Streaming AI Responses: SSE, WebSockets, and the Pitfalls

A 2026 production guide to streaming LLM responses — SSE vs WebSockets, TTFT targets, backpressure, client-disconnect handling, and error recovery.
A streaming LLM response feels fast even when total generation takes ten seconds, because the user sees tokens arriving immediately. The trade is operational: streaming is a long-lived connection with backpressure, partial-failure modes, and a different shape from a normal HTTP request. Here is what you should know before shipping.
SSE or WebSockets
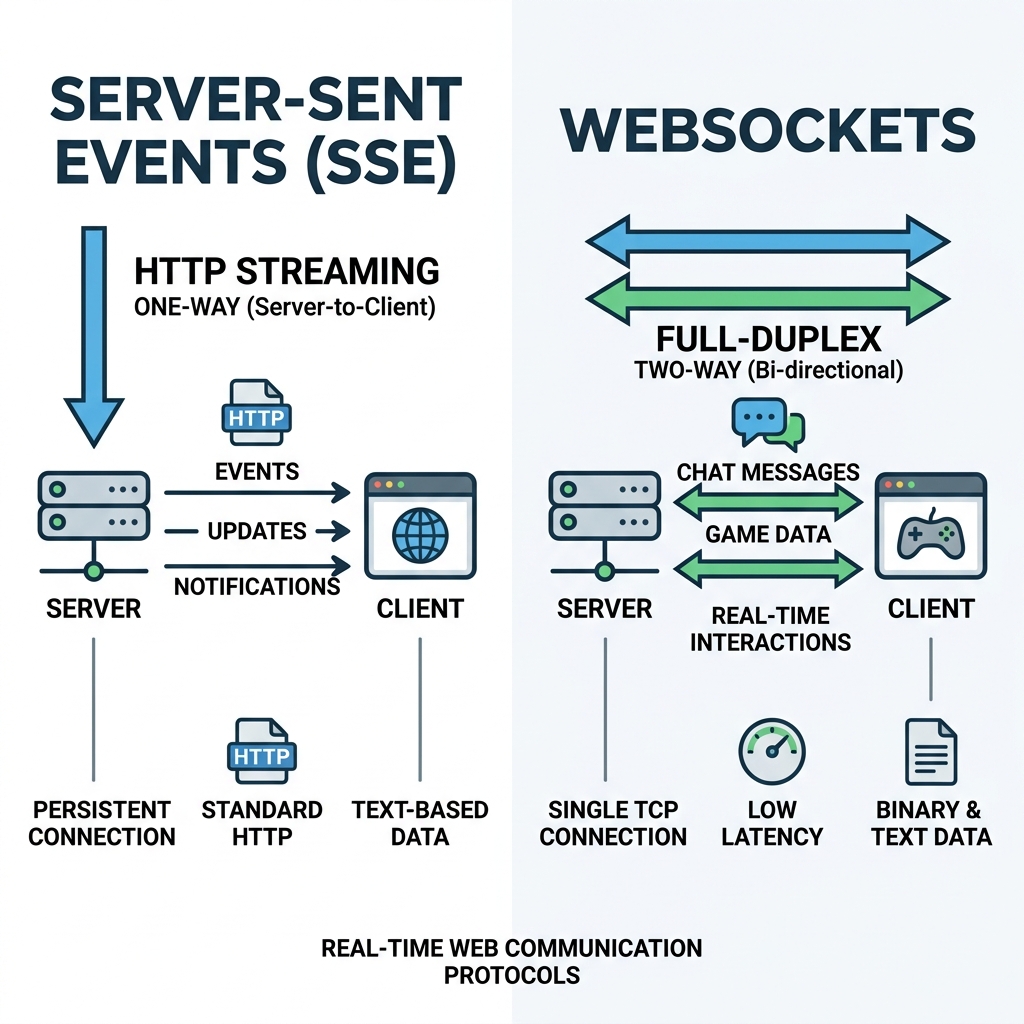
Two transports dominate streaming LLM responses:
- SSE (Server-Sent Events) — server-to-client, over plain HTTP/HTTPS, simple framing (
data: ... \n\n). Auto-reconnect built in. The default for most LLM streaming. - WebSockets — full duplex, lower-level. Right when you need bidirectional messaging during the stream (interruption, mid-stream user input, voice).
For a typical "user types a message, model streams a response" chat UX, use SSE. It is proxy-friendly, simpler to debug, and the protocol overhead is lower. Reach for WebSockets only when bidirectional matters. (Hivenet on streaming)
TTFT: the metric users feel
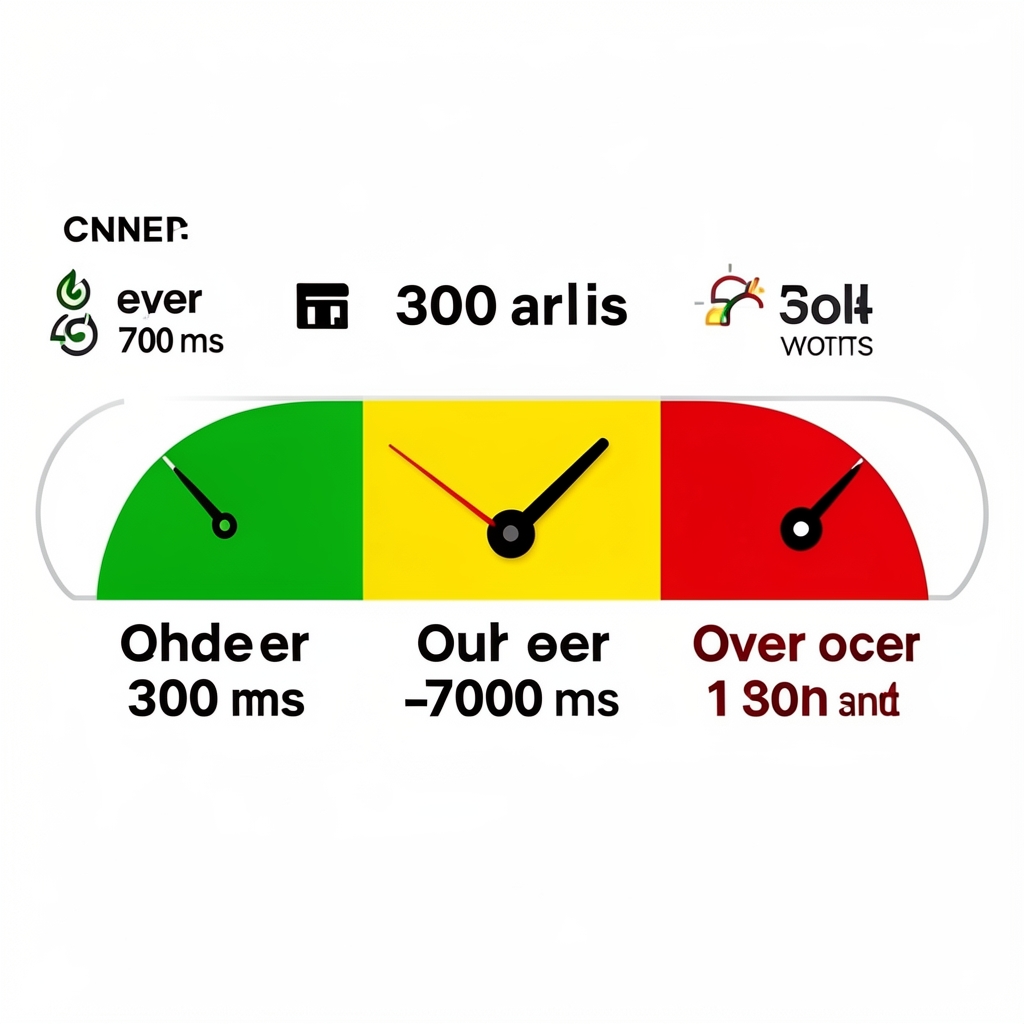
Time-to-first-token (TTFT) is the latency between request submission and the first token arriving. Users perceive TTFT as system responsiveness — total generation time matters less than how soon something starts appearing.
[Inference] Common targets:
- TTFT under 300 ms feels snappy
- TTFT 300–700 ms feels acceptable
- TTFT over 1 second feels broken
Drivers of TTFT: prompt length (prefill cost), model size, GPU contention, network distance, and any server-side work between request receipt and first token emission.
A reported optimization: prefix caching in vLLM can reduce TTFT from ~800 ms to under 100 ms for requests that share a prefix with a previous request. (sysart) [Unverified]
Backpressure: the failure mode most teams miss
Streaming connections are long-lived. If the client falls behind — slow network, throttled tab, mobile background — the server's write buffer fills up. Without backpressure handling, your process leaks memory until something OOMs.
Node.js example (SSE over Express/Fastify):
const written = res.write(chunk);
if (!written) {
await new Promise(resolve => res.once('drain', resolve));
}The Node.js docs put it bluntly: "the golden rule of streams is to always respect backpressure; never call .write() after it returns false but wait for drain instead." (Node.js docs)
For WebSockets, watch ws.bufferedAmount. If it grows beyond a threshold (say, 64 KB), pause emission. Resume when it drains.
Client disconnect: the leakier failure mode
The browser tab closes. The user navigates away. The mobile network drops. Your server is mid-generation, mid-write. What happens?
If you do not handle it, a common chain in Python (FastAPI / Starlette):
- Generator is iterating over the upstream LLM stream
- Client closes connection
- Server raises
ClientDisconnectorCancelledErrorsomewhere in the generator - The
finally:block runs — but if it does DB writes against the request-scoped session, the cancellation can leave a transaction "idle in transaction" on Postgres, holding row locks and exhausting the pool
[Inference] This pattern is widespread enough to be a known anti-pattern. The fix is to do post-stream writes against a fresh session with asyncio.shield so they complete even if the caller is cancelled.
In Node.js, listen to req.on('close') and abort the upstream model call. In Python/FastAPI, check await request.is_disconnected() periodically and bail out if it returns true.
Error recovery mid-stream
Once the headers are flushed, you cannot send a normal HTTP error. Options:
- Emit an error event —
event: error\ndata: {...}in SSE. Client switches to error UI on receipt. - Close the connection — last resort. Client sees an unexpected end-of-stream and may auto-reconnect.
The approach that works best is to send a typed event protocol end-to-end: event: token, event: usage, event: error, event: done. The client handles each event type explicitly; ambiguous protocols cause flaky UIs.
Reconnect, resume, and idempotency
Streaming connections drop. Mobile. Wifi. Long-tail networks. Three patterns to handle this:
- No resume — disconnection means restart the whole request. Acceptable for short interactions.
- Resume by event ID — SSE supports
Last-Event-ID; the server replays events from that point. Works only if the server retains state (often via Redis or DB log). - Idempotent retries — the client retries with a request ID; the server returns cached output if the request completed. The default for any LLM stream that costs more than a few cents.
For voice agents and other very-long sessions, design for resume from the start. For simple chat UIs, "lost connection, please retry" is acceptable.
Server architecture: connections, not requests
A streaming server is sized in concurrent active connections, not requests per second. A 30-second-average generation at 100 RPS requires headroom for ~3,000 simultaneous connections. Default web-server connection limits often need to be raised; long-running async runtimes (uvicorn, fastify, starlette) handle this better than thread-per-request models.
Token rendering on the client
Watch out for bursty token dumps — frameworks that batch token events and flush every 200 ms make streams feel jerky. Render small chunks frequently. Some teams smooth this on the client by adding a tiny artificial delay between word-level renders for visual rhythm; opinions vary on whether it helps or feels patronizing.
A short checklist
- SSE for one-way streams; WebSockets only when you need bidirectional.
- p95 TTFT instrumented and alerted; under 700 ms target for chat, under 300 ms for "snappy."
- Backpressure: respect
drainin Node, throttle onbufferedAmountin WS, slow upstream consumption when needed. - Client disconnect handler that aborts the upstream LLM call and uses a fresh DB session for post-stream writes.
- Typed event protocol (
token,error,usage,done) — never overloaddata:. - Connection limits sized for active connections, not RPS.
Bottom line
Streaming is a different shape than request/response. Most teams ship the happy path quickly and discover the failure modes — backpressure leaks, idle Postgres transactions, half-rendered messages — under load. Design for the failure cases up front, instrument TTFT, and treat client disconnect as a first-class event, not an exception.
Frequently Asked Questions
SSE or WebSockets for chat?
What's a good TTFT target?
How do I handle a client disconnecting mid-stream?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.