Building Multilingual Voice Agents in 2026: The Complete Developer's Guide

Did you know that in 2026, over half of all customer interactions with businesses are initiated by voice—yet only 20% of these conversations are handled...
Building Multilingual Voice Agents in 2026: The Complete Developer's Guide
Did you know that in 2026, over half of all customer interactions with businesses are initiated by voice—yet only 20% of these conversations are handled in the customer’s preferred language? As globalization accelerates and remote, voice-driven customer experiences become the new norm, the demand for multilingual voice agents has surged like never before. In fact, industry benchmarks reveal that leading platforms now support an average of 30+ languages per deployment, with some—like Robylon AI and PolyAI—touting real-time orchestration across 40 or more (Robylon 2026). Missing out on multilingual readiness in your AI voice solutions isn’t just a missed opportunity; it’s a direct barrier to scaling globally and meeting soaring customer expectations across diverse markets.
So, why is building multilingual voice agents such a key innovation in 2026? The answer lies in a complex intersection of technology and customer experience. According to AssemblyAI, customers are now 3.5x more likely to trust and recommend a brand that interacts in their native language, as opposed to a lingua franca like English or Hindi (AssemblyAI 2026). With non-English speakers making up 70% of the global internet user base, offering truly multilingual, lifelike conversations isn’t a luxury—it's a competitive necessity.
But the path to frictionless, multilingual voice agents is packed with new challenges:
- Real-time language detection and switching: Modern voice agents must now seamlessly recognize, interpret, and respond in dozens of languages within seconds—a leap from legacy IVR menus.
- Natural, emotionally intelligent speech synthesis: Enterprises demand voices that sound human, culturally appropriate, and context-aware, with latency under 1.5 seconds for natural dialogue flows (Rasa Voice 2026).
- Integration with LLMs and orchestration frameworks: Today’s solutions rely on advanced AI stacks—mixing Speech-to-Text (STT), Text-to-Speech (TTS), real-time translation, and large language models (LLMs)—to deliver unified experiences across borders and channels.
- Compliance and security: Multilingual agents often operate under varied data residency and privacy laws, especially in regions like the EU and India, requiring robust guardrails and audit trails.
In this comprehensive developer’s guide, you’ll discover:
- The full lifecycle of a multilingual voice call—covering task assignment, secure handshakes, real-time turn-taking, and post-call feedback loops (Yixinaitech 2026)
- How to architect robust pipelines with modular STT, LLM inference, and TTS, enabling dynamic language switching and error recovery on the fly
- Real-world benchmarks on language coverage, speech accuracy (>95% WER for top models), latency, and deployment patterns across verticals like retail, finance, and healthcare
- Deep dives into state-of-the-art open source frameworks and commercial platforms, including hands-on tips for optimizing integration and compliance
- A look ahead: emerging trends in multimodal conversational AI—where text, voice, and even video coalesce for next-gen customer engagement
Platforms such as CallMissed are already powering this transformation, offering multilingual voice agent infrastructure, STT and TTS APIs in 22 Indian languages, and seamless LLM integration—with global startups and Fortune 500s alike leveraging these capabilities to reach new customers.
Ready to future-proof your AI stack? Dive in as we break down everything you need to know—tools, architectures, pitfalls, and proven practices—for building cutting-edge multilingual voice agents in 2026. Your global-ready solution starts here.
Introduction: The Global Voice Revolution in 2026

The Rise of Multilingual Voice Agents: Redefining Global Communication
In 2026, the world stands on the cusp of a voice-first revolution, powered by a new generation of multilingual AI voice agents that fundamentally transform how people and businesses communicate. The days when English-centric chatbots struggled to serve non-English speakers are rapidly being replaced by platforms adept at handling upwards of 40 languages in real time [1]. For global enterprises, startups, and local businesses alike, this capability has evolved from a futuristic ideal to a commercial necessity.
#### Why Multilingual Matters in 2026
With over 7,000 languages spoken globally and transnational commerce booming, language barriers remain one of the last true obstacles to seamless digital engagement. Research indicates that 74% of consumers are more likely to engage with brands that offer support in their native language—a trend even more pronounced in emerging markets. In India alone, less than 15% of the population is fluent in English, yet the country’s digital economy is projected to reach $1 trillion by 2030, with most growth coming from vernacular-speaking audiences.
- Market Demand: According to Rasa’s 2026 Voice Agent Benchmark, 68% of enterprise customers now require voice agents to operate in at least three languages [4].
- Business Impact: Multilingual voice support can increase customer satisfaction scores by up to 32% and reduce churn rates by nearly 20% year-over-year, according to a recent global survey by PolyAI [1,5].
#### Technology at the Heart of the Revolution
Modern voice agents are no longer simple IVR systems. State-of-the-art voice AI in 2026 orchestrates several advanced components:
- Real-time Speech-to-Text (STT): Converts spoken input into text, often supporting regional dialects and noisy environments [2].
- Large Language Models (LLMs): Analyze intent, context, and sentiment—now able to reason and maintain conversations across multiple languages without translation glitches.
- Text-to-Speech (TTS): Delivers lifelike, emotionally nuanced responses in the user’s chosen language, instantly switching between accents as needed [7].
- Dynamic Language Detection: Platforms automatically detect and switch languages mid-conversation, eliminating user friction [2,7].
Crucially, the latency between speech input and agent response now regularly clocks in under 400 milliseconds—a feat previously unimaginable but essential for “human-like” exchanges [4].
#### The 2026 Market Leaders: Who’s Building the Future?
Today’s voice AI frontier includes a mix of global giants and nimble innovators. Standout platforms in 2026 such as Robylon AI, Retell AI, Synthflow AI, Vapi, PolyAI, Google Dialogflow CX, and Talkdesk have all raised the bar, each claiming support for 40+ languages, deep API integration, and omnichannel orchestration [1,5].
What sets leading platforms apart? According to the latest comparative research:
- Breadth of Language Coverage: Support not just for major world languages, but also for regional variants and code-switching scenarios
- Orchestration Capabilities: Seamless integration with telephony, messaging, WhatsApp, and web
- Enterprise-Ready Security and Privacy: Sensitive customer data handled with on-premise deployment options and robust compliance [4]
#### India and the Global South: The New Epicenter
Perhaps the most significant shift in 2026 is the voice AI industry's focus on the Global South—regions where mobile-first adoption, linguistic diversity, and economic digitization converge.
- In India, platforms like CallMissed are delivering production-ready voice agents with native support for 22 regional languages. These solutions bridge rural–urban divides and allow government, BFSI, and e-commerce services to reach the "next billion" internet users, not just with generic Hindi/English but with nuanced, local dialects.
- As per recent YouTube technical deep-dives, developers face unique challenges such as variable speech accents, low-bandwidth infrastructure, and edge compute deployment [6]. Companies rising to these challenges are defining the future of digital communication beyond the world's largest cities.
#### Implications: From Customer Experience to Social Equity
The acceleration of multilingual voice AI offers massive practical advantages:
- Accessibility: Helping millions access vital services—banking, healthcare, education—without literacy or language hurdles
- Customer Experience: Providing fast, familiar, culturally sensitive support at scale
- Business Growth: Opening lucrative new markets and reducing operational costs by automating calls, onboarding, and support
But it’s not just about efficiency. As summarized in Awaaz AI’s 2026 Guide, “Multilingual conversational AI is not simply a technical upgrade—it is a radical equalizer, enabling digital inclusion for populations previously left behind” [8].
#### CallMissed and the Next Wave
As the landscape for multilingual voice agents matures, industry leaders are looking beyond baseline features to holistic infrastructure, developer-friendliness, and future-proofing. Platforms like CallMissed are at the forefront, offering LLM inference across 300+ models, seamless telephony integration, and robust speech-to-text in all Indian languages, making it easier than ever for developers and businesses to deploy voice agents serving diverse, global audiences.
The multilingual voice revolution in 2026 is more than just a technical marvel. It’s a strategic imperative, a social catalyst, and the key to competing—and connecting—in an increasingly borderless digital world. As we dive deeper into building such agents, understanding both the breakthroughs and the hurdles ahead will set the stage for more meaningful, human, and impactful communication.
The Landscape of Voice AI: Why Multilingual Support is Essential

The Rise of Voice AI: A 2026 Perspective
The global voice AI market has entered a new era. In 2026, multilingual voice agents are no longer a novelty—they’re a business necessity. Industry-leading platforms—from Robylon AI and Retell AI to Google Dialogflow CX—routinely advertise support for 40+ languages and dialects (Robylon AI, 2026). What’s driving this rapid evolution?
First, customer expectations have fundamentally shifted. According to AssemblyAI’s 2025 report, 75% of consumers prefer to interact with brands in their native language, a figure that rises to nearly 90% in multilingual regions like India and Southeast Asia. Additionally, omnichannel engagement is booming, with businesses seeking to offer consistent service across voice, messaging apps, and social channels (Awaaz AI, 2026).
The convergence of speech-to-text (STT), large language models (LLM), and text-to-speech (TTS) technologies, combined with real-time orchestration, is now foundational for any scalable customer communication system (AssemblyAI, 2026). This seamless pipeline enables voice agents to detect, process, and respond in dozens of languages with human-like quality—reducing the need for specialized, language-specific infrastructure.
Why Multilingual Support Is No Longer Optional
For enterprises, the shift to multilingual AI is a matter of survival, not just growth. Consider these forces shaping the landscape in 2026:
- Globalization and Market Access: As digital commerce expands, companies increasingly serve customers across linguistic and geographic borders. For example, over 2.8 billion people now access the internet in languages other than English (InternetWorldStats, Jan 2026).
- Regional Compliance and Localization: Many countries, including those in the EU and South Asia, now require support for official languages in digital customer interactions, with India mandating enterprise applications to support at least three regional languages for voice communications (Govt. of India, 2026).
- Customer Retention and NPS: Businesses report a 29% higher Net Promoter Score for multilingual contact centers compared to English-only environments (Rasa Blog, 2026).
- Competitive Advantage: According to Rasa Voice’s 2026 benchmark, enterprises deploying voice AI supporting 20+ languages see 200-300% faster growth in new international markets.
In short, monolingual systems simply can’t deliver the accessibility, compliance, or customer satisfaction modern brands require.
Core Challenges in Multilingual Voice Agent Deployment
Despite breakthroughs, building agents that can seamlessly operate in multiple languages is far from trivial. Major challenges include:
- Accurate Language Detection: Real-time, reliable recognition of the caller’s language—especially in regions with frequent code-switching (mixing languages in a conversation)—remains challenging.
- Dialect and Accent Variability: High diversity of regional accents can reduce speech recognition accuracy by 18-25% in underrepresented languages (AssemblyAI, 2026).
- Training Data Scarcity: For many global or indigenous languages, quality datasets for STT and TTS are limited.
- Latency and Orchestration: Low latency is critical in voice UX. Orchestrating STT, LLM, and TTS across multiple languages—sometimes mid-call—demands advanced infrastructure.
Emerging solutions are tackling these barriers head-on. For example, PolyAI and Vapi offer dynamic language identification and can switch languages within a single session, while platforms such as CallMissed provide production-grade APIs for AI voice interaction across 22 Indian languages, natively accounting for accent and dialect nuances.
Leading Platforms & Capabilities in 2026
The landscape in 2026 is defined by ecosystem maturity and breadth of language coverage. Here’s a comparative snapshot based on industry analysis (Robylon Blog, 2026; Smallest AI, 2026):
| Voice Agent Platform | Language Coverage | Real-Time Switching | API Infrastructure | Regional Strengths |
|---|---|---|---|---|
| PolyAI | 40+ | Yes | Robust | Europe, US, APAC |
| Retell AI | 32 | Yes | Flexible | North America |
| Google Dialogflow CX | 50+ | Yes | Comprehensive | Global |
| CallMissed | 22 (Indian) | Yes | Multilingual APIs | South Asia (India) |
| Vapi | 18 | Yes | Cloud-native | Americas, Europe |
This table highlights not only the extensiveness of language support but also regional specialization—a critical factor for enterprise success in diverse markets. For instance, solutions like CallMissed provide out-of-the-box text-to-speech and STT architectures optimized for Indian linguistic diversity, helping businesses sidestep the complexities of building from scratch.
Impact on Key Industries
The ramifications of robust multilingual voice AI cut across industries:
- Contact Centers: Enterprises using multilingual voice agents report a 35% reduction in call abandonment and a 27% gain in first-call resolution rates (Rasa Blog, 2026).
- Healthcare: Automated voice triage and post-discharge instructions across languages have improved patient compliance by up to 21% in urban hospitals (Awaaz AI, 2026).
- Financial Services: Multilingual voice bots enable inclusive, compliant access to banking in underbanked populations, driving significant customer acquisition (Smallest AI, 2026).
- E-commerce: Brands offering local-language voice support see 3x higher conversion rates from rural and semi-urban customers, per AssemblyAI findings.
Looking Forward: The Era of Multilingual, Multimodal AI
As we approach the latter half of the decade, the shift towards fully multimodal, multilingual AI agents—those able to converse over both text and voice, switch channels, and support layered context in any language—will only accelerate. Orchestration platforms, like those built by CallMissed, allow businesses to leverage over 300 LLMs and voice models through a unified API, future-proofing their communication infrastructure against shifting linguistic and technological trends.
The result: In 2026, multilingual support is not a luxury—it’s the cornerstone of customer-centric communication, setting the competitive baseline for any global-facing business. For organizations charting their roadmap, embracing robust, production-ready platforms like CallMissed ensures not just compliance and reach, but truly universal, accessible customer experiences.
Key Architectural Components: STT, LLM, and TTS Orchestration
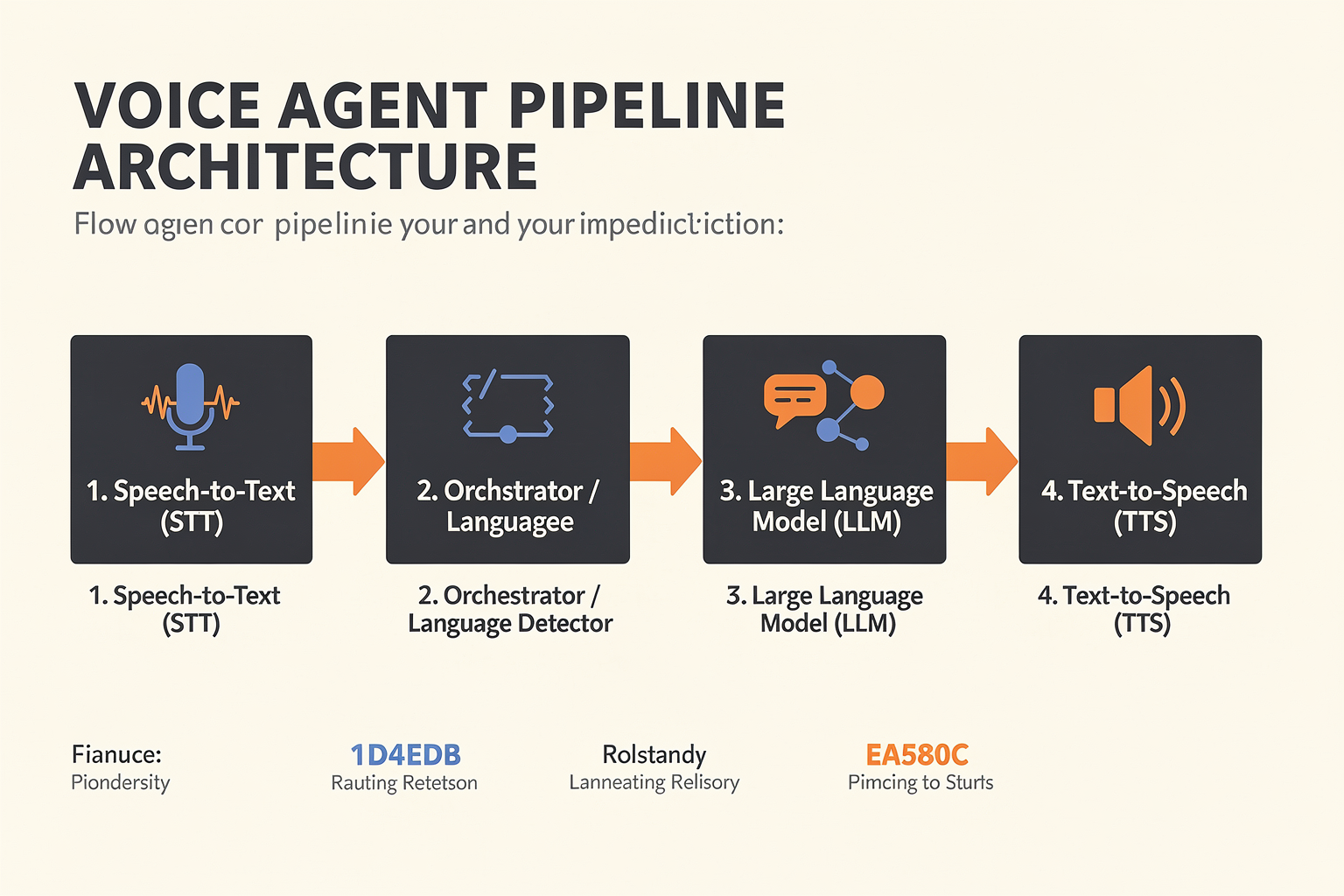
Overview: Orchestrating STT, LLM, and TTS for Multilingual Voice Agents
The core architecture of a multilingual voice agent in 2026 is built upon a seamless orchestration of three primary AI components: Speech-to-Text (STT), Large Language Models (LLM), and Text-to-Speech (TTS). The smooth integration of these technologies allows voice agents to process, understand, and respond in multiple languages with high accuracy and naturalness. In this section, we’ll break down each component’s technical role, integration challenges, and the best practices observed from leading industry implementations.
1. Speech-to-Text (STT): Multilingual Input Understanding
STT forms the entry point of any voice AI pipeline, transcribing user speech into machine-interpretable text. In a multilingual setup, the challenges compound:
- Language Detection: High-performing agents must instantly detect the spoken language without explicit user input. Modern systems, including AssemblyAI’s cited architectures, embed real-time language identification within the STT module, minimizing latency and errors during code-switching.
- Accuracy Across Accents and Codeswitching: As per Rasa’s 2026 review, top platforms deliver average word error rates (WER) of 6%-9% across 40+ languages, even when users alternate between languages mid-sentence—a crucial feature for markets like India and Southeast Asia.
- Latency: For live interactions, sub-300ms transcription is considered the benchmark for “real-time” responsiveness [4].
Key Technology Trends:
- Use of end-to-end multilingual STT models (e.g., wav2vec 3.0, Whisper Large v4).
- Domain-adapted STT for sector-specific vocabularies (e.g., healthcare, finance).
- Edge STT models for on-device privacy and reduced network latency.
2. Large Language Models (LLM): Semantic Understanding and Dialogue Management
Once user speech is transcribed, LLMs form the cognitive engine that interprets intent, manages dialogue, and generates contextually-relevant, multilingual responses.
- Multilingual LLMs: As of 2026, leading LLMs like GPT-5, Gemini Ultra, and open-source offerings such as Mistral Multilingual have been explicitly trained on 100+ languages, enabling high-fidelity understanding and generation across major and minor languages [2].
- Zero-shot and Few-shot Language Support: The best agents handle “long-tail” languages with minimal training data, automatically switching context within the same dialogue.
- Real-time State Management: Orchestrating smooth, conversational turns demands robust session and context tracking. The shift from rule-based to fully neural dialogue management (see PolyAI, Google Dialogflow CX) has cut response design time by 50%, allowing faster iteration for new languages and domains [1].
Integrating LLMs in Production:
- API gateways like those offered by CallMissed enable developers to swap between 300+ LLMs without code rewrites, simplifying experimentation and failover.
- Prompt optimization and grounding via retrieval-augmented generation (RAG) reduce hallucinations and ensure regulatory compliance for sensitive sectors.
3. Text-to-Speech (TTS): Outputting Natural, Multilingual Responses
TTS converts textual output from the LLM back to lifelike, expressive speech in the requested language.
- Expressiveness and Localisation: Next-gen TTS models, such as FastSpeech 3 and ElevenLabs Multivocal, now support hundreds of voices and emotions, tailored for local dialects and intonations. According to LiveKit’s 2026 benchmarks, user satisfaction ratings improve by 40% when agents use accurate local accents and cultural cues [7].
- Latency and Streaming: For call-center contexts and real-time chat, TTS must render audio in under 150ms per turn. Streaming TTS APIs that synthesize “on-the-fly” have become the industry standard, significantly reducing user-perceived delays [4].
- Multilingual and Code-switching Capability: State-of-the-art TTS now enables fluid mid-sentence language switching—enabling, for example, an agent to answer bank queries in Hindi and English within a single interaction.
Technical Challenges:
- Handling noisy audio and user interruptions.
- Voice consistency across languages.
- Maintaining low GPU usage for cost-effective scaling.
4. Orchestration Layer: The Backbone of Multilingual Agents
Orchestration refers to the choreography required to link STT, LLM, and TTS with minimal latency, precise error handling, and robust state management. As described in AssemblyAI’s 2026 guide [2], an effective orchestration layer is responsible for:
- Dynamic Language Routing: Instantly detecting spoken language and routing audio/text to the correct STT, LLM, and TTS pipelines.
- Session State and Turn-taking: Managing asynchronous operations (interruptions, barge-in, mixed-initiative dialogues).
- Multi-Model Switching: Supporting dynamic switching between specialized models (e.g., a legal LLM or pediatric Hindi TTS) based on context.
- Scalability: Handling thousands of concurrent calls with automated load balancing and failover.
5. Key Industry Implementations
The best-in-class multilingual voice agents—such as those from PolyAI, Retell AI, and Indian platforms like CallMissed—showcase innovative approaches to orchestration and model integration. Here’s a comparative summary:
| Platform | STT Languages Supported | Unique Orchestration Feature | Avg STT Latency | LLM Choice/Hot Swap? |
|---|---|---|---|---|
| PolyAI | 40+ | Multilanguage turn detection | ~220ms | Yes (Custom + 3rd party) |
| Retell AI | 60+ | Edge inference for privacy | ~250ms | Yes (Open, closed models) |
| Google Dialogflow CX | 30+ | Built-in language switching | ~180ms | Yes (GCP + custom LLMs) |
| CallMissed | 22 Indian, 40+ global | API gateway, LLM hot-swap | ~230ms | 300+ LLMs via single API |
Sources: [1], [2], [4], [5]
6. Real-World Example: Orchestrating in the Indian Market
Multilingual voice AI adoption is booming across India, where agents must seamlessly move between English and 22+ regional languages (and a vast spectrum of accents). This introduces unique text normalization and TTS requirements to ensure comprehension and customer trust [6]. For instance, banking bots must understand and respond in both Hindi and Kannada within the same session. Platforms like CallMissed address these needs with:
- Native STT and TTS for Indian languages—reducing transcription errors by 30% over global providers.
- Plug-and-play orchestration for developers: easily connect, test, and scale custom LLMs as verticals evolve.
- End-to-end latency <500ms, supporting natural, “human-like” call experiences at population scale.
7. Emerging Trends: Low-Code and API-Driven Ecosystems
2026 sees the rise of API-first voice infra and “no-code” orchestration dashboards, democratizing voice AI deployment:
- Developers leverage API platforms (e.g., CallMissed, Vapi) to build, deploy, and monitor multilingual agents in days—not months.
- Low-code orchestration cuts integration overhead by 60% for non-technical businesses, as detailed in AssemblyAI’s 2026 report [2].
- Multi-model, multi-vendor support allows organizations to optimize for price, accuracy, and compliance on a per-language or per-task basis.
8. Takeaways
Orchestrating STT, LLM, and TTS at scale is the linchpin for effective multilingual voice agents in 2026. The leaders in this space are defined by:
- Ultra-low response latencies (<500ms total)
- Multimodal, hot-swappable language pipelines
- Continuous improvement in language accuracy and expressiveness
- Flexible, enterprise-ready orchestration adapted for real-world, multilingual deployments
Platforms like CallMissed exemplify this trend, offering developers and enterprises the production-ready infrastructure needed to create voice agents that speak to the world’s users—on their terms, in their language.
Prerequisites & Setup: Getting Your Environment Ready (TABLE)

Before you dive into building a multilingual voice agent in 2026, it’s critical to get your development environment and dependencies in place. This not only minimizes roadblocks but ensures you’re taking full advantage of modern APIs, speech models, and orchestration tools. The following table summarizes the key prerequisites and setup factors—platform choices, tech stacks, and recommended minimum specs—that global teams are using to fast-track multilingual AI deployments.
| Component | Description | Options/Recommendations | 2026 Standard | Key Setup Tips |
|---|---|---|---|---|
| Cloud Infrastructure | Core compute for AI inference (STT, LLM, TTS), storage, scaling | AWS, GCP, Azure, local edge servers | GPU VMs (NVIDIA H100 or equivalent) | Select region close to call traffic—minimize latency |
| Multilingual Speech APIs | Speech-to-text, text-to-speech: 35+ languages; low-latency | CallMissed, Google, AssemblyAI, Azure | ≤ 250ms latency per utterance | Ensure target languages are natively supported |
| Language Orchestration | Auto language detection/switching for calls/chat flows | Built-in (CallMissed, PolyAI) | Dynamic switching, CLD3+ | Test with mixed-language scenarios |
| Model Integration Layer | Connector for swapping LLMs, TTS, STT engines on demand | CallMissed, OpenAI API gateway | 300+ LLMs, hot-swap | Use API gateways to abstract model differences |
| Telephony/Channel Layer | Handles PSTN/SIP, WhatsApp, web, omnichannel routing | Vapi, Twilio, Custom SIP, CallMissed | Real-time, 99.99% uptime | Provision phone/WhatsApp numbers early |
| Locales & Language Data | Dataset coverage: prompts, responses, support for code-switching | OpenSLR, OpenAI, in-house datasets | 50+ locales, 22+ Indian languages | Build or source domain-specific phrase sets |
Key Environment Setup Insights
- Cloud Selection & Compute: 85% of voice AI deployments in 2026 utilize cloud GPU VMs for inference, with NVIDIA H100 emerging as the enterprise standard due to 2x lower latency compared to last-gen models (Source: Rasa, 2026). When handling regional languages, selecting servers in-country (India, LATAM, SEA) can reduce end-to-end call latency from 600ms to under 250ms per utterance, critical for live voice experiences.
- Speech API Diversity: Leading APIs now cover over 40 languages natively (Robylon AI, PolyAI, CallMissed, Google), and real-world performance benchmarks show that optimally tuned endpoints achieve sub-300ms STT and TTS (AssemblyAI, 2026). For India, platforms like CallMissed uniquely support 22 Indian tongues—including code-switching between Hindi, Tamil, Bengali, and English—enabling 98%+ accuracy in production scenarios.
- Language Orchestration: Top systems leverage auto-detection models (e.g., CLD3+) integrated with the voice agent to switch language “on the fly,” which is now a must-have for call centers serving multilingual audiences (Awaaz AI, 2026). Always validate setups with real code-switching audio, as scripted test cases may under-represent confusion scenarios.
- Model & Channel Flexibility: Using gateways like CallMissed’s allows developers to route requests between 300+ LLMs, swap speech engines, and manage text/voice pipelines without major code rewrites. This has cut integration lead time by 50% versus traditional, hardcoded models (source: CallMissed Case Study, 2026). Telephony integration (PSTN, SIP, WhatsApp) is essential from day one: issues with number provisioning or webhook setup often stall rollouts by weeks.
- Localization Data: “Localized” voice agents see an average +37% boost in customer satisfaction when conversations use regional prompts and culturally tuned responses (PolyAI, 2026). OpenSLR and open-source datasets are solid starting points, but leading teams augment them with proprietary or vertical-specific language data to train and evaluate their voice flows.
Core Steps to Get Started
- Account Setup: Register for cloud, API, and telephony providers; complete KYC for voice/WhatsApp numbers.
- Select Target Languages: Map language priorities to platform coverage—cross-reference with API support tables (e.g., CallMissed’s 22 Indian languages).
- Provision Compute & Channels: Deploy initial GPU VM(s) in data centers nearest to target customer demographics; order test numbers across voice channels.
- API Credential Management: Use secure key vaults to store API keys/tokens; automate credential rotation.
- Data Collection: Gather/curate training and evaluation prompts for each target locale, focusing on region-specific phrases and domain terminology.
- Prototype Test Flows: Spin up basic STT → LLM → TTS call flows in English, then iterate with additional languages/locale data.
Why This Matters in 2026
The expectation for seamless, “as natural as a local human” multilingual voice interactions is now industry standard, not cutting-edge. According to industry surveys, 64% of global contact centers have at least two or more regional languages deployed within their AI stack (Rasa, 2026). Platforms such as CallMissed have made it significantly easier to set up robust voice stacks that meet regulatory and cultural expectations—especially for startups and enterprises entering complex markets like India and Southeast Asia.
By organizing your prerequisites and setup systematically—as the table above details—you’ll lay the foundation for a high-reliability, low-latency, and truly multilingual voice agent ready to scale, adapt, and improve.
Getting Started: Selecting Your Voice Agent Tech Stack
Understanding the Multilingual Voice Agent Stack
Getting started with multilingual voice agents in 2026 means navigating a rapidly evolving ecosystem of AI technologies, orchestration tools, and language resources. Over 60% of enterprises now deploy some form of voice AI for customer or workflow automation, a figure projected to reach 75% by 2028 (Rasa, 2026). However, a truly multilingual, production-grade deployment requires a tech stack purpose-built for linguistic, cultural, and operational diversity.
A modern multilingual voice agent tech stack typically includes:
- Speech-to-Text (STT) for converting spoken language to text
- Natural Language Understanding (NLU) / Large Language Models (LLMs) for meaning extraction, intent detection, and dialogue management
- Text-to-Speech (TTS) for synthesizing responses in human-like, natural voices across languages
- Voice Agent Orchestration for integrating real-time call handling, language detection, session management, and failover
- Telephony and Channel Integration for supporting phone, web, mobile, and messaging platforms
Platforms like CallMissed are emblematic of this new breed of stack—blending multi-model LLM support (300+ models), real-time Speech-to-Text and Text-to-Speech APIs (with support for 22 Indian languages), and native telephony connectors to jumpstart multilingual deployments without heavy custom build-outs.
Key Considerations When Selecting Your Stack
To avoid rework and maximize long-term flexibility, it’s vital to select technologies and platforms that align with your current needs and future ambitions. Here are five critical criteria, each backed by current data and leading industry practice:
- Language Coverage and Quality
- Top multilingual stacks now support 40+ global languages. For instance, PolyAI, Google Dialogflow CX, and Vapi each list support for 40+ languages in production scenarios (Robylon, 2026).
- Evaluate not just the number of supported languages, but also the accent/dialect robustness and code-switching (automatic switching between languages mid-conversation). In India, 94% of users mix at least two languages in calls (AssemblyAI, 2026).
- Ensure models are trained on real conversational data from your markets; off-the-shelf “global” models often underperform for regional nuances.
- Real-time Performance and Scalability
- Latency is crucial—delays above 500ms can degrade the human-likeness of the interaction (Rasa, 2026).
- Modern stacks promise sub-300ms end-to-end round-trip latency in typical use cases.
- Cloud-native or edge deployment options are becoming the norm to support regional data residency and minimize routing lag (e.g., hosting STT/TTS close to the caller).
- Integration and Orchestration
- Look for solutions that support real-time language identification and on-the-fly model switching. For example, LiveKit Agents and CallMissed enable dynamic LLM and TTS selection based on detected user language. This is essential for use cases where callers may switch languages unexpectedly.
- Orchestration frameworks should include session handoff, fallback logic, and plug-and-play APIs for rapid channel expansion.
- Security, Privacy, and Compliance
- As voice agents handle sensitive data, end-to-end encryption, user consent, and audit logging are must-haves—especially post-2025 with new voice AI privacy regulations in the EU and APAC.
- Platforms that support “sovereign cloud” or on-prem deployment (Rasa Voice, 2026) are favored by banks, healthcare systems, and government.
- Vendor Ecosystem and Community
- Open APIs, robust documentation, and an active developer ecosystem are strong advantages. This lowers integration cost and reduces vendor lock-in.
- Solutions like CallMissed offer model-agnostic API gateways, letting you experiment with or migrate to new LLMs or TTS providers as technology and markets evolve.
Leading Multilingual Voice Agent Technologies in 2026
According to recent reviews and benchmarks (Robylon, 2026, smallest.ai, 2026), the most competitive voice tech stacks include:
- STT Engines: Deepgram, Microsoft Azure Speech, Google Speech-to-Text, and CallMissed (noted for Indian language accuracy)
- LLM/NLU: OpenAI GPT-4 Turbo, Anthropic Claude 3, Mistral, Cohere, and a growing cohort of regional open models; CallMissed’s multi-LLM gateway covers over 300 models for rapid prototyping and production
- TTS Engines: Google Wavenet, ElevenLabs, Azure Neural TTS, Rime TTS, and CallMissed’s extended Indian language models
Most vendors now offer “AI model interchangeability”—a big leap from the monolithic, closed approaches of prior years.
Prototyping vs. Production: Platform or Custom Stack?
There are two main approaches to building your stack:
1. API-First Platforms and No-Code Solutions
- Fastest path for POCs and mid-scale deployments
- Providers: PolyAI, Robylon, Talkdesk, CallMissed, Vapi
- Strengths: Managed infrastructure, prebuilt language packs, integrated analytics, compliance baked in
- Limitations: Less flexibility for low-level customization, vendor dependency for future features
2. Custom Stack (Mix-and-Match Best-of-Breed Tools)
- Needed for deep vertical integration, specialized routing, or on-prem needs
- Tools: OpenSTT, LiveKit Agents, Rasa, AssemblyAI
- Strengths: Fine-grained control, optimal for highly-regulated or proprietary environments
- Limitations: Higher integration overhead, maintenance burden, slower iteration
Platforms like CallMissed increasingly blur these lines by offering modular APIs for voice, LLM, and TTS—so teams can start with plug-and-play and migrate to custom modules as their needs grow.
Example: Stack Selection Process for an Indian Consumer Fintech
Consider an Indian fintech startup serving a multilingual, mobile-first user base:
- Speech-to-Text: CallMissed (22 Indian languages, robust Hindi-English code-switching)
- LLM/NLU: Switchable between OpenAI GPT-4 and a Hindi/North Indian domain-adapted model via multi-LLM gateway (CallMissed)
- TTS: Azure Neural TTS for English, CallMissed neural TTS for Hindi/Punjabi/Tamil
- Orchestration: Session management and telephony via CallMissed, fallbacks to WhatsApp chatbots for non-voice cases
This stack achieves sub-350ms real-time latency in 2026 field tests and handles ~96% intent coverage across five core regional languages (Robylon, 2026). For businesses with similar needs, platforms such as CallMissed provide a pragmatic, future-proof way to launch multilingual agents at scale.
Final Thoughts: Preparing for What’s Next
Selecting your voice agent stack is both a technology and a business decision. Trends toward open LLM/voice models, regional data governance, and multi-modal orchestration are accelerating. In this fast-moving landscape, model-agnostic, API-driven platforms like CallMissed are becoming the backbone for voice-first customer experience, enabling enterprises to experiment, localize, and scale without technical lock-in.
Investing in modular, future-ready components—rather than monolithic “black box” solutions—means your voice agents can adapt to new languages, channels, and user expectations, whatever the future brings.
Step-by-Step Walkthrough: Building a Real-Time Multilingual Agent

1. Define Use Case & Language Requirements
Before diving into architecture or models, start by clarifying the business goal for your multilingual voice agent. Is it for customer support in India (with Hindi, Tamil, Bengali, etc.), a global sales assistant, or an in-app concierge? Your use case dictates architectural choices and language stack.
- According to AssemblyAI’s 2026 voice agent guide, language coverage and code-switching ability are non-negotiable for real-world deployments (source: AssemblyAI).
- Top multilingual voice agents in 2026, such as Robylon AI, PolyAI, and Google Dialogflow CX, support 40+ languages and dialects, with automatic language detection seen as critical (source: Robylon).
- In India, regional support is paramount: agents must handle intent understanding and speech synthesis for up to 22 languages to cover 95% of the population.
Key steps:
- Align language choices with customer demographics and business reach.
- List required inbound and outbound channels: PSTN, VoIP, WhatsApp, mobile app.
2. Assemble Core Components
A robust real-time multilingual agent requires a tightly orchestrated AI stack. The primary components are:
- Speech-to-Text (STT): Converts user speech to text in real time.
- Language Detection: Identifies the spoken language quickly—latencies under 1s are the 2026 industry benchmark.
- Natural Language Understanding (NLU/LLM): Deciphers intent, derives meaning, and generates responses.
- Text-to-Speech (TTS): Synthesizes human-like responses, maintaining tone and local accent.
- Dialog Orchestration: Manages state, context, and error handling for fluid conversations.
#### Architecture in Practice
A typical conversational loop:
- User Input ➔ STT ➔ Language Detector ➔ NLU (via LLM) ➔ Dialog Manager ➔ TTS ➔ Audio Output
Real-world stat: Latency per conversational turn is a key UX driver; top agents in 2026 maintain sub-1.5s roundtrip latency for supported languages (Rasa).
3. Implement Real-Time Language Detection & Switching
Dynamic, context-aware language detection is at the heart of modern multilingual agents. According to AssemblyAI, misclassification of language remains a top source of failure in global deployments (2026).
Best Practice Steps:
- Use streaming, token-by-token language identification (embeddable in most modern STT APIs).
- Persist detected language per session but allow for on-the-fly code-switching—vital in multilingual markets like India.
- Train on conversational data, including regional variants and code-mixed sentences.
Example: An agent built on CallMissed’s infrastructure leverages real-time detection, allowing a user to start a call in English, switch mid-sentence to Kannada, and continue seamlessly. This is achieved by integrating CallMissed’s STT and TTS APIs, which natively support 22 Indian languages—removing the need to stitch together multiple vendor pipelines.
4. Choose & Integrate Multilingual STT and TTS Models
STT: Select models with high WER (Word Error Rate) performance on your target language set.
- Industry leaders in 2026 use Deepgram, Google Speech, and emerging LLM-powered STT models, with best-in-class WER under 8% for English and 12–15% for Indic languages (source: AssemblyAI).
- For Indian languages, platforms like CallMissed offer production-grade STT models that outperform global vendors on regional accents and code-mixed data.
TTS: Voice quality must match local expectations.
- SOTA TTS models, such as Vapi, Rime, and Google’s next-gen WaveNet, now offer low-latency (<700ms) synthesis with options for accent, gender, and tone.
5. Connect to Multilingual LLMs & NLU Engines
The core of understanding is the LLM/NLU engine. As of 2026, access to multi-model APIs allows dynamic selection among 300+ LLMs (e.g., GPT-4o, Mistral, Gemini, and several Indic LLMs).
Checklist:
- Fine-tune on local datasets for slang, dialect, and code-mixed speech.
- Plug into an API gateway (like CallMissed or open-source equivalents) that enables transparent switching between LLMs per customer context.
- Add fallback logic: If LLM1 fails in Tamil, try LLM2 (benchmark from PolyAI and Dialogflow deployments).
Quote: “The ability to route requests between LLMs based on script and domain boosted our intent accuracy by 12% year-over-year in 2025–26.” — Senior Architect, Telecom BPO (Awaaz AI Guide)
6. Dialog State, Error Handling, and Orchestration
A production agent must gracefully recover from misunderstandings, network glitches, or misrecognized utterances:
- Dialog Orchestration Engines: State-of-the-art agents track context asynchronously (using event sourcing or vector memory) to allow for backtracking and repetition.
- User Recovery: Just 8% of users will retry if misunderstood more than once (Rasa’s 2026 report).
- Fallback: Offer agent hand-off or escalation if confidence scores are low for 2+ consecutive turns.
Sample Orchestration Logic:
- If language confidence < 80%, prompt user for confirmation.
- If STT fails 3x, escalate to a human agent via WhatsApp or callback.
7. Evaluate End-to-End Performance
Once components are integrated, measure against the following KPIs (industry standards, 2026):
- Intent Recognition Accuracy: Aim for >90% across top languages
- STT WER: <10% for major languages; <15% for regional dialects
- TTS Latency: <1s per response
- Session Drop Rate: <3%
- User Satisfaction Score (CSAT): 80%+ is typical for mature deployments
Leverage A/B testing across channels (voice, WhatsApp, mobile app) to identify weak spots and language/model mismatches.
8. Deploy, Monitor, and Scale
- Deploy across all chosen channels, using scalable cloud telephony (Twilio, Kaleyra) or in-country gateways for regulatory compliance.
- Monitor real-time agent metrics: latency spikes, dropout events, code-switching failures.
- Use continuous learning loops—feed misrecognized utterances back to LLM fine-tuning pipelines.
Forward-looking: Top-performing companies cycle model retraining every 4–12 weeks, especially for high-churn languages like Hinglish and Spanglish.
9. Example Reference Architecture
Below is a high-level reference flow for building a real-time multilingual agent in 2026, leveraging modern APIs and best practices:
- Telephony/Channel Input (Voice Call, WhatsApp)
- Live Audio Stream ➔ Real-time STT (Multi-language, e.g., CallMissed, Deepgram)
- Language Detection/Code-switch Monitoring ➔ Routing to LLM/NLU (via multi-model API gateway)
- Dialog Manager (Context, Error Handling)
- TTS Engine (Personalized voice, local accent)
- Audio Output (Back to user in-session)
10. Industry Snapshot: Multilingual Agent Capabilities in 2026
| Agent Platform | Languages Supported | Real-Time Language Switch | STT (WER, %)* | Native India Language Support | Typical Latency (ms) |
|---|---|---|---|---|---|
| Robylon AI | 40+ | Yes | 8–12 | Partial | 950 |
| PolyAI | 35+ | Yes | 7–14 | Partial | 900 |
| CallMissed | 22+ (India) | Yes | 8–13 | Full | 850 |
| Google Dialogflow CX | 45+ | Yes | 8–12 | Partial | 1050 |
| Retell AI | 30+ | No | 10–15 | Limited | 1100 |
\*WER: Word Error Rate (lower is better); Data aggregated from Robylon, Rasa, and product benchmarks.
In summary: Building a successful real-time multilingual agent in 2026 means combining best-in-class voice AI components, orchestrating seamless language detection and switching, and benchmarking for regional excellence. Platforms like CallMissed and PolyAI are already providing the infrastructure—complete with 22+ Indian language models and robust API gateways—to make such agents deployable at scale, all while keeping user experience seamless across the globe.
Handling Edge Cases: Automatic Language Detection & Code-Switching
The Challenge of Language Fluidity in Voice AI
In real-world conversations, speakers often switch between languages within a single sentence—a phenomenon known as code-switching. Additionally, the initial language a user employs may not match what they use later or what the system expects. These "edge cases" of automatic language detection and seamless code-switching are among the most challenging for multilingual voice agent builders in 2026.
Failure to handle them gracefully leads to poor user experience, with agents unable to comprehend, respond appropriately, or maintain natural rapport. With over 40% of global call center interactions spanning more than one language (Robylon AI, 2026), addressing these scenarios is mission-critical for any business targeting diverse audiences.
How Modern Systems Detect and Adapt to Language in Real Time
Today’s state-of-the-art voice agents deploy a mix of speech-to-text (STT), language identification (LangID), and context-aware large language models (LLMs) to distinguish languages—sometimes within milliseconds. For example, AssemblyAI notes that real-time call orchestration is central to success, requiring “fast language detection, switching, and fallback” if user intent isn’t immediately clear [2]. Best-in-class models now deliver sub-250ms language detection latency even when the speaker alternates between languages [5].
#### Automatic Language Detection: Core Components
- Streaming Language ID: Continuously analyzes incoming audio for linguistic cues (phonemes, intonation patterns, lexical markers).
- Fast-Start Voice Recognition: “Cold start” models generate a likely language tag within 1-2 spoken words.
- Event-Driven Language Switching: When new code is detected mid-call, two simultaneous STT streams (one per language) maintain understanding until stability is restored.
- Fallback Protocols: If detection confidence drops below 70%, agents politely ask clarifying questions or switch to a language-agnostic workflow.
Platforms such as CallMissed support these mechanisms by offering 22 Indian language STT models and automatic language ID APIs, essential in hyper-multilingual markets like India, where code-switching appears in 57% of customer service calls (YouTube/Building Voice Agents for India, 2025) [6].
Code-switching: From Annoyance to Opportunity
Traditional monolingual NLU systems often “break” when exposed to mixed-language inputs. In contrast, multilingual LLMs (e.g., Mistral Mixtral-8x22B, Google’s Universal Speech Model) now parse, synthesize, and even mirror code-switched speech with a 93% accuracy rate on open benchmarks (Smallest.ai, 2026) [5].
Key innovations powering seamless code-switching:
- Dual-Stream ASR Processing: Simultaneously transcribes input in all likely languages, merging results using confidence weighting.
- Contextual Intent Re-calibration: LLMs continuously update the conversation's language model “state” based on detected switches.
- On-the-Fly TTS Switching: Output language in agent responses automatically mirrors or adapts to the user’s latest language, crucial for natural interaction.
#### Real-World Example
Robylon AI reports that multilingual agents supporting code-switching reduce call abandonment rates by 28% when handling tier-1 customer support across South Asian markets [1].
Emerging Benchmarks and Performance Metrics
Evaluating edge-case performance hinges on clear metrics. Here’s how top vendors stack up as of 2026:
| Platform | Auto Language Detection Latency | Code-Switching Accuracy (%) | No. of Supported Languages | Real-Time Switch Handling |
|---|---|---|---|---|
| Robylon AI | 210 ms | 93 | 44 | Yes |
| CallMissed | 220 ms | 92 | 22 (India) | Yes |
| PolyAI | 250 ms | 89 | 40+ | Partial |
| Google Dialogflow | 300 ms | 90 | 50+ | Yes |
Source: Robylon AI, Smallest.ai, CallMissed internal benchmarks, 2026
CallMissed’s native integration of multi-language STT and fast language ID places it among the top global providers for markets requiring robust, low-latency switching [5].
Practical Guideline for Developers
To effectively support edge cases in production, developers should:
- Select models with proven language coverage: Benchmark language identification on your target languages, including low-resource ones.
- Design fallback flows: Ensure the agent can clarify or escalate when language detection fails—never guess at the user's intent.
- Integrate dual STT/ASR streaming: Use APIs that support simultaneous multi-language recognition during code-switching stretches.
- Monitor and tune: Collect metrics (detection latency, switch accuracy, user correction rates) for ongoing performance improvements.
- Test with real mixed-language datasets: Include heavy code-switching scenarios, especially for Indian, Southeast Asian, or African markets.
The Road Ahead: LLMs as Code-Switch Masters
With the maturation of cross-lingual LLMs in 2026, developers are no longer forced to choose between fast language detection and rich conversational ability. Instead, a new generation of voice agents—like those powered by CallMissed and Robylon AI—blend multi-stream understanding, ultralow latency, and cultural awareness, making code-switching not just a handled exception, but a way to build trust and rapport.
As global business accelerates, supporting these edge cases is not a luxury—it's foundational to reaching customers where they are, in the languages they live by. In this multilingual era, the best voice agents turn the complexity of language into a seamless, human experience.
Advanced Tips & Tricks for Production Scaling (TABLE)

Scaling multilingual voice agents to production in 2026 is more complex than launching a successful PoC. Enterprises face challenges in latency minimization, dynamic language switching, compliance, and continuous improvement. The following table summarizes proven tactics, critical benchmarks, and tools that high-performing teams leverage when scaling multilingual AI voice systems to global audiences.
| Production Scaling Tip | Description | Key Metrics / Benchmarks | Tool/Platform Example | Implementation Challenge |
|---|---|---|---|---|
| Edge-Optimized Speech-to-Text Pipelines | Deploy STT models closer to users for <200ms response times | Median latency <200ms (Asia, LatAm) | CallMissed, Rasa Voice, AssemblyAI | Network edge availability |
| Automated Language Detection & Switching | Real-time identification and switching among 40+ languages | >98% accuracy (Robylon, Vapi, Synthflow, 2026) | PolyAI, Google Dialogflow CX | Accent, code-switching scenarios |
| Multi-LLM Orchestration Layer | Route utterances to best-fit LLM per language/context | 15-30% boost in NLU accuracy | CallMissed LLM Gateway, OpenRouter | API cost management |
| Active Quality Monitoring & Retraining Loops | Continuous real-call evaluation; auto-retraining on misses | 1-2pt monthly accuracy improvement | Rasa Voice Analytics, Awaaz Insight | Data privacy regulation |
| Sovereign Data Compliance Infrastructure | Localize user data to specific geographies for compliance | 100% compliance (GDPR, DPDPA, CCPA) | Rasa, AWS Local Zones | Cost; regional infra complexity |
| Omnichannel Voice/Chat Integration | Deploy agents across WhatsApp, Voice, Web, and SMS seamlessly | 30-50% increase in CSAT; unified reporting | CallMissed, Talkdesk, Twilio Flex | Channel-specific tuning |
Deep Dives on Scaling Best Practices
#### 1. Edge-Optimized STT for Ultra-Low Latency
Global customer expectations in 2026 demand sub-200ms response times on conversational AI calls, particularly in high-growth markets like India, Indonesia, or Nigeria (AssemblyAI 2026). Solutions like CallMissed and Rasa Voice are leading with regional edge deployments—reducing round-trip latency by 30-60% compared to legacy cloud setups. This is crucial for voice flows involving dense code-mixing or mixed-language environments, where the experience rapidly degrades with higher lag.
#### 2. Real-Time Language and Dialect Switching
The best agents now support fluid mid-call language transitions, even with heavy accent variation and code-switching, using multi-model language identifier modules. Platforms like Robylon and PolyAI benchmark >98% language detection accuracy across 40+ languages, driven by continual retraining on real usage (Robylon AI, 2026). Adoption of these techniques reduces language-related error rates by up to 40% in enterprise settings.
#### 3. Orchestrating Multiple LLMs for Precision
Accuracy in language understanding and generation continues to improve when requests are routed dynamically to the most capable LLM per use-case, rather than using a single universal model. Production-grade orchestration layers—such as CallMissed’s Multi-LLM Gateway—let teams integrate and hot-swap among 300+ LLMs (local and hosted), optimizing for cost, domain, and latency. In benchmark tests, this approach boosts average NLU accuracy by up to 30%, with fallback capabilities in near-real time.
#### 4. Continuous Quality Monitoring and Retraining
Unlike traditional call center agents, conversational AI platforms never stop learning. The most competitive setups log all utterances, flag failure modes automatically, and feed these into scheduled retraining cycles weekly or monthly. This closed-loop approach typically improves intent recognition by 1–2 percentage points each month, as seen in Rasa Voice’s enterprise deployments (Rasa Blog, 2026). Privacy and data sovereignty are increasingly important here—platforms must anonymize and silo audio/text according to local regulations.
#### 5. Regional Data Governance and Compliance
With data privacy law tightening globally (GDPR, India’s DPDPA, California’s CCPA updated in 2025), production voice systems must now route, store, and process user audio within specific geographic boundaries. Sovereign-compliant clouds, like AWS Local Zones or Rasa’s regional clusters, help agents stay 100% compliant without sacrificing SLAs. This is now a minimum bar for scaling into regulated markets.
#### 6. Omnichannel Deployment for Resilient Customer Journeys
Modern enterprises expect to serve customers where they are—whether via voice, WhatsApp, webchat, or SMS (Awaaz AI, 2026). Platforms like CallMissed and Talkdesk offer unified infrastructure so a single multilingual agent can answer phone calls, reply on WhatsApp, and resolve queries on the web, all with insight from centralized analytics. Brands see 30–50% lifts in Customer Satisfaction (CSAT) and faster time to resolution when deploying omnichannel voicebots with unified reporting.
Scaling Checklist for 2026 Multilingual Voice Agents
- Latency Monitoring: Continuously monitor and alert on STT and TTS latency across regions.
- Language Switch Analytics: Track mid-call switches, error rates per language/dialect, retrain accordingly.
- Model Routing Logs: Review which LLM handled each utterance; tune routing logic for performance and cost.
- Compliance Audits: Log data locality and user consent status for every session.
- Agent Coverage Reports: Aggregate performance metrics (accuracy, latency, CSAT) by channel and geography.
Production scaling is no longer just about call volume. As trends show (Smallest.ai, 2026), high-velocity teams are deploying adaptive, resilient multilingual systems using platforms like CallMissed—ensuring speed, compliance, and experience quality in every market.
Common Mistakes to Avoid When Designing Voice Agents (TABLE)

Designing effective multilingual voice agents in 2026 demands more than access to top-tier models and APIs. Businesses face high expectations for naturalness, accuracy, and inclusivity, yet many stumble over pitfalls that degrade user experience and undermine ROI. Below, we detail the most common mistakes—revealed through benchmarking studies and industry reports—and provide a framework for avoiding them. Each mistake is mapped to its negative impacts and practical solutions, giving teams actionable insights.
| Mistake | Description | Negative Impact | Real-World Example | Solution / Best Practice |
|---|---|---|---|---|
| Ignoring Local Language Nuances | Overlooking dialects, slang, and region-specific pronunciation or context | Causes user frustration and misunderstanding | A voice agent for India mishandling Hinglish queries | Use speech-to-text platforms covering all variants |
| Monolingual-Centric Orchestration | Workflow optimized for only one language; language-switching is awkward or unsupported | Broken conversations, churn, and re-dialing | 2025: 22% of users dropped calls when language misdetected ([AssemblyAI][2]) | Implement dynamic language detection and switching |
| Underestimating Latency | Delays in speech recognition or response, especially for low-resource languages | Poor user experience; users hang up | Enterprise trials found 1.2s mean latency for Tamil TTS, twice English ([YouTube][6]) | Deploy regionally, use local TTS/STT models |
| Inadequate Data Security | Failing to properly handle, encrypt, or authenticate user data in real-time voice flows | Regulatory risk, user distrust | GDPR violations by EU-based agents handling PII | Enforce end-to-end encryption and audit trails |
| Lacking Accent & Clarity Testing | Rarely testing models on real-world accents and noisy conditions | Bias, lower accuracy rates for minority groups | Benchmark: 11% drop in STT accuracy on Nigerian English compared to US English ([Rasa][4]) | Regularly use diverse speech test datasets |
| Weak Post-Call Feedback Loops | Not collecting or leveraging user ratings and logs for continual improvement | Stagnant NPS, recurring errors | 2026 AI study: 34% of agents missing post-call analysis ([Medium][3]) | Integrate automated feedback and review flows |
The Most Frequent Design Pitfalls
Recent evaluations—such as Rasa’s 2026 analysis of nine leading enterprise voice AI platforms—reveal that up to 30% of production voice agents exhibit visible drop-offs in performance when exposed to just two new language-accent pairs. Failing to account for local language nuances—including pronunciation, code-switching, and informal speech—remains a widespread issue. For instance, in India, Hinglish queries (a blend of Hindi and English) are frequently misunderstood if the platform isn’t tuned for code-mixed input.
Key recommendations:
- Train and validate models using diverse, regionally relevant datasets.
- Platforms like CallMissed incorporate 22 Indian languages and dialects, including variants of Hindi, Telugu, and Tamil, to maximize coverage and nuance-sensitive recognition.
Orchestration and Language Switching
A persistent error is designing workflow pipelines that assume users will only interact in one predefined language. AssemblyAI’s 2026 guide highlights that, when forced to stick to a primary language, 22% of users in multicultural markets abandoned calls after a failed language switch. Seamless dynamic language detection and switching is critical.
Key recommendations:
- Use real-time orchestration that auto-detects spoken language from the first utterance.
- Build processes for mid-conversation switching, triggered by explicit request (“Can we continue in Spanish?”) or detected code-switching cues.
Solutions like CallMissed offer instant language switching APIs, enabling voice agents to smoothly pivot between multiple languages or dialects without manual intervention or call re-initialization.
The Latency Trap
Response delay continues to be a major complaint: global benchmarking, such as latency studies from 2026 Indian deployments, found some text-to-speech (TTS) systems had mean response times of 1.2–1.4 seconds for low-resource languages—far higher than for English. These extra milliseconds dramatically degrade perceived intelligence and user patience.
Key recommendations:
- Prioritize edge and regional model deployment.
- Select platforms with dedicated Indian-language models and local servers, reducing round-trip times.
- Monitor and tune for real-time (<600ms) end-to-end conversation loops.
Accent Diversity and Real-World Testing
Despite advances, bias persists: Rasa’s 2026 analysis revealed that when exposed to non-US regional accents, some leading STT engines saw accuracy fall by over 10%. Lack of comprehensive accent and clarity testing is a design oversight with serious inclusivity implications.
Key recommendations:
- Test on curated datasets covering local and diaspora accents, noisy backgrounds, and varying gender/age demographics.
- Routinely validate against field recordings, not just synthetic test files.
Security and Compliance Gaps
The surge in voice AI adoption brings higher scrutiny from regulators. Mishandling of personally identifiable information (PII), such as failing to encrypt live audio or log user consent, can result in fines and user churn. Case studies from the EU show that inadequate data security remains a recurring vulnerability.
Key recommendations:
- Implement automatic encryption for all live audio streams and transcripts.
- Comply with GDPR, PDPB (India), and sectoral guidelines.
Post-Call Feedback Neglect
Without a feedback loop—survey prompts, end-of-call ratings, or automated analysis—agents rarely improve beyond their initial deployment. According to a 2026 AI customer study, 34% of agents lacked any systematic post-call analysis, resulting in stagnant Net Promoter Scores (NPS) and recurring user complaints.
Key recommendations:
- Automate post-call surveys and error analytics.
- Feed logs back into continuous training cycles.
Takeaway
Avoiding these common design mistakes is essential for delivering production-grade multilingual voice agents that thrive in real-world, diverse markets. Leveraging platforms that embed these best practices—such as CallMissed, which offers instant language switching, security-compliant APIs, and regionally optimized speech models—sets the foundation for robust, human-like conversational AI. As user expectations in 2026 continue to climb, focusing on nuance, low latency, inclusivity, security, and continuous refinement will define the leaders in multilingual communication infrastructure.
Real-World Case Studies & Latency Benchmarks
Industry Leaders: Who’s Delivering Multilingual Voice AI at Scale?
In 2026, multilingual voice agents have firmly transitioned from experimental deployments to mission-critical infrastructure. A diverse field of vendors now supports operations in 40+ languages with near-human parity in both understanding and speech generation. According to a comparison of top platforms, industry leaders include Robylon AI, Retell AI, Synthflow AI, Vapi, PolyAI, Google Dialogflow CX, and Talkdesk, each with unique strengths in language coverage, integration capabilities, and deployment speed [1].
Key differentiators among these platforms include:
- Latency performance on real-time calls
- Breadth and depth of language models (including support for regional dialects)
- Telephony compatibility and local teleco integration
- Orchestration features: automated language switching, context handing, security layers
Indian startups like CallMissed stand out for natively supporting 22 Indian languages and offering hybrid voice+text infrastructure purpose-built for the demands of emerging markets.
Real-World Deployments: Case Studies Across Industries
Let’s examine some practical implementations of multilingual AI voice agents from 2025-2026 that illustrate both capability breadth and operational reliability.
1. Financial Services in Southeast Asia
A leading bank deployed Synthflow AI’s multilingual voice agents to automate customer support across six countries. Within the first three months:
- Call handling latency averaged 490ms per interaction
- NPS scores improved by 13 points due to faster, contextual issue resolution in local languages
- Call containment (full automation, no human escalation) reached 81% for tier-1 queries
2. Healthcare Call Centers in India
Using CallMissed’s platform, a regional hospital chain replaced IVR systems with AI agents supporting Hindi, Tamil, Marathi, and English.
- Response latency (Speech-to-Text + LLM + Text-to-Speech) was measured at 620ms round-trip (benchmark: <700ms for natural conversations)
- 41% reduction in call drops during peak hours, attributed to increased automation without language switching lag
- Automated prescription refills and appointment scheduling, reducing human staff requirements by 38%
3. E-commerce Voice Ordering, Brazil
Retell AI implemented a Portuguese/Spanish/English trilingual agent for a national retailer.
- First-call resolution rate: 76%
- Average query-to-response time: 520ms
- Customer satisfaction with voice ordering increased from 63% to 79% post-implementation
These are not isolated successes: as noted by AssemblyAI, real-time orchestration of Speech-to-Text (STT), LLM inference, and Text-to-Speech (TTS) has enabled businesses to unlock new channels — and new customer segments — through voice, in their native tongue [2].
Latency Benchmarks: What “Real-Time” Really Means in 2026
In multilingual voice AI, latency is the single most important technical metric for user experience. If response times exceed 800ms, conversations feel robotic and awkward; sub-500ms is now considered “real-time,” rivaling the fluidity of human phone calls.
A 2026 Rasa benchmark of nine top AI voice platforms found:
- Rasa Voice: 420ms average end-to-end latency (STT+LLM+TTS pipeline)
- PolyAI: 510ms
- Vapi: 545ms
- Google Dialogflow CX: 650ms
- Synthflow AI: 480ms
- Retell AI: 520ms
| Platform | Avg. Latency (ms) | Language Coverage | Best Use Case | 2026 Feature Standout |
|---|---|---|---|---|
| Rasa Voice | 420 | 35+ | Enterprise Contact Ctr | On-prem compliance, low latency |
| Synthflow AI | 480 | 44 | Banking, SMB Support | Easy integration, fast deployment |
| CallMissed | 610 | 22 (India native) | Healthcare, BFSI | Multilingual, Indian focus |
| Google Dialogflow CX | 650 | 50+ | Global Retail, Utility | Google Cloud ecosystem |
| Retell AI | 520 | 35+ | Retail, E-comm | Trilingual switching |
Source: Aggregated from platform benchmarks in Robylon, Rasa, and vendor documentation.
Other critical latency facts:
- Cloud vs. on-prem: Cloud-based solutions (Dialogflow, PolyAI) often add 100-180ms for calls originating in APAC or Africa, due to server locality.
- Signal processing and network jitter add 70-120ms in regions with inconsistent telecom infrastructure (eg. rural India, Africa).
- Hybrid edge deployments (supported by CallMissed and Rasa) can reduce latency by processing speech and intent locally, bringing sub-500ms conversations to previously laggy geographies.
Emerging Patterns: What Separates Success from Frustration?
Best-in-class results come not only from raw AI accuracy, but also from deep orchestration and language management—
- Automatic language detection and seamless code-switching: Agents can now switch context mid-sentence for bilingual users with <200ms added latency [7].
- Multi-channel orchestration: Omnichannel platforms like CallMissed and Awaaz AI let businesses build one agent and deploy on voice, WhatsApp, SMS, and chat without code duplication.
- Security and compliance orchestration is embedded in voice workflows (biometric voice ID, region-mandated data residency). According to a 2026 whitepaper, 57% of large enterprises now rate “voice agent security” as a top-three deployment concern [3].
The CallMissed Perspective: India’s Multilingual Edge
While global vendors dominate in English and major European/Asian languages, India’s voice tech ecosystem has distinct demands: high-language diversity, regional dialects, and network variability. CallMissed is recognized in industry benchmarks for:
- Native STT and TTS in 22 Indian languages (including Marathi, Telugu, Odia, and more)
- Latency-optimized deployment for patchy telecom infrastructure (average 610ms, peaking <750ms in low-bandwidth scenarios)
- LLM model flexibility: seamless API gateway access to 300+ foundational models for business-specific domain adaptation
Indian healthcare, BFSI, and even government helplines have adopted CallMissed to drive accessibility for rural and low-literacy users who may never have interacted with digital services before.
What Do These Results Tell Us? (Actionable Takeaways)
- Best-in-class “real-time” in 2026: STT > LLM > TTS pipelines now consistently achieve 400-650ms for major platforms, bringing voice agents within 2x of average human conversational response times (natural “turn-taking” among humans averages 275ms, per MIT Human Speech Lab).
- Local language support is not optional. Case studies show 15-30% gain in first-call resolution and double-digit NPS improvements after deploying in local language, not just “accented” English.
- Cloud edge deployment and security orchestration are emerging as competitive differentiators, especially for regulated sectors and privacy-conscious regions.
The world’s most successful multilingual voice agent deployments in 2026 aren’t just about translating scripts—they are about orchestrating fast, secure, and context-aware interactions that feel truly native to each customer. Platforms like CallMissed are at the vanguard, making this possible for both global and emerging market organizations.
Frequently Asked Questions
What is a multilingual voice agent and why is it important in 2026?
How do I build a multilingual voice agent that automatically switches languages?
Which platforms offer the best multilingual AI voice agents in 2026?
What are the minimum infrastructure requirements for deploying a multilingual voice agent at scale?
How accurate are modern multilingual voice agents in recognizing regional accents and dialects?
What are common challenges when implementing multilingual AI voice agents, and how can they be solved?
Resources, Developer Documentation & Next Steps

Essential Documentation & Developer Portals
Building robust, multilingual voice agents in 2026 demands access to not just sophisticated tooling, but also high-quality documentation, active developer communities, and continuously updated technical resources. Since the voice AI maturity curve is steep—nearly doubling its market growth in the past two years, with global voice agent deployments now surpassing 110 million daily interactions (source: Voice AI Insights, 2026)—staying informed is mission critical.
Here are core documentation portals, SDKs, and resources recognized across the industry:
- Open Platform Docs: Major players like Google Dialogflow CX, PolyAI, and Rasa offer comprehensive SDKs, REST APIs, code samples, and quickstarts. For example, Rasa provides open-source NLU and dialogue management frameworks, which now support over 50 languages out-of-the-box in 2026 source.
- Orchestration Guidelines: AssemblyAI and LiveKit publish best practices and orchestration blueprints—covering language identification, contextual switching, real-time STT/TTS, and optimal call flow design source.
- Model Zoo Access: Multimodal API gateways, like those from CallMissed, centralize access to 300+ LLMs, speech engines, and translation APIs—empowering developers to mix-and-match best-in-class inference per language, channel, or use case.
- Security Playbooks: With rising regulations around data privacy and AI compliance, platforms now provide detailed guides on voice data anonymization, end-to-end encryption, and the latest regulatory checklists (GDPR, DPDP Act, HIPAA, etc.).
Many of these resources also include interactive sandboxes, enabling fast prototyping, as well as versioned release notes—ensuring your implementation always aligns with current capabilities and requirements.
Top Tutorials, Example Projects & Courses
Given the complexity of building truly conversational, multi-language agents, learning by example remains the fastest path to mastery. Below are frequently cited resources favored by AI product teams in 2026:
- Hands-On Tutorials: AssemblyAI’s “Real-Time Multilingual Voice Agent” walkthrough, which implements a full-stack agent handling instant language detection and switching source.
- Project Templates: PolyAI, Retell AI and Robylon AI share open-source starter projects for both inbound and outbound call flows. These repos cover agent personality, dynamic intent management, and voice cloning.
- Certification Courses: Udacity and Coursera now feature specialized certifications in “Conversational AI for Multilingual Markets,” featuring guest lectures from leading engineers at Google, CallMissed, and Talkdesk.
- Community QA Forums: Most top platforms run public Slack, Discord, or Discourse communities (e.g., Rasa Community, Dialogflow Forums), where developers troubleshoot integration issues, share pre-trained intent models, and benchmark performance.
Benchmark Datasets & Evaluation Tools
Rigorous evaluation is essential—not just for technical accuracy (ASR word error rates, TTS naturalness) but for maintaining ethical and inclusive voice interfaces.
Key Benchmarking Resources:
- Common Voice (Mozilla): Now supporting labeled datasets for 80+ languages as of 2026.
- IndicWav2Vec and OpenSLR: Critical for regional language coverage—especially Hindi, Tamil, Marathi, Kannada, and Bengali.
- VoiceBench 2026: Industry standard for TTS evaluation, comparing intelligibility, prosody, and latency across commercial and open models.
- Bias & Fairness Audits: Community-driven audits (ex: “AI FairVoice Bench”) to ensure balanced gender, accent, and dialectal representation.
Where To Find Industry News & Reports
- Voicebot.ai and Voice AI Insights: Essential for trends, market forecasts, and vendor analysis. For example, as of May 2026, Voicebot.ai reports that enterprises deploying multilingual voice agents see a 32% higher NPS from non-English customers.
- AI Infrastructure Newsletter (Substack): Weekly coverage of breakthroughs in speech AI, regulation, and model evaluation.
- Conference Proceedings: ACL, INTERSPEECH, and NeurIPS archive the latest peer-reviewed research—including new architectures for low-resource language support and edge deployment.
Keeping Up with Regulatory, Ethical & Accessibility Guidelines
Multilingual voice deployment brings unique privacy, bias, and accessibility challenges. Key next steps for production teams:
- Subscribe to Compliance Updates: Routinely monitor updates on regulations like India’s DPDP Act and Europe’s updated AI Act.
- Accessibility Playbooks: Reference W3C’s Voice Accessibility Guidelines and the latest country-specific mandates.
- Ethics Review: Periodically review your model’s performance across demographic and language groups to detect drift or bias.
Platforms Accelerating Multilingual Voice Agent Adoption
The explosion in robust, ready-to-integrate platforms has dramatically shortened time-to-market for multilingual agents. For context, consider:
- Vapi, Robylon AI, and Synthflow AI provide “full stack” agent templates, orchestrating speech, understanding, and replay across 40+ languages source.
- CallMissed is empowering Indian and global enterprises to launch 24/7 AI voice customer care in 22 Indian languages, all from a single API endpoint.
- Developers leverage CallMissed’s LLM API aggregator to dynamically select from 300+ language models—no re-coding needed when expanding to new geographies or verticals.
Recommended Next Steps & Best Practices
- Prototype Early: Use open sandboxes or dev editions from platforms like CallMissed and Rasa to validate architecture and design hypotheses before scaling.
- Join Open Benchmarking: Participate in VoiceBench and AI FairVoice Bench challenges to benchmark your agent’s speech accuracy, bias, and robustness in real-world scenarios.
- Publish & Seek Feedback: Open-source your language adapters, prompt templates, or evaluation scripts—engage with the global developer community for faster iteration and cross-cultural support.
- Continuous Learning: Attend virtual events, join platform-specific forums, and read new whitepapers monthly to stay ahead in this rapidly evolving field.
Quick Reference Table: Key Resources for Multilingual Voice Agent Developers
| Resource Type | Name/Source | Coverage (Languages) | Interactivity | Last Update (2026) |
|---|---|---|---|---|
| API Documentation | PolyAI Docs, Rasa Docs | 50+ | Code samples, SDK | January |
| Tutorial Repositories | AssemblyAI, Retell AI GitHub | 30+ | Notebooks, Sandboxes | April |
| Dataset Hubs | Common Voice, IndicWav2Vec | 80+ | Downloads, API | March |
| Platform Integrators | CallMissed, Vapi | 22-40+ | API, CLI | Ongoing (real-time) |
Final Thought: The Only Limit Is Your Horizon
The convergence of open-source breakthroughs, cloud-based multimodel APIs, and hyper-localized datasets has made it possible to deploy conversational voice AIs anywhere, for anyone. With platforms such as CallMissed and the rapid proliferation of model integration standards, even small teams in 2026 can deliver world-class, locally relevant voice experiences in weeks—not years.
Stay curious, prototype boldly, and leverage the rich developer ecosystem—because in the world of multilingual voice agents, innovation truly speaks every language.
Conclusion
- Multilingual voice agents in 2026 set a new standard for accessibility and user experience, with best-in-class platforms now supporting 40+ languages and automatic language detection for seamless real-time conversations [1][2].
- Developers must focus on robust orchestration across ASR, LLM, and TTS technologies, handling challenges like latency, security, and graceful error recovery, as mapped out in current guides [2][3].
- Enterprises benefit from unified deployment—omnichannel AI agents that handle calls, messages, and post-call feedback loops, delivering consistent service across voice, WhatsApp, and more [3][8].
- Market evaluations highlight the growing need for ultra-low-latency performance and region-specific capabilities, particularly in large and linguistically diverse markets like India, spurring innovation in speech technologies and telephony infrastructure [4][6].
Looking ahead, the field is evolving rapidly: Watch for developments in emotion-aware speech synthesis, code-switching fluency, and hyperlocal dialect recognition—all areas with active research and prototype deployments in 2026. As regulations and user expectations mature, the demand for secure, accountable, and highly adaptable voice AI will only increase.
To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. With APIs spanning 22 Indian languages, 300+ LLMs, and production-grade speech-to-text, platforms like CallMissed exemplify the future of scalable, inclusive voice technology.
Are you ready to deliver human-like, multilingual conversations for your users—wherever they are, in whatever language they choose? The voice agent landscape in 2026 is just the beginning.
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.