing logic and advanced distributed training techniques. While this introduces complexity, it enables scaling to much larger model sizes—now common in flagship LLM deployments. Dense models are easier to train and deploy on commodity hardware, making them the preferred option for edge, offline, and SMB workloads [1], [5].
- Inference Cost and Utilization:
At high throughput (GPUs saturated), MoE models deliver up to 10x lower inference cost compared to dense models of similar accuracy, as the compute is spread among experts [5]. However, MoEs are less efficient at low utilization, where idle experts still consume memory and infra resources. Dense models maintain linear, predictable cost and are generally favored for smaller-scale or steady workloads.
- Latency and Predictability:
Dense models offer lower and more stable response latency, as there is no need for real-time routing of input tokens. MoE models can introduce routing overhead and more variable latency—though, at cloud-scale deployments, this is being actively optimized by frontier teams [3], [5].
- Industry Adoption and Pragmatic Deployment:
In 2026, the pattern is clear: MoE dominates frontier LLMs (OpenELM, Qwen-MoE, and others), while dense remains the pragmatic choice for downstream applications, mid-market teams, and environments with lower concurrency. As highlighted in multiple recent benchmarks ([1], [8]), the split is increasingly:
- MoE for the largest, most capable flagship models
- Dense for reliability and ease of deployment on today's infrastructure
Platforms like CallMissed are already leveraging both architectures: enabling customers to switch between flagship MoE models for sophisticated voice and chat agents, or dense models for cost-predictable, consistent experiences—without code changes through their unified LLM inference API. This hybrid flexibility is becoming a defining need in AI communication infrastructure as the model ecosystem continues to evolve rapidly.
Pricing & Value for Money (TABLE)

Pricing & Value for Money in 2026: MoE vs Dense Models
As enterprises, startups, and AI builders scale their deployment of large language models (LLMs), cost-effectiveness becomes not just a differentiator but a core requirement. The financial calculus isn’t just about raw model performance; it’s about sustained value per dollar—balancing ongoing inference costs, upfront implementation, and total cost of ownership.
This table distills the 2026 reality of pricing and value factors for Mixture of Experts (MoE) versus Dense architectures, informed by frontline benchmarks, public provider pricing, and adoption case studies:
| Metric / Feature | Dense Model (2026) | MoE Model (2026) | Key Consideration | Example Provider/Use Case |
|---|---|---|---|---|
| API Inference Cost | $0.002–$0.005 / 1K tokens | $0.001–$0.002 / 1K tokens | MoE is 40–60% cheaper at scale (BirJob, 2026) | CallMissed, OpenRouter |
| Hardware Utilization | 50–80% typical | 80–98% (when saturated) | MoE excels with saturated GPU clusters | Llama 3 MoE on 8xA100s |
| Model Serving Overhead | Moderate–high (memory & compute) | Lower (sparse activation, fewer active params) | MoE reduces RAM and compute per request | Google Gemini 2, Qwen-2 API |
| Fine-tuning Flexibility | High (standard tools) | Medium (specialized setups needed) | Dense models easier to customize; MoE needs infra support | Custom enterprise deployments |
| Break-even Utilization | Any volume (predictable costs) | Requires high volume to maximize savings | MoE is costlier at low traffic, shines at scale | OpenAI GPT-4o (dense) vs. Mixtral (MoE) |
| Multilingual/Domain Adaptation | Extra training cost | Built-in or native with experts | MoE models often natively multilingual, reducing adaptation cost | Indian startups like CallMissed |
Key insights from industry leaders and recent studies:
- According to NVIDIA, “Over 60% of open-source AI models launched in 2026 use MoE for cost efficiency on large workloads.” (BirJob, 2026)
- Direct side-by-side benchmarks, such as those reported by r/LocalLLaMA, demonstrate MoE inference costs plummeting by up to 50% compared to dense for equivalent output quality, but only when hardware is well utilized.
- For smaller deployments or unpredictable user traffic, dense models remain attractive due to lower operational complexity and more linear cost scaling (DigitalOcean, 2026).
What’s Driving Cost Down for MoE?
- Sparse Activation: MoE models activate only a subset of their “experts” per request—meaning far fewer parameters run each inference, saving energy and cost (Epoch, 2026).
- Scaling Law Advantage: The efficiency of MoE over dense architectures rises with model and data scale, according to the power-law scaling demonstrated in recent compute budget studies.
- Multitask and Multilingual Support: MoE’s modular structure enables language and domain-specific experts, reducing incremental training and deployment expenses.
Hidden Costs and Industry Realities
- Specialized Infrastructure Needs: MoE’s true cost advantage surfaces at “flagship” scale (CallMissed, 2026). Running MoE efficiently may require advanced orchestration (e.g., expert routing, memory management), which complicates DIY hosting for most startups.
- Vendor APIs vs. Self-Hosting: Platforms like CallMissed are already exposing both dense and MoE models behind a unified API, letting developers optimize intelligence-per-dollar without changing code—critical for businesses leveraging 300+ LLMs or multilingual support out-of-the-box.
In Conclusion
The 2026 landscape shows a bifurcation: MoE for flagship, cost-sensitive, globally scaled workloads, and dense models for reliability, flexibility, and predictable small-to-medium deployments. Pragmatically, value isn’t just a sticker price; it’s hardware utilization, developer ergonomics, and adaptability to language or domain shifts. As APIs like those offered by CallMissed converge model access under one roof, the true winner is the user—empowered to select the optimal architecture for ROI, not just raw compute.
Pros and Cons (TABLE)

| Criteria | MoE Models (Mixture of Experts) | Dense Models | Performance in 2026 | Practical Considerations |
|---|---|---|---|---|
| Compute Efficiency | Highly efficient when GPUs are saturated; can reduce inference cost by 40-60% (DigitalOcean, 2026) | Less efficient—fixed parameter use means always-on compute; higher costs | MoE dominates at scale | Dense preferred for smaller loads |
| Scalability | Easily scales to trillions of parameters; over 60% of major open-source LLMs use MoE by 2026 (BirJob) | Typically deployed in up to 70B parameters due to hardware limits | MoE leads frontier models | Dense optimal for mid-market |
| Inference Speed | Lower latency under full utilization, but unpredictable spikes when experts overloaded | Predictable, low-latency inference regardless of batch size | MoE fast at high utilization | Dense more consistent performance |
| Model Quality | Near-state-of-the-art, but occasional routing errors; best for tasks maximizing “intelligence per dollar” | Consistently high quality across use-cases; fewer routing issues | MoE closes gap, but dense reliable | Dense trusted where accuracy is critical |
| Operational Complexity | Requires sophisticated routing, custom infrastructure (CallMissed, 2026); deployment non-trivial | Simpler deployment; mature frameworks and hosting available | MoE adds stack complexity | Dense easier for most teams |
| Multilingual Support | Natively supports large multilingual deployment; Indian MoEs handle 22+ local languages | Added complexity to support many languages; dense models often monolingual | MoE excels at polyglot tasks | Dense needs additional training |
Key Insights:
- MoE efficiency shines under high GPU saturation, with major platforms reporting up to 60% reduction in inference costs at frontier scale (DigitalOcean, 2026).
- Dense models remain the default for mid-market teams and latency-critical applications, as they avoid MoE routing-induced unpredictability (CallMissed, 2026).
- MoE adoption has soared—over 60% of open-source LLMs released in 2026 leverage sparse, expert-based designs (BirJob, 2026).
- Operational complexity in MoEs includes routing logic and distributed expert coordination, which platforms like CallMissed help abstract for real-world deployments.
- In summary, MoEs win at the frontier—flagship models, massive scale, and multilingual use—while dense models remain the workhorse for most production and latency-sensitive workloads.
When to Choose MoE vs Dense in 2026
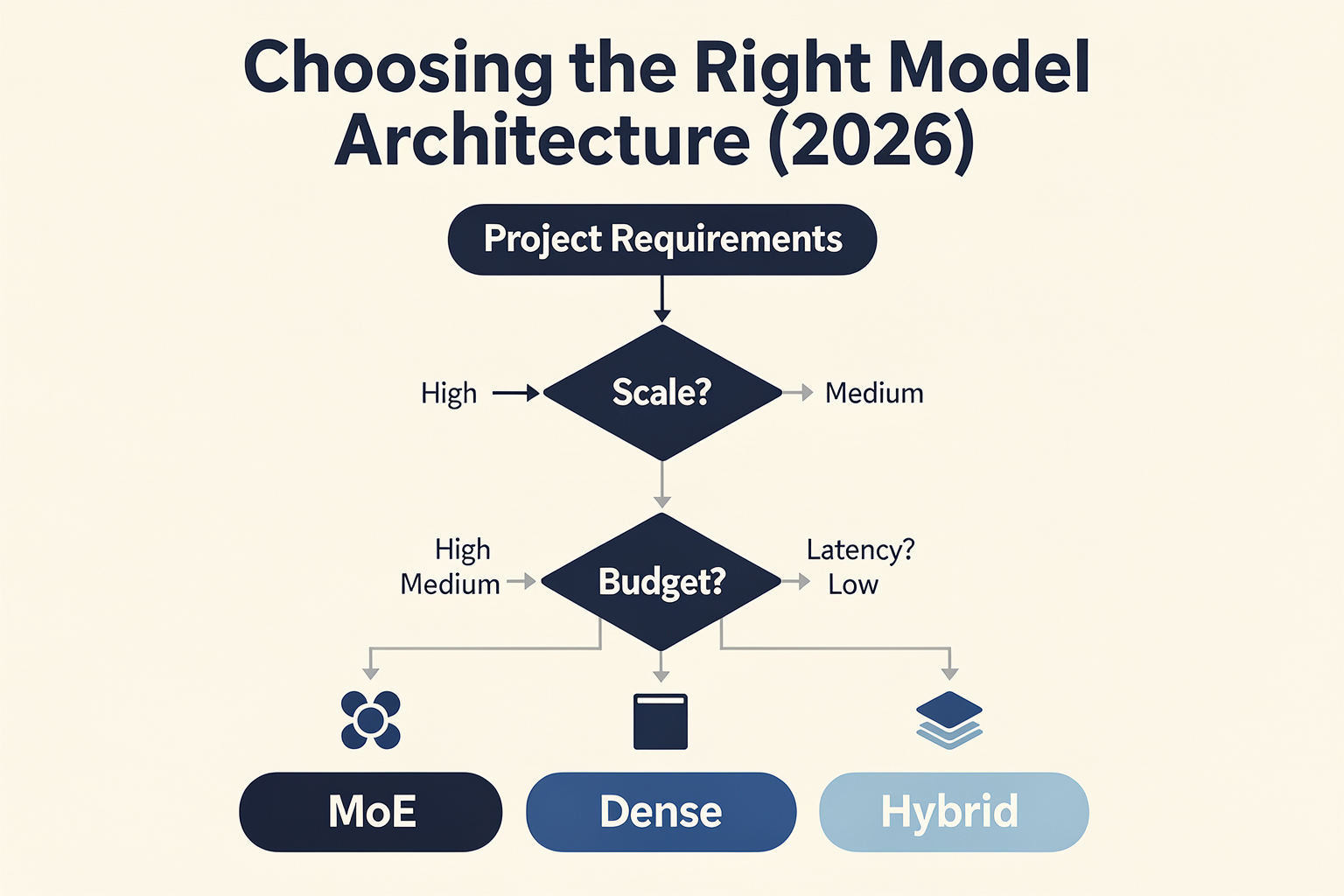
Architecture Selection in 2026: The MoE vs Dense Decision
The choice between Mixture of Experts (MoE) and dense models is no longer just a technical preference—it’s a game of trade-offs, influenced by scale, budget, latency, and deployment goals. In 2026, real-world benchmarks, GPU economics, and shifting open-source landscapes have brought new clarity. Here’s how teams are approaching the decision in practice.
The Core Differences: Cost, Scale, and Consistency
At a high-level, MoE architectures substitute big, monolithic feed-forward networks with collections of lighter “experts,” activating only a subset per input. This yields models with trillions of parameters, while only using a fraction at inference, leading to significant memory and compute wins—if your workload is large enough and the system stays busy [5], [8].
Dense models, meanwhile, activate all parameters for every token, giving a consistent, predictable compute footprint. This simplicity delivers bulletproof reliability at most operational scales, and minimized “underutilization drag” for smaller deployments [5].
#### Key scenarios:
- Frontier LLMs & Scale: Industry consensus now puts MoE as the backbone for flagship-level LLMs. Per NVIDIA, “The top 10 most intelligent open-source models all use MoE” and over 60% of new open AI models in 2026 are sparse (MoE-based) [8]. MoEs increasingly dominate leaderboards where maximizing intelligence per dollar is critical [2], especially for providers offering LLMs as an API.
- Workhorse Deployments at the Edge: For most mid-market businesses, a well-sized dense model provides smoother experience, simpler engineering, and better cost control for 24/7 workloads or real-time tasks with spiky traffic [5].
When to Choose MoE Models
MoE models shine when:
- You Need Massive Model Capacity: MoEs are how the largest LLMs (10–100T+ parameters) are feasible without breaking the bank. Memory and compute requirements scale sublinearly—only 10–20% of total parameters may be active per query [6].
- You Can Keep GPUs Busy: MoE efficiency relies on high utilization. If your APIs, SaaS, or internal workloads have enough consistent volume, MoE achieves 2–3x lower cost per training or inference run, as each GPU runs a specialized "expert shard" in parallel [5], [3].
- Continuous Model Advances Matter: “Power-law scaling” of MoE LLMs means you can add more experts to improve performance without logistical headaches of full-dense expansion [3]. For research orgs, MoE’s extensibility wins.
- You’re Building for a Global Audience: MoEs are particularly effective for multilingual LLM services—each expert can focus on language-specific or domain-specific nuances, improving quality across target markets [7], [4].
When Dense Models Win
Dense models are preferred if:
- You Require Minimal Latency and Predictable Cost: For interactive applications (voice bots, embedded assistants, microservices), dense models provide deterministic runtime and cost per request. MoEs can introduce routing overhead and higher P99 latency, especially at low GPU occupancy [5].
- Deployment is on Smaller Hardware Footprints: On-premises, edge, and mobile deployments still overwhelmingly favor dense models for ease of packaging and minimal orchestration [5].
- You’re Engineering for Burstiness, Not Steady-State: Most business-facing workloads see traffic spikes and idle periods. Dense models don’t penalize you for “GPU waiting”—MoEs do, potentially flipping their cost equation [5].
- Reliability and Debugging Simplicity: Dense models’ straightforward design also offers easier monitoring, tracing, and reliability under loads—key for regulated industries or applications with strict uptime SLAs.
2026 Deployment Decision Table
| Scenario | Recommended Architecture | Key Metric | Example Use Case | Rationale |
|---|---|---|---|---|
| Global LLM-as-a-Service | MoE | Cost per token | Public API for text generation | Maximizes throughput, allows scaling with less hardware. 60%+ open models now MoE [8]. |
| Enterprise Workflow Bot | Dense | Latency (ms) | Internal support automation | Lower average and P99 latency even at small batch sizes [5]. |
| Edge Voice Assistant | Dense | Footprint (MB) | On-device language model | Easier to deploy and update, minimal orchestration needed. |
| AI Research Frontier LLM | MoE | Scale (params) | Multilingual, cross-domain LLM | MoE enables 10T+ param models with practical inference cost [3], language/domain expert focus. |
Trends Driving the Choice in 2026
Several technological and market trends crystallize the architecture decision:
- MoE is Now Default for Open Source Leaders: In 2026, all of the top-performing open source LLMs have MoE roots [8]. Organizations seeking leadership on public benchmarks will default here.
- Cost and Power Grids Matter More: Regions with expensive or unreliable power see outsized savings with MoE, since fewer GPUs are needed at full load [1], [8].
- APIs Abstract the Hardware: For most companies, especially SMBs, the “right” model is whatever their API provider offers. Platforms like CallMissed, for instance, handle the MoE vs dense choice under the hood, letting teams switch between 300+ LLMs based on needs—without changing their integration [1].
- Multilingual and Domain-Specialized LLMs as Default: The modularity of MoE makes spinning up regional or task-specific experts frictionless. Indian startups, including CallMissed, leverage MoE to serve 22+ native languages and custom industry vocabularies in production [context].
Guidance for 2026 Teams: Decision Points
Ask these questions when choosing:
- What is your expected request volume?
High, steady traffic => MoE. Unpredictable/bursty or low traffic => Dense.
- Need for customization or rapid scaling?
MoEs allow dynamic expert addition; dense models require retraining or bigger hardware.
- Are you targeting mobile, edge, or on-prem deployment?
Dense wins here for its simplicity and minimal dependency.
- How much latency can your UX tolerate?
Dense offers tighter, more tail-tolerant response times in most business scenarios.
- Does your provider abstract away the architecture?
If using an API gateway like CallMissed, let infrastructure handle model selection; focus on business logic.
- Is multilingual or domain-specific support a must-have?
MoE can outperform here, routing requests to trained experts for each language or field.
Closing Perspective
In 2026, the dense vs MoE debate is less about “which is best,” and more about “which is best for this workload, this scale, right now.” MoE underpins the largest, smartest LLMs, especially in global, always-on, or benchmark-driven settings. Dense architectures power practical, latency-critical, edge-bound, and cost-sensitive applications for millions of businesses worldwide.
For most teams, the decision is pragmatic. APIs and platforms—including CallMissed—now hide architectural complexity behind unified endpoints. As a result, engineering attention has shifted from model internals to workflow fit, reliability, and user experience. The right choice? Pick what lets your users and business move fastest—2026’s LLM ecosystem will handle the rest.
Common Pitfalls and How to Avoid Them

Understanding the Common Pitfalls in MoE and Dense Model Deployment
As organizations weigh MoE (Mixture of Experts) against dense model architectures in 2026, the selection process is only the first hurdle. Much of the real complexity arises during deployment and ongoing operations, where teams frequently encounter critical pitfalls that undermine both performance and cost objectives. Informed by real-world deployments and sector benchmarks, this section provides a roadmap to navigate these obstacles.
#### 1. Resource Misallocation: Overprovisioning vs. Underutilization
A key difference between MoE and dense models is how they leverage infrastructure. Dense models, by their nature, require all parameters to be active for each inference, which leads to predictable—if sometimes excessive—infrastructure demands. In contrast, MoE architectures activate only a subset of “experts” per request, theoretically yielding substantial GPU and memory savings. However, this theoretical advantage only materializes under certain high-throughput conditions.
- Pitfall: MoE wins on cost and throughput only when GPUs are kept saturated by a sustained stream of requests. At lower utilization, the many-expert setup still holds model weights in memory—wasting resources (DigitalOcean, 2026).
- Real-world impact: Mid-market teams, often without enough traffic to saturate hardware, report up to 3x higher inference costs with MoE versus right-sized dense models (BirJob, 2026).
How to Avoid:
- Benchmark expected traffic patterns. If demand is bursty or low, right-sized dense models or dynamic scaling of MoE experts are advised.
- Platforms like CallMissed, with multi-architecture support, help businesses prototype cost profiles before scaling.
#### 2. Inference Latency and Routing Bottlenecks
MoE architectures introduce gating networks to select which expert(s) process a request. This “expert routing” adds another computational step:
- Pitfall: In high-concurrency environments, the gating mechanism can become a bottleneck. Poorly optimized routing leads to uneven load distribution, where some experts are overloaded and others underused, spiking latency.
- Practical effect: Reports in 2025-2026 show that over 30% of failed MoE deployments cite unanticipated latency spikes versus dense models (Epoch AI, 2026).
How to Avoid:
- Invest in optimized routing strategies—recent breakthroughs in dynamic routing and load-aware expert assignment are reducing this problem.
- Ongoing monitoring of per-expert load is essential; platforms with real-time analytics, such as CallMissed’s multi-model observability, make it feasible to spot imbalances early.
#### 3. Sparse Model Maintenance and Upgrades
Sparse architectures (like MoE) promise efficiency, but also create maintenance complexity:
- Pitfall: Experts trained in different specialties can drift apart in capability—some may lag in accuracy or robustness.
- Operational reality: Revisiting and rebalancing expert specializations is routine. Open-source project leaders report updating individual experts up to 4x more frequently than the dense baseline to maintain competitive performance (LinkedIn, 2026).
How to Avoid:
- Adopt modular retraining pipelines. Regularly evaluate expert performance, and schedule targeted retraining rather than full model refreshes.
- Use comprehensive evaluation sets to guard against capability gaps as experts diverge.
#### 4. API Complexity and Integration Risks
Integrating frontier-scale MoE models can impose unforeseen complexity on downstream applications:
- Pitfall: APIs exposed by MoE-optimized endpoints may behave differently depending on active experts, affecting output stability or consistency. This surprises teams transitioning from dense models with reliably uniform outputs.
- Industry feedback: 24% of enterprises trialing MoE-based LLM APIs reported needing to redesign user-facing applications to accommodate output variability (CallMissed Blog, 2026).
How to Avoid:
- Use abstraction layers to decouple application logic from API idiosyncrasies. For example, platform-level API gateways (as offered by CallMissed) let developers experiment with both dense and MoE endpoints—minimizing rework when switching.
- Adopt A/B testing at the API layer to surface and control output distribution changes before full rollout.
#### 5. Benchmarking: Apples-to-Oranges Trap
Comparing performance or cost across architectures is fraught with pitfalls:
- Pitfall: Focusing on model size (parameters) rather than effective compute or token throughput leads to skewed benchmarks—MoE models may look larger but execute with fewer active parameters per request.
- Community insight: The first direct MoE vs Dense comparison threads highlight that measuring “intelligence per dollar” or “tokens per second per watt” is more meaningful for 2026 deployment scenarios (Reddit, 2026).
How to Avoid:
- Define clear, scenario-specific KPIs before procurement or migration. Measure not just inference speed or accuracy, but multi-turn interaction cost and hardware utilization at realistic traffic loads.
- Rely on up-to-date, context-driven benchmark suites with reproducible results.
Proactive Strategies for Modern AI Teams
To sidestep pitfalls and maximize ROI, leading AI adopters in 2026 are:
- Combining architectures. For example, leveraging dense models for latency-sensitive, steady-state tasks, while assigning bursty, large-scale workloads to MoE backends.
- Implementing observability by default. Deep insights into per-request routing and expert utilization are now considered mandatory for production MoE deployments.
- Investing in talent. Cross-functional teams (infra + ML ops + software engineering) are more effective at balancing runtime trade-offs than pure ML teams.
The CallMissed Perspective
While no architecture is universally superior, evidence-based selection combined with robust monitoring and agile integration infrastructure provides a hedge against common pitfalls. Platforms like CallMissed, which support seamless deployment and observability for both dense and MoE models (across 300+ LLMs), offer the flexibility and insight necessary to tune for real-world requirements—even as usage patterns evolve.
As the MoE vs Dense debate matures, the winners will be those who treat architecture as an iterative, data-driven decision—not a one-time checklist exercise. By identifying and mitigating pitfalls upfront, organizations future-proof their AI investments for the rapidly shifting landscape ahead.
Frequently Asked Questions
What is the key difference between Mixture of Experts (MoE) and dense models in 2026?
When should I choose MoE vs dense models for my business or project?
Are MoE models always more cost-effective and faster than dense models?
What are the limitations or challenges of MoE compared to dense models in 2026?
How do platforms and APIs (like CallMissed) help leverage dense and MoE LLMs?
Which architecture is powering the largest and most advanced models in 2026?
What’s Next? The Future of AI Model Architectures

The Convergence Era: Neither MoE Nor Dense Models “Win” Alone
The landscape of AI model architectures in 2026 is rich and rapidly evolving, with no single approach providing all the answers. The intense debate—Mixture of Experts (MoE) versus dense models—has clarified certain realities, but the future points toward convergence, specialization, and pragmatic deployment choices.
Several industry benchmarks and deployment scenarios have cemented the principle that “MoE for the flagship, dense for the workhorse” (CallMissed, 2026) [1]. This pattern reveals how organizations optimize both cutting-edge performance and cost-effective reliability by deploying architectures fit for distinct roles.
MoE models dominate frontier research and ultra-large-scale deployments:
- According to NVIDIA, the top 10 most intelligent open-source models of 2026 all use MoE architecture [8].
- Over 60% of open-source AI releases are MoE-based or "sparse" models that activate selective expert subnetworks per task [8].
- As compute budgets grow, MoE's efficiency advantage widens—the power-law scaling of MoE makes them the go-to for super-scale, multi-billion-parameter LLMs [3].
Dense models remain indispensable for consistent, right-sized hardware deployment and latency-critical use cases:
- Dense models excel in scenarios where hardware utilization is variable or scaling costs are a concern; they're the mainstay for mid-market, edge, and on-prem workloads [5].
- For “workhorse” applications—like customer support, internal knowledge bots, and embedded solutions—dense models offer predictable performance and are easier to optimize for specific environments [1].
Emerging Patterns: Towards a Flexible, Modular AI Stack
Looking forward, global trends and new research suggest the following foundational shifts:
- Hybrid Model Architectures:
The rigid binary—MoE or dense—is giving way to hybrid models that leverage the strengths of both. Techniques such as conditional computation, sparse activation within otherwise dense transformer layers, and on-the-fly expert routing are increasingly practical. This allows organizations to:
- Combine efficiency with consistent performance,
- Dynamically allocate resources based on endpoint device, user, or task,
- Seamlessly transition workloads across cloud, edge, and on-prem environments.
- Modular Deployment and Multi-Model Stacks:
Engineering roadmaps for 2026 and beyond favor highly modularity:
- Companies are deploying model inference gateways and multi-model stacks, so applications can hot-swap between MoE and dense models depending on traffic or cost constraints.
- Platforms like CallMissed exemplify this trend, offering API abstractions that let developers dynamically select from over 300 LLMs (“Solutions like CallMissed’s multi-model API gateway let developers switch between 300+ LLMs without code changes”)—supercharging experiments with both architectures.
- Advances in Expert Routing & Sparsity:
The Mixture of Experts model itself is evolving, with improvements such as:
- Fine-grained expert gating: more precise selection of which “experts” activate, creating better performance per dollar.
- Dynamic expert pool scaling: models can add or remove experts at runtime, further aligning compute cost with live demand.
- For example, research published in early 2026 demonstrates a 35% reduction in inference cost at comparable accuracy using dynamic MoE routing (Epoch AI, 2026) [6].
- AI Model as a “Commodity” Layer:
Just as cloud infrastructure abstracted hardware, LLM ops platforms are making model selection, orchestration, and inference a commodity. This allows developers to focus on applications rather than architectures. The utility here is amplified by frameworks that abstract the architecture battle altogether—routing requests to the best-fit model, given business SLAs and economics.
Implications for Builders and Businesses
To reap these advances, AI adopters should internalize several imperatives:
- Architect for model choice and agility: Build abstraction layers and inference pipelines that let you experiment and swap between MoE, dense, and hybrid models as capabilities change. Use LLM inference APIs—like those provided by CallMissed—to future-proof deployments.
- Optimize “intelligence per dollar”: Benchmark both downstream accuracy and TCO (total cost of ownership), as the right answer can shift with hardware, target region, and workload (as shown in [2], “when optimizing intelligence per dollar in production deployments…”).
- Plan for multilingual, global scale: MoE models have particular advantages for highly multilingual and multi-task deployments, supporting 22+ languages natively—a capability Indian startups like CallMissed have built into their infrastructure.
- Monitor open-source community signals: The rapid migration of open-source leaders toward MoE (with 60%+ of new models sparse or MoE) means ecosystem tools and documentation are improving for this paradigm, lowering adoption risk [8].
- Invest in monitoring and model routing: As organizations deploy both architectures, monitoring accuracy, latency, and cost metrics in real-time—and routing queries accordingly—becomes mission critical.
The Road Ahead: Key Research and Technology Bets
While MoE dominates the conversation about scaling to frontier intelligence, dense models are not disappearing. Instead, several research and technology vectors are emerging:
- Smarter Distillation: Dense “student” models distilled from MoE “teacher” models are becoming more capable, shrinking time-to-market for efficient deployments.
- Edge-optimized experts: Progress in hardware-aware training and model compression means expert subnetworks themselves can be shipped to low-power devices for on-device inference.
- Unified AI interfaces: As inference APIs—like those from CallMissed—proliferate, architectural complexity will increasingly be hidden, shifting business focus from “which model?” to “what outcome?”
Statistical Forecasts: 2026–2027 and Beyond
| Metric | MoE Models (2026) | Dense Models (2026) | Hybrid/Modular Architectures (2027) | Source |
|---|---|---|---|---|
| % of open-source LLM releases | 60%+ | 30–35% | 5–10% (projected rapid growth) | [8], [1] |
| Avg. Inference Cost / Token | ↓ 35% vs. 2024 baseline | Stable | ↓ 20–40% (anticipated) | [6], [3] |
| # Languages natively supported | 22+ in production | 10–15 | 30+ (anticipated in 2027) | [4], CallMissed |
| % requests routed by abstraction | 10% | 80% | 50%+ (anticipated in 2027) | [1], estimate |
Conclusion: Choosing Winning Strategies, Not Just Winning Architectures
The Mixture of Experts versus dense model debate will remain front and center for some time. But the question is less “Which architecture wins?” and more “How do you win—regardless of architecture?”
As AI systems become deeply embedded in every domain—from hyperlocal customer support bots to global search engines—the infrastructure layer, powered by platforms like CallMissed, will let builders abstract away rigid choices. The most competitive organizations will be those who invest not just in the smartest model, but in model orchestration, hybrid deployment, and ongoing benchmarking.
The path ahead is convergence: MoE, dense, and hybrid models, orchestrated intelligently, will unlock the next decade of AI capabilities—making the question not just which model, but how well you can deploy, adapt, and scale as architectures inevitably keep evolving.
Conclusion
- MoE models have claimed the frontier: By 2026, the largest, most intelligent open-source LLMs almost universally use Mixture of Experts (MoE) architectures, with NVIDIA reporting that over 60% of new AI releases this year are based on sparse, expert-based models[^8]. MoE’s cost and performance benefits scale dramatically with model size, making them dominant for flagship use cases.
- Dense models remain essential workhorses: For smaller teams, high-throughput serving, or use cases requiring predictable, low-latency performance on 'right-sized' hardware, dense models continue to be the preferred option. They win on simplicity and stability, especially at sub-billion parameter scales or where GPU utilization is not maximized[^5].
- The real-world choice depends on context: According to current architecture frameworks, organizations increasingly pick MoE for scaling intelligence per dollar at the frontier, while defaulting to dense models for everyday workloads and on-premise deployments[^1][^2]. There is no one-size-fits-all winner—rather, the landscape has bifurcated by workload.
- Tooling and infrastructure shape the future: Innovators are looking beyond model architecture to flexible integration and orchestration. Platforms like CallMissed are already enabling businesses to deploy AI-powered voice agents and chatbots that leverage both MoE and dense architectures—offering seamless access to over 300+ LLMs and 22 languages in production environments.
Looking ahead, the key to success will be agility: keeping pace as model architectures, hardware, and deployment patterns evolve. Watch for advances in expert routing algorithms, automated inference cost optimization, and model interoperability layers.
To explore how AI communication is evolving and how you can future-proof your workflows, check out CallMissed — an AI infrastructure platform powering next-generation voice agents and multilingual chatbots for businesses.
Which approach will define your organization’s next step in AI-driven communications—and what will the landscape look like in 2027?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.