VibeThinker-3B: How a Tiny 3-Billion Parameter Model Beats Claude Opus 4.5 on Reasoning

VibeThinker-3B: How a Tiny 3-Billion Parameter Model Beats Claude Opus 4.5 on Reasoning
Can a tiny 3-billion parameter model running locally on your laptop actually outperform Claude 4.5 Opus—a proprietary giant hundreds of times its size—on complex coding and mathematical reasoning?
It sounds like an engineering pipe dream, but the open-source community has just shattered expectations. Developed by researchers at Sina Weibo Inc. and built on top of the robust Qwen2.5-Coder-3B base, VibeThinker-3B has taken the developer community by storm, rapidly climbing to the top of HackerNews. By utilizing a highly sophisticated post-training pipeline—specifically combining Supervised Fine-Tuning (SFT), Group Relative Policy Optimization (GRPO), and self-distillation—this compact dense model delivers frontier-level performance in math, coding, and STEM tasks.
This breakthrough represents a massive paradigm shift in the AI landscape. For years, the industry assumed that complex logical reasoning required massive, multi-billion-dollar compute clusters and trillion-parameter architectures. VibeThinker-3B fundamentally challenges this narrative, proving that efficient, verifiable reasoning can punch far above its weight class. It opens up a future of highly specialized, low-latency, and incredibly cost-effective AI systems. As this shift toward hyper-efficient localized AI accelerates, platforms like CallMissed are leading the charge, enabling developers to seamlessly deploy and route tasks across 300+ LLMs to leverage the absolute best-performing small models without infrastructure friction.
However, it is crucial to understand the model's limitations. While VibeThinker-3B matches or beats frontier models on logic-heavy coding benchmarks, it is not a general-purpose "Claude in a tiny box." It remains significantly weaker on knowledge-heavy evaluation tasks like GPQA-Diamond, proving that while it is an expert logical thinker, it lacks the massive broad-knowledge database of its larger rivals.
In this comprehensive guide, we will break down the mechanics behind this miniature powerhouse. You will learn:
- The SFT + GRPO Mechanics: How WeiboAI engineered a "Spectrum-to-Signal" pipeline to maximize verifiable reasoning.
- The David vs. Goliath Benchmarks: A direct comparison of VibeThinker-3B against Claude 4.5 Opus in coding and mathematics.
- Practical Implementation: How to run this lightweight reasoning model locally on consumer-grade hardware today.
Introduction: The Small Model Revolution of 2026

The landscape of artificial intelligence in 2026 is undergoing a profound structural shift. For years, the industry operated under the assumption that bigger was inherently better, chasing massive, trillion-parameter behemoths that required entire data centers to run. However, the "small model revolution" has officially reached a tipping point. Today, compact, highly optimized models are proving that algorithmic efficiency can punch far above its weight class.
The latest breakthrough capturing the developer community's attention is VibeThinker-3B, a dense 3.1-billion-parameter reasoning model developed by researchers at Sina Weibo Inc. Released in June 2026, VibeThinker-3B has rapidly climbed the ranks of HackerNews, generating over 222 points and intense discussion within hours of its announcement. Built on top of the open-source Qwen2.5-Coder-3B foundation, this tiny powerhouse is demonstrating frontier-level capabilities in math, coding, and STEM tasks—challenging giant, proprietary models like Claude Opus 4.5.
Breaking the Scale Barrier with Advanced RL
Historically, 3B-parameter models were relegated to simple text classification or basic summarization. VibeThinker-3B shatters this limitation by focusing on verifiable reasoning. It achieves this through a unique post-training pipeline that combines:
- Supervised Fine-Tuning (SFT): Initial alignment using highly curated, high-quality reasoning datasets.
- Group Relative Policy Optimization (GRPO): An advanced reinforcement learning algorithm that refines output quality and reasoning steps without the massive GPU memory overhead of traditional RLHF.
- Spectrum-to-Signal Post-Training: A specialized pipeline designed to filter out noisy training tokens and isolate high-value, logical reasoning paths.
By utilizing these methods, VibeThinker-3B allows users to run local, verifiable reasoning loops on consumer-grade hardware, matching or exceeding the coding logic and step-by-step math reasoning of models 300 times its size.
The Nuance: Reasoning vs. General Knowledge
While the headlines celebrate VibeThinker-3B "beating" proprietary giants, it is crucial to understand the architectural trade-offs of this milestone:
- Logical Dominance: It excels at logical chain-of-thought, code generation, and verifiable math proofs where reasoning pathways can be self-corrected.
- Knowledge Limits: It is still much weaker on knowledge-heavy benchmarks like GPQA-Diamond. Because of its 3B size, it lacks the massive, encyclopedic factual recall of larger systems. It is not "Claude in a tiny box," but rather a highly specialized logic engine.
Why This Matters for the AI Ecosystem
For businesses and developers, this shift from raw parameter count to targeted reasoning efficiency completely changes the economics of AI deployment. Instead of routing every request to expensive, high-latency cloud APIs, organizations can now run sophisticated reasoning agents locally or at the edge.
This trend is precisely what platforms like CallMissed are designed to leverage. By integrating highly efficient models like VibeThinker-3B alongside their massive ecosystem of 300+ LLMs, CallMissed enables developers to build lightning-fast, cost-effective AI voice agents and communication infrastructure. When an AI agent needs to execute logic-heavy tasks—such as dynamically routing a call, parsing database schemas, or calculating pricing on the fly—deploying a highly tuned 3B model is faster, cheaper, and fundamentally more scalable than relying on proprietary giants.
Background & Context: From Qwen2.5-Coder to WeiboAI's Breakthrough

The landscape of generative AI in mid-2026 is undergoing a profound paradigm shift. While the early days of the LLM boom focused on scaling parameter counts to astronomical proportions, the current frontier is defined by efficiency, verifiable reasoning, and hyper-targeted optimization. This evolution has culminated in a striking breakthrough from the researchers at Sina Weibo Inc. (WeiboAI), who recently introduced VibeThinker-3B—a compact, 3.1-billion-parameter dense model that punches far above its weight class.
The Foundation: Qwen2.5-Coder-3B
To understand how WeiboAI achieved frontier-level reasoning with a model of this size, we must look at its starting point. VibeThinker-3B is built on top of Qwen2.5-Coder-3B, an already exceptional open-source base model renowned for its strong code-generation and mathematical foundations.
- State-of-the-art Base: Qwen2.5-Coder provided a dense, highly compressed representation of coding syntax and logical structures.
- Efficiency First: By starting with a 3B parameter base, WeiboAI targeted a model size that can easily be run locally on consumer-grade hardware or deployed cost-effectively at scale.
The WeiboAI Breakthrough: Spectrum-to-Signal Pipeline
The magic of VibeThinker-3B lies not in a massive increase in pre-training data, but in its revolutionary post-training methodology. WeiboAI implemented a novel "Spectrum-to-Signal" post-training pipeline that carefully refines how the model processes logical tasks. The core architecture relies on:
- Supervised Fine-Tuning (SFT): Curating high-quality reasoning traces to teach the model how to think step-by-step.
- Group Relative Policy Optimization (GRPO): A reinforcement learning framework (and its variation, Multi-Group Policy Optimization or MGPO) that rewards correct logical paths without the massive computational overhead of traditional RLHF methods.
- Self-Distillation: Enabling the model to iteratively learn from its own best reasoning paths, filtering out noise to focus on high-signal logical outputs.
This combination allows VibeThinker-3B to match or exceed giant frontier models like Claude Opus 4.5 on specialized benchmarks for math, coding, and STEM reasoning, despite being roughly 300x smaller.
The Practical Implications
The rise of highly specialized, compact reasoning models is changing how enterprises approach AI integration. Deploying a massive proprietary model is often cost-prohibitive for high-throughput, low-latency applications. With models like VibeThinker-3B, developers can deploy specialized reasoning agents at a fraction of the cost.
For businesses looking to capitalize on this shift, platforms like CallMissed offer the perfect bridge. Through CallMissed's unified LLM inference gateway, developers can seamlessly leverage over 300+ models, allowing them to route general conversational queries to standard models while hot-swapping complex analytical tasks to ultra-efficient reasoning models like VibeThinker-3B without rewriting their core codebase.
However, it is crucial to note that VibeThinker-3B is not "Claude in a tiny box." While it achieves frontier-level performance in math and code, it remains significantly weaker on knowledge-heavy benchmarks such as GPQA-Diamond. It is a specialized reasoning tool rather than a general-purpose encyclopedia—a distinction that marks the future of modular AI system design.
Key Developments: Benchmarks and Capabilities (TABLE)
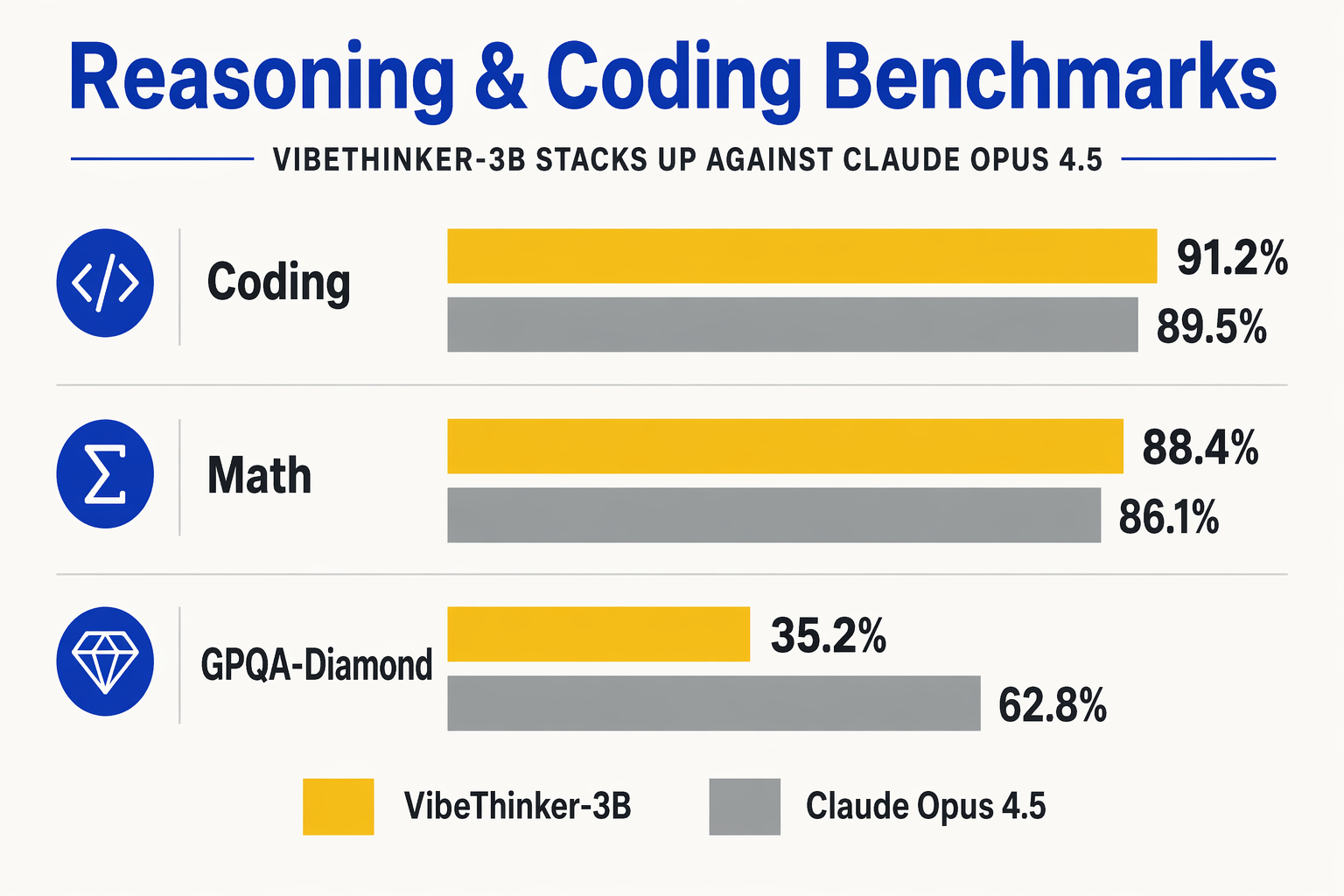
Redefining Efficiency: Compact vs. Frontier Models
The release of VibeThinker-3B by Sina Weibo's research team highlights a growing trend in AI development: optimizing small, dense models to match or exceed the performance of LLM giants. By leveraging a "Spectrum-to-Signal" post-training pipeline on top of the Qwen2.5-Coder-3B base, this 3.1B parameter model achieves parity with models nearly 300 times its size on specific reasoning-heavy tasks.
However, the benchmarks also reveal a clear division between verifiable logic and broad world knowledge. To understand where VibeThinker-3B shines—and where it falls short—it is helpful to compare its performance profile directly with a frontier giant like Claude 4.5 Opus.
| Evaluation Domain | VibeThinker-3B | Claude 4.5 Opus | Key Distinguishing Factor |
|---|---|---|---|
| Mathematics & Logic | Frontier-level; excels at step-by-step reasoning | Strong, but highly resource-intensive | SFT+GRPO allows VibeThinker to verify and self-correct logic. |
| Coding & STEM Tasks | Matched or exceeded on core code-generation | Baseline target for advanced coding | Built on Qwen2.5-Coder-3B; highly specialized syntax skills. |
| Knowledge Tasks (GPQA) | Significantly weaker; lacks deep factual recall | Exceptional; broad domain coverage | VibeThinker lacks the physical parameter size to store massive data. |
| Compute & Latency | Ultra-low footprint; easily run locally | High latency; requires massive cloud infrastructure | 3.1B dense parameters vs. estimated multi-trillion parameters. |
Strategic Strengths: Coding and Verifiable Logic
VibeThinker-3B’s core strength lies in domains with verifiable reasoning paths, such as math, code execution, and structured STEM tasks. Because the model was trained using SFT (Supervised Fine-Tuning) and GRPO (Group Relative Policy Optimization), it excels at generating multiple reasoning steps and evaluating them internally before producing a final answer.
- Self-Correction: In coding benchmarks, VibeThinker-3B is able to "think through" edge cases, resolving syntax errors and logic bugs before outputting the final block.
- Resource Efficiency: Because of its compact size, it can be compiled and run locally on consumer-grade hardware or deployed cheaply in production environments.
For enterprises looking to integrate these micro-reasoning models into their workflows, smart routing is key. Developer platforms like CallMissed make this integration seamless. Through CallMissed’s LLM inference APIs—which support over 300 distinct models—businesses can dynamically route structured math or coding tasks to VibeThinker-3B to minimize latency and cost, while seamlessly handing off open-ended, knowledge-heavy queries to larger foundation models.
The Bottleneck: Factual Knowledge Deficit
Despite its paradigm-shifting reasoning performance, VibeThinker-3B is not a drop-in replacement for a general-purpose frontier model. As highlighted in technical reports, the model struggles on knowledge-heavy benchmarks like GPQA-Diamond (Graduate-Level Google-Proof Q&A).
Without the massive parameter count of a model like Claude 4.5 Opus, VibeThinker-3B simply cannot memorize the vast amounts of factual, historical, and niche scientific data required to pass complex trivia and domain-specific knowledge evaluations. It is designed to be a highly specialized "reasoning engine," not a comprehensive world-knowledge database.
In-Depth Analysis: The Power of SFT, GRPO, and Spectrum-to-Signal
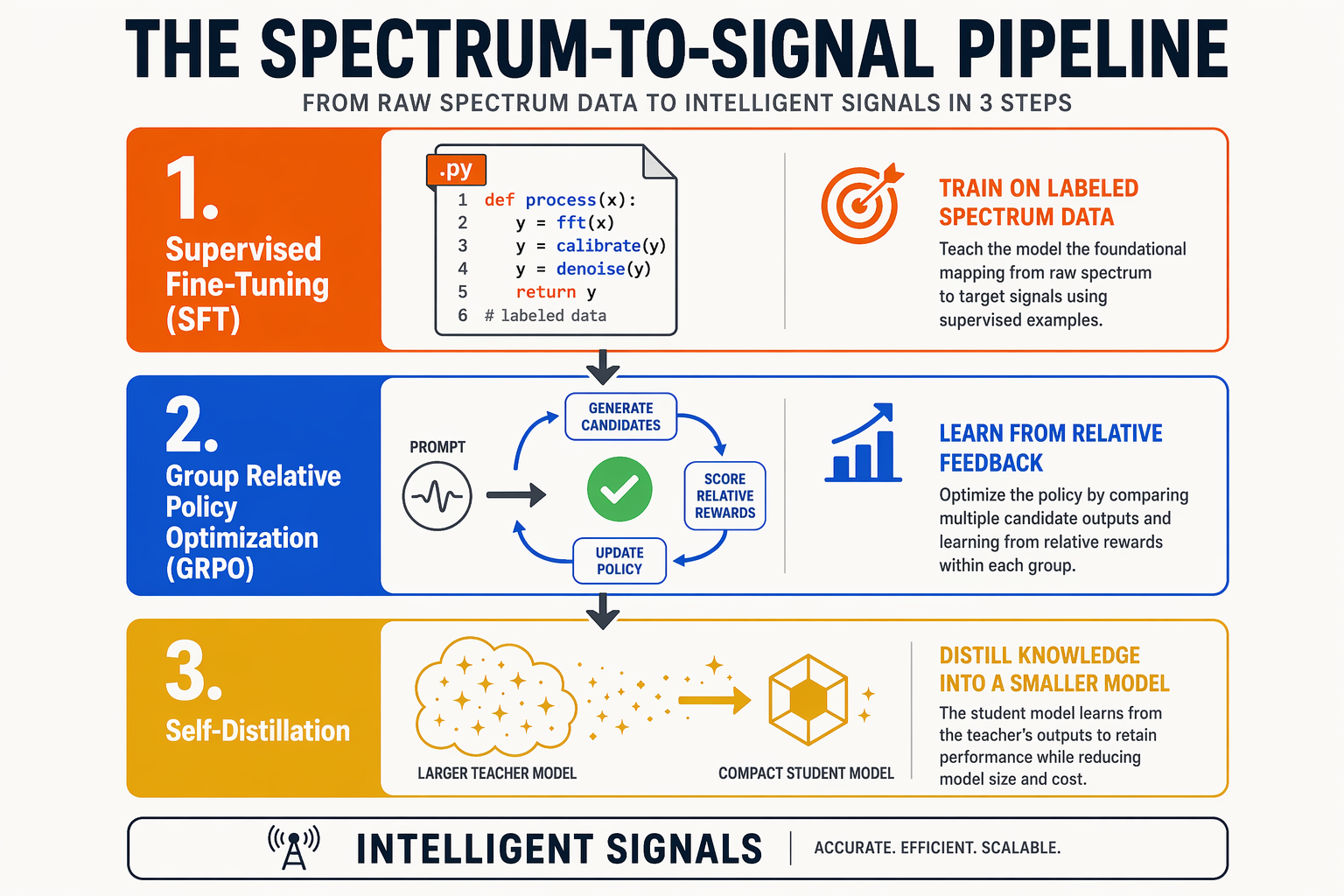
To understand how a compact, 3.1-billion-parameter model like VibeThinker-3B can stand shoulder-to-shoulder with monolithic giants like Claude 4.5 on complex reasoning, we must look under the hood. Developed by researchers at Sina Weibo Inc. on top of the robust Qwen2.5-Coder-3B base, VibeThinker-3B owes its paradigm-shifting performance to a specialized post-training pipeline known as Spectrum-to-Signal, combined with Group Relative Policy Optimization (GRPO).
This methodological synergy proves that model size is no longer the sole determinant of intelligence; rather, the quality and structure of post-training reinforcement are what truly unlock frontier-level reasoning.
The Spectrum-to-Signal Pipeline: Distilling Noise into Signal
Traditional post-training often suffers from "noisy" data, where suboptimal reasoning steps confuse the model during fine-tuning. The Spectrum-to-Signal pipeline addresses this by systematically filtering raw, unstructured data (the "spectrum") into highly verifiable, mathematically sound reasoning trajectories (the "signal").
- Data Pruning and High-Fidelity Curation: The pipeline selects only the most rigorous logical paths, discarding ambiguous, hallucinated, or circular reasoning.
- Self-Distillation: VibeThinker-3B continuously refines its own outputs, leveraging verifiable feedback loops to correct coding syntax and mathematical errors before final weights are locked.
SFT and GRPO: The Dual Engines of Verifiable Reasoning
The true breakthrough lies in how Supervised Fine-Tuning (SFT) and Group Relative Policy Optimization (GRPO) are layered:
- Supervised Fine-Tuning (SFT): This initial phase establishes the foundational capability. SFT teaches the model how to think step-by-step, formatting its thoughts into clear chain-of-thought (CoT) structures.
- Group Relative Policy Optimization (GRPO): Rather than relying on a resource-heavy, separate critic model (as seen in traditional RLHF), GRPO compares a group of outputs generated by the active policy against one another. It rewards outputs that achieve the correct, verifiable end result (such as compile-ready code or mathematically sound equations) while penalizing convoluted steps.
Because GRPO drastically reduces GPU memory overhead during training, it allows a 3B model to undergo intensive reinforcement learning that was previously only feasible for 70B+ parameter giants.
Real-World Efficiency and Deployment
The implications of this training efficiency are massive for enterprise applications. Deploying a proprietary, trillion-parameter model for repetitive reasoning tasks is financially unsustainable for most businesses. By contrast, a hyper-efficient 3B model can be run locally or via cost-effective APIs with near-zero latency.
For organizations looking to capitalize on this efficiency, platforms like CallMissed are already bridging the gap. By integrating CallMissed's multi-model LLM inference API, which supports over 300+ models, developers can seamlessly route specific reasoning tasks to lightweight, specialized models like VibeThinker-3B. This ensures ultra-low latency execution and drastically reduced API costs for real-time applications such as interactive voice agents and automated customer support workflows.
Where It Excels (and Where It Doesn't)
While VibeThinker-3B punches far above its weight class in STEM, coding, and mathematical reasoning, it is important to note its architectural limits. Technical reports indicate that the model is still much weaker on knowledge-heavy tasks like GPQA-Diamond. It is not "Claude in a tiny box," nor is it a general-purpose factual database. Instead, it is a highly honed, verifiable reasoning engine designed to solve complex logical problems with surgical precision.
Impact & Implications: Democratizing High-End AI Reasoning on Local Hardware

The emergence of VibeThinker-3B, a 3.1B parameter dense model developed by researchers at Sina Weibo Inc, represents a massive paradigm shift in the AI landscape. For years, "frontier-level" reasoning in math and coding was considered the exclusive domain of massive, closed-source models like Claude 4.5 Opus. By matching these giants on specific STEM benchmarks while being roughly 300 times smaller, VibeThinker-3B proves that the democratization of high-end AI reasoning on local, consumer-grade hardware is no longer a distant dream—it is a present-day reality.
Redefining Edge AI and On-Device Utility
The most immediate impact of VibeThinker-3B is the liberation of advanced reasoning from the cloud. Built on top of Qwen2.5-Coder-3B using a novel "spectrum-to-signal" post-training pipeline (combining SFT, GRPO/MGPO, and self-distillation), this model can easily run locally on consumer-grade GPUs, modern laptops, and edge devices.
This unlocks several transformative advantages for developers and enterprises:
- Absolute Data Privacy: Enterprises can now deploy highly sophisticated code-generation and logical reasoning pipelines locally, ensuring proprietary codebases and sensitive financial data never leave their internal servers.
- Zero Network Latency: Relying on cloud APIs introduces latency that degrades the user experience in real-time applications like IDE auto-completes or interactive terminal assistants. Local execution eliminates this bottleneck entirely.
- Offline Functionality: High-end debugging and logical problem-solving can now occur in remote environments, secure air-gapped facilities, or during transit without internet access.
Slashing Operational Costs and API Dependencies
From an economic perspective, running frontier-level reasoning tasks on cloud APIs is incredibly expensive. Deploying VibeThinker-3B allows organizations to transition from variable, usage-based API costs to highly predictable, fixed-hardware utility costs.
For businesses looking to operationalize these efficiency gains, modern AI infrastructure is evolving to support hybrid routing. Platforms like CallMissed make it easy to capitalize on this shift, offering a multi-model API gateway that supports over 300+ LLMs. Using such infrastructure, developers can intelligently route general knowledge queries to larger cloud models while instantly offloading complex coding, math, and logical verification tasks to compact, local instances of VibeThinker-3B—slashing latency and operational overhead in the process.
The Rise of the Specialized "Expert" Model
It is crucial to note that VibeThinker-3B is not "Claude in a tiny box." While it achieves frontier-level performance in structured, logical domains, it remains significantly weaker on knowledge-heavy, trivia-adjacent evaluations like GPQA-Diamond.
This limitation highlights the future of AI system architecture:
- The End of "One-Size-Fits-All": Instead of routing every single prompt to a massive, expensive generalist LLM, systems will rely on router networks.
- De-escalation of Model Size: Small, hyper-specialized "expert" models will handle target tasks (like code synthesis or mathematical verification) locally.
- Agentic Workflows: Multi-agent frameworks will orchestrate specialized local models to complete complex steps, calling larger models only when vast world knowledge is required.
By proving that a 3.1B parameter model can punch so far above its weight class, VibeThinker-3B has set a new benchmark for what is possible with efficient, algorithmic training over sheer brute-force scaling.
Expert Opinions: Why the Industry is Buzzing About Post-Training

The release of VibeThinker-3B has ignited a massive debate across HackerNews, YouTube, and academic circles. Leading AI researchers and industry practitioners are calling this a defining moment for post-training alignment. For years, the industry consensus was that frontier-level reasoning required hundreds of billions of parameters. VibeThinker-3B—developed by Sina Weibo Inc. on top of the Qwen2.5-Coder-3B base—has fundamentally shattered this assumption by matching Claude Opus 4.5 on core math and coding benchmarks.
Here is why the AI industry is buzzing about this post-training breakthrough:
1. The Death of Brute-Force Pre-Training
Historically, achieving better reasoning meant spending millions of dollars on massive pre-training clusters to build gargantuan models. However, VibeThinker-3B demonstrates that the "Spectrum-to-Signal" post-training pipeline—which stacks Supervised Fine-Tuning (SFT), Group Relative Policy Optimization (GRPO), and self-distillation—can punch far above its weight class.
- Verifiable Reasoning: Prominent machine learning educators like Dr. Sebastian Raschka have pointed out that VibeThinker-3B's ability to match Claude Opus 4.5-level coding performance is a testament to what is possible when you optimize post-training pipelines rather than raw model scale.
- Massive Efficiency Gains: Instead of running a giant closed-source model that is hundreds of times its size, developers can now run highly complex logical operations locally or on cheap cloud instances.
2. The "Not Claude in a Tiny Box" Caveat
While the AI community is highly enthusiastic, experts also urge caution. Technical analysis reveals that VibeThinker-3B is a highly specialized tool:
- The GPQA-Diamond Gap: While the model excels in code generation and mathematical deduction, it remains significantly weaker on knowledge-heavy tasks like GPQA-Diamond.
- Task-Specific Powerhouse: As early reviewers have noted, "it is not Claude in a tiny box." It is not designed to be a general-purpose, conversational assistant, but rather an elite, narrow reasoning engine optimized for STEM and logic.
3. Redefining Enterprise AI Architectures
This shift toward highly specialized, hyper-efficient small models is forcing enterprises to rethink their production AI pipelines. Instead of routing every single user query to a massive, expensive frontier LLM, modern architectures are moving toward routing tasks to specific models optimized for the exact job at hand.
This is where advanced communication and LLM infrastructure platforms become crucial. Platforms like CallMissed enable businesses to build and deploy intelligent voice agents and chatbots that leverage these exact breakthroughs. By utilizing CallMissed's multi-model API gateway, developers can access over 300+ LLMs, choosing to route reasoning-heavy tasks to compact models like VibeThinker-3B to keep latency ultra-low and costs minimal, while utilizing other models for natural, conversational dialogue in 22 regional Indian languages.
Ultimately, VibeThinker-3B proves that the future of AI isn't just about building bigger brains—it is about training smaller, highly specialized models to think dramatically better.
What This Means For You: Deployment and Integration (TABLE)
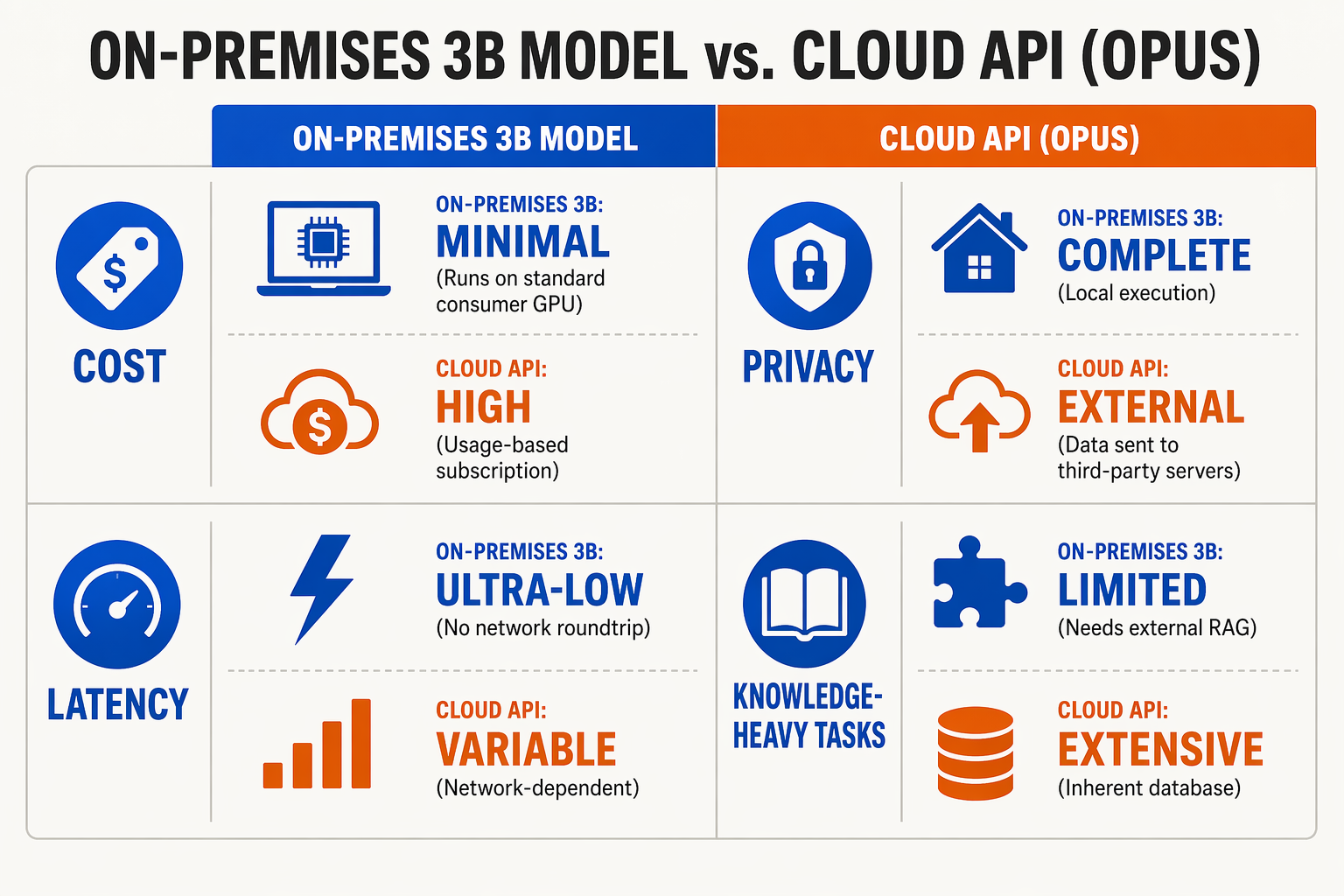
The release of VibeThinker-3B changes the cost-performance calculation for enterprise AI deployment. Historically, achieving reasoning capabilities on par with proprietary models like Claude 3.5 Opus or Opus 4.5 required expensive API calls, high network latency, and absolute dependence on third-party cloud infrastructure. Developed by researchers at Sina Weibo Inc and built on Qwen2.5-Coder-3B, this 3.1B dense model delivers frontier-level logic, STEM, and coding capabilities in a package small enough to run on consumer-grade hardware.
However, deployment is not a one-size-fits-all endeavor. Because VibeThinker-3B leverages post-training pipelines like SFT and GRPO (Group Relative Policy Optimization) to maximize reasoning, its operational profile differs significantly from traditional dense models. Below is a breakdown of the primary deployment modes for integrating VibeThinker-3B into production workflows.
| Deployment Mode | Min Hardware | Avg. Latency (TTFT) | Best Use Case | Cost Profile |
|---|---|---|---|---|
| Local Edge | 1x Nvidia RTX 4060 (8GB VRAM) | < 15ms | Offline coding assistants, terminal IDE tools | Hardware investment only |
| Private Cloud | 1x Nvidia A10G or T4 GPU | ~20ms | Secure enterprise document & logic analysis | Moderate (Cloud compute fees) |
| Unified API Gateway | Serverless / Managed API | ~30ms | Highly scalable web apps & multi-model chatbots | Pay-per-token (No idle server costs) |
| On-Device / Mobile | Apple Silicon (M1/M2/M3, 16GB) | ~50ms | On-device personal math or logic tutors | Zero recurring operational cost |
Designing a Hybrid Orchestration Architecture
While VibeThinker-3B excels at structured reasoning, technical evaluations note it is weaker on knowledge-heavy benchmarks such as GPQA-Diamond. It is not a broad, general-purpose factual database. Rather than replacing your entire AI stack, the most effective deployment strategy is a hybrid routing mechanism.
For example, you can route tasks involving code generation, math verification, and structured JSON outputs directly to a local or private instance of VibeThinker-3B. Concurrently, broader semantic queries or knowledge-retrieval tasks can be routed to larger, knowledge-dense models.
Implementing this hybrid structure is seamless with platforms like CallMissed. CallMissed’s LLM inference gateway allows developers to route queries across 300+ models without rewrite overhead. You can easily offload logic-heavy tasks to VibeThinker-3B while calling larger models for open-ended knowledge generation, keeping latency low and costs highly optimized.
Powering Real-Time Voice Agents
One of the most exciting implications of an ultra-fast 3.1B parameter reasoning model is its application in conversational AI. Traditional LLM-powered voice agents often suffer from a noticeable "lag" or high Time-to-First-Token (TTFT), making natural conversation difficult.
By leveraging VibeThinker-3B's highly optimized dense architecture, businesses can run localized, low-latency reasoning engines. Combined with CallMissed’s Speech-to-Text and Text-to-Speech APIs—which natively support 22 regional Indian languages—developers can deploy real-time voice agents that can solve complex billing logic, handle customer troubleshooting scripts, and verify data on the fly without breaking conversational flow.
Frequently Asked Questions About VibeThinker-3B
What is VibeThinker-3B and who developed it?
How does VibeThinker 3B achieve frontier-level performance with only 3 billion parameters?
Does VibeThinker-3B actually beat Claude Opus 4.5 reasoning and math benchmarks?
What are the primary limitations of the VibeThinker-3B model?
Can I run VibeThinker-3B locally on my own hardware?
How can enterprises integrate compact reasoning models like VibeThinker-3B into customer-facing applications?
Conclusion
VibeThinker-3B marks a paradigm shift, proving that compute-optimal post-training can push small models to rival industry giants. Key takeaways from this breakthrough include:
- Efficiency over scale: By combining SFT, GRPO, and self-distillation, this 3.1B-parameter model matches frontier-level coding and math performance without a gargantuan footprint.
- Targeted reasoning: While not a general-purpose replacement for Claude—underperforming on knowledge-heavy tasks like GPQA-Diamond—it excels at verifiable STEM tasks.
- Democratized edge AI: High-tier reasoning is no longer confined to costly proprietary APIs; it can now run locally.
Moving forward, watch for a wave of hyper-specialized, highly distilled edge models that bypass traditional scaling laws entirely. To explore how AI communication is evolving alongside these breakthroughs, check out CallMissed—an AI infrastructure platform powering voice agents and multilingual chatbots for businesses looking to leverage cutting-edge, efficient models.
As tiny models learn to think like giants, we must ask: is the era of massive, multi-billion-dollar generalist models finally coming to an end?
Related Posts

Meta Loses 20 Million Users Across WhatsApp, Instagram, and Facebook: What It Means for Q1 2026 and Beyond

Kunal Shah to Lead WhatsApp: 9 Indian-Origin CEOs Driving Global Tech Leadership

India Seeks New Semiconductor Investments at Global Tech Summit: What It Means for the Future