GPT-5.6 vs Claude Opus 4.8: What We Know So Far

GPT-5.6 vs Claude Opus 4.8: What We Know So Far
As of June 2026, the battle for frontier AI supremacy has reached a fascinating paradox: while Anthropic’s powerhouse Claude Opus 4.8 is already in the wild actively running enterprise workloads, OpenAI’s highly anticipated GPT-5.6 (spanning the Sol, Terra, and Luna model family) remains locked behind a curtain of limited developer previews. For enterprise leaders and developers, this timeline mismatch raises an urgent question: should you commit your workflows to Anthropic’s newly released powerhouse today, or hold out for OpenAI’s next-generation release?
This decision carries massive operational implications. The frontier AI landscape has shifted from simple chat interfaces to autonomous, long-horizon agentic workflows where the cost of a missed detail is incredibly high. Anthropic's Opus 4.8 has already set a formidable benchmark in this arena, pushing SWE-bench Pro software-engineering scores to an unprecedented 69.2%—a massive leap from the 58.6% managed by OpenAI’s widely used GPT-5.5. Opus 4.8 also introduces advanced efforts controls, a massive 1-million token context window, and unmatched precision in detail-sensitive legal and financial reasoning. Conversely, early previews of GPT-5.6 (particularly the 'Sol' model) suggest OpenAI is gearing up to retake the crown, promising unmatched performance in cybersecurity, scientific reasoning, and complex coding tasks.
With both models positioned at a premium tier—matching each other at $5 per million input tokens and $30 per million output tokens—building for flexibility is more critical than ever. Forward-looking communication platforms like CallMissed are already addressing this volatility by offering unified API gateways, enabling businesses to seamlessly deploy and switch between 300+ LLMs without rewriting their core code.
In this comprehensive preview of GPT-5.6 vs Claude Opus 4.8, we will unpack everything we know so far. We will analyze the architectural differences, contrast Opus 4.8's dynamic workflows with GPT-5.6’s rumored multi-modal advancements, and evaluate how these two titans stack up on prospective benchmarks to help you future-proof your AI strategy.
Introduction

The 2026 AI Model Faceoff: Real-World Stakes, Not Just Hype
As we enter the summer of 2026, the frontier of large language models (LLMs) is defined by one unavoidable fact: Anthropic’s Claude Opus 4.8 is live, while OpenAI’s GPT-5.6 is still behind closed doors. This creates a unique juxtaposition in AI adoption. Top-tier enterprises, startups, and product teams now face a split path—either move decisively with a production-ready Claude Opus 4.8, or wait for the full rollout of OpenAI's next-generation GPT-5.6 models: Sol, Terra, and Luna.
Why does this matter so acutely in 2026? Because LLMs have evolved from experimental chatbots into the backbone of mission-critical, high-value workloads—from end-to-end coding, to legal analysis, to autonomous, multi-step “agentic” workflows that power business operations. The margin for error is razor-thin, and the decision to bet on a model today determines competitive agility for quarters or years to come.
Claude Opus 4.8: Released, Reliable, and Raising the Bar
First, the clear differentiator: Claude Opus 4.8 is already in market and powering real-world applications. Since its June 2026 debut, it has redefined benchmarks for enterprise AI:
- SWE-bench Pro software engineering: Opus 4.8 achieved 69.2%—a decisive jump over GPT-5.5’s 58.6% (Source: Composio.dev [5]).
- Context window: 1 million tokens, enabling deep, persistent workflows and document-heavy tasks at a scale previously unreachable (Source: public model docs, June 2026).
- Efforts controls and dynamic workflows: Opus 4.8 introduces granular effort tuning and workflow customization, crucial for high-value industries like legal, finance, and healthcare.
- Input-output parity: Pricing matches GPT-5.6 at $5 per million input tokens and $30 per million output, but Opus 4.8 retains a swift “fast mode” for throughput-sensitive use cases.
Trusted reviewers describe Opus 4.8 as the best option “where the cost of a missed detail is high” (Source: Towards AI [4]). Its risk mitigation and accuracy improvements stand out in lawyered industries and mission-critical automations.
GPT-5.6: Set to Reshape the Benchmark, But Still in Preview
By contrast, GPT-5.6 is not yet generally available—but early access testers describe it as a potential leap forward. The “Sol” tier, in particular, is OpenAI’s flagship in this release wave, rumored to surpass all prior models on:
- Cybersecurity and scientific reasoning: Previews suggest a big jump, though no public head-to-head benchmarks exist yet.
- Coding and agentic autonomy: GPT-5.6 Sol is expected to retake the lead, particularly for automated code generation and advanced task planning.
- Multi-modal capability and model architecture: Limited public details, but leaks point to sweeping improvements in reasoning across text, code, and potentially images.
For developers, the lack of public benchmarks as of late June 2026 is a critical variable. Most performance claims are extrapolated by comparing Opus 4.8’s current lead over GPT-5.5, with the assumption that GPT-5.6 will close or reverse this gap upon full release (see DataCamp review [3]).
Decision Drivers: Pricing, Flexibility, and Future-Proofing
A key point for technical leaders: both Claude Opus 4.8 and GPT-5.6 Sol cost the same at the premium tier. This means workflow flexibility and rapid model-switching become the differentiators—especially as future releases accelerate and public benchmarks lag behind. Platforms like CallMissed epitomize this trend, offering a unified API gateway to 300+ LLMs. For organizations aiming to stay model-agnostic and responsive to the fast-moving landscape, such infra makes it possible to roll out new models or switch between Opus and GPT in production with minimal disruption.
The Stakes Going Forward
As we unpack technical and performance nuances in later sections, one fact stands: the era of slow, linear upgrades is over. The ability to deploy, switch, and scale with the newest, most capable model—be it Opus 4.8 or GPT-5.6—is foundational to AI-driven differentiation in 2026. As head-to-head data emerges, staying equipped for both possibilities is the pragmatic enterprise play.
Background & Context
The Release Dilemma: Public Reality vs. Preview Promise
The frontier AI landscape in mid-2026 is defined by two fundamentally different deployment strategies. Anthropic has fully democratized its premier model, Claude Opus 4.8, making it generally available for immediate production workloads. In contrast, OpenAI has opted for a highly controlled, phased rollout for its next-generation GPT-5.6 model family—consisting of the Sol, Terra, and Luna models—keeping them restricted to limited developer previews.
This mismatch has created a practical divide for enterprise leaders: organizations can actively build, test, and scale business-critical applications using Opus 4.8 today, whereas they can only plan, prototype, and speculate around the eventual public release of GPT-5.6.
Diverging Paths to Agentic Autonomy
The architecture and feature sets of both models reveal distinct priorities in how Anthropic and OpenAI envision the future of enterprise-grade AI assistants:
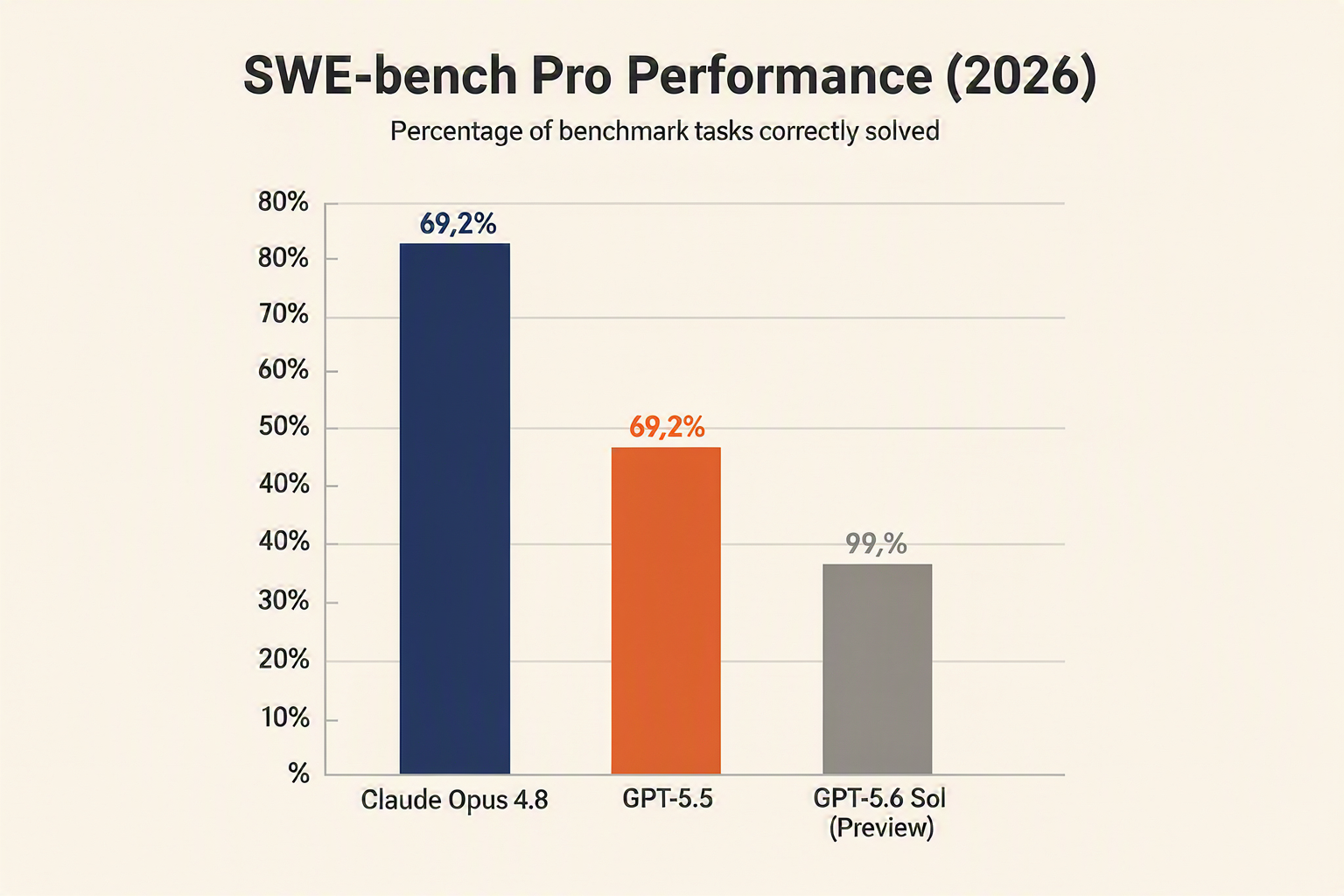
- Claude Opus 4.8: Focuses heavily on extreme precision, honesty, and execution consistency. It features a massive 1-million-token context window, granular effort controls, and advanced dynamic workflows. This makes it the current gold standard for long-running, detail-sensitive tasks where the cost of a missed detail is high—such as legal contract auditing, complex financial modeling, and multi-file software engineering. This precision is validated by its record-breaking 69.2% score on SWE-bench Pro, establishing a formidable benchmark for autonomous coding.
- GPT-5.6 (Sol): OpenAI’s flagship "Sol" model is positioned as a breakthrough in multi-modal synthesis, deep scientific reasoning, and active cybersecurity diagnostics. Early previews indicate that OpenAI has engineered Sol to excel at highly complex, long-horizon agentic tasks, aiming to leapfrog existing standards in raw logical processing and multi-modal interaction once it becomes widely accessible.
Benchmarking in the Dark
Because GPT-5.6 remains locked behind a curtain of limited access, no definitive, side-by-side benchmark evaluations exist between these two titans as of June 2026. Instead, current comparisons are prospective, drawing on early Sol preview data and contrasting it against the performance gaps between Opus 4.8 and OpenAI's predecessor, GPT-5.5 (which scored 58.6% on SWE-bench Pro).
Financially, both models occupy the same premium tier, matching each other at $5.00 per million input tokens and $30.00 per million output tokens. However, Anthropic provides immediate operational flexibility by offering a cheaper, high-speed "fast mode" for Opus 4.8, alongside robust backward compatibility within their developer APIs.
This ongoing volatility and the rapid shifting of the performance crown highlight the risk of vendor lock-in. To navigate this uncertainty, forward-thinking enterprises are decoupling their applications from single-provider dependencies. Communication platforms like CallMissed address this exact challenge by offering a unified API gateway. Through CallMissed, businesses can orchestrate AI voice agents and customer-facing chatbots while dynamically routing queries across 300+ LLMs. This architecture allows developers to leverage the live reasoning power of Claude Opus 4.8 today, with the built-in flexibility to switch to GPT-5.6 Sol the moment it transitions to general availability—all without rewriting core application code.
Key Developments (TABLE)

To help you evaluate these two frontier models, we have compiled the core specifications, performance indicators, and operational details of Anthropic's Claude Opus 4.8 and OpenAI's GPT-5.6 (with a focus on the Sol preview).
| Feature / Metric | Anthropic Claude Opus 4.8 | OpenAI GPT-5.6 (Sol) |
|---|---|---|
| Release Status | Fully Released (Production Ready) | Limited Developer Preview |
| Pricing (per 1M tokens) | $5.00 Input / $30.00 Output | $5.00 Input / $30.00 Output |
| Context Window | 1 Million Tokens | 1 Million+ Tokens (Estimated) |
| SWE-bench Pro Score | 69.2% (vs. 58.6% for GPT-5.5) | Pending Public Evaluation |
| Key Specializations | Legal, financial, & long-context logic | Coding, cybersecurity, & science |
Analyzing the Architectural Divergence
The data reveals a stark contrast in product readiness and target workloads. While Anthropic has focused on hardening Claude Opus 4.8 for immediate, high-stakes enterprise deployment, OpenAI is positioning GPT-5.6 to redefine the limits of autonomous, long-horizon intelligence.
- The Coding and Agentic Benchmark Leap: Opus 4.8 has set a new gold standard on SWE-bench Pro with a score of 69.2%. This is a major leap over the 58.6% managed by OpenAI’s widely used GPT-5.5 model, proving that Anthropic's updates to agentic logic and efforts controls are yielding massive real-world dividends.
- Targeted Strengths: Trusted developer reviews and early enterprise testing indicate that Opus 4.8 is the preferred model where the cost of a missed detail is exceptionally high, such as contract analysis and financial auditing. Conversely, early technical briefs of GPT-5.6 Sol suggest OpenAI is preparing to leap ahead in raw scientific reasoning, advanced cybersecurity threat modeling, and deeply complex multi-step coding.
- Infrastructure and Pricing Parity: Both providers have aligned their pricing at the premium tier of $5.00 per million input tokens and $30.00 per million output tokens. However, Anthropic offers immediate operational flexibility through a cheaper, low-latency fast mode and seamless backward compatibility in their APIs.
For businesses looking to implement these capabilities without getting locked into a single provider, platforms like CallMissed offer crucial infrastructure flexibility. By providing a unified multi-model API gateway that supports over 300+ LLMs, CallMissed allows enterprises to run Claude Opus 4.8 for detail-sensitive text workflows today, while seamlessly routing specialized tasks to GPT-5.6 as its public availability expands. This strategy ensures your AI communication agents remain state-of-the-art without requiring expensive pipeline redesigns.
In-Depth Analysis
Release Realities: Public Accessibility vs. Gated Previews
The defining operational difference between these two frontier models in June 2026 lies in their deployment strategies. Anthropic’s Claude Opus 4.8 is publicly available, offering stable API backward compatibility and a transparent evaluation suite. Developers can transition production pipelines from Opus 4.7 immediately.
Conversely, OpenAI’s GPT-5.6—spearheaded by its flagship "Sol" model—remains locked behind a limited developer preview. This gated release strategy means that while GPT-5.6's prospective capabilities look incredibly promising, there are no comprehensive, independent, side-by-side benchmark evaluations comparing the two yet. All current head-to-head analyses are prospective, mapping Opus 4.8's public metrics against OpenAI's teasers and the known gaps of the older GPT-5.5.
Task Specialization: Precision vs. Frontier Reasoning
Trusted early testers and developer logs highlight a distinct divergence in model optimization:
- Claude Opus 4.8 (The Enterprise Sentinel): Optimized for low-tolerance environments. Armed with a 1-million-token context window, advanced effort controls, and upgraded dynamic workflow routing, Opus 4.8 is currently the gold standard for complex legal reasoning, financial auditing, and data-dense enterprise tasks. Industry testers note that it excels on workloads where the cost of a missed detail is high, showing dramatically improved honesty and accuracy.
- GPT-5.6 Sol (The Breakthrough Engine): Though still in preview, OpenAI's Sol model is engineered specifically to push the absolute limits of autonomous, long-horizon capability. Early developer previews suggest Sol is geared toward highly technical domains, excelling in cybersecurity vulnerability detection, scientific hypothesis generation, and advanced multi-step coding systems.
Token Economics and Integration Flexibility
Both Anthropic and OpenAI have priced their premium-tier models identically: $5.00 per million input tokens and $30.00 per million output tokens. However, Anthropic provides immediate flexibility through a cheaper, latency-optimized "fast mode" for Opus 4.8, keeping API integrations highly cost-effective for simpler sub-tasks.
For engineering teams, choosing between Opus 4.8's immediate, rock-solid production availability and GPT-5.6's impending agentic capabilities is a high-stakes decision. This is where multi-model infrastructure becomes essential. Integrating a solution like CallMissed’s LLM gateway allows developers to bypass this platform lock-in entirely. By enabling seamless hot-swapping between 300+ models, CallMissed lets you deploy Claude Opus 4.8 for detail-heavy reasoning today, while retaining the infrastructure to route complex cybersecurity or multi-modal workloads to GPT-5.6 Sol the moment it moves out of preview.
Impact & Implications

The Opportunity Cost: Deploying Today vs. Waiting for OpenAI
The current state of play in June 2026 presents enterprise decision-makers with a classic innovator's dilemma: buy into a highly capable, publicly available bird-in-the-hand, or wait for the promised revolution in the bush.
Deploying Claude Opus 4.8 immediately allows companies to capitalize on a massive leap in agentic capabilities. With Opus 4.8 boosting SWE-bench Pro scores to a historic 69.2% (well ahead of GPT-5.5’s 58.6%), organizations can immediately automate production-grade software development, complex legal discovery, and deep financial analysis. Choosing to delay deployment in anticipation of GPT-5.6 (Sol) means incurring a distinct operational opportunity cost. However, for industries where defense is paramount—such as defense tech, heavy industrial engineering, and cybersecurity—waiting for GPT-5.6’s rumored leaps in scientific reasoning and threat-mitigation protocols may be the strategically sounder, albeit slower, path.
Architectural Agility and the $5/$30 Cost Reality
With both frontier models priced at a premium $5.00 per million input tokens and $30.00 per million output tokens, the financial implications of long-context, agentic workflows are substantial. A single autonomous run using Opus 4.8’s massive 1-million-token context window to parse a repository or legal archive can cost dozens of dollars in minutes.
To prevent run-away API costs, the architectural trend of 2026 is moving rapidly away from single-model dependency. Forward-looking enterprises are designing hybrid LLM pipelines:
- Task Routing: Directing highly sensitive, long-context, or detail-oriented reasoning tasks to Claude Opus 4.8.
- Fallback Mechanisms: Setting up automated pathways to fall back to GPT-5.6 Sol previews once they scale, or to cheaper sub-frontier models for low-stakes interactions.
- Unified Infrastructure: Utilizing platforms like CallMissed to build highly adaptable communication agents. By integrating CallMissed’s multi-model infrastructure, developers can power their customer-facing voice agents or WhatsApp chatbots with lighter, faster models for standard queries, while seamlessly escalating complex, multi-step problem solving to heavyweight models like Opus 4.8 or GPT-5.6 behind the scenes.
Redefining High-Stakes Industries
The sheer capabilities of these two architectures are actively rewriting the operating models of high-value sectors:
- Legal and Compliance: Opus 4.8’s superior precision and advanced "effort controls" mean legal departments can ingest thousands of pages of contracts with highly minimized hallucination rates. The model's improved honesty profile makes it a viable tool for automated compliance auditing.
- Cybersecurity: Early previews of GPT-5.6 Sol point to a model capable of autonomous vulnerability detection and patch generation. Security operations centers (SOCs) are preparing to deploy Sol as an active co-analyst to counter increasingly sophisticated AI-driven threats.
- Scientific Research: The deep-reasoning capacity of both systems allows research teams to automate literature reviews and synthesize complex biochemical hypotheses. This dramatically shortens the pre-clinical phase of drug discovery and materials science engineering.
Ultimately, the battle between GPT-5.6 and Claude Opus 4.8 is forcing a shift in how enterprise software is architected. Rigidity is dead; the future belongs to agile, multi-model systems that can dynamically swap the industry's best brains as fast as APIs and business needs evolve.
Expert Opinions

As industry analysts and enterprise architects evaluate the mid-2026 AI landscape, a clear consensus is emerging: the choice between Claude Opus 4.8 and GPT-5.6 is less about raw benchmarks and more about deployment philosophy. With OpenAI’s GPT-5.6 Sol still locked in limited developer preview while Anthropic’s Opus 4.8 actively runs production workloads, experts are urging decision-makers to weigh immediate stability against future potential.
The Developer Verdict: Opus 4.8's Pragmatism vs. GPT-5.6's Ambition
Prominent technical reviewers and developers across communities like Reddit’s r/codex and Towards AI have established a clear dividing line between how these two systems are utilized:
- The "Zero-Tolerance" Standard: Experts widely agree that Claude Opus 4.8 is the undisputed champion for workflows where the cost of a missed detail is exceptionally high. Its massive 1-million token context window, advanced effort controls, and unmatched performance on SWE-bench Pro (scoring 69.2% compared to GPT-5.5's 58.6%) make it the default choice for deep-dive software engineering, legal compliance, and detail-heavy financial auditing.
- The Frontier Leap: Conversely, early feedback from those with access to the GPT-5.6 "Sol" preview suggests that OpenAI is preparing a massive counter-offensive. Analysts predict that once GPT-5.6 achieves general availability, its novel reasoning architecture will set new industry benchmarks in advanced cybersecurity, complex scientific modeling, and long-horizon agentic execution.
Enterprise Architects: The Challenge of the "Waiting Game"
The lack of side-by-side, public benchmarks between Opus 4.8 and GPT-5.6 has created strategic friction for technology leaders. Enterprise architects note that while GPT-5.6 Sol matches Opus 4.8's premium pricing tier ($5 per million input tokens and $30 per million output tokens), committing to a model family that is still in limited preview carries integration and timeline risks.
Because of this, many top-tier consulting firms recommend a hybrid, model-agnostic approach. Since direct comparisons cannot be finalized until OpenAI's full suite (Sol, Terra, and Luna) is public, forward-looking organizations are building abstract integration layers.
This is where AI communication infrastructure platforms like CallMissed become invaluable. By offering a unified gateway to over 300+ LLMs, CallMissed allows companies to seamlessly leverage Claude Opus 4.8’s superior document analysis and customer agent capabilities today, while retaining the absolute flexibility to instantly route specific coding, translation, or voice-agent tasks to GPT-5.6 the moment OpenAI expands its API access.
Ultimately, experts view this era as the transition to specialized, agentic utility. Rather than a single absolute winner, the industry is shifting toward multi-model orchestration: using Opus 4.8 as the reliable, high-context cognitive anchor for complex reasoning, while preparing to integrate GPT-5.6 as a high-speed, multi-modal engine for autonomous workflows.
What This Means For You (TABLE)
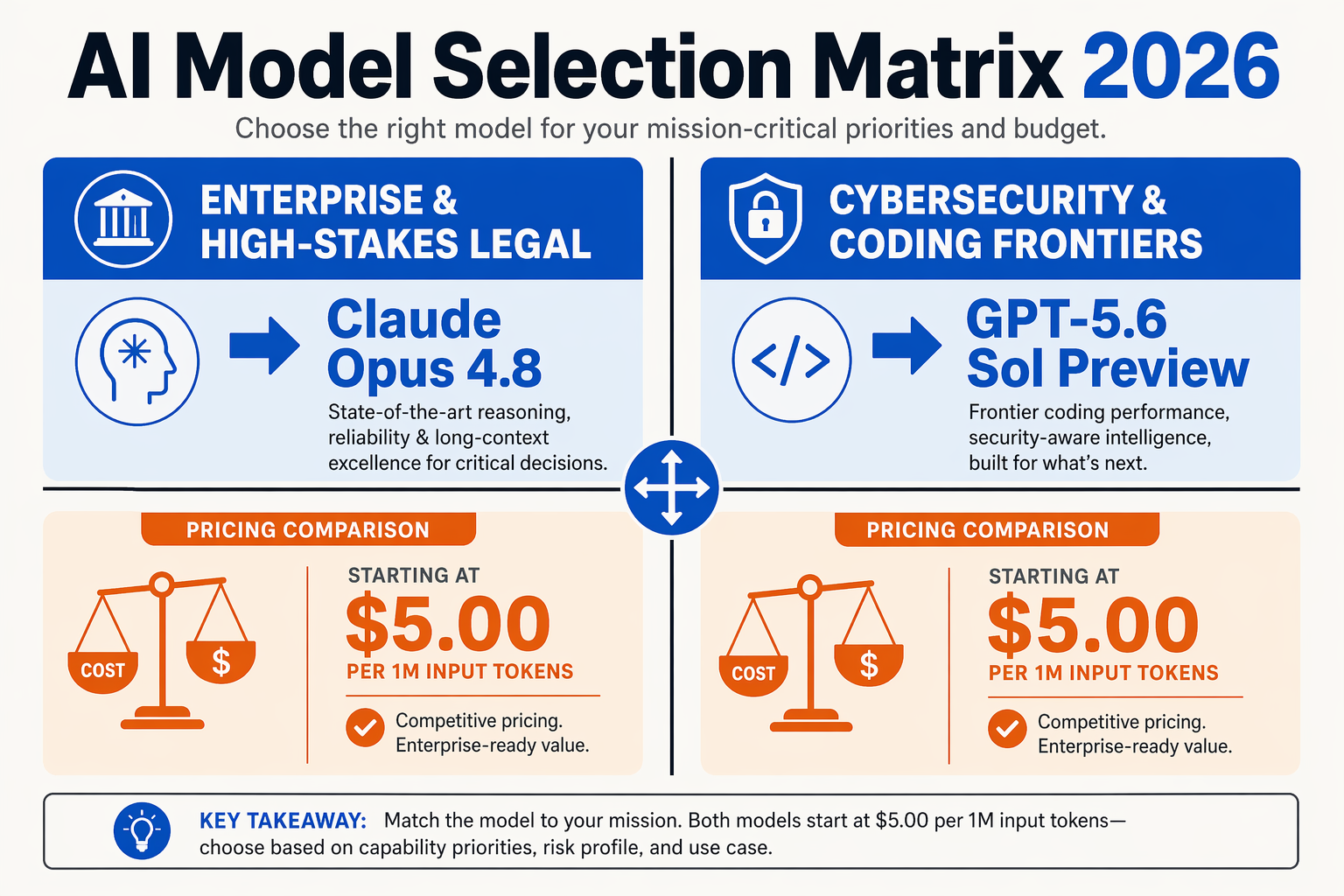
Deciding Between Immediate Value and Future Promises
As an enterprise leader, developer, or product manager, the divergence in release cycles between Anthropic and OpenAI presents a critical architectural crossroads. You cannot afford to stall your AI roadmap waiting for OpenAI to fully release its GPT-5.6 suite (spanning Sol, Terra, and Luna), yet you also want to avoid deep vendor lock-in with Anthropic’s Claude Opus 4.8 if OpenAI's upcoming family eclipses it later this year.
The optimal approach is not to choose a single side, but to build for architectural agility. For immediate, high-stakes workloads—such as automated software engineering, deep financial audits, or parsing million-token legal corpora—Claude Opus 4.8 is the undisputed, production-ready choice. Its 69.2% score on SWE-bench Pro (compared to GPT-5.5's 58.6%) means it can confidently execute complex code migrations and multi-file refactoring today.
However, for experimental pipelines focused on deep scientific modeling, advanced cybersecurity, and highly complex agentic flows, allocating resources to OpenAI’s limited developer preview of GPT-5.6 Sol is a wise hedge.
To navigate this transitional period, forward-looking engineering teams are bypassing direct API integrations altogether. By leveraging a unified AI communication infrastructure like CallMissed, businesses can deploy voice agents and customer-facing workflows powered by a multi-model gateway supporting over 300+ LLMs. This infrastructure allows you to run production workloads on Opus 4.8 today, utilize speech-to-text natively in 22 regional Indian languages, and instantly hot-swap to GPT-5.6 Sol as soon as its public API goes live—all without rewriting a single line of your core codebase.
Strategic Comparison: How to Direct Your AI Resources
The following table outlines how you should allocate your development resources based on current model availability, pricing structures, and prospective benchmarks.
| Primary Use Case | Recommended Model | Pricing (Input/Output) | Standout Advantage | Current Deployment Status |
|---|---|---|---|---|
| Detail-Sensitive Analysis | Claude Opus 4.8 | $5.00 / $30.00 (per 1M) | 1M token context window, high honesty/accuracy | Publicly available globally |
| Agentic Coding (SWE-bench) | Claude Opus 4.8 | $5.00 / $30.00 (per 1M) | 69.2% score on SWE-bench Pro; strong collaboration | Publicly available globally |
| Cybersecurity & Science | GPT-5.6 (Sol Preview) | $5.00 / $30.00 (per 1M) | Advanced long-horizon logic and code synthesis | Limited developer preview |
| Multilingual Voice Agents | Unified Gateway (e.g., CallMissed) | Multi-model optimized rates | Hot-swappable 300+ LLMs; 22 Indian languages | Available today for production |
The Bottom Line for AI Architects
Building on a single LLM provider is a legacy strategy. While Claude Opus 4.8 holds the crown for current, publicly available enterprise reasoning, the looming capabilities of GPT-5.6 Sol mean the frontier will shift again. By implementing a decoupled, gateway-based architecture, you ensure your applications remain state-of-the-art regardless of which AI laboratory holds the performance crown at any given moment.
Frequently Asked Questions
How does GPT-5.6 vs Claude Opus 4.8 compare in pricing and token costs?
Which model is better for complex software engineering and agentic coding?
What are the main architectural differences in the GPT-5.6 vs Claude Opus 4.8 matchup?
Can I use both GPT-5.6 and Claude Opus 4.8 in production right now?
Why is Claude Opus 4.8 preferred for legal and financial analysis over GPT models?
When will official head-to-head benchmarks for GPT-5.6 vs Claude Opus 4.8 be available?
Conclusion
As the frontier AI landscape of mid-2026 unfolds, choosing between these two titans depends heavily on your immediate deployment timeline and task complexity:
- Immediate Enterprise Execution: Claude Opus 4.8 is live and production-ready today, offering unmatched precision, a 1-million token context window, and a stellar 69.2% score on SWE-bench Pro for detail-sensitive enterprise workflows.
- Anticipated Frontier Leaps: OpenAI’s GPT-5.6 family (specifically Sol) remains locked in limited preview, poised to push the boundaries of cybersecurity, scientific reasoning, and autonomous agentic coding.
- Strategic Flexibility: Because both models match pricing at $5/$30 per million tokens, the ultimate winners are the businesses that remain completely model-agnostic.
The coming months will reveal if OpenAI’s full rollout can eclipse Anthropic's current enterprise stronghold. To explore how AI communication is evolving and keep your deployment agile, check out CallMissed—an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
Will you build on the proven, active capabilities of Claude Opus 4.8 today, or wait for the full power of GPT-5.6 to unlock tomorrow?
Related Posts

GPT-5.6: Comparing Sol, Terra, and Luna—Capabilities, Differences, and Use Cases

Trump Administration Asks OpenAI to Stagger GPT-5.6 Release: What It Means for AI Security

US Grows Anxious Over AI: Trump Administration Orders OpenAI to Delay GPT-5.6 Rollout