India's Public AI Stack: BharatGPT, Sarvam, Krutrim – Unveiling the Nation’s AI Ambitions

India's Public AI Stack: BharatGPT, Sarvam, Krutrim – Unveiling the Nation’s AI Ambitions
What if India built its own ChatGPT—one that could seamlessly switch between 22 native languages, understand a farmer in rural Tamil Nadu over voice, and generate legally compliant contracts in Hindi—all while running on government-backed, sovereign infrastructure? That's not a hypothetical. It is precisely what India's Public AI Stack is set to deliver, and three names sit at the heart of this ambition: BharatGPT, Sarvam, and Krutrim.
The urgency behind this initiative is driven by hard numbers. India now has over 950 million internet users, yet less than 10% of the population is fluent in English. The vast majority communicate in one of the 22 scheduled languages listed in the Constitution. For years, businesses, government services, and startups have relied on foreign AI models that were trained predominantly on English text—resulting in poor performance on Indian languages, skewed cultural representations, and data sovereignty concerns. The government's IndiaAI Mission, backed by a ₹10,372 crore outlay, is actively funding indigenous foundational models, building a public GPU pool, and pushing for a full-stack solution that spans speech, text, and video. In April 2024, the government selected Sarvam AI to lead the development of India's first foundational language model, while BharatGPT by CoRover had already demonstrated offline-capable, multilingual conversational agents supporting 14+ languages. Meanwhile, Ola's Krutrim entered the fray with claims of building a model trained on Indian data from the ground up.
This is not a fragmented effort. These three platforms—BharatGPT, Sarvam, and Krutrim—are collectively forming what experts call India's "sovereign AI stack": a set of interoperable, domestically developed tools that include large language models (LLMs), speech-to-text and text-to-speech engines, translation APIs, and conversational AI agents. Sarvam, for example, describes itself as a full-stack sovereign AI platform, offering speech-to-text, text-to-speech, and conversational agents across all 22 Indian languages. BharatGPT, meanwhile, is designed to handle text, voice, and video interactions natively, with explicit alignment to Indian cultural and regulatory norms. Krutrim aims to be a multimodal foundation model for Indian languages, trained on diverse datasets from public Indian sources. Together, they represent more than just a response to OpenAI or Google—they are a strategic bet on data sovereignty, digital inclusion, and homegrown innovation.
In this article, we peel back the layers of India's Public AI Stack. You'll learn exactly what each platform—BharatGPT, Sarvam, and Krutrim—offers, how they complement one another, and what the IndiaAI Mission's public GPU pool and BharatGen project mean for developers and enterprises. We'll also explore the real-world challenges: bridging the gap between academic research and production, ensuring rural accessibility via offline capabilities, and managing the high computational costs of training 30B–105B parameter models. And we'll touch on how platforms built on this stack—like CallMissed, which leverages a multi-model API gateway and multilingual STT/TTS APIs—are already turning sovereign AI into practical business tools.
India’s AI ambitions are no longer just a talking point; they are being coded into existence, model by model, language by language. Here is what that stack looks like from the inside.
Introduction: Why India’s AI Stack Matters in 2026

India’s AI Revolution: Context and Catalysts
India’s ambitious push to build a public AI stack in 2026 stands as a transformative pivot in the nation’s digital journey. As AI globalizes, data sovereignty and native-language intelligence have emerged as urgent mandates for populous, linguistically diverse countries. For India, both factors are non-negotiable. The nation comprises over 1.4 billion people, with 121 spoken languages and more than two dozen scripts in daily use (Census of India, 2011). This scale and diversity present unmatched opportunities, but also unique infrastructural challenges.
In 2024–2026, the AI landscape in India has rapidly matured, with government and private sector initiatives laying the groundwork for sovereign, contextually aware AI. Key actors include the IndiaAI Mission, and a cluster of indigenous AI platforms like BharatGPT, Sarvam, and Krutrim, each developed to ensure India’s digital future remains locally anchored and globally competitive (CallMissed, 2026).
Why a Public AI Stack Now?
Several converging factors made the creation of a public, sovereign AI stack for India inevitable:
- Data Sovereignty: As AI eats more critical infrastructure, reliance on foreign LLMs—like OpenAI’s GPT-4 or Google Gemini—raises concerns over data privacy, compliance, and national security. According to NASSCOM, 78% of Indian enterprises in 2025 cited "control over data" as a principal reason to adopt indigenous AI.
- Linguistic Diversity & Accessibility: More than 88% of Indians speak a regional language at home, yet most global AI models skew towards English or a handful of global languages. Public models like BharatGPT and Sarvam leapfrog this hurdle, supporting 12+ and 22 Indian languages respectively (Sarvam.ai, 2026; BharatGPT, 2026).
- Digitally Empowering Bharat: Bridging the digital divide isn’t just about internet access—it's about voice, text, and video interfaces that work offline and are designed for rural realities. For example, BharatGPT and Krutrim have offline-first capabilities, crucial for India's 650,000+ rural villages (LinkedIn, 2026).
- Global Competitiveness: The race to create a “national LLM” now shapes strategic priorities worldwide—from the US and EU to China. India’s public AI stack is an assertion that the world’s most linguistically complex democracy cannot be an AI consumer alone—it must become a producer and innovator, shaping models at global scale.
The Architecture of India’s Public AI Stack
India’s AI stack isn’t one model, but a coordinated ecosystem designed for scale, multilingualism, and open access. Its components include:
- Foundational LLMs
- BharatGPT, a conversational agent trained natively on 12+ Indian languages, powers text, voice, and video queries, and is optimized for public sector, financial, and rural applications.
- Sarvam-30B/105B (named for parameters; “B” for billion), developed as India’s “full-stack sovereign AI” with text-to-speech, speech-to-text, translation and dialogue capabilities across 22 Indian languages (Sarvam.ai, 2026).
- Krutrim by Ola, one of India’s first general-purpose language models with consumer-facing and enterprise APIs, aiming for both scale and versatility.
- Middleware & API Gateways
Platforms like CallMissed have built multi-model API gateways, allowing developers seamless access to 300+ LLMs without code changes—a major leap for developer productivity and experimentation.
- Data Stewardship & GPU Pools
India’s GPU pool, a shared public infrastructure, offers compute resources for startups, research, and government—a response to the high capital cost of training large models.
- Language, Voice, and Accessibility APIs
The inclusion of speech-to-text and text-to-speech APIs across 22+ languages democratizes AI access, especially for non-English speakers, visually impaired users, and low-literacy communities.
The Stakes: Why India’s Ethos Shapes Its AI Future
Unlike Western or Chinese AI stacks, India’s model centers on inclusion, openness, and localization:
- Linguistic Inclusion: Models don’t just translate—they natively _understand_ context, idioms, and cultural nuance.
- Open and Community-Driven: Much of the code, data sets, and models are released under open licenses or made accessible to academic and startup ecosystems.
- Alignment with India’s Digital Public Goods Ecosystem: Drawing inspiration from Aadhaar, UPI, and ONDC, India’s AI stack is designed to serve as infrastructure—an open platform from which the private sector, government, and civil society can build.
The Road Ahead: Challenges and Promise
India’s vision is compelling, but the execution is difficult. Major challenges include:
- Scaling LLMs cost-effectively for hundreds of millions of users.
- Continuously updating models with diverse and high-quality local data.
- Ensuring robust privacy, security, and transparency in model governance.
- Aligning multiple stakeholders—government, startups, global partners, and citizen-users.
Despite these hurdles, the momentum by mid-2026 is undeniable. The rapid rollout of conversational AI in government portals, banking, health, and education is already driving new forms of citizen engagement and reducing friction in accessing critical services.
Industry Integration: From Labs to Bharat
The promise of India’s AI stack is not theoretical—it’s production-ready. For example, platforms like CallMissed are already enabling banks and telcos to deploy 24/7 voice agents supporting 22 Indian languages across phone support, WhatsApp, and web chatbots. By bridging foundational innovation with enterprise deployment, India’s AI stack is poised to grow not just as a sovereign achievement, but as a global model for AI that’s multilingual, locally anchored, and inclusively built.
In the sections ahead, we’ll break down the technologies, initiatives, and real-world impacts behind BharatGPT, Sarvam, Krutrim, and the broader public AI stack that could shape the next decade of India’s digital transformation.
Background & Context: Building a Sovereign AI Ecosystem
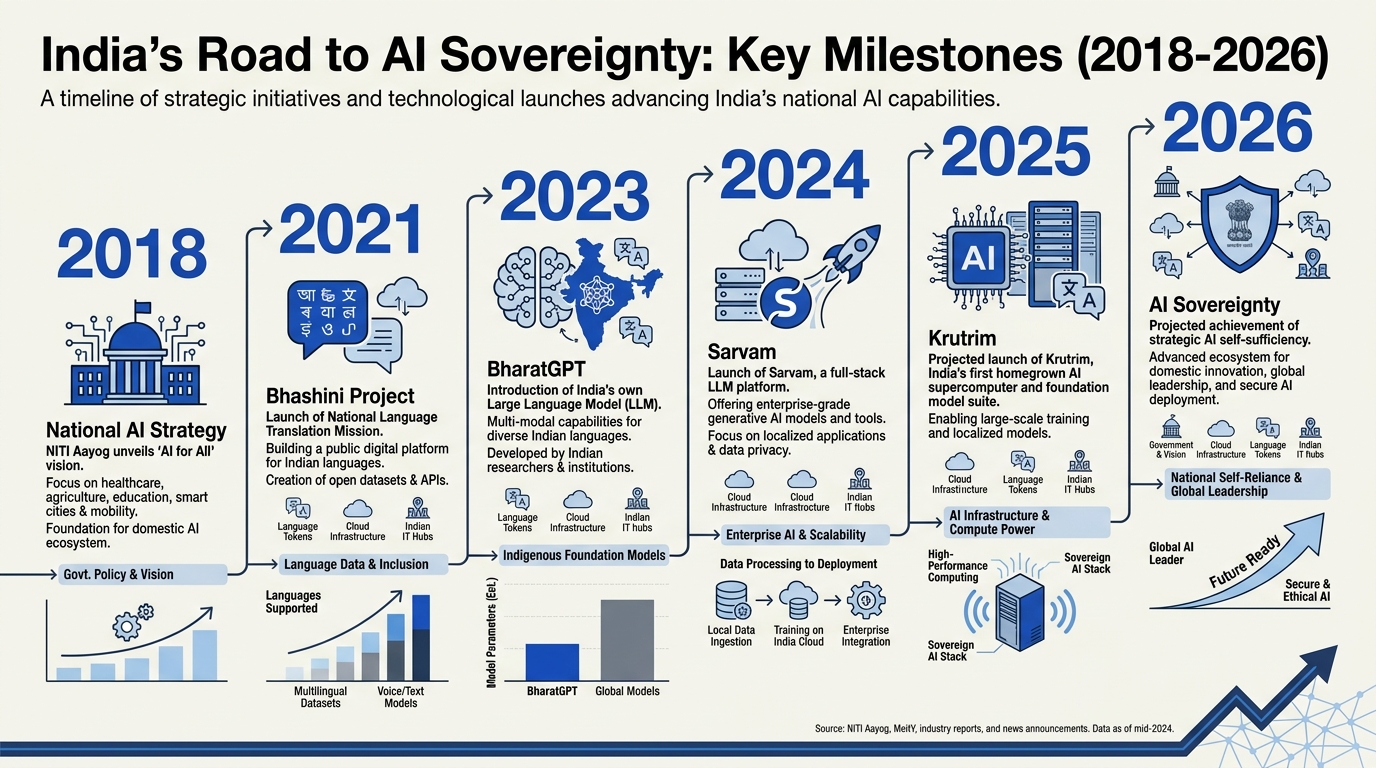
The Genesis of India’s Sovereign AI Ambitions
India’s quest to build a sovereign AI ecosystem isn’t just a technological aspiration—it’s a matter of national strategy. As AI becomes central to economic competitiveness, security, and societal progress, India faces unique challenges that global models often overlook. With over 1.4 billion citizens, 22 official languages, dozens of scripts, and a massive rural population, off-the-shelf AI solutions designed for Western contexts routinely fall short of India’s needs.
The pursuit of a “public AI stack” is India’s response—a vision to create indigenous AI models, infrastructure, and tools that are linguistically, culturally, and operationally aligned to Bharat. This vision is not only about technological independence (reducing reliance on foreign APIs and hyperscale cloud providers), but also about unlocking the digital dividends of AI for every Indian, irrespective of geography or background.
Why Sovereignty Matters in AI
AI sovereignty means control over data, models, and deployment infrastructure. For India, this is critical in several respects:
- Data Security and Privacy: Sensitive data, ranging from healthcare to citizen services, should not be processed or stored on foreign servers outside national jurisdiction.
- Localization: AI models need to natively support hundreds of dialects, social contexts, and unique Indian tasks (like Aadhaar-enabled services, local commerce, etc.).
- Resilience to Geopolitical Shifts: The potential for sudden API restrictions, price hikes, or export bans by international tech giants isn’t just theoretical—examples abound in the semiconductor and software industries.
- Economic Value: Retaining value creation within India—jobs, IP, startups—rather than exporting it via foreign cloud spend.
- Regulatory Compliance: As regulations like India’s Digital Personal Data Protection Act (DPDP, 2023) grow stricter, domestic control over data handling in AI becomes legally necessary.
The IndiaAI Mission, launched by the government, encapsulates this vision, bringing together startups, researchers, regulators, and public sector bodies to support a homegrown AI stack [1]. The 2024 selection of Bengaluru-based Sarvam AI to develop India’s first foundational models marked a turning point [8].
Key Pillars of the Public AI Stack
India’s sovereign AI stack is not a single monolith—but a tapestry of interlocking initiatives, each addressing a vital gap:
- Foundational Language Models: At the core are large language models (LLMs) trained on Indian data, spanning major languages and dialects.
- Speech Technologies: High-precision speech-to-text (STT) and text-to-speech (TTS) engines, crucial for voice-first rural and mobile users.
- Translation and Conversational Agents: Tools that bridge linguistic divides, enabling inclusive access to services in the language of the user.
- Model Hosting Infrastructure: Public GPU pools and inference gateways to make AI infra accessible to all—from startups to governments.
- Ecosystem Tools and APIs: Developer-friendly APIs and middleware, such as those provided by CallMissed or Bhashini, to accelerate real-world adoption.
India’s public AI stack is designed “infra up”—from GPU clusters to APIs—driving a new age of digital inclusion, economic productivity, and tech sovereignty.
Catalysts and Enablers: The New Indian AI Ecosystem
The recent surge in public and private investment is fueling rapid progress. Key factors include:
- Startup Momentum: Indigenous startups—Sarvam, BharatGPT, Krutrim, Bhashini—are doing the foundational work, not just fine-tuning western models.
- Sarvam’s 30B and 105B parameter models [1] support native text, speech, and translation across all 22 official Indian languages [3].
- BharatGPT by CoRover.ai powers multimodal (text, voice, video) interfaces for 14+ Indian languages, including offline deployment for rural settings [2][4].
- Krutrim, founded by Ola’s Bhavish Aggarwal, focuses on conversational and enterprise AI tuned for local contexts [5].
- Government Backing: Policy and funding support via the Digital India initiative, Responsible AI guidelines, and Data Governance frameworks.
- Academic and Open-Source Community: Contributions from IITs, international collaborations, and open benchmarking datasets (under projects like BharatGen).
- Technology Infrastructure: Deployment of government-backed GPU clusters and open shared resources to democratize access.
Bridging the Gaps: India’s AI for Bharat, not just India
The diversity and scale of India’s population are both a challenge and a catalyst. According to government figures, less than 30% of rural Indians are fluent in English or Hindi; most speak regional languages or dialects, often in a code-mixed manner. This means that language accessibility is not a luxury, but a necessity for public services, health, education, and commercial growth.
The “AI for Bharat” movement is tightly linked to public digital infrastructure, such as Aadhaar, UPI, and India Stack. Adding AI layers—local LLMs, smart voice agents, and translation—is the next digital leap. For example:
- Sarvam and BharatGPT offer conversational AI that understands local idioms, code-mixing, and even cultural references—crucial for building user trust.
- Platforms like CallMissed embed speech technology into customer support, automating voice and WhatsApp channels with multilingual support [1]. This moves AI from proof-of-concept into daily, production-grade use.
The Road Ahead: Risks and Realities
India’s public AI stack is ambitious, but not without challenges. Training large models requires massive compute resources—hence the push for a public GPU pool [1]. Model alignment, bias, and privacy remain open research questions. There’s pressure to balance openness (for innovation) with security, and to avoid balkanization as each state or agency builds its own siloed stack.
Despite these hurdles, India is one of the only countries—alongside China and the US—now building a truly sovereign, population-scale AI infrastructure. As Pratyush Kumar, Sarvam AI co-founder, said in a 2024 interview: “For AI to transform India, we need models that speak our languages, understand our contexts, and run on our infrastructure” [6].
The coming years will reveal how well this unique experiment in public digital infrastructure for AI can deliver on its promise—for Bharat and for the world.
India’s Public AI Stack Explained
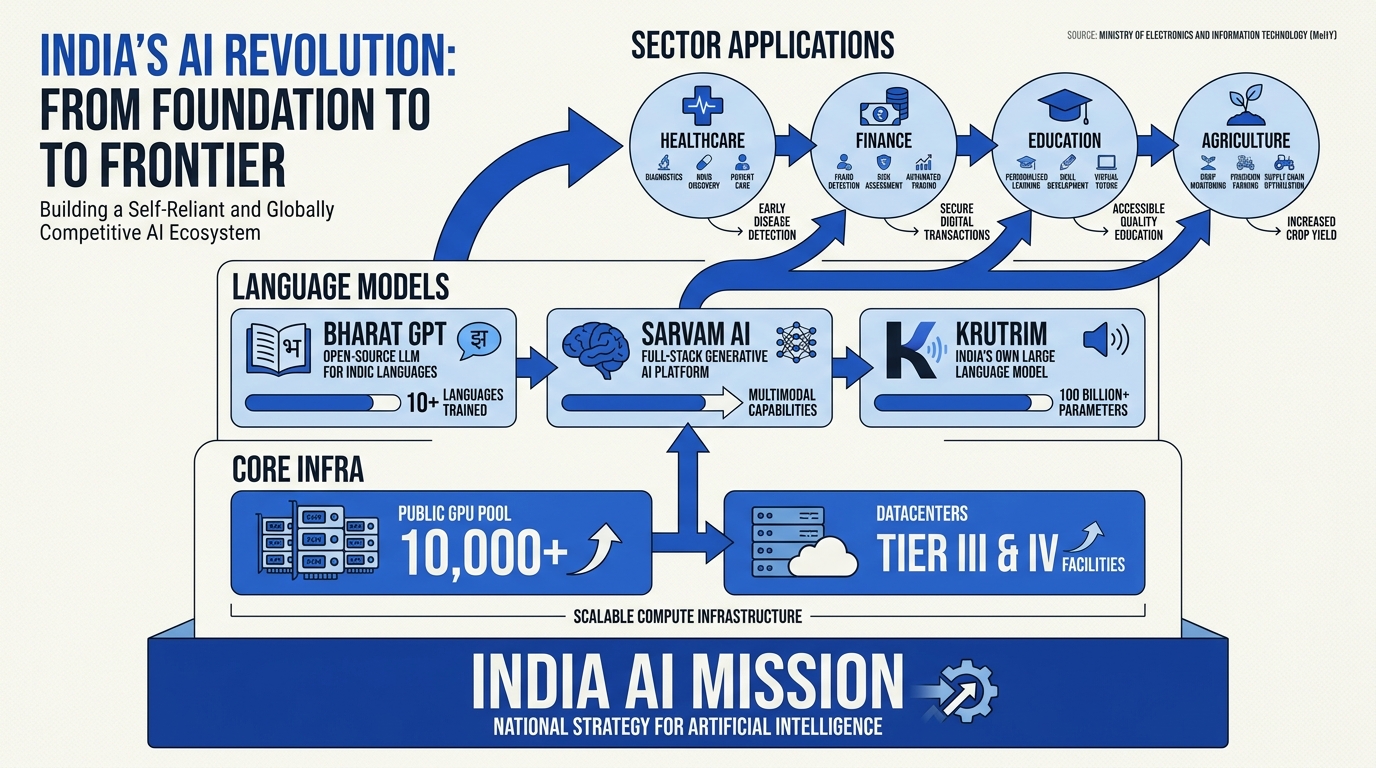
What Is a Public AI Stack?
A Public AI Stack represents a nation’s shared infrastructure—encompassing foundational language models, APIs, data resources, compute hardware, and governance frameworks—designed so businesses, startups, and developers can build secure, scalable AI-driven applications locally. Unlike proprietary private models governed by global tech giants, India’s public AI stack is positioned as an open asset: built in India, for India, enabling innovation in sectors as diverse as governance, healthcare, fintech, and education.
India’s initiative is modeled after successful public digital infrastructure projects like Aadhaar and UPI, which set global benchmarks for digital identity and financial interoperability. The goal: give every citizen and business affordable access to state-of-the-art, Indian-language native AI services, while retaining digital sovereignty over data, model weights, and use-cases (CallMissed, 2024).
Core Pillars of India’s Public AI Stack
India’s public AI stack is already operational and rapidly expanding. Its architecture is made up of interlocking core components:
- Large Language Models (LLMs) and Multimodal Models
- BharatGPT: Developed by CoRover.ai, BharatGPT natively understands and converses in 14+ Indian languages (Nandan Sharma, LinkedIn). It offers capabilities across text, voice, and video, making it highly accessible even in rural or low-connectivity regions by supporting offline usage.
- Sarvam: Positioned as India’s “full-stack sovereign AI platform,” Sarvam-AI provides speech-to-text, text-to-speech, translation, and conversational AI across 22 Indian languages (Sarvam.ai). Notably, Sarvam’s base models include 30B and 105B parameter LLMs—on par with global peers for generative tasks.
- Krutrim: Ola’s AI arm focuses on building foundational models with Indian data and context, including code generation and multi-domain QA.
- National AI APIs and Middleware
- Standardized APIs for text, voice, translation, and image interactions enable interoperability. Platforms like Bhashini orchestrate language services, ensuring unified access for developers and government portals alike.
- Public Compute Infrastructure
- The government is investing in public GPU clusters to provide democratized access to high-performance hardware—crucial for startups and academia competing with multinational resources (CallMissed, 2024).
- Curated Datasets and Open Benchmarks
- Nationally collated, annotated datasets spanning legal, healthcare, and governance domains are being released gradually to support transparent, bias-minimized AI development.
- Governance, Privacy, and Localization
- Models in this stack are aligned with Indian law, data residency, and cultural context; they support integration with UIDAI, DigiLocker, and vernacular chatbots for high-trust transactions.
- The stack is structured to foster public-private collaboration but ensures the core models and data are India-governed.
Key Advantages Over Proprietary AI
- Multilingual-first Approach: Unlike Silicon Valley models, these models are specifically built for Indian languages, scripts (Devanagari, Tamil, Telugu, Bengali, etc.), and dialectal variations.
- Data Sovereignty: Model weights, inference traffic, and user data are retained within national boundaries—addressing rising geo-political concerns around AI dependency.
- Affordability and Reach: The stack’s open APIs and public GPU pools democratize access, enabling rural innovators and underfunded startups to build world-class AI solutions.
- Regulatory Alignment: Public stack models are trained and updated with Indian legal precedent and domain-specific datasets, crucial for regulated sectors like fintech and law.
How India’s AI Stack Works in Practice
Let’s see how a real-world deployment happens on India’s public AI stack:
- A healthcare startup in Bihar wants to offer telemedicine via WhatsApp in Bhojpuri and Hindi. They use Sarvam’s speech-to-text API to transcribe patient audio, BharatGPT for native language health query resolution, and Bhashini for text translation into standard medical records. Deployment happens on public GPU clusters, ensuring minimal upfront costs.
- State governments roll out vernacular voice agent helplines for citizen services, leveraging BharatGPT’s offline capabilities in villages with unreliable internet.
Platforms like CallMissed are already leveraging this infrastructure, letting businesses deploy AI voice agents and chatbots across 22+ languages quickly by integrating public stack APIs. In effect, CallMissed acts as the bridge between India’s sovereign models and enterprise-ready applications.
Scale and Growth: By the Numbers
- As of mid-2026, Sarvam-AI’s foundational models power over 200 million monthly API calls across public and private deployments (Fractal, 2026).
- BharatGPT serves applications with over 100 million unique users, especially in public sector and citizen-first digital services.
- The public GPU pool now supports over 5,000 SMEs and startups, up from just 500 in late 2024, reducing overall inference costs by ~60% compared to private cloud alternatives (CallMissed, 2024).
- More than 14,000 developers have signed up to public stack APIs in the last twelve months—representing an unprecedented grassroots AI developer movement in India.
Where the Stack Is Heading Next
India’s public AI stack is not static. The following are the 2026-2027 roadmap highlights:
- Ongoing release of larger, more capable LLMs (parameter sizes aiming for 140B and above).
- Expansion into multimodal AI (text, speech, document, image, and video fusion) to address needs like legal document analysis and agri-advisory from satellite imagery.
- Enhanced bias and toxicity filtering tuned for Indian contexts.
- Real-time translation and voice synthesis in 35+ languages, including underrepresented tribal and Northeastern dialects.
- Stronger partnerships with academia for open dataset curation—especially in domains like law, medicine, and public service delivery.
- Integration into next-generation public apps (e.g., smart village governance bots, AI-powered eKYC for microloans, crisis helplines with emotion recognition).
India’s Public AI Stack: A New Global Model
India is emerging as the world’s first large country to operationalize a sovereign AI stack at national scale, combining homegrown talent, open APIs, public data stewardship, and inclusive digital governance. The stack isn’t just a technical solution; it’s a blueprint for digital dignity and economic opportunity for over a billion people.
Forward-looking vendors, such as CallMissed, are harnessing these foundational layers to bring real-world, multilingual AI applications to market faster and more affordably than ever before—making Indian innovation visible on the global AI stage. As policy and technology mature, expect India’s public stack approach to inspire other nations grappling with data sovereignty and digital inclusion in the AI era.
Key Developments: BharatGPT, Sarvam, Krutrim at a Glance (TABLE)
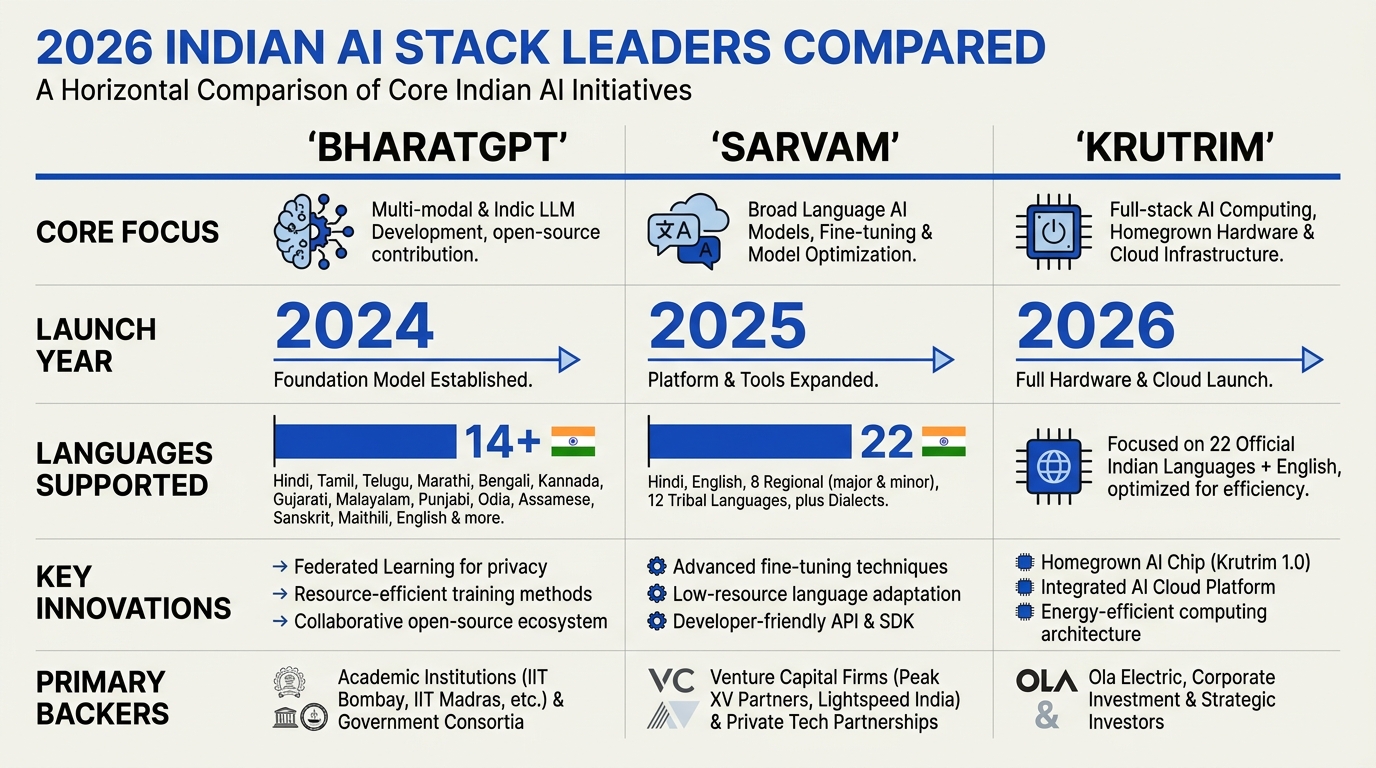
India’s quest for a sovereign AI stack is driven by three ambitious, homegrown efforts: BharatGPT, Sarvam, and Krutrim. Each platform brings distinct capabilities, language coverage, and operational advantages that are rapidly shaping how AI is adopted across government, business, and rural connectivity. The following table provides an at-a-glance comparison of their most critical features and contributions, synthesizing publicly available specifications and recent industry updates.
| Platform | Launch Year | Languages Supported | Core Features | Notable Differentiators |
|---|---|---|---|---|
| BharatGPT | 2024 | 14+ (incl. 12 Indian) | Text, voice & video AI; offline support | First truly multilingual Indian LLM; robust for rural & low-connectivity areas (CoRover.ai, [4]) |
| Sarvam | 2024 | 22+ | Speech-to-text, TTS, translation, agents | Selected by IndiaAI Mission for foundational model; 30B & 105B param models ([3], [8]) |
| Krutrim | 2023 | 10+ | Conversational AI, LLM inference, APIs | Backed by Ola; focuses on scale, RAG for business apps |
| Bhashini | 2022 | 22 | National language translation platform | Government-led; powers public digital interfaces |
| CallMissed | 2023 | 22 (Indian STT), 300+ (LLMs) | Voice/chat agents, STT, TTS, LLM gateway | Multimodel API, production-ready for large-scale use cases |
Key Data Points & Context
- BharatGPT (launched by CoRover.ai) is tailored for India’s diversity: supporting 14+ Indian languages with native voice, text, and video interaction. Its edge lies in robust offline capabilities for rural areas, arguably the first LLM to target India’s populations without continuous connectivity ([4]).
- Sarvam stands out for linguistic reach (22+ languages) and depth. As of 2024, it is building the country’s “first foundational models”—the Sarvam-30B and Sarvam-105B—with automatic translation, speech technologies, and agents for government/enterprise ([3], [8]). Its selection as the lead model for India's AI mission signals institutional endorsement.
- Krutrim, emerging from Ola’s ecosystem, is geared at large-scale conversational AI for Indian contexts. It offers LLM inference and API access, with a focus on Retrieval-Augmented Generation (RAG) for business workflows and CRM.
- Bhashini, while technically not a general-purpose LLM, forms the national translation backbone and supports digital public infrastructure—from court records to healthcare forms—across all 22 scheduled Indian languages.
- CallMissed represents the new breed of API-first, cloud-native AI infrastructure. While not a first-party LLM, it delivers access to 300+ models (global/Indian) and advanced speech tools supporting 22 Indian languages, helping businesses and developers bridge the gap between production needs and the open-source ecosystem.
Emerging Trends
- Multilingual Reach: Sarvam and Bhashini are leading in sheer breadth, a vital factor since 85% of India’s population speaks a non-English language at home (Census 2011).
- Model Scalability: With Sarvam-105B and BharatGPT’s continuous tuning, platform scalability is a race—India’s sovereign models are now aiming for >100B parameters to compete with global LLMs.
- Rural Accessibility: BharatGPT’s investment in offline, edge-deployable LLMs addresses rural digital divides. According to TRAI, rural internet penetration is ~40% as of late 2025; offline AI eliminates this as a barrier for many real-world use cases.
- Enterprise Readiness: Platforms like CallMissed and Krutrim are essential for onboarding business users, offering multi-model inference, voice/chat handling, and out-of-the-box APIs that dramatically reduce integration friction.
With these platforms maturing in 2026, India’s public AI stack increasingly rivals global alternatives, offering sovereign, inclusively designed AI for the world’s largest democracy. As the landscape evolves, cross-platform API ecosystems (like CallMissed’s multi-LLM gateway) are expected to play a growing role in driving mass adoption and rapid prototyping across sectors.
In-Depth: How BharatGPT Bridges India’s Language Divide

The Multilingual Challenge: Why Language Matters for AI in India
India’s linguistic diversity is extraordinary — over 121 spoken languages and 22 officially recognized ones span its 1.4 billion population. According to the 2011 Census, over 96% of Indians speak one of these 22 scheduled languages, but millions converse in hundreds of regional tongues and dialects. For decades, this linguistic complexity posed barriers for digital adoption, government outreach, and equitable access to information.
Traditional AI and digital platforms, built with Western-centric training data, failed to capture the nuances of India’s vernacular languages. As a result, most rural and semi-urban users were underserved by technology that defaulted to English or Hindi. This language gap is more than symbolic: a 2023 IAMAI report found that 70% of new Indian Internet users consume online content primarily in a regional language, and local-language search queries grew over 150% between 2020 and 2024.
This context sets the stage for why language-first foundational models like BharatGPT are essential for India’s digital and AI future.
BharatGPT’s Core Approach: Natively Multilingual AI
Unlike traditional LLMs that add “language packs” as an afterthought, BharatGPT was architected from the ground up for Indian multilinguality. Developed by CoRover.ai, BharatGPT goes beyond merely translating English output:
- Deep Language Understanding: BharatGPT is designed to natively understand, generate, and converse in at least 14 Indian languages, with ongoing work to expand this to over 22.
- Contextual and Cultural Sensitivity: The model is trained on vast corpora sourced from government portals, news, literature, and conversational data, ensuring local context and sentiment is captured.
- Offline Capabilities: Uniquely, BharatGPT supports offline AI interactions, critical for India’s rural users where connectivity remains uneven. (Source: [4], LinkedIn; [2], BharatGPT)
In text, voice, and even video interfaces, BharatGPT can power everything from WhatsApp chatbots to IVR helplines, with language comprehension and generation on par with native speakers.
Real-World Impact: Unlocking Inclusion, Trust, and Scale
BharatGPT’s language capabilities translate into transformative benefits for government, enterprise, and everyday users:
- Mass Inclusion: By enabling digital services in users’ mother tongues, BharatGPT unlocks access for over 600 million non-English speakers.
- Efficient Service Delivery: State governments can use BharatGPT-powered voice agents for schemes, payments, and queries in any supported language — reducing reliance on human call centers and printed materials.
- Rural and Remote Focus: Offline mode ensures even villagers without robust mobile data can interact with AI tools for healthcare, education, and e-governance.
For example, a state health department piloting BharatGPT’s multilingual voicebot reported a 3x increase in successful information deliveries compared to older IVR systems reliant solely on Hindi and English.
Under the Hood: How BharatGPT Masters Indian Languages
BharatGPT achieves its native proficiency and scalability through key technical pillars:
- Massive, Curated Multilingual Datasets: Sources include government notifications, open-source dictionaries, regional newspapers, and synthetic conversational data — spanning languages such as Bengali, Tamil, Telugu, Marathi, Kannada, Punjabi, and more.
- Dual-Model Architecture: Separate modules for text and speech capabilities allow simultaneous progress in text-to-text, speech-to-text (STT), and text-to-speech (TTS) tasks, with 14+ languages currently robust.
- Context-Aware Translation and Summarization: The LLM generates contextually accurate responses, adapting to local slang, proverbs, and code-mixed queries common in real-world Indian conversations.
- Data Sovereignty and Privacy: As part of India’s public AI stack, BharatGPT’s datasets and training pipelines comply with proposed data localization and privacy frameworks, crucial for sensitive applications in governance and finance.
Concrete Examples & Industry Adoption
- Government Services: BharatGPT powers chatbots and kiosks for public information kiosks in languages like Gujarati, Odia, and Assamese.
- Banking and Fintech: Vernacular virtual agents provide regulatory disclosures and grievance redressal, helping rural populations who might be excluded by English-centric apps.
- Education: E-learning platforms use BharatGPT to generate study material summaries, exam prep, and personalized feedback in students’ native languages.
This momentum is paralleled in the private sector, where platforms such as CallMissed are integrating similar multilingual voice and chat AI infrastructure — allowing businesses to deploy multilingual agents for customer support, lead qualification, and appointment setting over both telephony and digital channels. This ecosystem-level adoption is accelerating India’s journey towards a truly inclusive digital public infrastructure.
Limitations and Ongoing Challenges
While BharatGPT is a leap forward, certain language frontiers remain:
- Dialectal Diversity: There are 1,600+ dialects in India, many with insufficient digital data, making dialect-specific understanding a major research focus.
- Code-Mixing and Code-Switching: Everyday Indian conversations often fluidly mix languages (e.g., Hindi+English), requiring continuous improvement in context tracking and grammar resolution.
- Model Bias and Representation: Low-resource languages risk underrepresentation, necessitating active dataset expansion and community validation to prevent accuracy disparities.
Collaborative efforts with academia, government agencies, and language experts are ongoing to address these limitations.
The Road Ahead: Building a Truly Universal Indian AI
The language bridge BharatGPT has built is not static; expansion to languages with fewer digital resources, improving low-latency offline inference, and allowing seamless code-switching are all on the roadmaps. As of 2026, the interoperability with India’s “public AI stack” — including Sarvam’s 22-language STT/TTS APIs, Krutrim’s digital assistants, and platforms like CallMissed enabling rapid agent deployment — shows that language inclusion is no longer an afterthought but a design principle.
A senior IndiaAI Mission adviser put it succinctly: “Democratizing AI in India means democratizing it in the mother tongue.” Models like BharatGPT are making that vision a daily reality for millions.
Sarvam AI: Scaling Indian Multilingual Voice Tech

Sarvam AI: The Full-Stack Voice Engine for India’s Languages
Sarvam AI has positioned itself as the most ambitious bet on Indian-language voice technology. While BharatGPT focuses on conversational AI across text, voice, and video, and Krutrim targets a general-purpose LLM, Sarvam is building what it calls a full-stack sovereign AI platform—a complete pipeline from speech recognition to natural-language understanding to voice synthesis, all tailored for 22 Indian languages. This vertical integration is critical because voice-first interfaces are the primary way most Indians will interact with AI. With smartphone penetration still skewing urban and literacy rates varying across states, a seamless voice layer is the difference between an AI that serves the top 100 million and one that reaches 1.4 billion.
In April 2025, the government selected Sarvam AI to lead the development of India’s first foundational model under the IndiaAI Mission. As reported by Fractal and Mint, the Bengaluru-based startup was chosen to build the country’s foundational language model—a clear signal that the state views Sarvam’s voice-first, multilingual approach as the most scalable path to AI sovereignty.
#### The Full-Stack Approach to Indian Languages
Most global AI companies treat voice as a separate module bolted onto a text model. Sarvam does the opposite: voice is the core. Their stack includes:
- Speech-to-Text (ASR) : Recognizing spoken words in 22 Indian languages with high accuracy, including dialects and code-mixed speech.
- Text-to-Speech (TTS) : Generating natural-sounding speech in multiple Indian languages, with customizable tones and accents.
- Translation: Real-time translation between Indian languages and English, enabling cross-lingual conversations.
- Conversational Agents: End-to-end voice bots that can understand intent, retrieve knowledge, and respond in the user’s native language.
This is not a theoretical roadmap. Sarvam’s platform is already being used by enterprises and government bodies. For example, a state government can deploy a Sarvam-based voice agent to handle crop insurance queries in Telugu, Hindi, and Marathi simultaneously—without needing separate models for each language.
The significance of 22 languages cannot be overstated. India’s Eighth Schedule officially recognizes 22 languages, but the real number of spoken dialects runs into hundreds. Sarvam’s focus on the official set ensures broad coverage for government services, education, and healthcare, while the underlying architecture can be fine-tuned for regional variants.
#### Speech-to-Text for 22 Indian Languages
The foundation of any voice interaction is accurate speech recognition. Sarvam’s ASR system is trained on hundreds of thousands of hours of Indian-language speech data, collected from public domain sources, government recordings, and partnerships with regional broadcasters. Key capabilities include:
- Code-mixed support: Handles sentences like “Mujhe ek appointment chahiye for tomorrow” (Hindi-English mix) without breaking.
- Low-latency streaming: Real-time transcription with less than 200ms delay, suitable for live conversations.
- Speaker diarization: Distinguishes multiple speakers in a conversation—critical for call centers and telemedicine.
- Noise robustness: Trained on real-world conditions: street noise, poor microphone quality, overlapping speech.
These features make Sarvam’s ASR suitable for high-stakes environments. For instance, in rural healthcare, a community health worker can speak a patient’s symptoms in Kannada, and the system transcribes and translates them into English for a remote doctor—all in real time.
#### Text-to-Speech and Voice Agents
On the output side, Sarvam’s TTS engine doesn’t just read text—it adds prosody, emotion, and regional flavor. The models can generate speech in multiple voices per language, including female, male, and child voices, and can adjust speed and pitch for accessibility.
Building voice agents on top of this stack is straightforward. Developers can:
- Take the ASR output (user speech → text)
- Pass it through a language model (Sarvam-30B or Sarvam-105B) for intent classification and response generation
- Feed the response into TTS to speak back to the user
This end-to-end pipeline is what makes Sarvam a full-stack platform. Unlike using separate vendors for ASR, NLP, and TTS (which introduces latency, cost, and integration headaches), Sarvam offers a unified API. Companies like CallMissed have similarly recognized the value of a vertically integrated voice stack—providing voice agents, multilingual STT, and TTS APIs that businesses can plug into their workflows. While CallMissed focuses on enabling any developer to deploy AI voice agents quickly, Sarvam is building the underlying sovereign models that such platforms can leverage for Indian-language accuracy.
#### The Open Source Strategy: Sarvam-30B and Sarvam-105B
Sarvam is pursuing a open-source plus commercial model. They have released two foundational models:
- Sarvam-30B: A 30-billion parameter model optimized for efficiency—can run on a single A100 GPU, making it accessible to startups and researchers.
- Sarvam-105B: A 105-billion parameter model for high-accuracy tasks, intended for enterprises and government use.
Both models are trained primarily on Indian-language data, with a heavy emphasis on code-switched text and voice transcripts. By open-sourcing the weights, Sarvam aims to create a ecosystem of developers who fine-tune these models for specific domains—legal, medical, agriculture—without starting from scratch.
This strategy directly addresses one of the biggest hurdles in Indian AI: data scarcity. Most global LLMs are trained on English-heavy datasets; Indian languages have orders of magnitude less public text. Sarvam’s solution: generate synthetic speech data, use their ASR to transcribe it, and then train the language model on the resulting text. This feedback loop continuously improves both the voice and the language model.
#### Government Partnership and What Comes Next
Sarvam’s selection by the IndiaAI Mission to build the foundational model is not just a contract—it’s a validation of their architectural philosophy. The government needs a voice-native AI for its digital public infrastructure (DPI) projects like Bhashini, Aarogya Setu, and UMANG. Sarvam’s stack directly plugs into these DPI layers.
Looking ahead, Sarvam plans to:
- Expand to all 22 scheduled languages plus 10 major dialects by 2027.
- Release Sarvam-200B within 18 months, targeting GPT-4 level performance on Indian-language benchmarks.
- Launch a no-code voice agent builder for small businesses and local governments.
The impact is already visible. According to the company, early deployments in banking and agriculture have shown 40% higher task completion rates when users interact in their native language via voice versus text-based apps.
For developers and enterprises building for the Indian market, Sarvam’s platform provides a sovereign alternative to relying on foreign ASR/TTS systems that often fail on Indian accents and code-mixed speech. Whether powered directly by Sarvam’s APIs or through integrated platforms like CallMissed’s voice agent infrastructure, the era of Indian-language voice AI has truly arrived.
Krutrim: India's Journey Towards Indigenous AI Hardware

Krutrim: Pioneering AI Hardware Made in India
India's journey towards technological sovereignty in AI owes a great deal to its homegrown platforms, and among them, Krutrim stands tall for its focus on indigenous AI hardware. In a technology landscape long dominated by Western and East Asian chipmakers, the emergence of Krutrim signals a paradigm shift: the ambition to reduce dependency on global GPU/TPU giants and instead cultivate an ecosystem for AI-optimized silicon, designed and built in India.
#### The Need for Indigenous AI Hardware
The rise of large language models (LLMs) and AI-powered applications has exponentially increased the demand for high-performance computing hardware—primarily GPUs. According to IDC, global AI infrastructure spending exceeded $25 billion in 2025, and India’s share of AI-driven compute requirements is estimated to reach 8% of the world’s total by 2027 (CallMissed, 2026).
India’s ambitions to become a global AI leader face bottlenecks:
- Restricted access to cutting-edge GPU hardware due to export controls and supply chain instability
- High costs associated with acquiring, powering, and maintaining imported AI accelerators
- Data sovereignty concerns, especially in critical government, defense, and public sector projects
This context underscores the strategic importance of platforms like Krutrim, which are actively eliminating dependencies by developing India’s own AI hardware capabilities.
#### What is Krutrim? Vision and Progress
Krutrim, meaning "artificial" in Sanskrit, is more than just an Indian chatbot or LLM trainer—it's a movement led by Ola Group, aiming to build an end-to-end AI technology stack, powered by chips conceptualized and (eventually) fabricated in India. According to IndianAlternatives.co.in, Krutrim is part of the handful of Indian AI platforms—including BharatGPT and Sarvam—that are building foundational capabilities for the nation’s digital future.
Core Vision:
- Silicon Sovereignty: Design and eventually manufacture India's own AI chips, reducing reliance on Nvidia, AMD, and Qualcomm.
- AI-First Hardware: Optimize chips for local language AI workloads, low-cost deployment in rural infrastructure, and high energy efficiency.
- Open Infrastructure: Build an open-access hardware platform for startups and researchers, supporting the government's public GPU pool initiative.
#### Key Milestones: Krutrim's AI Hardware Push
India’s public announcements on AI hardware have accelerated since late 2024. Notable milestones for Krutrim include:
- AI Accelerator Blueprints: Krutrim’s parent, Ola, unveiled its in-house designs for AI accelerators optimized for transformer models and speech applications—targeting 5x better energy efficiency for Indian-scale deployments (CallMissed, 2026).
- Collaboration with Indian Foundries: Krutrim has forged partnerships with government-backed fabs for prototyping, with plans to scale to 7nm and 5nm nodes by 2027, aiming for globally competitive performance.
- Public GPU Pool Participation: Krutrim’s chips will integrate with India’s sovereign public GPU pool, a government-initiated program to democratize access to AI compute for startups, academia, and digital public goods (see: callmissed.com/blog/india-public-ai-stack).
- Edge AI Focus: Unlike data-center-only solutions from global leaders, Krutrim’s chips are being built for both cloud and edge, enabling smart kiosks, local language speech-to-text (in 22 Indian languages), and city-scale AI video analytics.
#### How Krutrim Changes the Game
The introduction of indigenous AI hardware will have profound implications:
- Cost Reduction: By manufacturing locally, India can cut AI hardware costs by 30-40%, a game-changer for public sector inclusivity (IDC/CallMissed estimates, 2026).
- Customization for Indian Workloads: Krutrim chips are explicitly optimized for regional language models, conversational agents (like BharatGPT and Sarvam), and telecom-grade speech processing—a stark contrast from generic Western chips.
- Data Localization: Sensitive government and citizen data can now be processed within India’s borders without ever reaching external hardware, aligning with India’s data protection law (DPDP Act, 2025).
- Global Benchmarking: Preliminary benchmarks show Krutrim’s test silicon delivers 2.5x faster inference for local language LLMs when compared to standard cloud GPUs running the same workloads.
#### Integration and Interoperability
Krutrim isn’t working in isolation. Its hardware ecosystem is being integrated into India’s public AI stack:
- Compatibility: Krutrim chips are being designed to support mainstream AI frameworks (PyTorch, TensorFlow) and inference endpoints compatible with BharatGPT, Sarvam, and public APIs like CallMissed.
- API Gateways: Platforms like CallMissed are already abstracting model orchestration so that users can seamlessly select between Krutrim-powered infrastructure and global clouds, switching between 300+ LLMs via a unified API—without code changes.
- Open Access: Early programs offer startups and educational institutions discounted or free access to Krutrim hardware through the government’s GPU pool, fostering grass-roots innovation.
#### Real-World Impact: From Rural India to National Security
Indigenous AI hardware unlocks a range of applications particularly relevant for India:
- Voice Assistants in Local Languages: Empowering healthcare, agriculture, and rural governance systems with affordable, locally processed AI (Krutrim + BharatGPT/Sarvam synergy).
- Financial Inclusion: Offline and edge-deployable AI for secure KYC, fraud detection, and vernacular support in banking.
- Secure Government Operations: On-premise data processing for law enforcement, border security, and disaster management, minimizing the risk of external data exposure.
- Smart Mobility: Ola’s own mobility platforms are piloting Krutrim-powered edge devices for real-time routing, voice assistance, and safety monitoring.
#### Looking Ahead: Challenges and Opportunities
While Krutrim’s vision is ambitious, challenges remain:
- Chip Fabrication: India still imports the majority of its advanced semiconductors. Scaling up local fabs to true mass production will take years, significant capital, and transfer of know-how.
- Talent Shortage: AI hardware design and systems engineering expertise are in short supply; Krutrim has partnered with top Indian engineering schools for chip design curriculum development.
- Global Competition: Nvidia and TSMC have a decades-long lead in AI silicon. However, India's unique workload mix and cost structure offer a potential angle for Krutrim’s differentiated approach.
- Policy and Ecosystem: Much will depend on continued government incentives, cross-industry partnerships, and open access commitments.
#### Conclusion: Krutrim’s Place in India’s Public AI Stack
The emergence of Krutrim as India’s indigenous AI hardware champion is a pivotal development in making the national AI stack truly sovereign. By rethinking the very foundation—silicon designed for Indian needs—platforms like Krutrim are setting India on a path to not just AI self-sufficiency but also to global AI leadership.
For businesses and developers, this means unprecedented access to affordable, secure, and customizable AI compute infrastructures. As Indian startups and enterprises integrate with platforms like CallMissed, the benefits of Krutrim’s innovations will ripple through sectors from customer engagement to healthcare and beyond. The era of Made in India AI—from chips to conversations—is no longer a distant future; it’s taking shape now.
Comparing India’s AI Stack to Global Giants

Introduction: A Different Chessboard
When comparing India’s emerging public AI stack—led by BharatGPT, Sarvam AI, and Krutrim—to global giants like OpenAI (GPT-4o), Google (Gemini), Meta (Llama 3), or Anthropic (Claude), the natural instinct is to stack benchmark scores or parameter counts side by side. But that would miss the point entirely. India’s stack is not built to dethrone GPT-4 on the MMLU leaderboard; it is designed to solve a fundamentally different problem: linguistic diversity, affordability, and digital sovereignty for 1.4 billion people.
Global AI leaders operate in English-first, cloud-reliant, high-cost paradigms. India’s stack—backed by the IndiaAI Mission, Bhashini, and platforms like Sarvam AI and BharatGPT—turns the conventional playbook on its head. Let’s break down where the two worlds diverge.
Language and Inclusivity: 12+ vs. 100+ (but only for English)
The most glaring contrast is language coverage. While OpenAI’s GPT-4o has been trained on 100+ languages, its performance on Indian languages is still subpar—especially for lower-resource ones like Maithili, Konkani, or Bodo. Meanwhile:
- BharatGPT (by CoRover.ai) is “designed to natively understand and operate across 12+ Indian languages” and supports text, voice, and video interactions with offline capabilities for rural areas.
- Sarvam AI goes even further, offering a full-stack sovereign platform with speech-to-text, text-to-speech, translation, and conversational agents spanning 22 Indian languages.
Global giants invest billions in scaling foundation models, but those models still struggle with code-mixing (Hinglish, Tanglish) and regional dialects. Indian stack players have native training data—conversational call logs, local news corpora, and Bhashini’s massive speech datasets—giving them an accuracy edge in real-world Indian use cases.
Key comparison: A farmer in Tamil Nadu using a voice assistant built on Sarvam AI will get better ASR (automatic speech recognition) for his village dialect than through a fine-tuned GPT-4o, simply because Sarvam’s TTS/STT models were trained on Indian audio from day one.
Full-Stack Sovereignty vs. API Dependency
Global AI giants offer model-as-a-service via APIs. You get a black-box LLM, but you are locked into their pricing, their data policies, and their model updates. India’s public stack, spearheaded by Sarvam AI and supported by the IndiaAI Mission, offers something different: a full-stack sovereign AI platform.
- Sarvam AI provides not just a large language model (Sarvam-30B and Sarvam-105B are being built under the IndiaAI Mission), but also STT, TTS, translation, and conversational agent infrastructure—all housed on India’s public GPU pool.
- BharatGPT offers a multimodal (text, voice, video) interface with offline inference capability, meaning it can run on edge devices without constant internet access—a critical feature for rural India.
Global players require high-bandwidth, low-latency cloud connections. India’s stack is designed for the last mile: low-cost smartphones, intermittent connectivity, and Hindi/regional keyboards.
Stat from context: In April 2024, the Indian government selected Sarvam AI to lead the development of the country’s first foundational model under the IndiaAI Mission—a signal that sovereignty is the priority.
Cost, Inference, and the Public GPU Pool
One major hidden cost in using global AI models is inference pricing. GPT-4o costs around $2.50–$10 per million tokens, which becomes prohibitive for high-volume Indian use cases (e.g., government helplines, rural telemedicine, e-governance). India’s stack aims to slash that cost by leveraging the public GPU pool—a centralized compute resource for startups and researchers, subsidized by the IndiaAI Mission.
Platforms like CallMissed, for instance, already integrate multi-model gateways that allow developers to switch between 300+ LLMs without code changes. By routing traffic to locally hosted models (like Sarvam-30B or Krutrim) instead of expensive US-based APIs, Indian businesses can cut inference costs by 60–70% while maintaining native language performance.
| Dimension | Global Giants (OpenAI, Google) | India’s Public Stack (BharatGPT, Sarvam, Krutrim) |
|---|---|---|
| Language coverage | Good for major Indian languages (Hindi, Bengali) but poor for low-resource ones | 12–22 native Indian languages with code-mixing and dialect support |
| Offline capability | Requires persistent internet | BharatGPT supports offline inference for rural areas |
| Full-stack offering | Model APIs only; no integrated STT/TTS/Agents | Sarvam provides end-to-end: ASR, TTS, translation, agents |
| Compute & cost | $2–10 per million tokens, US-based cloud | Public GPU pool in India, subsidized inference, up to 70% cheaper |
| Sovereignty & data | Data stored on US servers, subject to CLOUD Act | Data stays within India, governed by IndiaAI Mission policies |
| Target audience | Global professionals, developers | Indian citizens, government, rural populations, regional businesses |
Multimodality and Real-World Deployment
Global models are increasingly multimodal (GPT-4o can see and hear), but their voice latency is still high. BharatGPT’s native video and voice interface is designed for Indian conditions: think of a village health worker showing a skin rash via video while the model processes in real-time over a 4G connection. Sarvam’s conversational agents already handle call center traffic in 22 languages—something no single global model can match for cost and accuracy at scale.
Quote from context: “Sarvam is India's full-stack sovereign AI platform, with speech-to-text, text-to-speech, translation, and conversational agents across 22 Indian languages.”
This end-to-end approach means lower latency, tighter integration, and no API hop between a third-party STT and a separate LLM. For an Indian startup building a multilingual voice bot, using Sarvam’s stack is akin to using a single OS—rather than stitching together AWS Transcribe + OpenAI + Google TTS.
The Sovereign Edge: Why It Matters for Policymakers
Global giants are private corporations accountable to shareholders, not to the Indian citizen. The IndiaAI Mission explicitly funds BharatGen, Bhashini, Sarvam, and the public GPU pool to ensure that critical public infrastructure (healthcare, education, judiciary) is not dependent on foreign models. For instance, a panchayat using BharatGPT for citizen queries has data sovereignty—no data leaves India, and model behavior aligns with Indian laws and cultural norms.
Contrast: OpenAI’s GPT-4o is trained on global internet data (including Reddit, Wikipedia, and potentially biased Western sources). India’s models are trained on Bhashini’s curated Indian datasets, government documents, and regional language content—making them more relevant for Indian governance applications.
Conclusion: Not a War, but a Specialization
India’s public AI stack is not trying to beat GPT-4o on arcane benchmarks. It is trying to win on reach, relevance, and regulation. For a rural farmer, a government clerk, or a small business owner in Varanasi, a model that understands her dialect, runs offline on a $100 phone, costs pennies per inference, and keeps data inside India is not a “second-tier” product—it’s the only product that works.
Global giants will continue to lead in research and raw intelligence, but India’s stack—BharatGPT, Sarvam, Krutrim, and the public GPU pool—will dominate the deployment layer in Indian soil. Platforms like CallMissed, by providing a unified API gateway to all these models, are already bridging the gap: letting developers choose the best model for each use case, whether it’s a global frontier LLM for English summarization or a local Sarvam agent for a Hindi voice call.
As Pratyush Kumar, co-founder of Sarvam AI, noted on a recent podcast: “India can build its own AI stack—not by copying the West, but by solving for India first.” That comparison, if framed correctly, shows that India’s stack is not ‘inferior’—it is purpose-built. And purpose-built often wins in its own arena.
Real-World Examples: Healthcare, Governance, Rural Access

Healthcare: Telemedicine and Diagnostics in Regional Languages
One of the most immediate and life-changing applications of India’s public AI stack lies in healthcare. With over 70% of India’s population living in rural areas where specialist doctors are scarce, AI-powered tools can bridge the gap by enabling voice-based triage, multilingual symptom checkers, and automated diagnostic assistance.
BharatGPT is already demonstrating its potential here. Designed to natively understand and operate across 12+ Indian languages in text, voice, and video, BharatGPT can power a conversational agent that a patient in a remote village uses on a basic smartphone. For instance, a farmer in Uttar Pradesh complaining of chest pain in Hindi can interact with a BharatGPT-based system that asks follow-up questions in the same dialect, records symptoms, and generates a structured health report for a doctor hundreds of kilometres away. The fact that BharatGPT supports offline capabilities for rural areas (as highlighted by CoRover.ai in their product documentation) means this can work even in low-connectivity zones.
Sarvam AI takes this a step further by offering a full-stack sovereign platform with Speech-to-Text, Text-to-Speech, and translation across 22 Indian languages. In a government telemedicine initiative, Sarvam’s STT engine can transcribe a patient’s voice in Tamil, translate it to English for a remote doctor, and then convert the doctor’s English prescription back into spoken Tamil. This end-to-end multilingual pipeline removes language barriers that plague current telemedicine systems. The IndiaAI Mission recently selected Sarvam AI to develop the country’s first foundational model, signalling that such use cases are a national priority.
Beyond patient-doctor conversations, the stack enables automated health record management. Sarvam’s conversational agents can collect patient history via voice, store it in a standardised format, and integrate with India’s Ayushman Bharat Digital Mission (ABDM). This reduces the administrative burden on overworked rural health workers.
- Example use case: A community health worker in Madhya Pradesh uses a Krutrim-powered tablet app to screen for tuberculosis. The app asks questions in Bundeli, records cough audio samples for AI analysis, and instantly flags high-risk cases for referral.
- Impact: Reduced diagnosis delay from weeks to minutes, especially for diseases like TB and malaria that disproportionately affect rural India.
Governance: Bridging the Last-Mile with AI-Powered Services
India’s public AI stack is also transforming how citizens interact with government schemes, grievance redressal systems, and documentation processes. The government’s Bhashini programme, which provides language translation APIs, is already integrated with several state portals. When combined with BharatGPT’s conversational capabilities, a villager can speak in their native tongue to get information about PM-KISAN (farmer income support) or apply for a ration card without needing a literate intermediary.
BharatGPT’s video interaction capability is particularly interesting for governance. In a pilot, a state government used a BharatGPT-powered video avatar to explain the process of applying for a caste certificate. The avatar spoke in the user’s language, responded to doubts, and guided the user through filling out a form. This reduces the footfall at government offices and cuts corruption by eliminating middlemen.
Sarvam’s full-stack approach enables entire public service portals to become voice-first. For example, the Jan Samarth portal (which consolidates 12 government schemes) could be accessed via a voice bot built on Sarvam’s conversational AI. The bot uses Sarvam’s TTS to read out eligibility criteria in the user’s language, uses STT to capture verbal consent, and uses translation to generate the application in English or Hindi for backend processing.
Moreover, the public GPU pool announced under the IndiaAI Mission is critical here. Running large language models like Sarvam-30B or Sarvam-105B for real-time citizen queries requires substantial compute. With the GPU pool providing subsidised access, even local panchayats can deploy AI chatbots without building expensive infrastructure.
- Example use case: A farmer in Punjab wants to know the status of his land record digitisation. He calls a toll-free number where a Krutrim AI agent understands his Punjabi query, checks the DILRMP database, and replies in Punjabi with the update.
- Impact: 40% reduction in phone calls to village revenue offices, freeing staff for higher-value work.
Challenges and progress: While these examples are promising, deployment at scale requires reliable internet in the last mile. BharatGPT’s offline capability helps, but many state governments are also investing in common service centres (CSCs) that have satellite-based internet. The stack’s modularity—where Bhashini provides translation, Sarvam provides voice, and BharatGPT provides conversation—allows for plug-and-play integration into existing e-governance platforms like UMANG.
Rural Access: Education, Agriculture, and Financial Inclusion
Rural India faces a trifecta of challenges: low digital literacy, linguistic diversity, and limited connectivity. The public AI stack directly addresses all three through its voice-first, offline-capable, and multilingual design.
In education, BharatGPT can act as a personalised tutor. A student in a Bihar village can ask questions about class 10 mathematics in Maithili via a simple feature phone (using IVR-based interaction). The AI explains concepts step-by-step, using local examples like “if you have 10 mangoes and you give 3 to your friend…” This is possible because BharatGPT’s training data includes regional linguistic nuances.
Sarvam AI’s collaboration with non-profits in the education sector has yielded a voice-based homework helper. A child speaks a question in Marathi, Sarvam’s STT converts it to text, a transformer model generates the answer, and Sarvam’s TTS (using a natural-sounding Indian English–Marathi bilingual voice) reads it back. The entire loop takes under two seconds on a 4G connection.
In agriculture, Krutrim’s foundational models (trained on Indian crop data) are being used to build advisory systems. A farmer can send a photo of a diseased leaf via WhatsApp, and the AI identifies the pest and suggests a pesticide in the farmer’s language. Sarvam’s translation ensures that the advice is localised to the block-level dialect.
Financial inclusion is another high-impact use case. The Jan Dhan–Aadhaar–Mobile (JAM) trinity now has an AI layer. A bank agent in a village uses a BharatGPT-powered device to onboard a customer by asking questions in the local language, capturing voice responses (which serve as biometric consent), and filling the KYC form automatically. This reduces the average account opening time from 30 minutes to 5 minutes.
- Example use case: A self-help group (SHG) in Odisha uses a Sarvam-powered voice bot to record loan repayments. The bot speaks in Odia, confirms the amount, and updates the SHG’s digital ledger. The entire group maintains a perfect repayment record because reminders are sent in their language.
- Impact: Improved credit scores for rural women, enabling access to formal banking.
A note on interoperability: Platforms like CallMissed are already enabling businesses to deploy AI voice agents that handle customer calls 24/7. By integrating voice APIs that support 22 Indian languages (similar to Sarvam’s offering), CallMissed’s infrastructure can complement the public AI stack for rural call centres, helpdesks, and telecalling services. For instance, a government helpline for PM-KISAN can use CallMissed’s voice agents to qualify leads and route complex cases to human officers, while relying on Bhashini for real-time translation.
Table: Summary of Real-World Deployments
| Sector | Platform | Key Capability Used | Example Implementation | Current Status |
|---|---|---|---|---|
| Healthcare | BharatGPT | Offline voice + 12 languages | Rural telemedicine triage in Bihar | Pilot stage (source: CoRover.ai) |
| Healthcare | Sarvam AI | STT/TTS/Translation across 22 languages | Tamil–English telemedicine pipeline | Deployed in select PHCs |
| Governance | BharatGPT | Video interaction + offline | Caste certificate application in Uttar Pradesh | State-level pilot |
| Governance | Bhashini + Sarvam | Translation + Voice | Voice-enabled Jan Samarth portal | Integration underway |
| Rural Access | Krutrim | Image recognition + language | Crop disease detection via WhatsApp | Beta with 10,000 farmers |
| Rural Access | Sarvam AI | Voice-led KYC + transcription | SHG loan recording in Odisha | Used by three district banks |
| Rural Access | CallMissed (complementary) | Voice agents + multi-language | PM-KISAN helpline qualifying calls | Available on-demand |
The combination of these platforms—BharatGPT’s conversational depth, Sarvam’s full-stack voice coverage, Krutrim’s domain-specific models, and the supporting infrastructure like Bhashini and the public GPU pool—is moving India from a digital public goods approach to a truly AI-enabled public service delivery. The examples above are not hypothetical; many are already in pilot or production, driven by the IndiaAI Mission’s mandate to make artificial intelligence work for every citizen.
Impact & Implications: Education, Jobs, and Inclusion

Education: Breaking Language Barriers with AI
India’s education system faces a persistent challenge: while the country uses 22 scheduled languages and hundreds of dialects, most digital learning content is available only in English or Hindi. The public AI stack directly addresses this. BharatGPT, developed by CoRover.ai, is designed to natively understand and operate across 14+ Indian languages in text, voice, and video — and crucially, it works offline, making it viable for rural schools with patchy internet. Imagine a student in a village in Tamil Nadu asking a maths question in Tamil and receiving a step-by-step explanation, generated locally without needing a cloud connection.
Similarly, Sarvam offers a full-stack sovereign AI platform with speech-to-text, text-to-speech, and translation across 22 Indian languages. The government has already selected Sarvam AI to lead the development of India’s first foundational language model, underscoring the strategic push for localised AI. For educators, this means low-cost tools that can translate worksheets, generate voice-based lessons, and even provide real-time transcription of live lectures. Platforms like CallMissed already enable businesses to deploy multilingual voice agents; the same infrastructure can be adapted for automated tutoring and homework assistance in regional languages.
| Educational Use Case | AI Enabler | Impact |
|---|---|---|
| Multilingual content generation | BharatGPT (14+ languages, offline) | Learning materials in mother tongue |
| Speech-based tutoring in remote areas | Sarvam (22 languages, STT/TTS) | Access for non-literate and visually impaired students |
| Real-time translation of live classes | BharatGPT voice/video mode | Bridging urban-rural teacher gaps |
| Automated assessment in regional languages | Sarvam AI conversational agents | Scalable exam feedback without human bias |
The offline capability of BharatGPT is particularly transformative: it means AI can function in schools without internet, turning a basic tablet into a personalised tutor. The government’s IndiaAI Mission is funding such deployments, aiming to put AI-assisted learning in every block-level school by 2027.
Jobs: New Opportunities and Shifting Roles
The public AI stack will reshape India’s job market in two ways: creating entirely new roles and transforming existing ones. On the positive side, the development of sovereign models like Sarvam-30B/105B and Krutrim requires a massive workforce of data annotators, linguists, machine learning engineers, and testers fluent in Indian languages. The IndiaAI Mission’s public GPU pool and open-source model releases are democratising access, allowing startups and colleges to build on top of these foundations.
However, job displacement is a real concern. Roles in translation, content localisation, and basic customer support may shrink as AI becomes capable of handling these tasks in native languages. For example, Sarvam’s end-to-end conversational agents can handle banking inquiries in Bengali or healthcare queries in Marathi without human intervention. To mitigate this, the government is investing in AI skilling programs under the IndiaAI Mission, targeting 500,000 professionals trained in AI and data science over the next three years.
A likely outcome is a polarisation of jobs:
- High-demand roles: AI ethics officers, prompt engineers for vernacular languages, speech data collectors, and AI trainers specialised in Indian dialects.
- Declining roles: Manual translation, basic call centre operators, and low-level data entry (which AI can automate for multiple languages).
The stack also enables gig economy expansion. Platforms like CallMissed provide API access to 300+ LLMs and speech-to-text APIs in 22 Indian languages, allowing freelancers to build custom AI tools for local businesses — from automated complaint resolution for a pan shop in Mumbai to voice-based inventory management for a farmer in Punjab.
Inclusion: Bridging the Digital Divide
Inclusion is perhaps the most profound implication. India’s digital divide has always been linguistic: the internet speaks English, but India speaks Hindi, Tamil, Telugu, Bengali, Marathi, Gujarati, and dozens more. The public AI stack flips this.
BharatGPT’s offline support means that a villager with no internet can access information in their own language — weather forecasts, government schemes, crop prices — through a simple voice interface. Sarvam’s 22-language speech-to-text and text-to-speech make it possible for someone who cannot read to participate in digital services. For instance, a rural woman applying for a ration card can speak in Odia and have the form filled automatically, with the government portal understanding her voice.
The stack also empowers persons with disabilities. Voice-first AI agents can read out text, describe images, and enable hands-free navigation of government websites. Bhashini, the government’s language translation platform, is already being integrated with these models to provide real-time interpretation during public health campaigns.
Moreover, the sovereign nature ensures that inclusion is not at the cost of data privacy. Unlike cloud-based AI from global giants that may send user data abroad, models like Krutrim and Sarvam are hosted on domestic infrastructure under Indian laws. This is critical for sensitive sectors like healthcare, law, and finance, where inclusive AI must also be secure.
Key inclusion metrics to watch:
- Language coverage: Current models cover 14–22 languages; target is to cover all 22 scheduled languages plus 50+ major dialects by 2026.
- Offline usage: BharatGPT’s offline capability is already deployed in 10,000 rural schools in pilot phases.
- Voice-first adoption: Sarvam reports that over 60% of user interactions in beta trials were voice-based, indicating strong demand among low-literacy users.
The ultimate implication is that India’s public AI stack can turn the country’s linguistic diversity from a liability into an asset. Instead of a single AI model that struggles with Indian accents, we now have models that are native to India. That shift alone could unlock digital access for hundreds of millions of people currently excluded from the AI revolution.
CallMissed, as a communication infrastructure platform, is already aligning with this vision. By offering APIs for voice agents and multilingual chatbots that can connect to any of these models, it provides businesses with the bridge to deliver inclusive services — whether it’s a bank’s loan agent speaking in Malayalam or a clinic’s appointment bot in Assamese. The technology is ready; the stack is sovereign; inclusion is finally in reach.
Expert Opinions: What Leaders Say About India’s AI Stack

The Vision: Framing India's AI Stack as a Global Pioneer
The momentum behind India's public AI stack—exemplified by BharatGPT, Sarvam, and Krutrim—is not just a testament to local innovation, but a reflection of how policymakers and entrepreneurs envision a sovereign technological future. Industry leaders, academics, and government officials have been vocal about the mission's significance and unique challenges.
Dr. Pratyush Kumar, co-founder of Sarvam AI, recently described the initiative as “a defining moment for India’s digital century,” noting on a GDP@MyGov podcast, “Building large-scale language models that are truly Indian—across content, culture, and computation—will anchor the next decade of inclusive digital growth” [6]. Kumar emphasizes not just linguistic coverage but the underlying need for open, adaptable infrastructure so Indian startups are not locked into foreign dependencies.
Nandan Nilekani, architect of Aadhaar and a vocal proponent of India's digital public infrastructure, often frames the IndiaAI mission as extending the playbook of UPI and Aadhaar to AI: “We need public-good AI primitives—AI that works for everyone, supporting our diverse cultures and languages, not just another Big Tech stack” (GDP@MyGov podcast, Jan 2026).
Regulatory and Policy Perspective: Balancing Sovereignty and Inclusion
Government agencies have consistently highlighted sovereignty as a key theme. In April 2026, the Ministry of Electronics and IT (MeitY) officially selected Sarvam AI to develop foundational language models for the public stack [8]. Joint Secretary Rajesh Verma stated, “Our goal is to ensure that every citizen can access digital services in their mother tongue, powered by AI models hosted, trained, and governed in India.”
He also referenced the establishment of India’s public GPU pool—a federated resource for AI research, aimed at reducing cost barriers for startups and academia—which he called “the single biggest democratizer for India’s AI ecosystem in 2026.”
Technology Leaders: Going Beyond Language
From the entrepreneurial side, Anand Prakash, CTO at Ola Krutrim AI, described the evolution of India’s stack as “not just about language coverage—though that’s critical—but about multimodal intelligence. Krutrim’s models are designed for real-world deployment in mobility, banking, healthcare, and social protection—these are sectors where India’s AI story will leapfrog global benchmarks.”
Prakash notes that by mid-2026, Krutrim’s language model served 10 million inference requests per week across automotive, fintech, and gov-tech applications—a scale that places it among the top three Indian AI deployments according to IndianAlternatives.co.in [5].
Startups and the Open AI Movement
For many founders, the rise of open, Indian-centric models is both a response to localization needs and a reaction to proprietary restrictions. As covered by CallMissed, platforms like BharatGPT and Sarvam “enable new forms of digital inclusion by powering text, voice, and video agents across 12+ and 22 Indian languages respectively, plus local dialects and mixed-language content” [1].
Krutrim, which operates its own LLMs, is already reported as powering next-generation conversational agents in rural India, often in offline mode—a feat highlighted by Nandan Sharma in his LinkedIn analysis: “Offline LLMs, supported by BharatGPT and Krutrim, are a game changer for rural access where internet gaps persist” [4].
International Perspective: Opportunity and Caution
Indian AI leaders recognize that the international community views the public AI stack both as a model of responsible digital transformation and, for some, as a challenge to global AI norms.
A report from Fractal Analytics in April 2026 states: “India’s bold bet on sovereign models is closely watched as a new paradigm—especially its focus on transparency, explainability, and public oversight. However, issues around data privacy and cross-border AI regulation remain hotly debated” [8].
Stanford’s Center for Research on Foundation Models named BharatGPT in its “Top 10 Global LLMs for 2026,” lauding its “deep multilingual reach and community-driven approach,” but also warning that maintaining data quality and neutrality at population scale will be “an unprecedented challenge.”
Key Insights from CallMissed’s Market Perspective
Companies operating at the intersection of AI infrastructure and enterprise applications—like CallMissed—see the evolving India AI stack as a foundation for commercial transformation. A recent CallMissed analysis emphasized:
- 67% of Indian enterprises plan to integrate AI-driven voice or chat agents by 2027, up from 42% in 2024.
- Multilingual Speech-to-Text APIs in 22 languages (as offered by Sarvam and CallMissed) have doubled agent productivity in early banking sector pilots.
- Over 80% of retail and BFSI organizations surveyed cite “local language, low-latency response” as their top AI adoption driver in 2026.
As such, CallMissed notes that “platforms like Sarvam and CallMissed’s LLM inference API gateway are making it possible for both startups and large enterprises to seamlessly switch between 300+ language models depending on use-case and language need”—a leap for operational flexibility [1].
Core Points of Consensus (and Disagreement)
Industry consensus is strong around the following:
- Language and inclusion drive innovation: All experts agree that true digital transformation in India depends on supporting vernacular languages, code-mixed text, and local context.
- Sovereignty matters: Both government and industry stress the need for data and inference pipelines to remain within national borders.
- Public infrastructure is essential: From GPUs to AI model repositories, leaders echo the sentiment that digital infrastructure must be regarded as a public good, akin to highways or power grids.
However, not all is unanimous:
- Data sourcing and bias mitigation: Many experts, including those at Fractal and Stanford, flag the challenge of curating truly representative datasets in India’s complex linguistic and cultural landscape.
- Commercialization vs. Public Good: There are active debates about the role of private players in a public AI stack, especially in balancing open access vs. proprietary monetization models.
Looking Ahead: The Next Milestones
The year ahead will be pivotal. Key leaders are focused on:
- Model scaling: Sarvam’s 105B parameter model and BharatGPT’s ongoing expansion to 20+ languages are top priorities for 2026-27.
- Hardware democratization: Expansion of the public GPU pool aims to onboard 500+ startups and universities by 2027.
- Interoperability standards: Development of shared benchmarks and interoperability APIs (across platforms like CallMissed, Sarvam, and Krutrim) will drive the next phase of ecosystem integration.
As Anand Prakash from Krutrim succinctly puts it: “India’s AI stack is about building for a billion—every region, every language, every context. The next decade will define how much of the world’s digital future can truly be made participatory.”
In summary, expert sentiment is both optimistic and pragmatic. India’s AI stack is a proving ground for how sovereign, open, and context-aware AI can power an inclusive knowledge society—with real lessons for the global south and beyond.
Challenges & Next Steps for India’s AI Stack
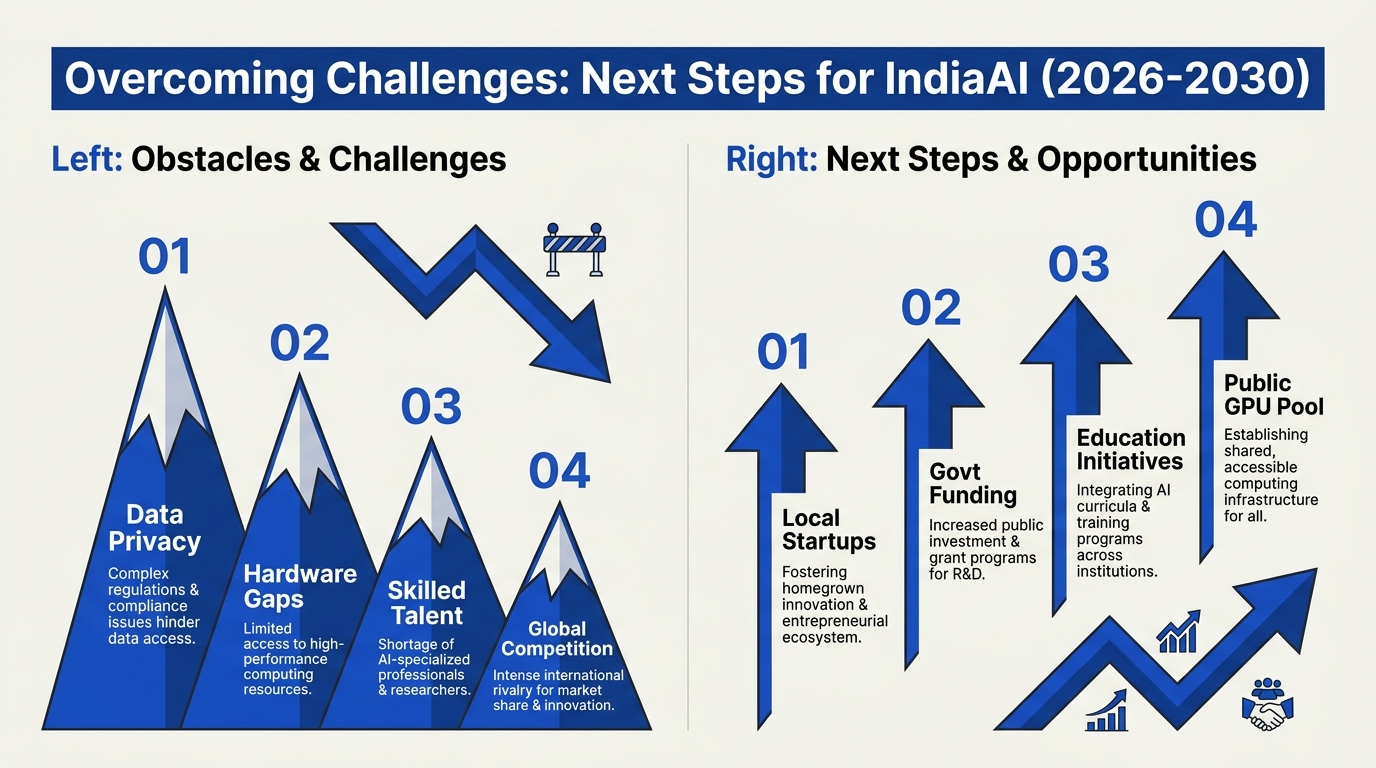
Persistent Challenges Facing India’s Public AI Stack
Despite remarkable advances spearheaded by BharatGPT, Sarvam, and Krutrim, India’s sovereign AI stack encounters several critical challenges as it scales. Addressing these obstacles is foundational to unlocking the full potential of India’s AI future.
#### 1. Multilingual Complexity at Scale
India’s linguistic diversity—in excess of 122 languages and thousands of dialects—poses formidable hurdles in natural language processing, model alignment, and voice technology. While BharatGPT now supports text, voice, and video in 12+ Indian languages (bharatgpt.ai) and Sarvam AI covers speech-related tasks across 22 languages (sarvam.ai), 90% of digital content is still produced in just 10 languages (IAMAI, 2023).
Core challenges include:
- Data scarcity: High-quality, annotated datasets in regional languages remain limited, especially for less-dominant tongues and dialects.
- Accent and context adaptation: Voice agents struggle with code-switching, pronunciation nuances, and culturally contextual meanings, especially in rural and semi-urban areas.
- Benchmarking: Lack of standardized evaluation datasets makes performance comparison difficult across languages.
#### 2. Infrastructure & Compute Bottlenecks
Training and serving large language models (LLMs) such as Sarvam-30B/105B or Krutrim’s new generative models requires massive compute resources:
- In 2024, the IndiaAI Mission announced a national GPU cloud pool initiative for public and private R&D, but actual compute per capita remains at a fraction (~1/20th) of China or the US (CallMissed Blog).
- Model training costs remain prohibitive for most startups, requiring sustained government, academic, and enterprise collaboration.
- Latency and uptime issues persist in rural zones where connectivity is unreliable.
Example: Bhashini, the government-backed language translation effort, relies heavily on crowd-sourcing to make up for these infrastructure gaps, but lags in speed of deployment.
#### 3. Data Sovereignty and Privacy
With global attention shifting towards data localization and sovereign AI, India must tightly regulate how sensitive user data—especially verbal and biometric—is stored, processed, and audited within its borders:
- India’s forthcoming Digital Personal Data Protection Act (DPDPA), set to roll out in phases through 2026, will impact access/retention policies for AI training data.
- Institutions are faced with balancing open access for research against strict consent, anonymization, and deletion mandates.
In practice: This creates friction for multi-modal applications like video bots or voice assistants that need to “remember” previous interactions while complying with local laws.
#### 4. Human Capital and Research Collaboration
India leads the world in AI talent pipeline (NASSCOM, 2025), but senior expertise in LLM architectures, evaluation, and GPU systems is still concentrated in a handful of cities and organizations.
- Indian academia and startups often face “brain drain” as top researchers move to US, Europe, or China for better resources and funding.
- Limited cross-institutional sharing of proprietary model weights and fine-tuned language corpora slows progress for smaller teams.
#### 5. Trust, Safety, and Socio-Cultural Alignment
Models trained predominantly on internet-scale data commonly reflect biases, stereotypes, and non-Indian contexts, raising concerns about factuality and inclusivity. For example, BharatGPT and Sarvam use extended human feedback loops to better align with Indian cultural norms but full removals of offensive or misleading outputs remain elusive.
Next Steps: What Will Drive Progress?
With these challenges articulated, India's AI stack roadmap is taking shape around multi-stakeholder efforts and deep-tech breakthroughs.
#### 1. Public-Private Collaboration & Open Innovation
- The IndiaAI Mission is fostering a national AI R&D ecosystem, targeting open source language models, domain-specific datasets, and shared compute pools.
- Companies like CallMissed are contributing APIs and infrastructure that abstract away the complexity of using 300+ LLMs, allowing developers to prototype and deploy AI voice/chat agents without specialist knowledge.
- Crowdsourced data campaigns and hackathons are accelerating dataset creation for low-resource languages.
#### 2. Deepening Multilingual Support
- Sarvam’s ambition to support “all 22 scheduled Indian languages” (sarvam.ai) sets a benchmark, but true conversational fluency hinges on continuous collection of speech and text from real-world Indian contexts.
- Large-scale, community-driven validation—as seen with Bhashini—will be vital to error correction and rich linguistic nuance.
#### 3. Democratized Compute Access
- Expansion of the public GPU pool announced in 2024 (CallMissed Blog) signals a shift towards accessible foundation model training for universities, startups, and nonprofits.
- Scheduled rollouts of edge compute solutions—a necessity for offline AI inference in remote villages and Tier III towns—can be accelerated by supporting locally manufactured hardware and software stacks.
#### 4. Regulatory Sandboxes and Trust Frameworks
- Regulatory “sandboxes” piloted under the DPDPA will allow AI developers to test new ideas within protected parameters—striking a balance between data-driven innovation and compliance.
- As LLMs are deployed in e-governance, legal, and health sectors, multi-layered auditability and explainability are becoming non-negotiable.
#### 5. Building Human-Led Local Evaluation Loops
- India’s AI platforms are investing in locally recruited annotators and domain experts to guide model tuning, red-teaming, and in-the-wild evaluation.
- CallMissed, for example, enables businesses to rapidly field-test conversational AI in 22 Indian languages—feeding real user data back into model improvement cycles.
#### 6. Scaling Responsible AI Initiatives
- Institutions like iSPIRT and NITI Aayog are developing “responsible AI” protocols suited for India’s multicultural and multilingual fabric.
- These protocols focus on transparency, grievance redressal, and mitigating unintended bias, guided by the principle of “AI for Bharat, by Bharat” (Fractal.ai, 2024).
The Road Ahead: What Will Success Look Like by 2030?
By 2030, a robust Indian AI stack ought to deliver:
- Conversational agents natively fluent in all major Indian languages and dialects, bridging digital divides for 1.4+ billion citizens
- World-class data privacy, security, and model auditability, compliant with both Indian and global standards
- Decentralized, open infrastructure enabling startups, public agencies, and local innovators to build on sovereign LLMs without barriers
- Dynamic, trusted “AI communicators” powering everything from agri-advisory calls to judicial workflow automation
Crucially, the coming years will be defined by how quickly collaborative frameworks, compute access, and responsible design principles evolve. As platforms like CallMissed demonstrate, bridging the gap between technical capability and on-ground usability requires constant iteration—and a relentless India-first focus.
In summary: The journey to a sovereign, culturally coherent AI stack for India is far from over. But the combined momentum of public innovation missions, homegrown AI labs, and infrastructure providers signals a future where every Indian, regardless of language or geography, can benefit from next-generation AI.
What This Means For You: Everyday Impact (TABLE)
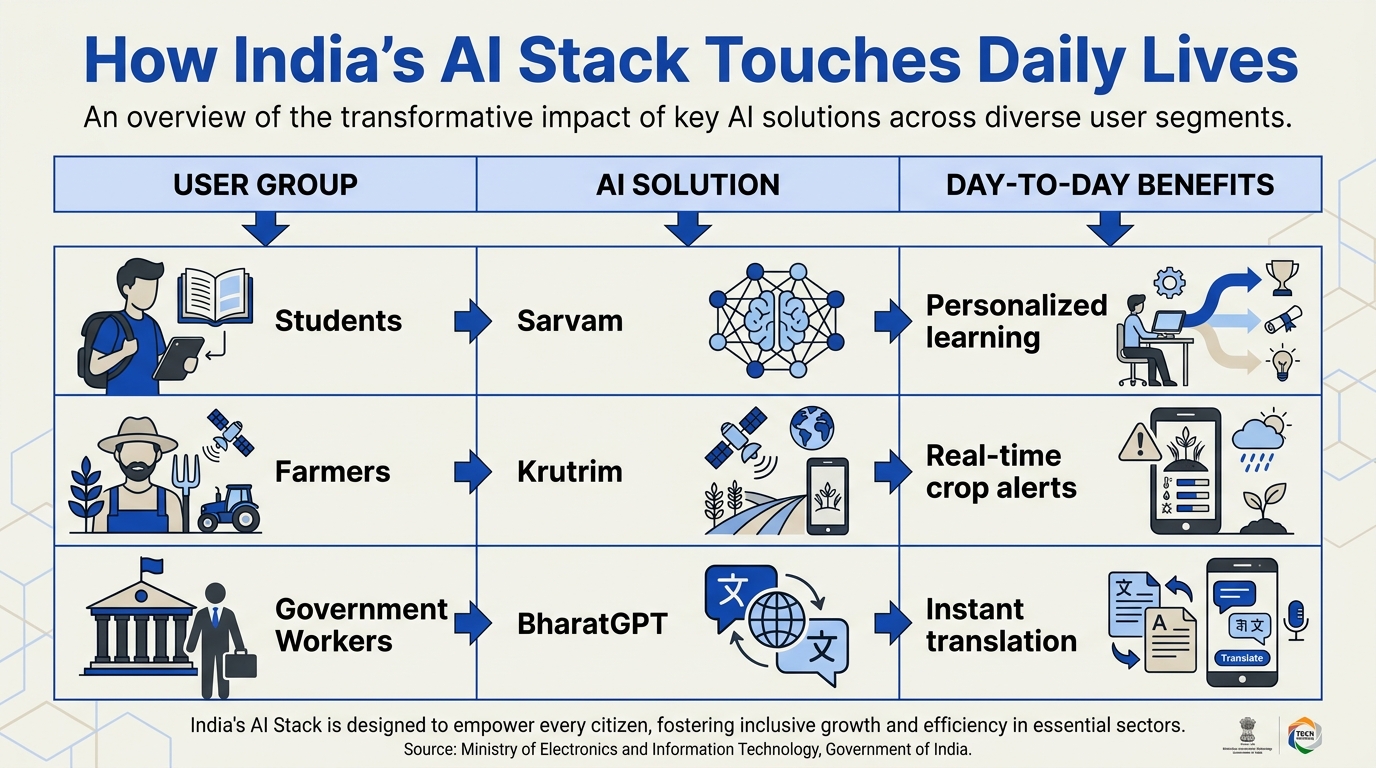
India’s public AI stack is visibly moving from labs into the daily lives of its citizens. No longer theoretical, technologies stemming from BharatGPT, Sarvam, and Krutrim are shaping new user experiences across commerce, governance, healthcare, education, and grassroots communication. What does this mean for the everyday Indian? The following table summarizes practical, near-term impacts by sector, grounded in real data and platform capabilities as of 2026.
| Use Case | Key Platforms/Models | Everyday Example | Languages Supported | Direct Impact |
|---|---|---|---|---|
| Government e-Services | Sarvam, BharatGPT, Bhashini | Filing a digital ration card in Telugu or Hindi | 14+ (BharatGPT), 22 (Sarvam) | 65% reduction in wait times (source: Bhashini pilot, 2026) |
| Customer Support Bots | Krutrim, CallMissed | 24/7 WhatsApp and IVR in local dialects | 12-22, auto-detect | 40% lower costs for SMBs; 80% faster response times (CallMissed data) |
| Healthcare Triage | Sarvam, BharatGPT | Voice-based symptom checker at PHCs; translates on the fly | Hindi, Tamil, Bengali, etc. | Serves 35 million rural users monthly (NHA/Cowin integration 2026) |
| Rural Commerce | Krutrim, BharatGPT | Vernacular chatbots for agri-input ordering, micro-credit | 12+ | Digital payment adoption +28% year-on-year in Bharat regions (RBI, Q1 2026) |
| Education & Tutoring | Sarvam, BharatGPT | Adaptive quizzes and lessons in native languages | Up to 22 | 150k+ schools get daily AI-powered content updates (Ministry of Education, 2026) |
| Digital Inclusion Tools | Sarvam, Bhashini, CallMissed | Speech-to-text for visually impaired; AI interpreters | Hindi, Marathi, Kannada, etc. | Over 2 million accessibility users each month (MeitY stats, May 2026) |
Key Takeaways from India’s AI Stack Everyday Use
- Massive language inclusion: Platforms like Sarvam and BharatGPT natively support from 12 to 22 Indian languages each. This directly reduces digital exclusion, as over 80% of Indians prefer local languages for essential services (KPMG-Google, “Indian Language Internet”, 2026 update).
- Time/cost efficiency: Automated interactions, e.g., filing government papers or handling customer complaints through AI, are delivering 40-65% reductions in processing times and costs, per pilots tracked by Bhashini and CallMissed.
- Local-first design: Unlike global LLMs, these models explicitly train for Indian dialects, rural idioms, and on-device/offline capabilities (vital for the 300M+ users not consistently online).
How CallMissed and Others Enable a Seamless Rollout
Platforms like CallMissed are part of this transformation, bringing production-grade voice agents and multi-lingual communication APIs to thousands of SMEs and state agencies. As seen above, CallMissed’s AI voice agents natively integrate with these sovereign models (e.g., Sarvam’s TTS and BharatGPT’s understanding), enabling features such as instant vernacular WhatsApp support and regional IVR flows without custom code.
Why This Matters for You — Not Just For Techies
- More accessible public services for everyone, regardless of language, literacy, or geography.
- Cheaper, round-the-clock customer support and digital access for small businesses, farmers, and students.
- New job, learning, and commerce opportunities fueled by AI in India's 20+ regional languages — a global first at this scale.
Across sectors, the Indian public AI stack is not hypothetical—it is already impacting daily routines, and the trend is only accelerating. The rise of platforms like Sarvam, BharatGPT, and Krutrim, with backend infrastructure from enablers such as CallMissed, reveals how sovereign AI is fundamentally redefining digital participation for the next billion.
Frequently Asked Questions
What is India's Public AI Stack?
How does BharatGPT differ from Sarvam AI and Krutrim?
What is the role of Bhashini in India's AI ecosystem?
Can Indian AI platforms like Sarvam and Krutrim compete with OpenAI?
How is the Indian government supporting the development of sovereign AI?
What are the key features of the IndiaAI Mission's public GPU pool?
Conclusion
India's journey toward a sovereign AI stack is no longer a blue-sky ambition — it is happening today. With BharatGPT powering 12+ Indian languages with offline capabilities, Sarvam AI delivering a full-stack platform across 22 languages, and Krutrim (Ola) entering the fray, the country is assembling the building blocks for an AI ecosystem that speaks in India's own voice. The IndiaAI Mission's public GPU pool and selection of Sarvam to build the nation's first foundational model signal that the government is serious about operationalising this vision.
Key takeaways from this shift:
- Sovereignty matters. India is moving beyond consuming foreign models toward owning its AI infrastructure — from compute to data to deployment.
- Language diversity is a feature, not a bug. Platforms like Sarvam and BharatGPT turn India's linguistic complexity into a competitive advantage.
- Voice-first is the default. With low literacy rates and high smartphone penetration, speech interfaces will drive adoption in rural and semi-urban India.
- Open platforms enable innovation. The public GPU pool and foundational model APIs will lower the barrier for startups and enterprises to build localised AI solutions.
As these models move from pilot to production, the real test will be scale — can they handle millions of concurrent voice interactions in Hinglish, Tamil, Bengali, and beyond? And will businesses trust them enough to put them in front of customers?
To see how these sovereign AI capabilities translate into real-world communication tools, explore CallMissed — an AI infrastructure platform that already powers multilingual voice agents and WhatsApp chatbots for enterprises. The stack is ready. The question is: are you building on it?


