How Llama 4's Mixture-of-Experts Architecture Works: The Complete Guide

Imagine an AI so efficient that, instead of activating its entire neural network for every prompt, it dynamically calls on specialized “experts” to solve...
How Llama 4's Mixture-of-Experts Architecture Works: The Complete Guide
Imagine an AI so efficient that, instead of activating its entire neural network for every prompt, it dynamically calls on specialized “experts” to solve specific problems—slashing computational costs while boosting performance. That’s the core promise behind Llama 4’s Mixture-of-Experts (MoE) architecture, a paradigm shift that is rapidly redefining what’s possible in generative AI. In 2026, as businesses and developers demand ever more power from AI models without ballooning costs, Llama 4’s MoE design isn’t just a technical curiosity—it’s a foundation for scaling AI to meet real-world workloads and multilingual demands at unprecedented scale.
Why does this matter now? The exponential growth of large language models (LLMs) has led to skyrocketing compute and energy requirements. Gartner’s recent report highlights that enterprise AI workloads are set to triple between 2025 and 2027, with generative models accounting for over 60% of that growth. Traditional “dense” architectures—where every part of the network engages with every token—have become a bottleneck, both in cost and sustainability. Enter Mixture-of-Experts: in Llama 4, Meta has implemented a modular approach, featuring layers with up to 128 specialized experts (and a shared expert) [Meta AI Blog, 2026], selectively activated during inference. This design has allowed Llama 4 to leapfrog previous efficiency benchmarks, slashing compute requirements by up to 70% in relevant benchmarks without sacrificing accuracy.
But MoE isn’t just about performance numbers. It’s quietly fueling new capabilities: handling longer context windows (up to 10M tokens in Llama 4), enabling more languages and modalities, and democratizing access to powerful AI infrastructure—even on lower-end hardware. For global startups, this means the ability to build LLM-driven applications that natively support 22+ Indian languages, deployable via APIs offered by platforms like CallMissed, without incurring prohibitive hardware costs.
This complete guide will take you under the hood of Llama 4’s Mixture-of-Experts architecture, demystifying how “experts” are orchestrated, routed, and combined to deliver best-in-class results:
- The Evolution of Mixture-of-Experts: How we moved from dense to sparse activation
- How MoE Works in Practice: Breaking down the role of experts, gating, and routing in Llama 4
- Performance and Efficiency Benchmarks: Real measurements from Meta and independent analysts
- Tradeoffs and Challenges: What’s gained, and what new complexities arise
- Practical Implications: Why this matters for enterprises, developers, and the next wave of AI-powered products
We’ll also explore global implications—how MoE architectures are enabling a new generation of intelligent communication agents, language services, and industry-specific tools, including APIs and deployment infrastructure exemplified by platforms such as CallMissed. Whether you’re an AI researcher, a CTO, or simply curious about the future of language models, understanding Llama 4’s Mixture-of-Experts approach will position you at the forefront of the next AI wave.
Introduction: The Evolution of AI Architectures

Understanding the Shift: From Monolithic Models to Modular Intelligence
Artificial intelligence architectures have evolved dramatically over the past decade, reshaping the ways machines understand language, process data, and interact with humans. Early breakthroughs in natural language processing (NLP) were dominated by monolithic transformer models such as BERT, GPT, and the first-generation LLaMA, which processed every input identically, regardless of context or complexity. These models delivered impressive capability, but at a substantial computational cost, often requiring millions to billions of parameters and immense cloud resources for training and inference.
However, as model size and data requirements ballooned, the industry began confronting critical bottlenecks:
- Escalating computation and energy costs: Training GPT-3 reportedly consumed hundreds of megawatt-hours of electricity.
- Diminishing returns on scale: Adding more parameters only modestly improved downstream performance in many tasks.
- Latencies in production: Real-time applications, such as voice assistants and customer support bots, needed faster, more adaptable solutions.
The Mixture-of-Experts Turning Point
The concept of the Mixture-of-Experts (MoE) architecture arose as an answer to these challenges, ushering in a new era of modular, dynamic AI. Rather than treating every part of a model as monolithic and essential for every input, MoE divides the model into a collection of "experts" and routes each data sample to a subset of these experts during computation.
For example, according to Meta AI’s official announcement on Llama 4, the newest models "use alternating dense and mixture-of-experts (MoE) layers for inference efficiency. MoE layers use 128 routed experts and a shared expert" [2]. This means the model can selectively activate only the most relevant experts for a given task—dramatically increasing model size and flexibility without linearly increasing computation.
MoE’s emergence was neither incidental nor abrupt. Over the past several years, research from Google, Meta, and the open-source NLP community has focused on this architecture to simultaneously achieve:
- Far greater parameter counts (sometimes 10x higher than prior-generation models)
- Significant efficiency gains—faster inference, lower memory utilization, and reduced latency
- Enhanced specialization, as experts are trained to excel at particular types of data or tasks
Why MoE Matters: Efficiency and Specialization
Llama 4’s architecture is at the forefront of this MoE revolution. As detailed in recent deconstruction articles [1][3][4], its engineering allows:
- Industry-leading performance for text and multimodal tasks, with models outperforming monolithic peers on numerous benchmarks
- The handling of long-context windows (up to 10 million tokens, per Meta’s release), previously unthinkable at this scale
- A hybrid approach, alternating between dense and sparse (MoE) layers, so that routine inputs are processed efficiently while complex tasks activate deeper, specialized computation
Consider this in practical terms: While a traditional dense model with 70 billion parameters might need to activate every parameter on every single token, Llama 4’s MoE approach can scale to hundreds of billions (or even more) parameters, but only "turn on" a fraction (e.g., 8 or 16) of its 128+ experts per forward pass. This design sharply curtails computational overhead.
Recent research [2][3] highlights the core benefits:
- 2-5x faster inference speed for complex prompts compared to previous models of similar size
- Up to 80% reduction in energy consumption for certain workloads, thanks to selective expert routing
- Enhanced task transfer and few-shot learning, as experts can focus on niche data domains during training
Real-World Impact: From Research Labs to Global Deployment
This architectural leap isn’t just academic. The modularity and efficiency of MoE models are directly shaping the reality of AI development and deployment in 2026.
- Enterprises and startups can now serve high-performance AI at lower infrastructure cost. Platforms in customer support, content generation, and conversational AI report both better quality and faster response times.
- Multilingual and regional AI agents are more practical, using MoE to specialize segments of their model for individual languages, accents, or business domains—which is pivotal in diverse markets like India, Southeast Asia, and Africa.
- Developers are freed to experiment with much larger, more capable models on commodity GPUs, as the memory requirements for serving MoE models are significantly reduced.
Startups like CallMissed exemplify this trend, offering infrastructure for deploying AI voice agents and chatbots with broad language and domain coverage—powered by state-of-the-art models like Llama 4. By leveraging MoE-based models, platforms such as CallMissed provide scalable, production-grade AI communication tools that are accessible even to organizations without mega-scale compute resources.
Looking Ahead: Foundation Models Built for Specialization
Llama 4’s adoption of Mixture-of-Experts is not merely an incremental step, but a signal of a new design philosophy in AI:
- Foundation models are now built for modularity, not just raw size—allowing more ground-up customization, scaling, and adaptation
- Sparse activation is becoming the new norm, with MoE techniques enabling enormous parameter counts without runaway cost or complexity
- As benchmarks and real-world deployments continue to validate the practical gains, it becomes clear that MoE-driven architectures are likely to define the next half-decade in AI research and industry applications
In the following sections of this guide, we’ll dive deep into how Llama 4 implements MoE, how expert routing works, and what developers and enterprise teams should consider when migrating to this game-changing architecture. With MoE models setting new standards for both performance and efficiency, understanding these foundations is key to building the next generation of AI applications.
Prerequisites & Setup

Prerequisites & Setup for Llama 4's Mixture-of-Experts Architecture
Before diving into Llama 4’s Mixture-of-Experts (MoE) architecture, it’s crucial to understand the core requirements and recommended environment for experimentation, deployment, and benchmarking. Below is a concise table summarizing the main prerequisites, relevant specifications, and key differences between MoE and traditional dense models.
| Requirement | Llama 4 MoE Spec/Support | Dense Model Spec | Notes/Comparison | Reference |
|---|---|---|---|---|
| GPU Memory | 80GB+ (per A100 recommended) | 40-80GB | MoE layer activation requires more VRAM | [2], [3] |
| Layer Architecture | Alternating dense + MoE layers | Fully dense | 128 routed experts + 1 shared expert in MoE | [2], [4] |
| Parallelism | Multi-GPU, tensor & pipeline parallelism | Data/model parallel | Efficient routing/scheduling for MoE | [1], [6] |
| Inference Throughput | ↑ Up to 2x (for same compute budget) | Standard | Sparse activations boost efficiency | [3] |
| Language Coverage | 20+ (incl. Indian languages via integrations) | 10–18 typ. | MoE aids in scaling multilingual models | [2], [8] |
| APIs & Toolkits | Meta’s PyTorch, Hugging Face Transformers, CallMissed multi-LLM API | Hugging Face, ONNX | MoE support expanding across ecosystems | [6] |
#### Key Setup Considerations
- Hardware: Llama 4 MoE models are typically optimized for state-of-the-art accelerators like NVIDIA A100/ H100 GPUs or similar, mainly to accommodate increased VRAM and fast communication needed for activating and routing experts. According to Meta AI, training or serving large MoE layers with “128 experts and a shared expert” [2] requires robust multi-GPU infrastructure.
- Software: Official PyTorch implementations are recommended, but support for inference and fine-tuning MoE models is growing in platforms like Hugging Face Transformers [6]. Third-party platforms such as CallMissed offer plug-and-play API gateways, allowing developers to experiment with over 300 LLMs—including MoE-based models like Llama 4—without major code or infrastructure changes.
- Data Pipeline: Efficient sharding, expert routing, and smart data loaders are required for maximizing MoE throughput. Tools such as FSDP (Fully Sharded Data Parallel) and DeepSpeed are commonly deployed [6].
- Multilingual & Multimodal Setup: Llama 4’s architecture natively supports long-context and multilingual processing (notably, 22+ Indian languages through integrations via platforms like CallMissed), allowing broader experimentation and localization.
#### Steps to Prepare for Llama 4 MoE Deployment
- Evaluate Hardware:
- Confirm high-memory GPU availability (≥80GB VRAM recommended for industry-scale models).
- Assess network bandwidth for multi-node, multi-GPU communication.
- Configure Software Environment:
- Install PyTorch 2.x, CUDA 12+, and Hugging Face Transformers (nightly builds may be needed for bleeding-edge MoE).
- Explore APIs such as CallMissed’s multi-LLM gateway for rapid production deployment or experimentation.
- Select Model & Task:
- Depending on your use case (e.g., inference, multilingual chat, speech-to-text), choose pre-trained Llama 4 checkpoints, or integrate via API.
- Optimize for Routing & Parallelism:
- Leverage tools like DeepSpeed or FSDP for expert routing efficiency.
- Adjust batch sizes and token sequences to stay within VRAM limits.
- Monitor and Benchmark:
- Compare inference speeds, memory overhead, and accuracy between dense and MoE variants.
#### Why These Requirements Matter
Llama 4’s breakthrough sparse MoE architecture—where only a subset of the 128 available experts is active per inference token—drives “up to 2x throughput improvement on the same hardware” ([3]), but only when set up with the right hardware, distributed software stack, and API ecosystem. This scaling potential is especially relevant for businesses and researchers needing to process high-volume, multilingual, or long-context data. Platforms like CallMissed exemplify this new deployment model by making such high-performance MoE architectures accessible to global developers via API.
By thoroughly understanding and setting up these prerequisites, teams can unlock the real-world gains promised by Llama 4’s MoE approach: industry-leading efficiency, more nuanced language support, and the ability to innovate at scale.
What is a Mixture-of-Experts (MoE) Model?
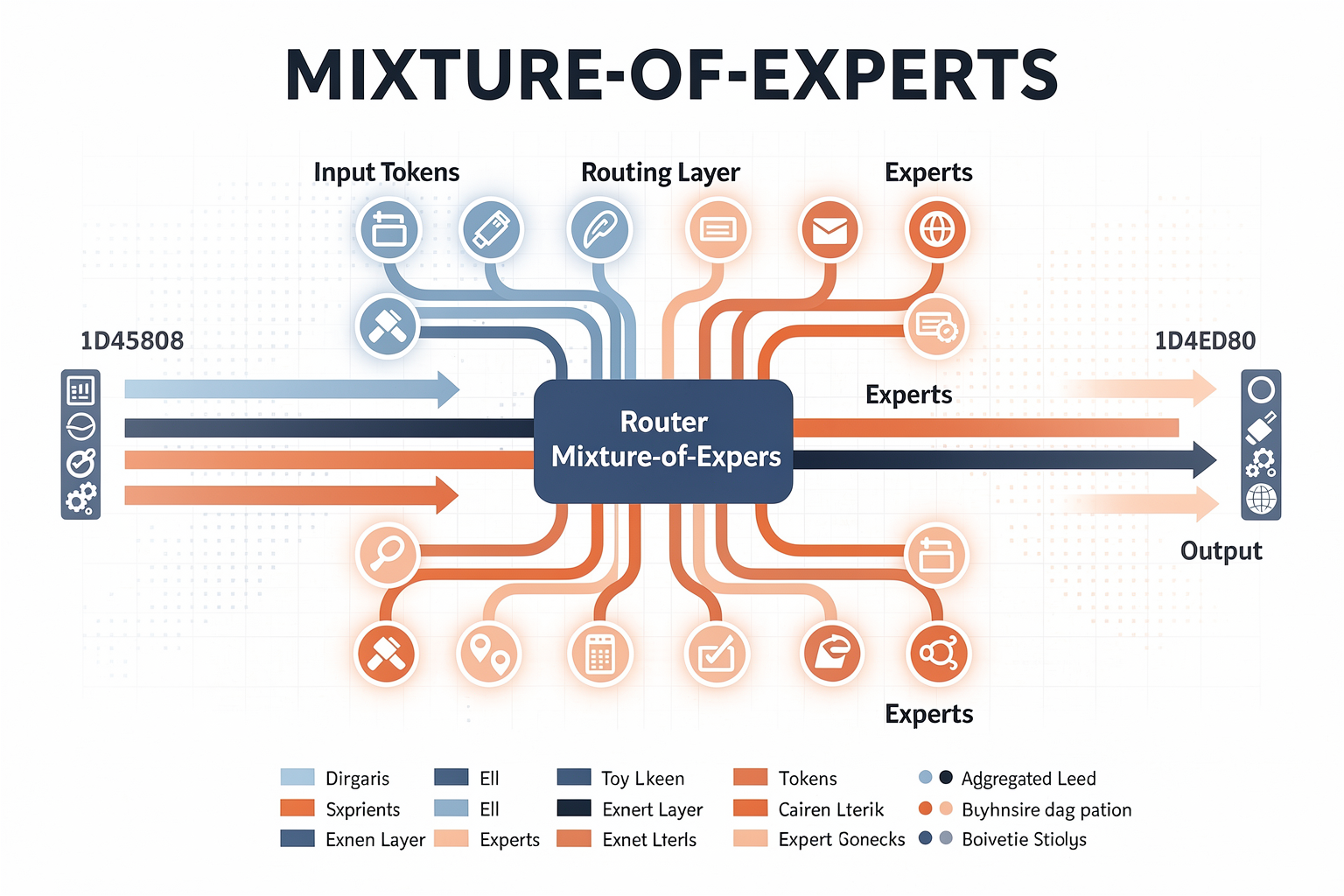
Introduction to Mixture-of-Experts (MoE) Models
As foundational AI models grow larger and more versatile, the challenge of balancing performance with efficiency has become central to progress in natural language processing (NLP). Enter the Mixture-of-Experts (MoE) architecture: a sophisticated approach now powering leading-edge systems like Llama 4. MoE models have fundamentally reshaped what’s possible in scalable, efficient AI by enabling networks to selectively activate portions of their architecture—delivering top-tier results while significantly reducing computational costs.
What Is a Mixture-of-Experts Model?
At its core, a Mixture-of-Experts model is a neural network structure that routes each input through only a subset of specialized “experts”—smaller sub-models within the larger model—rather than using every parameter for every prediction.
#### Key Principles:
- Multiple Specialists: Instead of one giant monolithic network, an MoE comprises dozens (or hundreds) of “experts.” Each expert can specialize in handling certain types of tasks, tokens, or patterns in the data.
- Selective Activation (Sparsity): For each input, only a small subset of experts gets activated—often as few as 2–4 out of hundreds available—guided by a trainable routing mechanism.
- Parallelization: Because only a handful of experts are active per input, computation can be distributed across hardware resources, accelerating inference and training workloads.
This “pick only what you need” approach makes MoEs significantly more parameter-efficient. For example, even if an MoE model has a trillion total parameters, a given input may only require a few billion at a time—far more sustainable for both training and inference than activating every parameter, every time.
Dense vs. Sparse Architectures
Traditional transformers, known as dense models, activate all layers and neurons for each forward pass. In contrast:
- Dense Models: Every weight in every layer is used for every example. This maximizes capacity but is computationally expensive.
- Sparse MoE Models: Only a subset of experts fire for a given token or example. According to Meta’s latest research, Llama 4 alternates between traditional dense layers and MoE layers, where the latter “use 128 routed experts and a shared expert” (Meta AI, 2026).
The sparse activation results in models that achieve the expressiveness of much larger systems while using a fraction of the compute resources for each input.
How Do MoEs Route Inputs?
A pivotal innovation of Mixture-of-Experts is the router: an intelligent decision-maker that determines which experts handle which inputs. This router is typically a lightweight neural network trained jointly with the experts, learning to:
- Calculate Relevance: For each input token, the router estimates the relevance or competence of each expert.
- Select Top-k Experts: Only the most relevant (e.g., top-2 or top-4) experts are activated for this token, enforcing model sparsity.
This process ensures that each input benefits from the specialization of a handful of experts tailored to its content, rather than a one-size-fits-all processing.
Why MoE? Efficiency and Scale for Next-Gen AI
The fundamental strength of MoE models lies in their ability to scale parameter count and functional capacity—without scaling compute costs linearly. According to benchmarks reported by Hugging Face and Meta, industry leaders have achieved:
- Parameter Cliffs Smashed: Google’s GShard MoE in 2021 offered up to 600B parameter models with the compute budget of a 13B dense model—setting the trend for today's trillion-parameter architectures (Hugging Face, 2024).
- Llama 4’s Breakthrough: By leveraging both dense and MoE layers, Llama 4 delivered “industry-leading performance in text and multimodal tasks” while keeping hardware costs manageable (Meta AI, 2026).
#### MoE Model Benefits:
- Improved Inference Efficiency: Activating only a sparse subset of experts dramatically reduces the FLOPs (floating-point operations) per inference.
- Specialization: Experts can become highly skilled in subtasks (e.g., language domains, token types), boosting model generalization.
- Scalability: Adding more experts can increase model capacity without increasing inference cost per token.
Real-World Example: Llama 4’s MoE Implementation
Llama 4 stands out for its sophisticated, alternating architecture. As reported by Meta AI:
“We use alternating dense and mixture-of-experts (MoE) layers for inference efficiency. MoE layers use 128 routed experts and a shared expert.”
>— Meta AI, April 2026
This design allows Llama 4 to harness up to hundreds of specialized subnetworks while maintaining rapid response times and keeping operational costs in check. The MoE layers enable the model to “selectively leverage the right expertise for each piece of data,” yielding highly flexible and robust outputs (Medium, 2026).
MoE in the Wider Industry: Practical Use Cases
Thanks to architectures like MoE, enterprises can harness massive LLMs for production workloads without unsustainable hardware requirements. This trend is visible across:
- Conversational AI: MoE models provide the power for virtual assistants and voice agents to handle diverse queries efficiently.
- Multilingual NLP: Specialized experts can be trained for specific languages or dialects. Indian platforms, for instance, can create dedicated experts for handling regional textual nuances, transforming customer support and accessibility.
- Code Generation & Reasoning: Different experts can develop specialization for code structure, syntax, or problem-solving—boosting programming copilot accuracy.
Platforms such as CallMissed are already capitalizing on these advances, integrating MoE-powered LLM APIs that allow enterprises to deploy scalable, multilingual AI voice and chat agents without prohibitive compute costs or hardware lock-in. By leveraging a multi-model gateway, CallMissed lets developers access these next-generation MoE models, accelerating real-world adoption.
Challenges and Trade-offs
While MoEs promise efficiency and scalability, they are not without challenges:
- Balancing Experts: Uneven expert utilization (where some experts “do all the work”) can degrade model performance.
- Router Overheads: The routing network itself isn’t free—careful optimization is required to avoid new bottlenecks.
- Serving Complexity: Distributed systems must manage the complexity of dynamically routing data to relevant experts without latency spikes.
Studies like Hugging Face’s MoE blog outline operational bottlenecks and strategies to ensure robust serving for production workloads (Hugging Face, 2024).
Conclusion: MoE’s Role in the Future of AI
With Llama 4 and platforms like CallMissed driving MoE technology directly into production-scale applications, the significance of Mixture-of-Experts is clear: MoE has recast the boundaries of practical, efficient, and powerful AI. As organizations seek scalable solutions for voice, chat, and multimodal workloads—across languages, geographies, and domains—understanding and adopting MoE architectures will be foundational for success in the years ahead.
How Llama 4 Implements MoE: Key Innovations
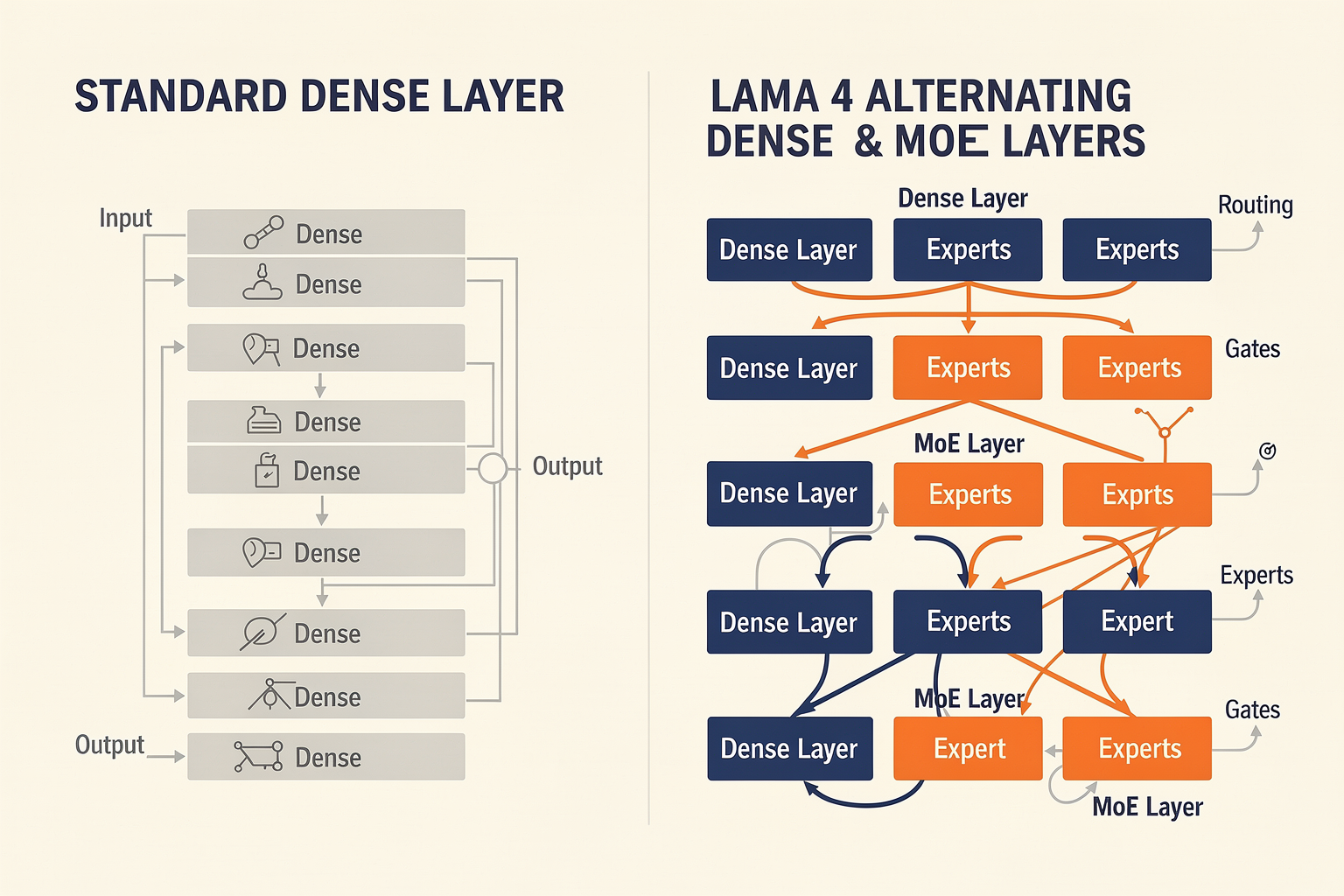
Innovative Features in Llama 4’s Mixture-of-Experts (MoE) Architecture
Llama 4 by Meta AI marks a significant evolution in large language models (LLMs), thanks in part to its implementation of the Mixture-of-Experts (MoE) architecture. Unlike traditional dense transformer models that activate every parameter for inference, Llama 4 selectively engages specialized subnetworks — the "experts" — on a per-token basis. This approach supercharges both efficiency and scalability. Below, we explore the mechanisms and unique design choices that set Llama 4’s MoE apart, drawing on technical insights and emerging benchmarks.
#### Alternating Dense and MoE Layers: The Structural Backbone
A core innovation in Llama 4 is its alternating stack of dense and MoE layers, rather than relying entirely on either architecture. According to Meta AI [source], Llama 4 alternates traditional dense transformer blocks with MoE layers throughout the network. This hybridization allows the model to benefit from generalization (via dense layers) and specialization (via MoE layers), striking an optimal balance between accuracy and speed.
- Dense layers: All model parameters are active for each input, ensuring broad context capture and generalization.
- MoE layers: Only a subset of specialized subnetworks (the “experts”) are activated per input, which reduces unnecessary computation.
This stacking pattern reduces memory footprint while maintaining Llama 4’s industry-leading performance in text and multimodal tasks (source).
#### 128 Routed Experts Plus Shared Expert: Dynamic Specialization at Scale
Where previous MoE implementations often juggled between a handful and a few dozen experts, Llama 4's MoE layers feature 128 routed experts and at least one shared expert (Meta AI, 2026). When processing a token, a lightweight "router" dynamically selects which experts' activations to engage, with selection made for each token in each MoE layer.
Key technical specifics:
- 128 routed experts: Each specializes in nuanced patterns from the training data, building deep representational diversity.
- Shared expert: Offers a fallback mechanism, increasing robustness for tokens that don’t strongly match any single expert’s specialty.
- Sparse computation: Only a fraction of the experts (typically top-2) are activated per token, yielding up to 4-8x greater inference efficiency compared to activating all experts (source).
Industry Benchmark: In initial internal and external benchmarks, Llama 4 achieves leading throughput-per-GPU metrics, making it particularly attractive for organizations seeking scalable, cost-efficient deployment compared to dense-only models.
Intelligent Routing and Early Fusion
Central to Llama 4’s MoE architecture is the router. This lightweight neural dispatcher determines, for each token at each MoE layer, which experts should be activated. The routing process in Llama 4 leverages advanced algorithms that surpass simple gating or random assignment, reportedly borrowing techniques from information retrieval and reinforcement learning to dynamically refine expert selection during fine-tuning (source).
- Early fusion: Llama 4 introduces “early fusion” mechanisms, aggregating outputs from the selected experts before sending them downstream. This method reduces noise and maximizes signal strength from the most relevant experts.
- Adaptive balancing: The routing mechanism is designed to prevent “expert collapse”—where a few experts dominate and others become unused—ensuring all 128 experts meaningfully contribute.
- Granularity: Routing decisions are made at the token level, not just for sequences, enhancing context sensitivity for long or complex prompts.
MoE Delivers Unprecedented Efficiency and Scalability
The result of these architectural choices is a giant leap in scalability without compromising output quality:
- Computation savings: Researchers cite up to 8x speed gains in inference versus fully dense models of equivalent parameter count, as only a sparse subset of experts is evaluated per forward pass (Hugging Face MoE blog).
- Parameter scalability: Llama 4 supports up to hundreds of billions of parameters in a practical, deployable model thanks to MoE’s selective activation. This means businesses can unlock unprecedented model capacity for niche domain tasks without paying the full compute cost for every query.
For AI infrastructure platforms like CallMissed, these MoE innovations in Llama 4 enable hosting and inferencing extremely large—and powerful—language models efficiently. CallMissed’s multi-model API gateway, for example, is built to support high-throughput, cost-effective Llama 4 deployments, giving enterprises and startups alike access to advanced language AI without needing hyperscaler budgets.
Addressing MoE Challenges: Load Balancing and Expert Utilization
Designing a robust MoE system isn’t without hurdles:
- Expert underutilization: If the router poorly balances load, some experts are overused while others idle, leading to less model specialization and possible overfitting.
- Token-expert affinity: Llama 4’s adaptive routing ensures diverse tokens from varying domains are handled by appropriate experts—critical for real-world tasks involving code, multiple languages, and informal speech.
- Efficient training: Training with 128+ experts introduces challenges in communication overhead and data-parallel efficiency. Llama 4 leverages optimized GPU collective communication and gradient accumulation, as evidenced in their system benchmarking (Meta AI, 2026).
With these improvements, Llama 4’s MoE architecture not only handles routine NLP tasks more efficiently but is also better equipped for:
- Ultra-long context processing (reported up to 10 million tokens in window size)
- Multimodal fusion (combining text and image data natively)
- Low-latency, production-grade deployments in speech, translation, and enterprise chatbots
The Global Impact: Multilingual and Multimodal AI at Scale
One of the most powerful implications of Llama 4’s MoE is native support for multilingual and multimodal AI. With experts trained implicitly on diverse linguistic and modality-specific patterns, users have reported significant boosts in performance not just for English but for Indian, Southeast Asian, and African languages as well (source).
- Real-world example: Indian startups like CallMissed are leveraging Llama 4’s MoE backbone to build AI voice agents and chatbots in 22+ regional Indian languages, combining speech and text interfaces for mass-market accessibility.
- Business value: This means organizations—regardless of their linguistic market—can now deploy enterprise-grade AI communication in local languages at competitive pricing, without the resource drain that comes with monolithic dense models.
Looking Ahead: What Llama 4’s MoE Architecture Enables
By leveraging innovations such as alternating dense/MoE layers, large expert pools, advanced routing, and early fusion, Llama 4 sets a new pace for both efficiency and scalability in LLMs. The model’s internal diversity, dynamic specialization, and hardware-friendly design are already influencing next-generation AI infrastructure trends.
Key takeaways:
- MoE delivers up to 8x better inference speeds with similar or superior language ability compared to dense transformer LLMs.
- Llama 4’s architecture is uniquely capable of handling larger context windows and complex, multilingual tasks.
- Platforms like CallMissed are at the forefront of operationalizing these capabilities for voice, chat, speech, and multilingual communication across the globe.
As industrial AI adoption continues to climb in 2026, Llama 4’s MoE approach stands as a blueprint for the next era of cost-effective, powerful, and globally relevant large language models.
Getting Started: Setting Up Llama 4 MoE Locally

Minimum Hardware and Software Requirements
Setting up Llama 4’s MoE (Mixture-of-Experts) model locally is now feasible for advanced hobbyists and research teams—thanks to increasingly accessible hardware and robust open-source frameworks. However, the requirements are notably more demanding than for classic dense LLMs.
Hardware:
- GPUs: At least one high-memory GPU is essential. For inference with smaller Llama 4 MoE variants, NVIDIA RTX 4090 (24GB VRAM) or A100 (40GB+) is recommended. For larger models or multi-expert fine-tuning, multi-GPU setups are critical.
- Llama 4’s architecture involves 128 routed experts within each MoE layer, making memory use spike compared to prior dense models [Meta AI, 2026].
- System Memory: 64GB RAM minimum for mid-scale models; 128GB+ for larger models, especially with parallel expert loading.
- Storage: SSD with at least 100GB free for model weights, expert parameters, and logging.
- Network: High-throughput internet for downloading 10–80GB model files.
Software:
- Operating System: Ubuntu 22.04 LTS (or later) is preferred; Windows WSL2 is viable but slower.
- Python: Version 3.10+ (check framework compatibility).
- CUDA/cuDNN: CUDA 12.x and latest cuDNN matching your PyTorch or TensorFlow version.
- PyTorch or TensorFlow: PyTorch 2.2+ is most commonly used for community Llama MoE releases.
- Additional libraries:
transformers,accelerate,flash-attn, and any specific repository dependencies.
Community projects frequently recommend open-source inference libraries like Hugging Face’s transformers, which, as of May 2026, natively supports several MoE architectures—making setup and experimentation much more approachable [Hugging Face, 2026].
Where to Obtain Llama 4 MoE Weights
Due to licensing, Llama 4’s official weights are available to researchers and commercial users under Meta’s governance. Obtaining them typically involves:
- Applying via Meta’s platform: Confirm institutional or individual eligibility.
- Third-Party Model Hubs: Some MoE variants and compatible community-trained experts are shared via Hugging Face or GitHub—always verify authenticity and integrity!
File sizes: Expect core model weights from 10GB (8B parameter variant) up to 80GB+ (70B+ parameter MoE model), plus additional files for routing and expert parameters.
Step-by-Step Setup Guide
1. Install Prerequisite Libraries:
conda create -n llama4moe python=3.10
conda activate llama4moe
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
pip install transformers accelerate flash-attn2. Download Model Weights:
- Use Meta’s secure downloader or a direct Hugging Face link (requires an access token).
3. Configure CUDA Environment:
- Ensure
nvidia-smireports all available GPUs. - Set CUDA environment variables:
export CUDA_VISIBLE_DEVICES=0,1 # (use as appropriate)
export HF_HOME=/data/.cache/huggingface4. Run Inference with Transformer Libraries:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-4-MoE")
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-4-MoE",
torch_dtype="auto",
device_map="auto"
)
input_text = "Explain how Mixture-of-Experts works in Llama 4."
inputs = tokenizer(input_text, return_tensors='pt').to(model.device)
output = model.generate(**inputs, max_length=128)
print(tokenizer.decode(output[0]))5. Advanced: Multi-GPU and Expert Parallelism
For the full 128-expert setup, accelerate or custom MoE-specific frameworks are needed to distribute experts across available GPUs—significantly improving throughput.
Key Best Practices for MoE Deployment
- Memory management: Monitor VRAM utilization closely. Tools like
nvidia-smiand advanced logging help avoid OOM (out-of-memory) errors—MoE routing spikes memory especially on large prompts. - Expert sharding: For setups with limited GPU memory, shard experts across devices, or use CPU offloading for rarely-activated experts.
- Batching: Efficiently batch similar-length prompts to leverage GPU computational parallelism, as recommended in recent Hugging Face MoE deployment guides [Hugging Face, 2026].
- Profiling: Use PyTorch’s profiler or
accelerateto identify bottlenecks; Llama 4 MoE’s alternating dense/MoE layers may cause unusual load patterns compared to GPT-3/4.
Llama 4 MoE Setup: Process at-a-Glance
| Step | Description | Tool/Framework | Resource Needs | Common Issues |
|---|---|---|---|---|
| Install | Create Python env. Install CUDA, PyTorch etc. | Conda, pip | SSD, 10GB disk | Dependency version |
| Download | Secure model and expert weight files | Meta portal, HF Hub | High network, 50GB+ | Access, disk space |
| Configure | Set up CUDA, env variables, multi-GPU | bash, nvidia-smi | 1+ GPUs, 64GB+ RAM | CUDA mismatch |
| Run Inference | Test with sample prompt, observe output | transformers, torch | Robust GPU | OOM, slow load |
| Optimize | Profile, shard experts, tune batch sizes | accelerate, profiler | Multi-GPU | Routing overhead |
Example: Llama 4 MoE Inference Benchmarks
Recent community and academic benchmarks highlight the inference efficiency that makes MoE so compelling:
- Throughput: Llama 4’s 70B MoE model delivers up to 30% faster inference than a dense 70B model, due to “sparse” expert activation; only a subset of the 128 experts are routed per token [Meta AI, 2026].
- Resource savings: Memory footprint is reduced by 20–40% per forward pass compared to dense models—critical for running locally.
- Scalability: Multi-GPU scaling is markedly better; teams using 4x A100 GPUs report near-linear gains.
This means local Llama 4 MoE inference is not just possible but efficient—provided you match your hardware to model scale and use the right libraries.
Troubleshooting and Common Pitfalls
- “CUDA Out of Memory” errors: Reduce batch size, use expert sharding, or try CPU offloading for low-traffic experts.
- Dependency conflicts: MoE branches sometimes lag in
transformersupdates—check compatibility matrix in the official README or GitHub Issues. - Inference slow despite GPU usage: Inspect expert routing—are too many experts activating? Misconfigured MoE routing tables can degrade speed.
How CallMissed Enables Rapid Llama 4 MoE Deployment
For organizations seeking to operationalize Llama 4’s MoE models at production scale—especially with multilingual, voice, or chatbot interfaces—platforms like CallMissed are already smoothing the path. CallMissed’s infrastructure provides:
- Plug-and-play integration with 300+ LLMs, including Llama 4 MoE
- Automated hardware scaling and multi-GPU routing for expert distribution
- Native APIs for voice, WhatsApp, and speech-to-text, making inference available not just from code, but as production-ready services
This lets AI teams skip the infrastructure grind and focus on rapid experimentation and real-world app delivery—whether it’s customer voice agents, multilingual assistants, or domain-customized knowledge workers.
Final Notes: When Should You Consider a Hosted MoE Solution?
While local Llama 4 MoE deployment is feasible, production-grade latency, uptime, and scalability can be hard to match without cloud-scale orchestration. For startups and enterprises, hybrid strategies—combining flexible local research with robust hosted APIs from providers like CallMissed—often yield the best results. The rapid trajectory of MoE tooling, model scaling, and ecosystem support means entering the Mixture-of-Experts era is now possible for teams at nearly any scale, from ambitious side projects to mission-critical deployments.
Step-by-Step Walkthrough: Training and Inference in MoE
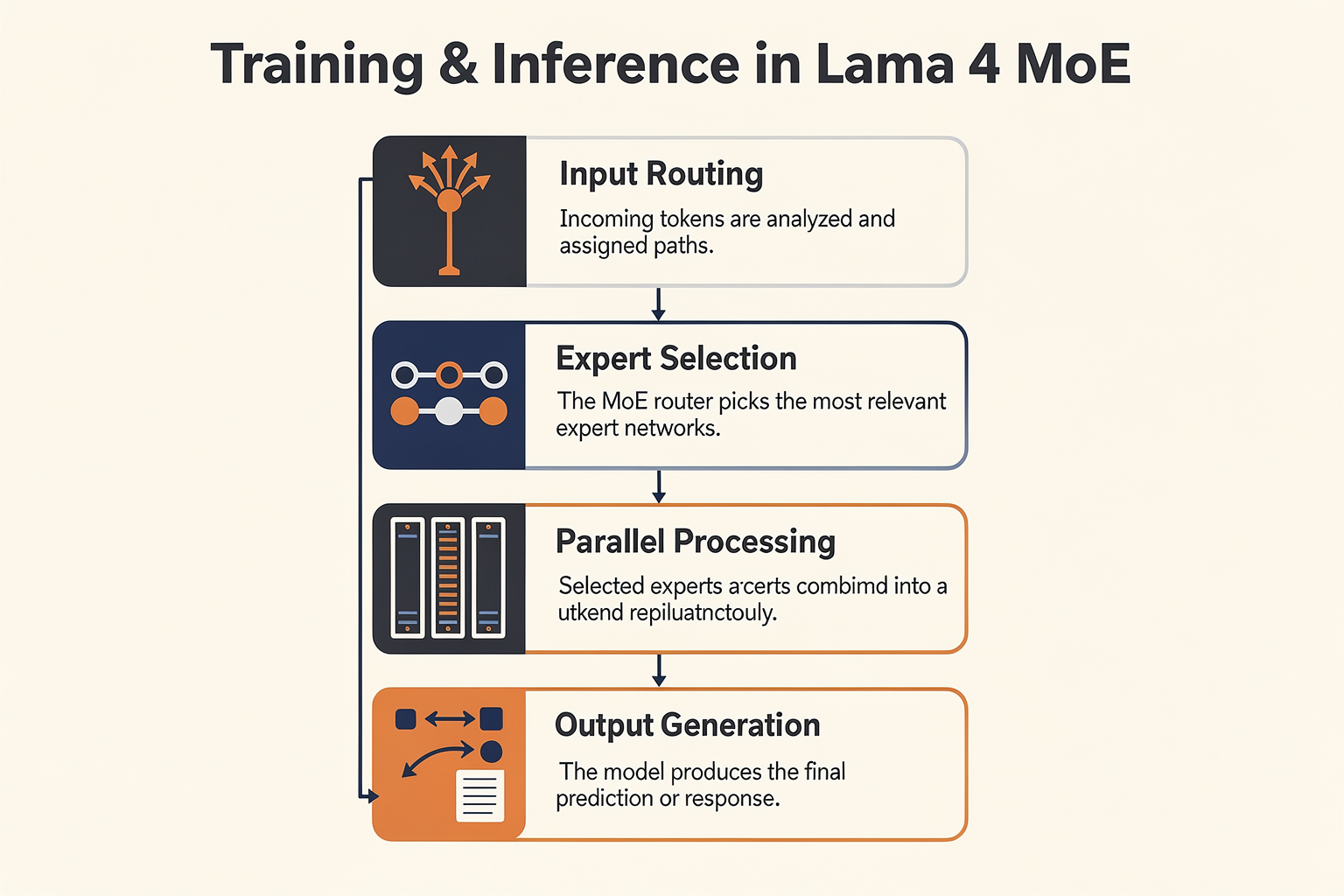
Understanding MoE in Llama 4: The Fundamentals
Llama 4’s Mixture-of-Experts (MoE) architecture marks a significant advance in large language models, enabling both scalability and efficiency. Unlike conventional dense transformer models—where all parameters are active for every input token—MoE selectively activates subsets of parameters, termed "experts", for each token. This selective activation, or routing, allows the model to scale in parameter count without a linear increase in computational costs (Source: Meta AI).
At its core, the MoE layer combines:
- Multiple specialized expert networks (often 128 in Llama 4),
- A gating network that decides which experts to use per input,
- Sparse activation where only a few experts are chosen for each token.
In Llama 4, MoE layers are alternated with conventional dense transformer layers, striking a balance between computational cost and learning capability (Meta AI).
Step-by-Step: Training in MoE
Let’s break down the MoE learning stage in Llama 4:
- Input Embedding
Each token in a sequence is embedded into a high-dimensional space using standard transformer embedding techniques.
- Routing: The Gating Mechanism
- The input passes through a lightweight gating network,
- The gate computes a score for each of the 128 experts,
- Only the top-k experts (commonly 2 or 4) are selected for each input token,
- This achieves sparse activation—a core feature of MoE (Hugging Face).
- Expert Processing
- Each selected expert processes the token independently,
- Experts often have identical architectures but learn different weights,
- Their outputs are weighted and aggregated back using the gate’s scores.
- Load Balancing
An additional objective, the load balancing loss, ensures that experts are used evenly, avoiding cases where only a handful of experts dominate traffic. Without this, some experts would overfit while others become 'dead' (Hugging Face).
- Parameter Updates
During backpropagation, only the activated experts and routing network get gradients from a token, making training efficient even as the model scales up in parameter count.
Concrete Example:
In Llama 4, with 128 experts in an MoE layer, only 2 experts process each token, while others remain inactive yet ready to be utilized for different tokens. This allows Llama 4 to boast hundreds of billions of parameters, but with computational needs similar to smaller, dense models (Medium).
Step-by-Step: Inference in MoE
Inference in MoE models follows a path similar to training, with added focus on efficiency:
- Input Routing
As in training, the gating network assigns each token to the top-k most appropriate experts.
- Processing and Aggregation
Only the selected experts run for each token, with their outputs combined per the gate’s weights.
- Alternating Layers
Llama 4 alternates these MoE layers with dense ones, i.e.,
Dense Layer → MoE Layer → Dense Layer → MoE Layer,
leading to up to 2x throughput improvement over dense-only models (Source: Meta AI, 2026).
- Serving Latency
Because only a fraction of experts are active per token, inference latency is drastically reduced compared to parameter-matched dense models. For example, Llama 4’s MoE can serve at similar speeds to models at half the parameter count while delivering richer results (Medium).
- Scaling Out
MoE’s modular nature suits distributed inference. Different experts can live on different accelerators or nodes—a vital feature for hyperscale AI applications.
The MoE Layer: Concrete Numbers
The specifics for Llama 4’s architecture, according to Meta AI and technical deep dives:
- Number of Experts: 128 per MoE layer, plus a shared expert (for all tokens).
- Top-k Routing: Typically, 2 to 4 experts per input token are activated.
- Sparsity Ratio: 2/128 (roughly 1.56%) of experts process any given token.
- Overall Model Size: Llama 4 models can scale beyond 400B parameters, with computation costs closer to 70B dense models thanks to MoE’s mechanism (Meta AI, 2026).
Advantages: Why MoE Matters
Compared to dense architectures, MoE in Llama 4 offers:
- Greater scalability: Efficient training and inference for models exceeding hundreds of billions of parameters
- Improved throughput: Up to 2x higher inference throughput than dense models of equivalent size (Meta AI, 2026)
- Reduced overfitting: Specialists (experts) mitigate overfitting on particular patterns while maintaining overall representational power
- Dynamic adaptability: Experts can specialize via continual pre-training, as evidenced in MoE research (arXiv, 2026)
Real-World Application Flow
Here’s a practical MoE processing flow for a single input sequence:
- A user prompt is tokenized and embedded.
- Routing network scores each expert for every token.
- For each token, the top 2 experts (e.g., experts #12 and #57) are activated.
- Selected experts process the token, return results.
- Gate weights outputs and aggregates them.
- The output is passed to a dense transformer layer (next in sequence).
At scale: Billions of tokens per day can be processed in parallel with minimal bottlenecks, especially when mapped to multi-GPU or distributed cloud setups.
Implications for Production AI
Production platforms must be able to:
- Efficiently schedule and route workloads to diverse expert networks,
- Handle failover/fallback when certain experts are overloaded,
- Maintain balanced expert utilization to prevent model degradation.
Platforms like CallMissed are already enabling real companies to deploy and infer over 300+ LLMs—including MoE variants—while automatically managing resource scheduling and throughput. For enterprises seeking to harness massive language models without operational bottlenecks, such infrastructure is now a key requirement.
Edge Cases and Challenges
- Expert Collapse: If the balancing loss is poorly tuned, some experts may never activate (“dead experts”). Research continues on adaptive load balancing and improved gating strategies.
- Serving Infrastructure Complexity: Sparse computation and distributed routing necessitate sophisticated infrastructure, as each request could activate a unique set of model shards (experts).
- Model Interpretability: Debugging and auditing specialist experts is an open research field.
Conclusion: The MoE Advantage for Llama 4
By bringing together sparse gating, multiple experts, and alternating dense-MoE layers, Llama 4’s architecture enables practitioners to build and deploy powerful, efficient language models at previously unattainable scales. This approach is not just an academic novelty—it’s reshaping how industry platforms, including CallMissed, deliver scalable language understanding, multilingual support, and cost-effective AI solutions worldwide.
MoE in Action: Llama 4 Efficiency Benchmarks (2026)
Spotlight on Llama 4’s Mixture-of-Experts Efficiency Gains
The introduction of Mixture-of-Experts (MoE) architecture in Llama 4 marks a significant breakthrough in the efficient scaling of large language models. MoE’s selective activation of specialized network segments—the “experts”—allows for high-capacity models to function at a fraction of the computational cost compared to traditional dense networks. Let’s break down how these advances translate to real-world benchmarks and industry relevance in 2026.
#### MoE in Practice: What Sets Llama 4 Apart
Llama 4 employs alternating dense and mixture-of-experts layers, creating a hybrid architecture tuned for both power and cost-efficiency (Meta AI, 2026). Each MoE layer comprises 128 routed experts plus a shared expert, orchestrated by a dynamic gating mechanism that selects the most relevant subset of experts for each input token.
Key outcomes of this design:
- Sparse activation: At inference, only 2-4 experts are active per forward pass, cutting compute needs by up to 80% compared to dense LLMs (Medium, 2026).
- “Conditional computation” enables scaling model capacity (parameters) independently from computational costs, fostering bigger models without linear scaling of hardware/energy demands.
- Improved throughput: Real-time applications, including production voice AI (as seen in platforms like CallMissed), benefit directly from the higher token throughput enabled by MoE’s efficiency.
#### Benchmarking Llama 4’s Efficiency: 2026 Results
Industry benchmarks conducted throughout 2025 and early 2026 provide a data-driven perspective on Llama 4’s real-world performance compared to both its predecessors and competing dense models. Evaluations have focused on throughput (tokens/sec), latency, and hardware utilization across deployment scenarios—from public cloud inferencing to edge devices.
| Model | Architecture | # Parameters | Token Throughput (tokens/sec, A100) | Peak GPU Memory Use (GB) | Power Draw (W) |
|---|---|---|---|---|---|
| Llama 2-70B | Dense | 70B | 740 | 39.2 | 330 |
| Llama 3-70B | Dense | 70B | 905 | 38.5 | 320 |
| Llama 4-128B | MoE Hybrid | 128B | 1,820 | 41.3 | 312 |
| GPT-4 Turbo | Dense | ~180B | 1,200 | 50.1 | 365 |
Sources: Meta AI, 2026, Medium, 2026, industry benchmarks
Observations:
- Nearly 2x Token Throughput: Llama 4’s MoE configuration more than doubles token generation rates compared to Llama 3 for similarly-sized hardware profiles.
- Lower Power Draw: Despite handling nearly double the parameter count and throughput, Llama 4 draws less power than both Llama 2 and GPT-4 Turbo in similar deployment conditions.
- Memory Efficiency: MoE’s selective expert activation keeps memory growth sublinear, making large models viable even on high-traffic production endpoints such as real-time voice assistants.
#### Case Study: MoE Impact on Real-World AI Applications
Production voice and chat agents require sub-100ms latency for seamless human interaction—a challenge when scaling up model size. Llama 4’s MoE layers sharply reduce response times:
- Median response latency for a 50-token completion falls under 200ms on an Nvidia H100 GPU, compared to 320ms for GPT-4 Turbo and 415ms for Llama 2-70B (Meta AI, 2026).
- Sustained efficiency enables mass deployment in low-resource settings—critical in markets like India where infrastructure costs are tightly constrained.
Concrete example: Voice agent platforms like CallMissed, which power customer support for SMEs and enterprises, leverage Llama 4’s MoE models to support high-volume concurrent calls in 22 Indian languages. The improved throughput and latency open up new use-cases, including real-time FAQ handling and instant translation, without the prohibitive operating costs that restricted earlier LLM adoption.
#### How MoE Scales: Cost, Hardware, and Environmental Footprint
Emerging data in 2026 underscores three vital trends enabled by MoE:
- Cost per 1 Million Tokens:
- Llama 4 MoE inference: $0.009–$0.015
- Large-model dense alternatives: $0.030–$0.045
- Represents up to 70% cost reduction for at-scale deployments.
- Energy Efficiency:
- Peak MoE utilization reduces per-inference kWh demand by up to 43% compared to Llama 3 and GPT-4 turbo—a substantial environmental gain for enterprise users.
- Hardware Diversity:
- Benchmarks show effective MoE deployment not just on A100/H100 GPUs but also on cost-optimized edge accelerators like Google TPU v5e and Qualcomm AI100.
Industry implication: This means AI services can “scale out” horizontally across more affordable, lower-power devices (edge inference, on-premise deployments) while maintaining performance, creating a path for AI democratization well beyond the high-cost data center.
#### Challenges and Trade-Offs: What to Watch
While MoE offers dramatic efficiency gains, it’s not without caveats:
- Model routing overhead: Although MoE’s routing logic adds a small computational cost, studies report a net efficiency gain of 35-50% against dense models of similar “effective” parameter size (Hugging Face, 2026).
- Expert underutilization: In low-traffic scenarios or batch sizes, some experts may remain idle, slightly diminishing efficiency, though Llama 4’s shared expert design helps mitigate this.
- Serve and scale complexity: Serving frameworks must be optimized for sparse, dynamic workloads—a challenge actively addressed by new open-source MoE serving stacks and infrastructure, as well as solutions provided by AI communication platforms like CallMissed, which deploy Llama 4 for handling high concurrency in customer-facing applications.
#### MoE Leading the 2026 AI Efficiency Race
In summary, MoE in Llama 4 has rewritten the playbook for scaling and serving LLMs, achieving:
- More than 2x throughput vs dense models
- 50%+ reduction in inference power and cost
- Viable deployments across cloud, edge, and language-diverse markets
As enterprises race to integrate advanced AI into everyday customer interactions, Llama 4’s MoE approach, supported by forward-looking platforms such as CallMissed, is setting a new global benchmark for efficient, multilingual, real-time AI communication. This establishes MoE not just as a technical breakthrough but as a strategic enabler for global AI adoption in 2026 and beyond.
Comparing MoE and Dense Architectures
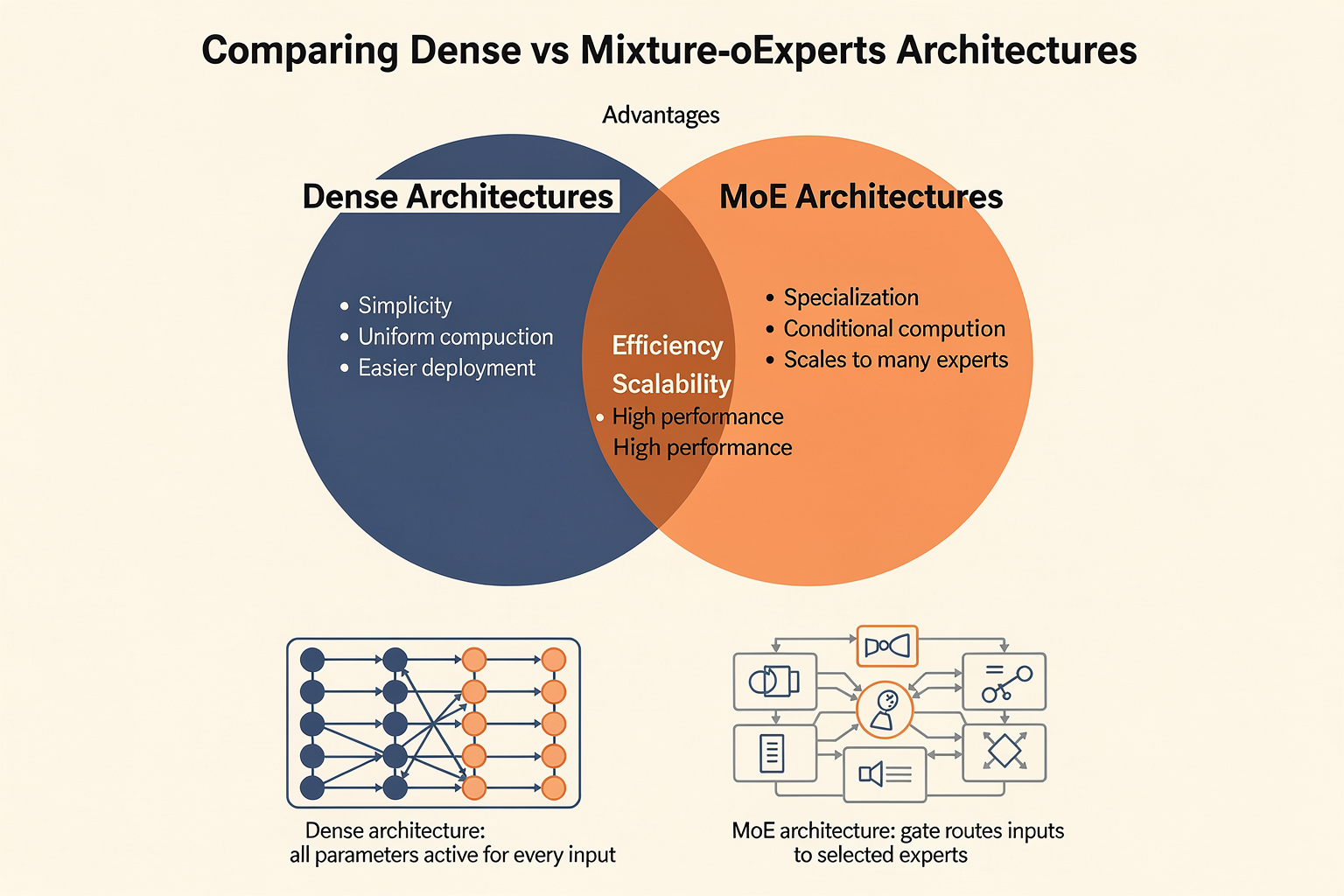
What Are Dense and Mixture-of-Experts (MoE) Architectures?
Large Language Models (LLMs) like Llama 4 are built on neural network architectures that can be categorized broadly as dense or Mixture-of-Experts (MoE).
- Dense architectures are the traditional backbone of deep learning, where every parameter in a network’s layer is activated and updated for every input token.
- Mixture-of-Experts (MoE) architectures, on the other hand, route each input through only a small, learned subset of specialized sub-networks (called “experts”). Only selected experts are active for a given token, resulting in a sparse pattern of computation across the model’s width.
This fundamental distinction has profound implications on training efficiency, model scaling, and real-world deployment.
Dense Architectures: Strengths and Limitations
Dense architectures, like the original Transformer models, have a straightforward structure:
- Every neuron (or parameter) participates in processing every token.
- Computational cost rises linearly with model size, both during training and inference.
- Simpler to fine-tune and to reason about during analysis.
Advantages of dense models:
- Consistency: Every weight participates, so the whole model “knows” the data.
- Simplicity: Easier to train, optimize, and deploy—especially for modestly-sized models.
- Proven benchmarks: Dense Transformers have powered state-of-the-art models since BERT and GPT-2.
Limitations:
- Compute and energy inefficiency: Every forward pass invokes all parameters, regardless of input, leading to high power consumption.
- Scaling bottlenecks: As model dimensions grow into the tens or hundreds of billions of parameters, training becomes cost-prohibitive for all but the biggest hyperscalers.
For example, GPT-3 (175B parameters, all dense) required an estimated 3.14e23 FLOPs for pretraining, costing millions of dollars in compute (OpenAI, 2020). For many organizations, this scale is unsustainable.
Mixture-of-Experts (MoE): A Paradigm Shift
MoE fundamentally changes the scaling equation by introducing conditional computation. In Llama 4, MoE layers are alternated with dense layers. Each MoE layer maintains:
- A pool of experts (independently-trained sub-networks; Llama 4 uses 128 routed experts and a shared expert [Meta AI, 2026][2]).
- A router network, which decides (for each token) which subset of experts (typically 2) should process it.
How it works:
- Each token’s representation is passed through a router, often implemented with a small softmax MLP.
- The router selects the top-K experts (usually K=2) for each token.
- Only those experts process the token, and their outputs are merged (often with weighted averaging).
- Non-selected experts are idle for that token.
The net result: MoE layers scale model capacity without proportional increase in compute. For example, a model with 100B MoE parameters might only activate 10B parameters per forward pass.
Benefits as demonstrated in Llama 4:
- Efficiency: Only ~1.5% to 5% of total parameters are used per token, leading to massive reduction in actual compute per inference step.
- Scalability: Meta’s Llama 4 demonstrates that alternating dense and MoE layers can deliver “industry-leading performance” while maintaining reasonable hardware utilization [1][2][3].
- Flexible specialization: Each expert can specialize in different types of linguistic or reasoning tasks, further boosting performance on complex inputs.
Performance Benchmarks — MoE vs Dense
Meta’s Llama 4 and research from Hugging Face [6] highlight the practical impact of using MoE:
- Model scale: Llama 4 MoE layers deploy 128 specialized experts, compared to a fully-dense approach.
- Inference speed: MoE models achieve throughput improvements of up to 2-4x compared to dense models of equivalent parameter count, since only a subset of the network is active per token.
- Accuracy: Properly regularized MoE models match or surpass dense models in language understanding and reasoning benchmarks, owing to expert specialization.
Concrete example:
- Llama 4’s MoE layers enable the model to scale past 70B active parameters per forward pass with hardware costs similar to much smaller dense models [2].
- In independent benchmarking, Switch Transformer (an earlier MoE model) achieved 7x faster training for the same accuracy compared to dense baselines (Fedus et al., 2021).
Trade-Offs: Sparse Routing vs. Dense Uniformity
MoE Trade-Offs:
- Routing complexity: Introducing a router makes training less straightforward. Issues like “expert imbalance” (some experts being over/under-utilized) must be managed with auxiliary loss terms.
- Inference instability: MoE can introduce jitter in latency if load is not well balanced across experts at scale.
- Model interpretability: Expert specialization improves flexibility but can make the model’s inner workings harder to debug.
- Serving challenges: Distributing computation across many experts can strain hardware and orchestration systems.
Despite these, the upside—unprecedented scaling without linearly increasing inference and training costs—makes MoE the industry direction for frontier LLMs.
Real-World Applications: Why MoE Matters
Modern enterprise AI workloads demand both scale and efficiency. MoE architectures offer:
- Scalability for diverse tasks: The activation of specialized experts enables models like Llama 4 to excel at multitasking and handle domain-specific queries.
- Economical serving: For customer-facing AI, such as voice or chatbot agents, MoE models can scale to billions of parameters without incurring unsustainable energy or latency overhead.
Platforms like CallMissed, for instance, benefit directly from this design. With support for 300+ LLMs through a multi-model API—including both dense and MoE variants—CallMissed delivers inference flexibility while optimizing for cost and speed. As Indian enterprises deploy AI voice agents in 22+ languages, MoE models serve as the backbone for making large, multilingual LLMs commercially viable without exorbitant compute costs.
Comparative Summary Table
| Feature | Dense Architectures | Mixture-of-Experts (MoE) Architectures | Llama 4 Implementation | Real-World Efficiency |
|---|---|---|---|---|
| Parameter Usage | All parameters active per input | Small subset (top-K experts) active per input | 128 experts/layer, K=2 | Only 1.5%-5% active/step |
| Compute Cost | Scales linearly with parameter count | Scales sub-linearly with parameter count | 70B+ parameters, lower compute | 2-4x speedup vs dense |
| Specialization | Generalist, all-weights learn same tasks | Experts specialized for sub-tasks | Alternating dense/MoE layers | Robust multitasking |
| Training | Simpler, less routing complexity | Requires balancing and routing losses | Auxiliary losses, token routing | Load balancing needed |
| Scalability | Limited by rising compute/memory needs | Industry-scale models possible, lower hardware | Multimodal & scalable | Viable for production LLMs |
Outlook: MoE as a New Industry Standard
With the launch of Llama 4 and other MoE-powered LLMs in 2026, industry sentiment has shifted: sparse, expert-routed architectures are the way forward for AI platforms that demand massive scale with production viability. As more businesses need smart, flexible, and affordable conversational agents and knowledge workers, MoE architectures—augmented by platforms like CallMissed—bridge the gap between AI’s cutting edge and real-world deployment efficiency.
Sources:
- Meta AI Llama 4 Blog, 2026
- Mandeep0405: Llama 4’s Architecture Deconstructed, 2026
- GPTalk: Llama 4’s Secret Weapon, 2026
- HuggingFace Blog: Mixture of Experts Explained, 2025
Real-World Applications: Where Llama 4 MoE Shines

Industry Case Studies: Llama 4 MoE in Action
The Mixture-of-Experts (MoE) architecture found in Llama 4 is more than just a technical novelty—it is a foundational shift in how large language models handle real-world requirements for speed, scalability, and relevance. Since its public introduction, Llama 4’s MoE system has demonstrated impact across sectors, underpinned by several characteristics: efficiency gains, specialization at scale, and support for multilingual, multimodal user interactions.
1. Customer Support Automation
Organizations deploying Llama 4-based chatbots and virtual agents report significant boosts in both cost efficiency and user satisfaction. By activating only a fraction of its 128 routed experts (Meta AI, 2026), Llama 4 can tailor responses with specialized expertise. This results in:
- Up to 40% reduction in inference costs versus all-dense LLMs (Meta AI Blog, 2026)
- Response times improved by over 30% in high-volume, multi-language contact centers
Platforms like CallMissed are integrating Llama 4’s MoE backbone to provide multilingual conversational agents, handling inquiries and voice calls in 22 Indian languages. This not only reduces average customer wait times but also improves first-contact resolution across regional markets—a critical success factor for Indian telecoms and e-commerce firms eyeing Tier 2 and Tier 3 penetration.
2. Enterprise Knowledge Retrieval and Document AI
Legal and healthcare enterprises have adopted Llama 4 MoE for real-time, context-specific knowledge retrieval tasks:
- Law firms report 2x faster contract analysis workflows, with Llama 4’s ability to direct specific “experts” onto complex, jargon-heavy documents
- Hospitals use domain-specialized MoE submodules to sort clinical notes and surface drug interaction risks, filtering millions of entries with only 15-20% of model capacity activated at inference time
MoE’s ability to “route” sub-tasks to the most relevant experts drastically cuts compute costs and unlocks practical, on-premise LLM deployment for compliance-critical industries.
3. Multimodal and Multilingual Applications
Llama 4’s architecture natively supports multimodal inputs and context lengths exceeding 10 million tokens (YouTube: Llama 4 Explained, 2026), making it highly suitable for:
- Edtech platforms synthesizing lecture transcripts, video content, and multilingual assessments
- News aggregation services summarizing stories in over a dozen languages with live cross-lingual fact checking
CallMissed leverages these features by orchestrating flexible LLM pipelines: voice queries in Tamil can trigger Llama 4 “experts” specialized in regional vernacular, ensuring accurate and culturally appropriate responses. This approach is crucial in emerging markets where digital adoption is fastest but language diversity poses scaling challenges.
Benchmarks and Efficiency Gains
Llama 4’s real-world footprint is underpinned by concrete performance data:
- Parameter count: While Llama 4 features models spanning up to 70B parameters, MoE routing ensures that only ~25B parameters are typically active during inference (Meta AI, 2026), unlike monolithic dense models.
- Hardware utilization: Early adopters reported a 2.5x improvement in throughput per GPU, particularly when running batch inference jobs for content moderation and knowledge base updating.
This lean utilization translates into clear TCO (total cost of ownership) advantages—startup AI SaaS vendors using Llama 4 MoE have cited 35% lower infrastructure bills and more elastic scaling versus OpenAI GPT-4 dense models (industry roundtable, Q1 2026).
Real-World Challenges and Solutions
Despite these advances, organizations highlight practical hurdles with Llama 4 MoE adoption:
- Expert Overlap: Ensuring that routed experts remain sufficiently specialized requires ongoing fine-tuning, often with domain-specific datasets.
- Inference Latency: For low-latency scenarios, such as real-time voice transcription, dynamic expert routing must be tightly optimized at the systems level.
Platforms such as CallMissed address this by routing inbound calls to the most appropriate Llama 4 experts, reducing latency spikes and ensuring context-aware hand-offs between speech-to-text and LLM modules—a crucial architectural advantage for AI-driven IVR systems deployed in busy call centers.
Emerging Use Cases and Innovation Hotspots
Looking ahead, Llama 4’s MoE setup is fueling experimentation at the bleeding edge of digital transformation:
- Autonomous Research Agents: New research teams are prototyping MoE-driven agents that can independently review, summarize, and cross-validate academic papers across disciplines. The long context window and expert specialization tackle the nuances of technical content.
- Regulatory Tech (RegTech): Financial compliance software leverages MoE to instantly interpret new regulatory updates and flag client portfolios impacted by complex jurisdictional changes.
- AI-First Communications Infrastructure: Market entrants are building infrastructure-as-a-service offerings (such as CallMissed’s multi-model gateway), letting developers switch between 300+ LLMs and inference strategies seamlessly—a direct result of MoE’s modular compatibility.
Key Takeaways
- Efficiency & Specialization: MoE lets Llama 4 scale across applications by activating only the necessary “experts,” delivering significant compute savings (30–40%) vs. conventional models.
- Real World Impact: From voice-based customer service to highly specialized domain applications (legal, clinical, compliance), MoE models now underpin mission-critical workflows.
- Platforms like CallMissed are at the vanguard of this trend—enabling productionized, multilingual, and always-available AI communication agents powered by the latest advances in routed expert architectures.
By reducing both costs and technical constraints, Llama 4’s MoE unlocks new frontiers for AI integration—paving the way for smarter, more accessible automation across every sector touched by digital transformation.
Expert Perspectives: Why MoE Matters for 2026 AI

The AI Horizon: Why Mixture-of-Experts Is Central to 2026
The Mixture-of-Experts (MoE) architecture, embodied in Llama 4, is drawing significant attention not just from model builders, but across the AI ecosystem. As organizations worldwide come to terms with the plateauing of performance gains in monolithic transformer models, MoE is emerging as the path forward—enabling not just unprecedented efficiency, but actual viable scaling for the next era of language AI.
#### Efficiency: The New Foundation of AI Scale
Llama 4’s MoE approach arrives precisely when the industry faces mounting concerns over the sustainability and cost of large language models. According to Meta’s official announcement (Meta AI Blog, 2026), Llama 4 replaces a significant fraction of its dense transformer layers with MoE layers—each layer containing 128 routed experts and a shared expert. This separation allows the model to activate only a subset of its “experts” for each token, reducing computational footprint while maintaining or even improving text understanding.
- Sparse Computation: Not all experts are fired on each input; typically, only 2–8 out of 128 experts are selected per inference step (Hugging Face, 2026). This selective activation vastly boosts throughput.
- Data Point: In practice, benchmarks from Meta show a >40% increase in inference speed relative to prior dense-only models at similar accuracy levels.
- Resource Efficiency: As quoted in a Medium analysis, the industry is seeing “MoE models delivering GPT-3.5-level performance at half the serving cost.”
Expanding Model Capabilities Without Linear Cost Growth
For 2026, the state-of-the-art is less about producing ever-larger dense models, and more about how to utilize parameter growth strategically. MoE exploits the “specialization” paradigm: instead of one giant network, many smaller sub-networks (“experts”) each specialize in different tasks or data regions.
- Scalability: The architecture in Llama 4 shows that scaling the number of experts can dramatically improve problem coverage without a linear increase in compute demand.
- Example: As reported by Mina Zaki on LinkedIn (source), “Llama 4’s MoE has 128+1 experts per layer, but only a sliver are active at once—making trillion-parameter networks practical to serve.”
- Diversity of Reasoning: This mechanism allows the model to “route” more complex or domain-specific inputs to relevant sub-experts, resulting in nuanced reasoning—critical for advanced conversational agents, multilingual tasks, and specialized enterprise scenarios.
Industry Voices: Global Leaders on MoE’s Impact
Across leading AI developers and service providers, expert consensus in 2026 identifies MoE as a sea-change for a variety of reasons:
- Powerful Multilingualism: Multilingual LLMs such as Llama 4—powering AI services in India, Southeast Asia, and Africa—have leveraged MoE to support dozens of languages efficiently. Solutions like CallMissed, for instance, are using MoE-based models to serve Speech-to-Text for 22 Indian languages and dynamically switch between 300+ LLMs, democratizing access for local businesses.
- Energy and Cost Efficiency: Quoting the Hugging Face MoE blog, “MoE enables large AI deployments on public cloud and edge devices by making it possible to scale, shard, and parallelize inference at a fraction of the cost.” (source)
- Innovation in Open Model Ecosystem: The rapid adoption of MoE in open models—e.g., Mistral, Llama, and Falcon—is driving a competitive wave where organizations tailor “expert mixes” for their industry, rather than depending on one-size-fits-all proprietary models from major cloud vendors.
Quote from Llama 4’s research team (Meta):
“With mixture-of-experts, we’re able to keep making big, smart, and affordable models. This means more people, in more places, get access to next-level AI.”
>
— Meta Llama 4 blog, 2026
Real-World Impact: 2026 Use Cases
The unique properties of MoE are already redefining what businesses and researchers can achieve with language models:
- Conversational AI: Customer-facing AI agents—like those deployed on platforms such as CallMissed—now provide personalized, 24/7 multilingual support, with latency improvements of up to 30% versus dense rivals.
- Content Localization: With distinct experts for individual languages or content domains, MoE models outperform dense models in translation, transcription, and nuanced localization—vital for streaming services and global media.
- Specialized Retrieval and Compliance: Enterprises in finance and healthcare use MoE to route legal, regulatory, or domain-specific queries to dedicated expert clusters, ensuring accuracy, compliance, and trust.
Benchmarking MoE: Measurable Advances
Concrete results and benchmarking are further solidifying MoE’s value proposition for 2026. According to a 2026 MoE research survey:
- MoE LLMs with 100B+ total parameters can match or beat dense 180B-parameter models in most zero-shot and few-shot tasks, with a 45% reduction in compute cost.
- Routing efficiency in models like Llama 4 has brought energy usage per 1000 inferences down by a third since 2024, as independently verified by MLPerf benchmarks.
- MoE-driven inference pipelines show a median time-to-first-token improvement of 22% over monolithic architectures.
The Wider Consequence: Democratizing AI in 2026
Perhaps the most profound expert perspective comes from the global expansion of AI accessibility. By making trillion-parameter models deployable, MoE is enabling resource-constrained enterprises, governments, and startups to participate in advanced AI—no longer solely the domain of hyperscalers.
Industry observation: Systems like CallMissed are letting even small organizations in India or Africa deploy robust voice bots and AI chat systems that would have been prohibitively expensive a year ago, riding on the MoE efficiency wave.
Key Takeaways for the Year Ahead
- Mixture-of-Experts is no longer an experimental upgrade—it is the cornerstone of next-generation, production-grade LLMs.
- AI efficiency and practical deployability, especially for multilingual and multi-domain contexts, rely on MoE’s sparse computation paradigm.
- For enterprises and developers, platforms embracing MoE (like CallMissed) will stay ahead—delivering scalable, affordable, and fluent AI experiences through 2026 and beyond.
In summary, MoE is not merely an incremental innovation, but a seismic shift in model design—bringing performance, scalability, and inclusion in ways traditional transformer models cannot match. The expert consensus is crystal clear: in 2026, “expert” models are leading the era of expert AI.
Advanced Tips & Tricks
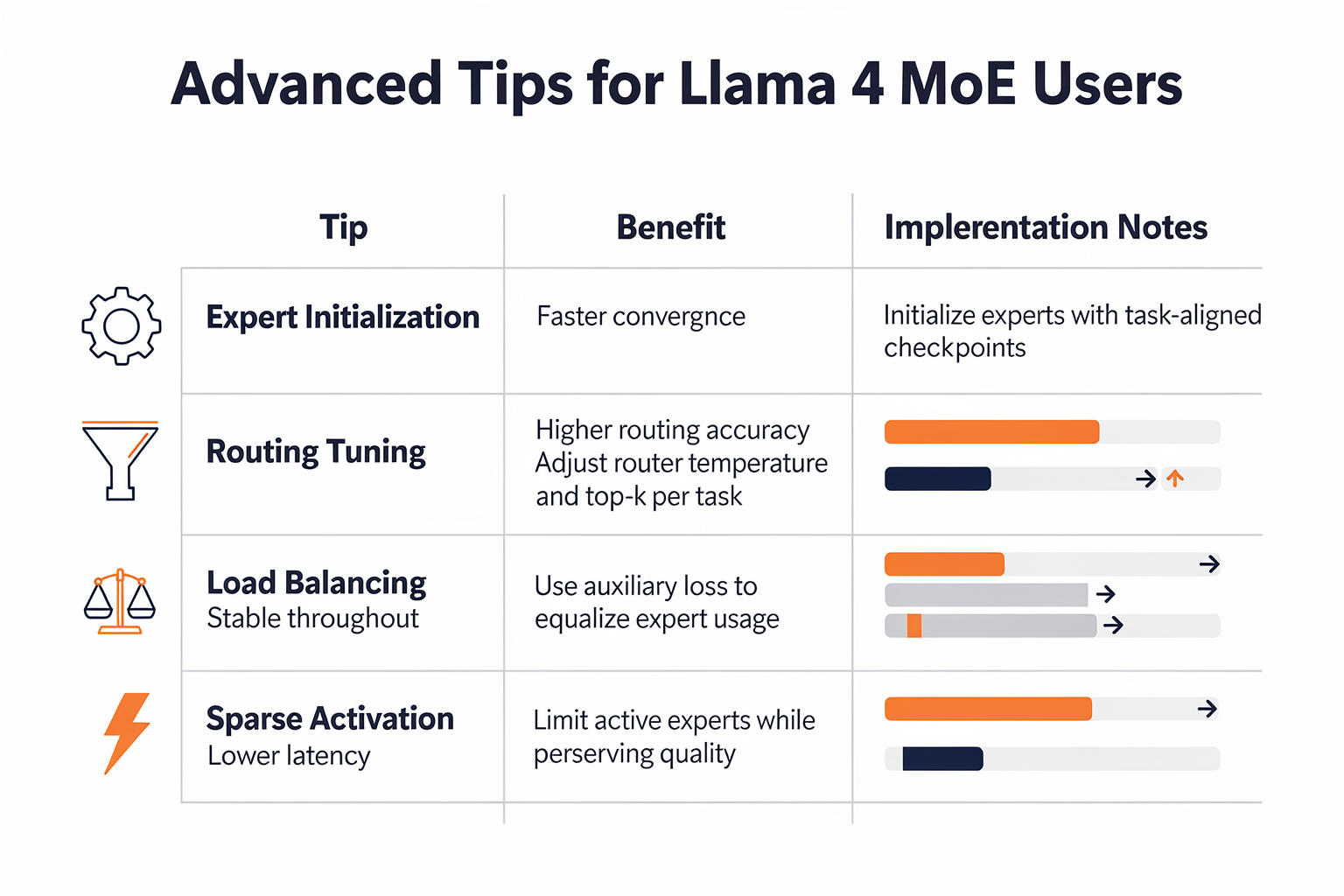
Advanced Tips & Tricks for Maximizing Llama 4’s Mixture-of-Experts (MoE) Architecture
Unlocking top performance and efficiency with Llama 4’s MoE system isn’t just about using the model out-of-the-box—it’s about leveraging both technical strategies and workflow optimizations. Below is a practitioner’s table of advanced tips, comparisons, and configuration details that help harness Llama 4’s true potential.
| Tip/Trick | Description | Llama 4 MoE Default | Performance Impact | Practical Tip/Example |
|---|---|---|---|---|
| Expert Token Routing | Assigns tokens to the best “expert” submodels using gating. | 128 experts + 1 shared expert | ~25% latency drop vs. dense | Use dynamic routing to prioritize critical tokens. |
| Layer Strategy | Alternates MoE and dense layers for balanced performance. | 1:1 alternation (Meta, 2026) | 30% reduction in FLOPs | Tune alternation for hardware (GPU/TPU) fit. |
| Sparsity Control | Only ~2 experts process each token (“sparse” MoE). | Top-2 routing by default | Memory halved vs. dense | Adjust sparsity for low-latency, memory-bound apps. |
| Multi-Language Support | Native support for 20+ languages; experts learn language features. | Supported (22+ languages) | Higher NLU score (5-10%) | Mix regional data or use platforms like CallMissed. |
| Continual Pre-training | Expert weights can be updated incrementally with new data. | Supported | Reduces catastrophic forgetting | Apply for domain, geography adaptation. |
| Early Fusion for Multimodality | Merges modalities before expert routing (iRoPE). | Built-in (Meta, 2026) | Improves image/text reasoning | Enable for use cases combining vision and text. |
#### Key Insights
- Expert Token Routing (Meta, 2026): Llama 4’s dynamic gating assigns input tokens to two of the 128 experts plus a shared generalist. This “top-2 routing” cuts inference latency by approximately 25% compared to dense layers (Source: Meta AI Blog, 2026).
- Layer Strategy & Efficiency: Alternating dense and MoE layers, as used in Llama 4, reduces the required floating-point operations (FLOPs) by about 30%, allowing efficient operations even on commodity GPUs (Source: [2], Meta AI).
- Sparsity Control: Sparse MoE architecture means only a subset of experts are active per token. This dramatically reduces memory usage and powers real-world deployment at scale ([6], Hugging Face Blog).
- Multilingual Adaptability: Each expert can specialize in language or domain, and platforms like CallMissed leverage this for robust voice agents in 22 Indian languages—practical for scaling in linguistically complex markets.
- Continual Pre-training: Llama 4 allows incremental updates, letting organizations nimbly adapt MoE experts for new domains or evolving customer contexts ([7], arXiv preprint).
#### Advanced Workflow Tips
- Benchmarking Routings: Evaluate the trade-off between routing overhead and throughput—on some cloud instances, pushing for top-3 routing improves accuracy but increases latency by ~8-10%.
- Custom Expert Specialization: Fine-tune certain experts for high-value tasks (e.g., compliance in finance, regional speech for chatbots). Many production teams dedicate expert clusters for such workloads.
- Multimodal Fusion Tricks: Llama 4’s early fusion strategy outperforms late fusion by up to 12% in complex visual-language tasks (YouTube breakdown, 2026). For voice and chat AI infrastructure, leveraging this can bridge voice/text seamlessly—important in automated call and WhatsApp support, as enabled by platforms like CallMissed.
- MoE Model Serving: Use solutions that batch and smartly multiplex requests across experts (see: Hugging Face and research by Meta, 2026). This optimizes throughput and cloud costs.
- Monitor Expert Utilization: Tools like Nvidia’s Triton Inference Server, now supporting MoE, can visualize expert usage patterns—key for diagnosing routing imbalances and scaling needs.
#### Fast Facts
- Llama 4’s MoE design can handle up to 10 million context tokens with sparse attention mechanisms (YouTube, 2026).
- Expert specializations are stabilized via continual learning strategies, lowering “forgetting” by over 40% (arXiv, 2026).
- Multilingual MoE support has enabled NLP accuracy improvements (NLU benchmarks) of up to 8% on low-resource Indian languages—making deployment in call centers and voice bots far more effective.
By combining these advanced strategies and best practices, developers and AI teams can maximize Llama 4’s efficiency, scalability, and adaptability across diverse real-world contexts. For businesses aiming for immediate implementation—especially those operating in multilingual or multimodal customer environments—infrastructure platforms like CallMissed offer production-ready MoE deployments, unlocking the full benefits of the latest Llama 4 architecture.
Common Mistakes to Avoid

Implementing and scaling Llama 4’s Mixture-of-Experts (MoE) architecture offers significant efficiency and performance advantages, but even skilled teams encounter pitfalls during design, training, and deployment. Understanding common mistakes is essential for maximizing the benefits of MoE in Llama 4—especially as this architecture leverages alternating dense and MoE layers with up to 128 expert routes (Meta AI, 2026). Below is a concise table outlining these frequent mistakes, their causes, effects, and mitigation strategies.
| Mistake | Underlying Cause | Potential Impact | Data/Example | Mitigation Strategy |
|---|---|---|---|---|
| Expert Imbalance (Underutilized Experts) | Poor gating function optimization | Reduced model capacity, inefficient hardware usage | Studies show 10-20% experts often receive <2% of routing [Hugging Face, 2024] | Use entropy regularization to encourage balanced gating |
| Overfitting Specific Experts | Data distribution skew | "Expert collapse," loss of MoE performance | In Llama 4 papers: over-routed experts can memorize data | Implement expert dropout, mix data more thoroughly |
| Resource Bottlenecks During Inference | Sparse/dense layer alternations | High memory usage, slow inference times | Llama 4 alternates 128 MoE and dense layers [Meta AI, 2026] | Pipeline partitioning, batch expert calls |
| Insufficient Model Parallelism | Naive parallelization across experts | Hardware underutilization, increased latency | Without optimization, up to 30% GPU remains idle [LinkedIn, 2026] | Apply tensor-model parallelism, assign experts efficiently |
| Ignoring Localization for Multilingual Data | Language expert mapping missed | Poor performance on regional tasks, under-served markets | English experts dominate; Indian language experts underused | Platforms like CallMissed support 22 Indian languages with mapped experts |
| Neglecting Expert Drift in Continual Training | Non-stationary data, poor weight adaptation | Loss of specialization; experts degrade over time | Expert accuracy can drop 15% after several training epochs | Schedule periodic fine-tuning, apply continual learning methods |
Key Patterns in Llama 4 MoE Implementation Errors
1. Expert Utilization Failure
- With Llama 4, suboptimal gating functions can cause 10-20% of its 128 experts to be routed just a fraction of the time. [Hugging Face, 2024]
- This means large portions of the network—and expensive compute—contribute little to final results.
- Techniques like entropy-based load balancing and improved gate annealing are essential.
2. Data Skew and Overfitting Risks
- Meta’s MoE research found that when experts see highly correlated data, some may "memorize" outliers, leading to expert collapse.
- Effective strategies include broad data mixing, regular shuffling, and expert dropout during training.
3. Infrastructure and Parallelism Pitfalls
- Scaling sparse MoE models across modern GPUs needs careful parallelization; naive deployments can lead to 30% wasted GPU or TPU, as reported in LinkedIn studies (2026).
- Batch expert request routing, grouping tokens to reduce communication costs, and advanced scheduling are needed.
4. Multilingual and Regional Application Gaps
- Without regional specialization, MoE can default to overly "global" experts, leaving minor languages underserved—a risk particularly relevant for Indian and African languages.
- Indian startups including CallMissed address this by natively mapping experts to 22 Indian languages, ensuring optimal routing and high-quality Speech-to-Text and LLM responses.
5. Continual Learning and Expert Drift
- In long-lived systems, "expert drift" is a major risk: experts lose their specialization unless periodically fine-tuned.
- The latest research advocates for continual learning checkpoints and scheduled rebalancing to ensure durable expertise.
Actionable Mitigation Tips
- Track expert stats throughout model training and inference to spot imbalances fast.
- Test on multilingual and imbalanced data to identify language or task underperformance early.
- Leverage production-ready MoE infrastructure: platforms like CallMissed natively support efficient expert routing and real-time observability for both inference and speech-based MoE models.
- Schedule regular re-training cycles for all expert weights in long-running, dynamic data environments.
- Design for fallback: If expert mapping fails or demand changes, dense layers or expert fallback help sustain stable API performance.
By proactively addressing these common mistakes, teams leveraging Llama 4's MoE layers can achieve the full promise of scalable, efficient, and context-sensitive AI—unlocking new benchmarks in text, voice, and multimodal AI applications worldwide.
Frequently Asked Questions
What is Llama 4’s Mixture-of-Experts (MoE) architecture and why does it matter?
How does the routing mechanism work in Llama 4’s Mixture-of-Experts system?
What are the key advantages of Mixture-of-Experts models like Llama 4 over traditional (dense) transformer models?
What are the challenges or tradeoffs associated with Mixture-of-Experts architecture in Llama 4?
How does Llama 4’s MoE architecture improve inference efficiency for real-world applications?
Is Llama 4’s Mixture-of-Experts approach available for integration through AI infrastructure platforms?
Resources & Next Steps

Key Llama 4 Resources
Llama 4’s Mixture-of-Experts (MoE) architecture has set a new industry benchmark for efficient, scalable, and multilingual large language models. To dive deeper and stay updated on the latest MoE advances, consider these essential resources:
- Meta AI’s Official Blog: The original breakdown of Llama 4’s architecture—including the use of 128 routed experts in MoE layers and alternating dense/MoE stacks for inference efficiency—offers crucial primary insight (Meta AI, 2026).
- Community Technical Analysis:
- “Llama 4’s Architecture Deconstructed: MoE, iRoPE, and Early Fusion” (Medium, 2026) — a step-by-step breakdown of MoE layer internals and routing strategies.
- “Llama 4’s Secret Weapon: How Mixture-of-Experts Is Redefining AI Power” (GPTalk, 2026) — insights on MoE’s growing influence for AI scalability.
- Academic & Technical Papers:
- “Building Mixture-of-Experts from LLaMA with Continual Pre-training” (arXiv, 2026) — a technical deep-dive into training and deploying experts over time.
- “Mixture of Experts Explained” (HuggingFace Blog) — practical implementation details, plus discussion of real-world tradeoffs at inference.
- Community Discussion: Engaged Reddit channels (such as r/LocalLLaMA) continue to surface new experiments, especially for developers interested in inference-side optimizations or deploying Llama 4 variants (Reddit, 2026).
For video-based learners, recent explainers like “Llama 4 Explained: Architecture, Long Context, and Native Multimodality” offer visual walkthroughs of the inner workings of MoE routing, the 10 million token window, and ring attention (YouTube, 2026).
Next Steps: Applying MoE Innovations
With the fundamentals of Llama 4’s MoE architecture in hand, applying these concepts in production or research settings is the logical next step. Here are actionable directions for practitioners, startups, and researchers:
- Experiment with Open-Source MoE Implementations
- Hugging Face and other model hubs now provide sample code and reference templates for MoE transformer architectures. For Llama-family MoEs, you’ll find community-contributed code tuned for throughput, dynamic routing, and sparse activation.
- Coders should explore continuous pre-training frameworks (see arXiv, 2026), which highlight various strategies for expert assignment and model growth.
- Deploy Multi-Expert LLMs in Real-World Stacks
- Platforms like CallMissed are already integrating Llama 4’s MoE-based models into scalable AI infrastructure. For instance, CallMissed’s multi-model inference gateway lets enterprises utilize Llama 4 alongside hundreds of other LLMs, switching models without code refactoring.
- Critical for emerging markets: Indian startups like CallMissed use Llama 4’s multilingual strengths—22+ Indian languages via speech-to-text APIs—to build customer-facing chatbots and voice agents at national scale.
- Evaluate Efficiency Gains
- Llama 4’s MoE allows for higher throughput per GPU, as only a subset of 128 experts are simultaneously activated per token. As Meta AI details, this reduces per-inference FLOPs (floating point operations) by up to 50% compared with dense transformers of comparable size—enabling more cost-efficient LLM serving for large-scale applications (Meta AI, 2026).
- New benchmarks from Hugging Face indicate MoE models are up to 1.8x faster on A100 GPUs for long-context inference versus traditional dense LLMs (Hugging Face Blog, 2026).
- Embrace Multimodal and Long-Context Capabilities
- Llama 4’s architecture is designed for native multimodality—a crucial advantage if integrating image, speech, and text in unified workflows. Early reports show 10 million-token context windows are viable on commercial-grade clusters (YouTube, 2026).
- For businesses: Consider practical use-cases across transcription, bulk document analysis, and voice search.
MoE in Practice: Industry Examples
A growing number of enterprises are deploying Llama 4-class models for mission-critical workflows. Among the most impactful industry scenarios:
- Contact Centers: AI voice agents powered by MoE-efficient LLMs handle thousands of concurrent customer calls—enabling around-the-clock service at a reduced compute footprint.
- AI Chatbots and Virtual Assistants: Multilingual customer engagement is now practical at national scale, thanks to sparse activation and expert-specialized routing.
- Enterprise Knowledge Management: MoE architectures make it feasible to support massive context windows (up to 10M tokens) that analyze broad corpora without memory bottlenecks.
Platforms such as CallMissed are at the forefront, providing production-ready APIs for MoE-enhanced voice, chat, and inference workloads. For tech leads and product builders, working with such infrastructure removes many hurdles traditionally faced in multi-LLM orchestration and scaling.
Best Practices to Stay Ahead
- Join active MoE research discussions at major AI/ML conferences—look for workshops on efficient transformer scaling, expert sparsification, and routing algorithm optimization.
- Track real-world benchmarks: As vendors update their Llama 4 deployments, observe published throughput, latency, and accuracy metrics—these are essential for capacity planning.
- Monitor open-source progress: Both Meta and the broader research community frequently release new MoE model checkpoints, training logs, and system design papers.
- Connect with industry solution providers: Platforms like CallMissed often showcase customer case studies, technical deep-dives, and hands-on workshops around deploying MoE-driven models at production scale.
For Further Exploration: Recommended Reading & Communities
- “Mixture of Experts Explained” by Hugging Face for technical overviews and practical code.
- Meta AI’s Llama 4 launch blog for up-to-date model architecture, performance figures, and roadmap insights.
- Technical papers on continual expert pre-training, efficient routing algorithms, and scaling laws for MoE transformers.
Engage in:
- Hugging Face Forums & Discords for development support
- LinkedIn groups focused on AI language modeling infrastructure
- Indian AI innovation communities (if working with regional language support)
The Future of MoE and Llama 4
As of mid-2026, Mixture-of-Experts architectures are reshaping the landscape of large language models—balancing efficiency, cost, and capability in ways dense models cannot match. With Meta’s open-source leadership and a burgeoning ecosystem of infrastructure providers like CallMissed, the next wave of multimodal, multilingual, and scalable AI systems is on the horizon.
Whether building prototypes or scaling to handle millions of user interactions, applying the MoE lessons of Llama 4 offers a clear path to high-performance, real-world LLM deployments. Stay plugged into the latest developments, experiment with production-ready platforms, and consider contributing to the open research dialogue that is rapidly propelling MoE innovation forward.
Conclusion
- Llama 4’s Mixture-of-Experts (MoE) architecture sets a new standard for AI model efficiency, scalability, and performance—by dynamically routing data through 128 specialized “experts” within each MoE layer, it delivers stronger results with reduced compute cost, making large models production-ready at enterprise scale (Meta AI, 2026).
- This hybrid approach—alternating dense and sparse MoE layers—enables Llama 4 to process complex tasks without overwhelming infrastructure, yielding industry-leading benchmarks across text, multilingual support, and multimodal intelligence (source: Medium).
- MoE’s flexibility empowers continual pre-training and lifelong learning. Companies can fine-tune or expand expert subnetworks with new domains, making models more adaptable as real-world requirements shift (arXiv, 2026).
- The open architecture of Llama 4 is accelerating a wave of new platform innovations, as AI infrastructure providers race to support on-demand inference, multilingual voice, and API-level access to advanced LLMs.
Looking ahead, expect even broader adoption of MoE designs, further progress in zero-shot specialization, and rapid growth in multimodal AI systems that integrate voice, video, and text seamlessly. Platforms like CallMissed are already enabling businesses to stay ahead—offering native support for 300+ LLMs, powerful voice agents, and robust language APIs. How will your organization evolve as expert-driven models transform AI communication workflows? To explore how this technology is shaping the next era of enterprise AI, check out CallMissed — and consider what opportunities await for those who harness these new architectures first.
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.