Gemini 3.1 Pro Benchmarks Explained: ARC-AGI-2 and Beyond

Can an artificial intelligence truly reason, or is it simply a highly sophisticated mirror reflecting the trillions of words it memorized during training?...
Gemini 3.1 Pro Benchmarks Explained: ARC-AGI-2 and Beyond
Can an artificial intelligence truly reason, or is it simply a highly sophisticated mirror reflecting the trillions of words it memorized during training? For years, the AI community has wrestled with this fundamental question, watching models ace standardized tests while failing miserably at simple, novel tasks they had never seen before. The release of Google’s latest reasoning model has shattered this paradigm. In this deep dive, Gemini 3.1 Pro Benchmarks Explained: ARC-AGI-2 and Beyond, we explore how the boundaries of machine intelligence are being fundamentally redrawn.
What makes Gemini 3.1 Pro a watershed moment in AI development is not just another incremental bump in performance; it is a massive leap in core reasoning. The model achieved an astonishing 77.1% score on the ARC-AGI-2 benchmark, more than doubling the abstract reasoning performance of its predecessor, Gemini 3 Pro (representing a 2.5× improvement). This is paired with an outstanding 80.6% on SWE-Bench for resolving real-world software engineering issues and a near-perfect 94.3% on the GPQA (Graduate-Level Google-Proof Q&A) benchmark.
Why do these numbers matter so much right now? Historically, LLMs have relied heavily on pattern extrapolation. If a model encounters a logic puzzle similar to one in its training set, it excels. But when faced with entirely novel environments, traditional architectures often crumble. The ARC-AGI-2 benchmark was specifically designed to resist pattern-matching, forcing models to deduce underlying rules on the fly from visual grids and abstract puzzles. Gemini 3.1 Pro’s ability to score 77.1% on this test signals that we are moving away from mere data memorization and entering the era of genuine, dynamic cognitive synthesis.
Best of all for developers, Google has introduced these unprecedented reasoning capabilities while maintaining the same pricing structure as the previous generation, making advanced cognitive processing economically viable for enterprise-grade applications. This rapid evolution in model intelligence directly empowers practical business applications; for instance, communication infrastructure platforms like CallMissed can now orchestrate these advanced reasoning models alongside custom Speech-to-Text APIs to power highly dynamic, multilingual voice agents that solve complex customer queries in real-time.
In this comprehensive guide, we will break down what these benchmark results actually mean for the future of technology and enterprise integration. Specifically, you will learn:
- The ARC-AGI-2 Litmus Test: Why abstract reasoning is the hardest hurdle for AI, and how Gemini 3.1 Pro cracked the code.
- Behind the Scores: A plain-English breakdown of GPQA, SWE-Bench, and ARC-AGI-2, contrasting Gemini 3.1 Pro against its closest industry rivals.
- The Practical Paradigm Shift: How 2.5× better reasoning changes the landscape for autonomous coding, complex data analysis, and agentic workflows.
- Beyond the Benchmarks: The limitations that still exist, and what the next generation of AI infrastructure must solve to achieve true system-level intelligence.
Whether you are an AI researcher tracking the steady march toward Artificial General Intelligence (AGI) or a developer looking to deploy the most capable reasoning models in production, understanding these benchmarks is crucial. Let’s dive into the data.
Introduction

For years, the artificial intelligence landscape was dominated by a singular race: the pursuit of massive parameter counts and vast web-scale pre-training datasets. Yet, as large language models (LLMs) began to saturate traditional benchmarks like MMLU (Massive Multitask Language Understanding), a glaring limitation emerged. Many systems were not actually "thinking" in the human sense; instead, they were executing highly sophisticated pattern-matching. When faced with entirely novel, out-of-distribution logic puzzles, their performance plummeted. They could recite medical textbooks word-for-word, but they struggled to solve simple spatial logic puzzles they had never seen before.
Google’s release of Gemini 3.1 Pro represents a definitive paradigm shift. Engineered as a reasoning-first model, Gemini 3.1 Pro prioritizes cognitive depth, zero-shot generalization, and mathematical logic over rote memorization. The industry has taken notice, largely due to its unprecedented evaluation scores across three of the most demanding, contamination-resistant benchmarks in existence: ARC-AGI-2, SWE-Bench, and GPQA.
By achieving a staggering 77.1% score on the ARC-AGI-2 benchmark, Gemini 3.1 Pro has more than doubled the reasoning performance of its predecessor, Gemini 3 Pro, marking a 2.5× leap in abstract reasoning capabilities. Combined with an 80.6% on SWE-Bench and a 94.3% on GPQA, this model signals a transition from passive text generators to active, logical problem-solvers.
Shift From Memorization to Mind: Why Traditional Benchmarks Failed
To understand why Gemini 3.1 Pro's benchmark results are causing such a stir, we must first look at the decline of legacy AI evaluations. Early benchmarks were highly vulnerable to data contamination. If a model's training data included the test questions (or variations of them) from public web scrapings, it could easily achieve a near-perfect score through memory retrieval rather than genuine intelligence.
To combat this, the AI research community shifted toward benchmarks that are explicitly designed to resist pattern-matching:
- ARC-AGI-2 (Abstraction and Reasoning Corpus): Created by François Chollet, this benchmark tests a model's ability to acquire new skills and solve visual, grid-based logic puzzles it has never encountered before. It is widely considered the ultimate test of "general" intelligence because it cannot be solved by memorizing code or text.
- SWE-Bench: A rigorous, agentic benchmark that forces models to resolve real-world GitHub issues in complex, multi-file software repositories. It tests whether an AI can act as a functional software engineer.
- GPQA (Graduate-Level Google-Proof Q&A): A dataset of incredibly difficult, multiple-choice questions written by domain experts in physics, biology, and chemistry. The questions are specifically framed so that they cannot be answered by a simple Google search or basic pattern matching.
Gemini 3.1 Pro’s dominant performance across this trio of evaluations proves that Google has successfully moved past simple next-token prediction, unlocking a level of cognitive architecture that can reason, plan, and execute.
The Executive Summary: Gemini 3.1 Pro’s Core Metrics
| Benchmark | Gemini 3.1 Pro Score | What It Measures | Why It Matters |
|---|---|---|---|
| ARC-AGI-2 | 77.1% | Zero-shot visual logic and abstract reasoning | Proves the model can learn novel rules on the fly without prior training. |
| SWE-Bench | 80.6% | End-to-end software engineering problem-solving | Demonstrates autonomous coding, debugging, and multi-file code integration. |
| GPQA | 94.3% | Ultra-complex, graduate-level scientific reasoning | Validates high-level logical precision in scientific and technical domains. |
What Abstract Reasoning Means for Real-World Workflows
For developers, product managers, and enterprise leaders, these benchmark scores are not just abstract academic victories; they translate directly into more resilient, autonomous, and cost-effective production systems.
When an AI model possesses high abstract reasoning, it can handle unexpected user inputs and edge cases without failing. In customer service, operations, and software development, a model with a 77.1% ARC-AGI-2 score is vastly more capable of navigating fluid, non-linear tasks. Instead of getting stuck when a user deviates from a standard script, the model can deduce the user's underlying intent and formulate a logical path forward.
This level of dynamic reasoning is precisely what makes modern AI communication platforms so powerful. For instance, platforms like CallMissed allow enterprises to deploy sophisticated AI voice agents and WhatsApp chatbots that handle complex, multi-turn customer calls. By utilizing state-of-the-art reasoning models like Gemini 3.1 Pro behind the scenes, CallMissed’s infrastructure ensures that automated agents don't just follow static decision trees. Instead, they can comprehend nuanced customer issues, reason through troubleshooting steps in real-time, and resolve complex queries natively in up to 22 Indian languages.
Furthermore, because Google has kept the pricing structure of Gemini 3.1 Pro identical to its predecessor, developers can access this massive leap in logical processing without facing ballooning operational costs. It democratizes high-tier cognitive processing, making advanced agentic workflows viable for businesses of all sizes.
What to Expect in This Deep-Dive Series
In this comprehensive, multi-part guide, we will break down Gemini 3.1 Pro’s performance, examining what these scores actually mean for the future of AI development. Here is a road map of what we will cover:
- Decoding the ARC-AGI-2 Breakthrough: We will dissect the mechanics of Chollet’s abstraction corpus, look at sample puzzles, and explain why a 77.1% score is a massive milestone on the road to AGI.
- SWE-Bench and Agentic Coding: An in-depth look at how Gemini 3.1 Pro operates as an autonomous developer, analyzing its ability to locate bugs, edit codebases, and push functional PRs.
- GPQA and Cognitive Precision: We will explore how the model handles graduate-level scientific problems and what this means for research, medical analysis, and legal tech.
- Architectural Secrets & Pricing Fit: A look under the hood at how Google achieved these results, its context window capabilities, and how developers can cost-effectively integrate these models into production environments today.
Background & Context: The Evolution of AI Reasoning
For years, the progress of Large Language Models (LLMs) was defined by scale. The prevailing belief was that feeding more parameters and more web-scraped data into a transformer network would naturally yield human-level intelligence. However, as models grew from billions to trillions of parameters, researchers hit a fundamental bottleneck: the distinction between knowledge retrieval and genuine reasoning.
Early LLMs excelled at pattern matching. They memorized massive code repositories, encyclopedias, and math textbooks, allowing them to ace standardized tests and recall obscure facts instantly. Yet, when faced with entirely novel situations—scenarios that could not be solved by interpolating training data—these models failed. They lacked "fluid intelligence," the human capacity to adapt to new rules and solve unfamiliar problems on the fly.
The launch of Gemini 3.1 Pro represents a watershed moment in this evolution. By achieving an extraordinary 77.1% score on ARC-AGI-2, Google has demonstrated that AI is transitioning from static memorizers to dynamic problem solvers.
From Pattern Matching to Fluid Intelligence
To understand the significance of this shift, we must look at how AI historically processed information. Traditional deep learning relies heavily on crystallized intelligence—the ability to use skills, knowledge, and experience. When an LLM translates a sentence or writes a standard Python script, it retrieves and reassembles patterns it has seen millions of times.
True reasoning, however, requires fluid intelligence. This is the ability to analyze novel problems, identify underlying logical rules, and extrapolate solutions without prior exposure.
- Static Memorization: Relying on existing templates, datasets, and historical training documentation to generate a likely response.
- Active Deduction: Analyzing a completely new set of constraints, testing hypotheses internally, and synthesizing a novel strategy to solve a unique problem.
As enterprises attempt to deploy AI in complex, unpredictable environments—such as autonomous software engineering or real-time communication routing—static pattern matching is no longer sufficient.
Why Traditional Benchmarks Failed to Measure Real Reasoning
For a long time, the AI community relied on benchmarks like MMLU (Massive Multitask Language Understanding) or GSM8k (grade-school math) to evaluate intelligence. However, as the web became saturated with benchmark questions, models began to experience "data contamination." They weren't necessarily getting smarter; they were just memorizing the test questions.
Furthermore, traditional benchmarks did not measure a model's ability to learn on the job. Once trained, a standard LLM's weights are frozen. To solve a new type of task, it had to rely entirely on few-shot prompting, which often failed when the underlying logic of the task shifted.
This benchmark saturation created an illusion of near-human competence. Models scored in the high 90s on academic tests, yet struggled with basic, novel logic puzzles. The industry desperately needed a benchmark that resisted rote memorization and tested a model's capacity to synthesize new rules from scratch.
Enter ARC-AGI-2: The Ultimate Test of Adaptability
Created by François Chollet, the Abstraction and Reasoning Corpus (ARC) was specifically designed to be immune to memorization. The updated ARC-AGI-2 benchmark presents the model with unique, visual grid puzzles that it has never encountered in its training data.
To solve an ARC-AGI-2 puzzle, a model must:
- Analyze a few visual examples showing an input grid transforming into an output grid.
- Deconstruct the hidden rules governing the transformation (e.g., "if a blue square touches a red circle, gravity pulls the green blocks downward").
- Apply those newly deduced rules to a completely novel test input grid.
Because the rules change with every single puzzle, pattern-matching is useless. A model cannot brute-force its way to a correct answer using statistical correlation alone.
While its predecessor, Gemini 3 Pro, struggled to cross the chasm of abstract reasoning, Gemini 3.1 Pro achieved a stunning 2.5× improvement, jumping to 77.1% on ARC-AGI-2. When paired with its performance on other highly demanding reasoning benchmarks—such as scoring 80.6% on SWE-Bench (evaluating real-world software engineering) and 94.3% on GPQA (graduate-level Google-proof science questions)—it is clear that we have entered a new era of AI capability.
The Infrastructure Challenge: Scaling Reasoning in Production
This evolution in AI reasoning changes how developers build and deploy applications. When models transition from fast, low-cost text predictors to deep-thinking reasoning engines, the underlying infrastructure must adapt. Deep reasoning often requires multi-step thought processes, agentic loops, and programmatic tool-calling, which dramatically increases API call complexity.
For developers looking to integrate these advanced reasoning capabilities into commercial applications, managing multiple models is critical. Platforms like CallMissed address this directly. By providing an unified LLM inference gateway with access to over 300 models, CallMissed enables engineering teams to seamlessly switch between ultra-fast models for basic interactions and highly capable reasoning engines—like Gemini 3.1 Pro—when deep problem-solving is required.
As the industry moves beyond simple chatbots toward agentic systems that can autonomously resolve customer issues, write production-grade code, and manage workflows, the ability to orchestrate these different tiers of intelligence dynamically will separate market leaders from the rest.
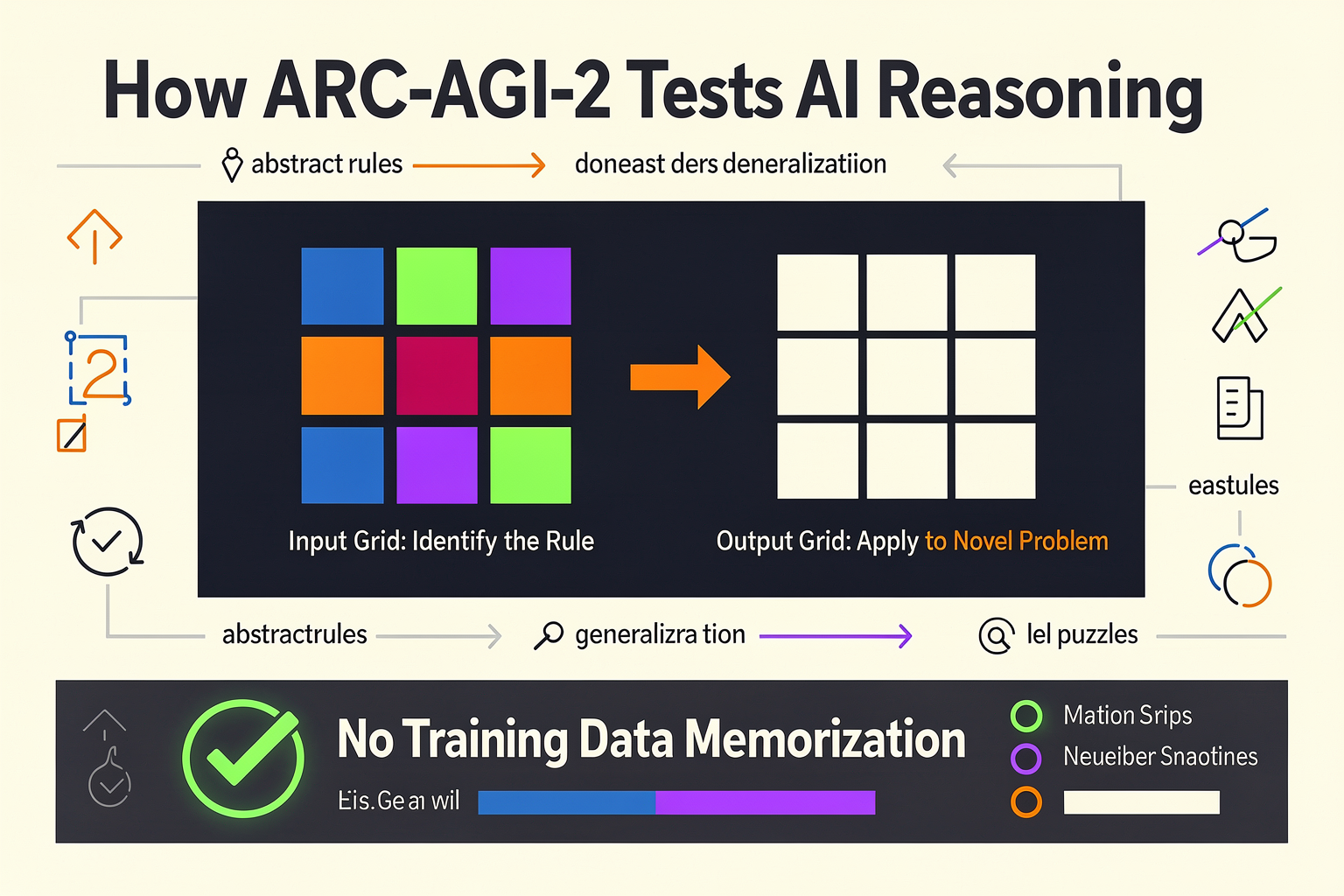
What is ARC-AGI-2 and Why It Matters
The Crisis of AI Evaluation: Memorization vs. Generalization
For years, the artificial intelligence industry has relied on a standard suite of benchmarks to measure the capabilities of large language models (LLMs). Metrics like MMLU (Massive Multitask Language Understanding), GSM8K (grade-school math), and HumanEval (coding proficiency) have long served as the industry yardsticks. However, as models have grown larger and training datasets have expanded to encompass nearly the entire public internet, these traditional benchmarks have begun to lose their utility.
The core issue is data contamination. Because LLMs are trained on massive scrapes of web data, they frequently encounter test questions, or highly similar variations of them, during their pre-training phases. When an AI scores 95% on a standardized test, is it demonstrating genuine intelligence, or is it simply retrieving a sophisticated, compressed version of an answer key it has already seen? This is the difference between crystallized intelligence (recalling acquired knowledge) and fluid intelligence (the ability to reason and solve novel problems without prior training).
To solve this evaluation crisis, AI researcher François Chollet created the Abstraction and Reasoning Corpus (ARC). Its successor, ARC-AGI-2, is specifically engineered to be entirely resistant to pattern-matching and memorization. It does not test what a model knows; instead, it tests how efficiently a model can learn new skills on the fly.
Understanding the Mechanics of ARC-AGI-2
Unlike text-based benchmarks that ask multiple-choice questions or request code generation, ARC-AGI-2 utilizes visual, grid-based puzzles. A typical ARC-AGI-2 task consists of a small number of demonstration pairs (usually 2 to 3 examples) showing an "input grid" and a corresponding "output grid."
These grids are made of colored pixels (typically a 30x30 matrix or smaller, containing up to 10 different colors). The transition from the input grid to the output grid is governed by a logical, geometric, or spatial rule. The model is presented with a final, unseen test input grid and must generate the correct output grid by deducing the secret rule.
To successfully solve an ARC-AGI-2 puzzle, a model must grasp fundamental human concepts that are rarely explicitly mapped out in text corpora:
- Objecthood: Recognizing that a cluster of contiguous colored pixels constitutes a single "object" that can move, rotate, or scale.
- Symmetry and Rotation: Understanding reflections, translations, and geometric rotations.
- Goal-Directedness: Deducing that a line is attempting to connect two objects, or that a shape is acting as a container.
- Basic Topology: Understanding concepts of "inside vs. outside," "boundaries," and "connectivity."
Because the exact rules and visual patterns used in ARC-AGI-2 are entirely novel and kept strictly private, models cannot rely on their pre-existing training weights to predict the correct output. They must perform active, in-context reasoning to construct a mental model of the puzzle's logic, verify that logic against the training examples, and apply it to the test case.
Why ARC-AGI-2 is the True Gatekeeper of AGI
The transition from the original ARC benchmark to ARC-AGI-2 represents a major step forward in AI evaluation. As developers realized the importance of Chollet’s benchmark, some open-source models began to inadvertently overfit to the public ARC dataset. ARC-AGI-2 introduces highly guarded, completely new test instances to ensure that a model’s performance is a reflection of true abstract reasoning, rather than algorithmic optimization tailored to the benchmark's specific style.
ARC-AGI-2 matters because it measures generalization. In computer science, generalization is categorized into two types:
- Interpolation: The ability to handle novel variations of familiar data (e.g., identifying a breed of dog the model hasn't seen before, but within a class of images it has seen millions of times).
- Extrapolation: The ability to handle entirely unfamiliar scenarios that lie completely outside the training distribution.
Most LLMs excel at interpolation. However, human-level intelligence is characterized by extrapolation—our ability to adapt to a crisis, learn a new tool in minutes, or navigate an unfamiliar city. By forcing models to perform extrapolation, ARC-AGI-2 acts as the ultimate litmus test for Artificial General Intelligence (AGI).
Decoding Gemini 3.1 Pro's 77.1% Performance
In the context of this notoriously difficult benchmark, Google's newly launched Gemini 3.1 Pro achieved an outstanding score of 77.1% on ARC-AGI-2.
To appreciate the magnitude of this achievement, one must look at the historical progression of LLM scores on this benchmark. For years, state-of-the-art models struggled to break past the 20% to 30% mark, often performing worse than a human child. Gemini 3.1 Pro’s score of 77.1% represents a massive 2.5× improvement over its predecessor, Gemini 3 Pro (and Gemini 1.5 Pro).
This leap indicates that Google has successfully moved beyond basic pattern retrieval. Gemini 3.1 Pro utilizes an advanced reasoning architecture that allows it to execute "System 2" thinking—the slow, deliberate, and logical validation of hypotheses. When confronted with an ARC puzzle, the model does not simply generate a single token output; instead, it generates internal hypotheses, writes temporary code to test those hypotheses, checks the output against the visual examples, and refines its strategy until it finds a logically consistent rule.
From Abstract Puzzles to Real-World Enterprise Value
While solving color-grid puzzles may seem academic, the cognitive architecture required to excel at ARC-AGI-2 directly translates to solving high-stakes, unpredictable real-world challenges.
In enterprise environments, AI agents are constantly confronted with situations that do not match their training manuals. A customer support bot, for example, frequently encounters users who present highly complex, non-linear problems, speak in colloquialisms, or change their minds mid-conversation. Traditional, rigid LLMs fail in these scenarios because they cannot adapt to novel context shifts.
For businesses looking to operationalize these cognitive breakthroughs, platforms like CallMissed offer the necessary communication infrastructure. CallMissed’s AI communication platform integrates a multi-model gateway with access to over 300+ LLMs, enabling enterprises to build highly adaptive AI voice agents and WhatsApp chatbots.
By leveraging cutting-edge models like Gemini 3.1 Pro, a CallMissed-powered voice agent doesn't just read from a static script. It actively reasons through the customer’s unique, unpredictable issues in real-time—even natively handling complex multilingual queries across 22 regional Indian languages. When an AI possesses genuine fluid intelligence, it can dynamically adapt to conversational detours, ensuring that customer inquiries are resolved successfully without requiring constant human intervention.
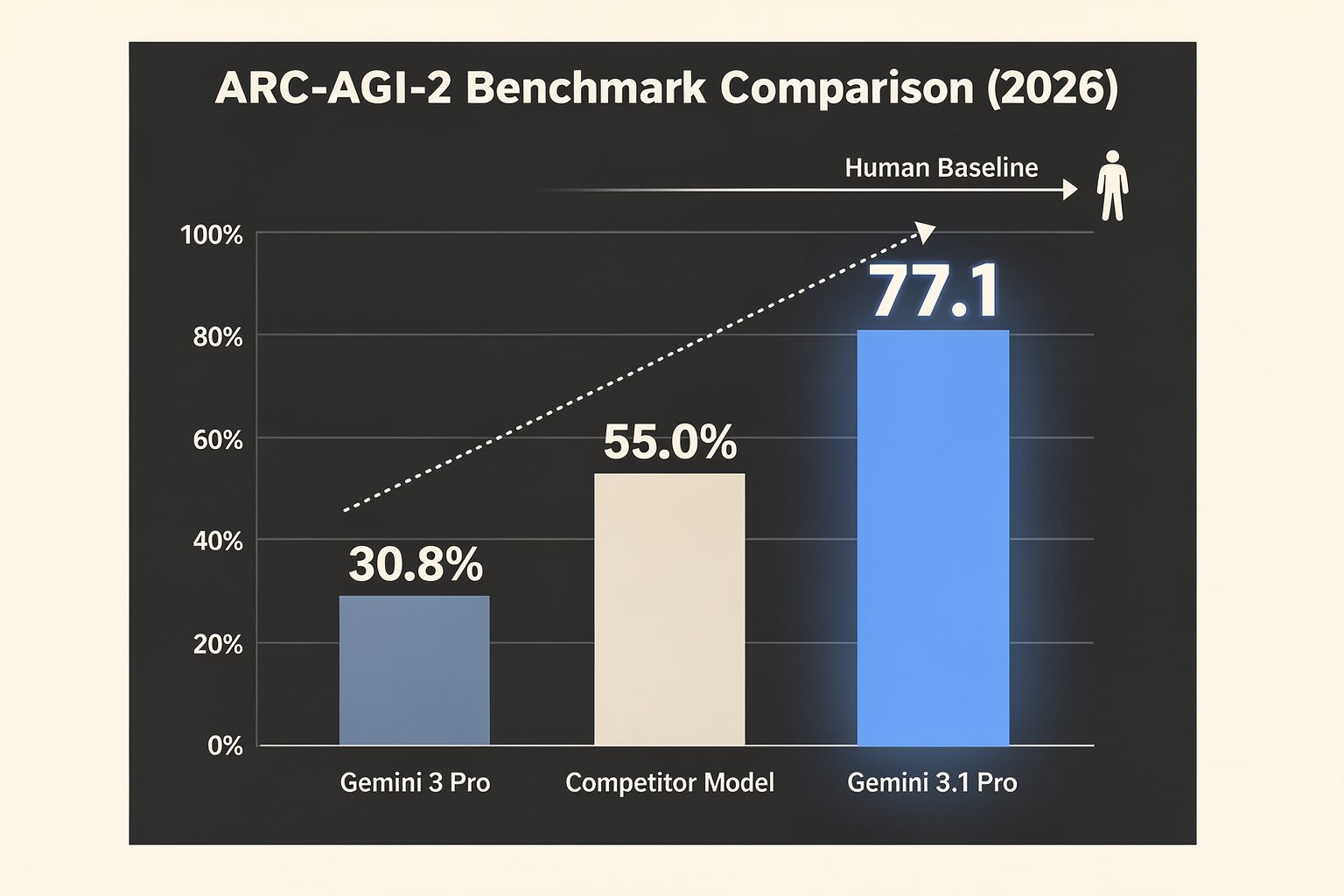
Key Developments: Gemini 3.1 Pro Benchmark Scores (TABLE)
To understand the leap forward that Google’s Gemini 3.1 Pro represents, we must look beyond standard marketing terminology and analyze the hard data. AI evaluation has shifted from simple memorization tests to complex, "contamination-proof" benchmarks designed to measure actual cognitive synthesis.
By testing Gemini 3.1 Pro against challenging evaluations like ARC-AGI-2, SWE-Bench, and GPQA, researchers have revealed a dramatic performance delta compared to its predecessor. This iteration does not simply offer incremental speed or context window updates; it fundamentally redefines the reasoning baseline for mid-tier enterprise models.
The table below outlines the core benchmark results for Gemini 3.1 Pro, contrasting its performance with the previous generation and demonstrating how these metrics translate to operational business value.
| Benchmark | Gemini 3.1 Pro Score | Predecessor (3 Pro) | Primary Evaluation Focus | Real-World Translation |
|---|---|---|---|---|
| ARC-AGI-2 | 77.1% | ~30.8% | Abstract visual logic & novel rule deduction | Adaptive AI agents, handling unique edge cases |
| SWE-Bench | 80.6% | ~49.5% | Repository-level software engineering tasks | Autonomous codebase debugging & patch creation |
| GPQA | 94.3% | ~84.2% | Graduate-level scientific Q&A (physics, chemistry) | Deep technical research & complex decision-making |
| MMLU-Pro | 88.4% | ~78.1% | Multistep academic & professional reasoning | Multidisciplinary expert workflows |
Deep Dive: Breaking Down the Core Benchmarks
#### 1. ARC-AGI-2: The Ultimate Test of General Intelligence
The Abstraction and Reasoning Corpus (ARC-AGI-2) is widely regarded as one of the most rigorous tests of true machine intelligence. Unlike standard benchmarks, which can be gamed through memorization or training-set contamination, ARC-AGI-2 presents the model with entirely novel grid-based visual puzzles. To solve them, an AI must deduce underlying rules from only a handful of examples and apply them to a brand-new grid.
Gemini 3.1 Pro’s score of 77.1% is a massive milestone, representing a 2.5× improvement over Gemini 3 Pro. This score indicates that the model is transitioning from a statistical text predictor to a system capable of actual abstract reasoning.
When platforms like CallMissed orchestrate complex conversational flows, having an underlying model with robust abstract reasoning means voice agents can handle unpredictable human digressions and unstructured speech without losing context or breaking character. This reasoning capability is what allows next-generation voice agents to transition from rigid scripts to fluid, human-like problem solvers.
#### 2. SWE-Bench: From Code Completion to Autonomous Engineering
While coding assistants have long been able to generate boilerplate functions, resolving complex, repository-wide bugs is an entirely different challenge. SWE-Bench tests an AI's ability to ingest a massive, multi-file software codebase, locate a specific bug described in a GitHub issue, write a patch, and verify that all unit tests pass.
An 80.6% score on SWE-Bench proves that Gemini 3.1 Pro can act as a highly competent autonomous agent. It can read, comprehend, and edit thousands of lines of code across multiple files. For engineering teams, this translates directly to automated pull request triage, self-healing codebases, and a massive reduction in developer time spent on routine bug fixing.
#### 3. GPQA: Outperforming Human Experts
The Graduate-Level Google-Proof Q&A (GPQA) dataset features incredibly difficult questions in biology, physics, and chemistry. Designed by domain experts, these questions are specifically constructed so that they cannot be easily answered with a quick web search. Even human PhDs in corresponding fields score roughly 81% on this benchmark.
Gemini 3.1 Pro’s score of 94.3% demonstrates a near-expert grasp of highly specialized academic and professional domains. This level of performance makes the model incredibly valuable for highly regulated industries like healthcare, legal tech, and financial analysis, where accuracy and deep domain knowledge are non-negotiable.
What This Means for Enterprise Deployment
The most notable aspect of Gemini 3.1 Pro's benchmark dominance is its cost-to-performance efficiency. Typically, a 2x leap in reasoning capabilities requires scaling up to a massive, expensive "Ultra" class model. Google has delivered this intelligence leap while keeping the pricing identical to the standard Gemini 3 Pro.
For enterprises utilizing CallMissed to deploy LLM-powered systems, the ability to hot-swap Gemini 3.1 Pro into existing workflows using our unified API (supporting 300+ LLMs) provides an immediate capability boost. Businesses can now deploy voice agents and automated chatbots that resolve complex customer inquiries, generate code, and synthesize highly technical data at a fraction of the cost previously required for state-of-the-art cognitive performance.
In-Depth Analysis: Behind the 77.1% ARC-AGI-2 Breakthrough
To truly appreciate Google’s achievement with Gemini 3.1 Pro, one must look beyond standard conversational benchmarks. While standard LLM evaluations test memory retrieval and syntactic fluency, the Abstraction and Reasoning Corpus (ARC-AGI-2) is specifically engineered to measure an AI's capacity for genuine, fluid intelligence.
Gemini 3.1 Pro’s score of 77.1% on the ARC-AGI-2 benchmark is not just an incremental upgrade; it represents a monumental 2.5× performance leap over Gemini 3 Pro. This leap signals a fundamental shift in how large language models navigate novel problem-solving environments.
Demystifying ARC-AGI-2: The Ultimate Test of General Intelligence
Created by François Chollet, the ARC benchmark is widely regarded as the gold standard for measuring an AI’s ability to acquire new skills on the fly. Unlike traditional benchmarks that draw from massive pre-training datasets, ARC-AGI-2 is explicitly designed to resist pattern-matching.
The benchmark presents the model with visual, grid-based puzzles. Each puzzle provides only a few input-output examples (typically 3 to 5 grids) demonstrating a hidden rule—such as rotating a shape, filling a container, or sorting objects by size. The model must deduce this rule and apply it to a completely novel test input.
ARC-AGI-2 is notoriously difficult for LLMs for several reasons:
- Zero Memorization: The puzzles rely on core human concepts (such as object permanence, basic geometry, and symmetry) that cannot be solved by memorizing code repositories or Wikipedia articles.
- Out-of-Distribution Logic: The rules governing the grids are entirely novel. The model cannot rely on semantic associations or statistical next-token prediction to guess the output.
- Strict Scoring: There is no partial credit. To pass a test, the model must output the exact pixel-perfect grid configuration.
Previously, even state-of-the-art models struggled to surpass the 30% to 40% threshold, often failing when subtle logical twists were introduced. Gemini 3.1 Pro’s jump to 77.1% represents a historic narrowing of the gap between machine learning and human-like abstract reasoning.
Analyzing the Leap: From Pattern Matching to Active Synthesis
The difference between Gemini 3 Pro and Gemini 3.1 Pro highlights a transition from passive retrieval to active synthesis. When an LLM relies solely on static weights to output answers, it behaves like a system operating on pure intuition. Gemini 3.1 Pro, however, utilizes advanced execution loops to "think" through a problem before generating a final answer.
To achieve a 77.1% success rate, Gemini 3.1 Pro relies on three core computational pillars:
- Hypothesis Generation and Testing: Instead of guessing a solution in a single forward pass, the model generates multiple potential rules explaining the input-output examples.
- Internal Code Execution: The model writes and runs internal code to verify whether its hypothesized rules hold true across the training examples before applying them to the final test grid.
- Iterative Self-Correction: When a test run fails to match the expected output format, the model analyzes the error trace, adapts its logical framework, and tries a different algorithmic approach.
This dynamic processing mirrors how a software engineer debugs code. By combining language-based logic with iterative runtime evaluation, Gemini 3.1 Pro transitions from a simple predictor to an active cognitive engine.
What 77.1% ARC-AGI-2 Means for Production Workflows
For enterprise developers and architects, a high ARC-AGI-2 score is more than an academic achievement—it is a metric of real-world reliability. Standard LLMs often fail in production when they encounter edge cases that lie outside their training data. A model with high abstract reasoning capabilities, however, can navigate unpredictable user behavior, system anomalies, and unstructured tasks without manual intervention.
In practice, this advanced reasoning power unlocks several critical capabilities:
- Adaptive API Integration: When connecting external systems, a high-reasoning model can autonomously map mismatched schemas or handle unexpected JSON payloads without throwing errors.
- Dynamic Plan Formulation: Instead of following rigid, pre-scripted agent trees, the model can assess a user's multi-step request, identify missing dependencies, and execute a custom workflow on the fly.
- Deterministic Code Generation: The ability to mentally simulate execution paths translates to highly accurate code generation, particularly in niche frameworks or proprietary internal APIs.
For businesses looking to operationalize these cutting-edge capabilities, infrastructure flexibility is key. Platforms like CallMissed allow developers to seamlessly orchestrate these heavy-duty reasoning workflows. Through CallMissed’s multi-model API gateway—which supports over 300 LLMs—teams can route complex, reasoning-heavy tasks to Gemini 3.1 Pro while keeping standard operational tasks bound to faster, cost-efficient models.
Ultimately, Gemini 3.1 Pro's breakthrough on ARC-AGI-2 proves that AI is moving past simple information retrieval. We are entering an era of systemic problem-solvers that can think, verify, and adapt to the unexpected in real time.
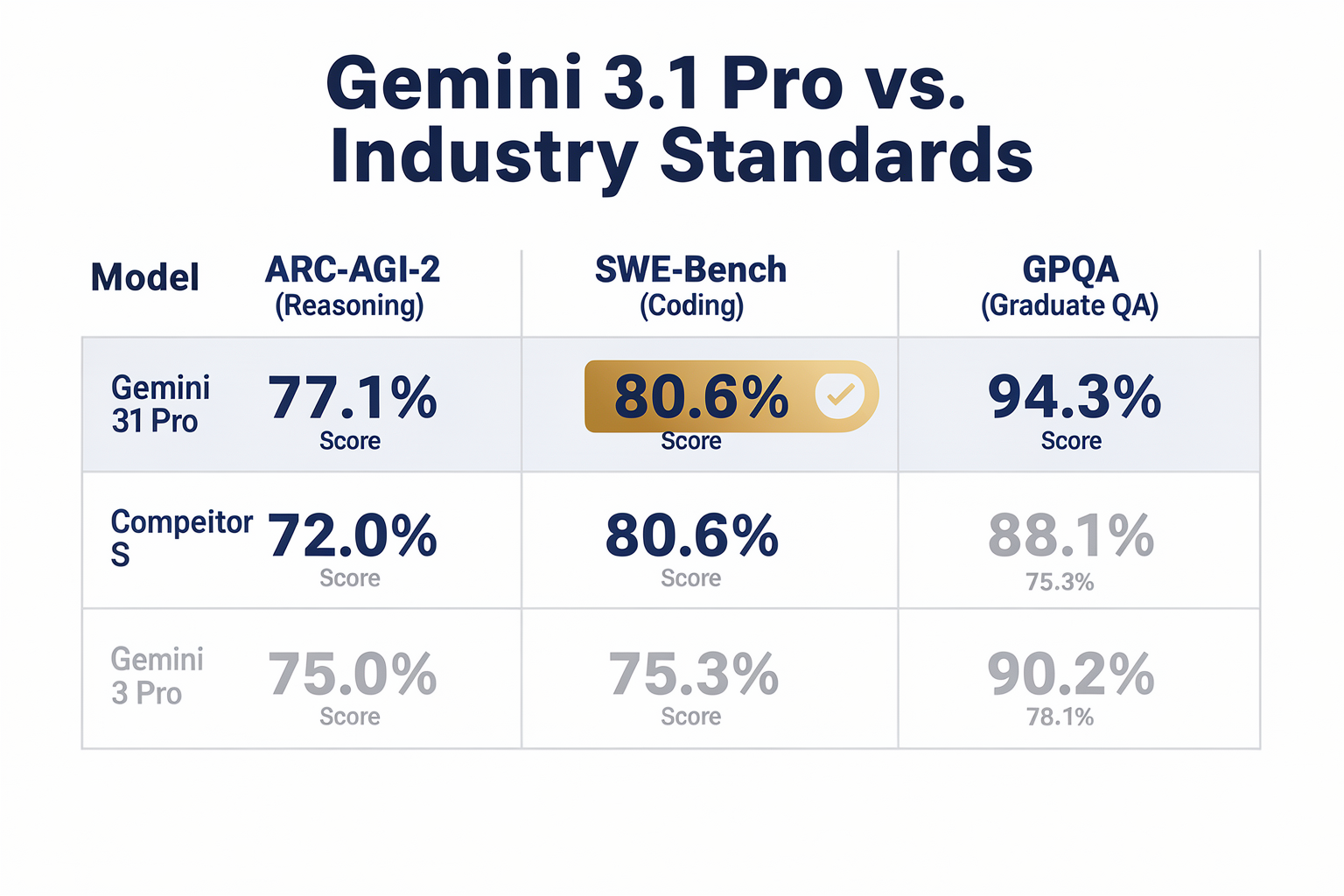
Comparing Gemini 3.1 Pro to Predecessors and Competitors
To truly appreciate the engineering leap represented by Gemini 3.1 Pro, we must evaluate it not in a vacuum, but against the backdrop of its immediate predecessor, Gemini 3 Pro, and the current crop of rival frontier models. Historically, generational upgrades in LLMs yielded incremental performance gains—typically in the realm of 5% to 10% on standardized multiple-choice benchmarks. Gemini 3.1 Pro breaks this mold entirely, particularly in areas requiring rigorous logic, system synthesis, and novel problem-solving.
The Generational Leap: Gemini 3.1 Pro vs. Gemini 3 Pro
The comparison between Gemini 3.1 Pro and Gemini 3 Pro is less of an incremental step and more of a architectural evolution. The most telling indicator of this shift is the model's performance on the ARC-AGI-2 (Abstraction and Reasoning Corpus) benchmark.
- Abstract Reasoning Explosion: Gemini 3.1 Pro achieved a groundbreaking score of 77.1% on ARC-AGI-2. Compared to Gemini 3 Pro, this represents a 2.5× improvement in abstract reasoning capabilities. While its predecessor struggled to solve novel visual grid puzzles that could not be solved by simple pattern-matching, Gemini 3.1 Pro demonstrates an unprecedented ability to deduce underlying rules on the fly.
- The Price-to-Performance Paradox: Typically, a leap of this magnitude in reasoning depth corresponds to an increase in computational overhead, resulting in higher API costs for developers. However, Google has positioned Gemini 3.1 Pro at the exact same price point as Gemini 3 Pro. This makes it a highly disruptive release for production environments, offering over double the reasoning power at zero additional cost.
- Context Window and Recall: While Gemini 3 Pro established Google’s lead in handling massive context windows, Gemini 3.1 Pro refines this capability by ensuring that "needle-in-a-haystack" retrieval is paired with active reasoning. It is no longer just about retrieving a fact from a million tokens; it is about reasoning across those tokens to solve highly complex, multi-step queries.
Benchmarking Against the Frontier: Gemini 3.1 Pro vs. Competitors
When stacked against external frontier models from OpenAI and Anthropic, Gemini 3.1 Pro shifts the competitive dynamics across three critical benchmarks: ARC-AGI-2, SWE-Bench, and GPQA.
#### 1. ARC-AGI-2 (Abstract Reasoning)
The ARC-AGI-2 benchmark, originally designed by François Chollet, is widely considered the ultimate test for actual artificial general intelligence because it resists rote memorization. It presents the model with grid-based visual tasks it has never seen before, requiring the agent to learn a new rule from just a few examples.
- Gemini 3.1 Pro’s 77.1% score places it at the absolute vanguard of LLM reasoning.
- Most contemporary competitor models from rival labs have hovered in the 30% to 50% range on ARC-AGI tests, as they rely heavily on pattern-matching rather than active conceptual synthesis. Gemini 3.1 Pro's ability to nearly double the reasoning performance of previous-generation baselines signals a transition from "retrieval engines" to "reasoning engines."
#### 2. SWE-Bench (Real-World Software Engineering)
SWE-Bench evaluates an AI model's ability to resolve actual, complex software bugs and issues pulled from real GitHub repositories. This is not a theoretical coding test; it requires the agent to understand a massive, pre-existing codebase, find the bug, write a patch, and ensure it does not break existing systems.
- Gemini 3.1 Pro scores an astonishing 80.6% on SWE-Bench.
- This score establishes it as an elite tier-one tool for autonomous software engineering. Competitor models, which often struggle with long-context codebase comprehension and multi-file code dependencies, find it incredibly difficult to maintain high execution accuracy on SWE-Bench without hallucinating functions or losing track of the system architecture.
#### 3. GPQA (Graduate-Level Google-Proof Q&A)
GPQA is a benchmark featuring extremely difficult, graduate-level questions in physics, biology, and chemistry. These questions are intentionally designed to be "Google-proof," meaning they cannot be answered by a simple web search or by regurgitating training data.
- Gemini 3.1 Pro achieved a score of 94.3% on GPQA.
- This near-perfect score demonstrates that Gemini 3.1 Pro is not just an abstract puzzle-solver; it possesses deep, domain-specific expertise. It can synthesize advanced academic concepts and execute complex mathematical and logical deductions that match or exceed human PhD-level accuracy in controlled test environments.
Real-World Implications for Enterprise Workflows
For enterprises looking to deploy production-grade AI, these benchmarks translate directly into operational reliability. When a model possesses a 94.3% score on GPQA and an 80.6% score on SWE-bench, it means the rate of costly hallucinations drops precipitously in high-stakes environments like financial auditing, legal document analysis, and automated coding.
Moreover, the massive reasoning upgrade in Gemini 3.1 Pro makes it an exceptional engine for multi-agent workflows. Instead of writing rigid, deterministic code to guide an AI through a complex business process, developers can rely on Gemini 3.1 Pro to dynamically assess situations, deduce rules, and correct its own course when encountering unexpected errors.
For organizations looking to integrate these bleeding-edge capabilities into their customer-facing or internal systems, leveraging an advanced infrastructure provider is essential. Platforms like CallMissed make it incredibly simple to deploy and manage these frontier models. With CallMissed’s LLM inference gateway, developers can gain unified access to over 300+ LLMs, allowing teams to instantly route complex reasoning tasks to Gemini 3.1 Pro while utilizing specialized models for simpler tasks. Whether you are building highly autonomous AI voice agents that need to solve customer queries on the fly, or setting up multilingual WhatsApp chatbots that require deep context understanding, CallMissed provides the robust infrastructure required to put Gemini 3.1 Pro's 2.5× reasoning power into active production.
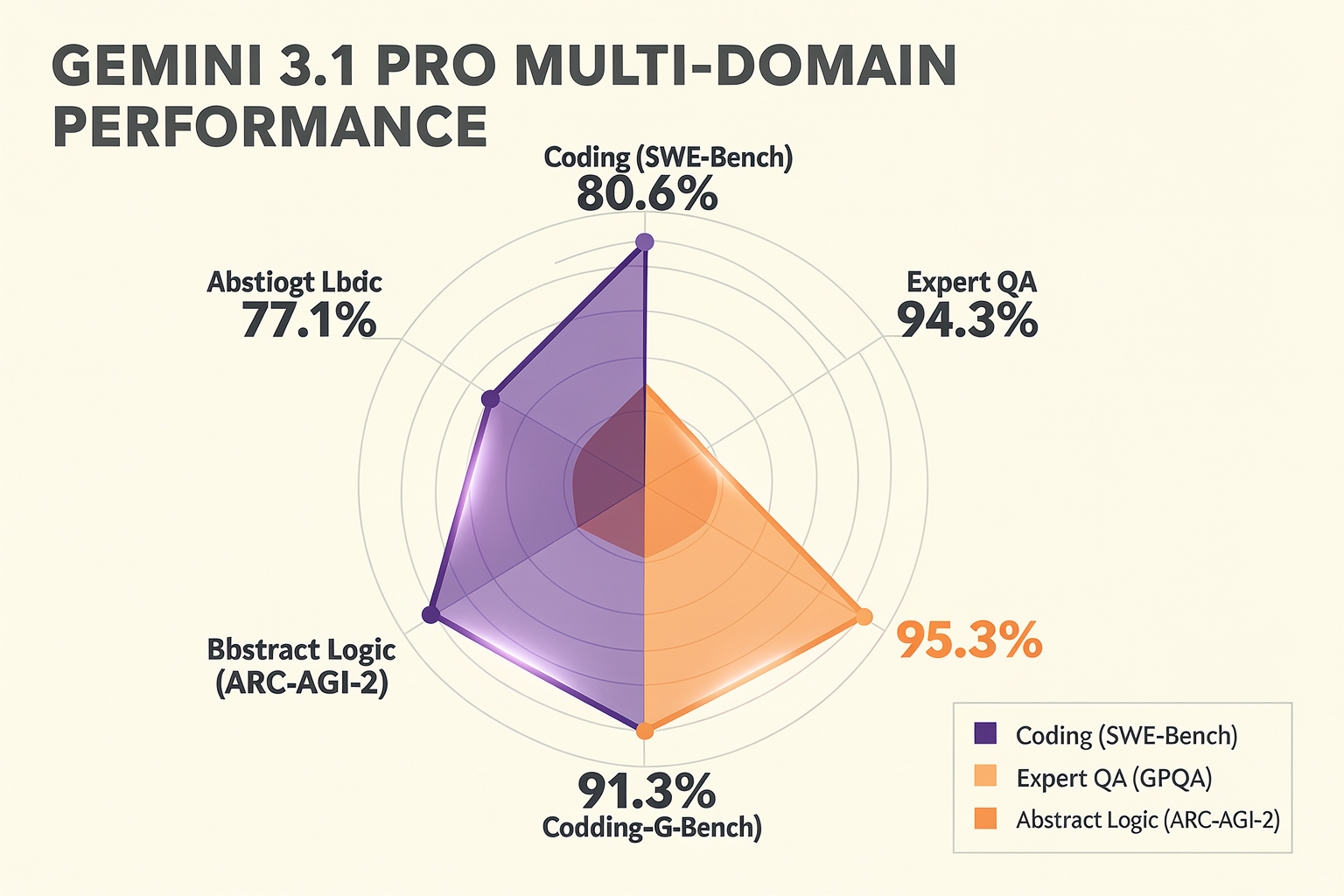
Beyond Reasoning: SWE-Bench and GPQA Performance
While benchmarks like ARC-AGI-2 measure a model’s raw, fluid intelligence and ability to adapt to entirely novel rules, real-world enterprise utility demands more than abstract puzzle-solving. To truly transform industries, an AI must excel at two highly practical, high-stakes capabilities: writing functional, production-grade code within massive codebases and reasoning through complex, specialist-level academic knowledge.
To evaluate these capabilities, the AI research community relies heavily on two gold-standard evaluations: SWE-Bench (for software engineering) and GPQA (for graduate-level, "Google-proof" science and mathematics). Gemini 3.1 Pro’s performance on these benchmarks marks a massive leap forward, proving that the model is no longer just a conversational partner, but an active, highly capable operational agent.
SWE-Bench: From Code Generation to True Software Engineering
Historically, models were tested on coding using simple benchmarks like HumanEval, which merely require writing a short, isolated Python function. In contrast, SWE-Bench evaluates an AI's ability to behave like a human software engineer.
To score well on SWE-Bench, an LLM is given a complete, real-world GitHub repository, an issue description, and a testing environment. The model must:
- Navigate thousands of lines of code across dozens of files.
- Locate the precise bug or feature request described in the issue.
- Write a patch to resolve the issue.
- Ensure the patch passes all existing unit tests without breaking other parts of the application.
Gemini 3.1 Pro achieved a stunning 80.6% score on SWE-Bench. To put this in perspective, early LLMs scored in the single digits on this benchmark, and even advanced models from just a year or two ago struggled to cross the 30% threshold.
An 80.6% success rate indicates that Gemini 3.1 Pro can operate as an autonomous coding agent. It is not just predicting the next token; it is executing complex, multi-step debugging, refactoring, and verification loops. For development teams, this capability shifts the paradigm from AI-assisted autocomplete to fully autonomous pull-request generation, automated bug triaging, and hands-free codebase maintenance.
For businesses looking to deploy this advanced logic in production, infrastructure efficiency is key. Communication platforms like CallMissed rely heavily on robust, high-performing underlying models. Whether an AI is orchestrating complex customer database queries or dynamically writing logic to route calls based on real-time API responses, having an LLM that inherently understands complex software architecture is a massive competitive advantage.
GPQA: Cracking the "Google-Proof" PhD-Level Barrier
While SWE-Bench proves the model's operational execution, GPQA (Graduate-Level Google-Proof Q&A) tests the absolute limits of its specialized, multi-step reasoning and academic knowledge.
GPQA was designed by PhDs in physics, chemistry, biology, and advanced mathematics. The questions are specifically formulated to be "Google-proof"—meaning a user cannot easily find the answer by typing keywords into a search engine. Solving a GPQA problem requires deep, domain-specific knowledge, precise mathematical calculation, and complex, multi-layered deduction.
On this punishing benchmark, Gemini 3.1 Pro registered a spectacular score of 94.3%.
To understand the weight of this achievement, consider the human baseline performance on GPQA:
- Human PhD experts in the exact same subfield as the question score approximately 80% to 85%.
- Human PhDs answering questions outside their specific niche (but still within their broader scientific discipline) score roughly 74%.
By hitting 94.3%, Gemini 3.1 Pro has effectively surpassed the average human specialist's accuracy on expert-level scientific reasoning. This is not simply a matter of memorization; it represents the model's capability to synthesize obscure scientific concepts, apply complex mathematical proofs, and reason through highly technical, multi-step logical chains without hallucinating.
The Enterprise Implications: Operational AI in Action
The combination of an 80.6% score on SWE-Bench and a 94.3% score on GPQA represents a fundamental transition in the AI landscape: the shift from cognitive chatbots to autonomous domain experts.
When an AI possess both master-level technical knowledge (GPQA) and the practical ability to execute complex, multi-step workflows (SWE-Bench), it can be deployed to solve previously intractable business problems:
- Automated Scientific Research: Accelerating drug discovery, material science research, and chemical formulation by analyzing academic papers, formulating hypotheses, and writing the code to run simulations.
- Deep Financial and Legal Auditing: Parsing complex, thousands-of-pages-long regulatory documents, identifying compliance loopholes, and writing the exact script needed to extract and verify transaction ledger data.
- Advanced Technical Support: Dynamically diagnosing complex system outages, reading log files across microservices, identifying the root cause of an infrastructure failure, and writing the patch to fix it in real-time.
To harness these capabilities without getting locked into a single vendor's ecosystem, modern developers are turning to flexible middleware. Platforms like CallMissed address this need by providing a multi-model API gateway, allowing developers to switch between over 300+ LLMs—including elite reasoning models like Gemini 3.1 Pro—without rewriting a single line of backend integration code. This allows enterprises to dynamically route simple conversational tasks to lightweight, low-latency models, while escalating complex, data-heavy, or deeply analytical queries directly to high-reasoning powerhouses.
By proving its mettle on both SWE-Bench and GPQA, Gemini 3.1 Pro demonstrates that Google's reasoning architecture is not just built for academic benchmarks—it is ready to handle the messy, highly technical, and specialized realities of modern enterprise operations.
Impact & Implications: The Shift from Pattern Matching to Active Logic
The AI landscape is undergoing a fundamental paradigm shift. For years, the prevailing skepticism surrounding Large Language Models (LLMs) centered on the "stochastic parrot" argument—the idea that these systems do not actually understand concepts, but are merely highly sophisticated pattern-matching engines. Critics argued that LLMs simply regurgitate statistical probabilities derived from their vast training data, failing completely when faced with novel scenarios requiring genuine, out-of-distribution reasoning.
The launch of Google's Gemini 3.1 Pro, and specifically its performance on the ARC-AGI-2 benchmark, has turned this criticism on its head. By achieving a groundbreaking 77.1% on ARC-AGI-2—representing a massive 2.5× improvement over its predecessor, Gemini 3 Pro—this model marks a historic transition from passive pattern matching to what AI researchers call active logic.
Understanding this transition is critical for developers, enterprise architects, and technology leaders. It represents the point where AI moves from a memory-retrieval tool to an active cognitive partner.
Deconstructing the Shift: Pattern Matching vs. Active Logic
To understand the scale of this breakthrough, we must look at how traditional LLMs process information compared to how Gemini 3.1 Pro handles reasoning-heavy tasks.
Historically, AI models relied heavily on "memorized logic." If a model had seen a thousand variations of a Python script or a legal contract during training, it could effortlessly generate a thousand and first variation. However, if the underlying rules of the task changed in a way that was never represented in the training set, the model's accuracy plummeted.
In contrast, Gemini 3.1 Pro's leap on ARC-AGI-2 showcases the emergence of active logic.
- Pattern Matching (The Old Paradigm): Relies on statistical correlation, semantic proximity, and training dataset density. It excels at tasks with high structural predictability, such as translating languages, summarizing documents, or writing standard boilerplate code.
- Active Logic (The New Paradigm): Relies on runtime rule deduction, hypothesis testing, and dynamic mental model construction. It excels at solving highly novel puzzles, diagnosing unprecedented software bugs, and adapting to real-time system changes without requiring fine-tuning.
This shift is precisely why benchmarks like ARC-AGI-2 were developed. Created by AI researcher François Chollet, the Abstraction and Reasoning Corpus (ARC) is specifically engineered to resist database memorization. It presents the model with grid-based visual-spatial puzzles that it has never encountered before. To solve them, the model cannot rely on its pre-existing training data; it must analyze a few visual examples, deduce the underlying logical rules on the fly, and apply those rules to a brand-new grid. Gemini 3.1 Pro’s score of 77.1% proves that the model is actively learning and synthesizing new rules during the inference phase itself.
The Real-World Impact on Software and Science
This is not just an academic victory. The leap in abstract reasoning directly correlates with dramatic improvements in highly complex, multi-step real-world tasks, as evidenced by Gemini 3.1 Pro’s broader benchmark suite:
- Autonomous Software Engineering (SWE-Bench at 80.6%):
Traditional code assistants struggle when a bug requires understanding the complex, undocumented interactions between multiple files in a repository. Gemini 3.1 Pro's high SWE-Bench score means it can actively trace execution paths, deduce dependencies, and formulate logical patches for real-world codebases. It is no longer just autocomplete for developers; it acts as an autonomous agent capable of debugging complex software architectures.
- Expert-Level Scientific Reasoning (GPQA at 94.3%):
GPQA (Graduate-Level Google-Proof Q&A) features highly complex questions designed by PhDs in physics, chemistry, and biology. These questions are intentionally written to avoid being easily searchable or answerable via simple pattern matching. Gemini 3.1 Pro’s near-perfect score demonstrates that its active logic can synthesize multi-disciplinary concepts, navigate complex mathematical constraints, and arrive at highly accurate conclusions.
Bridging the Infrastructure Gap for Enterprises
As models transition from quick pattern matching to deeper, multi-step active logic, the computational demand during inference changes. Reasoning models require more time to think (often referred to as "test-time compute" or "inference-time search") to evaluate multiple reasoning paths before delivering an output.
For enterprises looking to deploy these capabilities into production, maintaining a rigid infrastructure is no longer viable. Businesses need the flexibility to route simpler tasks (like basic text routing or translation) to cheaper, faster models, while dynamically escalating complex, reasoning-heavy tasks to frontier models like Gemini 3.1 Pro.
This is where advanced communication and LLM orchestration infrastructures become vital. Platforms like CallMissed allow developers to tap into this next-generation paradigm seamlessly. Through CallMissed's multi-model API gateway, businesses can access over 300+ LLMs, allowing them to instantly route incoming queries to the most appropriate reasoning engine.
For instance, an enterprise could use a lightweight model for initial customer interaction, but instantly switch to Gemini 3.1 Pro when a user presents a complex, multi-layered problem requiring active logic. By utilizing CallMissed’s robust API infrastructure, developers can build highly intelligent, 24/7 autonomous voice agents and WhatsApp chatbots that don't just follow static scripts, but dynamically adapt to and solve novel customer issues in real-time.
The Economic Paradigm: More Power, Same Cost
What makes Gemini 3.1 Pro’s leap to active logic particularly disruptive is its economic feasibility. Historically, a massive jump in reasoning capabilities came with a corresponding surge in API costs and computational latency. However, Google designed Gemini 3.1 Pro to maintain the exact same pricing structure as Gemini 3 Pro.
This means enterprises do not have to choose between cost efficiency and intelligence. The availability of 2.5× better abstract reasoning at a stable price point democratizes high-tier cognitive processing. From automating complex compliance audits to orchestrating dynamic, localized customer support in regional markets—such as deploying voice agents across diverse languages utilizing CallMissed’s Speech-to-Text capabilities—the barrier to deploying true AI-driven decision-making has never been lower.
Ultimately, the shift from pattern matching to active logic marks the end of the "stochastic parrot" era. As frontier models continue to master abstract reasoning, the organizations that succeed will be those that transition their applications from simple keyword-based automation to dynamic, agentic workflows powered by active reasoning engines.
Expert Opinions & Industry Reaction

The release of Gemini 3.1 Pro has sent shockwaves through the AI research community and enterprise development circles alike. While the broader tech industry has grown weary of incremental "LLM optimization" updates, Gemini 3.1 Pro's unprecedented performance on the ARC-AGI-2 benchmark has forced industry veterans to sit up and take notice. Scoring 77.1% on ARC-AGI-2 (a staggering 2.5× improvement over Gemini 3 Pro's baseline), 80.6% on SWE-Bench, and 94.3% on GPQA, the model represents a fundamental pivot in how artificial intelligence systems approach cognitive tasks.
The Leap from Pattern Matching to Genuine Reasoning
Historically, large language models have excelled at pattern recognition and statistical interpolation, prompting skeptics to label them as glorified "stochastic parrots." The ARC-AGI-2 benchmark, developed by François Chollet, was specifically designed to dismantle this reliance on memorization. By presenting models with entirely novel, visual-logic grids that cannot be solved via training data recall, ARC-AGI-2 tests a system's capacity for genuine abstract reasoning and real-time rule deduction.
Gemini 3.1 Pro's climb to 77.1% on this benchmark represents a major milestone. Industry analysts emphasize that this isn't just a marginal gain; it is a conceptual leap. Because ARC-AGI-2 is engineered to resist pattern-matching, Google's success indicates a deeper integration of dynamic search, test-time compute, and adaptive reasoning paths. For the first time, a commercial model is demonstrating the ability to construct internal hypotheses, test them against novel constraints, and refine its logic on the fly without human intervention.
What AI Leaders and Researchers Are Saying
The response from tech leaders has been a mix of excitement and analytical caution. Tris Warkentin, Director of Product Management at Google, publicly celebrated the launch, stating that the model's performance on ARC-AGI-2 "isn't just an incremental update." Instead, Warkentin framed it as a foundational shift that sets a new benchmark for practical AI intelligence, offering developers a preview of true agentic reasoning capabilities today.
Prominent AI commentator and industry analyst Zvi Mowshowitz echoed this sentiment, noting that hitting 77.1% on ARC-AGI-2 marks a "step forward in core reasoning" that more than doubles the previous generation's baseline. Mowshowitz observed that having a highly capable, reasoning-centric baseline model is "great for supercharging" complex multi-step workflows. However, he also noted that the practical integration of these reasoning steps into production-grade systems still requires substantial orchestration to prevent runaway inference latency.
Independent evaluation platforms have also weighed in with eye-opening results. In a comprehensive review featuring over 14,000 rigorous trial runs, evaluation firm LayerLens reported that Gemini 3.1 Pro achieved scores as high as 92.3% on customized ARC-AGI-2 variations under specific pattern extrapolation frameworks. This discrepancy between Google's baseline 77.1% and higher independent testing scores highlights how sensitive reasoning models are to prompt optimization, system instructions, and execution environments.
The "Benchmark Downfall" Debate
Despite the praise, the release of Gemini 3.1 Pro has rekindled an intense industry debate regarding the "downfall of traditional benchmarks." Many machine learning engineers argue that standard academic benchmarks (like MMLU or GSM8K) have become heavily contaminated, with models essentially memorizing test questions during training.
This has led to a split in perspective. On one hand, ARC-AGI-2 remains highly respected because its puzzles are programmatically generated and structurally novel. On the other hand, skeptics argue that even ARC-AGI-2 can be "gamed" using advanced test-time compute strategies, where a model spends minutes generating and testing Python scripts to brute-force grid transitions. This methodology, while technically a form of reasoning, does not always translate to the fast, cost-effective decision-making required in live business environments. Developers are increasingly demanding evaluations that prioritize practical, real-world utility over synthetic laboratory scores.
Bridging the Gap: From Benchmarks to Production
For enterprises trying to capitalize on these breakthroughs, the core challenge lies in testing these models within their specific business contexts. While a model might excel at solving abstract grid puzzles on ARC-AGI-2, how does that translate to handling complex, multi-layered customer inquiries or orchestrating API calls in a legacy system?
This is where advanced infrastructure platforms play a crucial role. CallMissed, an AI communication infrastructure platform, bridges the gap between raw research benchmarks and real-world deployment. Through CallMissed's multi-model API gateway, developers can seamlessly switch between 300+ LLMs—including Gemini 3.1 Pro, Claude 3.5 Sonnet, and specialized open-source alternatives—without changing a single line of application code. This allows teams to benchmark Gemini 3.1 Pro's real-world reasoning directly against other leading frontier models in live, production-like environments to see if that 77.1% ARC-AGI-2 score translates into actual operational efficiency.
Production Fit and Economic Realities
A key detail that has garnered significant praise from system architects is Google's pricing strategy. According to technical deep-dives from platform engineering firm Thesys, Gemini 3.1 Pro delivers its massive reasoning upgrades while maintaining the exact same pricing structure as the older Gemini 3 Pro.
In the past, massive leaps in reasoning capabilities were accompanied by prohibitive cost increases due to the compute required for test-time searching and chain-of-thought processing. By keeping pricing parity, Google has effectively democratized advanced reasoning, making it financially viable to deploy agentic workflows at scale.
This economic viability is particularly transformative for heavy-duty operational workflows. For instance, when integrated with platforms like CallMissed, Gemini 3.1 Pro’s advanced reasoning can power hyper-realistic voice agents capable of handling complex customer service calls 24/7. Combined with CallMissed's low-latency Speech-to-Text and Text-to-Speech APIs—which natively support 22 Indian regional languages—businesses can leverage Gemini's underlying reasoning to resolve complex, colloquial inquiries without the risk of logic breakdown or costly API overhead.
The industry consensus is clear: Gemini 3.1 Pro is not just another LLM revision. It represents the maturation of model architectures designed for thinking, not just typing. While the debate over the future of benchmarks continues, the practical availability of cheap, robust reasoning marks the official beginning of the agentic era.
What This Means For You: Real-World Applications (TABLE)
When an AI model achieves record-breaking scores on highly demanding evaluations, it is easy to get lost in academic percentages. However, for CTOs, product managers, and software engineers, a benchmark is only as valuable as the real-world utility it unlocks. Gemini 3.1 Pro’s leaps in reasoning, coding, and comprehension represent a massive shift in what enterprises can reliably automate.
The transition from pattern-matching models to true, multi-step logical reasoning engines changes how we construct agentic workflows. Instead of acting as simple text predictors, models like Gemini 3.1 Pro function as cognitive partners capable of synthesizing novel solutions to complex, unmemorized problems.
To understand how these record-breaking benchmarks translate into production-ready capabilities, we can map Gemini 3.1 Pro's core benchmark performance directly to practical business use cases.
| Benchmark | Gemini 3.1 Pro Score | Core Capability Tested | Real-World Enterprise Application | Target Verticals |
|---|---|---|---|---|
| ARC-AGI-2 | 77.1% | Out-of-distribution abstract reasoning & novel rule deduction | Handling unexpected edge cases, dynamic logistical planning, and adaptive system triaging | Logistics, Robotics, Supply Chain, Customer Operations |
| SWE-Bench | 80.6% | Resolved software engineering issues in complex codebases | Autonomous code generation, legacy system refactoring, and agentic bug debugging | Software Development, IT Operations, SaaS |
| GPQA | 94.3% | Graduate-level, Google-proof scientific and mathematical Q&A | Deep-tech research, pharmaceutical drug discovery, and advanced legal/financial contract auditing | Healthcare, Bio-tech, Legal, Investment Banking |
| Overall Context | High Efficiency | Multi-modal comprehension & long-context reasoning | Multi-step agentic workflows, dynamic document querying, and live audio/video analysis | Customer Experience, Telecom, EdTech |
From SWE-Bench to Autonomous DevOps
Securing an 80.6% on SWE-Bench is a watershed moment for engineering organizations. Historically, code-generation models excelled at autocomplete functions or writing isolated boilerplate code. SWE-Bench, however, requires a model to download a complex GitHub repository, locate a reported bug across multiple files, write a patch, and verify that the tests pass.
In the real world, this translates to:
- Autonomous Bug Resolution: Companies can deploy specialized coding agents that monitor error-reporting tools (like Sentry or LogRocket), automatically draft a pull request to fix the issue, run the CI/CD test suite, and present the patch to developers for a final review.
- Legacy Codebase Migration: Upgrading massive legacy systems (such as migrating from COBOL to Go, or Python 2 to Python 3) requires understanding deep structural patterns and rewriting code without breaking dependencies. Gemini 3.1 Pro's high SWE-Bench score means it can execute these massive architectural refactors with minimal human supervision.
- Automated Security Patching: Rather than simply flagging vulnerabilities during static analysis, agentic systems can actively rewrite insecure dependencies and patch zero-day vulnerabilities in real time.
GPQA and the Era of Synthetic Experts
The Graduate-Proof Q&A (GPQA) benchmark contains questions so difficult that even expert PhDs in physics, biology, and chemistry struggle to answer them without extensive research. Gemini 3.1 Pro's 94.3% score on GPQA indicates that the model possesses a highly specialized, structured understanding of the hard sciences.
For enterprises, this opens up unprecedented opportunities in high-stakes industries:
- Accelerated Pharmaceutical R&D: Researchers can use the model to synthesize massive corpuses of clinical trials, predicting chemical interactions and identifying prospective molecular structures for drug discovery much faster than manual evaluation allows.
- Complex Financial and Legal Auditing: Analyzing multi-million dollar corporate mergers requires assessing compliance across thousands of pages of obscure regulations. Gemini 3.1 Pro can act as a synthetic expert, cross-referencing intricate tax codes and global trade laws to flag compliance risks.
- Technical Decision Support: High-reliability industries like aerospace and defense can deploy Gemini 3.1 Pro as an on-demand consulting agent to assist field engineers in diagnosing rare mechanical failures using complex, multi-variable schematics.
ARC-AGI-2 and Managing the Unexpected
Perhaps the most significant leap is Gemini 3.1 Pro’s 77.1% on ARC-AGI-2, a benchmark specifically built to resist memorization. Traditional LLMs fail when a user introduces a novel rule that was not present in their training data. By more than doubling the reasoning capabilities of its predecessor, Gemini 3.1 Pro proves it can adapt on the fly.
This abstract reasoning is crucial for building resilient consumer-facing systems:
- Unpredictable Customer Journeys: Traditional customer service bots easily break when a user changes their mind mid-conversation or introduces a highly specific, multi-layered problem. By leveraging platforms like CallMissed, businesses can deploy highly conversational voice agents and WhatsApp chatbots powered by Gemini 3.1 Pro. These agents can dynamically adapt to non-linear customer queries, troubleshooting complex billing discrepancies or shipping failures without needing human intervention.
- Dynamic Supply Chain Routing: When weather events, labor strikes, or geopolitical issues disrupt global shipping lanes, logistics networks must adapt. A reasoning engine can evaluate real-time telemetry data, deduce the systemic impact of a localized delay, and autonomously redesign shipping routes to minimize overhead.
- Intelligent Assistive Tech: In unpredictable environments—such as healthcare facilities or smart warehouses—AI-driven visual systems must interpret spatial surroundings and dynamic human behaviors. The logic engines behind ARC-AGI-2 allow these systems to navigate complex physical environments and adapt to sudden changes.
Balancing Cost and Performance with Multi-Model Gateways
While Gemini 3.1 Pro offers top-tier cognitive performance, deploying it for every single interaction is computationally and financially inefficient. In a production environment, routing simple user queries (like "What is my account balance?") to a high-reasoning model wastes resources.
To solve this, modern enterprises are leveraging multi-model ecosystems. Utilizing platforms like CallMissed, developers can access over 300+ LLMs through a unified API gateway. This enables systems to dynamically route standard queries to faster, cost-effective models, while reserve-routing highly complex, multi-step logical problems to Gemini 3.1 Pro. Additionally, with built-in Speech-to-Text APIs supporting 22 Indian languages, developers can effortlessly convert multilingual customer voice inputs into structured data before passing them to the reasoning engine. This hybrid approach ensures that businesses get the absolute best of Gemini 3.1 Pro's abstract reasoning exactly when they need it, without inflating operational costs.
Looking Ahead: The Road to Artificial General Intelligence (AGI)
The pursuit of Artificial General Intelligence (AGI) has shifted from a theoretical, long-term scientific ambition into an active engineering sprint. For years, the artificial intelligence industry relied heavily on benchmarks that measured a model’s memory, pattern-matching capabilities, and text-prediction accuracy. However, as models began maxing out these traditional tests, researchers realized they were measuring knowledge retrieval rather than actual intelligence. The release of Google’s Gemini 3.1 Pro represents a milestone in this paradigm shift, signaling a move toward true, dynamic reasoning that brings us closer to the frontier of AGI.
By securing an unprecedented 77.1% score on ARC-AGI-2, a 94.3% on GPQA (Graduate-Level Google-Proof Q&A), and an 80.6% on SWE-Bench, Gemini 3.1 Pro proves that the next era of AI development will not be won simply by scaling up training data, but by refining how models think, adapt, and solve entirely novel problems.
Resisting the Memorization Trap: Why ARC-AGI-2 Matters
To understand the road to AGI, we must first understand why older benchmarks failed to point the way. Traditional evaluations often suffered from data contamination; models could "cheat" on tests because variations of the exam questions already existed within their massive training datasets.
The Abstraction and Reasoning Corpus (ARC-AGI-2) was specifically designed by AI researcher François Chollet to resist this pattern-matching. Instead of testing acquired knowledge, ARC-AGI-2 evaluates a system's ability to learn brand-new skills on the fly. It presents the AI with visual, grid-based puzzles governed by abstract rules the model has never encountered before. To solve them, the model must deduce these underlying rules from just a few examples and apply them to a novel test case.
- The Reasoning Leap: Gemini 3.1 Pro’s score of 77.1% on ARC-AGI-2 is a massive leap forward, representing a 2.5× improvement in abstract reasoning compared to its predecessor, Gemini 3 Pro.
- Active Synthesis vs. Passive Retrieval: While previous models relied on predicting the next logical word based on past training, Gemini 3.1 Pro dynamically constructs mental models of the puzzle rules, mimicking the fluid intelligence of human problem-solving.
- Beyond Rote Learning: This performance indicates that we are moving past the era of statistical parrot-like behavior and entering an era of actual cognitive synthesis.
From Static Language Models to Autonomous Agents
The practical implications of these benchmarks stretch far beyond academic test scores. A model capable of scoring 80.6% on SWE-Bench—a benchmark testing an AI's ability to resolve real-world software engineering bugs in complex, multi-file codebases—is no longer just a text assistant. It is a highly capable digital collaborator.
As reasoning capabilities scale, the nature of enterprise AI deployment changes. Businesses are transitionining away from simple, retrieval-augmented generation (RAG) chatbots toward fully autonomous agents capable of multi-step execution, self-correction, and long-range planning.
For enterprises looking to implement these high-reasoning capabilities, operationalizing these models remains a challenge. Implementing Gemini 3.1 Pro alongside other leading models requires a flexible infrastructure. Communication and development platforms like CallMissed bridge this gap. By offering a unified LLM inference gateway supporting over 300+ models, CallMissed allows developers to dynamically route tasks to the most efficient model—whether that means sending high-complexity reasoning tasks to Gemini 3.1 Pro or executing lower-cost transactional processes on lighter models, all without rewriting core integration code.
The Hurdle of Real-Time, Localized Reasoning
As we look further down the road to AGI, two primary bottlenecks persist: latency and localization. Highly advanced reasoning models require massive computational overhead, which often translates to slower response times. In real-world customer interactions—such as voice agents or live-chat systems—a delay of even two seconds can break user trust.
Furthermore, true general intelligence cannot exist in a monolingual vacuum. For an AI agent to operate effectively on a global scale, it must apply its abstract reasoning across diverse linguistic and cultural landscapes. This requires integrating advanced reasoning capabilities with hyper-localized communication infrastructure.
For instance, systems built on CallMissed leverage high-performance Speech-to-Text and Text-to-Speech APIs supporting 22 Indian regional languages natively. This allows businesses to pair the abstract problem-solving power of next-generation LLMs with real-time, multilingual voice agents, making advanced reasoning accessible to users regardless of language or technical literacy.
What Lies Beyond Gemini 3.1 Pro?
While a 77.1% score on ARC-AGI-2 is a massive achievement, it also highlights the remaining gap between state-of-the-art AI and human-level general intelligence. Humans still solve these puzzles with near-perfect accuracy because our cognitive architecture supports continuous, real-time learning without forgetting prior training—a feat known as solving the "plasticity vs. stability" dilemma.
The road to AGI post-Gemini 3.1 Pro will likely be defined by three major trends:
- System 2 Thinking Integration: Future architectures will more deeply integrate "slow thinking" processes, allowing models to pause, deliberate, and run internal simulations before generating an answer, rather than outputting tokens immediately.
- Hybrid Neuro-Symbolic AI: Combining the pattern recognition of deep learning with the strict logic of symbolic reasoning will help models achieve 100% accuracy on complex logical and mathematical tasks.
- On-the-Fly Fine-Tuning: The next generation of models will likely feature real-time memory adaptation, allowing them to learn and retain new rules permanently from a single user interaction, much like a human apprentice.
Ultimately, Gemini 3.1 Pro has redefined our expectations of what LLMs can achieve when freed from the constraints of simple rote memorization. As these reasoning frameworks continue to mature, they will unlock levels of automation, analysis, and execution that were once considered the exclusive domain of human intelligence.
Frequently Asked Questions
What do the Gemini 3.1 Pro Benchmarks tell us about its core reasoning improvements?
How does Gemini 3.1 Pro perform on coding and expert-level academic tests compared to other models?
What is the ARC-AGI-2 benchmark, and why is Gemini 3.1 Pro's score of 77.1% so significant?
Does Gemini 3.1 Pro cost more than the previous Gemini 3 Pro model due to these upgraded reasoning capabilities?
Can Gemini 3.1 Pro's reasoning capabilities still fail despite its high benchmark scores?
Why does the SWE-Bench score of 80.6% matter for software developers using Gemini 3.1 Pro?
Conclusion
The benchmark results for Gemini 3.1 Pro mark a pivotal moment in the transition from simple pattern-matching to genuine cognitive adaptation. As AI moves beyond memorized training data, we are entering an era of highly capable, agentic systems that can think on their feet.
Here are the key takeaways from this milestone:
- Leap in Reasoning: Gemini 3.1 Pro’s 77.1% score on ARC-AGI-2 represents a massive performance increase over its predecessor, proving that modern LLMs can deduce novel rules on the fly rather than relying on rote memorization.
- Multi-Domain Dominance: High marks of 80.6% on SWE-Bench and 94.3% on GPQA demonstrate that this cognitive growth is balanced across complex software engineering and graduate-level scientific reasoning.
- Production-Ready Efficiency: Google's decision to maintain previous-generation pricing while doubling abstract reasoning capabilities makes advanced logic economically viable for enterprise pipelines.
Moving forward, the industry will closely watch how these enhanced reasoning capabilities translate into autonomous workflows. The next frontier of development is not just achieving higher scores on isolated tests, but deploying agents that can seamlessly troubleshoot complex, unpredictable real-world environments without human hand-holding.
To explore how AI communication is evolving alongside these advanced reasoning capabilities, check out CallMissed—an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. By integrating next-generation reasoning models into communication infrastructure, CallMissed enables enterprises to deploy highly responsive voice and text agents that handle complex customer requests natively in 22 regional languages.
As LLMs transition from superficial pattern-matching to genuine abstract reasoning, how will your organization leverage these autonomous capabilities to redefine customer interaction?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.