vLLM vs TGI vs SGLang: Inference Engines Compared

A 2026 comparison of vLLM, TGI, and SGLang inference engines — PagedAttention, RadixAttention, throughput, and which engine fits which production workload.
If you self-host an LLM, the inference engine is the single highest-leverage piece of infrastructure you choose. By 2026 the decision has narrowed: most teams pick vLLM, some pick SGLang for prefix-heavy workloads, and TGI has entered maintenance mode. Here is the picture.
TGI: end of an era
Hugging Face's Text Generation Inference was the default OSS inference server for years. As reported in late-2025 announcements summarized by industry blogs, TGI entered maintenance mode in December 2025, with Hugging Face recommending vLLM or SGLang for new deployments. (premai 2026 comparison) [Unverified — secondhand source]
What this means in practice:
- TGI still works for existing deployments
- New optimizations (FP8 kernels, latest sampling algorithms) land in vLLM and SGLang first
- For new builds in 2026, TGI is no longer the default choice
vLLM: the broad default
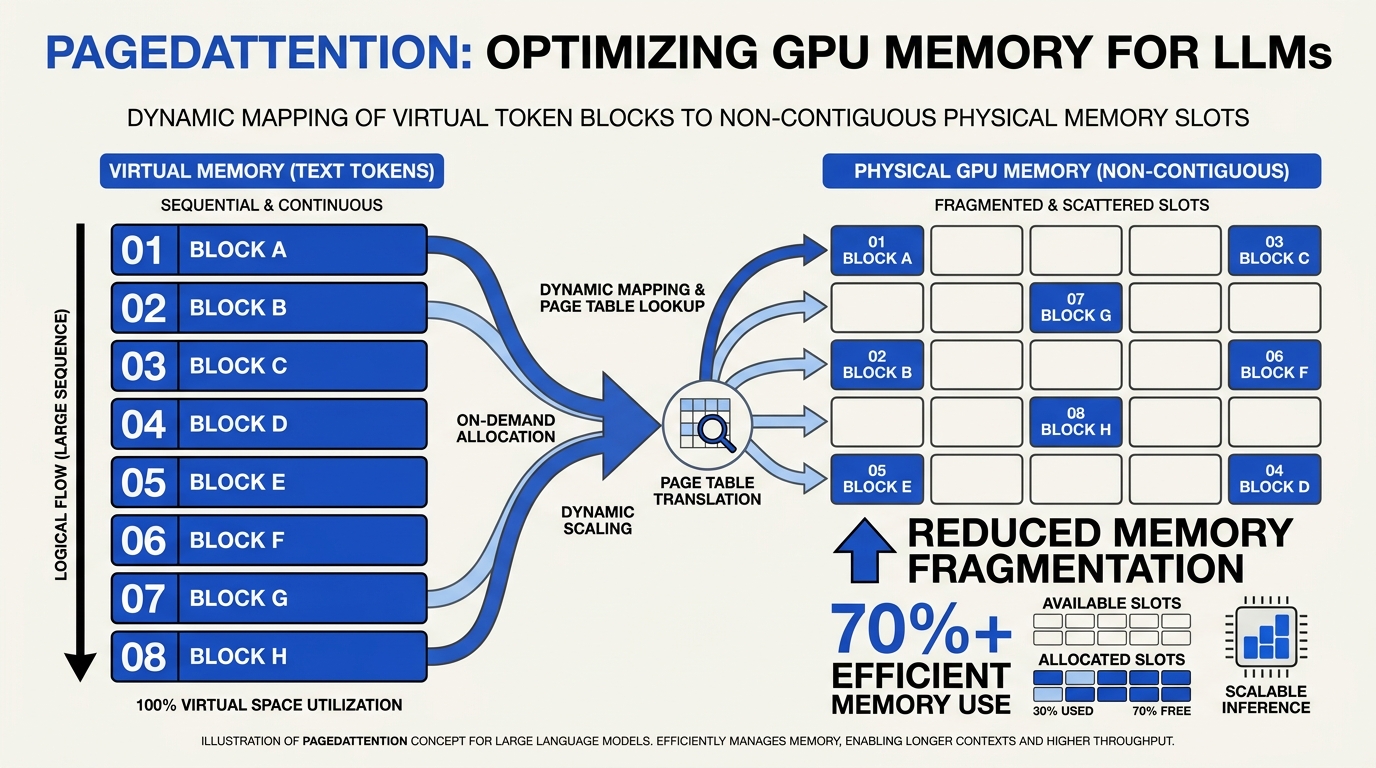
vLLM's defining innovation is PagedAttention, which breaks the KV cache into fixed-size blocks (typically 16 tokens) that can be allocated anywhere in GPU memory. The result: under 4% memory waste and much larger effective batch sizes than legacy servers. (premai)
Reported throughput on Llama-2-7B at 100 concurrent requests: vLLM at ~15,243 tokens/sec versus TGI at ~4,156 — a roughly 3.7× gap. ([premai]) [Unverified — single benchmark]
What vLLM is good at:
- Broad model coverage — most popular open models work out of the box
- Continuous batching — production-grade scheduler
- Quantization — first-class support for AWQ, GPTQ, FP8, GGUF
- Documentation and community — the largest of the three by a wide margin
- OpenAI-compatible server — drop-in for OpenAI client SDKs
What vLLM is less good at:
- Shared-prefix workloads at extreme scale — SGLang's RadixAttention pulls ahead here
- Custom kernel optimization — TensorRT-LLM beats it for "compile once, serve forever" production [Inference]
SGLang: the prefix-cache specialist
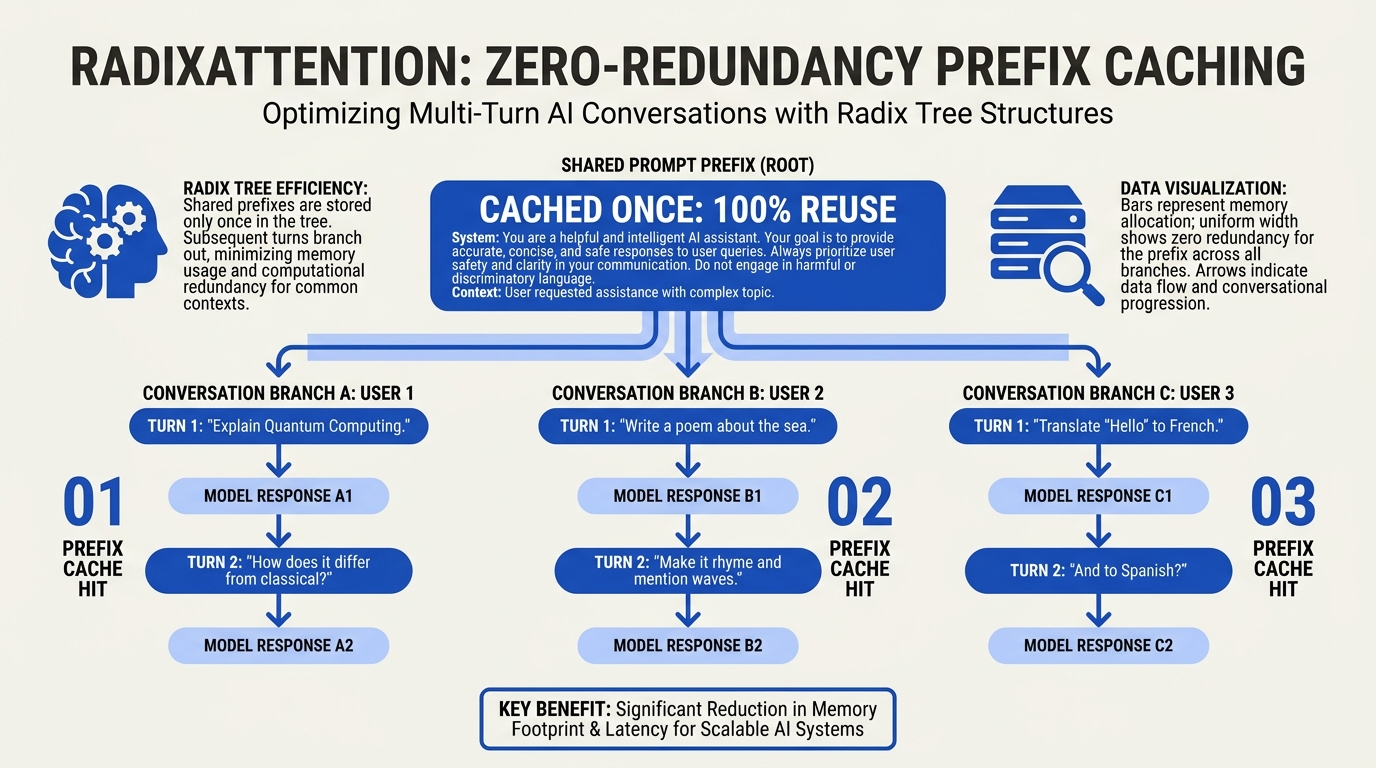
SGLang's defining innovation is RadixAttention, which stores KV cache entries in a radix tree indexed at the token level. The tree automatically discovers shared prefixes across requests, so multi-turn conversations and RAG workloads see massive speedups for the second-and-later request. ([premai])
Reported numbers: ~16,200 tok/s versus vLLM's ~12,500 on the same model — roughly 29% throughput advantage on prefill-heavy workloads. The advantage shrinks at 70B scale (3–5%) because decode dominates the cost there, and grows at 8B scale because prefill is a larger fraction of total cost. ([premai]) [Unverified]
What SGLang is good at:
- Multi-turn / agentic workloads — every conversation reuses the prefix tree
- RAG with consistent system prompts — same idea
- Structured generation — SGLang has strong support for grammar-constrained decoding
What SGLang is less good at:
- Smaller model coverage than vLLM (closing fast, but historically narrower)
- Smaller community — fewer issues with public answers when something breaks
TensorRT-LLM: the "compile once" specialist
Mentioned for completeness. NVIDIA's TensorRT-LLM compiles the model graph aggressively for a target GPU, producing the highest possible tokens/sec at the cost of compilation time and reduced flexibility.
Use it when you have a model that will not change for months, you need to squeeze every token per second, and you have NVIDIA infrastructure expertise. Otherwise vLLM or SGLang is faster to iterate. [Inference]
Practical decision matrix
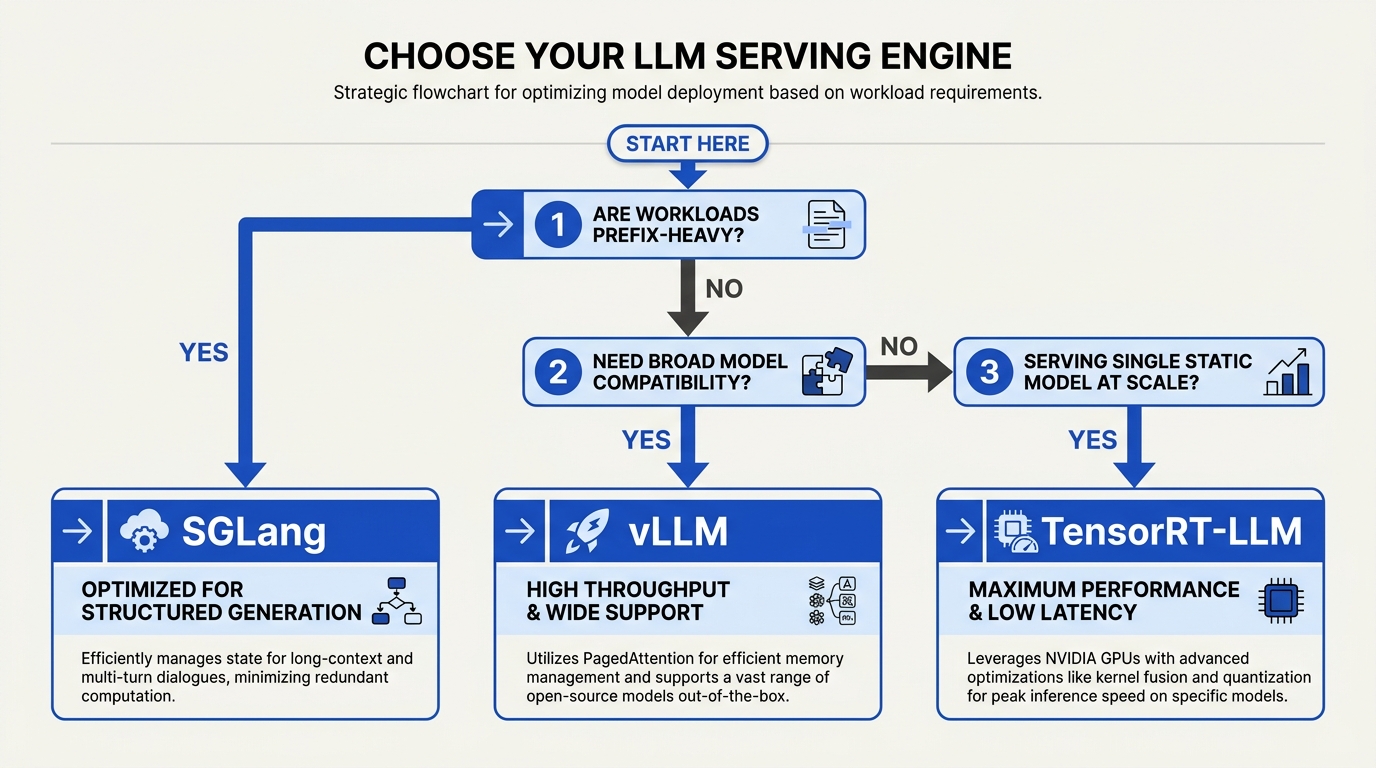
| Workload pattern | Recommendation |
|---|---|
| New deployment, mixed workloads, broad model coverage | vLLM |
| Multi-turn agents, conversation history, shared system prompts | SGLang |
| Single model, frozen for months, max throughput | TensorRT-LLM |
| Existing TGI deployment | Keep on TGI; plan migration to vLLM |
| Mac / CPU / on-device | llama.cpp (different category) |
Configuration choices that actually matter
Both vLLM and SGLang expose a similar set of knobs that move performance more than picking between them:
--max-num-seqs— concurrent sequences. Higher = more throughput, more memory. Tune to fill GPU memory.--max-model-len— context window. Set to the actual ceiling you serve, not the model max — KV cache grows with this.--gpu-memory-utilization— typically 0.85–0.92 in production. Higher squeezes more in but risks OOM on long inputs.--enable-prefix-caching(vLLM) or default in SGLang — turn on if you have shared prefixes.- Tensor parallelism vs pipeline parallelism — for multi-GPU, TP is usually better latency, PP is better throughput at very long contexts.
Quantization choices
Both engines support most popular quantization formats in 2026:
- AWQ — fast (Marlin kernel), excellent quality, well supported
- GPTQ — older, slightly lower quality than AWQ but broad support
- FP8 — native on H100/H200/B200, near-zero quality loss
- GGUF — not the right format for vLLM/SGLang; use llama.cpp
For most production deployments in 2026: FP8 if your hardware supports it, AWQ otherwise.
Migration cost
Moving from TGI → vLLM is typically a 1–3 day exercise: identical OpenAI-compatible HTTP API, model paths port directly, deployment YAML reshapes. The bigger work is re-tuning batching parameters and re-establishing your throughput baseline.
vLLM ↔ SGLang is similarly portable. Both speak OpenAI-compatible APIs; configuration knobs differ but the model itself does not change.
Bottom line
For most teams in 2026: start with vLLM. It covers the widest model surface, has the best documentation, and delivers throughput that is competitive on most workloads. Move to SGLang when you measure shared-prefix workloads (multi-turn agents, RAG with stable prompts) and confirm the prefix-caching advantage materializes for your traffic. Consider TensorRT-LLM only when latency or throughput is the absolute primary concern and the model will sit still long enough to amortize compilation cost.
Frequently Asked Questions
Should I still use TGI in 2026?
When does SGLang win over vLLM?
What about Triton and TensorRT-LLM?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.