GLM-5.2: How to Run This Powerhouse Model Locally (2026 Guide)

GLM-5.2: How to Run This Powerhouse Model Locally (2026 Guide)
Did you know that running one of the world's most powerful open-weights AI models locally can cost you as little as $0.51 to $2.00 per hour in electricity and hardware amortization? With the release of Zhipu AI’s GLM-5.2, the local AI landscape has shifted dramatically, triggering intense discussions across the tech community and skyrocketing to the top of Hacker News with over 419 points and 183 comments in under 15 hours.
For developers and privacy-conscious enterprises, this release is a massive win. Historically, leveraging frontier-class reasoning and multilingual capabilities meant sending sensitive data to external, proprietary APIs—resulting in spiraling costs and potential security risks. GLM-5.2 changes the game. By deploying this powerhouse model locally, teams can execute 24/7 continuous looping, private chats, and deep security code reviews for a fraction of the cost of calling closed APIs like Claude Opus. While businesses often deploy production-ready, high-scale customer interactions via advanced AI communication platforms like CallMissed—which seamlessly orchestrates multi-model pipelines and multilingual voice agents—having local, offline control over a model of this caliber is the ultimate superpower for internal development, testing, and secure data processing.
But how do you actually deploy this powerhouse on your own hardware without a enterprise-grade data center?
In this comprehensive 2026 guide on GLM-5.2 – How to Run Locally, we will walk you through everything you need to know to get started. You will learn the exact hardware configurations required—from running highly optimized 2-bit quants on a 256GB Mac Studio to setting up multi-GPU RTX 4090 rigs. We will also provide a step-by-step setup walkthrough using llama.cpp, LM Studio, and Unsloth Studio (which automatically offloads layers to system RAM and auto-detects multi-GPU setups). By the end of this guide, you will have a private, fully functional, and incredibly fast deployment of GLM-5.2 running right on your machine.
Introduction

The landscape of open-weights AI has shifted dramatically. The launch of Zhipu AI's GLM-5.2 has ignited the developer community, quickly claiming the top spot on Hacker News with over 419 points and 183 comments within hours of its release. For developers, researchers, and privacy-conscious enterprises, this represents a massive milestone: frontier-class reasoning and deep multilingual capabilities are no longer locked behind proprietary, expensive cloud APIs.
The Economics of Local AI: Why GLM-5.2 is a Game-Changer
Historically, leveraging elite models meant sending sensitive data to external servers, risking intellectual property exposure while racking up unpredictable API bills. GLM-5.2 changes this equation completely. Running this model locally on your own hardware for 24/7 continuous workloads costs an estimated $0.51 to $2.00 per hour in electricity and hardware amortization. Compared to the compounding token costs of calling closed models like Claude Opus, local deployment offers a predictable, flat-rate alternative that pays for its hardware in a matter of months.
This makes GLM-5.2 highly practical for resource-intensive, offline use cases:
- Continuous Autonomous Looping: Running agentic workflows around the clock without worrying about token budgets.
- Deep Security Code Reviews: Scanning proprietary, enterprise codebases for security vulnerabilities without exposing intellectual property to third parties.
- Confidential RAG Pipelines: Powering private knowledge management systems containing highly sensitive legal, financial, or medical data.
Scaling Local Success to Global Infrastructure
While running GLM-5.2 locally is the ultimate developer superpower for private testing and sandbox development, scaling these models to thousands of concurrent users requires a different class of infrastructure. For businesses transitioning from local proof-of-concepts to high-scale production, platforms like CallMissed bridge the gap. CallMissed provides an advanced AI communication infrastructure that lets companies orchestrate production-grade voice agents, WhatsApp chatbots, and multi-model LLM inference (supporting over 300+ models) with built-in Speech-to-Text capabilities across 22 regional Indian languages.
What You Will Learn in This Guide
To help you get this powerhouse model running on your own machine, this guide will walk you through the practical steps of local deployment:
- Hardware Optimization: How to size your system, including running highly optimized 2-bit quants on a 256GB Mac Studio or configuring multi-GPU RTX 4090 rigs.
- Deploying with llama.cpp & LM Studio: Step-by-step setup for running GGUF quants locally with minimal friction.
- Leveraging Unsloth Studio: How to use this modern open-source web UI to automatically offload layers to system RAM and auto-detect multi-GPU setups.
Let's dive into the exact hardware and software configurations you need to unlock local GLM-5.2 execution.
Background & Context

The Origins of GLM-5.2: Zhipu AI’s Breakthrough
Developed by the prominent AI research institution Zhipu AI, the GLM (General Language Model) series has consistently pushed the boundaries of open-weight capabilities. Historically, global developers relied almost exclusively on western-centric models from Meta or Mistral. However, the release of GLM-5.2 in 2026 has completely rebalanced the geopolitical AI landscape.
What makes GLM-5.2 stand out is its native architecture. It is built from the ground up to support deep multilingual reasoning—with an emphasis on highly accurate bilingual English/Chinese outputs—and complex logic-based tasks. On community forums like r/LocalLLaMA, developers are noting that GLM-5.2 matches or even surpasses proprietary giants like Claude Opus on specific workflows, particularly:
- Continuous Loop Workloads: Executing long-running autonomous agent cycles.
- Advanced Code Auditing: Scanning massive enterprise codebases for security vulnerabilities without exposing sensitive intellectual property to third-party APIs.
- Privacy-First Interaction: Handling highly sensitive personal, medical, or corporate data with zero cloud data retention.
Why the Shift to Local Architectures is Accelerating
The massive engagement surrounding GLM-5.2 on Hacker News—peaking at 419 points and 183 comments in under 15 hours—reflects a broader macroeconomic shift in software engineering. Relying solely on closed cloud APIs introduces critical vulnerabilities: unpredictable latencies, sudden rate-limiting, escalating token costs, and compliance risks under strict data privacy regulations.
Financially, the math is stark. Running a model of GLM-5.2's caliber on proprietary APIs for continuous 24/7 pipelines can cost thousands of dollars a month in token fees. Locally, once you factor in hardware amortization and electricity, running GLM-5.2 costs an estimated $0.51 to $2.00 per hour.
For organizations requiring this level of control but also needing to scale customer-facing operations, hybrid architectures are becoming the standard. While developers run secure, offline tests and code reviews locally, they can transition production-scale user interactions to communications infrastructure platforms like CallMissed. CallMissed supports seamless routing across 300+ LLMs, offering native Speech-to-Text in 22 regional languages and highly optimized voice agent workflows, ensuring that local model testing translates effortlessly to cloud-scale enterprise deployment.
The Tools Making Local Deployment Possible
Previously, running a frontier-class model required complex cluster configurations and deep machine learning expertise. However, the open-weight ecosystem has matured rapidly in 2026. GLM-5.2 is supported out-of-the-box by leading local runtimes:
- llama.cpp: The industry-standard C/C++ port allows highly optimized quantized execution on consumer hardware, enabling highly optimized 2-bit quantization runs even on a 256GB Mac Studio.
- Unsloth Studio: This advanced open-source web UI simplifies local LLM orchestration by automatically offloading inactive layers to system RAM and auto-detecting multi-GPU setups (like dual RTX 4090 rigs) without manual partitioning.
- LM Studio and Ollama: Providing user-friendly GUI deployments that handle model quantization (GGUF format) natively, making local setup accessible to non-technical developers.
This alignment of state-of-the-art model weights and highly optimized software runtimes has democratized elite AI, allowing developers to run a powerhouse model directly from their own hardware.
Key Developments (TABLE)
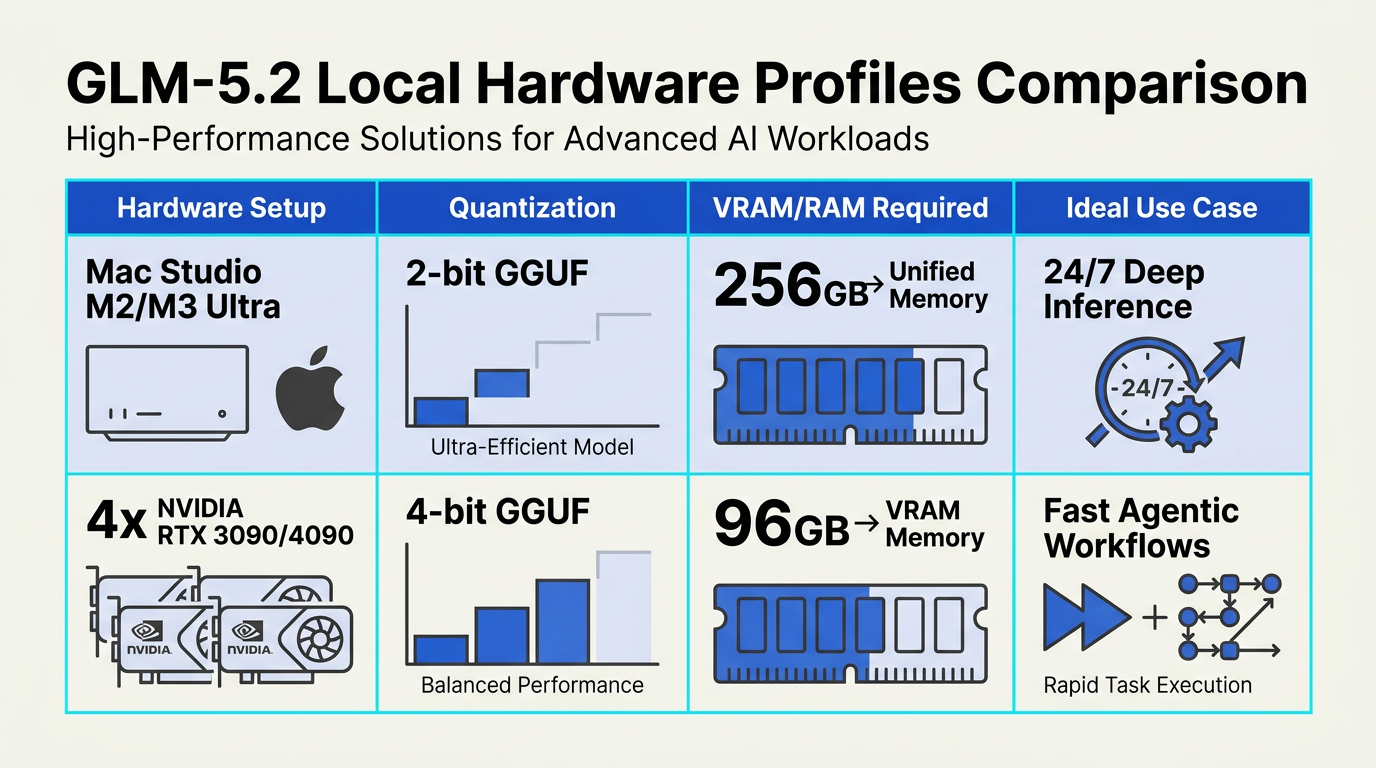
The Open-Weights Optimization Breakthrough
The ability to run Zhipu AI's flagship GLM-5.2 locally on consumer and prosumer hardware represents a massive paradigm shift in local machine learning. Just a short while ago, models of this scale and reasoning capacity required dedicated enterprise-grade cloud servers. However, 2026 has brought forward exceptional strides in quantization algorithms and software-layer memory management, allowing developers to choose from multiple lightweight execution environments.
These software developments mean that highly optimized GGUF quants (even down to aggressive 2-bit quantization) can run comfortably on a 256GB Mac Studio or a decentralized multi-GPU setup. These breakthroughs dramatically lower the financial barrier to entry, shifting the economics of AI development from expensive, metered cloud APIs to predictable local electricity costs of $0.51 to $2.00 per hour for continuous, 24/7 workloads.
Comparing Local Deployment Ecosystems for GLM-5.2
To understand how to best run GLM-5.2 locally, we must evaluate the primary deployment platforms available today. The table below details the top runtime environments, their resource optimization capabilities, and ideal hardware targets:
| Platform | Optimization Engine | Target Hardware | Core Advantage | UI Interface |
|---|---|---|---|---|
| llama.cpp | GGUF quantization (2-bit to 8-bit) | Apple Silicon (M-Series), CPUs, CUDA GPUs | Maximum portability and bare-metal performance | CLI / API Endpoint |
| Unsloth Studio | Dynamic RAM Offloading | Multi-GPU setups, system RAM | Auto-detects multi-GPU and offloads layers to system RAM | Open-source Web UI |
| LM Studio | GGUF integration & local server | Apple Silicon, Windows, Linux CUDA | One-click GUI deployment with Hugging Face integration | Built-in Chat & Playground |
| Ollama | Automated Modelfile orchestration | macOS, Linux, Windows | Zero-config model downloading and daemon-based API | Terminal & local REST API |
| CallMissed | Cloud-native multi-model gateway | High-concurrency cloud infrastructure | Enterprise scalability, hybrid failover, 300+ LLMs | Advanced UI Dashboard |
Local Prototyping vs. Production-Scale Deployment
While local platforms like Unsloth Studio and llama.cpp are excellent for secure code reviews, private internal testing, and offline development, they face natural hardware scaling bottlenecks when transitioned to high-volume, customer-facing applications. Under heavy, concurrent enterprise traffic, local consumer hardware can experience high latency spikes and queue backlogs.
For production-grade customer interactions, modern enterprises utilize hybrid architectures. Developers use local GLM-5.2 setups for offline prompt engineering and secure pipeline design, and then deploy production workloads via infrastructure platforms like CallMissed. CallMissed bridges this gap by offering low-latency access to over 300+ LLMs alongside built-in, multilingual Speech-to-Text and Text-to-Speech APIs (supporting 22 Indian languages), ensuring that the transition from a local prototype to a global, high-scale rollout is seamless and reliable.
In-Depth Analysis
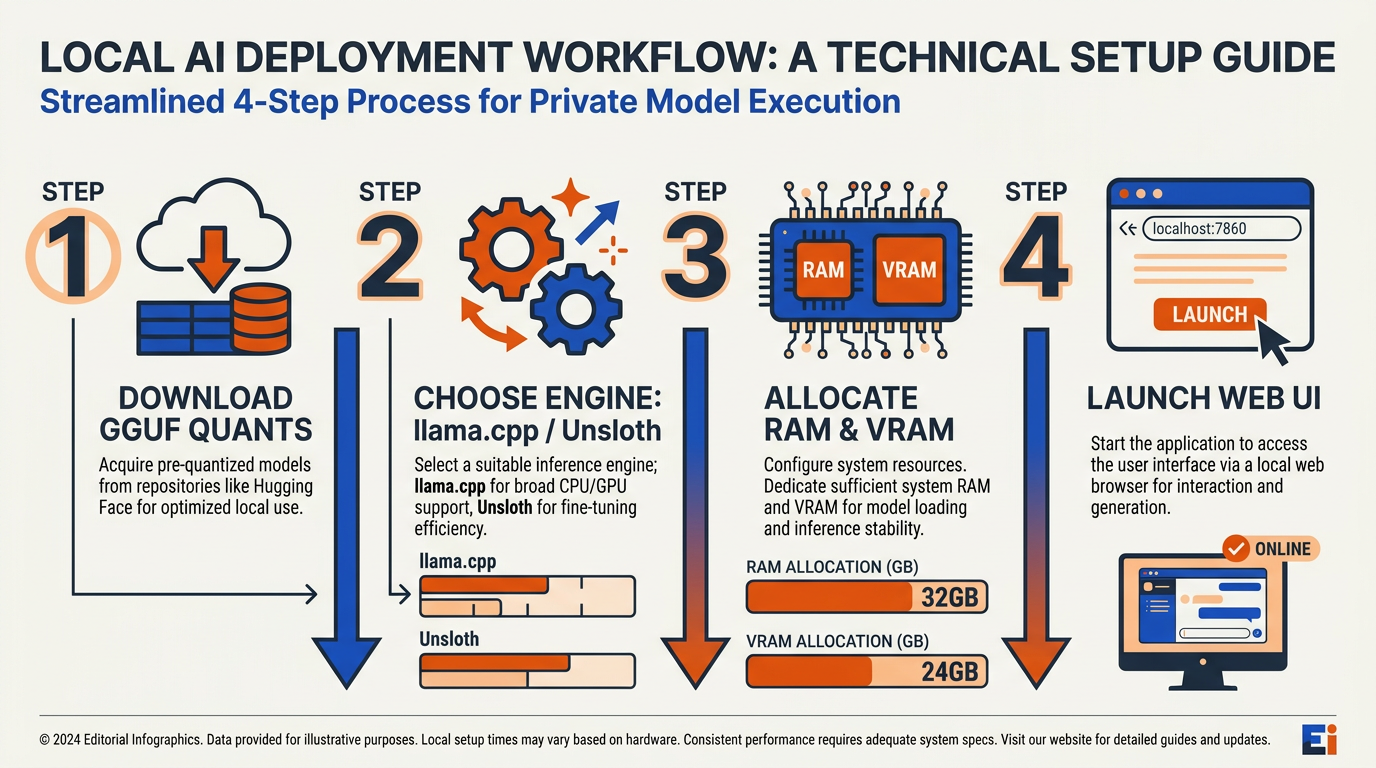
To truly understand why GLM-5.2 is dominating discussions across developer hubs like Hacker News and r/LocalLLaMA, we must look closely at its architectural efficiency. Zhipu AI has delivered a model that breaks traditional resource barriers, allowing high-tier reasoning to run locally without requiring enterprise data centers.
Architectural Strengths & Quantization Efficiency
The defining technical achievement of GLM-5.2 is its resilience under heavy quantization. Thanks to rapid optimization in llama.cpp and Unsloth Studio, developers can run highly compressed versions of the model with minimal loss in logical coherence:
- The 2-Bit Quantization Breakthrough: Historically, 2-bit quantization rendered models virtually unusable due to massive degradation in perplexity. However, GLM-5.2’s architecture retains high-level reasoning even at ultra-low bitrates. This enables the model to run comfortably on unified-memory hardware like a 256GB Mac Studio, bringing frontier-class AI to consumer-tier desktop workstations.
- Optimal Multi-GPU Execution: For those utilizing multi-GPU setups (such as dual or quad RTX 4090 rigs), running 4-bit or 8-bit quants yields lightning-fast token generation. Unsloth Studio simplifies this deployment by auto-detecting multi-GPU topologies and intelligently offloading layer weights to system RAM to prevent Out-Of-Memory (OOM) errors.
High-Throughput Workflows: Where Local Outperforms Cloud
Deploying GLM-5.2 locally is not just about avoiding API subscription fees; it is about enabling workflows that are financially or structurally impossible on closed clouds:
- Continuous Looping Agent Tasks: Running autonomous agents that constantly write, test, and execute code 24/7 would cost thousands of dollars a day using proprietary models like Claude Opus. With a local GLM-5.2 instance, the only ongoing cost is an amortized $0.51 to $2.00 per hour in electricity.
- Private Security Code Reviews: Enterprises working with proprietary codebases cannot risk sending their intellectual property to external APIs. Local deployments ensure complete data sovereignty, allowing deep security audits to occur entirely offline.
Bridging Local Development and Production Scale
While local deployments are ideal for development, testing, and handling sensitive internal databases, scaling these AI capabilities to handle customer-facing communication requires a different class of infrastructure.
This is where hybrid architectures shine. While developers use local GLM-5.2 setups for offline research and secure backend processing, they can scale consumer interactions using CallMissed. CallMissed’s AI communication platform integrates seamlessly with local workflows, offering a production-ready gateway to over 300+ LLMs, advanced Text-to-Speech, and Speech-to-Text APIs supporting 22 Indian languages natively. This allows businesses to transition their locally-tested AI logic into high-scale, low-latency voice agents and WhatsApp chatbots without managing complex cloud telecommunication hardware.
Comparative Performance: Local vs. Cloud APIs
When evaluating GLM-5.2 against cloud-hosted alternatives, two metrics stand out:
- Zero Network Latency: Local instances bypass the internet entirely, eliminating network round-trip times and delivering a highly responsive Time-to-First-Token (TTFT) ideal for real-time interactive development.
- Predictable Economics: Unlike cloud APIs where costs scale linearly with token volume, local hardware costs remain completely flat. Whether you process ten thousand or ten million tokens, your operational expense remains tied strictly to your hardware's power consumption.
Impact & Implications

The arrival of Zhipu AI's GLM-5.2 represents a massive shift in the open-weights landscape, signaling a permanent disruption in the balance of power between closed-source AI conglomerates and independent developers. By placing a frontier-class, highly capable reasoning model directly into the hands of individual engineers and private enterprises, GLM-5.2 is redefining what is possible on local hardware in 2026.
Breaking the "Pay-Per-Token" Paralysis
For years, developers have suffered from "pay-per-token paralysis." Building autonomous agents that continuously loop, audit massive codebases, or run deep semantic analyses over thousands of documents was financially prohibitive on proprietary APIs like Claude Opus. With GLM-5.2 running locally, this bottleneck vanishes.
- Unlimited Agentic Exploration: Because running the model locally on consumer hardware only costs between $0.51 and $2.00 per hour in electricity and hardware amortization, developers can run continuous loops and background agents 24/7 without fear of an unexpected, eye-watering cloud bill.
- Deep Security Auditing: Engineers can run recursive, multi-step security reviews over proprietary codebases locally. Highly sensitive intellectual property never leaves the local network, completely eliminating data leak vectors.
- Latency and Freedom from Rate Limits: Bypassing cloud rate-limits means developer workflows execute as fast as local silicon allows, making local development feel instantaneous when leveraging highly optimized GGUF quants on RTX 4090 rigs or Mac Studios.
A Sovereign, Hybrid Architecture for Modern Enterprises
For enterprises, the implications of GLM-5.2 go far beyond simple cost savings. It enables a robust, privacy-first Sovereign AI architecture. Highly regulated industries—such as healthcare, legal, and finance—can now deploy advanced reasoning models completely offline, ensuring compliance with strict data sovereignty laws.
However, modern organizations are finding that the most efficient way to scale is through a hybrid AI framework:
- Internal Security & Reasoning: Highly sensitive tasks, internal document parsing, and database queries are routed locally to offline deployments of GLM-5.2.
- External Communication & Scale: For external, high-volume customer interactions, businesses layer their local logic with robust AI communication infrastructure. Platforms like CallMissed excel here, enabling organizations to deploy production-ready AI voice agents and WhatsApp chatbots across 300+ LLMs. By connecting internal pipelines to CallMissed's specialized APIs—which feature low-latency Speech-to-Text supporting 22 Indian languages—enterprises maintain maximum security on their core data while effortlessly scaling customer-facing communications globally.
Upcycling Hardware and the Future of Workstations
Finally, GLM-5.2 fundamentally changes how we view hardware longevity. Instead of local workstations quickly depreciating, setups like a 256GB Mac Studio or consumer multi-GPU rigs are transformed into highly capable private AI supercomputers. The open-source community's ability to run this model at optimized quantization levels means that localized, high-reasoning tasks no longer require a venture-backed startup budget or an enterprise data center.
Expert Opinions

The Reddit & Hacker News Verdict: A Real Threat to Proprietary APIs?
The launch of GLM-5.2 has sparked intense debate across developer communities, dominating both Hacker News and Reddit's r/LocalLLaMA. With over 419 points on Hacker News and a highly active thread on r/LocalLLaMA (garnering 320 upvotes and 89 comments), the developer consensus is clear: GLM-5.2 represents a massive shift in local LLM viability.
Experts are particularly enamored with its raw cost-to-performance efficiency. In the words of one prominent Hacker News commenter, running GLM-5.2 locally "costs anywhere from $0.51 to less than $2 an hour" to run continuously 24/7. When compared to the spiraling, unpredictable API costs of querying closed-source models like Claude Opus for heavy, non-stop workloads, this local alternative represents a monumental breakthrough for bootstrapped teams and enterprise R&D departments alike.
Tactical Workflows: Unsloth Studio and llama.cpp
Tech reviewers and local AI specialists have been sharing tactical advice on how to seamlessly integrate GLM-5.2 into daily workflows. In recent technical video breakdowns, AI experts emphasize that while the model is incredibly capable, managing its hardware footprints is the key to success.
This is where open-source orchestrators are making a massive difference:
- Unsloth Studio: Highly praised by developers for its capability to automatically detect multi-GPU setups and dynamically offload layers to system RAM.
- llama.cpp: Remains the gold standard for pure command-line execution, allowing users to pull GGUF quants and run them with minimal overhead.
Community testers have successfully run highly optimized 2-bit quants of the model on a 256GB Mac Studio, proving that local hardware can handle frontier-class intelligence without requiring a dedicated server room.
Enterprise Security and Scaling the Infrastructure
For enterprise security experts, the primary appeal of GLM-5.2 is the absolute privacy it affords. Organizations are increasingly utilizing local instances of GLM-5.2 for tasks that were previously deemed too sensitive for third-party cloud APIs, such as:
- Deep security code reviews: Analyzing proprietary source code for vulnerabilities without risking IP exposure.
- Confidential R&D workflows: Running continuous looping experiments on sensitive data.
- Private chat interfaces: Offering employees internal AI assistants with zero data-retention risks.
However, system architects note that while running GLM-5.2 locally is the ultimate superpower for internal development, testing, and private data pipelines, scaling these workloads for massive customer-facing operations requires a different architecture.
When businesses need to transition from local R&D to global, production-grade engagement—such as deploying multilingual WhatsApp chatbots or low-latency AI voice agents—they look to specialized AI communication infrastructure platforms. For instance, CallMissed enables organizations to seamlessly scale their AI pipelines, offering production-ready APIs for Speech-to-Text (supporting 22 Indian languages natively) and a multi-model gateway with access to over 300+ LLMs. This hybrid approach—using local GLM-5.2 for secure back-end processing and platforms like CallMissed for high-concurrency customer communication—is quickly becoming the blueprint for modern enterprise AI architecture.
What This Means For You (TABLE)
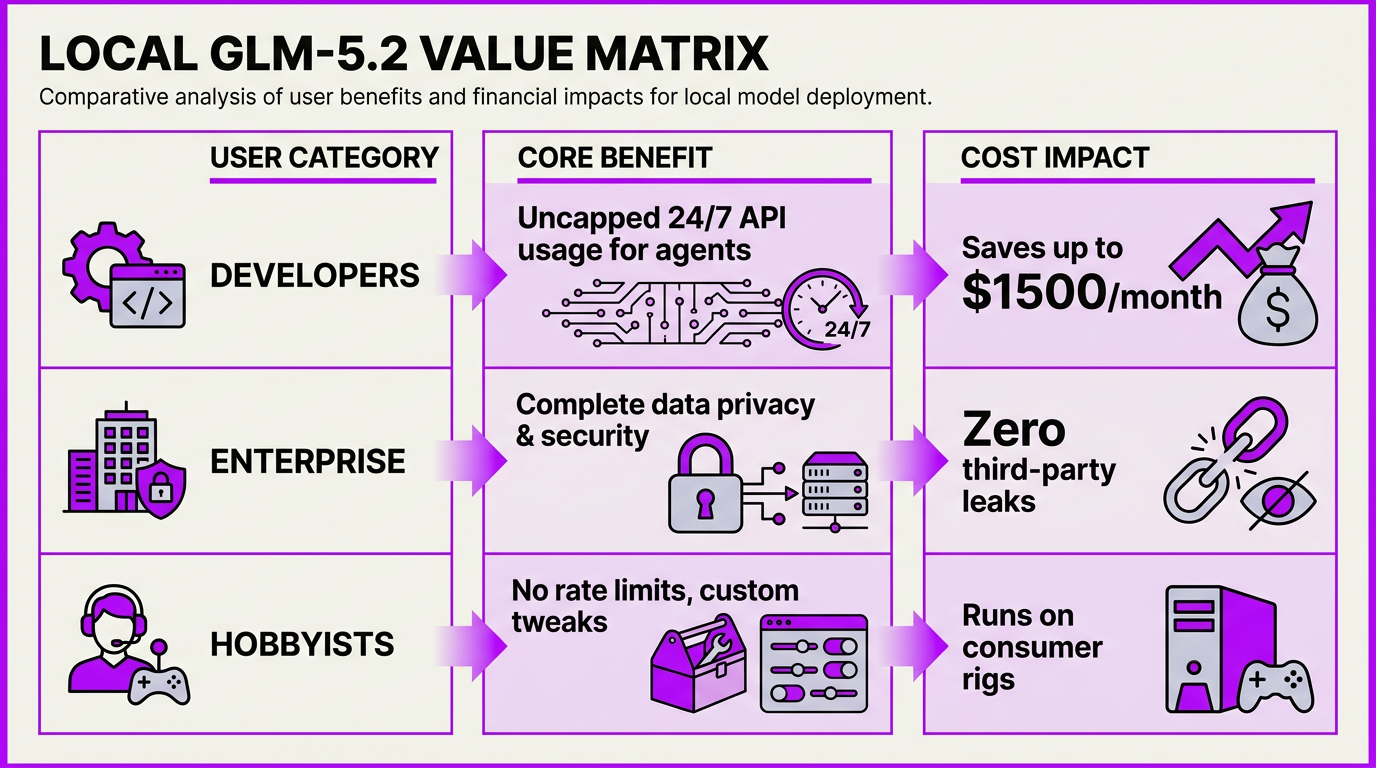
The local deployment of Zhipu AI’s GLM-5.2 represents a massive paradigm shift in how developers and enterprises build, test, and run frontier-grade AI. Instead of renting compute in someone else's cloud and paying per token, teams can now anchor their intelligence pipeline locally. For secure code reviews, 24/7 autonomous agents, and highly sensitive database orchestration, running GLM-5.2 locally delivers absolute data privacy and predictable, ultra-low operating costs.
To help you decide how to best leverage this powerhouse, we have mapped out the practical deployment pathways based on your hardware budget, precision needs, and primary workloads.
| Setup Scenario | Hardware Platform | Recommended Quant | Operational Cost | Primary Use Case |
|---|---|---|---|---|
| Budget Dev Rig | Single NVIDIA RTX 4090 | 2-bit or 3-bit GGUF | ~$0.51 - $1.00/hr | Private chat & local code reviews |
| Unified Memory | Apple Mac Studio (256GB) | 2-bit to 4-bit GGUF | ~$0.80 - $1.50/hr | Long-context document analysis |
| Enterprise Local Server | Multi-GPU RTX 4090 Node | 4-bit to 8-bit GGUF | ~$1.50 - $2.00/hr | Continuous 24/7 background loops |
| High-Scale Production | Hybrid Cloud (e.g., CallMissed) | Unquantized/Native API | Elastic API Tiering | Customer-facing voice & WhatsApp |
Redefining the Economics of Frontier AI
Historically, developers were caught in a frustrating trap: choose a weak, heavily quantized local model that hallucinated on complex tasks, or pay spiraling API bills to closed models like Claude Opus. GLM-5.2 breaks this compromise.
- Continuous 24/7 Execution: Running continuous looping agents (such as agents searching for security vulnerabilities in codebases or parsing continuous streaming log files) on cloud APIs is financially ruinous. Doing it locally on a multi-GPU rig costs only the electricity used (averaging $0.51 to $2.00 per hour in hardware amortization and power).
- Absolute Privacy: For proprietary internal code, health records, or sensitive financial data, running the model locally on your own hardware guarantees zero data leaks or external logging.
- Prototyping Freedom: Developers can experiment freely with complex agentic architectures, deep reasoning chains, and prompt optimization without worrying about token budgets, strict rate limits, or unexpected API bills.
Hybrid Architectures: Connecting Local and Cloud
While running GLM-5.2 locally is the ultimate superpower for internal development, testing, and secure data processing, production-grade applications that interface with external customers demand a different architecture.
Forward-thinking enterprises typically adopt a hybrid approach. They leverage local GLM-5.2 instances using frameworks like llama.cpp and Unsloth Studio for internal developer environments and sensitive backend data tasks. Meanwhile, they outsource high-scale, external customer interactions to specialized communication platforms.
For instance, platforms like CallMissed offer the production-ready infrastructure needed to manage high-volume customer touchpoints. By combining local development on GLM-5.2 with robust services like CallMissed—which natively orchestrates AI voice agents, WhatsApp chatbots, multi-model API gateways with 300+ LLMs, and Speech-to-Text in 22 regional Indian languages—businesses can maintain complete privacy in-house while delivering reliable, low-latency, and highly accessible AI agents to their global users.
Frequently Asked Questions
What are the minimum hardware requirements to run GLM-5.2 locally?
How do I run GLM-5.2 locally using Unsloth Studio?
What is the estimated cost of choosing to run GLM-5.2 locally over cloud APIs?
Can I run GLM-5.2 on consumer-grade hardware like Macs or single GPUs?
Which software frameworks currently support local GLM-5.2 deployment?
When should I run GLM-5.2 locally versus using a managed platform like CallMissed?
Conclusion
The release of GLM-5.2 marks a monumental shift toward high-performance, private, and localized artificial intelligence. By bringing frontier-class reasoning directly to your hardware, you gain total control over your workflows, costs, and data security.
Here are the key takeaways from this guide:
- Unmatched Cost Efficiency: Running GLM-5.2 locally costs just $0.51 to $2.00 per hour, bypassing expensive cloud APIs.
- Flexible Deployments: Deploy easily across systems—from 2-bit quants on a 256GB Mac Studio to multi-GPU RTX 4090 rigs using Unsloth Studio, LM Studio, or
llama.cpp. - Absolute Privacy: Run continuous looping, secure code reviews, and private chats completely offline.
As open-weights models continue to close the gap with proprietary giants throughout 2026, the future belongs to hybrid setups that combine secure local development with scalable production systems. To explore how this rapidly evolving AI technology is transforming customer interactions, check out CallMissed — an AI infrastructure platform powering production-ready voice agents and multilingual chatbots.
How will you leverage the power of GLM-5.2 to revolutionize your daily development workflow?
Related Posts

From Vibe Coding to Agentic Engineering: How to Access Z.ai's Flagship GLM-5.2 via CallMissed's Unified API

GLM-5.2 Local Deployment Guide: Run the 1M-Context Frontier Model on Your Hardware

Meta Loses 20 Million Users Across WhatsApp, Instagram, and Facebook: What It Means for Q1 2026 and Beyond