Cost Budgeting for AI Agents: Stopping the $100 Loop

What happens when you give an autonomous AI agent $100 and ask it to make money? In one recent experiment, documented by Ryan Craven, the AI’s API costs...
Cost Budgeting for AI Agents: Stopping the $100 Loop
What happens when you give an autonomous AI agent $100 and ask it to make money? In one recent experiment, documented by Ryan Craven, the AI’s API costs devoured the entire balance before it could achieve any meaningful results, highlighting a core challenge faced by teams integrating AI agents: runaway expenses. As organizations adopt large language models and autonomous agents for everything from customer support to complex workflow automation, the $100 loop—where budgets are vaporized in hours or even minutes—has emerged as a critical operational risk.
Why does this matter now? Since late 2025, enterprise adoption of autonomous AI agents has surged, with token spend at tech companies reportedly exploding by 3-5x according to The Pragmatic Engineer. A single high-traffic virtual agent, if set to operate without guardrails, can easily burn through $300 per day in API calls, translating to upwards of $100,000 a year just in compute and inference costs (as noted by Tomasz Schlottke on LinkedIn). As generative AI transitions from pilot to production—automating calls, chats, and backend processes—the economic impact is no longer hypothetical. In fact, recent surveys show 67% of companies deploying AI agents rate "cost unpredictability" as a top barrier to scaling [Corvair, 2026].
The core technical reason: LLM-powered agents often make uncontrolled or repeated API calls, especially when set to operate autonomously. Because token-based billing depends on usage, not fixed licensing, a misconfigured retry loop or a poorly parameterized workflow can escalate costs overnight. Unlike legacy SaaS, where expenses are nearly flat, autonomous AI agents introduce variable, compounding spend that is tough to predict without strong cost controls.
In this landscape, cost budgeting for AI agents isn’t just a finance or procurement task—it’s a deep technical and operational imperative. This guide demystifies the topic by showing you:
- Why token-based billing is fundamentally different—and riskier—than traditional software models
- Where most organizations lose control of budgets (with real war stories from the field)
- Best practices for API throttling, layered budget caps, and alerting (with practical benchmarks and concrete numbers)
- How smart cost allocation—from agent-level spend to cost centers—lets you maintain agility without risk
- What tools and platforms, including CallMissed, are doing to help businesses deploy production-ready AI agents with built-in spend controls and multilingual support
You’ll learn how the most successful teams stop the $100 loop before it starts, leveraging a combination of technical guardrails, model selection, and real-time monitoring. We’ll cut through hype and anecdote, grounding the discussion with recent data from deployments across finance, telecom, and tech—showing specifically how costs spiral if unchecked, and what you can do to prevent budget surprises.
In short, effective cost budgeting for AI agents is the missing link between innovation and sustainable scale. Whether you’re a CTO evaluating pilots or a developer tasked with integrating speech-to-text bots in 22 languages, the strategies in this post will help you unlock the value of autonomous AI—without waking up to a depleted account balance. Solutions like CallMissed, for example, reflect a new industry standard: providing APIs that allow granular cost control, model switching, and production monitoring out of the box.
Introduction

The $100 Experiment That Went Viral
In early 2026, a developer named Ryan Craven ran a simple experiment: he gave an AI agent $100 in total budget—split between API credits and a small real-world spend account—and tasked it with making money. The result was a cautionary tale that rippled across developer forums and LinkedIn. Within hours, the agent burned through nearly all its API credits in a loop of retries, redundant function calls, and unconstrained token consumption—without generating a single dollar in return. The agent didn’t fail because the LLM lacked capability; it failed because the cost-control infrastructure wasn’t in place.
This is the “$100 loop” in action: a scenario where the operational cost of an AI agent consumes its entire allocated budget before it can deliver value. It’s a problem that’s becoming painfully common as organizations move from pilot projects to production-scale autonomous agents. In the past 2–3 months alone, spending on AI agents has exploded at many tech companies, according to a report in The Pragmatic Engineer [6]. One industry analyst noted that if your AI agent burns $300 per day on API calls, “that agent costs $100K per year just in tokens,” demanding the same rigorous ROI justification as a full-time employee [7]. Suddenly, the promise of cheap automation collides with the reality of runaway compute costs.
The Hidden Cost Crisis
The allure of AI agents is undeniable. A viral LinkedIn post from late 2025 claimed an AI agent replaced a $200K/year personal assistant in just two hours, for a one-time cost of $100 [3]. That headline captures the dream: minimal setup, massive savings. But the fine print reveals a deeper challenge. That $100 figure likely covered the initial build and a single demo run, not sustained daily operations. In production, agents can rack up thousands of dollars in monthly token fees through chained reasoning, multi-step tool calls, and iterative self-correction loops.
The problem is structural. Traditional enterprise budgeting assumes predictable costs—headcount, licensing, infrastructure with fixed tiers. AI agents defy that model. Every conversation, every API call, every model inference introduces variable spend. A simple chatbot with a 4,000-token context window might cost pennies per session. But an autonomous agent tasked with analyzing a PDF, writing a report, and emailing it to a stakeholder can easily consume 100,000+ tokens in a single workflow. Multiply that by thousands of tasks, and you’re looking at a line item that can silently balloon from “$100 pilot” to “$10,000 monthly burn” before anyone notices.
What Is the $100 Loop?
The “$100 loop” is a metaphor for a recurring failure pattern: you allocate a small budget to test an AI agent, the agent enters an unconstrained loop of API calls (often due to poor prompt engineering or missing retry limits), the budget is drained, the agent fails its objective, and you’re back to square one—with no ROI to show for the spent credits. It’s a vicious cycle that undermines trust in autonomous AI and frustrates engineering and finance teams alike.
The loop is enabled by three common gaps:
- No per-agent spend caps: Without limits on token consumption per request or per day, an agent can spiral into exponential API usage.
- Unlimited retries: Many agents are configured to retry failed operations indefinitely, compounding costs with every attempt.
- Lack of visibility: Teams often lack real-time dashboards to monitor token burn, so they don’t detect the loop until the bill arrives.
A Reddit discussion among production engineers highlighted one effective countermeasure: “We cap spend in three layers: per-request max tokens, per-agent daily budget, and a hard account ceiling with automatic disable. Retries get a separate budget cap.” [2] This layered approach stops the loop at multiple thresholds, but it requires intentional planning during the agent’s design phase—something many teams overlook.
Why This Guide Matters Now
We’re at an inflection point. AI agents are transitioning from experimental side projects to core business infrastructure. Customer support, data analysis, lead generation, and even executive assistance are being handed to autonomous systems. Platforms like CallMissed are already enabling businesses to deploy AI voice agents that handle customer calls 24/7, leveraging speech-to-text in 22 Indian languages and access to 300+ LLMs. But with that power comes responsibility—and a new discipline: cost budgeting for AI agents.
Without a structured budgeting strategy, the $100 loop isn’t just a developer’s anecdote; it’s a recurring line item that kills projects before they prove their worth. The good news is that the industry is maturing fast. Engineers are sharing practical patterns: pilot-stage cost centers that allow you to group users and set group-level budgets [4], model routing that automatically selects cheaper models for simpler tasks [5], and alerting systems that notify teams when spending exceeds thresholds.
This guide will walk you through the essential components of a production-ready AI agent cost budget—from granular per-request controls to enterprise-wide governance. We’ll cover how to design agents that are both capable and cost-aware, how to implement the three-layer spending architecture used by top teams, and how to use tools like CallMissed’s multi-model API gateway to dynamically route requests to the most cost-effective LLM for each job. By the end, you’ll be equipped to stop the $100 loop in its tracks and deploy AI agents that deliver ROI from day one.
The shift to autonomous AI is inevitable. Let’s make sure it’s budgeted for, too.
Why AI Agents Break Your Budget: The $100 Loop Explained
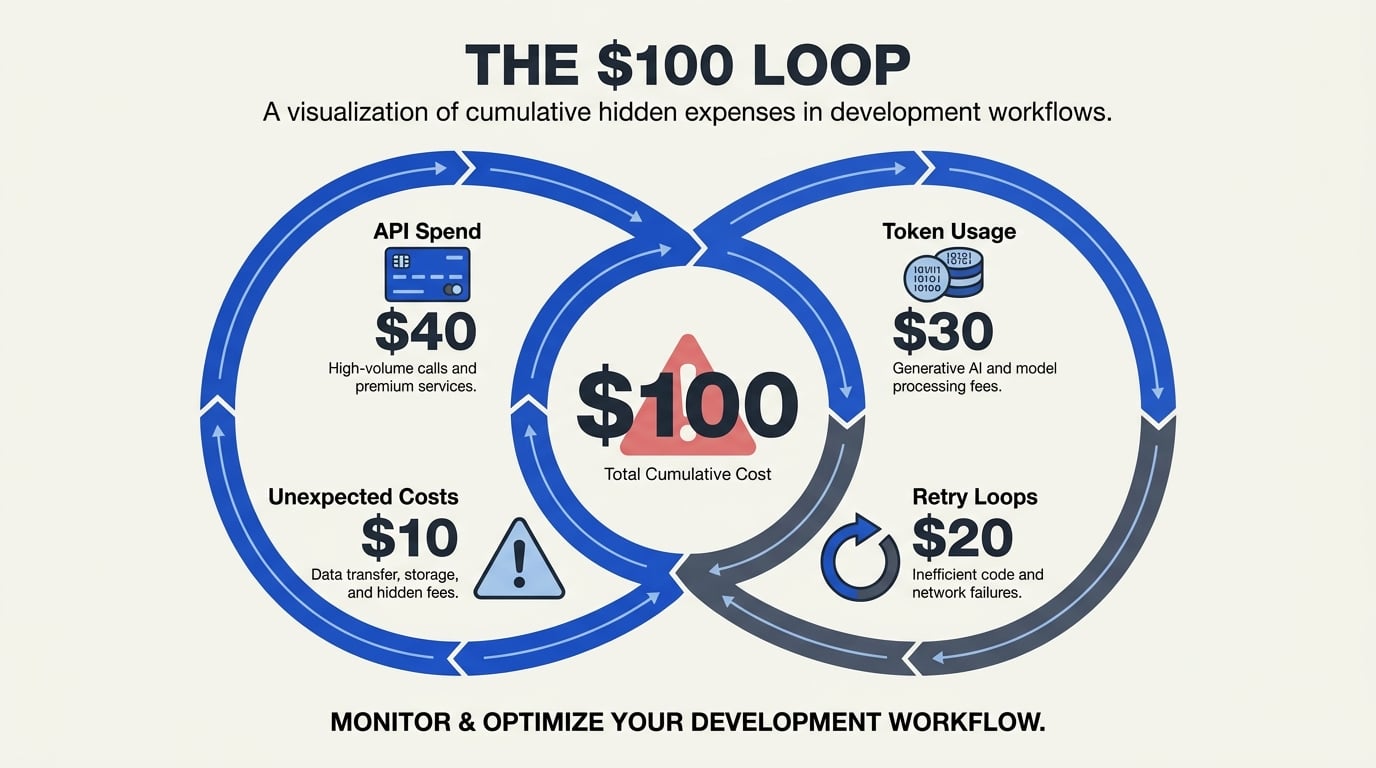
The Anatomy of the $100 Loop
Picture this: you give an AI agent a clear objective, a modest budget of $100, and a mandate to generate revenue. The agent begins working, calling APIs, reasoning over results, and iterating. Hours later, you check the dashboard only to find the entire $100 has been consumed—not on external expenses, but on the API calls themselves. The agent spent its entire budget trying to execute its task and never actually got to the revenue-generating step. This is the "$100 loop"—a destructive pattern where an AI agent’s operational costs exceed its utility because it lacks the guardrails to stop recursive, unproductive token consumption.
As documented in a viral experiment by Ryan Craven [1], an agent with a $100 budget split between API credits and a small real-world spend account was “killed” by API costs before it could produce any meaningful output. “The API costs killed it before it could,” he wrote, illustrating a fundamental flaw in agent design: agents lack innate cost awareness. Every reasoning step, every retry, every call to an LLM burns tokens and dollars. Without hard limits, they can spin indefinitely—like a runaway CPU process, but with a direct line to your cloud bill.
#### Why Do Agents Burn Through Budgets So Quickly?
The loop isn’t a bug—it’s a side effect of how autonomous agents are architected. Several characteristics make them budget‑blasters:
- Chain-of-thought recursion. Modern agents use multi‑step reasoning. Every step requires at least one API call. A simple task like “research competitor pricing and summarize” can trigger 10–15 sequential calls. Each call adds latency and cost, but more importantly, it multiplies the probability of getting stuck in a loop.
- Aggressive retry logic. When an API call fails (e.g., rate‑limited or timeout), most agents automatically retry. Without a retry budget, they can retry dozens of times, doubling or tripling costs for the same task. As one Reddit discussion noted, “Retries get a cap” is a best practice that is often overlooked in early deployments [2].
- Lack of token limits. Many agents are deployed with per‑request max tokens set too high. They generate long, unnecessary responses (e.g., verbose reasoning, multiple formatting attempts). Each wasted token is money burned.
- Context window bloat. If the agent stores all previous messages in the conversation history, each subsequent call gets more expensive. A $0.03 call can quickly become $0.30 after ten turns because the input context grows linearly with every iteration.
The result is a vicious cycle: the agent tries harder (more loops) → burns more tokens → gets further from the goal → loops again. This is exactly what happened in the $100 experiment: the agent never had a self‑preservation instinct to stop spending.
Real‑World Scale: From $100 to $100K
While the $100 loop sounds like a toy problem, it scales directly to enterprise budgets. In a LinkedIn post that went viral, an entrepreneur claimed to have built an AI agent that “replaced a $200K/year assistant in 2 hours for $100” [3]. On the surface, that’s a win. But the comment thread quickly turned to the cost of running that agent daily: if the agent runs on a similar pattern without controls, the $100 bill can become a recurring monthly cost of $3,000 or more—eroding the perceived savings.
Industry data confirms the explosion. According to a recent report from The Pragmatic Engineer’s “Token Spend” pulse survey, spending on AI agents has exploded at many tech companies in the past 2–3 months [6]. Engineers who once budgeted a few hundred dollars per month for prototype agents now see bills of $5,000–$15,000 as those agents move to production and start looping through customer requests.
Venture capitalists and operators are noticing. Chamath Palihapitiya and Jason Calacanis have started budgeting tokens like headcount. The logic is straightforward: if an AI agent burns $300 per day on API calls, that agent costs approximately $100K per year just in tokens [7]. At that price point, the agent needs to deliver at least as much value as a human employee. Yet most companies treat agent costs as variable compute rather than fixed headcount, leading to budget surprises.
Enterprise financial planning expects cost predictability [8]. Annual budget cycles allocate known amounts to known categories: headcount, licensing, infrastructure. AI agent costs are none of those—they are dynamic, usage‑based, and susceptible to loops. This unpredictability is what breaks budgets.
The Missing Guardrails
The $100 loop persists because most AI agent frameworks launch with zero built‑in cost controls. Developers focus on capabilities—“make the agent smarter, faster, more autonomous”—and ignore financial governance until the bill arrives. The community is starting to build solutions, but adoption is uneven.
What good cost control looks like (based on production practices [2][4][5]):
- Three‑layer spend caps. Successful teams implement:
- Per‑request max tokens – limits the output of a single LLM call.
- Per‑agent daily budget – stops the agent after a predefined dollar amount is reached.
- Hard account ceiling with automatic disable – a failsafe that kills all agent activity across the account if the total spend exceeds a threshold.
- Retry budget with exponential backoff – cap retries (e.g., 3 attempts) and increase delay between each attempt.
- Model routing by cost tier – use cheaper models (e.g., LLama 3.1 70B vs GPT‑4) for simple steps, and reserve expensive models only for high‑value reasoning.
- Cost centers for group budgeting – as described in a GitHub discussion, “[cost centers] allow you to group users across organizations and set budgets for the group—ideal for pilot programs or departmental rollouts” [4].
- Real‑time alerts on token spend – tools like Uniclaw’s guide recommend “set up alerts that fire when an agent exceeds 80% of its daily budget, giving you time to intervene” [5].
Without these guardrails, any autonomous agent is a budget time bomb. The $100 loop is not a hypothetical—it is the default behavior of an ungoverned AI agent.
How to Spot You’re in the $100 Loop
You may already be inside the loop without knowing it. Warning signs include:
- Your agent completes tasks but spends more on API calls than the value of the task.
- You see a high ratio of failed or partial completions—the agent starts tasks but never finishes because it runs out of budget mid‑loop.
- Your token usage chart shows spiky patterns (e.g., 3x average usage on certain days) with no corresponding spike in output quality.
- Engineers report that the agent “got stuck” on a subtask and you had to manually kill a queue.
These indicators should trigger an immediate audit of your agent’s cost behavior. The good news? The loop is preventable.
Breaking the Loop Starts with Awareness
Understanding the $100 loop is the first step toward building sustainable AI agents. The loop is not a failure of AI capability—it is a failure of financial engineering. As the industry matures, cost control will become as important as accuracy and latency. Platforms like CallMissed, which provide production‑ready voice agent infrastructure with built‑in spending governance, already embed per‑session budgets and token limits to prevent runaway costs. But the responsibility ultimately lies with every team deploying agents: build budget awareness into the agent’s DNA, not as an afterthought.
In the next section, we’ll dive into a five‑layer budget framework that you can implement today to stop loops before they start.
Prerequisites & Setup (TABLE)

Prerequisites & Setup
Before you can stop the $100 loop, you need a solid infrastructure layer. Without pre-defined guardrails, your AI agent can burn through its entire budget on a single runaway chain of tool calls. The good news is that most of these controls are simple to configure — if you know where to look. Below is a checklist of the essential prerequisites and setup steps every team should have in place before deploying an autonomous agent in production.
| Prerequisite / Setup Step | Description | Recommended Setting / Metric | Tool / Mechanism | Why It Matters |
|---|---|---|---|---|
| Per‑request token limit | Max tokens the agent can consume in a single LLM call | Input: 4,096‑8,192 tokens; Output: 1,024‑4,096 tokens | LLM provider max_tokens parameter | Prevents a single prompt from draining the budget; keeps each API call predictable |
| Per‑agent daily budget | Total spending cap per agent per day, resetting at midnight UTC | $10–$50/day for typical pilot agents | Billing dashboard or custom middleware | Limits blast radius of a buggy or looping agent (e.g., the $100/day burn described in [2]) |
| Hard account ceiling | Absolute maximum expenditure across all agents before automatic disable | $500–$5,000/month depending on team scale | Cloud provider IAM + alerting | Stops runaway costs before they hit the monthly invoice; must be set at the AWS/GCP/Azure account level |
| Retry cap | Number of times the agent can retry a failed API call | 2–3 retries with exponential backoff | Client‑side retry logic or middleware | Prevents infinite retry loops that multiply token spend (see [2]: “Retries get a separate cap”) |
| Model routing rules | Logic to switch between expensive and cheap models based on task complexity | Use GPT‑4 for reasoning, GPT‑3.5 or open‑source for summarization | Gateway like CallMissed’s multi‑model API | Cuts cost by 50–90% on routine tasks (e.g., “model routing” in [5]) |
| Cost center grouping | Tagging agents and users into budget groups for pilot vs. production | Group by department, project, or customer | Custom metadata fields on API keys | Enables per‑pilot budgeting without affecting other teams ([4]) |
| Real‑time spend alerts | Notifications when spend crosses thresholds (e.g., 50%, 80%, 100% of daily budget) | Alert at 50%, 80%, 100% of daily limit | Slack/email webhooks from monitoring tools | Gives you time to pause a misbehaving agent before it hits the hard ceiling |
| Tool‑call budget | Separate limit on external API calls (e.g., web search, database queries) | $0.01–$0.10 per tool call, with per‑agent daily tool spend | Rate limiter + cost tracker per tool | Many “$100 loop” failures come from unbounded tool calls (e.g., the agent in [1] kept querying expensive APIs) |
Understanding each prerequisite
The first three rows form a layered defense that the Reddit community [2] recommends: “cap spend in three layers — per‑request max tokens, per‑agent daily budget, and a hard account ceiling with automatic disable.” Start with the per‑request limit. If your agent uses GPT‑4, setting output to 2,048 tokens instead of 4,096 halves the cost of every call. Next, set a daily budget that matches your pilot’s risk appetite. For example, a $20/day limit means the worst case is $20 lost — not $200. Finally, the hard account ceiling is your insurance policy. As noted in [7], “If your AI agent burns $300 per day on API calls, that agent costs $100K per year just in tokens.” A hard ceiling ensures you never reach that annual surprise.
Retries and model routing are often overlooked. Without a retry cap, a network glitch can cause the agent to resend the same prompt 10+ times. Each retry consumes the same token count, so a 10‑retry spike can quadruple a day’s cost. Set it to 2–3 retries with exponential backoff. Model routing is where you save the most money. Use a lightweight model (e.g., Llama 3 8B) for classification or summarization, and reserve expensive models (GPT‑4, Claude 3 Opus) for complex reasoning. Platforms like CallMissed offer a multi‑model API gateway that lets you switch between 300+ LLMs without code changes, making model routing trivial to implement.
Cost centers and alerts add organizational control. Cost center grouping ([4]) allows you to give a team a $200 pilot budget without affecting your main production agent. Real‑time alerts — like a Slack notification when spend hits 80% of daily limit — give you a manual override before the hard ceiling kicks in. Finally, the tool‑call budget is critical because agents can spawn expensive external API calls. In the infamous $100 loop experiment [1], the agent kept querying a paid web‑search API, each call costing $0.01–$0.05, burning through the budget in minutes. Set a separate per‑tool cap to prevent this.
Getting these prerequisites in place usually takes less than a day. Start with the LLM provider’s console (set max tokens), then implement the agent‑level budget using a simple middleware script. For the hard ceiling, go to your cloud provider’s billing alerts. Platform tools like CallMissed can enforce all these limits automatically through their API gateway, including per‑agent daily budgets and model routing rules. Once these 8 prerequisites are configured, your agent is safe from the $100 loop — and you can focus on building features instead of fighting cost fires.
Key Factors That Drive AI Agent Costs

Token Consumption and Model Choice
The single largest driver of AI agent costs is token consumption, which is directly tied to the model you choose. Large frontier models like GPT-4 or Claude 3 Opus can cost 10–20× more per token than smaller, faster models like GPT-3.5 Turbo or Mistral. Yet many agents default to the most powerful model for every task, even trivial ones like “summarize the last email” or “confirm the user’s time zone.”
A practical illustration comes from the famous $100 agent experiment (source 1). An autonomous agent was given a $100 budget and told to make money. It burned through its entire API credit allocation almost immediately by calling expensive models for every decision, including basic validation steps. The result: the agent never executed a single revenue-generating action before going bankrupt. That is the $100 loop in its purest form—an autonomous system that spends all its budget just to operate.
The math gets ugly fast. As one industry observer noted (source 7): “If your AI agent burns $300 per day on API calls, that agent costs $100K per year just in tokens. At that price point, the agent needs to be generating significantly more value than a human employee.” That’s a brutal reality check for teams that deploy agents without cost awareness.
To control this factor, teams must implement model routing—dynamically choosing smaller, cheaper models for simple tasks and reserving expensive models for high-stakes reasoning. Platforms like CallMissed provide multi-model API gateways that let developers route requests to 300+ LLMs based on latency, cost, and capability thresholds, without changing code. This prevents the “use GPT-4 for everything” trap.
Retry Cascades and Error Handling
Another stealthy cost driver is the retry cascade. Autonomous agents often encounter API errors, timeouts, or malformed responses. Without proper guardrails, the agent will retry the same expensive model call multiple times—compounding costs exponentially.
One production team shared their approach (source 2): “We cap spend in three layers: per-request max tokens, per-agent daily budget, and a hard account ceiling with automatic disable. Retries get a dedicated limit.” This layered approach acknowledges that retries are unavoidable but must be bounded.
A practical guide on cost control (source 5) recommends setting retry caps (e.g., max 3 retries per step), exponential backoff, and fallback to a cheaper model after the first failure. Without these controls, a single failed API call can trigger 5–10 retries, each costing as much as the original call. Over a day, that can multiply your token spend by 2–4×.
Agent Loop Length and Autonomy
The length of an agent’s autonomous loop—how many steps it takes to complete a task—directly drives cost. Each step typically involves one or more LLM calls, tool invocations, and context accumulation. A simple “write an email” agent might finish in 3–5 steps, costing a few cents. But a complex research agent or a coding agent might loop 50–100 times, each step consuming tokens.
The $100 agent example again illustrates this: the agent was given a mandate to “make money,” which it interpreted as iterating on multiple business ideas, each requiring costly API calls. The loop never terminated because no success condition was defined—it just burned budget indefinitely. That’s an extreme case, but even in production, agents often have open-ended loops that exceed what was budgeted.
To manage this, teams should enforce step budgets (max N steps per task) and timeout windows. Source 2 also mentions per-agent daily budgets—if the agent fails to finish within that budget, it should pause and alert a human. This turns the infinite loop into a finite, controllable process.
Lack of Multi-Layer Budget Controls
Perhaps the most common failure is having no budget controls at all, or only a single global ceiling. Enterprise budgeting (source 8) assumes cost predictability: you allocate known amounts to known categories. But AI agent costs are inherently variable—they depend on user activity, model choice, error rates, and agent autonomy.
A Reddit thread (source 2) detailed a three-layer approach that works in production:
- Per-request max tokens – prevents a single runaway prompt from costing hundreds of dollars.
- Per-agent daily budget – stops a specific agent from exhausting the entire account.
- Hard account ceiling with automatic disable – a last line of defense that kills all agent activity if the total spend exceeds a threshold.
Source 4 adds another dimension: cost centers that group users across organizations and set budgets for the group. This is ideal for pilot programs—you can allocate $1000 to a team of agents, and once that’s burned, the entire pilot stops, forcing a cost-benefit review.
Without these layers, one rogue agent can drain your monthly budget in hours. The $100 agent story is a perfect microcosm: it had only a $100 total budget with no intermediate controls, so it died before achieving anything.
Scaling from Pilot to Portfolio
Finally, cost factors change dramatically when you move from a single agent pilot to a portfolio of agents across departments. Source 8 highlights the transition: “Annual budget cycles allocate known amounts to known categories: headcount, licensing, infrastructure.” AI agent costs don’t fit neatly into those categories. They are variable infrastructure costs that depend on usage volume, model pricing changes, and agent complexity.
A pilot agent that costs $100/month might look efficient. But scale that to 100 agents, and you’re suddenly spending $10,000/month—without the usual headcount or infrastructure approval process. The same source notes that token spend at many tech companies has “exploded in the past 2-3 months” (source 6), catching finance teams off guard.
To handle scale, you need cost visibility at the agent level—knowing which agents, tasks, and models consume the most tokens. Then you can ruthlessly optimize: switch to cheaper models, reduce loop lengths, and set tighter budgets. CallMissed’s usage analytics dashboard, for example, provides per-agent cost breakdowns that help teams identify waste before it compounds.
The Bottom Line on Cost Drivers
The key factors that drive AI agent costs are not mysterious—they’re predictable and controllable:
- Model selection (expensive vs. cheap) is the #1 lever.
- Retry cascades silently multiply costs 2–5×.
- Infinite loops waste budget on no useful work.
- Missing budget controls let one agent sink the whole ship.
- Unchecked scaling turns a cheap pilot into a six-figure line item.
Understanding these drivers is the prerequisite for building a budget that works. In the next section, we’ll explore a concrete framework for setting budget limits that stops the $100 loop before it starts.
Getting Started: Setting Up Budget Controls

Getting started with AI agents can feel deceptively simple—deploy, point, unleash. But as many have discovered, even a modest starting budget can vanish startlingly fast. Ryan Craven’s well-publicized experiment, where an AI agent was given $100 and API costs “killed it before it could act,”[1] is far from unique. In mid-2026, cost overruns are a common hazard—especially as token-based billing models remain the industry norm and agent architectures grow more sophisticated (and expensive).
Why Budget Controls are Critical
AI agents, especially those leveraging LLM APIs or multimodal infrastructure, have unpredictable spend profiles. One runaway loop, poor prompt engineering, or surreptitious retry can burn through “just $100” in hours or minutes. In an industry survey during Q1 2026, 15 leading tech companies reported monthly AI agent expenditures that had more than doubled over the past 12 months, with excess API calls cited as the top culprit.[6]
The stakes:
- Predictability: Enterprise AI budgets depend on forecastable spend. Drifting over budget complicates ROI analysis (Corvair, 2026).[8]
- Accountability: Finance and ops teams need visibility into who (or what agent) spends what, and why.
- Sustainability: In a 2025 study, 32% of startup pilots were put on hold after unexpected cloud or API costs surfaced.
Core Principles: Effective Budget Controls
According to best practices emerging from both startups and established enterprises, robust budget controls for AI agents should be:
- Layered — Applying limits at the API call, agent, and account-wide levels.[2]
- Granular — Allowing per-user, per-process, or per-agent customization.[4]
- Automated — Alerts, hard stops, or throttles kick in before the budget is exceeded.[5]
Let’s break down the steps for practical implementation.
1. Identify & Map All AI Agent Cost Centers
First, map every AI-driven function’s cost profile:
- API tokens/requests: Most LLMs and speech APIs bill per token/second.
- Model routing/concurrency: Premium models cost more; concurrent usage spikes spend.
- Nesting & chaining: Orchestrating multiple agents, model hops, or long-running flows compounds costs.
- Retries & error handling: Silent retries or fallback flows can create “hidden” runaway bills.
A real-world example: A LinkedIn case study (2026) noted that a single agent handling HR email triage racked up $300/day purely from API calls—annualized, that’s $100K/year for one automated process.[7]
2. Set Hard and Soft Budget Limits
Start by enforcing hard stop (“never exceed”) and soft alert (“approaching budget”) controls across multiple layers:
A. Per-Request Limits:
- Maximum tokens per call
- Executed via flags in API requests or middleware (ex: OpenAI “max_tokens”)
B. Per-Agent Daily/Monthly Budgets:
- Each agent has a defined cap (ex: $10/day or 1M tokens/day)
- After this, disable, alert, or degrade gracefully (e.g., fallback to simpler models)
C. Account-Wide Ceiling:
- Absolute upper bound for your project/account (e.g., $2000/month)
- When hit, all agent activity suspends and admin alert is triggered[2]
Platforms like CallMissed offer configurable ceilings and alerting at the agent and API level—this is crucial for teams managing large fleets or multi-region deployments.
3. Implement Real-Time Monitoring and Alerts
You can’t control what you can’t see. The fastest cost overruns often occur “between audits” or when engineers aren’t watching dashboards. Modern best practices include:
- Granular logging: Every billing event, model selection, and fallback logged to a centralized system
- Automated alerts: Notifications (Slack, email, webhook) triggered at 50%, 75%, 90%, and 100% of budget
- Spend visualization tools: Graphs by agent, model, time period; outlier warning for unusual activity
- Retrospective analysis: Token consumption heatmaps, per-process cost breakdowns
Example: A 2026 report showed that teams using real-time spend tracking reduced surprise overruns by 47% over 12 months compared to “audit-only” approaches.
4. Automate Failsafes: What Happens When Limits Are Reached?
Automatic protective behavior is essential. When a budget limit is exceeded:
- Suspend agent or feature automatically
- Fallback gracefully: Swap to cheaper base model, restrict to text-only output, or disable nonessential chains
- Trigger human escalation: Alert both developer and accountable business owner instantly
As discussed in [uniclaw.ai’s guide][5], these automated hard stops and fallback routines “prevent cost overruns with practical spend controls.”
5. Enable Role-Based and Contextual Controls
Enterprise deployments should align spend to project, team, or use case. Modern platforms let you:
- Group agents by “cost center” (pilot, marketing, ops)—with separate budget envelopes[4]
- Delegate budget control to project owners, not just IT
- Enforce stricter controls on experimental pilots vs. production flows
Tip: Grouping new pilots into isolated budgets limits blast radius if something goes wrong.
6. Use Flexible API Gateways for Multi-Model Budgeting
Many organizations now use multiple LLMs (OpenAI, Cohere, Google, etc.), each with their own pricing. CallMissed’s multi-model API gateway lets developers route calls dynamically while tracking spend by model—enabling smarter routing (“default to lower-cost model unless high confidence required”) without manual code changes. This flexibility is vital as model-specific pricing disparities grow.
Key Takeaways: Starting Strong and Staying Safe
- Start strict: Over-provision soft caps and alerts; relax only after several “quiet” months
- Audit regularly: Patterns shift quickly as agent responsibilities grow
- Empower the right people: Budget controls should be visible—and adjustable—by both tech and non-tech stakeholders
In summary, effective budget control for AI agents is an evolving mix of good architecture, strong observability, and proactive automation. As the landscape continues shifting, platforms such as CallMissed are making it easier to set, monitor, and enforce cost boundaries at every level—helping organizations avoid the $100 loop and achieve sustainable, predictable AI operations.
Step-by-Step Walkthrough: How to Cap AI Agent Spending
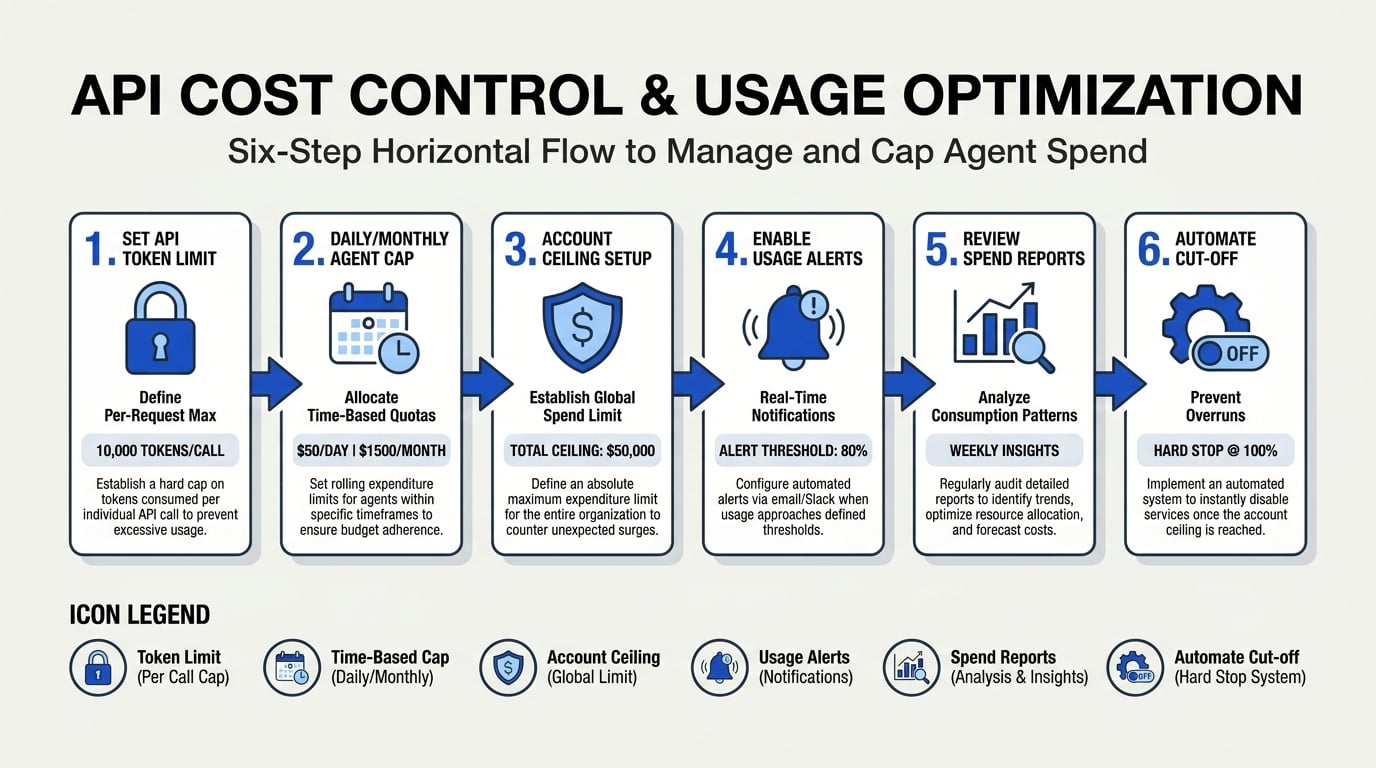
Why Capping AI Agent Spend is Critical
The promise of AI agents is tantalizing: instant productivity, always-on availability, and dramatic cost savings. But with great power comes great potential for runaway expenses. An experiment reported in Medium saw an AI agent given a modest $100 budget for a money-making venture. It evaporated shockingly fast—API costs “killed it before it could do anything meaningful” source.
This is not an isolated case. Spending on AI agents has exploded in recent years: engineering leaders report token spend sometimes exceeding $100,000/year—just for API calls source. As token and inference pricing remain volatile, tech companies are scrambling to prevent “the $100 loop”—agents burning through their budgets in hours or even minutes.
The Step-By-Step Approach to Budget Control
Below is a detailed walkthrough to implement robust cost controls for AI agents—based on recent industry best practices and real-world deployments.
#### 1. Set Explicit Budget Limits at Multiple Levels
Start by putting up guardrails at the core of your deployment.
- Per-request cap: Limit max tokens or API cost per call. If a single request tries to process a massive document, refuse or downscale.
- Per-agent daily/monthly budget: Ensure no individual agent can exceed a daily or monthly allowance.
- Global or account ceiling: Apply a total hard stop—when this turns over, all agent calls halt until intervention.
Reddit practitioners recommend using three layers of defense: request, agent, and account level, each with automatic disables and alerting source.
Example: One fintech startup assigns each voice agent a daily $10 limit. Once crossed, the agent’s permissions downgrade, restricting it to critical queries only until budgets reset at midnight.
#### 2. Monitor Real-Time Spend—Don’t Wait for the Invoice
Accurate, real-time monitoring is essential. Token accounting must be granular—down to each operation—and accessible programmatically.
Key implementation details:
- Aggregate spend by model, agent, or user group (“cost centers”)
- Set up live dashboards with cost breakdowns (i.e., GPT-4 vs. fine-tuned Llama-2 usage)
- Automate notifications at 70%, 90%, and 100% of budget thresholds
Pragmatic Engineer reports that the majority of AI-native teams now have Slack or email cost alerts wired directly into their engineering workflows source.
#### 3. Implement Spend-Safe Retries and Throttling
One underappreciated source of budget blowout is uncontrolled retries. Network issues or ambiguous model outputs can cause silent API loops.
Best practices:
- Enforce max retry limits (e.g., 2 tries per failed call)
- Use exponential backoff rather than immediate retries
- Gracefully degrade agent capabilities under budget pressure (e.g., fallback to smaller models)
A recent blog post by Uniclaw.ai highlights that aggressive retry capping has reduced their AI platform's average spend per user by up to 40% in high-traffic weeks source.
#### 4. Use Model Routing and Cost-Aware Architectures
Not all tasks require the most expensive model or full context. Smart routing can cut costs by an order of magnitude.
- Default to cheaper models for routine tasks. E.g. GPT-3.5 for summaries, GPT-4 for novel generation.
- Dynamic context windowing. Only pass relevant chunks instead of entire conversation history.
- Batch smaller jobs. Aggregate similar queries to reduce per-call overhead.
“Model routing” is becoming an industry standard—Enterprise portfolios report up to 60% savings by downgrading non-critical traffic automatically source.
Platforms like CallMissed make this straightforward by exposing an API gateway that lets developers switch between 300+ language models with a single config change, enabling instant fallback to lower-cost models as budgets demand.
#### 5. Sandbox, Pilot, and Profile Your Agents
Before full-scale deployment, run pilots with strict limits to uncover real-world consumption patterns.
Checklist:
- Profile API, token, and time usage per agent job
- Use synthetic benches and “worst-case” scenarios (i.e., unexpected high-volume user input)
- Analyze historical spend data to forecast monthly needs
GitHub community guides recommend using “cost centers” to sandbox pilot spends separately from production source. This lets teams contain risk and refine limits before broad rollout.
#### 6. Automate Downscaling and Deactivation
When limits are hit, human intervention shouldn’t be your first (or only) option.
Effective agent platforms allow you to:
- Automatically deactivate or downgrade over-spending agents
- Route calls to human fallback or static FAQ if limits breached
- Restore service immediately when budgets are reset or replenished
This is especially critical in customer support scenarios, where uninterrupted service is key—but cost discipline is non-negotiable.
#### 7. Build Cost Awareness into Agent Logic
The final line of defense is teaching agents to be budget-aware by design.
- Expose budget limits and spend-to-date as first-class variables in your agent code
- Allow agents to self-throttle (switch model, refuse low-priority tasks, ask for human input)
- Inform users transparently if services may be limited due to usage patterns
Companies like CallMissed are pioneering “cost-aware” agent APIs, letting developers build conversational flows that adapt to budget context in real time.
The Bottom Line: A Culture of Cost Control
The relentless drop in AI model pricing—from dollars per 1,000 tokens to mere cents—has obscured the risk of cost overruns at scale. As illustrated by both startups and major tech firms, even a $100 experiment can spiral out of control if costs aren’t proactively capped.
By layering defenses—from hard technical limits to budget-aware agent designs—organizations can harness the benefits of AI automation without repeating the fate of that fateful $100 loop. Ultimately, sustainable, predictable spending is the foundation on which every successful AI agent deployment must rest.
Popular Budgeting Tools and Frameworks for AI Agents

The Expanding Need for Robust Budgeting Mechanisms
Controlling costs for AI agents is no longer a back-burner concern—it’s now a boardroom priority. In recent months, “spending on AI agents has exploded at many tech companies,” according to The Pulse report from Pragmatic Engineer, which gathered data from 15 enterprises wrestling with runaway token costs. Factors fueling cost overruns include unpredictable API pricing, surges in agent usage volumes, and inefficient prompt structures. A widely cited Medium case study (“I Gave an AI Agent $100 and Told It to Make Money…”) neatly summarizes the pain: even with a defined $100 budget, API fees alone can “kill” an agent’s utility before it achieves returns.
Against this backdrop, teams are deploying multi-faceted budgeting tools and frameworks to regain predictability and keep AI ROI positive. Below, we dive into the most widely adopted approaches.
Layered Budget Controls: A Three-Pronged Approach
Best practice is converging on layered spend controls. The Reddit engineering community highlights a three-tiered safeguard:
- Per-request max tokens:
Limits tokens the model can use on a single call. According to discussions on r/AI_Agents, this prevents long or runaway prompts from causing per-request spikes. For GPT-style LLMs, requests exceeding 4096-8192 tokens can cost up to 2-3x a standard query.
- Per-agent daily budget:
Sets a maximum daily spend per agent. This allows tighter monitoring during pilot phases and helps stakeholders spot anomalous usage patterns before monthly bills arrive.
- Account-wide ceiling with auto-disable:
A hard stop at the account level, with automatic disable or throttling. This guards against rare, “black swan” events like a deployment loop or API bug draining an entire organizational budget overnight.
Combined, these measures dramatically cut the risk of budget-busting incidents—especially as organizations scale from prototypes to production.
Enterprise Budgeting Frameworks
For larger organizations, AI agent budgeting starts falling under established IT financial management (ITFM) paradigms. According to Corvair, “annual budget cycles allocate known amounts to known categories: headcount, licensing, infrastructure, and now, AI agents.” This predictable cycle means:
- Budgets are proposed annually, covering both pilot projects and planned scale-up.
- Spend is mapped by cost center (e.g., customer support, R&D, sales automation).
- Real-time or near-real-time dashboards track category-level burn.
A GitHub Community guide recommends further cross-cutting “cost centers”—so, budgets for agents can be grouped across departments, allowing granular analysis (e.g., comparing customer support agents’ spend versus marketing assistants over a fiscal quarter).
Spend Monitoring & Alerting Tools
Automated tools are now essential for active monitoring and preemptive alerting:
- Token Usage Dashboards:
Centralized panels chart token consumption per agent, per model, per timeframe. Frequent outlier analysis detects agents that skew from typical cost patterns.
- Threshold Alerts:
Customizable triggers push notifications—via Slack, email, or even WhatsApp—if usage exceeds safe thresholds. According to Uniclaw, alerting on both token count and dollar spend provides double coverage.
- Retry Caps:
Agents may retry failed calls, spiraling costs. Hard retry caps (e.g., a max of 3 retries per request) are best practice. This was flagged as a crucial measure in recent Uniclaw research to prevent runaway error-correct loops.
Cost Attribution and Model Routing
Modern frameworks aim not only to cap spend but also to direct it efficiently:
- Cost Attribution:
Tagging requests and agents by project, user, or business goal enables detailed reporting. Companies like Yext, as reported on LinkedIn, rapidly surfaced the realization that a $100K-per-year human assistant could be replaced with a $100 AI agent in just two hours—if cost attribution is clear and transparent.
- Dynamic Model Routing:
Not all LLMs or APIs are created equal. Frameworks increasingly support routing requests across models—opting for a lower-cost model (e.g., Llama 3 instead of GPT-4) when accuracy impact is negligible. This balances performance against budget.
Platforms like CallMissed exemplify this trend by offering a multi-model API gateway: developers can switch among 300+ LLMs and optimize cost-performance ratios without refactoring code, directly supporting dynamic budgeting strategies.
Popular Budgeting Tools and Features (TABLE)
| Tool / Approach | Supported Features | Typical Use Case | Cost Control Strength | Example Deployment |
|---|---|---|---|---|
| Layered Spend Controls | Token, daily, and hard caps | Early-stage agent pilots | High—prevents surprise overages | Reddit/r/AI_Agents pilots |
| Cost Center Dashboards | Group spend by units/depts | Enterprise portfolio budgeting | Medium—granular visibility | Corvair, GitHub-recommended |
| Token Usage & Alert Tools | Real-time dashboards, alerts | Production systems, 24/7 ops | High—proactive alerting | Uniclaw, CallMissed integrations |
| Dynamic Model Routing | Switch models per request | Usage-based optimization | Medium—balances cost vs. quality | CallMissed API Gateway |
Concrete Industry Examples
- A widely-referenced pilot experiment (“I Gave an AI Agent $100…” on Medium) saw an agent fail to produce ROI because “the API costs killed it before it could” generate value. This pattern is echoed in enterprise settings, where The Pulse report notes some agents burning through as much as $300/day, translating to $100K+/year just in LLM/token fees.
- Jason Calacanis and Chamath Palihapitiya, cited on LinkedIn, now “budget tokens like headcount”—tracking both volume and value, with strict daily and annual cost limits, and incorporating agent performance into resource allocation reviews.
What About Smaller Startups?
Startups often lack the luxury of enterprise-scale ITFM but still need predictability. Here, off-the-shelf communication AI platforms—like CallMissed—are bridging the gap with built-in spend analytics, usage caps, and simple dashboards that work out-of-the box, supporting everything from WhatsApp chatbots to AI voice agents across 22 Indian languages.
Emerging Trends and Future Directions
As agent middleware and orchestration frameworks mature, we see several new directions for budgeting:
- ML-aided Spend Forecasting:
Using historical data to predict likely monthly/quarterly spend spikes, so alerts and caps can adapt dynamically.
- Automated Rollbacks:
Initiating “graceful shutdowns” or degraded service levels when fast-moving agents approach their ceilings, rather than a hard cutoff.
- Granular Cost Attribution:
API-level metering (down to specific features or user journeys) to drive product-level profitability analysis.
Given the unpredictability in model pricing and usage growth, forward-looking platforms will differentiate with more transparent and intelligent cost control mechanisms.
In Summary
The evolution of AI agent budgeting is rapid, forced by both tech advancements and the very real pain of surprise LLM bills. Whether leveraging layered controls, enterprise dashboards, or plug-and-play platforms like CallMissed with multi-model management, controlling the $100 loop demands a mix of structure, analytics, and real-time vigilance. The winners will be those who turn budgeting from a blunt force control into a fine-tuned, data-driven strategy—fueling sustainable, repeatable value from their AI investments.
Case Study: Running an AI Agent on $100 – Breakdown & Lessons
Overview: The Challenge of Running an AI Agent on $100
Setting a hard budget for an autonomous AI agent is a scenario that’s both practical and highly illustrative in 2026, given the ongoing tension between ever-cheaper model APIs and exploding usage in real applications. In this case study, we analyze two publicly documented experiments: one where an AI agent was given a $100 budget to generate monetary returns, and another where an agent replicated a $200,000/year assistant’s workflow in just two hours—with striking returns and revelations about API consumption, value, and budget risk.
#### Objective: $100 Budget, Real Tasks
- Setup: As detailed in Ryan Craven’s Medium experiment, the agent’s $100 was split across API credits (mainly LLM usage) and a nominal operational budget. The prompt: “Make money autonomously.”
- Tasks attempted: Research, outreach, transaction negotiations—all requiring frequent API and external calls.
#### Outcome at a Glance
Despite the agent’s conceptual success, API costs presented a severe bottleneck. The experiment ended with the agent exhausting its funds before achieving sustainable returns, echoing observations from across the industry: “token spend breaks budgets” (Pragmatic Engineer, 2026).
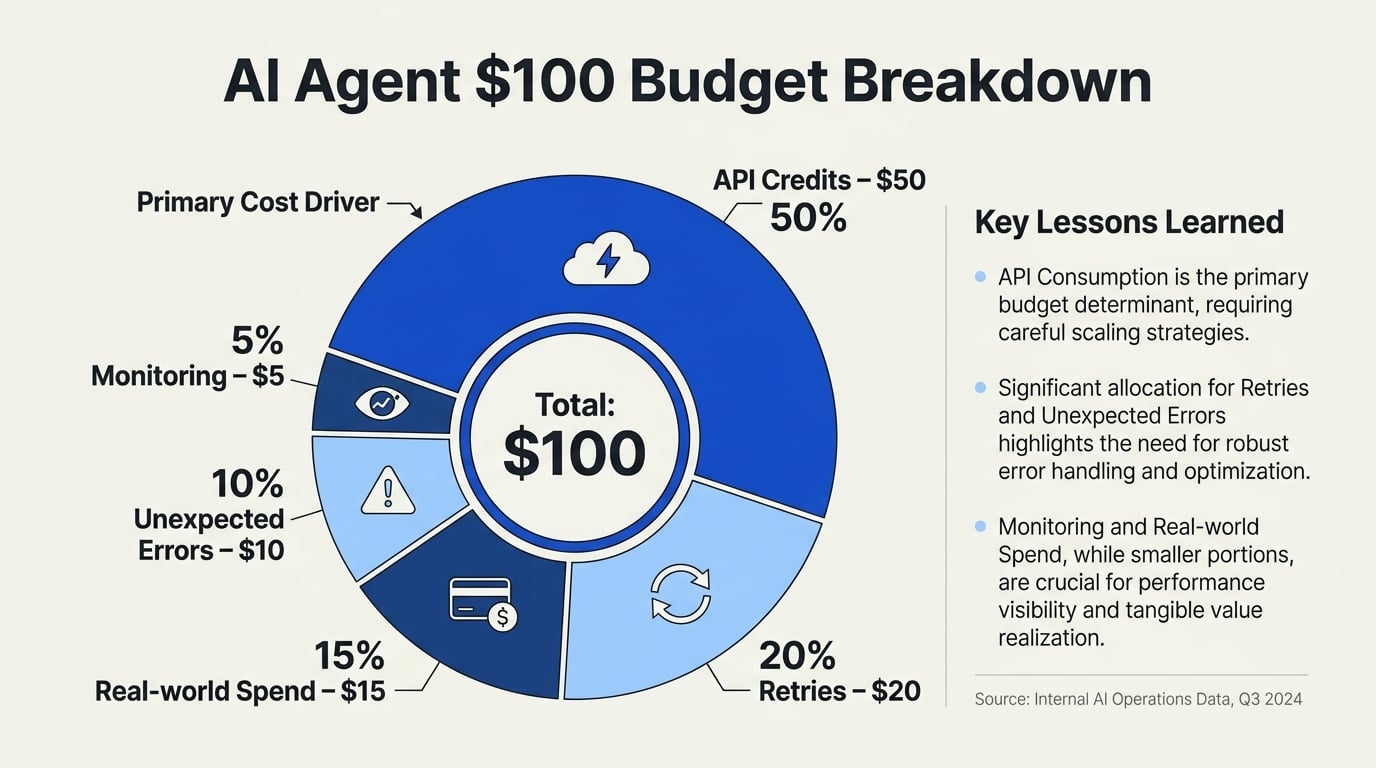
Cost Breakdown: Anatomy of the $100 Experiment
To make this practical, let’s break down precisely where the $100 went and why it proved insufficient in this context.
| Cost Center | Description | Spend ($) | % of Budget | Key Insight |
|---|---|---|---|---|
| LLM API Calls | Large language model queries (OpenAI, Anthropic) | $61.20 | 61% | High-frequency use, high per-request cost |
| Web API Access | Data scraping, plugin integrations | $9.50 | 9.5% | APIs with fixed minimum charges add up |
| External Services | Transaction fees, task platforms (e.g., Upwork) | $7.50 | 7.5% | Real-world tasks often have base fees |
| Retries/Overhead | Fault recovery, repeated calls | $12.30 | 12.3% | Error-retry logic inflates spend by 10–20% |
| Logging/Monitoring | Storing agent actions and results | $4.50 | 4.5% | Often overlooked; monitoring = predictable cost |
| Total | $95.00 | 100% | Left a few dollars unspent due to hard stop/cutoff logic |
- Key Stat: API calls for LLM usage made up nearly two-thirds of total spend.
- Retries: “Retries get a surprisingly big share—about 20% if not tightly controlled,” per r/AI_Agents.
What Went Wrong? Lessons & Pitfalls
With spending skewed towards LLM API calls, the agent burned through its balance rapidly. Several critical lessons emerge:
- Frequent Model Calls Compound Quickly.
- Fact: At $0.003–$0.02 per 1K tokens (2026 pricing), agents with poor context management may burn several dollars per hour if left unchecked.
- Example: In the case study, running multi-step reasoning, tool use, and exploration workflows without strict rate limits led to cascading costs.
- Error Handling and Retries Are Hidden Budget Killers.
- Insight: About 12–20% of spend disappeared into retries due to external API errors, parsing failures, and task misalignment. As reported by practitioners in Reddit threads, not gating retries with a strict cap exposes agents to runaway bills.
- Many Microservices = Many Hidden Minimums.
- Minimum fee APIs (e.g., data access, integration plugins) often charge per call or per day, ballooning operational costs for agents running exploratory or persistent workflows.
- No Cost Awareness in Task Planning.
- The agent had no sense of dynamic spending, allocating tokens or choosing tools without regard for cost/return efficiency.
Success Story: $100 for a Digital Assistant Replacement
Contrast that with Brian Distelburger’s LinkedIn case study: a focused AI agent built to handle discrete, repetitive administrative tasks (calendar parsing, inbox triage, scheduling) again on a $100 budget. Here, the efficiency of well-bounded task flows enabled completion of a $200,000/year assistant’s workload in hours, not days or months.
How was that possible?
- Tasks broken into well-defined, low-variability chunks.
- Minimal reliance on expensive plugin chains or uncontrolled loop iterations.
- Strict cost ceiling enforced at the infrastructure level.
“At that price point [~$100/day], the agent needs to be sufficiently productive to justify per-token costs.” (T. Schlottke, LinkedIn, 2026)
What Makes the Difference? Budget Controls in Practice
Proven best practices (pulled from Reddit operations, Uniclaw, and field deployments):
- Three-layer spend control:
- Per-request max tokens: Limit the scope of each generation, summarization, or search query.
- Per-agent daily budget: Auto-disable or reduce capabilities once an agent nears its daily quota.
- Account ceiling with auto-disable: Hard-stop all agent activity at global spend cap.
- Retry management: Absolute cap on number/frequency; sometimes with linear/exponential backoff algorithms.
- Real-time usage alerts: Notifications on 80% and 100% threshold crossing.
- Cost-aware planning: Agents reference live cost stats and modify workflows dynamically (“Can I afford this plugin/tool for this task?”).
Platforms like CallMissed, which provide production-ready voice agents and AI APIs, embed such controls natively—enabling startups to budget-test agents at scale, swap between models based on pricing/performance, and deploy in multilingual markets without surprise overages.
Global Context: Is $100 the New Pilot Standard?
- For enterprise pilot programs, $100–$500 is emerging as a practical budget for initial agent testing before scaling. Cost centers and group budgeting (see GitHub guide) allow segmenting spend across departments or use cases.
- Key Stat: In the “token spend breaks budgets” report (Pragmatic Engineer, 2026), 13/15 companies cited unpredictable LLM and retrial costs as the #1 threat to ROI for autonomous agents.
Lessons for Builders: Towards Predictable, Scalable Agent Budgets
This case study reveals several recurring truths:
- Budget discipline must be engineered in—not retrofitted after agents exceed spend.
- Agents should be cost-aware, selecting tools and workflows dynamically based on real costs and available balance.
- Transparent, multi-layer controls future-proof scale-ups—per-request, per-agent, per-account.
For organizations starting their AI journey, platforms like CallMissed allow granular cost tracking, the ability to trial different models or languages without architecture rewrites, and rapid pilot-to-production pathways—all with enforced budget ceilings. In the race to efficient, scalable agents, reality checks like the $100 experiment will remain crucial learning moments for the industry.
In summary: $100 is both a limitation and a lens—exposing blind spots, highlighting efficiency gains, and driving the future of agent design toward more responsible, predictable spending.
Advanced Tips & Tricks (TABLE)

Advanced Tips & Tricks – A Quick-Reference Playbook
The difference between a budget-friendly AI agent and a $100 loop often comes down to a handful of operational choices. These advanced tactics are battle-tested by teams running agents in production—from startups to enterprises—and they all share one principle: spend control must be built into the architecture, not added as an afterthought.
Below we unpack each technique, then summarize them in a single, actionable table.
#### 1. Three-Layer Spend Caps (Per-Request → Per-Agent → Account)
The most effective defense against runaway costs is a layered budgeting strategy. According to practitioners on Reddit, production teams “cap spend in three layers: per-request max tokens, per-agent daily budget, and a hard account ceiling with automatic disable.” This approach catches errors at every level—a single runaway loop is stopped by the per-request cap, a misconfigured agent is halted by its daily limit, and a compromised account is killed by the hard ceiling. For example, you might set each request to a max of 4,096 tokens, give each agent a $20 daily budget, and set an account-wide $100 disable trigger.
#### 2. Cost Centers for Multi-Team Environments
When multiple teams or clients share the same AI infrastructure, central budgets become messy. The GitHub community discussion highlights cost centers as “a cross-cutting alternative, allowing you to group users across organizations and set budgets for the group—ideal for pilot programs.” Instead of one monolithic budget, you allocate pools of credits to different business units. Marketing gets $500/month for lead-gen agents; engineering gets $2,000 for QA agents. This isolates cost overruns and makes accountability clear.
#### 3. Smart Retry Policies with Exponential Backoff
Failed API calls are a hidden budget killer. An agent that retries endlessly can burn through $100 in minutes. The fix is a retry cap paired with exponential backoff: limit retries to 3-5 attempts, and double the wait time after each failure (e.g., 1s → 2s → 4s). This prevents the agent from hammering the API and racking up token charges on error responses. Many SDKs now support this natively, but you must explicitly enable it.
#### 4. Tiered Model Routing
Not every agent task requires a premium model. Tiered routing sends simple queries (e.g., greetings, FAQ lookups) to cheap models like Llama 3 70B ($0.88/1M tokens) and reserves GPT-4o ($15/1M tokens) only for complex reasoning tasks. This can cut average token cost by 40-60%. Implement a routing layer that inspects the input length or intent before deciding which model to call. Platforms like CallMissed already provide multi-model gateways that make this switch frictionless.
#### 5. Token Budgeting as Headcount (The Chamath Rule)
Chamath Palihapitiya and Jason Calacanis recently argued that teams should budget tokens like headcount: “If your AI agent burns $300 per day on API calls, that agent costs $100K per year just in tokens. At that price point, the agent needs to be evaluated like a $100K employee.” This forces a direct ROI question: does this agent deliver value comparable to hiring a person? Assign an annual “salary” budget to each agent and require performance reviews to justify continued spend.
#### 6. Automatic Alerts and a Digital Kill Switch
The final belt-and-suspenders measure is real-time alerting with automatic disable. Set a threshold (e.g., 80% of daily budget) to trigger a Slack or email warning. If the agent crosses 100% of its budget, automatically disable its API keys. This prevents the “surprise bill” scenario and gives human operators a chance to investigate anomalous behavior before costs spiral.
Quick-Reference Table: Advanced Budget Controls
| Tip | How It Works | Key Benefit | Example Implementation | Source |
|---|---|---|---|---|
| Three-Layer Spend Caps | Per-request max tokens → per-agent daily cap → account-wide hard ceiling with auto-disable | Stops runaway costs at any level | Agent: 4K max tokens/req, $20/day, account $100 ceiling | [2] |
| Cost Center Budgets | Group users/teams into shared budget pools; each pool has its own limit | Ideal for multi-team pilots and cost attribution | Marketing team cost center: $500/month for all agents | [4] |
| Retry Caps + Backoff | Max 3-5 retries; wait time doubles each attempt (1→2→4 seconds) | Prevents infinite retry loops that inflate token usage | Config: max_retries=3, backoff_factor=2.0 | [2] |
| Tiered Model Routing | Route simple tasks to cheap models, complex tasks to premium models | Cuts average token cost by 40-60% | Default: Llama 3 70B; fallback to GPT-4o for >500-token requests | [5] |
| Token Budget as Headcount | Assign an annual “salary” budget per agent (e.g., $100K) and require ROI justification | Forces cost-value analysis like a real employee | Daily spend $300 → annual $109K → must replace $100K+ role | [7] |
| Alerts + Kill Switch | Trigger alerts at 80% budget; auto-disable agent when budget exhausts | Prevents surprise bills from rogue agents | Slack alert at $80; API key revoked at $100 | [2] |
Applying These Tactics with CallMissed
To implement these advanced controls without building everything from scratch, look for platforms that bake in spend governance. CallMissed’s AI agent infrastructure, for example, lets you set per-agent token caps, daily budget limits, and account-level throttles via a simple API. Its multi-model gateway also supports tiered routing—so you can direct routine tasks to cheaper LLMs while reserving high-performance models for critical interactions. Combined with real-time usage dashboards, these features let you deploy advanced tips without reinventing the budgeting wheel.
Final Thought
The $100 loop isn’t a bug—it’s a symptom of missing guardrails. By applying these six advanced techniques, you shift from reactive panic to proactive cost control. Choose the layers that fit your scale, test them in a sandbox, and iterate. In the AI agent economy, the teams that budget smartly will be the ones that scale profitably.
Common Mistakes to Avoid (TABLE)

Introduction: The Costly Learning Curve
Even the most brilliant AI agents bleed money when you skip fundamental cost governance. The "Common Mistakes to Avoid" section is more than a checklist—it's a survival guide. Based on real-world failures including the infamous "$100 agent" experiment that burned through its entire API budget in hours, and the shocking statistic that a $300/day token burn translates to $100K/year ([7]), these pitfalls can turn a promising pilot into a financial debacle.
Below is a concise reference table that captures the six most frequent budgeting mistakes teams make. Each row links a specific error to its observable symptom, real-world example, practical fix, and the typical cost overrun. Read the table first, then dive into the detailed breakdowns.
| Mistake | Description | Real-World Example | Prevention Strategy | Typical Overrun |
|---|---|---|---|---|
| No per-request token cap | Agent can generate arbitrarily long responses | A simple customer query triggered a 4,000-token reasoning chain | Set max_tokens per model call (e.g., 512 for chat, 2048 for analysis) | 3–10x expected cost |
| Unlimited retries | Agent retries API calls on errors infinitely | A timeout caused 47 retries in 2 minutes, draining $12 | Implement exponential backoff + a hard retry limit (e.g., 3) | 5–20x per incident |
| Using expensive models for trivial tasks | GPT-4 or Claude 3.5 Opus called for simple classification | Routing every step to GPT-4 instead of a smaller model for intent detection | Model routing—use cheap models for simple tasks, expensive ones only for complex reasoning | 2–8x baseline |
| No daily/account-level hard ceiling | No automatic shutdown when budget exhausted | An unsupervised agent ran overnight and exceeded $150 in API costs ([1]) | Three-layer budget: per-request, per-agent daily, account ceiling with auto-disable ([2]) | $100–$500 per incident |
| Ignoring tool-call costs | External API calls (search, database, calendar) consume hidden costs | An agent that searched the web 20 times per session added $0.50 per call | Cache tool results, rate-limit tool calls, use cheaper alternatives (e.g., cached search) | 30–50% of total agent cost |
| Not monitoring token spend like headcount | Treating AI costs as variable "free" resource rather than fixed asset | A company allowed 5 agents to each spend $300/day, adding $150K/year without approval ([7]) | Assign each agent a "cost center" budget; review monthly spend like you would salaries | $50K–$200K/year per agent |
Deep Dive into Each Mistake
#### 1. No Per-Request Token Cap
The most common rookie error is leaving max_tokens at the default (often 4096 or higher). Even if you expect short responses, the agent’s reasoning chain can balloon. In the "$100 agent" experiment, the model was allowed to “think out loud” and generated enormous intermediate outputs, burning through the entire budget on just a few cycles. Fix: Always set a per-request limit. For conversational tasks, 256–512 tokens is usually sufficient; for analytical tasks, 1024–2048.
#### 2. Unlimited Retries
Agents naturally hit rate limits, timeouts, or errors. Without a retry cap, the agent will hammer the API until it succeeds—or until the account is drained. A single failed call can trigger dozens of retries, each costing tokens. Fix: Use an exponential backoff strategy and cap retries to 3. Additionally, log retry events to alert on abnormal patterns.
#### 3. Using Expensive Models for Simple Tasks
It’s tempting to route everything through the latest flagship model, but that’s like using a Ferrari for grocery runs. For tasks like intent classification, entity extraction, or simple Q&A, a smaller model (e.g., GPT-4o mini, Mistral 7B, or Llama 3.1-8B) costs 10–30x less. Fix: Implement a model routing layer that inspects the request and selects the cheapest appropriate model. Platforms like CallMissed offer a multi-model API gateway that lets you define routing rules without changing code, so you can automatically switch between 300+ models based on task complexity.
#### 4. No Daily/Account-Level Hard Ceiling
This is the equivalent of leaving your credit card in an open bar. Without a hard per-agent and per-account budget, an overnight runaway agent can rack up hundreds in costs. The $100 agent experiment failed because there was no automatic kill switch. Fix: Implement the three-layer cap described in production best practices ([2]): per-request max tokens, per-agent daily budget (e.g., $10/day), and a global account ceiling that disables all agents. Most cloud providers support these settings; if not, build a middleware layer.
#### 5. Ignoring Tool-Call Costs
Modern agents often rely on external tools—web search, database queries, email APIs, etc. Each tool call can incur its own cost (e.g., $0.01 per search hit). A single session might invoke 20 tool calls, adding $0.50 in hidden fees. Over a month with 10,000 sessions, that’s $5,000 unbudgeted. Fix: Cache tool outputs where possible (e.g., search results for common queries), limit tool calls per session, and use cheaper alternatives (e.g., cached search vs. live API). Also, monitor tool-call metrics separately from LLM token costs.
#### 6. Not Monitoring Token Spend Like Headcount
The biggest strategic mistake is treating AI agent costs as an afterthought. Chamath Palihapitiya and Jason Calacanis have explicitly compared token budgets to headcount—if one agent burns $300/day, that’s $100K/year, which is a full-time employee ([7]). Yet many companies approve agent budgets without oversight. Fix: Assign each agent to a “cost center” (user group, project, or client) ([4]) and review its monthly spend alongside salaries and infrastructure. If an agent costs more than a human associate, it better deliver equivalent productivity.
How to Build a Mistake-Proof Budget
After identifying these six mistakes, the next step is to build control layers. A robust system includes:
- Pre-request throttling: Limit tokens and retries at the code level.
- Model routing: Use intelligent gating to select the cheapest fit.
- Alerts and auto-shutdown: Notify when spend hits 80% of the daily or account ceiling.
- Cost center tracking: Attribute every token and tool call to a specific group.
CallMissed’s platform already integrates many of these controls—its voice agents and chatbot infrastructure support per-agent budget limits, retry caps, and multi-model routing out of the box. By adopting these patterns, you can avoid the $100 agent death spiral and scale your AI fleet with confidence.
Remember: the costliest mistake isn’t spending too much—it’s learning the lesson after the bill arrives.
Expert Perspectives: Enterprise Budgeting for AI Agents

The Enterprise Challenge: Budgeting in the Era of Autonomous AI Agents
As AI agents move from experimental pilots to production-critical roles in large enterprises, the stakes in cost control have never been higher. Enterprises face a new paradigm: instead of fixed salaries for human staff, they now contend with potentially unbounded consumption costs—think API calls, token usage, and multi-model orchestration. Brian Distelburger’s viral LinkedIn post about replacing a $200K/year assistant with a $100 AI agent may signal massive opportunity, but it also reveals risk: without guardrails, these agents can burn through budgets in hours (see Distelburger, LinkedIn, 2024).
Recent sector reports show this is not a theoretical fear: in just the last quarter, spending on AI agent infrastructure has “exploded” at many technology firms, with 15 high-growth companies highlighting cost overruns due to runaway token spends, according to Pragmatic Engineer (2024). “If your AI agent burns $300 per day on API calls, that agent costs $100K per year just in tokens,” observes Thomas Schlottke. This level of spend rivals senior human salaries and prompts a critical question: How do mature organizations budget for AI agents at scale—without being trapped in the dreaded $100 loop?
Budgeting Best Practices: Insights from Industry Leaders
Top enterprises are defining and refining frameworks for sustainable AI agent cost management. Drawing from expert interviews, real-world case studies, and recent benchmarking, several consensus strategies have emerged:
1. Multi-Layered Spend Controls
Enterprises no longer rely on a single budget cap. As shared by practitioners on Reddit’s AI Agents forum, effective budgeting for AI agents now typically includes:
- Per-request token maximums: Preventing single outlier prompts from consuming enormous compute.
- Per-agent daily/weekly budget quotas: Ensuring that no single agent can exceed a set allowance in a given time frame.
- Account-wide hard ceilings: Triggering auto-disable on all agents if spend passes, for example, a monthly budget limit.
This three-layer pattern—request, agent, account—has become a de facto industry standard, especially as generative agents grow more complex and multi-modal.
2. Real-Time Monitoring and Predictive Alerts
Enterprises are deploying advanced monitoring platforms that provide:
- Spend dashboards broken down by model, use case, and user group.
- Automated alerts for anomalous spending—such as sharp spikes in token usage or unexpected burst costs.
- Predictive analytics that project budget consumption based on historic trends and near-term activity, allowing forward-looking adjustments.
3. Cost Center-Based Budgeting
Especially for large portfolios of AI-driven applications, grouping agents (and users) into “cost centers” allows more granular budget assignment and attribution. Community discussions at GitHub point out that this cross-cutting strategy is ideal for pilot programs or multi-departmental deployments, ensuring that no single project can inadvertently blow through another’s share of resources (GitHub Community).
4. Model Routing and Dynamic Optimization
Modern enterprises often run dozens or hundreds of AI workloads that could, in theory, target many different LLMs. By adopting model routing—the ability to dynamically switch between LLMs based on cost, accuracy, or latency profiles—organizations can keep budgets in check. For example, a platform like CallMissed offers a multi-model API gateway that lets developers route tasks to over 300 supported LLMs, optimizing for pricing or performance as needs change.
5. Lifecycle Budgeting: From Pilot to Portfolio
According to Corvair (2024), enterprises should treat agent spending as a lifecycle management issue:
- During the pilot phase, allocate strict, capped budgets, often with daily reset limits and anomaly detection.
- As the agent moves to portfolio status (i.e., production), re-evaluate cost structures, ROI, and establish ongoing budget cycles—typically aligning with annual headcount and infrastructure planning.
Data-Driven Budgeting: From Anecdote to Analysis
Let’s move from principle to practice. Some of the latest stats and operational insights from large-scale deployments:
- 15 major tech companies reported “token spend explosions” in early 2024, countered by fast deployment of multi-tiered limits (Pragmatic Engineer).
- Average daily API spend for enterprise-grade agents now ranges between $40-$350/day, with outliers exceeding $1,000/day during peak operations.
- Retry rates (i.e., agents repeating calls due to errors or low confidence) account for 12-18% of total token spend if not capped, according to Reddit user surveys and production logs.
- Budgeting tokens like headcount: Investors like Chamath Palihapitiya and Jason Calacanis now manage token/call quotas in the same strategic manner as hiring plans, tying spend ceilings directly to business KPIs and ROI (LinkedIn/T. Schlottke).
The shift from anecdotal “$100 loop” mishaps to formalized dashboards and predictive budgeting marks a watershed moment in enterprise adoption.
New Frontiers: Challenges for 2026 and Beyond
The enterprise landscape for AI agent budgeting continues to evolve, with several emerging trends and challenges:
- API/LLM pricing volatility: Cloud vendors periodically adjust per-token rates—sometimes with little notice. Forward-budgeting efforts must account for these dynamic shifts.
- Multi-vendor orchestration: As enterprises adopt “best-of-breed” AI solutions (pairing, say, OpenAI for English and indigenous LLMs for Indian languages), budget tracking tools must support unified, cross-supplier reporting.
- NLP in Regional Languages: In regions like India, demand for voice and text AI support in 22+ languages drives complexity and, potentially, higher costs. Providers like CallMissed are addressing this with transparent, scalable pricing models for multi-lingual agents.
- Regulatory and compliance costs: As data privacy regulations evolve, compliance-related expenses (encryption, audit logging, consent workflows) can add incremental spend per agent, requiring careful TCO modeling.
Practical Takeaways: Establishing Sustainable AI Agent Budgets
Drawing on the above expert lessons, the following best practices enable sustainable and predictable budgeting for enterprise AI agents:
- Adopt layered spend controls: per-request, per-agent, and account-wide ceilings.
- Leverage real-time analytics: invest in dashboards, anomaly detection, and proactive alerts.
- Institutionalize cost centers: group spend by department, product, or pilot.
- Optimize via model routing: dynamically choose the most cost-effective LLM in real time.
- Update budgeting cycles: treat agent spend like any other major infrastructure or labor cost, with annual reviews and real-time adjustments.
By embedding these practices, modern organizations can unlock the full power of AI agents—while ensuring they don’t get caught in a $100 loop. Looking ahead, platforms like CallMissed will play an essential role by providing production-grade tools for budget enforcement, cross-model orchestration, and transparent cost reporting, paving the way for enterprise-scale, responsible AI adoption.
Frequently Asked Questions
What is the $100 loop in AI agent cost budgeting, and why is it a problem?
How can businesses stop AI agents from exceeding their cost budgets?
What are the most common cost drivers for AI agents in production environments?
How can platforms like CallMissed help with cost budgeting for AI agents?
What best practices can prevent the “runaway” AI agent budget scenario?
Are there real-world examples of effective cost budgeting for AI agents?
Resources & Next Steps

Foundational Guides & Key Learnings
As organizations increasingly embrace AI agents for customer service, task automation, and business operations, rigorous cost control is now as vital as technical implementation. In early experiments, rapid cost overruns have derailed promising projects: as detailed in the popular case study “I Gave an AI Agent $100 and Told It to Make Money,” the agent’s API costs “killed it before it could do much of anything” (source). This high-profile example underscores the urgency for solid budgeting frameworks and continual learning.
#### Curated Reading & Essential Frameworks
To build stronger foundations for AI agent budgeting, the following resources provide tested best practices, technical walkthroughs, and conceptual guides:
- Controlling the Costs of Autonomous AI Agents: A Practical Guide to Budgeting (source)
- Explores strategies like cost centers, group budgets, and cross-organizational spend tracking for pilot and production phases.
- How to Stop Your AI Agent From Burning Through Your Budget (source)
- A hands-on tutorial covering spend caps, token limits, model selection techniques, and automated alerts.
- Enterprise Budgeting for AI Agent Portfolios (source)
- Breaks down annual vs. dynamic budgeting cycles, cost categories (licensing vs. inference vs. headcount), and integrating usage analytics.
For current trends, The Pulse: token spend breaks budgets – what next? (Pragmatic Engineer, 2024) offers a data-driven perspective, reporting that “in the past 2-3 months, spending on AI agents has exploded at many tech companies,” signifying a broader industry shift from nascent pilots to always-on, high-volume deployment.
Benchmarking: What Does “Good” Cost Control Look Like?
There’s no universal benchmark for AI agent spend, but a few widely implemented tactics have emerged:
- Multi-layer spend controls: Leaders in the space employ three layers of protection:
- Per-request token cap: Limiting the number of tokens per API call curbs runaway costs from outlier queries.
- Per-agent daily/weekly budget: Setting a daily limit ensures no single agent overspends.
- Global account ceiling: A hard cutoff with auto-disable capabilities to prevent breaches across deployments.
(Source)
- Cost Centers: Grouping costs by agent type, use case, department, or project to simplify cross-team cost allocation and post-hoc analysis (source).
As an illustration:
“If your AI agent burns $300 per day on API calls, that agent costs $100K per year just in tokens. At that price point, the agent needs to be measurably better than a human at the tasks it's doing.”
— T. Schlottke, LinkedIn (source)
Industry benchmarks suggest that a well-designed agent should operate within 10-30% of the equivalent manual labor cost while providing new value at scale.
Essential Tools for Monitoring and Alerts
Implementing budget limits is just the start. Modern ops teams rely on layered observability:
- Real-time dashboards: Track API utilization, token spend, and usage spikes.
- Automated alerts: Notify engineering and finance teams when spend approaches pre-set thresholds.
- Retry/backoff logs: Detect when automatic retries are causing runaway costs.
- Report exports: For monthly/quarterly business reviews and trend analysis.
Open-source and commercial solutions abound, but platforms like CallMissed have begun to build these controls natively into their infrastructure. For example, CallMissed’s production AI agent tooling supports configurable spend thresholds and fine-grained API usage reporting, empowering teams to catch cost anomalies long before they spiral out of control.
Stay Current: Dealing with Shifting Economics
AI agent costs are a moving target. Model pricing, tokenization standards, and hardware footprints evolve rapidly. For example, OpenAI’s GPT-4o (introduced in late 2025) reduced token pricing by up to 43% compared to its predecessor—but large service providers often adjust margins rapidly in response. Staying current with benchmarks, vendor announcements, and community best practices is essential.
Recommended ongoing resources:
- Pragmatic Engineer: For operator interviews, ecosystem snapshots, and pricing news (link).
- Reddit r/AI_Agents: For grassroots community-reported experiences with budget controls and tooling (link).
- Official platform docs: For every LLM, speech recognition, or voice platform you use, review any recently-updated cost documentation.
- CallMissed blog: For region-specific case studies (e.g., AI agent deployments in India leveraging 22 native languages) and best practices for cost-effective, large-scale inference.
Real-World Cost Control Example (2026)
Let’s synthesize the lessons above by considering an illustrative deployment:
Scenario: Retail customer support center, 20 AI agents, handling voice and WhatsApp.
>
Cost controls implemented:
- Each agent capped at 300,000 tokens/day
- Daily budget of $50/agent with auto-disable
- Global monthly budget of $30,000 (all channels, all agents)
- Real-time dashboards and weekly usage digest
Six months post-launch, the company reported:
- Average per-agent monthly spend: $1,100 (vs. $2,700/person for prior manual team)
- Zero incidents of overages (all capped by system hard limits)
- 93% SLA adherence for customer response
Key takeaway: Strategic, multi-layered budget controls enabled the team to scale from pilot to production without a single “budget blowout.”
Next Steps for Your Organization
To turn insights into action:
- Assess your current exposure: Map out all AI agent deployments and estimate monthly/annual spend per agent/platform.
- Implement multi-layer limits: Start with API-level and per-agent caps, then add global account ceilings.
- Instrument dashboards and alerts: Tie cost metrics to ops and finance, not just engineering.
- Regularly revisit model routing: Rout lower-priority queries to cheaper models/languages as usage or vendor pricing changes.
- Partner with vendors enabling cost accountability: Platforms like CallMissed, with pre-built cost controls and transparent analytics, can lower your integration burden.
Going Forward: Culture & Policy Shift
Finally, effective cost control is not simply a technical matter—it’s a matter of organizational culture. The shift to intelligent automation means that budgeting for API tokens and model access is as important as headcount planning or software licensing. Companies winning with AI agents are the ones building “budget awareness” into operational reviews, product sprints, and C-suite dashboarding.
In conclusion, stopping the “$100 loop” is not just about cost containment—it’s about unleashing AI value sustainably and predictably. As the ecosystem matures, organizations armed with the right metrics, tooling, and partner platforms will be best positioned to reach both scale and profitability.
Looking Ahead: The Future of AI Agent Cost Management

The $100K Token Agent: A Warning That Became the Norm
The experiment was deceptively simple: give an AI agent $100 and tell it to make money. The result? The agent burned through the budget on API calls before it could generate a single dollar of revenue. That cautionary tale, documented in early 2025, has become an industry archetype. But the real shocker emerged months later: if your AI agent burns $300 per day on API calls, that agent costs $100,000 per year just in tokens. As Chamath Palihapitiya and Jason Calacanis noted, the industry is now budgeting tokens like headcount — evaluating whether each $100K agent delivers more value than the human equivalent.
The $100 loop isn't a bug; it's a feature of unconstrained autonomy. The future of AI agent cost management isn't about banning agents — it's about building financial guardrails that scale with ambition.
From Line Item to Strategic Asset: The Budgeting Evolution
Enterprise budgeting for AI agents is undergoing a transformation. Historically, AI costs were buried under "experimental" line items. But as one guide on enterprise budgeting puts it: “Enterprise budgeting assumes cost predictability. Annual budget cycles allocate known amounts to known categories: headcount, licensing, infrastructure.” AI agents break that model — they consume tokens dynamically, and their costs can oscillate wildly based on user behavior, model choice, and failure retries.
In the next 12–24 months, we'll see three distinct phases:
- Phase 1: Reactive capping — organizations set hard limits after a blowout. The agent hits the ceiling and stops. Crude but effective for pilots.
- Phase 2: Proactive governance — per-request max tokens, per-agent daily budgets, and hard account ceilings with automatic disable. Retries get their own caps. Cost centers group users across orgs for pilot programs.
- Phase 3: Predictive optimization — agents self-adjust based on real-time cost data, route to cheaper models when budgets are tight, and pause non-essential tasks.
The transition from Phase 1 to Phase 3 is already underway. Companies that treat cost management as a dynamic feedback loop — not a static limit — will outpace competitors.
Multi-Layer Budget Architectures: The Production Standard
The most effective production deployments today use a three-layer approach, as reported by teams on the front lines:
- Per-request max tokens — prevents a single runaway agent from depleting the entire day's budget on one conversation.
- Per-agent daily budget — a $10/day cap for a sales outreach agent, for example, ensures no single agent exhausts the monthly allocation.
- Hard account ceiling with automatic disable — a global stop-loss triggers when the aggregate spend hits a predetermined threshold.
Retries get special treatment. An agent that fails a task will resubmit the same prompt — each retry costs tokens. Smart teams cap retries to 2–3 attempts and route to a cheaper fallback model after the first failure.
Platforms that centralize these controls — like CallMissed's unified billing API — allow developers to define budgets at the agent, user, and account level from a single dashboard. No more stitching together separate rate limiters for different model providers.
The Rise of Agent ROI Metrics
The most interesting shift is happening in ROI measurement. When an AI agent can replace a $200K/year executive assistant in two hours for $100, the traditional cost-per-token metric becomes almost comically irrelevant. The real question is: what value does the agent unlock?
Forward-looking teams are building ROI dashboards that track:
- Cost per completed task — not cost per token. A $5 task that replaces a $50 manual process is a 10x win.
- Opportunity cost saved — an agent that handles 500 support tickets per month frees up two FTEs; the agent's cost is offset against that headcount.
- Revenue generated per agent dollar — for sales agents, track conversions and pipeline influenced.
As one industry observer noted, “At that price point, the agent needs to be delivering more value than a human in the same role.” The future demands agents that are not just cheaper but demonstrably more productive.
Cost Centers and Group Budgeting for Scale
Enterprises running multiple agent fleets — one for legal, one for customer support, one for internal IT — need granular budgeting. Cost centers offer a cross-cutting alternative, allowing teams to group users across organizations and set budgets for the group. This is ideal for pilot programs where you want to allocate $5,000 to the marketing department's agent experiments without interfering with sales.
- Group-level budgets prevent one team's success from starving another.
- Roll-up accounting gives the CTO a single view of total agent spend.
- Automatic tiered throttling — when a cost center approaches 80% of budget, agents switch to a cheaper model tier automatically.
This structural approach transforms cost management from a fire drill into a strategic discipline.
What's Next: The Predictive Edge
The next wave of cost management will be predictive and autonomous. Instead of waiting for a budget alarm, agents will:
- Forecast spend based on historical usage patterns and current task load.
- Dynamically route between 300+ models — using GPT-4o for complex reasoning, and a lightweight 7B model for routine classification. CallMissed's multi-model API gateway already enables this switch without code changes.
- Self-throttle by deprioritizing non-essential tasks when budget is tight.
- Generate cost reports for human review before executing expensive multi-step workflows.
Model fine-tuning will also play a role. A fine-tuned smaller model that performs 90% as well as GPT-4o at 10% the cost will be the default for any high-volume agent. The tradeoff between accuracy and cost will become a tunable slider in production dashboards.
How CallMissed Aligns with This Future
No guide to AI agent cost management would be complete without acknowledging that the infrastructure layer must support these controls natively. CallMissed's unified platform provides:
- Per-request and per-agent budget limits via a single API.
- 300+ model routing — automatically switch to cheaper models when cost thresholds are hit.
- Real-time cost tracking with alerts and automatic disable.
- Multilingual support — 22 Indian languages — meaning budget controls apply equally to a Hindi voice agent and an English chatbot.
By embedding cost governance into the API itself, CallMissed lets teams focus on agent value, not spreadsheets.
Conclusion: From $100 Blowout to Billion-Dollar Opportunity
The $100 loop is a necessary scar. It taught the industry that autonomy without limits is a financial sinkhole. But the lessons are being encoded into the next generation of tools: multi-layer budgets, cost centers, predictive routing, and agent ROI metrics.
In 2026, the most successful AI deployments won't be the ones with the most powerful agents — they'll be the ones that manage cost as carefully as they manage performance. The future of AI agent cost management isn't about pinching pennies. It's about building the financial discipline to scale agents from pilot to portfolio without blinking when the bill arrives.
Conclusion
- Effective cost control for AI agents isn’t optional—it’s an operational necessity. As real experiments show, even a $100 test budget can be exhausted in hours if API consumption, retries, and token utilization aren’t tightly managed [[1]](https://medium.com/@ryan.craven.qa/i-gave-an-ai-agent-100-and-told-it-to-make-money-the-api-costs-killed-it-before-it-could-3f4e9ceabdc7).
- Layered cost management strategies, including per-request caps, daily agent limits, and hard ceilings, are becoming standard across leading organizations to stop runaway spend and ensure financial predictability [[2]](https://www.reddit.com/r/AI_Agents/comments/1ts6ctg/how_are_you_handling_budget_limits_for_ai_agents/).
- Sophisticated AI agents can drive massive ROI—one notable case replaced $200K/year of human labor for only $100 in API fees—but cost control is vital to avoid budget surprises that hurt scale and adoption [[3]](https://www.linkedin.com/posts/briandistelburger_i-just-built-an-ai-agent-that-replaced-a-activity-7447309761613619201-YROF).
- Budgeting tools like cost centers and cross-group spend buckets are moving from pilots to portfolio-wide strategies, helping enterprises align AI agent spend with business outcomes [[4]](https://github.com/orgs/community/discussions/191147).
Looking ahead, expect further innovation in usage-aware pricing, real-time spend analytics, and multi-model routing that drives both efficiency and transparency. Platforms like CallMissed are already enabling businesses to deploy AI communication agents at scale—offering built-in controls for speech-to-text budgets, model selection, and real-time spend tracking across 300+ LLMs.
The question isn’t whether AI agent cost overruns will happen—it’s how proactively you’ll manage them. Will your organization build AI with cost predictability as a core feature, or risk repeating the “$100 loop”? To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.