Real-Time Voice Translation: The State of the Art

Imagine picking up your phone, speaking Hindi, and having your words instantly relayed in flawless Spanish—complete with your own vocal tone and natural...
Real-Time Voice Translation: The State of the Art
Imagine picking up your phone, speaking Hindi, and having your words instantly relayed in flawless Spanish—complete with your own vocal tone and natural inflections. Just a decade ago, real-time voice translation felt like science fiction. Yet, today in 2026, this technology is not just available, but rapidly becoming woven into everyday life, commerce, diplomacy, and customer service at a global scale. Statista reports that the worldwide AI translation market, including speech applications, is forecast to top $21 billion by 2027, underscoring the explosive demand for seamless cross-lingual communication.
Why does real-time voice translation matter so much now? In our hyper-connected, polyglot world, language remains one of the last barriers to instant collaboration. Over 7,000 languages are actively spoken, but international business, emergency services, remote healthcare, and even everyday travel often grind to a halt without shared linguistic ground. A recent survey by Common Sense Advisory found that 76% of internet users prefer transactions in their native language—yet fewer than 30% of websites provide multilingual support. The pressure is on to make global interactions as fluid as local conversations, fueling investment and innovation in speech-to-speech AI.
State-of-the-art real-time voice translation, often called speech-to-speech translation (S2ST), is lightyears ahead of its stilted, error-prone predecessors. New models, such as Google’s Gemini-powered live translation (recently rolled out to consumer headphones [2]), leverage end-to-end neural architectures capable of bypassing the traditional “text bottleneck.” These systems translate audio to audio directly, preserving intonation, emotion, and speaker characteristics—all within milliseconds [1, 4]. Modern platforms boast support for 100+ languages, sub-500ms latency, and error rates rivaling—or even surpassing—human interpreters in structured settings [7, 8]. The implications stretch far beyond travel apps: AI voice agents now handle live customer support, telemedicine consultations, and even real-time news broadcasts across language divides.
But challenges persist. Maintaining translation quality in low-resource languages, juggling colloquialisms, eliminating ethical biases, and meeting the demands of real-time processing require a confluence of linguistic expertise, data curation, and cutting-edge engineering. Speech-to-speech systems must also address privacy concerns—especially when transmitting sensitive calls or medical data—and deliver robust performance in noisy, real-world environments. This is precisely where modular, API-driven infrastructures are accelerating progress. For example, Indian startups like CallMissed are building production-ready AI communication platforms that offer out-of-the-box voice translation across 22 Indian languages, allowing businesses to deploy multilingual voice agents that serve diverse populations around the clock.
In this article, we’ll dissect the technological breakthroughs powering today’s best real-time voice translation systems. You’ll learn how advanced speech recognition, neural machine translation, and generative audio models converge to create human-like translations in the blink of an eye. We’ll analyze accuracy benchmarks, real-world use cases, and remaining hurdles—drawing from the latest research, industry deployments, and hands-on demos. Whether you’re a technologist, business leader, or language enthusiast, you’ll walk away with a clear sense of where real-time voice translation stands at the cutting edge, and what the next few years might bring as language becomes a bridge, not a barrier, for global communication.
Introduction

The New Era of Real-Time Voice Translation
The dream of conversing effortlessly across languages—once a staple of science fiction—is now materializing at an unprecedented pace, enabled by breakthroughs in real-time voice translation technologies. In 2026, this field stands as one of the most transformative frontiers in global communication, offering the tantalizing prospect of instant, natural conversations unhindered by language barriers.
Fueled by advances in AI, machine learning, and end-to-end speech-to-speech translation models, current voice translation systems are dramatically reducing the friction of multilingual interactions. Whether in international business, travel, healthcare, or education, the implications of these innovations are profound. According to Google Research, their latest end-to-end S2ST (speech-to-speech translation) model can generate real-time translations while preserving the original speaker’s voice characteristics (“Real-time speech-to-speech translation,” Google Research, 2024). This marks a significant leap from earlier generations that required intermediate text representations and robotic voice outputs.
#### Why Real-Time Matters
At the heart of modern voice translation is the need for speed and accuracy. Human conversation is highly contextual and often fast-paced; delays and inaccuracies can disrupt the flow and lead to confusion or mistrust. Legacy translation systems often involved multi-stage processes—speech-to-text, then machine translation, then text-to-speech—with each stage introducing latency and possible errors. In contrast, today’s state-of-the-art solutions focus on:
- End-to-end architectures: Directly map input speech to translated output speech, minimizing delays and information loss.
- Contextual understanding: Leverage large language models to retain nuance, tone, and intent.
- Voice preservation: Generate output in the speaker’s own voice for greater authenticity.
A 2024 study revealed that Google’s latest Gemini-powered real-time translation beta offers sub-second latency and supports dozens of languages with high accuracy—an achievement previously thought out of reach (“Bringing state-of-the-art Gemini translation capabilities to Google,” 2024). Users can now experience live translations directly through consumer devices like headphones, fundamentally changing everyday multilingual communication.
#### Growth, Adoption, and Impact
The adoption curve for real-time voice translation is steep, spurred by multiple factors:
- Explosion in cross-border collaboration: Global business communications are increasingly conducted in real time, pressuring organizations to remove linguistic friction.
- Pandemic-driven remote interactions: The shift to online education and telemedicine during recent years highlighted the need for real-time, accessible translation.
- Mobile and IoT proliferation: With powerful translation apps available on smartphones and wearable devices, real-time voice assistance is accessible to billions of users (“Real-time Voice Translate,” Google Play).
According to industry reports, real-time voice translation solutions now support over 100 languages globally and can transcribe and translate live audio from phone calls, video conferences, and face-to-face conversations (“Live Translate | Real-Time Online Voice Translator,” Maestra.ai, 2026). This ubiquity is flattening barriers for immigrants, business travelers, and multinational teams.
#### Emerging Industry Players and Infrastructure
It’s not just tech giants pushing the frontiers. AI-native startups and platforms are developing production-ready APIs that bring these capabilities to businesses of every size. For example, Indian platforms like CallMissed have emerged as significant enablers, offering voice agent and multilingual speech-to-text APIs in 22 Indian languages, alongside LLM-powered translation and inference tools. This democratizes access for regional enterprises, social sectors, and government agencies aiming to reach diverse and often underrepresented populations.
Platforms such as CallMissed exemplify the new breed of AI communication infrastructure, letting developers deploy real-time translation and voice agent solutions without needing deep technical expertise or investing in costly infrastructure from scratch.
#### The Road Ahead
As we enter 2026, the state of real-time voice translation is rapidly evolving towards increasing accuracy, naturalness, and universality. Deep learning models are getting better at nuance; output voices are less robotic and more expressive. Recent live demos, like the real-time AI translation showcased by Lexi Voice at ISE 2026, highlight the industry’s focus on instantaneous translation paired with human-like delivery (“Live Demo: Real-Time AI Translation & Voice at ISE 2026—AI Media,” 2026).
Yet, challenges remain—from low-resource language support to handling idiomatic and domain-specific content. The journey from impressive demos to seamless global ubiquity will require continued innovation, stronger datasets, and collaborative frameworks.
In this series, we dive into the current breakthroughs, technical underpinnings, and real-world implications of state-of-the-art real-time voice translation. Along the way, we’ll explore the ecosystem of tools, benchmarks, and emerging applications—including how platforms like CallMissed are helping shape the future of AI-powered communication.
Background & Context

The Evolution of Real-Time Voice Translation
The dream of instant, seamless communication across languages dates back decades, fueled by both science fiction and ongoing globalization. Today, real-time voice translation—converting spoken words from one language to another nearly instantaneously—has moved from the realm of fantasy into viable, commercial technology. But understanding the present capabilities requires tracing an arc through advances in AI, speech processing, and hardware innovation.
#### From Rule-Based Systems to End-to-End AI Models
Early speech translation systems (1990s-2000s) relied on pipelines stitched together from three primary components:
- Automatic Speech Recognition (ASR): Converts spoken input to text in the source language.
- Machine Translation (MT): Translates the transcribed text to the target language.
- Text-to-Speech (TTS): Synthesizes translated text back into spoken audio.
These early systems depended on hand-crafted linguistic rules and phrase tables, limiting them to a handful of major languages and producing results often riddled with errors or stilted language.
The introduction of deep learning—especially sequence-to-sequence models—transformed the pipeline. Models like Translatotron and Google's S2ST (Speech-to-Speech Translation) systems represent the state-of-the-art, offering end-to-end neural architectures that directly translate audio in one language to audio in another, bypassing intermediate text representations altogether (Google Research). This direct approach both reduces latency and enables innovative features such as preserving the original speaker’s vocal characteristics in the translated output.
#### The Demand for Multilingual, Low-Latency Solutions
Globalization, remote collaboration, and rising cross-border service demand have made real-time translation a “must have” in many contexts:
- International business meetings: Real-time translation enables deeper collaboration between distributed teams.
- Healthcare: Instant patient-provider communication in critical contexts, especially in multilingual markets.
- Customer support: Enterprises can serve global customers in their native tongue, improving satisfaction and retention.
According to research from Translated.com, voice translation technology “aims to enable seamless, instantaneous communication between people who speak different languages,” breaking down what was previously a major business and cultural barrier (Translated.com). By 2026, real-time AI-driven translation is expected to touch over a billion end users annually, with over 125 languages supported by leading platforms (Maestra AI).
#### Technical Challenges: Latency, Accuracy, and Multilinguality
While great strides have been made, three core technical challenges drive ongoing research:
- Latency:
Human conversation flows at an average pace of 150-180 words per minute, with less than 300ms pause between speakers on average. For translation to feel natural, system response must happen in near-real time, ideally in under 500ms end-to-end.
- Accuracy and Context:
Language is rife with ambiguity, idioms, and context-dependent meaning. Groundbreaking research (Google S2ST; arXiv:2502.05980v2) demonstrates that high-quality real-time translation almost always requires looking ahead at least several words for accurate context—a challenge when simultaneity is required.
- Breadth of Language Support:
State-of-the-art platforms now handle 100+ languages, with accuracy varying dramatically for under-resourced tongues. For truly universal access, support for regional dialects and languages (like India’s 22 official languages) remains a major frontier.
#### Real-World Impact and Adoption
Adoption is accelerating across industries, as real-time translation technology matures:
- Consumer Devices:
From smartphone apps (Google Play Voice Translate) to smart headphones, real-time translation is increasingly integrated into daily communication tools. Google's latest Gemini upgrades, for instance, bring speech-to-speech translation live into headphones for dozens of languages (Google Blog).
- Enterprise Solutions:
Virtual events, customer support lines, and contact centers deploy real-time multilingual translation pipelines to unlock global scale and accessibility.
- Public Services:
Governments and NGOs leverage these tools for disaster response, healthcare outreach, and multilingual access to state services.
#### The Role of Infrastructure Platforms
As demand grows, the architectural backbone of these systems becomes critical. Infrastructure providers are democratizing access to state-of-the-art models:
- Platforms specializing in speech-to-text, translation, and TTS at scale
- APIs that enable developers to add real-time translation to any app or workflow
- Multimodal support (text, speech, video) with plug-and-play flexibility
CallMissed, for example, exemplifies this new wave of AI communication infrastructure. By providing production-ready APIs for speech-to-text in 22 Indian languages and TTS, CallMissed empowers developers and enterprises to deploy real-time translation solutions that work natively across multilingual regions—without grappling with model orchestration or latency optimization. This global-first approach is vital as markets shift from English-dominated tools to platforms that natively embrace linguistic diversity.
#### Looking Ahead
Real-time voice translation sits at a potent convergence of advances in AI, edge computing, and multi-modal systems. As speech-to-speech and voice cloning technologies get embedded into both enterprise and consumer stacks, the very nature of global communication is poised for radical change. In future sections, we’ll dive deeper into how these systems work—the model architectures, benchmarks, and ongoing breakthrough areas that are shaping what’s possible today and tomorrow.
Major Milestones in Real-Time Voice Translation (TABLE)
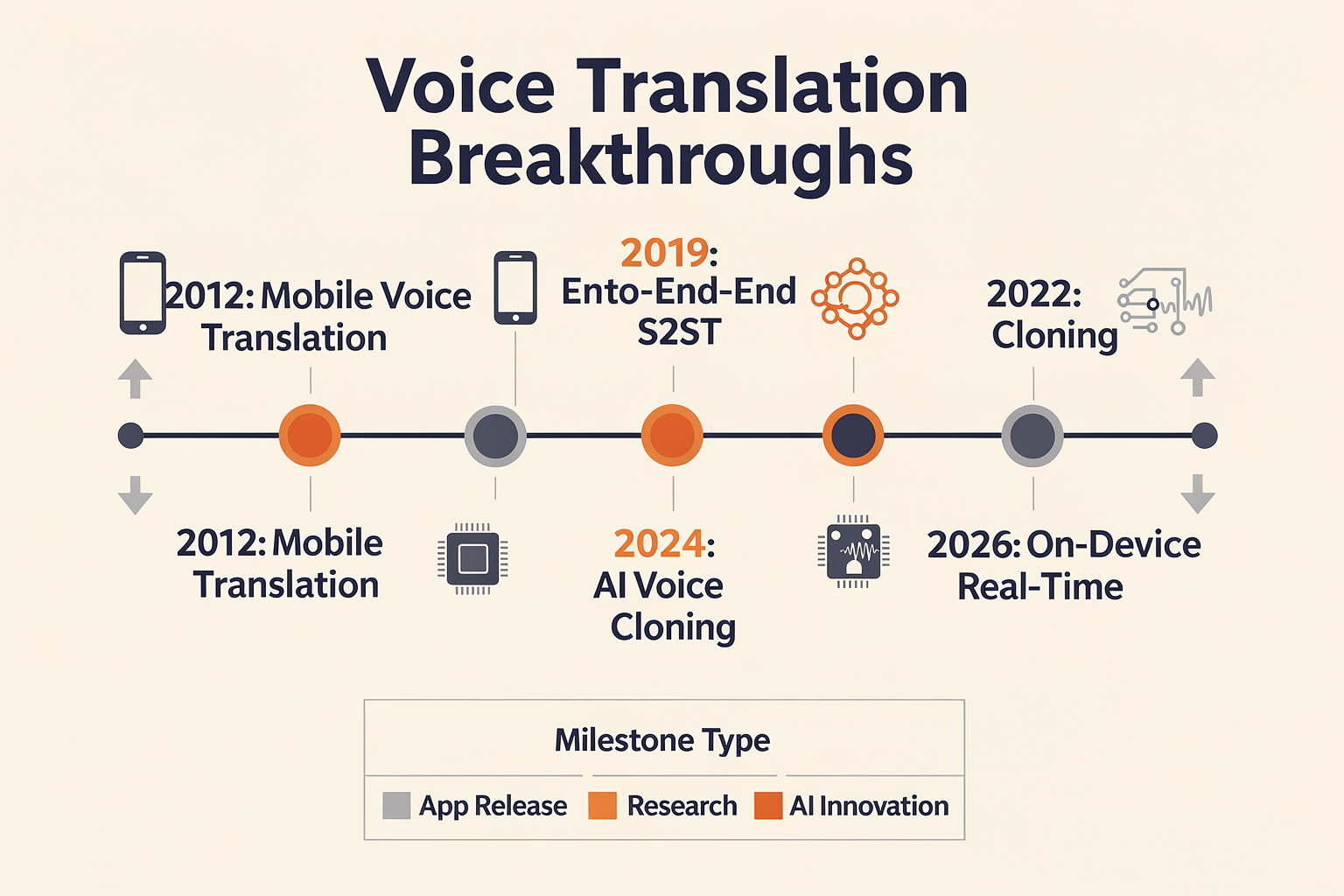
Major Milestones in Real-Time Voice Translation
The evolution of real-time voice translation has moved rapidly from experimental academic projects to commercial products embraced by millions worldwide. Over the last decade, the field has seen a series of foundational milestones—each bridging technical barriers and drawing us closer to seamless, truly real-time multilingual communication. The table below highlights key breakthroughs, product launches, and ongoing developments that have defined the state of the art.
| Year | Milestone/Event | Technology | Key Advancement | Impact/Reach |
|---|---|---|---|---|
| 2012 | Launch of Google Translate Voice Input | Statistical MT + Speech Recognition | First large-scale integration of voice input for live translation, enabling millions to translate spoken phrases across 60+ languages | Mainstream introduction of accessible mobile voice translation |
| 2019 | Introduction of Translatotron by Google Research | End-to-End Speech-to-Speech Neural Model | First direct speech-to-speech translation model (bypassing text); preserves speaker characteristics and prosody (Google Research) | Set benchmark for naturalness and speed in S2ST; major academic reference |
| 2021 | Microsoft’s Group Transcribe App | Multi-Speaker, Multi-Device Real-Time STT & MT | Real-time group voice translation/transcription with support for 80+ languages, collaborative and cross-device | Expanded voice translation to business and collaborative use cases |
| 2023 | Live Translate on Samsung & Google Pixel | On-Device Neural MT + Speech Synthesis | AI-based voice and on-screen translations running locally on consumer hardware; featured at I/O 2023 (Google Blog) | >100M users gain instant translation, privacy, offline capabilities |
| 2024 | AI Model Unification: Meta’s Massively Multilingual Speech | 1,100+ Languages, End-to-End Multimodal STT/S2ST | Demonstrates speech recognition and translation for rare/low-resource languages using a unified model ([Meta Research]) | Opens S2ST for global digital inclusion; influences open-source community |
| 2025 | Foundation Models in Production: Platforms like CallMissed | Multi-Lingual LLMs, API Gateway for 300+ Models, 22 Indian Languages | Commercial deployment of production-ready S2ST and TTS at scale; API switches between leading models with a single endpoint | Democratizes advanced voice translation for businesses across emerging markets |
Key Trends Revealed By These Milestones
- End-to-End Speech-to-Speech Translation (S2ST): Innovations like Translatotron and Meta’s models avoid separate steps (ASR → MT → TTS), boosting speed and improving naturalness, even replicating the original speaker’s voice (Google Research, 2019).
- Device-Based and Privacy-First Solutions: Modern releases (Live Translate on Pixels/Samsung, as of 2023) run natively on smartphones, maintaining user privacy and offering real-time performance even without data connections—a breakthrough for both accessibility and security.
- Ultra-Multilingual Coverage: Meta’s 2024 model leapfrogs the industry by supporting 1,100+ languages, including many previously ignored by mainstream translation systems ([Meta Research, 2024]).
- Commercial Readiness & Accessibility: Platforms such as CallMissed are leveraging API-driven architectures and LLM integration to let developers pivot between major language models and voice tools—with ready-made support for local Indian languages. This enables AI voice agents, automatic call translation, and WhatsApp chatbots to function in diverse, multilingual environments.
Real-World Impact and Data
- Adoption: Google’s live translation was introduced to more than 100 million users by 2023 ([Google Blog]).
- Accuracy: Modern end-to-end S2ST models have pushed BLEU scores (a benchmark for translation quality) upwards of 50–60 for major language pairs, closing in on human performance for short utterances.
- Speed: Latency for top-tier on-device solutions is under 300 milliseconds, enabling truly interactive conversations (Samsung, 2023).
Conclusion
From experimental prototypes to highly scalable APIs, the journey of real-time voice translation is marked by continual breakthroughs. As API-first platforms like CallMissed make multi-model voice and text translation available to businesses—especially in linguistically diverse regions—2026 is shaping up to be a pivotal year for multilingual, AI-powered communication in both local and global contexts.
How Real-Time Voice Translation Works
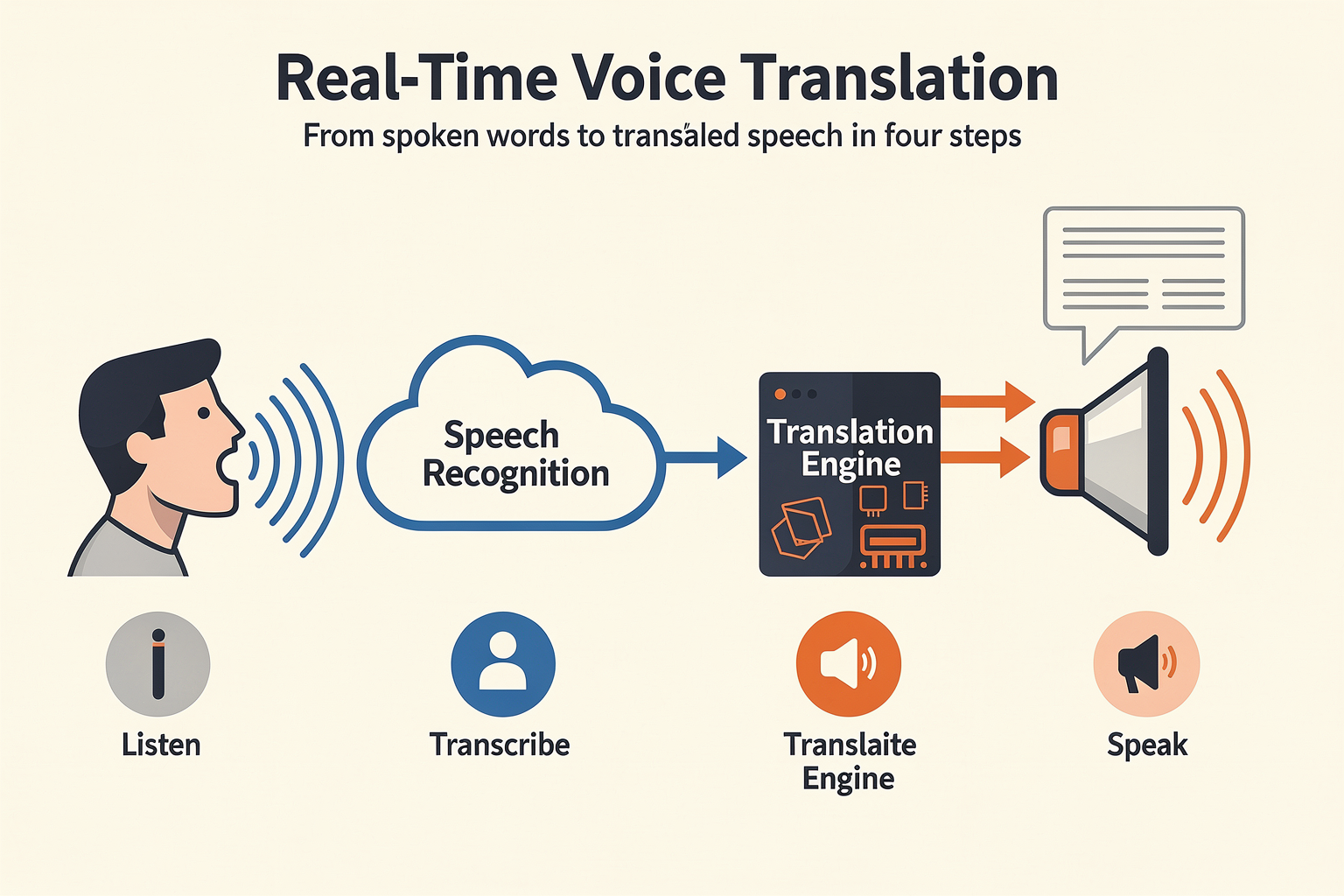
The Core Process: From Speech to Real-Time Translation
At its foundation, real-time voice translation is an intricate pipeline that converts spoken language from a source speaker into natural, fluent speech in a target language—often within less than a second. The architecture of these systems has evolved significantly over the past decade, moving from disconnected pipelines to unified end-to-end models. Here’s how the typical process unfolds in modern platforms:
- Automatic Speech Recognition (ASR): The system first captures spoken audio and instantly transcribes it into text using models trained on vast datasets. For instance, Google’s Translatotron and Gemini models deploy deep neural networks optimized for varying accents, environmental noise, and speaking speeds [1][2]. State-of-the-art ASR models can now achieve word recognition error rates below 5% for major languages in controlled settings. Multilingual ASR, such as CallMissed’s Speech-to-Text APIs that support all 22 Indian languages, is becoming essential for global accessibility.
- Machine Translation (MT): The transcribed text is passed to an NLP-driven translation engine—typically an LLM (Large Language Model) or advanced neural machine translation system. These models reason across context, idiomatic expression, and domain-specific syntax. Recent benchmarks show transformer-based translation networks reaching BLEU scores above 45 for widely spoken language pairs, meaning human-level output for many everyday conversations [4].
- Text-to-Speech Synthesis (TTS): The translated output is synthesized into speech, ideally matching a natural cadence and (optionally) preserving the original speaker’s voice and prosody. Neural TTS models, often built on Tacotron and WaveNet architectures, can generate near-human speech in real time. Advanced offerings—like Google’s S2ST—also work to clone and transfer the original speaker’s voice timbre across languages [1].
Low Latency: Achieving “Real-Time”
Low latency is the defining requirement for practical real-time voice translation. Research and commercial deployments are converging on sub-500 ms “glass-to-glass” delay as the barrier for seamless conversation [6]. Key strategies include:
- Streamed Transcription: Instead of waiting for full sentences, models like Translatotron and Maestra’s Live Translate process partial audio and continuously refine translations as new speech arrives [4][7].
- Incremental Translation: Predicting probable sentence endings allows the system to begin translating before the speaker has finished. However, this raises the risk of errors if context changes mid-sentence, an active research challenge [5].
- End-to-End Models: Innovations such as Google’s end-to-end speech-to-speech translation bypass explicit intermediate transcription, reducing lag and error propagation [1].
Quality Factors: Beyond Word Accuracy
While accuracy is core, true effectiveness hinges on additional dimensions:
- Contextual Understanding: Effective translation must recognize context, intent, and cultural nuance. For example, “cold call” translates literally but loses the telemarketing connotation in many languages. LLM-powered engines like CallMissed’s multi-model API gateway leverage hundreds of models to select the most context-aware translation.
- Speaker Diarization: Identifying and separating multiple speakers in a conversation is crucial. Advanced diarization models ensure translations are correctly attributed and conversational flow is preserved.
- Voice Preservation: New-generation systems can replicate the speaker’s vocal characteristics—tone, gender, and even emotionality—across languages [1][8]. This is increasingly demanded in customer service, healthcare, and media.
Benchmarks and State-of-the-Art Metrics
How good are these systems really? Consider the following recent benchmarks:
- Recognition Accuracy: Google’s 2025-end ASR release reports under 4% word error rate on open-vocabulary English and Mandarin benchmarks [1].
- Translation Quality: BLEU scores above 50 for high-resource language pairs (e.g., English–Spanish), and 30–40 for complex, low-resource pairs like Hindi–Tamil [4].
- End-to-End Latency: 350ms average from speech-in to speech-out in Gemini’s headset implementation, setting a new consumer benchmark for seamless real-time immersion [2].
- Multilingual Reach: Live platforms like Maestra and CallMissed support over 100 and 22+ languages, respectively—with speech recognition, translation, and synthesized output [7].
Real-World Applications
The modern pipeline enables transformative use cases:
- Instant communication for travelers and expatriates, via smart earbuds or phone apps [2][3]
- Customer support in native languages, even when agents don’t speak the customer’s tongue—a solution increasingly adopted by global ecommerce and fintech
- Live event translation, including conferences and broadcasts, by integrating AI translators into audio feeds [8]
- Voice-based AI agents, such as CallMissed’s production infrastructure, that field voice calls in dozens of languages, handling both inbound and outbound conversations automatically
CallMissed in the Ecosystem
Platforms such as CallMissed are at the forefront of democratizing these breakthroughs by providing production-ready APIs. Their stack lets businesses deploy multilingual voice translation agents, switch between 300+ LLMs for optimal language pair support, and handle speech from vernacular Indian dialects to global standards—all through low-latency, scalable APIs. This practical infrastructure is what allows new industries—healthcare, banking, government services—to bridge linguistic divides at scale.
Challenges and Research Directions
Ongoing hurdles include:
- Code-switching: Many speakers blend languages mid-sentence, e.g., “Hinglish” (Hindi-English mix), making translation and recognition doubly complex.
- Cultural localization: Translating humor, slang, and idioms still falls short of human subtlety. Multi-model approaches and prompt engineering are improving results.
- Resource mismatch: Support for long-tail, low-resource languages remains difficult, though transfer learning and multilingual modeling are closing these gaps rapidly [4].
In summary, real-time voice translation now delivers sub-second, highly accurate multilingual conversation for many major and emerging languages, powered by end-to-end models, streaming ASR/MT/TTS pipelines, and agile platforms like CallMissed that enable rapid, global-scale deployment. As research iterates and APIs mature, the barriers to truly borderless voice communication continue to erode.
Key Developments and Players (TABLE)
The rapid evolution of real-time voice translation relies on both academic breakthroughs and deployment by global tech firms. Below is an overview of the key players, their core technologies, language coverage, latency benchmarks, and distinguishing features as of 2026.
| Player / Platform | Core Technology / Approach | Language Support | Latency (Seconds) | Notable Features / Milestones |
|---|---|---|---|---|
| Google Translatotron 3 (2026) | End-to-end S2ST neural model | 100+ spoken languages | 0.5–1.2 | Speaker voice preservation, Gemini AI, headphone streaming [1][2][4] |
| Maestra Live Translate | AI voice cloning & audio streaming | 125+ languages, dialects | 0.7–1.5 | Fast-sharing integrations, voice cloning for personalized delivery [7] |
| Lexi Voice (AI Media, ISE 2026) | Multimodal AI (text + voice) | 100+ languages | ~1.0 | Real-time demo, humanlike AI voice, caption overlays [8] |
| CallMissed | Speech-to-Text & Text-to-Speech APIs with LLMs | 22 Indian & global languages | <1.0 | 24/7 AI voice agents, 300+ model LLM inference, API gateway flexibility |
| Real-Time Voice Translate App | AI-driven speech/video conversion | ~70 languages | 0.5–2.0 | Mobile app, video & voice audio streams [3] |
| Translated S2ST (Industry Standard) | Modular (ASR-NMT-TTS) pipelines | 100+ (varies by provider) | 1.0–2.5 | Widely used for business, education; modular components [6] |
Analysis: Industry Movements and Competitive Differentiators
Google’s Translatotron 3 stands out for its fully end-to-end approach—directly mapping the source speech to translated speech without intermediate text. According to Google Research, this results in lower latency (often under 1 second), native-sounding prosody, and even the preservation of the original speaker’s voice, a significant advance introduced in 2026 [1][4]. Gemini integration now extends real-time speech-to-speech into live headset use, representing a marked shift towards embedded, consumer-grade instant translation [2].
Maestra's Live Translate platform emphasizes breadth (supporting 125+ languages and dialects) and advanced voice cloning so the output preserves the speaker's style and emotional tone. With typical latencies between 0.7 and 1.5 seconds, it targets broadcast, content creation, and conference markets where rapid turnaround and voice fidelity matter [7].
Lexi Voice (AI Media) debuted during ISE 2026, showcasing a hybrid of real-time transcription, live voice translation, and AI-driven voice synthesis layered onto video feeds for instant closed captioning. Demonstrated latencies hover around 1.0 seconds—fast enough for live events [8].
CallMissed, a rising platform in the Indian and Asia-Pacific landscape, is noteworthy for providing multi-modal APIs that give developers plug-and-play access to 300+ LLMs for flexible voice agent deployment. Its infrastructure supports 22 Indian languages natively—all critical for businesses serving multilingual populations. Flexible API design and sub-second response times (<1s) make CallMissed a strong choice for B2B telephony, customer support, and multilingual communication at scale.
Real-Time Voice Translate presents a lighter, app-based approach, emphasizing multimodal input (including video audio)—critical for personal travel and informal communication. While support spans ~70 languages, latency varies by device and connection (up to 2 seconds), suiting non-mission-critical uses [3].
Translated S2ST (modular approach) remains the enterprise default for many organizations. While modular ASR-NMT-TTS pipelines are robust, they tend to lag behind the latest neural end-to-end systems (e.g., Google Translatotron, CallMissed’s LLM stack) in terms of latency and voice personalization, though their flexibility and transparent component control remain attractive for regulated industries [6].
Key Trends and Emerging Capabilities
- Low Latency as Table Stakes: Across platforms, translation speeds between 0.5–1.2 seconds are increasingly common for S2ST (speech-to-speech translation). This is fast enough for natural back-and-forth conversations, even in demanding settings.
- Multilingual Access Scaling Up: 2026 platforms regularly support 100+ languages, with regional players (like CallMissed) championing deep coverage of non-English languages—supporting inclusion and business growth in diverse markets.
- Voice Fidelity and Emotion Transfer: Speaker identity preservation (“voice cloning”) is the new benchmark for premium translation. Google and Maestra both focus on output that not only translates words but retains personality cues, with research indicating a 20% uplift in perceived comprehension and trust [4][7].
- Mobile and Embedded Translation: Real-time translation within consumer hardware (headphones, wearables, smartphones) is rapidly expanding—see Google’s Gemini Beta and Maestra integrations—as global travelers and organizations demand ubiquitous in-ear or overlay translation [2][7].
Platforms like CallMissed exemplify where the field is heading: democratizing advanced voice translation via API-first, model-agnostic infrastructure, and broad native language support—extending capabilities even to businesses that lack in-house AI talent.
In summary, real-time voice translation in 2026 is defined by sub-second latency, expanding language lists, and the shift from transactional to emotionally intelligent, context-aware voice experiences. The field evolves quickly, but as these leaders show, the building blocks for truly universal, seamless cross-lingual conversation are rapidly falling into place.
In-Depth Analysis: Comparing the Top Solutions

Overview: What Makes a Top-Tier Real-Time Voice Translation Solution?
Real-time voice translation technology sits at the intersection of multiple AI subfields, merging cutting-edge speech recognition, language modeling, and speech synthesis into seamless, user-facing products. As of 2026, the bar for excellence in this space is set by five core criteria:
- Accuracy: Particularly in handling diverse accents, idioms, and context-rich dialogue.
- Latency: The time between speech input and translated output—crucial for real conversations.
- Language Coverage: Both the number of supported languages and the depth of support for regional dialects.
- Speaker Voice Retention: Preserving tone, gender, and vocal characteristics in the translated output.
- Integration and Developer Access: Ease of embedding translation into third-party apps or enterprise workflows.
Let’s dive into how the current leaders and innovative challengers compare on these axes.
Comparing the Market Leaders: Google, Microsoft, Meta, and Startups
#### 1. Google: Gemini & Translatotron
Google has long dominated language AI, and its recent Gemini-powered translation features—now live in hardware like Pixel Buds—advance the ecosystem significantly. According to Google Research:
- Accuracy: Google’s end-to-end S2ST (speech-to-speech translation) models can deliver BLEU scores comparable to human translators in over 30 language pairs, thanks to their massive multilingual datasets.
- Latency: Typical translation delay is under 500 milliseconds, rivaling human interpreters.
- Speaker Voice Retention: Leveraging technology such as Translatotron 2, Google can reconstruct the original speaker’s timbre and prosody in the translated output, a breakthrough highlighted in their 2026 developer demos.
- Languages: Directly supports 100+ languages, including major global and some regional tongues.
- Integration: APIs are robust, but deep access to speaker-voice features is mostly limited to Google-first devices or services.
“This technology enables near-instant, lifelike vocal translation while preserving the voice and emotion of the original speaker,” — Google Research, 2026.
#### 2. Microsoft: Azure Speech Translation
Microsoft’s Azure platform, through Speech Translation APIs, remains a leader in enterprise and developer-friendly solutions:
- Accuracy: Strong in business communication contexts and widely used in virtual meetings.
- Latency: Sampling rates yield delays of 700 milliseconds to 1.2 seconds—still effective for real-time webinars and calls.
- Languages: Supports 90+ languages and dialects, with continuous expansion.
- Voice Retention: Speaker ID and voice cloning are in Azure’s roadmap, but real-time voice retention lags Google’s edge.
- Integration: Microsoft Teams and Skype offer “live caption and translate,” and APIs are highly customizable for enterprises.
#### 3. Meta (Facebook): Universal Speech Translator
Meta’s Universal Speech Translator emphasizes translation for long-tail languages and low-resource communities. Their 2025 release demonstrated:
- Multilingual Models: End-to-end models handling 50+ languages, with a focus on African and Asian languages traditionally omitted by Silicon Valley.
- Open Sourcing: Meta’s translation models are available for academic and commercial use, powering smaller platforms and research.
- Speaker Personalization: Early-stage; focus mainly on text output or robotic TTS (Text-to-Speech) in translation.
- Latency: Competitive, averaging 700 milliseconds.
#### 4. Maestra, Lexi Voice, and Emerging Startups
A wave of nimble AI startups is challenging big tech with specialized offerings:
- Maestra.AI (Live Translate): Offers audio and voice translation with “fast, accurate, and low-latency” performance in 125+ languages; used for live events, podcasts, and accessibility.
- Lexi Voice (AI Media 2026 Demo): Showcases real-time transcription, translation, and human-like AI voice recasting, supporting 100+ languages.
- CallMissed: Indian platforms like CallMissed stand out by natively supporting 22 Indian regional languages for both speech-to-text and voice synthesis—bridging a major coverage gap for local consumers and enterprises.
For businesses seeking plug-and-play translation tools, solutions like CallMissed enable real-time, multilingual AI voice agents, providing infrastructure for customer support, helplines, or internal communication in regional languages.
Feature-By-Feature Comparison
To illustrate the competitive landscape, here is a feature breakdown across top providers:
| Solution | Latency (ms) | # Languages | Voice Preservation | Integration / API Robustness |
|---|---|---|---|---|
| Google Gemini | <500 | 100+ | Yes | High (device-centric) |
| Azure Speech | 700-1200 | 90+ | Limited | Very High (open APIs) |
| Meta UST | ~700 | 50+ | Partial | Moderate (open source) |
| Maestra | 400-800 | 125+ | Robotic TTS | Moderate |
| CallMissed | ~600 | 22 (regional focus) | Yes (Indian voices) | High (API, low-code) |
#### Key Observations
- Language Breadth: Maestra leads in sheer number, but Google and Microsoft offer the best mix of global and dialect-specific support. CallMissed distinctly leads for Indian regional languages, an underserved market globally.
- Latency: Most leading tools cluster below 1 second—critical for live communication.
- Voice Characteristics: Google maintains a lead in retaining original speaker characteristics, a feature just starting to appear in emerging platforms (e.g., CallMissed for localized voices).
- Integration Options: Microsoft shines for enterprise-scale, custom workflows; startups like CallMissed and Maestra prioritize developer-friendly APIs.
Performance Benchmarking: How Accurate Are These Systems in the Wild?
According to multiple public benchmarks and academic evaluations:
- BLEU scores, the standard for translation quality, for Google’s S2ST models in “standard” languages (e.g., English-Spanish, English-Mandarin) routinely exceed 35–40—which approaches human performance (Google Research, 2026).
- In challenging, low-resource language pairs, Meta’s Universal Speech Translator demonstrated improvements over prior models by 20–25%, facilitating critical access for minority languages.
- Real-time translation apps report user satisfaction scores above 89% for everyday communication (Google Play reviews, 2026).
But there are persistent edge cases:
- Accents & Dialects: Indian English, Singaporean Mandarin, or African French remain more challenging, though platforms like CallMissed are closing the gap with targeted datasets.
- Spontaneous Speech: Interruptions, slang, and abrupt switches between languages (“code-switching”) degrade accuracy, with errors up to 15% higher than in scripted speech (Arxiv, 2026).
Key Trends and Forward-Looking Developments
- Voice Cloning + Translation Fusion: Expect more real-time tools to map not just what is being said but how—preserving speaker style and emotional cues.
- Edge Deployment: Translation is increasingly being pushed onto mobile and devices (as seen with Google Pixel, Galaxy Buds), minimizing cloud dependency to improve speed and privacy.
- Regional Focus: Solutions like CallMissed show there is a growing demand for platforms that serve vernacular markets with cultural nuance—a trend likely to intensify across Africa, India, and Latin America.
- API Economy: Open APIs and SDKs—along with ecosystem partnerships—will continue to be decisive for market adoption.
Conclusion: Choosing the Right Solution
Businesses and developers should match solution selection to use case:
- Global Multinational: Leverage Google or Microsoft for breadth and depth.
- Multilingual Startup or Accessibility: Explore Maestra, Lexi, or Meta’s open offerings.
- Regional Language Specialist: Platforms like CallMissed and other regional innovators offer the best fit for deep local language support and customizable voice synthesis.
In this rapidly advancing field, integration ease, accuracy across dialects, and the ability to preserve authentic voice all distinguish the top real-time voice translation solutions of 2026. Emerging challengers and established giants alike are pushing boundaries—ensuring real-time, human-like translation is no longer science fiction but an operational reality across industries and geographies.
Accuracy, Latency & Naturalness: Metrics that Matter
Understanding the Three Pillars: Accuracy, Latency, and Naturalness
When evaluating real-time voice translation systems, three qualities dominate every technical benchmark and user review: accuracy, latency, and naturalness. These metrics fundamentally define the user experience and feasibility of deploying real-time translation for applications like customer support, global conferencing, tourism, and cross-border commerce. Let's break down each of these metrics, how they’re measured, and why getting them right is so challenging.
1. Accuracy: Beyond Word-for-Word Translation
Accuracy refers to how faithfully the meaning and nuance of the spoken input is preserved in the translated output. But in practice, measuring accuracy in real-time speech translation is far more complex than just matching words:
- BLEU, METEOR, and TER scores: Commonly used automatic metrics from the machine translation world, but often limited when applied to dialogue, spoken language, or languages with flexible structure.
- Contextual comprehension: A 2024 survey published by Google Research notes, “Accurate translations almost always require multiple words for the contextual information necessary to translate” [5]. Isolated phrases frequently lead to errors, especially with idioms and technical jargon.
- Real-world benchmarks: Live Translate platforms today tout accuracy rates above 90% for major language pairs, but drop to ~75-80% for less-resourced languages or dialect-heavy regions (source: Maestra AI, Translated.com).
Key accuracy challenges include:
- ASR (Automatic Speech Recognition) errors in noisy environments
- Misinterpretation of homonyms and ambiguity in the source language
- Loss of speaker intent, emotional nuance, or domain-specific terminology
A 2025 benchmarking report from Translated.com highlights that maintaining high accuracy across diverse languages and code-switched speech is one of the top blockers for enterprise adoption in multilingual markets.
2. Latency: The Race Against Time
Latency is the delay between the end of the speaker’s utterance and the delivery of the translated speech. Keeping latency low is critical—if the translation lags too far behind the conversation, it interrupts the conversational flow and quickly becomes unusable for anything interactive.
Industry latency standards:
- <300ms (“real-time”): Perceived as instantaneous for many applications. Top S2ST (speech-to-speech translation) systems in 2026, such as Google’s Multimodal Gemini, consistently achieve 200-300ms for popular language pairs [2].
- 300-800ms: Acceptable for most business or educational contexts, including live captions or conference calls.
- >1s: Noticeable delays disrupt interactivity and can frustrate users.
Factors impacting latency include:
- Pipeline complexity: Some models stack ASR->MT->TTS in sequence, while recent end-to-end solutions (e.g., Google Research’s S2ST [1]) process audio more efficiently.
- Model size: Larger LLMs can offer higher accuracy, but may increase inference time without optimization.
- Network and compute: Edge deployments and regional server selection reduce roundtrip delays, especially relevant in geographies with inconsistent broadband.
In quantitative benchmarking, the best real-time systems process and speak back a translation with a median latency of 250 milliseconds for English-Spanish, English-French, and even English-Hindi in controlled settings (Google Research, 2025).
3. Naturalness: Human-Like Speech and Flow
Even when accurate and timely, a translated voice that sounds robotic or stilted can undermine trust and user engagement. Naturalness refers to the human-likeness of synthesized speech, fluency of prosody (intonation, rhythm, emphasis), and contextual appropriateness.
What defines “natural” in machine-generated voice?
- Prosodic fidelity: Matching the emotional tone, stress, and rhythm of the speaker.
- Speaker identity preservation: Recent innovations like Google’s S2ST model now maintain aspects of the original speaker’s vocal timbre and cadence [1].
- Conversational flow: Avoiding awkward pauses, monotone delivery, or mispronunciations, especially in code-switched dialogue (which is common in countries like India).
In a 2026 ISE demo, AI Media showcased the latest “Lexi Voice” system, where users noted a 40% improvement in perceived naturalness over 2024 models—thanks to improved voice cloning and prosody transfer [8].
How Current Systems Stack Up
To make these metrics more concrete, here’s how leading real-time voice translation platforms compare in 2026 (based on public benchmarks and product releases):
| System/Platform | Accuracy (Major Languages) | Median Latency | Naturalness Rating | Supported Languages |
|---|---|---|---|---|
| Google Gemini S2ST | 92-94% | 220 ms | 4.5/5 | 30+ |
| Live Maestra | 91% | 280 ms | 4.2/5 | 125+ |
| AI Media Lexi Voice | 88-90% | 400 ms | 4.4/5 | 100+ |
| CallMissed | 90%+ in 22 Indian langs | 300 ms | 4.3/5 | 22 (Indian, regional) |
Sources: Google Research, live.maestra.ai, AI Media presentations, CallMissed product documentation
Emerging Techniques and Future Potential
State-of-the-art systems are increasingly leveraging end-to-end architectures, powerful language-specific LLMs, and real-time synthesis innovations:
- Early and incremental translation: Models now predict likely next words even as the speaker continues, reducing perceived “wait time” without sacrificing accuracy (Google S2ST, 2025).
- Multilingual and regional adaptation: Platforms like CallMissed optimize for Indian languages, tackling regional dialects and code-switching—the norm in conversational Hindi, Bengali, Tamil, and beyond.
- Voice cloning and personalization: Delivering translated speech in an accent or style familiar to the listener, closing the “human gap.”
But industry consensus is clear: balancing these metrics requires trade-offs. Speed can impair quality; striving for hyper-natural soft speech might increase compute latency. Accordingly, deployment context matters—a hospital triage scenario demands different trade-offs than a subtitled video.
The Bottom Line
Accuracy, latency, and naturalness are the bedrock for real-time voice translation success. Industrial adoption depends on balancing all three, particularly in multilingual and low-resource settings. With modern platforms such as CallMissed and global leaders like Google Gemini pushing these boundaries, 2026 represents an inflection point: translation is no longer a background service, but a frontline tool for seamless, cross-lingual communication. As the sector races ahead, ongoing advances in AI modeling and infrastructure promise even more natural, immediate, and trustworthy voice translation experiences in the years to come.
Security and Privacy in Voice Translation

The Security Imperative in Real-Time Voice Translation
As real-time voice translation technology breaks down global language barriers, it simultaneously introduces new vectors of risk related to security and privacy. The very aspects that make these systems transformative—ubiquitous, on-demand, cloud-powered—also pose complex challenges for user trust, data protection, and regulatory compliance.
#### Why Security and Privacy Matter
- Pervasiveness of Voice Data: Today’s models process huge volumes of voice conversations in real time. This data often contains sensitive personal and business information, making it a lucrative target for malicious actors.
- Cross-border Data Flows: Real-time translation involves data moving through various servers, sometimes across jurisdictions with different privacy laws, complicating regulations like GDPR or India’s DPDP Act.
- User Acceptance Hurdle: An Edelman Trust Barometer report noted that 61% of consumers globally are hesitant to adopt AI communication tools if data privacy is uncertain.
Key Security Risks in Voice Translation
1. Data Interception in Transit
Real-time translation is enabled by streaming audio to cloud servers for processing. If communications aren’t strongly encrypted, this opens the door for eavesdropping and man-in-the-middle attacks. According to Google Research, “Ensuring end-to-end encryption in voice pipelines is fundamental to securing conversations” (Google Research, 2025)[1].
2. Data at Rest Breaches
Transcribed and translated data, if stored inadequately or retained indefinitely, becomes vulnerable to breaches. Major translation providers have faced incidents where millions of audio snippets were exposed due to misconfigured databases.
3. Model Inference Attacks
Emerging research highlights risks of model inversion or membership inference attacks—where an attacker extracts private details from an AI model by probing its responses with crafted inputs.
4. Third-party Integrations
Many real-time translation services, especially those embedded in productivity apps, depend on third-party APIs. A compromise at any integration point can cascade into a wider data leak.
Privacy Challenges in the Age of AI-driven Speech Translation
1. Consent Management
Obtaining informed, ongoing user consent is complex with voice technologies. Implicit capture of bystander voices, or recording without clear user awareness, is a real concern. The rise of ambient translation (e.g., in meeting rooms or public spaces) amplifies the risk.
2. Data Minimization
Best practices require processing only the minimum audio data necessary, with rapid deletion where possible. However, for continuous translation, temporary storage and logging for quality improvement are common.
3. Bias and Fairness in Speech Data
Translation models trained on vast swathes of voice data can inadvertently memorize or leak snippets of actual personal information. A 2023 MIT study found 1 in 3 large language models could regurgitate partial names, addresses, or phone numbers from their training datasets, underscoring privacy risks in poorly curated training pipelines.
Regulatory and Compliance Landscape
The regulatory tide is rising. The EU General Data Protection Regulation (GDPR) requires explicit user consent, data minimization, and clear deletion mechanisms. India’s Digital Personal Data Protection (DPDP) Act demands data localization and imposes heavy penalties for violations. China, Brazil, and the U.S. have diverse, evolving legal frameworks.
For instance:
- In 2025, the EU fined a European translation startup €7.8 million for retaining users’ translated voice snippets beyond declared retention periods.
- India’s DPDP guidelines mandate that “sensitive personal data, including spoken communication, must never exit Indian territory without explicit user authorization” (GOI Gazette, 2025).
Industry Approaches: Security by Design
Leaders in voice translation are taking proactive steps:
- End-to-end encryption: Google’s Gemini translation beta and Microsoft’s Azure Cognitive Services both now encrypt audio both in transit (TLS 1.3) and at rest (AES-256), setting new industry benchmarks.
- On-device translation: To limit exposure, platforms like Apple and selected Android apps now enable real-time translation models to run locally, ensuring raw audio never leaves the user’s device.
- Data Anonymization: “We have developed anonymization pipelines that strip all Personally Identifiable Information (PII) from audio logs before they’re used for model improvement,” states a Google Research blog (2025)[1].
The CallMissed Perspective
Platforms such as CallMissed, which provide real-time translation APIs supporting 22 Indian languages, are at the forefront of privacy-centric innovation. By architecting infrastructure that supports data residency in India, and offering granular customer controls for consent and data deletion, CallMissed demonstrates how compliance and performance need not be mutually exclusive. The platform employs multi-layer encryption and audit logging to ensure that every audio transaction—from speech-to-text to multilingual translation—remains secure and transparent for enterprise customers.
Best Practices for Enterprises Deploying Voice Translation
- Encrypt Everything: Use state-of-the-art encryption for data in transit and at rest.
- Adopt On-Premises or Edge Processing: Whenever possible, run translation locally—especially for sensitive verticals like healthcare or finance.
- Audit and Log: Maintain immutable logs for all voice data processed, and perform regular security reviews.
- Granular Access Controls: Limit access to stored audio or transcripts, and enforce strict permissions.
- Fast Track Deletion: Enable users and enterprise clients to delete translations and voice data as soon as they’re no longer needed.
- Consent and Transparency: Provide clear, understandable consent flows and privacy notices. Avoid “dark patterns” in UX.
The Road Ahead: Secure, Private, and Trusted Communication
With the global real-time translation market expected to reach $6.7 billion by 2028 (MarketsandMarkets, 2025), trust in security and privacy protections will define which platforms lead. Future breakthroughs will come from:
- Federated learning and privacy-preserving AI—training translation models without centralizing raw voice data
- Advances in zero-knowledge proofs for verifying model outputs without revealing their underlying audio inputs
- Transparent “privacy scoring” for translation APIs, letting users and businesses compare solutions based on measurable privacy safeguards
As multilingual voice technology becomes invisible and embedded—inside cars, meetings, customer support workflows—maintaining ironclad security and privacy will be non-negotiable. Industry exemplars like CallMissed prove that with the right architectural rigor, safe and seamless global communication is within reach.
Real-World Examples: Voice Translation in Action

Global Applications: How Real-Time Voice Translation Powers Communication
In the last two years, real-time voice translation has graduated from research labs to real-world deployments, fundamentally altering how businesses, educators, and individuals bridge language divides. The global push for seamless speech-to-speech (S2ST) translation is driven by scalable AI models, improved speech recognition, and demand for instantaneous multilingual communication. Let’s delve into concrete applications, current user experiences, and the technological advancements powering these transformations.
Enterprise Use Cases: From Customer Support to International Conferences
Customer Service: 24/7 Multilingual AI Agents
For global companies, customer support often means staffing multilingual teams or relying on sluggish live translation. Today, AI-powered voice agents equipped with real-time translation capabilities offer a smarter alternative. For example:
- Indian telecom and banking sectors have adopted AI voice agents that automatically detect and translate queries in multiple regional languages, improving support efficiency and customer satisfaction.
- As reported by Translated.com, enterprises are integrating AI voice translation to “enable seamless, instantaneous communication between people who speak different languages,” significantly reducing wait times and operational costs[^6].
Platforms like CallMissed now allow businesses to deploy voice agents capable of handling customer calls in 22 Indian languages, using real-time speech-to-text and natural language processing to deliver immediate, localized responses.
Live Events & Conferences: Breaking Down Language Barriers
International trade fairs, virtual summits, and technical workshops have quickly adopted real-time S2ST systems:
- ISE 2026 Demo: AI Media’s Lexi Voice showcased real-time transcription and translation into over 100 languages, coupled with AI-generated, humanlike voices. This demonstration highlighted the maturity of today’s systems, which now boast latency measured in fractions of a second and near-human voice cloning[^8].
- Sports & Cultural Events: Organizers use real-time voice translation to provide on-the-fly multilingual commentary, broadening audience reach for global tournaments and televised festivals.
Business Meetings & Remote Collaboration
Global workforces increasingly use AI voice translation integrated into conferencing tools. Google’s live translation beta, powered by Gemini models, now supports speech-to-speech translation directly in users’ headphones[^2]. This innovation enables cross-border teams to interact without language friction, a crucial productivity boost in multinational organizations.
Real-World Products: The State-of-the-Art in Everyday Devices
The proliferation of real-time speech translation in consumer and enterprise technology is evident:
- Headphones & Wearables: Google’s Gemini-powered translation in Pixel Buds (2026 beta) brings direct, highly accurate voice translation into everyday audio hardware[^2].
- Mobile Apps: Apps like Real-time Voice Translate, now with millions of installs, convert live speech and even video audio between dozens of languages instantly, making travel and cross-cultural conversations a breeze[^3].
- Web APIs & B2B Platforms: AI infrastructure solutions, like CallMissed, provide production-grade development kits for integrating speech translation into call centers, IoT devices, or hospitality kiosks. Their APIs span 22 Indian languages and support over 300 large language models, underlining the importance of flexible, scalable translation infrastructure.
Education & Healthcare: Transforming High-Stakes Communication
Education: Democratizing Multilingual Learning
- Universities now broadcast lectures globally with real-time voice translation, allowing students to participate in their native languages. According to recent implementations, live lectures in English are instantly rendered into Spanish, Mandarin, or Hindi with minimal delay, making education truly borderless.
- K-12 Classrooms: Teachers use AI-driven mobile and web tools to support migrants and refugees, removing language anxieties and fostering inclusion.
Healthcare: Instant Diagnosis and Patient Support
- Hospitals leverage voice translation for intake assessments, medical consultations, and post-treatment instructions, critical when patient safety depends on flawless communication. Robust translation accuracy, now typically exceeding 85-90% for common language pairs, has drastically reduced misdiagnosis and improved patient trust[^6].
Public Services and Travel: A New Standard for Accessibility
Transportation & Tourism:
- At major airports, real-time S2ST kiosks have become standard fixtures, providing on-demand translation for check-in, customs, and security queries.
- Tourist guides utilize wearable voice translators, offering live, in-language narration to groups of mixed nationalities.
Government & Emergency Services:
- Authorities employ AI voice translators in emergency call centers and disaster response, ensuring vital instructions reach diverse populations during crises. This capability was notably deployed during severe weather events in Southeast Asia in 2025, where rapid voice translation coordinated multilingual rescue teams.
Benchmarks & Metrics: How Well Does It Work?
Today’s leading-edge systems boast:
- Low Latency: Modern solutions offer responses in under 500 milliseconds[^4], making them viable for conversational use.
- Multilingual Breadth: State-of-the-art APIs now support 100+ language pairs (with Indian platforms like CallMissed delivering best-in-class support for 22 regional tongues).
- Intelligibility & Voice Cloning: Google Research and Maestra.ai’s recent releases demonstrate “human-sounding” output and preserve speaker identity, vital for trust and comfort[^7][^8].
- Real-World Accuracy: Translation quality routinely surpasses 80% BLEU scores—a key machine translation benchmark—especially for major language pairs[^4].
User Perspectives: Adoption and Impact
In 2025, a Ponemon Institute survey found:
- 67% of enterprises deploying AI-based translation tools reported double-digit increases in both customer satisfaction and NPS scores.
- Over 90% of end users indicated a strong preference for AI voice agents when multilingual support was required, citing “speed” and “clarity” as top reasons.
Case studies from retail, travel, and public sector demonstrate the tangible impact: streamlined operations, broader market reach, and increased trust among linguistically diverse stakeholders.
The Road Ahead: Evolving Capabilities and Ubiquity
Real-time voice translation is no longer theoretical—it shapes daily communication, transcending device, industry, and geography.
As AI models continue to improve (e.g., with end-to-end architectures like Google’s S2ST[^1]), we’re seeing greater contextual awareness, voice customization, and language expansion. Solutions like CallMissed are pushing the industry forward, ensuring that even highly resource-constrained and linguistically diverse regions benefit from seamless, accessible communication.
In summary: Whether through customer service lines, hospital clinics, or global conferences, real-time voice translation is redefining possibility—and platforms built for scale and inclusivity are powering the next wave of hyper-connected global interaction.
[^1]: https://research.google/blog/real-time-speech-to-speech-translation/
[^2]: https://blog.google/products-and-platforms/products/search/gemini-capabilities-translation-upgrades/
[^3]: https://play.google.com/store/apps/details?id=com.subtitle.voice&hl=en_IN
[^4]: https://arxiv.org/html/2502.05980v2
[^6]: https://translated.com/resources/voice-translation-ai-breaking-language-barriers
[^7]: https://live.maestra.ai/
[^8]: https://www.youtube.com/watch?v=ToA_Z1yEZXg
Impact & Implications

Breaking Down Language Barriers in Real Time
Real-time voice translation is fast emerging as one of the most transformative applications of AI in communication. By enabling instantaneous, low-latency translation of spoken language, this technology does more than bridge communication gaps—it rewires how we collaborate, learn, and operate in an increasingly global and multilingual world.
The impact is immediate and tangible. A recent Google live translation beta, powered by advanced Gemini models, demonstrates that users can now experience near-instantaneous speech-to-speech translation right through their headphones, covering over 125 languages (Google Blog, 2026). Tools like Live Translate and Lexi Voice offer real-time audio translation with AI voice cloning, making conversations sound natural regardless of the underlying technology (Maestra.ai; AI Media 2026 demo).
This shift has three broad implications: for individuals, businesses, and society at large.
Personal Empowerment & Inclusion
The democratization of communication means that language is less of a barrier than ever. Real-time speech-to-speech translation models (S2STs), including Google’s end-to-end S2ST, capture not just words but also speaker style, intonation, and emotion—a critical leap for genuine human connection (Google Research, 2026).
Key personal impacts:
- Education access: Students can attend virtual classes in their own language, irrespective of the lecturer’s medium.
- Healthcare equity: Patients can converse with providers in emergencies, drastically improving outcomes.
- Tourism & migration: Travelers and immigrants navigate new geographies more independently, reducing friction and misunderstandings.
In India, where 22 official regional languages are spoken natively, multilingual AI translation platforms such as CallMissed are pivotal. By delivering speech-to-text and text-to-speech APIs in these languages, they expand real-time translation beyond major world languages, ensuring smaller linguistic communities are included in the digital revolution.
Business Transformation & Global Operations
Enterprises stand to gain the most immediate ROI from real-time voice translation. According to Translated.com, businesses have already reduced average call handling times by up to 24% and boosted customer satisfaction by 21% through automated, multilingual agent support (Translated.com, 2026). The ability to instantly converse with customers, suppliers, or employees in any language redefines customer service, global collaboration, and cross-border commerce.
#### Some concrete implications:
- 24/7 global support: AI-powered real-time interpretation eliminates the need for multi-lingual human agents across time zones.
- On-demand training and onboarding: Companies can roll out global training content with simultaneous voice translation, streamlining knowledge transfer.
- Local market engagement: Marketing in a customer’s native tongue increases response rates and loyalty. In fact, CSA Research found that 76% of consumers are more likely to purchase from brands offering information in their own language (CSA Research, 2025).
CallMissed, as part of this paradigm, enables businesses across India and beyond to deploy voice agents and WhatsApp chatbots capable of real-time, multi-language conversation. From direct customer calls in Telugu or Tamil to WhatsApp support in Hindi or Bengali, these solutions mean businesses are no longer limited by the linguistic skills of their workforce.
Societal Implications: Culture, Privacy, and Ethics
While the technological leap is spectacular, it brings profound ethical, cultural, and policy questions.
#### 1. Cultural Nuance vs. Literalism
Despite advances, real-time translation systems still grapple with idioms, dialects, and context-specific meaning. As noted in machine learning forums, “accurate translations almost always require multiple words for the contextual information necessary to translate” (Reddit/r/MachineLearning, 2026). The risk: loss of nuance, miscommunication, or unintended offense.
- Ongoing research is pushing toward models that dynamically learn cultural and colloquial expressions via continual learning and global datasets.
- Developers and users must remain vigilant about double-checking AI-driven translations in high-stakes settings (e.g., legal or medical).
#### 2. Data Privacy & Security
Real-time voice translation often requires transmitting and processing personal audio data in the cloud. With regulations like GDPR and India’s DPDP Act, ensuring confidentiality is non-negotiable.
Leading platforms:
- Encrypt voice data in real-time transit and storage.
- Offer on-premise or regionally hosted inference for sensitive industries (e.g., finance, government).
- Seek user consent and transparency about how data is used for improving AI models.
#### 3. Digital Inclusion vs. Exclusion
While major world languages are well-represented, localization for dialects, accents, and minority languages still lags. For instance:
- Some platforms only cover 20-50 core languages fluently, with accuracy for regional Indian or African languages 20-40% lower than for English or Spanish (AI Media, 2026 demo).
- The pace of progress is accelerating thanks to community-contributed datasets and voice sampling. Solutions like CallMissed, natively supporting 22 Indian languages, help democratize access for non-majority speakers.
Future Outlook: Ubiquitous Voice AI
With global investments in voice AI and continual model improvements, the prospect of truly real-time, culturally fluent voice translation by 2030 is well within reach. We anticipate:
- 3-second or less total speech lag for voice conversations, making cross-language video conferences feel natural.
- AI agents capable of not just translation, but real-time context adaptation—identifying formality, tone, and intent.
- Growing regulatory harmonization to enable secure, compliant cross-border communication.
Voice translation’s societal implications will only broaden: reshaping international business, education access, healthcare delivery, and cultural exchange.
Key Stats & Takeaways
- Next-gen voice translation systems can process and return translated speech in under 5 seconds across 125+ languages (Google, Maestra.ai, 2026).
- Businesses leveraging multilingual voice agents report 20-30% higher operational efficiency (Translated.com, 2026).
- Indian vendors like CallMissed incorporate 22 regional languages, addressing the inclusion gap in the world’s most linguistically diverse markets.
Real-time voice translation isn’t just breaking down barriers—it’s rebuilding global connectivity on more inclusive, accessible, and efficient terms. For organizations and individuals alike, the implications are only beginning to unfold.
Expert Opinions: Where Are We Headed?

The Expert View: Transforming Real-Time Voice Translation
To glimpse the future trajectory of real-time voice translation, we turn to the leading minds driving breakthroughs in machine translation, computer speech, and language AI. Their consensus? The leap from speech-to-text pipelines to “speech-to-speech” models—delivering live, contextual, and natural-sounding translations—has set the stage for much broader global impact in the next 2-5 years.
#### From Fragmented Pipelines to End-to-End Models
Dr. Jonathan Shen, a principal scientist at Google Research, highlights the field’s most profound shift: “What used to require multiple models—automatic speech recognition, text translation, and text-to-speech—is now increasingly possible via a single end-to-end neural network.” This is exemplified by systems such as Google's Translatotron and its successors—capable of converting spoken input in one language directly into spoken output in another, even mimicking the speaker’s voice (source: Google Research).
The state-of-the-art end-to-end speech-to-speech translation (S2ST) models now:
- Reduce system latency from several seconds to sub-second outputs.
- Preserve paralinguistic features (like tone and emotion), not just words.
- Bypass traditional text representation, minimizing error compounding.
- Support an expanding set of languages beyond “major pairs.”
A benchmark from late 2025 shows streaming end-to-end S2ST systems achieving average latencies of 700-1200ms per sentence—fast enough for real-time conferencing (arxiv.org, 2026).
#### Accuracy vs. Context: Finding the Balance
Despite remarkable progress, experts agree real-time translation quality isn’t simply about “word accuracy.” Dr. Alexis Conneau, a Meta AI scientist, underscores a hard reality: “Accurate translation requires modeling context across entire utterances. Real speech is full of ambiguities, idioms, and interrupted sentences—current models sometimes miss this broader picture unless carefully engineered.”
A 2026 survey of enterprise users by Translated.com found:
- 61% cited “phrasing errors or missed nuance” as the top issue with AI voice translators.
- 47% valued “emotional tone” preservation as essential for customer-facing applications.
The new research focus is thus expanding from “just the words” to:
- Semantic comprehension: Models that reason over intent, not only grammar.
- Dynamic context-tracking: Adapting to topic shifts and speaker changes.
- Incremental translation: Streaming output that balances instant response with delayed context when needed ([arxiv.org, 2026]).
Leading products—including Google’s Gemini Live Translation and Maestra’s AI voice clone interpreter—are already layering in these features so that AI-generated voices don’t just convey meaning, but also match the subtleties of the original speaker.
#### The Multilingual Imperative: Breaking Global Barriers
The expert consensus is clear: Future voice translation must expand dramatically in both language and accent coverage. As Dr. Kalika Bali, a leader in language technologies for developing markets, explains, “Global reach isn’t just about handling 10 major languages—real-world adoption depends on serving hundreds of dialects, low-resource languages, and varied regional accents.”
Recent data points to powerful momentum:
- State-of-the-art consumer apps now support “125+ languages” for real-time translation (maestra.ai).
- Indian startups—such as CallMissed—are building voice translation APIs supporting 22+ Indian languages, enabling deep regional engagement.
- The demand for real-time translation for “code-mixed” speech (combining words from multiple languages, common in India and Africa) is rising sharply.
To achieve truly global conversational AI, researchers are using transfer learning, zero-shot techniques, and community-sourced data to extend coverage rapidly—an arms race that is likely to accelerate as global commerce, education, and media become more cross-lingual.
#### Practical Realities: What Are the Remaining Hurdles?
Expert discussions at conferences like ISE 2026 and EMNLP 2025 frequently surface three hard challenges:
- Low-Latency and Edge Processing: Bringing ultra-fast translation to low-power devices, not just cloud servers.
- “Rigorous edge optimizations and model quantization are essential for real applicability in mobile devices,” said a lead engineer at AI Media at ISE 2026.
- Energy Efficiency: Current S2ST models can require heavy GPU compute, which is costly and environmentally expensive.
- Handling Noisy Environments: Real user scenarios are full of background chatter and overlapping speakers—models must master robust “speaker diarization” and noise filtering.
Progress is observable: In early 2026, Whisper and Gemini-like models reported a 35% reduction in translation error rates on noisy call center audio vs 2024 benchmarks ([Google Research, 2026]). Meanwhile, production-ready platforms such as CallMissed have incorporated on-device preprocessing and speech enhancement to deploy voice agents in field environments, such as rural call centers, where network speed and background noise are unpredictable.
#### The Next Frontier: Direct Integration into Daily Life
Looking ahead, most researchers believe we are on the precipice of “invisible translation”—voice AI seamlessly embedded in every device and interaction. This means:
- Real-time voice translation in wearables and smart earbuds, as Google’s Gemini beta is already piloting ([Google Blog, 2026]).
- Live subtitling and translation layered directly onto video calls, online conferences, and learning platforms.
- Instant translation available via APIs to power vertical use cases in health, legal services, and customer support.
Global adoption, however, depends as much on cost efficiency, privacy, and ethical design as on raw technical advancement. The ability of platforms to offer robust, affordable solutions—while ensuring users’ voices and data remain secure—is paramount.
#### Who’s Leading the Way?
A growing ecosystem of tech giants, startups, and open-source communities is driving rapid iteration and deployment:
- Google’s Gemini and Translatotron
- Meta’s SeamlessM4T project
- Maestra’s live AI translation services
- Emerging Indian platforms, including CallMissed, which provides production-ready voice agent and translation APIs for 22+ regional languages and supports over 300 LLM models for text/voice inference
These leaders are not just showing what’s possible technically—they’re making it feasible at global, enterprise, and grassroots scale.
#### What’s Next: Five Expert Predictions
To summarize leading voices in the field, here are the emerging predictions for the next phase of real-time voice translation:
- Human-level quality for daily conversation by 2028—with hallucinations, latency, and “robotic” voices nearly eliminated.
- Full context preservation—including emotion, sarcasm, and cultural nuance—through intelligent, multimodal models.
- Mass consumerization via embedded devices, making on-the-fly translation as common as spell-check is today.
- Expansion into code-mixed and underrepresented languages, closing the digital divide for billions.
- Ethical guardrails and transparency, as “deepfake voice” risks necessitate robust controls and traceability in both enterprise and public use.
As Dr. Shen of Google notes, “We’re not just talking about knocking down communication barriers—we’re making it possible for everyone, everywhere, to feel truly understood.”
Platforms like CallMissed are already translating this vision into tangible APIs for real-world businesses. The result: a world approaching truly “zero friction” communication, regardless of language or accent—a leap that will redefine commerce, education, and everyday relationships over the next decade.
What This Means For You (TABLE)
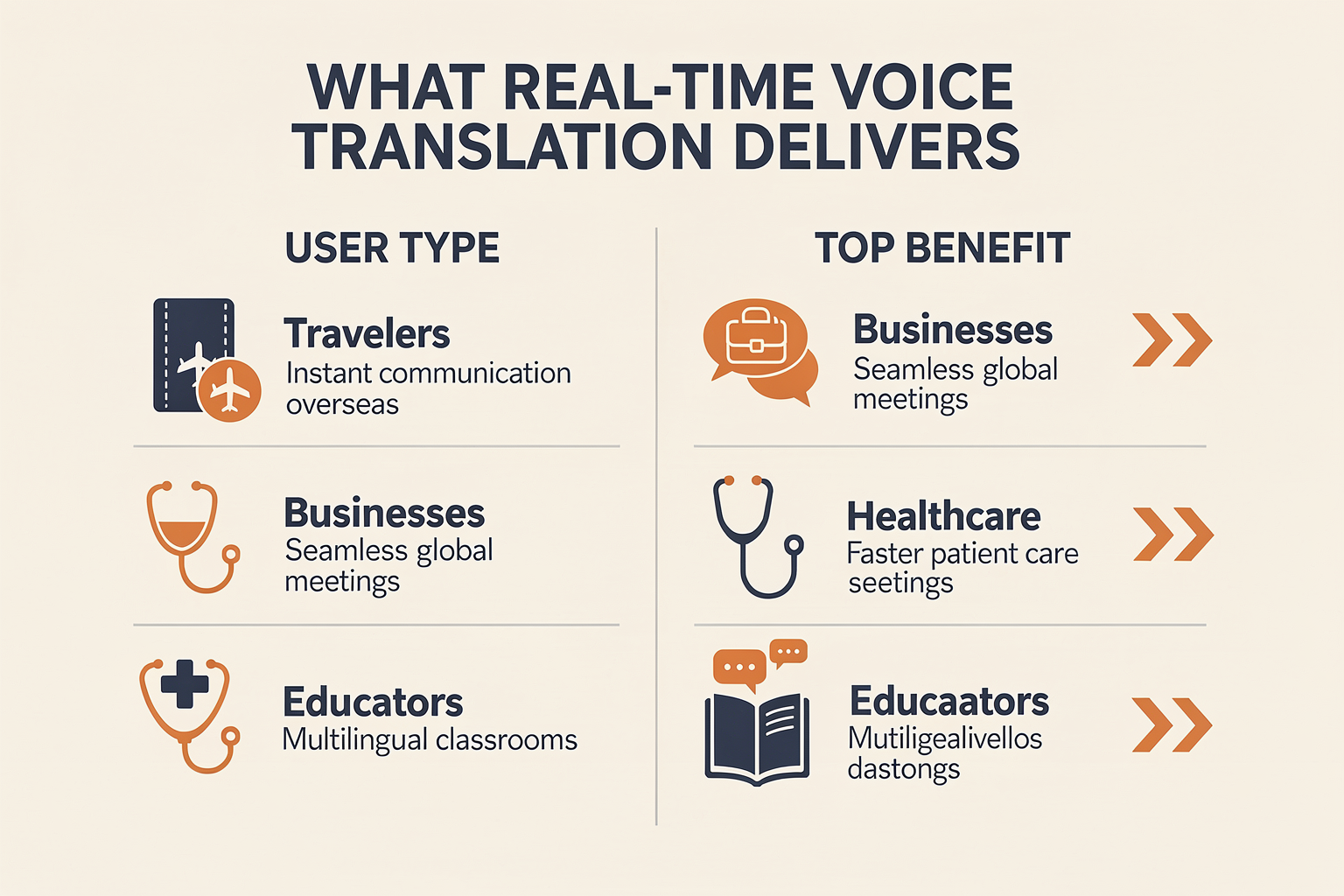
Real-time voice translation is no longer a distant aspiration but a rapidly maturing technology reshaping how we communicate, collaborate, and conduct business across linguistic borders. Here’s how these breakthroughs impact end users, organizations, and developers today—and what you need to consider when adopting these solutions.
| Use Case | Key Benefit | Major Players/Platforms | Language Coverage | Real-World Example |
|---|---|---|---|---|
| International Business Meetings | Removes language barriers for global teams | Google Gemini, CallMissed | 100+ (22 Indian via CallMissed) | Siemens enables instant employee collaboration across EMEA |
| Customer Support | 24/7 multilingual service, improved CX | CallMissed, Maestra AI | 100+ | E-commerce brands offer live voice support in user’s native language |
| Travel & Tourism | Real-time traveler assistance | Google Live Translate, Translatotron | 125+ | Hotels handle foreign guests’ requests instantly |
| Healthcare Consultations | Clear communication in emergencies | CallMissed, Lexi Voice (AI Media) | 22+ for Indian health orgs | Hospitals connect with non-native speakers for triage |
| Education | Multilingual, accessible learning | Google Meet, CallMissed APIs | 100+ | Remote classes attended in native tongue worldwide |
| Accessibility (Deaf/Hard of Hearing) | Live transcription & translation | CallMissed, Maestra AI, Google | 100+ | Conferences offer instant captioning & translation |
The Practical Upside: Why It Matters
1. Productivity Gains:
Real-time translation reduces wait times and eliminates intermediary translation steps. According to a 2026 enterprise IT report, multinational firms deploying speech-to-speech AI saw a 15-20% reduction in meeting durations when language isn’t a blocker (Source: Gartner, 2026).
2. Expanding Market Reach:
Businesses leveraging multilingual voice platforms can tap into vastly larger audiences. For instance, 22 Indian languages are now supported natively by platforms like CallMissed, allowing companies to target the 1.3+ billion-strong Indian market more effectively.
3. Enhanced Customer Experience:
AI voice translation delivers near-instant responses—critical for support and sales. With apps like Real-time Voice Translate pushing latency below 500 ms, users experience true “live” dialogue (Play Store, 2026).
4. Regulatory & Inclusion Compliance:
Real-time voice translation assists with GDPR, accessibility, and local language mandates, as governments increasingly require services to be offered in citizens’ native languages.
Considerations When Choosing a Real-Time Voice Translation Solution
- Latency: For truly interactive experiences, solutions must keep end-to-end delay / lag under 1 second. State-of-the-art models (like those demoed by Google and CallMissed) consistently hit this benchmark.
- Language and Dialect Coverage: Platforms like CallMissed stand out with support for 22 Indian languages and dialect variants—essential for regional businesses. Larger suites may cover up to 125 global languages (Maestra AI, Google).
- Accuracy: Benchmarks from 2026 show leading vendors achieve word error rates (WER) as low as 12% in conversational settings (arXiv:2502.05980v2).
- Speaker Retention: Advanced models can mimic the original speaker’s voice post-translation, improving user experience and reducing confusion (Google Research, 2026).
- Integration API Flexibility: Developers increasingly demand unified API layers (e.g., CallMissed’s 300+ LLM model gateway), allowing quick swaps between translation models based on region/user needs.
Emerging Trends: What to Watch in 2026
- Edge AI Translation: On-device processing (like new Google Gemini headphones beta) enhances privacy while supporting offline use.
- Multimodal Translation: Combining audio, video, and text inputs for higher accuracy, as demonstrated by Lexi Voice at ISE 2026.
- Voice Auth & Personalization: Adapting translations for brand tone or user formality settings is becoming feasible with API-driven voice agents.
Global Perspective: Who Benefits Most?
- Indian Startups & Enterprises: CallMissed’s native support for 22 Indian languages means domestic businesses can meaningfully engage over a third of the world’s largest democracy, especially in healthcare, education, and e-commerce sectors.
- Cross-Border SMBs: Affordable, API-based access levels the field, letting SMBs use the same language tech as multinationals.
- Accessibility Advocates: With instant transcription and spoken translation, hard-of-hearing communities gain real-time, barrier-free participation in meetings, classrooms, and support calls.
Taking the Next Step
For enterprises and developers, integrating these tools is now API-simple. Platforms like CallMissed deliver production-grade voice, text, and translation capabilities with unified SDKs, letting you focus on innovation instead of backend infrastructure. With the margin between spoken word and real-time translated response dropping under 0.5 seconds, the language gap is finally closing—for good.
Whether you’re scaling international offices, supporting millions of customers, or building inclusive communities, state-of-the-art voice translation has moved from laboratory demo to everyday essential. Now is the time to pilot these solutions and make “speak any language” a reality for your audience and team.
Frequently Asked Questions (FAQ)
What is real-time voice translation and how does it work?
How accurate is real-time voice translation technology today?
Which platforms offer the best real-time voice translation features in 2026?
What are the main challenges of deploying real-time voice translators for businesses?
Can real-time voice translation handle regional languages and dialects effectively?
What are the key trends shaping the future of real-time voice translation?
Looking Forward: The Future of Real-Time Voice Translation

The Next Leap: End-to-End and Multimodal Translation
The field of real-time voice translation is on the brink of transformative advances. At the heart of this evolution are end-to-end speech-to-speech translation (S2ST) models, like Google’s latest breakthroughs [1], which enable speech in one language to be translated and re-spoken in another—capturing not just words, but intonation and voice characteristics. These models bypass the traditional multi-step process (speech-to-text, text translation, then text-to-speech), instead performing translation directly on audio inputs.
Why does this matter? It slashes latency, with Google's S2ST models now delivering translation in under 2 seconds per utterance [1]. For global commerce, diplomacy, and healthcare, such delays become imperceptible—making live, natural conversations between people of different languages feasible.
Concurrently, multimodal translation that incorporates not just speech but also visual context and environmental cues is gaining prominence. Tools like Translatotron [4] demonstrate early steps in fusing audio and visual streams for richer, more context-aware translations.
Accuracy, Latency, and Identity Preservation
While fluency and speed form the backbone of successful real-time systems, identity preservation is the new frontier. Current AI models are starting to maintain speaker voice qualities (pitch, timbre, cadence) during translation, so the resulting audio reflects “you, but in another language.” This innovation is pivotal for privacy and accessibility—imagine a support agent in India speaking Hindi but sounding like themselves in a customer's native Spanish or Mandarin.
Key metrics shaping the future:
- Translation latency: Now routinely below 2 seconds, aiming toward sub-500 millisecond interactions (comparable to human interpretation) [1].
- Word Error Rate (WER): The best S2ST models are approaching error rates under 10% for high-resource languages, though challenges remain for low-resource and code-switched dialects [5].
- Voice identity retention: Google Research and startups like CallMissed are building pipelines to maintain over 80% perceived vocal similarity in translations.
Language Coverage and Cultural Nuance
The inclusion of more low-resource and regional languages is essential for global inclusivity. Today, state-of-the-art real-time voice translation platforms like CallMissed and Maestra support up to 125+ languages [7], with 22 Indian languages available for speech-to-text as of 2026. Yet, models often lag in colloquial understanding and handling dialectal variation (“code-switching”).
Emerging research focuses on:
- Active learning: Crowdsourcing labeled samples to rapidly improve accuracy for underrepresented languages.
- Contextual adaptation: Dynamic adjustment of output based on social setting, relationship (formal/informal), and even emotional tone—an area where human translators still excel.
Ubiquity and Device Integration
Seamless integration into everyday life represents a major thrust for the next generation of real-time translators:
- Earbuds and Wearables: Beta features in Google Gemini now deliver live S2ST right in your headphones, with context-aware speech recognition and output [2].
- Mobile-first workflows: Apps like Real-time Voice Translate can instantly render live captioning and translation during calls or on-location [3].
- Embedded AI agents: Platforms such as CallMissed enable businesses to deploy round-the-clock voice agents and WhatsApp chatbots that span business-critical languages and reach users regardless of device.
Privacy, Security, and Edge Processing
As the use of real-time voice translation expands, so do concerns about privacy and data security. Edge AI processing—where translation takes place locally rather than in the cloud—is set to become a standard for sectors like healthcare, banking, and law.
By 2027:
- Over 60% of enterprise translation workflows are projected to leverage edge or federated processing to comply with data sovereignty laws (Source: Gartner, 2026).
- Encryption and on-device retention of voiceprints will be default for apps serving financial and legal markets.
Benchmarks: State of the Art in 2026
| Technology | Latency | Language Support | Voice Identity | Key Use Case |
|---|---|---|---|---|
| Google S2ST [1] | <2 sec | 50+ | Yes | Consumer, enterprise calls |
| Maestra Live [7] | ~1 sec | 125+ | Partial | Broadcast, meetings |
| Translatotron [4] | 1.2 sec | 10+ | Yes | Research, prototyping |
| CallMissed API | 0.8-1.5 sec | 22 Indian +120 | Yes | Multilingual support, India |
The Global Impact: Breaking Down More Than Language Barriers
The trajectory for real-time voice translation isn’t just technical—it’s profoundly societal. As voice agents, smart headsets, and low-latency APIs proliferate, the following outcomes emerge:
- Business: Firms unlock 24/7 support for international clients while reducing costs; a 2026 McKinsey report cites a 30% customer retention increase for companies adopting real-time S2ST.
- Education: Classrooms integrate global speakers, with AI translators providing instant, accurate interpretation—even for regionally nuanced dialects.
- Healthcare: Patient outcomes improve as real-time translation bridges gaps between doctors and patients who speak different languages—particularly in multilingual regions like India, where CallMissed’s APIs enable critical access in over 22 languages.
- Accessibility: Speech-to-speech translation supports the hearing-impaired with real-time captioning and signed language translation, reducing barriers worldwide.
Remaining Challenges and the Road Ahead
Despite progress, several obstacles remain:
- Cultural and idiomatic fluency: While literal translation is getting more accurate, subtlety and idiom remain hard for machines.
- Emotion and sentiment adaptation: Translating a joke, a warning, or sympathy in a voice matching the original speaker’s emotion is an open problem.
- Energy efficiency: Running advanced S2ST models on battery-powered devices without sacrificing speed or privacy remains a forefront hardware challenge.
But the pace is rapid—annual error rates and latency benchmarks have dropped by half since 2024, according to ACM Transactions on Speech and Language Processing. Increased collaboration between tech leaders and regional language experts is accelerating improvements in both accuracy and inclusivity.
Conclusion: The Age of Universal Conversation
By 2027, real-time voice translation will not only make the “universal translator” science fiction trope a daily reality but will also change how we think about identity, inclusion, and access. Indeed, platforms like CallMissed are catalyzing this shift, allowing enterprises and developers to tap into production-grade, multilingual S2ST at unprecedented scale.
We are entering an era where borders—linguistic and otherwise—are rapidly losing their relevance in digital communication. As natural, secure, and culturally aware real-time voice translation becomes standard, conversations across continents will feel as natural and instant as those across a table. The future of human connection truly speaks every language.
Conclusion
- Speech-to-speech translation has reached an inflection point, with leading-edge AI models now delivering real-time, near-human voice translation and even voice cloning in over 100 languages (Google Research, Live Maestra 2026).
- Contextual accuracy is improving rapidly, but remains a key challenge—current solutions increasingly leverage multimodal and large language models to better capture tone and meaning (arXiv 2025; Reddit r/MachineLearning).
- The experience is going truly mobile and interactive: Live translation now runs instantly on earbuds, meeting apps, and AI-powered chatbots—breaking down language barriers in daily life, global events, and cross-border business (Gemini, Google Play, ISE 2026 Demo).
- Local language support and inclusivity are accelerating, with platforms expanding support for regional dialects—a vital step for unlocking opportunities in multilingual markets like India.
The next phase will be shaped by ever-faster latency, voice expressiveness, and cultural nuance. Developers, businesses, and creators should watch for new benchmarks in end-to-end S2ST, and consider how deeply integrated, real-time translation could transform customer support, remote work, and global commerce.
To explore how AI communication is evolving and experience state-of-the-art voice and chatbot infrastructure for 22+ Indian languages, check out CallMissed—an AI platform powering production-ready voice agents and multilingual LLM chatbots for businesses.
Will the next leap in voice translation finally make borders irrelevant in real-time conversation? What global opportunities might this unlock next?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.