Load Balancing AI Workloads: Routing Across Providers

A 2026 guide to load balancing AI workloads — gateway patterns, multi-provider failover, latency-aware routing, caching, cost guardrails, and observability.
LLM providers go down. Rate limits hit. Regional latency spikes. New models ship and old models deprecate. By 2026 most production AI systems have stopped pretending a single provider is enough — the question has shifted from "which provider?" to "how do I route across providers reliably?"
Why route at all
A typical 2026 production system needs at least three properties no single provider gives:
- Failover — when OpenAI is rate-limited or Anthropic has an incident, requests route to the working provider
- Cost optimization — different models for different request shapes, with the cheapest competent option chosen automatically
- Latency control — route to the regionally-closest endpoint or the lowest-loaded one
- Vendor diversification — exposure to a single provider's pricing changes or policy decisions is a real risk
The architectural answer is an LLM gateway — a unified API in front of multiple providers.
What a gateway gives you
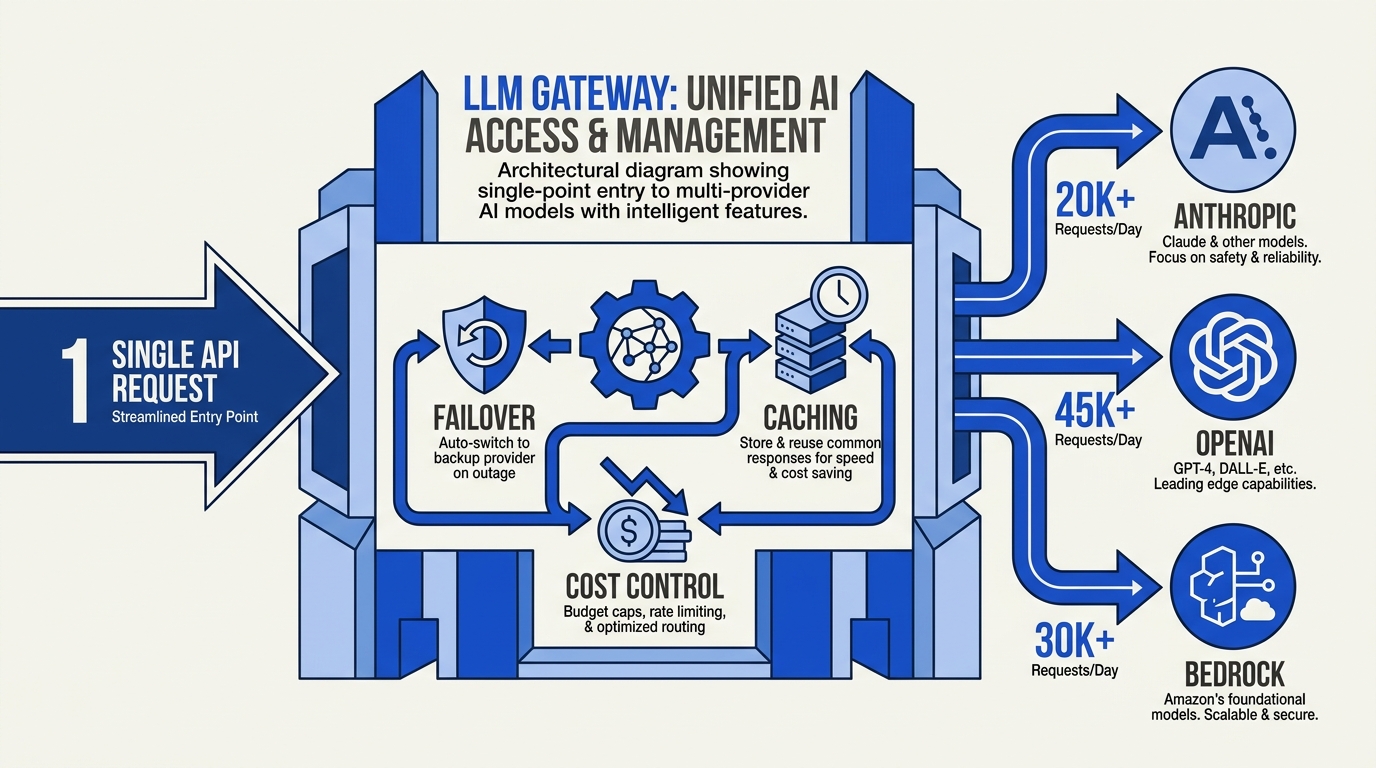
Modern LLM gateways act as a unified control plane. Core capabilities (Maxim's 2026 gateway roundup):
- Multi-provider routing — one OpenAI-compatible API in front of OpenAI, Anthropic, Bedrock, Vertex, Mistral, Groq, Cohere, Cerebras, Ollama, etc.
- Automatic failover — fallback chains: try Anthropic Sonnet → if 429 try GPT-4o → if 5xx try Bedrock Claude
- Cost governance — budgets and limits per tenant, alerts on overruns
- Caching — semantic and exact-match
- Observability — request/response logging, cost attribution, latency tracking
- Access control — per-team API keys with policies
Leading gateway options in 2026
[Unverified — landscape shifts; verify before committing]
- LiteLLM — Python-first, OpenAI-compatible, OSS, the de facto standard for "I want a gateway in code." Trade: Python overhead adds latency under load.
- Bifrost — Go-based, reportedly adds ~11 microseconds of overhead per request at 5,000 RPS. (Maxim)
- Cloudflare AI Gateway — managed, edge-deployed, no infra. Caching, rate limiting, analytics, fallbacks built in.
- Kong AI Gateway — enterprise API-management vendor with AI extensions. Right when you already run Kong.
- OpenRouter — hosted aggregator of 100+ models behind one OpenAI-compatible API. Easiest path; you do not run anything.
Routing strategies

A gateway is only as smart as the routing logic you configure. The strategies that matter:
Static priority (failover chain)
Primary: anthropic/claude-3.5-sonnet
Fallback 1: openai/gpt-4o
Fallback 2: bedrock/claude-3.5-sonnet (different account, different region)Simple, deterministic, easy to reason about. Good default for most workloads.
Weighted load balancing
Send 70% to provider A, 30% to provider B. Useful for canarying a new model or splitting cost between two accounts.
Latency-aware routing
Probe each provider periodically; route to the one with lowest p95 latency. Re-evaluates on health-check intervals.
Context-aware routing
Route based on request properties — small prompts to a small model, large reasoning to a large model, code to a code-specialized model. This is model cascading dressed up as routing.
Multi-key load balancing
Spread requests across multiple API keys for the same provider. Smooths throughput when per-key rate limits are tighter than your aggregate demand. Especially useful for high-volume teams hitting Anthropic or OpenAI rate-limit ceilings. ([Maxim])
Health checks and failover
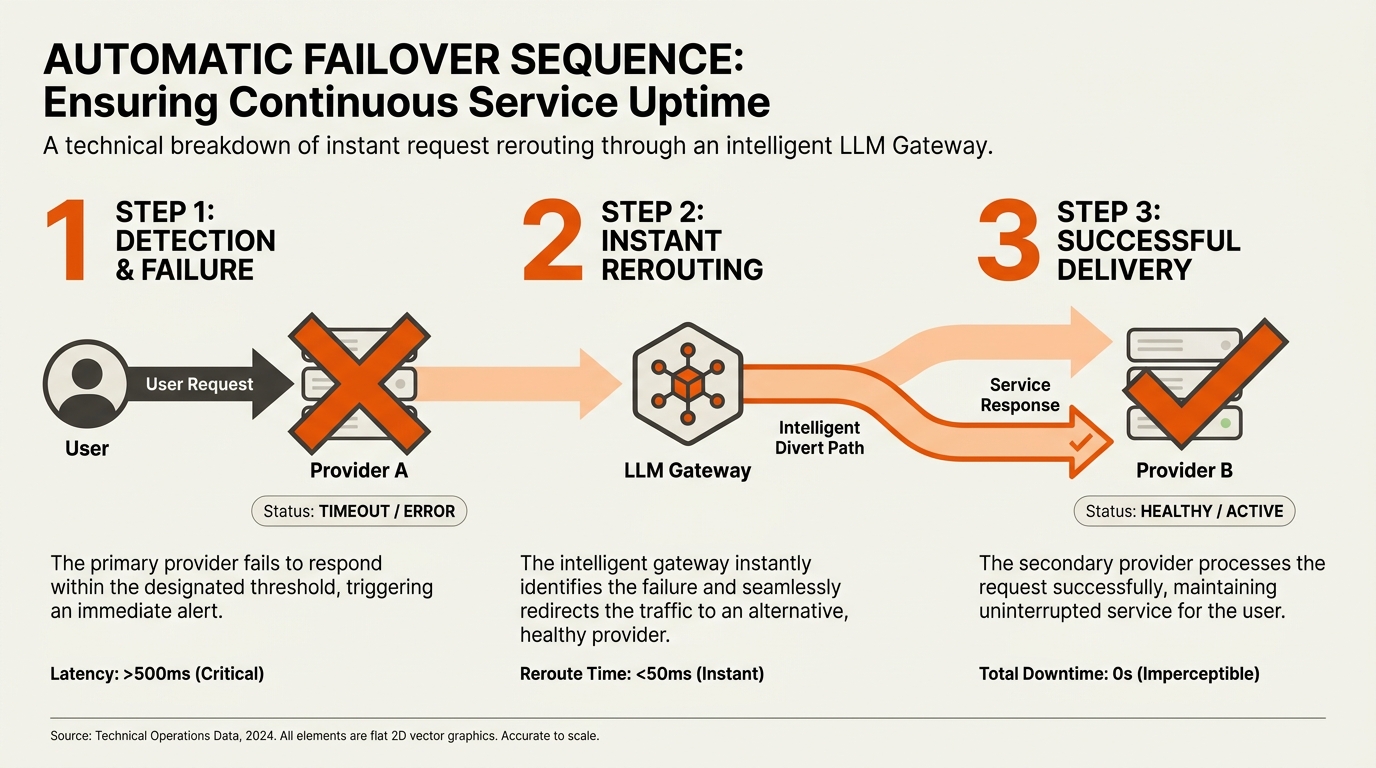
A failover chain is only useful if it triggers correctly. Two approaches:
- Reactive — failover only on observed errors (429, 5xx, timeout). Cheaper, but the first user of an outage takes the hit.
- Active — periodic synthetic probes (a small known-good prompt) verify each provider is healthy. Failover triggers before user requests fail.
For low-traffic systems, reactive is usually fine. For high-stakes user-facing systems, run active probes every 30–60 seconds and pre-emptively shift traffic when a provider degrades. [Inference]
Caching at the gateway layer
Two flavors:
- Exact-match caching — same prompt (full hash match) returns cached response. Useful for repeated identical queries.
- Semantic caching — embedding similarity above a threshold returns the cached response. Useful for paraphrased queries; risky when small wording differences should produce different answers.
Cache TTL is the knob most teams under-tune. Too short and the cache barely helps; too long and you serve stale answers when source data changes. Sensible defaults: 5–15 minutes for chat, hours-to-days for static-knowledge queries. [Inference]
Cost guardrails
A gateway should let you set per-tenant or per-feature budgets. Common patterns:
- Hard budget cap — at $X spent in the period, the gateway rejects requests with a 429-style error
- Soft alert — at 80% of budget, send a webhook or page
- Per-user rate limits — combined with budgets; abuse-resistance and cost control in one
Without these, a single misbehaving feature (a runaway agent loop, a leaked API key) can torch a month's budget overnight.
Observability
A gateway is your single best place to instrument LLM calls. Capture per request:
- Provider, model, route taken (primary or fallback?)
- Input tokens (cached vs uncached), output tokens, total cost
- TTFT, total latency
- Tenant / user / feature attribution
- Cache hit type (exact, semantic, none)
Send this to your usual observability stack (Prometheus, Datadog, Honeycomb, etc.). The visibility a gateway gives you is, in many teams, more valuable than the routing itself.
When NOT to use a gateway
- Very low volume — gateway overhead and operational complexity outweigh benefits below ~100K requests/month.
- Single-provider mandate — if your security or contractual constraints lock you to one provider, much of the gateway's value evaporates.
- Latency-critical real-time — every gateway adds some hop; for sub-100ms TTFT requirements, evaluate whether the gateway latency is acceptable.
Bottom line
In 2026, an LLM gateway is the closest thing to a free architectural win. You get failover, cost control, observability, and provider diversification for the price of one additional service hop. Start with a managed option (Cloudflare AI Gateway or OpenRouter) if you do not want to operate infrastructure; move to LiteLLM or Bifrost when you need self-hosted control.
Frequently Asked Questions
Do I need a gateway if I only use one provider?
What's the latency overhead of an LLM gateway?
Should I use LiteLLM or a managed service?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.