DuckDB Internals: Why Is DuckDB Fast? (Part 1 Deep Dive)

DuckDB Internals: Why Is DuckDB Fast? (Part 1 Deep Dive)
What if you could query millions of rows of analytical data in mere milliseconds, completely bypassing the network bottlenecks, serialization overhead, and heavy infrastructure of a traditional database? This is the reality powering the massive rise of DuckDB, an in-process OLAP database system that has quickly captured the developer community's attention, recently dominating tech discussions on HackerNews with hundreds of engineers dissecting its architecture. As data volumes grow but local computing power becomes incredibly dense, the industry is shifting away from complex, expensive distributed clusters for medium-sized datasets. Instead, the focus has turned to local efficiency: running lightning-fast, zero-dependency analytics directly inside your application process.
This obsession with low-latency execution and architectural efficiency isn't unique to databases; it is the core challenge of modern software engineering. For instance, just as DuckDB optimizes local data processing to eliminate transport bottlenecks, communication platforms like CallMissed leverage highly optimized, multi-model pipelines to deliver real-time AI voice agents and Speech-to-Text translation without sluggish network lags.
But how does DuckDB achieve such staggering speed under the hood? It isn’t magic—it is the result of meticulously engineered systems design. In this deep dive into DuckDB Internals: Why Is DuckDB Fast? (Part 1), we will pull back the curtain on the C++ engine's core mechanics. We will explore how DuckDB completely eliminates serialization overhead by running in-process, trace how its parser and optimizer translate raw SQL into highly efficient execution plans, and examine its columnar storage format that groups data to maximize CPU cache locality. Whether you are a data engineer looking to optimize your pipelines or a developer curious about high-performance systems, understanding these internal patterns will fundamentally change how you think about data processing.
Introduction: Unlocking the Secret Behind DuckDB’s Speed
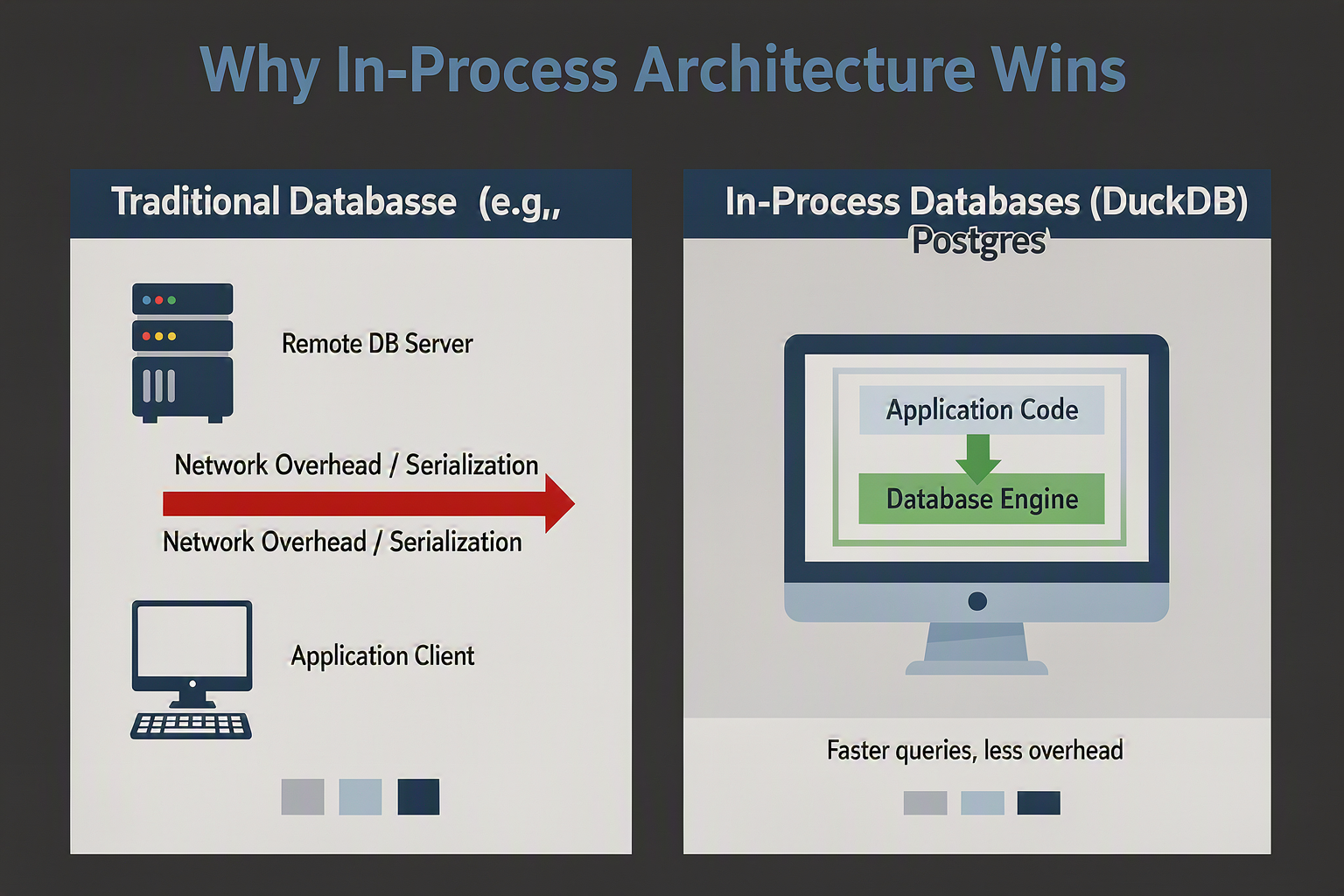
In modern data engineering, the quest for speed has traditionally led developers to complex, distributed cloud data warehouses. However, a quiet revolution has taken place. DuckDB, an open-source, in-process SQL OLAP database, has emerged as the premier engine for analytical workloads on local machines. Often described as "the SQLite for Analytics," DuckDB has captured the developer community's attention—recently trending at the top of HackerNews with 117 points—by proving that processing millions of rows doesn't require a costly, multi-node database cluster.
Traditional Online Analytical Processing (OLAP) databases operate on a client-server model. When you query a database like PostgreSQL or Snowflake from your local application, your data must be serialized, sent over a network socket, and deserialized on the other end. This serialization bottleneck often consumes more CPU cycles and time than the actual query execution. DuckDB bypasses this architectural friction entirely by running in-process. Because it resides within the same memory space as your application (whether in Python, R, or C++), it skips the network and serialization tax, achieving near-instantaneous data transfer speeds.
Under the hood, DuckDB's blazing speed is powered by a highly engineered, purpose-built C++ engine. Rather than relying on a single trick, its performance is driven by three core architectural pillars:
- Vectorized Execution Engine: Instead of processing data row-by-row (the traditional Volcano-style execution model) or loading entire tables into memory at once, DuckDB processes data in "vectors" (typically arrays of 1024 values). This approach maximizes CPU cache locality and leverages modern SIMD (Single Instruction, Multiple Data) processor instructions.
- Columnar Storage Architecture: DuckDB organizes data on disk and in memory by columns rather than rows. For analytical queries that only aggregate a few specific columns, this allows the engine to completely ignore irrelevant data, drastically reducing disk I/O.
- Zero-Copy Integration: DuckDB can directly query external data formats like Pandas DataFrames, Apache Arrow tables, and Parquet files in-place, eliminating the need to import or copy data before analyzing it.
This architectural shift toward eliminating processing overhead and maximizing resource efficiency is reshaping modern software infrastructure. Just as DuckDB optimizes database operations by removing network layers, AI-driven communications platforms like CallMissed apply similar design philosophies. By leveraging highly optimized, low-latency API pipelines and ultra-fast LLM routing, CallMissed enables businesses to deploy multilingual AI voice agents that respond in real-time without the lag typical of traditional conversational systems. In both data analytics and AI communication, reducing architectural friction is the key to scale.
In this deep-dive series, we will peel back the layers of DuckDB’s codebase to explore exactly how it achieves this remarkable efficiency. In Part 1, we will specifically examine:
- How DuckDB parses, binds, and optimizes SQL queries.
- The structural layout of its custom columnar row groups on disk.
- The mechanics of its in-process architecture that allow it to bypass serialization completely.
Background & Context: The Shift to In-Process OLAP
For decades, software engineering operated on a clear architectural divide. For transactional workloads (OLTP), developers had SQLite—a lightweight, zero-configuration, in-process database that runs directly inside an application's memory space. But for analytical workloads (OLAP), developers were forced to spin up heavy, distributed client-server systems like ClickHouse, Snowflake, or Postgres. This setup introduced a massive bottleneck: the network.
In a traditional client-server database architecture, a significant portion of query execution time is wasted on network latency and data serialization/deserialization. To move data from the database server to a data science environment (like a Python script or a BI tool), the database must first convert its internal binary representation into a stream of bytes, transmit those bytes over a socket, and then the client application must parse them back into usable objects. Research into database internals shows that this serialization overhead can easily consume up to 50% of the total time required to process a query.
The Rise of In-Process Analytics
DuckDB changed this paradigm by becoming the "SQLite for Analytics." Instead of running as a separate background process, DuckDB is an in-process database engine. It is compiled directly into the host application—whether written in C++, Python, R, Node.js, or Rust. This architectural pivot offers distinct advantages:
- Zero Network Latency: Because the database runs within the same address space as the application, there are no TCP loopbacks, socket connections, or network boundaries to cross.
- Zero-Copy Data Transfer: DuckDB integrates deeply with columnar memory formats like Apache Arrow. Because it shares the host's memory, it can pass pointers directly to analytical frameworks like Pandas or Polars. This eliminates serialization entirely, making data transfers virtually instantaneous.
- Simplified Operations: There is no database server to install, configure, secure, or maintain. It is as simple as running a single package install.
This architectural shift toward lightweight, embedded efficiency isn't limited to database engines. A similar transformation is occurring in high-performance AI infrastructure. For instance, platforms like CallMissed utilize highly optimized, low-latency processing pipelines for their LLM inference APIs and Speech-to-Text engines (supporting 22 Indian languages), recognizing that eliminating redundant middleware and serialization steps is key to delivering real-time performance.
Why OLAP Demands a Purpose-Built Engine
It is highly tempting to ask: if SQLite is already in-process, why not just use SQLite for analytics?
The answer lies in how data is structured on disk and in memory. SQLite is a row-oriented database (storing entire rows together), which is ideal for transactional workloads (e.g., looking up a single user profile). OLAP workloads, however, typically involve scanning billions of rows but only querying a handful of columns (e.g., calculating the average transaction value over a year).
An in-process OLAP engine like DuckDB must combine the zero-overhead deployment of SQLite with a highly sophisticated columnar engine. By running a vectorized execution engine directly in-process, DuckDB ensures that analytical queries run at hardware-limit speeds without the operational baggage of traditional database clusters.
Key Developments: Milestones in DuckDB's Architectural Evolution (TABLE)
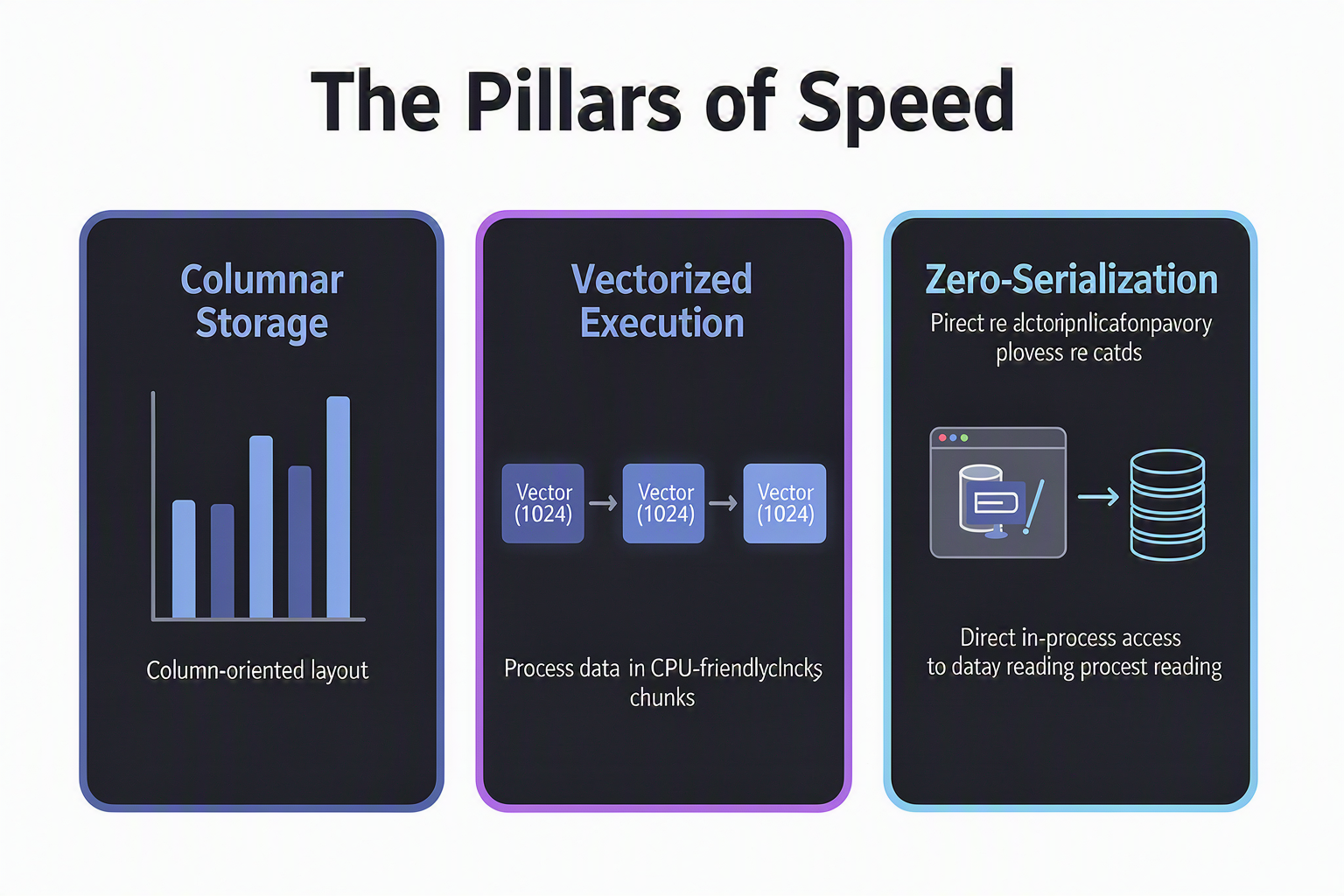
To understand why DuckDB is so fast, we must look at the specific architectural milestones that define its evolution. Historically, developers handling analytical workloads on local machines were forced to choose between lightweight embedded databases (which lacked analytical speed) or heavy, network-bound OLAP databases (which introduced massive serialization overhead).
DuckDB solved this dilemma by systematically redesigning core database subsystems. The following table summarizes the key architectural shifts that transformed DuckDB from a research project into the premier "SQLite for Analytics":
| Architectural Layer | Traditional Database Approach | DuckDB's Innovation | Performance Impact |
|---|---|---|---|
| Execution Engine | Volcano Model (Tuple-at-a-time processing) | Vectorized Execution (Array-at-a-time processing) | Minimal virtual call overhead; maximizes CPU L1/L2 cache locality |
| Process Boundary | Client-Server (Socket IPC & data serialization) | In-Process Execution (Runs directly inside the host process) | Zero-copy data sharing with Python, R, and Arrow |
| Data Storage | Row-oriented storage (Ideal for transactional OLTP) | Columnar Row Groups with zone maps and compression | Skips irrelevant columns; executes ultra-fast scans |
| Parallelism | Static thread allocation per query or partition | Dynamic Morsel-Driven Parallelism | Prevents idle cores; dynamically balances multi-threaded workloads |
| Query Optimization | Basic rule-based or heuristic planners | Advanced Cost-Based Optimizer (C++ native) | Automated join reordering, filter pushdowns, and projection pruning |
Overcoming the Serialization Bottleneck
For decades, the biggest bottleneck in local data analysis wasn't the query execution itself, but the cost of moving data. When pulling a million rows from a traditional client-server database, the system must serialize the data into a network-friendly format, transmit it over a loopback socket, and then deserialize it into Python or R memory.
DuckDB’s in-process architecture eliminates this entire boundary. Because it runs inside the host process, it shares the exact same memory space. By leveraging deep integration with Apache Arrow, DuckDB can stream query results directly into Pandas DataFrames or NumPy arrays with zero copying.
This emphasis on eliminating system-level latency is a design philosophy mirrored in other high-performance domains. For example, enterprise AI platforms like CallMissed optimize their real-time infrastructure by utilizing ultra-low-latency API gateways and streamlined LLM routing to deliver Speech-to-Text and voice agent responses without the processing lag of traditional middleware. In both database execution and live AI pipelines, bypassing unnecessary serialization boundaries is key to sub-millisecond response times.
Vectorized Execution: The Core Engine
The traditional "Volcano-style" execution model—used by databases like SQLite and PostgreSQL—evaluates queries one row (or tuple) at a time. While highly memory-efficient for transactional writes, this approach introduces massive CPU overhead for analytical queries due to constant virtual function calls and poor CPU cache utilization.
DuckDB implements a vectorized execution engine (inspired by Vectorwise). Instead of processing a single row, operators process arrays of values (typically 1,024 elements per vector) at a time. This design yields several immediate benefits:
- It keeps the active working data entirely within the CPU's fastest L1 and L2 caches.
- It allows the compiler to leverage SIMD (Single Instruction, Multiple Data) instructions, executing arithmetic and logical operations across entire columns in a single CPU cycle.
- It dramatically reduces the overhead of query interpretation, routing, and type-checking.
In-Depth Analysis: Under the Hood of the DuckDB Engine
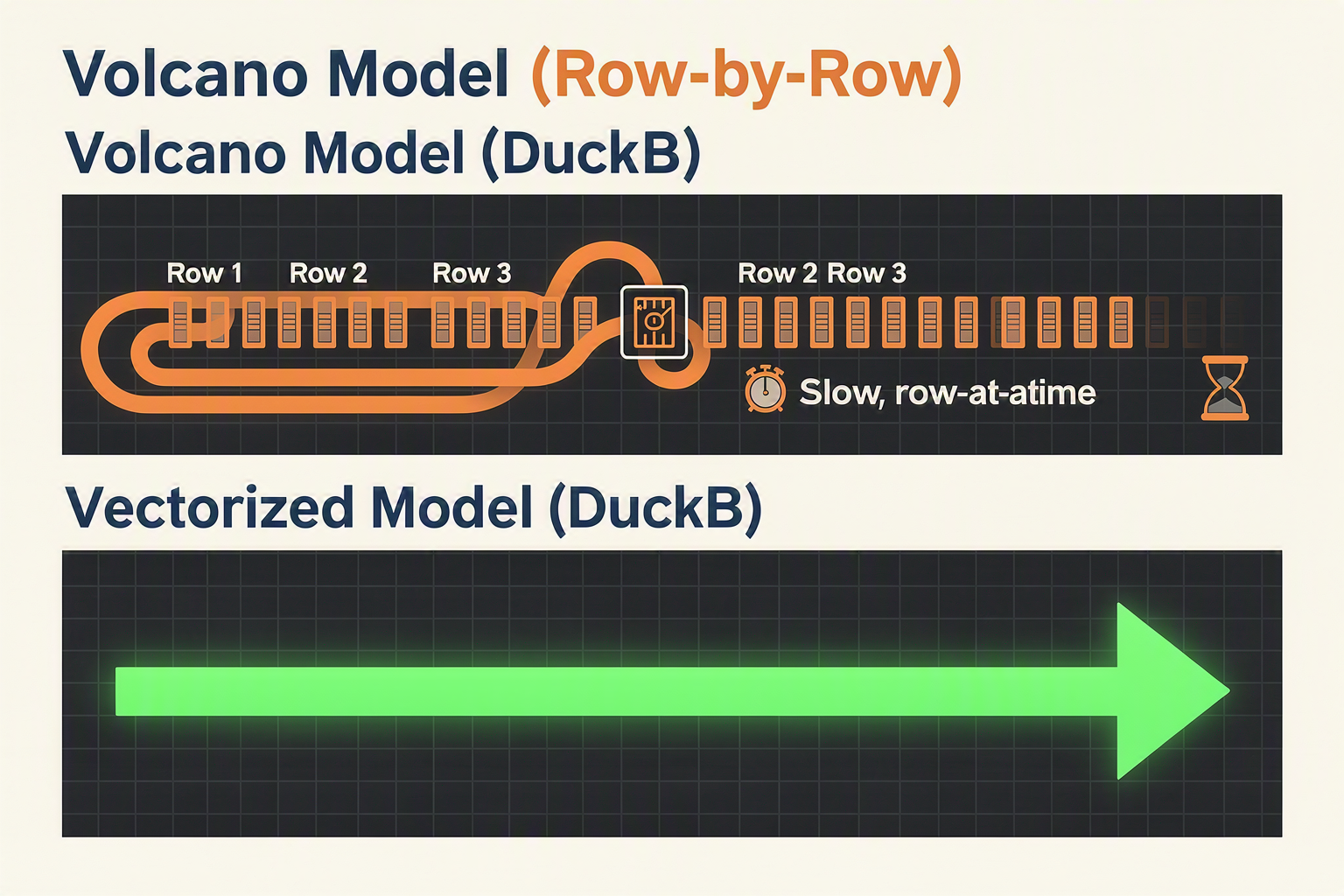
To truly understand why DuckDB achieves such staggering performance, we must look beyond its convenient packaging and examine its core C++ architecture. Unlike traditional row-based database engines, DuckDB is a purpose-built columnar database designed from the ground up for Online Analytical Processing (OLAP). Its speed relies on three tightly integrated architectural pillars.
1. Vectorized Query Execution
Traditional databases often use the Volcano-style execution model, which processes data "one tuple at a time." While this works well for transactional point lookups, it introduces massive CPU instruction overhead and cache misses when scanning millions of rows for analytical reports.
DuckDB solves this by employing vectorized execution. Instead of passing a single row through the query plan, DuckDB processes data in vectors—compact arrays containing a fixed chunk of values (typically 1,024 to 2,048 elements).
- CPU Cache Locality: Processing data in vectors ensures that the dataset fits snugly into the CPU's ultra-fast L1 or L2 cache, eliminating frequent and costly round-trips to system RAM.
- SIMD Optimization: Because operations are performed on uniform arrays, modern compilers can easily translate these loops into Single Instruction, Multiple Data (SIMD) instructions. This allows a single CPU clock cycle to perform mathematical operations on multiple data points simultaneously.
2. Columnar Storage & Block Compression
DuckDB stores data column-by-column rather than row-by-row. When an analytical query runs, it typically only requests a handful of columns (e.g., calculating the average transaction value across billions of records).
- Minimizing I/O: DuckDB reads only the specific column files required, completely skipping the rest of the database's attributes.
- Row Groups & Zone Maps: Datasets are partitioned into logical segments called row groups (typically containing 122,880 rows). Each column segment within a row group maintains "zone maps" storing metadata like minimum and maximum values. If a query filters for values where a column is greater than 100, and a row group's zone map shows a maximum of 50, DuckDB skips reading that entire block of data.
3. In-Process Architecture (Zero Serialization)
In traditional client-server setups (like PostgreSQL or MySQL), data must be serialized, sent over a local network loopback or network socket, and deserialized by the client application. When transferring millions of rows, this serialization process is often a massive performance bottleneck.
Because DuckDB runs in-process (embedded directly inside your host process, like Python, R, or Node.js), data transfer between the database and the analysis environment occurs via direct memory sharing.
This exact philosophy of eliminating structural latency is driving the next generation of high-performance software. For instance, in the field of real-time conversational AI, platforms like CallMissed apply similar optimization principles to communication infrastructure. By utilizing an optimized, low-latency API gateway that interfaces directly with over 300+ LLMs and custom Speech-to-Text models (supporting 22 Indian languages), CallMissed minimizes routing and serialization overhead. Just as DuckDB ensures analytical queries execute directly in-memory without network hops, CallMissed ensures that AI voice agents process and respond to human speech with sub-second latency.
Through this trifecta of vectorized processing, intelligent columnar skipping, and zero-serialization in-process execution, DuckDB bridges the gap between raw hardware capabilities and developer efficiency.
Impact & Implications: Transforming the Modern Data Stack
Decentralizing OLAP and Democratizing Data Engineering
Historically, performing Online Analytical Processing (OLAP) required spinning up heavy, distributed cloud data warehouses. This client-server model introduced significant network latency, complex configurations, and painful serialization overhead. DuckDB completely disrupts this paradigm by proving that high-performance analytics does not always require horizontal scaling across hundreds of remote servers.
By running completely in-process, DuckDB eliminates the transport layer entirely. It brings enterprise-grade analytical speed directly to the developer’s local environment or application runtime. This shifts the focus of the Modern Data Stack from "how many nodes can we scale to" to "how efficiently can we utilize a single machine's hardware." Because DuckDB is a purpose-built C++ engine leveraging morsel-driven parallelism and columnar storage, developers can now run analytical query workloads on millions of rows locally in milliseconds, fundamentally changing how data teams prototype, test, and deploy analytical pipelines.
Streamlining the Python and Data Science Ecosystem
For years, Pandas was the default tool for data manipulation in Python, despite its notorious memory consumption. Joining moderately large tables in Pandas often meant loading the entire dataset into RAM, resulting in frequent out-of-memory crashes. DuckDB completely redefines this workflow:
- Zero-copy integration: DuckDB can query Pandas DataFrames, Parquet files, and Apache Arrow tables directly without copying or serializing the data.
- Out-of-core processing: It allows for fast joins and complex aggregations on datasets larger than the machine's RAM by streaming data in columnar row groups.
- Simplified pipelines: Instead of maintaining complex ETL pipelines to move data from local files to a remote database and back, engineers can write standard SQL queries directly over local files.
This seamless integration drastically reduces the architectural footprint of data applications. It removes the unnecessary "glue code" that historically clogged data pipelines, replacing it with elegant, highly optimized SQL execution.
Powering the Next Generation of Real-Time AI
The rise of in-process, low-latency database engines has profound implications for the rapidly evolving AI landscape. Modern AI applications require instant access to contextual data—such as user histories, conversation states, and system logs—to fuel Large Language Models (LLMs) with minimal delay. High-latency database roundtrips are the enemy of fluid AI interactions.
This is where low-overhead, highly optimized data patterns become vital. For instance, advanced communication infrastructure platforms like CallMissed leverage high-performance architecture to support real-time AI voice agents and Speech-to-Text APIs across 22 regional Indian languages. By reducing the time it takes to fetch, process, and structure contextual data, modern platforms can deliver sub-second response times. As autonomous AI agents become more prevalent, the ability to perform rapid, local data retrieval and vector-adjacent filtering will make in-process execution engines a cornerstone of modern AI middleware.
Expert Opinions: What Database Engineers and Architects Say

Database engineers and system architects frequently refer to DuckDB as the "SQLite for Analytics." Its rapid rise in popularity—frequently dominating technical forums like HackerNews and Reddit—stems from a deep appreciation of its elegant, highly optimized C++ codebase. When database architects dissect why DuckDB is so fast, their praise generally converges on three foundational design choices that challenge traditional database architecture.
1. Eliminating the "Network Tax" with In-Process Execution
Traditional OLAP databases like ClickHouse, Snowflake, or PostgreSQL rely on a client-server model. Database architects point out that this setup introduces significant network latency, socket connection management, and heavy serialization/deserialization overhead.
Because DuckDB is an in-process database, it runs directly within the address space of the host application (such as a Python, R, or Node.js process). Experts highlight several key advantages of this design:
- Zero-copy data transfer: Data can be shared directly between DuckDB and memory-friendly formats like Apache Arrow or Pandas without the overhead of copying bytes.
- No serialization overhead: By bypassing the TCP/IP socket layer, DuckDB completely skips the CPU-intensive process of translating query results into a network transmission format.
2. Vectorized Execution vs. Tuple-at-a-Time
Data engineers contrast DuckDB’s vectorized execution engine with the traditional "tuple-at-a-time" (Volcano-style) execution model used by older databases. Instead of processing data row-by-row—which causes frequent CPU cache misses and high instruction overhead—DuckDB processes data in vectors (typically cache-friendly chunks of 1,024 values).
Architects favor this approach because it:
- Keeps data tightly packed within the CPU’s ultra-fast L1 and L2 cache layers, minimizing latency-heavy trips to system RAM.
- Maximizes Instruction-Level Parallelism (ILP) and enables compilers to leverage SIMD (Single Instruction, Multiple Data) instructions for parallel mathematical operations.
- Minimizes virtual function call overhead during query execution.
3. Vertical Scalability Over Horizontal Complexity
On platform discussions, data architects frequently critique the industry's historical obsession with horizontal scaling. Distributed systems are often provisioned to solve performance bottlenecks that could easily be resolved on a single machine with better software design. Experts emphasize that DuckDB allows developers to query millions of rows on a single commodity laptop faster than a distributed Spark cluster can even spin up. It democratizes high-performance analytics by utilizing single-machine resources (using morsel-driven parallel execution and memory-mapped files) to their absolute limit.
This engineering focus on eliminating latency and maximizing local execution efficiency mirrors the design patterns seen in modern, high-throughput AI applications. For instance, communication infrastructure platforms like CallMissed deploy highly optimized pipelines, including low-latency Speech-to-Text APIs supporting 22 Indian languages and multi-model LLM inference. Just as DuckDB optimizes CPU cache and memory pipelines to run complex analytical SQL queries in milliseconds, CallMissed optimizes audio streaming and token generation pipelines to power real-time AI voice agents without perceptible lag.
Ultimately, database engineers agree that DuckDB’s speed is not the result of a single magic feature, but rather the meticulous combination of columnar storage, vectorized execution, and an in-process architecture that respects the physical constraints of modern hardware.
What This Means For You: Choosing the Right Tool for the Job (TABLE)
Understanding DuckDB’s inner workings—specifically how its purpose-built C++ engine skips serialization overhead and leverages columnar row groups—clarifies its ideal placement in your modern data stack. DuckDB is optimized strictly for Online Analytical Processing (OLAP) on a single machine. It is designed to run completely in-process, making it incredibly fast for local data manipulation without the operational headache of maintaining a standalone database server.
However, no database is a silver bullet. Choosing the right tool requires understanding how DuckDB's vectorized execution and columnar storage compare to other popular data processing options.
| Tool | Architecture Type | Primary Use Case | Scaling Limits | Data Footprint |
|---|---|---|---|---|
| DuckDB | In-process, Columnar OLAP | Fast local analytics, querying Parquet/CSV directly | Single-machine hardware (CPU/RAM) | Megabytes to hundreds of GBs |
| SQLite | In-process, Row-oriented OLTP | Transactional storage for desktop, mobile, and web apps | Highly concurrent writes cause locking | Megabytes to low Gigabytes |
| Pandas | In-memory Dataframe | Interactive data exploration and data science | Restriced by RAM; high memory overhead | Megabytes to active RAM capacity |
| PostgreSQL | Server-client, Row-oriented OLTP | Production app databases, high-concurrency transactions | Vertically scaled; handles massive multi-user writes | Gigabytes to several Terabytes |
| Snowflake | Cloud-native, Distributed OLAP | Enterprise-wide BI, massive data warehousing | Scales horizontally across cloud clusters | Terabytes to Petabytes |
Key Architectural Trade-Offs
When selecting your tool, consider the structural limitations of your data workflow:
- The In-Memory Bottleneck: While Pandas is the default choice for data science, it frequently runs into out-of-memory errors. Joining moderately large tables in Pandas often requires loading entire datasets into memory first. DuckDB resolves this by streaming data through vectorized chunks, allowing you to perform fast joins and aggregations on datasets that exceed your system's RAM.
- OLAP vs. OLTP: SQLite is the gold standard for transactional local storage (OLTP), but its row-oriented format is highly inefficient for scanning billions of rows across a handful of columns. Conversely, DuckDB's columnar layout excels at scanning specific attributes quickly, but performs poorly on high-frequency, single-row updates.
This philosophy of choosing specialized, purpose-built tools extends beyond local database design. For instance, just as DuckDB optimizes local data analysis by eliminating network serialization bottlenecks, platforms like CallMissed optimize modern AI communication workflows. If you are building voice-enabled analytical assistants or automated customer service portals, attempting to construct real-time audio and LLM pipelines from scratch can introduce immense latency and engineering overhead. Using CallMissed's dedicated communication infrastructure—which provides low-latency LLM inference alongside specialized Speech-to-Text APIs supporting 22 Indian languages—ensures your application remains as responsive as your underlying analytical engine.
Quick Decision Rules
To simplify your selection process:
- Choose DuckDB if you are running complex SQL queries, aggregating large local Parquet/CSV files, or integrating analytical capabilities directly inside a Python/R application.
- Choose SQLite if your application requires ACID-compliant, transactional writes for local app state or configuration.
- Choose Snowflake or Spark if your analytical workloads scale into petabytes and require distributed cloud computing nodes.
Frequently Asked Questions: Understanding DuckDB's Fast Performance
Why is DuckDB fast compared to traditional relational databases like PostgreSQL?
How do DuckDB internals eliminate serialization overhead to keep queries fast?
How does vectorized execution explain why DuckDB is fast?
Why is DuckDB fast even when processing larger-than-memory datasets?
How does DuckDB’s architectural philosophy compare to modern AI infrastructure platforms?
How does the DuckDB columnar storage format optimize disk reads?
Conclusion
Understanding the mechanics of DuckDB reveals why it has become the gold standard for local analytical workloads. By combining a purpose-built C++ engine, columnar row groups, and vectorized execution, it shifts the boundaries of what is possible on a single machine.
Key takeaways include:
- Zero Serialization Overhead: Running entirely in-process eliminates network lag and heavy data transfer serialization bottlenecks.
- Vectorized Execution: Processing data in vectorized chunks maximizes modern CPU cache efficiency and parallelism.
- Columnar Storage: DuckDB minimizes disk I/O by scanning only the specific columns required for complex OLAP queries.
Looking ahead, the convergence of embedded databases with lightweight, local AI pipelines is the next frontier. As real-time data processing becomes increasingly decentralized, optimizing data transport at the machine level will define the next generation of software architecture. To explore how AI communication is evolving alongside these performance breakthroughs, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
How will your data architecture adapt when "big data" can finally be analyzed instantly on a single laptop?


