Building Voice Agents on CallMissed: From WebRTC to Sub-Second Round-Trip

Building Voice Agents on CallMissed: From WebRTC to Sub-Second Round-Trip
Did you know that in normal human conversation, the average gap between speakers is just 200 milliseconds? If a conversational partner pauses for even a second before responding, our brains immediately flag the delay as awkward, unnatural, or confused. Yet, for years, developers building voice AI had to force users to endure painful three-to-five-second silences while legacy systems cobbled together fragmented speech-to-text, text-to-text LLM inference, and text-to-speech generation.
That era of high-latency lag is officially over. In 2026, the convergence of native speech-to-speech models—with pioneers like OpenAI’s Realtime API and Gemini Live hitting a stunning 150 to 300 milliseconds end-to-end—and advanced real-time transport protocols has made sub-second, bi-directional voice agents the baseline expectation. Achieving this level of fluid, human-like interaction requires more than just a fast language model; it demands a deep understanding of WebRTC infrastructure, network packet handling, and state orchestration.
Building a truly responsive voice agent means conquering an incredibly tight "latency budget." Every single millisecond counts. When a user speaks, their audio must be compressed using the highly efficient Opus codec, transmitted over UDP, decrypted, and processed by Voice Activity Detection (VAD) to determine exactly when they have finished speaking. From there, the audio stream is processed by the AI intelligence layer, synthesized back into audio packets, and streamed back to the listener—all in under 1,000 milliseconds. Traditional HTTP polling simply cannot survive under these constraints. This is why WebRTC, with its Secure Real-time Transport Protocol (SRTP) and robust ability to bypass network firewalls via STUN/TURN servers, has emerged as the definitive transport layer for conversational AI.
This is precisely why Building Voice Agents on CallMissed has become the preferred choice for developers looking to bypass complex infrastructure headaches and instantly deploy production-ready, ultra-low-latency voice agents that natively orchestrate WebRTC pipelines and multi-model LLM inference.
In this comprehensive guide, we will break down the engineering blueprint required to design, optimize, and deploy high-performance voice agents. We will demystify the core WebRTC architecture—including Selective Forwarding Units (SFUs), TURN servers, and signaling pathways—and weigh the trade-offs between traditional cascading STT-LLM-TTS pipelines and the latest omni-model architectures. You will also learn how to tackle real-world production challenges such as packet loss, network jitter, dynamic interruption handling, and SIP integration. By the end of this guide, you will have a clear, actionable roadmap to transition your voice applications from clunky, turn-based prototypes into fluid, sub-second conversational experiences.
Introduction

The landscape of human-computer interaction is undergoing a profound shift. For years, automated voice systems were defined by frustrating, rigid, and high-latency Dual-Tone Multi-Frequency (DTMF) menus or robotic Interactive Voice Response (IVR) systems. Even early-generation AI voicebots, bound by traditional HTTP polling and slow, sequential pipelines, suffered from conversational pauses of two to four seconds. In natural human conversation, however, the typical gap between turns is a mere 200 to 300 milliseconds. Any delay longer than a second breaks the illusion of a live dialogue, transforming a natural flow into a disjointed, frustrating exchange.
In 2026, this latency barrier has been comprehensively broken. The industry standard has shifted from "asynchronous response" to sub-second round-trip latency. The modern standard for production-grade AI voice agents demands an end-to-end response time of under 500 milliseconds—from the moment the user finishes speaking to the moment the agent begins to reply. Achieving this level of performance requires a fundamental architectural transition away from legacy protocols like standard HTTP or basic WebSockets, moving instead toward WebRTC (Web Real-Time Communication) as the transport backbone, paired with highly optimized, parallelized AI inference pipelines.
The Real-Time Voice Pipeline: Deconstructing the Latency Budget
To build an agent that feels truly human, developers must manage a strict "latency budget." Every millisecond must be accounted for across five distinct phases of the real-time voice loop:
- Network Transport (Ingress): Capturing the user’s audio from their browser or device and streaming it to the server.
- Speech-to-Text (STT): Transcribing the incoming audio stream into text in real time.
- Language Model Inference (LLM): Processing the text prompt, executing agentic workflows, and generating the text response (measured as Time to First Token, or TTFT).
- Text-to-Speech (TTS): Synthesizing the generated text back into high-quality, expressive audio.
- Network Transport (Egress): Streaming the synthesized audio back to the client’s device for playback.
Traditional architectures handled these steps sequentially: the system would wait for the user to finish speaking, transcribe the entire utterance, send the full text to the LLM, wait for the complete LLM text generation, pass that text to the TTS engine, and finally play the resulting audio file. This serial approach inevitably resulted in latencies of 3 to 5 seconds.
To achieve sub-second round-trips, modern systems utilize bidirectional streaming and pipelining. Audio is streamed continuously over WebRTC using the Opus codec. STT systems perform real-time, word-by-word transcription. As soon as the first few words are processed, they are fed into the LLM. The LLM generates tokens which are immediately streamed to a neural TTS engine, which synthesizes audio chunks on the fly. Rather than waiting for the entire process to complete, every component of the pipeline operates concurrently, shaving valuable milliseconds off the round-trip time.
Why WebRTC is the Standard for Voice AI
While WebSockets can stream audio, they rely on TCP, which prioritizes complete data delivery over speed. If a single packet is lost, TCP halts transmission until that packet is retransmitted, causing audible stutters and compounding latency.
WebRTC, by contrast, operates primarily over UDP. It is designed from the ground up for low-latency, real-time audio and video. It handles network jitter, packet loss, and changing bandwidth conditions dynamically via features like NetEQ (an adaptive jitter buffer and packet loss concealment algorithm) and native support for the highly efficient Opus audio codec.
When deploying WebRTC at scale for AI agents, developers must move beyond simple Peer-to-Peer (P2P) connections. An enterprise-grade architecture requires a Selective Forwarding Unit (SFU) or media server acting as the bridge between the user and the AI agent's infrastructure. This setup ensures that the AI agent can intercept, analyze, and respond to the media stream directly, while utilizing STUN and TURN servers to reliably traverse complex firewalls and NAT configurations.
Bridging the Infrastructure Gap with CallMissed
Building and maintaining this infrastructure from scratch is an immense engineering challenge. Developers must configure media servers, optimize turn-taking algorithms, handle interruptions gracefully, manage SIP-to-RTC trunking, and integrate a mosaic of speech and language models.
This is where platforms like CallMissed become essential. CallMissed provides a comprehensive, production-ready AI communication infrastructure that abstracts away the complexities of real-time audio transport and model orchestration. With CallMissed, developers can leverage:
- Sub-Second WebRTC Gateways: Instantly connect client-side audio streams to high-performance agent backends with minimal network overhead.
- Unified Multi-Model API: Switch seamlessly between 300+ LLMs to find the perfect balance between reasoning capability and Time to First Token (TTFT).
- Multilingual STT & TTS: Build globally accessible applications with native support for 22 regional Indian languages alongside global dialects, ensuring accurate transcription and synthesis.
- Intelligent Orchestration: Native handling of interruptions, voice activity detection (VAD), and agentic workflows without writing thousands of lines of boilerplate code.
What This Guide Covers
This step-by-step guide is designed to take you from the core concepts of real-time voice to a fully functional, production-ready voice agent. Throughout this post, we will cover:
- The WebRTC Voice Stack: A deep dive into SFUs, TURN servers, and the Opus codec.
- Optimizing the STT-LLM-TTS Pipeline: Techniques for streaming audio chunks, reducing TTFT, and managing audio synthesis.
- Handling Interruptions and Turn-Taking: How to detect when a user speaks over the agent and cleanly halt the outgoing audio stream.
- Deploying with CallMissed: Practical code examples and architectural blueprints for launching your own sub-second voice agent.
By the end of this guide, you will have a clear, actionable understanding of how to architect, build, and deploy low-latency voice agents that deliver natural, human-like conversational experiences.
Understanding the WebRTC Latency Budget in 2026

In human-to-human conversation, the average pause between turns is remarkably brief—typically hovering between 150 milliseconds and 300 milliseconds. If a conversational partner takes longer than 500 milliseconds to respond, we perceive a drag in the conversation. If they take longer than 1,000 milliseconds (one full second), the pause feels unnatural, often prompting us to repeat ourselves or ask if the connection was lost.
For an AI voice agent to feel human, it must operate within this strict window. This is what engineers call the latency budget. In 2026, the baseline for production-ready voice agents has shifted from "sub-second response times" to "sub-500ms responsiveness," with next-generation native speech-to-speech (S2S) architectures pushing the envelope down to 150ms–300ms end-to-end.
To hit these targets, developers cannot rely on traditional HTTP-based architectures. WebRTC (Web Real-Time Communication) has become the mandatory transport layer for real-time AI, providing the foundation upon which every millisecond of the audio pipeline must be strictly managed and optimized.
Anatomy of the Latency Budget: The Traditional vs. Omni Pipelines
To understand how to allocate your latency budget, you must first examine how audio travel time is consumed. The journey of a single utterance from a user's mouth to the AI’s spoken response involves multiple sequential operations.
Historically, this has been handled by a Cascaded Pipeline (STT + LLM + TTS). Today, developers also have access to Omni/Speech-to-Speech (S2S) models. Let's look at how the latency budget is spent in both architectures:
#### 1. The Cascaded Pipeline (STT ➔ LLM ➔ TTS)
In a cascaded pipeline, the system must process audio in three distinct phases, each introducing its own processing overhead:
- Ingress Transport (WebRTC): 20ms – 50ms. Audio is digitized, packetized via the Opus codec, and sent over UDP to the media gateway.
- Voice Activity Detection (VAD): 100ms – 200ms. The system must decide when the user has finished speaking. If the VAD threshold is too short, the agent will interrupt; if it is too long, it wastes valuable latency budget.
- Speech-to-Text (STT) Transcription: 100ms – 250ms. The incoming audio stream is converted into text. High-performance, low-latency engines must transcribe in real-time, sending partial transcripts to the LLM.
- LLM Time-to-First-Token (TTFT): 150ms – 300ms. The Large Language Model processes the text prompt and generates its very first token of response.
- Text-to-Speech (TTS) Generation: 100ms – 200ms. The generated text is streamed to a TTS model, which must synthesize the first chunk of audio bytes (typically 20ms to 50ms chunks) to stream back to the client.
- Egress Transport (WebRTC): 20ms – 50ms. The synthesized audio is packed into RTP packets and routed back to the user.
Total Cascaded Latency: 490ms – 1,050ms. In a perfectly optimized cascaded system, you can just squeeze under the 500ms mark, but network jitters or model cold starts can easily push this past 1,000ms.
#### 2. The Native Speech-to-Speech (S2S) Pipeline
Native audio-in, audio-out models (such as Gemini Live or OpenAI's real-time API framework) consolidate the STT, LLM, and TTS steps into a single neural network forward pass.
- Transport & VAD: 120ms – 250ms.
- Inference (Audio Token in to Audio Token out): 100ms – 200ms.
- Egress Transport: 20ms – 50ms.
Total Native S2S Latency: 240ms – 500ms. By removing the serialization and deserialization boundaries between text and audio, these models drastically shrink the latency budget, leaving more breathing room for complex agentic workflows.
Why WebRTC is Mandatory for Voice AI
Standard web protocols like HTTP/2 or WebSockets are fundamentally ill-suited for real-time bi-directional audio. To achieve sub-second latency, WebRTC is required due to several architectural advantages:
- UDP-Based Transport: Unlike TCP (used by WebSockets and HTTP), which enforces strict packet ordering and retransmits lost packets—causing catastrophic "head-of-line blocking" under poor network conditions—WebRTC runs over UDP (via SRTP). If an audio packet is dropped, WebRTC skips it and continues, prioritizing immediacy over perfect reconstruction.
- The Opus Codec: WebRTC utilizes the Opus audio codec natively. Opus is highly dynamic, supporting a wide range of bitrates (6 kbps to 510 kbps) and frame sizes as low as 20ms. It also features built-in Packet Loss Concealment (PLC), which uses predictive algorithms to fill in micro-gaps of lost audio data on the fly, preventing audio crackling.
- STUN, TURN, and NAT Traversal: In production environments, users sit behind strict firewalls and symmetric NATs. WebRTC utilizes STUN (Session Traversal Utilities for NAT) and TURN (Traversal Using Relays around NAT) servers to establish direct, secure media paths, ensuring peer-to-peer or client-to-server media streams are established instantly.
- Selective Forwarding Units (SFUs): In enterprise voice AI applications, connecting peer-to-peer is highly inefficient because the AI agent needs to process the stream centrally. Utilizing an SFU media server architecture allows the network to route the audio stream directly to the AI's processing nodes with minimal routing hop latency.
Navigating Latency Bottlenecks: Real-World Mitigations
To keep your voice agent within the sub-500ms budget, you must design around three primary architectural bottlenecks:
#### The VAD Dilemma
The biggest variable in perceived latency is the VAD silence threshold. If you set the threshold to 500ms, the system waits for half a second of dead air before sending the audio to the LLM. This guarantees a latency of at least 500ms before processing even begins.
- The Mitigation: Implement hybrid VAD architectures. Use a very fast, low-footprint local VAD (often running directly on the client browser or device using WebAssembly) to detect the start of speech, and a more robust, semantic-aware VAD on the server-side to detect the end of speech by analyzing linguistic cues (e.g., determining if a sentence is grammatically complete rather than just waiting for a pause).
#### Chunking and Streaming
You cannot wait for an LLM to finish generating an entire paragraph before starting TTS synthesis, nor can you wait for the TTS engine to generate an entire sentence before sending audio packets over WebRTC.
- The Mitigation: Implement aggressive chunk-based streaming. The LLM should stream tokens to the TTS engine as they are generated. Once the TTS engine receives a small window of text (often just 3 to 5 words, or a clause), it should begin synthesizing and pushing the resulting PCM/Opus audio chunks down the WebRTC data pipe in 20ms packets.
#### Infrastructure Co-location
If your WebRTC media gateway is in Oregon, your LLM host is in Virginia, and your user is in Mumbai, network transit time alone will blow past your 500ms budget.
- The Mitigation: Co-locate your media gateways, STT engines, LLMs, and TTS servers within the same physical data center or high-speed edge cloud network.
This is where platforms like CallMissed become indispensable for developers. CallMissed’s communication infrastructure handles this complex co-location natively. By integrating edge-deployed WebRTC media servers directly with a multi-model LLM gateway supporting 300+ models, CallMissed minimizes cross-network hops. Whether routing to specialized speech-to-speech models or utilizing high-speed localized STT engines that natively support 22 regional Indian languages, CallMissed enforces strict latency budget control, ensuring your agent-to-user round-trip remains consistently under the sub-second threshold.
Prerequisites & Setup (TABLE)
Before we can write the signaling code and initiate real-time audio streams, we must establish a robust development environment. Real-time voice agents operate under strict network, security, and hardware constraints. Because WebRTC relies on bi-directional media transmission, it requires secure contexts, specialized audio codecs, and proper NAT (Network Address Translation) traversal mechanisms to prevent dropped connections.
The following table outlines the essential system, network, and account prerequisites required to build a sub-second voice agent on CallMissed.
| Setup Component | Technical Requirement | Recommended Specification | Primary Purpose |
|---|---|---|---|
| Local Runtime | Node.js (v18+) or Python (3.10+) | Node.js v20 LTS / Python 3.11 | Runs the backend signaling server and generates ephemeral session tokens. |
| Security Protocol | HTTPS (SSL/TLS) & WSS | Valid SSL cert (or localhost for local dev) | Browser requirement for accessing local media devices (getUserMedia). |
| Audio Codec | Opus (via RTP packetization) | 16 kHz sampling, mono, 20ms packet duration | Optimizes speech clarity while minimizing network transmission payload. |
| NAT Traversal | ICE (STUN/TURN) | CallMissed Managed SFU / TURN Relays | Bypasses restrictive firewalls and symmetric NATs to keep media paths open. |
| API Credentials | CallMissed API Key & Project ID | Active developer account on CallMissed | Authenticates WebRTC signaling requests and instantiates the AI pipeline. |
Client-Side Environment & Audio Constraints
To capture and stream audio with sub-second response times, the client browser must be strictly configured to optimize microphone input. WebRTC utilizes the browser's Web Audio API and navigator.mediaDevices.getUserMedia() to capture raw audio. However, modern browsers impose strict sandboxing rules: microphone access is blocked on insecure origins. For local development, http://localhost is treated as a secure context, but any external deployment or testing on physical mobile devices requires HTTPS.
For real-time voice AI, the target audio format is critical. While high-fidelity music streaming requires 48kHz stereo audio, speech recognition engines operate most efficiently at 16kHz mono. Configuring your audio constraints at the browser level ensures you are not wasting valuable upstream bandwidth on useless audio frequencies:
- Sample Rate: Explicitly request 16000 Hz. Higher sample rates like 44.1kHz or 48kHz must be downsampled by the Speech-to-Text (STT) engine, adding 10ms to 50ms of unnecessary processing latency.
- Echo Cancellation & Noise Suppression: These should be enabled (
echoCancellation: true,noiseSuppression: true) to filter out background hums and feedback loops. However, turn off auto-gain control (autoGainControl: false) if you want the agent to accurately perceive voice inflections. - Packetization (Opus): WebRTC utilizes the Opus codec as its default audio format. Ensure your client configuration sets the packet frame size to 20ms. Shorter frames (10ms) increase packet overhead, while longer frames (40ms or more) introduce noticeable delays in the client-to-server transmission queue.
Network Topology and NAT Traversal
In an ideal network, two peers establish a direct peer-to-peer (P2P) connection to exchange media. In production environments, however, client devices sit behind residential routers, corporate firewalls, and complex symmetric NAT setups. Direct P2P connections fail in roughly 15% to 20% of real-world scenarios.
To overcome this, WebRTC uses ICE (Interactive Connectivity Establishment):
- STUN (Session Traversal Utilities for NAT): Allows the client to discover its public-facing IP address and port.
- TURN (Traversal Using Relays around NAT): If a direct connection cannot be established, media is relayed through a public TURN server.
When building voice agents, using a P2P architecture is highly inefficient because the AI agent resides in the cloud, not on another user's browser. Instead, we route all client WebRTC media to a server-side SFU (Selective Forwarding Unit). Platforms like CallMissed solve this architectural challenge by providing a globally distributed, low-latency SFU network paired with high-performance TURN relays out of the box. This ensures that whether a user is calling from a highly restrictive corporate office or a patchy mobile connection, their RTP audio packets bypass firewall bottlenecks and route directly to the nearest processing node.
CallMissed Portal Provisioning & Pipeline Architecture
Before writing your backend signaling server, you must configure your voice pipeline on the CallMissed developer dashboard. CallMissed supports two distinct architectural pipelines for voice agents:
- Cascaded Pipelines (Modular): This classic setup decouples the components into separate, highly-optimized blocks: Speech-to-Text (STT) ➔ Large Language Model (LLM) ➔ Text-to-Speech (TTS). By utilizing CallMissed's unified platform, developers can access low-latency Speech-to-Text supporting 22 regional Indian languages natively, route the resulting text to a selection of 300+ LLMs via a single API gateway, and stream the generated response to high-performance TTS engines like Cartesia or ElevenLabs.
- Speech-to-Speech (S2S) Pipelines: This emerging architecture bypasses textual intermediate steps entirely. By streaming user audio directly into multimodal models (such as GPT-4o Realtime or Gemini Live), the end-to-end latency drops to an astonishing 150ms to 300ms, preserving emotional tone, laughter, and natural interruptions.
To provision your workspace:
- Navigate to the CallMissed Console and generate a new set of API keys.
- Configure your webhook endpoints. Webhooks are essential for receiving real-time session logs, cost metrics, and recording URLs once a voice session terminates.
- Set up your default LLM configurations, specifying the system prompt, temperature, and any custom tools (using Model Context Protocol or SIP triggers) your agent can invoke mid-call.
Setting Up the Local Development Gateway
With your system specs aligned, organize your local project folder. To prevent exposing your master CallMissed API keys to the client-side browser, you must build a lightweight signaling gateway. The client requests a WebRTC connection token from your secure backend, and your backend securely calls CallMissed's orchestrator to provision the session.
A standard project directory follows this pattern:
voice-agent-root/
├── .env # CallMissed API Key, Project ID, and Webhook secrets
├── server.js # Express/Fastify app serving client tokens & signaling endpoints
└── public/
├── index.html # Front-end UI with microphone access request buttons
└── agent.js # WebRTC peer connection configuration and RTP stream handlingUsing tools like ngrok during local development is highly recommended. Because WebRTC signaling and bidirectional media streams are incredibly sensitive to latency, routing your local environment through a secure HTTPS tunnel via ngrok allows you to test mobile microphone capture and real-time interruption parameters without deploying to a cloud server prematurely. With this infrastructure securely in place, you are ready to implement the WebRTC signaling handshake.
Getting Started
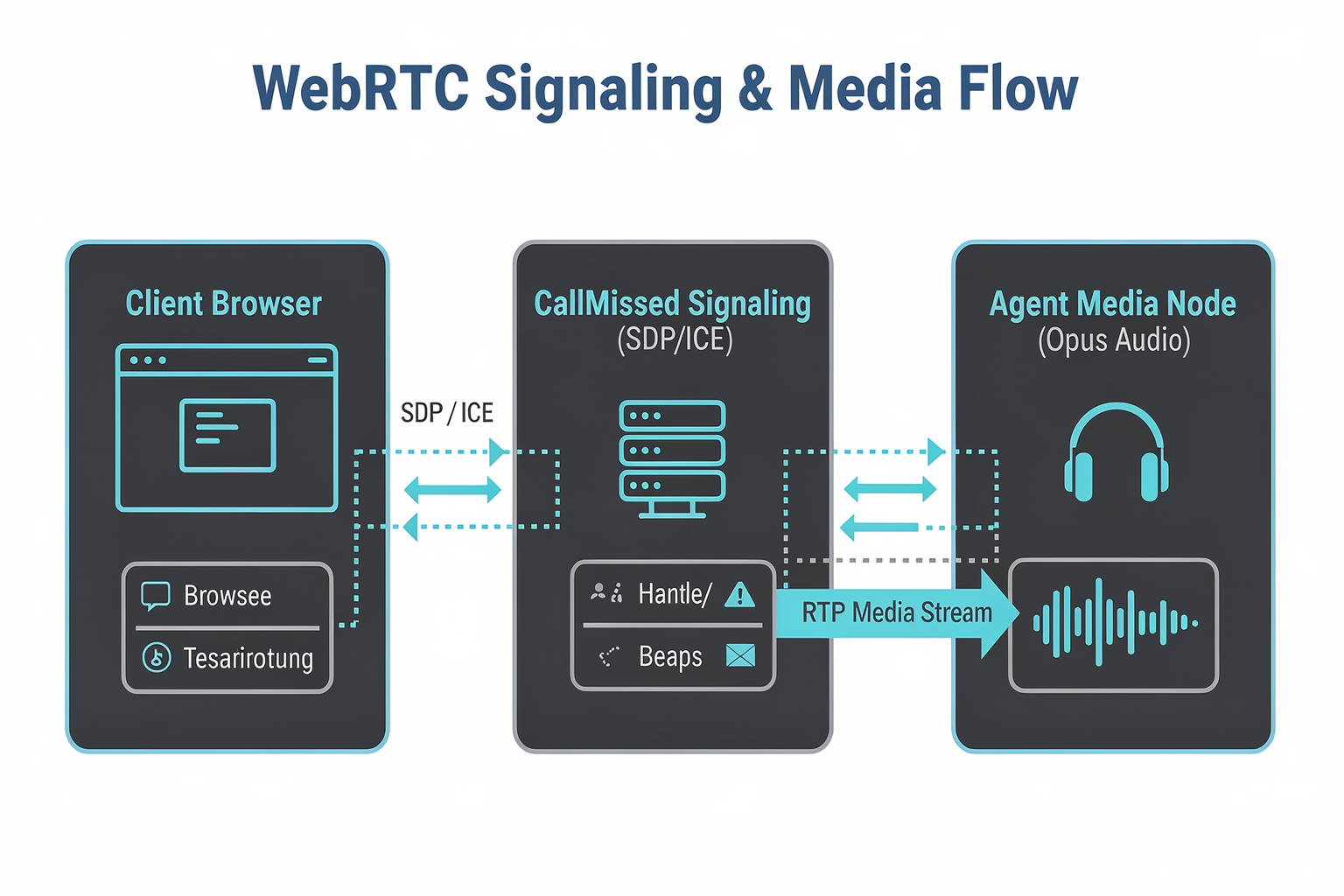
To build a voice agent capable of natural, bi-directional conversation, developers must abandon traditional request-response architectures. In a standard HTTP-based voice setup, the latency accumulated by waiting for complete audio file uploads, sequential API execution, and unbuffered audio downloads easily pushes response times past 3 or 4 seconds—well beyond the 1,000-millisecond threshold where human conversation begins to feel disjointed.
To achieve a true sub-second round-trip, we must stream data continuously. This is where WebRTC (Web Real-Time Communication) comes into play, serving as the high-throughput, low-latency transport layer that feeds real-time audio directly into our AI pipeline.
Understanding the CallMissed Real-Time Architecture
Before writing your first line of code, it is critical to understand how media and data flow through a low-latency voice agent built on CallMissed. The architecture is structured to minimize serialization overhead and network hops by consolidating transport and intelligence into a unified pipeline:
- The Client Layer (WebRTC Peer): The caller’s browser, mobile app, or SIP/telephony gateway captures local microphone audio, encodes it using the highly efficient Opus codec, and streams it via RTP (Real-time Transport Protocol) over UDP.
- The Signaling Layer: Before media can flow, the client and server must agree on media formats, network paths, and security keys. This negotiation is performed via a lightweight signaling protocol (typically WebSockets) to exchange SDP (Session Description Protocol) offers and answers.
- The CallMissed Gateway (SFU/TURN): To ensure reliable connections across complex network topologies, CallMissed utilizes a managed Selective Forwarding Unit (SFU) paired with global STUN/TURN servers. This ensures NAT traversal is handled automatically, delivering media streams to the processing pipeline with minimal routing latency.
- The Processing Pipeline: Once audio reaches the gateway, it is routed to either a cascaded pipeline (Speech-to-Text -> Large Language Model -> Text-to-Speech) or a native, end-to-end Speech-to-Speech (omni) model.
Prerequisites and Environment Setup
To begin building your voice agent, ensure your development environment is properly configured. You will need:
- A CallMissed developer account to retrieve your API credentials and access keys.
- A backend environment running Node.js (v18+) or Python (3.10+). This server will act as your orchestration layer and signaling coordinator.
- A secure HTTPS/WSS environment. WebRTC security standards mandate that client-side media capture (
getUserMedia) and signaling only operate over secure origins (localhost is permitted for local development). - A basic frontend interface capable of capturing user microphone input and establishing a WebRTC
RTCPeerConnection.
Step 1: Initiating the WebRTC Connection
The first step in establishing a voice session is negotiating the connection between the user's client and the CallMissed media server. This handshake relies on exchanging SDP descriptions.
On the client side, you must initialize the peer connection and define the media constraints. Standardize on the Opus audio codec, configuring it for voice-optimized performance (typically a 16 kHz sampling rate, mono channel, and a target bitrate of 16-24 kbps to minimize bandwidth overhead while maintaining crystal-clear voice quality):
// Client-side initialization
const peerConnection = new RTCPeerConnection({
iceServers: [
{ urls: 'stun:stun.l.google.com:19302' }, // Fallback STUN
// CallMissed managed TURN servers will be injected dynamically via your signaling server
]
});
// Capture local microphone input
const localStream = await navigator.mediaDevices.getUserMedia({
audio: {
echoCancellation: true,
noiseSuppression: true,
autoGainControl: true
}
});
// Add audio track to the WebRTC connection
localStream.getTracks().forEach(track => peerConnection.addTrack(track, localStream));Once the tracks are added, your client generates an SDP offer. Send this offer to your backend signaling server, which passes it to the CallMissed API. CallMissed processes the media requirements, reserves routing resources, and returns an SDP answer. When the client applies this answer via peerConnection.setRemoteDescription(), a direct WebRTC media channel is established.
Step 2: Configuring the Agent’s AI Pipeline
Once the raw audio stream is successfully connected to the CallMissed infrastructure, you must declare how the agent processes this stream. Developers on CallMissed have two primary pathways to execute the core conversational logic:
#### Option A: The Cascaded Pipeline (STT -> LLM -> TTS)
This classic architecture is highly customizable and modular. Because CallMissed supports an inference gateway with over 300+ LLM models and highly optimized Speech-to-Text APIs supporting 22 Indian regional languages, developers can easily localize their agents for global audiences. To keep latency sub-second within this pipeline:
- Streaming STT: Audio is analyzed in 100ms chunks using sliding-window VAD (Voice Activity Detection). Transcriptions are streamed word-by-word.
- Token Streaming: The transcript is piped into the LLM, which begins streaming output tokens immediately, rather than waiting for the entire sentence to generate.
- Chunked TTS: CallMissed's Text-to-Speech engine synthesizes audio on the fly from the incoming token stream, sending audio segments back to the client as soon as the first clause is ready.
#### Option B: Native Speech-to-Speech (Omni Models)
For applications where context, tone, and ultra-low latency are paramount, CallMissed allows you to route WebRTC audio directly to native speech-to-speech models (such as GPT-4o Realtime or Gemini Live). By bypassing the intermediate text translation step, these end-to-end models reduce cognitive overhead and cut latency budgets down to an astonishing 150–300 milliseconds, matching or exceeding natural human response times.
Step 3: Handling Turn-Taking and Interruptions
A common pitfall of early-stage voice agents is their inability to handle interruptions gracefully. In a natural conversation, if a user speaks while the agent is talking, the agent should instantly stop generating audio and begin listening.
Using WebRTC data channels alongside the audio stream, CallMissed provides real-time signalling to manage conversational state:
- Client-Side VAD: The client's browser or device continuously monitors audio input levels.
- Interruption Signal: As soon as user speech is detected while the agent is playing back audio, the client sends a rapid interrupt signal via the WebRTC Data Channel or stops rendering the incoming RTP audio stream.
- Server-Side Halt: Upon receiving the interruption signal, the CallMissed platform immediately cancels the current LLM generation queue and purges the downstream TTS audio buffer. This prevents the agent from "talking over" the user, creating a natural, fluid conversational flow.
Step-by-Step Walkthrough
Building a sub-second voice agent requires orchestrating multiple complex components—WebRTC signaling, Voice Activity Detection (VAD), Speech-to-Text (STT), Large Language Models (LLMs), and Text-to-Speech (TTS)—into a single, highly optimized pipeline. In 2026, user expectations have shifted: conversational AI must feel natural, which means achieving an end-to-end round-trip latency of under 500 milliseconds.
Here is a step-by-step technical walkthrough to design, configure, and deploy a low-latency voice agent using the CallMissed infrastructure.
Step 1: Establish the WebRTC Connection and Signaling
To eliminate the latency overhead of traditional HTTP requests, we use WebRTC for bi-directional, real-time audio streaming. This step involves setting up a signaling server (typically over WebSockets) to negotiate the connection between the client browser (or SIP/telephony gateway) and your AI agent media server.
- Initialize the Peer Connection: On the client-side, instantiate a new
RTCPeerConnectionobject. Configure it with high-performance STUN/TURN servers to bypass NAT and firewalls. - Configure the Audio Track: Capture the user’s microphone input using
getUserMediaand constrain the audio track to use the Opus codec. Set the configuration to prioritize voice: a sample rate of 16,000 Hz, mono channel, and a low bitrate (around 16–24 kbps) to minimize bandwidth. - The SDP Exchange:
- The client generates an Session Description Protocol (SDP) offer and sends it to your signaling gateway via WebSockets.
- Your backend, integrated with CallMissed's WebRTC infrastructure, receives the offer, allocates media ports on its Selective Forwarding Unit (SFU), and generates an SDP answer.
- Once the SDP answer is returned to the client and ICE candidates are gathered and resolved, a secure, direct Datagram Transport Layer Security (DTLS) media channel is established.
Step 2: Stream Ingest and Speech-to-Text (STT) Processing
Once the RTP packets start flowing from the client to the server, they must be decoded and transcribed with minimal buffering.
- Audio Demuxing and VAD: The server receives the raw Opus audio packets. A lightweight, server-side Voice Activity Detection (VAD) algorithm monitors the stream. VAD determines exactly when the user starts speaking and, crucially, when they stop (silence detection).
- Streaming STT Transcription: Rather than waiting for the user to finish their entire sentence, the audio stream is chunked (typically in 100ms blocks) and piped directly into an STT engine.
- Multilingual Routing: For global applications, regional language support is critical. By leveraging CallMissed’s high-speed STT APIs, you can transcribe audio natively across 22 Indian regional languages alongside major global dialects. The system uses real-time, streaming diarization to clean up background noise and isolate the primary speaker's voice, outputting partial transcriptions (interim results) within milliseconds.
Step 3: LLM Orchestration via Multi-Model Gateways
Once the VAD detects a complete thought (usually after 250ms of continuous silence), the final transcribed text is sent to the LLM orchestration layer.
- API Gateway Routing: To maintain sub-second round-trip times, you need an LLM that balances speed and intelligence. CallMissed’s multi-model API gateway lets developers access and switch between over 300 LLMs (including specialized, low-latency models like Gemini Live, Groq-hosted open models, or GPT-4o Realtime) with zero code modifications.
- Server-Sent Events (SSE) and Streaming: Never wait for the complete LLM response generation. The orchestration layer must configure the LLM request with
stream: true. This ensures that as soon as the first token is generated by the model, it is pushed directly to the next stage of the pipeline via Server-Sent Events (SSE) or WebSockets. - Context and Prompt Tuning: Keep system prompts concise. Extra tokens in system instructions add processing overhead. Use system instructions optimized for spoken dialogue—instructing the LLM to write in short, conversational sentences rather than long paragraphs.
Step 4: Just-In-Time Text-to-Speech (TTS) Synthesis
The streaming tokens emitted by the LLM are fed instantly into the TTS synthesis engine. Waiting for a full sentence to generate before speaking introduces massive latency; instead, we implement a "chunking" strategy.
- Token Aggregation: A buffer aggregates incoming text tokens until it detects a natural linguistic boundary, such as a comma, period, question mark, or a minimum word threshold (usually 4–6 words).
- Streaming TTS Synthesis: These text chunks are immediately dispatched to CallMissed's ultra-low-latency TTS engines. The engine synthesizes the text into raw PCM or Opus audio buffers on the fly.
- Queue Management: The resulting audio buffers are queued in a playback buffer on the server. The media engine sequentially packets these buffers into RTP packets and streams them down the established WebRTC media track to the client.
Step 5: Handling Interruptions and Conversational State
The defining characteristic of a human-like voice agent is its ability to handle interruptions naturally. If the user starts speaking while the agent is still talking, the agent must stop immediately.
- Continuous VAD Monitoring: While the server is transmitting downstream audio, it must continue to analyze the incoming upstream audio track.
- The Interruption Trigger: The moment the upstream VAD detects human speech (with a confidence score above a set threshold, e.g., >85% for more than 100ms), an interruption event is triggered.
- Clearing the Pipeline:
- The server immediately stops transmitting the remaining RTP audio packets to the client.
- It sends a signal to the client to purge its local playback buffer (minimizing "overhang" audio).
- The server cancels the ongoing LLM generation API call and flushes the TTS synthesis queue.
- The conversation state is updated, appending the interrupted agent response (truncated at the exact word it was stopped) to the chat history, ensuring the LLM knows exactly what the user actually heard before they interrupted.
By implementing this tightly coupled pipeline—orchestrated through CallMissed's real-time voice infrastructure—you can confidently deploy conversational agents that respond in under 500ms, creating highly engaging, fluid, and natural customer experiences.
Managing Interruptions & Barge-In Dynamics

In human conversation, we rarely wait for a speaker to finish their entire paragraph before responding. We offer "mhm"s of agreement, ask clarifying questions mid-sentence, or abruptly change direction when we get the information we need. In the context of conversational AI, this is known as barge-in.
Achieving natural barge-in dynamics is one of the steepest engineering challenges in Voice AI. Without a highly optimized pipeline, an agent will either awkwardly talk over the user or cut itself off at the slightest background noise.
The Mechanics of the Interruption Loop
To execute a seamless, sub-second interruption, a voice agent's pipeline must coordinate across four distinct layers almost instantaneously:
- Voice Activity Detection (VAD): The client-side or server-side engine must analyze incoming audio frames to detect human speech. This must happen within 50–100ms.
- The "Kill" Signal: The moment speech is detected, the system must broadcast an interruption signal. Using WebRTC Data Channels, this signal bypasses heavy media pipelines to reach the orchestration layer in milliseconds.
- Buffer Truncation: The player must immediately flush the client-side audio playback buffer, stopping the agent's voice mid-syllable.
- State Reconciliation: The backend must stop LLM inference and TTS generation immediately. Crucially, the system must calculate exactly where the agent was interrupted so the conversation history reflects only what the user actually heard.
Overcoming the Echo and Noise Bottlenecks
The primary technical roadblock to robust barge-in is Acoustic Echo Cancellation (AEC). When an agent is speaking, its voice travels out of the user's device speaker and right back into the microphone. Without sophisticated AEC, the agent's voice-to-text (STT) system will hear its own output, mistake it for user input, and interrupt itself.
WebRTC provides built-in, hardware-accelerated AEC, which is essential for filtering out this feedback loop. However, network jitter and hardware variances can still cause leakage.
To combat this, production-grade architectures use dual-path VAD systems:
- Local VAD: Monitors the local microphone input at the client level.
- Server-Side Verification: Double-checks the signal against the outgoing TTS stream.
Another common issue is backchanneling—non-interruptive utterances like "uh-huh," "sure," or "right." If the agent interprets every "mhm" as a hard stop, the conversation becomes disjointed. Developers must train classification models or configure VAD thresholds (typically looking for continuous speech segments longer than 200–300ms) to ignore brief backchannel signals while immediately responding to actual interruptions.
How CallMissed Architectures Handle Barge-In
Implementing this orchestration loop from scratch requires deep WebRTC and systems engineering expertise. Infrastructure platforms like CallMissed simplify this process by providing native, end-to-end event synchronization.
When building voice agents on CallMissed, the platform uses ultra-low latency WebRTC gateways to manage the active media session. If a user interrupts, CallMissed’s edge-optimized VAD triggers an instant interruption event over WebRTC. This event automatically:
- Truncates the active Text-to-Speech (TTS) stream on the server.
- Instantly flushes the browser or device audio buffer.
- Tracks the exact timestamp of the interruption, allowing the LLM to seamlessly resume or pivot based on the new input.
By offloading this complex state machine to CallMissed, developers can focus on prompt engineering and business logic, confident that their agents will exhibit human-like conversational pacing and seamless, sub-500ms barge-in responsiveness.
Advanced Tips & Tricks (TABLE)
Squeezing every millisecond out of a voice agent requires looking beyond basic API integrations. In 2026, building conversational AI that feels natural requires an end-to-end optimization of the WebRTC media pipeline, network topology, Voice Activity Detection (VAD), and state management. When target end-to-end latency is sub-500ms, every layer of your stack must be tuned for speed, resilience, and surgical precision.
Below are advanced strategies and architectural tips to optimize your voice agents for production grade performance.
Optimizing the Audio Pipeline (Opus & Frame Sizes)
The Opus codec is the gold standard for WebRTC audio, but its default configurations are rarely optimized out-of-the-box for low-latency machine consumption. By default, many WebRTC clients package audio in 20ms frames. While this is highly resilient for human-to-human calls, developers looking for maximum responsiveness can tweak frame sizes down to 10ms.
However, reducing frame size increases network packet overhead (more IP headers per second). For most enterprise voice applications, a 20ms frame size strikes the perfect balance between network efficiency and packetization delay.
Another key area is the audio sampling rate. While Opus supports up to 48kHz (Fullband) audio, sending high-fidelity music-grade audio to an AI Speech-to-Text (STT) engine is incredibly wasteful. Most modern STT models and LLMs are natively trained on 16kHz (Wideband) or even 8kHz (Narrowband) audio. Downsampling your audio to 16kHz at the client edge before it enters the WebRTC pipeline reduces bandwidth usage by nearly 66%, lowering packet loss rates and ingestion processing time on the server.
Network Resilience: Handling Packet Loss and NAT Traversal
No matter how fast your AI model is, a dropped packet or a blocked port can ruin the user experience. Real-time voice agents cannot afford the latency penalties of TCP-based retransmissions. Instead, they must rely on UDP and resilient WebRTC protocols.
- Leveraging WebRTC FEC (Forward Error Correction): Opus has built-in in-band FEC. If a packet is lost, the decoder can reconstruct a lower-quality version of the missing audio using data embedded in subsequent packets. Ensure your WebRTC peer connection configuration enables
useinbandfec=1. - Optimized TURN Server Routing: Approximately 15% to 20% of enterprise users sit behind symmetric NATs or restrictive firewalls that block direct peer-to-peer UDP connections. In these cases, media must run through a TURN (Traversal Using Relays around NAT) server. Standard TURN implementations can add hundreds of milliseconds of latency if the relay server is geographically distant. Platforms like CallMissed solve this by maintaining a globally distributed network of TURN servers, ensuring that media packets are routed through the closest edge node to the user.
Smart Interruption Handling & VAD
Perhaps the most difficult engineering challenge in voice AI is handling human interruptions. If an agent is in the middle of speaking and the user interrupts, the agent must instantly stop talking, flush its playback buffer, and begin listening.
To do this successfully, you need highly accurate Voice Activity Detection (VAD).
- Edge-side vs. Server-side VAD: Running VAD on the client side (in the browser or mobile app) is faster because it avoids network round-trips. Once user speech is detected, the client immediately mutes the incoming agent audio track and sends an interruption signal over a WebRTC Data Channel.
- Managing VAD Hangover Time: The VAD "hangover" is the duration of silence the system waits before deciding the user has finished speaking. If it is too short (e.g., <100ms), the agent will interrupt the user during natural conversational pauses. If it is too long (e.g., >400ms), the agent feels slow to respond. The sweet spot for conversational agents in 2026 is 150ms to 250ms, dynamically adjusted based on the current background noise levels.
For complex environments, developers can utilize CallMissed’s voice infrastructure, which supports advanced VAD tuning and automated interruption signaling, ensuring that agent speech streams are terminated instantly across both the signaling and media layers.
Selecting the Right Architecture: Pipeline vs. Omni Models
When building on CallMissed, developers have two architectural choices for their voice engines: a Cascaded Pipeline (separate STT, LLM, and TTS steps) or a Native Speech-to-Speech (Omni) Model.
While Omni models (like Gemini Live or GPT-4o Realtime) yield ultra-low latencies of 150ms to 300ms, they can be highly expensive. On the other hand, a cascaded pipeline using CallMissed’s ultra-fast LLM inference engine (with support for 300+ models) coupled with optimized Speech-to-Text (supporting 22 Indian regional languages) can still achieve a sub-500ms round-trip at a fraction of the operational cost.
CallMissed WebRTC Optimization Parameters
To help you configure your production environment, use the following configuration guidelines to optimize your WebRTC voice agent setup:
| Optimization Parameter | Recommended Target Setting | Estimated Latency Saved | Practical Implementation Tip |
|---|---|---|---|
| Audio Frame Size | 20ms | 10ms - 20ms | Keeps packet overhead low while maintaining low packetization delay. |
| Opus Audio Bandwidth | 16kHz (Wideband) | 30ms - 50ms (Processing) | Avoids server-side downsampling; matches native STT model inputs. |
| VAD Hangover Time | 150ms - 200ms | 100ms - 250ms | Prevents mid-sentence cuts while maintaining rapid back-and-forth flow. |
| ICE Candidate Gathering | Trickle ICE Enabled | 500ms - 1500ms (Setup) | Starts the media connection handshake before all network paths are gathered. |
| Interruption Signaling | WebRTC Data Channels | 100ms - 300ms | Bypasses standard WebSocket signaling to flush audio buffers instantly. |
By fine-tuning these network, media, and VAD parameters, you can transition your voice agents from a sluggish, walkie-talkie style experience to a seamless, real-time conversation that rivals human interaction.
Bridging to the Real World: SIP, PSTN, and WebRTC Gateways
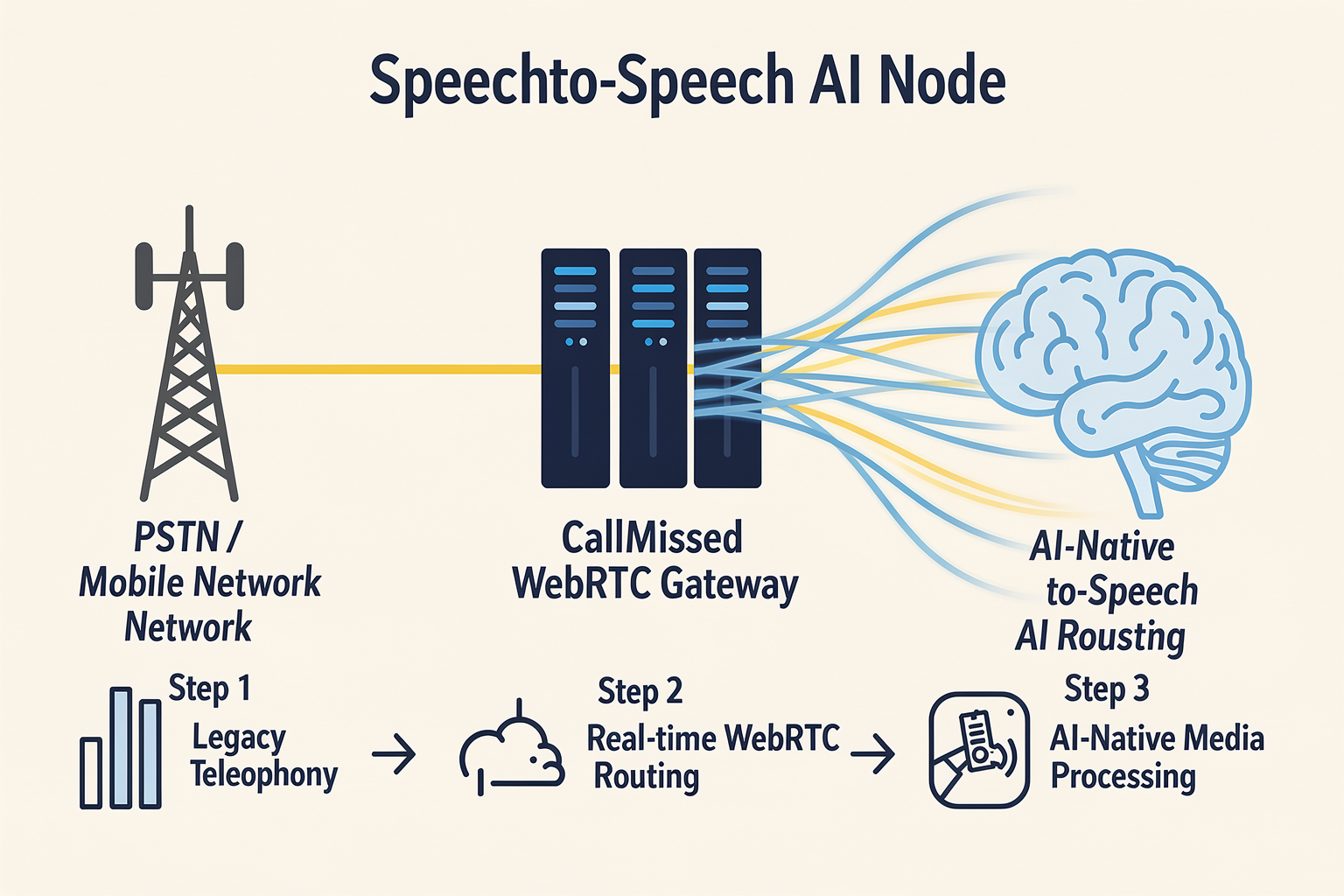
While building a sub-second voice agent for a web browser or a native mobile app using WebRTC is a massive achievement, the reality of enterprise communications is that millions of daily customer interactions still occur over traditional phone lines. To build a truly omni-channel AI assistant, you must bridge the modern, low-latency world of WebRTC with the legacy infrastructure of the Public Switched Telephone Network (PSTN) and Session Initiation Protocol (SIP).
Bridging these two distinct technological eras introduces unique architectural challenges, specifically regarding signaling, media transcoding, and latency budget preservation.
The Protocol Chasm: WebRTC vs. SIP/PSTN
WebRTC was built for the modern internet. It is highly dynamic, secure by default, and optimized for variable network conditions. PSTN and SIP, on the other hand, are built on decades-old telecommunications standards designed for dedicated copper wires and managed fiber networks.
To connect an AI voice agent to a traditional phone call, you must bridge several fundamental differences:
- Signaling: WebRTC does not mandate a specific signaling protocol, commonly relying on secure WebSockets to exchange Session Description Protocol (SDP) offers and answers. Conversely, telecom networks use SIP (RFC 3261) to initiate, maintain, and terminate sessions.
- Media Transport & Security: WebRTC mandates encryption via DTLS-SRTP (Datagram Transport Layer Security / Secure Real-time Transport Protocol) and relies on ICE, STUN, and TURN for NAT traversal. Traditional SIP trunks often transport unencrypted RTP directly over public or private networks without complex NAT traversal mechanisms.
- Audio Codecs: WebRTC standardizes on the Opus codec—a highly resilient, variable-bitrate codec capable of full-band (48 kHz) audio. The PSTN relies almost entirely on narrowband legacy codecs, primarily G.711 (u-law or a-law at 8 kHz) or wideband G.722 (16 kHz).
The Role of Session Border Controllers and Gateways
To resolve these incompatibilities, architecture teams deploy Session Border Controllers (SBCs) and media gateways. When a customer dials a phone number, the call travels over the PSTN to your SIP trunk provider. The SIP provider routes the call to your SBC, which acts as the gateway to your WebRTC-based AI pipeline.
The gateway performs three vital functions in real time:
- Signaling Translation: The gateway translates incoming SIP messages (such as
INVITE,RINGING,OK, andBYE) into the signaling events that your WebRTC orchestration layer expects. - Media Transcoding: This is the most computationally expensive task. The gateway must transcode legacy G.711 or G.722 audio packets from the telephony network into Opus packets for the WebRTC agent pipeline, and vice versa.
- DTLS-SRTP Termination: The gateway terminates the secure DTLS-SRTP session from the WebRTC side and transitions the media to standard RTP (or SDES-SRTP) for the SIP trunk.
Navigating the Transcoding Latency Tax
Every millisecond counts when trying to keep your agent’s round-trip response time under 500 milliseconds. Transcoding audio from G.711 to Opus is not instantaneous; it introduces a transcoding latency tax that can derail your sub-second target.
- Packetization Delay: G.711 typically packets audio in 20ms chunks. Opus can support packet frames from 2.5ms up to 60ms. If the gateway must buffer multiple G.711 packets to construct an optimal Opus packet, it introduces an immediate 20ms to 40ms delay.
- Resampling Overhead: Converting audio from 8 kHz (G.711) up to 48 kHz (Opus) requires mathematical interpolation. While modern CPUs handle this rapidly, doing this across thousands of concurrent channels adds up.
- Jitter Buffer Alignment: Because PSTN routing is relatively stable, jitter buffers can be small (10–20ms). WebRTC paths over mobile networks are highly erratic, requiring dynamic jitter buffers. Aligning these two buffers at the gateway without dropping packets requires sophisticated clock-drift compensation.
To minimize this overhead, production architectures deploy regional, edge-optimized SBCs. By placing the media gateways geographically close to both the telecom carrier's point of presence (PoP) and the AI agent's inference engines, network transit latency (Round-Trip Time, or RTT) is kept to a single-digit minimum.
Managing Interruptions and Signaling State
In a standard web-based WebRTC connection, handling user interruptions is straightforward. If the user starts speaking while the AI agent is talking, the client-side VAD (Voice Activity Detection) immediately sends a signal over a WebRTC Data Channel to halt the agent's Text-to-Speech (TTS) stream.
In a PSTN-to-SIP architecture, managing interruptions is significantly more complex:
- In-Band Tone Detection: The gateway must continuously monitor the incoming PSTN media stream for Dual-Tone Multi-Frequency (DTMF) tones (RFC 2833) if the user presses keypad buttons, translating these into clean digital events for the AI.
- Barge-In Handling: Since the phone network does not have an active WebRTC Data Channel, the media gateway must feed the incoming user audio directly to an ultra-fast server-side VAD. The moment the caller utters a sound, the gateway's orchestrator must trigger a SIP
re-INVITEor a rapid control packet to immediately mute the outbound RTP stream, preventing the AI from talking over the caller.
Streamlining the Infrastructure with CallMissed
Building, scaling, and maintaining high-availability SIP gateways, SBCs, and WebRTC transcoders is an immense engineering burden. This is where leveraging a specialized platform like CallMissed becomes invaluable.
CallMissed provides enterprise-grade, built-in SIP and PSTN termination that bridges directly to its high-performance WebRTC and AI agent infrastructure. Instead of deploying custom Asterisk or FreeSWITCH clusters, developers can use CallMissed's unified APIs to spin up virtual phone numbers, connect existing corporate SIP trunks, and route those calls directly into an ultra-low-latency, multi-model AI pipeline.
By handling the complex media transcoding, security handshakes, and jitter-buffer alignment at the edge, platforms like CallMissed ensure that your telephone-based AI voice agents achieve the exact same sub-second response times as their native WebRTC counterparts.
Common Mistakes to Avoid (TABLE)
Designing and deploying a real-time, conversational voice agent is fundamentally different from building a text-based LLM chatbot. In a text interface, a two-second delay is acceptable; in a voice conversation, a delay of more than 800 milliseconds feels like an awkward pause, and anything over 1.5 seconds completely breaks the illusion of human-like interaction.
As developers transition from building basic proof-of-concepts to deploying production-grade, sub-second voice agents in 2026, they frequently encounter architectural hurdles. Below is a comprehensive diagnostic breakdown of the most common mistakes made during voice agent development, their underlying technical causes, and how to resolve them to achieve production-grade reliability.
| Common Mistake | Why It Ruins UX | Technical Impact | Correct Architecture (Best Practice) |
|---|---|---|---|
| Sequential Execution (STT → LLM → TTS) | Long pauses between turns (1.5s to 3s latency) make conversation feel unnatural and disjointed. | Blocking API calls prevent real-time audio streaming, forcing the user to wait for the entire generation process to complete. | Implement fully streamed chunking or native speech-to-speech (S2S) models to target sub-500ms round-trips. |
| Neglecting TURN Server Infrastructure | Remote users fail to connect entirely or experience one-way silent audio, leading to immediately dropped calls. | ICE negotiation fails for 15% to 25% of enterprise users sitting behind restrictive symmetric corporate NATs and firewalls. | Deploy global STUN/TURN clusters with fallback to TCP/TLS (TURN over TCP on port 443) for reliable WebRTC handshakes. |
| Lack of Real-Time Interruption (Barge-In) | The agent keeps talking over the user, creating frustration and making the system feel robotic and deaf. | Output TTS audio buffer is not immediately flushed, causing overlapping audio streams and audio buffer bloat. | Use high-performance VAD (Voice Activity Detection) to instantly trigger a pipeline flush and halt TTS playback on the client. |
| Suboptimal WebRTC Audio Codec Settings | Crackly, robotic, or delayed audio that forces users to constantly repeat themselves. | Misconfigured Opus settings (e.g., forcing high bitrates or using high-latency 60ms frames instead of low-latency 20ms frames). | Configure Opus for voip application mode, dynamic bitrate (16-32 kbps), and standard 20ms packet intervals to minimize latency. |
| Ignoring Multilingual Accents & Dialects | System fails to transcribe regional accents, leading to hallucinated responses and complete task failure. | STT error rates (WER) spike on non-native accents, feeding garbage text into the downstream LLM. | Use a highly optimized, multilingual STT engine supporting regional dialects natively (e.g., CallMissed's 22 Indian languages engine). |
1. The Sequential Pipeline Trap (STT → LLM → TTS)
The most common mistake for developers transitioning from text to voice is utilizing a synchronous, sequential architecture. In this outdated pattern, the system waits for the user to finish speaking, transcribes the entire audio file using a Speech-to-Text (STT) API, sends the complete text string to an LLM, waits for the entire LLM text response to generate, and finally sends that text to a Text-to-Speech (TTS) engine to synthesize the audio.
This sequential block-and-wait approach yields an end-to-end latency of 1.5 to 3 seconds. To bypass this bottleneck:
- Stream Audio Chunks: You must use WebSockets or WebRTC to stream raw audio in real-time. The STT engine should transcribe audio on the fly, emitting partial transcripts.
- Leverage LLM Streaming: The LLM must stream token-by-token. As soon as the first sentence or clause is generated, it should be sent immediately to the TTS engine.
- Utilize Native Speech-to-Speech (S2S): For the absolute lowest latency, deploy native speech-to-speech models (like Gemini Live or OpenAI's real-time engines) which bypass text intermediate steps entirely, achieving end-to-end response times of 150ms to 300ms. Platforms like CallMissed make this transition seamless by providing a multi-model gateway with access to over 300 optimized LLMs, allowing developers to switch from sequential pipelines to low-latency streaming configurations with minimal code changes.
2. Failing to Plan for Firewalls and Restrictive Corporate NATs
During local development, WebRTC connections usually connect instantly because both the client and the server reside on the same network or utilize open local IP routes. In production, however, your users will access your voice agents from office networks, public Wi-Fi, or cellular connections protected by symmetric Network Address Translation (NAT) and strict firewalls.
If your system relies solely on direct Peer-to-Peer (P2P) connections or poorly configured STUN servers, 15% to 25% of your calls will experience connection failures or "one-way audio" (where one party cannot hear the other).
- Always configure a robust distributed network of TURN (Traversal Using Relays around NAT) servers. TURN acts as a media relay when direct connection fails.
- Configure your WebRTC client to fall back to TURN over TCP (or TURN over TLS on port 443) to guarantee that even the most restrictive corporate firewalls cannot block your voice agent's audio traffic.
- Platforms like CallMissed eliminate this infrastructure headache by providing native, pre-configured STUN/TURN infrastructure alongside their WebRTC gateways, ensuring your voice agents achieve a 99.9% connection success rate globally.
3. Ignoring Interruption and "Barge-In" Physics
In a natural conversation, humans interrupt each other. If an AI voice agent is in the middle of a long sentence and the user says, "No, wait, that's not what I meant," the agent must stop speaking immediately.
Failing to implement an elegant "barge-in" mechanism results in a highly frustrating user experience where the agent keeps blabbing over the user's voice. Technically, resolving this requires a highly synchronized double-feedback loop:
- Asymmetric Voice Activity Detection (VAD): Run a lightweight, ultra-fast VAD model (such as Silero VAD) on the client side or at the media gateway edge. As soon as the user's speech is detected for more than 100–150ms, the client must send an immediate interruption signal to the backend.
- Buffer Clearing & State Reset: The server must instantly stop sending downstream audio packets, clear its output TTS audio queues, and send a signaling packet to the client to flush its local WebRTC audio playout buffer. The LLM must also be notified of the interruption so it can adjust its context history to reflect exactly where the user cut off the agent.
4. Overlooking WebRTC Codec and Network Packetization
WebRTC uses Opus as its default audio codec, which is highly flexible and capable of delivering crystal-clear speech. However, developers often leave Opus on default, unoptimized settings designed for high-bandwidth music streaming rather than low-latency voice over IP (VoIP).
Misconfigured frame sizes and bitrates can lead to unnecessary packetization overhead and increased latency. To optimize Opus for AI voice agents:
- Set the Application Mode to VoIP: Force the Opus encoder into
voipmode rather thanaudioorlowdelay. This optimizes the codec for human speech patterns and frequencies. - Adjust Frame Duration: Use 20ms frame sizes. While 10ms frames offer slightly lower latency, they double the network packet overhead; 60ms frames reduce overhead but add 40ms of unnecessary latency directly to your round-trip budget.
- Enable Dynamic Bitrate: Keep your target bitrate between 16 kbps and 32 kbps. Going higher does not noticeably improve speech intelligibility for AI processing but increases packet loss vulnerability over weak cellular connections.
5. Neglecting Accent and Dialect Nuances in Global Deployments
If your voice agent is deployed globally, a generic STT model trained purely on standard American or British English will fail when confronted with regional accents, colloquial dialects, or localized speech patterns (such as Indian accents or localized code-switching). This failure spikes the Word Error Rate (WER), causing your LLM to receive highly corrupted transcriptions and return irrelevant answers.
When deploying multilingual voice applications, you must choose an STT pipeline capable of understanding localized nuances without adding to your latency budget. For example, if you are targeting the South Asian market, utilizing CallMissed's specialized Speech-to-Text APIs with native support for 22 regional Indian languages allows your agent to process localized accents, dialects, and multilingual phrasing with high accuracy and minimal processing overhead, ensuring your sub-second voice agent remains both fast and contextually intelligent.
Frequently Asked Questions
What is the ideal latency budget when building voice agents on CallMissed?
Why is WebRTC preferred over WebSockets for real-time voice AI communication?
How does CallMissed handle user interruptions and barge-in during an active call?
What role do SFUs and TURN servers play when building voice agents on CallMissed?
Can I integrate speech-to-speech models like GPT-4o Realtime or Gemini Live on CallMissed?
What are the best practices for optimizing the audio codec when building voice agents on CallMissed?
Resources & Next Steps

Building a sub-second, production-grade voice agent requires a meticulous combination of low-latency network protocols, highly optimized audio streaming pipelines, and state-of-the-art AI infrastructure. Transitioning from a local proof-of-concept to a global, scalable system capable of natural, bi-directional conversations demands systematic engineering.
To help you successfully transition your voice agent from development to production, this guide outlines the vital technical resources, step-by-step pathways, and architectural patterns you should implement next.
Step-by-Step Developer Roadmap
Achieving a highly responsive voice experience—ideally staying well under the 500ms end-to-end latency threshold—requires a phased implementation strategy.
#### Phase 1: Establish the WebRTC Signaling and Media Transport
Start by setting up your real-time communication framework. P2P (Peer-to-Peer) connections are rarely suitable for server-side AI processing, so you must establish a reliable infrastructure using Selective Forwarding Units (SFUs) or specialized media servers.
- Signaling Protocol: Implement a robust signaling channel (typically via Secure WebSockets) to negotiate the Session Description Protocol (SDP) and exchange Interactive Connectivity Establishment (ICE) candidates.
- NAT Traversal: Deploy STUN and TURN servers (using TURN-over-TLS on port 443 to bypass restrictive corporate firewalls) to ensure reliable connection establishment across diverse network topologies.
- Audio Codec Optimization: Configure your WebRTC peer connections to use the Opus codec. Ensure your SDP negotiate parameters favor voice-optimized configurations: a 16kHz sampling rate (mono) is generally the sweet spot for Speech-to-Text (STT) engines, balancing high fidelity with minimal bandwidth consumption.
#### Phase 2: Select and Optimize Your Intelligence Pipeline
Depending on your use case, budget, and latency requirements, you can choose between two primary backend architectures:
- The Cascaded Pipeline (STT -> LLM -> TTS):
- Speech-to-Text (STT): Utilize high-speed, streaming transcription engines. For regional deployments, platforms like CallMissed provide localized, low-latency Speech-to-Text APIs supporting 22 Indian languages natively.
- Large Language Model (LLM): Leverage highly optimized inference frameworks. Use models optimized for Time-To-First-Token (TTFT). For maximum flexibility without code rewrites, CallMissed’s multi-model API gateway allows you to benchmark and switch between over 300+ open and closed-source LLMs.
- Text-to-Speech (TTS): Implement chunk-based streaming TTS. Do not wait for the entire LLM sentence to complete; stream raw audio buffers back to the client as soon as the first phrase or clause is synthesized.
- The Native Speech-to-Speech (S2S) Pipeline:
- For the lowest possible latency, bypass cascading altogether by routing WebRTC audio channels directly into native multimodal speech models such as OpenAI's GPT-Realtime or Gemini Live. As of 2026, these end-to-end models routinely hit 150ms to 300ms round-trip latency, providing incredibly lifelike conversation flows.
#### Phase 3: Implement Interruption Handling and Echo Cancellation
A voice agent that cannot be interrupted feels robotic and frustrating. Your frontend and backend must work in tandem to handle natural conversation flow:
- VAD (Voice Activity Detection): Run a lightweight VAD model on the client-side (or edge server) to detect when the user starts speaking.
- Asynchronous Interrupt Signals: Immediately upon VAD activation, send a high-priority control signal over a WebRTC Data Channel or signaling socket to the server.
- Immediate Playback Clearance: The server must instantly stop the LLM generation and clear the TTS outbound audio buffer. Simultaneously, the client-side audio player must flush its local playback queue to silence the agent immediately.
Understanding Your Latency Budget
To deliver an interface that feels human, your system must operate within a strict latency budget. The table below represents the target budget for a sub-second cascaded pipeline versus a native speech-to-speech architecture.
| Pipeline Phase | Cascaded Pipeline Target | Native Speech-to-Speech Target | Optimization Strategy |
|---|---|---|---|
| Network Ingestion (WebRTC) | 20–50ms | 20–50ms | Use global edge nodes, TURN-over-UDP. |
| Transcription / Encoding | 100–200ms | N/A (Direct Audio Input) | Stream chunked audio, use VAD locally. |
| AI Inference / Generation | 200–400ms (LLM TTFT) | 100–200ms (End-to-End) | Use speculative decoding, small parameter models. |
| Synthesis / Generation | 100–200ms (Streaming TTS) | N/A (Direct Audio Output) | Synthesize in small buffer chunks (e.g., 20ms). |
| Network Playout | 20–50ms | 20–50ms | Jitter buffer tuning on the client side. |
| Total End-to-End Latency | 440ms – 900ms | 140ms – 300ms | Sub-second conversation loop achieved. |
Core Technical Resources
To dive deeper into the code and architecture, explore these critical guides and specifications:
- CallMissed Developer Guides:
- Build Voice Agents with CallMissed: WebRTC + STT + LLM + TTS Pipeline: A hands-on tutorial detailing session initialization, managing audio queues, and configuring the end-to-end pipeline for sub-second responses.
- WebRTC for Voice AI: SFU, TURN, and the Opus Codec: A technical deep-dive outlining how to navigate NAT traversal, optimize the Opus audio codec specifically for speech interfaces, and structure an efficient media routing architecture.
- Industry Standards & Specifications:
- RFC 7587: The official specification for using the Opus Codec in WebRTC, highlighting parameters ideal for interactive voice applications.
- Model Context Protocol (MCP): An emerging standard for linking LLM-powered voice agents directly to external databases, enterprise APIs, and local development environments securely.
- W3C WebRTC 1.0 Real-Time Communication: The foundational browser API specification for capturing, encoding, and transmitting real-time media streams.
Next Steps: Moving from Sandbox to Production
As you prepare to roll out your voice agent to real-world users, keep these operational considerations in mind:
- Transition to Telephony (SIP/PSTN Bridging): While WebRTC is excellent for web and mobile apps, many enterprise use cases require phone line integration. Look for platforms like CallMissed that provide built-in SIP trunking, allowing you to bridge your ultra-low latency WebRTC agents directly to standard phone numbers without re-engineering your core intelligence pipeline.
- Monitor Network Jitter and Packet Loss: Real-world networks are chaotic. Implement adaptive jitter buffers on your client applications to smooth out audio delivery without adding unnecessary latency.
- Global Edge Deployment: Deploy your media servers and orchestration layers as close to your end-users as possible. Reducing the physical distance audio packets must travel is the single most effective way to shave off those final, critical 50 milliseconds of network latency.
Conclusion
As we navigate 2026, the technical barriers that once made real-time AI conversations feel clunky and disjointed have officially crumbled. Achieving a sub-second round-trip latency is no longer an aspirational engineering milestone—it is the baseline standard for production-grade voice systems.
Here are the critical takeaways to remember when building low-latency conversational agents:
- WebRTC is Non-Negotiable: Leveraging WebRTC’s real-time, bi-directional media transport—backed by the Opus codec, SFUs, and optimized TURN signaling—is the only way to strip away transport lag.
- Pipeline Optimization Matters: Every millisecond saved during the Speech-to-Text (STT), LLM inference, and Text-to-Speech (TTS) steps directly contributes to keeping overall response times under the critical 500ms user-experience threshold.
- Intelligent Turn-Taking: Success in production depends on handling human-like conversational dynamics, such as immediate interruption detection and smart background noise cancellation.
Looking forward, the industry is rapidly transitioning toward native, end-to-end speech-to-speech models that merge hearing, thinking, and speaking into a single neural network. These architectures are already pushing response times down to a staggering 150–300ms. As conversational AI becomes indistinguishable from a human phone call, organizations must move away from slow, legacy communication infrastructures.
Is your organization ready to transition to a seamless, zero-lag voice experience? To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. Deploying your first sub-second voice agent is no longer a complex engineering hurdle, but a plug-and-play reality.


