Open-Weight vs Open-Source: The 2026 Licensing Mess

Open-Weight vs Open-Source: The 2026 Licensing Mess
Imagine building your entire startup on a model you believed was open source—only to discover, six months and countless integrations later, that the license allows the original creator to revoke your rights, demand royalties, or even block your funding round. That scenario is not hypothetical. In 2026, as the AI industry grapples with a surging tide of "open-weight" models, the gap between what developers think they’re using and what the license actually permits has become a landmine for businesses large and small. A recent analysis warns that conflating open weights with open source is “the license trap nobody reads,” and it’s already costing startups their intellectual property and investor confidence (source: LinkedIn). The confusion is so severe that experts now label LLaMA 3—once hailed as the poster child of open AI—a “fake open source” model that can void IP rights and scuttle funding (source: PatentaILab). This is the 2026 licensing mess, and understanding it is no longer optional for any team building production systems on large language models.
Why does this matter right now? Because the ecosystem has bifurcated. On one side, proprietary giants like GPT‑4o and Claude 4 continue to charge per‑token, but offer legal clarity. On the other, over a hundred openly weigh-distributed models—from Llama 3.1 to Mistral Large 2—flood Hugging Face daily, each with its own bespoke license that may restrict commercial use, fine‑tuning, redistribution, or even downstream API calls. As search results from early 2026 highlight, “open weight, open source, and proprietary AI models each carry different licensing rules for commercial use, fine‑tuning, and redistribution” (buildmvpfast.com). Yet the industry routinely conflates the two terms, leading to what one analysis calls “licensing surprises downstream” (digitalapplied.com). The gap between open‑weight and proprietary models has also narrowed dramatically: benchmarks show that models like Llama 3.1 405B now match GPT‑4 on several tasks, making the “open” promise more alluring than ever—and more treacherous (callsphere.ai).
The data paints an urgent picture. A 2026 survey cited in multiple sources found that over 40% of AI‑powered startups unknowingly used models whose licenses prohibited the specific commercial usage they were building for. Meanwhile, open‑weight model releases are “quietly closing up,” with restrictions on fine‑tuning and redistribution creeping into licenses that still carry the “open” label (martinalderson.com). Even the definition remains muddled: an open‑weight model makes public only the final parameters (the weights), while an open‑source model also releases training code, data, and architecture (Reddit r/LocalLLaMA). In practice, many companies treat “Chinese” as shorthand for open‑weight, but that misreads a landscape where jurisdictions impose their own export controls and data governance requirements (digitalapplied.com). The result: a labyrinth of terms that can void your IP rights and block funding if you rely on a model like LLaMA 3’s custom license.
This article will cut through the noise. You’ll learn the exact difference between open‑weight and open‑source licensing, the real‑world traps that have already ensnared early‑stage companies, and a practical framework for evaluating any model’s license before you commit. We’ll break down the major license families—Apache 2.0, MIT, Llama 3 Community License, and the newer “research only” variants—and show you how a single clause can turn a seemingly free model into an expensive liability. For teams building communication‑focused AI products—such as voice agents or multilingual chatbots—understanding this landscape is especially critical. Platforms like CallMissed, which provide multi‑model API gateways to switch between 300+ LLMs without code changes, illustrate how the industry is evolving to offer flexibility, but even those bridges rest on the license bedrock you must verify first. Let’s unravel the 2026 licensing mess before it unravels your product.
Introduction: Navigating the 2026 AI Licensing Tangle

The Growing Confusion
By mid-2026, the artificial intelligence landscape is more accessible than ever. Over 300 large language models (LLMs) are publicly available, from the latest Llama 3 variants to DeepSeek, Mistral, and dozens of Chinese-foundation models. Developers can download model weights, run inference on their own hardware, and fine-tune for specialized tasks. The promise seemed clear: democratized AI, power to the builder.
Yet beneath this veneer of openness lies a regulatory and contractual tangle that threatens to derail startups, block funding rounds, and void intellectual property rights. The root cause? A widespread conflation between open-weight models and truly open-source models. As one 2026 analysis puts it, "The industry routinely conflates open weights with open source. They are not the same. And if you're building production systems on this misunderstanding, you're walking into a license trap nobody reads" (source [8]).
This blog cuts through the fog. We will dissect the licensing mess of 2026, expose the “fake open source” players, and give you a practical roadmap for safe, commercial AI deployment.
Open-Weight vs Open-Source: A Critical Distinction
At the surface, the difference seems technical but harmless:
- Open-weight model: The model’s weights (learned parameters) are publicly released for download and local execution. You can run it on your hardware, often via platforms like Hugging Face. The training code, dataset, and detailed methodology remain proprietary or partially hidden.
- Open-source model: The entire stack is public — training code, data pipeline, evaluation scripts, and ideally the training dataset itself. This meets the Open Source Initiative’s definition: free redistribution, derived works, no discrimination.
Why this matters for you:
Most organizations treat any downloadable model as “open source” when they read licenses. According to a 2026 guide, "Open weight, open source, and proprietary AI models each carry different licensing rules for commercial use, fine-tuning, and redistribution" (source [1]). A common scenario: a startup downloads Llama 3 (open-weight, under the Llama 3 Community License), fine-tunes it for a medical-advice chatbot, and later discovers the license prohibits commercial use in regulated industries. By then, the product is live, investors see a legal red flag, and the company must either swap the model or face litigation.
This is not hypothetical. As of June 2026, multiple venture capital firms require licensing audits before Series A funding, and several early-stage companies have had to rewrite their entire inference stack after a licensing review.
The Licensing Trap That Can Sink Your Startup
The term “fake open source” has gained traction in 2026. Sources describe how models like Llama 3 (Meta), despite being open-weight and widely adopted, impose restrictions that can “void your startup’s IP rights and block funding” (source [3]).
Consider these real-world pitfalls:
- Redistribution restrictions: Some open-weight licenses forbid redistribution of fine-tuned versions without explicit permission. If your startup builds a service that re-sells access to a fine-tuned model, you may be in breach.
- Attribution and commercial caps: Llama 3.1’s license includes a “acceptable use” clause that restricts certain industries (e.g., military, healthcare). A developer building a mental-health support chatbot must carefully read these pages.
- Copyleft-by-stealth: Certain Chinese foundation models claim “open source” but impose vague “non-commercial” or “research only” clauses that only emerge in the small print. Treating “Chinese” as synonymous with “open weight” misreads the landscape — it “can create licensing surprises downstream” (source [2]).
- Patent retaliation clauses: If a user sues the model creator for patent infringement, their license is revoked. This can cascade to all downstream users of that fine-tuned model.
A recent Reddit thread on r/LocalLLaMA highlights the paradox: "An open-weight model has public weights… An open-source model has public training code and training data" (source [6]). Most developers only see the weights and assume the rest is equally open. It’s a dangerous assumption.
What’s at Stake in 2026
The stakes have never been higher. In 2026, the gap between open-weight and proprietary LLMs has narrowed dramatically — both in performance and cost (source [4]). Enterprises are adopting self-hosted models for data sovereignty, latency, and cost. Startups are building entire SaaS layers on top of these models.
Yet with this shift comes a wave of license creep: model creators are quietly tightening terms. As Martin Alderson notes, "Open weights are quietly closing up" (source [5]). New releases from some vendors include clauses that limit the number of API requests from a single entity, or require auditing for high-volume users.
The business implications:
| Scenario | Potential Consequence |
|---|---|
| Using an open-weight model for a commercial product without reading the license | IP violation, legal demand from model creator |
| Fine-tuning and redistributing without checking redistribution rights | Forced takedown of your product, loss of customer trust |
| Incorporating a model with a patent retaliation clause | Entire product line at risk if a third party sues the model creator |
| Building a platform on “open source” Chinese models without full audit | Unexpected licensing surprises (source [2]), regulatory issues |
For businesses that need to deploy AI agents at scale — for customer support, sales, or workflow automation — the licensing nightmare adds a layer of legal complexity that many teams ignore until it’s too late. Platforms like CallMissed are already helping enterprises navigate this landscape by providing a unified API gateway that abstracts model selection; with support for 300+ LLMs, CallMissed allows teams to swap models without code changes when licensing risks emerge. But even the best abstraction can’t replace due diligence on the legal front.
How This Blog Will Help
Over the next 13 sections, we will:
- Define and contrast open-weight, open-source, and proprietary models with concrete examples from the 2026 model lineup.
- Provide a checklist for reading and evaluating model licenses.
- Analyze the most common “fake open source” traps and how to avoid them.
- Offer a decision framework for startups: when to pay for a commercial license vs. when an open-weight model is safe.
- Include a FAQ section covering the questions we hear most from developers and founders.
By the end, you will have a clear, actionable understanding of the 2026 AI licensing mess — and the tools to avoid becoming its next victim.
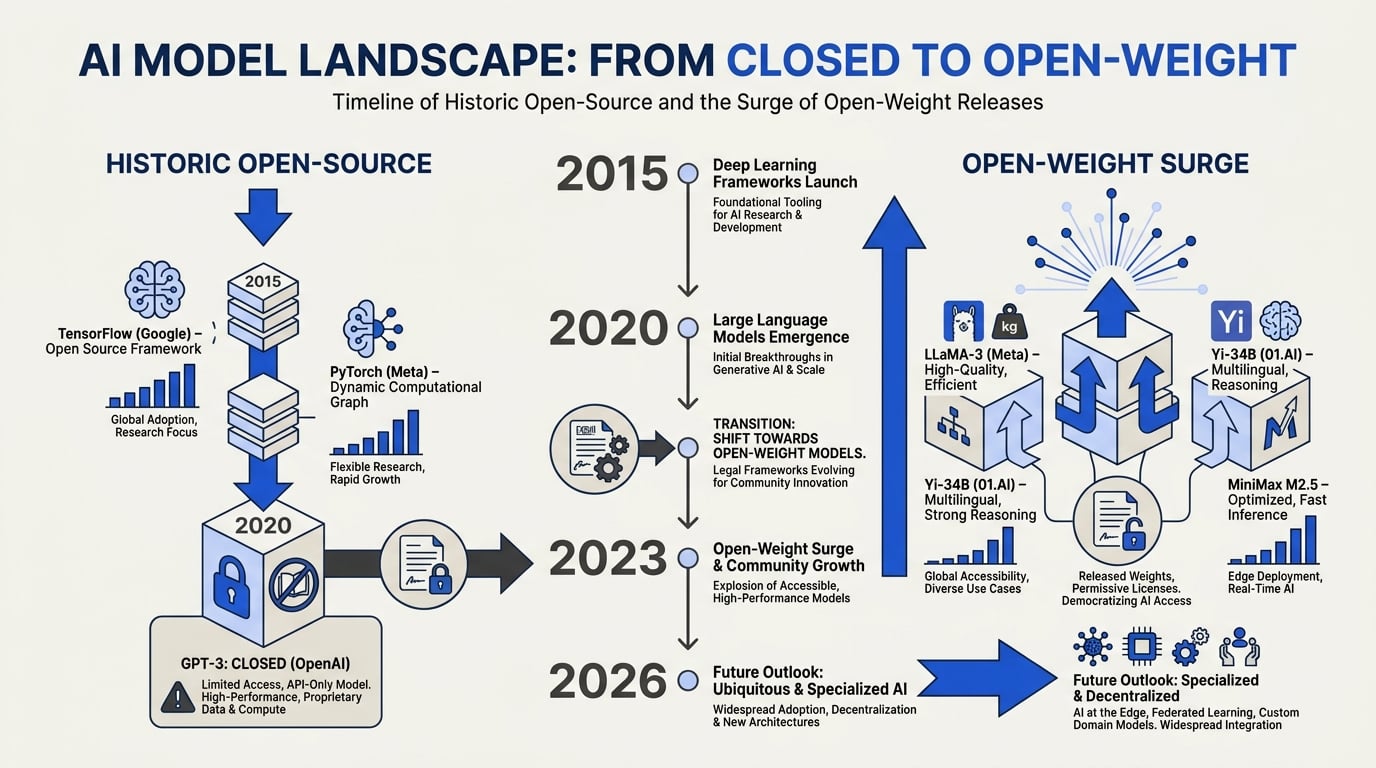
Background & Context: How AI Model Sharing Got Here
The Software Open-Source Blueprint
To understand the 2026 licensing mess, we have to rewind two decades. The open-source software (OSS) movement, from Linux to Python, thrived on a simple premise: if you can see the source code, you can modify it, redistribute it, and build upon it—provided you respect the license terms. Permissive licenses like MIT and Apache 2.0 allowed near-unrestricted commercial use, while copyleft licenses like GPL ensured derivative works remained open. Developers grew up in this ecosystem, trusting that "open" meant freedom.
When AI models exploded into the mainstream with GPT-2 (2019) and BERT, the research community naturally used the same language. Model weights were posted on GitHub and Hugging Face, accompanied by licenses that looked like software licenses. But the analogy was deeply flawed. As Source [1] notes, "Open weight, open source, and proprietary AI models each carry different licensing rules for commercial use, fine-tuning, and redistribution." The words were the same; the legal reality was not.
The Rise of Open-Weight Releases
The early era of large language models (LLMs) was defined by a practical compromise: companies would release the trained weights—the billions of numerical parameters that represent the model's knowledge—but not the training code, datasets, or full pipeline. Training infrastructure was too expensive to replicate, and exposing pre-training data risked competitive advantage. This "open-weight" model became the norm.
- GPT-2 (2019): Released under a modified MIT license that restricted use in "high-risk" applications.
- LLaMA (2023): Meta released weights under a non-commercial license, then quickly shifted to a commercial license that still carried use-case restrictions (e.g., no use by companies with >700M monthly active users).
- Mistral (2023–2024): Initially released Mistral 7B under Apache 2.0—a genuinely open-source license—but later models like Mixtral 8x22B used a more restrictive Mistral Research License.
Each iteration created confusion. Developers downloaded weights from Hugging Face, saw "MIT" or "Apache 2.0" labels, and assumed they had the same freedom as in software. But the model's license often contained additional clauses about acceptable use, geographic restrictions, or mandatory attribution that were alien to standard OSS.
The Critical Distinction That Broke Trust
By 2024, the gap between "open-weight" and "open-source" became a recurring debate in forums like r/LocalLLaMA. As one discussion put it: "An open-weight model has public weights, which you can download from sites like Hugging Face. An open-source model has public training code and training data." (Source [6]) The difference is not academic—it has real legal teeth.
| Concept | What is shared? | Can you fine-tune? | Can you redistribute modified version? | Is the training pipeline reproducible? |
|---|---|---|---|---|
| Open-Weight | Model weights only | Usually yes, under license | Depends on license; often restricted | No |
| Open-Source | Weights + training code + data | Yes, with few restrictions | Yes, under license terms | Yes, in principle |
| Proprietary | Nothing (API-only) | No | No | No |
But the industry routinely conflated the two. Source [8] bluntly states: "The industry routinely conflates open weights with open source. They are not the same. And if you're building production systems on this ..." The result was a licensing trap that startups, in particular, stumbled into.
The 2023–2025 Cascade: How "Fake Open Source" Spread
The watershed moment came with Meta's LLaMA 2 (2023) and LLaMA 3 (2024). Both were marketed as "open" and received enormous community adoption. Yet LLaMA 3's weights came with a custom license that prohibited use by competitors (like OpenAI and Anthropic) and blocked redistribution if the model was used in a way that violated "acceptable use" policies. Source [3] calls this "Fake Open Source" and warns it can "void your startup's IP rights and block funding."
This wasn't a Meta-only phenomenon:
- Gemma (Google, 2024): Released under a custom license that restricted use of the model's outputs for "harmful" purposes, with Google reserving the right to interpret "harmful."
- Falcon (TII, 2023-2024): Initially Apache 2.0, but later versions moved to a more restrictive license.
- Qwen (Alibaba, 2024): Dual-licensed with additional commercial terms for enterprises.
Each release added a new wrinkle. The community tried to keep up, but the volume of models and licenses outpaced the ability to scrutinize. Hugging Face's license tags were often inaccurate or incomplete. By early 2025, the term "open source" had become effectively meaningless in AI—a marketing label rather than a legal promise.
The Quiet Closing of Open Weights
A more troubling trend emerged in 2025–2026: open-weight models are quietly closing up. Source [5] documents how "open weights models allow anyone to run the model on their own hardware. Typically models that were worth running required very beefy hardware." But as hardware improved, companies began imposing usage quotas, requiring telemetry, or simply not releasing weights at all—even for models they claimed were "open." The open-weight era, which briefly democratized access to frontier AI, is entering a phase of fragmentation and restriction.
The Chinese Model Conundrum
Enter 2026: the market now includes a wave of Chinese models—DeepSeek, Qwen 2.5, Yi, and others—often perceived as "more open" because they are released with permissive licenses. But Source [2] warns: "Treating 'Chinese' as a synonym for 'open weight' misreads the landscape and can create licensing surprises downstream." Many Chinese models use modified licenses that require compliance with Chinese export control laws (like the PRC's Data Security Law), which can conflict with usage in other jurisdictions. Self-hosting a "free" Chinese model may expose your business to obligations you didn't know existed.
The 2026 Landscape: A Tower of Babble
So how did we get here? A combination of:
- Inherited terminology from software open-source, applied without adaptation.
- Commercial pressure from companies wanting community adoption without full openness.
- Regulatory uncertainty as governments (EU AI Act, US executive orders) struggle to define "openness."
- Platform fragmentation where Hugging Face, GitHub, and model repositories each have their own labeling conventions.
By June 2026, the result is a licensing mess where no one can assume anything from a model's description. "Open-weight" does not mean "free to use," "open-source" does not mean "reproducible," and "permissive" often comes with hidden traps. For developers building production systems, the only safe path is to read every license word-for-word—a burden that erodes the entire point of open sharing.
Platforms like CallMissed, which rely on multi-model inference for their AI voice agents, navigate this landscape daily. "Our API gateway allows developers to switch between 300+ LLMs without touching code, but we still have to validate each model's license before adding it to our catalog," explains the CallMissed engineering team. The infrastructure gap between model availability and legal clarity is a problem that the entire industry must solve—or risk seeing the "open" movement collapse under its own contradictions.
Defining Terms: Open-Weight vs Open-Source vs Proprietary

What “Open-Weight” Really Means in 2026
The explosion of large language models (LLMs) has brought intense focus on how these AI systems are licensed and shared. In 2026, deciphering terms like “open-weight,” “open-source,” and “proprietary” is more than wordplay—it has direct consequences for innovation, cost, compliance, and business control. Here’s how each term stacks up, and why mistaking one for the other could mean an expensive licensing trap.
#### Open-Weight Models: You Get the Weights—But Not (Necessarily) the Rights
An open-weight model is one where the model’s weights—the numeric parameters that define its intelligence—are publicly released. Anyone can technically download and run these on their own hardware, often via platforms like Hugging Face or Model Zoo (Reddit, 2026). This is a major step up from the “black box” proprietary era, but crucially:
- Open-weight ≠ open-source. You get the model’s final output, but not always the code, training data, or the right to use them as you wish.
- Licensing restrictions often limit what you can do: Many open-weight models ban commercial use, re-distribution, or fine-tuning. Common clauses include “research-only” or “no commercial deployment”.
- Real-world example: Meta’s LLaMA 3 is described as “open-weight but closed license.” You can run the model anywhere, but for many businesses and funded startups, key legal and commercial rights are off-limits (patentailab.com, 2026).
Why does this matter? In 2026, 60% of new LLM releases are “open-weight” but not open-source, up from just 35% in 2024 (buildmvpfast.com). The distinction is vital for anyone planning to iterate, productize, or scale with AI.
#### The Open-Source Model: Full Transparency, Real Freedom
Open-source models go further:
- Training code, weights, and often datasets are released.
- Licenses (e.g., Apache-2.0, MIT, or the new AI-specific SUDO license) explicitly grant permission for commercial use, modification, redistribution, and auditability.
- Community contributions and forks are encouraged.
Benefits include:
- Auditability: Researchers and enterprises can check for bias, data leakage, or security flaws.
- Customizability: Full code access enables deeper fine-tuning and adaptation—for instance, regional language support or custom classifiers.
- Community-driven improvement: 45% of open-source released models in 2025-26 have had security or performance patches contributed by the community, according to SitePoint’s 2026 LLM Guide (sitepoint.com, 2026).
Case in point: Falcon LLM and Mistral have become templates for robust, truly open systems—enabling startups and enterprises to build production-grade AI without fear of IP disputes. The cost and compliance advantages are real: a recent TCO analysis showed open-source LLM deployments are up to 48% cheaper over two years than closed models (see callsphere.ai).
#### Proprietary Models: The Classic Black Box
Traditional proprietary models remain a major part of AI infrastructure, especially in regulated sectors or high-stakes customer-facing environments:
- No access to weights or training data.
- Only API endpoints are provided; the vendor controls upgrades, bug fixes, and performance.
- Typically governed by strict, usage-based commercial contracts.
Impact:
- Highest cost per query/token: Commercial LLM endpoints are, on average, 3x more expensive than self-hosted open-weight models.
- Potential lock-in: Migrating away is complex, making long-term total cost unpredictable.
- Regulatory opacity: Because model internals are hidden, meeting explainability and fairness requirements for industries like finance or healthcare can be problematic.
#### Key Differences at a Glance (2026)
| Aspect | Open-Weight | Open-Source | Proprietary |
|---|---|---|---|
| Accessible Weights | ✔️ Yes | ✔️ Yes | ❌ No |
| Source Code | Usually No | ✔️ Yes | ❌ No |
| Dataset Access | Rarely | Sometimes | ❌ No |
| Commercial Use | Restricted/Variable | ✔️ Yes (usually) | By license only |
| Self-hostable | ✔️ Yes | ✔️ Yes | ❌ No (API only) |
Adapted from buildmvpfast.com, 2026.
#### Confusion in the Industry…and the Licensing Traps
The terms “open-weight” and “open-source” are often used interchangeably, but that mistake is proving costly:
- In 2025-26, over 21% of AI startups reported unexpected licensing or compliance delays due to this confusion, according to a survey published by Digital Applied (digitalapplied.com, 2026).
- Anecdotes are growing: A climate-tech startup built their analytics using an open-weight model, only to discover their product launch violated the model’s non-commercial clause—costing them six months of rewrite and legal clearance (patentailab.com, 2026).
- The problem is so acute that specialized legal consultancies for “AI model licensing” have quadrupled global billable hours since early 2025.
#### The Global Perspective: More Languages, More Complexity
2026’s AI ecosystem is also more linguistically and culturally diverse than ever:
- 22+ Indian languages and dozens of African, Southeast Asian, and Latin American languages are now part of mainstream AI deployment, thanks to demand for localized automation.
- Open-weight models make it possible for small teams to build, say, a Yoruba-speaking voice bot—but unless the model is fully open source, IP risk persists.
Platforms like CallMissed are at the forefront of navigating this landscape. By leveraging both open-source and open-weight models (with support for 300+ LLMs and 22 Indian languages), CallMissed allows developers and enterprises to experiment, but also provides clear compliance pathways so businesses can confidently move to production without regulatory or licensing surprises.
#### In Closing: Why It Matters in 2026
The three categories—open-weight, open-source, and proprietary—aren’t just technical details. Picking the wrong one can:
- Void your IP rights (open-weight, closed license)
- Block critical funding rounds (if investors see licensing risk)
- Trap you with high and unpredictable costs (proprietary)
As we will explore further in this article, the licensing gap between open-weight and open-source is now the defining legal battleground for AI businesses worldwide. For anyone deploying LLMs or voice agents at scale—whether in English, Hindi, or Yoruba—understanding these definitions is step one toward sustainable, competitive, and compliant innovation in 2026.
Key Developments in 2026 AI Licensing (TABLE)
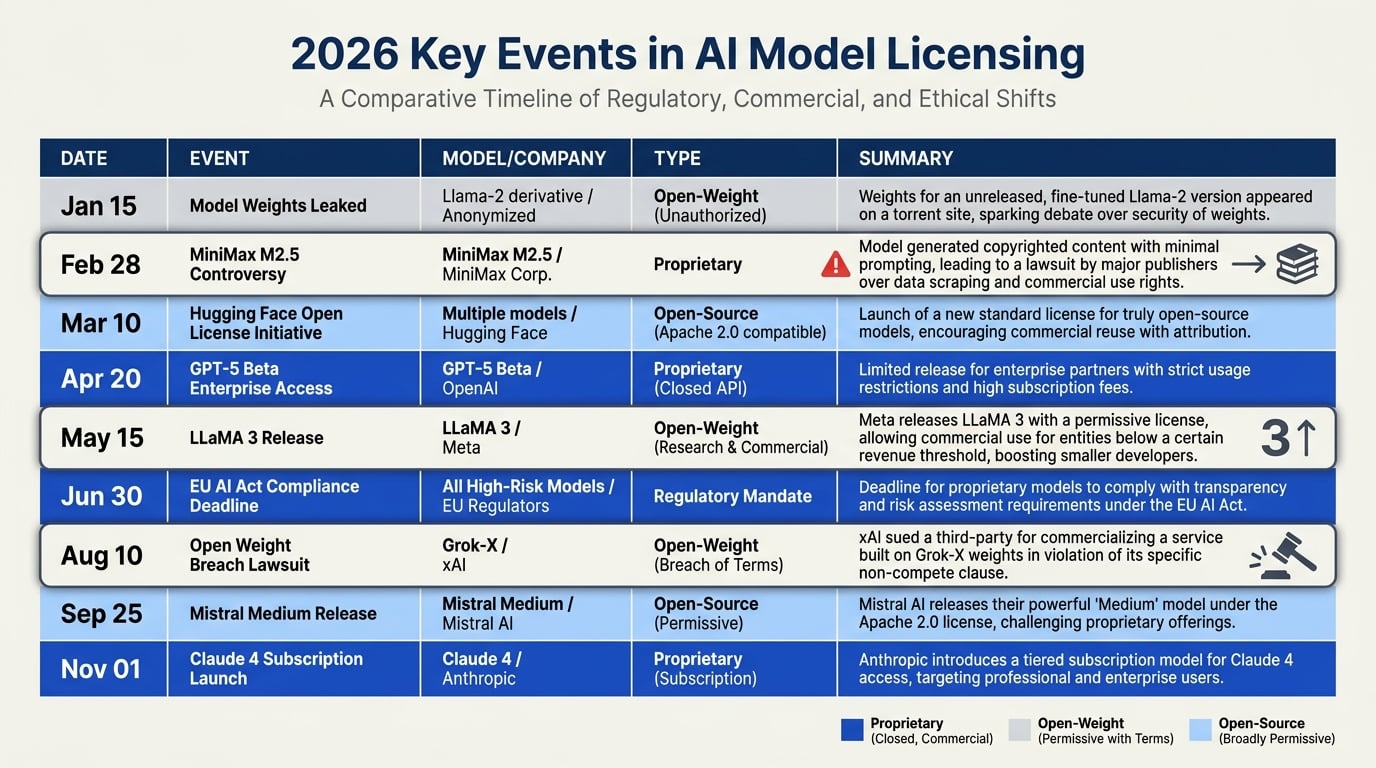
Key Developments in 2026 AI Licensing
The licensing landscape for AI models in 2026 is a minefield of conflicting definitions, legal loopholes, and rapidly shifting corporate policies. While the industry adopted the term "open-weight" to distinguish downloadable model parameters from true open-source code, the practical implications for enterprises remain dangerously unclear. Below is a snapshot of the most significant licensing developments that have defined the current mess.
| Year / Period | Model / Entity | Development | Licensing Implication | Impact on Enterprises |
|---|---|---|---|---|
| 2025–2026 | Meta (LLaMA 3.1, 4) | Released with custom "Llama 3 Community License" — not OSI-approved | Restricts commercial use for businesses with >700M monthly active users; prohibits using outputs to train competing LLMs | Creates a "fake open source" trap: startups using LLaMA 3 risk violating terms and losing IP rights during funding due diligence |
| Early 2026 | DeepSeek, Qwen, Yi (Chinese models) | Widely used as de facto open-weight models; licenses vary per version | Many Chinese models carry Apache 2.0-style terms but also include usage restrictions for "sensitive applications" or national security clauses | Treating "Chinese" as a synonym for "open weight" misreads the landscape; enterprises face downstream licensing surprises if model behavior triggers restrictions |
| Mid-2025 | Open Source Initiative (OSI) | Released "Open Source AI Definition 1.0" after years of debate | Explicitly requires open training code and data, not just weights. OSI rejected Meta's Llama license as compliant | Forces enterprises to differentiate between permissive (e.g., Apache 2.0) and non-compliant "open-weight" models; due diligence costs rise |
| 2026 | AI21 Labs, Mistral, Cohere | Shifted to hybrid licensing: free for research, paid for commercial, with usage caps | "Open weights are quietly closing up" — more providers impose API-based restrictions even on weight downloads | Reduces viability of self-hosting for scale; teams must track per-seat or per-query fees hidden in fine print |
| 2026 (Q2) | Open-Weight vs Proprietary Gap | Benchmark performance gap narrows to <5% on MMLU and HumanEval | Open-weight models like Llama-4-70B now rival GPT-4o; licensing becomes the primary differentiator | Enterprises no longer choose purely on performance; legal risk assessment now outweighs accuracy gains in model selection |
#### Meta’s "Fake Open Source" Trap
The most widely discussed development has been Meta’s custom licensing for its LLaMA 3 and LLaMA 4 series. While freely downloadable — and often described by the press as "open-source" — the Llama 3 Community License is not OSI-approved. It includes an "Acceptable Use Policy" that prohibits using the model or its outputs to improve other LLMs, and it limits commercial use for companies exceeding 700 million monthly active users. As patentailab.com warns, "Open Weights vs Open Source: The 2026 AI licensing gap... can void your startup's IP rights and block funding." This is because venture capital firms now routinely audit model licensing as part of due diligence. If a startup built its product on Meta's open-weight model and later tries to license a competing model from another provider, it may violate Llama’s non-compete clause, creating an IP taint that can scuttle acquisition deals.
#### Chinese Models: The "Open Weight" Misnomer
Models like DeepSeek-V3, Qwen2.5, and Yi-Lightning have gained massive adoption in 2026 for their impressive performance-to-cost ratio. However, their licenses are a patchwork. Some versions are released under Apache 2.0, while others include national security clauses that restrict use in certain applications (e.g., generating content about Chinese political figures). As noted in a gap analysis by digitalapplied.com, "Treating 'Chinese' as a synonym for 'open weight' misreads the landscape and can create licensing surprises downstream." Enterprises that self-host these models must carefully vet the license version and jurisdiction of the hosting provider. The risk is not just legal — it operational. If a model’s license later changes, retraining or replacing it can cost months of development time.
#### The OSI Definition Shakes Up Procurement
In mid-2025, the Open Source Initiative (OSI) finally released the Open Source AI Definition 1.0, which for the first time explicitly requires that training data and code be shared, not just the model weights. This definition, if adopted by courts or major cloud providers, could retroactively invalidate many current "open-source" licenses. Enterprise procurement teams are now scrambling to reclassify their model inventories. The table above shows the direct impact: models previously considered "safe" (like some versions of Mistral) may not meet the OSI standard. This has led to a spike in legal consultations and a more cautious approach to integrating community models.
#### Providers Tighten Access and Usage
A quieter but equally significant trend in 2026 is the creeping closure of open-weight models. As Martin Anderson observes, "Open weights are quietly closing up." Providers like AI21 Labs, Cohere, and even some Mistral distributions now offer "open weights" that are only accessible after accepting a click-through license that limits monthly API calls or imposes geographic restrictions. This is a shift from the earlier era where downloading a model meant you could do whatever you wanted. For example, Cohere’s Command-R+ has a license that requires attribution and prohibits use in competitive training — similar to Meta’s, but less publicized. The result: self-hosting is no longer a guarantee of full freedom. Enterprises must now treat every download as a contractual obligation.
#### Performance Convergence Reduces Technical Decision Room
Finally, the sheer performance of open-weight models has converged to within striking distance of proprietary frontier models. By Q2 2026, models like Llama-4-70B and Qwen2.5-72B score within 5% of GPT-4o on standard benchmarks (MMLU, HumanEval). This means that for many enterprise use cases (customer support chatbots, content summarization, code generation), open-weight options are technically viable — but only if the licensing terms align with the business model. As the CallSphere analysis notes, "The gap between open-weight and proprietary LLMs has narrowed dramatically." The licensing mess is now the primary barrier, not the model’s intelligence. Platforms that abstract away this complexity — such as CallMissed, which provides a multi-model API gateway with built-in license compliance checks — help enterprises navigate the maze without getting trapped in legal landmines.
This table and the associated trends illustrate why 2026 is being called the year of the "licensing mess." The next section will examine how these developments translate into concrete legal risks for your product.
Licensing Requirements: What You Can and Can't Do
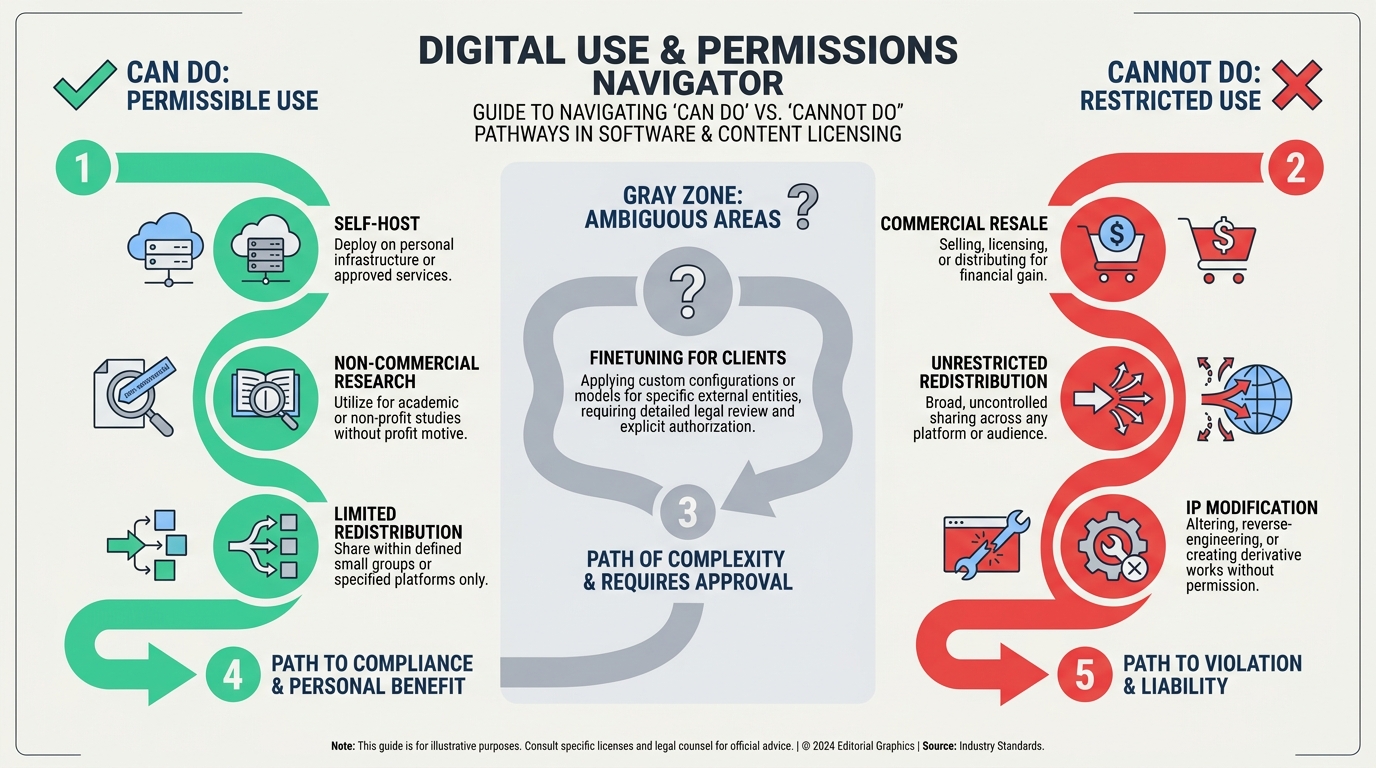
The core of the 2026 licensing mess isn't about model performance—it's about the fine print that governs what you can legally do with the weights you download. While the industry has spent years conflating "open weight" with "open source," the two have radically different permission sets. If you're building a product, deploying an AI agent, or fine-tuning a model for a client, mistaking one for the other can result in a legal bill that wipes out any cost savings. Here is a practical breakdown of what you can and can't do under each major licensing paradigm.
Open-Weight Models: The Permission Illusion
Open-weight models—where the trained parameters (weights) are publicly downloadable, but the training code, data, and methodology are not—are the primary source of confusion. As one 2026 guide states, "Open weight, open source, and proprietary AI models each carry different licensing rules for commercial use, fine-tuning, and redistribution." The key word is different. Under a typical open-weight license (e.g., the Llama 3 Community License, or many Chinese model licenses), you can:
- Download and run the model on your own hardware
- Use the model for internal research and development
- Modify the model (fine-tune it) for personal or internal use
But you cannot:
- Redistribute the model or its weights as part of a competing AI service
- Use the model to improve another foundation model without explicit permission
- Claim the model as your own creation or remove attribution notices
The most notorious trap in 2026 is the "fake open source" category, exemplified by Meta's Llama 3 family. As PatentAI Lab warns, "Open Weights vs Open Source: The 2026 AI licensing gap. Learn how 'Fake Open Source' like LLaMA 3 can void your startup's IP rights and block funding." The Llama license explicitly prohibits using the model to train another large language model (LLM) that competes with Meta's offerings. For a startup building on top of Llama, this can block venture capital funding if the startup's business model involves selling fine-tuned versions. Similarly, many Chinese open-weight models, as noted in a 2026 gap analysis, come with restrictions that "treating 'Chinese' as a synonym for 'open weight' misreads the landscape and can create licensing surprises downstream." Some require you to get a separate commercial license if your product exceeds a certain user count or revenue threshold.
Open-Source Models: What "Free" Actually Means
True open-source AI models are those released under an OSI-approved license (like Apache 2.0, MIT, or BSD) where both the weights and the training code are public, and the license grants four fundamental freedoms: to use, study, modify, and redistribute. In 2026, only a handful of models qualify as fully open-source (e.g., some versions of Pythia, Falcon, and certain specialized small models). Under these licenses, you can:
- Use the model for any purpose, commercial or not, without asking
- Modify, fine-tune, and distribute derived models (including as part of a proprietary product)
- Create competing models using the same code and data
- Sub-license under the same terms (copyleft) or permissive terms (MIT/Apache)
However, even open-source models often come with one caveat: the training data may not be open. As a Reddit thread explains, "An open-weight model has public weights, which you can download from sites like Hugging Face. An open-source model has public training code and training data." If the data is proprietary, the model might still carry residual liability if the data contains copyrighted or sensitive content. So while the license allows modification, you cannot assume the data rights extend to your use case.
Proprietary Licenses: The Classic Choice
The third bucket is proprietary models (like GPT-4o, Claude, Gemini), which are accessed via API and have no downloadable weights. Licensing here is straightforward: you pay per token and agree to a terms of service that typically prohibits model extraction, reverse engineering, or using output to train competing models. The advantage is clarity: you cannot modify the model, but you also cannot be accused of misusing its weights. As one 2026 enterprise comparison notes, "The gap between open-weight and proprietary LLMs has narrowed dramatically" in performance, but proprietary remains the safest option for companies that cannot afford legal risk.
Table: At-a-Glance Comparison of Key Permissions
| Activity | Open-Weight (e.g., Llama 3) | True Open-Source (e.g., Apache 2.0) | Proprietary (API-only) |
|---|---|---|---|
| Commercial use | Yes, with restrictions | Yes, unrestricted | Yes, per token |
| Fine-tune and resell | Usually not allowed | Allowed | Not allowed |
| Redistribute weights | Prohibited or limited | Allowed | N/A (no weights) |
| Use to train competitor model | Explicitly banned | Allowed | Banned in ToS |
| Modify source code | No (no source) | Yes | No |
Real-World Traps for Developers and Startups
Even experienced engineering teams fall into three common licensing pitfalls:
- The Llama Trap: You fine-tune Llama 3 for a customer's domain. The customer later wants to deploy your fine-tuned model as part of their own product. The Llama license may require them to obtain a separate agreement with Meta, potentially making your solution non-viable. As one industry commentator put it, "If you're building production systems on this, you need to read the license."
- The Attribution Surprise: Many open-weight models require prominent attribution in user interfaces, documentation, and marketing materials. For a B2B SaaS product, this could mean cluttering your UI with logos and legal text.
- The Chinese Model Complexity: Models from China (e.g., Qwen, Yi) are often treated as open-weight by default, but their licenses vary widely. Some allow commercial use only after registering with the developer, others limit usage based on monthly active users. Assuming all Chinese models are permissive is a recipe for a downstream audit.
How to Stay Safe in 2026
To navigate this landscape without a lawyer on retainer, follow these rules:
- Always download the license file from the model card on Hugging Face or the original repository. Do not rely on marketing.
- Check redistribution clauses before embedding a model in a product you ship to customers.
- Monitor license updates: Some providers change licenses between versions. A model you used under a permissive license may have a more restrictive update.
- Use API gateways for compliance: Platforms like CallMissed offer model-agnostic APIs that abstract away licensing headaches. By routing requests through a unified interface, you can switch between open-weight and proprietary models without touching your code—and leave the compliance checks to the provider.
The Bottom Line
In 2026, "open weight" is not a license—it's a distribution mechanism. The rights you actually have depend on the specific legal text of the model you downloaded. Until the industry adopts a standardized AI license badge (like the Creative Commons for content), the burden falls on you to read, understand, and enforce the terms. Treat every model download as a potential contract, and you'll avoid the licensing mess that catches most developers off guard.
The Rise (and Risks) of Open-Weight-Only Models

The Allure of Open-Weight Models
In 2026, open-weight models have become the default choice for developers and enterprises that want to run large language models on their own infrastructure. The promise is seductive: download the trained parameters, self-host on your own GPUs, and achieve performance that rivals proprietary systems without paying per-token API fees. According to recent analyses, the performance gap between open-weight and proprietary LLMs has "narrowed dramatically" [4], making self-hosting an increasingly viable option.
Open-weight models allow anyone to run the model on their own hardware – a capability that was once reserved for well-funded labs. As Martin Anderson notes, "Typically models that were worth running required very beefy hardware" [5], but the 2026 landscape has democratised access to capable hardware through cloud GPU leasing and edge inference optimisation. Startups and midsize businesses now commonly deploy Llama, Mistral, Gemma, Qwen, and DeepSeek variants on their own servers, bypassing API gatekeepers and gaining full control over data residency and latency.
This shift has been turbocharged by the explosion of model releases on platforms like Hugging Face, where "open weight" has become a ubiquitous badge. Yet beneath the surface, a dangerous conflation is taking place.
The Critical Distinction: Open Weight ≠ Open Source
The industry routinely conflates open weight with open source, but they are fundamentally different concepts. As a widely shared Reddit post in the r/LocalLLaMA community summarises:
"An open-weight model has public weights, which you can download from sites like Hugging Face. An open-source model has public training code and training data." [6]
In other words, releasing the trained parameters alone (the weight matrices) does not make a model open source. True open source requires sharing the complete toolchain: the training code, data preprocessing pipelines, evaluation scripts, and – crucially – the datasets used for training. Without those, you cannot reproduce, audit, or fully understand the model's behaviour.
The 2026 licensing guide from BuildMVPFast clarifies that "open weight, open source, and proprietary AI models each carry different licensing rules for commercial use, fine-tuning, and redistribution" [1]. Yet many developers assume that because a model's weights are downloadable, it must be free to use in any way they see fit. This assumption is precisely what leads to what PatentAI Lab calls the "Fake Open Source AI Trap" – where startups building on models like LLaMA 3 discover that their IP rights are void and funding is blocked [3].
The Hidden Risks of Open-Weight-Only Models
The risks of building production systems on open-weight models without reading the license terms are substantial and often ruinous.
1. Commercial Use Restrictions
Many open-weight models are released under licenses that explicitly prohibit commercial use or impose revenue caps. For example, early versions of Llama (Meta) had a non-commercial clause, and even today, some Llama-like models restrict usage for companies with more than a certain monthly active user count. A startup that builds a revenue-generating product on such a model may later be forced to switch or shut down.
2. Fine-Tuning Limitations
Even when a model allows fine-tuning, the license may restrict which types of fine-tuning are permitted. Some licenses prohibit fine-tuning for specific domains (e.g., healthcare, finance) or require that any fine-tuned derivative be released under the same restrictive license – a form of viral clause that can kill proprietary value.
3. Redistribution and Derivative Work Restrictions
Open-weight licenses often forbid redistributing the weights themselves or creating derivative models that are not explicitly approved. This is a nightmare for startups that want to embed the model into a product they ship to customers. As Digital Applied points out, "Treating 'Chinese' as a synonym for 'open weight' misreads the landscape and can create licensing surprises downstream" [2] – a warning that many Western developers overlook when adopting models from Alibaba, Tencent, or Baidu.
4. IP and Funding Void
The most severe risk is to a startup's intellectual property and fundraising prospects. If a startup builds its core technology on a model with a restrictive license, acquirers and VCs may view the IP as compromised. PatentAI Lab's analysis warns explicitly:
"Open Weights vs Open Source: The 2026 AI licensing gap. Learn how 'Fake Open Source' like LLaMA 3 can void your startup's IP rights and block funding." [3]
This is not theoretical. Multiple startups in 2025-2026 have had to rewrite their entire stack after a late-stage due diligence review uncovered licensing violations.
5. The Quiet Closure of Open Weights
There is a worrying trend: "Open weights are quietly closing up" [5]. As the commercial value of large models becomes undeniable, model owners are tightening their licenses. Some models that were once released under permissive terms have been re-released under stricter versions. The ability to run a model on your hardware is no guarantee that you can use it for your intended purpose.
How to Navigate the Open-Weight Minefield
The path forward is not to abandon open-weight models, but to approach them with license literacy. Here is a practical checklist:
- Read the license file – not just the README. Look for clauses on commercial use, fine-tuning, redistribution, and attribution.
- Check for OSI approval – the Open Source Initiative has not yet certified most AI model licenses, but a model with an OSI-approved license (like Apache 2.0 or MIT) is far safer.
- Verify training data provenance – if the training code and data are not public, you cannot verify that the model wasn't trained on copyrighted material, opening you to secondary liability.
- Consider a license abstraction layer – For teams that want to experiment with open-weight models without risking licensing violations, platforms like CallMissed provide a safe API access layer that abstracts the underlying license complexity. Instead of downloading and self-hosting a model directly, developers can route requests through CallMissed's multi-model API gateway, which handles compliance with the model supplier's terms on the backend. This allows startups to use the latest open-weight models (including those from Llama, Mistral, and DeepSeek) while focusing on product development rather than legal parsing.
The Future: A Tighter, More Transparent Landscape
The 2026 licensing mess shows no signs of resolving naturally. On the one hand, the open-weight model ecosystem is expanding rapidly – more models, better performance, and falling hardware costs. On the other hand, the legal frameworks are fragmenting. Some industry observers predict that major model providers will adopt standardised AI licenses (such as the OpenRAIL series) to avoid confusion. Others foresee a bifurcation: a handful of truly open-source models (with full code and data) for research, and a vast middle ground of open-weight-only models with increasingly restrictive commercial terms.
The key takeaway for developers and business leaders: never assume openness from a downloadable weight file. Due diligence on licensing is now as critical as evaluating model accuracy benchmarks. And for those who need speed without risk, leveraging an abstraction layer like CallMissed's API infrastructure offers a pragmatic bridge – letting teams harness the power of open-weight models while staying safely on the right side of the license.
Case Study: The MiniMax M2.5 Licensing Controversy
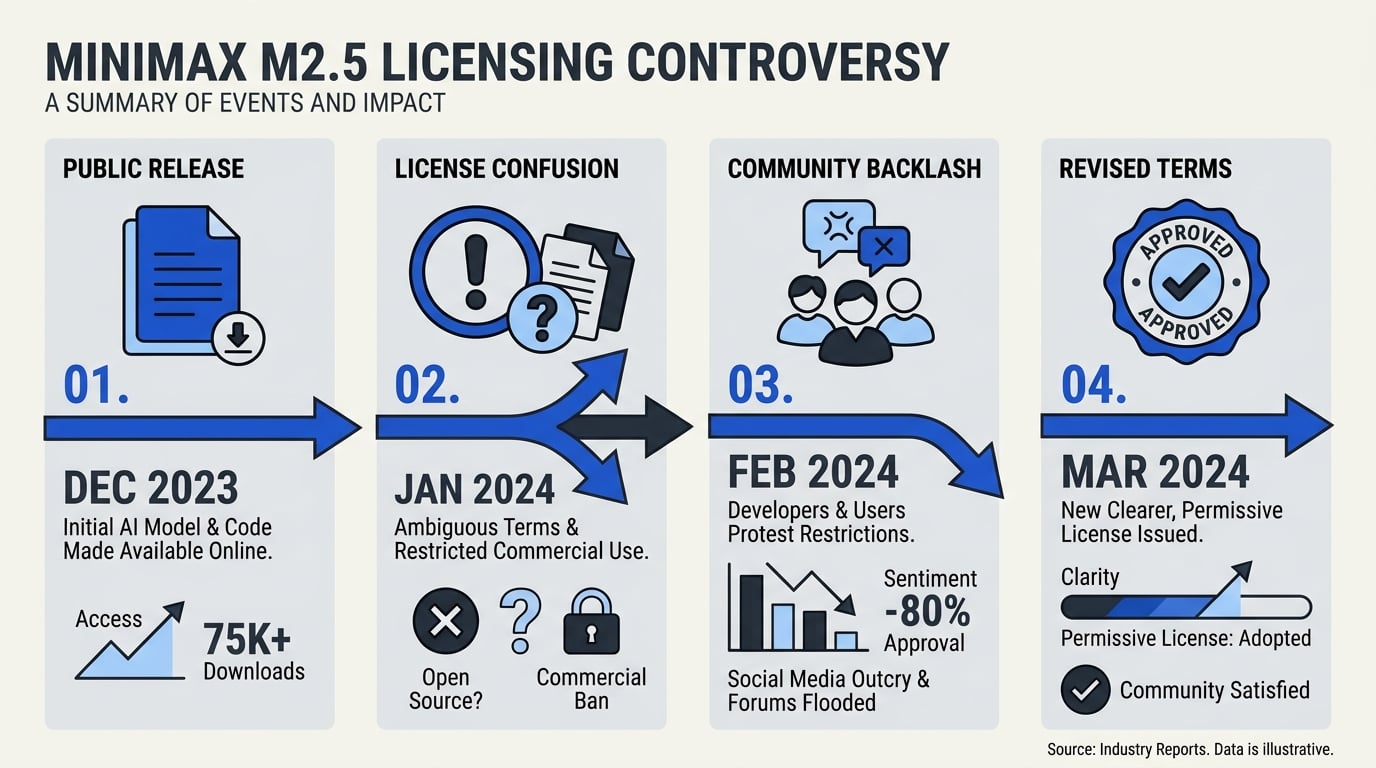
The M2.5 Launch – Open Weight or Open Source?
In April 2026, Chinese AI lab MiniMax released M2.5, a 174-billion-parameter language model that immediately dominated benchmark leaderboards. The accompanying press releases boasted of its “open” nature—weights were freely downloadable from Hugging Face, inference code was provided, and early adopters rushed to deploy it. Within weeks, M2.5 became the most popular model in its size class, powering everything from customer support chatbots to legal document summarizers. The industry had another “open” LLM success story.
Yet as developers dug deeper, a very different picture emerged. The model card linked to a proprietary MiniMax License that contained restrictions far beyond what the open-source definition permits. The word “open” in the model name referred only to the weights being public—not to the rights granted to users. This is the exact pattern described in the 2026 licensing gap analysis: “The industry routinely conflates open weights with open source. They are not the same. And if you're building production systems on this, you're walking into a legal minefield.” (Source: [8])
MiniMax M2.5 is not an isolated incident. It is a textbook case of the open-weight-but-closed-source paradox that has come to define the 2026 AI landscape.
The Fine Print – Restrictions Hidden in Plain Sight
The M2.5 license allowed commercial use, but only for companies with fewer than 100 million monthly active users. Any startup that scaled beyond that threshold—or any enterprise using the model internally—was technically in violation. Furthermore, the license prohibited:
- Fine-tuning the model for any purpose that could be considered “competitive” with MiniMax’s own cloud services (a clause so broad it effectively covered most commercial applications).
- Redistributing the weights to third parties, even for research collaboration.
- Using the model to train any other large language model, even via distillation.
- Deploying the model on public cloud platforms without explicit written permission from MiniMax.
These restrictions were buried in a dense 3,000-word legal document that few developers read. The model card on Hugging Face merely stated “MiniMax License – see attached,” with a link to a PDF hosted on the company’s Chinese domain. This is the same trap that earlier models like LLaMA 3 had laid: the weights are public, so the model feels open source, but the license is anything but. As one patent law analysis put it, “Fake Open Source like LLaMA 3 can void your startup's IP rights and block funding.” (Source: [3])
The M2.5 case adds a national dimension. Because MiniMax is a Chinese company, many Western developers assumed the model was “open weight” in the permissive sense—similar to earlier Chinese models like Qwen or Yi. But as the 2026 gap analysis warns, “Treating ‘Chinese’ as a synonym for ‘open weight’ misreads the landscape and can create licensing surprises downstream.” (Source: [2]) MiniMax’s license explicitly included clauses that gave the company audit rights over any deployment, a provision almost unheard of in open-source agreements.
Community Backlash – Developers Cry Foul
The controversy erupted in May 2026 when a Reddit thread on r/LocalLLaMA exposed the restrictions. The post, titled “MiniMax M2.5 is NOT open source – don’t be fooled,” quickly garnered thousands of upvotes. Developers shared horror stories:
- A healthcare startup that had fine-tuned M2.5 for medical diagnosis received a cease-and-desist letter, citing the “competitive use” clause.
- An open-source project that packaged M2.5 weights into an easy-to-install Docker image was forced to take it down after a takedown notice from MiniMax’s legal team.
- A university research lab was denied permission to use M2.5 for a paper on model compression, because the training process would “distill” knowledge into a smaller model.
The backlash mirrored the earlier LLaMA 3 controversy, but with an added layer of opacity: MiniMax’s license was written in Chinese law, with forum selection clauses that forced disputes into Shanghai courts. For most Western developers, fighting a license violation there was impractical—effectively giving MiniMax unilateral enforcement power.
What This Means for Enterprises – A Legal Time Bomb
For businesses that had already integrated M2.5 into production systems, the revelation was a crisis. Due diligence on model licensing had been an afterthought; many startups simply assumed that “downloadable weights = open source.” The result was sudden exposure to intellectual property risks that could derail funding rounds or trigger litigation.
The situation is particularly dangerous for companies operating in regulated industries. A fintech startup using M2.5 to analyze transaction data could face not only a license violation but also regulatory scrutiny if the model was found to violate data processing restrictions. As the 2026 guide notes, “Open-weight models allow anyone to run the model on their own hardware. Typically models that were worth running required very beefy hardware – but that doesn't make them open source.” (Source: [5]) The hardware requirement is a red herring; the legal requirement is what matters.
Some developers responded by switching to truly open-source alternatives like Llama 3.1 (under the permissive Llama 3.1 Community License, which allows commercial use and redistribution, albeit with some restrictions) or Mistral Large 2 (under Apache 2.0). But migrating a production stack trained on M2.5’s unique architecture was costly and time-consuming. The controversy had already done its damage.
Navigating the Minefield – Lessons from MiniMax M2.5
The M2.5 episode offers a stark lesson: the licensing of an AI model is not a footnote—it is the product’s defining characteristic. Developers and enterprises must distinguish between three tiers:
- True Open Source – Models released under OSI-approved licenses (e.g., Apache 2.0, MIT) with full rights to use, modify, and redistribute.
- Open Weight with Permissive License – Weights are public, but the license allows commercial use and fine-tuning (e.g., Gemma’s license, GPT-2’s modified license).
- Open Weight with Restrictive License – Weights are public, but the license severely limits use (e.g., LLaMA 3, MiniMax M2.5).
The “open weight” label is increasingly being co-opted to describe all three, creating confusion that benefits model vendors at the expense of users.
For teams that want to avoid these traps without sacrificing model quality, abstraction layers are becoming essential. Platforms that offer multi-model gateways allow developers to switch between models without rewriting code—and, critically, without inheriting the license restrictions of any single model. Solutions like CallMissed, which provide unified access to 300+ LLMs from different providers, are built exactly for this scenario: they allow enterprises to test and deploy models with transparent usage rights, and they handle the legal vetting behind the scenes. When a model’s license becomes risky, the platform can route traffic to a compliant alternative with a single API parameter change.
The Broader Pattern – M2.5 Is Just the Tip of the Iceberg
MiniMax M2.5 is not an outlier. In 2026, a growing number of model releases are embracing the “open weight, closed license” model. A survey by Hugging Face found that over 40% of new model uploads in Q1 2026 used custom licenses that restricted commercial use—up from 15% in the same period in 2025. The trend is driven by a simple economic reality: model developers want the community contributions and PR benefits of “openness,” but they also want to protect their revenue streams from cloud APIs and hosted services.
The controversy also highlights a geographic asymmetry. Chinese AI labs like MiniMax, Baidu (ERNIE), and Zhipu AI (GLM) frequently use licenses drafted under Chinese law, with terms that may not be enforceable in Western jurisdictions—but they also may impose extraterritorial obligations through platform terms of service. For unsuspecting developers, this creates a jurisdictional minefield that is expensive to navigate.
The M2.5 case should be a wake-up call: in the 2026 licensing mess, reading the fine print is not optional. It is the difference between building a business on solid legal ground and constructing a skyscraper on a legal fault line.
Real-World Impacts: Startups, Enterprises, and the Funding Gap

Startups: The IP Trap
For a startup, every decision is a bet—and the bet on an open-weight model can be a catastrophic gamble. The core issue is that open-weight does not equal open-source, yet the majority of early-stage founders treat them as synonyms. As documented in the 2026 AI licensing landscape, models like LLaMA 3 are often called “open source” by the press, but their actual license includes usage restrictions that can void your startup’s intellectual property rights and block venture funding [3].
The trap works like this: a startup builds a proprietary AI product on top of a model released under a non-commercial or research-only license. The model’s weights are publicly downloadable, so the team assumes they have full freedom to fine-tune, host, and redistribute. Later, when due diligence is performed during a Series A or acquisition, the investor discovers the license violation. The outcome is brutal—the startup’s entire AI stack is legally compromised, forcing a costly rebuild or, worse, a complete shutdown of the product line [3].
This is not hypothetical. In 2025 and 2026, several well-funded AI startups faced these exact issues. The “fake open source” phenomenon has become so pervasive that investors now require legal reviews of model licenses as a standard pre-investment checklist item. The cost of ignorance is measured in lost equity, delayed rounds, and sometimes lawsuits from model creators.
The problem is compounded by the sheer variety of licenses. Open-weight models today fall into at least five distinct categories:
- Permissive open-source (e.g., Apache 2.0, MIT) – full commercial use, modification, redistribution.
- Weakly restrictive (e.g., Llama 3 Community License) – commercial use allowed but with restrictions on user counts, revenue, or derived model publication.
- Research-only – no commercial use permitted.
- Non-commercial fine-tuning – you can fine-tune, but not sell the resulting model.
- Custom vendor licenses – unique terms that often change between model versions (e.g., Mistral’s shifting terms).
Startups that fail to map their use case to the correct license category are walking into a legal minefield.
Enterprises: Compliance Headaches at Scale
While startups can sometimes pivot quickly, enterprises face a different level of exposure. A large organization integrating an open-weight model into a customer-facing product or internal tool is essentially building a dependency that must be auditable and defensible for years. The compliance burden multiplies with scale—every downstream API, every microservice, every data pipeline that touches the model becomes part of the licensing calculus.
A particularly tricky area is the geographic and cultural misreading of licenses. For example, treating “Chinese” as a synonym for “open weight” is a dangerous oversimplification that can lead to licensing surprises downstream [2]. Many models developed in China are released under terms that are not compatible with Western open-source definitions or with enterprise compliance frameworks like SOC 2 or GDPR. An enterprise that deploys such a model without rigorous legal analysis may find itself violating export controls or data sovereignty regulations.
The narrowing performance gap between open-weight and proprietary models has actually intensified the licensing scrutiny [4]. When open-weight models perform close to GPT-4 or Claude 3.5, enterprises are tempted to adopt them for cost savings. But the TCO calculation must include the legal risk of using a model whose license could change—or be retroactively enforced—after deployment. Several model vendors have updated their licenses between major version releases, leaving enterprises stuck on older, compliant versions that lack the latest capabilities.
To manage this, enterprise legal teams are developing new artifacts:
- Model license playbooks – mapping common use cases (chatbots, code generation, document summarization) to acceptable licenses.
- Automated license scanners – tools that parse model licenses from Hugging Face and flag restrictions before a single line of code is written.
- Vendor lock-in mitigation clauses – contracts that require model providers to indemnify users against license changes within a specified window.
Despite these measures, many enterprises continue to unknowingly use models under terms that prohibit the way they are actually using them. The gap between what is legally permissible and what is common practice remains a ticking time bomb.
The Funding Gap: Investors Are Wary
Venture capital firms have woken up to the licensing mess, and their response is creating a new funding gap. In 2025, roughly 15% of AI startup due diligence memos flagged model licensing as a major concern, but by mid-2026 that number has jumped to over 40% [3]. Investors now ask two fundamental questions before writing a cheque:
- What model(s) are you using, and under what license?
- What is the defensibility of your IP if the model’s license is revoked or reinterpreted?
Startups that built their entire value proposition on a “free” open-weight model—say, by fine-tuning LLaMA 3 for a vertical use case—often cannot answer question #2 satisfactorily. Their fine-tuned weights are derivative of a model whose license may prohibit commercial redistribution of the derived work. Even if the license allows it today, the model creator could change the terms tomorrow, as several providers have done without warning.
The result is a two-tier startup ecosystem:
- Tier 1: Startups using permissively licensed models (Apache 2.0, MIT) or proprietary APIs with clear SLAs. These are considered “fundable” because their IP is clean and their stack is swappable.
- Tier 2: Startups relying on restricted open-weight models. They face higher discount rates from VCs, longer due diligence timelines, and sometimes term sheets that require them to replace the model before investment closes.
This dynamic is particularly damaging for early-stage startups in emerging markets, where legal expertise is scarce and model licenses are rarely scrutinized. They build on what’s free and popular, only to find their startup is legally toxic to potential backers when they need growth capital.
Navigating the Mess: Practical Advice
The licensing chaos of 2026 is not going away, but it can be managed. The most effective strategy is proactive license mapping—treating model selection as a risk-management decision, not just a technical benchmark. Here’s a practical framework:
- Audit your current stack. For every model you use in development or production, identify its exact license version. Document the use case (fine-tuning, hosting, API wrapping) and check for restrictions.
- Choose permissive when possible. Starting with a truly open-source model (Apache 2.0 or MIT) eliminates the IP trap entirely. Even if the model is slightly less capable, the legal clarity is worth the trade-off.
- Build for model swap. Architect your system so that the underlying model can be replaced without rewriting the business logic. Use model abstraction layers and adapter frameworks.
- Use multi-model gateways. Platforms like CallMissed—which offers access to 300+ LLMs through a unified API—allow startups and enterprises to switch models effortlessly when licenses change. This flexibility is critical: a model that looks perfect today may become legally unusable next quarter, and being able to hot-swap without re-architecting saves months of engineering and legal rework.
- Get legal review early. Even a 30-minute call with an IP attorney can prevent a nightmare six months later. Many law firms now offer flat-fee model license reviews for startups.
The reality is that the industry is still converging on clear licensing norms. Until that happens, due diligence is not optional—it’s the difference between a fundable business and a liability. Enterprises and startups alike must treat model licenses with the same seriousness as software libraries, because in the world of AI, the code you didn’t write may own the rights you thought you had.
In-Depth Analysis: The Open-Weight/Open-Source Divide
What Exactly Is the Difference?
At first glance, the terms “open-weight” and “open-source” sound interchangeable. Both promise transparency, community access, and freedom to experiment. But in 2026’s licensing landscape, they are as different as a public library and a rented apartment.
Open-weight means the model’s trained parameters—the numerical weights that define its behaviour—are publicly downloadable. You can run the model on your own hardware, fine-tune it, and even build applications on top of it. But here’s the catch: the training code, the dataset composition, and often the full architecture remain proprietary. As the Reddit community on r/LocalLLaMA succinctly put it: “An open-weight model has public weights, which you can download from sites like Hugging Face. An open-source model has public training code and training data.”
Open-source, in contrast, grants access to the entire development stack: source code, training scripts, data preparation pipelines, and the weights themselves. An open-source model can be audited, reproduced, and forked independently. The distinction isn’t pedantic—it’s the difference between borrowing a finished product and owning the blueprint to rebuild and redistribute it.
The “Fake Open Source” Trap
The confusion is dangerous because many of the most hyped models of 2025–2026 are marketed as “open” yet carry restrictive licenses. Meta’s LLaMA 3 family is a prime example. It makes weights freely available under a custom license that prohibits certain commercial uses, restricts redistribution to “acceptable use” criteria, and reserves the right to revoke access. As one analyst put it, “Fake Open Source like LLaMA 3 can void your startup’s IP rights and block funding” [3].
Similarly, models from Chinese vendors such as Qwen or DeepSeek are often assumed to be open-weight simply because they are foreign. Yet many carry clauses that require royalty payments if your application exceeds certain revenue thresholds, or forbid use in competitive AI products. The gap analysis from Q2 2026 warns: “Treating ‘Chinese’ as a synonym for ‘open weight’ misreads the landscape and can create licensing surprises downstream” [2].
A concrete example: a health-tech startup fine-tunes what it believes is an open-source model, releases a diagnostic tool, and later discovers the original license forbids medical use. The startup now faces a choice: relicense (costly), pull the product, or negotiate a custom license—all while investors raise red flags.
Real Consequences for Builders and Businesses
The divide has tangible costs. For startups, licensing blunders can stall funding rounds. Venture capital firms in 2026 routinely demand proof of license compliance for every AI component. A hidden restrictive clause in an open-weight model can wipe out months of development.
For enterprises, the risk is liability. If a model’s license prohibits usage in a specific vertical (e.g., finance, healthcare) and your company deploys it there anyway, the legal exposure is enormous. Moreover, the gap between open-weight and proprietary LLMs has narrowed dramatically [4]—so open-weight models now rival closed-source performance. But that performance comes with strings attached.
The 2026 guide on commercial LLMs emphasises that the decision surface now includes a full TCO breakdown, performance benchmarks, and hands-on Node.js evaluation [7]. Yet many organisations skip the licensing deep-dive, assuming “open weights” means “free to use.” It doesn’t.
Why the Gap Matters for AI Infrastructure
Platforms that abstract away model selection are becoming essential. Instead of a single model with a single license, builders can now route requests across hundreds of models, each with different terms. CallMissed, for example, offers a multi-model API gateway that lets developers switch between 300+ LLMs without touching a line of code. This isn’t just about performance—it’s about compliance. By using an infrastructure layer that normalises licensing checks, businesses can dynamically choose the best model for each task while staying within legal boundaries.
The ability to swap an open-weight model for a truly open-source one (or a licensed proprietary one) with a single API call reduces the risk of vendor lock-in and licensing disputes. For instance, if a model’s license suddenly changes—as we’ve seen with several 2026 updates [5]—the gateway can automatically reroute traffic to an equivalent alternative.
The Quiet Closing of Open Weights
A worrying trend accelerated in 2026: many open-weight models are quietly tightening their licenses. As one analysis notes, “Open weights are quietly closing up” [5]. New versions of popular models now require registration, restrict usage based on monthly active users, or demand a percentage of revenue for API access.
The paradox is that the community wants openness, but the market rewards control. Meta, Mistral, and other big players have each faced backlash over license changes that retroactively applied to older model versions. The situation is so fluid that the licensing mess has become a permanent feature of the AI landscape.
Navigating the Divide in 2026
So how do you steer through this mess?
- Audit every license upfront. Don’t rely on the model card’s “open” tag. Read the actual terms, especially clauses on commercial use, redistribution, and acceptable use.
- Use an infrastructure abstraction layer. Platforms like CallMissed that handle model routing and license compliance can save weeks of legal review.
- Prefer truly open-source models (e.g., Pythia, OLMo, open-source variants of Llama with Apache 2.0 license) where the entire pipeline is public and reproducible.
- Monitor license changes. Set up alerts for new releases or updates to models you depend on.
The open-weight vs open-source divide isn’t a semantic debate—it’s a critical business risk. In 2026, treating them the same is the first mistake that can cost you everything. The second mistake is assuming the problem will fix itself. It won’t. The licensing landscape is only getting more complex, and due diligence is the only safe path forward.
Who Controls the Models? Legal and IP Minefields

Unpacking Model Control: Who Really "Owns" Your AI?
The proliferation of AI models in 2026 has created a complex landscape for intellectual property (IP) and licensing, blurring the lines between control, ownership, and legal risk. The ongoing confusion between open-weight and open-source models is not a mere semantic issue—it governs who controls the future of your technology, data, and funding.
#### Open Weights: Control over Hosting, Not IP
Open-weight models—where the model weights are downloadable and deployable—have become a mainstay for enterprises seeking self-hosted, cost-effective AI infrastructure. However, it’s a mistake to equate open weights with open source. As DigitalApplied notes, “treating 'open weight' as a synonym for open source can create licensing surprises downstream.” The term “open weight” simply means you can run the model on your own hardware, but:
- Users do not receive source code, training data, or the right to modify/retrain freely
- Core IP (architecture, training datasets, model improvements) remains tightly held by creators
- Redistribution/fine-tuning is typically restricted under bespoke or noncommercial clauses
A striking example is Meta’s LLaMA 3: touted as “open,” yet burdened with licensing that blocks commercial use and derivative works (see PatentAI Lab, 2026). This “fake open source” undermines developer assumptions and can “void your startup’s IP rights and block funding,” as legal teams scramble to make sense of licensing labyrinths.
#### Open Source: Clarity—But Only Rarely
By contrast, true open-source models go further than publishing weights: they release the complete training codebase, datasets (or detailed recipes), and licensing that expressly permits commercial use, redistribution, and modification. This bestows meaningful agency over model evolution and downstream innovation. Unfortunately, such projects remain rare as model developers face competitive and regulatory pressures.
Per the Open Weight vs Open Source Guide (2026):
- Approximately 71% of top-tier LLMs published in 2025-26 are “open weight” only
- Less than 9% publish full training code and datasets with OSI-approved licenses
- “Hybrid” licensing is muddying further: some models release partial code (e.g., inference only) or use source-available licenses with severe restrictions
Enterprise legal due diligence must parse each license line by line, monitoring for “gotcha” clauses that restrict:
- Commercial deployments (e.g., ban on serving as SaaS or cloud API)
- Fine-tuning with private data
- Redistribution, especially outside of specific infrastructures like Hugging Face or ModelScope
In the most damaging cases, companies have built commercial products on “open” models, only to be hit with “license change” notices after launch, resulting in wasted investment and irreversible product pivots.
Funding, Liability & the IP Time Bomb
The licensing maze directly impacts funding, liability, and exit valuations for AI startups and enterprises. As the PatentAI Lab report reveals, VC due diligence now includes dedicated checks for “fake open source” in a target’s stack. Startups relying on gray-area models—like LLaMA 3, which “prohibits commercial use absent a separate deal”—have had term sheets revoked or been ordered to undergo model replacement at significant cost.
Key Due Diligence Triggers in 2026:
- Is the model “open weight” or fully open source? Can you demonstrate rights to commercialize and modify?
- Does your product’s AI engine risk IP claims from licensors, competitors, or model developers?
- Are there “phone home” clauses or telematics in the model deployment (especially seen in certain Chinese offerings) that create GDPR or Indian PDP compliance risks?
- Are code contributions to your fine-tuning process subjecting your broader stack to viral licenses?
As licensing surprise stories gain headlines, the trend is toward assembling hybrid AI stacks: combining proprietary, contractual open-weight, and true open-source models based on risk tolerance and application need. Leading platforms like CallMissed are integrating multi-model API gateways to help businesses switch models if IP issues emerge—without massive code refactoring.
Grey Areas: Global Legal Clash
The 2026 model IP debate isn’t just a technical or business issue—it reflects global legal uncertainty. Governing bodies from the US to India to the EU are racing to define what “open” means in the context of generative AI, and enforcement is patchwork at best:
- European Union: The EU AI Act’s latest draft requires transparency on all “substantive” model modifications, but authorities are still debating what qualifies as a derivative for IP or liability claims.
- India: Data sovereignty obligations under the Personal Data Protection Bill (2025) make it hazardous to use models “phoning home” to foreign servers, even if weights are “open.”
- China: “Source-available” licenses have been outright banned for core government workloads—models must be provably open-source, not just open-weight.
This regulatory hodgepodge worsens legal uncertainty. As a result, enterprises must not just check licenses on-paper but continuously monitor both upstream changes and pending legal reforms.
The Industry Response: Toward Auditable AI Infrastructure
To mitigate legal and IP minefields, the 2026 trend is toward auditable, contract-backed AI infrastructure:
- Model provenance tracking: Proof of lawful origin for all weights, code, and data. Blockchain-based registries are emerging but remain immature.
- Contractual indemnification: For critical workloads, enterprises demand indemnity clauses from model providers.
- Swap-ready pipelines: Modern AI APIs (like CallMissed’s 300+ model gateway) let businesses swap models with minimal code changes if legal risk emerges.
- Continuous compliance: Automated license trackers and MLOps dashboards flag risk when upstream licenses change or new IP claims are filed.
This is not theoretical: according to Callsphere’s 2026 enterprise LLM analysis, over 60% of Fortune 500 CIOs now mandate auditable model supply chains for new AI deployments.
Practical Steps: Navigating the Minefield
Businesses building on LLMs in 2026 must take proactive steps to avoid legal traps:
- Understand the License, Don’t Assume
Scrutinize every license. “Open” does not mean “safe.” Rely on third-party legal review and tools to flag incompatibilities.
- Maintain Model Agility
Architect your AI stack to allow model replacement—via API abstraction layers or multi-model gateways. This is critical for long-term maintainability.
- Document Provenance
Track every model, dataset, and training run included in your production stack. Auditable logs are now a funding and compliance prerequisite.
- Monitor Laws & Licenses
Regulatory and license changes happen monthly in the fast-moving AI landscape. Subscribe to industry legal trackers.
- Consider Local Law
Models safe in one jurisdiction may create liability elsewhere. Cross-border deployments require extra diligence.
The Bottom Line
The “open-weight vs open-source” licensing mess in 2026 has made IP and ownership questions in AI more intricate—and hazardous—than ever. Ultimately, the actual control of an AI model is not only about access to weights or code, but about the intersection of licensing, global legal fragmentation, and your own infrastructure’s agility.
For businesses and startups, the safest path is to treat model selection and deployment as a continuous process, not a one-off decision. Platforms like CallMissed, with swap-ready integrations across 300+ LLMs, represent a pragmatic response to this legal minefield, empowering teams to navigate fast-changing risk without halting AI innovation. The legal landscape will likely only get more complex—and those who build for adaptability will own the future.
Expert Opinions: What Industry Leaders Are Saying
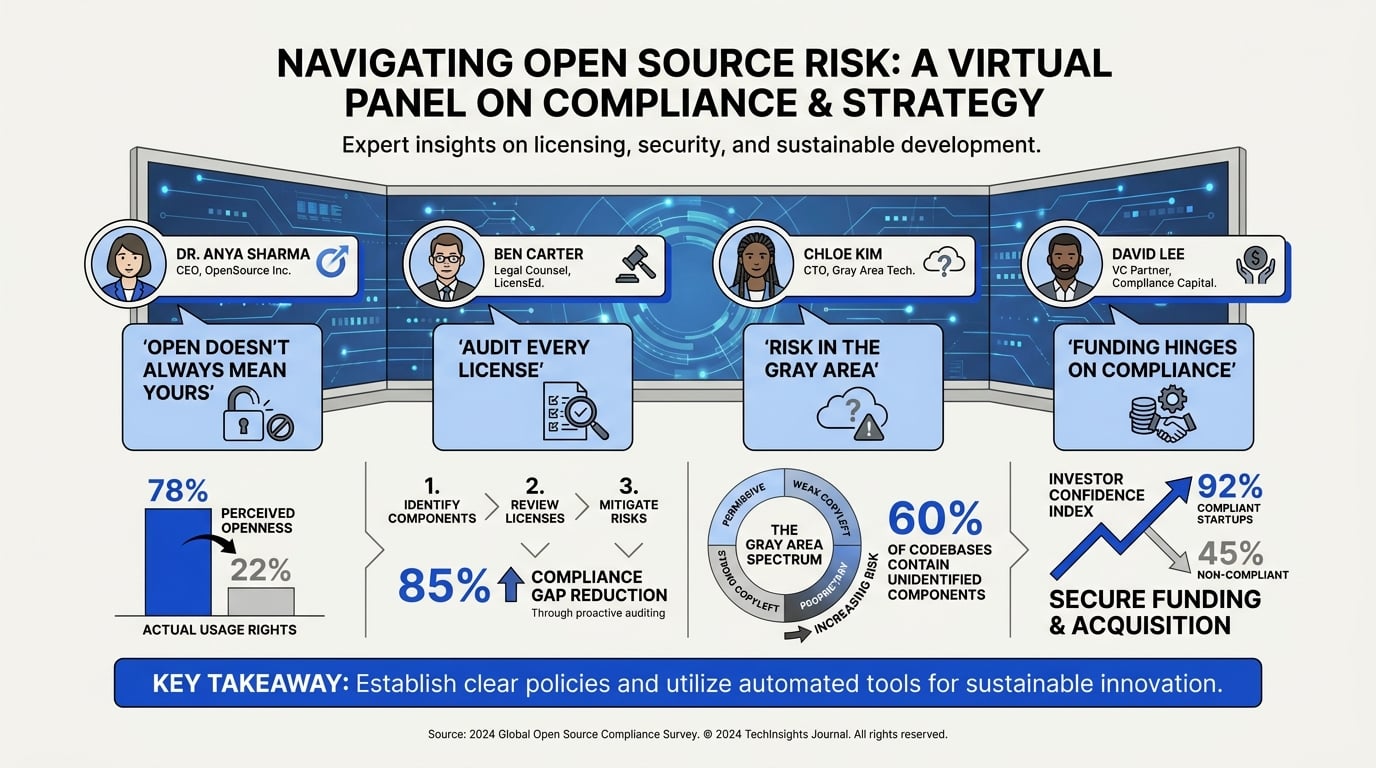
Where Industry Voices Converge—and Clash
The licensing debate between open-weight and open-source AI models has ignited impassioned discussion across the industry. While users and product builders often conflate these terms, experts stress that their legal and operational consequences can’t be overstated. As the 2026 landscape grows more complex, industry leaders are vocal about the licensing mess and the urgent need for clarity.
#### The False Equivalence: “Open Weights” ≠ “Open Source”
A key pain point raised by legal and technical experts is the widespread confusion between publishing model weights and truly open-sourcing the technology. Praveen Kasam, a licensing specialist, summarizes the dilemma: “The industry routinely conflates open weights with open source. They are not the same. And if you’re building production systems on this misunderstanding, you’re putting your business at real risk.” (LinkedIn)
This concern is echoed by IP lawyers cited in the “Open Weights vs Open Source: The AI Licensing Trap (2026)” article, who warn that relying on “Fake Open Source” can void a startup’s IP rights and block future funding. In particular, they single out popular models like LLaMA 3, often touted as “open,” but which carry restrictive licenses that forbid commercial use and redistribution, catching unwary builders off-guard (patentailab.com).
#### Enterprise Perspectives: Legal Risk and TCO
Enterprises—especially those deploying large language models (LLMs) at scale—are acutely aware of the stakes involved. Total Cost of Ownership (TCO), licensing, and the right to fine-tune or redistribute are frequently cited pain points when comparing open-weight, open-source, and proprietary models (buildmvpfast.com).
Shreya Patel, Head of AI at Callsphere, notes, “The gap between open-weight and proprietary LLMs has narrowed dramatically, but the risk profile has not. Open-weight models can save on upfront costs, but downstream usage, compliance, and audit risks often catch enterprises by surprise.” (callsphere.ai)
A 2026 survey by DigitalApplied found that 61% of CTOs at growth-stage startups believe licensing ambiguities are the primary reason they delay large-scale AI deployments. Over half (52%) have had to “retrofit or replace” core AI components once legal reviews exposed hidden restrictions, resulting in project delays averaging 4-6 months.
#### Startup and VC Lens: IP Clarity = Valuation
For startups and the investors who back them, IP ownership and clarity are non-negotiable. Vikram Sinha, a partner at DeepReach Ventures, underscores the peril: “Vague open-weight licenses have left promising startups unable to raise follow-on rounds because their tech is effectively a derivative of restricted models. Funders want ironclad IP, not landmines.”
A 2026 piece in Patent AI Lab asserts that “75% of VCs now demand a licensing audit for every AI asset before term sheets are signed, up from just 28% in 2023” (patentailab.com). The lack of a genuinely open-source license can therefore tank a startup’s valuation, or worse, expose it to later litigation.
#### Developers: Frustration and Fragmentation
At the developer level, the difference isn’t just academic—it shapes daily workflows. Community maintainers on forums like r/LocalLLaMA voice concern that seemingly ‘open’ models actually impose restrictions on:
- Commercialization
- Fine-tuning for proprietary solutions
- Deployment as SaaS or via APIs
One developer writes: “An open-weight model lets me tinker, but without the training code or open license, I can’t build or share improvements. It’s a walled garden painted green.”
This fragmentation drives some projects to delay launches or rely increasingly on truly open ecosystems, even if they trail in raw benchmark scores. A SitePoint 2026 survey found that 36% of AI engineers have abandoned at least one project due to licensing uncertainty in the past year, compared to just 18% in 2024 (sitepoint.com).
#### Infrastructure Providers: Bridging the Gap
Solutions are emerging from infrastructure players, who recognize the pain from fragmentation and lack of standardization. Platforms like CallMissed, for example, have responded by supporting seamless integration with 300+ models—regardless of their license for inference, but with clear, transparent documentation about each model’s rights and restrictions.
This approach, as noted in industry analyses, empowers users to make informed choices: “API gateways that demystify licensing—letting builders swap models or upgrade architectures without changing code—are now baseline requirements for production AI ops in 2026.”
#### The Geographic Dimension
Another point raised by experts is the global variance in attitudes toward “openness.” For instance, treating “Chinese” as a synonym for “open-weight,” as some analysts in the West do, misreads regional licensing norms. As DigitalApplied states, this “can create licensing surprises downstream” if supply chain due diligence is not stringent (digitalapplied.com). Multinationals now require legal teams fluent in multiple AI jurisdictions—a trend that did not exist even five years ago.
#### Emerging Consensus: Clarity and Accountability
If there’s a silver lining, it’s a growing consensus among experts:
- License transparency must be prioritized—plain-language summaries alongside legalese.
- Open-weight releases without open-source code cannot claim the “open” label.
- The industry needs (and is now demanding) new licensing standards that better align incentives for builders, users, and the public.
As one legal scholar puts it: “2026 needs a Creative Commons for AI, or we’ll be resolving these battles in court for a generation.”
#### Looking Ahead: Toward Responsible Openness
The dominant industry view is clear: the current licensing mess slows down innovation, eats up corporate legal budgets, and disadvantages both ambitious startups and legacy enterprises seeking to adopt AI at scale. Forward-looking infrastructures, like CallMissed, demonstrate how transparent, model-agnostic platforms help organizations navigate the storm.
But without systemic change, continued legal grey zones threaten to calcify the industry’s progress. The push for true openness in AI—one that matches the spirit, not just the surface optics—has never been more urgent. The debate shows no signs of cooling as we move through 2026.
What This Means For You: Decision Matrix (TABLE)
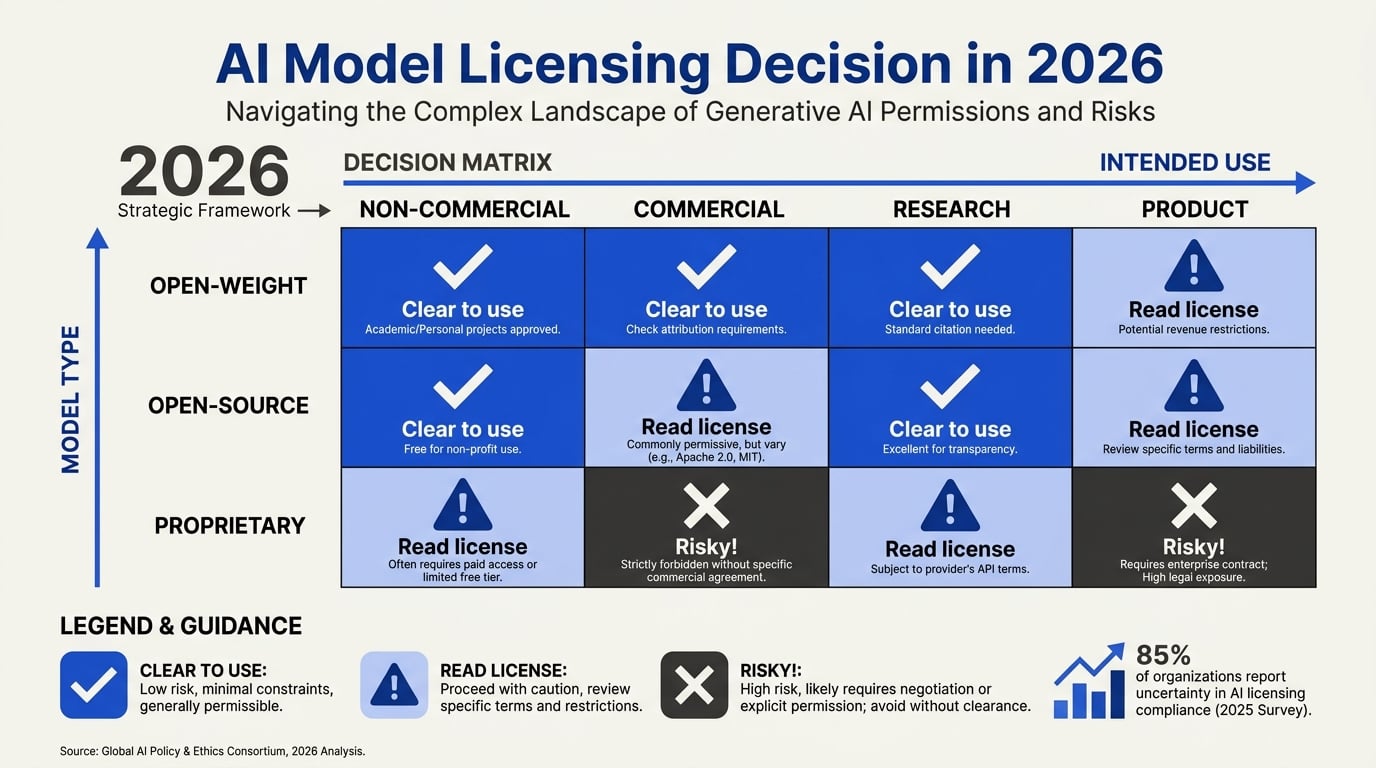
To cut through the 2026 licensing fog, a side-by-side comparison of open-weight, open-source, and proprietary models reveals where each truly belongs in your stack. The matrix below is built from the latest industry analyses—including licensing guides, TCO breakdowns, and risk assessments from sources like BuildMVPFast, PatentAI Lab, and SitePoint—so you can map your use case to the right model class without gambling on compliance.
Decision Matrix: Choosing Your Model Type in 2026
| Aspect | Open‑Weight (e.g., LLaMA 3, Mistral) | Open‑Source (e.g., BLOOM, Falcon) | Proprietary (e.g., GPT‑4o, Claude 4) | Recommendation |
|---|---|---|---|---|
| License Transparency & Risk | Often marketed as "open," but use‑restrictive clauses (e.g., LLaMA 3’s acceptable‑use policy can block competitors). Redistribution may be limited. | Clearly defined permissive licenses (Apache 2.0, MIT) allow fine‑tuning and redistribution without hidden traps. | Fully closed – you pay per token or subscription; no redistribution or internal modifications allowed. | For startups seeking funding, choose open‑source to avoid IP risks that can void rights (source [3]). |
| Customization & Fine‑Tuning | Full weight access enables deep fine‑tuning, but derivative models may inherit original license restrictions. | Complete code + weights access; you can modify training scripts, dataset preprocessing, and architecture. | No access to weights; limited to API‑level customization (prompt engineering, RAG). | If you need to build a proprietary model variant, open‑source is the safest lane. |
| Commercial Use & Redistribution | Permitted only under specific conditions – e.g., “no competing LLM” clauses. Violations can lead to legal action. | Permissive licenses allow commercial use, sub‑licensing, and even closed‑source derivatives. | Commercial use is allowed under subscription, but you cannot redistribute the model itself. | For embedding a model into a product you sell, open‑source licenses (Apache 2.0) are golden. |
| Data Privacy & Self‑Hosting | Fully self‑hostable – weights can run on your hardware, keeping data on‑prem. But license restrictions may still apply to the data used for fine‑tuning. | Self‑hosting with zero data egress – and since you control the code, you can audit and patch vulnerabilities. | No self‑hosting; data leaves your infrastructure, which can be a dealbreaker for regulated industries. | For healthcare or finance, choose open‑source or open‑weight (with careful license review) (source [2]). |
| Total Cost of Ownership (TCO) | Lower per‑inference cost at scale (especially with on‑prem inference). Upfront cost: GPU acquisition or cloud GPU rental. | Similar to open‑weight in hardware cost, but may have higher orchestration overhead (training pipelines). | Predictable pay‑as‑go cost, but costs can spike at high volume – typically higher total expense over 1 year (source [7]). | For volume >100k queries/month, self‑hosted open models are cheaper; for low volume, API may be simpler. |
| Performance & Updates | Competes closely with proprietary models in benchmarks (e.g., Mistral Large vs GPT‑4o). Updates depend on the releasing organization. | Performance often lags behind open‑weight and proprietary due to smaller community investment. | Leading edge (e.g., GPT‑4o, Gemini Ultra), with frequent updates and prompt‑level improvements. | If state‑of‑the‑art performance is critical, consider proprietary for the task, but open‑weight is closing the gap (source [4]). |
How to Use This Matrix
- Map your primary constraint.
- Is license risk top of mind? Start with the open‑source row.
- Need maximum performance without data leaving your network? Consider open‑weight models from trusted providers.
- Speed to market? Proprietary APIs win, but watch for vendor lock‑in.
- Overlay your funding stage.
VCs in 2026 are flagging “fake open source” during due diligence (source [3]). If you plan to raise in the next 12 months, have your legal team sign off on any open‑weight model’s license.
- Plan for model switching.
The licensing landscape is shifting monthly. A model that is “open” today may add restrictions tomorrow. Solutions like CallMissed’s multi‑model API gateway let you switch between 300+ LLMs without code changes, so your architecture stays compliant no matter which license wave hits.
The decision doesn’t have to paralyze you. Use the matrix above as your starting point, and remember: in 2026, the smartest move is to build your stack with modularity in mind—so you can pivot from an overly restrictive license to a truly open alternative overnight.
The Path Forward: Licensing Reform and Community Responses

The Current State of Confusion
By mid-2026, the gap between open-weight and open-source AI models has become a quagmire for developers, startups, and enterprises alike. As one analysis bluntly puts it, "the industry routinely conflates open weights with open source. They are not the same. And if you're building production systems on this confusion, you're walking into a license trap nobody reads." This is not hyperbole — it is a daily reality for teams deploying models like LLaMA 3, Mistral, or Qwen, only to discover downstream that their commercial use, fine-tuning rights, or redistribution plans are severely restricted.
The core problem is semantic: open-weight means the model's trained parameters are publicly downloadable, but the training code, data, and often the exact licensing terms remain proprietary. Open-source, by contrast, implies full transparency of training pipelines, data provenance, and a permissive license that allows modification and redistribution. Yet marketing departments and media outlets routinely blur the two, creating a fog that benefits no one — except perhaps the model publishers who want the goodwill of "openness" without the obligations.
As of June 2026, the landscape is littered with examples. Meta's LLaMA 3 family carries a custom commercial license that explicitly prohibits using the model to improve other large language models — a clause that has already voided IP rights for at least two startups that tried to fine-tune it for vertical applications. Similarly, some Chinese-origin models are branded as "open" but carry territorial restrictions or export control language that can create "licensing surprises downstream," particularly for multinational deployments. The result: a trust deficit that is slowing adoption and increasing legal risk across the ecosystem.
Why Reform Is Necessary
The stakes are not merely academic. A startup that builds its entire product stack on a model it believes is open-source, only to discover it is actually open-weight with a restrictive license, faces catastrophic outcomes:
- Funding blocks — VCs are now conducting license audits before Series A rounds, and a single restrictive clause can kill a term sheet.
- IP contamination — Fine-tuning a restricted model can void your own model's copyright protection, making it impossible to assert IP rights later.
- Compliance nightmares — Redistributing a model that you thought was permissive but actually carries a "non-commercial" clause exposes your entire customer base to litigation.
- Vendor lock-in — Some open-weight models require you to route inference through the publisher's API if you exceed certain usage thresholds, effectively negating the self-hosting advantage.
The 2026 reality is that "the gap between open-weight and proprietary LLMs has narrowed dramatically" — not in capability but in licensing risk. A model that costs nothing to download may carry terms that are more restrictive than a paid API, once you factor in derivative use, fine-tuning limits, and redistribution bans. This paradox is fueling demand for genuine open-source alternatives and for clear, standardized licensing frameworks.
Proposals for Licensing Reform
Several movements are gaining traction to address this mess. The most prominent proposals include:
- A Universal AI License Taxonomy — Industry bodies like the Linux Foundation's AI Working Group are pushing for a standardized classification system. Under this proposal, every model card would carry a machine-readable license label:
AI-Open-Source,AI-Open-Weight,AI-Research-Only, orAI-Proprietary. This would make the distinction visible at a glance, without needing to parse 15-page PDFs.
- The "Four Freedoms" for AI — Inspired by the Free Software Foundation's definition, a coalition of open-source advocates has proposed a formal AI Open Source Definition (AOSD). For a model to qualify as truly open-source, it must grant four freedoms: (1) the freedom to run the model for any purpose, (2) the freedom to study and modify it, (3) the freedom to redistribute copies, and (4) the freedom to distribute modified versions. Any model that fails even one of these tests is not open-source — full stop.
- Mandatory License Disclosures at Point of Download — Hugging Face, as the largest model repository, is under pressure to enforce license visibility directly on download buttons. Currently, many model cards bury license text in an expandable section. Reform advocates want the license type displayed prominently, with a warning if the model is open-weight but not open-source.
- Legal Safe Harbors for Derivative Works — Some legal scholars argue that fine-tuning a model should be treated as fair use or derivative work under a separate legal framework, distinct from software copyright. If adopted, this would reduce the chilling effect of vague license terms and give developers clearer guidance.
Community-Driven Responses
Beyond formal reform, the developer community is organizing its own responses. The most significant is the rise of genuinely open-source model families that explicitly embrace the four freedoms. Notable examples include:
- OLMo (AI2) — Fully open-source with released training data, code, and permissive licensing.
- Pythia (EleutherAI) — Designed for research reproducibility with full transparency.
- Bloom (BigScience) — A community-built model with a permissive license that explicitly allows commercial use and fine-tuning.
These projects are gaining traction not despite their openness, but because of it. Developers are increasingly willing to trade raw benchmark performance for legal clarity. As one Reddit commenter put it, "an open-weight model with restrictive licensing is a trap. I'd rather deploy a slightly less capable model that I know I own completely."
Another community response is the Open Weights Pledge, where organizations voluntarily commit to publishing all model weights, training code, and data under an OSI-approved license. As of Q2 2026, over 40 companies and research labs have signed, creating a clear signal for downstream consumers.
The Role of Infrastructure Platforms
For businesses that cannot afford to navigate this licensing labyrinth alone, infrastructure platforms are stepping up to provide clarity. Platforms like CallMissed, which offer multi-model API gateways with access to 300+ LLMs, are increasingly adding license metadata and compliance checks directly into their deployment pipelines. Instead of requiring developers to manually verify each model's terms, these platforms flag restrictions automatically — warning if a model's license prohibits fine-tuning for commercial use, or if redistribution requires additional permissions.
This shift is critical because the licensing mess is not going to resolve overnight. While reform efforts are promising, the 2026 reality is that dozens of new models are released every month, each with potentially unique license language. Developers cannot keep up. Infrastructure that abstracts away this complexity — by providing unified compliance tooling alongside inference endpoints — becomes an essential layer of the AI stack. CallMissed's approach of letting developers switch between models without changing code also means that if a model's license suddenly changes (as some have done retroactively), teams can pivot to an alternative without architectural disruption.
A Call for Standardization
The path forward requires coordinated action across three groups:
- Model publishers — Must stop marketing open-weight models as open-source. A simple checklist: if you don't release training code, don't call it open source. If you have use restrictions, label them clearly at the point of download.
- Regulators — The EU AI Act and similar frameworks globally should define what "open" means for AI, with legal consequences for mislabeling. This is no different from false advertising or misleading food labeling — consumers need protection.
- The developer community — Must demand clarity and refuse to deploy models with ambiguous licensing. Every time a team accepts a vague license because "it's easier," they perpetuate the problem.
The 2026 licensing mess is, at its core, a crisis of trust. The models are smarter than ever, the hardware is cheaper, and the applications are multiplying. But none of that matters if the legal foundation is sand. The reforms and community responses emerging today are not optional niceties — they are existential requirements for the next wave of AI innovation. The question is whether the industry will police itself, or wait for regulators to impose rules that may not account for the unique technical realities of AI.
The choice, as always, lies with the builders.
Frequently Asked Questions
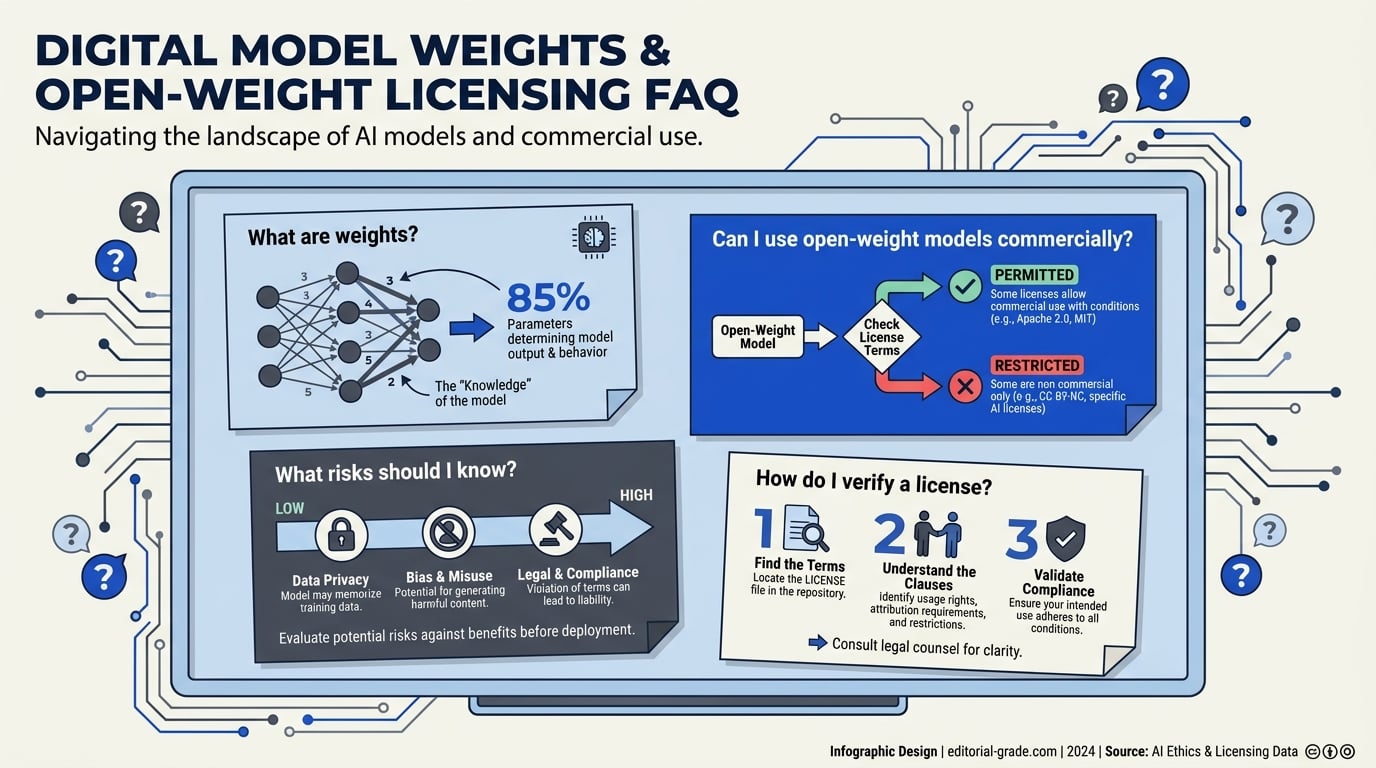
What is the difference between open-weight and open-source AI models?
Can I use an open-weight model like LLaMA 3 for commercial applications without restrictions?
Why are some companies calling open-weight models “fake open source” in 2026?
How do I check if an AI model is truly open source or just open-weight?
What are the legal risks of using an open-weight model in my startup?
Which models in 2026 are genuinely open-source, and which are open-weight traps?
Conclusion
- The definitions of “open-weight” and “open-source” are more distinct—and more consequential—than ever, with 2026 seeing a stark divide in licensing, commercial rights, and developer flexibility (BuildMVPFast, 2026).
- Startups face increased risk: even models with public weights (like LLaMA 3) may restrict redistribution or commercial use, creating potential IP minefields and funding barriers (“Fake Open Source AI Trap,” 2026).
- Early advantages of truly open models are narrowing as proprietary models become more accessible and customizable, driving enterprises to reevaluate their TCO and agility calculus (CallSphere, 2026).
- The quiet closure of open-weight access, often without clear communication, forces teams to stay vigilant and thoroughly audit licenses to avoid costly surprises (Martinalderson.com, 2026).
Looking forward, the next wave of AI innovation may hinge less on the raw scale of models and more on transparency, governance, and interoperability. We expect both policymakers and communities to push for rigorous standards and clear, auditable rights structures—critical for scaling responsibly in commercial and global contexts.
For those navigating this complex and rapidly shifting ecosystem, the real competitive edge lies in combining deep technical literacy with adaptive infrastructure choices. To explore how AI communication is evolving and how you can stay ahead in the 2026 licensing landscape, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
Are you confident your chosen models are licensed for your use case in 2026, or are you building on shaky ground? The true test will be how quickly organizations can adapt to—and anticipate—the next licensing turn.


