Claude Sonnet 5 vs. GPT-5.5: The Ultimate 2026 Developer Showdown

Compare Anthropic's Claude Sonnet 5 (Fennec) and OpenAI's GPT-5.5. Analyze benchmarks, agentic coding, API pricing, and deep reasoning to choose your tool.
Claude Sonnet 5 vs. GPT-5.5: The Ultimate 2026 Developer Showdown
Did you ever think we’d see an AI model autonomously resolve over 82% of production-grade GitHub issues? Welcome to mid-2026, where the release of Anthropic’s Claude Sonnet 5 (codenamed 'Fennec') and OpenAI’s GPT-5.5 has turned what once seemed like science fiction into standard developer workflow. This year, the battle for the IDE has escalated from simple autocomplete suggestions to fully autonomous, agentic system engineering.
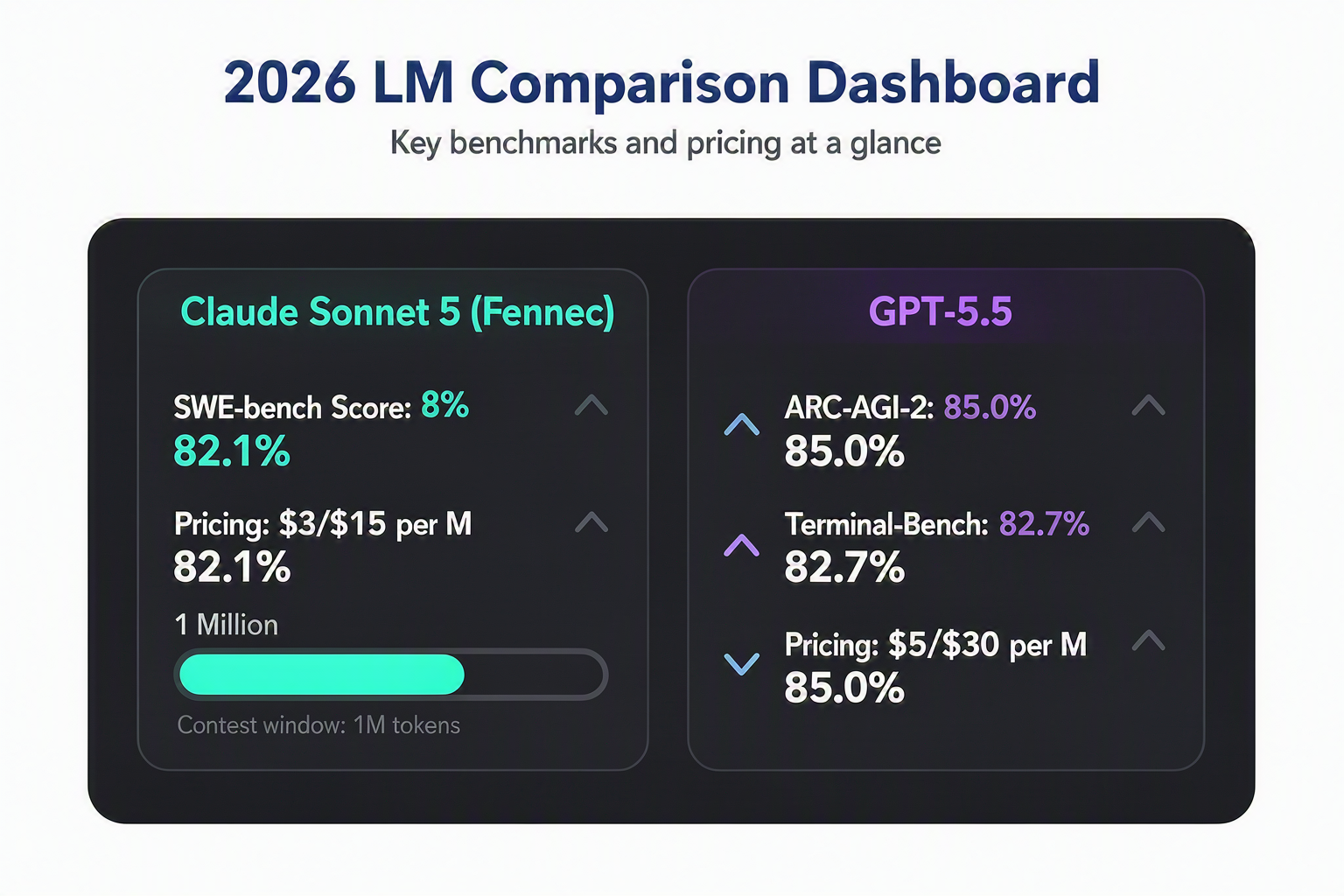
For developers building next-generation applications, choosing between these two giants is the most critical architectural decision of the year. On one side stands Claude Sonnet 5, Anthropic's flagship agentic model, which has shattered software engineering records by scoring a mind-boggling 82.1% on SWE-bench, making it the premier choice for rapid, direct "vibe coding" and agentic execution pipelines. On the other side is OpenAI's GPT-5.5, a peak reasoning engine that leverages systematic, high-effort thinking to dominate complex logic and terminal-based agent workflows, scoring an unprecedented 85.0% on ARC-AGI-2.
But raw capability is only half the story; unit economics and deployment strategies are where the real divergence begins. Claude Sonnet 5 emerges as the clear efficiency champion, priced aggressively at $3 per million input tokens and $15 per million output tokens. Meanwhile, GPT-5.5's deep-reasoning cycles demand a premium, costing $5 per million input and $30 per million output tokens. With both models featuring massive 1-million-token context windows—effectively eliminating codebase ingestion bottlenecks—developers must weigh GPT-5.5’s heavy-reasoning terminal dominance against Sonnet 5's cost-efficient, lightning-fast execution.
As multi-model developer architectures become the industry standard, platforms like CallMissed are already enabling businesses to seamlessly deploy these elite models across unified, production-ready voice and chat workflows. In this ultimate developer showdown, we will dissect the benchmark data, API unit economics, and real-world coding performance of Claude Sonnet 5 and GPT-5.5 to help you determine which model deserves a permanent place in your development stack.
Introduction: The 2026 LLM Heavyweight Battle

Did you ever think we’d see an AI model autonomously resolve over 82% of production-grade GitHub issues? Welcome to mid-2026, where the release of Anthropic’s Claude Sonnet 5 (codenamed 'Fennec') and OpenAI’s GPT-5.5 has turned what once seemed like science fiction into standard developer workflow. This year, the battle for the IDE has escalated from simple autocomplete suggestions to fully autonomous, agentic system engineering.
For developers building next-generation applications, choosing between these two giants is the most critical architectural decision of the year.
The Contenders: Agentic Execution vs. Deep Reasoning
On one side stands Claude Sonnet 5, Anthropic's flagship agentic model. Sonnet 5 has shattered software engineering records by scoring a mind-boggling 82.1% on SWE-bench, making it the premier choice for rapid, direct "vibe coding" and agentic execution pipelines. It is designed to act, execute, and integrate seamlessly into active codebases with minimal friction.
On the other side is OpenAI's GPT-5.5, a peak reasoning engine that leverages systematic, high-effort thinking (often referred to as 'xhigh' or systematic reasoning) to dominate complex logic and terminal-based agent workflows. It achieves an unprecedented 85.0% on ARC-AGI-2, asserting its dominance in novel problem-solving and rigorous algorithmic design.
Context Windows and the Death of Ingestion Bottlenecks
In 2026, the physical limits of context are no longer a major bottleneck. Both models feature massive 1-million-token context windows, effectively eliminating codebase ingestion limits. Developers can now feed entire repositories, multi-language documentation libraries, and full system architectures directly into a single session. However, how each model processes this massive context window differs fundamentally:
- Claude Sonnet 5 excels at scanning and editing direct code pathways, making it highly efficient for codebase-wide refactoring.
- GPT-5.5 uses its deeper reasoning cycles to map abstract dependencies, excelling in multi-layered system architecture generation.
The Economics of Code: API Unit Pricing
While raw capability is highly competitive, the developer's choice often comes down to unit economics and execution speed:
- Claude Sonnet 5 is priced aggressively at $3 per million input tokens and $15 per million output tokens, positioning it as the clear efficiency champion.
- GPT-5.5 demands a premium for its systematic reasoning cycles, costing $5 per million input and $30 per million output tokens.
Because GPT-5.5 relies heavily on high-effort reasoning to solve complex tasks, its token consumption can scale rapidly, making Sonnet 5 the go-to for high-throughput, cost-sensitive agentic pipelines.
To successfully manage these varying models without getting locked into a single ecosystem, developers are increasingly turning to multi-model architectures. Platforms like CallMissed provide a crucial bridge here. With its unified API gateway supporting over 300+ LLMs, CallMissed allows developers to dynamically route tasks—sending high-effort reasoning queries to GPT-5.5 while leveraging Claude Sonnet 5 for rapid, cost-effective agentic execution, voice agent deployment, and multilingual chat workflows.
In this ultimate developer showdown, we will dissect the benchmark data, API unit economics, and real-world coding performance of Claude Sonnet 5 and GPT-5.5 to help you determine which model deserves a permanent place in your development stack.
Background & Context: The Evolution of Sonnet 5 'Fennec' and GPT-5.5

The Path to 'Fennec': Anthropic’s Pursuit of Agentic Autonomy
The journey to Claude Sonnet 5—internally codenamed 'Fennec'—represents a fundamental shift in Anthropic's architectural philosophy. In earlier generations, the focus rested heavily on predictability, alignment, and helpfulness. However, as the industry transitioned into the agentic era of 2026, Anthropic engineered 'Fennec' to move beyond passive chat interactions and toward autonomous execution.
Rather than relying on bloated reasoning traces that inflate token costs, Sonnet 5 is built for high-velocity, direct agentic execution. It excels at "vibe coding"—a development paradigm where developers orchestrate high-level logic while the model handles real-time refactoring, debugging, and multi-file code generation. By optimizing Sonnet 5's internal activation pathways, Anthropic has delivered a model that acts as a highly reliable, autonomous software engineer capable of navigating vast, multi-layered codebases without human intervention. This optimization culminated in its historic 82.1% score on SWE-bench, proving that a model does not need to pause for minutes of "deep thinking" to solve complex, real-world engineering problems.
The Rise of GPT-5.5: OpenAI’s Peak Reasoning Paradigm
In stark contrast, OpenAI’s development of GPT-5.5 represents the zenith of systematic, high-effort reasoning. Emerging from the foundational breakthroughs of the o1 and o2 reasoning series, GPT-5.5 is designed to "think" before it speaks. It leverages an advanced, multi-stage chain-of-thought architecture (often referred to in API configurations as GPT-5.5 xhigh) to systematically decompose highly abstract logic.
Where previous iterations struggled with novel, out-of-distribution logical puzzles, GPT-5.5 thrives. It is optimized for terminal-based agent workflows, system-level architecture planning, and rigorous mathematical proofs. This systematic approach is why GPT-5.5 dominates logical benchmarks, achieving an unprecedented 85.0% on ARC-AGI-2 (Abstraction and Reasoning Corpus). It does not just predict the next most likely token; it executes internal tree-of-thought simulations to verify its code logic before outputting a single line to the developer.
Bridging the Divide: Context Windows and the Infrastructure Layer
While their cognitive philosophies diverge, both giants have converged on a massive technical milestone in 2026: 1-million-token context windows. This expansion marks a generational shift where codebase ingestion bottlenecks have effectively been eliminated. Developers no longer need to meticulously prune codebase files or rely on lossy vector embeddings to fit their code into a prompt window; they can upload entire repositories, documentation libraries, and active terminal logs directly into the model’s active memory.
| Feature / Metric | Claude Sonnet 5 ('Fennec') | GPT-5.5 (xhigh) |
|---|---|---|
| Primary Philosophy | Direct Agentic Execution / Vibe Coding | Systematic Deep Reasoning (Chain-of-Thought) |
| SWE-bench Score | 82.1% | ~78.5% |
| ARC-AGI-2 Score | 74.3% | 85.0% |
| Context Window | 1,000,000 Tokens | 1,000,000 Tokens |
As developers build production-grade applications on top of these massive context windows, managing the underlying infrastructure becomes highly complex. Implementing these multi-model developer workflows requires robust API orchestration. Unified platforms like CallMissed are playing a critical role in this ecosystem, allowing developers to seamlessly integrate these 1-million-token models with advanced Speech-to-Text and multilingual agents, ensuring that whether a system relies on GPT-5.5's deep logic or Sonnet 5's rapid execution, the deployment pipeline remains unified and highly scalable.
Key Developments: Architectural & Benchmark Breakdown (TABLE)
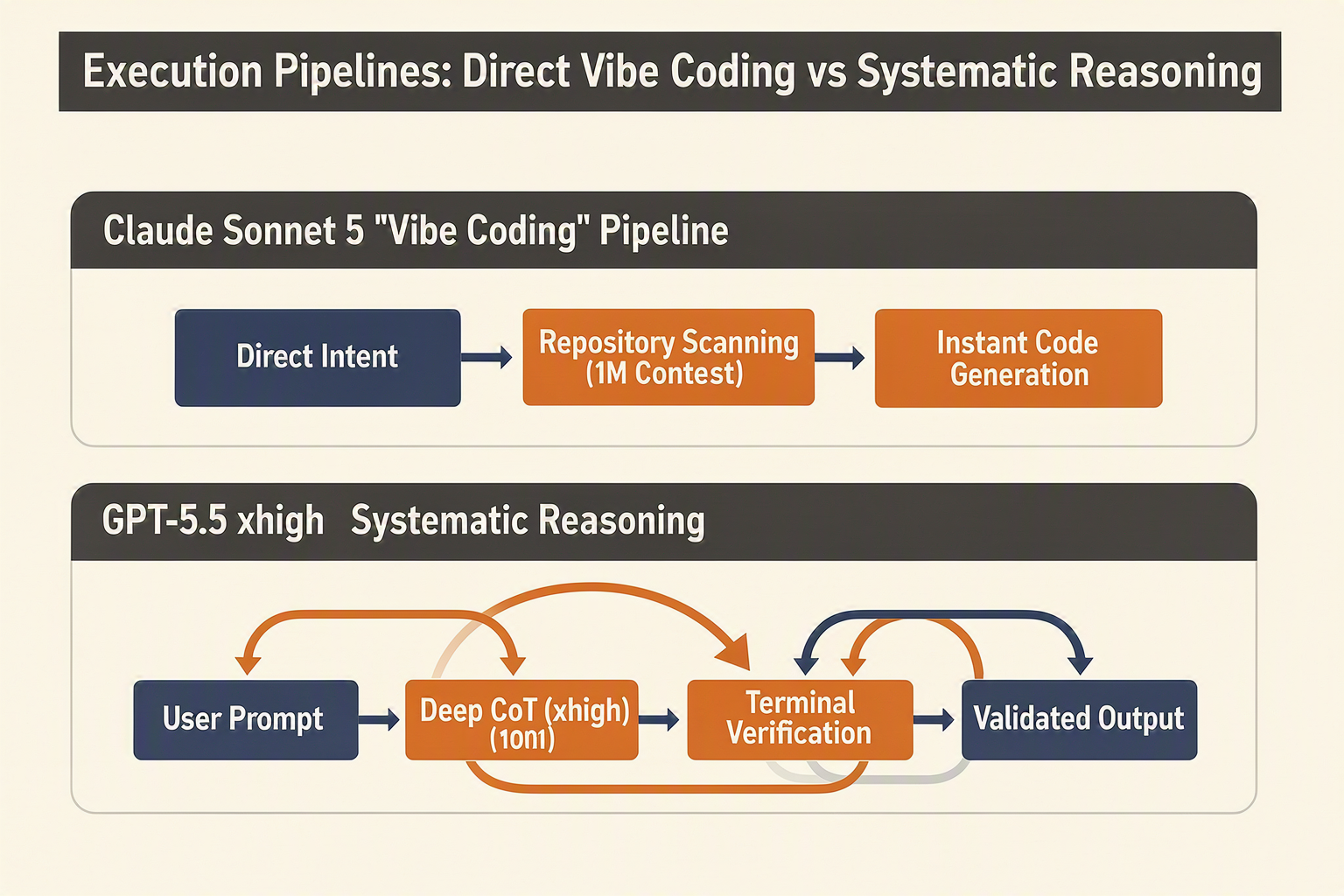
The Architectural Divide: Direct Execution vs. Systematic Reasoning
Beneath the raw benchmark numbers lies a fundamental divergence in how Anthropic and OpenAI approach machine intelligence in 2026.
Claude Sonnet 5 (codenamed 'Fennec') is built for speed, direct action, and streamlined execution. It is highly optimized for "vibe coding" and autonomous agentic workflows where the model quickly edits codebases, runs tests, and iterates without unnecessary overhead. This direct-execution approach minimizes latency and keeps output token usage highly efficient.
In contrast, GPT-5.5 relies on OpenAI's advanced systematic thinking framework (often utilizing "xhigh" or high-effort reasoning states). Instead of responding instantly, GPT-5.5 pauses to construct internal, multi-path reasoning steps before emitting its first token. While this systematic thinking is incredibly powerful for resolving deeply nested logical dependencies and debugging complex terminal-based environments, it inherently consumes more compute resources and output tokens.
For developers architecting real-world applications, this architectural split dictates your deployment strategy. If your system requires real-time conversation, multilingual voice integration, or rapid iterative code edits, Sonnet 5's streamlined footprint is ideal. If you are building a system that must solve novel, highly abstract logical puzzles where correctness is the only metric that matters, GPT-5.5's reasoning engine becomes necessary.
To help navigate these trade-offs, platforms like CallMissed allow developers to deploy unified, multi-model architectures. By using CallMissed's infrastructure, you can dynamically route high-volume agentic tasks and voice agent pipelines to the most cost-effective model, while reserving deep-reasoning engines for edge-case logical validation.
Head-to-Head: Developer Specifications & Benchmarks
The table below breaks down the hard technical specs, pricing models, and benchmark achievements of both models as of mid-2026.
| Metric / Feature | Claude Sonnet 5 ("Fennec") | GPT-5.5 (High-Effort) | Architectural Winner |
|---|---|---|---|
| SWE-bench Score | 82.1% (Agentic Benchmark) | ~79.5% (Standard Run) | Claude Sonnet 5 (Agentic Coding) |
| ARC-AGI-2 Score | ~74.2% (Visual/Logic Test) | 85.0% (Systematic Reasoning) | GPT-5.5 (Abstract Logic) |
| Input Token Pricing | $3.00 per million tokens | $5.00 per million tokens | Claude Sonnet 5 (40% Cost Savings) |
| Output Token Pricing | $15.00 per million tokens | $30.00 per million tokens | Claude Sonnet 5 (50% Cost Savings) |
| Context Window | 1,000,000 Tokens | 1,000,000 Tokens | Tie (Generational Standard) |
| Primary Use Case | Direct agentic execution & fast edits | Multi-step terminal debugging & complex logic | Context-Dependent |
Analyzing the Unit Economics
The economic contrast between these two frontrunners is stark. At $15 per million output tokens, Claude Sonnet 5 is exactly half the cost of GPT-5.5’s $30 per million output tokens. Because agentic software workflows require continuous loops of reading, writing, and testing code, output token consumption accumulates rapidly.
Furthermore, because GPT-5.5 utilizes high-effort reasoning cycles to solve problems, it frequently generates a higher volume of internal tokens during its systematic thinking phase, which can silently inflate API bills. For bootstrap startups and enterprise engineering teams alike, Sonnet 5 offers a highly predictable, budget-friendly baseline for continuous deployment. However, when a critical pipeline failure occurs or an abstract logical bug blocks production, switching to GPT-5.5's reasoning pathways often justifies the premium cost.
In-Depth Analysis: Agentic Coding vs. High-Effort Reasoning
The shift in 2026 is no longer about which model autocompletes code faster; it is about how they think and execute tasks within a developer's workflow.
The Architectural Split: Direct Execution vs. Cognitive Deliberation
Anthropic's Claude Sonnet 5 (Fennec) and OpenAI's GPT-5.5 represent two fundamentally different approaches to software engineering. Sonnet 5 is built for high-speed, predictable agentic execution. When integrated into a workspace, it bypasses long, drawn-out internal deliberation cycles to edit files and iterate rapidly. This direct "vibe coding" paradigm is what propelled it to its record-breaking 82.1% score on SWE-bench, making it the premier choice for autonomous pull request resolution, automated refactoring, and direct workspace interaction.
Conversely, GPT-5.5 is designed as a peak reasoning engine, relying on systematic, high-effort thinking (xhigh). Before writing a single line of code, GPT-5.5 uses extensive internal chain-of-thought processing to map out edge cases, verify architectural patterns, and simulate terminal executions. This heavy cognitive deliberation is why GPT-5.5 dominates logical reasoning benchmarks like ARC-AGI-2 with an 85.0% score, making it incredibly powerful for complex terminal-based agent workflows, multi-threaded system design, and algorithmic troubleshooting.
Inside the IDE: Pragmatic "Vibe Coding" vs. Intricate Logic
When developers put these models to work on real-world codebases, the operational differences become stark:
- System-Wide Refactoring: Claude Sonnet 5 excels at sweeping through existing repositories, reading entire directories, and steadily refactoring legacy code with predictable, stable integration readiness.
- Root-Cause Debugging: GPT-5.5 shines when a bug exists deep within nested asynchronous logic or system-level environment configurations. It will systematically isolate variables, analyze terminal logs, and solve the issue with surgical precision.
This divergence is highly evident in how they handle 2026’s standard 1-million-token context windows. While both models can ingest an entire codebase at once, they utilize that context differently. Sonnet 5 processes massive contexts with incredible speed and predictability, while GPT-5.5 analyzes them deeply, often generating highly targeted output but requiring more computational time to complete its reasoning steps.
Unit Economics: Scaling Your Agentic Fleet
For production-grade software operations, performance is inseparable from cost. Claude Sonnet 5 offers unmatched efficiency at $3 per million input tokens and $15 per million output tokens. This aggressive pricing makes it the ideal candidate for high-frequency, autonomous agent pipelines running in continuous integration/continuous deployment (CI/CD) loops.
GPT-5.5’s high-effort reasoning commands a premium at $5 per million input and $30 per million output tokens. While its systematic thinking can produce elegant logic with fewer iterations, the sheer cost of sustained reasoning cycles means developers must be highly deliberate about when to call it.
To optimize these operational costs, forward-thinking teams are avoiding single-model lock-in. Platforms like CallMissed allow developers to deploy multi-model architectures seamlessly. For example, you can route routine UI generation and standard API scaffolding to Claude Sonnet 5’s cost-efficient engine, while dynamically triggering GPT-5.5’s high-effort reasoning only when dealing with complex system integrations, multi-model routing, or sensitive database migrations. This hybrid approach delivers peak agentic execution and cognitive precision without breaking your API budget.
Impact & Implications: The Economics of 1M-Token Context Windows
With 1-million-token context windows now the standard in mid-2026, developers no longer need to rely on brittle RAG (Retrieval-Augmented Generation) pipelines for mid-sized projects. Instead, they can ingest entire codebases, massive system logs, or hours of customer interaction transcripts directly into a single prompt. However, just because you can load a million tokens into memory does not mean it is financially viable to do so blindly. The economics of these massive context windows create a stark divergence in operational API spend.
Consider the math behind a typical autonomous agent workflow that ingests a 500,000-token repository to debug a production issue:
- Claude Sonnet 5 (Fennec): At $3.00 per million input tokens, ingesting this context costs exactly $1.50 per run.
- GPT-5.5: At $5.00 per million input tokens, the same ingestion costs $2.50 per run.
While a single dollar difference seems negligible, scale this across a team of 50 developers running continuous integration (CI) tests and autonomous coding agents multiple times an hour, and the 66% input cost premium for GPT-5.5 quickly compounds into thousands of dollars in weekly overhead.
The Hidden Tax of Deep Reasoning
The economic gap widens further when analyzing output tokens. GPT-5.5’s peak reasoning engine relies on systematic, high-effort thinking (xhigh). To solve complex logic problems, the model generates internal chain-of-thought tokens. While this systematic thinking is what allows GPT-5.5 to dominate logic benchmarks, these reasoning steps consume output tokens.
Because OpenAI prices GPT-5.5 output at $30.00 per million tokens—double Claude Sonnet 5's rate of $15.00 per million—a highly iterative reasoning loop can rapidly deplete API budgets.
In contrast, Claude Sonnet 5 is highly optimized for direct agentic execution and "vibe coding" pipelines. It acts quickly with minimal conversational filler, using fewer output tokens to achieve its groundbreaking 82.1% SWE-bench score. For developers running agent loops that modify code across multiple files, Sonnet 5 provides a lightning-fast, highly predictable, and incredibly lean cost structure.
Architecting a Hybrid, Multi-Model Solution
To survive in this high-context, agentic era, forward-thinking engineering teams are abandoning single-model monocultures in favor of hybrid architectures. They use each model where its unit economics make the most sense.
For instance, platforms like CallMissed offer multi-model API gateways that allow developers to build dynamic routing systems. A high-volume, high-context application can route massive codebase-ingestion tasks and conversational workflows to Claude Sonnet 5 to capitalize on its $3/$15 pricing structure. If the agent hits a highly complex logic roadblock, the system can dynamically escalate that specific sub-task to GPT-5.5's reasoning engine.
To maximize your ROI when building with 1M-token context windows in 2026, developers should implement three key strategies:
- Aggressive Prompt Caching: Both Anthropic and OpenAI support prompt caching. Keeping your 1M-token codebase "warm" in the cache can slash recurring input costs by up to 90%.
- Token-Budget Caps: Implement hard token limits on agentic loops. An unconstrained reasoning agent on GPT-5.5 can easily run up a triple-digit bill on a single runaway debugging task.
- Intent-Based Routing: Route raw code generation and refactoring to Sonnet 5, and reserve GPT-5.5 for high-level architectural planning and edge-case validation.
Expert Opinions: What the Dev Community is Saying

Synthetic benchmarks tell one story, but real-world engineering teams and the vibrant communities on platforms like Reddit's r/vibecoding tell the true story of how Claude Sonnet 5 and GPT-5.5 behave in production. In mid-2026, the developer consensus is clear: we are no longer looking for a single, all-purpose model. Instead, teams are building multi-model architectures designed to exploit the distinct strengths of both systems.
Claude Sonnet 5: The "Vibe Coder’s" Execution Engine
Within the developer community, Anthropic’s Claude Sonnet 5 (codenamed ‘Fennec’) has solidified its reputation as the premier model for rapid, intuitive, and highly predictable software development. Software engineers praise Sonnet 5 for its stability and integration readiness, making it the default choice for agentic pipelines.
- Predictability and Flow: Developers note that Sonnet 5 excels at "vibe coding"—the practice of describing a feature in high-level terms and letting the model handle the end-to-end file edits. Its ability to maintain structural integrity across large, 1-million-token codebase ingests without "forgetting" key variables has made it a favorite for IDE integrations.
- The Economy of Scale: With pricing set at $3 per million input and $15 per million output tokens, startups and enterprise teams alike are using Sonnet 5 to run continuous, autonomous agents. Developers report they can let Sonnet 5 run in loops, refactoring hundreds of files overnight, without worrying about runaway API bills.
GPT-5.5: The High-Effort Reasoning Powerhouse
Conversely, when the task requires systematic, high-effort logical reasoning, the community turns to OpenAI's GPT-5.5. Despite its premium pricing ($5 input / $30 output per million tokens), terminal wizards and systems engineers argue that GPT-5.5 is irreplaceable for complex architecture design and terminal-based agent workflows.
- Systematic Code Efficiency: A common observation on forums is GPT-5.5's incredible code conciseness. When utilizing its "xhigh" reasoning modes, GPT-5.5 often produces up to 72% fewer output tokens than non-reasoning or older models to solve the exact same logical puzzle. It avoids the "boilerplate bloat" that occasionally plagues other LLMs, delivering tight, highly optimized code on the first attempt.
- Zero-Shot Correctness: For mission-critical tasks like smart contract auditing, complex database migrations, and writing intricate terminal scripts, developers prefer GPT-5.5. The consensus is that while it is slower and costlier per token, its systematic thinking saves hours of human debugging time.
The Hybrid Multi-Model Standard
Because both models offer such distinct operational advantages, the leading engineering teams in 2026 are refusing to settle for just one. The industry has rapidly shifted toward hybrid developer pipelines.
To orchestrate this, teams are relying on next-generation developer infrastructure. Platforms like CallMissed are crucial here, offering unified LLM gateways with access to over 300+ models. By integrating CallMissed, developers can seamlessly route high-intensity logic, terminal validation, and reasoning tasks to GPT-5.5, while leaving agentic execution, customer-facing communication, and standard code generation to the faster, highly cost-efficient Claude Sonnet 5. This hybrid approach ensures developers achieve peak reasoning when necessary, without sacrificing the cost-efficiency required to scale operations.
What This Means For You: Choosing Your Model (TABLE)
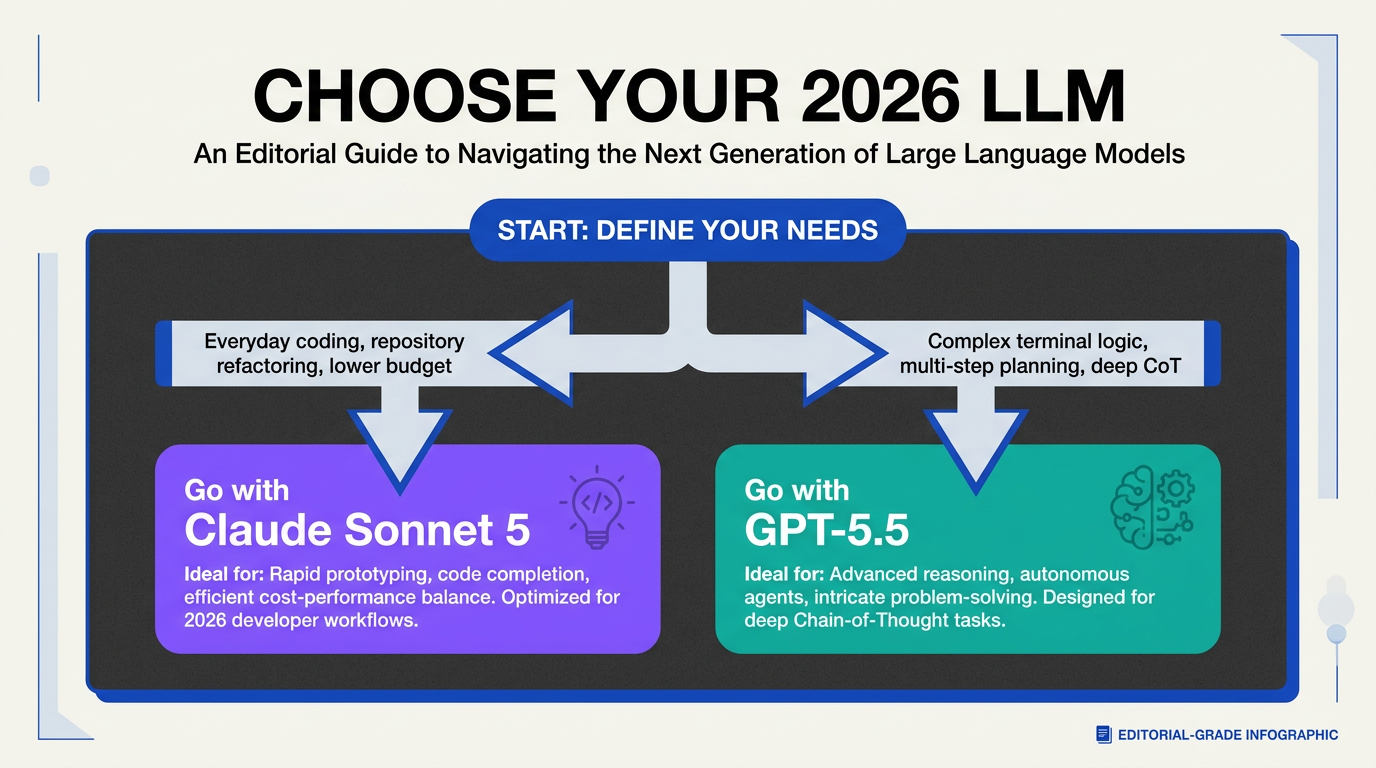
Choosing between Claude Sonnet 5 and GPT-5.5 isn’t about finding the "better" model; it is about mapping your specific engineering constraints to the right architectural profile. As we navigate mid-2026, the era of the single-model stack is officially over. To build resilient, production-ready applications, developers must dynamically route tasks to balance raw reasoning depth against lightning-fast, cost-effective agentic execution.
The Developer Decision Matrix
The table below breaks down the technical specs, pricing, and optimal deployment targets for both models to help you align your development pipeline with the right engine:
| Metric / Parameter | Claude Sonnet 5 ('Fennec') | OpenAI GPT-5.5 | Strategic Advantage |
|---|---|---|---|
| Input Price (per M) | $3.00 | $5.00 | Sonnet 5 is 40% more cost-effective |
| Output Price (per M) | $15.00 | $30.00 | Sonnet 5 reduces generation costs by 50% |
| Key Benchmark Score | 82.1% on SWE-bench | 85.0% on ARC-AGI-2 | Sonnet 5 wins on code repair; GPT-5.5 wins on logic |
| Context Window | 1 Million Tokens | 1 Million Tokens | Parity; zero bottlenecks for deep codebase ingestion |
| Core Coding Style | Direct agentic execution / "Vibe coding" | Systematic, high-effort terminal workflows | Sonnet 5 for fast loops; GPT-5.5 for complex reasoning |
Navigating the Architectural Choice
If your team's development priorities lean toward rapid, autonomous feature implementation, Claude Sonnet 5's direct agentic execution and unrivaled SWE-bench performance make it the definitive choice. Its aggressive unit economics allow you to run recursive debugging loops, refactoring pipelines, and dense coding agent chains without ballooning your monthly API bill.
Conversely, if your application demands systematic, high-effort reasoning to untangle highly complex legacy logic or execute multi-step terminal workflows, GPT-5.5 remains the premium engine. While its systematic thinking cycles consume a higher volume of tokens, the model's unparalleled precision on complex logical puzzles justifies the premium price tag.
Leveraging Multi-Model Infrastructure
Because both models bring specialized superpowers to the table, modern engineering teams are moving away from single-provider lock-ins. This is where unified infrastructure platforms like CallMissed become indispensable.
By leveraging CallMissed's robust developer APIs—which provide seamless integration with over 300 LLMs alongside native speech-to-text and multilingual capabilities—teams can deploy hybrid, multi-model architectures effortlessly. You can route daily codebase ingestion and high-volume code generations to Claude Sonnet 5 to maximize efficiency, while seamlessly escalating heavy, systematic logical tasks to GPT-5.5 under a single, unified orchestration layer.
To guide your immediate deployment, prioritize your goals:
- Choose Claude Sonnet 5 if you are building autonomous coding agents, executing bulk refactoring jobs, or operating under strict API unit economic targets.
- Choose GPT-5.5 if you require rigorous, systematic planning, verification of complex system logic, or deep terminal-based agent debugging where precision is paramount.
Frequently Asked Questions

How does the pricing of Claude Sonnet 5 vs. GPT-5.5 compare for large-scale enterprise deployments?
Which model performs better for autonomous coding and SWE-bench tasks?
What is the main architectural difference in the reasoning styles of Claude Sonnet 5 vs. GPT-5.5?
How do the context windows of Claude Sonnet 5 and GPT-5.5 handle massive codebases?
Can I integrate both Claude Sonnet 5 and GPT-5.5 into a single developer workflow?
Which model should I choose for building real-world AI agents in 2026?
Conclusion
The showdown between Claude Sonnet 5 and GPT-5.5 in mid-2026 marks a paradigm shift in software engineering. Choosing between them is no longer about finding a single "best" LLM, but rather matching your specific development workflows to their architectural strengths:
- Claude Sonnet 5 ('Fennec') excels in rapid, direct "vibe coding" and agentic execution pipelines, offering incredible cost-efficiency ($3/$15 per million tokens) and an 82.1% SWE-bench score.
- GPT-5.5 is the premier reasoning engine for highly intricate logic and terminal-based workflows, though its systematic thinking commands a premium ($5/$30 per million tokens).
- Infinite Context: Both models boast 1-million-token windows, effectively eliminating codebase ingestion limits for developers.
As we move forward, the most successful developers will leverage multi-model routing architectures rather than relying on a single provider. To explore how AI communication is evolving alongside these elite models, check out CallMissed — an AI infrastructure platform powering autonomous voice agents and multilingual chatbots for businesses. Which model will you orchestrate to power your 2026 developer stack?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.