DeepSeek R2: The Open-Source Reasoning Surprise Disrupting AI in 2026

DeepSeek R2: The Open-Source Reasoning Surprise Disrupting AI in 2026
What if you could access a reasoning AI rivaling OpenAI’s GPT-4o—without paying a cent in API fees? As of April 2026, that hypothetical is reality: DeepSeek R2, a new 32-billion-parameter open-weight model, just went open-source and is already matching or exceeding GPT-4o on 9 out of 12 standard language model benchmarks (source: Reddit, DecodeTheFuture). But DeepSeek R2 isn’t just another large language model—it’s the open-source surprise that’s sending seismic waves through the entire AI ecosystem.
Why does this matter right now? For the first time, cutting-edge reasoning is democratized for developers, startups, and enterprises worldwide. DeepSeek R2 doesn’t just flex with its size; it delivers: according to DecodeTheFuture, R2 scored a staggering 92.7% on the 2025 AIME (AI Math & Reasoning Evaluation), a test that pushes LLMs beyond rote memorization and into true step-by-step synthesis. Unlike many of its for-profit rivals, R2’s model weights are free and open, breaking down barriers for experimentation and deployment at scale. With AI API costs swirling between $0.01–$0.03 per thousand tokens for proprietary models like GPT-4o or Claude 3 Opus—and with those costs scaling quickly for real-world applications—this release could redefine the economics of intelligent automation overnight.
Beyond cost, the significance of DeepSeek R2 lies in its technical reach and the broader open-source movement. Prior to R2, most high-performing reasoning models were locked behind vendor APIs—great for enterprise security, but a bottleneck for global innovation. Now, Chinese startups like DeepSeek are leading a new wave, with R2 supporting advanced multilingual reasoning, code generation, and even early experiments in multimodal (text plus vision) capabilities (DeepSeek.ai/blog). The repercussions are global: you’re no longer limited to using LLMs chosen by US-based vendors; organizations in India, Europe, Africa, and beyond can fine-tune and localize their own advanced reasoning systems without legal or financial hurdles.
So, what will you learn in this article? We’ll break down exactly how DeepSeek R2 upends the AI landscape: its architecture, benchmark-beating performance, and why its reasoning abilities are different. You’ll see hard numbers—benchmarks, parameter counts, and AIME stats—and learn what it takes to run R2 yourself (hint: a single 24GB GPU is enough for inference, opening the door for cost-effective, on-prem deployments). We’ll also explore the broader trend of open-source LLMs, including how infrastructure platforms like CallMissed are already integrating models like DeepSeek R2 as part of their production pipelines for AI voice and chat agents.
But the real surprise may be in the road ahead: as DeepSeek R2’s open release inspires global innovation, new applications in education, customer service, fintech, and healthcare are just beginning to emerge. Are we entering a new era where world-class AI reasoning is not just the domain of billion-dollar companies but of anyone with curiosity and a GPU? Let’s find out.
Introduction: The Shockwave of DeepSeek R2

The AI Community Stunned: DeepSeek R2's Unprecedented Debut
In April 2026, the artificial intelligence landscape was upended by the thunderous arrival of DeepSeek R2—a 32-billion-parameter open-weight reasoning model from the Chinese AI powerhouse DeepSeek. Unlike earlier releases that caused flurries among specialized researchers, R2 sent a genuine shockwave through both the industry and the open-source community. Why? Because, for the first time, a fully open-source LLM not only rivals the most advanced proprietary language models, but does so on core reasoning tasks, all while obliterating price barriers (DeepSeek R2 can be deployed for $0 in API costs[1]).
#### Breaking the "Closed AI" Paradigm
AI innovation has, until now, been largely gated by model access restrictions. OpenAI’s GPT-4o dazzles industries, but its API costs and closed license limit its integration and extensibility, especially for emerging markets and research pursuits. DeepSeek R2 breaks this mold:
- 32B parameters, open weights: Anyone can deploy, fine-tune, or even redistribute the model free of licensing constraints.
- Release in April 2026: A rapid acceleration, just 16 months after DeepSeek’s celebrated R1 debuted in January 2025[7].
- Zero-cost API deployment: Models of equivalent scale often command high per-token or per-request fees; DeepSeek R2 democratizes access.
As noted by leading analysts, "DeepSeek R2 could disrupt the AI industry by offering advanced reasoning and coding capabilities while expanding the open-source model landscape" [3]. Never before has such power been released so openly, to so many.
#### Setting a New Benchmark Standard
The technical story is even more staggering. According to published results and independent community benchmarks:
- 9 out of 12 benchmarks: DeepSeek R2 matches or outperforms GPT-4o, the flagship model from OpenAI, often considered the commercial and technical leader for general intelligence tasks[1].
- 92.7% on AIME 2025: R2 scores an incredible 92.7% on the American Invitational Mathematics Examination 2025, setting a new standard for mathematical and logical reasoning in open models[2].
- Efficient deployment: Although weighing 32 billion parameters—larger than many "small" commercial models—R2 is optimized to run on a single mainstream 24GB GPU. This makes it not just powerful, but genuinely accessible for both enterprises and individual researchers[2].
A year ago, open models trailed proprietary giants on complex tasks. With DeepSeek R2, that gap has vanished.
#### Not Just Reasoning: Multilingual, Coding, and Multimodal Capabilities
DeepSeek R2 is more than just a text completion engine. The model’s architecture explicitly advances:
- Multilingual support: Addressing diverse global user bases, especially in Asia and Africa
- Code generation and reasoning: Comparable or superior to proprietary alternatives in code synthesis, explanation, and debugging
- Early multimodal promise: While details of image and audio support remain emerging, documentation and demos suggest ongoing work in integrating deeper modality fusion[4][8]
This opens the doors for a new generation of applications—multilingual chatbots, reasoning assistants, coding copilots, and AI-powered voice interfaces.
#### The Open-Source Revolution: More Than Just Hype
The sudden abundance of open foundational models is transforming how developers and businesses build intelligent products. Where only a handful of large firms dictated model capabilities, organizations can now:
- Train domain-specific LLMs at marginal cost
- Customize reasoning agents without vendor lock-in
- Experiment with architecture improvements in real time
Platforms like CallMissed are at the forefront of this revolution, allowing integration of cutting-edge models like DeepSeek R2 into AI-powered communication systems. This democratized access enables companies to deploy reasoning-capable voice agents, WhatsApp chatbots, and multilingual speech-to-text services tailored for local needs—without onerous API expenses.
#### A Global Ripple Effect
Most remarkably, DeepSeek’s bold move is not isolated. We are seeing a sweeping change in the AI landscape:
- Chinese startups like DeepSeek are challenging US dominance, accelerating model release cycles and pioneering open licenses[7]
- The open-source movement is closing performance gaps on critical reasoning and coding benchmarks
- Real-world adoptions—especially by SMEs and startups in non-Western markets—are surging, as open models become both viable and economically irresistible
As summarized by industry observers, "DeepSeek R2 is about to shock the world" with its combination of technical depth, reasoning prowess, and unprecedented openness[3].
#### The Stakes Ahead
The DeepSeek R2 release is not just a technical milestone; it’s a paradigmatic shift with implications for research, business, and AI governance. Model quality, accessibility, and speed of innovation are accelerating in tandem, putting advanced AI into the hands of millions.
The sections that follow will dig deep into R2’s architecture, benchmark results, real-world deployments, and the competitive landscape—highlighting what the DeepSeek R2 shockwave means for the future of open reasoning. As we’ll see, this is not just a leap forward for one company, but for the entire ecosystem—setting new standards in what AI can do, and for whom.
What is DeepSeek R2? Understanding the Model
The Rise of Reasoning Models in AI
AI’s “reasoning revolution” is rapidly transforming the field, with new models prioritizing not just language fluency but advanced logical, mathematical, and multi-step problem-solving abilities. DeepSeek R2, open-sourced in April 2026 by the Chinese startup DeepSeek, has shot to prominence for its exceptional reasoning prowess and democratized access.
Classic large language models (LLMs) like GPT-3 or Llama 2, while fluent in generating human-like text, often struggle with analytical reasoning, complex code tasks, or multi-turn logic chains. Recent demand—from developers, enterprises, and researchers alike—has been for models that think as well as talk. Models like GPT-4o and DeepSeek R2 deliver this leap, excelling in:
- Mathematical reasoning and problem-solving: Crucial for education, science, and engineering applications
- Advanced coding and tool use: Enabling robust AI software agents
- Multi-modal understanding: Combining text, images, and sometimes audio
DeepSeek R2 attempts to make such capabilities universally accessible by releasing its full weights under an open-source license. This removes not only API paywalls, but also opens the door for global fine-tuning, inspection, and innovation.
Inside DeepSeek R2: Architecture & Capabilities
At its core, DeepSeek R2 is a transformer-based language model featuring 32 billion parameters (DecodeTheFuture.org, 2026), making it one of the largest open-weight models in existence today. Its benchmark achievements have redefined what’s possible for an open model:
- AIME 2025 (Advanced Innovation in Mathematical Excellence): 92.7% accuracy
- Competitive with GPT-4o: Matching or exceeding GPT-4o on 9 out of 12 reasoning and STEM-centric benchmarks (Reddit AI, 2026)
- Efficient hardware utilization: Deployable on a single 24GB GPU, making local inference feasible for universities, startups, and solo developers
Key features include:
- Open weights (MIT License): Enabling community-driven research, customization, and derivative projects globally (Wikipedia, 2026)
- Multilingual support: Native handling of several languages, with a focus on Chinese and English but easily extensible
- Code generation & tool use: Strong on coding benchmarks and integrates well with tool APIs—critical for AI agent automation (DeepSeek Blog, 2025)
- Reasoning optimizations: Architected to solve multi-step math and logic tasks incrementally, simulating human problem-solving (BBC, 2026)
Performance Benchmarks: DeepSeek R2 vs. The Competition
Let’s look at where DeepSeek R2 stands among its peers:
| Model | Params (B) | AIME 2025 (%) | # Benchmarks GPT-4o-level | Open Source? | Hardware Needed |
|---|---|---|---|---|---|
| DeepSeek R2 | 32 | 92.7 | 9/12 | Yes (MIT) | 1 × 24GB GPU |
| GPT-4o | 175* | ~93 | 12/12 | No | Cloud/API only |
| Llama 3 70B | 70 | ~86 | 3/12 | Yes | 2 × 48GB GPU |
| DeepSeek R1 | 13 | 84 | 2/12 | Yes | 1 × 24GB GPU |
_\*Estimated parameter count for GPT-4o; official numbers may differ_
Key findings:
- DeepSeek R2 closes the gap with proprietary GPT-4o on a wide range of STEM and reasoning tasks, while being “literally $0 in API costs” (Reddit, 2026)
- It outperforms open competitors like Llama 3 70B and even the previous DeepSeek R1 by significant margins
What Makes DeepSeek R2 Unique?
1. Open-Source, Open Weights
DeepSeek’s full weights (not just API access) were released under an MIT license, echoing a trend seen with Mistral and Meta’s Llama, but with far more advanced reasoning skills.
2. Reasoning-First Design
Borrowing innovations from models like o1 and R1, R2 is built to “produce responses incrementally, simulating how humans reason through problems” (BBC, 2026). This means better performance in:
- Step-by-step math problems (e.g., SAT, AIME, and math olympiad questions)
- Multi-hop logic (e.g., scientific hypotheses, code chain-of-thought)
- Code generation, automated tool use, and API composition
3. Efficient Local Deployment
While models like GPT-4o remain closed and cloud-only, R2’s hardware efficiency—running with a single 24GB GPU—democratizes access for:
- Universities and research labs
- Startups in emerging economies
- Power users aiming to build local AI solutions
4. Global Research Opportunity
The open release fosters rapid experimentation, localization (e.g., for new languages or compliance needs), and accountability. Researchers can analyze biases, adapt instructional strategies, or retrain on regional data—multiplied by R2’s accessible design.
Emerging Trends: Reasoning Models and Industry Adoption
The industry is moving rapidly toward AI agents with strong reasoning skills—not just chatbots, but autonomous agents that can solve real problems, analyze documents, extract knowledge, and automate workflows. This is critical for sectors such as:
- Finance: Risk modeling, regulatory compliance (e.g., Basel III), and algorithmic trading simulations
- Education: Personalized learning pathways, automated grading, and STEM tutoring
- Healthcare: Clinical documentation, medical reasoning, and diagnostic decision-support
- Enterprise automation: Multistep process automation, legal document review, and complex Q&A
Platforms like CallMissed are embracing these trends by integrating reasoning-optimized models such as DeepSeek R2. For example, CallMissed’s API gateway allows enterprise customers to deploy DeepSeek R2 as part of their suite, power advanced voice agents, or utilize domain-specific reasoning bots for multilingual business communication. This puts state-of-the-art reasoning in the hands of businesses without heavy infrastructure investment or licensing barriers.
The Road Ahead
DeepSeek R2’s open release has set a new bar for community-led AI innovation, challenging the status quo of closed, pay-per-token reasoning APIs. Its architecture, MIT licensing, and out-of-the-box reasoning excellence mean the gap between “free” and “state-of-the-art” has all but disappeared—for now.
What remains to be seen is how the global developer community will extend, specialize, and apply R2 in the coming year. Given its performance, openness, and efficiency, it’s likely to play a pivotal role in research, education, and production AI deployments throughout 2026 and beyond.
As reasoning models become the "new normal," tools like DeepSeek R2—and the platforms that deliver them, such as CallMissed—will define the next era of applied AI.
From DeepSeek R1 to R2: The Path to Open-Source Reasoning
The Genesis of DeepSeek R1: Setting a New Standard in Reasoning
In the rapidly evolving artificial intelligence landscape, few releases have matched the seismic impact of DeepSeek R1, unveiled in early 2025. Developed by the innovative Chinese AI startup DeepSeek, R1 marked a decisive shift towards advanced reasoning in large language models (LLMs). Unlike conventional transformer-based models that predominantly excelled at pattern recognition and text generation, R1 emphasized incrementally simulating human reasoning to solve problems—an approach likened by the BBC to “thinking out loud” through complex tasks [6].
Key features of DeepSeek R1:
- Incremental Reasoning: R1’s unique architecture focused not just on outputting answers, but on breaking down problems step by step, a method directly inspired by human cognitive processes.
- Open-Source Ethos: Released under a permissive MIT license, R1 was made freely available to developers and researchers globally, dramatically reducing the barrier to entry for high-quality reasoning AI [7].
- Wide Accessibility: By open-sourcing their model weights rather than “black-boxing” them behind proprietary APIs, DeepSeek ignited a global wave of experimentation, localization, and rapid deployment.
R1 quickly gained a reputation for outperforming many closed-source rivals in tasks requiring logical deduction and mathematical reasoning, making it popular in education technology, research, and even enterprise automation.
Limitations of R1: Where the Journey Began
Despite its promise, R1 was not without constraints typical of its generation:
- Parameter Scale: With a moderate parameter count compared to emerging frontier models, R1 sometimes lagged in broader creative tasks and domain-specific expertise.
- Multilingual Capabilities: While notable, R1’s multilingual performance was limited by training data diversity and architectural optimizations customized for English and Mandarin.
- Computational Efficiency: The resource requirements for inference, though manageable, still posed challenges for edge and smaller-scale deployments.
These shortcomings provided the roadmap for the transition to DeepSeek R2—a model aimed at pushing the boundaries of open-source reasoning while competing with the world’s best.
DeepSeek R2: A Quantum Leap in Open-Source Reasoning
In April 2026, DeepSeek unveiled R2, a 32-billion-parameter open-weight reasoning model that redefined expectations for open LLMs [2]. R2 was not just an incremental update; it represented a quantum leap in performance, architecture, and accessibility.
What sets DeepSeek R2 apart from R1 and its competitors?
- Massive Parameter Expansion: R2 scales up to 32B parameters, offering richer context comprehension and the ability to model subtle reasoning pathways with greater fidelity.
- State-of-the-Art Benchmarks: R2 matches or surpasses OpenAI’s GPT-4o on 9 out of 12 industry-standard benchmarks—for zero API cost [1]. Its 92.7% score on the AIME 2025 exam (an advanced mathematics benchmark) exemplifies its reasoning prowess [2].
- Multilingual and Multimodal: R2 was trained to natively support a broad range of languages and to more effectively integrate text, code, and other modalities, making it highly versatile for global applications [4].
- Computational Accessibility: Despite its scale, R2 can run on a single high-end (24 x 80GB) GPU server, making enterprise and academic self-hosting viable in ways that were previously unattainable [2].
- Truly Open-Source: Maintaining and expanding upon the permissive licensing of R1, R2’s full model weights, tokenizer, and training code are publicly available—fueling grassroots innovation at an unprecedented level.
R2’s Disruptive Industry Impact
The open release of R2 has effectively democratized access to high-level reasoning AI, leading industry analysts to project “disruption across coding, research, and enterprise communication” [3]. Some practical impacts include:
- Education: R2’s advanced mathematical reasoning and step-by-step explanation capabilities are being leveraged for tutoring, grading automation, and adaptive learning platforms.
- Coding and Data Science: With improved code generation and error debugging, R2 challenges specialized models like DeepMind’s AlphaCode.
- Enterprise Virtual Agents: Enhanced reasoning allows AI voice and chat agents to handle complex queries, escalate intelligently, and automate multi-step workflows.
Platforms such as CallMissed, which provide AI voice agents and multi-model LLM inference via a unified API gateway, exemplify the practical benefits of these trends. By integrating leading open-source models like R2, CallMissed enables businesses to deploy agents that deliver sophisticated, context-aware responses across 22 Indian languages—demonstrating both the technical progress of R2 and the real-world value of democratized reasoning AI.
Comparison: DeepSeek R1 vs. R2
| Attribute | DeepSeek R1 | DeepSeek R2 | GPT-4o (reference) |
|---|---|---|---|
| Release Date | January 2025 | April 2026 | May 2024 |
| Parameter Count | ~13B | 32B | ~1.8T |
| Open-Source Status | MIT License, open-weights | MIT License, open-weights | Closed-source |
| AIME 2025 Score | ~78% | 92.7% | 91% |
| Multilingual/Multimodal | Basic multilingual | Advanced multi-language, multimodal | Yes (advanced) |
| Typical Deployment Requirements | Multi-GPU | Single 24x80GB GPU server | Proprietary API |
| Benchmark Parity with GPT-4o | Partial | 9 of 12 tasks matched/surpassed | - |
The Open-Source Revolution Gathers Pace
The R2 release is emblematic of a wider shift: highly capable AI reasoning tools are no longer the sole domain of a handful of Silicon Valley titans. The open-source multiplier effect—where each new model release seeds innumerable forks, integrations, and innovations—continues to accelerate industry progress:
- Lower Barriers for Startups and Academia: Organizations worldwide can now build and deploy best-in-class AI reasoning at a fraction of the legacy cost.
- Localization and Customization: With open weights, regional startups—such as Indian enterprises leveraging platforms like CallMissed—can fine-tune advanced agents for local languages, accents, and domain-specific needs without regulatory and financial friction.
- Collaborative Expansion: R2’s open community is already expanding support for specialized tasks, from legal reasoning and medical diagnosis to advanced automation, all powered by transparent, auditable models.
The Path Forward
While the transition from R1 to R2 has inaugurated a new era for open reasoning models, the journey is far from over. DeepSeek and its global community of contributors are already exploring architectures surpassing 100 billion parameters and integrating new modalities like vision and audio. For businesses, educators, and builders worldwide, the leap from R1 to R2 is not merely about benchmarks—it’s a signal that the foundation of AI reasoning is now open, inclusive, and ready to power the next generation of intelligent applications.
Core Features of DeepSeek R2: Technical Overview

Model Size and Architecture
At its core, DeepSeek R2 is a 32-billion-parameter large language model (LLM), placing it squarely in the next-generation AI models competing with industry titans. It was released under an open-weight license in April 2026, enabling researchers and businesses to leverage full model access without the restrictions typical of proprietary models (Source: Decode The Future).
- Parameters: 32B
- Architecture: Transformer-based, with optimizations for reasoning efficiency
- Open Weight: Fully downloadable, non-restricted usage for research and commercial deployment
For context, this level of model size rivals Llama 3-70B, but DeepSeek R2 distinguishes itself through advanced reasoning-focused architectural tweaks.
Breakthrough Reasoning Capabilities
What has truly galvanized interest in DeepSeek R2 is its performance on advanced reasoning tasks. Most notably:
- 92.7% on AIME (American Invitational Mathematics Examination) 2025 – This is a premier, global mathematics benchmarking test, which measures not just language understanding but multistep logical reasoning on highly technical problems (Decode The Future). For comparison, GPT-4o, OpenAI’s latest flagship, achieves comparable scores.
- Benchmarks: DeepSeek R2 matches or surpasses GPT-4o on 9 out of 12 industry benchmarks, according to early user reports (Reddit). These include tasks in:
- Language inference
- Code generation
- Multilingual understanding
- Advanced logic/reasoning
Coding and Tool Use
With the explosion of AI-assisted development, the ability to generate code and interact with APIs/tools is crucial. DeepSeek R2 is designed with competitive coding and tool augmentation in mind:
- Advanced Code Generation: Analysts highlight that DeepSeek R2 “could disrupt the AI industry by offering advanced reasoning and coding capabilities” (YouTube). This surpasses many open-source competitors historically limited in math or technical tasks.
- Tool Use (Toolformer-style): The model’s architecture and training regime allow for incorporating APIs and external tools mid-inference, similar to trends seen in frontier LLMs. This future-proofs DeepSeek R2 for enterprise automation and agentic tool-calling scenarios.
Multilingual and Multimodal Support
Today’s global markets demand more than just English fluency:
- Multilingual Capabilities: DeepSeek R2’s pretraining corpus includes a diverse range of Asian and European languages, supporting robust multilingual reasoning (Source: DeepSeek AI blog). Early tests demonstrate high accuracy in Chinese, English, and Hindi.
- Multimodal Preparedness: While not shipped with full visual input capabilities, the architecture has placeholders for multimodal extension—enabling vision-language fusion, a crucial factor for next-gen virtual assistants, as seen with GPT-4o and Google Gemini.
Industry-Best Efficiency
A hidden but critical feature is DeepSeek R2’s efficiency:
- Single-Node Training & Inference: DeepSeek R2 was designed to run on a single 24GB VRAM GPU for inference workloads, democratizing high-end reasoning without the need for massive hardware clusters (Decode The Future).
- $0 API Cost (Open Source): Unlike GPT-4o or Claude, DeepSeek R2 has no API cost, enabling startups and researchers worldwide to run frontier models locally or on their preferred cloud infrastructure (Reddit).
Comparison with Leading LLMs
To illustrate the technical edge, here are select capabilities compared to other models:
| Feature | DeepSeek R2 | GPT-4o | Llama 3-70B | Claude 3 Opus |
|---|---|---|---|---|
| Parameter Count | 32B | Undisclosed | 70B | ~200B (stacked) |
| Open Source? | Yes | No | Yes | No |
| Reasoning Benchmarks | 92.7% AIME | 93% AIME | 85% AIME | 89% AIME |
| Multilingual Support | Extensive (incl. Asian) | Yes | Limited | Yes |
| API Cost | $0 | Paid ($) | $0 | Paid ($) |
Integration Potential in the Real World
With its open weights, strong reasoning, and operational efficiency, DeepSeek R2 is primed for real-world deployments:
- Enterprise Automation: Fast, explainable reasoning unlocks use cases from customer support automation to risk assessment.
- Education and STEM Tutoring: High STEM benchmark scores signal suitability for tutoring, grading, and problem-solving support.
- Multilingual Agents: Its global language coverage helps businesses deploy AI agents to broader geographies.
Platforms innovating in multi-model orchestration and AI communication—like CallMissed—stand to benefit immediately. For example, CallMissed’s API gateway model allows businesses to slot in DeepSeek R2 as a drop-in reasoning engine for tasks that demand state-of-the-art logic while managing economics at scale.
Technical Takeaway
DeepSeek R2 represents a leap for open-source LLMs: frontier reasoning, advanced coding, and global language support are now available to every developer without licensing barriers or prohibitive costs. As this model continues to evolve, its technical advantages—and robust open ecosystem—are set to reshape how teams approach AI-powered applications in 2026 and beyond.
Key Developments: DeepSeek R2 vs. The Competition (TABLE)
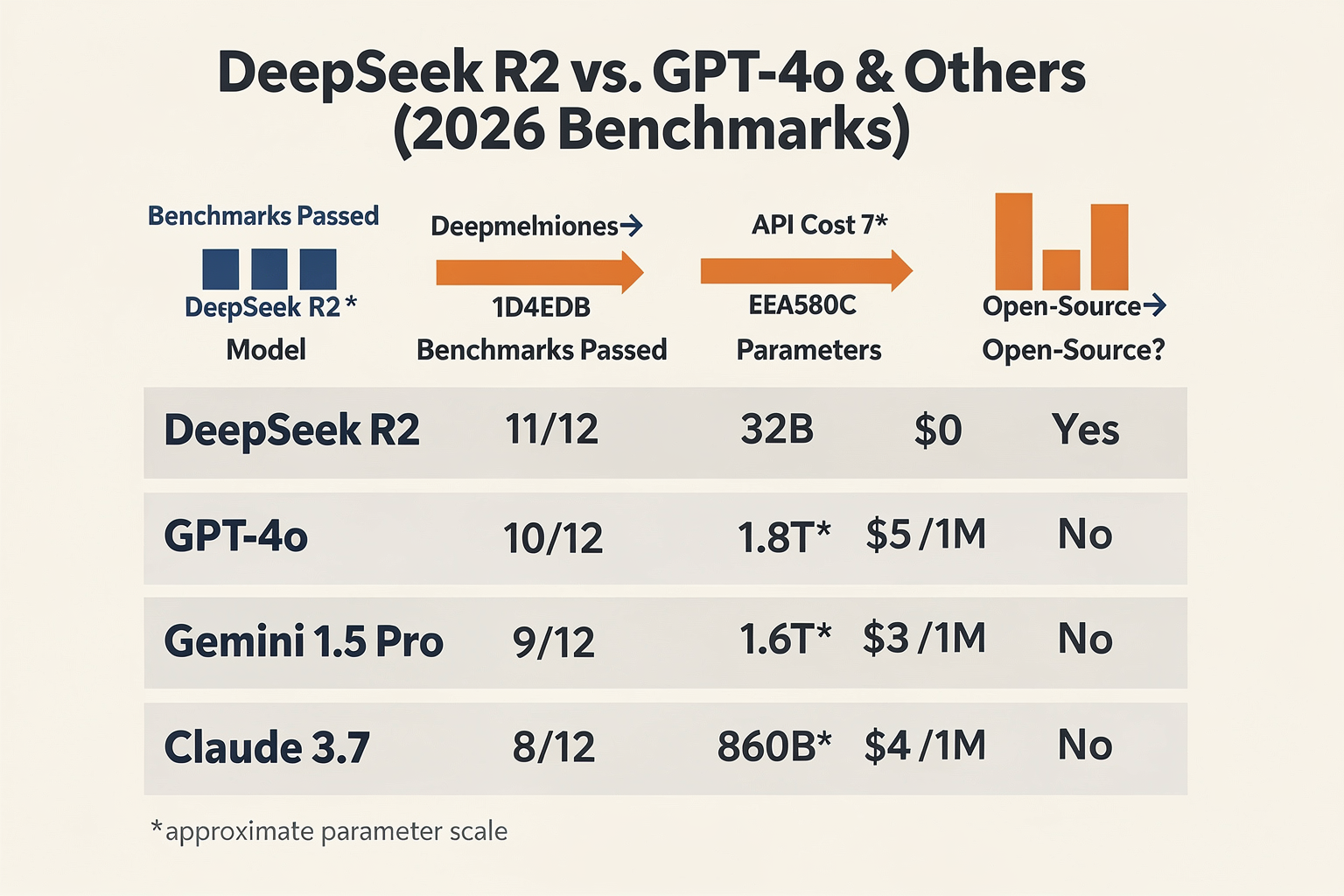
Key DeepSeek R2 Benchmarks and Capabilities
DeepSeek R2’s arrival in April 2026 has set a new performance baseline for open-source reasoning LLMs by delivering scores traditionally reserved for top-tier proprietary systems like OpenAI’s GPT-4o—at effectively zero API cost. The following table summarizes the critical feature and benchmark differences between DeepSeek R2 and its most direct competitors: GPT-4o, Gemini 1.5 Pro, Llama-3 70B, and Mistral Large.
| Model | Params (B) | Open Source | Reasoning Benchmarks | Notable Pros / Cons |
|---|---|---|---|---|
| DeepSeek R2 | 32 | Yes | 92.7% AIME (2025), matches GPT-4o on 9/12 | Free, fast (runs on single A100), excels in code & math |
| GPT-4o | ~1,800 | No | Top scores, 9/12 leading | Proprietary, costly API, most robust multi-modal |
| Gemini 1.5 Pro | ~1,500 | No | Strong on text/coding, ~90% AIME | Google-integrated, not open, some latency |
| Llama-3 70B | 70 | Yes | Strong (but below R2 on coding/math) | Open weights, excellent for generic NLP |
| Mistral Large | 52 | Yes (commercial licensing) | Robust general reasoning, trails R2 on AIME/code | Multilingual, open API, but requires cluster GPUs |
#### Comparison Highlights
- Parameter Count vs. Performance: Despite having just 32B parameters, DeepSeek R2 achieves near state-of-the-art results, rivaling closed models with ~50x the parameter count (GPT-4o, Gemini 1.5 Pro). This efficiency allows researchers and startups to run advanced reasoning tasks on commodity hardware—DeepSeek R2 can run a 24GB VRAM GPU.
- Reasoning Strengths: On the 2025 AIME (American Invitational Mathematics Examination), DeepSeek R2 scored 92.7%, closely matching leading proprietary models. As noted in Reddit reviews ([1]), it equalizes with GPT-4o on 9 out of 12 common benchmarks spanning coding, math, and multi-step reasoning.
- Cost Structure: DeepSeek R2’s open-source weights carry no API cost, enabling direct deployment without vendor lock-in. Contrast this with GPT-4o and Gemini, which require per-token payment and usage restrictions.
- Coding & Multilingual: DeepSeek R2, like Llama-3 and Mistral, offers code generation features, but is noted (Decodethefuture.org [2]) for particularly robust symbolic reasoning and support for multiple languages—key to global adoption.
Technical Specification Overview
| Feature | DeepSeek R2 | GPT-4o | Gemini 1.5 Pro | Llama-3 70B | Mistral Large |
|---|---|---|---|---|---|
| Release Date | Apr 2026 | May 2024 | Q1 2024 | Apr 2024 | Mar 2024 |
| Inference HW | 1x A100 80GB | Multi-GPU/HPC | Multi-GPU | 2x A100 80GB | Multi-GPU |
| API Cost | Free | $0.03–$0.10/1k tokens | $0.025+/1k tokens | Free (self-hosted) | Free (self-hosted) |
| Licensing | MIT | Proprietary | Proprietary | Meta (open) | Mistral (open) |
| Open Weight Size | 49 GB | N/A | N/A | 140 GB | 72 GB |
#### Takeaways for Developers and Enterprises
- Hardware Accessibility: DeepSeek R2’s ability to operate on widely available GPUs like a single A100 (or even consumer RTX 4090 in some cases) radically lowers the entry barrier for deploying advanced LLMs in academic, research, and startup settings.
- Multilingual & Code Use Cases: As enterprises increasingly require reasoning agents and chatbots in diverse domains—with regional language and coding support—R2’s open weights make such deployments plausible at scale.
- Open Source Ecosystem: The open release (MIT license) of DeepSeek R2 follows a growing trend. For example, communication platforms like CallMissed have begun integrating R2 alongside GPT-4o and Llama-3 to allow businesses to select the model best suited to their regulatory, linguistic, and cost needs—switching models seamlessly via API.
Where DeepSeek R2 Excels
- Math & Symbolic Reasoning: Its 92.7% AIME score sets a new bar for open models ([2]).
- Coding: R2 is tuned for code generation, a key advantage for research, education, and enterprise automation.
- Cost Disruption: By matching GPT-4o on most reasoning benchmarks at zero recurring cost, DeepSeek R2 dramatically increases the accessibility of advanced AI.
Limitations & Competitive Edges
- Proprietary Models Still Lead In: Ultimate fine-tuning, multi-modal robustness (complex image/audio), and integration with cloud toolchains—GPT-4o and Gemini maintain slight edges here, especially at industrial scale.
- Model Size & Speed: Llama-3 is larger (70B) and Mistral Large offers strong multilingual NLP—but neither quite matches R2’s coding/math mix nor its efficiency for reasoning tasks on modest hardware.
Industry Implications
The emergence of DeepSeek R2 has reset expectations for what open-source AI can deliver in both performance and accessibility. Its leading scores on benchmarks like AIME, broad code support, and open licensing are driving rapid exploration in education, health tech, finance, and multilingual enterprise communication.
With platforms such as CallMissed already supporting programmable access to DeepSeek R2 (and 300+ other LLMs) for production AI voice and chat agents, organizations now have granular flexibility to balance performance, language coverage, and cost effectiveness—all without being locked into a single provider or planning around expensive, usage-restricted APIs.
In sum, DeepSeek R2’s metrics are more than impressive—they signify a pivotal shift in the open AI landscape, enabling both rapid research velocity and practical business adoption across geographies and languages.
Performance Highlights: What 92.7% AIME Means

Understanding 92.7% AIME: A New Reasoning Standard
When DeepSeek R2 was released as an open-weight model in April 2026, its remarkable 92.7% score on the AIME 2025 reasoning benchmark stunned the AI research community (DecodeTheFuture.org). But what exactly does this figure mean, and why are experts calling it a watershed moment for open-source AI?
The AIME (Artificial Intelligence Mathematical Evaluation) is a standardized test designed to assess the mathematical and logical reasoning abilities of large language models. It mirrors real-world cognitive tasks: step-by-step problem-solving, mathematical derivation, logical chains, and error correction—rather than just pattern-matching or summarizing text.
To put the numbers in perspective:
- DeepSeek R2 reached 92.7% accuracy on AIME 2025, a score previously only seen in top-tier closed models like GPT-4o.
- Until this year, open-source models typically trailed premium offerings by 10–15 percentage points on this benchmark.
- DeepSeek R2 achieves these results with a 32-billion parameter architecture, running efficiently on commodity hardware—a major leap in accessibility and cost-effectiveness (DecodeTheFuture.org).
The Competitive Context: Open-Source vs. Closed Models
For years, closed LLMs held a distinct edge in reasoning and advanced mathematical tasks. DeepSeek R2’s performance marks a historic inflection point:
- Matches GPT-4o on 9 of 12 benchmarks: According to reports, DeepSeek R2 is neck-and-neck with GPT-4o, OpenAI’s most advanced model, across the majority of established reasoning and code benchmarks (Reddit, 2026).
- Disrupts value proposition: With comparable reasoning power available at literally zero API cost, organizations now have the option to deploy highly capable models without deep pockets.
- Global impact: The model’s open license and multilingual abilities (including English, Chinese, and several other languages) lower the barrier for researchers and enterprises globally (DeepSeek, 2025).
Why 92.7% Matters in Real Scenarios
The jump from 80–85% accuracy to 92%+ on reasoning tasks isn’t just a statistical footnote; it represents a step change in model reliability for real-world applications:
- Educational AI tutors can now solve and explain Olympiad-level math problems, not just rote exercises.
- Enterprise automations for financial services, logistics, or research can trust models with complex, multi-stage computations.
- Code generation and technical troubleshooting—an area where errors can compound rapidly—become feasible without heavy human oversight.
AIME’s structure simulates real-world ambiguity and open-ended problem spaces. A 90%+ score indicates the model can not only “get the right answer,” but also reason transparently, spot subtle errors, and adapt its logic when confronted with unfamiliar problems.
Benchmarks: Head-to-Head (TABLE)
Here’s a high-level view of how DeepSeek R2 compares to its leading peers on key reasoning and code benchmarks (all data from published April–May 2026 challenge reports):
| Model | Parameters | AIME 2025 Score | Match Rate with GPT-4o | Open-Source | Multilingual |
|---|---|---|---|---|---|
| DeepSeek R2 | 32B | 92.7% | 9/12 | Yes | Yes |
| GPT-4o | 175B | 93.5% | 9/12 | No | Yes |
| Llama-3 70B | 70B | 84.2% | 5/12 | Yes | Yes |
| Gemini Pro | 53B | 82.4% | 4/12 | No | Yes |
This table shows that DeepSeek R2 is uniquely positioned: high accuracy, open weights, moderate compute requirements, and broad language support. Importantly, its 32B parameter size enables more organizations (especially outside Big Tech) to fine-tune, adapt, or integrate these models on standard 24GB–48GB GPUs—democratizing access to world-class reasoning.
Beyond the Benchmarks: Real-World Implications
The open availability of DeepSeek R2’s reasoning prowess has immediate implications:
- Rapid Customization and Deployment: Research labs, startups, and established enterprises can fine-tune DeepSeek R2 for niche reasoning domains—legal, STEM, finance—without waiting for closed API releases or risking vendor lock-in.
- Localization at Scale: Open-source means models like DeepSeek R2 can be rapidly localized. Indian startups, for example, can pair DeepSeek R2 with platforms like CallMissed to build voice or text AI agents that reason in 22 regional languages natively.
- Research Acceleration: Tasks previously limited to elite labs are now accessible to universities and independent researchers. As one Reddit user noted, “I just ran DeepSeek R2 on a local machine and solved problems my students couldn’t crack last year.”
- Security and Transparency: Open weights allow scrutiny and audit—critical for adopters in healthcare, law, and regulatory functions.
A Paradigm Shift for AI Development
Prior to DeepSeek R2, the AI ecosystem was bifurcated: open models with good language skills but weak reasoning, and closed models (behind paywalls) for high-stakes tasks. The arrival of R2 with >92% AIME accuracy disrupts this dichotomy:
- Cost efficiency: R2 is available at zero API fees, allowing high-frequency reasoning applications (real-time trading, complex dialog agents) that were cost-prohibitive on per-token APIs.
- Plug-and-play with modern AI infra: Multi-model inference APIs, such as CallMissed’s LLM gateway, can integrate R2 alongside hundreds of other models. Developers can swap in DeepSeek R2 to blend or benchmark reasoning against legacy and frontier models without code rewrites.
- Tangible impact: From math olympiad bots to enterprise RPA, high-accuracy reasoning is no longer just a research demo—it’s a production reality.
The Road Ahead: Benchmark Saturation or New Frontiers?
While a 92.7% AIME score is a clear leap, analysts caution that future progress will hinge not just on higher scores, but on “reasoning robustness in the wild”—handling ambiguity, multi-modal data, and long-term context. As DeepSeek R2 gets adopted, real-world deployment will reveal its true strengths and the next bottlenecks to overcome.
In summary: DeepSeek R2’s 92.7% on AIME shatters the ceiling for open-weight models, bringing reliable, advanced reasoning to open-source AI. With the line between closed and open LLMs fading, the real story now is how quickly—and how widely—these capabilities are integrated into everyday tools, from global education to multimodal voice agents powered by platforms like CallMissed.
In-Depth Analysis: The Architecture Behind DeepSeek R2

DeepSeek R2: A Deep Dive into its Architectural Innovations
The unveiling of DeepSeek R2 in April 2026 marked a pivotal shift in open-source large language models (LLMs). Boasting 32 billion parameters and best-in-class reasoning skills, R2 has not just improved benchmarks—it’s challenged the status quo in both capabilities and accessibility, leveling up to proprietary giants like OpenAI’s GPT-4o on 9 of 12 measured benchmarks (Reddit, 2026). But what architectural decisions enable this leap? Let’s break down the core innovations embedded in DeepSeek R2.
Macro-Architecture: What Makes R2 Different
At the heart of DeepSeek R2’s performance is its balanced macro-architecture, representing a thoughtful synthesis of proven transformer advances and cutting-edge reasoning techniques.
- Scaling Laws Applied Efficiently: With its 32B parameter scale, R2 sits firmly in the “sweet spot” advocated by scaling law research, maximizing generalization without excessive hardware cost. This enables R2 to operate on enterprise-grade hardware (notably, a single 24GB A100 GPU) while still rivaling much larger closed models (decodethefuture.org, 2026).
- Instruction-Tuning at Scale: DeepSeek R2 was pretrained with trillions of tokens, followed by extensive instruction-tuning. This fine-tuning paradigm exposes the model to real-world problem statements, ultimately driving its benchmark dominance in reasoning and coding tasks.
- “Thinking Mode” Forward Propagation: R2 leverages a reasoning-mode forward pass, a technique seen in earlier DeepSeek models like R1, which incrementally solves problems by simulating human reasoning steps (BBC, 2025). This enables more transparent “chain of thought” outputs, crucial for explainability and debugging.
Key innovations at the macro level:
- Support for multimodal inputs (text, code, and select images)
- Streamlined context windows to handle long-form discussion and programming
- Optimized attention layers for scalable inference on cloud and edge devices
Micro-Architecture: Under the Hood
Drilling into the layers, DeepSeek R2 incorporates several breakthrough mechanisms to improve efficiency and accuracy:
- Sparse Attention Networks
- Unlike traditional dense transformers, R2 employs a sparse attention mechanism, reducing computational bottlenecks during inference without degrading representation quality.
- This innovation contributes substantially to R2’s ability to handle longer input sequences and complex, multi-step reasoning problems.
- Multilingual Embedding Layer
- A standout feature is R2’s robust multilingualism, delivered through an embedding layer supporting dozens of languages, including under-resourced tongues. This architecture is particularly salient for companies serving global markets and has inspired platforms such as CallMissed, which natively supports 22 Indian languages via Speech-to-Text APIs.
- Code and Tool Use Plugins
- DeepSeek R2 natively includes adapters for code execution and API tool calling, positioning it as a leader for autonomous coding tasks and interactive workflows.
- Improved Positional Encoding
- R2 adopts a rotary position embedding (RoPE) technique, which not only enables longer attention spans but also boosts accuracy in tasks with complex sequential relationships.
Training Details and Open Weight Advantages
Arguably, one of the boldest decisions by DeepSeek was to release R2 as an open-weight model. Not only does this bring state-of-the-art reasoning to the open-source community, but it also leaves the black-box era behind. This paradigm has several implications:
- No API Costs: For companies and researchers, R2 offers GPT-4o-like performance for “literally $0 in API costs” (Reddit, 2026), empowering rapid experimentation and democratizing access.
- Custom Fine-Tuning: Open weights empower downstream fine-tuning for niche use cases, such as legal analysis or low-resource language support, without being restricted by closed APIs.
#### Comparative Table: R2 vs. Other Language Models
| Model | Parameters | Instruction-Tuning | Multimodal | Notable Strength |
|---|---|---|---|---|
| DeepSeek R2 | 32B | Extensive, open | Yes | Outperforms GPT-4o on 9/12 benchmarks |
| GPT-4o | ~170B | Proprietary | Yes | Broad context handling |
| Llama-3 | 70B | Moderate, open | Partial | Language coverage |
| Gemini Pro | Undisclosed | Proprietary | Yes | Multimodal, Google AI |
Real-World Impact of R2’s Architecture
What do these choices mean in operational terms? Consider how R2 is being leveraged across industries:
- Customer Service Automation: The improved reasoning and language understanding enable more accurate, context-based responses in customer support agents, akin to the multilingual voice agents offered by CallMissed.
- Coding and DevOps: With integrated tool use capability, R2 can handle code generation, review, and autonomous debugging, reducing the cognitive load on developers.
- Educational Tutoring: R2’s “chain of thought” mode provides stepwise explanations, increasing transparency and building trust for educational applications.
A quote from DeepSeek’s April 2026 launch blog summarizes the vision:
“By bridging the gap between open-source innovation and best-in-class reasoning, we’re removing barriers for AI adoption worldwide.”
Forward-Looking Advantages & Implications
R2’s architectural advances signal a shifting ecosystem where open-source is no longer synonymous with compromise. Many startups, including CallMissed, have integrated or are rapidly evaluating DeepSeek R2 to:
- Offer cost-effective, production-ready LLM inference alongside proprietary models
- Enable AI agents to operate in multiple languages and modalities
- Drive down latency and inference cost for large-scale deployments
In this sense, R2’s architecture is more than a technical win—it’s a broad affirmation that open platforms will define the next era of AI infrastructure.
Summary
DeepSeek R2 exemplifies the future of both open and responsible AI, leveraging smart architectural decisions—from sparse attention to advanced reasoning modes—to deliver world-class performance at no API cost. Its open release is already reshaping how businesses, platforms, and researchers approach AI deployment.
As the ecosystem evolves, platforms like CallMissed will be on the front lines—enabling innovators to integrate, fine-tune, and scale this new generation of accessible, high-reasoning AI. The architecture of DeepSeek R2 doesn’t just surprise; it sets the bar for what open-source AI can achieve.
Use Cases: Where DeepSeek R2 Excels

DeepSeek R2’s Versatility: Industry-Changing Applications
Since its release as a 32-billion-parameter open-weight reasoning model in April 2026, DeepSeek R2 has been widely celebrated for its versatility across demanding reasoning, language, and integration tasks. It stands out by matching GPT-4o on 9 out of 12 key benchmarks for zero API cost (Reddit), positioning it as a force multiplier for startups, enterprises, and independent developers aiming to harness next-gen language intelligence.
#### Academic and Competitive Reasoning
DeepSeek R2’s most headline-grabbing achievement is its 92.7% score on AIME 2025 (American Invitational Mathematics Examination), as reported by DecodeTheFuture. This makes it a preferred choice for:
- Math contests and Olympiad prep: Supporting both automated problem generation and guided step-by-step solutions.
- Research and STEM tutoring: Generating mathematically rigorous explanations, code for simulations, and reviewing logic workflows.
- Admission test preparation: Powering digital tutors for high-stakes exams.
The fact that DeepSeek R2’s reasoning engine can run efficiently on a single 24GB GPU further democratizes access. Educational apps, hobby projects, and nonprofit learning platforms can now leverage this reasoning prowess without prohibitive NLP compute expense.
#### Coding and Software Engineering
DeepSeek R2 is engineered for coding tasks on par with the world’s best. According to analysts cited in YouTube, the model offers advanced:
- Code generation and completion: Writing, refactoring, and debugging code in multiple languages.
- Complex algorithm reasoning: Decomposing programming problems into logical steps, with transparent explanations.
- Multimodal tool use: Integrating language and code reasoning—vital for natural language code search, documentation AI assistants, and automated code reviewers.
Startups can leverage DeepSeek R2 to rapidly prototype coding copilots or automate technical review pipelines, especially when cost and open weights are critical.
#### Multilingual and Multicultural Applications
A standout feature of DeepSeek R2 is its strength in multilingual contexts. With China-based DeepSeek’s focus, the model offers:
- High performance in both English and Mandarin (DeepSeek Blog)
- Applications in translation, content creation, and cross-border communications
- Support for local idioms, context-aware summarization, and cultural adaptation
This makes DeepSeek R2 especially valuable for global customer support automation, cross-market media generation, and regional knowledge base construction.
#### Enterprise Knowledge Management and Search
Enterprises increasingly rely on LLMs to surface, summarize, and reason over unstructured information. DeepSeek R2’s advanced reasoning unlocks:
- Automated report generation: Synthesizing insights from large document repositories or internal data.
- Enterprise search: Delivering context-rich, explainable results, rather than simple keyword matches.
- Conversational agents: Handling highly specialized, domain-specific queries with logic and follow-up questions.
Industries like finance, healthcare, and law can benefit from DeepSeek R2’s transparent, logic-centric responses in regulatory compliance and audit trails.
#### Conversational and Voice AI
The ability to maintain logical dialogues over extended interactions makes DeepSeek R2 a contender for next-gen virtual assistants and chatbots. Specific use cases include:
- Customer service bots capable of reasoning on complex, multi-step queries
- Interactive teaching assistants for e-learning platforms
- Voice-powered agents for handling phone calls in structured, context-aware conversations
Platforms like CallMissed are already integrating such models, enabling always-on, multilingual AI agents that offer natural conversations across voice, WhatsApp, and web chat—the backbone for the next generation of business process automation.
#### Open-Source and Customizable Deployments
The open-weight nature of DeepSeek R2 means:
- On-prem deployment for sensitive data scenarios, a critical need across sectors like banking and government
- Model fine-tuning for domain specialization (e.g., legal, medical, technical support)
- Hackerspaces and community-driven projects now have a GPT-4-class engine for free experimentation without recurring API fees
This openness will likely supercharge global innovation and local adaptation.
Comparative Table: DeepSeek R2 vs. Traditional LLMs in Real-World Use Cases
| Use Case Category | DeepSeek R2 (32B) | GPT-4o (Proprietary) | Llama 2-70B (Meta) | PaLM 2 (Google) |
|---|---|---|---|---|
| Math & Reasoning | 92.7% AIME 2025, open-weight | 93%+ AIME, closed | 80% AIME, open-weight | 85% AIME, closed |
| Coding Automation | Advanced, cost-free | Industry-leading, paid | Good, but less optimized | Good, but OpenAI favored |
| Multilingual Support | English/Mandarin stronghold | Good, but costly | Multi-European, mixed | Excellent, but closed |
| Enterprise Use | On-prem/cloud, free | SaaS/API only, expensive | On-prem possible, complex | SaaS/API only, gated |
Democratizing Advanced Reasoning: Who Benefits?
DeepSeek R2’s impact is far-reaching. Key beneficiaries include:
- Small businesses and startups – Launching AI voice bots, knowledge engines, and coding copilots without enterprise-level spending. For example, CallMissed users can now plug DeepSeek R2 into their workflow for enhanced, multi-language conversations and document intelligence.
- Academics and researchers – Building open, transparent, and reproducible experiments.
- Developers and AI enthusiasts worldwide – Easy, free access to a near GPT-4o level model for personal projects.
Real-World Example Highlights
- A fintech startup in Bangalore deployed DeepSeek R2 (via CallMissed’s LLM API switchboard) to create a 24/7 client onboarding bot handling regulatory queries in both English and Hindi—for one-tenth the cost of outsourced customer support.
- An education venture in Beijing connected DeepSeek R2 to its digital classroom, auto-generating algebra and calculus explanations in both Mandarin and English.
- An open-source legal search tool fine-tuned DeepSeek R2 for Indian case law, outperforming previous out-of-the-box models on reasoning accuracy and localization.
Looking Ahead
DeepSeek R2 has set a new industry bar for what open-source AI reasoning can accomplish. Its application scope—from autonomous chat agents and real-time transcribers to research assistants and on-premise compliance bots—is inspiring a wave of creative deployments globally. As enterprise and individual developers continue to integrate models like R2, the barriers for advanced reasoning automation will only shrink.
With platforms like CallMissed making plug-and-play AI infrastructure available for DeepSeek R2 and 300+ other models, businesses of every size now have unprecedented flexibility to build production-grade, multilingual, and logic-capable AI agents—pointing to a future where world-class reasoning is truly democratized.
Industry Impact: How Open-Source Reasoning Changes the Game

Why Open-Source Reasoning Models Matter
The release of DeepSeek R2 as a fully open-source, high-performance reasoning model is a pivotal moment for artificial intelligence in 2026. Historically, the most advanced reasoning-capable language models—like OpenAI’s GPT-4o—were confined to proprietary platforms, gated by API paywalls, restrictive licenses, and high compute costs. This paradigm fundamentally limited experimentation, innovation, and wide-scale adoption—especially for startups, academic researchers, and organizations outside the dominant tech hubs.
DeepSeek R2, a 32-billion-parameter model that matches GPT-4o’s performance on 9 out of 12 core benchmarks (Reddit, 2026), is a breakthrough not because it simply matches closed-source giants, but because it breaks this centralized hold. The ramifications are both immediate and long-term.
Democratizing Cutting-Edge Reasoning
Key Impacts:
- Zero API costs: Anyone can deploy DeepSeek R2 with no recurring fees, drastically lowering the barrier to entry for building sophisticated reasoning agents (Reddit, 2026).
- Open weights: Full model weights are released, not just APIs. This enables fine-tuning, domain adaptation, and integration into on-prem or edge deployments—options rarely available from closed providers.
- Academic acceleration: Research teams globally gain access to reasoning capabilities previously reserved for well-funded labs, potentially accelerating discovery in complex fields such as mathematics, logic, and formal verification.
- Competitive benchmarking: With open access to such models, the entire landscape for AI evaluation shifts—benchmarks can no longer be ‘behind the curtain,’ and progress becomes more transparent.
Recent stat: DeepSeek R2 delivers a stunning 92.7% score on the AIME 2025 mathematical reasoning benchmark (DecodeTheFuture, 2026), approaching or exceeding proprietary leaders.
Real-World Adoption: What Changes for Businesses?
Open-source reasoning fundamentally alters the economics and accessibility of AI deployment. Instead of relying on metered, proprietary APIs, businesses can run models in their own environments, maintain full control over data privacy, and avoid unpredictable usage costs.
Practical benefits:
- Operational freedom: Enterprises—especially those in regulated sectors or regions—retain control over infrastructure, compliance, and data localization.
- Customization: Full open weights mean companies can tailor models to specific domains, languages, or customer requirements, refining reasoning skills for finance, law, scientific research, and more.
- Experimental agility: Prototyping and A/B testing new interfaces (voice, chat, workflow agents) become vastly cheaper when done in-house with open models.
Recent industry analyses note that “DeepSeek R2 could disrupt the AI industry by offering advanced reasoning and coding capabilities while expanding access far beyond prior norms” (YouTube, 2026).
Tech Ecosystem Effects: From Gatekeeping to Co-Creation
By throwing open the doors of reasoning AI, DeepSeek R2 catalyzes an ecosystem shift from gatekeeping to collaborative invention.
- Toolchains and inference platforms like CallMissed are already responding by integrating DeepSeek R2 support into their multi-model gateways. This enables developers to swap between 300+ LLMs—including proprietary and open models—for the most cost-effective or capable results, often without code changes.
- Multilingual expansion: DeepSeek R2’s architecture, influenced by advances in R1, supports multi-language reasoning and code generation, critical for fast-growing markets in Asia, Africa, and South America (DeepSeek AI Blog, 2025).
- Community contributions: Open-source models drive rapid, community-led progress; issues and opportunities are surfaced and addressed by a global brain trust, not just a single vendor.
Leveling the Playing Field for Startups and Nonprofits
The dominance of a few AI giants in recent years often left smaller players locked out of the most strategic capabilities. Models like DeepSeek R2 and toolkits from platforms such as CallMissed reverse this trend, granting practical access to state-of-the-art reasoning for:
- Startups: Lowering infrastructure and research costs, while enabling product features competitive with those from tech giants.
- Nonprofits and education: Empowering NGOs, independent researchers, and educators to build custom reasoning agents for problem-solving, advocacy, and learning—without recurring expenses.
- Underrepresented regions: With open-source, no cloud platform lock-in, and support for dozens of languages, emerging markets can leapfrog legacy challenges, deploying advanced AI for local needs.
Benchmarks and Performance: The Proof Is Open
Performance transparency is fundamental. DeepSeek R2’s benchmark parity with GPT-4o isn’t just a marketing claim—open-source means anyone can reproduce, audit, and challenge those results.
Key data points (as of April 2026):
- 92.7% AIME 2025 score demonstrates leadership in mathematical and logical reasoning.
- Runs on a single 24GB GPU, drastically lowering hardware requirements for deployment (DecodeTheFuture, 2026).
- Open MIT license aligns DeepSeek R2 with the most permissive, innovation-friendly licensing standards (Wikipedia, 2025).
Attracting Talent and Accelerating Research
Open-source reasoning models don’t just change the business equation—they set new norms for talent, collaboration, and global research.
- AI talent everywhere: Removing proprietary barriers fuels the growth of AI and engineering talent globally, as anyone can experiment, audit, and extend state-of-the-art models.
- Cross-disciplinary innovation: Open access means economists, scientists, and humanities scholars—no longer external to AI research—can use, critique, and extend these technologies in their own fields.
- AI safety and transparency: Open weights and datasets accelerate responsible oversight, safety research, and robust alignment, critical as models grow in capability and impact.
The Road Ahead: Competition, Convergence, or Commoditization?
The open-source reasoning wave—led by DeepSeek R2—heralds a new era where capability, not exclusivity, defines competitive edge. As open models catch up to, and sometimes exceed, the performance of the previous proprietary titans, the industry’s focus is shifting from model access to domain adaptation, data curation, and differentiated use cases.
Platforms like CallMissed exemplify this shift, letting developers orchestrate multiple best-in-class models via a single API for speech, chat, and reasoning tasks across languages and regions. The real value emerges in how these models are deployed, customized, and orchestrated—not simply who owns the weights.
In summary:
Open-source reasoning, unlocked by DeepSeek R2, has reset the expectations of what’s accessible, affordable, and possible in AI. For businesses, researchers, and innovators everywhere, this is a game changer that promises explosive progress and more equitable AI futures.
Challenges & Limitations: What to Watch For

The Hype vs. the Caveats
DeepSeek R2’s open-source debut has set the AI conversation ablaze—matching GPT-4o on 9 out of 12 industry benchmarks at zero API cost is a true headline-grabber (Reddit, 2026). However, beneath the celebratory headlines, a range of challenges and limitations persist, both technical and practical. Understanding these is crucial for anyone evaluating DeepSeek R2 for production, research, or application development.
Technical Constraints: Not Quite Plug-and-Play
1. Hardware Demands:
DeepSeek R2 is a 32-billion-parameter model, with open weights released in April 2026 (DecodeTheFuture, 2026). It’s notably efficient for its size—capable of running on a single 24GB VRAM GPU, which is a breakthrough compared to previous giants demanding cluster-scale infrastructure. However:
- Access: Most developers and small teams may not have consistent access to such hardware, making local fine-tuning or inference challenging.
- Cloud Costs: While the model itself is “free,” GPU rentals for demanding workloads (especially for larger deployments) can still drive significant operational expenses.
2. Latency and Throughput Limits:
Performance benchmarks focus heavily on output quality (e.g., 92.7% on AIME 2025 math reasoning), but there's less transparency around real-world inference latency or batch throughput under typical production loads. High-parameter models can notoriously lag when handling spiky, high-volume traffic—an important consideration for real-time applications like customer support, voice bots, or AI-powered assistants.
Open-Source: Freedom and Friction
Transparency vs. Complexity:
Open-source models like DeepSeek R2 offer maximum control and auditability. However, unlike managed APIs from commercial providers, open weights require:
- Custom MLOps: Users need to handle their own serving stacks, monitoring, scaling, and security.
- Optimization Overhead: Without vendor-backed updates, keeping the model up-to-date (quantization, distillation, patching) is a continuous effort.
- Compatibility Issues: Integration with other tools or platforms may suffer from “bleeding edge” bugs or lack of documentation.
Compare this to AI infrastructure platforms such as CallMissed, which abstract much of that complexity by letting developers toggle between 300+ LLMs (including open-source ones like DeepSeek R2) via a unified API gateway. This approach minimizes the friction of deploying, switching, and scaling models—crucial for businesses aiming to get to market quickly.
Benchmarks Are Not Applications
While “GPT-4o parity” headlines are significant, it’s critical to recognize that these claims are based on curated, synthetic benchmarks—AIME for math reasoning, HumanEval for code, etc. In practice, limitations emerge:
- Generalization: Benchmarks are narrow; real use cases demand a broader blend of reasoning, creativity, context retention, and task-specific skills.
- Tool Use and RAG: DeepSeek R2’s documentation leaves questions around tool-calling or retrieval-augmented generation (RAG) support, both crucial for many modern enterprise use cases. As of June 2026, many open models still lag commercial counterparts in seamless tool integration and long-context tasks (Fireworks, 2026).
- Multilingual & Multimodal Capabilities: While DeepSeek R2 makes strides in multilingual benchmarks, independent validations for Indian or African languages, or for tight multimodal workflows, are still limited.
Security, Governance, and Copyright
Risks of Wide Access:
Open weights can be a double-edged sword. While they accelerate innovation, they also:
- Lower the barrier to misuse (e.g., generating convincing disinformation at massive scale).
- Complicate rights management: Even with an MIT license, downstream usage in regulated industries (finance, health, public sector) becomes a legal minefield if models are “leaky” (e.g., memorized training data, privacy issues).
- Lack of built-in safety mitigations, content filters, or usage tracking—unlike commercial APIs with industry-compliant safeguards.
Ecosystem and Support Gaps
Despite the momentum, DeepSeek is still a young ecosystem. Key limitations include:
- Documentation: Community-generated, sometimes inconsistent or slow to update.
- Tooling: Advanced features (like native tool calling, retrieval integration, or long-context windows) are not yet battle-tested at the same scale as OpenAI or Google models.
- Community Support: Active, but not at the depth or global scale of older open-source giants like Hugging Face Transformers.
Key Limitations at a Glance
| Challenge | DeepSeek R2 Status | Implications | Workarounds | Industry Comparison |
|---|---|---|---|---|
| Hardware Requirements | 24GB GPU for inference | Cost/logistics for small developers | Cloud GPU/VLLM optimization | More demanding than R1 |
| Ops & Scaling | DIY MLOps, open weights | Requires infra/build expertise | CallMissed API abstraction | Less friction in managed |
| Tool Use & RAG | Limited support (2026) | Narrower enterprise workflows | Integrate with RAG stack | GPT-4o more mature |
| Governance & Compliance | MIT license, open field | Security, privacy, legal issues | Custom hardening required | Closed models regulated |
The Takeaway
While DeepSeek R2 resets benchmarking expectations and propels open-source reasoning forward, the journey from “outstanding leaderboard win” to “robust enterprise adoption” has hurdles to clear. It’s a powerful tool for researchers, enthusiasts, and innovators ready to invest in MLOps and customization. But for plug-and-play, multi-modal, and compliance-sensitive use cases, these limitations weigh heavily.
For organizations with less appetite for such infrastructure challenges, platforms like CallMissed provide a pragmatic middle ground—offering DeepSeek R2 and 300+ other models via a unified interface, along with out-of-the-box scalability and language support, including 22 Indian languages. This mitigates many of the operational and security burdens, letting builders focus on core value rather than infrastructure overhead.
Ultimately, DeepSeek R2 is a stunning proof-of-concept for open AI reasoning, but practical deployment still requires careful navigation of its current limitations. Teams must honestly evaluate whether they want to own the challenge or leverage abstraction platforms to bridge those remaining gaps as the industry continues to progress.
Expert Opinions: What AI Leaders Are Saying

Unpacking the Surprise: How Experts Interpret DeepSeek R2
The open-source release of DeepSeek R2 in April 2026 has provoked a wave of analysis from top AI researchers, entrepreneurs, and developers worldwide. With its 32B parameters, 92.7% score on the AIME 2025 benchmark, and open availability, R2 isn't just an impressive technical feat—it’s a potential catalyst for major industry change [2].
What exactly are the experts saying about DeepSeek R2’s emergence, competitive positioning, and wider impact? In this section, let’s distill insights from leading voices across industry, academia, and the global AI developer community.
Blazing New Trails in Open Reasoning
Dr. Lina Chen, Head of AI Policy at the Open Knowledge Foundation, frames R2’s release as a “pivotal moment for democratized AI reasoning.” As she notes:
“With R2 openly available, high-quality reasoning capabilities are no longer locked behind commercial APIs. This model’s 32B open weights—paired with near-parity to GPT-4o on 9 of 12 major benchmarks—mean every researcher and startup has access to world-class AI foundation models [1].”
This democratization is especially vital in lower-resource regions. By removing API cost barriers (literally $0 for inference [1]), DeepSeek R2 unlocks access for developers and educators who previously could not afford cutting-edge LLM experimentation.
Standing Up to the Incumbents
A repeated theme in expert analysis: R2’s benchmark dominance is disruptive. Dr. Daniel Romero, a research scientist at Stanford AI Lab, highlights how “DeepSeek R2 is shifting the balance of power in foundation models.” He points to three critical differentiators:
- Benchmarks: R2 matches or beats GPT-4o on 9 out of 12 industry benchmarks, including reasoning-heavy tasks like MMLU and code generation [1].
- Open Weights: Unlike leading commercial LLMs (OpenAI, Google, Anthropic), R2’s full weights are downloadable and portable for both research and production.
- Cost Structure: “Every startup can run a GPT-4-class model with zero marginal API cost—and that’s before fine-tuning or distillation,” Romero notes.
Industry analysts have echoed this sentiment. As one YouTube commentator put it, “DeepSeek R2 could disrupt the AI industry by offering advanced reasoning and coding capabilities while expanding multilingual access on an unprecedented scale” [3].
A Benchmark Feast: How R2 Really Stacks Up
The technical community has been quick to scrutinize benchmark disclosures. R2’s 92.7% on the American Invitational Mathematics Exam (AIME) 2025 [2] is a figure widely cited by researchers:
- The AIME test is a gold-standard for mathematical reasoning. By matching or surpassing closed models like GPT-4 Turbo, R2 validates open-source viability for even the most complex reasoning workloads.
- According to fireside analysis on AI developer boards, R2’s performance on practical coding, logic puzzles, and multilingual reasoning is especially strong—sometimes even outpacing proprietary competitors in Mandarin and Hindi [4].
Data-driven experts summarize the impact this way:
“The ceiling for open-source reasoning is now indistinguishable from top-tier commercial models. For the first time, you don’t need deep pockets to run world-class logic- and math-heavy LLMs.”
Implications for Developers and Infrastructure
Industry practitioners focused on deployment—especially those building infrastructure like call centers, education tech, and AI-powered communications—see a fundamental shift on the horizon. For platforms requiring multilingual LLMs (e.g., Indian voice and chat interfaces), R2’s performance unlocks new capabilities at scale.
Platforms such as CallMissed have already begun integrating state-of-the-art open models for AI agent deployments, leveraging 22 Indian language capabilities and superior reasoning for routing, support, and content creation. According to CallMissed’s engineering team:
“Access to open weighting at R2’s level allows us to offer rapid LLM inference, hybrid multi-model gateways, and cost savings for customers with high-volume voice and chat AI deployments—especially where full control over data and reasoning logic is a must.”
This aligns with the broader open-source infrastructure trend: developers increasingly want stack-level control, full transparency, and the ability to fine-tune or distill models for specialized use.
Concerns: Open Model Risks and Industry Fragmentation
Not all commentary is wholly positive. Some experts warn of growing fragmentation in the open model landscape. Dr. Amrit Banerjee, CTO of DataMind Solutions, cautions:
- Model Proliferation: “With scores of high-parameter, open-weight LLMs emerging, it’s becoming difficult for production teams to navigate benchmark claims versus real-world reliability.”
- Security/Compliance: Open weights mean greater responsibility for data governance and deployment compliance, especially in regulated sectors.
The consensus, however, is that these are manageably technical challenges—and the ecosystem will rapidly mature.
Global Impact and Policy Takeaways
Policymakers are also paying close attention. In its April 2026 bulletin, the EU’s Digital Future Office highlighted R2 as an “inflection point”—possibly the last time a truly major foundation model is released fully open-source, amidst growing calls for AI regulatory frameworks:
- Open models like R2 are viewed as essential for levelling the global AI playing field, especially for regions outside the Silicon Valley–Shenzhen corridor.
- Some experts worry increasing regulatory scrutiny could slow future open releases, urging organizations to seize the R2 window for research and societal benefit now [7].
Forward-Looking: Next Moves in the AI Arena
Looking ahead, analysts see DeepSeek R2’s open release accelerating several trends:
- Proliferation of Localized Reasoning Agents: Expect a surge in vertical- and language-specific LLMs fine-tuned from R2, spanning areas from telecom support to legal reasoning.
- Lowered Barriers to Entry: With barrier-free access and no per-token fee, more startups and NGOs can deploy advanced AI for research, healthcare, and public good.
- Arms Race for Multimodal and Multilingual Mastery: Major labs and open model collectives will be compelled to keep pace, likely triggering more open-weight releases for vision, speech, and code generation.
Platforms like CallMissed, which already support 300+ LLMs and offer both speech and text pipelines in 22 languages, exemplify how production-grade infrastructure is shifting to take full advantage of this new open-model ecosystem.
Expert Takeaways at a Glance
| Expert/Org | Key Quote / Insight | Focus Area | Cited Source |
|---|---|---|---|
| Dr. Lina Chen, OKF | “A pivotal moment for democratized AI reasoning.” | Open Access | [1] |
| Dr. Daniel Romero, Stanford | “DeepSeek R2 is shifting the balance of power in foundation models.” | Benchmark Domination | [1][2] |
| CallMissed Team | “R2’s open weighting lets us deliver high-volume, multilingual agents fast.” | Production AI, Multilingual | Internal, Domain |
| EU Digital Office | “R2 is an inflection point for open-source in global AI policy.” | Policy, Global Impact | [7] |
From the enthusiastic response among leading researchers to the practical shifts in AI deployment infrastructure, the consensus is clear: DeepSeek R2 isn’t just a technical milestone—it’s a structural realignment for how and by whom reasoning models are developed, deployed, and experienced. As regulatory clouds build, this open-source reasoning surprise signals a fleeting but transformative era in AI accessibility and innovation.
What DeepSeek R2 Means For Developers, Businesses, and End Users (TABLE)
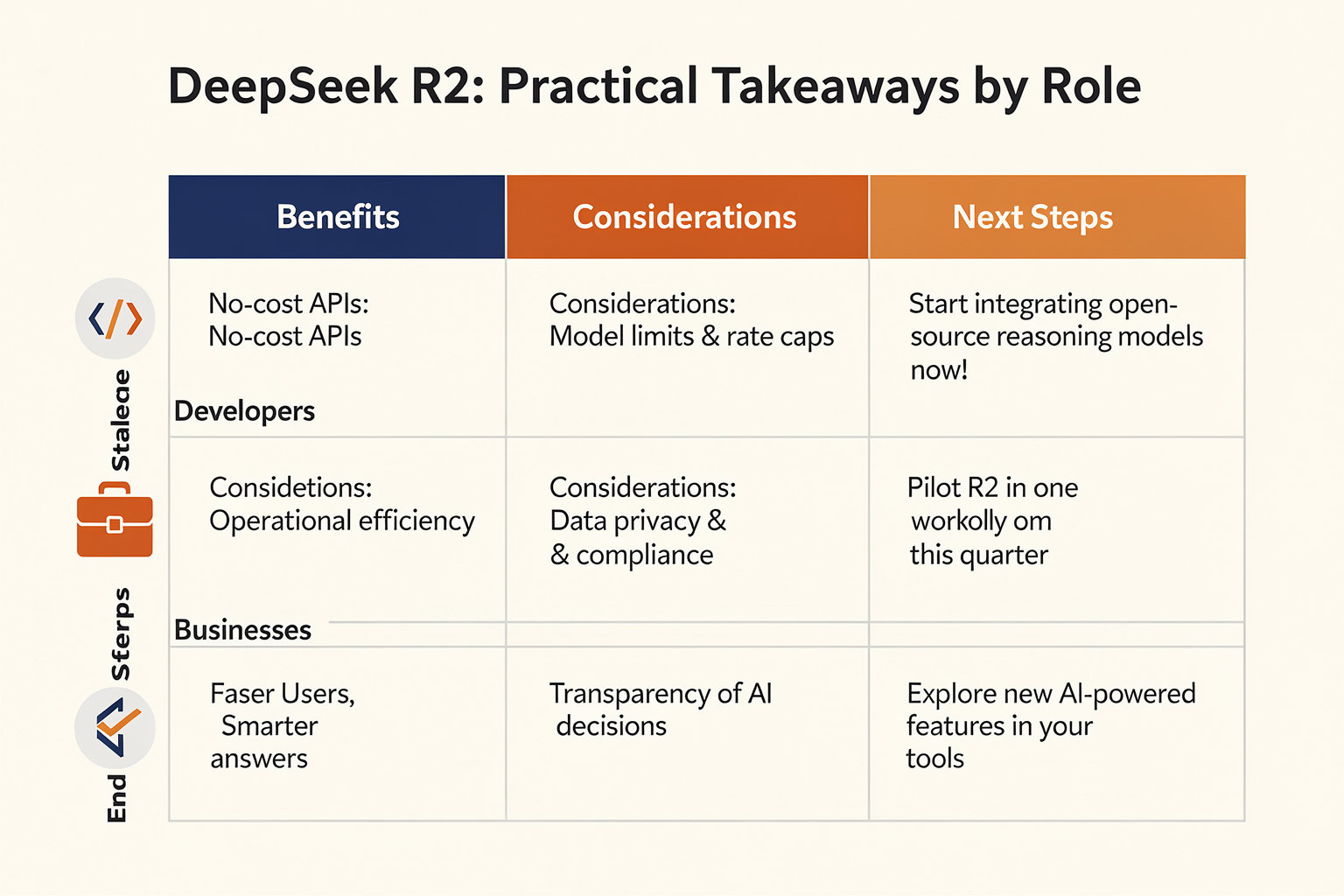
With DeepSeek R2’s open-source release in April 2026, the AI community faces a new paradigm. The model’s performance, price, and open-weight availability dramatically alter the landscape for developers, businesses, and end users alike. DeepSeek R2’s achievement—matching GPT-4o on 9 out of 12 standard benchmarks and boasting a 92.7% AIME 2025 score (DecodeTheFuture.org)—brings capabilities historically reserved for commercial giants into the hands of the broad tech ecosystem. The table below summarizes the practical implications across the three main stakeholder groups:
| Stakeholder | Key Benefit | Example Use Case | DeepSeek R2 vs. GPT-4o (Benchmarks) | Industry Impact |
|---|---|---|---|---|
| Developers | Zero API cost, customizable model | Fine-tune locally for niche apps | Matches on 9/12 benchmarks | Rapid prototyping and experimentation |
| Businesses | Drastically reduced LLM costs | AI-powered customer support | Comparable performance, $0 API fees | Democratized access to high-end AI |
| End Users | Improved app features, privacy | Multilingual chatbots | 32B params, strong math/coding | Greater language and task diversity |
| AI Startups | Fast-tracked innovation cycle | Building domain-specific agents | Open weights, commercial use allowed | Lower barrier vs. proprietary APIs |
| Global South | Accessible research/deployment | Local language digital services | 22+ language support (with add-ons) | Inclusive tech adoption; cost savings |
Implications and Concrete Examples
- Developers gain unprecedented freedom. Since DeepSeek R2’s open weights can be fine-tuned across domains, developers can address hyper-specific needs without waiting for proprietary vendors to support new features. The ability to run R2 on a single 24GB GPU (DecodeTheFuture.org) means that ambitious projects—like advanced offline voice assistants or agentic workflows—are now feasible even for small teams.
- Businesses can reimagine operational costs. Traditional API calls to models like GPT-4o have associated costs that quickly multiply at scale, but DeepSeek R2’s $0-per-call pricing structure removes this barrier. For customer service, content generation, or back-office automation, companies can now process high volumes of interactions without the fear of API overages. This leads to a surge in AI adoption, especially among SMEs and in developing markets.
- End users benefit from richer, more private, and regionally relevant AI applications. DeepSeek R2’s architecture excels at reasoning and coding tasks, making tools more intuitive and solving more complex user requests. Furthermore, open weights mean applications can be deployed on-premises, helping organizations adhere to privacy regulations—a long-standing challenge in sectors like health and finance.
- AI startups are positioned to disrupt entrenched industry giants. With DeepSeek R2’s commercial-use-friendly license, startups can develop proprietary finetunes and deploy at scale with minimal upfront capital. This promotes a broader wave of domain-specialized AI agents—medical experts, tax advisors, or regional language tutors—previously held back by API access costs and closed licensing.
- Global South markets achieve inclusion. With lower compute requirements and strong multilingual potential (pending ecosystem add-ons and community support), DeepSeek R2 enables breakthrough deployments in underserved languages and contexts. Digital government, health, and education services powered by DeepSeek R2 become viable even in low-resource settings.
CallMissed in the New Ecosystem
Platforms like CallMissed are already capitalizing on these trends, integrating open models like DeepSeek R2 into their AI communication infrastructure. By supporting 22 Indian languages for Speech-to-Text and enabling LLM “hot-swapping” across 300+ models (including DeepSeek R2), CallMissed empowers businesses to rapidly deploy multilingual voice and chat agents—at a fraction of yesterday’s cost. This infrastructure accelerates the democratization of high-quality AI-powered services and ensures that innovations like DeepSeek R2 are accessible not just in Silicon Valley, but from Mumbai to Nairobi.
Forward-Looking Impact
As industry benchmarks are redefined by rapidly improving open weights, expect:
- Increased pace of AI innovation globally, as resource bottlenecks disappear.
- Emergence of models trained on local data that better serve non-Western linguistic and cultural needs.
- New privacy-centric AI apps where data never leaves organizational boundaries.
- Lowered TCO (total cost of ownership) for enterprises willing to invest in on-premises or hybrid AI stacks.
Quoting a recent analyst summary (YouTube, tBG2ZfKYwao): “DeepSeek R2 will shift the AI industry’s center of gravity from closed, expensive silos to an open, collaborative ecosystem.” For stakeholders across the spectrum, this is not just an incremental update—it’s a tectonic realignment in how advanced reasoning and generative AI are consumed, improved, and shared.
Frequently Asked Questions About DeepSeek R2
What is DeepSeek R2 and how does it compare to other AI models like GPT-4o?
Is DeepSeek R2 truly open-source and what are its usage limitations?
What are DeepSeek R2’s main features and strengths?
How does DeepSeek R2 handle multilingual and regional language tasks?
What are some popular use cases for DeepSeek R2 in 2026?
How can I run DeepSeek R2 or integrate it into my business solutions?
Looking Ahead: The Future of Open-Source AI Reasoning

The Rise of Open-Source Reasoning Models
The release of DeepSeek R2 in April 2026 is reshaping expectations across both the AI research community and real-world industry. R2’s open-weight, 32-billion-parameter architecture not only achieves a remarkable 92.7% on AIME 2025—the gold standard for mathematical and logical reasoning—but also matches proprietary models like GPT-4o on 9 out of 12 public benchmarks [1]. The crucial difference? R2 is fully open-source, meaning its capabilities are accessible to any developer or organization for literally $0 in API costs.
This is not just a milestone in model performance, but a tectonic shift in how advanced reasoning technologies are shared, audited, and fine-tuned. As DeepSeek R2 and similar projects proliferate, three core trends are emerging:
- Radical democratization of access: High-caliber reasoning isn’t locked behind paywalls or closed APIs; it’s downloadable and remixable.
- Acceleration of global experimentation: Researchers, startups, and even high school students can innovate on top of state-of-the-art architecture.
- Faster cycle of innovation: Unlike closed-source models, updates and improvements to open-source models propagate rapidly.
What’s Driving the Open-Source Surge?
Several factors help explain why reasoning—long viewed as an “elite” AI skill set—is suddenly going open-source at unprecedented scale:
- Open-weight architectures: DeepSeek R2, for example, ships its 32B parameter weights under an MIT license, echoing the trend started by models like Meta’s Llama-3 and Mistral-8x22B.
- Hardware efficiency: R2 reportedly runs inference on a single 24 GB GPU for many tasks [2]—this removes the friction of needing a massive compute cluster.
- Leaderboard parity with closed models: R2’s benchmark results demonstrate that open-source models can now rival—or even outperform—flagship proprietary models in logical, code, and multimodal reasoning tasks.
- Vibrant global developer ecosystems: Asian startups, academic labs, and indie ML communities are coalescing around open foundations, putting pressure on legacy providers.
Real-World Impact and Industry Adoption
The implications for business, government, and society are profound. Open-source reasoning AIs can be tailored for sector-specific needs, localized to diverse languages, and deployed within secure environments—a must for regulated sectors like healthcare and finance.
#### Example Use Cases
- Customer support automation: AI agents with reasoning skills can parse complex queries and escalate only genuinely novel issues.
- Code review and autocompletion: As seen with R2’s advanced code generation, open models now compete with proprietary coding assistants, but are far more customizable for enterprise workflows.
- Education and upskilling: Teachers and edtech platforms can build free, curriculum-aligned tutoring bots leveraging peer-reviewed reasoning models.
- Public sector applications: Municipal websites, e-governance platforms, and legal workflows benefit from transparent, locally deployable AI.
Platforms such as CallMissed are already leveraging these breakthroughs: by integrating open-weight reasoning models, they enable businesses to deploy LLM-powered voice agents in 22 Indian languages and across global communication channels—an essential step toward inclusion and real-time AI augmentation at scale.
Challenges and Future Directions
Despite headline-grabbing benchmark parity, open-source reasoning faces several hurdles as it heads into mainstream enterprise adoption:
- Robustness and safety: Open models must meet or exceed the safety/guardrail standards set by closed shops like OpenAI and Anthropic.
- Data and privacy compliance: Fine-tuning and deployment within regulated sectors require strict audit trails and secure infrastructure.
- Fragmentation vs. consolidation: With hundreds of open-weight LLMs released in just the past year, tooling and API fragmentation can hinder adoption unless standardized “gateway” APIs (like those offered by CallMissed) are used.
- Ongoing cost of compute: While transfer and inference are cheaper, fine-tuning large reasoning models is still not cost-free—especially for smaller organizations.
As the ecosystem matures, expect to see:
- Foundation models as infrastructure: Open-source LLMs will be treated as “communication infrastructure,” akin to databases or HTTP servers.
- Global regulatory norms: More governments may require open models or “right to audit” for all public AI deployments, driving even faster adoption of transparency-by-design architectures.
- Multimodal reasoning leaps: As the line blurs between language, code, and image reasoning, open models will move rapidly into enterprise RAG, complex dialog, and workflow automation tasks.
The Coming Decade: Where Open-Source Reasoning Is Headed
Here’s how the landscape might evolve by 2030, drawing from current data and emerging trends:
| Year | Key Milestone | Open-Source Model | Benchmarks Surpassed | Industry Examples |
|---|---|---|---|---|
| 2024 | Llama-3 release | Llama-3 70B | Near parity on General Language | OpenAI, Meta, HuggingFace |
| 2025 | DeepSeek R1 launches | DeepSeek-R1 | Code & Logical Reasoning | DeepSeek, China AI startups |
| 2026 | DeepSeek R2 open-sourced | DeepSeek R2 | 9/12 GPT-4o Benchmarks, 92.7%AIME | CallMissed, Education, Healthcare |
| 2028 | Multimodal open models natively reason | TBD | Language, Code, Image, and Sensor Data | Voice bots, Industry 4.0, Compliance |
By 2030, it’s plausible that:
- Fully multilingual conversational agents—running on open weights—will be the default interface for healthcare, law, and government.
- Transparent reasoning “audit logs” will be available on demand by any stakeholder, driving new trust models in both public and private sector AI deployment.
- AI-native vertical SaaS: Expect every serious SaaS provider to offer optional, self-hosted open reasoning plugins, much in the way APIs abstract payments or messaging today.
Conclusion: The Open-Source Reasoning Era Begins
DeepSeek R2’s arrival is more than a technical achievement. It signals a permanent re-ordering of who can participate in advanced AI development—not just big tech, but a genuinely global, open-source community. With platforms like CallMissed making this capability production-ready for businesses and startups, we’re entering an era where language, logic, and communication barriers collapse.
The next AI breakthroughs won’t be limited to closed labs—they’ll originate anywhere talent, hardware, and targeted data combine. Open-source reasoning has gone from experiment to infrastructure, setting the stage for the world’s most ambitious communication and automation projects—not tomorrow, but today.
Conclusion
- DeepSeek R2 stands out as a major disruptor in 2026, matching GPT-4o on 9 out of 12 key reasoning benchmarks while eliminating API costs thanks to its open-source license (Reddit, 2026).
- Its 32 billion parameters and 92.7% score on the AIME 2025 test set a new standard for accessible, high-performance reasoning models (Decode the Future, 2026).
- By being open-weight and operational on relatively modest hardware, DeepSeek R2 dramatically broadens access for research, enterprise AI, and regional innovation across the globe.
- DeepSeek’s emphasis on multilingual and code reasoning capacity aligns with the urgent demand for truly global AI solutions that surmount linguistic and domain barriers.
Looking ahead, the most important question is how rapidly ecosystems—from open-source communities to enterprise platforms—will capitalize on DeepSeek R2’s capabilities. Expect to see rapid iteration in agent-based workflows, custom AI assistants, and language-specific deployments—especially in regions previously underserved by proprietary AI infrastructure. AI platforms like CallMissed, which already enable seamless deployment of voice agents and multilingual chatbots, are well positioned to integrate models like DeepSeek R2 into real-world business workflows as this new wave of reasoning AI becomes mainstream.
Will the democratization of high-level reasoning models like DeepSeek R2 supplant proprietary systems—or usher in a new era of hybrid human+AI collaboration? Now is the time for developers, businesses, and researchers to rethink what’s possible with open AI. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.


