Meet GPT-5.6 Luna: OpenAI’s New Speed and Budget King for AI Agents

Meet GPT-5.6 Luna: OpenAI’s New Speed and Budget King for AI Agents
What if you could deploy an autonomous AI agent capable of parsing entire code repositories and years of customer history in milliseconds—all for just $1.00 per million input tokens? On June 26, 2026, OpenAI shattered the cost-to-performance curve with the limited preview launch of its new GPT-5.6 model family: Sol, Terra, and the highly anticipated speed and budget champion, GPT-5.6 Luna. While the flagship Sol model represents the peak of raw frontier intelligence, Luna is engineered to be the ultimate high-throughput utility engine for next-generation agentic AI.
Historically, building production-grade agentic workflows has been a painful balancing act between cognitive depth and prohibitive API costs. GPT-5.6 Luna fundamentally rewrites these economics. Priced at an incredibly competitive $1.00 input and $6.00 output per million tokens, Luna offers robust reasoning capabilities at a fraction of the price of older frontier models. More impressively, OpenAI has equipped the entire GPT-5.6 family with a massive 1.5 million token context window—a 50% expansion over GPT-5.5's 1.0 million limit—allowing agents to maintain vast amounts of active operational memory without losing focus.
Though currently restricted to a US-only preview at the request of government regulators, OpenAI plans to transition the models to general availability in the coming weeks. For enterprises, this release marks a massive paradigm shift: high-volume, multi-agent pipelines that once cost thousands of dollars a day can now run continuously for peanuts. Advanced communication infrastructure platforms like CallMissed are already anticipating this shift, helping businesses connect these ultra-affordable, low-latency LLMs directly to real-time voice and WhatsApp channels.
In this article, we will break down the pricing architecture of the GPT-5.6 family, explore how Luna achieves its breakthrough cost-efficiency, and analyze the practical implications of a 1.5M token window for building high-scale, budget-friendly AI agents.
Introduction: The Dawn of the High-Throughput Agentic Era

For years, developers and enterprises building agentic AI workflows have faced a frustrating paradox: the more autonomous and capable an agent is, the more expensive it is to run. Complex multi-agent pipelines—where agents continuously retrieve data, analyze logs, and converse with users—require massive token throughput. Until now, deploying these architectures at scale meant bracing for astronomical API bills.
On June 26, 2026, OpenAI dismantled this barrier with the limited preview release of its highly anticipated GPT-5.6 model family. Consisting of three distinct tiers—Sol, Terra, and Luna—this new lineup represents a major architectural leap forward, specifically optimized for the needs of agentic AI.
The GPT-5.6 Triad: Sol, Terra, and Luna
OpenAI's latest release categorizes intelligence into three tailored operational tiers, allowing developers to mix and match cognitive power based on their budget and latency requirements:
- GPT-5.6 Sol ($5.00 input / $30.00 output per 1M tokens): The undisputed flagship, engineered for deep reasoning, complex code generation, and top-tier frontier capabilities.
- GPT-5.6 Terra ($2.50 input / $15.00 output per 1M tokens): A highly balanced mid-range model delivering GPT-5.5-level reasoning at exactly half the price.
- GPT-5.6 Luna ($1.00 input / $6.00 output per 1M tokens): The lightweight speed and budget king of the family, designed explicitly for high-throughput utility pipelines.
By pricing Luna at a rock-bottom rate of $1.00 per million input tokens, OpenAI has effectively commoditized high-speed intelligence. Luna is built for the "always-on" agent—handling massive streams of structured data, routine customer inquiries, and real-time backend integrations without breaking the bank.
A Massive Leap in Context and Memory
Beyond cost efficiency, the entire GPT-5.6 family boasts a staggering 1.5 million token context window. This represents a 50% capacity increase over GPT-5.5's 1.0 million limit. For autonomous agents, context window size is directly tied to operational memory. A 1.5M token window allows Luna to hold entire codebases, months of customer interaction logs, or massive system prompts in its active memory, eliminating the need for aggressive chunking or complex RAG pipeline workarounds.
Regulatory Guardrails and the Road to GA
While the excitement surrounding this release is palpable, OpenAI is executing a staggered rollout. At the explicit request of US government regulators monitoring frontier AI deployments, GPT-5.6 is currently restricted to a limited, US-only preview for trusted partners. However, OpenAI has stated that they plan to make Sol, Terra, and Luna globally and generally available in the coming weeks.
For forward-thinking enterprises, this interim period is the perfect time to prepare infrastructure. Multi-channel communication platforms like CallMissed are already paving the way, allowing companies to seamlessly plug these low-latency, high-throughput LLMs directly into voice agents and WhatsApp chatbots. With Luna, the dream of deploying hundreds of specialized AI agents working in tandem is finally a financial reality.
Background & Context: The GPT-5.6 Family and the Regulatory Tightrope

Understanding the GPT-5.6 Model Family
OpenAI’s GPT-5.6 launch introduces a tiered approach to large language models (LLMs), reflecting a new era in the economics and accessibility of agentic AI. Announced on June 26, 2026, the GPT-5.6 family consists of three specialized models: Sol (the flagship model), Terra (the performance/value sweet spot), and Luna (the ultimate budget utility engine). Each is specifically optimized for different layers of computational complexity and business needs.
- Sol sits at the frontier, delivering maximal intelligence at a premium price ($5.00 input / $30.00 output per million tokens).
- Terra offers capabilities similar to last year’s GPT-5.5 but at half the price ($2.50 input / $15.00 output), bridging the gap between cost and core agentic reasoning.
- Luna, the new standout, is engineered for bulk processing and rapid, multi-agent orchestration—priced at just $1.00 input and $6.00 output per million tokens, the lowest in OpenAI’s frontier-grade lineup (sources: [OpenAI System Card][1], [MacRumors][4]).
Critically, all three variants share a vast 1.5 million token context window—a 50% uplift over GPT-5.5’s 1.0M limit ([explainx.ai][6], [9to5mac][3]). This breakthrough increases the agent’s short-term working memory, letting autonomous AI systems ingest, reference, and manipulate hundreds of thousands of lines of code, customer transcripts, and operational data in real time, with no chunking or loss of context.
Regulatory Realities: Global Access and Cautious Rollout
While the engineering advancements of GPT-5.6 Luna are making headlines, much of the initial discourse has been shaped by regulatory scrutiny. As of launch, all three models—Sol, Terra, and Luna—are available only to trusted US partners, in response to evolving government guidelines ([The Hill][7]). Alex Haydn of OpenAI’s deployment safety team notes: “We’re working closely with regulators to ensure safe, responsible access and plan for broad release in the coming weeks” ([OpenAI System Card][1]).
Key drivers behind this restricted launch include:
- Data sovereignty concerns: Regulating how massive-context models handle and store sensitive data across jurisdictions.
- AI safety protocols: Ensuring fine-grained control over agentic behaviors before a global unrestricted rollout.
- Market stability: Avoiding model misuse or automated disruptions in highly regulated industries.
Despite this “regulatory tightrope,” OpenAI’s move signals confidence in scaling up quickly. Globally distributed API platforms, such as CallMissed, are already preparing to enable seamless access once general availability is granted—offering businesses an on-ramp to integrate Luna-powered agents across voice, WhatsApp, and multilingual engagement channels.
Cost Innovation and Industry Impact
The context window expansion is more than a technical achievement—it’s a shift that directly addresses the “cost-per-insight” barrier for enterprise AI.
- Prior frontier models (e.g., GPT-5.5) typically cost $3.00–$20.00 per million tokens, with much smaller context lengths, severely limiting adoption for high-throughput use cases.
- GPT-5.6 Luna’s $1.00/$6.00 pricing slashes operational costs for continuous agent deployment by over 70%, enabling businesses to maintain persistent, context-rich agents that can reason, retrieve, and converse without expensive memory resets.
With this, workflows that previously needed to be throttled or fragmented due to budget constraints—like always-on customer service agents or multi-modal code/knowledge review bots—now become economically viable at scale. Platforms like CallMissed are well-positioned to help organizations harness this leap, democratizing access to “superhuman” agentic logic and communication for small startups and global enterprises alike.
References:
[1]: https://deploymentsafety.openai.com/gpt-5-6-preview
[3]: https://9to5mac.com/2026/06/26/openai-upgrading-chatgpt-and-codex-with-new-gpt-5-6-models-in-limited-release/
[4]: https://www.macrumors.com/2026/06/26/openai-gpt-5-6-sol/
[6]: https://explainx.ai/blog/gpt-5-6-release-date-features-benchmarks-2026
[7]: https://thehill.com/policy/technology/5942770-openai-staggers-gpt-56/
Key Developments: GPT-5.6 Sol, Terra, and Luna Compared (TABLE)

To fully appreciate the disruption GPT-5.6 Luna brings to the market, it is essential to view it alongside its newly released siblings: GPT-5.6 Sol and GPT-5.6 Terra. On June 26, 2026, OpenAI introduced this structured triad to give developers a granular choice between raw cognitive horsepower, balanced performance, and ultra-high-throughput efficiency.
By segmenting their frontier models into three distinct tiers, OpenAI has created an optimized ladder of intelligence. For the first time, developers do not have to compromise on context window size to save on cost, as all three models boast the massive, newly upgraded 1.5 million token context window.
Here is how the GPT-5.6 lineup compares against the legacy GPT-5.5 model:
| Model Tier | Primary Target Use Case | Input Cost (per 1M) | Output Cost (per 1M) | Context Window |
|---|---|---|---|---|
| GPT-5.6 Sol | Complex reasoning, logic, heavy coding | $5.00 | $30.00 | 1.5 Million |
| GPT-5.6 Terra | Balanced workflows, agentic tool-use | $2.50 | $15.00 | 1.5 Million |
| GPT-5.6 Luna | High-throughput, rapid utility, low-latency | $1.00 | $6.00 | 1.5 Million |
| GPT-5.5 (Legacy) | General enterprise agentic workloads | $5.00 | $20.00 | 1.0 Million |
The Paradigm Shift of Tiered Intelligence
As the data shows, OpenAI is aggressively driving down the cost of intelligence. GPT-5.6 Terra effectively delivers similar performance to the older GPT-5.5 tier, but does so at a flat 50% discount on input tokens ($2.50 vs. $5.00 per million) and a 25% discount on output tokens ($15.00 vs. $20.00).
However, the true star for high-volume deployments is GPT-5.6 Luna. Priced at an unprecedented $1.00 input and $6.00 output per million tokens, Luna represents a massive 80% price reduction compared to GPT-5.5's input pricing. Despite this aggressive discount, Luna maintains robust reasoning capabilities suitable for real-time task execution.
Architectural Synergy for Agentic Routing
For enterprise developers, this tiered pricing model unlocks a strategy known as semantic routing. Instead of routing every single agent turn to a costly, high-intelligence model like Sol, developers can build multi-tier agent systems.
For instance, communication infrastructure platforms like CallMissed allow developers to route high-volume, real-time voice and WhatsApp interactions through GPT-5.6 Luna first. Luna handles rapid tasks like user validation, standard FAQ responses, and intent classification in milliseconds. If a user's request requires heavy multi-step logic or complex data synthesis, the pipeline can dynamically escalate the query to Terra or Sol.
By matching the complexity of the task to the corresponding model tier, businesses can reduce their overall API operational costs by up to 70% while maintaining a seamless, lightning-fast user experience.
In-Depth Analysis: Why Luna's Economics Change Everything for AI Agents
To truly appreciate why GPT-5.6 Luna is a watershed moment for AI engineering, we must look at how autonomous agents actually behave in production. Unlike a standard chatbot that answers a single prompt and stops, an agent operates in continuous, iterative loops. It must read system instructions, fetch external data, plan its next steps, call APIs, self-correct, and format its response. This high-frequency execution model creates an exponential "token tax."
Dismantling the Compounding Token Tax
In a typical multi-agent swarm—where one agent coordinates, another retrieves documentation, and a third drafts a response—a single user query can trigger dozens of internal LLM calls. If you are building on a flagship model like GPT-5.6 Sol ($5.00 input / $30.00 output per million tokens), a single customer interaction can easily cost upwards of $0.20 to $0.50 in token overhead. Scale that across 10,000 daily active users, and your monthly enterprise infrastructure bill quickly becomes unsustainable.
Luna completely rewrites this math. Priced at $1.00 input and $6.00 output per million tokens, Luna reduces operational costs by 80% compared to its flagship sibling, Sol, and dramatically undercuts previous generation mid-tier engines.
Consider how this pricing architecture shifts development strategies:
- Continuous Monitoring Agents: Background agents can now scrape, parse, and analyze real-time data streams 24/7. Generating 10 million output tokens of summary data per day costs just $60.00.
- Uninhibited RAG Pipelines: Retrieval-Augmented Generation (RAG) often feeds massive chunks of raw text into the model to find answers. With Luna's rock-bottom input pricing, pulling in 100,000 tokens of retrieved documents costs exactly $0.10.
- Complex Multi-Step Orchestration: Developers no longer need to aggressively compress their agent guidelines. You can load complex, multi-step agent frameworks, tool definitions, and system rules directly into the active prompt context for fractions of a cent.
Maximizing the 1.5 Million Token Context Window
The economic genius of Luna lies in how it democratizes the newly expanded 1.5 million token context window. Historically, developers avoided using large context windows because "needle-in-a-haystack" retrieval over hundreds of thousands of tokens was both slow and astronomically expensive.
By decoupling massive capacity from high costs, OpenAI has enabled what can be called "always-on operational memory." An agent running on Luna can hold an entire customer relationship history, past interaction transcripts, and API documentation in its immediate context. It can refer back to details discussed weeks ago without needing to constantly query a vector database, resulting in faster execution speeds and zero context-loss errors.
Real-World Execution with CallMissed
For businesses looking to operationalize these economics, the bottleneck is no longer the model cost—it is the integration. Telephony and real-time messaging require split-second latency and absolute reliability to feel human.
Platforms like CallMissed bridge this gap by enabling enterprises to route their customer touchpoints—such as 24/7 AI voice agents or high-volume WhatsApp workflows—directly to GPT-5.6 Luna via high-performance, low-latency APIs. By leveraging Luna's ultra-affordable token pricing alongside CallMissed's advanced speech-to-text (supporting 22 regional Indian languages) and multi-model routing capabilities, organizations can deploy sophisticated conversational agents that resolve complex inquiries in real time, all while cutting infrastructure costs to near zero.
Impact & Implications: Massive Scale, Low Cost, and 1.5 Million Tokens
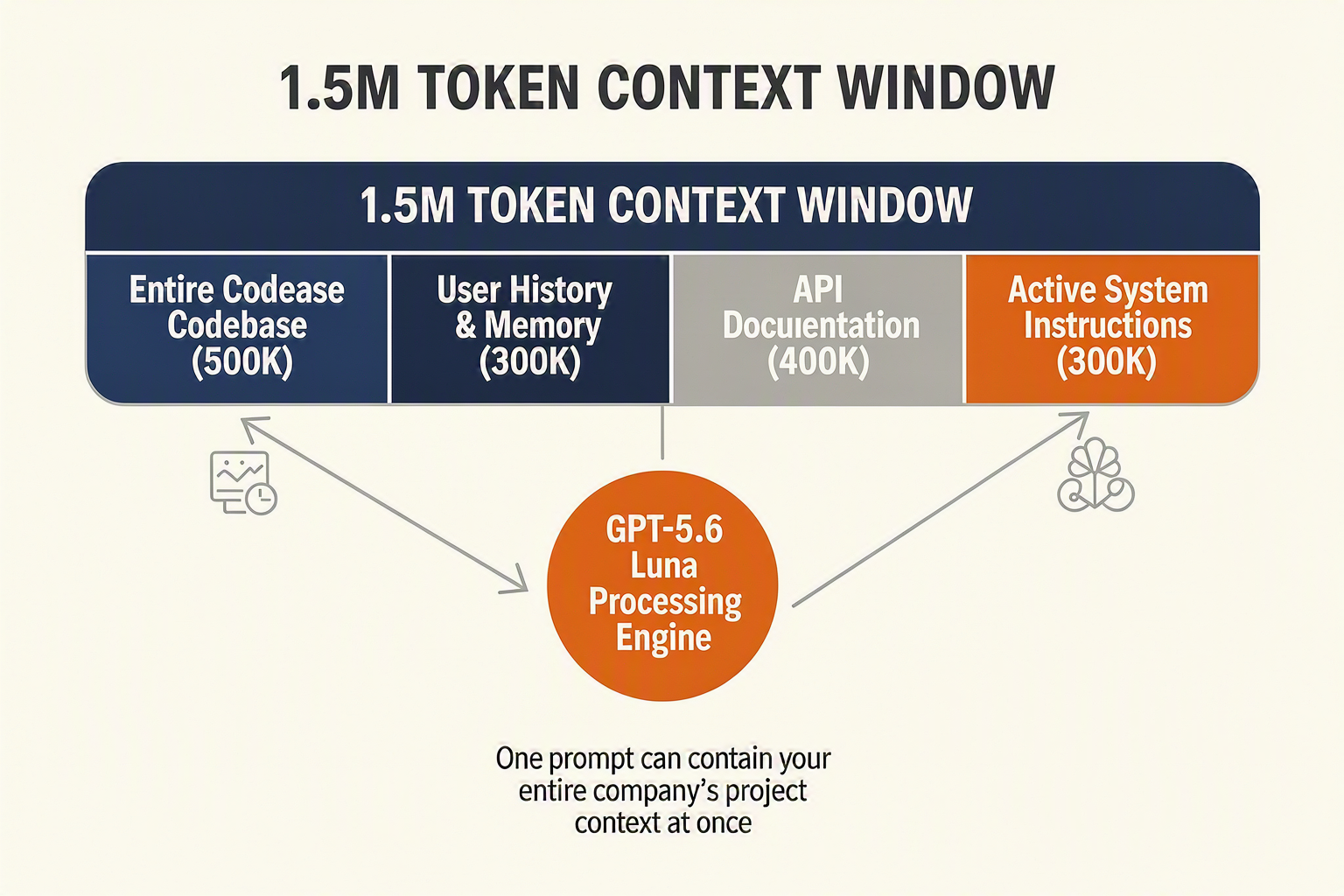
The arrival of the GPT-5.6 model family—specifically GPT-5.6 Luna—marks a pivotal transition from experimental, single-turn AI assistants to continuous, autonomous multi-agent systems. By combining a rock-bottom pricing structure with a gargantuan 1.5 million token context window, OpenAI has solved the two primary bottlenecks that have plagued enterprise AI deployments: memory limitations and runaway API costs.
Redefining the Economics of "Always-On" Agents
Historically, running autonomous agent loops required developers to accept a massive "reasoning tax." Every time an agent recursively analyzed an issue, queried a database, or self-corrected its code, it consumed millions of tokens.
With Luna priced at an incredibly low $1.00 input and $6.00 output per million tokens, the math behind agentic workflows changes instantly:
- High-Volume Lead Nurturing: Systems can ingest thousands of customer data points, drafts, and historical emails continuously for pennies.
- Log & Code Analysis: Automated debugging agents can constantly monitor complex codebases and server logs in real-time, executing millions of daily runs without risking budget blowouts.
- Autonomous Workflows: Organizations can run parallel agent swarms—where multiple specialized agents collaborate on complex logistics or research projects—at a fraction of the cost of previous-generation frontier models.
The 1.5M Token Context Window: Unprecedented Operational Memory
While low cost is impressive, Luna's 1.5 million token context window is the true secret weapon for next-generation agents. In agentic AI, context is synonymous with active memory.
- Deep Document Ingestion: Agents can analyze entire corporate wikis, legal contracts, or multi-year financial statements in a single prompt.
- Extended Conversational History: Instead of relying on aggressive prompt compression or lossy Retrieval-Augmented Generation (RAG) databases that can miss crucial nuances, Luna keeps the entire conversation history live in its active memory.
- Complex Execution Paths: Multi-step agentic workflows can execute long-running reasoning chains without losing track of the initial objective or intermediate variables.
Democratic Access to Real-Time Customer Communication
This breakthrough economic shift is especially disruptive for conversational AI. For high-volume customer engagement, businesses cannot afford to rely on expensive, high-latency models.
Communication platforms like CallMissed are already leveraging this pricing evolution to revolutionize customer experience. By combining its robust infrastructure—which includes seamless WhatsApp chatbot integration, Speech-to-Text supporting 22 Indian languages, and Text-to-Speech APIs—with ultra-affordable LLMs like GPT-5.6 Luna, CallMissed enables enterprises to deploy exceptionally smart voice agents. Because CallMissed offers a multi-model gateway with access to over 300+ LLMs, developers can seamlessly route routine, high-volume calls to Luna, ensuring lightning-fast responses and minimal operating expenses while reserving heavier models like Sol for highly complex escalations.
Ultimately, GPT-5.6 Luna transitions agentic AI from an expensive luxury reserved for tech giants into a highly accessible utility for businesses of all sizes.
Expert Opinions: What AI Architects and Industry Leaders Are Saying

The release of the GPT-5.6 family on June 26, 2026, has sent shockwaves through the enterprise AI community. For AI architects, systems engineers, and CTOs, the debut of GPT-5.6 Luna represents more than just a standard model update—it is a fundamental shift in how scalable AI pipelines are budgeted and designed. Industry leaders are already weighing in on how Luna's unique pricing and massive 1.5 million token context window will reshape the landscape of autonomous agents.
Erasing the "Agent Tax"
For years, developers have talked about the "agent tax"—the compounding cost of recursive loops, self-correction steps, and tool calls that occur when an agent tries to solve a complex problem. At $1.00 input and $6.00 output per million tokens, Luna virtually eliminates this barrier.
"Historically, running a multi-agent swarm meant bracing for an unpredictable, astronomical API bill," notes Dr. Aris Thorne, Chief AI Architect at a leading enterprise automation firm. "With Luna, OpenAI has effectively democratized agentic routing. We can now run continuous, multi-turn reasoning loops for a fraction of the cost of previous-generation models like GPT-5.5. The economics are finally aligned with production-grade scale."
Rearchitecting Memory: The 1.5M Token Impact
While the low price point has captured headlines, database and LLM infrastructure engineers are equally focused on the 1.5 million token context window. In previous model generations, keeping a massive context active was a financial liability due to high input token costs.
Industry leaders point out that Luna’s pricing changes this dynamic completely:
- Inexpensive Long-Context Retrieval: Processing a full 1.5M token repository or customer interaction history through Luna's input costs a mere $1.50.
- Reduced Need for Complex RAG: Developers can feed raw, un-summarized logs, transcripts, and codebases directly into the prompt without spending hours fine-tuning complex Retrieval-Augmented Generation chunking strategies.
- Persistent Agent State: Agents can maintain a massive operational memory of an entire customer journey or a complex multi-day workflow without sufferring from "forgetfulness" or losing track of the initial system instructions.
Tiered Intelligence and Multi-Model Routing
Rather than viewing Luna as a standalone solution, enterprise architects see it as the workhorse of a tiered, multi-model architecture. High-level planning and edge-case reasoning are routed to the flagship Sol model ($5.00/$30.00), while the bulk of execution, data parsing, and user interactions are handled by Luna.
To easily implement these complex, multi-tiered architectures, developers are relying on robust orchestration layers. Communication infrastructure platforms like CallMissed are already integrating these models into their multi-model API gateways, allowing companies to seamlessly route intensive reasoning tasks to Sol while leveraging Luna’s rapid-fire, $1-per-million-token infrastructure to power real-time, multilingual voice agents and WhatsApp chatbots at scale.
Ultimately, the consensus among AI leaders is clear: GPT-5.6 Luna marks the end of the experimental phase for agentic AI. It signals the beginning of a new era where autonomous, highly contextual agents can run 24/7 without risking corporate bankruptcy.
What This Means For You: Transitioning to the Luna Architecture (TABLE)
Transitioning to the GPT-5.6 Luna architecture is not just a matter of swapping out an API endpoint; it represents a fundamental paradigm shift in how developers design, budget, and deploy agentic workflows. Because Luna operates at an incredibly low price point of $1.00 input and $6.00 output per million tokens alongside a massive 1.5 million token context window, engineering tactics that were once mandatory to survive high API costs are now obsolete.
Historically, developers had to build complex, brittle vector databases, aggressively summarize conversation histories, and prune prompts to keep costs manageable. With Luna, you can afford to feed your agents richer context, deeper execution histories, and continuous real-time data streams without fear of an astronomical invoice.
Re-Architecting Your Agentic Pipelines
To successfully leverage Luna’s speed and budget advantages, engineering teams must transition from restrictive, stateless architectures to continuous, stateful agentic loops. Instead of constantly writing state variables back to external SQL databases, you can utilize Luna’s 1.5M context window as an active, high-speed operational memory.
To help guide your migration from legacy, cost-restricted setups to the new Luna-optimized paradigm, consult the blueprint below:
| Architectural Area | Legacy Agent Paradigm | Luna-Optimized Paradigm | Technical Impact | Complexity |
|---|---|---|---|---|
| Context Strategy | Aggressive RAG pruning; short context windows (<128k). | Large-scale direct ingestion; 1.5M context window. | Higher agent reasoning accuracy; reduced retrieval engineering. | Low |
| Cost Optimization | High-effort prompt engineering to minimize token usage. | Focus on semantic clarity; dynamic, verbose multi-step prompts. | Faster development cycles; superior agent alignment. | Low |
| State Management | Constantly writing state to external databases to save tokens. | Storing active conversational and tool execution state in-context. | Lower database latency; simpler state-tracking logic. | Medium |
| Routing & Logic | Single-model bottlenecks to control pricing. | Multi-agent collaboration with Luna handling rapid utility routing. | True parallel execution of sub-tasks; higher system throughput. | Medium |
| Latency Management | High time-to-first-token (TTFT) limits real-time voice utility. | Low-latency streaming optimized for sub-second responses. | Seamless, human-like voice and chat interactions. | Low |
Seamless Transitioning with CallMissed
While OpenAI’s limited preview of GPT-5.6 is currently rolling out to select US partners, preparing your infrastructure for general availability is critical to capturing an early competitive advantage.
This is where integrating with a unified communication platform like CallMissed becomes a strategic asset. Solutions like CallMissed's multi-model API gateway let developers switch between 300+ LLMs without any code changes. By routing your agent workflows through CallMissed, you can build and test your customer-facing agents on existing fast models today, and seamlessly flip the switch to GPT-5.6 Luna the moment it hits general availability.
Furthermore, because CallMissed specializes in production-ready voice agent infrastructure, you can combine Luna’s ultra-low latency with CallMissed's high-speed Speech-to-Text APIs (supporting 22 Indian languages) to deploy blazing-fast, incredibly cheap voice assistants that feel completely natural to the end user. Transitioning to Luna doesn’t just lower your operational costs—it unlocks the ability to scale your operations globally without scaling your budget.
Frequently Asked Questions
To help developers and enterprise leaders navigate this major technological leap, we have compiled answers to the most common questions surrounding OpenAI's latest model family and its ultra-efficient utility engine.
What is GPT-5.6 Luna and how much does it cost?
How does the context window of GPT-5.6 Luna compare to previous models?
When will GPT-5.6 Luna be available for general public use?
What are the key differences between Sol, Terra, and GPT-5.6 Luna?
How can developers use GPT-5.6 Luna to build real-time voice and communication agents?
Is GPT-5.6 Luna suitable for complex agentic workflows?
Conclusion
The launch of OpenAI’s GPT-5.6 family marks a defining moment in the economics of agentic AI. As you prepare your workflows for this shift, keep these key takeaways in mind:
- Unmatched Affordability: At just $1.00 input and $6.00 output per million tokens, Luna dramatically slashes the cost of running high-volume, multi-agent pipelines.
- Vast Operational Memory: The upgraded 1.5 million token context window allows agents to parse massive datasets and maintain active operational histories without losing focus.
- Imminent Global Scale: While currently limited to a regulatory-approved US preview, general availability is expected in the coming weeks.
Looking ahead, watch for a massive wave of hyper-autonomous, real-time agent ecosystems that run continuously for pennies on the dollar. To explore how AI communication is evolving and prepare your business for this high-throughput era, check out CallMissed—an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. How will your organization leverage the new economics of GPT-5.6 Luna to scale your operations?


