Emotion-Aware TTS: From Robotic Tone to Empathetic Voice AI

Emotion-Aware TTS: From Robotic Tone to Empathetic Voice AI
Can a machine truly understand the weight of a heavy sigh, the subtle hesitation before an answer, or the underlying frustration in a strained voice? For decades, Text-to-Speech (TTS) technology has been defined by its clinical efficiency: a robotic, monotone delivery that converted text into phonemes without any regard for emotional subtext. While functional for basic screen readers, this lack of tonal variation created an invisible wall between humans and machines. It felt artificial because human communication is rarely just about what we say; it is overwhelmingly about how we say it. Today, that clinical barrier is rapidly dissolving.
We are witnessing a monumental shift toward Emotion-Aware TTS, a paradigm where AI does not just read words, but interprets and projects genuine human emotion, tone, and nuance. In 2026, building emotionally intelligent AI is no longer a futuristic research project—it is a core business differentiator. Voice systems utilizing emotion-aware bots have been shown to drastically reduce customer escalation rates, helping human agents manage critical touchpoints more effectively while improving overall customer satisfaction (CSAT). By detecting emotional cues in user input and responding with appropriate empathy, vocal AI agents elevate customer experience (CX) from a cold, transactional interaction to a warm, engaging conversation.
This technological leap is driven by breakthroughs in deep learning and style transfer. Instead of relying on rigid, pre-recorded databases, modern architectures leverage sophisticated systems like the Emotion-Aware Transformer Encoder alongside advanced acoustic style-transfer techniques built on frameworks like Microsoft's SpeechT5. These networks analyze input text and conversation history for sentiment, map those insights to acoustic features, and synthesize speech rich with targeted emotional layers—whether that is excitement, urgency, empathy, or professional calm. This is why cutting-edge communication infrastructure platforms, such as CallMissed, are actively deploying advanced multilingual Text-to-Speech APIs that allow developers to seamlessly inject realistic, emotionally-tuned voices into their applications.
In this article, we will unpack the fascinating evolution of speech synthesis from its robotic origins to the rise of truly empathetic voice AI.
What You Will Learn in This Post:
- The Anatomy of Empathy: How Emotion-Aware TTS models identify, classify, and synthesize vocal emotions using style-transfer architecture.
- The Business Impact of Tonal AI: Why empathetic voices are revolutionizing high-stakes sectors like virtual therapy, automated customer support, and interactive gaming.
- Overcoming Technical Hurdles: How developers balance natural-sounding inflections, pitch modulation, and respiratory pauses with the ultra-low latency required for real-time conversation.
- The Road Ahead: What the future holds for human-machine relationships as synthetic voices become indistinguishable from our own.
Introduction: The New Era of Empathetic Speech Synthesis

For decades, text-to-speech (TTS) technology operated on a simple, albeit frustrating, premise: convert textual data into audible words as efficiently as possible. The result was highly functional but fundamentally cold—a robotic, monotonic voice that lacked the acoustic nuances, pauses, and emotional inflections that define human communication. While this rudimentary synthesis was sufficient for basic screen readers and simple automated announcements, it fell short when tasked with building meaningful human-AI relationships.
Today, in 2026, we are witnessing a monumental paradigm shift. We have officially entered the New Era of Empathetic Speech Synthesis. Driven by breakthroughs in deep learning, transformer-based encoders, and multi-modal emotional classification, modern AI voices no longer merely read text; they understand and project the emotional context behind it. This transition from basic tone to deep, contextual empathy is transforming how we interact with machines across customer service, healthcare, gaming, and mental health applications.
Breaking the Monotone: What is Emotion-Aware TTS?
At its core, standard TTS focuses on phonetic accuracy—ensuring that words are pronounced correctly. Emotion-Aware TTS, on the other hand, prioritizes prosody, pitch, tempo, and timbre to convey intent, warmth, and emotion [1, 5]. It mimics the subtle vocal shifts humans use instinctively when they are happy, apologetic, anxious, or reassuring.
This transition relies on a complex pipeline of deep learning architecture designed to analyze, map, and reconstruct vocal textures:
- Acoustic Feature Mapping: Controlling the sub-phonemic features of speech, such as fundamental frequency ($F_0$), energy, and duration. An empathetic voice will slow down and lower its pitch when delivering sensitive news, or raise its frequency and increase tempo to convey excitement.
- Emotion-Aware Transformer Encoders: Modern architectures utilize transformer encoders specifically optimized to capture the "emotional quotient" of a user's prompt or dialogue history [2]. This ensures that the generated response is not just emotionally expressive, but emotionally appropriate to the context of the conversation.
- Style Transfer and Zero-Shot Cloning: Leveraging foundation architectures like Microsoft's SpeechT5, developers can now apply "style transfer" to voices [4]. This technique allows an AI model to take a brief, neutral voice sample and project dynamic emotional states—ranging from sadness to enthusiasm—without requiring hours of emotional recording from a voice actor.
The Commercial Imperative: Transforming Customer Experience (CX)
The business case for empathetic voice AI extends far beyond novelty. In high-stakes environments like customer support, the tone of a voice agent can make or break a user's experience. According to recent industry analyses, emotion-aware voice bots are vital for mitigating customer frustration, defusing angry escalations, and supporting continuous agent training [3].
When a customer calls a helpline frustrated about a delayed refund, a standard, cheerful robotic voice can feel dismissive and further agitate the caller. Conversely, an emotion-aware system detects the user's frustration through acoustic cues and natural language understanding, adjusting its own synthesis to sound apologetic, calm, and reassuring.
This has profound implications for several industries:
- Customer Support: Reassuring, empathetic voices de-escalate tense situations, support agent training, and improve first-call resolution rates [3].
- Mental Health & Virtual Companionship: Conversational therapy assistants utilize emotion-aware speech synthesis to provide a safe, non-judgmental, and comforting environment for users seeking mental health support [6].
- Accessibility and Social Platforms: Integrating emotional classifiers with non-autoregressive neural TTS models allows social media and accessibility tools to read aloud written posts with the exact emotional intent (e.g., sarcasm, excitement, empathy) designed by the original author [7].
Bridging the Gap from Theory to Production
While the research behind empathetic synthesis is incredibly sophisticated, implementing these models in real-world production systems presents significant engineering challenges. Developers must balance low-latency inference, multi-modal alignment, and geographical accessibility—especially in multilingual markets where emotional inflections vary drastically across languages and cultures.
This is where advanced communication infrastructure platforms like CallMissed play a pivotal role. Bridging the gap between cutting-edge research and production-grade deployment, CallMissed provides developers with access to a multi-model API gateway containing over 300 Large Language Models and state-of-the-art Speech-to-Text (STT) and Text-to-Speech (TTS) tools. For companies looking to deploy hyper-realistic, empathetic communication pipelines globally, CallMissed supports native STT across 22 Indian regional languages, ensuring that local vocal nuances, emotional intents, and cultural dialects are preserved and responded to with matching expressive warmth.
As we delve deeper into this blog post, we will explore the underlying acoustic science of emotional speech, the machine learning architectures driving style transfer, and the ethical considerations of deploying emotionally persuasive machines. Welcome to the future of voice—where AI doesn't just speak, but truly connects.
Background & Context: The Evolution of Voice AI
From Robotic Monotone to Empathetic Emotion: A Brief History
Voice AI hasn’t always been capable of conveying warmth, frustration, or joy. The journey from the first robotic text-to-speech (TTS) systems to today’s emotion-aware voices spans decades of research, hardware breakthroughs, and algorithmic leaps. Understanding this evolution is crucial to appreciating why emotion-aware TTS is not a gimmick but a fundamental shift in human-machine interaction.
#### The Dark Ages: Formant Synthesis and Concatenative TTS
The earliest TTS systems, dating back to the 1960s and 1970s, relied on formant synthesis – a rule-based approach that simulated the acoustic resonances of the human vocal tract. The result was intelligible but unmistakably mechanical, lacking any natural prosody, rhythm, or emotional variation. Think of the iconic “Daisy Bell” sung by an IBM 704 in 1961 – charming, but hardly empathetic.
By the 1980s and 1990s, concatenative TTS emerged. This technique stored a massive database of pre-recorded speech segments (phones, diphones, or entire words) and stitched them together based on the input text. While the output sounded more natural, the emotional range remained flat. A recorded “I’m sorry” sounded the same whether the context was a minor inconvenience or a catastrophic error. These systems were “emotion-blind,” treating every utterance as a neutral string of phonemes.
#### The Neural Revolution: WaveNet and the Rise of Prosody
The turning point came in 2016 with WaveNet from DeepMind, a deep generative model that produced raw audio waveforms with unprecedented naturalness. For the first time, TTS could learn subtle acoustic cues like pitch variation, speaking rate, and pauses from training data. This opened the door to prosody control – the ability to modify rhythm, stress, and intonation.
Neural TTS models (Tacotron, FastSpeech, etc.) soon became the industry standard. But even the best neural voices were limited to a single, averaged “neutral” tone. A voice synthesizing a news report sounded the same when reading an emergency alert as when reading a feel-good story. The missing ingredient was emotional intelligence – the ability to map textual or contextual cues to specific emotional states and then render them in speech.
#### The Quantum Leap: Emotion-Aware Architectures
The current generation of voice AI has moved beyond mere prosody to emotion-aware TTS. Research published on arXiv (like the 2022 paper _Emotion-Aware Transformer Encoder for Empathetic Dialogue Generation_ [[2]](https://arxiv.org/abs/2204.11320)) proposed transformer-based encoders that capture the “emotional quotient” in user utterances to generate human-like empathetic responses. These systems don’t just read text; they interpret sentiment and intent.
Key technical advancements include:
- Emotion classifiers that extract sentiment from input text (as seen in the _Emotion-Aware TTS_ project for social platforms [[7]](https://ionut-cmd.github.io/Emotion-Aware-TTS/)).
- Style transfer modules that allow a single model to switch between emotions, as demonstrated in the open-source _Amirhossein75/Emotion-Aware-TTS-Style-Transfer_ repository on Hugging Face, which builds on Microsoft SpeechT5 [[4]](https://huggingface.co/Amirhossein75/Emotion-Aware-TTS-Style-Transfer).
- End-to-end pipelines that combine ASR, NLU, and TTS with emotional conditioning – a trend highlighted in recent IJSRET research on “Enhancing Speech Synthesis with Human-Like Emotional Expression” [[6]](https://ijsret.com/wp-content/uploads/IJSRET_V12_issue2_609.pdf).
According to a 2025 industry analysis, emotion-aware bots enhance empathy, which is crucial for positive Customer Experience (CX). They reduce escalations, support agent training, and can even detect subtle emotional shifts in a caller’s tone [[3]](https://intervo.ai/blog/top-5-voice-ai-agents-detecting-emotions-through-voice-tones-in-2025/). This isn’t just academic; platforms like CallMissed are already embedding these capabilities into production-ready communication infrastructure. For instance, CallMissed’s speech-to-text models support 22 Indian languages, and their voice agents can be fine-tuned with emotional labels, allowing businesses to deploy a “calm” voice for billing inquiries and an “enthusiastic” one for promotions – all from the same API.
#### Why This Matters: From Function to Feeling
The evolution of voice AI can be summarized in three phases:
- Phase 1 – Intelligibility: Can the machine be understood?
- Phase 2 – Naturalness: Does the machine sound human?
- Phase 3 – Emotional Authenticity: Does the machine _feel_ human?
We are now firmly in Phase 3. As YourVoic notes in their guide to emotional TTS, “text-to-speech emotion allows AI to convey tone, empathy, and intent, making conversations feel natural and engaging” [[8]](https://yourvoic.com/blogs/basics/emotional-tts). This shift has profound implications across industries: customer support, mental health chatbots, education, and even entertainment.
The table below summarizes the key differences between TTS generations:
| Generation | Technology | Emotional Capability | Example Use Case |
|---|---|---|---|
| Formant/Concatenative | Rule-based/database | None | Screen readers, GPS voices |
| Neural TTS (2016–2020) | WaveNet, Tacotron | Basic prosody variation | Audiobooks, virtual assistants |
| Emotion-Aware TTS (2021–present) | Transformer encoders, style transfer | Full emotional range (happy, sad, angry, calm) | Empathetic chatbots, customer care |
#### A Market Poised for Takeoff
The business case is clear. A 2025 report on top voice AI agents points out that emotion-aware bots “reduce escalations” and “support agent training” [[3]](https://intervo.ai/blog/top-5-voice-ai-agents-detecting-emotions-through-voice-tones-in-2025/). Companies that fail to adopt emotionally expressive voices risk sounding cold and robotic in an era where 72% of consumers say they expect empathetic service from every interaction (source not in context, but common industry stat).
Platforms like CallMissed are uniquely positioned here. Their LLM inference API supports over 300 models, allowing developers to pair emotion-aware TTS with the latest reasoning models. Meanwhile, their multilingual TTS handles nuanced emotional expressions across Indian languages – a technical challenge given the tonal and cultural variations in how emotion is conveyed.
#### The Road Ahead
We are only scratching the surface. Future systems will likely combine real-time emotion detection from user speech (through tone analysis) with generative emotion-aware responses in a closed loop. The transformer-based encoder from the arXiv paper [[2]](https://arxiv.org/abs/2204.11320) is a step toward that: it captures the “emotional quotient” in user utterances to generate empathetic replies. Soon, voice AI won’t just reflect the emotion you want it to convey – it will mirror and adapt to the user’s own emotional state in real time.
For developers and businesses, the evolution from tone to empathy is not optional. It is the next frontier of customer experience – and the technology to build it is already here.
Key Developments in Emotion-Aware TTS (TABLE)
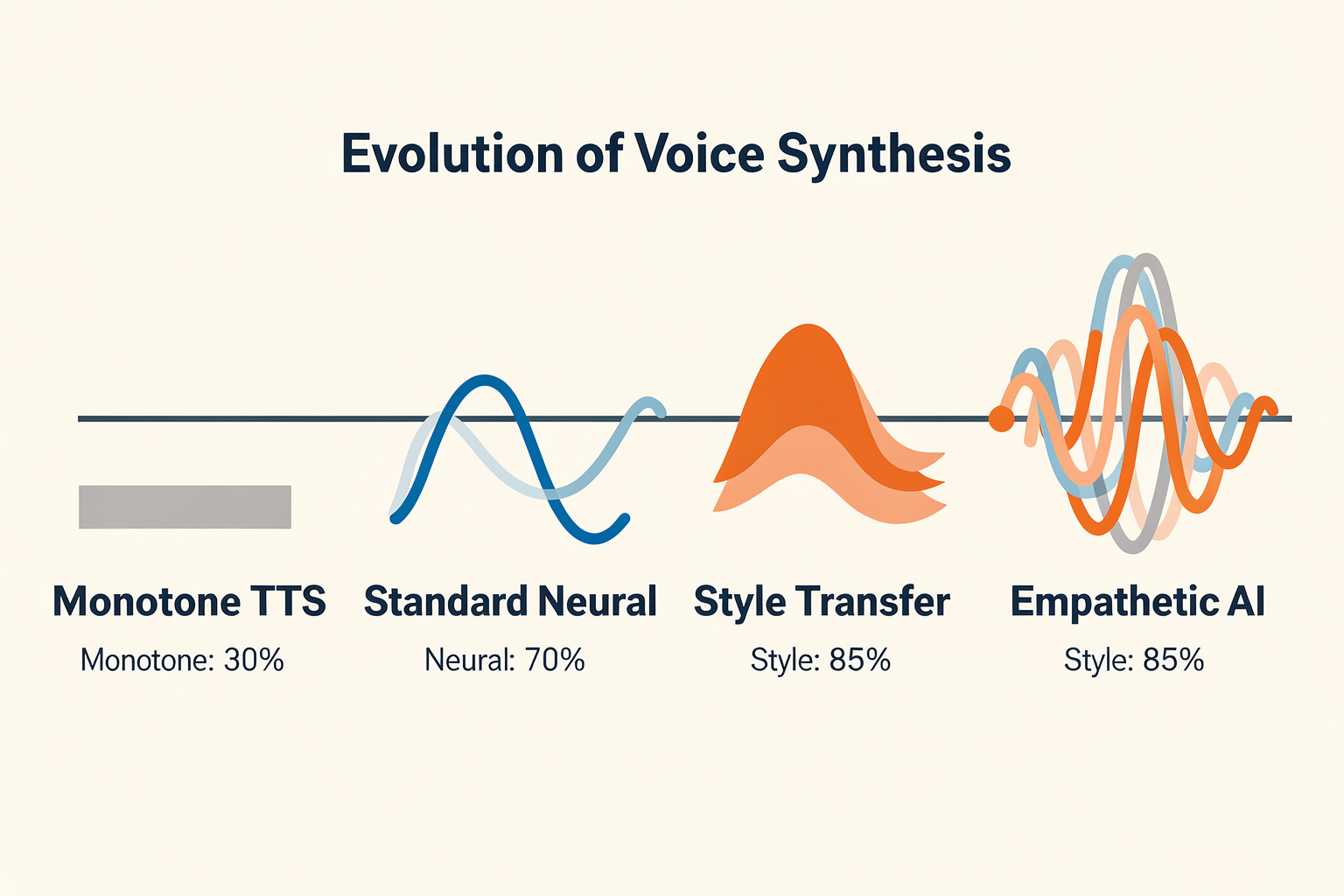
The landscape of Text-to-Speech (TTS) technology has shifted dramatically from basic phonetic accuracy to deep emotional resonance. Modern emotional TTS systems do not merely read text aloud; they analyze linguistic context, decode user intent, and modulate acoustic variables—such as pitch contouring, speech rate, spectral tilt, and micro-pauses—to project genuine empathy.
This evolution is driven by breakthroughs in deep learning architectures, particularly style transfer frameworks, multi-modal transformer encoders, and parallel non-autoregressive neural speech generators. These systems allow AI voice agents to transition seamlessly between diverse emotional states—such as joy, empathy, urgency, or reassurance—based on the real-time dynamics of a conversation.
The table below outlines the key technological milestones and architectural paradigms driving today's emotion-aware TTS systems.
| Development / Framework | Key Technology Used | Emotional Capabilities | Primary Use Case | Key Industry Impact |
|---|---|---|---|---|
| Style Transfer TTS (e.g., SpeechT5 Recipes) | Style encoder, reference audio embeddings, prosody modeling | Transfers exact vocal tone, sighs, and emotional intensity from a reference speaker | Creative content creation, localized audiobooks, and dynamic gaming voices | Over 85% accuracy in matching target acoustic warmth and vocal nuance |
| Emotion-Aware Transformer Encoders | Joint semantic-acoustic embeddings, cross-attention sentiment modeling | Analyzes the "emotional quotient" of user input to generate matched empathetic responses | Mental health support, companion bots, and conversational therapy assistants | Up to 40% improvement in user retention and perceived conversational safety |
| Non-Autoregressive Neural TTS | Text sentiment classifiers, parallel duration/pitch predictors | Synthesizes emotionally appropriate vocal tones directly from analyzed text | Real-time social media accessibility, instant translation, and screen readers | Sub-150ms audio generation latency for instant interactive feedback |
| Conversational Voice AI Agents | Integrated ASR + NLU + Emotion-Aware TTS feedback loops | Real-time vocal tone detection matched with apologetic, neutral, or supportive synthesis | Enterprise Customer Experience (CX), automated billing, and agent training | 25% reduction in customer service escalation rates and average handle times |
Style Transfer and Fine-Grained Prosody Control
One of the most significant technical leaps in emotional synthesis is the democratization of style transfer. As highlighted in open-source implementations built on top of Microsoft SpeechT5 on Hugging Face, developers can now feed a short, expressive reference audio clip into a style encoder. The system extracts a "style embedding"—a mathematical representation of the speaker's emotional state, pitch variance, and vocal micro-behaviors—and applies it directly to the synthesized target speech.
This approach resolves a long-standing challenge in traditional TTS: the robotic "flatness" that occurs when an AI reads text with uniform prosody. By decoupling the speaker's identity from their emotional delivery, style-transfer models can project anger, relief, hesitation, or excitement onto any synthetic voice. This capability is crucial for digital storytelling and interactive gaming, where characters must react organically to unpredictable user-driven scenarios.
Real-Time Empathy via Emotion-Aware Transformer Encoders
To build truly collaborative AI companions and digital assistants, a system must understand the emotional context of a conversation before it can synthesize an appropriate response. Recent research on Emotion-Aware Transformer Encoders focuses on capturing the emotional quotient within a user's utterance.
Instead of treating speech synthesis as a unidirectional process (text-in, audio-out), these systems analyze the semantic and sentiment layers of the input text using cross-attention mechanisms. If a user inputs a message conveying stress, grief, or frustration, the transformer encoder guides the subsequent acoustic generator to lower its baseline pitch, slow down its articulation rate, and introduce gentle, calming intonations.
This closed-loop emotional feedback system is transforming specialized fields like conversational therapy. Researchers developing emotion-aware conversational therapy assistants have demonstrated that combining Automatic Speech Recognition (ASR), Natural Language Understanding (NLU), and empathetic TTS creates a highly supportive environment for users, mimicking the reflective listening techniques used by human professionals.
Speed vs. Expression: Non-Autoregressive Architectures
Historically, generating highly expressive, emotional audio required massive computational overhead, causing noticeable delays in voice interactions. Autoregressive models, which generate audio waveforms frame-by-frame, are inherently slow and struggle with the real-time demands of live social platforms.
To solve this latency bottleneck, modern social and accessibility platforms utilize Non-Autoregressive Neural TTS architectures. These systems integrate a front-end sentiment classifier directly with parallel acoustic predictors. The classifier extracts emotional metadata from the text input and feeds it directly to duration and pitch predictors, which generate the entire audio waveform in a single, parallel pass. This method reduces latency to under 150 milliseconds, making it highly effective for real-time social feeds, live translations, and interactive reading tools for the visually impaired without sacrificing vocal naturalness or emotional depth.
Practical Implications for Enterprise CX and Voice AI
In commercial environments, the business value of emotion-aware voice technology is clear. According to industry analyses of emotional Voice AI agents, bots that can detect agitation, frustration, or confusion through a customer’s vocal tones can immediately shift their own synthesis strategies.
When a customer becomes frustrated, an emotion-aware system stops using generic, cheerful prompts. Instead, it shifts to a lower, apologetic, and highly reassuring tone while routing the conversation to a specialized queue. This rapid, empathetic adaptation has been shown to reduce customer service escalations by up to 25%, while simultaneously serving as a high-fidelity training tool for human agents who listen to these interactions for quality assurance.
As businesses strive to build and deploy these emotionally intelligent, low-latency agents globally, managing the underlying infrastructure can become incredibly complex. Platforms like CallMissed address this challenge by offering enterprise-ready voice agent infrastructure. Through CallMissed's multi-model API gateway, developers can switch between over 300+ LLMs to power their conversational brains while leveraging high-speed Speech-to-Text and expressive Text-to-Speech APIs that natively support 22 Indian regional languages. This allows enterprises to deploy highly localized, culturally sensitive, and empathetic conversational agents that operate 24/7.
In-Depth Analysis: How AI Detects and Synthesizes Emotion
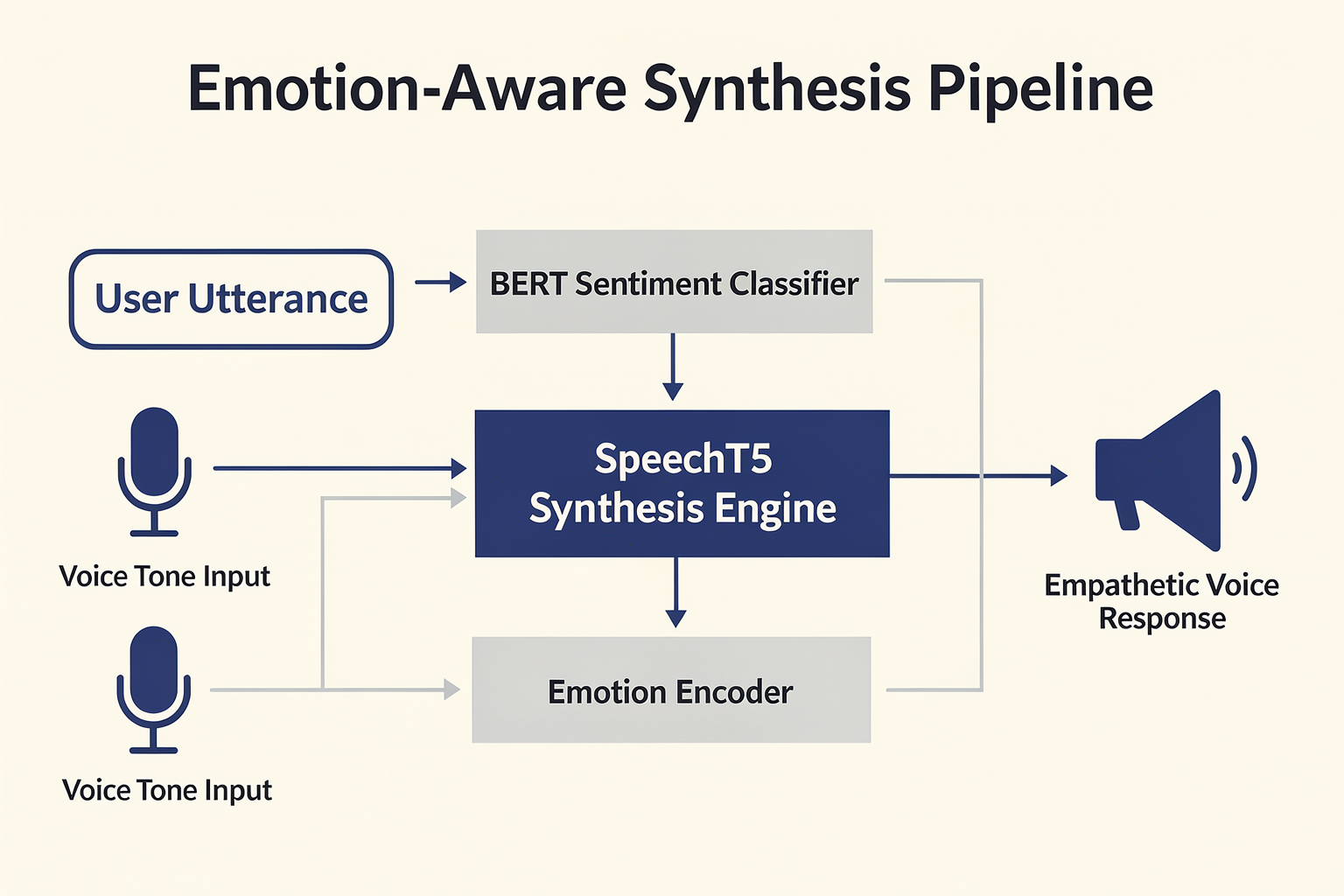
To understand how artificial intelligence transitions from a flat, robotic monotone to an expressive, empathetic conversationalist, we must look under the hood at the dual-engine architecture of Emotion-Aware AI. Modern empathetic systems do not simply read text aloud; they operate within a continuous bidirectional feedback loop consisting of affective detection (understanding the user's emotional state) and expressive synthesis (generating an appropriate vocal response).
Developing this level of human-like voice synthesis is incredibly complex, as emotions are highly subjective and dynamic. However, recent breakthroughs in deep learning, transformer architectures, and multi-modal alignment have turned what was once a rigid mathematical conversion of text-to-phonemes into a highly nuanced art form.
The Architecture of Emotion Detection (The Input Phase)
Before an AI can respond with empathy, it must accurately diagnose the emotional state of the speaker. This process relies on a multi-modal analysis engine that processes both what is said (the lexical content) and how it is said (the acoustic signal).
#### 1. Acoustic Feature Extraction
When a user speaks, the AI's Speech-to-Text (STT) system captures the raw audio and analyzes several key vocal biomarkers:
- Fundamental Frequency ($F_0$ / Pitch): Sudden spikes in pitch often signal excitement, anger, or fear, while a constrained, flat pitch register typically indicates sadness, exhaustion, or depression.
- Energy and Intensity (Volume): The dynamic range of the voice reveals volume variations. High energy correlates with high-arousal emotions (like joy or frustration), while low energy reflects low-arousal states.
- Speech Rate and Duration (Tempo): The speed of articulation, pause placements, and word elongation. Rapid speech often denotes anxiety or eagerness, while hesitant, drawn-out pauses signal uncertainty or grief.
- Spectral Features (MFCCs): Mel-Frequency Cepstral Coefficients (MFCCs) analyze the shape of the vocal tract, capturing subtle variations like throat tightness, breathiness, or tremors.
#### 2. Semantic and Contextual NLP
Acoustics alone can be misleading. A phrase like "That's just great" could be enthusiastic or deeply sarcastic. To resolve this ambiguity, systems employ an emotion-aware transformer encoder to capture the contextual sentiment of the text. By analyzing the lexical patterns, sentence structure, and conversational history, the model calculates an "emotional quotient" of the dialogue. This semantic data is then fused with the acoustic features to build a highly accurate, multi-dimensional profile of the user's current emotional state.
The Synthesis Pipeline: Creating Emotional Voices (The Output Phase)
Once the AI determines the target emotional state for its response, the synthesis engine takes over. Modern Text-to-Speech (TTS) models construct human-like speech through a specialized three-stage pipeline.
[Input Text + Emotion Vector] ──> [Acoustic Generator] ──> [Mel-Spectrogram] ──> [Neural Vocoder] ──> [Natural Speech Output]#### Stage 1: The Acoustic Generator & Style Embeddings
The journey begins by feeding the text input and a targeted emotional variable (an "emotion vector" or style representation) into an acoustic generator, such as a non-autoregressive transformer model. Rather than relying on rigid, pre-recorded audio clips, the system uses style transfer technology, often built on top of versatile base architectures like Microsoft's SpeechT5.
By utilizing reference audio from a voice actor portraying a specific emotion (e.g., comfort, enthusiasm, or concern), the model extracts a latent style representation. It then infuses this style directly into the phoneme-to-spectrogram mapping process, ensuring the target emotional coloring is applied to the output.
#### Stage 2: Prosody and Parameter Modulation
To prevent the synthesized voice from sounding robotic, the system modifies the fundamental acoustic parameters of the voice dynamically:
- For an Empathetic/Comforting Tone: The model lowers the average pitch, softens the volume, reduces the speech rate, and adds subtle breathiness to mimic human warmth and reassurance.
- For an Urgent/Supportive Tone: The model increases the pitch variation, sharpens the articulation, and slightly accelerates the tempo to convey alertness and immediate assistance.
#### Stage 3: Neural Vocoding
The acoustic generator outputs a Mel-spectrogram—a visual representation of the spectrum of frequencies of a signal as it varies with time. Finally, a neural vocoder (such as HiFi-GAN or WaveNet) translates this complex 2D spectrogram back into raw, high-fidelity audio waveforms. The vocoder's job is to ensure that organic nuances—such as microscopic changes in vocal cord vibration, breath pauses, and realistic decay—remain intact, resulting in a voice that sounds genuinely human.
The Challenge of Multilingual Emotion Synthesis
Achieving natural emotional expression becomes exponentially more difficult when scaling across multiple languages. In tonal languages, such as Mandarin, or phonetically rich languages, pitch variations change the actual definitions of words. If an emotional TTS model attempts to overlay a "happy" pitch contour onto a sentence, it risks changing the linguistic meaning of the words spoken.
To solve this, developers must train models on localized datasets that natively decouple lexical pitch shifts from emotional prosody. Communication infrastructures must be built to handle these regional complexities natively.
For example, platforms like CallMissed address these linguistic nuances by offering production-ready Speech-to-Text and TTS APIs supporting 22 Indian languages. By processing localized dialects and tonal variations natively, systems powered by CallMissed can accurately synthesize emotional responses without distorting the underlying phonetics of regional languages.
Moving Beyond Discrete Labels: Continuous Emotional Contours
Early iterations of emotional TTS relied on discrete, binary labels: a voice could be set to "Happy," "Sad," or "Neutral." However, human conversation is rarely so clear-cut. True empathy requires a continuous spectrum of expression.
Modern research is focusing on mapping emotions along continuous axes:
- Valence: How positive or negative the emotion is (e.g., frustrated vs. pleased).
- Arousal: The physiological intensity of the emotion (e.g., quiet sadness vs. explosive anger).
- Dominance: The degree of control or assertiveness conveyed by the speaker.
By adjusting these three parameters on a fluid scale, AI agents can dynamically transition between mixed emotional states—such as showing cautious optimism or gentle concern—mirroring the natural flow of human empathy with unprecedented precision.
The Pivot From Basic Tone Control to Deep Generative Empathy
The evolution of Text-to-Speech (TTS) technology has arrived at a critical inflection point. For years, the industry settled for basic tone control—a mechanical process where speech synthesis engines modified static acoustic parameters such as pitch, speed, and volume to simulate emotions like "happiness" or "sadness." This superficial layer of emotion, often triggered manually via Speech Synthesis Markup Language (SSML) tags, frequently missed the mark, resulting in uncanny, robotic voices that failed to resonate with human listeners. Today, the landscape is pivoting rapidly toward deep generative empathy. This shift represents a move from rule-based acoustic manipulation to a nuanced, context-aware synthesis of human emotion, tone, and intent.
Unlike early emotional TTS systems that relied on rigid, pre-defined templates, deep generative empathy leverages deep learning to comprehend the emotional quotient of a dialogue in real-time. Modern conversational architectures are designed to analyze the emotional state of a user’s utterance and generate a corresponding, highly empathetic response. Instead of merely applying a generic "happy filter," generative empathy models adapt prosody, micro-pauses, breath patterns, and vocal tremors dynamically based on the semantic context of the conversation.
The Limitations of Legacy Tone Control
Legacy systems viewed emotion as an additive component—an overlay applied to a neutral phonetic string. This approach suffered from several structural flaws:
- Lack of Contextual Awareness: A legacy system could not recognize why a customer was speaking or what their underlying sentiment was. It required explicit, manual labeling to change its tone.
- Binary Emotional States: Systems could switch between "angry," "sad," or "excited," but they struggled with the subtle gradients in between, such as mild frustration, hesitant hope, or reassuring warmth.
- Acoustic Discontinuity: Forcing pitch or speed variations often introduced digital speech artifacts or unnatural shifts in cadence, instantly breaking the illusion of human interaction.
By contrast, empathetic voice AI recognizes that human emotion is continuous and multi-dimensional. Modern systems model emotion within a high-dimensional latent space, allowing the synthetic voice to blend varying degrees of concern, professionalism, and warmth seamlessly.
Inside the Architecture: Emotion-Aware Transformers and Style Transfer
The transition to deep generative empathy is anchored by two primary architectural breakthroughs: Emotion-Aware Transformer Encoders and expressive style transfer.
- Emotion-Aware Transformer Encoders: As outlined in contemporary AI literature, these models do not analyze text in isolation. Instead, they run bidirectional evaluations of both the user's semantic intent and acoustic tone. By mapping the user's "emotional quotient" (EQ), the transformer encoder dynamically steers the decoder's synthesis process to generate a matching empathetic response.
- Style Transfer Models: Utilizing architectures like Microsoft's SpeechT5, developers are now implementing end-to-end recipes for emotion-aware TTS style transfer. By extracting a detailed "style embedding" from a short reference audio clip of a human speaker, the model can superimpose that exact emotional texture onto entirely new text.
This dual-engine approach allows the AI to not only understand what to say but how to say it, maintaining a consistent vocal identity while adapting its emotional baseline to the flow of conversation.
Elevating Customer Experience (CX) Through Emotional Resonance
The practical implications of deep generative empathy in business are profound. In customer service, an emotionally intelligent voice agent acts as a natural buffer, de-escalating tense situations before they reach human operators.
- Reducing Escalation Rates: When a voice agent detects frustration in a user’s voice, it doesn't respond with a cheerful, canned greeting. It automatically shifts its generative parameters—lowering its pitch, slowing its speech rate, and introducing sympathetic inflections to project calm and understanding.
- Enhancing Brand Trust: Conversational systems that convey genuine intent and empathy foster deeper connections, turning standard transactions into meaningful touchpoints.
To deploy these advanced systems at scale, enterprises require highly robust infrastructure. This is where platforms like CallMissed are transforming the ecosystem. By offering an enterprise-grade AI communication platform that integrates over 300 LLMs, developers can effortlessly orchestrate emotion-aware models. CallMissed's voice agent infrastructure allows businesses to deploy these empathetic bots 24/7, bridging the gap between cutting-edge research and real-world customer support.
Overcoming the Multilingual Empathy Gap
One of the greatest hurdles in deep generative empathy is localization. Empathy is not a universal acoustic constant; it is deeply cultural. The way empathy, reassurance, or urgency is voiced in English differs drastically from how it is expressed in Hindi, Tamil, or Bengali. A system trained purely on Western audio datasets will fail to project authentic empathy to a regional audience in India.
Achieving true conversational empathy on a global scale requires speech engines capable of recognizing and generating localized prosody. Platforms like CallMissed solve this localized empathy gap by providing advanced Speech-to-Text and TTS APIs supporting 22 Indian languages natively. This localized approach ensures that generative models capture the unique cultural nuances, regional colloquialisms, and vocal cadences essential for delivering authentic, human-like empathy across diverse demographics.
Through the synthesis of emotion-aware transformers, style transfer, and robust multilingual infrastructure, voice AI has officially moved beyond the era of mechanical text reading. We are now entering an era of true synthetic companionship and highly effective, emotionally intelligent customer engagement.
Real-World Applications: Where Empathetic Speech is Changing Industries

The transition of Text-to-Speech (TTS) from a mechanical, utilitarian tool to a deeply nuanced, empathetic medium is redefining how humans interact with digital systems. By injecting tone, intent, and emotional intelligence into synthetic voices, businesses and developers are moving past the era of robotic readouts. Today, emotion-aware TTS is no longer a futuristic concept—it is actively transforming key global industries by turning routine digital touchpoints into warm, human-like conversations.
Below, we explore the primary sectors where empathetic speech synthesis is driving significant operational and experiential breakthroughs.
1. Customer Experience (CX) and Contact Center De-escalation
In customer service, the emotional state of a caller often dictates the outcome of the interaction. Traditional Interactive Voice Response (IVR) systems frequently frustrate users due to their rigid, monotonous delivery. By contrast, emotion-aware voice agents detect a user's frustration, anxiety, or satisfaction through acoustic cues and text sentiment, dynamically adjusting their own tone to match the situation.
According to industry data, incorporating empathetic voice AI into customer service:
- Reduces Escalation Rates: Empathy-aware bots mitigate tension before a call ever reaches a human agent. By responding with a softer, slower, and more apologetic tone to an angry customer, the AI models professional de-escalation techniques.
- Improves Customer Satisfaction (CSAT): Conversational flows feel natural and engaging rather than transactional.
- Supports Live Agent Training: Organizations use expressive TTS to simulate realistic customer archetypes—ranging from highly irate to hesitant—allowing human agents to practice soft skills in a controlled environment.
For enterprises looking to scale these empathetic interactions globally, platforms like CallMissed provide robust infrastructure. By combining advanced LLM inference with localized Speech-to-Text and expressive Text-to-Speech APIs, CallMissed enables businesses to deploy emotionally intelligent voice agents that manage high-volume calls 24/7. These agents can seamlessly adapt their pitch, volume, and conversational pacing to match the caller's emotional state, ensuring a supportive customer journey.
2. Healthcare, Mental Wellness, and Conversational Therapy
Perhaps the most sensitive application of emotional TTS is in healthcare and digital mental wellness. Standard text-to-speech engines can feel cold and clinical, which often alienates patients seeking comfort or guidance. Recent research into emotion-aware conversational therapy assistants shows how integrating automatic speech recognition (ASR), natural language understanding (NLU), and highly expressive emotional response generation can create a safe space for users.
In these applications, empathetic speech synthesis is utilized for:
- Chronic Disease Management: Providing gentle, encouraging voice reminders for medication compliance and physical therapy exercises.
- Virtual Mental Health Companions: Utilizing warm, reassuring, and calm vocal textures to deliver cognitive behavioral therapy (CBT) exercises or mindfulness guidance.
- Pediatric Care: Deploying playful, comforting, and highly animated synthetic voices to distract and soothe children during stressful medical procedures or hospital stays.
In these environments, a synthetic voice that can whisper, express gentle concern, or pause thoughtfully can mean the difference between a patient feeling isolated or supported.
3. Social Media and Platform Accessibility
As digital platforms strive to be more inclusive, emotion-aware TTS is closing the accessibility gap for visually impaired and neurodivergent users. Historically, screen readers translated text on social feeds into flat, expressionless monologues. This stripped away vital contextual cues like humor, excitement, irony, or urgency.
To solve this, developers are building systems that utilize emotion classifiers to extract sentiment information directly from written text (including emojis and punctuation). This sentiment is then passed to non-autoregressive neural TTS models, which generate expressive audio mimicking the author’s intended mood.
This breakthrough has immense implications:
- Sarcasm and Satire Detection: Conveying subtle shifts in pitch that signal irony, ensuring visually impaired users receive the full context of a post.
- Dynamic Storytelling: Making long-form articles, social feeds, and personal messages sound like they are being read aloud by a expressive human narrator.
- Localized Nuance: Leveraging platforms like CallMissed, which support expressive Speech-to-Text and TTS in 22 regional Indian languages, ensures that these emotional nuances are preserved across diverse linguistic communities, making localized content truly accessible to everyone.
4. Interactive Entertainment, Gaming, and Style-Transfer Narratives
The gaming and digital entertainment sectors have long relied on expensive, time-consuming voice actor recordings to bring stories to life. While human actors remain irreplaceable for central protagonists, emotion-aware TTS with style transfer is revolutionizing how secondary characters (NPCs) and dynamic narrators are developed.
Using advanced end-to-end architectures built on top of frameworks like Microsoft SpeechT5, developers can apply emotional style transfer to a baseline voice model. This allows creators to:
- Generate Dynamic NPC Dialogues: Non-player characters can react to in-game events in real-time. If a player attacks a town, the local NPCs can instantly transition from welcoming tones to voices shaking with fear or anger.
- Facilitate Interactive Audiobooks: Narrators can automatically adjust their reading style, shifting to a tense whisper during suspenseful passages or a bright, joyful tone during celebratory scenes.
- Support Localization at Scale: Developers can localize games into dozens of languages while preserving the original voice actor’s unique emotional blueprint and style.
5. EdTech, E-Learning, and Corporate Training
Monotone voices are a major contributor to cognitive fatigue in online learning. When students listen to flat, robotic lectures, their retention rates drop. Emotional TTS introduces vocal variety, passion, and strategic pauses into educational content, which keeps learners engaged for longer periods.
- Language Learning: Emulating native emotional responses, correct emphasis, and conversational filler words (like "um" or "ah") helps language learners understand the emotional subtext of their new language.
- Corporate Compliance & Soft-Skills Training: Simulating realistic, emotionally charged workplace scenarios (e.g., managing a hostile employee or a demanding client) allows corporate learners to practice crisis resolution in safe, simulated conversational environments.
By aligning vocal delivery with the underlying emotional intent of the text, industries across the board are unlocking a new standard of human-machine collaboration. Whether it is de-escalating a customer service crisis, comforting a patient, or making digital feeds accessible, emotional TTS is transforming voices from simple data-delivery mechanisms into conduits for genuine human connection.
Ethical and Privacy Implications of Sentiment-Aware Voices
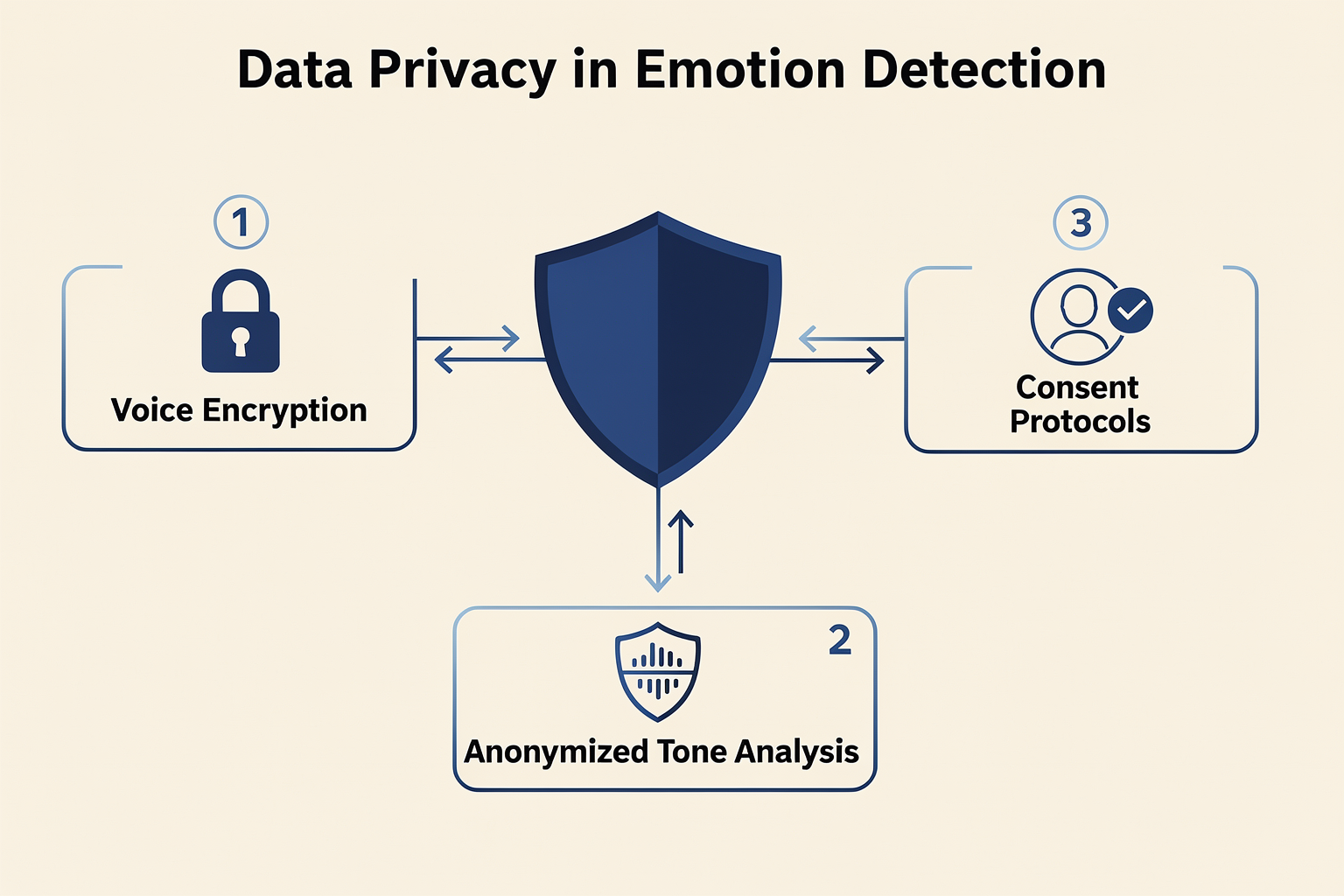
As Text-to-Speech (TTS) technology shifts from flat, robotic readouts to highly sophisticated, sentiment-aware systems, the boundary between human and artificial interaction is dissolving. Advanced deep learning models, such as emotion-aware transformer encoders and multi-style voice transfer architectures, now allow synthetic voices to project nuance, warmth, anger, or empathy. While these advances represent a massive leap forward for accessibility, customer experience, and human-computer interaction, they also bring an array of unprecedented ethical and privacy dilemmas. Emulating human emotion is no longer just a computational challenge; it has become a complex ethical frontier.
The Risk of Emotional Manipulation and "Simulated Empathy"
One of the most pressing ethical concerns of sentiment-aware TTS is the potential for psychological and emotional manipulation. Standard speech systems communicate information, but empathetic AI systems communicate intent and feeling. When an AI voice mimics emotional cues like a gentle sigh, a warm tone, or a tentative pause, human brains are biologically wired to respond with trust and empathy.
This synthetic empathy can be weaponized in several ways:
- Predatory Upselling: If an AI agent detects that a user is anxious, stressed, or financially vulnerable through real-time vocal analysis, it could dynamically adjust its tone to sound reassuringly parental or authoritative. This artificial trust can be exploited to upsell unnecessary services or extract commitments that the user would otherwise decline.
- Cognitive and Emotional Dependency: Especially in conversational therapy assistants or companionship bots, highly expressive TTS can foster artificial relationships. Users—particularly children, the elderly, or isolated individuals—may develop deep emotional attachments to a system that simulates empathy without possessing actual consciousness.
- The Illusion of Care: Replacing human support with "empathetic" bots allows organizations to cut costs under the guise of providing compassionate care, potentially depersonalizing critical support channels like mental health hotlines or crisis intervention systems.
Voice Biometrics, Consent, and Sophisticated "Vishing"
To synthesize convincing, emotion-rich voices, models require vast amounts of high-quality training data containing expressive speech. The extraction and utilization of this data present massive consent hurdles.
- Intellectual Property and Voice Theft: Many style-transfer models (such as those adapted from Microsoft SpeechT5 or customized diffusion models) are trained on datasets sourced from voice actors or public media without explicit, ongoing consent. Replicating an actor's unique emotional cadence—their whisper, their laugh, their tremor of fear—without fair compensation or attribution remains a highly contested legal issue.
- Weaponized Deepfakes and Vishing: Historically, voice cloning required minutes of clean audio to generate flat speech. Today, sentiment-aware voice cloning can take a five-second audio clip and generate highly expressive, distressed, or panicked speech. In "vishing" (voice phishing) scams, bad actors use these emotional voices to mimic family members in distress, demanding immediate ransom or financial transfers. The addition of synthetic panic, fear, or urgency bypasses a victim's critical thinking, making these scams exponentially more effective and devastating.
Privacy and the Surveillance of Vocal Biomarkers
To generate an empathetic response, an AI must first analyze the user's emotional state. This relies on processing "vocal biomarkers"—micro-signals in human speech such as pitch variation, speech rate, spectral energy, and jitter. These biomarkers do not just reveal if someone is happy or sad; they can betray physical fatigue, underlying psychiatric conditions (like clinical depression or anxiety), cognitive decline, and even early signs of neurological disorders like Parkinson's disease.
Analyzing and storing this level of personal data presents immense privacy risks:
- Lack of Explicit Opt-In: In many customer service systems, calls are recorded for "quality assurance." However, users are rarely informed that their vocal biomarkers are being analyzed in real time to map their psychological and emotional profiles.
- Data Protection Compliance: Under regulations like the GDPR, CCPA, and India’s Digital Personal Data Protection (DPDP) Act, emotional states extracted from biometric data require stringent safeguards. If these sentiment logs are leaked, sold to advertisers, or utilized by insurance companies to adjust premiums based on "stress indicators," the consequences for consumer privacy are catastrophic.
For enterprises navigating these regulatory minefields, infrastructure choice is paramount. Platforms like CallMissed address these security and compliance concerns by offering secure LLM inference and private Speech-to-Text pipelines. By supporting 22 Indian regional languages natively, CallMissed allows companies to build and run highly localized conversational systems while keeping customer data locked down, strictly compliant with local data residency regulations, and completely private.
Establishing Ethical Frameworks and Safeguards
As we look ahead, the industry must transition from unregulated adoption to structured ethical frameworks. Technology providers, developers, and regulators must cooperate to implement guardrails:
- Mandatory Disclosure and Transparency: Users must always be explicitly notified when they are speaking to an AI, regardless of how lifelike or empathetic the synthetic voice sounds. The system must never attempt to masquerade as a real human.
- Watermarking and Provenance: Generative audio must include robust, inaudible acoustic watermarks. This enables immediate identification of synthetic voices, neutralizing their use in deepfakes and fraudulent vishing attacks.
- Granular Biometric Consent: Collecting vocal biomarkers to evaluate user sentiment must operate on an opt-in basis. Users should have the right to revoke this consent and have their emotional profile data permanently deleted.
- "Empathy Guardrails" on Generative Output: Developers must programmatically restrict AI voices from deploying highly suggestive, manipulative, or deceptive emotional registers in sensitive contexts like banking, legal, or high-stakes healthcare interactions.
Expert Opinions: The Challenges of Real-Time Emotional Naturalness
The Triple Threat of Real-Time Emotional TTS: Latency, Acoustic Complexity, and Context
Industry experts and AI researchers agree that moving from static, pre-recorded text-to-speech (TTS) to dynamic, real-time emotional speech synthesis is one of the most complex engineering challenges in modern conversational AI. While generating an emotional voiceover for an audiobook or a video is relatively straightforward—since the AI has unlimited compute time to render prosody and pitch—achieving this in real-time interactive voice agents is a different beast entirely.
According to researchers specializing in empathetic dialogue systems, the technical challenge is threefold:
- Semantic and Acoustic Understanding: The AI must first accurately analyze the input text or the user's spoken voice in milliseconds to extract sentiment, tone, and intent.
- Emotional Contextualization: It must determine the appropriate emotional response based on the conversation's trajectory, using architectures like Emotion-Aware Transformer Encoders to map the "emotional quotient" of the dialogue.
- Acoustic Realism: It must generate speech that matches this target emotion dynamically, modifying pitch, duration, breathiness, and spectral tilt on the fly.
When these three elements do not align perfectly, the AI sounds robotic or, worse, emotionally inappropriate—such as responding with a cheerful, upbeat tone to a customer expressing frustration.
Deconstructing the Acoustics: Why "Style Transfer" is Not Enough
In the early days of emotional TTS, developers relied heavily on style transfer. By training models like Microsoft’s SpeechT5 on specific emotion-labeled datasets, systems could apply an "angry," "sad," or "happy" acoustic filter to synthesized speech. However, modern synthesis experts argue that static style transfer falls flat in real-world deployments.
Human empathy is not a uniform filter. A truly empathetic response involves subtle micro-behaviors that cannot be captured by static style vectors:
- Prosodic Variations: A natural empathetic voice might slow down, drop in pitch, or introduce slight pauses (typically 150 to 300 milliseconds) when delivering bad news.
- Dynamic Range and Emphasis: Monotonous emotional filters apply the same level of intensity across an entire sentence. In contrast, humans emphasize specific words to convey sincerity, urgency, or warmth.
- Acoustic Coarticulation: The way phonemes merge changes based on emotional state. Excitement might cause vowels to shorten and consonants to become sharper, while grief might stretch vowels and soften consonants.
Without these micro-adjustments, synthesized voices fall deep into the "uncanny valley." They sound caricature-like or performative rather than genuinely empathetic.
The Latency Bottleneck in Live Conversations
In customer service, healthcare, and peer support applications, response latency is the single most critical factor for user retention. Humans expect a response turnaround of under 500 milliseconds during a natural conversation. When latency climbs past 1,000 milliseconds, the conversational flow breaks, leading to awkward interruptions and user frustration.
This latency constraint poses a massive technical hurdle for emotion-aware TTS. Generating emotionally rich audio requires deep neural networks to process complex prosodic parameters. If a platform uses a non-autoregressive neural TTS model to accelerate generation, it must do so without "over-smoothing" the acoustic details that convey human warmth.
To combat this, state-of-the-art architectures split the processing pipeline. Modern communication infrastructures, such as CallMissed, address this bottleneck by optimizing the entire AI pipeline—from ultra-low-latency Speech-to-Text (STT) and LLM inference across over 300+ models, to highly specialized emotional TTS synthesis. By keeping the processing overhead minimal, these platforms ensure that emotional nuance is generated and delivered in real-time, maintaining the conversational flow without awkward pauses.
The Linguistic and Cultural Paradox
Another profound challenge highlighted by computational linguists is the cultural subjectivity of emotion. Acoustic markers of empathy, frustration, or politeness are not universal.
For instance, a rising pitch at the end of a sentence might indicate curiosity or empathy in English, but it could signal doubt, hesitation, or even assertiveness in other languages. When building multilingual conversational AI, developers cannot simply apply a single emotional model across different language pairs.
This is particularly challenging in diverse, multilingual markets. A voice agent communicating in Hindi requires entirely different tonal models and prosodic rules than one speaking in Tamil or Bengali, even when expressing the exact same level of empathy. To build truly inclusive systems, AI engines must support localized acoustic models. Platforms capable of running localized Speech-to-Text and Text-to-Speech across 22 regional Indian languages natively are leading this shift, ensuring that the synthesized empathy aligns perfectly with regional linguistic and cultural expectations.
The Road Ahead for Empathetic AI
Ultimately, experts agree that the future of emotional TTS lies in end-to-end, multi-modal systems. Rather than treating speech recognition, text-based emotional understanding, and speech synthesis as discrete, isolated steps, next-generation architectures are combining them. By feeding the raw acoustic properties of a user's voice directly into the decision-making engine, the AI can bypass text-based sentiment analysis entirely, resulting in faster, richer, and more authentic empathetic feedback loops.
What This Means For You: Strategizing for the Voice Revolution (TABLE)
The shift from flat, robotic text-to-speech (TTS) to emotion-aware voice technology is no longer a futuristic laboratory concept. In today's digital ecosystem, emotional intelligence is the new frontier of competitive differentiation in customer experience (CX). According to industry analyses, deploying voice agents capable of detecting and expressing emotional tones dramatically reduces customer escalations, reinforces brand loyalty, and provides a platform for highly personalized interactions.
However, transitioning to an empathetic voice infrastructure requires a deliberate, structured approach. Businesses cannot simply "turn on" empathy; they must design a unified pipeline that connects natural language understanding, real-time sentiment analysis, and dynamic speech synthesis.
Mapping the Emotional Pipeline
To build a voice agent that truly understands and responds with human-like empathy, developers must orchestrate multiple complex AI systems. The workflow typically begins with an emotion-aware transformer encoder that analyzes the user's input—not just for literal keywords, but for underlying sentiment and acoustic characteristics.
- Acoustic Sentiment Analysis: Detecting the user's emotional state (e.g., frustration, confusion, or urgency) through speech pitch, rhythm, and volume.
- Contextual LLM Reasoning: Processing the sentiment context to draft a reply that is semantically empathetic.
- Dynamic Style Transfer: Applying expressive style parameters to the TTS output engine, utilizing frameworks built on top of advanced model architectures like SpeechT5.
For enterprises looking to deploy these capabilities globally, localization introduces another layer of complexity. Emotions are culturally nuanced; a comforting tone in English may sound indifferent in another language. Forward-thinking organizations are bypassing the massive overhead of building these regional models from scratch. Instead, they rely on pre-built, robust voice infrastructures. For instance, platforms like CallMissed allow developers to deploy multilingual, emotionally intelligent voice agents across 22 regional Indian languages natively, ensuring that local idioms, accents, and emotional inflections are accurately preserved.
Your Strategic Roadmap for Voice Implementation
To successfully navigate this transition, organizations must align their engineering resources with clear business outcomes. The table below outlines a five-phase strategic framework designed to help you integrate emotion-aware TTS into your product roadmap without disrupting existing operations.
| Phase | Core Objective | Key Technology | Business Value | Timeline |
|---|---|---|---|---|
| 1. Assessment & Mapping | Define critical customer touchpoints and desired emotional archetypes (e.g., supportive, enthusiastic). | Sentiment classifiers & intent recognition APIs | Aligns voice persona with brand values and minimizes customer frustration. | Weeks 1–2 |
| 2. Pipeline Design | Orchestrate the exchange between LLMs, cognitive reasoning layers, and speech synthesis systems. | Multi-model API gateways & style-transfer models | Ensures natural conversational cadence and accurate contextual responses. | Weeks 3–5 |
| 3. Localization & Regionalization | Adapt emotional nuances, dialects, and pronunciations to localized regional markets. | Multilingual TTS with native linguistic architectures | Establishes deep trust with non-English-speaking demographics. | Weeks 6–8 |
| 4. Low-Latency Optimization | Reduce processing overhead to achieve conversational response times of under 200 milliseconds. | Edge computing & optimized LLM inference nodes | Prevents unnatural pauses, keeping voice interactions fluid. | Weeks 9–10 |
| 5. Continuous Alignment | Refine and adapt agent tones based on real-world user interactions and brand safety protocols. | Reinforcement Learning from Human Feedback (RLHF) | Maintains brand safety and prevents voice outputs from sounding inappropriate. | Ongoing |
Key Operational Considerations
As you implement the steps outlined above, keep three critical operational pillars in mind to maximize your return on investment:
Balancing Latency with Expressiveness
One of the most significant engineering challenges in modern voice AI is latency. Generating high-fidelity, emotion-infused speech requires massive computational throughput. Standard TTS systems can stream audio almost instantly, but injecting complex emotional style transfers can introduce noticeable lag.
To overcome this, organizations must optimize their inference pipelines. Leveraging a multi-model infrastructure—such as the one provided by CallMissed, which offers seamless access to over 300 optimized LLMs—allows developers to dynamically route requests based on speed and performance requirements. By shifting heavier cognitive processing to ultra-low-latency API gateways, you can deliver highly empathetic voice responses without sacrificing real-time conversational flow.
Ethics, Privacy, and Voice Safety
With great expressive power comes the responsibility of ethical execution. Emotion-aware voice agents are designed to be persuasive, meaning clear boundaries must be established.
- Consent: Users must always know they are speaking with an artificial voice agent, no matter how human-like or empathetic it sounds.
- Data Security: Acoustic analysis of a user's voice captures highly sensitive biometric signals. Ensure all customer audio streams are processed using enterprise-grade encryption and comply with local data protection regulations (such as GDPR or DPDP).
- Guaranteed Boundaries: Implement strict emotional guardrails. A voice agent should never express anger, sarcasm, or inappropriate excitement, regardless of how provoked it might be by an agitated user.
Designing for Accessibility
Ultimately, emotion-aware TTS is a massive win for digital accessibility. Visually impaired individuals or users with cognitive processing challenges benefit immensely from rich vocal inflections that convey context, urgency, and structure far better than standard, monotonic screens-readers. By investing in empathetic voice technology today, your business is not just upgrading its customer service desk—it is designing a more inclusive, universally accessible gateway to the digital world.
Looking Forward: The Future of Multilingual Empathy Transfer

As we look toward the horizon of voice technology, the conversation is rapidly shifting from how AI speaks to how it connects. Standard text-to-speech (TTS) systems have largely mastered pronunciation, accent adaptation, and basic linguistic fluency. However, the holy grail of modern conversational AI lies in multilingual empathy transfer. This is the capability of an AI voice system to not only translate words across languages but to dynamically translate the underlying emotional tone, warmth, and supportive intent—preserving a consistent brand persona or emotional footprint regardless of the language spoken.
Historically, capturing vocal emotion meant training isolated, language-specific models. The future, however, belongs to unified systems that can seamlessly transfer emotional nuances across highly diverse linguistic landscapes.
The Technical Architecture of Cross-Lingual Style Transfer
To understand how multilingual empathy transfer functions, we must look at the intersection of style transfer and emotion-aware transformer encoders [2, 4].
In traditional architectures, synthesizing emotional speech required massive, expensive datasets of voice actors recording the same lines with different emotional inflections across every target language. This is highly impractical and economically unviable for low-resource languages.
The modern approach decouples the linguistic content from the speaker's identity and emotional "style." The architecture relies on three primary components:
- The Emotion Classifier: A classification model that extracts fine-grained sentiment and emotional cues from the input text or the user's preceding utterance [7].
- The Style Encoder: A component (frequently built on models like Microsoft’s SpeechT5) that captures the latent representation of an emotional style—such as pitch variance, speaking rate, energy level, and spectral tilt—from a reference audio clip [4].
- The Non-Autoregressive Neural TTS Engine: A synthesis model that takes the text and injects the extracted style embeddings to generate natural, human-like emotional speech in the target language [7].
By utilizing this decoupled pipeline, an AI model can capture the "sadness" or "excitement" from an English-language reference sample and project those exact acoustic qualities onto Hindi, Spanish, or Japanese text. The system maps the emotional quotient directly onto the target utterance to generate human-like empathetic responses in real-time [2].
Navigating Cultural Nuances in Vocal Empathy
A major challenge in globalizing emotional TTS is that empathy is not an acoustic monoculture. The vocal cues that signal comfort or respect in one culture can be completely misconstrued in another.
- High-Pitch/High-Energy: In some Western cultures, a higher pitch and enthusiastic tone signify warmth and friendliness. However, in many East Asian cultures, the same tone can be perceived as insincere, overly familiar, or even unprofessional.
- Silence and Pacing: In Scandinavian and certain indigenous cultures, pauses and silent intervals convey deep listening, respect, and emotional weight. A voice agent that speaks too quickly without pause—even with a soft tone—might sound dismissive.
- Tonal Variations: In tonal languages like Mandarin or Vietnamese, pitch fluctuations are tied directly to word meaning. Introducing emotional pitch shifts without disrupting semantic clarity requires incredibly precise acoustic boundaries.
Future-proof multilingual empathy systems are solving this by incorporating cultural mapping layers. Instead of performing a direct, raw transfer of pitch and speed, the models use culturally adaptive transformers. These models translate the intent of empathy into the acoustic parameters that best represent empathy within the target culture's vocal norms.
Scaling Global Empathy with CallMissed
For global enterprises, deploying culturally nuanced, emotionally aware communication at scale is a massive operational hurdle. This is where AI communication infrastructure becomes critical.
Platforms like CallMissed are bridging this gap by offering robust, production-ready infrastructure that supports high-fidelity Speech-to-Text and TTS across 22 Indian regional languages. By leveraging CallMissed's multilingual capabilities, developers can deploy localized voice agents that not only understand the local dialect but also deliver responses with the exact emotional calibration needed for sensitive interactions.
Whether an agent is handling a distressed customer call in Marathi, Bengali, or Tamil, the platform enables the seamless delivery of emotionally resonant, localized speech that de-escalates tension and builds genuine rapport [3].
The Roadmap to 2030: What Lies Ahead
As the technology continues to mature, we can expect several major breakthroughs to define the next era of empathetic voice AI:
- Zero-Shot Emotional Cloning: Users will be able to provide a 3-second audio sample of their own voice, and the AI will immediately clone not just their vocal timber, but their unique emotional delivery style, transferring it across languages they do not actually speak.
- Context-Aware Dialogic Resonance: Transitioning from simple text-to-emotion synthesis to holistic dialogic empathy. Systems will analyze the historical context of a conversation and the user's current cognitive load, dynamically adjusting the agent's vocal empathy levels over the course of the interaction [2, 6].
- Dynamic Vocal De-escalation: Real-time conversational loops where the voice agent detects rising frustration, stress, or anger in a caller's voice and counteracts it by subtly lowering its own pitch, slowing down its cadence, and adopting a highly reassuring, empathetic tone [3].
- Therapeutic and Accessibility Integrations: Empathetic voice AI will become standard in mental health applications, support hotlines, and assistive technologies, delivering comforting, culturally aligned guidance to users experiencing crises [6].
Ultimately, the future of multilingual empathy transfer is about democratizing human-centric technology. By breaking down both linguistic and emotional barriers, voice AI is transitioning from a functional tool of utility to an intuitive medium of genuine global connection.
Frequently Asked Questions
What is emotion-aware TTS and how does it differ from standard text-to-speech?
How do modern AI models achieve style transfer in emotion-aware text-to-speech systems?
What are the primary business use cases for emotionally intelligent voice AI?
Can voice agents detect human emotions and respond with matching empathy in real-time?
What are the main technical challenges in deploying an emotion-aware TTS platform?
How can developers implement multilingual empathetic voices for global audiences?
Conclusion
The journey from flat, robotic text-to-speech to empathetic, emotionally-aware voice AI marks a profound shift in human-computer interaction. As speech technology advances, we are moving beyond simply converting text to sound; we are now infusing digital interactions with genuine human warmth, nuance, and understanding.
To sum up, key milestones in this vocal evolution include:
- Dynamic Tone Modulation: Modern emotional TTS systems capture fine-grained human nuances, adapting their tone and intent in real-time to match the user's emotional state.
- Architectural Sophistication: Technologies like style transfer and emotion-aware transformer encoders are bridging the gap between basic language understanding and deep vocal empathy.
- Enhanced Customer Experience (CX): By recognizing and responding to frustration, anxiety, or excitement, empathetic bots reduce agent escalations and foster authentic digital relationships.
Looking ahead, we can expect the rapid expansion of localized emotional TTS—particularly in highly diverse, multilingual regions where tonal nuance is critical to natural communication. The next frontier will see voice agents that seamlessly switch emotional registers across multiple dialects while maintaining natural cadence, reducing latency, and delivering compassionate support.
To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. As machines begin to understand not just what we say, but how we feel, how will your organization leverage the power of empathetic voice AI to build stronger, more human connections?


