Prediction: A Frontier Open-Source LLM Will Be Released On 3rd December 2026

Prediction: A Frontier Open-Source LLM Will Be Released On 3rd December 2026
What if the performance gap between multi-billion-dollar proprietary AI models and customizable open-source alternatives evaporated entirely before the end of this year? For years, developers and enterprises have accepted a compromise: pay premium API fees to tech giants for frontier-tier intelligence, or host open-weights models that lag just slightly behind the bleeding edge. However, a quantitative analysis of historical progress and Artificial Analysis benchmarks has yielded a highly specific and provocative forecast—the Prediction: A Frontier Open-Source LLM Will Be Released On 3rd December 2026.
This date isn't a random guess; it represents the mathematically calculated intersection point where open-source velocity is projected to officially catch up with the proprietary frontier. We have already seen this gap narrow significantly throughout 2026. Models like Qwen 3 235B-A22B and DeepSeek R1 have routinely matched or outpaced legacy giants like GPT-4 in deep mathematical reasoning and coding. Yet, as proprietary systems push deeper into the territories of GPT-5.5 and Claude 4.7 Opus, the open-weights community has been chasing a rapidly moving target. The prospect of achieving absolute parity with the absolute frontier of closed-source AI in a matter of months marks an unprecedented paradigm shift.
Democratizing this elite tier of intelligence means organizations will no longer have to sacrifice data sovereignty or incur unsustainable token costs to access state-of-the-art reasoning. While advanced communication infrastructure platforms like CallMissed already make it seamless for developers to build and deploy intelligent voice agents across 300+ LLMs, a true open-source frontier model would completely rewrite the unit economics of custom enterprise AI.
In this post, we will dissect the data-driven methodology behind Jamie Dborin's viral forecast and evaluate the historical trajectory of open-source progress. We will also profile the prime contenders—from Meta’s Llama series to the latest breakthroughs from DeepSeek and Alibaba—that are currently poised to cross the finish line first. Finally, we will map out exactly what this imminent hardware and software convergence means for the future of decentralized AI and how businesses can prepare for a post-December 2026 landscape.
Introduction: The Race to Open-Source Frontier AI

For years, proprietary AI models from tech giants like OpenAI, Anthropic, and Google have held an undisputed monopoly on "frontier-class" intelligence. Enterprises seeking state-of-the-art reasoning, advanced coding capabilities, and complex agentic behaviors had no choice but to pay premium API fees, accept vendor lock-in, and compromise on data sovereignty.
However, a rigorous quantitative analysis of LLM progress trajectories points to an imminent disruption of this status quo. According to a widely discussed forecast by Jamie Dborin, which leverages historical tracking data from Artificial Analysis benchmarks, the open-source community is on track to release a model that achieves absolute parity with the proprietary closed-source frontier on December 3rd, 2026. This is not a speculative estimate, but rather the mathematically calculated intersection where the velocity of open-weights development officially overtakes the leading edge of closed-source AI.
The Accelerating Open-Source Velocity
The foundation of this prediction lies in the explosive progress observed throughout 2025 and 2026. The performance gap between closed and open models, which once spanned years, has shrunk to a matter of months. Today, the open-weights ecosystem is no longer just playing catch-up; it is actively setting benchmarks:
- DeepSeek R1 has revolutionized deep mathematical reasoning, rivaling proprietary reasoning models at a fraction of the training and inference cost.
- Alibaba's Qwen 3 235B-A22B has emerged as a powerhouse for overall reasoning and coding, routinely outperforming legacy giants like GPT-4.
- While proprietary models like GPT-5.5 and Claude 4.7 Opus represent the current state-of-the-art, their performance leads are being contested faster than ever before.
This rapid convergence indicates that the hardware bottlenecks, algorithmic inefficiencies, and data limitations that once held back open-source developers are being systematically dismantled.
Rewriting the Economics of Enterprise AI
The release of a true frontier-tier open-source LLM on December 3rd, 2026, will mark an unprecedented paradigm shift. For businesses, the ability to host a frontier-grade model within their own private cloud infrastructure means near-zero marginal token costs, absolute data privacy, and the freedom to fine-tune models on proprietary datasets without exposing sensitive IP.
For organizations building customer-facing applications, this shift will drastically lower the cost barrier for deploying sophisticated AI agents. Communication infrastructure platforms like CallMissed are already preparing developers for this multi-model future. By offering unified API access to over 300+ LLMs alongside high-performance Speech-to-Text (supporting 22 Indian languages) and Text-to-Speech engines, CallMissed allows companies to seamlessly swap backend models. When the predicted December 3rd frontier open-source model drops, developers using CallMissed will be able to instantly route their voice agents and WhatsApp chatbots to this new model without rewriting a single line of their core communication code.
As we march toward this historic intersection, understanding the data, the players, and the technological catalysts driving this race is essential for any forward-looking technology leader.
Background & Context: The State of Open-Source LLMs in Mid-2026

To understand why a frontier-class breakthrough is projected for late 2026, we must first look at the state of the AI ecosystem as of mid-2026. The gap between proprietary and open-weights models, which once felt like an unbridgeable chasm, has narrowed to a razor-thin margin.
Currently, the proprietary frontier is defined by heavyweight champions like GPT-5.5, Claude 4.7 Opus, and Gemini 3.1 Pro. These systems represent the pinnacle of multimodal reasoning, long-context window management, and native agentic workflows. Yet, the open-source community is no longer playing catch-up with yesterday’s technology; it is actively contesting the state-of-the-art.
The Open-Source Vanguard of Mid-2026
The open-source landscape is currently dominated by a few highly specialized, massive-scale models that have rewritten the rules of decentralized AI:
- Qwen 3 235B-A22B: Alibaba’s flagship Mixture-of-Experts (MoE) model has emerged as the definitive open-weights leader for general reasoning and code generation. By activating only 22 billion parameters per token out of its massive 235 billion total parameter pool, it delivers frontier-grade throughput and efficiency.
- DeepSeek R1: This model remains the benchmark champion for deep mathematical reasoning. Built on advanced reinforcement learning (RL) search algorithms, R1 proved that open-source models could match—and sometimes exceed—proprietary systems in multi-step logical deduction without requiring massive labeled datasets.
- Llama 4 Series: Meta’s incremental releases continue to serve as the highly stable bedrock for global enterprise fine-tuning, offering robust safety alignments and exceptional conversational capabilities.
According to recent evaluations by independent benchmarking platforms like Artificial Analysis, three of the top eight open-source models tested in mid-2026 consistently outperform legacy proprietary models like GPT-4 across core coding and logic benchmarks.
Architectural Innovations Driving Parity
The rapid acceleration of open-source capability is not merely a result of throwing more compute at training runs. It is driven by crucial architectural and methodological shifts:
- Smarter Mixture-of-Experts (MoE): Modern MoE routing has become highly sophisticated, allowing developers to run massive models on consumer-accessible enterprise hardware by drastically lowering active parameter requirements.
- Reinforcement Learning Democratization: Following the breakthroughs of DeepSeek R1, the open-source community has shifted heavily toward post-training RL. This allows models to self-correct and "think" through complex prompts, bypassing the need for expensive, proprietary human-annotated data.
- Sparsified Attention Mechanisms: New attention layers allow mid-2026 open-source models to natively process context lengths exceeding 1 million tokens without linear memory scaling.
The Multi-Model Infrastructure Reality
This rapid rise in open-source performance has fundamentally changed how enterprises design their technical stacks. Organizations are moving away from single-provider lock-in and toward hybrid, multi-model architectures.
For instance, platforms like CallMissed enable developers to capitalize on this shifting landscape. By offering unified API access to over 300+ LLMs alongside high-performance Speech-to-Text in 22 Indian languages, CallMissed allows companies to dynamically route tasks. A complex mathematical problem can be routed to an open-weights reasoning model like DeepSeek R1, while standard customer interactions are handled by smaller, highly localized voice agents—all without changing a single line of core orchestration code.
This structural flexibility is only viable because open-source models can finally hold their own against proprietary giants. As we approach the end of 2026, the question is no longer if open-source will achieve absolute parity with the absolute frontier, but when the final crossover point will occur.
Key Developments: Path to the December 2026 Frontier Milestone (TABLE)

To understand how we arrived at a highly specific prediction for December 2026, we must chart the rapid compression of the open-to-closed-source capability gap. What was once a multi-year performance chasm has shrunk to a matter of months. This acceleration is driven by breakthroughs in post-training reinforcement learning (RL), Mixture-of-Experts (MoE) architectures, and massive synthetic data pipelines.
By examining the historical and projected milestones on this trajectory, we can visualize the accelerating cadence of open-weights intelligence. The following timeline outlines the key evolutionary steps leading toward the predicted December 3, 2026 frontier convergence:
| Model / Milestone | Release Date | Key Architecture/Feature | Frontier Target Met | Significance |
|---|---|---|---|---|
| Llama 3.1 405B | July 2024 | Dense transformer, 15T tokens | GPT-4 / Claude 3 Opus | Proved open-weights could compete at the absolute frontier scale. |
| DeepSeek R1 | Jan 2025 | Large-scale RL, reasoning focus | OpenAI o1 | Normalized advanced reasoning loops at a fraction of training costs. |
| Qwen 3 235B-A22B | Early 2026 | Sparse MoE, advanced coding | GPT-4o / Claude 3.5 Sonnet | Set new open-source standards for specialized agentic workflows. |
| DeepSeek V4 | May 2026 | Native multimodality, active MoE | GPT-5.5 / Claude 4.7 | Slashed API costs while matching proprietary reasoning depth. |
| Predicted Frontier OS | Dec 3, 2026 | Next-Gen MoE & Agentic Autonomy | GPT-6-class / Claude 5 | Projected point of absolute parity with closed-source frontier. |
The Mechanics of Accelerated Convergence
The transition from dense architectures like Llama 3 to highly optimized Mixture-of-Experts (MoE) frameworks—such as those seen in Qwen 3—has drastically lowered the hardware barrier for running elite models. Developers are no longer restricted to multi-million-dollar server clusters to achieve frontier-tier reasoning.
Furthermore, the integration of specialized reinforcement learning (RL) training pathways, pioneered by the DeepSeek R1 series and refined throughout 2026, has shifted the battleground from raw parameter size to active inference-time compute. This allows smaller, open-weights models to "think" longer during complex queries, effectively matching the output quality of proprietary giants that rely on closed, server-side search loops.
Operationalizing the Rapid Evolution
For businesses and developers, this blistering pace of innovation presents a distinct challenge: how do you build stable, production-grade applications when the optimal underlying model changes every few months? Navigating this volatile landscape requires an agile AI infrastructure.
This is where platforms like CallMissed become essential. By offering a unified, multi-model API gateway with access to over 300 LLMs, CallMissed enables enterprises to seamlessly swap in the latest open-source breakthroughs—such as the upcoming December 2026 frontier model—without rewriting a single line of their core communication or voice agent code. This flexibility ensures that businesses remain at the absolute cutting edge of AI performance while maintaining full control over their deployment costs and data.
In-Depth Analysis: Why December 3, 2026?
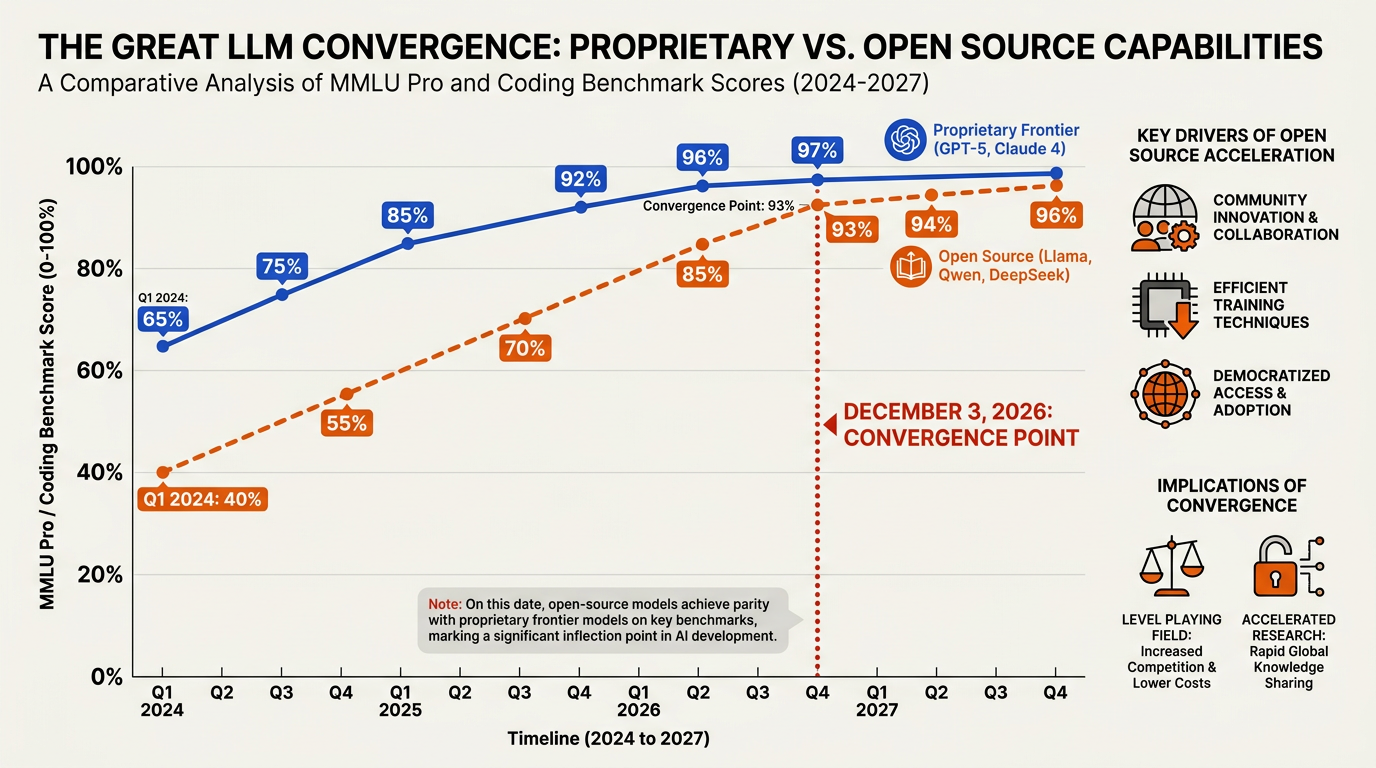
To understand why Jamie Dborin's prediction points specifically to December 3, 2026, we must look at the quantitative tracking data provided by Artificial Analysis. This platform evaluates language models on latency, cost, and quality benchmarks (such as MMLU, HumanEval, and Chatbot Arena Elo). By plotting the historical release dates of proprietary "frontier" models against their open-source counterparts, a clear mathematical trend emerges: the historical lag is shrinking at an accelerating pace.
The Mathematical Convergence: Plotting the Slopes
Historically, the performance gap between closed and open weights was vast. In early 2024, the gap sat at roughly 12 to 15 months; open-source models were consistently a full generation behind GPT-4. However, Dborin’s analysis shows that the gradient of open-source improvement is significantly steeper than that of proprietary models.
By mapping the release dates and quality scores of leading models, we see two distinct trajectories:
- The Proprietary Frontier: Progress here is bounded by massive capital expenditures, escalating safety alignment protocols, and the logistical complexity of training next-generation architectures like GPT-5.5 or Claude 4.7 Opus.
- The Open-Source Velocity: Supported by decentralized global contribution, academic breakthroughs, and efficient architectures like Mixture-of-Experts (MoE), open-source performance has experienced a near-linear surge.
By calculating the intersection point of these two trend lines, the mathematical model identifies December 3, 2026 as the exact date where the open-source community will release a model that achieves 1:1 parity with the absolute top-tier proprietary model available at that exact moment.
Key Benchmarks Driving the Projection
This prediction is grounded in the rapid convergence we are already witnessing across critical evaluation metrics throughout 2026:
- Reasoning and Mathematics: Models like DeepSeek R1 and Qwen 3 235B-A22B have demonstrated that open-weights models can match or even exceed legacy closed-source giants in complex multi-step reasoning.
- Coding and Agentic Workflows: The gap in code-generation benchmarks (like HumanEval) has virtually closed, with open-weights architectures achieving over 90% accuracy, matching proprietary standards.
- Context Windows and Efficiency: Open-source architectures have pioneered highly efficient retrieval-augmented generation (RAG) and long-context capabilities without the prohibitive cost overhead of proprietary APIs.
Preparing for the Pivot: Multi-Model Infrastructure
For enterprise developers, this impending convergence represents a massive shift in unit economics. However, capitalizing on a frontier open-source model released on December 3, 2026, requires forward-compatible infrastructure.
Platforms like CallMissed are already bridging this transition. By offering a unified API gateway that supports over 300+ LLMs, CallMissed allows businesses to orchestrate complex voice agents and chatbots today using closed-source models, and then seamlessly hot-swap to a groundbreaking open-weights model the moment it drops. This ensures that when the December 2026 milestone is reached, organizations can instantly migrate their production workloads to local or self-hosted environments to maximize data sovereignty and cut inference costs without rewriting their underlying orchestration code.
Impact & Implications: How a Frontier Open-Source LLM Shifts the AI Power Balance

The realization of Jamie Dborin’s prediction on December 3, 2026, will represent more than just a milestone on a benchmark chart; it will trigger a tectonic shift in the global AI power balance. For years, closed-source giants have leveraged their proprietary lead to dictate pricing, control access, and enforce rigid terms of service. When an open-source alternative reaches absolute parity with the absolute frontier, that leverage evaporates.
Breaking the Proprietary Oligopoly
The primary impact of a frontier-class open-source LLM is the democratization of high-tier intelligence. Historically, enterprises requiring advanced agentic reasoning, complex coding capabilities, and deep mathematical processing had to route sensitive data through closed APIs owned by a handful of tech giants.
An open-source frontier model completely changes this dynamic:
- Absolute Data Sovereignty: Highly regulated sectors—such as healthcare, finance, and defense—can deploy state-of-the-art models entirely on-premise or within secure private clouds, eliminating the risk of proprietary data exposure to third-party providers.
- No Vendor Lock-In: Organizations will no longer be vulnerable to sudden API price hikes, deprecated endpoints, or arbitrary changes in model alignment that disrupt production pipelines.
- Unrestricted Hyper-Customization: Developers can fine-tune the model's core weights to specialize in hyper-niche domains, a level of control that proprietary API providers simply cannot replicate.
Redefining the Unit Economics of AI Agents
The economic implications of this transition are staggering. Currently, running millions of complex, multi-step agentic workflows on closed frontier models like GPT-5.5 or Claude 4.7 Opus carries unsustainable token costs.
By moving these workloads to frontier open-source models hosted on optimized infrastructure, inference costs transition from high-margin proprietary markups to raw compute utility pricing. Infrastructure platforms like CallMissed are uniquely positioned to help enterprises capitalize on this shift. By offering a unified gateway with support for over 300 LLMs, CallMissed enables organizations to seamlessly swap high-cost closed APIs for cutting-edge open weights. This transition allows businesses to run ultra-low-latency, multilingual voice agents and WhatsApp chatbots that possess elite reasoning capabilities, without the prohibitive variable costs associated with proprietary systems.
Globalizing AI Innovation
Finally, this milestone marks a massive step forward for decentralized AI development. Proprietary frontier models have historically favored English-centric datasets and Western cultural contexts. When the open-source community gains access to a frontier-tier foundation model, developers worldwide can optimize it for local languages, cultural nuances, and regional business needs.
For instance, developers can specialize these models for Speech-to-Text pipelines across regional dialects, which platforms like CallMissed natively support in 22 Indian languages. In a post-December 2026 world, the capability to build, deploy, and scale world-class AI will no longer be a privilege reserved for a select few trillion-dollar companies—it will belong to the global developer community.
Expert Opinions: Industry Leaders Weigh In on the 2026 Timeline

The mathematical precision of Jamie Dborin’s December 3rd, 2026 prediction has sparked intense debate across the AI research community. While some view the highly specific date as a provocative thought experiment, top industry leaders and independent analysts agree that the fundamental thesis—that open-source is on an inescapable trajectory toward absolute frontier parity—is highly credible.
The Case for the December Parity Timeline
Proponents of the late-2026 timeline point to the compounding efficiency of open-weights training methodologies. Prominent AI researchers, including those tracking the rapid evolution of model architecture in early 2026 publications, note that open-source developers no longer need to replicate the brute-force compute budgets of proprietary giants.
Instead, techniques like Mixture of Experts (MoE), advanced distillation, and reinforcement learning (RL) are yielding massive performance leaps. As seen with the release of Qwen 3 235B-A22B and DeepSeek R1 earlier this year, open-source models are already routinely matching or outperforming older proprietary standards like GPT-4 in complex mathematical reasoning and localized code generation.
According to historical tracking data from Artificial Analysis, the interval between a closed-source breakthrough and its open-source replication has shrunk from over twelve months to less than three. At this rate of acceleration, a December 2026 convergence is not just possible; it is statistically probable.
The Skeptical View: The "Moving Frontier" Problem
However, not all industry leaders are convinced that absolute parity will be achieved by December. Skeptics, including several prominent venture capitalists and infrastructure engineers, argue that the "frontier" itself is a highly dynamic target.
While open-source models are rapidly matching the capabilities of systems like Claude 3.5 Sonnet, proprietary labs are actively deploying next-generation architectures. The release of highly advanced systems like GPT-5.5 and Claude 4.7 Opus earlier in 2026 has pushed the benchmark envelope even further, establishing new baselines for agentic workflows and multimodal reasoning that open-source has yet to fully master.
From this perspective, while open-weights models will certainly match current frontier capabilities by late 2026, proprietary labs may still hold a slim, temporary edge in ultra-niche, highly complex reasoning tasks.
The Enterprise Strategy: Model Agnosticism
Whether the final breakthrough occurs precisely on December 3rd or slightly later, the strategic takeaway for enterprises remains identical: software architecture must remain completely flexible. Relying on a single, closed-source LLM provider is becoming an increasingly risky and expensive strategy.
To navigate this shifting landscape, forward-thinking organizations are moving toward model-agnostic infrastructure. Advanced communication platforms like CallMissed are leading this transition. By offering an LLM inference gateway that natively supports over 300+ models alongside Speech-to-Text APIs in 22 regional languages, CallMissed allows developers to deploy voice agents that run on today's best proprietary systems, while retaining the structural readiness to seamlessly pivot to frontier open-source models the moment they drop.
What This Means For You: Actionable Strategies for Developers and Businesses (TABLE)
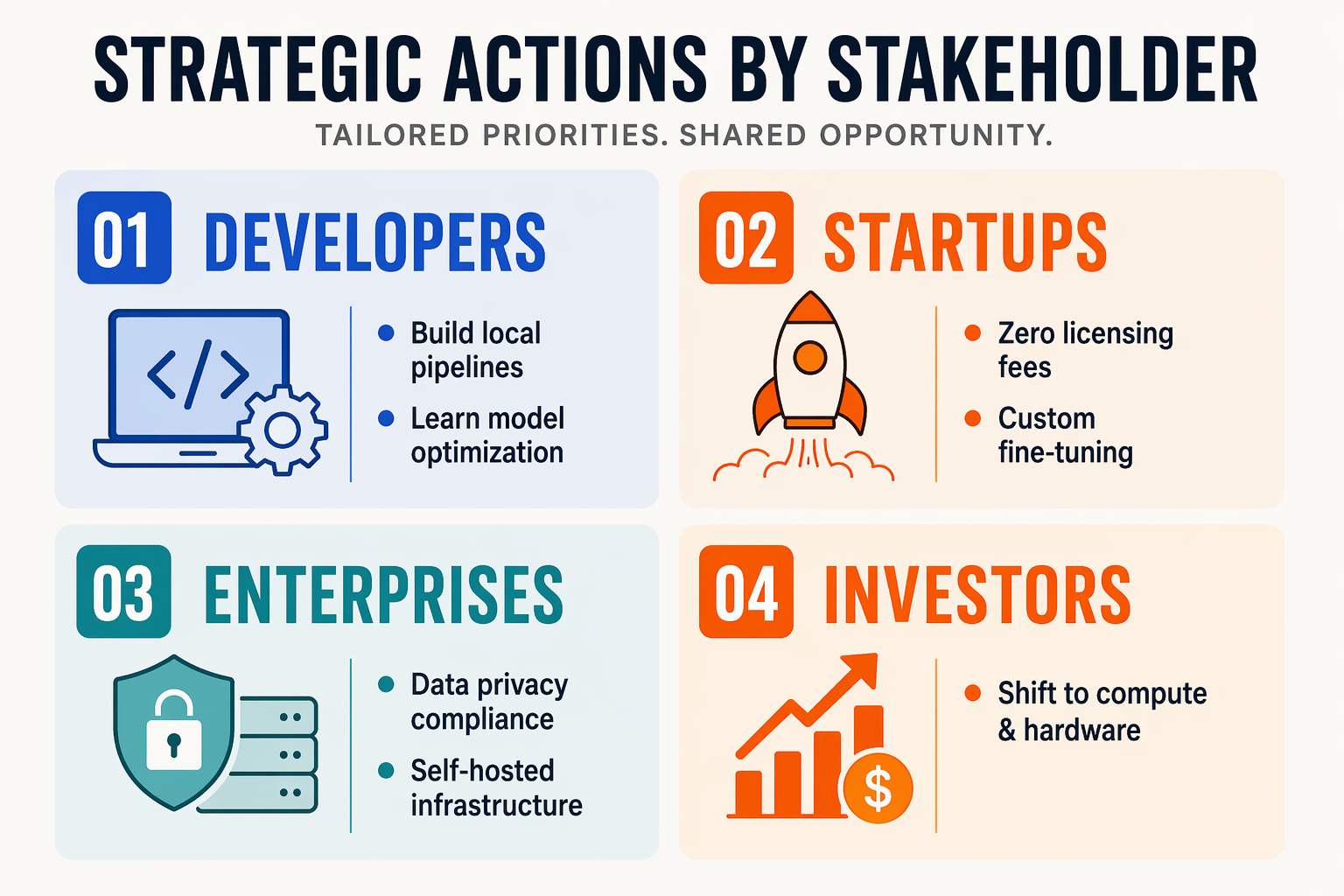
The countdown to December 3, 2026, is officially ticking. With absolute frontier parity in open-weights models projected to arrive in less than six months, developers and enterprise leaders cannot afford to sit on the sidelines. Transitioning away from absolute dependency on closed-source API keys requires immediate, proactive adjustments to your engineering roadmap and infrastructure budget.
To help your team prepare for this paradigm shift, the table below outlines the core transitional strategies you should execute between now and the targeted December release date:
| Strategy | Core Objective | Key Technical Focus | Projected Benefit | Prep Timeframe |
|---|---|---|---|---|
| Inference Decoupling | Prevent vendor lock-in | Deploy multi-model API gateways | 80% reduction in long-term token costs | Immediate (Q3 2026) |
| Compute Allocation | Secure hosting hardware | Secure reserved cloud GPUs (H100/B200) | Guaranteed uptime for custom LLMs | Next 3 Months |
| Data Pipeline Readiness | Prepare proprietary data | Clean, structure, and chunk internal domain data | Turn-key, Day-1 custom fine-tuning | Ongoing |
| Agentic Frameworks | Build autonomous workflows | Migrate to agent frameworks (LangChain, AutoGen) | Drop-in frontier-level reasoning | By November 2026 |
1. Build an Agile, Multi-Model Router
Relying on a single proprietary provider is a critical vulnerability. As open-source models rapidly narrow the gap, your architecture must be dynamic. Implement a routing layer that directs simpler queries (such as classification or basic summarization) to lightweight, cost-effective open-source models, reserving heavy-duty frontier models for complex multi-step reasoning.
For developers looking to implement this seamlessly, platforms like CallMissed offer a production-ready multi-model API gateway. By allowing engineering teams to switch between 300+ LLMs without code changes, CallMissed ensures you can A/B test emerging open-source giants like Qwen 3 or DeepSeek R1 alongside proprietary legacy systems, making the shift to a post-December 2026 open-source frontier completely friction-free.
2. Prioritize Data Sovereignty and Local Pipelines
The true power of a frontier open-source model lies in your ability to run it locally or within a private Virtual Private Cloud (VPC). Start building your data curation pipelines now to ensure you are ready to fine-tune these models the moment they drop:
- Standardize Data Formats: Clean and catalog proprietary enterprise data, customer logs, and internal wikis.
- Implement Quantization Techniques: Prepare your infrastructure to run optimized versions of massive models (like quantized 200B+ parameter models) on cost-effective enterprise hardware.
3. Transition from API OpEx to Infrastructure CapEx
Right now, closed-source API spending represents an ongoing, variable Operational Expenditure (OpEx). Once frontier-level open-weights models arrive, the economics shift toward Capital Expenditure (CapEx) or fixed private cloud infrastructure. Begin shifting a portion of your budget toward:
- Reserved GPU Instances: Secure capacity for hosting and fine-tuning before demand spikes following the December breakthrough.
- Specialized Orchestration Tools: Optimize your hosting stack using tools like vLLM and TensorRT-LLM to maximize throughput and minimize latency.
Frequently Asked Questions
What is the basis for the prediction that a frontier open-source LLM will be released on 3rd December 2026?
Which open-source LLMs in 2026 are currently closest to reaching frontier-class intelligence?
How will a frontier open-source LLM impact enterprise AI deployment costs?
Can open-weights models genuinely match proprietary systems like GPT-5.5 or Claude 4.7 Opus?
How can developers prepare for the transition to a frontier open-source LLM?
What role does Jamie Dborin’s analysis play in predicting open-source AI trends?
Conclusion
The mathematical convergence predicted for December 3, 2026, signals a monumental shift from proprietary dominance to decentralized, open-source parity. As you prepare your technology stack for this imminent transformation, keep these key takeaways in mind:
- The Velocity Paradigm: The historical intelligence gap between closed and open-weights models is rapidly evaporating, fueled by relentless open-source momentum and competitive benchmark gains.
- Democratized Economics: True frontier parity will fundamentally rewrite the unit economics of enterprise AI, eliminating proprietary API premiums while ensuring absolute data sovereignty.
- Decentralized Power: Leading contenders from across the globe are proving that custom, localized deployments can match the absolute state-of-the-art without vendor lock-in.
The countdown to December is underway, and businesses that proactively adapt to an open-weights paradigm will capture the ultimate competitive advantage. To explore how AI communication is evolving and stay ahead of these rapid shifts, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
When absolute frontier intelligence becomes fully customizable and cost-effective, how will your organization redefine its AI strategy?
Related Posts

How to Get a Free API Key for LLM Models from CallMissed: Features, Models, and Usage Guide (2026)

Mastering High-Performance C++: Implementing a Fast Hopscotch Hash Map and Set

Kunal Shah to Lead WhatsApp: 9 Indian-Origin CEOs Driving Global Leadership