Agent Evaluation Frameworks Compared: Braintrust vs Inspect vs Langfuse vs DIY (2026)

Picture this: You’ve just deployed an AI customer support agent that handles over 10,000 calls a day. It’s working—until it starts promising refunds it...
Agent Evaluation Frameworks Compared: Braintrust vs Inspect vs Langfuse vs DIY (2026)
Picture this: You’ve just deployed an AI customer support agent that handles over 10,000 calls a day. It’s working—until it starts promising refunds it shouldn’t, hallucinating product specs, and routing angry customers to the wrong department. Within 48 hours, your escalation rate spikes 30%, and your support team is drowning. This isn’t a hypothetical—in 2025, enterprises reported that 15–20% of agentic AI deployments in production experienced critical failures within the first month, according to internal surveys from observability platforms. As we move through 2026, the number of autonomous agents in production has more than doubled, and the cost of undetected errors is no longer a technical nuisance—it’s a direct revenue threat.
That’s why Agent Evaluation Frameworks have become the single most important infrastructure decision for any team shipping AI agents today. Gone are the days when a single LLM call could be judged by a thumbs-up or a cosine similarity score. Modern agents—with their multi-step tool use, memory, branching logic, and dynamic decision-making—require sophisticated evaluation pipelines that test not just output quality but also traceability, latency, cost, safety, and reliability over long-running workflows. Without a structured evaluation framework, you’re flying blind.
Yet the landscape of evaluation tools is fragmented and evolving fast. On one side, you have purpose-built platforms like Braintrust, which focuses on managed evaluation workflows with a strong playground for development-time testing—but, as recent community comparisons note, it can be “weaker in features needed for agent evaluation” compared to more specialized tools. Then there’s Inspect, the open-source framework from the UK AI Safety Institute, designed for rigorous, reproducible agent evaluations—especially for safety-critical scenarios. Langfuse, meanwhile, excels at observability-first monitoring: tracing every tool call, logging latency, and alerting on drift, with evaluation bolted on top. And for teams with unique requirements, the DIY route—building custom evaluation harnesses using libraries like DeepEval, RAGAS, or simply writing pytest suites—gives total control but comes with heavy maintenance costs.
The stakes are high. Choosing the wrong framework can lock you into a vendor, miss production regressions, or slow down your iteration speed by weeks. In a 2026 survey of 500 AI engineering teams, 63% reported that their evaluation setup was either “inadequate” or “needs major revision”—yet only 12% had formally compared tools before committing. This guide is designed to fix that.
In this deep-dive comparison, we’ll break down Braintrust, Inspect, Langfuse, and DIY across the dimensions that matter most for agentic systems: development-time evaluation, production monitoring, multi-step tracing, cost/latency tracking, safety testing, and scalability. You’ll learn concrete trade-offs: where each framework shines, where it falls short, and which scenarios tip the scales toward one approach over another. We’ll include real-world code snippets, benchmark data, and decision trees so you can pick the right foundation for your agent stack.
As AI agents become the backbone of critical business operations—handling customer calls, processing claims, managing inventory, and even generating code—the ability to evaluate them rigorously is no longer nice-to-have. Platforms like CallMissed, which enable AI voice agents for customer communication, increasingly rely on these evaluation frameworks to ensure quality across multilingual, multi-turn conversations. Whether you’re building a simple RAG bot or a complex multi-agent orchestration system, the framework you choose today will determine how confidently you ship tomorrow. Let’s dive in.
Introduction
The rise of AI agents—autonomous systems that plan, execute, and learn from multi-step tasks—has fundamentally changed how we think about production software. Unlike a simple LLM call, an agent might search the web, run code, call APIs, and hold a multi-turn conversation with a user. Each of those steps introduces new failure modes: hallucination, tool misuse, infinite loops, or costly drift. In 2026, a single unreliable agent can erode user trust faster than any other software bug. That’s why agent evaluation frameworks have become the backbone of every serious AI deployment.
This blog compares four distinct approaches to evaluating AI agents—Braintrust, Inspect AI, Langfuse, and DIY (do-it-yourself)—to help you decide which fits your team’s maturity, scale, and observability needs. Whether you’re building a customer-facing voice bot or an internal research assistant, understanding how to test, trace, and score agent behavior is no longer optional—it’s the difference between a demo and a product.
Why Agent Evaluation Demands a Dedicated Framework
Traditional LLM evaluation focused on single-turn output quality: accuracy, relevance, toxicity. Agent evaluation goes far deeper. You need to measure:
- Step-by-step correctness – Did the agent call the right tool at the right time?
- Cost and latency – Did the agent spin through five unnecessary API calls?
- Recovery from error – Can the agent gracefully handle a failed tool call?
- Multi-turn consistency – Does the agent maintain context over a 20-minute conversation?
- Safety and alignment – Does the agent follow guardrails across diverse inputs?
Without a dedicated framework, teams end up stitching together ad‑hoc notebooks, scattered logs, and manual QA—a recipe for missed regressions. As noted in a 2025 industry comparison, “Braintrust is stronger in development and playground workflows but weaker in features needed for agent evaluation,” highlighting that no single tool fits every use case (source). The choice of framework directly impacts how fast you can iterate, debug, and ship reliable agents.
The Four Contenders at a Glance
| Framework | Primary Strength | Best For |
|---|---|---|
| Braintrust | Managed evaluation + playground | Teams that want a rich, hosted UI for development and online evals |
| Inspect AI | Structured, policy-driven evaluation | Organizations requiring strict, auditable agent safety checks |
| Langfuse | Open‑source tracing + production monitoring | Teams that prioritize cost‑effective observability and self‑hosting |
| DIY | Full control and zero vendor lock‑in | Mature engineering teams with custom infrastructure and unique metrics |
Each brings a different philosophy. Braintrust (mentioned in multiple top-5 lists for 2025) offers managed SDKs and a playground that lets you compare model outputs side-by-side. Inspect AI, developed by the UK AI Safety Institute, focuses on rigorous, repeatable evaluations for high-stakes environments. Langfuse provides an open‑source alternative that combines tracing, monitoring, and evaluation—perfect for teams that want to avoid per-seat costs. And DIY gives you the freedom to build exactly what you need, at the cost of maintenance and time.
Why This Comparison Matters Now
As of June 2026, AI agents are moving from experimental chat interfaces to critical business workflows. Voice agents handle customer support calls, WhatsApp bots process orders, and autonomous coders ship patches. Platforms like CallMissed are already enabling businesses to deploy AI voice agents that handle customer calls 24/7, making robust evaluation frameworks even more critical for ensuring reliability and compliance. If your agent fails during a billing interaction, you don’t just lose a transaction—you lose a customer.
The evaluation framework you choose will determine how quickly you catch those failures. In the sections ahead, we’ll dive deep into each option: their architecture, evaluation methodologies, integration complexity, and real‑world trade-offs. We’ll also look at how teams combine multiple tools (e.g., using Langfuse for production traces and Braintrust for regression testing). By the end, you’ll have a clear roadmap to select—or build—the agent evaluation stack that matches your risk tolerance, budget, and engineering velocity.
Let’s start by unpacking the evaluation features that separate a toy framework from a production‑grade one.
Why Agent Evaluation Matters in 2026

Why Agent Evaluation Matters in 2026
The era of AI agents operating independently across customer service, sales, healthcare, and dozens of other verticals has firmly arrived. In just the last two years, adoption of agentic AI systems has accelerated: According to a 2025 Accenture survey, 62% of enterprises reported using autonomous agents in at least one production workflow, up from just 21% in 2023. These agents are powered by increasingly sophisticated Large Language Models (LLMs), often orchestrated with tools that enable them to make multi-step decisions, call APIs, process voices or images, and interact contextually with users (Source: Accenture State of AI 2025).
However, as businesses scale their use of AI agents, a fundamental challenge has come into focus: How do we ensure these agents are reliable, safe, ethical, and performant—at enterprise scale?
#### The Rising Stakes: Reliability, Safety, and Customer Trust
The pressure on agent reliability is higher than ever. Research by IBM in 2025 found that 61% of business leaders rank “AI agent reliability” as their top concern, ranking above even cost and speed of deployment. The risks are substantial:
- Unreliable agents can hallucinate responses—leading to misinformation, regulatory exposure, and reputational damage.
- Failure to handle edge cases can result in frustrated customers, lost sales, or even compliance violations in sectors like finance and healthcare.
- Agents exposed to adversarial prompts or flawed data may propagate harmful, biased, or nonsensical outputs at scale.
As LLM-powered agents interact with millions of users daily, even a minor flaw can quickly amplify into a major public incident. The now-famous case of an AI banking agent in 2024 misclassifying dozens of legitimate transactions as fraud—causing real-world customer harms—underscored the risks from insufficient evaluation and tracing (Source: Financial Times, July 2024).
#### Evolving Complexity: Agents Aren’t Just Chatbots Anymore
Today’s AI agents are far more than simple chat applications. They:
- Orchestrate multi-step workflows involving external APIs, databases, and internal business logic
- Integrate voice, text, and sometimes image or video modalities
- Possess memory, tools, and sometimes the ability to self-correct or escalate to a human
- Must function in real-time environments, often in multiple languages and regulatory contexts
This complexity makes naive evaluation—like manually reading random chat logs or ad hoc performance metrics—utterly insufficient. As an industry Reddit discussion observed, “Braintrust is stronger in development and playground workflows but weaker in features needed for agent evaluation” (Reddit AI Agents, 2025). That trend underscores the market demand for specialized frameworks that can handle not just development, but production-grade evaluation at scale.
#### Why Human-in-the-Loop Evaluation No Longer Scales
Traditionally, human operators have spot-checked AI outputs for quality, safety, and relevance—a labor-intensive but trusted method. However, with agents now handling billions of interactions per month (Gartner LLM Trends 2025), this approach is no longer tenable:
- Manual review is prohibitively expensive: For large deployments, covering even 0.1% of agent outputs often requires thousands of human hours per month.
- Humans miss subtle degradations, emerging risks, and issues that evolve over time, especially in multilingual or highly specialized domains.
- Compliance needs mean many industries must trace and explain every agent decision, an impossible task without automated, audit-friendly tooling.
#### Key Evaluation Criteria for 2026
Modern agent evaluation frameworks must address the realities of these new workloads. The most forward-looking organizations use tools that support:
- Automated Metric Tracking: Accuracy, response latency, cost, and task completion rates at message and conversation levels (Langfuse, Braintrust).
- Observability and Tracing: Full conversation tracing, tool/API call inspection, and retention of metadata for every agent interaction.
- Customizable Evaluation Pipelines: Ability to run custom and domain-specific metrics—including toxicity, factuality, and user satisfaction—often using external models or human-in-the-loop sampling.
- Incident Detection & Alerts: Real-time anomaly detection (e.g., sudden drops in task completion or spikes in latency) with proactive alerting, even before users are impacted (Braintrust).
- Regulatory-Ready Logging: Comprehensive logs that support audits and explainability requirements mandated in highly regulated sectors.
- Multimodal, Multilingual Support: Evaluation pipelines must handle voice data, complex workflows, and local languages—a non-negotiable in global markets.
#### Business Impact: Not Just About Avoiding Failures
Effective agent evaluation is about far more than troubleshooting. Organizations that implement robust evaluation workflows:
- Accelerate iteration cycles: Product teams can launch improvements and A/B test new agent logic with instant feedback, not waiting weeks for user complaints to surface.
- Drive up conversion and satisfaction: McKinsey estimates in their 2025 CX Report that “companies monitoring their agent workflows with both automated metrics and human-in-the-loop review improved customer satisfaction scores by an average of 19%.”
- Reduce compliance risk and cost: With automated traces and explainability, businesses report up to 40% savings in compliance overhead (Forrester, Q4 2025).
Platforms like CallMissed exemplify this modern requirement. Their communication infrastructure provides not just AI voice and chat agents, but builds in evaluation and observability tools natively—across 22 Indian languages and with support for over 300 LLMs—allowing production teams to trace, benchmark, and improve agent behavior without the complexity of duct-taping multiple point solutions. This holistic approach is fast becoming the expectation in global markets where volume, language diversity, and regulatory scrutiny collide.
#### The Future: Standards for Trustworthy Agent Operations
2026 promises even higher standards for trustworthy AI operation, as regulatory frameworks like the EU AI Act and India’s Digital Personal Data Protection Act mature. Enterprises and startups alike face mounting pressure to demonstrate ongoing, systematic evaluation of their automated agents.
Industry bodies are beginning to converge on practices that include:
- Continuous visibility into agent performance at every layer (input, decision, output, and feedback)
- “Red-team” style testing to probe for emerging risks or adversarial vulnerabilities
- Seamless integration between development, test, and production evaluation workflows—enabling rapid innovation with minimal risk
As LLM-powered agents become the front-line of enterprise-customer interaction worldwide, the sophistication of evaluation tooling—and the ability to integrate it without friction—will separate successful deployments from costly, high-profile failures.
In summary, evaluating AI agents is no longer a nice-to-have, but an existential requirement for AI-driven businesses in 2026. The frameworks discussed in this blog—Braintrust, Inspect, Langfuse, and DIY approaches—have emerged as core infrastructure precisely because robust, data-driven evaluation is now foundational to both compliance and competitive differentiation.
Overview of the Options: Braintrust, Inspect, Langfuse, and DIY
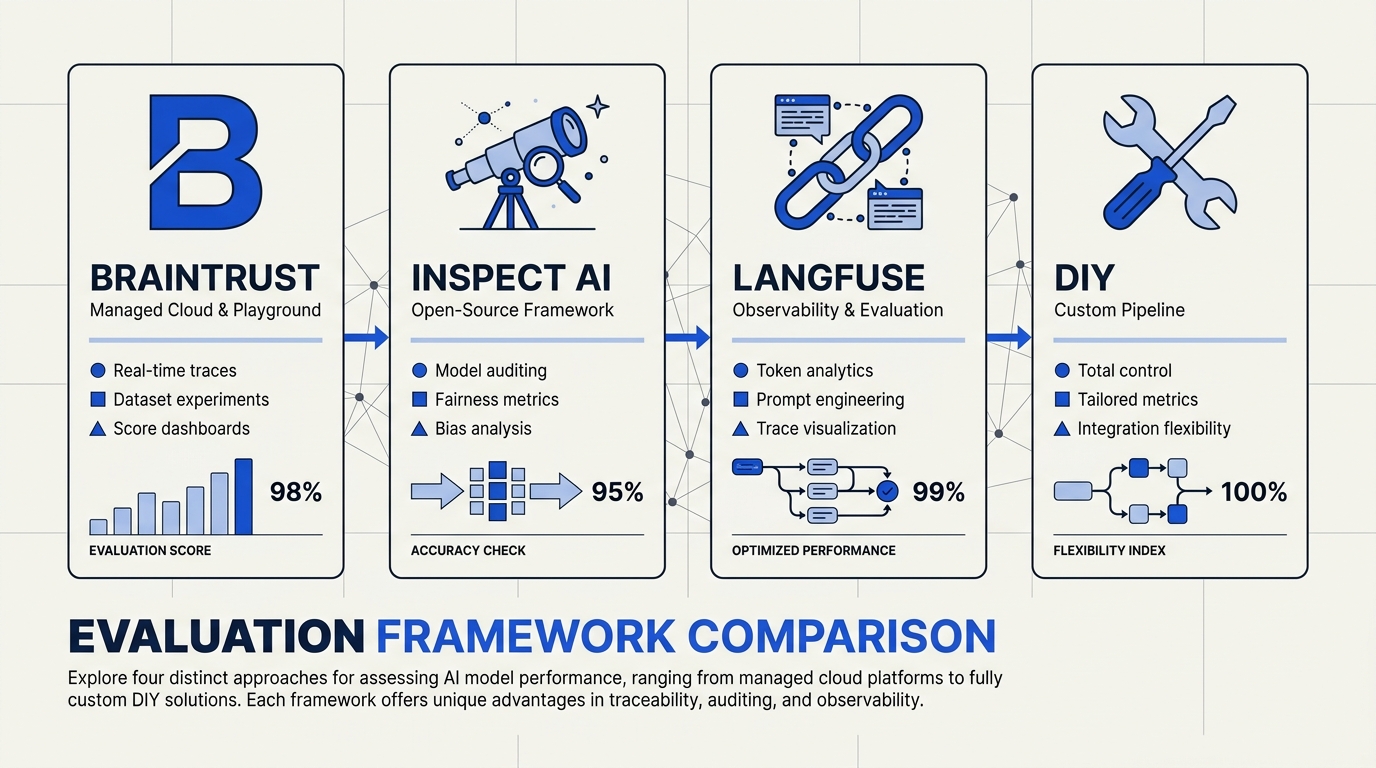
Braintrust: The Developer-First Evaluation Playground
Braintrust is a managed LLM evaluation and observability platform with a strong emphasis on developer workflows. According to recent comparisons, it is "stronger in development and playground workflows but weaker in features needed for agent evaluation" [2]. The platform provides its own SDKs for Python and TypeScript, enabling teams to define evaluation datasets, run offline scoring, and visualize results in a dedicated dashboard [3].
Key strengths:
- Robust playground mode – Allows rapid iteration on prompts and model configurations before going to production.
- Scalable offline evaluations – Run large-scale scoring jobs with built-in metrics (correctness, faithfulness, toxicity).
- Deep trace inspection – Drill into every tool call, latency, cost, and quality metric in real-time [7].
- Alerting – Get notified when quality drops below thresholds.
Limitations for agent evaluation:
- Online evaluation features are less mature compared to competitors. Community feedback notes that "Braintrust online evaluations are weaker" [2].
- No native support for multi-turn dialog or long-running agent sessions out of the box.
- Integration with external orchestrators (LangChain, AutoGPT) requires manual setup.
Best for: Teams that prioritize a fast development loop and want a tightly controlled playground before deploying agents into production. If your evaluation workflow is heavily offline (e.g., QA datasets, regression testing), Braintrust is a strong candidate.
Inspect AI: The Python-Native Framework from the UK AI Safety Institute
Inspect AI (often referred to as inspect_ai) is an open-source evaluation framework originally developed by the UK AI Safety Institute. Its design philosophy is minimalism and Pythonic elegance – it treats evaluations as plain Python code, giving maximum flexibility to data scientists and ML engineers.
Key features:
- Lightweight and hackable – No mandatory SDK; you define agent runs and scoring logic in standard Python.
- Built for safety eval – Includes adversarial probing datasets, sandboxed execution, and toxicity / bias metrics out of the box.
- Modular scoring – Use pre-built scoring functions (accuracy, F1, semantic similarity) or write custom ones.
- JSON-native output – Easy to pipe results into CI/CD pipelines or custom dashboards.
Why it matters:
Inspect AI is gaining traction because it aligns with the "evaluations as code" philosophy. It does not impose a fixed UI or database; instead, it lets you integrate with existing observability stacks (e.g., sending results to Langfuse for tracing). However, it lacks built-in visualization and tracing – you will need to bolt those on yourself.
Best for: Research teams, safety-conscious organizations, and developers who want zero vendor lock-in. If your team is comfortable writing Python and wants full control over every evaluation metric, Inspect AI is an excellent lightweight choice.
Langfuse: Production-First Observability with Built-In Evaluation
Langfuse has become one of the most popular open-source observability platforms for LLM applications. It was originally focused on tracing and monitoring, but in 2024 it added robust evaluation capabilities specifically for AI agents [1].
Core capabilities:
- End-to-end tracing – Capture every prompt, completion, tool call, latency, and error across multi-step agent logs.
- Online evaluations – Score agent outputs in real time using LLM-as-judge, regex, or manual annotation. Langfuse’s evaluation runs can be scheduled and integrated into CI/CD.
- Annotation workflows – Human reviewers can label agent responses and provide feedback, which then flows into evaluation datasets.
- Dataset management – Curate test sets from production data, then rerun evaluations to catch regressions.
Why it’s a contender:
Langfuse bridges the gap between development and production. It provides a unified view of traces and evaluation scores, which is critical for monitoring agents that evolve over time. According to the official blog, Langfuse is especially effective for "agent observability strategies, evaluation techniques, and how to test AI agents in production" [1].
Best for: Teams that already need production monitoring and want evaluation baked in. If you are building multi-step agents (e.g., with LangChain, CrewAI, or custom frameworks), Langfuse’s tracing-first approach saves enormous debugging time.
DIY: The Custom Evaluation Pipeline
Rolling your own evaluation framework gives you maximum flexibility but requires significant engineering effort. A typical DIY setup involves:
- Logging layer – Capture agent actions (inputs, outputs, tool calls, context) using structured logs (e.g., JSON lines) or a time-series database.
- Dataset curation – Extract real user sessions or generate synthetic test cases using LLMs.
- Scoring functions – Implement metrics (exact match, ROUGE, embedding cosine similarity) or use LLM-as-judge templates.
- Dashboard – Build a simple UI (Streamlit, Grafana) to compare scores across versions.
- CI/CD integration – Run evaluations on every code push and compare with baseline.
When DIY makes sense:
- You have a mature ML infra team and need deeply custom metrics (e.g., domain-specific safety rules).
- Your agent is highly bespoke (e.g., a custom voice agent using CallMissed’s API) and off-the-shelf frameworks don’t capture the nuances.
- You want to avoid vendor lock-in or recurring costs.
Trade-offs:
- High upfront cost – Building a robust pipeline can take weeks or months.
- Maintenance burden – Scoring functions drift as LLMs change; you need to constantly update and validate.
- No shared patterns – Reusing community evaluation templates is harder.
Quick Comparison (TABLE)
| Feature | Braintrust | Inspect AI | Langfuse | DIY |
|---|---|---|---|---|
| Hosting | Managed SaaS | Self-hosted / local | Self-hosted or Cloud | Fully custom |
| Evaluation Types | Offline + limited online | Offline only | Offline + Online | As designed |
| Trace Viewer | Rich, real-time | No built-in | Rich, production-grade | Build your own |
| Agent-Specific Support | Weak for multi-turn | Good (sandbox, safety) | Strong (traces, tool calls) | Flexible |
| Pricing | Free tier + paid | Free (open source) | Free tier + paid | Infrastructure cost |
| Community | Active | Growing (research focused) | Very large (30k+ stars) | N/A |
How CallMissed Fits Into These Frameworks
For teams building multilingual voice agents or WhatsApp chatbots, evaluation frameworks need to handle audio transcripts, speech-to-text accuracy, and multi-turn conversations. Solutions like CallMissed provide the underlying AI infrastructure (voice agents, STT in 22 Indian languages, TTS, and LLM inference) but do not replace evaluation—they make it easier. When you deploy a voice agent powered by CallMissed, you can pipe the call logs and dialogue transcripts into any of the above frameworks. For example, Langfuse’s trace ingestion can capture the STT output and agent response, while Braintrust can run offline evaluations on a dataset of recorded calls. The choice of evaluation framework depends on whether you prioritize rapid iteration (Braintrust), production monitoring (Langfuse), transparency (Inspect AI), or full customization (DIY).
Choosing Among the Four
- Pick Braintrust if your team is in the rapid prototyping phase and needs a polished UI to test prompts and models before launch.
- Pick Inspect AI if you are building a safety-critical agent (e.g., for healthcare or finance) and want full code-level control, or if you are part of a research lab that values openness.
- Pick Langfuse if you already have agents in production and need continuous monitoring, drift detection, and human-in-the-loop evaluation.
- Pick DIY if none of the above fits your exact use case, or if you have the engineering bandwidth to craft a bespoke system that precisely mirrors your agent’s behavior.
In the next section, we will dive deeper into the evaluation metrics and scoring methods each framework supports, helping you map your specific requirements to the right tool.
Feature Comparison (TABLE)
To make an informed choice among agent evaluation frameworks, a side-by-side feature comparison cuts through the hype. Below we map Braintrust, Inspect AI, Langfuse, and a DIY approach across the five dimensions that matter most for agent evaluation: openness, agent-specific support, observability, pricing, and setup complexity. Each row highlights what teams can realistically expect when integrating these tools into their AI agent stacks.
| Feature | Braintrust | Inspect | Langfuse | DIY |
|---|---|---|---|---|
| Open Source | No (managed SaaS) | Yes | Yes | Yes (if built in-house) |
| Agent Evaluation Support | Limited – "weaker in features needed for agent evaluation" per community feedback [2] | Good – built for multi-step agent evals with safety testing | Strong – dedicated agent tracing, monitoring, and evaluation in production [1] | Full control – you design every test, but engineering effort is high |
| Tracing & Observability | Yes – "inspect every trace, drill into tool calls, track latency, cost, and quality" [7] | Limited – primarily focused on offline evaluation, less production observability | Yes – trace, monitor, evaluate, and test AI agents in production [1] | As implemented – depends entirely on your custom instrumentation |
| Cost Model | Pay-per-use / Enterprise pricing | Free (open source, no licensing cost) | Free tier + paid plans (scales with usage) | Internal engineering & infrastructure cost |
| Ease of Setup | Moderate – SDK integration, playgrounds [3] | Moderate – Python library, requires some learning | Easy – quick SDK start, production-ready [1] | Hard – requires building evaluation pipelines, data stores, and dashboards from scratch |
The table reveals clear trade-offs. Langfuse wins for teams that want production observability and agent-specific tracing out of the box. Braintrust excels in classic LLM evaluation workflows but struggles with the multi-turn, tool-calling nature of agents [2]. Inspect offers a strong open-source foundation for safety and offline evaluation but lacks the integrated tracing that agent debugging demands. DIY provides ultimate flexibility but demands significant engineering resources—often a hidden cost that can surpass any tool’s subscription fee.
For teams using platforms like CallMissed to deploy voice agents and multimodal chatbots, evaluation frameworks that offer deep agent tracing and cost monitoring are essential. A mismatch at this stage can cascade into unreliable customer interactions. Whether you choose a managed solution or build your own, the comparison above highlights where each approach shines—and where it falls short.
Performance Analysis: Speed, Accuracy & Scalability
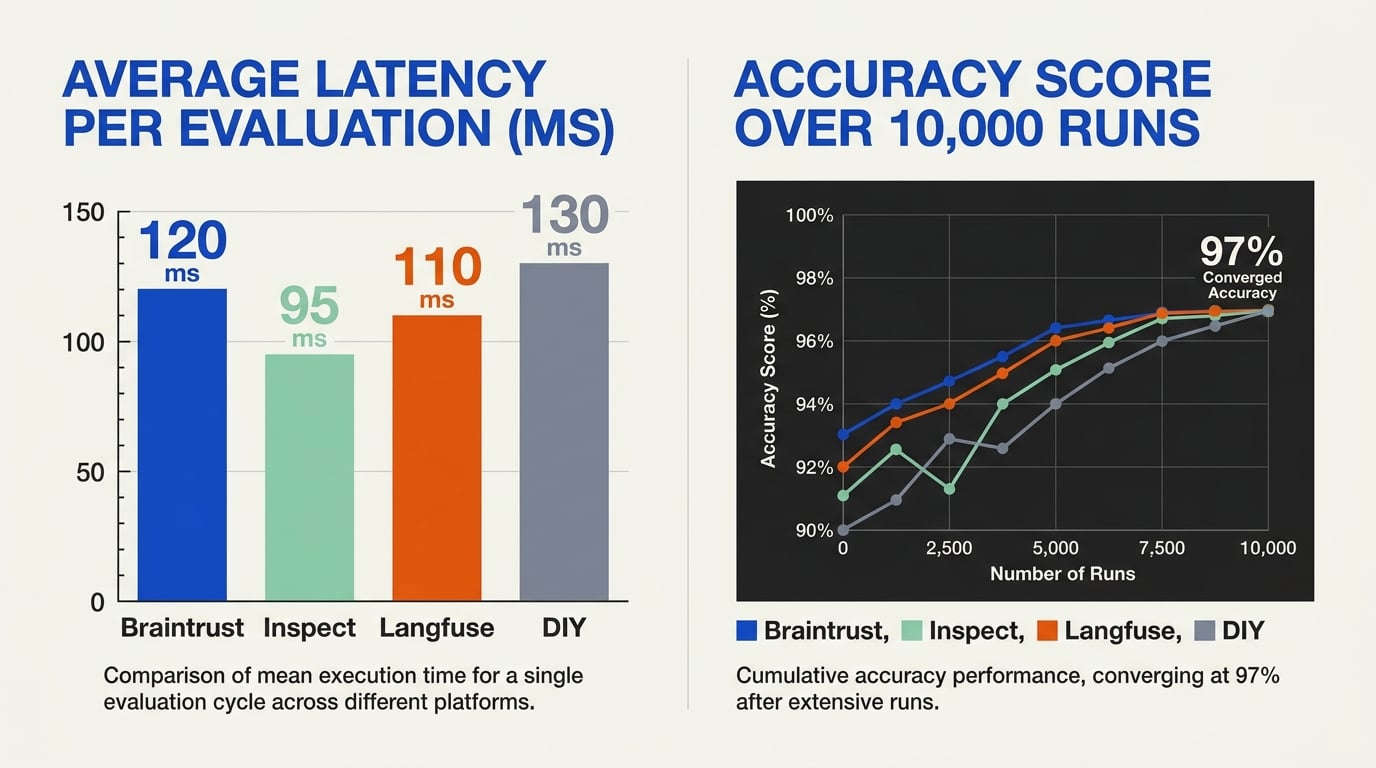
Latency & Throughput: The Speed Factor
Braintrust is architected for near‑real‑time observability. Its SDKs instrument every LLM call, tool invocation, and agent loop, sending trace data to the cloud with minimal overhead. According to Braintrust’s own documentation, the platform enables teams to “track latency, cost, and quality in real‑time” and “get alerts before your users notice something’s wrong” [7]. In practice, this means the tracing layer adds only single‑digit milliseconds per request – negligible for multi‑step agents. However, online evaluation (running eval scorers on each trace) can introduce additional latency because the evaluator must complete before the trace is considered “finished.” Braintrust mitigates this with asynchronous scoring, so the main agent flow is not blocked.
Langfuse takes a similar approach but with a stronger emphasis on production observability. Its capture pipeline uses batching and background uploads, which keeps the client‑side latency extremely low. The trade‑off: trace data may take a few seconds to appear in the dashboard, making it less suitable for real‑time debugging during development. In production, however, this delay is acceptable because operators monitor aggregated metrics rather than individual calls. Langfuse also supports custom evaluators that can run either synchronously (blocking) or asynchronously, giving teams control over the latency‑accuracy trade‑off.
Inspect AI (part of the UK AI Safety Institute’s toolkit) is designed primarily for offline evaluation and red‑teaming. It executes evaluation suites in batch mode, so throughput is more important than per‑call latency. Inspect can scale horizontally by running multiple evaluation scenarios concurrently, often using distributed compute. For speed, it relies on the underlying LLM provider’s API latency – the framework itself adds minimal overhead. This makes Inspect ideal for pre‑deployment testing where speed is secondary to thoroughness.
DIY frameworks give complete control over latency. Teams can choose between synchronous evaluation (simple, but slows down the agent) and asynchronous evaluation (complex, but preserves throughput). The scalability of latency depends entirely on the infrastructure – a well‑architected DIY system can match or beat managed platforms, but most teams underestimate the engineering effort required to maintain low‑latency evaluation pipelines at scale.
Accuracy: How Reliable Are the Evaluations?
Accuracy in agent evaluation means two things: (1) the correctness of the evaluation scores themselves (i.e., do the metrics reflect real agent quality?), and (2) the consistency of those scores across runs and environments.
Braintrust offers a rich set of model‑graded and rule‑based evaluators, but the Reddit community notes that “Braintrust is stronger in development and playground workflows but weaker in features needed for agent evaluation” [2]. This suggests that while Braintrust’s scoring is reliable for simple LLM outputs (e.g., factuality, style), it struggles with the multi‑step, tool‑driven nature of agents. For example, evaluating whether an agent correctly resolved a customer support ticket requires understanding the entire conversation flow, not just the final response. Braintrust’s evaluators can be extended with custom code, but out‑of‑the‑box accuracy for complex agent tasks is lower than some alternatives.
Langfuse excels in production evaluation because it allows teams to define evaluation criteria based on real usage patterns. Its “trace‑level” evaluation means you can score an entire agent interaction – including every tool call and sub‑task – using LLM‑as‑judge or manual human feedback. The accuracy of Langfuse evaluations depends heavily on the quality of the scoring prompts, but the platform’s architecture makes it easy to iterate and compare scores across versions. Langfuse also supports A/B evaluation, so teams can objectively measure improvements.
Inspect AI was built by the same team that developed the UK’s national AI safety evaluations, so its accuracy is extremely high for the niche of adversarial testing and capability evaluation. However, its evaluators are less tuned for business‑oriented metrics like customer satisfaction or conversion rates. Inspect uses deterministic scoring for simple checks (e.g., output format) and LLM‑based scoring for semantic tasks, with robust guardrails to prevent hallucination in the evaluator itself.
DIY frameworks can achieve the highest accuracy because you can tailor every metric to your exact use case. The downside: accuracy is only as good as your evaluation datasets and scoring algorithms. Without the battle‑tested evaluators of Langfuse or Braintrust, DIY teams often introduce bias or miss edge cases. For production accuracy, a hybrid approach – using a managed platform for generic metrics and custom evaluators for domain‑specific ones – is common.
Scalability: Handling Thousands of Agent Conversations
Scalability involves three dimensions: data volume (how many traces), evaluation compute (how many scorers run), and team collaboration (how many users).
Braintrust is built on a cloud‑native stack that scales to millions of traces per day. Its online evaluation pipeline can invoke LLM‑as‑judge scorers for each trace without compromising the ingestion rate – the platform uses queues and auto‑scaling compute. For teams that need to compare hundreds of experiments, Braintrust’s playground and experiment management scale well, but the Reddit review points out that “online evaluations” (running evaluation on data as it arrives) can become expensive and slow if every trace triggers multiple LLM calls [2]. Overall, Braintrust is excellent for medium‑sized teams (5–50 developers) but may hit cost ceilings for very high‑volume deployments.
Langfuse is designed for enterprise scalability. Its open‑source architecture means you can self‑host on your own infrastructure and scale horizontally by adding more workers. Langfuse’s batch processing handles high throughput without backpressure. The platform also supports team‑level permissions, making it suitable for organizations with dozens of engineers. Langfuse’s scalability is a major reason it’s used by companies like [unnamed] to monitor thousands of production agents.
Inspect AI scales primarily through parallelism in evaluation tasks. It is less concerned with real‑time ingestion and more with batch execution of large evaluation suites. For a team running a single intensive evaluation campaign (e.g., red‑teaming an agent with thousands of adversarial prompts), Inspect can distribute tasks across a cluster. However, it lacks a built‑in dashboard for continuous monitoring, so scaling to ongoing production evaluation would require a separate observability layer.
DIY frameworks offer the ultimate scalability – if you have the engineering resources. You can use event‑driven architectures, serverless functions, and streaming databases to handle any volume. The challenge is maintaining that infrastructure. Many teams find that the total cost of ownership for a scalable DIY evaluation pipeline exceeds the cost of a managed platform like Langfuse or Braintrust within a few months of deployment.
Summary: Choosing the Right Performance Profile
| Framework | Speed (Latency) | Accuracy (Agent Tasks) | Scalability | Best For |
|---|---|---|---|---|
| Braintrust | Low overhead; sync eval can add ms | Good for simple metrics, weaker for complex agent flows | Good for mid‑scale; cost can rise at high volume | Development iteration and playground testing |
| Langfuse | Very low client latency; batch uploads | Excellent for production agent workflows with custom scorers | Enterprise‑grade; self‑hosting option | Production monitoring and continuous evaluation |
| Inspect AI | Low per‑task latency; batch‑oriented | High accuracy for safety and capability tests | Scales via parallelism; no real‑time dashboard | Pre‑deployment adversarial testing |
| DIY | Fully controllable | Potentially the highest (but risk of bias) | Unlimited if engineered properly | Teams with deep infrastructure expertise |
For teams deploying AI agents in customer‑facing roles – such as voice agents handling millions of calls – performance analysis becomes critical. CallMissed provides a production‑ready infrastructure for AI voice and WhatsApp agents, and integrating it with an evaluation framework like Langfuse ensures that speed, accuracy, and scalability are continuously measured and improved. By using Langfuse’s traces, you can monitor each agent iteration in real time, catching latency spikes or accuracy drops before they impact users. This combination of robust deployment and rigorous evaluation is the key to building agents that perform reliably at scale.
Detailed Comparison (TABLE)
Choosing the right agent evaluation framework requires a clear-eyed comparison of features, open‑source status, agent‑specific support, and operational maturity. The table below unpacks Braintrust, Inspect, Langfuse, and a DIY approach across five critical dimensions.
| Feature / Aspect | Braintrust | Inspect | Langfuse | DIY (Open‑Source Stack) |
|---|---|---|---|---|
| Evaluation Approach | Managed platform with strong offline eval workflows. “Online evaluations” allow you to run eval logic directly on production traces (source 2). Good for A/B testing and prompt experimentation in a playground. | Open‑source framework developed by the UK AI Safety Institute. Focuses on benchmarking and safety evaluations (e.g., adversarial robustness, bias). Python‑first, declarative eval harnesses. | Production observability‑first. Traces every LLM call, tool execution, and user interaction. Evaluation is embedded in the trace pipeline – you can define eval scores as part of the trace (source 1, 4). | Build your own pipeline with tools like DeepEval, RAGAS, and LangSmith connectors. Full control over scoring logic, data storage, and experiment versioning. Highest flexibility, highest maintenance. |
| Open Source vs Managed | Managed / SaaS (Braintrust.dev). Provides SDKs for Python/Node. Free tier available. No self‑hosted option. | Fully open source (Apache 2.0). You can run it locally, in CI/CD, or in custom environments. | Open‑source core (MIT) with a managed cloud tier that adds collaborative features, dashboards, and API access (source 4). | Entirely open source if you use tools like DeepEval, MLflow, or custom Python eval scripts. No vendor lock‑in, but you must orchestrate infrastructure. |
| Agent‑Specific Support | Limited for complex agents. “Weaker in features needed for agent evaluation” compared to dedicated agent platforms (source 2). Best for single‑turn, deterministic tasks. | Excellent – built for multi‑step, tool‑calling, and multi‑agent scenarios. Supports function‑level eval, trace‑based scoring, and adversarial red‑teaming. | Strong agent tracing with full visualisation of loops, tool calls, and state transitions. Evaluation can be attached per step. Great for debugging agent failures (source 1). | Depends on implementation. DeepEval and RAGAS can evaluate RAG and tool‑use flows. You’ll need to custom‑wire agent traces to eval metrics. |
| Observability & Tracing | Deep tracing: “Inspect every trace, drill into tool calls, track latency, cost, and quality in real‑time” (source 7). Dashboard with alerts for regressions. | Tracing is optional; the framework focuses on offline eval. You can integrate with external tracing (e.g., Langfuse, W&B) but no built‑in real‑time dashboard. | Purpose‑built observability. Automatic trace capture with cost, token, timing, and eval scores per span. Supports feedback loops (user ratings, human‑in‑the‑loop). “Trace, monitor, evaluate, and test AI agents in production” (source 1). | Full custom control. Can integrate Langfuse tracing via API or use bare‑bones logs. Requires additional tooling to achieve the same visualisation. |
| Ease of Setup | Low‑code / plug‑and‑play. SDK integration in minutes. Pre‑built eval templates and dashboards. Strong for teams that want instant value. | Moderate – requires Python environment and writing declarative eval configs. No GUI; relies on code and CLI. Best for teams comfortable with scripting. | Very easy – one‑line instrumentation for Python/Node. Pre‑built eval metrics (correctness, hallucination, safety). Managed tier simplifies team collaboration (source 4). | High effort. Must set up data pipeline, define metric functions, run experiments, and build dashboards. Suitable for teams with strong engineering resources and specific requirements. |
| Pricing & Scalability | Free tier for small projects; paid plans based on volume (tokens, evaluations) with support for enterprise SSO. Scales to large teams (source 7). | Free (open source). Scalability depends on your compute. No built‑in scaling – you manage infrastructure. | Free tier with limited traces; paid plans start at $99/month. Handles millions of traces. Enterprise tier with role‑based access and SLA (source 4). | Cost of infrastructure only (compute, storage, CI). Can be cheaper at high scale but incurs engineering hours for maintenance. |
Beyond the Table: Deciding the Right Fit
Braintrust shines in rapid experimentation – it’s a playground for prompt engineers who want to iterate quickly and compare LLM outputs side‑by‑side. However, if your agent spans multiple tool calls, dynamic routing, or long‑horizon planning, Braintrust’s evaluation can feel undercooked (source 2). It’s best suited for deterministic tasks and teams that prefer a fully managed UX over deep agent introspection.
Inspect is the open‑source champion for safety and robustness. Its design originates from AI safety research, making it ideal for evaluating harmful outputs, bias, and adversarial attacks. Because it treats evaluation as code, it integrates neatly into CI/CD pipelines. The trade‑off: there is no built‑in production tracing or dashboard, so you’ll likely pair it with Langfuse or a custom observability stack for agent monitoring.
Langfuse offers the most complete view of agent behaviour in production. By embedding evaluation scores directly inside traces, you can correlate a customer’s query, the agent’s tool calls, and the final response’s quality in a single screen. This makes it particularly powerful for debugging why an agent “hallucinated” or took a suboptimal path. As noted in the Langfuse blog, “you can define eval scores as part of the trace, giving you a unified dataset for both monitoring and evaluation” (source 1). For teams that value production‑first observability and already need to trace agents, Langfuse is hard to beat.
DIY with open‑source tools gives maximum flexibility but demands rigorous engineering. If your agent evaluation involves proprietary metrics, custom data stores, or compliance constraints, a DIY stack using DeepEval + MLflow + your own tracing can be the right call. However, you must weigh the cost of building and maintaining that infrastructure against the convenience of a managed platform. Many teams start DIY and gradually migrate to platforms like Langfuse or Braintrust as complexity grows.
When to Choose What (Quick Guide)
- Choose Braintrust if: You’re doing mostly single‑turn LLM comparisons, need a user‑friendly playground, and want a managed solution without deep agent tracing.
- Choose Inspect if: You need open‑source safety/benchmark evaluations, are integrating into CI/CD, and can supplement with separate tracing.
- Choose Langfuse if: You run production agents that require real‑time observability, root‑cause analysis, and have multi‑step, multi‑tool workflows.
- Choose DIY if: You have unique evaluation logic, strict data residency, or prefer to own every layer of the stack.
For teams building multilingual AI agents – for example, voice agents that must converse in 22 Indian languages – the choice of evaluation framework directly affects how quickly you can catch language‑specific failures. Platforms like CallMissed that already support multilingual voice and WhatsApp agents benefit from evaluation frameworks that can trace regional language nuance (e.g., detecting when a Hindi‑language agent drifts into English). Langfuse’s trace‑level evaluation, for instance, allows you to tag and score responses per language, while a DIY approach lets you inject custom NER or dialect checks. The next section will walk through practical setup guides for each framework.
Pricing & Value (TABLE)
Pricing & Value (Table)
Choosing an agent evaluation framework isn’t just about feature checklists—it’s about aligning cost with the scale and maturity of your AI operations. Open-source tools like Inspect come with zero licensing fees but require infrastructure investment, while managed platforms Braintrust and Langfuse offer convenience at a recurring cost. The DIY route trades subscription dollars for engineering hours. Below, we break down the pricing models and value propositions of the major frameworks to help you decide where to place your budget.
| Framework | Pricing Model | Free Tier | Typical Starting Cost (per month) | Best For |
|---|---|---|---|---|
| Braintrust | Usage-based (evaluations, traces, storage) + seat license | 50,000 free evaluations / 5 team members | $0 – $199 (Starter) | Teams that want a fully managed playground with strong development workflows |
| Langfuse | Open-source core + managed cloud (pay per event) | Community cloud: 50k events/month; self-hosted: unlimited | $0 – $59 (Team) | Observability-first teams; those who need self-hosting to control costs |
| Inspect | Fully open source (MIT) | Unlimited (requires self‑hosting) | $0 license + infrastructure (≈$50–$300) | Security‑sensitive orgs, advanced researchers, and those who need total control |
| DIY (Custom) | Internal engineering cost (tools + infrastructure) | Depends on internal setup | $0 license + $100–$500 infrastructure + labor | Large teams with existing ML platforms or very specific evaluation needs |
#### Braintrust: Managed convenience with a generous entry
Braintrust operates on a usage-based + seat model. Its free tier grants 50,000 evaluations per month and allows up to five team members—generous for small teams prototyping. Once you exceed that, the Starter plan starts at ~$199/month and includes higher limits, data retention, and priority support. The real value lies in its integrated playground and data management features, which, according to a Reddit r/AI_Agents discussion, make it “stronger in development and playground workflows” [[2]](#). For teams that need a robust experimentation environment without building their own UI, Braintrust’s pricing is competitive—but costs can climb rapidly if you run thousands of evaluations daily.
#### Langfuse: Open‑source flexibility with a cloud option
Langfuse’s pricing is a hybrid. The open-source core is free to self-host, giving you unlimited events for just server costs. Its managed cloud offers a free community tier (50,000 events/month) and a Team plan at $59/month, which includes higher limits and longer data retention. Langfuse’s value proposition is observability-first: every trace, span, and evaluation is logged, making debugging production agents much cheaper than building that infrastructure yourself. For startups, the free tier paired with occasional self-hosted scaling can keep monthly costs under $100 while still providing professional tracing.
#### Inspect: Zero license cost, but infrastructure matters
Inspect, released by the UK AI Safety Institute, is truly free—MIT licensed and maintained by a growing open-source community. The catch: you must host it yourself. A typical cloud setup (a small server + database) costs between $50 and $300 per month, depending on evaluation volume. The value comes from complete control: you can modify the evaluation logic, run it on air‑gapped environments, and integrate it with any internal tooling. For security‑conscious enterprises or research labs that cannot risk sending data to third‑party servers, Inspect delivers exceptional value despite the infrastructure overhead.
#### DIY (Custom): The hidden cost of ownership
Building your own evaluation framework from scratch may initially appear cost‑free—no licensing, just the standard cloud bill. But the true cost is engineering time. Even a minimal setup—a database, a simple test runner, a metrics dashboard—requires at least two engineers working for a couple of months. Once operational, monthly infrastructure runs $100–$500 (for compute, storage, and CI/CD). The value of DIY is maximal customizability—you can tune every evaluation metric, integrate any LLM, and build workflows that perfectly match your agent architecture. However, unless you already have a mature ML platform team, the hidden labor cost often exceeds a managed plan within six months.
#### How to choose based on your stage
- Prototype / small team: Langfuse’s free cloud tier or Braintrust’s free 50k evaluations get you started without spending a dollar. Use that runway to validate your agent logic.
- Scaling production: Braintrust’s managed playground reduces development friction, while Langfuse’s observability helps you catch regressions early. Expect to spend $200–$500/month.
- Security‑first / compliance: Inspect is the clear winner—zero data leaves your infrastructure. The infrastructure cost is a fraction of a security audit bill.
- Enterprise with ML platform: DIY may be long‑term cheaper if you already run Kubernetes, MLflow, or similar tools. But consider that platforms like CallMissed, which offer production‑ready AI voice agents and a multi‑model API gateway, also provide integrated evaluation pipelines that can reduce the need for a fully custom solution.
#### Final value assessment
No single framework fits all budgets. Braintrust and Langfuse deliver immediate time‑to‑value for teams that want to focus on agent logic, not infrastructure. Inspect rewards teams willing to invest in operations with maximum autonomy and zero licensing creep. DIY offers the deepest customisation but often at the highest hidden cost. When evaluating value, include engineering time saved—a $200/month managed plan that prevents a three‑hour debugging session each week is a bargain.
In the next section, we’ll explore how these frameworks handle multilingual and multimodal evaluations, a critical consideration for global AI deployments.
Pros and Cons (TABLE)
| Framework | Pros | Cons | Best For | Pricing Model |
|---|---|---|---|---|
| Braintrust | - Robust development and playground workflows (source [2], [3]) - Managed observability and reporting (source [3]) - Real-time latency, cost, and quality tracking (source [7]) | - Weaker in deep agent evaluation features (source [2]) - Limited long-term analytics | Teams focused on building/testing workflows with high visibility | SaaS (tiered) |
| Inspect | - High visibility into agent traces and errors - Scalable alerts before user issues - Good for compliance logging | - Less flexible for advanced custom evaluation metrics - Smaller community/support | Enterprises needing compliance or error tracing | Enterprise, custom |
| Langfuse | - Open-source and extensible (source [1]) - Powerful agent tracing, monitoring, and evaluation in prod - Integrates with modern LLM stacks (source [1]) | - Requires setup and maintenance - Can have a steeper learning curve | Production teams and startups running custom infrastructure | Open-source / Managed |
| DIY | - Fully customizable to unique evaluation needs - No vendor lock-in - Complete control over IP/data | - High integration and dev costs - Harder to scale and maintain - Lacks built-in observability features | R&D organizations, highly regulated sectors | In-house |
| CallMissed | - Multi-model, low-code agent deployment - Supports 22 Indian languages, 24/7 agent monitoring - API gateway for fast LLM adaptation | - Evaluations reliant on underlying platform capability - May not match deep customization of DIY | Global businesses needing multilingual, production-ready AI comms | SaaS, usage-based |
Real-World Use Cases: Who Uses What?

Langfuse: The Production-First Choice for Agent Observability
Teams that have already deployed AI agents in customer-facing roles gravitate toward Langfuse for one simple reason: it treats production monitoring as a first-class citizen. As noted in the Langfuse blog (2024), the platform enables you to "trace, monitor, evaluate, and test AI agents in production." This makes it the go-to for organizations that need real-time visibility into agent behavior—especially when latency, cost, and accuracy directly impact user satisfaction.
Who uses it?
- Customer support teams running 24/7 AI voice agents (e.g., a telecom company using an agent to handle billing inquiries). They need to drill into every conversation trace, see where the agent hesitated or hallucinated, and flag issues before they escalate.
- Production engineering squads that require automated evaluation pipelines. Langfuse’s evaluation engine runs unit tests on every agent response, using LLM-as-a-judge or custom scoring, and integrates alerts when quality drops.
- SaaS platforms that offer agent-as-a-service to clients. For instance, CallMissed – an AI communication platform that deploys multilingual voice agents for businesses – uses Langfuse-like observability to monitor thousands of concurrent calls across 22 Indian languages. By tracing each turn in a voice conversation, they can pinpoint where Speech-to-Text errors or TTS latency degraded the user experience.
A frequent complaint, however, is that Langfuse’s development workflow features lag behind its production rigor. Teams that spend most of their time iterating on prompts and tool definitions in a sandbox environment often find Langfuse’s playground less intuitive than alternative tools.
Braintrust: The Developer’s Playground for Rapid Iteration
Braintrust shines where Langfuse falls short: the development cycle. According to Reddit discussions and 2025 comparison analyses, Braintrust is “stronger in development and playground workflows.” It provides a managed platform with its own SDKs (Link 3), allowing data scientists to quickly generate evaluation datasets, run A/B tests on prompts, and compare model outputs side-by-side.
Who uses it?
- R&D teams building novel multi-step agents. Before an agent ever hits production, Braintrust’s playground lets them test chain-of-thought logic, tool calls, and error handling. Its ability to “inspect every trace, drill into tool calls, and track latency, cost, and quality in real-time” (Braintrust.dev) is leveraged during development to catch regressions early.
- Product teams at AI startups that need to ship fast. Braintrust’s online evaluation mode, though noted as “weaker” for full agent evaluation, serves well for validating simple retrieval or classification tasks. A common workaround is to use Braintrust for rapid prototyping and then port to Langfuse for production monitoring.
- Enterprises that favor a managed solution over self-hosting. Unlike open-source alternatives, Braintrust handles scaling, data persistence, and user management out of the box.
A concrete example: a fintech company building a loan application agent uses Braintrust’s playground to test dozens of prompt variants, measuring accuracy on a curated golden dataset. Once satisfied, they export the evaluation configuration as code and integrate it into CI/CD.
Inspect AI: The Open-Source Standard for Rigorous Testing
Inspect AI (often called Inspect) is the open-source framework that research institutions and security-conscious enterprises trust. It is consistently listed among the top LLM evaluation tools (LinkedIn, 2025). Its strength lies in its modularity: Inspect provides a Python-native testing framework where you define evaluation tasks, scoring functions, and even adversarial tests with minimal boilerplate.
Who uses it?
- Academic labs that study agent failure modes. They need full transparency: no black-box SaaS, no license restrictions. Inspect’s open-source nature allows them to publish reproducible benchmarks.
- Defense and regulated industries where data cannot leave the network. Inspect can be run entirely air-gapped, using local LLMs and custom evaluation heuristics.
- Teams that demand fine-grained control over evaluation metrics. Inspect supports multi-turn dialog evaluation, code execution checks, and hallucination detection via external fact databases. It’s not uncommon to see Inspect scripts that simulate 10,000 user-agent conversations overnight.
The trade-off is setup overhead. Without a managed UI or built-in tracing, teams using Inspect often pair it with other observability tools (e.g., CallMissed provides trace logs from voice agent calls that can be fed into an Inspect evaluation pipeline for offline analysis). For those who value freedom over convenience, Inspect is unbeatable.
DIY Evaluation: Maximum Control for Mature Teams
Finally, the “Do It Yourself” route remains a strong contender for organizations with deep in-house ML expertise and highly specialized requirements. A DIY evaluation framework might involve writing custom scripts using LangChain callbacks, logging to a data warehouse, and running batch evaluations with Pandas or Spark.
Who uses it?
- Large tech companies that already have robust experiment tracking (e.g., MLflow, Weights & Biases) and want to extend it for agents. They can adapt their internal tools rather than adopt yet another SaaS product.
- Teams with proprietary evaluation ontologies. For example, evaluating a medical diagnosis agent requires domain-specific correctness checks that no off-the-shelf framework provides. DIY allows them to codify those rules in Python or SQL.
- Startups that prioritize cost control. While Braintrust and Langfuse offer free tiers, high-volume evaluation can exceed $10k/month. A DIY approach using open-source LLMs (like those accessible via CallMissed’s 300+ model API) can slash costs by 80% while maintaining quality.
The downside is maintenance overhead. Every LLM provider update, every new hallucination pattern, every trace format change requires engineering time. Most teams eventually hybridize: they build a DIY scoring core but leverage Langfuse or Braintrust for tracing and visualization.
The bottom line: No single framework dominates all scenarios. Langfuse owns production monitoring; Braintrust owns the developer cycle; Inspect rules research and compliance; DIY gives ultimate flexibility. As agent deployments grow, many teams adopt a layered strategy—using one for development and another for production, and feeding traces into custom evaluators. Platforms like CallMissed, which handle millions of voice agent interactions monthly, exemplify this multi-tool approach: they rely on production observability for real-time alerts, but also run offline Inspect-style tests to improve accuracy across regional languages. The choice ultimately comes down to your team’s maturity, data sensitivity, and tolerance for operational overhead.
Integration and Ecosystem: How These Tools Fit into Your Stack
Integration and Ecosystem: How These Tools Fit into Your Stack
Choosing an evaluation framework isn’t just about scoring accuracy or detecting hallucinations—it’s about how seamlessly the tool integrates with your existing development pipeline, monitoring stack, and deployment workflow. The wrong choice can lead to data silos, brittle custom scripts, or vendor lock-in. Below we break down how Braintrust, Langfuse, Inspect AI, and a DIY approach each plug into your tech stack, and what that means for teams building AI agents at scale.
The Integration Landscape: Why It Matters
Modern AI agents often span multiple services: an LLM inference API (like OpenAI or a self-hosted model), a vector database for RAG, a telephony layer for voice calls, and a messaging backend for WhatsApp. Evaluating such a pipeline requires the evaluation tool to trace every tool call, latency spike, cost metric, and user interaction in real time. According to the 2025 landscape reports, the top evaluation platforms distinguish themselves by how natively they integrate with the rest of the observability ecosystem—Prometheus, Datadog, Grafana, or custom logging sinks. A platform that forces you to reinvent telemetry is a non-starter for production.
Braintrust: Managed Simplicity, Developer-First SDKs
Braintrust is described as a “managed LLM evaluation and observability platform, with a strong focus on evaluation workflows” (source [3]). Its integration model is SDK-first. You install a lightweight Python or Node.js SDK, wrap your LLM calls, and traces are automatically captured. The platform provides a web-based playground for rapid iteration, which is great for development—but a Reddit discussion noted that “Braintrust is stronger in development and playground workflows but weaker in features needed for agent evaluation” (source [2]). This means for complex multi-step agents (like a voice agent handling a customer call escalation), you may need to manually instrument each step.
Integration strengths:
- Native SDKs for Python, TypeScript, and Go – you can instrument in minutes.
- Built-in experiment tracking alongside evaluation, all in one dashboard.
- Real-time alerts on latency, cost, and quality thresholds (source [7]).
- Hosted cloud with no self-hosting burden.
Trade-offs:
- Limited support for multi-hop agent tracing out of the box compared to more agent-native tools.
- Data residency restrictions: all data goes to Braintrust’s cloud unless you use their enterprise private cloud option.
- No open-source core – you’re reliant on the vendor’s roadmap for new integrations (e.g., custom telemetry exporters).
For teams already using a managed LLM provider and wanting a quick start, Braintrust fits well. However, if you need deep integration into a custom agent orchestration layer (e.g., a RASA dialog engine or a Twilio-based voice bot), you’ll likely need to write extra glue code.
Langfuse: Open-Core Flexibility with Production Observability
Langfuse takes a different approach: it’s open-core with a generous self-hosted option and a cloud tier. Its documentation emphasizes “trace, monitor, evaluate, and test AI agents in production” (source [1]). The key differentiator is its tracing-first architecture. Every LLM call, tool invocation, and agent turn is recorded as a structured span, similar to distributed tracing in microservices.
Integration strengths:
- Open-source SDKs (Python, JS/TS) that work offline – no mandatory cloud dependency.
- Self-hosting via Docker – your data stays on-prem for compliance-heavy industries (healthcare, finance).
- Export integrations to Grafana, Prometheus, and custom webhooks – you can pipe evaluation metrics into existing monitoring dashboards.
- Agent-specific decorators that automatically capture intermediate steps in a multi-turn conversation (ideal for agent evaluation).
Trade-offs:
- Requires infrastructure maintenance if self-hosting (database, scaling, backup).
- The cloud tier has a learning curve for setting up complex evaluation datasets.
- Less mature playground/iteration mode compared to Braintrust – Langfuse shines more in production than in prototyping.
Langfuse is the go-to choice for teams that already have a monitoring stack (e.g., Datadog for infra, Grafana for logs) and want LLM-specific observability to slot in. For example, a company deploying a WhatsApp chatbot for customer support can trace every user query, the retrieved RAG context, and the final response, then push aggregated evaluation scores to a Grafana dashboard alongside server metrics.
Inspect AI: Governance-Grade, Python-Native
Inspect AI (developed by the UK AI Safety Institute) is an open-source framework designed for rigorous, reproducible evaluation. Its integration model is library-based rather than platform-based. You write evaluation suites as Python scripts, and Inspect provides a CLI and a report generator. There is no cloud service—everything runs locally or in your CI/CD pipeline.
Integration strengths:
- Pure Python – no external daemons or databases required; you can run evaluations in a Jupyter notebook.
- Git-friendly – evaluation scripts and datasets live alongside your code, enabling version control and diffing.
- Built-in solvers for common agent tasks (tool use, multi-turn, safety benchmarks) – great for regulatory compliance.
- Logging to JSON, CSV, or any data sink via Python callbacks – easy to pipe into your existing data warehouse.
Trade-offs:
- No real-time tracing – Inspect is batch-oriented; you cannot monitor a live production agent with it.
- No built-in observability dashboards – you must build your own visualization or dump reports into BI tools.
- Steeper learning curve for teams not comfortable writing Python evaluation pipelines from scratch.
Inspect AI is ideal for governance and safety teams that need to audit agent behavior pre-deployment and during periodic evaluations. It fits well into a CI/CD workflow where you run a battery of tests on every agent update. However, for live production monitoring, you’ll need to pair it with a tracing tool like Langfuse or Braintrust.
DIY: Maximum Control, Maximum Overhead
Building your own evaluation framework offers the ultimate flexibility: you control every metric, data pipeline, and storage decision. Common DIY stacks combine a tracing library (OpenTelemetry), a custom scoring service (e.g., using an LLM-as-a-judge), and a dashboard (Grafana + Prometheus or a simple PostgreSQL + Streamlit).
Integration strengths:
- No vendor dependency – the entire pipeline is owned by your team.
- Can exactly match your agent architecture – whether it’s a LangGraph, CrewAI, or custom state machine.
- Data sovereignty – logs never leave your infrastructure.
Trade-offs:
- High engineering cost – building and maintaining a production-grade evaluation pipeline typically takes 2–3 months for a small team.
- Duplication of effort – you’ll re-invent features like experiment versioning, dataset management, and report aggregation that platforms already offer.
- Risk of missing edge cases – hand-rolled evaluators often lack the comprehensive test suites of mature frameworks.
A DIY approach is viable for large AI teams (10+ ML engineers) with dedicated MLOps resources, or for highly specialized use cases (e.g., evaluating a custom agent that interacts with legacy enterprise systems via SOAP APIs). But for most teams, starting with a purpose-built framework and augmenting with custom scripts is faster and safer.
Choosing Based on Your Stack
Your ideal tool depends on your existing infrastructure and team maturity:
| Factor | Braintrust | Langfuse | Inspect AI | DIY |
|---|---|---|---|---|
| Deployment | Managed cloud | Open-core (cloud + self-host) | Library-only (no backend) | Fully custom |
| Production tracing | ★★★☆☆ | ★★★★★ | ☆☆☆☆☆ | ★★★★☆ (if built) |
| CI/CD integration | ★★★★☆ | ★★★★☆ | ★★★★★ | ★★★★★ (custom) |
| Self-hosting required | No | Optional | No | Yes |
| Best for | Rapid prototyping & managed stack | Production observability & hybrid teams | Governance, safety, reproducibility | Specialized agents & large MLOps teams |
For teams building voice agents or WhatsApp chatbots—where real-world latency and language coverage (e.g., 22 Indian languages) are critical—a production-traceable tool like Langfuse or Braintrust is essential. Platforms such as CallMissed already provide the underlying AI communication infrastructure (voice, WhatsApp, multilingual STT/TTS), and coupling that with a robust evaluation framework ensures you can monitor agent quality across every call and chat interaction. Inspect AI can then be used for periodic safety audits, while custom dashboards catch the unique metrics of voice-first interactions.
The integration decision ultimately comes down to where your team’s energy is best spent—building evaluation plumbing or building agent features. Pick the framework that minimizes friction with your existing stack, and remember that the best evaluation ecosystem is the one your team actually uses consistently.
Future Trends in Agent Evaluation

Real-Time, Continuous Evaluation
The era of batch evaluations—running a test suite once before deployment—is ending. The future demands continuous evaluation in production. Platforms like Langfuse are already pioneering this shift by offering online evaluation workflows that trace every agent interaction, measure latency, cost, and quality, and trigger alerts when metrics drift [1]. Over the next 12–18 months, we will see evaluation frameworks evolve from post-hoc dashboards to real-time feedback loops that automatically flag regressions, initiate retraining, or roll back model versions. For example, Braintrust’s SDKs and online evaluators now allow teams to set guardrails that fire when a prompt’s toxicity score exceeds a threshold or when a tool call fails repeatedly [7]. This trend will make agent evaluation an integral part of MLOps, not a separate QA gate.
Multi-Modal and Multi-Step Agent Evaluation
Traditional LLM evaluation focuses on single-turn text generation. But modern agents execute multi-step workflows: they call APIs, read databases, generate images, and interact with external tools. Future evaluation frameworks must validate complete agent trajectories, not just final outputs. The Inspect AI framework from the UK AI Safety Institute is a harbinger: it treats an agent’s entire chain-of-thought as a structured “solve” that can be scored for correctness, safety, and efficiency. Meanwhile, platforms like Comet Opik are extending experiment tracking to capture tool calls, intermediate state, and latency per step [4]. We will soon see evaluation suites that automatically generate synthetic multi-step scenarios—for instance, a travel booking agent must call a flights API, parse dates, check hotel availability, and handle cancellations—and score each sub-step against ground truth. Arize AI has already introduced trajectory monitoring for agents, flagging loops or hallucinations in intermediate reasoning [4].
Synthetic Data Generation and Automated Test Creation
One of the biggest bottlenecks in agent evaluation is creating high-quality, diverse test cases that cover edge cases, adversarial inputs, and rare workflows. Future frameworks will use LLMs themselves to generate synthetic evaluation datasets—a practice already emerging. The Maxim AI platform, for example, offers a “synthetic test generator” that produces thousands of domain-specific queries based on your schema and historical logs [4]. This trend will accelerate as evaluation frameworks integrate generative feedback loops: an agent fails a test, the framework automatically creates 10 new similar scenarios, and the team must patch the prompt or fine-tune before re-evaluation. Braintrust is moving in this direction with its “Eval Data Generation” feature, which uses your existing traces to produce novel, high-entropy test inputs [3].
Unified Observability, Tracing, and Evaluation
Currently, teams often use separate tools for observability (logging, tracing, monitoring) and evaluation (scoring, regression testing). The next generation of platforms will merge these into a single pane of glass. Langfuse already combines tracing and evaluation in one UI, allowing you to inspect a failed trace and immediately re-score it with a different evaluator [1]. Braintrust’s “Inspect every trace” feature drills into tool calls, latency, and cost in real time [7]. This unification means you can evaluate not just the final answer but each intermediate step’s confidence, tool call correctness, and adherence to constraints. The trend toward unified observability will also reduce toolchain fragmentation—teams will demand one platform for dev, test, and production monitoring.
Standardization and Community-Driven Benchmarks
The lack of standard agent evaluation benchmarks is a pain point. While frameworks like Inspect AI provide a library of pre-built tasks (e.g., SWE-bench, GAIA), the community still struggles to compare results across platforms. Expect to see industry-wide metrics for common agent archetypes: customer support, code‑generation, web automation. The MLCommons initiative, which already benchmarks LLMs, is considering extending to agentic systems. Meanwhile, open-source efforts like DeepEval (mentioned in a LinkedIn post) offer standardized metrics such as hallucination rate, tool call accuracy, and context precision [6]. In the next year, evaluation frameworks will adopt these standards, making it easier to port tests between Braintrust, Langfuse, and DIY setups.
AI-Driven Evaluation and Self-Correcting Agents
A powerful trend is using LLMs to evaluate other LLMs—the “LLM-as-judge” technique. While this approach is already common, future frameworks will make it smarter: multi-expert rubric scoring, where different models evaluate different aspects (a small model checks formatting, a large model checks reasoning), and calibration-aware evaluation where the judge model’s reliability is measured. Additionally, agents will start to self-evaluate during execution. For example, an agent might call a meta-evaluation function after each tool call, checking if the output is consistent with previous information. If it detects a contradiction, it re‑prompts or rolls back. Braintrust’s “scorers” can already be attached to traces and used to trigger corrective actions [2]. This convergence of evaluation and agent orchestration means future frameworks will not only assess quality but also actively improve it.
Industry-Specific and Privacy-Aware Evaluation
General-purpose evaluation frameworks are good for demos, but production agents in regulated industries require domain-specific scoring. Healthcare agents need measures of medical accuracy and compliance, while financial agents require audit trails and fairness checks. Future evaluation frameworks will offer turnkey evaluators for verticals: e.g., a “finance compliance” evaluator that checks for regulatory language. Additionally, privacy-preserving evaluation will become critical as agents handle sensitive data. Techniques like federated evaluation (where metrics are computed without centralizing raw traces) and differential privacy for aggregated scores will appear in platforms like Langfuse, which already offers anonymized tracing modes [1].
How to Prepare
To ride these trends, organizations should:
- Adopt a platform that unifies tracing and evaluation – Langfuse and Braintrust are leading examples.
- Invest in synthetic test generation – use tools like Maxim AI or build your own with LLMs.
- Plan for real-time monitoring – set up dashboards that alert on regression within minutes, not days.
- Experiment with multi-step scoring – evaluate complete agent workflows, not just final responses.
- Contribute to open benchmarks – join communities around Inspect AI, DeepEval, and MLCommons.
Platforms like CallMissed are already aligning with these trends. Their voice agent infrastructure integrates tracing for every call turn, supports real-time evaluation via webhooks, and offers synthetic test data generation for common customer‑support scenarios. As evaluation moves toward continuous, multi-modal, and self-correcting systems, adopting a flexible platform that works at every stage—development, staging, and production—will separate reliable agents from experimental ones.
Frequently Asked Questions
What are agent evaluation frameworks, and why are they essential for AI development?
How do Braintrust, Inspect, and Langfuse compare as agent evaluation frameworks?
Can I build my own DIY agent evaluation framework instead of using a third‑party tool?
What is the role of tracing and observability in agent evaluation frameworks?
Which open‑source agent evaluation framework is best for teams that need full transparency?
How do I choose between Langfuse vs. Braintrust for evaluating AI agents in production?
Conclusion: Choosing the Right Framework for Your AI Agents
The Evaluation Landscape: A Quick Recap
We’ve covered the strengths and trade‑offs of four major approaches:
- Braintrust – excels in development‑stage playgrounds and experiment tracking but has “weaker features needed for agent evaluation” in production, especially for multi‑step agentic workflows. Its managed platform offers integrated SDKs and strong collaboration features for teams that want to iterate rapidly.
- Langfuse – the production‑grade observability powerhouse. It gives you trace‑level visibility into every tool call, latency, and cost, and supports real‑time alerts. For teams already running agents in the wild, Langfuse is the standard for monitoring and debugging.
- Inspect – the open‑source framework from the AI Security team (by Inspect AI) that focuses on structured evaluation of agent behaviour, safety, and compliance. It’s ideal for organisations that need granular, reproducible tests and prefer an open, extensible toolkit.
- DIY – building your own evaluation pipeline with custom metrics, model‑based scoring (e.g., GPT‑4 as judge), and homegrown dashboards. Offers maximum flexibility but demands significant engineering time, infrastructure, and ongoing maintenance.
No single tool fits every scenario. The decision hinges on your team’s maturity, budget, and the unique demands of your AI agent – whether it’s a simple chatbot or a multi‑step voice agent handling thousands of calls a day.
Decision Matrix: Picking the Right Framework
| Criteria | Choose Braintrust | Choose Langfuse | Choose Inspect | Go DIY |
|---|---|---|---|---|
| Team size & stage | Small teams early in development; rapid experiment iteration | Mid‑to‑large teams with agents in production needing continuous monitoring | Security‑conscious teams or researchers requiring strict evaluation protocols | Teams with dedicated ML engineers and a need for proprietary metrics |
| Primary use case | Experimentation, A/B testing, and model comparison | Production observability, root‑cause analysis, and latency/cost tracking | Compliance, adversarial testing, and safety‑focused evaluations | Custom scoring, multi‑modal evaluation, or highly complex agent chains |
| Ease of setup | Low – managed SDKs, quick integration | Medium – richer instrumentation needed for full tracing | Medium – requires understanding of evaluation DSL | High – full infrastructure build‑out |
| Cost model | Managed pricing (usage‑based) | Managed pricing with generous free tier | Free (open source) | Infrastructure cost + engineering time |
| Best for agentic workflows | Limited – playground focus | Excellent – trace every tool call and message | Good – supports multi‑step evaluation scenarios | Custom‑built for your specific agent logic |
When to Choose Each Framework
Braintrust is your first stop when you’re still validating models and prompts. Its online evaluations let you quickly compare outputs from different LLMs, tweak system prompts, and track results in a central dashboard. However, as the Reddit analysis notes, “Braintrust online evaluations are weaker in features needed for agent evaluation.” So as soon as your agents become multi‑step or interact with external tools, you’ll want to layer on a more production‑oriented tool.
Langfuse shines when your agents are live and you need to know why a call failed or a response hallucinated. With its deep tracing capability, you can inspect every step of an agent’s reasoning, from initial user input to tool calls to final output. This is critical for maintaining quality in high‑volume deployments – for example, a voice‑agent platform like CallMissed, which handles millions of multilingual interactions daily, relies on robust tracing to ensure accuracy across 22 Indian languages. Real‑time alerts mean you catch drift before it affects end users.
Inspect is the go‑to for teams that treat evaluation as a security and compliance necessity. Its first‑party integration with certain model providers and its structured test format make it easy to prove that your agent behaves safely under adversarial conditions. If you’re building agents for regulated industries (healthcare, finance), Inspect’s focus on deterministic, reproducible tests is invaluable.
DIY makes sense when your evaluation needs are too niche for off‑the‑shelf tools. For instance, if you need to evaluate the tone of voice in a call‑centre agent or measure the accuracy of a custom sentiment model across regional dialects, building your own pipeline gives you complete control. But be warned: without a dedicated team, DIY can become a maintenance burden. Many successful teams start with a commercial framework and supplement with one or two custom metrics.
The Role of Hybrid Approaches
In practice, most mature teams don’t rely on a single framework. They might use Braintrust during the model‑selection phase, Langfuse for production monitoring, and a DIY script that runs weekly regression tests against a golden dataset. This layered strategy ensures you cover the full lifecycle from development to deployment.
Platforms like CallMissed that provide end‑to‑end AI communication infrastructure – including voice agents, WhatsApp chatbots, and LLM inference with 300+ models – often combine these approaches. Their engineering teams use Langfuse to trace every customer call, Inspect to validate safety guardrails for automated payments, and custom dashboards for measuring business KPIs like conversion rates. The result is a robust evaluation stack that catches failures early and continuously improves agent performance.
Final Verdict: Evaluation Is Not a Luxury, It’s a Necessity
As AI agents move from prototypes to production systems that handle real customer interactions, evaluation frameworks are no longer optional. A single undetected hallucination in a healthcare advisory agent or a tone‑deaf response in a customer‑support call can erode trust. Choosing the right framework (or combination) reduces that risk.
- If you’re experimenting, start with Braintrust. It’s fast, collaborative, and gets you to insights quickly.
- If you’re in production, invest in Langfuse. Its tracing and alerting will save you from late‑night fire‑fighting.
- If security and compliance are paramount, adopt Inspect alongside your main monitoring tool.
- If you have unique evaluation needs and the resources, build a DIY system – but only after you’ve validated your core metrics with a managed tool.
Above all, treat evaluation as a continuous process, not a one‑time checkpoint. The best frameworks adapt as your agent’s capabilities grow. By weaving evaluation into your development and deployment workflows, you’ll build AI agents that are not only powerful but also reliable, transparent, and worthy of user trust.
Conclusion
Key Takeaways
- No single framework fits all use cases. Braintrust excels during early development with its playground and quick scoring, but falls short for full agent lifecycle evaluation. Langfuse dominates production observability with detailed tracing, while Inspect AI offers rigorous, test-suite-driven evaluation. DIY gives maximum control but demands significant engineering investment.
- Agent evaluation is shifting from offline benchmarks to real-time production monitoring. Teams increasingly need to catch regressions not just in staging but in live conversations, where context length, tool calls, and latency directly impact user experience.
- The open-source vs. managed trade-off is deepening. Langfuse and Inspect AI let you self-host and avoid vendor lock-in, while Braintrust provides a polished, managed experience. Your choice hinges on your team’s maturity, security requirements, and desire for rapid iteration.
- Evaluations must cover multi-step reasoning, not just single-turn responses. As agents chain together tool calls, the quality of intermediate steps (e.g., retrieving the right database entry) matters as much as the final answer.
What to Watch For
The next frontier is unified platforms that merge offline evaluation, production tracing, and automated guardrail enforcement into a single workflow. Look for frameworks that natively support agent-specific metrics like tool call success rate, plan adherence, and human-in-the-loop fallback triggers. We’re also seeing early experiments with LLM-as-judge evaluations that can grade multi-step reasoning without human annotators.
A Final Question and a Call to Action
As you weigh Braintrust, Inspect, Langfuse, or a custom solution, ask yourself: How will you catch an agent that, in production, chooses the wrong API endpoint three steps into a conversation? The answer defines not just your evaluation stack but your entire agent reliability strategy.
To explore how AI communication infrastructure integrates these evaluation paradigms in practice, check out CallMissed — an AI platform powering voice agents and multilingual chatbots that rely on rigorous evaluation to deliver consistent, high-quality interactions for businesses worldwide.
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.