Evaluating Voice Agents: Beyond Word Error Rate

Did you know that a voice agent boasting a near-perfect 98% Speech-to-Text accuracy rate can still drive customers to hang up in frustration within...
Evaluating Voice Agents: Beyond Word Error Rate
Did you know that a voice agent boasting a near-perfect 98% Speech-to-Text accuracy rate can still drive customers to hang up in frustration within seconds? For decades, developers and enterprises have relied on Word Error Rate (WER) as the ultimate benchmark for measuring conversational AI success. If the machine transcribed the words correctly, the system was deemed a success. However, as we navigate the landscape of generative AI in 2026, this metric is proving to be remarkably outdated. In the era of highly interactive, LLM-powered voice assistants, optimizing for WER alone is no longer enough to guarantee a great user experience; in fact, it often masks critical flaws that completely ruin customer interactions.
Why is WER no longer the gold standard? Because transcription accuracy is only one small link in a complex, multi-layered conversational pipeline. Today's voice agents do not just transcribe speech; they must comprehend intent, manage turn-taking, extract structured data, and synthesize natural speech—all in real-time. If an agent takes three seconds to formulate a response (high per-turn latency) or fails to recognize when a user interrupts them (barge-in detection), the conversation breaks down instantly, regardless of whether every word was transcribed with 100% accuracy. Recent industry benchmarks show that human-to-human conversations typically feature response latencies of around 200 milliseconds. For an AI voice agent to feel natural, it must target a p95 latency (the time it takes to respond in 95% of cases) of under 1 to 1.5 seconds. A low WER does nothing to solve a laggy, unnatural conversation.
To navigate these complex dynamics, forward-thinking infrastructure providers are moving away from isolated benchmarks. For example, platforms like CallMissed are helping developers build production-ready voice agent infrastructure that natively optimizes for low-latency, multilingual support across 22 Indian languages, balancing transcription quality with real-world conversational speed.
This guide, Evaluating Voice Agents: Beyond Word Error Rate, will dissect the new paradigm of conversational AI evaluation. We will explore why traditional speech-to-text metrics fall short and introduce the multi-dimensional framework required to evaluate interactive voice systems.
Specifically, you will learn about:
- The Critical Six Metrics: Understanding the key technical indicators that actually define voice agent performance, including p50 and p95 latency distribution, barge-in detection accuracy, and entity capture rate.
- Evaluating Under Real-World Noise: How to test your agent's ability to maintain high task success rates and avoid hallucinations when confronted with background noise, heavy accents, and colloquial phrasing.
- Task Success vs. Transcription Success: Why a system can have a high WER but still achieve a 100% completion rate on booking a flight, routing a call, or resolving a support ticket.
Let’s dive into why Word Error Rate is no longer the metric to watch, and look at what you should be measuring instead to build truly seamless, human-grade voice experiences.
Introduction
For years, the speech technology industry operated under a single, dominant metric: Word Error Rate (WER). Originating in the early days of Automatic Speech Recognition (ASR), WER measures the exact percentage of insertions, deletions, and substitutions a system makes compared to a perfect human reference transcript. It was an objective, math-heavy benchmark that worked beautifully when speech technology was a one-way street—designed simply to convert dictated audio files into static text blocks.
But we no longer live in a world of simple dictation. Today, in 2026, we are witnessing the mass deployment of highly interactive, generative AI voice agents. These agents are tasked with booking appointments, resolving complex customer service tickets, guiding patients through medical triages, and driving sales pipelines. In this dynamic, real-time conversational landscape, relying solely on WER to measure the quality of a voice agent is not just outdated; it is actively misleading.
An agent can boast a near-perfect 95% transcription accuracy (a stellar 5% WER) but still deliver a catastrophically bad customer experience. If the agent takes four seconds to process that highly accurate transcript before responding, or if it hallucinates a critical piece of user data, or fails to detect when the customer interrupts ("barks in") to correct a mistake, the interaction fails. To build voice systems that feel natural, intuitive, and genuinely helpful, we must look beyond the transcript and establish a new paradigm for voice agent evaluation.
Why Word Error Rate is Broken for Conversational AI
To understand why we need to move beyond WER, we first have to understand what WER measures—and, more importantly, what it completely ignores.
WER treats all words with equal weight. In a mathematical formula, missing an insignificant filler word like "uh" or "um" carries the exact same penalty as missing the word "not" in "I do not want to authorize this charge." In a business or clinical setting, that single-word error completely flips the user's intent, leading to catastrophic action errors. Yet, on a standard WER evaluation sheet, both transcriptions might score a highly acceptable 98% accuracy.
Furthermore, WER is a static, post-hoc metric. It assumes a linear, offline process:
- Audio is recorded.
- Audio is sent to an ASR engine.
- Text is generated and compared to a human transcript.
Modern voice agents operate in a complex, multi-layered feedback loop where three core engines work in continuous, real-time synchronization:
- Speech-to-Text (STT): Translating raw audio waves into text tokens.
- Large Language Model (LLM) / Orchestration: Processing those tokens to understand intent, make decisions, and generate a textual response.
- Text-to-Speech (TTS): Converting those response tokens back into high-fidelity, expressive audio.
When these three components interact, new classes of errors emerge that WER cannot capture. A minor transcription error might be seamlessly corrected by a robust LLM, resulting in a perfect task completion despite a "poor" WER. Conversely, a perfect transcript might trigger a hallucinated or toxic response from an unaligned LLM, resulting in an absolute failure of the call despite a 0% WER.
The Five Pillars of Modern Voice Agent Evaluation
If WER is no longer the gold standard, what is? Leading research from AI practitioners and platforms has converged on a holistic, multi-dimensional evaluation framework. To evaluate how a voice agent performs in the real world, developers and enterprise leaders must track five core pillars:
- Latency Distribution (p50, p95): Latency is the ultimate killer of conversational flow. While mean or average latency is a common metric, it hides catastrophic spikes. Modern systems must evaluate the p50 (median) and p95 latency—the threshold under which 95% of all agent responses fall. This measures the exact time from the user's last spoken word to the agent's first audio response. In human conversations, the typical gap is roughly 200 milliseconds. If an agent’s p95 latency stretches past 1.5 or 2 seconds, the conversation rapidly degrades into awkward pauses and mutual interruptions.
- Barge-in Detection and Handling: In real conversations, people do not wait for a robotic prompt to finish playing before they speak. They interrupt, clarify, and redirect. A high-performing voice agent must accurately detect a user's voice mid-prompt (barge-in), instantly halt its own audio output, listen to the new input, and seamlessly adjust its conversational trajectory.
- Entity Capture Rate: Voice agents are frequently used to gather critical structured information—such as account numbers, email addresses, dates, and physical addresses. Entity Capture Rate measures the agent's ability to extract and structure this vital data correctly under noisy, real-world conditions (such as background traffic, crying children, or poor cellular reception).
- Task Success and Goal Completion Rate: Ultimately, a voice agent is deployed to perform a job. Did the caller successfully book the flight? Was the password reset? Evaluating voice agents requires tracking end-to-end task completion rates, ensuring that the conversational logic successfully guides the user to their desired outcome.
- Hallucination and Safety Under Noise: Unlike text-based chatbots, voice agents must parse raw acoustic data which is inherently messy. Background noise, accents, and stuttering can feed corrupted text into the LLM. Evaluation frameworks must test how robustly the agent's cognitive layer handles corrupted inputs without hallucinating false information or executing unauthorized actions.
Building for the Next Era of Voice AI
Navigating this complex evaluation landscape requires a shift in how we build and deploy voice infrastructure. Developing custom pipelines to benchmark latency, manage multi-model synchronization, and process multilingual inputs is a massive engineering hurdle.
This is where advanced communication infrastructures play a pivotal role. Platforms like CallMissed are built specifically to handle these real-time, multi-modal challenges. By offering production-ready voice agent infrastructure, low-latency execution pipelines, and a multi-model gateway supporting over 300 LLMs, CallMissed enables developers to swap, test, and optimize models to achieve the perfect balance of latency, cost, and task success. Furthermore, with native support for Speech-to-Text in 22 regional Indian languages, it ensures that evaluation metrics remain robust across diverse linguistic and acoustic environments.
What This Guide Will Cover
Evaluating voice agents is no longer just an AI research problem; it is a core business requirement. This comprehensive guide is designed to take you beyond the limitations of legacy metrics like Word Error Rate and equip you with the practical frameworks needed to build, benchmark, and scale production-grade conversational agents.
Over the course of this guide, we will dive deep into:
- The structural differences between static STT testing and real-time agent benchmarking.
- How to measure and optimize the critical "Time to First Audio" and per-turn latency distribution.
- Strategies for testing barge-in behavior and handling conversational interruptions.
- Advanced evaluation methodologies for entity capture, intent classification, and task success.
- How to build automated simulation pipelines to stress-test your agents before they ever take a live call.
By shifting your focus from "did the agent write down the right words?" to "did the agent successfully help the human?", you can build voice systems that don't just work on paper, but delight users in the real world. Let's get started.
The Limits of STT: Why Word Error Rate is Broken

For decades, Automatic Speech Recognition (ASR) systems have bowed to a single, undisputed metric: Word Error Rate (WER). Calculated as the sum of substitutions, deletions, and insertions divided by the total number of words in a human-verified reference transcript, WER was long considered the gold standard of transcription accuracy. If you were transcribing a static lecture or dictating a memo, a lower WER meant a better system.
But in the era of generative AI and interactive voice agents, relying solely on WER to evaluate performance is not just outdated—it is fundamentally broken. Modern voice agents do not operate in static environments. They are dynamic conversational partners that must listen, comprehend, synthesize, and respond in real time. Optimizing a voice agent exclusively for WER is a classic case of Goodhart’s Law: when a measure becomes a target, it ceases to be a good measure.
The Math Behind WER: A Flawed Equal-Weight Equation
To understand why WER fails, we must look at its mathematical formula:
$$\text{WER} = \frac{S + D + I}{N}$$
Where $S$ represents substitutions, $D$ represents deletions, $I$ represents insertions, and $N$ is the total number of words in the reference transcript.
The structural flaw in this equation is that WER treats every error with equal weight. In a live, conversational customer support interaction, however, some errors are completely harmless, while others are catastrophic. Consider these two contrasting scenarios:
- Reference: "Yes, please cancel my account immediately."
- ASR Transcript A: "Yes, please council my account immediately." (1 Substitution)
- Reference: "No, do not charge my card."
- ASR Transcript B: "No, do charge my card." (1 Deletion)
From a pure mathematical standpoint, both transcripts yield the exact same WER. Yet, the downstream impact is night and day. Transcript A features a minor phonetic substitution ("council" instead of "cancel") that any modern Large Language Model (LLM) can easily contextualize, auto-correct, and act upon correctly. Transcript B, on the other hand, deletes a single, critical word: "not." This deletion completely reverses the user's intent. If an automated voice agent processes Transcript B, it will execute an unauthorized financial transaction, resulting in severe customer frustration, churn, and potential regulatory liability. WER is entirely blind to this distinction.
The Text Normalization Trap
Another major limitation of WER is its sensitivity to formatting, text normalization, and transcription style. ASR models often transcribe spoken words into numerical digits, abbreviations, or alternative spellings, while human-labeled reference transcripts might use fully written-out words.
Consider this example:
- Reference: "He lives at eighty-eight Union Street on May thirty-first."
- ASR Output: "He lives at 88 Union St on May 31."
To a downstream LLM or a database, the ASR output is 100% accurate, highly readable, and perfectly structured. However, under a strict WER calculation, this output is penalized heavily for multiple insertions, deletions, and substitutions, resulting in a deceptively high error rate. While text normalization pipelines attempt to clean up these discrepancies before calculating WER, they add processing overhead, introduce extra latency, and rarely cover all specialized domains—such as medical jargon, alphanumeric product codes, or regional spelling variations.
The LLM Paradigm: Robustness to Noise
The transition from traditional, rule-based Natural Language Processing (NLP) to LLM-driven reasoning has radically changed how we process transcribed speech. Modern LLMs are incredibly resilient when dealing with minor grammatical, spelling, and phonetic errors. If an ASR system outputs "I want to buy a ticket to San Fran sicko," an advanced LLM will seamlessly resolve the destination to "San Francisco" based on semantic context.
Because LLMs can handle a reasonable amount of noise in the text stream, striving to lower an ASR's WER from 5% to 1% often yields zero improvement in end-to-end task success. Instead of obsessing over perfect word-for-word transcriptions, developers must focus on semantic accuracy and intent classification. If the downstream model can perfectly understand and execute the user's request, the exact spelling of the intermediary transcript becomes irrelevant.
Leaving Critical Conversational Dynamics Out of the Equation
A natural voice conversation is a complex, fast-paced interaction defined by timing, acoustics, and turn-taking. By focusing entirely on static text accuracy, WER completely ignores the metrics that actually determine whether a voice call feels natural or frustrating to a human user:
- Latency Distribution (p50, p95): This measures the time elapsed from when a user finishes speaking to when the voice agent utters its first word. An ASR model could achieve a flawless 0% WER, but if it takes 3 seconds of processing time to output that perfect text, the voice agent will feel sluggish, awkward, and unusable.
- Barge-in and Interruption Handling: Humans interrupt each other naturally. A high-performing voice agent must detect when a user starts speaking mid-sentence (barge-in) and immediately halt its Text-to-Speech (TTS) engine. WER provides absolutely no signal on how well an agent manages these interruptions.
- Acoustic Robustness: Real-world phone calls are plagued by background noise, cellular packet loss, and varying accents. Evaluating an ASR model using clean, studio-recorded datasets tells you nothing about how the agent will perform when a customer calls from a noisy subway station or a windy street.
The Multilingual and Code-Switching Challenge
In globalized markets, conversations rarely happen in a single, textbook language. In regions like India, speakers constantly code-switch, blending English with local languages (e.g., "Hinglish" or "Tanglish") within a single sentence.
Traditional WER benchmarks completely fall apart in these environments. Transcribing code-switched speech requires phonetic flexibility and deep cultural context. If a user says "Mera refund kab aayega?" (When will my refund arrive?), an ASR optimized purely for rigid English or native Hindi WER will struggle to accurately represent the phonetic mix, leading to artificial penalties.
This is why modern AI platforms are shifting their focus from rigid transcription matching to end-to-end conversational intelligence. Platforms like CallMissed address this challenge directly by offering a Speech-to-Text API that natively supports 22 Indian languages. Instead of forcing developers to chase arbitrary WER benchmarks on standardized English datasets, CallMissed focuses on optimizing multilingual semantic fidelity, ensuring that regional dialects and code-switched speech are parsed accurately for downstream LLM comprehension without adding latency.
Transitioning to a Holistic Evaluation Framework
To build voice agents that customers actually enjoy interacting with, engineering teams must move away from evaluating components in isolation. A low WER does not guarantee a successful voice agent, just as a high-quality TTS engine does not guarantee a natural conversation.
To measure what truly matters, the industry must transition to a holistic evaluation framework. This framework should prioritize end-to-end metrics like task success rate, p95 latency, barge-in detection accuracy, and entity capture rate. By shifting our focus from pedantic word matching to downstream utility and natural conversational flow, we can design voice systems that truly match human-level performance.
The Modern Paradigm: Critical Metrics Beyond WER
For decades, automatic speech recognition (ASR) systems were evaluated using a single, monolithic metric: Word Error Rate (WER). While WER remains a useful benchmark for transcribing static audio files, it has proven fundamentally inadequate for evaluating the interactive, bi-directional, and real-time nature of modern generative AI voice agents.
In the current landscape, a voice agent is not a passive transcriber; it is a dynamic conversational partner. It must listen, comprehend context, manage interruptions, synthesize information, and respond in real time. Evaluating these agents requires a multi-dimensional approach that measures the entire conversational pipeline—from the physical constraints of audio transmission to the cognitive limits of large language models (LLMs).
To build production-grade voice agents that customers actually want to talk to, developers and product teams must transition to a modern paradigm of evaluation. This paradigm prioritizes four critical categories of performance metrics.
1. Latency Distribution: Optimizing the p50 and p95 Experience
In human-to-human conversation, the typical pause between speakers lasts between 200 to 400 milliseconds. If an AI voice agent takes longer than 1.5 seconds to reply, the silence feels unnatural, causing users to speak over the agent or assume the system has crashed.
When evaluating latency, looking at simple averages is highly misleading. A system with a "good" average latency of 800 milliseconds can still deliver a terrible user experience if one in every ten responses takes four seconds. Instead, engineering teams must track the latency distribution:
- p50 Latency: The median response time. This represents what the typical user experiences on an average conversational turn.
- p95 and p99 Latency: The tail-end response time (the 95th and 99th percentiles). This is the true measure of system stability and architecture quality. High p95 latency is usually caused by cold-start LLM inferences, API rate limits, or network jitter.
- Time to First Audio (TTFA): The exact duration from the millisecond the user stops speaking to the millisecond the Text-to-Speech (TTS) engine streams the first packet of audio back to the user.
Modern architectures minimize latency by running highly optimized streaming pipelines. Platforms like CallMissed address this bottleneck by leveraging a high-performance LLM gateway supporting over 300 models alongside unified, low-latency Speech-to-Text and Text-to-Speech APIs, ensuring p95 latencies remain safely within conversational thresholds.
2. Conversational Fluidity: Barge-in Detection and Interruption Dynamics
Unlike pre-recorded IVR systems where users must wait for a prompt to finish, natural conversations are highly collaborative. Humans constantly interrupt, clarify, or provide "backchanneling" cues (such as "uh-huh," "sure," or "right") without intending to halt the other speaker.
To evaluate how well a voice agent handles these dynamics, we track metrics dedicated to conversational flow:
- Barge-in Sensitivity and Success Rate: Measures how accurately the voice agent detects when a user has started speaking over its output, and how gracefully it halts its own audio generation.
- False Interruption Rate: The frequency with which the agent mistakenly stops speaking due to background noise, a user sighing, or ambient room coughs. High false interruption rates lead to frustrated users who feel they cannot get a complete sentence out.
- Backchanneling Accuracy: The agent’s ability to recognize supportive non-verbal cues without treating them as conversational interruptions, keeping the audio playback smooth.
3. Semantic Integrity: Entity Capture Rate and Intent Accuracy
A voice agent can have a mediocre WER and still be highly effective, or it can have an excellent WER and fail completely. For example, if a user says, "I want to transfer fifty dollars to John," and the ASR transcribes, "I want to transfer fifty dollars to Don," the WER is incredibly low (only one word wrong out of eight). However, the semantic failure is catastrophic—money is sent to the wrong person.
To evaluate what truly matters to the business logic, teams use semantic and task-centric metrics:
- Entity Capture Rate (ECR): This measures how accurately the agent extracts critical, high-value data points—such as names, account numbers, dates, currency values, and email addresses—from the spoken stream. This is especially vital in multilingual environments. For instance, CallMissed's specialized STT engine supports 22 Indian regional languages natively, optimizing specifically for high ECR across diverse dialects and phonetic variations where standard global models frequently fail.
- Intent Classification Accuracy: The percentage of turns where the underlying LLM correctly identifies the user’s core objective, regardless of colloquialisms, stuttering, or grammar mistakes in the transcript.
- Hallucination Under Noise: A metric that tests the agent's robustness when processing audio overlaid with static, street noise, or poor cellular reception. It measures how often the agent hallucinates a response or acts on incorrect assumptions when the incoming transcript is partially degraded.
4. End-to-End Resolution: Task Success Rate (TSR)
Ultimately, the goal of any enterprise voice agent is to solve the customer's problem without human intervention. An agent could have instantaneous latency and perfect word transcription, but if it fails to resolve the user's issue, the deployment is a failure.
- Task Success Rate (TSR): The percentage of calls where the agent successfully completes the user’s requested action (e.g., booking a flight, resetting a password, or updating a shipping address) without needing to escalate the call to a human agent.
- Mean Turns to Resolution (MTTR): The average number of back-and-forth conversational turns required to complete a task. A lower MTTR indicates a highly efficient agent that asks clarifying questions quickly and gets straight to the point.
- Unassisted Deflection Rate: The proportion of inbound calls handled fully autonomously, reducing the operational burden on traditional contact centers.
| Metric Category | Key Evaluation Metrics | Primary Operational Focus | Why It Matters Over WER |
|---|---|---|---|
| Latency | p50, p95, Time to First Audio (TTFA) | System architecture & API performance | Keeps the conversation moving naturally; prevents awkward pauses. |
| Conversational Flow | Barge-in success, False Interruption Rate | Audio streaming & VAD (Voice Activity Detection) | Allows users to interrupt and speak naturally without breaking the agent. |
| Semantic Accuracy | Entity Capture Rate (ECR), Intent Accuracy | LLM comprehension & NLU validation | Ensures critical business data (names, IDs, amounts) is processed correctly. |
| Business Impact | Task Success Rate (TSR), MTTR | End-to-end integration & UX | Measures actual ROI and customer satisfaction instead of technical performance. |
By transitioning from simplistic WER measurements to this multi-dimensional evaluation matrix, developers can identify the exact bottlenecks in their voice systems—whether it is a slow TTS model, an over-sensitive voice activity detector, or an LLM that struggles to extract variables in noisy environments.
Prerequisites & Setup (TABLE)
Before you can begin evaluating a real-time voice agent on advanced metrics like barge-in detection, p95 latency, or entity capture rate, you must first build a testing environment that accurately mirrors the chaotic reality of production voice calls.
Testing a voice agent is fundamentally different from evaluating a text-based LLM. A text chatbot is transactional: the user sends a prompt, and the model returns a response. A voice agent, however, operates over a continuous, bidirectional stream of audio. It must simultaneously listen, transcribe, reason, synthesize speech, and handle sudden user interruptions (barge-ins) over varying network conditions.
To benchmark this complex workflow without exposing untested agents to live customers, you must construct an automated simulation pipeline. Below, we outline the exact architecture, software stack, and testing datasets required to establish a robust evaluation framework.
The Voice Agent Evaluation Stack
To systematize your setup, construct your evaluation pipeline using the specialized components detailed in the table below:
| Component | Purpose | Key Metric to Monitor | Recommended Stack |
|---|---|---|---|
| Audio Streamer | Simulates live, bidirectional voice calls using WebSockets or SIP trunking | Time to First Audio (TTFA) | WebRTC, Twilio Media Streams, SIP |
| Noise Simulator | Injects background babble, traffic noise, and packet loss | WER under noise, Barge-in sensitivity | FFmpeg, Sox (Sound eXchange) |
| Evaluation Runner | Orchestrates synthetic test cases and records response transcripts | Task Success Rate, Entity Capture Rate | Braintrust, Hamming AI, custom scripts |
| Telemetry Engine | Captures timestamped events across the voice pipeline | Per-turn Latency (p50, p95 distributions) | OpenTelemetry, Prometheus, Grafana |
| Multi-Model Gateway | Hot-swaps LLM, STT, and TTS engines to compare performance | API Response Latency, Cost-to-Performance | CallMissed API Engine |
Step-by-Step Environment Setup
To get your testing environment up and running, follow this sequential setup guide to configure your telemetry, audio pipelines, and test data.
1. Instrumenting Your Telemetry Pipeline
You cannot optimize what you do not measure. Traditional logging only tracks total execution time, but to evaluate a voice agent, you must break down per-turn latency into its constituent phases.
Your application code must emit highly precise timestamps (with millisecond resolution) at the following five transition points:
-
t0(User Stops Speaking): The exact moment the user's speech energy drops below your Voice Activity Detection (VAD) threshold. -
t1(STT Complete): The moment your Speech-to-Text engine outputs the final transcript segment. -
t2(First LLM Token): The millisecond the Large Language Model generates its first token. -
t3(LLM Complete): The moment the LLM finishes generating the entire text response. -
t4(First Audio Chunk Generated): The moment the Text-to-Speech (TTS) engine generates the first byte of synthesised audio. -
t5(Audio Playout Begins): The moment the first audio chunk is delivered to the user's receiver.
Using these metrics, your evaluation runner should calculate:
- Per-Turn Latency (p50 and p95): Measured as $t_5 - t_0$. This captures the full round-trip delay experienced by the end user.
- STT + LLM Time-to-First-Token (TTFT): Measured as $t_2 - t_0$. This determines how fast your reasoning engine spins up.
- TTS Generation Latency: Measured as $t_4 - t_3$. This isolates the synthesis bottleneck.
2. Preparing the "Golden Dataset"
Evaluating with random prompts will yield inconsistent results. You need a curated "Golden Dataset" consisting of at least 100-200 high-fidelity conversational test cases. Each test case in your dataset must contain:
- An Audio File (.wav): A pre-recorded user prompt. Do not use synthetic TTS for your testing audio; instead, use diverse human voice recordings representing various accents, speech speeds, and ages.
- The Human Reference Transcript: A perfect, manually verified text transcript of the audio file to calculate baseline ASR accuracy.
- Expected Semantic Entities: The key data points the agent must extract (e.g.,
"booking_date": "2026-06-15","account_number": "98765"). - Target Intent/Goal: The expected final action or API call the agent should trigger.
To evaluate robustness, create three variations of this Golden Dataset:
- The Clean Set: High-quality audio with minimal background noise.
- The Noisy Set: The clean audio mixed with background noise (e.g., street noise, office chatter) at different decibel levels using FFmpeg.
- The Interruption Set: Audio files containing sudden mid-sentence shifts, pauses, or vocalized fillers ("uh," "um," "wait, actually...") to test how your system handles speech disfluency.
3. Simulating Real-World Network Conditions
Voice agents do not live in high-bandwidth, zero-latency local environments. When deployed globally, they navigate mobile cellular networks, packet loss, and varying jitter.
To simulate this in your staging environment, run your automated evaluations through a network emulator tool (like tc-netem on Linux). Inject a standard mobile network profile:
- Latency: Introduce a simulated base network latency of 50ms to 150ms.
- Packet Loss: Inject a 1% to 3% packet loss rate.
- Jitter: Set a jitter rate of 10ms to 20ms to evaluate how well your WebRTC jitter buffers handle packet reordering without causing audio degradation.
4. Deploying a Flexible API Infrastructure
If your testing infrastructure is hard-coded to a single LLM or STT provider, benchmarking alternative configurations becomes highly labor-intensive. An optimal testing environment should allow you to seamlessly switch out backends—such as swapping a heavy, high-latency model for a lightning-fast, smaller model—without modifying your core routing logic.
For teams looking to streamline this setup, platforms like CallMissed provide a production-ready AI communication infrastructure that simplifies model evaluation. CallMissed’s multi-model API gateway allows you to instantly toggle between 300+ LLMs, while its high-throughput Speech-to-Text engine natively supports 22 regional Indian languages. By routing your agent's voice channels through a unified pipeline like CallMissed, you can easily isolate variables, test multiple STT/TTS combinations, and collect precise latency distribution metrics across different language modules without having to stitch together disconnected vendors.
Getting Started

Transitioning from traditional speech system benchmarking to a modern evaluation framework for generative AI voice agents can feel like a paradigm shift. Historically, developers relied almost exclusively on Word Error Rate (WER) to judge the quality of voice systems. However, as organizations like AssemblyAI and academic researchers have demonstrated, WER is fundamentally broken when applied to conversational, interactive agents. A voice agent doesn't need to transcribe every "um," "uh," or filler word perfectly to solve a customer's problem. Conversely, a low WER score can still result in a failed call if the agent misinterprets a critical negative (e.g., transcribing "do not cancel" as "do cancel").
To build voice agents that deliver human-grade performance, you must establish an evaluation strategy that prioritizes real-world conversational dynamics over static transcription accuracy. Below is a step-by-step roadmap to help you get started.
Step 1: Define Your Multi-Dimensional Metric Stack
Before running your first test call, you must replace your single-metric (WER) focus with a comprehensive scorecard. Your evaluation pipeline should track a mix of audio engineering, linguistic, and task-completion metrics.
- Latency Distribution (p50 and p95): Measured as the time from the user’s last spoken word to the agent’s first audio response. While the median (p50) latency gives you an average feel, the p95 latency is critical for identifying worst-case performance dips that ruin user experience.
- Barge-in Detection Rate: The percentage of times the agent successfully stops speaking when the user interrupts, preserves the user’s interrupted utterance, and adapts its state dynamically.
- Entity Capture Rate (ECR): How reliably the agent extracts crucial structured data—such as phone numbers, alphanumeric booking codes, and email addresses—even when surrounding words are garbled.
- Task Success Rate (TSR): The percentage of calls where the agent successfully resolves the customer's intent without requiring manual human intervention.
- Hallucination Rate Under Noise: How robustly the downstream Large Language Model (LLM) handles transcription errors caused by background noise without generating false or misleading information.
Step 2: Build a Realistic Simulation Environment
Testing a voice agent in a quiet laboratory environment with a high-speed fiber connection is a recipe for production failure. In the real world, your users will call from busy street corners, moving vehicles, and crowded offices using unstable cellular connections.
To build a robust evaluation pipeline, you must simulate these conditions in your test bed:
- Acoustic Noise Injection: Overlay test audio with standard background noise profiles, including street traffic, coffee shop chatter, and white noise.
- Network Impairment Simulation: Inject synthetic latency, jitter, and packet loss into your SIP or WebRTC streams to see how gracefully your voice gateway handles degraded network environments.
- Linguistic Diversity: Ensure your test datasets include a wide range of regional accents, colloquialisms, and multilingual speech patterns. If you are deploying agents globally or in highly diverse regions, evaluating how your pipeline handles code-switching (mixing languages) is vital.
Step 3: Integrate Telemetry-Rich Voice Infrastructure
You cannot optimize what you do not measure. Standard web application monitoring tools are insufficient for tracking the split-second interactions of real-time voice. You need infrastructure built specifically to expose deep telemetry at every stage of the audio-to-text-to-speech loop.
This is where leveraging an optimized AI communication platform becomes essential. Infrastructure solutions like CallMissed allow developers to orchestrate voice agents with built-in telemetry tracking. By using platforms like CallMissed—which features low-latency LLM inference across more than 300 models, Speech-to-Text APIs supporting 22 Indian languages natively, and high-fidelity Text-to-Speech—you can easily pinpoint exactly where latency is accumulating. Is the delay coming from the initial STT chunking, LLM time-to-first-token (TTFT), or TTS audio generation? Rich telemetry from your infrastructure provider eliminates this guesswork.
Step 4: Deploy Agent-on-Agent Simulation (LLM-as-a-Judge)
Manual QA testing of voice agents is slow, expensive, and impossible to scale. To run continuous regression testing, you must automate the conversational loop using an agent-on-agent testing harness.
- The Customer Simulator: Configure an LLM to act as a customer with a specific persona, goal, and background environment (e.g., "An impatient caller trying to reschedule a flight while walking through a noisy airport").
- The Call Execution: Have the Customer Simulator place an automated call to your production-ready Voice Agent.
- The Evaluator (LLM-as-a-Judge): Record the call, generate transcripts, and pass the data to an independent LLM evaluation system. This evaluator scores the conversation against your defined KPIs: Did the voice agent successfully reschedule the flight? Did it handle the customer's interruptions gracefully? Did it capture the flight number accurately despite the simulated airport noise?
By running hundreds of these simulated calls in parallel, you can generate statistical benchmarks for your agent’s conversational performance overnight.
Step 5: Implement Regression Testing in Your CI/CD Pipeline
A voice agent is never truly finished. Every time you tweak a system prompt, update your LLM backend, optimize your STT engine, or alter a database schema, you risk breaking conversational flow or introducing latency spikes.
Incorporate your agent-on-agent evaluation suite directly into your continuous integration and continuous deployment (CI/CD) pipeline. Before any code changes are merged into production, run a "golden dataset" of at least 50 critical customer journeys. If the p95 latency exceeds your 1.5-second threshold, or if the Task Success Rate drops by even 1%, block the deployment. Treating conversational quality with the same engineering rigor as application uptime is the key to delivering reliable, delightful AI voice experiences.
Step-by-Step Walkthrough
To transition from theoretical metrics to a production-ready voice agent, you must design a structured, repeatable evaluation pipeline. Relying solely on isolated Word Error Rate (WER) tests will result in a system that performs beautifully on paper but fails in real-world environments.
This step-by-step walkthrough provides a practical blueprint for establishing a multi-dimensional evaluation framework that measures latency, conversational dynamics, and semantic accuracy.
Step 1: Establish Your Multilingual "Golden Dataset"
Before writing evaluation code, you need a highly representative test suite—often called a "Golden Dataset." This dataset should contain raw audio recordings that mimic actual customer environments, rather than pristine, studio-recorded audio.
Your dataset must capture:
- Acoustic Variety: Include background noise (such as coffee shop chatter, traffic, or cellular static), varying volume levels, and cross-talk.
- Linguistic Diversity: Ensure representation for regional accents, dialects, and colloquialisms. If you are building for a global or highly diverse market, your test suite must reflect this. For instance, when constructing localized test suites, platforms like CallMissed—which offers Speech-to-Text APIs supporting 22 Indian languages natively—can help you benchmark performance across highly diverse, multilingual user bases where language mixing (e.g., "Hinglish") is common.
- Edge Cases: Include audio files featuring sudden pauses, mid-sentence self-corrections (e.g., "Book for Tuesday—no, wait, Wednesday"), and background interruptions.
Step 2: Measure and Isolate Per-Turn Latency (p50 and p95)
In interactive voice applications, speed is the ultimate determinant of user experience. You must measure the time elapsed from the millisecond the user stops speaking to the millisecond the agent plays its first syllable of audio. This is known as Time to First Audio (TTFA) or Per-Turn Latency.
To measure and isolate bottlenecks, implement the following steps:
- Instrument Your Pipeline: Log timestamps for each stage of the turn lifecycle:
- $T_0$: User stops speaking (End-of-Speech detection).
- $T_1$: Speech-to-Text (STT) transcription complete.
- $T_2$: Large Language Model (LLM) generates the first token.
- $T_3$: Text-to-Speech (TTS) synthesizes the first chunk of audio.
- $T_4$: Audio begins playback on the user’s device.
- Calculate the Delta: Subtract $T_0$ from $T_4$ to find the end-to-end latency.
- Analyze Latency Distribution: Do not rely on averages, which mask poor experiences. Calculate p50 (median performance) and p95 (the 95th percentile, representing worst-case scenarios). A healthy voice agent should target a p50 latency under 1.2 seconds and a p95 latency under 2.0 seconds.
If your p95 latency spikes, trace the timestamps to see if the delay is coming from a slow STT transcription, LLM cold starts, or TTS chunking.
Step 3: Evaluate Barge-In and Interruption Handling
A natural conversation requires turn-taking. If a user interrupts your voice agent mid-sentence, the agent must stop speaking immediately, process the new input, and respond contextually.
To test Barge-In Detection:
- Configure Interruption Benchmarks: Program a automated tester to send an audio interruption exactly 1.5 seconds into the voice agent's spoken response.
- Measure Turnaround Time: Calculate how quickly the agent cuts off its audio output stream once the user begins speaking. Ideally, the agent's playback should cease within 200–400 milliseconds of user vocalization.
- Evaluate State Management: Verify that the agent's backend discards the remaining portion of its interrupted response and registers the new user input without losing the broader conversational context.
Step 4: Quantify Semantic Accuracy and Entity Capture Rate
Traditional WER penalizes minor, non-critical transcript differences. For example, if a user says, "Book a flight for November 3rd," and the STT outputs "Book a flight for November third," a WER algorithm marks this as an error. For your business logic, however, the meaning is identical.
Instead of relying strictly on WER, evaluate your pipeline on Entity Capture Rate (ECR) and Intent Classification Accuracy:
- Map Expected Entities: For every test case in your Golden Dataset, define the critical information that must be extracted (e.g., dates, account numbers, names, locations).
- Run Semantic Validation: Feed the transcribed output to an LLM evaluator or structured parser.
- Calculate the Score: Check if the agent correctly captured the core intent and extracted the necessary variable values. If the agent successfully books the flight for the correct date, the turn is a success—regardless of minor phonetic spelling variations in the raw transcript.
Step 5: Implement Continuous Automated Simulation (LLM-as-a-Judge)
Manual testing does not scale. To ensure your voice agent remains robust against regression as you update your system, implement an automated simulation pipeline:
- Deploy synthetic callers: Set up an LLM-powered "synthetic user" to call your voice agent. Program these synthetic callers with specific personas (e.g., an angry customer, a user with a heavy accent, or a user who changes their mind mid-sentence).
- Use an LLM-as-a-Judge: Have an independent LLM review the call transcripts. This judge evaluates high-level qualitative metrics such as conversation flow, compliance with instructions, and hallucination rates (such as the agent making up policies or prices under pressure).
- Consolidate Infrastructure: Managing distinct STT, TTS, and LLM endpoints across multiple vendors can introduce unwanted latency overhead. Using cohesive platforms like CallMissed simplifies this process; its unified infrastructure gives developers direct access to over 300+ LLMs, optimized low-latency speech pipelines, and real-time APIs to run end-to-end evaluations without maintaining complex integration code.
Advanced Tips & Tricks (TABLE)
Moving from theoretical evaluation to real-world deployment requires shift in focus: you must transition from aggregate statistical averages to localized, actionable system optimizations. Relying solely on a single metric like Word Error Rate (WER) creates blind spots in your pipeline. Instead, production-grade engineering teams rely on a multi-dimensional matrix of performance indicators to fine-tune their voice systems.
The table below outlines the advanced metrics, target benchmarks, and core technical tricks required to optimize interactive voice agents for enterprise environments.
The Voice Agent Optimization Matrix
| Metric | Target Benchmark | Focus Area | Primary Failure Mode | Key Optimization |
|---|---|---|---|---|
| Per-Turn Latency (p95) | < 1,200 ms | Round-trip execution speed | Disjointed conversation & overlapping speech | Stream STT output directly into LLM chunking engines |
| Barge-In Precision | > 95% accuracy | Interruptibility & turn-taking | Cutting off users prematurely or ignoring cues | Calibrate VAD hangover times dynamically based on user state |
| Entity Capture Rate (ECR) | > 98% accuracy | Accurate payload parsing | Broken downstream APIs due to missing variables | Inject context-specific dictionaries and custom biasing |
| Task Success Rate (TSR) | > 85% unassisted | End-to-end goal resolution | Circular loops or unnecessary human escalations | Optimize prompt guardrails and semantic routing tables |
| Robustness under Noise | < 1% critical failures | Audio artifact handling | Hallucinating responses based on background chatter | Deploy specialized neural noise suppression (e.g., RNNoise) |
Deep-Dive: Architecting for Low p95 Latency
While median latency (p50) gives you a general idea of your voice agent's speed, p95 latency (the time-to-response for the slowest 5% of calls) is the true test of conversational quality. High p95 latency results in agonizing pauses that break the illusion of human-like interaction.
Optimizing this metric requires a highly pipelined execution architecture:
- Streaming STT to LLM: Do not wait for a user to finish their sentence before sending text to your Language Model. Stream partial transcriptions continuously. This allows the LLM to begin drafting intent structures even before the user has fully concluded speaking.
- Time-to-First-Audio (TTFA) Pipelining: Configure your Text-to-Speech (TTS) engine to begin synthesis on the very first chunk of text returned by the LLM, rather than waiting for the entire LLM response to complete.
- Dynamic Model Routing: Choose your inference engines strategically. For standard turns, route requests to faster, smaller models. Reserve larger reasoning models only for complex, multi-step queries. Infrastructure platforms like CallMissed streamline this process by providing a multi-model API gateway with access to over 300+ LLMs, allowing developers to switch between model classes programmatically to keep latency within the sub-second threshold.
Fine-Tuning Voice Activity Detection (VAD) and Barge-In
Creating a voice agent that "bites its tongue" when a human interrupts is one of the hardest engineering tasks in conversational AI. To achieve high barge-in precision, you must tune your Voice Activity Detection (VAD) parameters:
- VAD Hangover Time: This is the duration of silence the agent tolerates before assuming the user has finished talking. A low hangover time (e.g., 200ms) makes the agent incredibly snappy but causes it to interrupt users who pause to think. A high hangover time (e.g., 800ms) leads to awkward pauses. The industry standard is to start with a dynamic threshold between 400ms and 600ms, shifting shorter when the agent is asking a simple yes/no question, and longer during open-ended prompts.
- Acoustic Echo Cancellation (AEC): Ensure your audio input stream implements hardware-level or software-level AEC. Without it, the agent's own spoken audio will feed back into the microphone, triggering false-positive barge-ins and causing the agent to interrupt itself.
Moving from WER to Entity Capture Rate (ECR)
Traditional Speech-to-Text evaluations treat all words equally. If an agent transcribes "I want to go to Boston" as "I want to go to Austin", a standard WER evaluation records a single-word error (an acceptable ~20% error rate). However, for a booking agent, this error completely breaks the transaction.
To address this, track your Entity Capture Rate (ECR). ECR measures the percentage of critical variables (such as phone numbers, dates, locations, and names) that are successfully captured and mapped to downstream API schemas.
- Dynamic Context Biasing: If your voice agent is handling logistics, inject a real-time list of current inventory items, street names, or tracking numbers into the STT decoder's vocabulary. This drastically boosts transcription accuracy for high-importance target entities.
- Semantic Fallbacks: Do not rely on exact-string matching. Utilize LLM-based post-processing to normalize variations (e.g., converting "the first of next month" directly into a standardized
YYYY-MM-DDpayload).
Deploying Multilingual Evaluations at Scale
As voice agents expand into global markets, maintaining conversational fidelity across languages, accents, and local dialects becomes a primary challenge. A voice pipeline optimized purely for US English will experience a sharp degradation in performance when exposed to regional accents or code-switched speech (such as Spanglish or Hinglish).
To run high-quality multilingual deployments, teams must move away from generic, monolithic STT engines. Using localized models trained natively on regional speech is essential for preventing catastrophic drops in Entity Capture Rates. For example, developers deploying voice interfaces in linguistically diverse regions utilize platforms like CallMissed, which offers high-accuracy Speech-to-Text APIs supporting 22 Indian languages natively. This native coverage ensures that phonetic variations, regional idioms, and localized terminology are accurately transcribed, bypassing the accuracy loss common in general-purpose translation models.
Common Mistakes to Avoid (TABLE)
When migrating from legacy, static Interactive Voice Response (IVR) systems to generative AI-driven voice agents, engineering teams often bring along legacy evaluation frameworks. The most common error is treating an interactive, real-time voice agent as if it were a passive, batch transcription service. This mismatch leads to critical blind spots, where an agent with an impressive lab-tested accuracy score fails spectacularly when answering real customer calls.
To build voice agents that deliver human-like, natural conversational experiences, developers must pivot from simplistic, static benchmarks toward multi-dimensional, real-time metrics. Avoiding the common pitfalls outlined below is essential to preventing poor customer experiences and high call abandonment rates.
| Common Mistake | Why It Happens | Customer Impact | Key Metric to Use | Best Practice Fix |
|---|---|---|---|---|
| Over-indexing on WER | Evaluating voice agents like static transcription systems rather than interactive applications. | High development costs spent fixing harmless grammatical variations while missing semantic failures. | Entity Capture Rate & Intent Classification | Evaluate downstream task success and semantic comprehension, not just literal word matches. |
| Ignoring tail latency (p95) | Measuring average (p50) latency instead of tracking the longest, worst-case delays. | Occasional, frustrating 4-second silences that break conversational flow and prompt user hang-ups. | p95/p99 Latency & Time to First Audio (TTFA) | Optimize the entire agent pipeline—from STT to LLM to TTS—aiming for sub-2-second p95 latency. |
| Failing to test barge-ins | Designing linear dialog trees that assume users will wait patiently for the agent to finish speaking. | Double-talking, awkward interruptions, and repetitive prompts that make the agent feel robotic. | Barge-in Success Rate & State Sync Latency | Implement aggressive, low-latency Voice Activity Detection (VAD) to immediately pause audio playback. |
| Testing in clean environments | Restricting QA cycles to quiet conference rooms and high-fidelity headsets. | Sudden drop in agent performance when real-world users call from noisy streets, cars, or call centers. | Task Success Rate under Noise & Robustness Score | Stress-test voice agents using synthetic background noise, varied compression codecs, and diverse accents. |
| Ignoring regional languages | Assuming high-accuracy English models translate seamlessly to localized or multilingual customer bases. | Poor comprehension of regional dialects, accents, or code-switched phrases, alienating key user demographics. | Multilingual Accuracy & Localized Intent Precision | Deploy localized models like those from CallMissed, which natively support 22 regional Indian languages. |
Mistake 1: Treating Word Error Rate (WER) as the Gold Standard
Word Error Rate is an excellent metric for comparing dictation software, but it is a poor indicator of voice agent performance. If a customer says, "Yeah, I'd love to cancel my subscription," and the Speech-to-Text (STT) engine transcribes it as "Yes, I would love to cancel my subscription," the WER registers multiple errors. However, the downstream Large Language Model (LLM) still captures 100% of the customer's intent.
Conversely, if the customer says, "Do not charge my card," and the STT engine misses the word "not," the WER is incredibly low (only one missed word), but the semantic impact is catastrophic. Over-indexing on WER causes engineering teams to spend cycles optimizing transcription engines for literal accuracy when they should be focusing on downstream Entity Capture Rate (e.g., correctly capturing dates, email addresses, and account numbers) and Intent Classification Accuracy.
Mistake 2: Relying on Average (p50) Latency
Many development teams celebrate when their testing dashboards show an average response latency of 1.2 seconds. However, average latency (the 50th percentile, or p50) hides systemic issues. If your p50 latency is acceptable but your p95 or p99 latency spikes to 4 or 5 seconds, it means that 5% to 10% of your callers are experiencing painfully long, awkward silences.
In a voice conversation, a 4-second pause feels like an eternity. It prompts the user to ask, "Hello, are you still there?" which interrupts the agent's eventual response and breaks the state machine. Platforms like CallMissed address this by optimizing the entire media pipeline, ensuring that tail latencies (p95) remain tightly bound. This is achieved through aggressive streaming, orchestrating ultra-low latency LLM inference, and utilizing fast Text-to-Speech (TTS) models to deliver a consistently natural flow.
Mistake 3: Poorly Orchestrated Barge-in Handling
In natural human conversation, people do not always wait for the other person to finish a sentence before speaking. They interrupt, acknowledge points with "uh-huh" or "okay," or ask clarifying questions mid-sentence.
A common design mistake is failing to implement robust barge-in detection. When an agent continues talking over a user who is trying to interrupt, the user experience rapidly deteriorates. To resolve this, systems require low-latency Voice Activity Detection (VAD) coupled with immediate state synchronization. The moment the user speaks, the agent must instantly halt its TTS playback, parse the incoming audio, and update its conversational state without losing context.
Mistake 4: Testing Exclusively in Sterile QA Environments
Developers typically build and test voice agents using high-quality USB microphones in quiet offices or home environments. In production, however, your voice agent will encounter users calling from windy streets, crowded public transit, echoey rooms, or over low-bandwidth cellular connections.
If your evaluation framework does not incorporate synthetic noise injection, packet loss simulation, and diverse telephone codecs (like G.711 or Opus), your agent's real-world performance will plummet. A robust testing regimen must evaluate the agent's task success rate under realistic, noisy conditions to ensure the LLM doesn't hallucinate or fail when the audio input is less than perfect.
Mistake 5: Overlooking Multilingual Requirements and Code-Switching
For global deployments or diverse regional markets, assuming a standard English voice model is sufficient is a critical error. In many markets, users naturally blend languages—a phenomenon known as code-switching or "Hinglish" (a mix of Hindi and English).
Standard English-centric models often fail to capture the intent of code-switched phrases, leading to dropped calls and frustrated users. When deploying conversational agents in linguistically diverse regions, it is essential to utilize localized platforms. For example, CallMissed provides native, production-ready Speech-to-Text support for 22 regional Indian languages, allowing voice agents to understand and converse fluently with localized accents, dialects, and mixed-language inputs. This capability ensures high task success rates regardless of how your customers choose to speak.
Real-World Performance: Evaluating Under Network Jitter
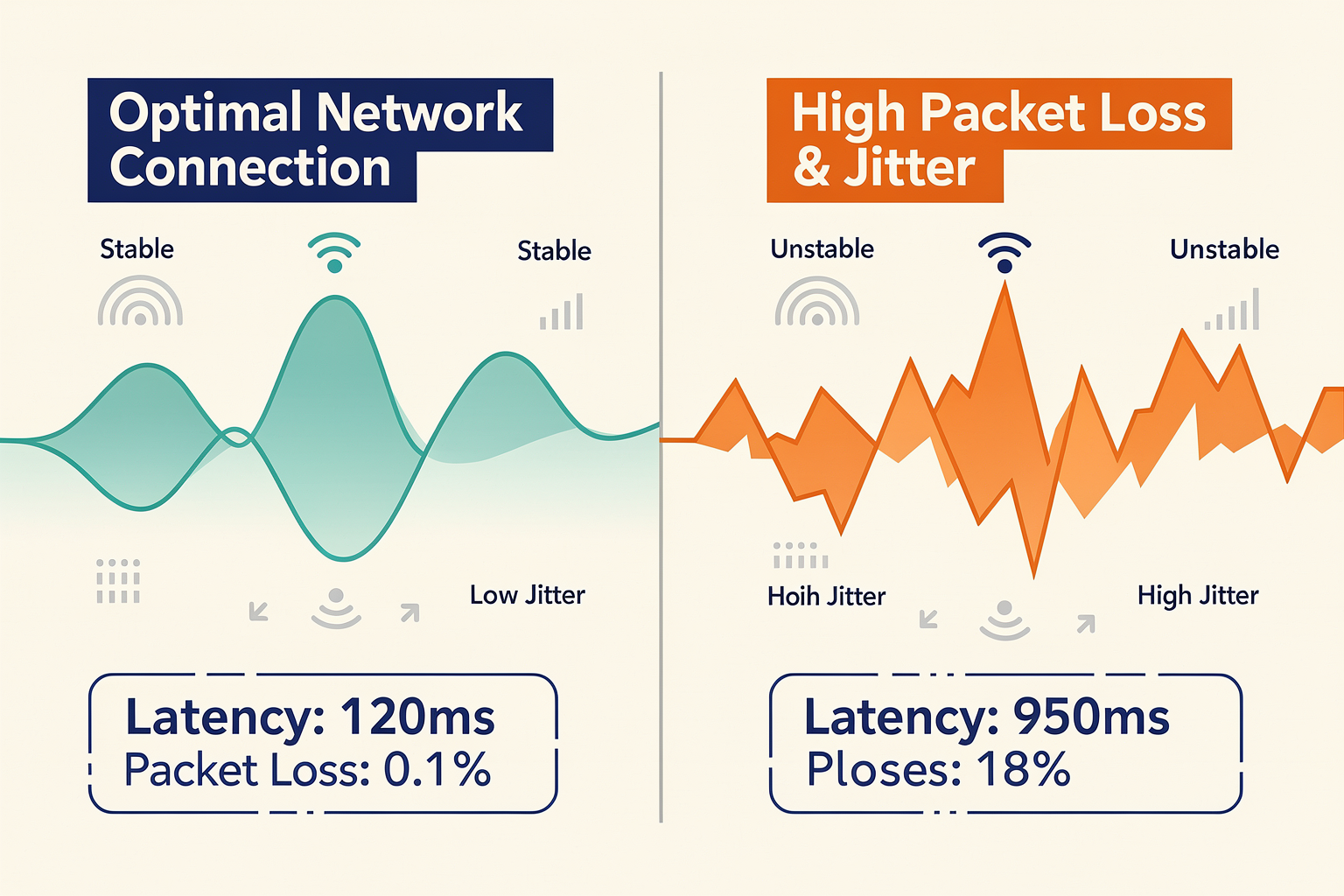
Why Pristine Labs Fail: The Reality of Network Jitter
Standard automated speech recognition (ASR) benchmarking usually happens in a sanitized laboratory environment. Developers run test audio suites through an API over high-bandwidth, symmetrical fiber connections with zero packet loss. In these controlled spaces, Word Error Rate (WER) looks exceptional, and round-trip latency seems imperceptible.
But the real world is chaotic. When a customer interacts with an AI voice agent, they are rarely sitting next to a router on a quiet fiber-optic connection. They are driving through highway dead zones, walking through crowded shopping malls with congested public Wi-Fi, or speaking on spotty VoLTE connections in basement offices. In these environments, network jitter—the variation in the arrival time of data packets—and packet loss become the primary destroyers of conversational flow.
In real-time communications, voice data is chopped into tiny chunks (typically 20ms packets) and sent over UDP (User Datagram Protocol) using RTP (Real-Time Transport Protocol). Unlike TCP, UDP does not retransmit lost packets; doing so would introduce unacceptable delays. If packets arrive out of order, too late, or not at all, the voice pipeline begins to fracture. To build a voice agent that feels human, you must evaluate performance not just in the lab, but under simulated conditions of network degradation.
The Cascade Failure: How Jitter Destroys the Conversational Loop
When packet arrival times fluctuate, the impact is not confined to a single component of the voice agent. Instead, network jitter triggers a cascade failure across the entire streaming pipeline:
- Voice Activity Detection (VAD) and "Silence" Hallucination:
Streaming Speech-to-Text (STT) engines rely on VAD to determine when a user has finished speaking. If a burst of network jitter delays several consecutive audio packets by 200–300 milliseconds, the VAD engine perceives this sudden lack of data as silence. It mistakenly assumes the user has finished their sentence, cuts them off mid-thought, and prematurely sends an incomplete transcript to the Large Language Model (LLM).
- Speech-to-Text (STT) Fragmentation:
When the delayed audio packets finally arrive, they often arrive in a clump. The STT engine must process this burst of audio out of order or under intense time pressure, leading to catastrophic degradation of transcription quality. Words are dropped, merged, or completely misrecognized, sending gibberish to the LLM.
- Latency Amplification (The p95/p99 Spike):
While your median (p50) latency might sit at a comfortable 1.2 seconds, network jitter blows out your tail latency (p95 and p99). If a packet delay pauses the pipeline, the LLM cannot begin inference, and the Text-to-Speech (TTS) engine cannot begin generating audio. A 100ms network hiccup can compound into a 3-to-4-second delay in the agent's response, breaking the natural rhythm of turn-taking.
- Barge-In Failures:
If the agent is speaking and the user interrupts (a "barge-in"), the agent needs to stop talking immediately. However, if the user’s audio packets are delayed by jitter, the agent will continue speaking for several hundred milliseconds after the user started interrupting. This creates an awkward "over-talking" loop where both parties speak simultaneously.
Critical Metrics for Jitter Evaluation
Evaluating a voice agent under network jitter requires tracking dynamic, real-time metrics rather than static post-call averages. When testing your agent under simulated network stress, focus on the following key metrics:
- p95 and p99 Per-Turn Latency under Jitter: This measures the time elapsed from the user's last actual spoken word to the agent’s first outbound audio chunk, specifically looking at the worst 5% and 1% of turns when network conditions degrade.
- VAD False Trigger Rate: The frequency with which the voice agent cuts off the user or responds prematurely due to packet gaps.
- Barge-In Latency under Packet Loss: The duration between when the user starts speaking over the agent and when the agent actually stops playing audio, measured in milliseconds. In poor network conditions, this should ideally remain under 400ms.
- Audio Chunk Drop Rate & Recovery Time: How effectively the streaming connection recovers after a burst of 5% packet loss without dropping the call or losing context.
Simulating Real-World Degradation in Your Testing Suite
To ensure your voice agent survives the real world, you must introduce synthetic network degradation into your continuous integration (CI/CD) pipelines. Software tools like Linux tc (Traffic Control) or netem (Network Emulator) can be used to inject precise levels of packet loss, latency, and jitter into your test environment.
When evaluating different architectures, run your test suite through four standard profiles:
| Profile Name | Latency (One-Way) | Jitter | Packet Loss | Target Experience |
|---|---|---|---|---|
| Pristine Fiber | < 10ms | 0ms | 0% | Benchmark baseline |
| Typical 4G/VoLTE | 50ms | ±15ms | 0.5% | Standard mobile conversation |
| Degraded Wi-Fi | 80ms | ±40ms | 2.0% | Congested home/office network |
| Extreme Edge (3G/Tunnel) | 200ms | ±100ms | 5.0% | Extreme stress-test limit |
By stress-testing your voice agent against these profiles, you can identify precisely where your pipeline breaks. For instance, does your STT engine time out? Does your LLM receive fragmented sentences?
To combat these challenges, modern communication infrastructure like CallMissed leverages highly optimized, low-latency WebRTC streaming pipelines. By utilizing adaptive jitter buffers and resilient edge routing, platforms like CallMissed ensure that even when packets arrive out of order, the underlying speech-to-text pipeline—which natively supports 22 regional Indian languages—remains stable, preventing premature agent responses and keeping conversation flows fluid.
Architecting Jitter-Resilient Voice Agents
Building a voice agent that shrugs off network jitter requires engineering resilience into every layer of the conversational stack:
- Implement Adaptive Jitter Buffers:
Your application client should feature an intelligent jitter buffer that dynamically adjusts its size based on real-time network conditions. If jitter increases, the buffer expands slightly to collect late-arriving packets, smoothing out the audio playback at the cost of minimal, controlled latency.
- Use Streaming, Multi-Model API Gateways:
Instead of relying on monolithic, rigid API connections, use gateways that can gracefully handle network drops. Solutions like CallMissed's multi-model API gateway allow developers to connect to 300+ LLMs and dynamically adjust packet-streaming behavior depending on connection stability.
- Smart Silence Detection (Hybrid VAD):
Do not rely solely on simple amplitude-based silence detection. Implement a hybrid VAD approach that combines local, client-side audio analysis with cloud-side semantic context. If the STT engine detects an unfinished sentence structure (e.g., the user stopped on the word "and..."), the agent should wait longer for late packets before assuming the user is done.
- Graceful Degradation Protocols:
If packet loss exceeds a certain threshold, the system should automatically degrade gracefully. This might mean switching from a high-fidelity stereo audio codec to an ultra-low-bandwidth mono codec (like Opus at 8kbps), or transitioning the UI from full-duplex voice to a text-fallback interface rather than dropping the call.
By moving your evaluation criteria beyond sterile Word Error Rates and stress-testing against real-world network jitter, you ensure your voice agent remains reliable, conversational, and genuinely useful to customers—no matter where they are calling from.
Frequently Asked Questions
Why is evaluating voice agents beyond Word Error Rate (WER) necessary for modern conversational systems?
What key metrics should companies prioritize when evaluating voice agents beyond Word Error Rate?
How does response latency impact user experience, and what benchmarks should developers target?
What is barge-in detection, and why is it critical for natural voice interactions?
How can developers accurately measure the task success rate of voice agents in production?
How do regional accents and multilingual environments affect voice agent evaluation?
Resources & Next Steps

The Paradigm Shift: From Transcription to Real-Time Interaction
For over a decade, Word Error Rate (WER) reigned supreme as the primary benchmark for automatic speech recognition (ASR) performance. This metric—calculating the percentage of insertions, deletions, and substitutions against a human reference transcript—was highly effective for offline transcription and dictation software.
However, as the conversational AI ecosystem transitions to highly dynamic, agentic interactions, optimizing solely for WER is no longer sufficient. Modern interactive voice agents do not operate in a vacuum of static audio files; they operate in a live, bidirectional conversational loop where success is measured by user experience, objective completion, and natural turn-taking dynamics.
If a voice agent transcribes a sentence with 100% accuracy but takes 3.5 seconds to respond, the user experience collapses. Conversely, an agent that suffers from a 12% WER but accurately captures critical entities, handles background noise gracefully, and responds within a natural human cadence of 600 milliseconds will feel significantly more intuitive and helpful. To build production-ready voice interfaces, engineering teams must transition from measuring transcriptional accuracy to evaluating dynamic conversational performance.
A Checklist for Designing Your Voice Evaluation Framework
Upgrading your evaluation architecture from simple WER checks to a multi-dimensional testing pipeline requires a systematic approach. Below is a structured checklist to guide your engineering team's implementation:
- Establish Multi-Tiered Latency Tracking (p50, p95, p99)
- What to measure: Do not rely on average (mean) latency, which hides unacceptable outliers. Track the latency distribution from the user's last spoken phoneme to the agent's first audio response.
- Target: Aim for a p50 latency under 800ms and a p95 latency under 1.2 seconds to maintain a natural conversational flow.
- Quantify Entity Capture Rate (ECR) Over Raw WER
- What to measure: Identify critical data points within user utterances (e.g., account numbers, dates, addresses, product names). Calculate the percentage of turns where these key entities are successfully captured and parsed, even if minor filler words (like "um," "ah," or "like") are misidentified.
- Target: Achieve >98% ECR on critical fields, using semantic correction layers to normalize spelling or format errors downstream.
- Assess Barge-In and Interruption Latency
- What to measure: Measure how quickly the agent stops speaking once a user begins talking over it (barge-in detection). If an agent continues talking for more than 400ms after an interruption, the conversation becomes awkward and frustrating.
- Target: Implement low-latency Voice Activity Detection (VAD) to trigger immediate agent playback pause within 200–300ms of user utterance detection.
- Stress-Test Under Real-World Noise Conditions
- What to measure: Run synthetic evaluations by mixing pristine voice recordings with ambient noise profiles (e.g., street noise, coffee shop chatter, low-signal cellular distortion). Evaluate how degradation in audio quality impacts task success rates and LLM hallucination rates.
- Target: Ensure conversational flow remains stable and task-oriented even at low Signal-to-Noise Ratios (SNR).
- Track End-to-End Task Success Rate (TSR)
- What to measure: Use LLM-as-a-judge frameworks to analyze complete call transcripts and determine if the user's original intent was resolved without requiring human agent escalation.
- Target: Map TSR across distinct intent categories to quickly pinpoint where your LLM prompt routing or business logic is breaking down.
Leveraging Modern Infrastructure to Bridge the Evaluation Gap
Designing, benchmarking, and maintaining an infrastructure capable of handling these complex evaluations is a massive engineering undertaking. Developers are often forced to stitch together separate low-latency VAD models, real-time ASR engines, orchestration layers, multiple LLMs, and high-quality TTS pipelines, which inevitably introduces latency stacking.
This is where advanced communications platforms step in to simplify the architecture. Platforms like CallMissed offer developers production-ready, low-latency voice agent infrastructure designed specifically for modern conversational AI requirements.
Instead of building complex custom routing logic to balance latency and intelligence, CallMissed provides access to over 300+ LLM models through a unified, high-performance inference gateway. This allows you to quickly swap models during testing—such as trading a massive reasoning model for a lightning-fast, highly-optimized fine-tuned model—without rewiring your application code.
Furthermore, for global enterprises deploying voice interfaces in diverse linguistic landscapes, CallMissed's native Speech-to-Text APIs support 22 Indian regional languages. This localization eliminates the need to route audio through multiple translation layers, significantly reducing the compounding latency that traditionally degrades international voice applications.
Curated Resources for Deeper Exploration
To help your team dive deeper into advanced speech and voice agent evaluation metrics, we recommend exploring the following foundational research papers, technical articles, and industry insights:
- "Evaluating Speech-to-Text Quality: Beyond Word Error Rate" (Cresta): An excellent analysis of why traditional transcription benchmarks fall short in live-agent environments, focusing on the critical role of p50 and p95 latency distributions in user retention.
- "Word Error Rate is Broken" (AssemblyAI): A comprehensive breakdown of the technical limitations of WER when applied to modern LLM-driven applications, illustrating how semantic accuracy and intent detection have overtaken literal word matching.
- "How to Evaluate Voice Agents: Beyond ASR to Task Success, Barge-in, and Hallucination Under Noise" (Marktechpost): A forward-looking guide detailing practical methodologies for stress-testing interactive voice agents in challenging acoustic environments.
- "Building GenAI Voice Agents: A Complete Evaluation Guide" (Hamming.ai): A practical exploration of the six core audio metrics—including Time to First Audio (TTFA), Entity Capture Rate, and interruption latency—essential for operationalizing customer-facing voice bots.
- "Voice Agent Evaluation: Beyond Word Error Rate" (CallMissed Blog): Our deep dive into the practical realities of deploying voice AI in production, focusing on minimizing real-world conversational friction and optimizing multi-turn agent telemetry.
Conclusion
As we navigate the next era of conversational AI, the benchmark for evaluating voice agents has fundamentally shifted. Relying solely on Word Error Rate (WER) is no longer sufficient to measure the performance of highly interactive, real-time AI. To build agents that feel natural and effective, organizations must adopt a holistic, multi-dimensional evaluation framework.
The critical takeaways for modern engineering teams include:
- Optimize for Latency: Track p50 and p95 latency distribution to minimize the time between the user's last word and the agent's response.
- Master Interactivity: Implement robust barge-in detection and entity capture rates to handle natural human interruptions smoothly.
- Focus on Business Value: Prioritize task success rates and response accuracy over dry transcription metrics, especially under noisy, real-world conditions.
Looking ahead, the industry is transitioning rapidly toward native end-to-end speech-to-speech models that collapse the traditional STT-LLM-TTS pipeline. This shift will make classical WER virtually obsolete, turning the evaluation spotlight entirely onto conversational flow, emotional intelligence, and semantic intent resolution.
To explore how AI communication is evolving and build systems designed for this new paradigm, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. As you refine your system, ask yourself: is your voice agent built to pass a transcription test, or is it truly optimized to solve your customers' problems in real time?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.