Claude Sonnet 5 vs. GLM-5.2: The Ultimate Agentic Coding Showdown (Closed vs. Open-Weight)

Compare Anthropic's Claude Sonnet 5 and Zhipu AI's GLM-5.2 on SWE-bench Pro, 1M context windows, API pricing, and real-world agentic coding speed.
Claude Sonnet 5 vs. GLM-5.2: The Ultimate Agentic Coding Showdown (Closed vs. Open-Weight)
Did you know that a single open-weight AI model from Beijing can now go toe-to-toe with Silicon Valley's most sophisticated proprietary coding engine—at just a fraction of the operating cost? As we cross the midpoint of 2026, the landscape of software development has shifted from basic autocomplete to fully autonomous, long-horizon "agentic" software engineers. At the absolute pinnacle of this paradigm shift lies a fierce, cross-border rivalry: Claude Sonnet 5 vs. GLM-5.2. This head-to-head matchup represents the ultimate showdown between premium, western closed-source engineering and highly disruptive, Chinese open-weight innovation.
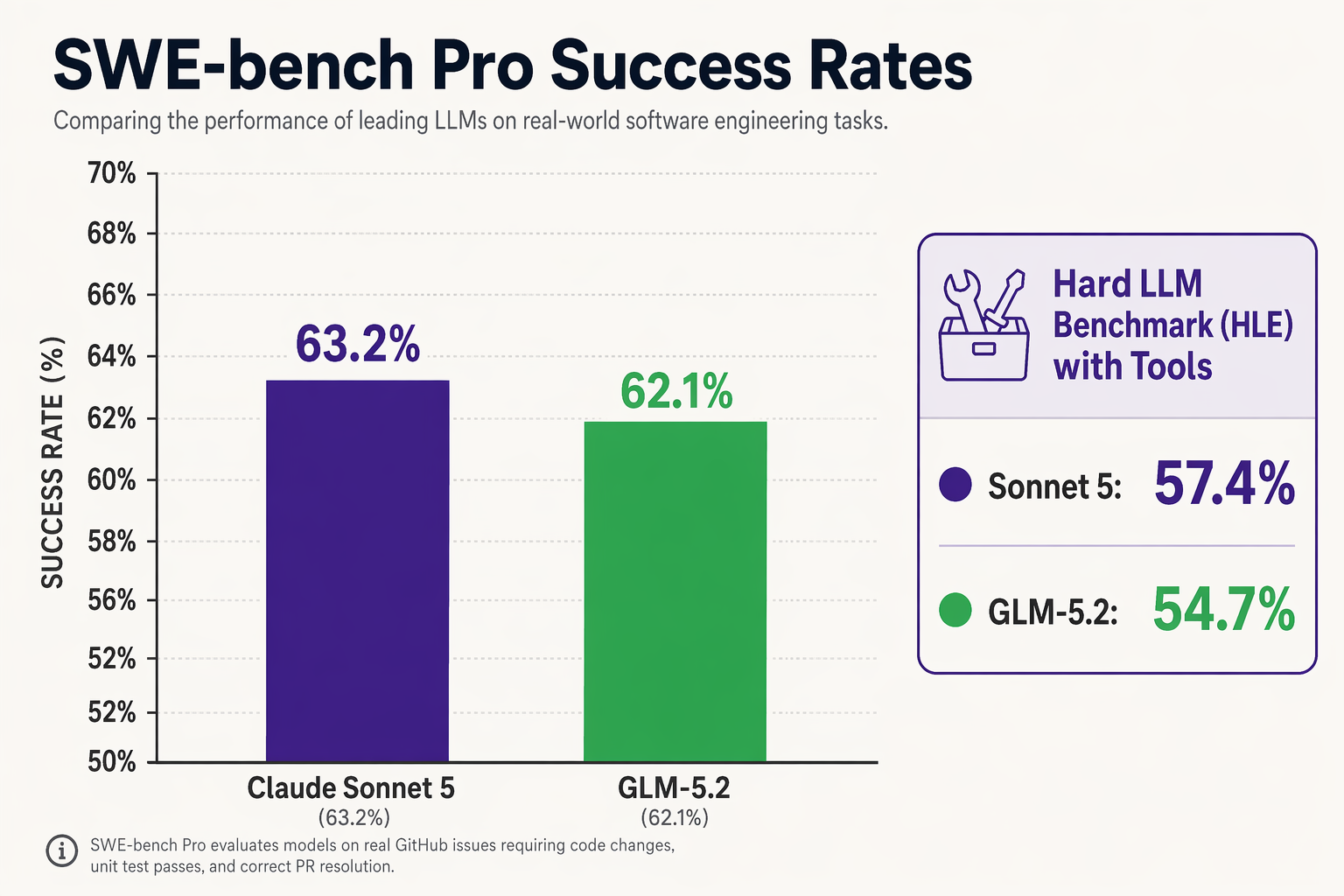
The stakes have never been higher for developers and enterprises deciding where to commit their compute budgets. Anthropic’s newly minted Claude Sonnet 5 represents a masterclass in proprietary optimization, edging out competitors with an unprecedented 63.2% on SWE-bench Pro and a 57.4% score on the Hard LLM Benchmark (HLE) using tools. Yet, Zhipu AI’s GLM-5.2—a colossal 745-billion parameter open-weight Mixture-of-Experts (MoE) model—is hot on its heels, scoring 62.1% on SWE-bench Pro while offering a massive 1-million-token context window.
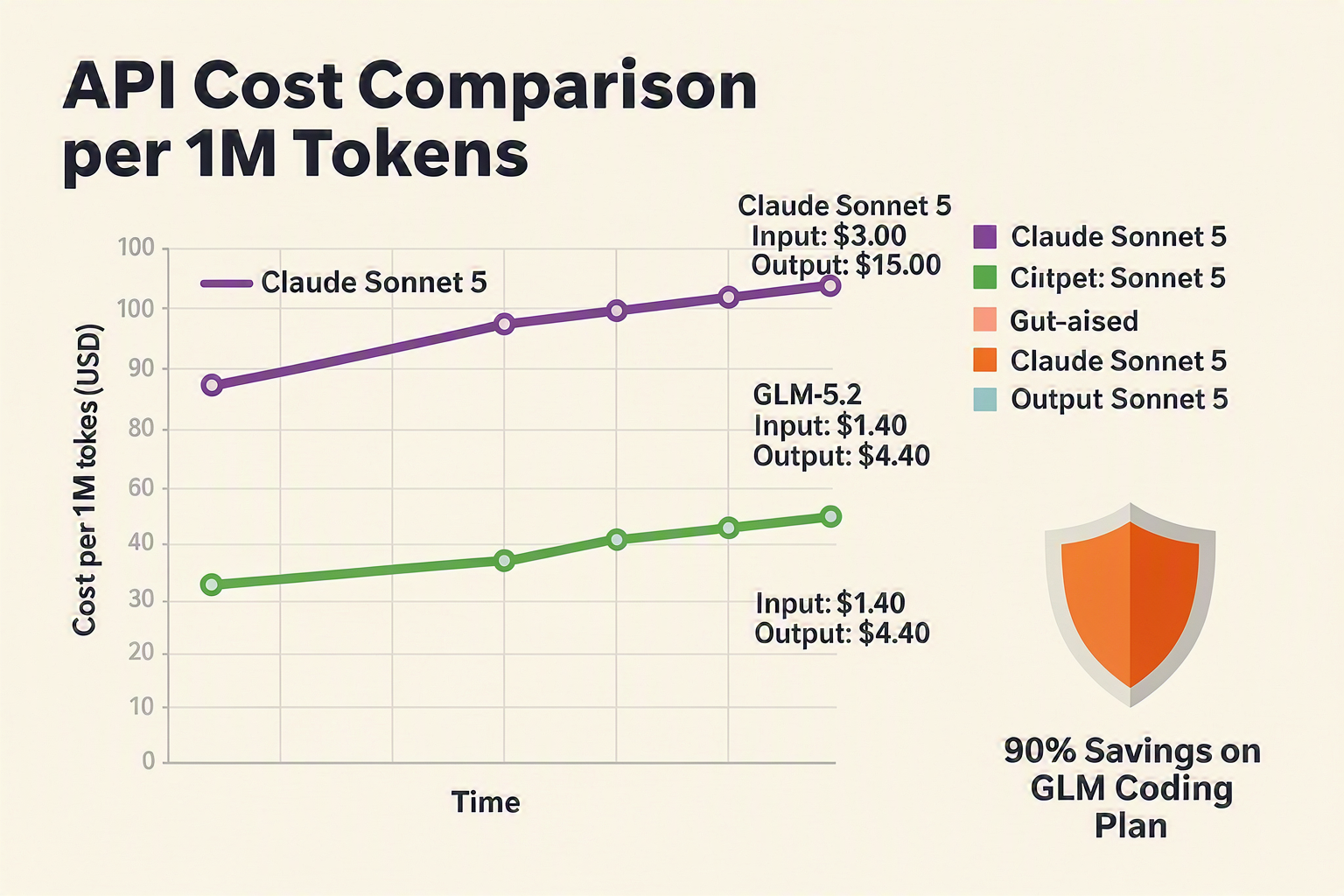
In this ultimate showdown, we will dissect how these two 2026 heavyweights compare across real-world agentic execution, architectural differences, and developer usability. We will also analyze the stark pricing divide: while Sonnet 5 commands a premium at $3/M input and $15/M output, GLM-5.2 dramatically undercuts the market at just $1.40/M input and $4.40/M output. Whether you are building autonomous software agents or optimizing enterprise pipelines, understanding this division is critical. For engineering teams looking to navigate this fast-evolving ecosystem, platforms like CallMissed's multi-model API gateway make it easy to seamlessly deploy, test, and switch between 300+ cutting-edge LLMs to find the perfect balance of cost and performance. Let's dive into the benchmarks to see which model truly reigns supreme.
Introduction: The 2026 Agentic Coding Frontier

The Era of Autonomous Software Engineers
As we navigate the middle of 2026, the software engineering landscape has progressed far beyond the era of simple AI autocomplete and basic code generation. Today, development pipelines are driven by autonomous, long-horizon "agentic" software engineers—AI systems capable of independently navigating complex code repositories, debugging distributed microservices, and refactoring legacy architectures over hours of continuous, multi-step execution.
At the absolute center of this paradigm shift lies a high-stakes battle between two contrasting philosophies: the premium, closed-source optimization of Silicon Valley and the highly disruptive, open-weight innovation emerging from Beijing. This is the ultimate showdown: Claude Sonnet 5 vs. GLM-5.2.
The Contenders: Proprietary Polish vs. Open-Weight Scale
Anthropic's newly released Claude Sonnet 5 represents the pinnacle of proprietary LLM engineering. It is a highly specialized model designed for speed, extreme logical efficiency, and native integration with advanced developer environments like Claude Code. Boasting an impressive 82% developer preference rate over previous generations, Sonnet 5 has quickly become the gold standard for low-latency, high-precision agentic workflows.
Conversely, Zhipu AI's GLM-5.2 represents a massive leap forward for the open-weight community. Built as a colossal 745-billion parameter Mixture-of-Experts (MoE) model, GLM-5.2 challenges the proprietary monopoly by offering state-of-the-art reasoning at a fraction of the cost. Crucially, its specialized glm-5.2[1m] variant boasts a massive 1-million-token context window, allowing agentic workflows to ingest and reason over entire codebases simultaneously.
The Agentic Battleground: Benchmarks and Economics
The gap between proprietary and open-weight performance has narrowed to razor-thin margins in 2026:
- SWE-bench Pro: Claude Sonnet 5 holds a narrow lead at 63.2%, but GLM-5.2 is hot on its heels at 62.1%—an astonishing achievement for an open-weight model.
- Hard LLM Benchmark (HLE) with Tools: Sonnet 5 showcases its tool-use mastery at 57.4% compared to GLM-5.2’s 54.7%.
- The Pricing Divide: Sonnet 5 commands a premium API price of $3.00/M input and $15.00/M output. GLM-5.2 dramatically undercuts this at $1.40/M input and $4.40/M output, offering enterprise-grade coding intelligence at a fraction of the cost.
While GLM-5.2 provides unprecedented economic freedom, real-world usability reveals distinct trade-offs. The massive MoE model can experience higher latency and increased token consumption during long-context operations, whereas Sonnet 5 maintains highly optimized, predictable execution speed.
Navigating the Multi-Model Paradigm
Choosing between these two powerhouses is no longer a binary decision. Forward-thinking engineering teams are increasingly adopting hybrid architectures. By leveraging platforms like CallMissed, developers can access a unified multi-model API gateway supporting over 300+ LLMs. This infrastructure allows teams to dynamically route tasks: utilizing Claude Sonnet 5's high-precision reasoning for critical, complex system refactoring, while offloading massive repository parsing and routine test generation to the highly cost-efficient GLM-5.2.
In the sections that follow, we will dissect their agentic capabilities, evaluate their raw architectural differences, and help you determine which model deserves a spot in your 2026 development stack.
The Contenders: Closed-Source SOTA vs. Open-Weight Titan

Claude Sonnet 5: The Proprietary Apex
Anthropic’s release of Claude Sonnet 5 represents the zenith of closed-source engineering. Built specifically to power autonomous, agentic coding workflows, Sonnet 5 isn't just a language model; it is a highly optimized execution engine. This generation introduces native adaptive thinking mechanisms, making the model incredibly robust against complex logic failures, nested code errors, and adversarial prompts.
When paired with Claude Code—Anthropic’s CLI-based developer agent—Sonnet 5 acts as a seamless, high-velocity co-developer. It delivers blistering inference speeds and exceptional reasoning capabilities, earning an 82% developer preference rating over previous generations. This polished, elite developer experience, however, comes at a premium. Anthropic structures its API pricing at $3.00 per million input tokens and $15.00 per million output tokens, positioning it as a high-end enterprise solution where accuracy, low latency, and zero-maintenance infrastructure are paramount.
GLM-5.2: The Open-Weight Disruptor
Emerging from Beijing’s Zhipu AI, GLM-5.2 represents a massive paradigm shift. It is a colossal 745-billion parameter Mixture-of-Experts (MoE) open-weight giant designed to democratize elite-tier AI coding. What makes GLM-5.2 particularly fearsome is its architectural flexibility; developers can deploy it locally on private enterprise infrastructure or access it via cost-efficient APIs.
The crown jewel of GLM-5.2’s architecture is its massive context option, glm-5.2[1m], which boasts a 1-million-token context window. This allows developers to ingest entire codebases, multi-volume documentation, and exhaustive dependency trees in a single prompt. Furthermore, Zhipu AI has aggressively disrupted the market on price. At just $1.40 per million input tokens and $4.40 per million output tokens, GLM-5.2 operates at a fraction of the cost of its western proprietary counterparts, offering premium coding capability at up to 1/10th the overall operating budget for self-hosted enterprise setups.
Architectural Philosophies and Usability Tradeoffs
While both models excel at agentic execution, they represent completely different engineering philosophies and user experiences:
- Agentic Benchmarks: In head-to-head coding benchmarks, Sonnet 5 holds a narrow lead. It scores 63.2% on SWE-bench Pro and 57.4% on the Hard LLM Benchmark (HLE) using tools. GLM-5.2 follows closely behind, securing 62.1% on SWE-bench Pro and 54.7% on HLE, proving that open-weight models can functionally match proprietary giants.
- Throughput and Efficiency: Sonnet 5 is engineered for rapid, multi-turn tool calling. In contrast, GLM-5.2's massive 745B MoE framework can sometimes result in slower initial time-to-first-token (TTFT) and massive token consumption when utilizing the full 1-million-token context window.
- Deployment Freedom: Sonnet 5 requires complete reliance on Anthropic's cloud infrastructure. GLM-5.2 offers total data sovereignty, allowing enterprises to host their weights securely within private VPCs.
For engineering teams hesitant to lock themselves into a single ecosystem, modern infrastructure makes this decision painless. Multi-model API gateways, like CallMissed, allow developers to dynamically switch between these 300+ LLMs. This enables hybrid architectures where GLM-5.2 can handle high-volume code parsing and local repository ingestion, while Claude Sonnet 5 is dynamically called for hyper-complex debugging and final deployment logic.
Key Developments: Specifications at a Glance (TABLE)

To truly understand how the balance of power has shifted in mid-2026, we must look beyond high-level marketing and examine the hard engineering specifications. Choosing between Claude Sonnet 5 and GLM-5.2 is not just a matter of selecting a model; it is a strategic decision that impacts an enterprise's compute architecture, budget, and data sovereignty.
While Anthropic delivers premium, closed-source optimization, Zhipu AI offers massive open-weight scale. The table below provides a direct, head-to-head comparison of their core specifications, benchmark performance, and developer economics.
| Specification / Metric | Claude Sonnet 5 | GLM-5.2 (Mixture-of-Experts) | Key Developer Takeaway |
|---|---|---|---|
| Model Architecture | Closed-source Proprietary | Open-weight MoE (745B total parameters) | GLM-5.2 offers self-hosting flexibility; Sonnet 5 is fully managed. |
| SWE-bench Pro Score | 63.2% | 62.1% | Sonnet 5 holds a razor-thin 1.1% lead in real-world software engineering. |
| Hard LLM Benchmark (HLE) | 57.4% (with tools) | 54.7% (with tools) | Sonnet 5 excels in ultra-complex, multi-step logical reasoning. |
| Context Window | 200,000 tokens | 1,000,000 tokens (via glm-5.2[1m]) | GLM-5.2 can ingest up to 5x more codebase data simultaneously. |
| Pricing (per 1M tokens) | $3.00 Input / $15.00 Output | $1.40 Input / $4.40 Output | GLM-5.2 cuts input costs by 53% and output costs by over 70%. |
Analyzing the Architectural and Financial Trade-Offs
This side-by-side comparison highlights a crucial 2026 trend: open-weight models are no longer "budget compromises."
- The Reasoning Advantage: Claude Sonnet 5 remains the gold standard for pure, unassisted logical execution. Its 57.4% score on the Hard LLM Benchmark (HLE) with tools shows its high adaptability. It integrates deeply with command-line developer workflows via Claude Code, securing an impressive 82% developer preference rating over previous generations.
- The Scale and Cost Advantage: Zhipu AI’s GLM-5.2 disrupts the market by leveraging a colossal 745-billion parameter Mixture-of-Experts (MoE) architecture. By only activating a fraction of its parameter network during active inference, it matches Sonnet 5's elite SWE-bench capabilities while operating at a fraction of the cost.
- The Context Advantage: For long-horizon agentic workflows, context is everything. GLM-5.2's dedicated 1-million-token context window (
glm-5.2[1m]) allows autonomous agents to parse entire microservice repositories at once. However, early developer feedback notes that GLM-5.2 can occasionally suffer from higher latency and increased token consumption under dense, multi-turn agentic loops compared to Sonnet 5’s highly streamlined token efficiency.
For engineering teams looking to leverage both approaches, platforms like CallMissed make it incredibly simple to optimize these workflows. By utilizing CallMissed's multi-model API gateway, developers can seamlessly deploy, test, and dynamically switch between over 300 models—allowing them to route routine coding tasks to the highly economical GLM-5.2, while reserving Claude Sonnet 5 for ultra-complex reasoning challenges.
In-Depth Analysis: Benchmarks, SWE-bench Pro, and Real-World Execution
The Benchmark Showdown: SWE-bench Pro and HLE
To truly understand how these models perform when tasked with autonomous software engineering, we must look beyond synthetic evaluations to rigorous, multi-step benchmarks. The gold standard for agentic coding in 2026 is SWE-bench Pro, which evaluates an AI’s ability to resolve real, complex GitHub issues in massive codebases.
- Claude Sonnet 5 commands the lead with a groundbreaking 63.2% success rate on SWE-bench Pro. This is complemented by its stellar 57.4% score on the Hard LLM Benchmark (HLE) using tools, proving its elite capacity for mathematical and logical reasoning during long-horizon coding tasks.
- GLM-5.2 is breathing down Anthropic's neck, scoring an impressive 62.1% on SWE-bench Pro and 54.7% on HLE with tools. For an open-weight model to come within a single percentage point of Silicon Valley's flagship closed-source model on agentic execution represents a monumental shift in the open-source landscape.
These benchmarks demonstrate that both models have transitioned from basic syntax autocomplete to highly capable virtual teammates capable of diagnosing, writing, testing, and shipping production-ready code.
Architecture and Context Dynamics: MoE vs. Proprietary Precision
The underlying architectures of these two models dictate how they behave in production environment sandboxes:
- GLM-5.2 is built on a massive 745-billion parameter Mixture-of-Experts (MoE) architecture. Through its specialized
glm-5.2[1m]variant, it offers a staggering 1-million-token context window. This allows developers to ingest entire codebases, system architectures, and dependency trees directly into the active prompt window. - Claude Sonnet 5 takes a different path, focusing on hyper-efficiency, rapid execution speed, and flawless tool-use optimization. While its context window is tighter, its seamless integration with tools like Claude Code and extreme resistance to agentic drift make it highly reliable for iterative development loops.
However, this structural difference impacts real-world usability. Developer feedback reveals that while GLM-5.2’s massive context is a superpower for legacy system refactoring, it can sometimes experience latency spikes and consume significant token volumes during extended sessions. Conversely, Sonnet 5 maintains low-latency execution and high efficiency, though it demands a premium price point.
Real-World Execution: Balancing Cost and Performance
In everyday engineering pipelines, the choice between these two powerhouses often comes down to economics and deployment flexibility. While Sonnet 5 enjoys an 82% developer preference rating due to its intuitive code generation and low-friction debugging, its API pricing ($3.00/M input, $15.00/M output) can scale rapidly for high-volume enterprise pipelines. GLM-5.2, priced aggressively at just $1.40/M input and $4.40/M output, presents an incredibly disruptive alternative for self-hosting and high-throughput agentic workflows.
Navigating this delicate balance of performance, cost, and latency is critical for modern development teams. This is where platforms like CallMissed become indispensable. By utilizing CallMissed’s multi-model API gateway, developers can seamlessly route tasks dynamically—orchestrating GLM-5.2 to ingest massive logs or map vast code repositories via its 1M context window, while instantly calling upon Claude Sonnet 5's precise reasoning capabilities for critical, high-risk code refactoring. This hybrid approach ensures you get the maximum ROI from the 2026 agentic coding frontier.
The Cost-Efficiency Battle: API Pricing and the 1/10th Premium Disruption
The Token Economics of Autonomous Agents
When evaluating AI models for simple autocomplete tasks, API pricing is a minor operational line item. However, in the 2026 agentic landscape, where autonomous software engineers operate in multi-hour execution loops, pricing becomes a defining architectural constraint. An agent resolving a single complex bug on SWE-bench Pro may execute dozens of sequential steps—reading codebase files, writing scratchpads, running test suites, and self-correcting. This process routinely consumes millions of tokens per task, turning API cost-efficiency into a make-or-break metric for enterprise deployment.
This is where the pricing strategies of Anthropic and Zhipu AI wildly diverge, creating a high-stakes trade-off between proprietary premium polish and highly disruptive, open-weight economics.
Head-to-Head API Pricing
Anthropic’s Claude Sonnet 5 maintains its premium positioning. It is priced at $3.00 per million input tokens and $15.00 per million output tokens. While this pricing matches previous generations, the financial burden adds up quickly during long-horizon coding tasks where agentic loops generate massive output files and detailed reasoning steps.
In contrast, Zhipu AI's GLM-5.2 acts as a major market disruptor. By pricing its API at $1.40 per million input tokens and $4.40 per million output tokens, GLM-5.2 drastically undercuts the proprietary competition.
| Metric / Model | Claude Sonnet 5 | GLM-5.2 | Cost Savings % (GLM-5.2) |
|---|---|---|---|
| Input Cost (per M tokens) | $3.00 | $1.40 | ~53% |
| Output Cost (per M tokens) | $15.00 | $4.40 | ~70% |
| SWE-bench Pro Score | 63.2% | 62.1% | — |
The most dramatic gap lies in the output pricing, where GLM-5.2 is over 70% cheaper than Sonnet 5. For a software agent that generates extensive code refactors and intermediate diagnostic logs, this pricing gap represents an order-of-magnitude shift in Total Cost of Ownership (TCO).
The "1/10th Premium" Subscription Disruption
Zhipu AI’s pricing aggression extends beyond raw API tokens. In the subscription space, the company has introduced a "1/10th Premium" model, offering enterprise developer packages at a fraction of the cost of western proprietary equivalents.
Yet, despite this massive cost delta, Anthropic maintains a strong hold on developers. Claude Sonnet 5 boasts an impressive 82% developer preference rating over older models. For many engineering teams, the 1.1% performance edge on SWE-bench Pro (63.2% vs. 62.1%) and Sonnet 5's seamless integration with tools like Claude Code justify the premium. When a single missed bug or faulty architectural decision can cost thousands of dollars in developer triage time, paying a premium for Sonnet 5's unmatched reliability is often seen as a necessary tax.
Optimizing the Spend with Hybrid Infrastructure
Fortunately, choosing between these two giants does not have to be an all-or-nothing decision. Forward-thinking engineering teams are increasingly turning to hybrid routing. By utilizing platforms like CallMissed, developers can access a multi-model API gateway supporting over 300 models. This allows teams to dynamically route high-volume, exploratory agent steps (such as codebase indexing and initial syntax drafting) to the cost-disruptive GLM-5.2, while escalating complex reasoning, system architecture decisions, and final code reviews to Claude Sonnet 5. This hybrid approach delivers the best of both worlds: premium proprietary intelligence at open-weight operating costs.
Expert Opinions: Developer Workflows and Integration Ecosystems

The Closed Ecosystem: Anthropic's Claude Code and Native Tooling
For developers entrenched in the western software ecosystem, Claude Sonnet 5 delivers an unparalleled, ready-to-use developer experience. The standout differentiator in 2026 is its native integration with Claude Code, Anthropic’s official agentic command-line tool. Because Anthropic tightly optimizes both the model and the client interface, Sonnet 5 functions as a highly polished, local agent that can execute terminal commands, edit files directly, and run test suites with minimal latency.
DevOps architects favor Sonnet 5 because it minimizes setup friction. Key advantages of this closed ecosystem include:
- Zero-config agentic loops: Out-of-the-box tools for repository indexing, git integration, and step-by-step debugging.
- High-efficiency execution: Sonnet 5 is optimized for rapid, iterative tasks, making it ideal for interactive terminal-based coding sessions where developer focus is critical.
- Enterprise compliance: Standardized API access contracts, guaranteed data privacy, and predictable SLA boundaries that satisfy rigorous corporate security audits.
The Open Ecosystem: Orchestrating GLM-5.2 with Open-Source Frameworks
In contrast, Zhipu AI's GLM-5.2 thrives in the open-source community, appealing to teams that demand complete control over their deployment and runtime environments. As a massive 745-billion parameter Mixture-of-Experts (MoE) model, GLM-5.2 is designed to be self-hosted on private cloud infrastructure (using runtimes like vLLM, DeepSpeed, or TensorRT-LLM) or accessed via highly customizable APIs.
Integration advocates point out that GLM-5.2 is a powerhouse when coupled with open agentic frameworks like LangGraph, AutoGen, and CrewAI. Developers can modify system prompts at a granular level, fine-tune the model on highly proprietary internal codebases, or run local instances to completely bypass external compliance hurdles. Furthermore, its massive 1-million-token context option (glm-5.2[1m]) allows developers to feed entire codebases directly into the context window for macro-level architectural refactoring. However, experts warn that this open-weight flexibility comes with infrastructure overhead: self-hosting a 745B MoE requires a robust GPU cluster, and handling massive contexts can occasionally lead to token bloat and increased latency.
The Hybrid Reality: Multi-Model Orchestration
As engineering teams scale their agentic pipelines in 2026, they rarely rely on a single model. The emerging consensus among enterprise architects is to adopt a hybrid workflow: utilizing Claude Sonnet 5's premium reasoning (boasting a 63.2% SWE-bench Pro score) for complex, high-stakes system design, while routing high-volume, repetitive tasks—such as boilerplate generation, unit test creation, and multi-lingual documentation—to the cost-effective GLM-5.2 ($1.40/M input).
This is where advanced AI infrastructure platforms like CallMissed become indispensable. By leveraging CallMissed's multi-model API gateway, engineering teams can seamlessly orchestrate interactions across more than 300 LLMs. Developers can dynamically switch between Sonnet 5's premium capabilities and GLM-5.2's open-weight versatility, ensuring that their agentic coding pipelines maintain peak performance and global reach without exceeding their computational budgets.
What This Means For You: Choosing Your Agentic Engine (TABLE)
Navigating the Architectural Divide
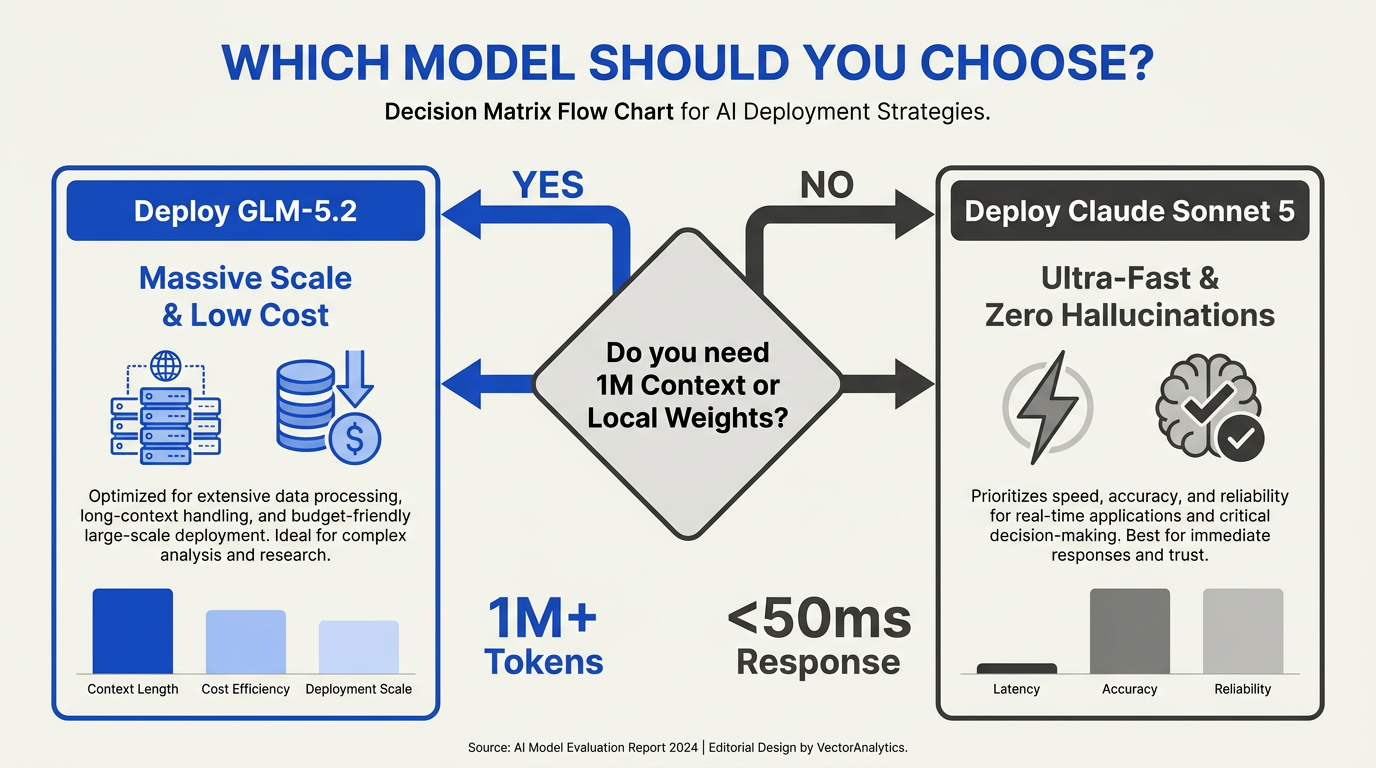
Selecting the ideal core engine for your agentic coding workflows in 2026 isn't just about picking the highest benchmark score. It requires a balanced evaluation of execution accuracy, context length, operational cost, and data sovereignty. While Anthropic’s proprietary Claude Sonnet 5 offers unparalleled, highly polished tool integration, Zhipu AI's GLM-5.2 presents an incredibly disruptive, cost-effective alternative that can be deployed within your private cloud infrastructure.
To help your engineering team make the right architectural decision, we have synthesized the key trade-offs between these two 2026 titans:
| Feature / Metric | Claude Sonnet 5 | GLM-5.2 (745B MoE) | Strategic Winner |
|---|---|---|---|
| SWE-bench Pro Score | 63.2% (Top tier) | 62.1% (Highly competitive) | Claude Sonnet 5 (Slight edge) |
| API Pricing (per M) | $3.00 Input / $15.00 Output | $1.40 Input / $4.40 Output | GLM-5.2 (Over 50% cheaper) |
| Context Window | 200,000 tokens | Up to 1,000,000 tokens | GLM-5.2 (Long-horizon tasks) |
| Deployment Model | Closed-weight (Anthropic API) | Open-weight (Self-hostable/Cloud) | GLM-5.2 (Data Sovereignty) |
| HLE (With Tools) | 57.4% | 54.7% | Claude Sonnet 5 (Better tool use) |
Decoding the Choice for Your Enterprise
When deciding which model to standardize on, consider the structure of your development pipeline:
- Choose Claude Sonnet 5 if you are building complex, multi-agent workflows that require flawless tool execution, rapid turnarounds, and minimal developer intervention. Its 63.2% SWE-bench Pro capability and 57.4% Hard LLM Benchmark (HLE) performance mean fewer broken agent loops and highly accurate code generation out of the box.
- Choose GLM-5.2 if you are working with massive legacy codebases that require a giant context window (up to 1 million tokens) or if your organization operates under strict compliance guidelines that mandate local, private-cloud hosting. At $1.40/M input and $4.40/M output, GLM-5.2 is also the clear winner for high-volume batch refactoring where operational costs would otherwise spiral out of control.
Fortunately, this does not have to be an all-or-nothing decision. Modern AI engineering teams are increasingly adopting hybrid, multi-model routing. By utilizing platforms like CallMissed, which provides an advanced LLM inference gateway supporting over 300+ models, developers can deploy a unified API infrastructure that dynamically routes simple debugging and massive codebase queries to GLM-5.2, while escalating high-complexity, logic-heavy architectural tasks to Claude Sonnet 5. This multi-model approach ensures your autonomous coding pipelines operate at peak performance without breaking your compute budget.
Frequently Asked Questions
How does the performance of Claude Sonnet 5 vs. GLM-5.2 compare on standard coding benchmarks?
What are the main architectural differences between Claude Sonnet 5 and GLM-5.2?
glm-5.2[1m]). Conversely, Claude Sonnet 5 is a highly optimized, closed-source proprietary model designed for speed, extreme token efficiency, and seamless integration with developer ecosystems like Claude Code. This structural divide means GLM-5.2 provides deep local customization, while Sonnet 5 delivers polished, low-latency API execution.Which model is more cost-effective for enterprise deployment: Claude Sonnet 5 vs. GLM-5.2?
Can I run Zhipu AI's GLM-5.2 completely offline or locally?
Does Claude Sonnet 5 support a 1-million-token context window like GLM-5.2?
glm-5.2[1m] variant, is designed to ingest massive codebases of up to a million tokens, though users should note that processing such long contexts can sometimes result in slower execution speeds and higher token consumption.What should developers consider when choosing between Claude Sonnet 5 vs. GLM-5.2 for agentic coding?
Conclusion
The battle between Claude Sonnet 5 and GLM-5.2 highlights a rapidly maturing agentic ecosystem where closed-source polish and open-weight economics are converging:
- Performance Edge: Claude Sonnet 5 maintains a razor-thin lead in complex, long-horizon software engineering, scoring 63.2% on SWE-bench Pro compared to GLM-5.2's 62.1%.
- Economic Disruption: Zhipu AI's GLM-5.2 dramatically undercuts proprietary pricing ($1.40/M input vs. Sonnet's $3/M) while offering a massive 1-million-token context window.
- Architectural Flexibility: While Sonnet 5 excels in speed and tight developer integrations, GLM-5.2’s open-weight 745B MoE architecture offers unprecedented self-hosting potential and customization.
Looking ahead, the line between proprietary and open-weight agentic capabilities will continue to blur, forcing engineering teams to weigh execution speed and platform lock-in against raw API costs and data sovereignty. To explore how AI communication is evolving alongside these LLM breakthroughs, check out CallMissed—an AI infrastructure platform powering advanced voice agents and multilingual chatbots for modern businesses.
Will your organization choose the premium, managed execution of Claude Sonnet 5, or will you leverage GLM-5.2 to build a custom, self-hosted developer platform?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.