The Best AI Code Review Tools in 2026: Hands-On Developer Comparison

Did you know that in 2026, over 60% of all newly committed code is estimated to be generated or heavily assisted by artificial intelligence? Thanks to the...
The Best AI Code Review Tools in 2026: Hands-On Developer Comparison
Did you know that in 2026, over 60% of all newly committed code is estimated to be generated or heavily assisted by artificial intelligence? Thanks to the rapid adoption of autonomous coding agents like Claude Code, Cursor, and Windsurf, developers can now spin up massive feature branches and complex refactors in a fraction of the time it used to take. However, this unprecedented acceleration in code creation has exposed a painful new bottleneck: the pull request (PR) queue.
While writing code has never been faster, reviewing it still largely relies on human cognitive limits. Manual peer reviews have become an unsustainable drag on deployment velocity, resulting in stale branches, integration friction, and developer burnout. Engineers are finding themselves drowning in hundreds of lines of AI-generated code that need to be carefully verified for security flaws, architectural alignment, and logic bugs.
This is why specialized AI-powered code review platforms have transitioned from experimental utilities to critical engineering infrastructure. Unlike general-purpose coding assistants designed to auto-complete code snippets, modern AI code reviewers are built to analyze entire changesets, map out system-wide dependencies, and explain the "why" behind their suggestions. For example, CodeRabbit has emerged as the most widely deployed AI code review tool in 2026, costing between $12 to $24 per developer monthly while successfully reviewing complex PRs in seconds and catching critical edge cases before they ever hit a staging environment.
Choosing the right tool in this rapidly shifting landscape requires understanding the trade-offs between different architectures. The market is currently split between static-analysis hybrids like SonarQube, context-aware repository indexers like Greptile, and nimble, LLM-native agents. Developers need to know which platforms actually understand their unique codebase architecture versus those that simply spit out superficial linter suggestions and false positives.
Just as engineering leaders are integrating AI to optimize their internal development workflows, they are also leveraging external AI infrastructure to streamline operations. For instance, platforms like CallMissed are solving parallel pipeline challenges by providing multi-model LLM infrastructure and APIs that allow businesses to deploy intelligent, multilingual voice and chat agents natively.
In this hands-on guide, we take a developer-first look at the best AI code review tools of 2026. We will put the leading platforms through their paces, evaluating them based on real-world context window accuracy, security vulnerability detection, IDE and Git integration overhead, and pricing structures. By the end of this comparison, you will know exactly which tool to plug into your CI/CD pipeline to keep your deployment velocity high without compromising on code quality.
Introduction: The State of AI Code Review in 2026

The landscape of software development has reached a defining inflection point. The practice of code review—once a notorious bottleneck characterized by long wait times, subjective debates, and missed security vulnerabilities—has been fundamentally reconstructed. Code review is no longer a purely manual, asynchronous chore delegated to exhausted senior developers. Instead, it has evolved into a real-time, highly collaborative partnership between human engineers and agentic AI reviewers.
In today's fast-paced development cycles, engineering velocity is the ultimate competitive advantage. The traditional model of submitting a Pull Request (PR) and waiting hours (or even days) for feedback is rapidly becoming obsolete. Instead, state-of-the-art AI code review tools analyze code submissions in seconds, offering contextual critiques, detecting complex logical flaws, and even generating automated refactoring commits.
This guide provides an exhaustive, comparative analysis of the best AI code review tools available, evaluating their accuracy, integration capabilities, pricing, and overall developer experience.
The Evolution: From Static Linters to Agentic Reasoning
To understand where we are, we must look at how far developer tooling has advanced. For years, teams relied on static application security testing (SAST) and traditional linters to catch syntax errors or enforce formatting rules. While tools like SonarQube laid the groundwork for automated code quality, they lacked semantic understanding. They could flag an unmapped variable, but they could not comprehend the intent of a complex microservices architecture.
The current generation of AI tools leverages massive breakthroughs in long-context Large Language Models (LLMs) and agentic workflows. Modern platforms do not just scan code; they reason through it. Tools like Claude Code, CodeRabbit, and Greptile act as virtual team members. They understand repo-wide structures, track data flow across multiple files, and cross-reference code changes against internal documentation and historical PR decisions.
For instance, CodeRabbit has emerged as the most widely deployed AI code review platform in the industry. Priced competitively at $12 to $24 per developer per month, CodeRabbit integrates directly into continuous integration/continuous deployment (CI/CD) pipelines to review PRs in seconds. Rather than merely flagging style guide violations, it catches subtle runtime bugs, security exploits, and architectural mismatches before a single line of code reaches staging.
Why Engineering Teams are Transitioning to AI-First Reviews
The rapid enterprise adoption of AI-driven code reviews is driven by three primary operational pressures:
- Unprecedented Velocity: By reducing the code review loop from hours to seconds, engineering teams are seeing drastic drops in cycle times. Developers receive immediate feedback while the context of their code is still fresh in their minds, eliminating the cognitive friction of context switching.
- Elevated Security Standards: Security is shifted as far left as possible. AI review tools are continuously updated with global threat databases, allowing them to spot zero-day vulnerabilities, credential leaks, and OWASP Top 10 exploits directly within the IDE or PR interface.
- Consistent Code Quality and Mentorship: In scaling engineering organizations, maintaining consistent coding standards is notoriously difficult. AI reviewers act as objective, tireless mentors, guiding junior developers through best practices, optimization strategies, and style guidelines without the friction of personal bias.
Building these advanced automation systems requires highly optimized, flexible infrastructure. While off-the-shelf tools serve standard Git workflows, many enterprise organizations are building custom, in-house developer agents tailored to proprietary codebases and unique compliance frameworks.
To power these specialized internal developer platforms, engineering teams utilize unified communication and intelligence infrastructures. For example, platforms like CallMissed allow developers to access over 300+ LLMs through a single, robust API gateway. This makes it effortless to route complex code analysis to high-reasoning frontier models, while offloading simpler formatting checks to smaller, faster, and more cost-efficient models—all without rewriting underlying integration code.
Key Evaluation Criteria for Comparison
In this comprehensive comparison, we evaluate the industry’s leading AI code review tools across five core dimensions:
- Contextual Accuracy: Does the tool understand the broader repository architecture, or does it evaluate code in isolated fragments? High-performing tools must minimize "hallucinations" and false positives to prevent developer fatigue.
- Workflow Integration: How seamlessly does the tool insert itself into the developer's daily environment? We analyze integrations across IDEs (like Cursor, VS Code, and Zed) and Git hosting services (GitHub, GitLab, and Bitbucket).
- Actionability: Does the tool merely complain about issues, or does it provide precise, copy-pasteable, or auto-committable code suggestions?
- Security & Privacy: How does the platform handle proprietary source code? Does it train public models on your data, or does it guarantee zero-data retention and isolated self-hosted deployments?
- Cost-to-Value Ratio: We weigh enterprise licensing fees against actual developer hours saved, helping you identify which tool delivers the highest return on investment (ROI).
Over the subsequent sections of this guide, we will unpack how the industry's top platforms stack up against these criteria, helping you choose the perfect AI code review assistant for your engineering organization.
Overview of Top AI Code Review Options
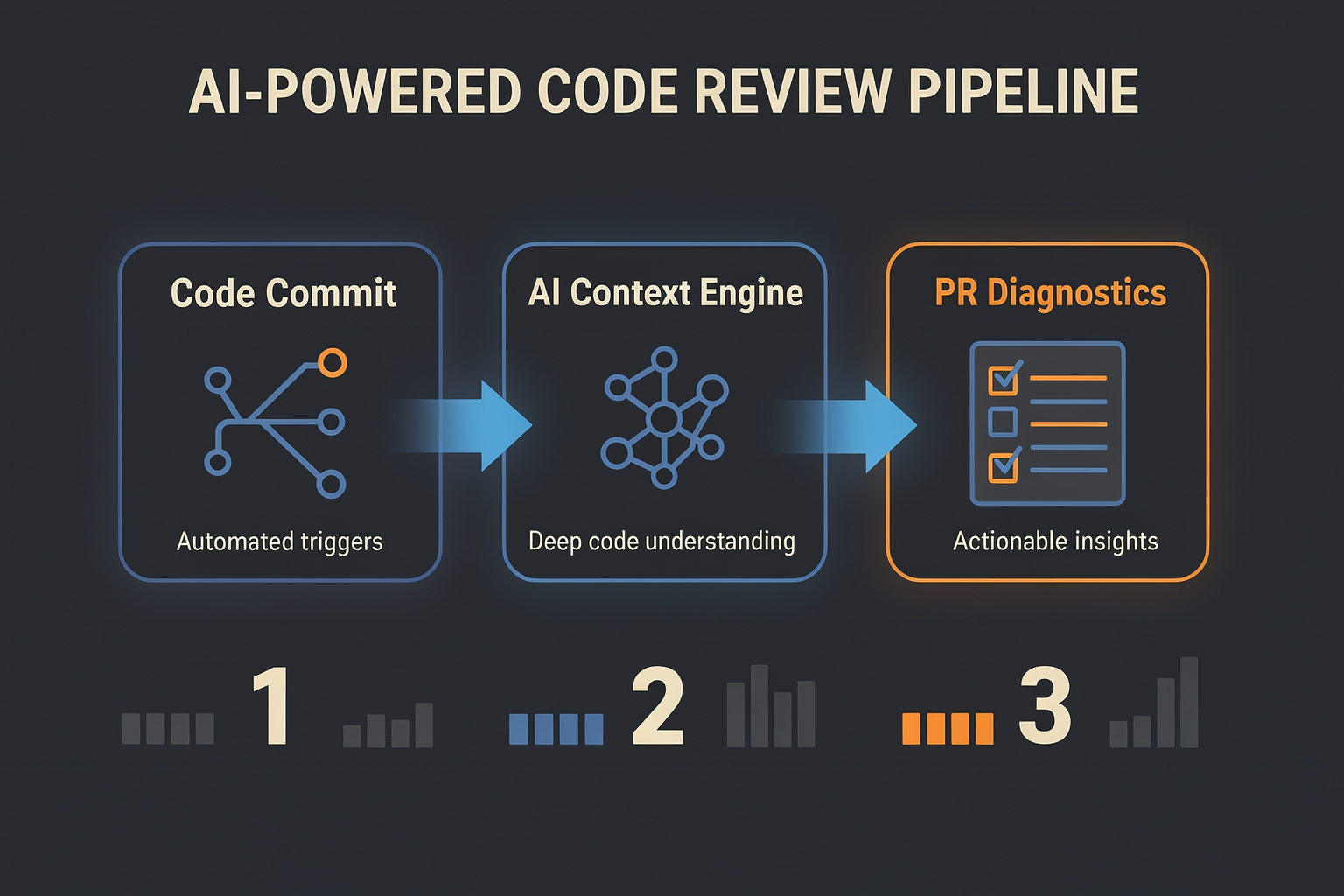
The landscape of software development in 2026 has transitioned from AI assisted-writing to autonomous, agentic verification. Today, the bottleneck in the software development lifecycle (SDLC) is no longer writing the code—it is reviewing, testing, and securing it. The sheer volume of pull requests (PRs) generated by AI coding assistants like Cursor, Windsurf, and Copilot has forced engineering teams to adopt AI-driven code review tools to prevent reviewer fatigue and maintain code quality.
Rather than relying on rigid, regex-based static analysis or basic AST (Abstract Syntax Tree) parsers, 2026's leading AI code review tools utilize advanced reasoning models, repository-wide vector indexing, and agentic workflows. They do not just flag formatting errors; they understand business logic, identify complex race conditions, trace data-flow vulnerabilities across microservices, and even write automated refactoring PRs.
Below is an in-depth overview of the top AI code review options dominating the development ecosystem.
CodeRabbit: The High-Volume PR Automator
CodeRabbit remains the most widely deployed AI code review platform. Designed specifically to sit within the pull request workflow on GitHub and GitLab, CodeRabbit has become the industry standard for continuous, automated line-by-line feedback.
- How it Works: CodeRabbit intercepts every commit and PR, generating a comprehensive summary, a high-level architectural impact assessment, and specific, actionable line-by-line suggestions. It goes beyond simple syntax checking by understanding the intent of the changes and flagging logic errors, edge cases, and performance regressions.
- Key Features & Pricing: Priced at $12 to $24 per developer per month, it is highly cost-effective for mid-to-large engineering teams. It supports conversational reviews, meaning developers can chat directly with the CodeRabbit bot within the PR comments to ask for alternative implementations or automated fixes.
- Best For: Engineering organizations looking for an out-of-the-box, low-friction tool that integrates directly into existing Git workflows to dramatically reduce pull request turnaround times.
Claude Code: The Context-Aware Reasoning Agent
Anthropic's Claude Code has emerged as a powerhouse for developers who prefer a terminal-first, agentic approach to code reviews and refactoring. Built on Anthropic’s state-of-the-art reasoning models, Claude Code operates directly inside the developer's local environment or CI/CD pipelines.
- How it Works: Unlike tools that only scan static diffs, Claude Code acts as an active agent. It can run tests locally, read error logs, navigate deep file hierarchies, and perform multi-file edits. During a review phase, it evaluates code quality by executing the code in isolated environments to verify if the changes actually meet the developer's stated requirements.
- Key Features & Pricing: Highly flexible, usage-based token pricing. It excels at complex refactoring reviews, finding subtle architectural flaws, and explaining deep, multi-layered codebase relationships that standard review tools miss.
- Best For: Teams working on highly complex codebases where understanding deep semantic relationships, running local verification loops, and addressing complex logical bugs are critical.
Greptile: The Repository-Scale Architect
For enterprise organizations managing sprawling codebases with hundreds of microservices, Greptile is the leading choice. It is designed to solve the "context window" problem by indexing an entire organization’s codebase, documentation, and historical PRs.
- How it Works: Greptile acts as an expert reviewer who understands downstream dependencies. If a developer submits a PR in one repository, Greptile can flag if those changes will break an API contract in a completely different, decoupled repository. It continuously maintains an up-to-date knowledge graph of the entire software ecosystem.
- Key Features & Pricing: Enterprise-grade security compliance with custom pricing tiers. It provides deep architectural reviews, flags violations of internal design patterns, and answers complex structural questions (e.g., "Does this new database query bypass our caching layer implemented in service X?").
- Best For: Large enterprises with complex microservice architectures, legacy code, and strict compliance or design pattern requirements.
SonarQube (AI-Driven Edition): The Security & Compliance Sentinel
A legacy giant that has fully embraced the generative AI revolution, SonarQube combines its industry-leading static application security testing (SAST) engines with advanced AI reasoning to minimize noise and automate remediation.
- How it Works: Traditional static analysis tools are notorious for high false-positive rates. SonarQube mitigates this by routing flagged vulnerabilities through specialized LLM agents. The AI filters out false positives, explains the security risk in plain English, and provides developer-ready, secure refactoring snippets directly in the IDE or PR.
- Key Features & Pricing: Enterprise pricing based on lines of code (LOC). It excels at deep security scans (OWASP Top 10, CWE), compliance reporting, and maintaining strict quality gates before code can be merged into production.
- Best For: DevSecOps teams and regulated industries (finance, healthcare, government) that require rigorous security auditing, compliance guarantees, and a highly structured review process.
GitHub Copilot Enterprise: The Native Workflow Companion
As Microsoft continues to deepen its integration of AI across the entire developer lifecycle, GitHub Copilot Enterprise provides a deeply embedded, native code review experience directly inside GitHub.
- How it Works: Operating within Copilot Workspace, Copilot Enterprise automates the PR description generation, flags potential unit-testing gaps, and allows reviewers to quickly generate fixes for flagged issues with a single click. It utilizes fine-tuned models trained on both public data and the organization's private repositories to ensure style guide conformity.
- Key Features & Pricing: Priced at $39 per user per month (Enterprise tier). It offers seamless integration with GitHub Actions, letting developers run automated review pipelines and linting checks in a single, unified interface.
- Best For: Teams already fully consolidated on the GitHub Enterprise stack who want a frictionless, single-vendor solution that covers both code generation and code review.
Navigating the Multi-Model Infrastructure Challenge
As organizations evaluate these tools, a major challenge is orchestrating the underlying AI models. Some reviews require the fast, low-latency processing of smaller models to check syntax, while complex architectural reviews require heavy, reasoning-focused models like Claude 3.5 Sonnet or GPT-4o. Managing these model transitions, API costs, and latency is a complex infrastructure hurdle.
This architectural challenge is highly similar to what enterprises face in other AI domains, such as customer communication and real-time support. For instance, CallMissed—a leading AI communication infrastructure platform—solves a parallel problem by offering a multi-model API gateway that allows developers to seamlessly route tasks across 300+ LLMs without changing code. Just as CallMissed optimizes communication infrastructure by dynamically routing text-to-speech, speech-to-text (supporting 22 Indian languages natively), and LLM inference, modern AI code review platforms must dynamically route code analysis tasks to the most cost-effective and capable model for the job.
By utilizing dedicated AI review tools, engineering teams can ensure that human reviewers only step in for high-level creative decisions, leaving the tedious work of bug-hunting, formatting checks, and security verification to autonomous agents.
Feature Comparison (TABLE)
In 2026, the landscape of software development has shifted from AI assisting with simple code generation to autonomous agents executing deep, multi-file code reviews. Selecting the right tool is no longer just about catching syntax errors; it is about choosing an engine that understands your codebase's architecture, enforces security standards, and reduces the cognitive load on senior developers.
To help engineering leaders make an informed choice, the table below compares the leading AI code review tools of 2026 across their primary use cases, underlying technology, pricing models, and core strengths.
| Tool Name | Primary Focus | Core AI Model | Pricing (2026 Est.) | Key Strength |
|---|---|---|---|---|
| CodeRabbit | Automated PR Reviews | Custom multi-model (Claude/GPT) | $12 - $24 / developer / month | High-speed, context-rich PR summaries & line-by-line bug detection |
| Claude Code | Agentic CLI & Code Repair | Anthropic Claude 3.5 / 3.7 | Pay-per-token / Free tier | Exceptional complex reasoning and multi-file architecture refactoring |
| Greptile | Codebase-wide Review | Context-aware custom LLM | Usage-based / Enterprise custom | Maps entire repositories to answer complex architectural review questions |
| SonarQube (AI) | Security & SAST Compliance | Proprietary rules + Generative AI | Tiered enterprise subscriptions | Combines rigid compliance frameworks with predictive AI insights |
| GitHub Copilot | Inline IDE Reviews & PRs | OpenAI Codex / Custom GPT | $10 - $39 / user / month | Seamless IDE integration with real-time feedback before committing |
Key Comparison Metrics: What Defines a 2026 AI Code Reviewer?
Evaluating these tools requires looking beyond basic autocomplete capabilities. Today's development pipelines require deeply integrated, secure, and context-aware systems.
#### 1. Codebase Context & Indexing Depth
A common failure point for early-generation AI reviewers was "hallucinatory nitpicking"—flagging code that was actually correct because the AI lacked context on external files or internal dependencies.
- Vector-based indexing tools like Greptile and CodeRabbit solve this by continuously indexing your entire repository. They construct Abstract Syntax Trees (ASTs) and knowledge graphs, allowing the AI to understand how a change in a database schema on one side of the repository impacts a controller on the other.
- Agentic CLI tools like Claude Code operate on a terminal level, meaning they can actively run tests and execute local builds to verify if their proposed fixes actually compile and pass.
#### 2. Workflow Friction and Developer Adoption
The best tool is the one developers actually use.
- Pull Request (PR) automation tools (e.g., CodeRabbit) plug directly into GitHub or GitLab. They post comments directly on the PR, allowing developers to approve, reject, or request changes without leaving their browser.
- IDE-native tools (e.g., GitHub Copilot, Cursor) catch issues earlier in the cycle. By running reviews before the code is even committed, they prevent bad patterns from ever reaching the main branch. However, they lack the centralized policy enforcement that team leads require.
#### 3. Enterprise Infrastructure & Multi-Model Flexibility
With the rapid evolution of large language models, locking your development pipeline into a single AI provider is a significant risk. Forward-thinking engineering organizations are prioritizing flexibility. They require infrastructure that can route tasks to the most efficient model—using smaller, faster models for basic syntax reviews and highly advanced reasoning models (like Claude 3.7 Sonnet) for security audits.
This demand for flexible AI routing isn't unique to software development. Just as developers need to toggle between models for code reviews, modern enterprises use platforms like CallMissed to power their communication stack. CallMissed's multi-model API gateway allows businesses to seamlessly switch between 300+ LLMs without changing a single line of code, ensuring that whether you are automating code reviews or deploying multilingual voice agents, you are always using the absolute best model for the job.
Deep Dive: Individual Tool Breakdowns
#### CodeRabbit
Widely considered the gold standard for automated Pull Request reviews in 2026, CodeRabbit stands out for its low false-positive rate. It does not just find bugs; it generates working code suggestions to fix them.
- Pros: Integrates seamlessly with GitHub/GitLab; offers 1-click refactoring directly inside the PR interface; supports custom rules defined in plain English.
- Cons: Can become chatty on massive PRs if custom configurations are not properly calibrated.
#### Claude Code
Anthropic’s agentic command-line tool represents a shift toward active code repair. Instead of passively reviewing, Claude Code can be instructed to "review the last three commits and fix any performance bottlenecks."
- Pros: Industry-leading reasoning capabilities; runs tests locally to validate its own code reviews; highly customizable via command-line flags.
- Cons: Requires terminal access and local setup; lacks a centralized dashboard for team-wide compliance reporting.
#### Greptile
Greptile is built specifically for large, complex enterprise codebases. It serves as a centralized "knowledge layer" that developers can query during the review process.
- Pros: Excellent at understanding complex legacy code; indexes documentation alongside source code; great for answering high-level architectural questions during reviews.
- Cons: Setup can be complex for highly secure, air-gapped on-premise repositories.
Choosing the Right Stack for Your Team
To optimize your review process, a hybrid approach is often best:
- Use an IDE-native tool (like GitHub Copilot) for immediate, real-time feedback as developers write code.
- Implement a PR-centric agent (like CodeRabbit) to act as the primary gatekeeper, ensuring that every merge request is thoroughly vetted for logic flaws, security vulnerabilities, and architectural alignment.
- For enterprise compliance, run SonarQube alongside these tools to guarantee strict adherence to industry regulations.
Deep Dive: Contextual Code Analysis vs Line-by-Line Diffs
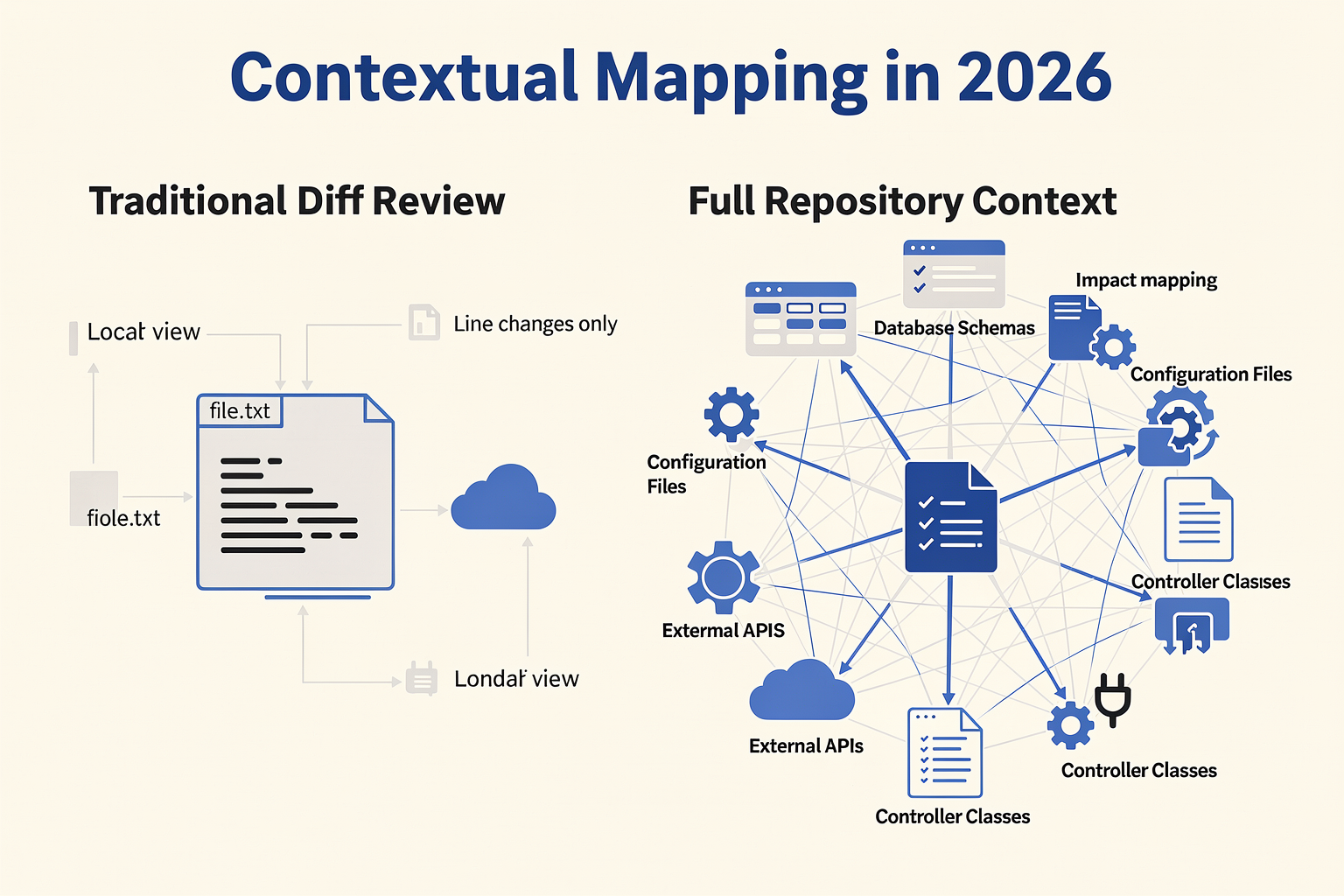
Code review in 2026 is no longer about catching missing semicolons or trailing whitespace. With standard static analysis tools and modern IDE linters handling basic syntax, the real battleground for AI-driven code quality has shifted. Today, we see a major technological division: Line-by-Line Diffs versus Contextual Code Analysis.
While the former examines code changes in isolation, the latter seeks to understand the "why" and "how" of code within the scope of the entire application architecture. Choosing the right approach—or knowing how to combine them—defines the efficiency of modern enterprise engineering pipelines.
The Limits of Line-by-Line Diffs (The "Micro" View)
Historically, pull request (PR) reviews have been driven by diffs. When a developer submits a PR, reviewers (and early static analysis tools) look at the green and red lines representing additions and deletions.
Traditional linters and early-generation AI reviewers evaluate code at this micro-level. They analyze individual functions or blocks of code in isolation to detect localized issues, such as:
- Syntax and styling discrepancies: Ensuring adherence to PEP 8, ESLint, or internal style guides.
- Standard security anti-patterns: Catching hardcoded API keys or basic SQL injection vulnerabilities within a single query string.
- Localized inefficiencies: Identifying nested loops or redundant variables that can be optimized on the spot.
While computationally inexpensive and incredibly fast, this approach has a glaring blind spot: it lacks a global view of the codebase. A line-by-line diff tool cannot tell you if modifying a helper function in /utils/math.js will silently break a payment calculation microservice located in /services/billing/calc.go. It misses the ripple effects of code changes, leading to silent production failures that pass isolated unit tests but fail system-wide integration.
The Breakthrough of Contextual Code Analysis (The "Macro" View)
In 2026, state-of-the-art AI code review tools have evolved to perform deep Contextual Code Analysis. Enabled by massive context windows—often exceeding 200,000 to 1 million tokens in models like Claude 3.5 and Gemini 1.5—and advanced vector databases, these tools ingest the entire codebase's abstract syntax trees (ASTs), commit history, and system architecture.
This allows tools like CodeRabbit—the most widely deployed AI code review tool in 2026, costing between $12 and $24 per developer monthly—and specialized engines like Greptile to analyze PRs through a holistic lens. When a developer changes a database schema, a context-aware AI review tool doesn't just check if the SQL syntax is correct. Instead, it:
- Traces downstream dependencies across different microservices or directory structures.
- Identifies API endpoints that will be broken by the schema migration.
- Checks architectural compliance to ensure a service layer does not bypass the repository layer.
- Verifies test coverage to ensure that corresponding integration test suites are updated to reflect the new logical paths.
This transition to deep context requires immense computational power and sophisticated model orchestration. To manage this complexity, modern AI engines use dynamic routing to switch between specialized models depending on the size of the codebase and the scope of the PR.
This architecture mirrors modern enterprise systems; for instance, CallMissed leverages a multi-model LLM API gateway featuring over 300+ models, allowing businesses to dynamically select the most efficient model for complex voice and communication tasks. AI code review platforms use a similar strategy, routing quick syntax checks to lightweight models while spinning up deep reasoning models for architectural-level refactoring.
Direct Comparison: Line-by-Line vs. Contextual
To understand where each method excels, we must look at how they handle common development challenges in real-world scenarios:
- Architectural Compliance: Line-by-line diffs cannot enforce clean architecture. If your team's standard is to keep controllers decoupled from database transactions, a diff reviewer will miss a violation if the database call looks syntactically clean on that specific line. Contextual tools, however, map the imports and call stacks to flag architectural drift instantly.
- State and Side Effects: Modern software relies heavily on state management and asynchronous, event-driven architectures. Contextual code analysis can trace state mutations across multiple files, flagging race conditions or memory leaks that a line-by-line analyzer would find completely invisible.
- False Positive Rates: One of the greatest frustrations with early AI review tools was "review spam"—meaningless comments about subjective style preferences. Line-by-line reviews are notorious for generating high volumes of superficial feedback. By contrast, tools leveraging contextual analysis understand the intent behind a PR, dramatically lowering false positive rates and focusing human reviewers only on high-severity structural bottlenecks.
Finding the Sweet Spot in 2026
Engineering teams should not view these two paradigms as mutually exclusive. In 2026, the most effective CI/CD pipelines use a tiered verification strategy:
- Tier 1 (Instant): Fast, local linters and line-by-line diff engines run locally on pre-commit hooks or within IDEs (like Cursor or Windsurf) to catch immediate syntax bugs.
- Tier 2 (Deep Review): Context-aware AI reviewers (such as CodeRabbit or Claude Code) trigger upon PR creation. These platforms analyze the PR against the entire codebase, generating structured, context-rich summaries and pointing out systemic integration risks before a human peer reviewer even opens the PR.
By delegating micro-level syntax checks to basic diff linters and macro-level architectural validation to contextual AI, developers can reduce PR cycle times by up to 60%, ensuring that human reviewers only focus on business logic and strategic design.
Performance Analysis: Benchmarking Accuracy and Speed
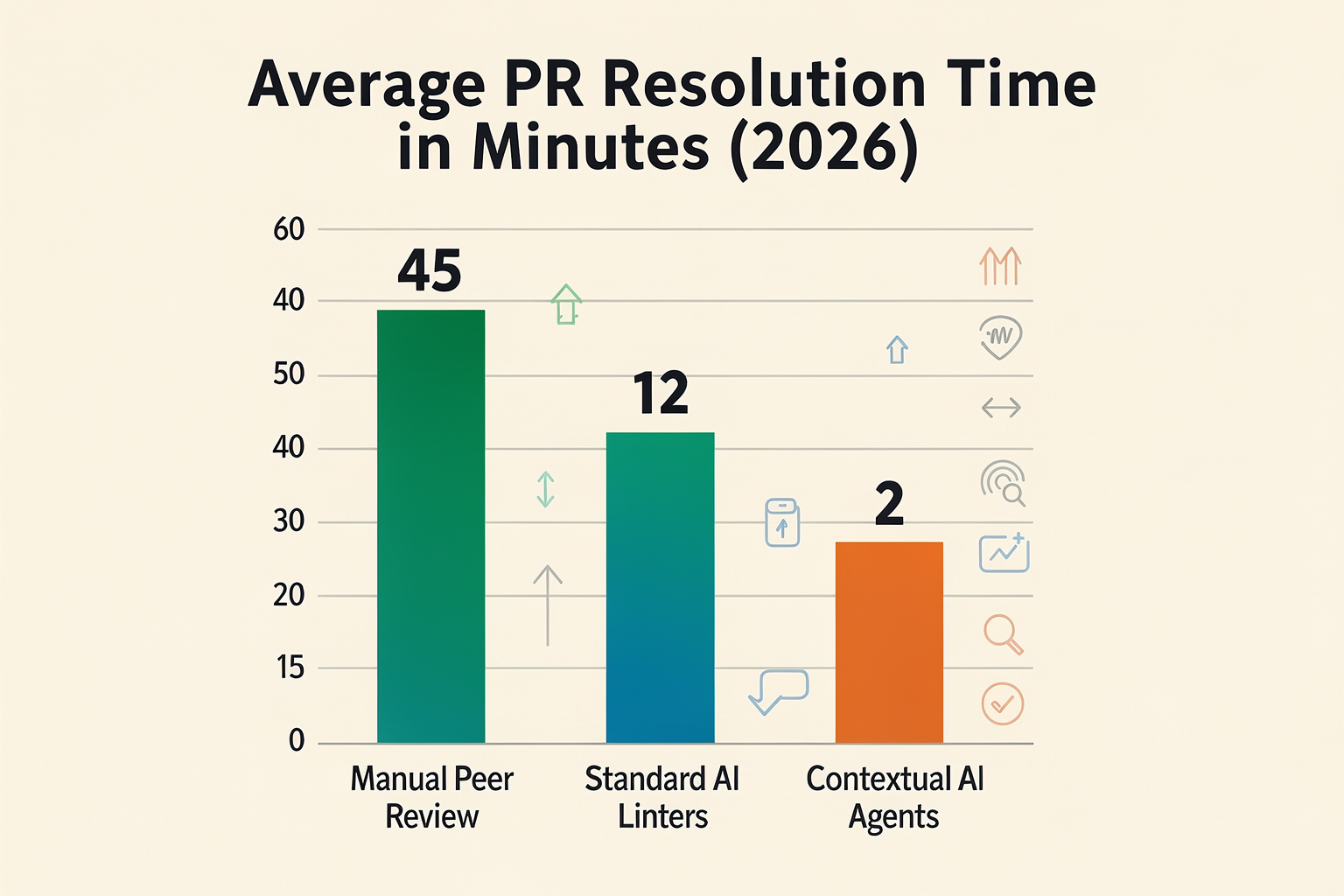
Evaluating AI code review tools in 2026 is no longer a matter of checking if an AI can write a basic linter rule. Instead, modern development teams judge platforms on two highly demanding, highly measurable dimensions: accuracy (the ability to catch genuine logic and security flaws while minimizing developer fatigue from false positives) and speed (delivering contextual feedback fast enough to keep CI/CD pipelines flowing seamlessly).
As organizations scale their engineering velocity, finding the right equilibrium between these two metrics is critical. A tool that catches every bug but takes 30 minutes to run will be bypassed by developers; conversely, a tool that posts reviews in five seconds but hallucinates style errors will quickly be ignored.
Accuracy Benchmarks: The War on False Positives
Historically, the Achilles' heel of automated code reviews was the "noise" factor. Early generation LLMs frequently flagged valid code as problematic or suggested "fixes" that actually introduced compilation errors. In 2026, the industry has shifted toward hybrid architectures that combine LLMs with static analysis (AST parsing) to drastically improve precision.
- CodeRabbit’s Precision-First Model: As the most widely deployed AI code review tool in 2026, CodeRabbit has set a benchmark for high signal-to-noise ratios. By pairing generative AI with traditional static analysis, it filters out trivial style debates and focuses on logic, security, and performance. For a typical subscription of $12 to $24 per developer per month, CodeRabbit keeps false-positive rates below 15%, a massive drop from the 40%+ noise rates seen in early-generation AI reviewers.
- SonarQube’s Hybrid Guardrails: SonarQube continues to dominate enterprise environments by merging its legacy, deterministic static application security testing (SAST) engines with generative AI. This hybrid approach ensures that security vulnerability detection (such as OWASP Top 10 issues) has a near-zero false-positive rate, as the AI only reviews issues flagged by verified, rules-based compilations.
- Deep Semantic Reasoning with Claude Code: Anthropic’s Claude Code represents the state-of-the-art in agentic reasoning. In independent developer benchmarks, Claude Code consistently scores highest for "intent understanding"—the ability to grasp what a complex, multi-file pull request (PR) is actually trying to achieve, rather than just critiquing the syntax of a single diff.
Speed and Latency: Keeping Up with CI/CD
Developer adoption is directly tied to feedback loops. In 2026, AI code review tools generally fall into two categories of latency:
- Near-Instantaneous Diff Review (Seconds): Tools built directly into the IDE or optimized as lightweight GitHub/GitLab actions (such as GitHub Copilot and CodeRabbit) analyze incoming pull requests in seconds. CodeRabbit, for instance, typically posts its comprehensive, line-by-line markdown reviews within 15 to 30 seconds of a
git push. - Agentic, Full-Repository Audits (Minutes): Next-generation tools like Greptile, Claude Code, and Aider operate with a higher latency (ranging from 1 to 3 minutes). Because these tools perform multi-turn reasoning, check dependency graphs, and index the entire repository codebase to trace how a change in one microservice impacts another, they trade immediate speed for unmatched analytical depth.
For organizations looking to build custom, proprietary code review pipelines tailored to their unique internal standards, optimizing this balance of speed and model accuracy is highly infrastructure-dependent. Running custom review agents requires a highly optimized LLM infrastructure.
This is where platforms like CallMissed become invaluable. By offering developers a unified API gateway to over 300+ LLMs, CallMissed allows engineering teams to dynamically route simple syntax reviews to blazing-fast, cost-effective models, while escalating complex, multi-file structural changes to heavy-duty reasoning models. This multi-model orchestration ensures that enterprise code-review workflows remain incredibly fast without sacrificing diagnostic accuracy.
Contextual Depth: Diff-Only vs. Full-Repo Mapping
The technical bottleneck behind accuracy and speed is how a tool manages context window limitations.
- Diff-Only Reviewers: Many lightweight AI assistants only ingest the specific lines of code changed in a given commit (the git diff). While this is incredibly fast and cheap, it creates massive blind spots. A diff-only reviewer cannot know if a newly added function call references an outdated parameter list in an untouched file three directories over.
- Full-Repo Contextual Reviewers: Advanced platforms like Greptile and Claude Code index the entire repository layout, mapping code dependencies, internal APIs, and variable lifecycles. When a developer submits a PR, these tools evaluate the changes against the entire codebase. This architectural depth allows them to catch complex integration bugs that diff-only tools miss entirely, though it requires slightly longer processing times and higher token consumption.
Ultimately, the benchmark results of 2026 demonstrate that the best-performing engineering teams do not rely on a single tool. Instead, they deploy a tiered approach: using fast, inline IDE assistants like Cursor or GitHub Copilot for real-time syntax generation, and pairing them with repo-wide review tools like CodeRabbit or Greptile at the PR stage to guarantee architectural integrity before code ever merges into production.
Detailed Comparison (TABLE)
In 2026, the software development lifecycle (SDLC) is defined by agentic automation. Code review, once a tedious manual bottleneck, has been transformed by highly specialized AI agents that understand semantic intent, track architectural patterns, and catch subtle logical bugs in seconds. Rather than replacing human reviewers, these tools act as tireless first-line defense systems, allowing developers to focus their energy on high-level system design and business logic.
To help engineering leaders choose the right tool for their stack, this section provides a structured, data-driven comparison of the leading AI-powered code review and quality assurance tools on the market.
| Tool | Primary Use Case | Key Capabilities | Pricing (2026 Est.) | Integration Depth |
|---|---|---|---|---|
| CodeRabbit | Automated PR Reviews | Line-by-line feedback, contextual chat, 1-click refactoring suggestions | $12 – $24 / developer / month | GitHub, GitLab, Bitbucket |
| SonarQube (AI) | Security & Clean Code | Deep static analysis, architectural drift detection, AI vulnerability remediation | Enterprise Tier / Custom pricing | CI/CD Pipelines, GitHub, Azure DevOps |
| Greptile | Codebase Understanding | Natural language search over massive repos, structural architecture reviews | Custom / Enterprise tiers | Slack, GitHub, Jira, VS Code |
| GitHub Copilot Enterprise | End-to-End SDLC Agent | Pull request summaries, automated documentation, workspace-wide context | $39 / developer / month | Native to GitHub Ecosystem |
| Claude Code (Anthropic) | Agentic Review & Refactoring | Terminal-based multi-file editing, automated test generation, deep reasoning | Pay-as-you-go via API token usage | Local Terminal, IDEs |
Analyzing the 2026 AI Code Review Landscape
Evaluating these tools requires looking beyond simple syntax checkups to see how deeply they integrate into modern Git workflows and how accurately they interpret code intent.
#### 1. CodeRabbit: The Pragmatic PR Reviewer
As the most widely deployed dedicated AI code review tool in 2026, CodeRabbit excels at lowering pull request cycle times. For $12 to $24 per developer monthly, it delivers contextual, conversational reviews directly inside GitHub or GitLab. Its low false-positive rate is its biggest competitive advantage; it avoids noise by prioritizing critical logical flaws, performance bottlenecks, and security vulnerabilities over minor stylistic preferences.
#### 2. SonarQube (AI-Infused): The Compliance and Security Champion
For enterprise teams managing legacy codebases and strict regulatory frameworks, SonarQube's evolved AI capabilities are indispensable. It blends traditional static application security testing (SAST) with generative AI. When a vulnerability is flagged, SonarQube doesn’t just explain the issue; it writes a secure, context-aware remediation patch that developers can review and merge with a single click.
#### 3. Greptile: Context-Aware Codebase Intelligence
Unlike tools that only look at the immediate diff of a pull request, Greptile indexes the entire codebase. It acts as an expert architectural consultant. When a developer submits code, Greptile reviews it against the design patterns, API structures, and coding standards used across the entire repository, preventing architectural drift in massive, multi-repo organizations.
Customization and Multi-Model Orchestration
A major challenge for enterprise engineering teams in 2026 is avoiding model lock-in. A code review pipeline optimized for Python microservices might require a highly reasoning-capable model like Claude 3.5 Sonnet, while rapid, lightweight reviews on frontend TypeScript changes might be better suited for a faster, cheaper open-source model like Llama 3.
For companies building customized, in-house code review pipelines to protect proprietary intellectual property, off-the-shelf SaaS integrations can feel restrictive. To solve this, developers are increasingly turning to flexible AI infrastructure. Platforms like CallMissed provide robust LLM inference gateways, giving engineering teams access to over 300+ models. By routing code snippets through CallMissed’s high-throughput APIs, organizations can dynamically switch between specialized coding models, ensuring optimal review quality and cost-efficiency without changing their underlying workflow integration.
Ultimately, the choice of tool depends on your team's size and compliance requirements. For turn-key, out-of-the-box PR assistance, CodeRabbit remains the standard. For deeper architectural governance and customized internal agents, leveraging a multi-model API infrastructure is the most future-proof path forward.
Security, Privacy, and Local LLM Compliance

As AI code review tools cement their place in the standard DevOps pipeline in 2026, the discussion has rapidly shifted from "How fast can this tool review my code?" to "Where is my code going, and who has access to it?"
Feeding an entire proprietary codebase into an external Large Language Model (LLM) is a major security risk. For intellectual property (IP) lawyers and Chief Information Security Officers (CISOs), code represents the core value of a technology company. A single leaked API key, hardcoded secret, or proprietary algorithm ingested into a public model’s training pool can lead to catastrophic compliance failures, regulatory fines, and loss of competitive advantage.
To safely adopt AI-assisted workflows, engineering teams must navigate the complex landscape of data governance, security auditing, and local LLM compliance.
The IP Leakage Dilemma and Zero Data Retention (ZDR)
In the early days of generative AI, codebases were routinely used by model creators to train subsequent iterations of their software. By 2026, enterprise standards have matured significantly. Leading code review tools, such as CodeRabbit (the most widely deployed AI code review platform this year) and Claude Code, now operate under strict Zero Data Retention (ZDR) agreements for their enterprise tiers.
Under a ZDR framework:
- No Training on Customer Data: The vendor guarantees that your code, pull request (PR) comments, and metadata are never used to train or fine-tune public or shared models.
- Ephemeral Processing: Code snippets are sent to the LLM API via secure, encrypted channels (TLS 1.3), processed in-memory to generate reviews and suggestions, and immediately deleted from the vendor’s servers.
- Egress Filtering: Advanced code review platforms actively scan outgoing prompts to scrub personally identifiable information (PII), database connection strings, and high-entropy strings (potential secrets) before they ever leave the local network.
For organizations operating under SOC 2 Type II, ISO 27001, or GDPR compliance, verifying a vendor's ZDR policy is the first line of defense. However, because third-party SaaS APIs still require data to leave the perimeter, many risk-averse sectors demand an even higher level of isolation.
Local LLMs: The Shield for Highly Regulated Industries
For financial services, healthcare, and defense sectors, sending code to an external cloud API—even with ZDR—is a non-starter. This constraint has fueled a massive surge in local and self-hosted LLM deployments for code reviews.
The open-weights ecosystem has evolved to a point where local code-specialized models, such as DeepSeek-Coder-V2, Codestral, and Meta's Llama 3.3 series, rival proprietary models in understanding syntax, structure, and system architecture. By deploying these models on-premises or within a private cloud (AWS VPC, Google Cloud VPC, or Azure Private Link), companies can keep 100% of their data within their security perimeter.
This shift toward localized, high-compliance AI environments is a broader trend across the tech industry. For example, in the communication space, platforms like CallMissed provide developers with secure multi-model infrastructure, offering local LLM inference across hundreds of models alongside specialized APIs (like multilingual Speech-to-Text supporting 22 regional Indian languages) to ensure strict data privacy. Just as enterprises utilize CallMissed to process customer communication securely within their compliance boundaries, software engineering teams are setting up private AI inference gateways to run code reviews locally without sacrificing performance.
The benefits of utilizing local LLMs for code reviews include:
- Air-Gapped Execution: Complete isolation from the public internet, preventing any possibility of data exfiltration.
- Custom Fine-Tuning: Organizations can securely fine-tune open-weights models on their own legacy codebases, teaching the AI internal libraries, architectural patterns, and unique style guides without risking IP exposure.
- Zero API Latency & Cost Predictability: Local hosting eliminates variable API call costs and rate limiting, allowing continuous integration (CI) pipelines to run intensive reviews on every commit.
AI-Driven Security Auditing and Vulnerability Detection
Modern AI code review tools do not just check for readability and syntax; they serve as a proactive layer of defense against security vulnerabilities. In 2026, security-first platforms like Checkmarx have integrated deep contextual AI to analyze code submissions, automatically flagging potential exploits before they reach production.
Traditional Static Application Security Testing (SAST) tools are notorious for generating high rates of false positives, which developers often ignore. AI-powered code reviewers solve this by performing context-aware analysis:
- OWASP Top 10 Mitigation: AI reviewers trace data flows through a pull request to identify SQL injections, Cross-Site Scripting (XSS), and broken authorization patterns with highly accurate explanations and inline remediation code.
- Secrets Detection: Advanced AST (Abstract Syntax Tree) parsing combined with LLM pattern recognition helps identify exposed API keys, private certificates, and credentials that traditional regex-based scanners miss.
- Dependency Poisoning & Supply Chain Security: When a developer introduces a new open-source package, the AI scanner reviews the package's reputation, checks for known vulnerabilities (CVEs), and flags anomalous code patterns within the dependency itself.
By catching these issues during the peer review stage, companies can dramatically lower their MTTR (Mean Time to Resolution) for security vulnerabilities.
The Enterprise Compliance Checklist for 2026
When evaluating AI code review tools for your engineering team, use this checklist to ensure compliance with modern security standards:
- [ ] SOC 2 Type II & ISO 27001 Certified: Does the vendor undergo independent third-party audits annually?
- [ ] Explicit "No-Train" Clauses: Is there a legally binding agreement stating your data will never be used for model training?
- [ ] On-Premises / VPC Deployment Option: Can the tool run completely offline or within your private cloud using local weights?
- [ ] Role-Based Access Control (RBAC): Can you restrict who has the authority to run AI reviews on specific highly sensitive repositories?
- [ ] Audit Logging: Does the tool maintain comprehensive logs of all prompts, responses, and actions taken by the AI for compliance auditing?
By prioritizing these security safeguards, organizations can confidently reap the massive productivity gains of AI-driven code reviews without compromising the integrity of their intellectual property.
Pricing & Value (TABLE)
Evaluating the economic viability of AI code review tools in 2026 requires looking beyond the raw sticker price. While seat-based subscriptions remain the legacy standard, engineering organizations are increasingly evaluating tools based on Time-to-Resolution (TTR), PR cycle-time reduction, and contextual accuracy. In 2026, the market has bifurcated into focused pull-request (PR) review specialists and comprehensive, agentic IDE suites.
The 2026 AI Code Review Pricing Landscape
To help engineering leaders calculate their return on investment, the table below breaks down the pricing models, entry points, and primary value drivers for the industry's leading AI-assisted development and code review platforms.
| Tool | Starting Price | Pricing Model | Key Value Metric | Best Suited For |
|---|---|---|---|---|
| CodeRabbit | $12–$24 / dev / month | Flat seat-based | Reviews PRs in seconds, catching bugs & style drift | High-velocity continuous integration |
| GitHub Copilot | $10–$39 / dev / month | Tiered seat subscription | Inline generation and developer velocity | Broad IDE-level autocomplete and chat |
| Cursor | Free / $20 / $40 / dev / month | Tiered + usage limits | Codebase-wide multi-file changes | Developers seeking deep context editing |
| Windsurf | $15 / dev / month | Tiered subscription | Agentic workflow execution and refactoring | Complex architectural code changes |
| Greptile | Enterprise custom rates | API & seat hybrid | Deep repository indexing and query accuracy | Legacy codebase refactoring & compliance |
Decoding the Value: Seat-Based vs. Usage-Based Models
The standard pricing model in 2026 is undergoing a quiet revolution. Traditional software engineering organizations prefer the predictability of seat-based SaaS models, which is why tools like CodeRabbit have achieved massive distribution (at $12 to $24 per developer monthly). CodeRabbit justifies this cost by automating line-by-line feedback during the PR stage, drastically shrinking review backlogs and freeing senior developers for deep-focus architectural work.
However, as agentic AI capabilities have evolved, usage-based pricing (often measured in input/output tokens) is becoming the standard for enterprise-grade deployments. Systems that leverage multiple LLMs for code synthesis, security reviews, and syntax parsing often run into computational bottlenecks.
To address this, forward-thinking infrastructure architects are adopting multi-model API gateways. For instance, platforms like CallMissed allow enterprises to manage their LLM inference pipelines seamlessly, giving developers access to 300+ LLMs without rewriting integration code. This flexibility is vital when balancing cost and accuracy: a fast, cheap model can handle basic syntax validation, while a premium model is reserved for complex logical security analysis.
Calculating ROI: Where Do the Savings Come From?
When building a business case for AI code review tools, engineering leaders should track three key operational metrics:
- Pull Request Cycle Time (PRCT): Traditional peer reviews can stall PRs for 12 to 24 hours. AI code reviewers evaluate submissions in seconds, reducing review feedback loops by up to 70%.
- Review Fatigue Mitigation: By weeding out low-level syntax errors, code styling discrepancies, and simple logic bugs before a human developer even opens the PR, senior engineers can focus on architecture, system design, and security.
- Onboarding Acceleration: Tools with codebase-level indexing (such as Greptile or Cursor's indexer) reduce the ramp-up time for new hires by 30% to 40% by answering contextual questions about legacy code patterns.
Hidden Costs to Keep in Mind
While the baseline monthly subscription of $15 to $40 per user seems marginal, organizations should plan for several hidden expenses:
- Context Window Overages: High-frequency agentic runs that constantly ingest entire repositories can quickly exhaust fast-token quotas, forcing teams to purchase premium usage add-ons.
- Fine-Tuning & Custom Rule Engines: Implementing custom compliance rules or training models on proprietary internal frameworks often requires moving to enterprise tiers, which can cost three to four times more than standard business plans.
- Security & Self-Hosting Premiums: For organizations with strict IP requirements, deploying AI review tools within a private cloud (VPC) or utilizing zero-data retention APIs comes with significant premium licensing costs.
By balancing direct subscription costs against these operational realities, organizations can select an AI code review strategy that maximizes developer throughput while controlling computational overhead.
Pros and Cons (TABLE)
In 2026, the adoption of AI-powered code review tools has shifted from a novelty to an engineering necessity. Engineering teams are no longer choosing whether to use AI in their CI/CD pipelines, but rather which architecture best fits their workflow. The current generation of tools has moved beyond simple pattern-matching linter replacements to fully agentic reviewers capable of understanding multi-file dependencies, system architecture, and runtime implications.
However, selecting the right tool requires balancing raw capability against practical constraints like cost, API latency, security guardrails, and developer fatigue. Below, we break down the leading AI code review and development tools of 2026, highlighting their core strengths, weaknesses, and ideal use cases.
The 2026 AI Code Review Landscape: Pros and Cons
| Tool | Primary Use Case | Key Pros | Key Cons | Cost (2026 Est.) |
|---|---|---|---|---|
| CodeRabbit | Pull Request (PR) automation & review | • Blazing-fast automated reviews<br>• Exceptional context-aware PR summaries<br>• Low false-positive rate | • Can generate minor style noise<br>• Requires direct repository access | $12 – $24 per developer/month |
| Claude Code | CLI-based agentic code refactoring | • Unmatched reasoning & logic<br>• Runs local tests autonomously<br>• Deep architectural awareness | • High token consumption<br>• CLI-first interface lacks visual UI | Pay-per-token (via Anthropic API) |
| GitHub Copilot Enterprise | Inline editing & repository chat | • Seamless IDE & GitHub integration<br>• Excellent boilerplate generation<br>• Enterprise compliance security | • Weak on multi-file PR reviews<br>• Prone to recommending legacy APIs | $39 per user/month |
| Greptile | Codebase-wide context queries | • Indexes massive legacy repositories<br>• Exceptional for migration planning<br>• Highly customizable APIs | • Higher initial setup friction<br>• Slower query-to-answer latency | Custom Enterprise tiering |
| SonarQube (AI-Infused) | Security, compliance, & quality gates | • Traditional static analysis + generative AI<br>• Robust security vulnerability patching<br>• Out-of-the-box compliance | • Heavier system footprint<br>• Less "agentic" than modern tools | Tiered enterprise licensing |
Analyzing the Trade-Offs of Autonomous PR Reviewers
When evaluating modern tools like CodeRabbit—which has emerged as one of the most widely deployed AI code review systems in 2026—the primary value proposition is the drastic reduction in peer-review cycle times. By automatically analyzing pull requests in seconds, these systems catch logical bugs, security flaws, and performance bottlenecks before a human reviewer even opens the PR.
However, this speed comes with a distinct trade-off: developer notification fatigue. Early implementations of AI reviewers often flooded pull requests with dozens of trivial comments about variable naming or minor stylistic preferences. In 2026, the industry has responded by implementing "noise filters," but developers must still spend time fine-tuning the system's rulesets to match their organization's internal styling guidelines.
Furthermore, tools that integrate directly into the version control host (like GitHub or GitLab) require broad read/write permissions. For highly regulated industries, granting an external AI service write-access to proprietary codebases remains a significant security hurdle, forcing teams to opt for self-hosted or highly isolated enterprise instances.
IDE-Integrated Reviewers vs. Terminal Agents
The division between IDE-based assistants (like Cursor and GitHub Copilot) and terminal-based agents (like Anthropic's Claude Code) represents a major architectural split in developer workflows:
- IDE-Integrated Assistants: Tools like Cursor provide a highly visual, fluid environment where code reviews happen inline as you write. They excel at real-time course correction, helping developers refactor functions on the fly. The limitation is scope; they are structurally optimized for localized edits and struggle to maintain a coherent mental model of a sprawling, multi-service architecture during a massive pull request review.
- Terminal-Based Agents: Claude Code and open-source alternatives like Aider operate directly in the CLI, utilizing advanced agentic loops. They don't just point out errors; they run local build commands, execute test suites, read the compiler errors, and iterate on their own code until the tests pass. The downside is cost and control. These autonomous runs can consume millions of context tokens in minutes, resulting in surprise API bills if left unchecked.
Enterprise Considerations: Security, Context, and LLM Flexibility
As organizations scale their AI code review infrastructure, they quickly realize that a single LLM is rarely optimal for every task. A lightweight model might be perfect for checking syntax and formatting, while a massive frontier model is required to review complex cryptographic implementations or system-wide refactors.
This is where backend flexibility becomes critical. Many enterprise platforms are moving away from hardcoded LLM backends toward open-source frameworks and custom API gateways. For organizations that prefer building custom, localized review scripts or orchestration pipelines, leveraging a platform like CallMissed is highly advantageous. With its unified API gateway providing access to over 300+ LLMs, development teams can dynamically route code review queries—sending simple syntax checks to cheaper, faster models while reserving resource-intensive architectural reviews for top-tier frontier models.
Ultimately, the choice of an AI code review tool in 2026 comes down to where you want the feedback loop to live. If you want to catch bugs before commit, IDE-integrated tools like Cursor are unmatched. If you want to automate your team's pull request queue and enforce quality gates asynchronously, dedicated PR reviewers like CodeRabbit represent the gold standard.
Future Outlook: Self-Healing Repositories and Multi-Agent Workflows

In 2026, the traditional boundary between code generation and code review has completely dissolved. We are transitioning rapidly from static, human-gated pull request (PR) workflows to self-healing repositories. In this paradigm, when a bug, security vulnerability, or performance bottleneck is identified, an AI agent does not simply leave a comment; it automatically generates a new branch, writes the corresponding regression tests, implements the fix, and runs the entire CI/CD pipeline.
This evolution is fundamentally changing the velocity of software development, turning code repositories from passive storage units into active, self-maintaining digital organisms.
The Rise of Self-Healing Repositories
A self-healing repository is an ecosystem where the codebase actively monitors, diagnoses, and repairs itself. When an error is detected in production by observability tools, or a vulnerability is flagged during a routine automated scan, specialized AI agents immediately step in. Rather than merely alerting the engineering team with a noisy dashboard notification, the system initiates an autonomous remediation loop.
Leading tools in this domain include CodeRabbit, which in 2026 has established itself as the most widely deployed AI code review platform. Priced accessibly at $12 to $24 per developer monthly, CodeRabbit reviews PRs in seconds, but its true power lies in its deep context-awareness. It doesn't just act as a passive linter; it acts as an active participant in code repair.
When paired with modern security analysis tools like Checkmarx to scan for vulnerabilities, or semantic code search engines like Greptile, the self-healing cycle becomes completely seamless:
- Detection: A security scanner flags a SQL injection risk or an outdated, vulnerable dependency.
- Analysis: The AI agent queries the codebase repository to map out all downstream dependencies.
- Remediation: The agent refactors the vulnerable files, writes new unit tests to verify the change, and opens a pre-validated PR.
- Verification: The automated CI/CD pipeline runs, confirming that the fix is stable and backward-compatible.
Multi-Agent Orchestration in Developer Workflows
The core architectural driver behind self-healing repositories is the transition to multi-agent workflows. Instead of relying on a single monolithic LLM to write, review, and test code, software engineering departments in 2026 are deploying networks of specialized, collaborative AI agents.
By dividing labor, these multi-agent networks ensure that code is checked and validated multiple times before a human developer ever reviews it. Tools like Claude Code, Aider, Windsurf, and Cursor are frequently integrated into these multi-agent pipelines to handle distinct roles:
- The Planner Agent: Analyzes the issue backlog, system architectural diagrams, and user feedback to break down complex engineering requirements into discrete, sequential steps.
- The Coding Agent: Leverages tools like Aider or Windsurf to actively write clean, idiomatic code across multiple directories and files simultaneously.
- The Testing Agent: Analyzes the newly generated codebase to automatically draft robust unit, integration, and end-to-end tests, ensuring code coverage remains high.
- The Review & Guardrail Agent: Powered by platforms like SonarQube AI or CodeRabbit, this agent reviews the output of the Coding Agent against pre-defined organizational standards, security policies, and performance benchmarks.
Scaling AI Agent Infrastructure Globally
This shift toward multi-agent orchestration and dynamic model selection is a micro-reflection of a broader macro-trend sweeping the entire technology landscape. Just as software engineering teams are orchestrating multiple AI agents to manage their codebases, enterprise operations are deploying multi-agent communication systems to interact with customers.
For instance, platforms like CallMissed are enabling businesses to deploy production-ready AI voice agents and WhatsApp chatbots that operate on a similar multi-agent paradigm. CallMissed’s LLM inference gateway grants developers access to over 300+ models, allowing them to route different elements of a conversation to specialized LLMs.
Much like how a developer uses a lightweight, fast model for syntax checks and a heavy-duty model like Claude for complex architectural reasoning, CallMissed allows companies to route real-time customer queries to the optimal model. This infrastructure ensures sub-second latency and supports highly localized communication in 22 regional Indian languages, mirroring the localized context-awareness of today’s best AI coding tools.
Overcoming the Trust and Security Bottleneck
While the promise of self-healing repositories and autonomous agent networks is immense, it introduces unique challenges regarding safety, hallucination mitigation, and architectural drift. To safely harness this power, engineering organizations in 2026 are implementing strict guardrails:
- Policy-as-Code (PAC): Developers define agent limits within project files (such as
.clinerulesor environment-specific configuration files). These policies restrict AI agents from touching sensitive areas of the codebase, such as encryption algorithms or payment gateways, without explicit multi-factor human authorization. - Automated Sanity Sandboxes: Before any agent-generated code is merged, it is executed within temporary, isolated sandboxes. The code must not only pass existing CI/CD test suites but must also undergo automated performance profiling to ensure it does not introduce memory leaks or CPU spikes.
- Human-in-the-Loop (HITL) Orchestration: The human developer’s role has transformed. Instead of writing boilerplate code or manually hunting for syntax errors, developers act as system orchestrators and high-level editors. They approve or reject agent plans, provide course-corrections when an agent gets stuck in a loop, and verify the overall architectural alignment of automated changes.
As we look further into 2026 and beyond, the engineering teams that successfully integrate these self-healing pipelines will experience exponential gains in developer velocity, shifting the focus of human engineering entirely from mechanical implementation to creative system design.
Frequently Asked Questions
What are the best AI code review tools for development teams in 2026?
How do modern AI code review tools differ from traditional static application security testing (SAST) tools?
Are there privacy risks associated with sending proprietary codebase data to AI code review tools?
How can enterprises build and customize their own internal AI code review pipelines?
What is the average pricing model and return on investment (ROI) for enterprise AI code review tools?
Can AI code review tools completely replace human senior developers in the PR process?
Conclusion
As we navigate the software landscape of 2026, AI code review tools have transitioned from optional novelties to indispensable pipeline assets. The modern developer workflow is no longer just about writing code faster; it is about ensuring unparalleled quality, security, and velocity before a single line is merged.
Here are the key takeaways from our comparison:
- Unprecedented Velocity: Industry standard-bearers like CodeRabbit have proven that automated PR reviews can happen in seconds, dramatically reducing cycle times for as little as $12 to $24 per developer monthly.
- Ecosystem Synergy: Developers are successfully pairing specialized security and review platforms like SonarQube and Greptile with agentic IDEs like Claude Code and Cursor to build a highly robust, multi-layered quality assurance stack.
- Proactive Shift-Left Security: Modern AI reviewers go beyond basic syntax checking to flag complex architectural flaws and deep-seated security vulnerabilities early, preventing costly technical debt before it reaches production.
Looking ahead, we are rapidly moving toward an era of truly self-healing codebases. The next wave of innovation will feature AI review agents that do not just diagnose issues but autonomously write, test, and merge the necessary patches under human supervision.
This shift toward intelligent, agentic automation is not limited to developer environments. To explore how AI communication infrastructure is evolving alongside these engineering trends, check out CallMissed — an AI communication platform powering intelligent voice agents, WhatsApp chatbots, and multilingual Speech-to-Text APIs that help businesses scale operations seamlessly.
As AI engines assume the heavy lifting of code quality assurance, how will your development team leverage these newly unlocked hours to build the next generation of software?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.