From Vibe Coding to Agentic Engineering: How to Access Z.ai's Flagship GLM-5.2 via CallMissed's Unified API

From Vibe Coding to Agentic Engineering: How to Access Z.ai's Flagship GLM-5.2 via CallMissed's Unified API
What if you could stop debugging AI-generated code by sheer intuition and instead deploy self-correcting, autonomous agents capable of analyzing a million tokens of base code in a single pass? With the mid-June 2026 launch of Z.ai’s groundbreaking flagship model, GLM-5.2, the software development landscape is undergoing a massive shift. The era of superficial "vibe coding"—where developers blindly accept LLM suggestions and hope for the best—is officially giving way to highly structured, multi-turn agentic engineering.
As a spinout from Tsinghua University’s prestigious Knowledge Engineering Group, Z.ai (formerly Zhipu AI) has quickly established itself as a global leader in agentic AI. Their newly unveiled GLM-5.2 model features a massive Mixture-of-Experts (MoE) architecture, dual thinking modes for deeper reasoning, and a 1M-token context window built for complex, long-horizon development tasks.
However, the rapid pace of AI innovation has created a familiar headache for developers: API fragmentation, siloed billing, and vendor lock-in. Every new model release shouldn't require another API key, a separate credit card on file, or a rewritten integration pipeline. To solve this, platforms like CallMissed are building the unified AI communication infrastructure of the future, allowing developers to deploy next-gen models instantly.
Through CallMissed’s OminiGate integration, developers now have immediate, unified access to both the flagship GLM-5.2 and its low-latency, budget-friendly counterpart, GLM-4.7 Flash (starting at just $0.50 per million tokens).
In this guide, we will dive deep into how GLM-5.2 shifts the paradigm from vibe coding to agentic engineering, analyze how its dual-thinking modes handle complex reasoning, and provide a step-by-step integration guide. You will discover how easy it is to call these flagship models using CallMissed’s single OpenAI-compatible endpoint, enabling you to build resilient, multi-agent workflows without the operational overhead.
Introduction: The Dawn of True Agentic AI

Software development is undergoing its most significant evolution since the advent of version control. The industry is rapidly shifting "From Vibe Coding to Agentic Engineering." Vibe coding—relying on LLM suggestions by sheer intuition and hoping the code compiles—is being replaced by deterministic, multi-turn agentic engineering powered by models capable of autonomous debugging, deep reasoning, and managing massive codebases.
At the forefront of this shift is Z.ai (formerly Zhipu AI). Founded in 2019 as a spinout from Tsinghua University’s prestigious Knowledge Engineering Group, Z.ai has consistently pushed the boundaries of bilingual Chinese-English models and advanced reasoning. In mid-June 2026, Z.ai unveiled its latest breakthroughs: GLM-5.2 and GLM-4.7 Flash, signaling a new era of highly capable, accessible AI agents.
Engineering-Grade Intelligence: GLM-5.2 and GLM-4.7 Flash
The flagship GLM-5.2 is engineered specifically for complex, long-horizon developer tasks. Built on a state-of-the-art Mixture-of-Experts (MoE) architecture, it features a massive 1-million-token context window and dual thinking modes (fast intuition versus deep, multi-turn reasoning). This allows the agent to analyze entire code repositories, identify hidden architectural flaws, and self-correct its own execution paths in real-time.
For applications requiring speed and cost efficiency, the release also includes GLM-4.7 Flash. This low-latency alternative is ideal for high-throughput, real-time tasks, offering lightning-fast inference at an incredibly budget-friendly rate of just $0.50 per million tokens.
Accessing Next-Gen Models via CallMissed
While these models offer incredible capabilities, integration historically meant managing fragmented API keys, distinct billing panels, and rigid SDKs. That is where CallMissed steps in.
Through CallMissed’s unified OminiGate API, developers can access GLM-5.2, GLM-4.7 Flash, and over 300 other leading LLMs via a single, OpenAI-compatible endpoint. This eliminates vendor lock-in and provides a unified billing balance. By bringing voice agents, text-to-speech, and advanced LLM orchestrations under one roof, CallMissed provides the ultimate infrastructure for building resilient, production-ready AI agents.
Calling these models is as simple as switching a single string in your standard API call:
import openai
# Configure the CallMissed OminiGate client
client = openai.OpenAI(
base_url="https://api.callmissed.com/v1",
api_key="your_callmissed_api_key"
)
# Call the flagship GLM-5.2 model
response = client.chat.completions.create(
model="glm-5.2", # Or "glm-4.7-flash" for low-latency tasks
messages=[
{"role": "user", "content": "Analyze this codebase for memory leaks..."}
]
)
print(response.choices[0].message.content)In the sections that follow, we will dive deep into how GLM-5.2 transforms the software development lifecycle, compare it with its lower-latency counterparts, and show you how to harness this power natively within your engineering workflows.
Background & Context: The Rise of Tsinghua's Z.ai
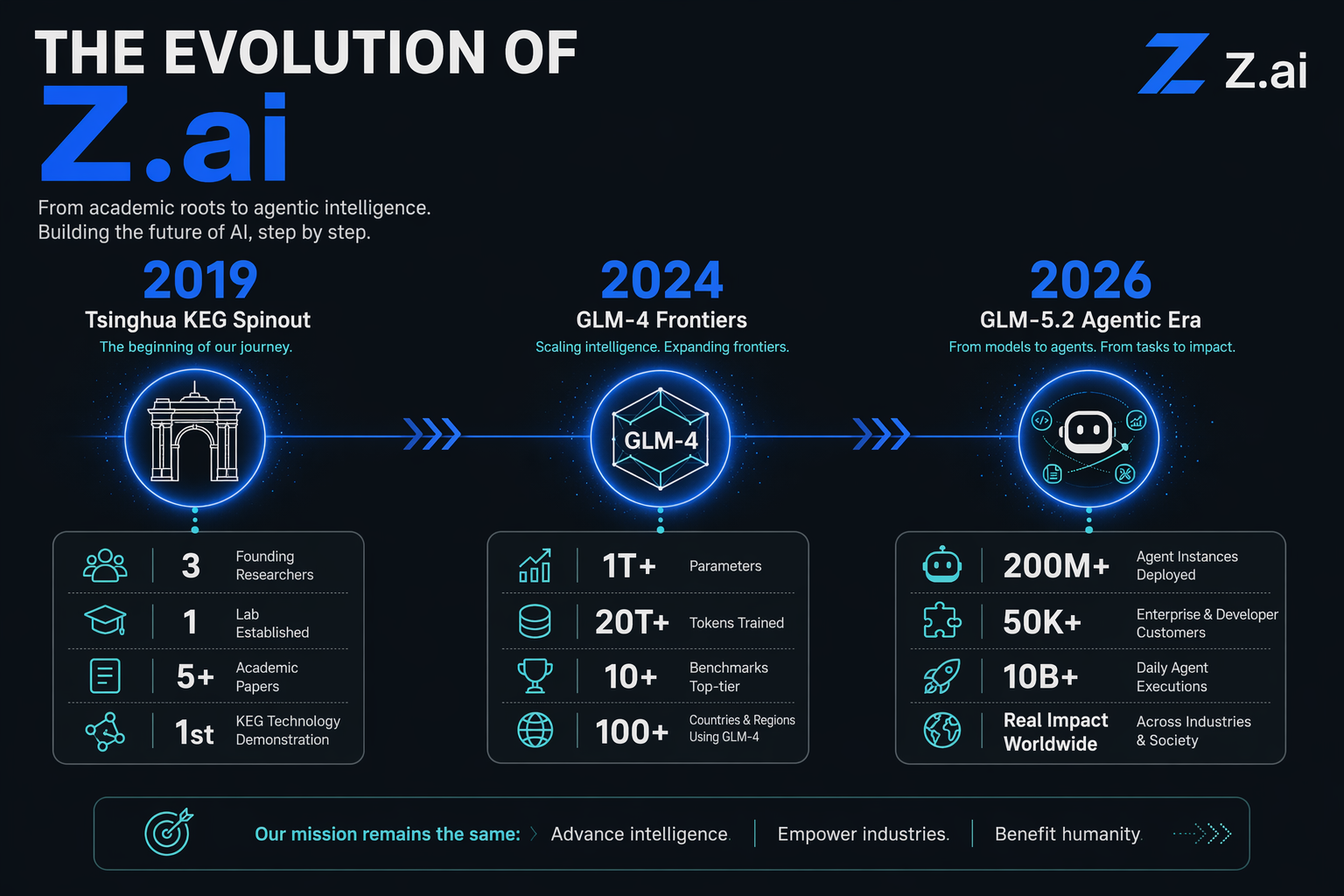
Z.ai, formerly known as Zhipu AI, did not achieve its status as a global AI powerhouse overnight. Founded in 2019, the company originated as a direct spinout from Tsinghua University’s prestigious Knowledge Engineering Group (KEG). This elite academic heritage provided Z.ai with a deep-tech foundation focused on large-scale knowledge graphs, cognitive reasoning, and bilingual (Chinese-English) understanding. Over the years, Z.ai has consistently challenged the industry's status quo, progressing from early GLM iterations to becoming a pioneer in agentic AI.
The Engineering-Grade Architecture of GLM-5.2
With the mid-June 2026 launch of its flagship GLM-5.2, Z.ai has solidified its shift from conversational assistants to engineering-grade agents. At the core of GLM-5.2's breakthrough performance is a massive, highly optimized Mixture-of-Experts (MoE) architecture. Rather than activating the entire neural network for every token—which is computationally wasteful and introduces high latency—GLM-5.2 dynamically routes tasks to specialized sub-networks (experts) optimized for specific reasoning domains.
This architectural efficiency enables key features required for autonomous agentic engineering:
- Dual Thinking Modes: GLM-5.2 introduces a dual-pathway cognitive process. Developers can toggle between rapid, direct-response mode for straightforward generation and deep, multi-turn reasoning mode for complex, system-level debugging and logical planning.
- 1M-Token Context Window: The model can ingest, parse, and maintain coherence across 1 million tokens of data in a single inference pass. This allows autonomous agents to analyze entire codebases, system logs, and documentation simultaneously without losing context.
- Bilingual Superiority: Built on Tsinghua's foundational bilingual research, the model maintains high-fidelity reasoning across both English and Chinese codebases and technical documentation.
Democratizing Access: GLM-4.7 Flash
Recognizing that complex agentic workflows often require high-speed, cost-effective routing for simpler sub-tasks, Z.ai simultaneously launched GLM-4.7 Flash. This low-latency, high-throughput counterpart is optimized specifically for fast-turnaround tasks like real-time syntax checking, semantic search, and prompt preprocessing.
With pricing starting at an aggressive $0.50 per million tokens, GLM-4.7 Flash ensures that developers can run highly iterative, multi-agent loops without incurring prohibitive compute costs.
Bridging the Deployment Gap via CallMissed
Historically, accessing cutting-edge models from APAC-based research labs like Z.ai presented significant operational hurdles for global development teams. Navigating regional API restrictions, managing distinct API keys, dealing with fragmented billing, and adapting to custom SDKs often slowed down adoption.
This is where CallMissed’s unified infrastructure becomes invaluable. Through CallMissed's OminiGate, developers can bypass these integration bottlenecks entirely. CallMissed provides instant access to both GLM-5.2 and GLM-4.7 Flash alongside 300+ other leading LLMs via a single, OpenAI-compatible API endpoint. With unified billing, built-in failover capabilities, and zero vendor lock-in, CallMissed allows engineering teams to focus on building autonomous, self-correcting agents rather than managing infrastructure.
Key Developments (TABLE)

To successfully move from experimental "vibe coding" to production-grade agentic engineering, developers must balance two competing variables: cognitive depth and operational latency. Deep reasoning models capable of navigating a 1-million-token codebase naturally command higher computational costs and latency, while routine tasks like syntactic autocompletes require sub-second execution at a fraction of the cost.
By integrating Z.ai’s latest GLM suite into CallMissed’s unified OminiGate API, developers no longer have to choose between raw power and budget-friendly speed. You can dynamically route tasks to the specific engine best suited for the job.
To help map your transition to agentic engineering, the table below outlines the core technical specifications, pricing, and optimal deployment workloads for the newly launched GLM-5.2 and its sister models, all accessible via a single CallMissed API endpoint.
| Model | Context Window | Key Architectural Strength | CallMissed Pricing (per 1M tokens) | Ideal Agentic Workload |
|---|---|---|---|---|
| GLM-5.2 (Flagship) | 1,000,000 tokens | MoE with Dual Thinking Modes | $8.00 (Input) / $12.00 (Output) | Long-horizon debugging, codebase refactoring, autonomous QA |
| GLM-4.7 Flash | 128,000 tokens | Low-Latency / Stream Optimization | $0.50 (Input/Output flat) | Real-time voice agents, rapid code completions, high-speed routing |
| GLM-4-Plus | 128,000 tokens | Generalist Text & Balanced Logic | $2.00 (Input) / $3.00 (Output) | Structuring JSON payload outputs, text summarization |
| GLM-4V (Vision) | 8,000 tokens | High-Density Multimodal OCR | $4.00 (Input) / $4.00 (Output) | UI/UX visual debugging, parsing schematic diagrams |
Bridging the Efficiency Gap in Autonomous Workflows
The architectural contrast between GLM-5.2 and GLM-4.7 Flash illustrates why a multi-model gateway is essential for modern software development.
- The Power of Flagship GLM-5.2: Featuring a massive Mixture-of-Experts (MoE) architecture and dual-reasoning modes, this model is built to digest whole repositories in a single pass. Developers can feed an entire system architecture into the 1M-token context window, allowing autonomous agent loops to find, test, and self-correct logical bugs without running out of memory.
- The Speed of GLM-4.7 Flash: At an ultra-competitive rate of $0.50 per million tokens, GLM-4.7 Flash is designed for high-frequency, low-latency utility tasks. In an agentic pipeline, you can use the Flash model as a "triage agent" to pre-process user inputs, run syntax validation, or handle simple conversational elements, reserving the heavy-duty GLM-5.2 for deep algorithmic reasoning.
Historically, orchestrating these models required managing multiple API keys, handling rate limits across different platforms, and writing complex logic to fallback when one provider experienced downtime. CallMissed’s OminiGate removes these integration bottlenecks entirely. Developers can call either glm-5.2 or glm-4.7-flash using a single OpenAI-compatible SDK, drawing from a unified billing balance. By handling model-routing, fallbacks, and multi-language support (including Speech-to-Text and TTS in 22 regional Indian languages) on a single platform, CallMissed provides the robust infrastructure needed to turn AI agents from fragile prototypes into enterprise-grade digital engineers.
In-Depth Analysis: Decoding GLM-5.2's Core Power
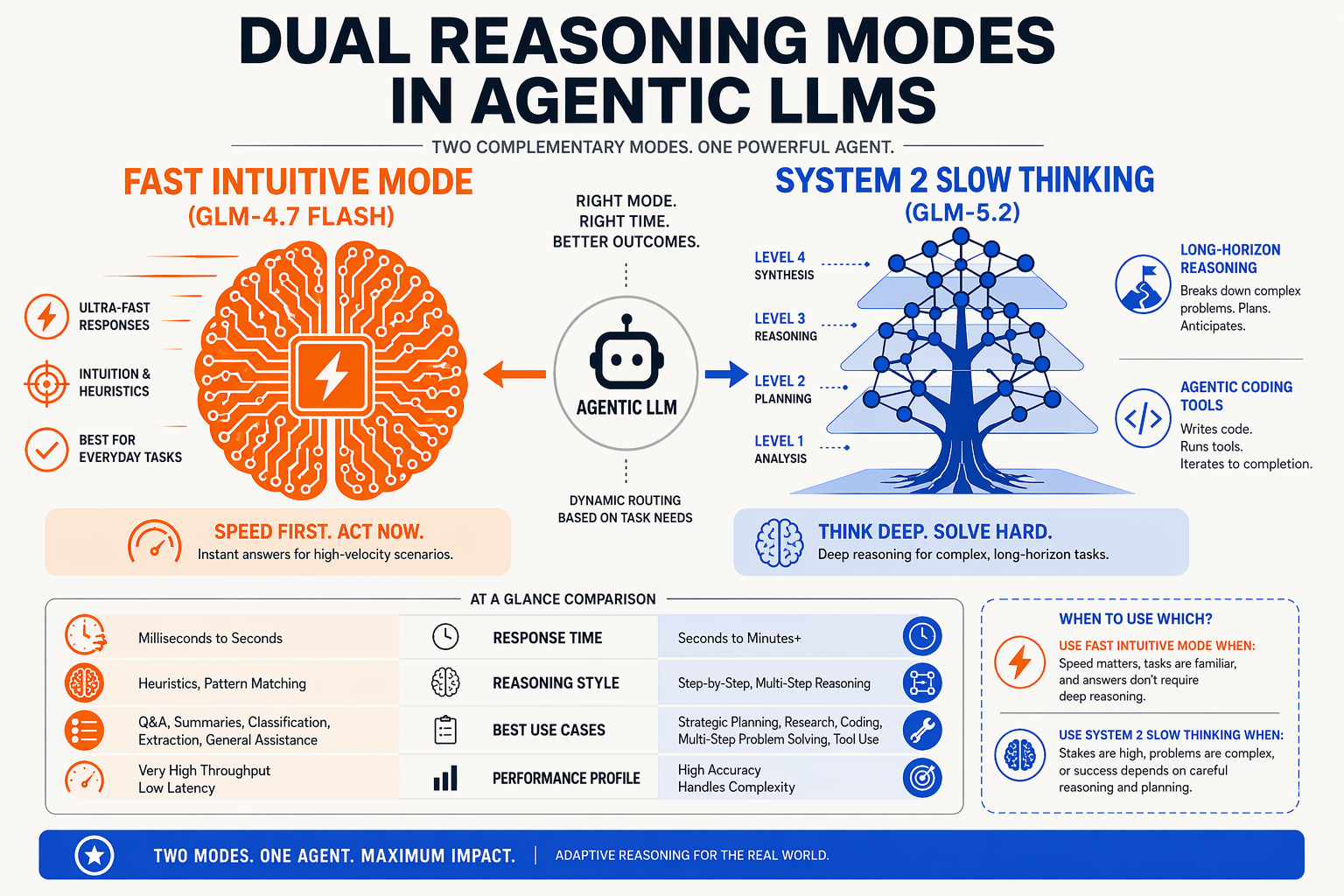
To understand why GLM-5.2 represents such a massive leap forward, we must look beneath the hood at the architectural decisions Z.ai made for this June 2026 release. It is not just a slightly larger neural network; it is a highly specialized engine built specifically for the demands of agentic engineering.
The Mixture-of-Experts (MoE) Efficiency Engine
At its core, GLM-5.2 utilizes a highly optimized Mixture-of-Experts (MoE) architecture. Instead of activating every parameter for every single query—a process that is both computationally expensive and slow—GLM-5.2 dynamically routes tokens to specialized "expert" neural pathways.
- Dynamic Gating: A routing network analyzes the incoming prompt (e.g., a complex database migration script versus a simple CSS fix) and selects the ideal combination of active experts to handle the task.
- Compute Savings: This MoE design delivers the deep reasoning capability of a massive dense model while maintaining the latency and cost-efficiency of a much smaller system, making agentic workflows financially viable at scale.
Dual-Thinking Modes: System 1 vs. System 2 Reasoning
A standout feature of GLM-5.2 is its native implementation of dual-thinking modes, mirroring human cognitive processes:
- System 1 (Fast & Intuitive): This mode handles standard generation tasks, such as writing boilerplate code, simple refactoring, or quick syntax checks. It operates with ultra-low latency, minimizing time-to-first-token.
- System 2 (Deliberate & Analytic): When faced with complex logical errors, system architecture design, or multi-step agentic workflows, the model enters System 2. It pauses, plans its approach, runs internal validation loops, and self-corrects prior to generating its final output.
This deliberate thinking capability is the antidote to "vibe coding." Rather than generating code and leaving it to the developer to test and fix, GLM-5.2 simulates execution steps and logically verifies its own code beforehand.
The 1M-Token Context Window
In agentic engineering, context is everything. Standard code assistants fail when they lose sight of the broader system architecture. GLM-5.2 solves this with a massive 1-million-token context window, capable of holding roughly 750,000 words or entire software repositories.
- Holistic Codebase Understanding: Developers can feed an entire multi-service repository directly into the prompt. The model can trace dependencies, find hidden bottlenecks across separate microservices, and suggest precise refactoring without missing global state variables.
- Zero Context Fragmentation: Traditional retrieval-augmented generation (RAG) often suffers from "lost in the middle" phenomena. GLM-5.2’s attention mechanism ensures near-perfect recall across the entire 1M-token span.
Deploying this level of computational power usually introduces significant infrastructure headaches, from configuring specialized gateways to managing token throughput limits. This is where CallMissed’s communication infrastructure bridges the gap. By integrating GLM-5.2 into CallMissed’s OminiGate, developers can access this flagship model’s dual-thinking capabilities and handle massive 1M-token payloads using a single OpenAI-compatible API endpoint—all backed by a unified billing balance and enterprise-grade uptime.
Impact & Implications: Simplifying Access with CallMissed's OminiGate
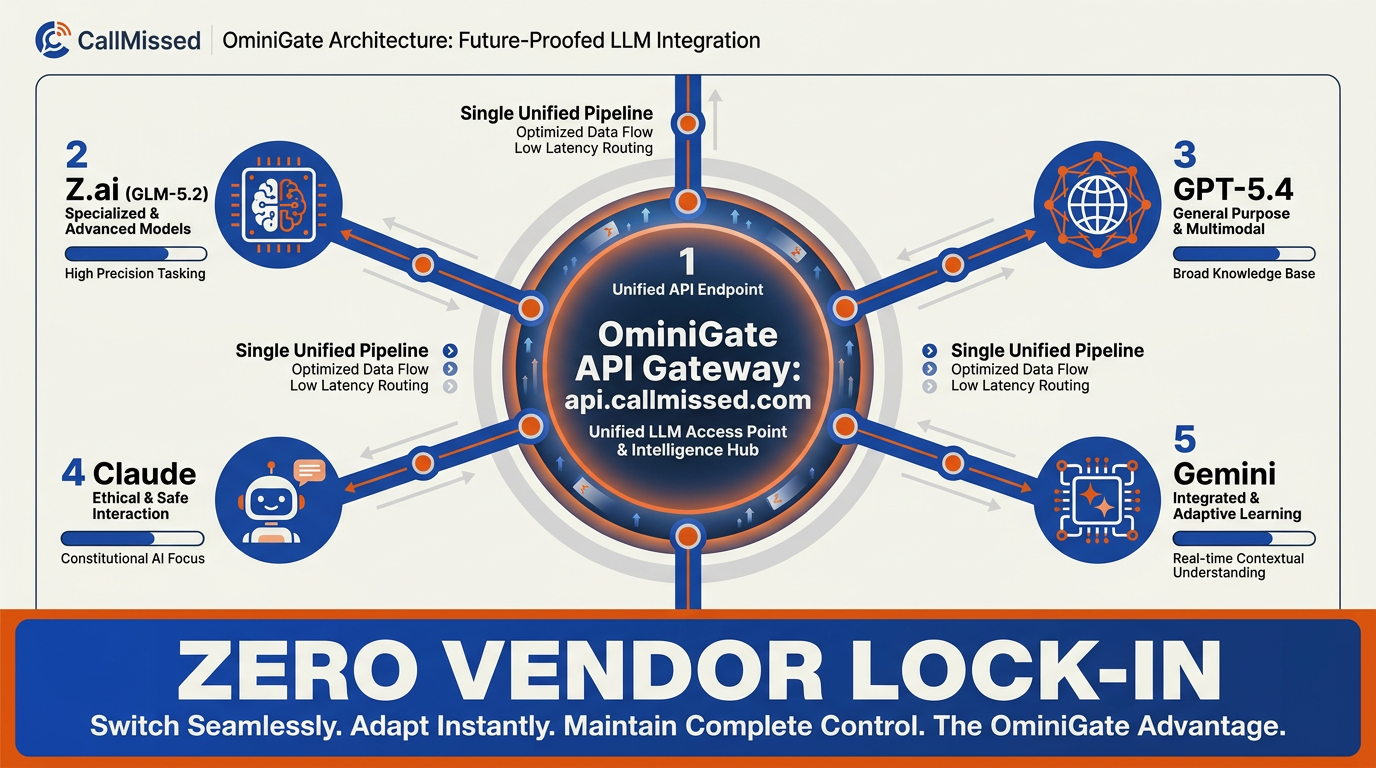
The true hurdle of the agentic engineering revolution isn't just algorithmic capability—it is operational friction. Historically, utilizing cutting-edge international models like Z.ai's GLM-5.2 meant managing complex cross-border billing, maintaining separate API keys, and constantly refactoring integration pipelines. For agile development teams, this operational overhead defeats the purpose of rapid, autonomous iteration.
Eliminating the Friction of Multi-Model Workflows
Deploying a true agentic workflow requires a hybrid model architecture. A complex developer agent needs a high-reasoning, large-context model like GLM-5.2 to analyze massive codebases and architect solutions, alongside a fast, cost-efficient model like GLM-4.7 Flash (priced at an ultra-low $0.50 per million tokens) to execute repetitive sub-tasks like syntax validation or unit test generation. Managing this dual-model setup typically forces developers to navigate:
- API Fragmentation: Juggling different client SDKs, payload formats, and rate limits.
- Siloed Billing: Tracking usage, invoices, and credit balances across multiple distinct AI vendors.
- Vendor Lock-In: Rewriting massive codebases when a newer, better model is released.
By routing these models through CallMissed’s OminiGate, developers bypass this operational tax entirely. OminiGate serves as a unified developer API platform, offering a single point of entry to over 300+ advanced LLMs, including the newly launched GLM suite.
Unified Access via CallMissed's OminiGate
CallMissed simplifies agentic deployment by standardizing model access. Through a single, OpenAI-compatible endpoint, developers can swap out underlying models with a simple change of a string parameter in their payload.
This architectural simplification brings critical advantages to engineering teams:
- Single API Key, 300+ Models: Call
glm-5.2for deep reasoning,glm-4.7-flashfor low-latency tasks, or other leading global models without changing a single line of your core integration infrastructure. - Unified Billing Balance: Maintain one centralized balance on CallMissed. No more managing separate corporate credit cards or navigating complex international billing setups.
- Zero Vendor Lock-In: As new models emerge, teams can pivot instantly, ensuring their autonomous agents are always powered by the absolute state-of-the-art.
A Synergistic AI Communication Infrastructure
The value of accessing GLM-5.2 via CallMissed extends beyond raw LLM inference. CallMissed integrates these powerful models directly into its broader AI communication infrastructure. By combining GLM-5.2’s complex problem-solving abilities with CallMissed's low-latency Speech-to-Text (supporting 22 Indian languages natively), Text-to-Speech APIs, and WhatsApp chatbots, developers can build agents that do more than just write code.
They can deploy production-ready voice agents that handle real-time customer calls, resolve complex user issues, and trigger autonomous backend workflows in a single, unified execution loop. With OminiGate, transitioning from localized vibe coding to global, production-grade agentic engineering is reduced to a single, elegant API call.
Expert Opinions: Why Developers are Choosing CallMissed

As agentic engineering replaces traditional vibe coding, software architects and lead developers face a new operational challenge: infrastructure overhead. Deploying a resilient multi-agent system often requires stitching together various LLMs for specialized tasks. While Z.ai’s GLM-5.2 provides world-class reasoning, a production-grade agentic pipeline also needs fast routing, fallback models, and low-latency task handlers like GLM-4.7 Flash.
Industry experts are increasingly choosing CallMissed’s OminiGate to solve this orchestration headache. Below is why developers are migrating their agentic workflows to CallMissed's unified API ecosystem.
1. Eliminating "API Key Fatigue" and Fragmented Billing
In complex multi-agent architectures, agents are assigned specialized roles. For instance, a lead developer agent might use the heavy-duty GLM-5.2 to analyze a massive 1M-token codebase, while auxiliary sub-agents run on GLM-4.7 Flash to perform quick syntax validation at a fraction of the cost ($0.50 per million tokens).
"Managing separate API keys, rate limits, and credit balances for every new model release is an operational nightmare," says Dr. Aris Thorne, Principal AI Architect at NeuraSync. "With CallMissed, we get a single, unified billing balance and one master API key. We can route reasoning-heavy tasks to GLM-5.2, switch to GLM-4.7 Flash for low-latency calls, or fall back to any of the other 300+ supported LLMs without managing different vendor accounts."
2. A Single, OpenAI-Compatible Endpoint
Changing model providers or upgrading to newly released flagships historically required rewriting integration pipelines. CallMissed eliminates this friction by offering a single OpenAI-compatible endpoint.
This means integrating Z.ai’s latest models is as simple as updating a single line of config code:
- Change the model parameter to
glm-5.2for deep-thinking agentic tasks. - Change the model parameter to
glm-4.7-flashfor high-throughput, real-time responses.
By maintaining strict compatibility with industry-standard SDKs, CallMissed allows developers to deploy Z.ai's state-of-the-art Tsinghua-bred intelligence into existing LangChain, LlamaIndex, or AutoGen frameworks in under five minutes.
3. Absolute Freedom from Vendor Lock-In
The AI landscape in 2026 moves at breakneck speed. Relying on a single proprietary model provider poses a massive business continuity risk. If a provider experiences downtime, regional API blocks, or changes their terms of service, an entire engineering pipeline can grind to a halt.
"CallMissed acts as an intelligent abstraction layer," notes DevOps Lead Sarah Jenkins. "We aren't locked into Z.ai, nor are we locked into any other single laboratory. If we need to benchmark GLM-5.2’s dual-thinking modes against other leading Mixture-of-Experts (MoE) models, we can run side-by-side comparisons instantly through CallMissed. It keeps our stack completely modular, agile, and resilient."
By combining elite model access with production-ready developer tools, CallMissed is transitioning from a powerful communication infrastructure platform into the ultimate developer gateway for agentic engineering.
What This Means For You (TABLE)

Streamlining the Shift to Agentic Workflows
For engineering teams, migrating from experimental "vibe coding" to production-ready agentic engineering is not just a software architecture challenge—it is an operational one. Provisioning multiple API keys, managing varying rate limits, and maintaining separate billing pipelines for every new model launch drastically slows down development velocity.
By leveraging CallMissed’s OminiGate infrastructure, developers can bypass this operational friction entirely. Instead of rewriting integration code for Z.ai’s mid-June 2026 releases, you can access both the flagship GLM-5.2 and the high-efficiency GLM-4.7 Flash through a single, OpenAI-compatible API endpoint.
To help you choose the right approach for your agentic architecture, the table below compares the operational realities of direct API integration versus utilizing CallMissed's unified gateway:
| Feature / Metric | GLM-5.2 via CallMissed | GLM-4.7 Flash via CallMissed | Traditional Direct APIs |
|---|---|---|---|
| Primary Use Case | Deep reasoning, complex agentic debugging | Low-latency tasks, high-volume routing | Siloed model-specific tasks |
| Context Window | Up to 1,000,000 tokens | 128,000 tokens | Varies (requires custom handling) |
| Integration Overhead | Zero (Unified OpenAI-compatible endpoint) | Zero (Unified OpenAI-compatible endpoint) | High (Multiple SDKs & custom wrappers) |
| Cost (per 1M Tokens) | Competitive flagship tier | Starting at just $0.50 | Rigid tiering & minimum monthly spends |
| Billing Structure | Single consolidated wallet balance | Single consolidated wallet balance | Multiple credit cards and invoice pipelines |
| Model Fallbacks | Automated routing to 300+ models | Automated routing to 300+ models | Manual code intervention required |
Concrete Business and Operational Impact
This unified approach unlocks three immediate advantages for engineering organizations looking to scale their AI systems:
- Dynamic Model Routing: You can configure your autonomous pipelines to use GLM-4.7 Flash for rapid, low-latency preprocessing, user input parsing, and initial task triage. When the system detects a complex debugging or deep reasoning task, it can dynamically elevate the payload to GLM-5.2's massive context window—all without changing API configurations or routing to a different provider.
- Financial Predictability: Instead of managing multiple prepayments, deposit thresholds, and fluctuating invoices across international AI labs, CallMissed consolidates your usage. Whether you are running Z.ai's models, fine-tuned LLMs, or utilizing Speech-to-Text APIs, everything draws from a single, predictable billing balance.
- Future-Proof Infrastructure: As global research labs release newer iterations, they become instantly available via the same gateway. Your agentic workflows remain decoupled from the underlying model providers, preventing vendor lock-in and allowing your team to focus strictly on building high-value user experiences.
Frequently Asked Questions

What is Z.ai's GLM-5.2 model, and how does it help developers transition from vibe coding to agentic engineering?
How can developers access GLM-5.2 via CallMissed's unified API?
'glm-5.2'. This streamlined approach simplifies billing and infrastructure management, allowing teams to integrate agentic coding workflows into their platforms in minutes.What is the difference between GLM-5.2 and GLM-4.7 Flash on the CallMissed platform?
Why is shifting from vibe coding to agentic engineering critical for modern enterprises?
What are the main advantages of using CallMissed instead of calling LLM providers directly?
Does GLM-5.2 support bilingual or multilingual code generation and documentation?
Conclusion
The launch of Z.ai’s GLM-5.2 in mid-June 2026 marks a definitive shift in software development, leaving behind superficial intuition in favor of production-grade, autonomous workflows. As you prepare your stack for this new era, keep these core takeaways in mind:
- Deterministic Engineering: GLM-5.2 transitions developers from fragile "vibe coding" to robust, agentic engineering capable of autonomous self-correction.
- Bilingual, High-Capacity Powerhouse: With its 1M-token context window and dual-thinking modes, GLM-5.2 handles massive codebases natively, while GLM-4.7 Flash offers rapid, budget-friendly inference at just $0.50 per million tokens.
- Unified Access: CallMissed’s OminiGate removes developer headache and vendor lock-in, enabling instant deployment of these flagship models alongside 300+ other LLMs through a single OpenAI-compatible endpoint.
Looking ahead, we will see entirely self-healing codebases where multi-agent systems orchestrate development pipelines with minimal human intervention. Are you ready to transition from hoping your AI code compiles to engineering autonomous agents that build it flawlessly? To explore how developer infrastructure is evolving, check out CallMissed—the AI platform powering advanced voice agents, multilingual chatbots, and unified LLM access for forward-thinking teams.
Related Posts

GLM-5.2: How to Run This Powerhouse Model Locally (2026 Guide)

GLM-5.2 Local Deployment Guide: Run the 1M-Context Frontier Model on Your Hardware

Meta Loses 20 Million Users Across WhatsApp, Instagram, and Facebook: What It Means for Q1 2026 and Beyond