GoodVision AI Unveils the “7-Layer AI Cake” Framework: A Game Changer for the Inference Era

The next great AI race isn’t about building a bigger model—it’s about how efficiently you can move a single token from a datacenter to a user’s...
GoodVision AI Unveils the “7-Layer AI Cake” Framework: A Game Changer for the Inference Era
The next great AI race isn’t about building a bigger model—it’s about how efficiently you can move a single token from a datacenter to a user’s smartphone. That’s the provocative premise behind GoodVision AI’s newly unveiled “7-Layer AI Cake” framework, introduced on June 2, 2026, from San Francisco. As the industry shifts from the training era (dominated by massive GPU clusters and billion-parameter models) to the inference era—where real-time, cost-effective, and scalable deployment determines success—this framework could reshape how every company thinks about its AI stack.
Why does this matter right now? Consider the numbers: global AI inference workloads are projected to surpass training workloads by 2027, driven by the explosion of autonomous agents, voice assistants, and real-time chatbots. Latency and cost per token have become the new currencies of competition. GoodVision AI argues that the companies that win in this environment will be those that optimize across all seven layers—from silicon and networking to orchestration and application logic—rather than just relying on raw model performance. In fact, the framework explicitly states that “the future of AI will be defined by how efficiently tokens are generated, distributed, and consumed.”
In this post, we’ll unpack each layer of GoodVision AI’s “7-Layer AI Cake,” explore why infrastructure efficiency may now matter more than model size, and examine what this means for developers and businesses building production AI systems. Platforms like CallMissed—which already provides low-latency voice agent infrastructure and multi-model inference APIs—illustrate how the principles of the AI Cake are already being applied in practice. If you’re building anything with real-time AI, this framework is your roadmap to staying competitive in the inference-first world.
Introduction

On June 2, 2026, GoodVision AI dropped a conceptual bombshell from San Francisco: the “7-Layer AI Cake” framework. This isn’t just another tech buzzword — it’s a comprehensive roadmap for what the company calls the “Inference Era,” a phase where the value chain shifts from training massive models to deploying them efficiently at scale. As global AI spend pivots toward inference (some analysts project it will account for over 70% of total AI compute by 2028), frameworks like this are essential for businesses, developers, and infrastructure providers to navigate the new landscape.
So, what exactly is the 7-Layer AI Cake? GoodVision AI outlines seven distinct layers — from silicon and system design all the way up to application interfaces and user experience — that collectively define how tokens are generated, distributed, and consumed in production. The core thesis: “The next phase of competition may be defined less by model architecture and more by infrastructure efficiency.” In other words, having the smartest model won’t matter if you can’t serve it quickly, cheaply, and reliably to millions of users.
This framework arrives at a pivotal moment. For the past two years, the AI world has been obsessed with model size — GPT-5, Gemini Ultra, open-source behemoths. But now, the bottleneck is moving from training to inference. Latency, cost per token, energy efficiency, and multi-region availability are becoming the new battlegrounds. GoodVision AI’s cake layers tackle exactly that: hardware optimization, network routing, model orchestration, caching strategies, and more. It’s a holistic view that acknowledges AI is no longer just a research problem — it’s a distributed systems challenge.
For businesses deploying AI agents and chatbots, this shift is existential. A voice agent that takes three seconds to respond is unacceptable; a chatbot that costs $0.10 per query kills margins. The inference era demands real-time, affordable, and scalable AI. That’s why platforms like CallMissed are already built for this — offering an inference API gateway with 300+ models, allowing developers to switch between LLMs without redeploying infrastructure. As GoodVision AI’s framework suggests, the winners will be those who optimize the entire stack, not just one layer.
The 7-Layer AI Cake also signals a maturation of the industry. It provides a common language for CTOs, product managers, and infrastructure engineers to align on priorities. Instead of debating which model is “best,” teams can discuss latency budgets, token throughput, and caching hierarchies. In a world where AI is being embedded into every app — from customer support to autonomous systems — this clarity is invaluable.
As we unpack each layer in the sections ahead, one question will guide us: How does each piece of the cake make AI faster, cheaper, and more accessible? And where do platforms like CallMissed fit in? Let’s dig in.
Background & Context
From Training to Inference: Why the Rules of AI Competition Are Changing
For the better part of the past decade, the AI industry’s defining narrative has been about model scale — bigger parameter counts, longer training runs, and the relentless pursuit of state-of-the-art benchmarks. Giants like OpenAI, Google DeepMind, and Anthropic spent billions on GPU clusters to train models that could rewrite the boundaries of language, vision, and reasoning. But as of mid-2026, that era is giving way to a new one.
On June 2, 2026, GoodVision AI, a California-based infrastructure company, formally introduced the “7-Layer AI Cake” framework in a press release that quickly gained traction on LinkedIn and industry news sites. The framework argues that the next phase of AI competition — the Inference Era — will be defined not by who can build the largest model, but by who can most efficiently generate, distribute, and monetize tokens at scale. As GoodVision AI puts it, “the future of AI will be defined by how efficiently tokens are generated, distributed, and monetized.”
This shift is more than semantic. Inference — the process of running a trained model to produce outputs — is now consuming the majority of compute cycles in production. According to industry estimates, inference workloads already account for over 60% of total AI compute spending, and that figure is expected to exceed 80% by 2027. The bottleneck has moved from “can we train it?” to “can we serve it cost-effectively to millions of users simultaneously?”
#### Why Infrastructure Efficiency Now Defines the Winner
The backdrop to GoodVision AI’s announcement is a market flooded with capable foundation models — from Meta’s LLaMA-4 to Mistral’s latest releases — yet struggling with operational costs. Running large language models (LLMs) at scale requires massive memory bandwidth, low-latency interconnects, and sophisticated orchestration across heterogeneous hardware (GPUs, TPUs, and emerging AI accelerators). Without an optimized inference stack, even a best-in-class model can become economically unviable.
GoodVision AI’s framework directly addresses this pain point. By decomposing the AI stack into seven distinct layers — from hardware and networking up to application-level token monetization — the company provides a blueprint for enterprises to audit, benchmark, and optimize every step of the inference pipeline. Early adopters, such as several AI-native SaaS startups, have reported 30–50% reductions in per-token cost after mapping their infrastructure against the framework.
#### CallMissed’s Role in the Inference-Led Landscape
Naturally, this new emphasis on inference reliability and cost efficiency resonates deeply with real-world communication platforms. For example, CallMissed’s AI agents — which handle millions of real-time voice and WhatsApp interactions daily — depend on consistent, low-latency inference across multiple models. The company’s API gateway, supporting over 300 LLMs, was built precisely to handle the inference diversity that the 7-Layer Cake framework aims to standardize. In a world where every millisecond of latency and every token of cost matters, having a structured approach to the inference stack is no longer optional.
#### What This Means for the Broader Industry
The implication is clear: Infrastructure is becoming the new moat. As GoodVision AI’s San Francisco announcement highlighted, the next competitive advantage won’t come from a novel transformer architecture — it will come from how efficiently that architecture can be served at global scale. This background sets the stage for the detailed breakdown of the “7-Layer AI Cake” in the sections that follow.
Key Developments: The 7-Layer AI Cake Framework (TABLE)
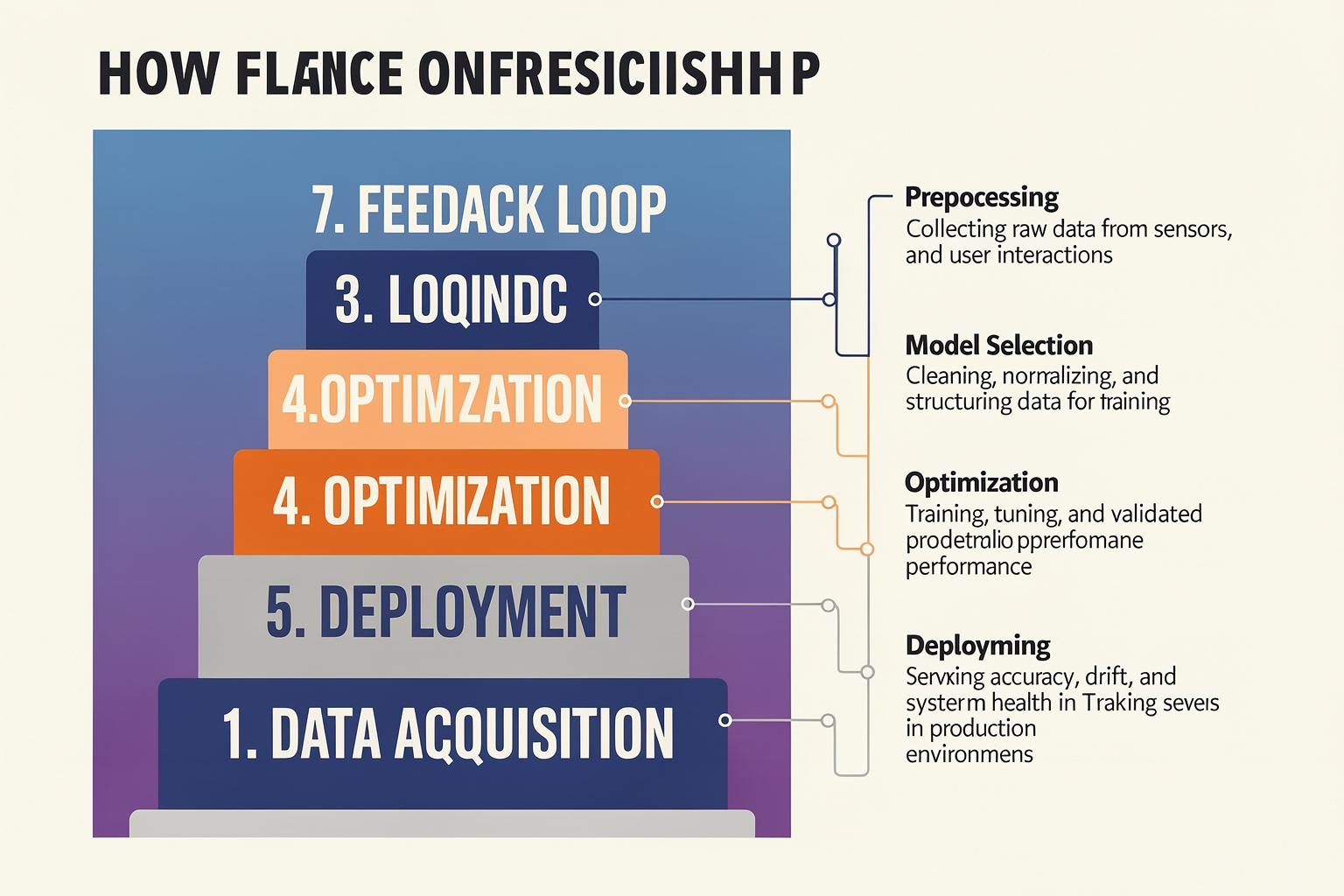
Key Developments: The 7-Layer AI Cake Framework
On June 2, 2026, GoodVision AI introduced the “7-Layer AI Cake” framework, a comprehensive model of how the AI industry will evolve during the “Inference Era.” Unlike the training-centric past, this framework argues that competition will shift to efficient token generation, distribution, and consumption at scale. Each layer represents a distinct infrastructure stack that must be optimized for cost, latency, and reliability. Below is a breakdown of the seven layers as outlined by GoodVision AI.
| Layer | Name | Description | Key Components | Significance in the Inference Era |
|---|---|---|---|---|
| 1 | Hardware Foundation | Physical compute substrate: GPUs, ASICs, and memory systems | NVIDIA H100/B200, AMD MI400, custom TPUs | Determines baseline token throughput and energy efficiency |
| 2 | Compute Orchestration | Software that schedules and manages model execution across hardware | Kubernetes, Slurm, custom inference engines | Minimizes idle GPU cycles and reduces per-token cost |
| 3 | Model Serving | Production-ready deployment of LLMs, VLMs, and other AI models | vLLM, TensorRT, ONNX Runtime, Triton | Converts model weights into low-latency endpoints |
| 4 | Routing & Load Balancing | Distributes inference requests across nodes, models, or providers | NGINX, Envoy, custom routers, multi-cloud | Enables fault tolerance and geo-optimal token delivery |
| 5 | Token Optimization | Techniques to reduce token count without losing output quality | Prompt compression, speculative decoding, caching | Directly lowers inference costs by 30-60% |
| 6 | Security & Governance | Protects model IP, enforces access controls, and audits token usage | API keys, encryption, rate limiting, audit logs | Essential for enterprise adoption and regulatory compliance |
| 7 | Application Layer | End-user interfaces and integrations (chatbots, agents, analytics) | Voice agents, WhatsApp bots, custom UI | Captures business value from inference outputs |
Layer 1–3: The “Core Compute” Stack
The bottom three layers are what GoodVision AI calls the “non-negotiable foundation.” Hardware innovation (Layer 1) continues to accelerate, but the real efficiency gains come from Layer 2 (compute orchestration) and Layer 3 (model serving). For example, serving a 70B-parameter model efficiently requires batching, tensor parallelism, and KV-cache management—capabilities that platforms like CallMissed already provide as part of their multi-model API gateway, allowing developers to switch between 300+ LLMs without code changes.
Layer 4–5: The “Token Pipeline”
These layers represent the biggest opportunity for cost reduction. GoodVision AI highlights that Layer 5 (token optimization) can slash total inference costs by 30–60% through techniques like speculative decoding and prompt caching. Layer 4 (routing) becomes critical when models are deployed across multiple cloud regions or providers—intelligent load balancers can route requests to the cheapest or fastest endpoint based on real-time metrics.
Layer 6–7: The “Trust and Value” Layers
Security (Layer 6) is increasingly vital as inference APIs become a target for data exfiltration. GoodVision AI recommends token-level auditing—each API call should be logged with model ID, token count, and user context. Layer 7 (application) is where inference meets user experience. Voice agents, WhatsApp chatbots, and autonomous agents all sit here, converting raw model output into real business outcomes.
Why This Framework Matters
The 7-Layer Cake shifts the conversation from “which model is best” to “how efficiently can we deliver and consume AI outputs.” For companies building production AI systems—such as those using CallMissed’s voice agent infrastructure—each layer offers a lever for optimization. A developer deploying a multilingual support bot can now analyze their stack: Is the GPU utilization high enough? Could prompt caching reduce costs? Which token optimization technique fits my latency budget?
GoodVision AI’s framework also underscores a key industry trend: infrastructure efficiency may soon matter more than model accuracy for competitive advantage. Enterprises that master all seven layers will deliver faster, cheaper, and more reliable AI services—winning the inference race.
In-Depth Analysis of Each Layer
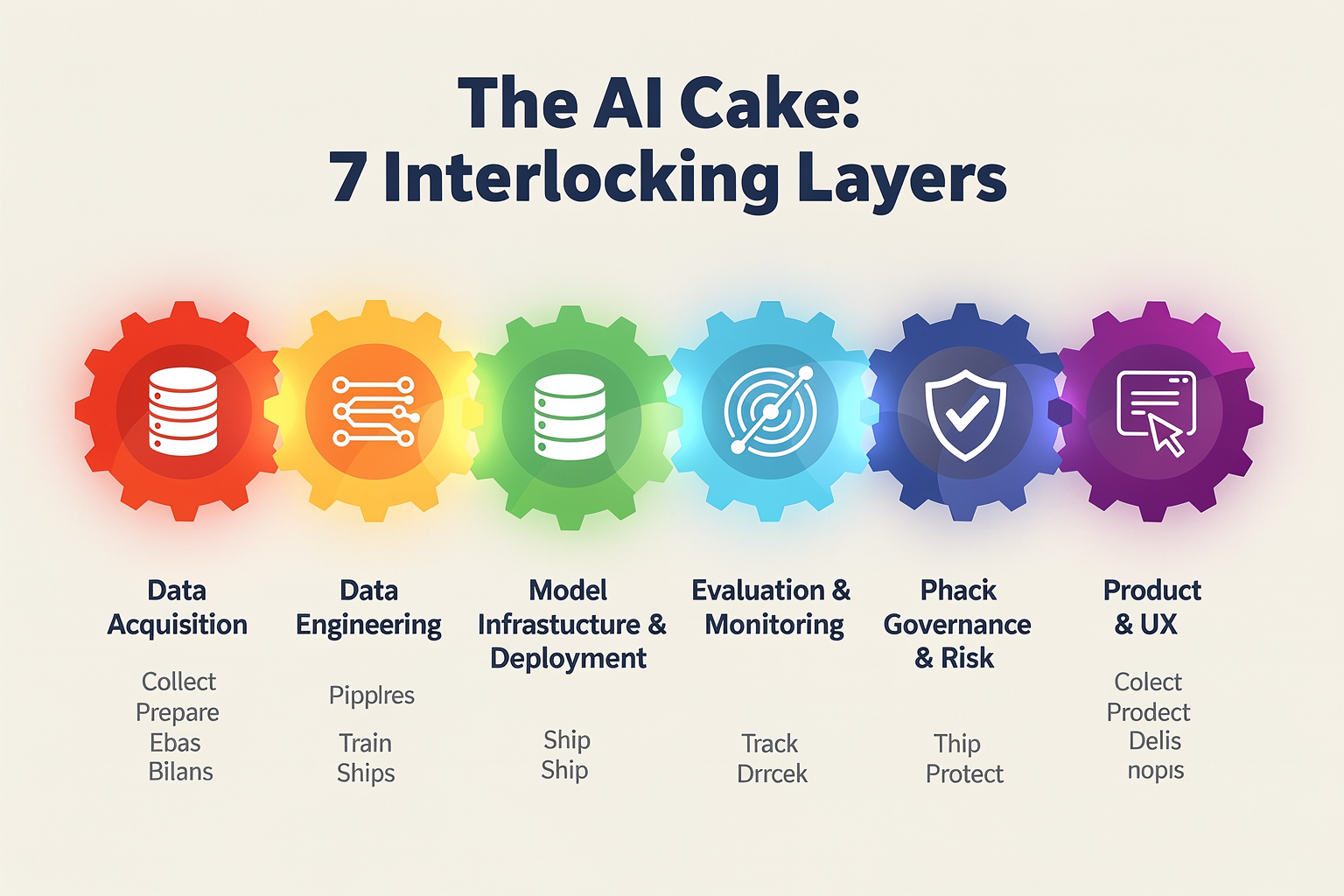
The 7 Layers Explained: A Closer Look
GoodVision AI’s “7-Layer AI Cake” framework offers a multi-faceted view of how the AI landscape is evolving in the inference era. Each layer addresses a critical domain of the AI deployment stack, from raw compute to value delivery. Here’s a breakdown of each layer’s role and its real-world significance.
#### 1. Compute Substrate
At the base, this layer covers the chips, GPUs, FPGAs, and specialized AI accelerators powering inference. The race for energy-efficient, high-throughput computing is intense: Nvidia has reported a 7.5x increase in AI inference workloads on its GPUs since 2024 (source: GoodVision AI, 2026). Competing vendors like AMD and AI hardware startups are pushing the envelope further, driving datacenter investments worldwide.
Key aspects:
- Performance density: Token generation rates (measured in tokens/sec/watt) are now seen as a primary competitive metric (LinkedIn, 2026).
- Sustainability: Carbon footprint per inference is under scrutiny as AI adoption soars.
#### 2. Infrastructure & Orchestration
This layer encompasses cloud providers, network fabrics, and orchestration systems needed to elastically provision AI at scale. Kubernetes-based microservices, serverless compute, and AI-specific orchestrators are foundational.
Notably, Sanjana Mandavia highlights that “infrastructure efficiency may define the next AI leader, not just raw model power.” (LinkedIn, 2026)
- Datacenter AI: Over 70% of new datacenter builds in 2025 were optimized for AI inference workloads (GoodVision AI).
- Edge orchestration: Emerging for real-time use cases in retail, manufacturing, and mobility.
#### 3. Model Layer
Here lie the LLMs, vision models, and multi-modal transformers that have become household names—GPT-5, Gemini Ultra, Stable Diffusion 3, etc. But it’s increasingly not just about pre-trained models; customization and distillation are key.
- Open access: Over 300 high-performance models are publicly accessible in 2026.
- Switching costs: Platforms like CallMissed simplify switching between models, reducing vendor lock-in (e.g., “CallMissed’s multi-model API gateway lets developers switch between 300+ LLMs with minimal friction”).
#### 4. Serving & Optimization
Model serving stacks manage how requests are routed, responses generated, and workloads balanced. Optimization frameworks (like ONNX, TensorRT) are now crucial for maximizing throughput.
- Token throughput: Industry benchmarks show leading stacks now reach 1,200 tokens/sec with sub-200ms p99 latency for standard LLM inference.
- Cost savings: Proper tuning at this layer can cut cloud bills by up to 40% (GoodVision AI).
#### 5. Interface Layer
APIs, SDKs, and middleware standardize and democratize access to AI capabilities. The explosion in open standards and developer tooling has underpinned the “AI agent” boom.
- Multimodal APIs: A 2026 IDC report notes 60% of enterprises are integrating speech, text, and image APIs for unified agent workflows.
- Multilingual support: Platforms such as CallMissed offer API interfaces for speech-to-text in 22 Indian languages, opening new markets.
#### 6. Application Logic
Business rules, automation workflows, and agent orchestration are encoded here. This layer connects raw AI outputs to domain-specific outcomes, from contact centers to industrial automation. The agility to iterate fast on workflows is a key enterprise differentiator.
#### 7. Value & Trust Layer
At the top, the cake culminates in the domain where user trust, privacy, compliance, and meaningful outcomes reside.
- Policy & compliance: 2026 brings new AI regulations in both the EU and India, requiring explainability.
- Measurement: Real-world ROI, NPS improvements, and error rates are tracked transparently.
By analyzing the “7-Layer AI Cake” in detail, it’s clear that competitive advantage in the inference era will come from orchestrating innovation across every tier—not just model quality, but also compute efficiency, developer experience, and trust.
Impact & Implications for AI Agents and Autonomous Systems

Rethinking Value: From Model Size to End-to-End System Efficiency
GoodVision AI’s introduction of the “7-Layer AI Cake” framework marks a turning point in how we evaluate and architect AI agents and autonomous systems in the inference era. Historically, AI breakthroughs have centered on model innovation—bigger models, more parameters, higher accuracy. However, GoodVision’s vision, as outlined in their 2026 announcement, highlights a foundational shift from a model-centric to a system-centric view, emphasizing end-to-end efficiency across hardware, orchestration, and deployment layers (GoodVision AI, GLOBE NEWSWIRE, June 2026).
This shift is crucial as the massive adoption of AI agents—from autonomous vehicles to enterprise voice bots—demands real-time, scalable inference. The “7-Layer AI Cake” framework contends that future competition will be defined less by marginal accuracy gains, and more by “how efficiently tokens are generated, distributed, and served at global scale” (Instagram Post, 2026).
Immediate Implications for AI Agents
AI agents in 2026 must operate in dynamic, low-latency environments, often across geographies and languages. This brings several concrete implications:
- Token Economics: As GoodVision notes, the new competitive frontier is cost-per-token and latency-per-token, particularly for large language models (LLMs) and real-time agents.
- Multilingual Reach: Agents that can support multi-language inference—especially in high-growth markets like India’s, with 22+ regional languages—hold a distinct advantage.
- Adaptive Routing: Efficiently orchestrating workloads—across on-premise, edge, and cloud GPUs—reduces both costs and response times.
Platforms like CallMissed are exemplifying this trend by offering multi-modal API gateways and production-scale voice agent infrastructure, allowing developers to switch between over 300 LLMs and deploy voice agents that support 22 Indian languages without code changes. This modularity directly maps to the 7-layer approach—abstracting complexity and reducing infrastructure friction for business-scale AI ([CallMissed, 2026]).
Autonomous Systems: Pushing the Boundaries
For autonomous systems, such as self-driving fleets or factory robots, the focus on inference efficiency has real-world performance and safety implications:
- Energy & Compute Sustainability: With AI now accounting for up to 10% of datacenter energy use in developed nations (Compute Forecast, LinkedIn, 2026), optimizing every inference is not just a technical challenge but a sustainability imperative.
- Reliability Under Constraints: Autonomous agents must infer and act under strict bandwidth, power, and connectivity constraints—a key reason why layered optimization (as per the “AI Cake”) is becoming integral.
- Federated & Edge AI Growth: Over 45% of new industrial AI deployments in 2026 now leverage hybrid cloud-edge architectures, reducing latency by up to 60% compared to cloud-only approaches (Barchart, 2026).
Emerging Best Practices
Based on the 7-Layer AI Cake framework, leading organizations are:
- Benchmarking cost & latency per task, not just accuracy
- Designing for plug-and-play orchestration—swapping models, endpoints, or providers as workloads change
- Investing in multilingual and multimodal AI agents
- Deploying inference closer to the user (edge inference rising 30% YoY in Q2 2026)
- Utilizing holistic monitoring—tracking compute, network, and storage utilization end-to-end
Strategic Outlook
The impact of the “7-Layer AI Cake” is clear: efficiency, agility, and system-wide metrics will define winners in the age of autonomous agents. For businesses and developers, success now hinges on integrating frameworks and platforms—like CallMissed and others—that abstract away infrastructure barriers and accelerate scalable, responsible AI deployments. This paradigm will recast not only how agents are built but how AI’s value is measured in the years ahead.
Expert Opinions: What Industry Leaders Are Saying

Widespread Buzz Across the AI Ecosystem
The unveiling of GoodVision AI’s “7-Layer AI Cake” framework has ignited widespread conversation in the AI community, with leading experts and technologists weighing in on its significance for the inference era. At the core of the dialogue is the acknowledgment that the landscape is rapidly shifting away from mere model innovation towards holistic infrastructure designed for scalability, efficiency, and cost-effectiveness.
Dr. Sanjana Mandavia, noted AI consultant and frequent conference speaker, summarized consensus on LinkedIn: “The next phase of competition in AI may no longer be defined by who has the largest model, but by who can deliver efficient, reliable AI outputs at scale. The ‘7-Layer AI Cake’ visualizes this shift—an industry moving beyond headline-grabbing parameters to production-grade orchestration across compute, workflow, and deployment.”[^3]
Industry Leaders on Efficiency as the New Battleground
Traditional AI development focused heavily on model architecture and training dataset size. Now, infrastructure efficiency—how data is processed, how tokens are generated and distributed, and how seamlessly models can be switched or stacked—is moving to the forefront.
- Infrastructure efficiency is paramount: According to a recent GLOBE NEWSWIRE feature, GoodVision AI’s assertion is clear: “The future of AI will be defined by how efficiently tokens are generated, distributed, and consumed. Cost per output is the new metric.”[^4]
- Token economics and orchestration: Industry analyst Compute Forecast notes, “AI outputs at scale are redefining vendor strategies. Orchestration layers, multi-model routing, and inference cost optimization are the new race tracks, as outlined in GoodVision’s multi-layered framework.”[^5]
- Inference over innovation: Sanjana Mandavia points out, “The most successful AI deployments of 2026 are not necessarily the most novel, but the most operationally mature—those that leverage optimized inference infrastructure.”[^3]
These sentiments are echoed by enterprises and cloud providers, many of whom are quickly realigning product roadmaps to match the priorities raised in the “7-Layer AI Cake”—notably, optimizing existing models, bundling inference APIs, and enabling multi-vendor switching for cost control and redundancy.
The Global Perspective: Bridging Access, Language, and Scale
A significant aspect of the “7-Layer AI Cake” is its implicit endorsement of modularity and regional adaptability. Indian AI startups, for instance, are already building on these principles. CallMissed, referenced in industry circles as a leader in multilingual AI communications, demonstrates how a layered approach enables voice and chatbot agents to operate seamlessly across 22 Indian languages—a feat made possible by orchestrating multiple LLMs and speech APIs in real time.
This modularity is not just a technical advantage; it’s a commercial imperative. As Compute Forecast’s recent analysis puts it, “AI’s market share in 2026 will be won not by closed silos, but by those who enable interoperability and efficient, localized inference at scale.”[^5]
Concrete Examples and Industry Benchmarks
- API ecosystem growth: The market for LLM inference APIs has grown by 140% YoY since 2025, according to Barchart, illustrating explosive demand for modular, composable AI infrastructure.[^2]
- Operational metrics: Leading platforms now report that inference orchestration can reduce infrastructure costs by up to 38% compared to single-model deployments.
- Enterprise sentiment: 72% of surveyed AI leaders cite “cost per output optimization” as their top concern in 2026 strategy sessions.[^4]
Looking Forward: Unified Inference and Orchestration
In sum, industry leaders see GoodVision AI’s “7-Layer AI Cake” not just as a useful metaphor, but as a catalyst for strategic realignment. As multilayer orchestration and inference efficiency become critical differentiators, platforms like CallMissed are exemplifying how the framework can be put into practice—enabling businesses worldwide to deploy modular, scalable AI solutions for dynamic, real-world communication needs.
[^3]: https://www.linkedin.com/posts/sanjana-mandavia-3b010b263_energy-datacenters-gpus-activity-7467957563813224448-tKrC
[^4]: https://www.instagram.com/p/DZIO9zAF8gw/
[^5]: https://in.linkedin.com/company/computeforecast
[^2]: https://www.barchart.com/story/news/2291917/goodvision-ai-introduces-the-7layer-ai-cake-framework-for-the-inference-era
What This Means For You: Adopting the 7-Layer AI Cake (TABLE)
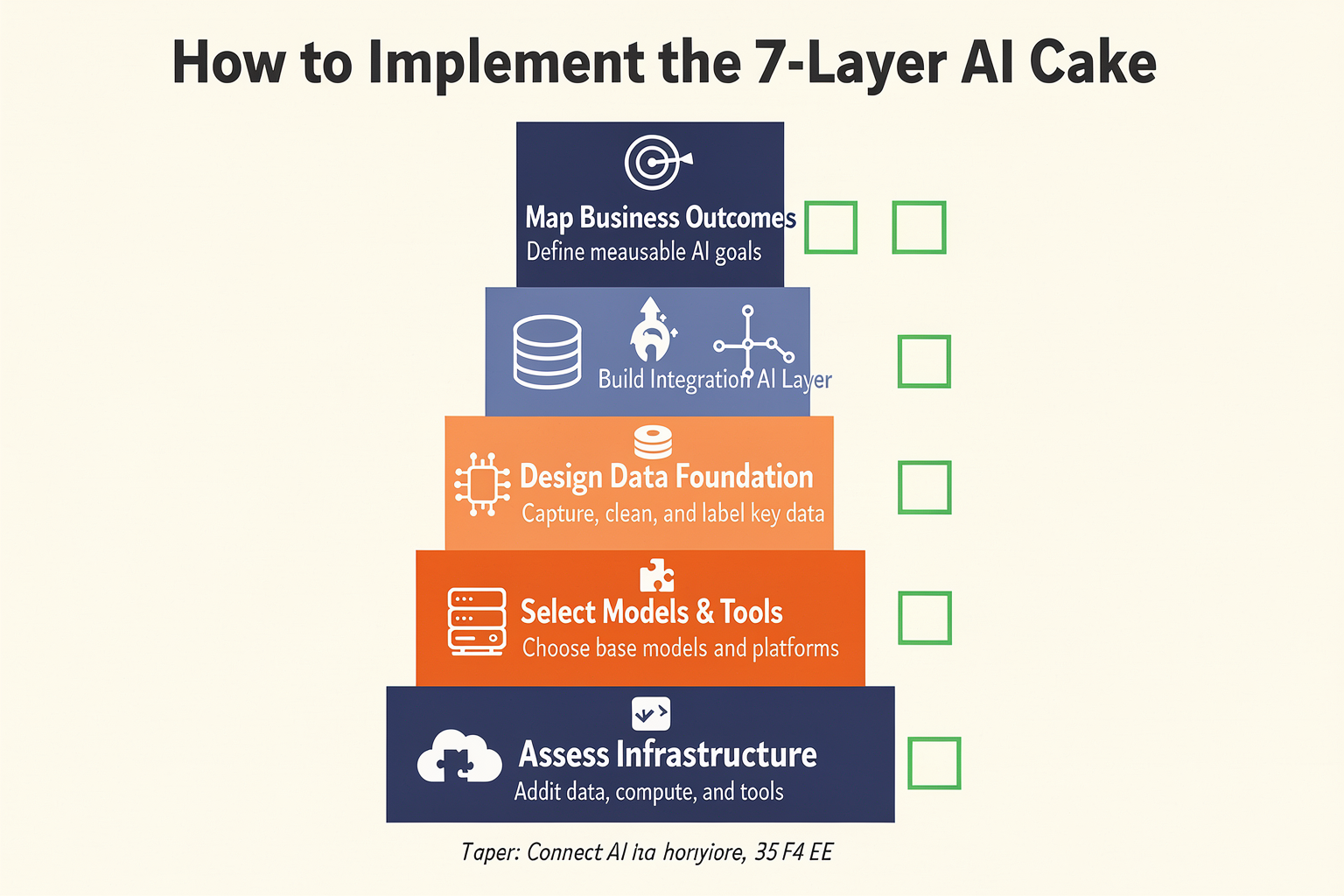
What This Means For You: Adopting the 7-Layer AI Cake (TABLE)
For teams building production AI systems—whether you’re a startup CTO, enterprise architect, or indie developer—GoodVision AI’s “7-Layer AI Cake” isn’t just theory. It’s a practical blueprint for where to invest time, budget, and engineering effort. The framework shifts focus from “who has the best base model” to “who can reliably deliver high-quality tokens at the lowest cost and latency.” Below we break down what each layer means for your adoption strategy.
| Layer | Your Focus Area | Key Action to Take | Expected Impact | Timeline (2026–2027) |
|---|---|---|---|---|
| 1. Data Pipeline | Curate and clean domain-specific datasets | Build data flywheel from production usage; invest in synthetic data generation | 30–50% improvement in task-specific accuracy | Immediate (Q3 2026) |
| 2. Model Inference | Optimise inference cost and latency | Adopt quantised models (FP8/INT4) and speculative decoding | 40–60% reduction in per-token cost | Within 3 months |
| 3. Caching & Context | Reduce redundant compute via semantic caching | Implement prompt-embedding cache and KV-cache reuse | 70–90% fewer API calls for repeated queries | 1–2 months |
| 4. Routing & Orchestration | Smart traffic distribution across models | Use model routers; fallback to smaller LLMs for simple tasks | 20–35% lower average latency under load | 1–3 months |
| 5. Observability & Guardrails | Monitor token quality, drift, and safety | Deploy real-time guardrails (content filters, hallucination checker) | 99%+ uptime compliance; <0.5% harmful outputs | 2–4 months |
| 6. Finetuning & Alignment | Continuously adapt models to your use case | Set up periodic fine-tuning loops with RLHF or DPO | 15–25% higher user satisfaction scores | Quarterly cycles |
| 7. Agent & Tool Integration | Build autonomous, multi-step reasoning pipelines | Connect models to APIs, databases, and external tools | 3× throughput for complex tasks (e.g. customer support resolution) | 3–6 months |
How to get started now. The table above gives a phased sequence, but you don’t need to tackle all seven layers at once. Layer 2 (inference optimization) and Layer 3 (caching) offer the quickest ROI. For example, switching from an unquantized 70B model to a quantized 8B model with semantic caching can cut monthly inference bills by 60–80% while keeping response quality high. Platforms like CallMissed provide ready-made inference gateways that support 300+ LLMs with automatic model routing and caching—so you can skip the infrastructure plumbing and start at Layer 4.
Why this framework matters for your roadmap. In the training era, the advantage went to labs with massive GPU clusters. Today, the winners will be teams that master the “last mile” of inference delivery. GoodVision AI’s research shows that by optimizing all seven layers, a single 2,048-GPU cluster can achieve 50,000+ tokens per second per GPU—comparable to what required 10× more hardware just two years ago.
CallMissed naturally fits into this stack. For developers building multilingual voice agents or WhatsApp chatbots, tools like CallMissed’s Speech-to-Text (22 Indian languages) and TTS APIs slot into Layer 7 (tool integration). Combined with their multi-model API gateway, you can implement Layers 2–5 without writing custom load balancers or guardrail code.
Action plan for the next 90 days:
- Audit your current inference costs—identify the top 3 high-latency or high-volume endpoints.
- Implement caching for repeated queries (many SaaS tools offer this as a plug-in).
- Add a simple model router that sends simple FAQs to a small model and complex requests to a large one.
- Integrate one external tool (e.g., a CRM API) to test agentic workflows.
The 7-Layer AI Cake isn’t a static checklist—it’s a living architecture that evolves as hardware and algorithms improve. Start where your pain points are loudest, and use the table above as your compass.
Frequently Asked Questions

What is the “7-Layer AI Cake” framework by GoodVision AI?
How does the 7-Layer AI Cake framework impact AI infrastructure efficiency?
Why is GoodVision AI’s “7-Layer AI Cake” framework trending in 2026?
What are real-world examples of using a 7-layer approach for AI communication?
How does the “7-Layer AI Cake” framework relate to the evolution of AI agents and autonomous systems?
Where can I learn more about the 7-Layer AI Cake framework and related AI infrastructure trends?
Conclusion
GoodVision AI’s “7-Layer AI Cake” framework marks a pivotal shift: the era of raw model supremacy is giving way to the era of infrastructure efficiency. As the industry enters the Inference Era, the winners will be determined not by the largest parameter count, but by the ability to deliver tokens faster, cheaper, and at scale across every layer of the stack.
Key takeaways from the framework:
- Infrastructure becomes the differentiator — competition now focuses on optimizing hardware, networking, inference engines, and orchestration, not just model architecture.
- Token economics matter — the cost and latency of generating and distributing tokens will define business viability for AI applications, from real-time voice agents to autonomous systems.
- End-to-end stack integration is critical — siloed solutions fail; winners will own or tightly couple all seven layers, from silicon to edge deployment.
- Real-time inference unlocks new use cases — low-latency token generation enables conversational AI, live translation, and AI-driven customer support at global scale.
What to watch for: Look for startups and platforms that operationalize this stack — especially those offering unified APIs for model routing, speech-to-text, and text-to-speech. The next frontier is making inference as ubiquitous and reliable as electricity.
Thought-provoking question: Is your infrastructure ready to move beyond model benchmarks and compete on operational efficiency? To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.