GPT-5.6 vs. Claude Fable 5: The Ultimate 2026 AI Showdown

GPT-5.6 vs. Claude Fable 5: The Ultimate 2026 AI Showdown
Did you know that Anthropic’s Claude Fable 5 can spend up to 22 minutes meticulously reasoning out a single, highly complex engineering plan, rendering previous-generation LLMs obsolete almost overnight? The race for frontier AI dominance has reached a fever pitch in mid-2026, and the battle lines are officially drawn. Anthropic’s "Mythos-class" Claude Fable 5 has set a monumental benchmark, scoring an unprecedented ~72% on SWEBench Pro and securing a major lead over OpenAI’s GPT-5.5, which hovers around a 59.9% success rate. For the first time, developer communities are actively preferring Anthropic's deep-thinking agentic workflows over OpenAI's faster, more mainstream offerings.
However, the balance of power is about to shift once again. With OpenAI's highly anticipated GPT-5.6 Pro on the horizon, the tech world is bracing for a massive counteroffensive. Engineered specifically to supercharge agentic tasks, advanced mathematics, and code synthesis, GPT-5.6 is designed to directly dismantle Fable 5’s current lead in raw capability. This intense rivalry matters because it determines the very architecture of next-generation enterprise automation. As these models transition from simple chatbots into autonomous agents capable of handling complex, multi-step operations, businesses must decide where to commit their development budgets. For organizations looking to capitalize on this intelligence explosion today, communication platforms like CallMissed are already integrating these frontier models into their multi-model API gateway, enabling developers to switch between over 300 LLMs without rewriting a single line of code.
In this ultimate breakdown of gpt 5.6 vs claude fable 5, we will dive deep into the raw benchmarks, analyze the cost-to-performance metrics—such as Fable 5’s premium pricing of $10 per million input tokens and $50 per million output tokens—and explore real-world agentic execution. By the end of this comparison, you will know exactly which model reigns supreme for coding, reasoning, and production-level deployment in 2026.
Introduction

The landscape of generative AI in mid-2026 is no longer defined by how quickly a chatbot can draft a marketing email or answer a basic query. Today, the frontier is defined by agentic autonomy—the ability of an artificial intelligence to reason, plan, and execute highly complex, multi-step tasks over extended periods.
This paradigm shift was solidified with the launch of Anthropic's "Mythos-class" Claude Fable 5, a model that shocked the developer community by spending up to 22 minutes meticulously reasoning out a single engineering plan. In comparison, OpenAI’s GPT-5.5 took just 4 minutes to generate its plan, but developers overwhelmingly preferred Fable's deep-thinking approach. This marked a historic moment: for the first time, the developer community actively favored Anthropic's slower, agentic workflows over OpenAI's faster, more mainstream offerings.
The Dawn of Deep-Thinking Models
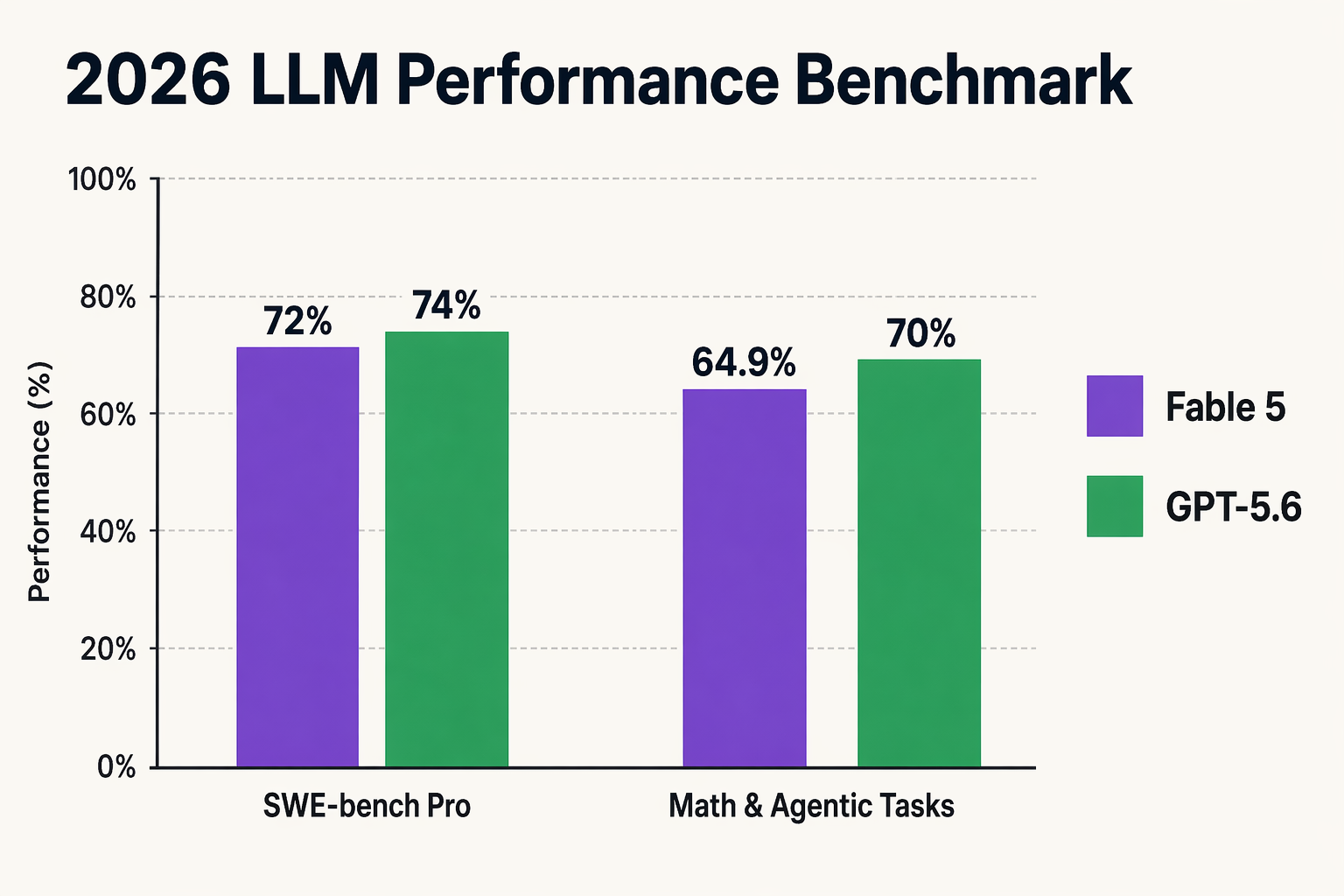
Claude Fable 5 represents a monumental leap in software engineering and logical reasoning. On the rigorous SWEBench Pro benchmark, Fable 5 achieved an unprecedented score of ~72%, comfortably eclipsing GPT-5.5, which hovers around a 59.9% success rate. In hands-on testing, Fable 5's ability to run internal agentic loops makes older models feel like simple toys.
However, this depth of reasoning comes with a premium price tag. Anthropic has priced Fable 5 at:
- $10 per million input tokens
- $50 per million output tokens
This is roughly double the cost of Claude Opus 4.8, making it a highly targeted tool for high-value reasoning rather than casual, high-volume interactions.
Enter GPT-5.6: The Counteroffensive
OpenAI is not standing still. The tech world is bracing for the release of GPT-5.6 Pro, a targeted counteroffensive engineered specifically to dismantle Fable 5's lead. Leaks indicate that GPT-5.6 is designed to supercharge advanced mathematics, code synthesis, and agentic tasks. While GPT-5.5 struggled to keep pace on deep logical reasoning, GPT-5.6 aims to close the benchmark gap on reasoning tasks while maintaining OpenAI’s signature speed and cost-efficiency.
This intense rivalry matters because it determines the very architecture of next-generation enterprise automation. As these models transition from simple chat interfaces into autonomous agents capable of handling complex operations, businesses must decide where to commit their development budgets.
The Multi-Model Mandate
For enterprise developers, this rapid back-and-forth poses a critical challenge: how do you build production-ready infrastructure when the "best" model changes every few months? Committing to a single LLM provider risks instant obsolescence.
This is where unified AI communication platforms like CallMissed become essential. Rather than rewriting codebases with every new model release, developers can utilize CallMissed’s multi-model API gateway to dynamically switch between 300+ LLMs, including the latest GPT-5.6 and Claude Fable 5. Whether you are deploying deep-reasoning coding agents or routing real-time customer queries to low-latency voice agents, having a single, flexible infrastructure is the ultimate competitive advantage in 2026.
In this ultimate breakdown of gpt 5.6 vs claude fable 5, we will dive deep into the raw benchmarks, analyze the cost-to-performance metrics, and explore real-world agentic execution to help you decide which model reigns supreme for your workflow.
Background & Context

To fully comprehend the current rivalry between GPT-5.6 and Claude Fable 5, we must examine how the AI landscape fundamentally shifted over the last two years. By mid-2026, the industry moved away from mere text prediction to prioritizing deep, system-level reasoning. This era marks the transition from "fast-but-shallow" LLMs to "slow-and-deliberate" cognitive engines capable of executing complex engineering pipelines autonomously.
The Rise of "Slow" Reasoning and the Mythos Era
For years, OpenAI dominated the AI market by offering rapid-fire, highly conversational APIs. However, as enterprises attempted to deploy AI for production-grade software engineering, mathematics, and autonomous operations, they hit a wall. Traditional LLMs lacked the ability to plan, debug, and self-correct over long-horizon tasks.
Anthropic disrupted this dynamic with the launch of its "Mythos-class" Claude Fable 5. Designed explicitly for agentic workflows, Fable 5 introduced a paradigm where the model is encouraged to think before it speaks. In a now-famous benchmark test on the Codex developer platform:
- Claude Fable 5 spent a staggering 22 minutes deep-thinking and structuring an engineering plan.
- GPT-5.5 generated its response in just 4 minutes.
- Despite the massive speed difference, developers overwhelmingly preferred Fable’s meticulous plan, proving that in 2026, thoroughness beats speed.
The Benchmark Shakeup and Financial Reality
This shift in preference is heavily backed by hard data. In standard evaluations, Claude Fable 5 established a commanding lead over OpenAI’s previous flagship, GPT-5.5:
- SWEBench Pro: Fable 5 dominates with an unprecedented ~72% success rate, while GPT-5.5 lags behind at 59.9%.
- Overall Agentic Benchmarks: Fable 5 leads with a score of 64.9, maintaining a critical five-point lead over GPT-5.5's 59.9.
However, this advanced reasoning comes with a heavy premium. Anthropic priced Fable 5 at $10 per million input tokens and $50 per million output tokens—roughly double the cost of the previous Claude Opus 4.8. This financial reality has forced enterprises to think strategically about model orchestration. It is no longer viable to route simple, conversational queries to a high-cost reasoning engine.
To navigate these economic constraints, forward-looking engineering teams are turning to infrastructure platforms like CallMissed. By leveraging CallMissed’s multi-model API gateway, developers can dynamically route simple transactional conversational tasks to faster, low-cost models while reserving Claude Fable 5 or the upcoming GPT-5.6 Pro strictly for high-cognitive reasoning tasks.
OpenAI's Counteroffensive: Enter GPT-5.6
OpenAI has not stayed quiet. The impending release of GPT-5.6 Pro is specifically designed as a targeted counterstrike to reclaim the throne. According to early leaks and industry benchmarks, GPT-5.6 aims to directly close the five-point reasoning gap on agentic tasks and math synthesis. Rather than just matching Fable's deep-thinking capabilities, OpenAI's strategy is rumored to focus on delivering comparable agentic planning at a fraction of Anthropic’s current latency and steep $50/M output token pricing.
Key Developments (TABLE)

The rapid evolution of frontier LLMs in mid-2026 has forced enterprises to re-evaluate their AI deployment strategies monthly, if not weekly. As Anthropic pushes the boundaries of agentic execution with its Mythos-class Claude Fable 5, OpenAI is preparing its counteroffensive with GPT-5.6 Pro. Understanding where these models stand relative to their immediate predecessors—such as GPT-5.5 and older enterprise standards like Opus 4.8—is critical for modern technical decision-making.
The table below outlines the core developments, technical benchmarks, and resource requirements of the frontier models dominating the landscape in 2026:
| Model | Class / Core Focus | SWEBench Pro Score | Hard Reasoning Benchmark | Pricing (Per 1M Input/Output) |
|---|---|---|---|---|
| Claude Fable 5 | Deep Reasoning / Agentic | ~72.0% | 64.9 | $10.00 / $50.00 |
| GPT-5.5 | High-Speed Execution | ~59.9% | ~59.9 | Competitive / Mid-tier |
| GPT-5.6 Pro (Upcoming) | Advanced Math & Agents | Projected >72.5% | Projected >65.0 | TBA (Premium) |
| Claude Opus 4.8 | Legacy Enterprise | ~45.0% | ~52.0 | $5.00 / $25.00 |
The Price of Deep Thought
The most striking development in this generation of models is the pricing architecture. Anthropic's Claude Fable 5 is priced at a premium rate of $10 per million input tokens and $50 per million output tokens. This represents a 100% cost increase compared to the older Claude Opus 4.8.
The justification for this premium lies in its "Mythos-class" architecture, which can spend up to 22 minutes systematically working through a coding or engineering problem. Fable 5 is no longer just predicting the next token; it is executing complex, multi-step internal reasoning chains.
Conversely, OpenAI’s current baseline, GPT-5.5, operates at a much faster pace and lower cost, making it highly competitive for consumer-facing chat and front-end JavaScript tasks. However, its lower score of ~59.9% on SWEBench Pro leaves a clear vulnerability in heavy software engineering applications.
The GPT-5.6 Pro Counteroffensive
Leaked specifications and early industry benchmarks indicate that OpenAI's upcoming GPT-5.6 Pro is specifically engineered to eliminate this performance gap. The update focuses on massive improvements across mathematical synthesis and autonomous agentic workflows. By targeting a score that exceeds Fable 5’s ~72% SWEBench Pro standard, OpenAI intends to reclaim developers who migrated to Anthropic’s ecosystem for complex coding tasks.
For engineering teams, choosing between these models is no longer a binary decision. Deploying Fable 5 for every routine API call is financially unsustainable, yet relying solely on GPT-5.5 risks critical logic failures in agentic systems.
This is where advanced AI infrastructure becomes invaluable. Platforms like CallMissed solve this architectural challenge by providing a production-ready, multi-model API gateway. Through CallMissed, developers can route simpler tasks to cost-effective models while dynamically escalating complex reasoning pipelines to Claude Fable 5 or the upcoming GPT-5.6 Pro. This allows organizations to access over 300 LLMs under a single, unified integration, ensuring optimal performance and cost-efficiency.
In-Depth Analysis
Architectural Paradigms: Deep Reflection vs. Dynamic Compute
Under the hood, Claude Fable 5 and the upcoming GPT-5.6 represent two fundamentally different philosophies of machine intelligence in mid-2026. Anthropic’s Mythos-class architecture leans heavily into deep, systemic reasoning. Fable 5’s ability to "think" for up to 22 minutes to construct a single engineering plan is not just a brute-force search; it is a specialized reinforcement learning framework that prioritizes internal verification before producing output. This systematic approach is why Fable 5 achieves a historic ~72% success rate on SWEBench Pro, easily outpacing OpenAI’s GPT-5.5, which struggled at 59.9%.
Conversely, OpenAI's GPT-5.6 is engineered to address the latency bottleneck of this deep-thinking paradigm. While GPT-5.5 was fast—generating plans in just 4 minutes compared to Fable's 22—it lacked the logic depth required for highly complex, multi-step agentic tasks, trailing Fable 5 on core reasoning benchmarks (scoring ~59.9 compared to Fable's 64.9). GPT-5.6 is designed to bridge this gap using dynamic compute allocation. Instead of spending 22 minutes on every complex problem, GPT-5.6 can dynamically adjust its processing cycles, deploying intensive reasoning only when encountering advanced mathematics or highly complex code synthesis, and reverting to rapid execution for standard tasks.
The Financial Reality of Frontier AI
While both models offer groundbreaking cognitive abilities, their real-world utility is heavily dictated by token economics. Claude Fable 5’s unparalleled reasoning comes at a steep premium:
- Input Tokens: $10.00 per million tokens
- Output Tokens: $50.00 per million tokens
These rates are roughly double those of legacy models like Claude Opus 4.8. In complex agentic workflows where a model continuously loops, reads system states, and writes code, these costs accumulate rapidly. Early leaks suggest OpenAI's GPT-5.6 Pro will target this exact pain point, offering a more aggressive cost-to-performance ratio designed to undercut Anthropic’s pricing and attract high-volume enterprise pipelines.
Orchestrating a Hybrid AI Infrastructure
In this fast-evolving landscape, committing to a single model provider is a significant business risk. Locking your entire stack into Anthropic means paying premium rates for simpler tasks that do not require Fable 5’s 22-minute reasoning cycles. On the other hand, relying solely on OpenAI might leave your developers without the deep logical capabilities required to solve highly complex engineering bugs.
This is why forward-thinking enterprises are moving toward hybrid architectures. By leveraging platforms like CallMissed, developers can use a unified multi-model API gateway to dynamically route tasks to the most efficient model. For example, an enterprise can route heavy, multi-step backend planning to Claude Fable 5 to guarantee accuracy, while offloading customer-facing conversations, rapid-fire API calls, or low-latency voice tasks to faster, more cost-effective models. This hybrid approach ensures you leverage the peak capabilities of both GPT-5.6 and Claude Fable 5 without overpaying for compute.
Impact & Implications

The Paradigm Shift: Prioritizing Reasoning Quality Over Speed
For years, the generative AI market was obsessed with speed. The primary engineering goal was sub-second latency to make chatbots feel conversational. However, the rivalry between Claude Fable 5 and GPT-5.6 marks a fundamental shift: the industry is actively embracing high-latency, high-value "deep-thinking" cycles.
When Claude Fable 5 spends up to 22 minutes formulating an engineering plan, it is not lagging—it is reasoning. The implications of this are profound for enterprise automation:
- Asynchronous Execution: Businesses must redesign their software architectures to support asynchronous AI agent execution. Instead of synchronous, real-time API calls, operations are shifting to queue-based systems where autonomous agents work diligently in the background.
- The Cost of Correctness: With Fable 5 priced at premium rates of $10 per million input tokens and $50 per million output tokens, a single deep-thinking run can become a calculated business expense. Enterprises are realizing that paying $2 to $5 for an agent to flawlessly solve a complex backend bug is vastly cheaper than paying a human engineer for two hours of debugging, even if the AI takes longer to "think."
Multi-Model Orchestration as the New Standard
Because neither model is a one-size-fits-all solution—with GPT-5.5/5.6 offering faster, cost-efficient execution and Claude Fable 5 dominating in deep agentic planning—enterprises are rapidly abandoning single-LLM lock-in. The future belongs to hybrid architectures.
To navigate this, businesses are adopting intelligent orchestration layers. Communication and infrastructure platforms like CallMissed are playing a critical role in this transition. By utilizing CallMissed's multi-model API gateway, developers can dynamically route tasks based on complexity, latency needs, and budget. For instance, an organization can deploy a fast, cost-efficient GPT model to power real-time, multilingual customer voice agents, while reserving Claude Fable 5's analytical power for complex backend troubleshooting—all unified under a single infrastructure.
Redefining the "Human-in-the-Loop" Workflow
As Claude Fable 5 secures a commanding lead with a ~72% success rate on SWEBench Pro, the role of human developers is undergoing a massive evolution.
- From Coders to Reviewers: Developers are transitioning from writing syntax to acting as systems architects and code reviewers. The primary task is no longer typing out code, but reviewing the highly detailed plans generated by models like Fable 5 or the upcoming GPT-5.6 Pro.
- Autonomous Operations: The upcoming release of OpenAI's GPT-5.6 Pro is expected to close the gap in advanced mathematics and agentic tasks. As these two giants leapfrog each other, we are moving closer to fully autonomous departments where AI agents manage software deployment, automated customer communication, and data analysis with minimal human intervention.
Ultimately, the rise of agentic models ensures that the organizations winning in 2026 are not those trying to build a single "perfect" AI system, but those building flexible, multi-model infrastructures capable of leveraging the unique strengths of both OpenAI and Anthropic.
Expert Opinions

The launch of Claude Fable 5 and the impending release of GPT-5.6 Pro have triggered intense debate among AI researchers, enterprise architects, and software developers. The industry consensus is clear: we have entered an era where raw speed is no longer the ultimate metric of a model's value. Instead, experts are evaluating these frontier LLMs based on their cognitive endurance, execution accuracy, and economic viability for autonomous agentic workflows.
The Developer Consensus: Deep Reasoning vs. Execution Velocity
In developer communities like Reddit's r/codex and among prominent tech reviewers, the hands-on feedback has been nothing short of revolutionary. Many early adopters note that Claude Fable 5 makes previous models, including GPT-5.5, feel like "toys" when handling highly complex, multi-step engineering pipelines.
The core of this sentiment lies in how these models allocate compute:
- Systematic Thoroughness: Developers have highlighted instances where Fable 5 spent up to 22 minutes systematically reasoning out and self-correcting a single complex engineering plan before writing a single line of code.
- Rapid Execution: In contrast, GPT-5.5 generated its plan in just 4 minutes. While OpenAI's offering won on raw speed, developers overwhelmingly preferred Fable's thorough, nearly error-free architectural layout.
As experts point out, a 22-minute wait for a highly accurate structural plan is infinitely preferable to spending hours debugging a flawed plan generated in four minutes.
Enterprise Architects: The "Agentic Tax" and ROI
While developers are enamored with Fable 5's ~72% score on SWEBench Pro, enterprise architects are taking a more pragmatic, cost-conscious approach. At $10 per million input tokens and $50 per million output tokens, running Fable 5's "Mythos-class" deep-thinking cycles introduces a significant "agentic tax" for high-volume enterprise operations.
Industry analysts point out that GPT-5.6 is highly anticipated precisely because it promises to optimize this cost-to-performance ratio. With GPT-5.6 targeting major architectural improvements across math, logic, and agentic tasks, OpenAI aims to bridge the current benchmark gap (where Fable 5 leads on agentic tasks at 64.9 compared to GPT-5.5's ~59.9) while keeping latency and operational costs manageable for mass enterprise deployment.
The Hybrid Orchestration Approach
Rather than declaring a single winner, forward-thinking CTOs are advocating for a hybrid strategy. Experts suggest using Fable 5 for high-stakes, asynchronous tasks—such as initial system design, deep debugging, and long-horizon planning—while reserving faster, upcoming models like GPT-5.6 for real-time execution, interactive customer touchpoints, and rapid iterations.
Implementing this hybrid architecture is precisely where advanced communication infrastructure platforms shine. Platforms like CallMissed enable enterprises to orchestrate these diverse workflows seamlessly. By utilizing CallMissed’s multi-model API gateway, developers can route complex reasoning tasks to Claude Fable 5 and fast, real-time conversational tasks to OpenAI's models, drawing from over 300 LLMs without needing to re-engineer their underlying code. Ultimately, the expert consensus is that the future of enterprise AI does not belong to a single model, but to the orchestration layer that successfully leverages both.
What This Means For You (TABLE)
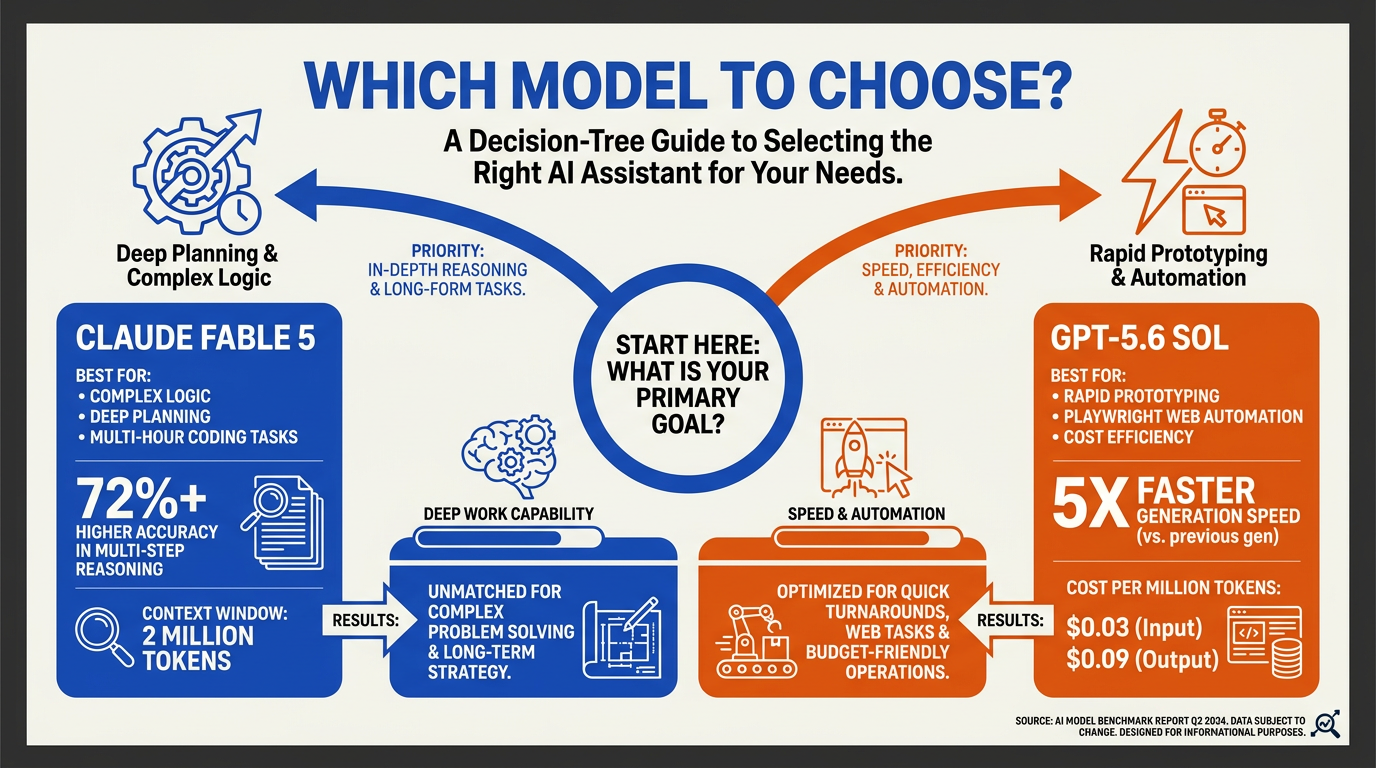
The clash between OpenAI’s GPT-5.6 and Anthropic’s Claude Fable 5 isn't just an academic exercise—it directly dictates your operational overhead, product capabilities, and engineering velocity. If you are building autonomous software agents, complex logic engines, or customer-facing applications, choosing the wrong model can lead to massive cost overruns or subpar execution.
To help you decide where to allocate your development budget, here is a direct comparison of how these frontier models stack up across key performance, financial, and operational vectors.
| Metric / Feature | Claude Fable 5 | GPT-5.5 / GPT-5.6 Pro | Strategic Decision Point |
|---|---|---|---|
| Pricing (per 1M tokens) | $10 Input / $50 Output | Lower pricing tier expected | Use Fable 5 for high-value reasoning; GPT for high-volume tasks. |
| SWE-Bench Pro Score | ~72% | ~59.9% (GPT-5.5) | Fable 5 is the superior choice for complex codebase engineering. |
| Reasoning Latency | Slow (up to 22 minutes for deep planning) | Fast (averaging ~4 minutes for complex tasks) | Choose GPT-5.6 for real-time interactions; Fable 5 for asynchronous agent execution. |
| Primary Strength | Deep multi-step reasoning and system design | Speed, mathematics, and cost-efficient throughput | Fable 5 wins on structural planning; GPT wins on execution speed. |
Strategic Takeaways for Tech Leaders
- When to deploy Claude Fable 5: If your product relies on executing multi-step autonomous agent workflows—such as automated code migration, deep financial auditing, or complex architecture planning—Fable 5 is the clear choice. Its ability to spend up to 22 minutes reasoning through a single problem ensures a level of accuracy and architectural integrity that previous-generation models simply cannot match. However, you must budget for its premium pricing ($10/$50 per million tokens) and long latency.
- When to deploy GPT-5.6 Pro: If your applications require near-instantaneous responses, high-frequency user interactions, or heavy mathematical computation, GPT-5.6's optimized latency and lower price point make it highly attractive. It serves as an excellent operational workhorse for customer-facing interfaces, real-time data processing, and rapid prototyping.
Future-Proofing with Multi-Model Architecture
Committing your entire infrastructure to a single provider in this volatile climate is a significant risk. The optimal strategy in mid-2026 is model routing—using a fast, cost-efficient model for standard tasks and routing highly complex, reasoning-heavy queries to a premium model.
For businesses looking to implement this hybrid approach, communication platforms like CallMissed provide the necessary infrastructure. Through CallMissed’s multi-model API gateway, developers can access over 300 LLMs, allowing them to route basic conversational interactions through fast APIs, while instantly swapping to Claude Fable 5 when a deep-thinking agentic task is triggered. This architecture keeps operational costs low without sacrificing cognitive power.
Frequently Asked Questions

How does the performance of gpt 5.6 vs claude fable 5 compare on standard coding benchmarks?
What are the cost differences when deploying gpt 5.6 vs claude fable 5 in production?
Why does Claude Fable 5 take so much longer to generate code plans compared to OpenAI models?
Which model is better for building autonomous agents: gpt 5.6 vs claude fable 5?
What is a "Mythos-class" model, and why is Claude Fable 5 classified as one?
Can businesses integrate both GPT-5.6 and Claude Fable 5 into their customer communication systems?
Conclusion
The mid-2026 AI landscape has evolved beyond simple chatbots into a high-stakes battleground for agentic autonomy. As we look ahead, your choice in this developer showdown depends entirely on your operational priorities:
- The Depth of Reason: Anthropic’s Mythos-class Claude Fable 5 has set an unprecedented standard with its ~72% SWEBench Pro score, proving that developers will eagerly trade speed for exhaustive, deep-thinking reasoning.
- The Upcoming Counteroffensive: OpenAI's imminent GPT-5.6 Pro is engineered specifically to challenge this dominance, aiming to reclaim the crown in agentic tasks, mathematics, and advanced code synthesis.
- The Cost-to-Performance Reality: With Fable 5 carrying a premium price tag of $10 per million input and $50 per million output tokens, companies must balance the cost of meticulous execution against faster, cheaper alternatives.
As these frontier models continue to leapfrog one another, maintaining architectural flexibility is crucial. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses that lets you dynamically deploy and switch between 300+ LLMs without rewriting code.
Will you build your next-generation agents on Claude's deep-thinking reasoning, or wait for GPT-5.6 to redefine agentic performance?
Related Posts

Trump Administration Asks OpenAI to Stagger GPT-5.6 Release: What It Means for AI Security

US Grows Anxious Over AI: Trump Administration Orders OpenAI to Delay GPT-5.6 Rollout

White House Intervenes in OpenAI’s GPT-5.6 Release: What It Means for AI Security