AI Product Pricing Models in 2026: Per-Token vs. Per-Seat vs. Per-Outcome

AI Product Pricing Models in 2026: Per-Token vs. Per-Seat vs. Per-Outcome
Did you know that some enterprise organizations are racking up jaw-dropping SaaS bills of up to $900,000 a month for seat-based AI licenses, only to realize that a usage-based alternative would have cost them a fraction of that amount? For over two decades, the "per-seat" pricing model has been the undisputed king of software-as-a-service (SaaS). It was simple, predictable, and aligned perfectly with a world where human employees sat at desks manually operating tools. But as autonomous AI agents increasingly do the heavy lifting—often executing the workload of several human workers simultaneously—charging per seat makes less and less sense. In fact, it actively penalizes software vendors for building highly efficient, automated products. If an AI agent resolves a complex task in seconds without human intervention, who exactly occupies the "seat"?
This paradigm shift has forced a massive reckoning in how software is monetized, putting AI Product Pricing Models at the center of modern business strategy. If your product can draft thousands of lines of code or process high-volume customer inquiries in an afternoon, pricing that value based on active users is a relic of the past. Today, businesses and developers are caught in a complex tug-of-war between budget predictability and realized value. Buyers want to know exactly what they will spend each month, while sellers need to cover the highly variable, computationally expensive costs of large language model (LLM) inference—costs that can swing wildly based on user prompts, system integrations, and background workflows.
To navigate these challenges, the market has segmented into three dominant paradigms. On one end, we have raw, usage-based pricing like the per-token model, where costs typically range from $0.0001 to $0.10 per 1,000 tokens. This model is highly transparent for developers but can be incredibly volatile and difficult for corporate finance departments to forecast. On the other end sits the traditional per-seat model (typically ranging from $50 to $200 per seat, per month), which offers budgeting peace of mind but fails to scale with the true utility of generative tools. Emerging rapidly as the ultimate value-aligned option is per-outcome (or per-resolution) pricing, where customers pay a flat fee—such as $1.50 per successfully resolved customer ticket—only when the AI delivers a concrete, verifiable result.
Navigating this complex landscape requires a deep understanding of infrastructure costs and deployment patterns. For instance, communication infrastructure platforms like CallMissed are already helping companies mitigate these exact pricing headaches by offering flexible multi-model LLM inference gateways alongside scalable voice and messaging APIs, allowing developers to optimize their token spend behind the scenes.
In this comprehensive guide, we will break down the mechanics, math, and trade-offs of the dominant AI Product Pricing Models currently shaping the market. You will learn the hidden economics behind per-token usage, why enterprise buyers are aggressively pushing back against legacy per-seat pricing, and how to structure a modern, hybrid "per-outcome" model that aligns your software's pricing with the actual value it delivers. Whether you are a product leader designing a monetization strategy or an enterprise buyer looking to optimize your technology spend, this playbook will provide the framework you need to make the right choice.
The Shifting Economics of AI: Why Traditional SaaS Pricing is Breaking in 2026
The Cost Revolution AI Has Triggered
The surge in generative AI and automation is transforming not just how businesses operate, but how software gets sold and consumed. In 2026, traditional SaaS pricing models—monthly per-seat subscriptions—are being stretched to the breaking point in the face of fundamentally new consumption and value patterns. Where software once merely amplified human productivity, AI solutions often replace repetitive tasks, scale instantly, or perform work on behalf of humans altogether. This shift means that pricing based on “number of seats” can actually discourage efficiency and raise difficult, even existential, budgeting questions.
As Pranav Pathak notes in BuilderLab.ai: “When your AI agent does the work of five people, charging per seat penalizes you for the exact outcome your product delivers.” Instead, usage-based and outcome-based models are gaining ground as they align better with how value is created in an AI-first world (source: BuilderLab.ai).
Why Per-Seat Pricing Breaks Down in the Age of AI
The classic per-seat billing method—charging $50-$200 per user per month as still seen across enterprise SaaS platforms (Korix, 2026)—has always presupposed human engagement as the bottleneck. With AI, that bottleneck evaporates:
- AI augments or replaces manual human input (e.g., in support, coding, translation, lead gen).
- Workloads can scale exponentially with minimal incremental cost.
- Value becomes decoupled from user logins—the same AI agent might serve 5,000 or 50,000 interactions, with no additional “seats” provisioned.
For example, federal and state agencies faced with $300,000–$900,000 per month per-seat bills for legacy software are now evaluating AI-powered alternatives at a fraction of the cost, especially where usage (not user count) drives the expense (IBL.ai, 2026). Many small businesses, too, are caught between rigid seat-based contracts and the dynamic needs that only AI can address.
The Rise of Usage and Outcome-Based Pricing
AI’s core innovation is programmable intelligence at scale. That triggers new economic models, notably:
- Per-Token Billing (Usage-Based):
Customers pay per token, API call, or model inference. For LLMs, this often ranges from $0.0001–$0.10 per 1,000 tokens (Korix, 2026). This aligns directly with actual consumption, making costs far more predictable and transparent—especially critical at enterprise scale.
- Per-Outcome or Per-Ticket Models:
Rather than charging for the “potential” to use the product (a seat), fees are incurred only when a task is completed, such as a resolved customer ticket, successful insight, or automated transaction. This approach was cited as $0.30–$1.50 per outcome in 2026 pricing surveys (Korix).
Why the shift?
AI technology is not simply another tool in the tech stack; it’s now the performing agent. Customers want to pay for the value and impact delivered—not for idle potential or unused access.
The Impact: What Businesses Are Experiencing Now
The financial implications for organizations are profound:
- Seat-based models now penalize efficiency: A single AI agent might replace the work of a team, but legacy pricing inflates costs as if each human was still in the seat.
- Usage and outcome-based approaches optimize for scale and ROI, enabling startups and enterprises alike to right-size their investment to their actual needs.
- IT leaders can much more easily forecast and control expenditures, avoiding bill shock from unforeseen “user” growth.
A notable trend in 2026: over 60% of net-new AI commercial products are launching with usage-based pricing as the default (DataMania, 2026), and global enterprises are demanding hybrid or fully outcome-based agreements for major deployments.
Beyond Cost: Adoption, Trust, and Business Model Alignment
The pricing model a provider chooses does more than just set a price—it shapes how AI gets adopted, scaled, and trusted across an organization (LinkedIn, 2026):
- Lower barriers to entry: Usage-based and per-outcome billing allow for easier pilots, sandboxing, and rapid iteration without heavyweight commitments.
- Alignment of interests: Providers are incentivized to help customers drive value—such as speedier ticket resolution or higher conversion rates—rather than simply sell more seats.
- Cloud-native economics: AI’s infrastructure roots make variable, metered pricing a natural fit, mirroring the flexibility customers expect from modern cloud platforms.
Pioneers: Modern AI Infrastructure in Action
Platforms like CallMissed exemplify this transformation, offering LLM inference across 300+ models, Speech-to-Text APIs for 22 languages, and voice/chat agents—all built on scalable, usage-based pricing. This allows Indian startups and global enterprises alike to deploy AI voice agents and chatbots without the lock-in or rigidity of seat-based legacy systems.
By treating language, inference, and agent “work effort” as metered resources, businesses can experiment, scale, and optimize for outcomes—paying only for what they use or the value received. The result: AI adoption becomes a variable OPEX spend, not a fixed overhead, opening the doors to new use cases previously cost-prohibitive under traditional SaaS contracts.
Conclusion: Traditional SaaS Pricing Must Evolve
The old enterprise playbook—“seats sold equals growth”—is fast becoming obsolete. AI alters not only the unit economics of software, but also the customer-provider relationship itself. By 2026, per-token, usage-based, and outcome-driven pricing have moved from fringe options to the industry default for AI-powered products. Companies leveraging platforms such as CallMissed, which embody this new model, are better positioned to lead and innovate in an AI-first world.
In the sections that follow, we’ll break down the specifics of per-token, per-seat, and per-outcome pricing models, their trade-offs, and the strategic implications for AI vendors and buyers alike.
The Evolution of Software Pricing: From Seats to Compute
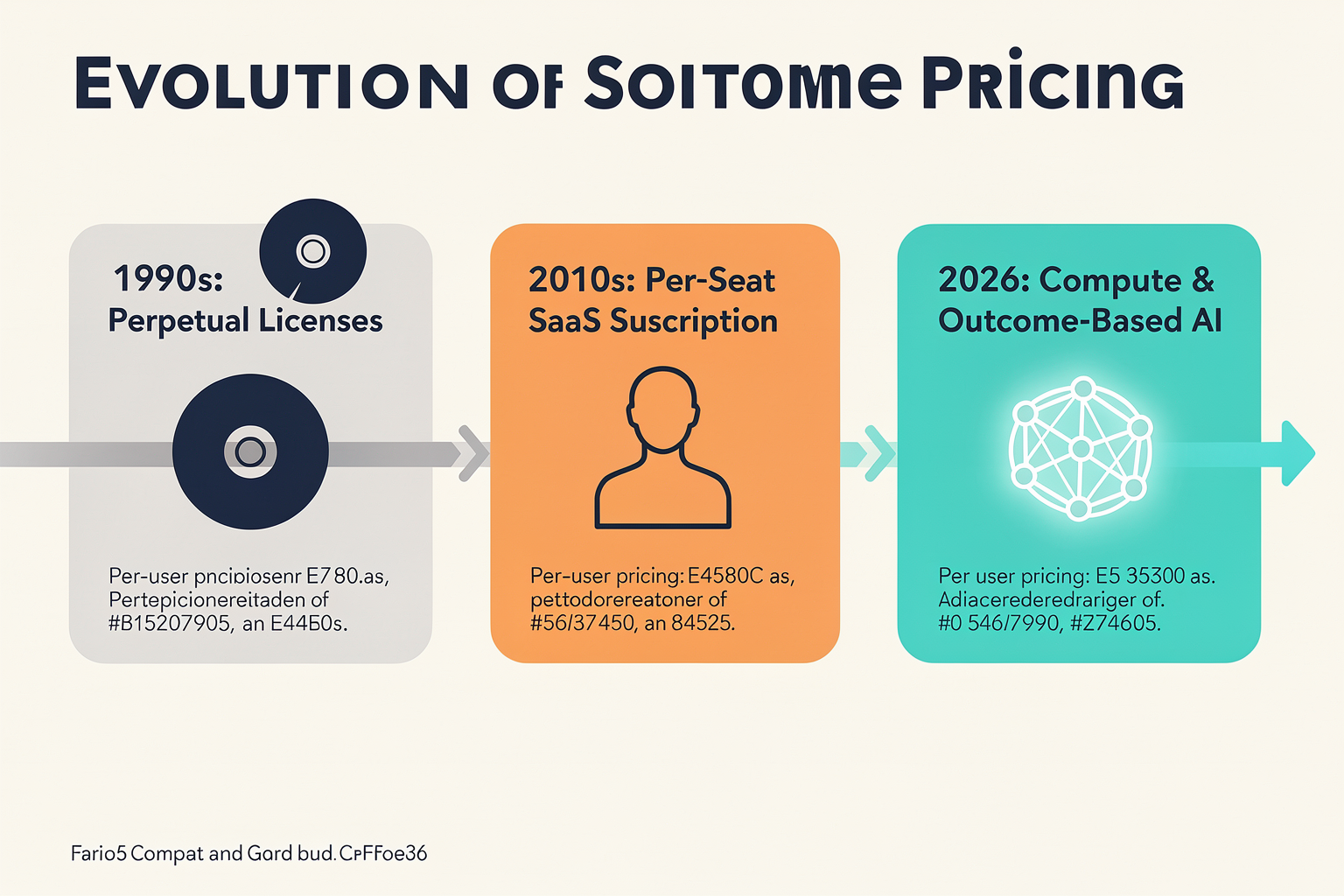
For nearly three decades, software pricing was defined by a simple, highly predictable metric: the human user. The per-seat subscription model, pioneered by early SaaS giants in the 2000s and cemented by platforms like Salesforce, Microsoft, and Slack, became the golden standard of software monetization. If an enterprise had 500 employees who needed access to a tool, they bought 500 licenses.
This model worked spectacularly well for both buyers and vendors because traditional software economics relied on near-zero marginal costs. Once a software platform was built, hosting an additional user cost the vendor pennies, yielding enviable gross margins of 80% to 90%. For buyers, per-seat licensing provided budget predictability—a fixed cost that scaled linearly with headcount.
However, the rapid ascent of Generative AI has broken this traditional paradigm. We are currently living through a fundamental shift in how software value is calculated, transitioning from seat-based pricing to compute-based and outcome-based pricing. As software evolves from a passive tool used by humans to an active agent doing the work instead of humans, charging per human seat is no longer economically viable or logical.
The Economics of Traditional SaaS vs. AI Compute
To understand why the per-seat model is crumbling, one must look at the shifting Cost of Goods Sold (COGS) in the AI era. In traditional SaaS, a user typing a search query, updating a CRM record, or moving a card on a Kanban board consumes negligible server resources.
With Generative AI, every single interaction is incredibly resource-intensive. When a user prompts a Large Language Model (LLM) to write a report, analyze a dataset, or generate code, they kickstart a cascade of heavy matrix multiplications across specialized GPU clusters.
This introduces a massive variable cost for software vendors. Instead of paying a flat, predictable hosting fee, AI vendors pay for raw compute, which is measured in tokens (the basic units of text or data processed by an LLM). This variable cost exposure creates a dangerous mismatch under a pure seat-based pricing model:
- Traditional SaaS seat pricing typically ranges from $50 to $200 per seat, per month. For this price, the user has unlimited access to the application’s standard features.
- AI compute costs are strictly usage-based, with LLM token pricing ranging from $0.0001 to $0.10 per 1,000 tokens depending on the size and complexity of the model being utilized.
- The Power User Risk: If a single "power user" on a flat $30/month AI plan runs thousands of complex prompts, processes millions of tokens, or generates hours of synthetic voice content, their raw API and GPU compute costs can easily exceed their monthly subscription price. The vendor suddenly finds themselves losing money on their most active customers.
To stay profitable while leveraging cutting-edge models, developers must carefully manage their LLM usage and routing. This infrastructure challenge is why many forward-thinking teams rely on modern middleware. For example, CallMissed provides a unified multi-model LLM API gateway that lets developers seamlessly route queries across more than 300+ models. By dynamically switching between heavy-duty frontier models for complex tasks and faster, highly cost-effective models for simpler prompts, platforms can prevent runaway compute costs from eating their margins.
The Incentive Paradox of "Software as Labor"
Beyond the variable cost shock of GPUs, the per-seat model suffers from a deeper, structural flaw when applied to AI: it creates a direct conflict of interest between the software vendor and the buyer.
In the traditional software era, applications were designed to increase human efficiency. A better CRM helped a salesperson log more calls; a better design tool helped a designer create assets faster. But the human was still the bottleneck. The vendor's revenue grew as the customer hired more people and bought more seats.
AI, however, is not a tool to help a human do work; in many cases, the AI is the worker. Autonomous AI agents can now handle customer support queues, draft legal contracts, or execute outbound sales campaigns with minimal human intervention.
This shift triggers what industry analysts call the AI Incentive Paradox: when your AI agent does the work of multiple people, charging per seat penalizes you for the exact value and efficiency your product delivers.
Consider an enterprise customer support team. If a company deploys an advanced conversational AI agent that successfully automates 80% of their customer support tickets, they will inevitably shrink their human support staff. If the AI customer support software is priced per-seat, the software provider’s revenue will drastically decrease because the customer needs fewer human seats. The more effective, autonomous, and valuable the AI software becomes, the less money the software creator makes.
To resolve this paradox, the software industry is forced to decouple value from human headcount and link it directly to the digital labor performed—either through raw compute metrics or specific, measurable outcomes.
The Rise of Compute-Based and Token-Based Metrics
As a bridge between the old world of flat-rate subscriptions and the future of automated work, many B2B and consumer AI applications have embraced compute-based pricing (often referred to as usage-based or token-based pricing).
Under this model, customers are billed directly for the computational volume they consume. This can manifest in several ways:
- Direct Token Metering: Popularized by infrastructure and API providers, this model charges customers fractions of a cent per token processed (both input and output). This aligns costs perfectly with resource consumption but can be incredibly difficult for non-technical enterprise buyers to predict or budget for.
- Credit-Based Systems: Many SaaS applications abstract the complexity of tokens by selling "credits." A user might buy a monthly plan that includes 10,000 credits. A simple text prompt costs 1 credit, an image generation costs 10 credits, and running a complex data analysis agent costs 50 credits.
- Per-Inference or Per-API Call: For non-text workflows, such as voice agents, video generation, or translation, pricing is tied to execution units—such as cents per minute of synthesized speech, or a flat rate per API call.
While compute-based pricing protects the margins of AI vendors, it shifts the burden of predictability onto the customer. Finance departments, accustomed to predictable, recurring software expenditures, are often hesitant to sign off on variable utility bills that can fluctuate wildly based on user behavior.
This tension is driving a rapid evolution toward hybrid pricing structures. In 2026, we are seeing the emergence of sophisticated models that combine a low-cost, predictable platform "seat" fee (to cover basic hosting, UI, and data storage) with a flexible, tiered usage tier for heavy AI actions.
Ultimately, the transition from pricing "seats" to pricing "compute" is merely a stepping stone. As AI systems become more reliable and autonomous, the industry is already moving toward the ultimate monetization model: pricing based on the actual outcomes and resolutions the AI achieves.
Comparing the Big Three: Per-Seat, Per-Token, and Per-Outcome (TABLE)
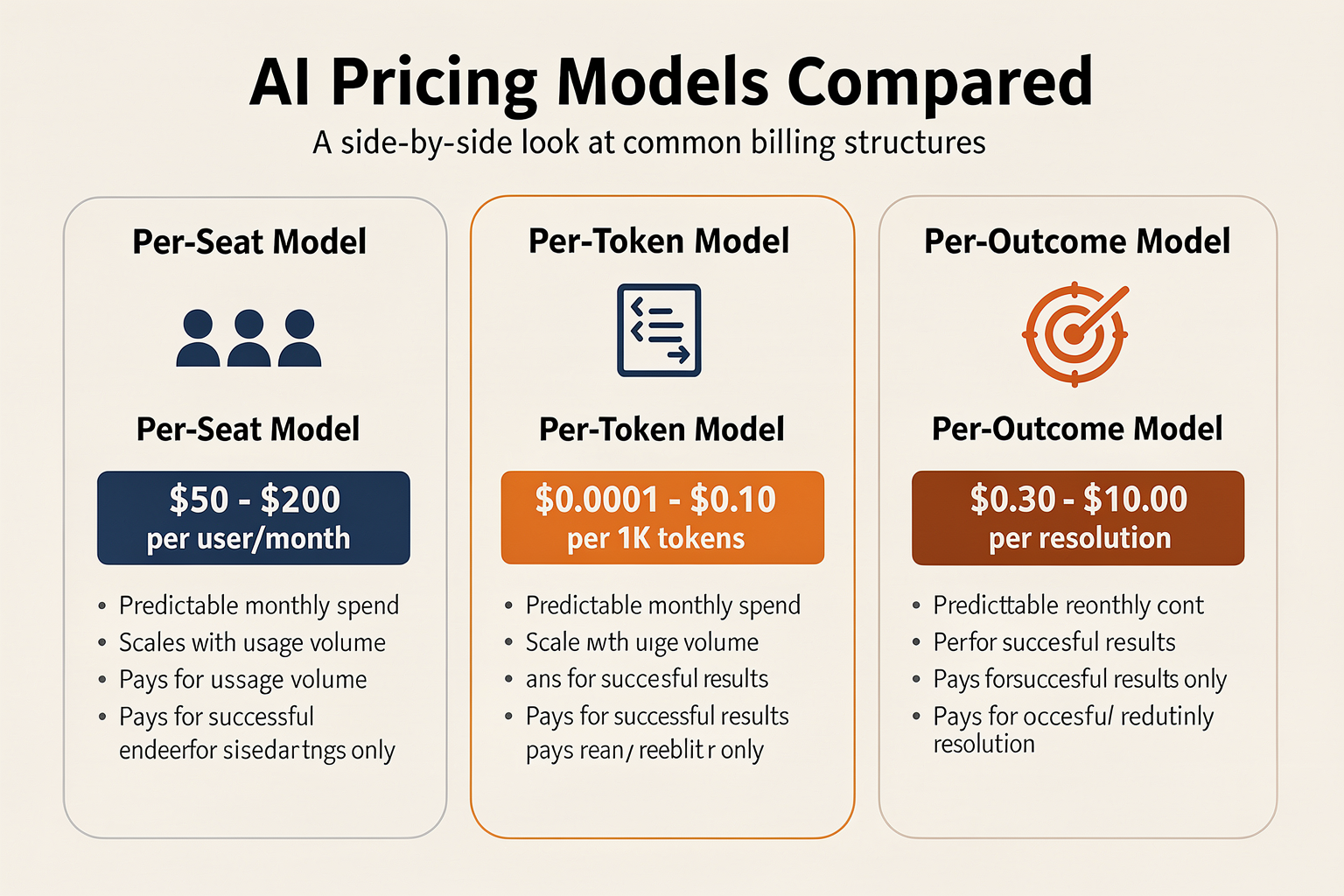
To understand how to price or purchase AI services, you must first understand the fundamental mechanics of the "Big Three" monetization models: Per-Seat, Per-Token (Usage-Based), and Per-Outcome (Value-Based).
Each model shifts the financial risk, budget predictability, and value alignment between the vendor and the buyer. While traditional SaaS relied almost entirely on the predictability of seat licenses, the heavy compute costs and autonomous capabilities of modern generative AI have forced a massive shift toward usage-based and outcome-driven frameworks.
The table below outlines the core differences, current market rates, and typical use cases for these three primary models, along with the hybrid credit model that often bridges the gap.
The AI Pricing Matrix
| Pricing Model | Typical Rates | Primary Benefit | Key Drawback | Best Used For |
|---|---|---|---|---|
| Per-Seat | $50 – $200 / user / month | High budget predictability; highly familiar to SaaS procurement teams. | Penalizes software efficiency; vendor loses money as AI productivity increases. | Co-pilots, text editors, and human-in-the-loop productivity suites. |
| Per-Token (Usage) | $0.0001 – $0.10 / 1,000 tokens | Perfectly aligns vendor costs with customer compute consumption. | Unpredictable billing; difficult for non-technical buyers to budget. | Raw LLM APIs, database vector search, and background batch processing. |
| Per-Outcome | $0.30 – $1.50+ / successful resolution | Direct ROI alignment; customers only pay when the AI successfully delivers. | Complex to define "success"; high financial risk for the vendor if AI fails. | Customer support agents, autonomous lead qualification, and voice agents. |
| Hybrid (Credit-Based) | Tiered subscription packages (e.g., $99/mo for 10,000 credits) | Balances SaaS predictability with flexible usage across different AI models. | Adds a confusing abstraction layer; customers struggle to map credits to tasks. | Multi-modal platforms (combining text, voice, and image generation). |
Deep-Dive: The Mechanics of the Big Three
To choose the right model for your business or to evaluate vendors effectively, you must look beyond the pricing sheet and analyze how these structures affect adoption, scaling, and ROI.
#### 1. Per-Seat Pricing: The Legacy Model Under Pressure
The traditional Per-Seat model charges a flat monthly fee per user license. This model remains popular for generative AI tools that act as "co-pilots" rather than "autopilots." If your software requires a human user to sit in front of the screen, input prompts, and manually edit the output (like Microsoft 365 Copilot or Github Copilot), seat-based pricing makes complete sense.
However, as AI agents become autonomous, charging per seat creates a major paradox. If an AI agent does the work of five human customer service agents, a business might only need one "seat" to manage the system. Under a strict seat-based model, the software vendor is heavily penalized for creating an incredibly efficient product that reduces human headcount.
#### 2. Per-Token (Usage-Based) Pricing: The Developer's Utility
Per-Token pricing charges directly for the compute resources consumed. In natural language processing, a token represents roughly four characters or 0.75 words. Prices typically scale based on the intelligence and context window of the underlying model, ranging from fractions of a cent ($0.0001 per 1,000 tokens) for basic models to $0.10 or more for advanced reasoning engines.
While this utility-style pricing protects the vendor's profit margins against heavy GPU hosting costs, it creates severe budgeting anxiety for enterprise buyers. An accidental infinite loop in an autonomous agent's code can easily rack up thousands of dollars in API bills overnight. Furthermore, business users do not think in "tokens"—they think in reports, emails, or solved customer queries.
#### 3. Per-Outcome Pricing: The New Frontier of Value
Per-Outcome (or per-resolution) pricing represents the ultimate evolution of AI monetization. Instead of paying for the tools to do the work, buyers pay for the completed work itself. For instance, instead of paying $100/month for a customer service software seat, a company might pay $1.50 for every customer ticket the AI agent resolves without human intervention.
This completely aligns incentives. The customer only pays for tangible ROI, and the software creator is highly incentivized to make their AI agent as fast, accurate, and autonomous as possible. However, implementing this model requires bulletproof telemetry and mutual agreement on what constitutes a "successful outcome" versus a failed attempt that requires human escalation.
How CallMissed Simplifies the Infrastructure Behind Pricing Models
Regardless of which pricing model a company chooses to offer its customers, managing the backend infrastructure to support these models can be incredibly complex. Tracking API token usage across multiple LLMs, monitoring voice call duration, and measuring successful customer resolutions requires robust middleware.
This is where platforms like CallMissed become invaluable. CallMissed provides an AI communication infrastructure that allows developers to access over 300+ LLMs via a unified API gateway. By offering built-in Speech-to-Text in 22 regional Indian languages, high-quality Text-to-Speech APIs, and autonomous voice agent orchestration, CallMissed handles the heavy lifting of tracking token consumption and call outcomes. Businesses can leverage CallMissed's scalable infrastructure to easily test different pricing strategies—whether they want to charge their customers per token, per call minute, or per successful resolution.
The Comfort and Constraints of Per-Seat AI Pricing
For the past two decades, Software-as-a-Service (SaaS) has lived and breathed by one core metric: the per-seat pricing model (also known as per-user licensing). When the pioneers of modern cloud software built their empires, they did so on a simple, elegant premise: more employees using the software equated to more value delivered to the enterprise.
As we navigate the current landscape of 2026, the generative AI boom has forced a massive, structural reckoning with this legacy pricing system. While the per-seat model remains highly popular among enterprise buyers—with typical industry rates for AI productivity seats sitting between $50 to $200 per seat per month—the underlying mechanics of large language models (LLMs) and autonomous agents are fundamentally at odds with charging per human login.
Evaluating the comfort of seat-based pricing alongside its hidden constraints reveals why this traditional SaaS model is cracking under the weight of cognitive automation.
The Familiar Appeal: Why Buyers Crave the "Seat"
For enterprise procurement teams, IT departments, and Chief Financial Officers, the seat-based model represents the ultimate psychological safety net. It offers a predictable, highly controllable software spend that fits neatly into existing spreadsheet formulas.
- Predictability and Budget Control: Corporate budgets are planned months, sometimes quarters, in advance. If a department head has 150 customer support agents, they can easily calculate that a $100/seat AI copilot will cost exactly $15,000 per month. There is no fear of "billing shock" or a runaway query loop costing the company tens of thousands of dollars overnight.
- Frictionless Purchasing: Buying software per-user requires no complex architectural planning. Because enterprises are already configured to provision seats via identity providers like Okta or Microsoft Azure Active Directory, buying AI seats matches their established operational workflows.
- A Clear Proxy for User Adoption: For internal project managers, the number of active seats is an easily trackable metric to prove to executive leadership that an AI tool is actually being utilized across the organization.
The Margin Squeeze: The Silent Killer of Per-Seat SaaS
While buyers love the predictability of per-seat models, AI software vendors face a massive financial risk: the variable cost of compute.
In traditional SaaS, the marginal cost of hosting one additional user is near-zero, resulting in gross margins of 80% to 90%. In the world of generative AI, however, every query sent to an LLM incurs a direct cost measured in tokens. A "light" user might cost the vendor pennies a month, while a "power" user utilizing advanced reasoning models for coding or deep data analysis can easily consume millions of tokens, turning a flat $50/month subscription unprofitable.
For instance, with advanced LLM pricing hovering between $0.0001 to $0.10 per 1,000 tokens, a single heavy user can easily bypass their monthly seat cost in API expenses. Vendors are forced to either set aggressive rate limits—which degrades the user experience—or absorb the losses, destroying their SaaS margins.
The Value Paradox: When Efficiency Cannibalizes Revenue
The most critical flaw of per-seat pricing in the age of AI is the value cannibalization paradox.
Traditional SaaS sells tools that make human workers more productive. AI, however, does not just make workers faster; it frequently replaces the need for additional human hours entirely.
Consider an customer support department with 20 representatives. If a business deploys a highly advanced AI agent that automates 75% of incoming support tickets, they may only need 5 human agents to handle the remaining complex cases.
- Under a Per-Seat Model: The customer reduces their seat count from 20 to 5. The AI software vendor is effectively "punished" with a 75% drop in recurring revenue, despite delivering immense business value by drastically cutting the client's payroll.
- The Conflict of Interest: Charging per seat directly incentivizes the software creator to keep human workers in the loop. The more efficient and autonomous the AI becomes, the less money the software company makes. As industry analysts note, when an AI agent successfully executes the workload of multiple people, charging per seat penalizes you for the exact outcome your product delivers.
Redefining the Math: Per-Seat vs. Outcome Economics
To understand how this plays out in real-world scenarios, we can compare the financial commitments of different structures for a mid-sized operation:
- The Pure Per-Seat Commitment: A customer service department licenses an AI copilot for 20 agents at $100 per seat. The fixed cost is $2,000 per month, regardless of whether those agents handle 1,000 or 10,000 customer resolutions.
- The Usage or Outcome Alternative: The same company switches to an AI agent billed at $1.50 per successful resolution. If the agent autonomously resolves 5,000 inquiries that month, the bill is $7,500. While the bill is higher, the customer gladly pays it because it successfully deflected thousands of expensive human touchpoints, while the software vendor is justly compensated for the work performed.
Bridging the Gap with Hybrid Infrastructure
As businesses realize the constraints of traditional user seats, they are increasingly shifting toward hybrid pricing strategies—combining flat base seat fees with usage-based token or API metering—or transitioning entirely to infrastructure-first models.
For organizations deploying automated communication channels, forcing AI voice agents or multilingual automated systems into a "per-seat" box is highly restrictive. Modern AI infrastructure platforms like CallMissed resolve this structural bottleneck. Rather than licensing arbitrary human seats for digital workflows, platforms like CallMissed allow developers and enterprises to scale their communication ecosystems programmatically.
By offering unified API-driven access to more than 300+ LLMs, state-of-the-art Speech-to-Text supporting 22 regional Indian languages, and highly customizable Voice Agents, CallMissed aligns software costs directly with actual volume and business output. This infrastructure-first approach frees organizations from the constraints of per-seat models, ensuring they only pay for the exact volume of customer interactions they handle.
Per-Token and Usage-Based Pricing: Aligning Costs with Consumption
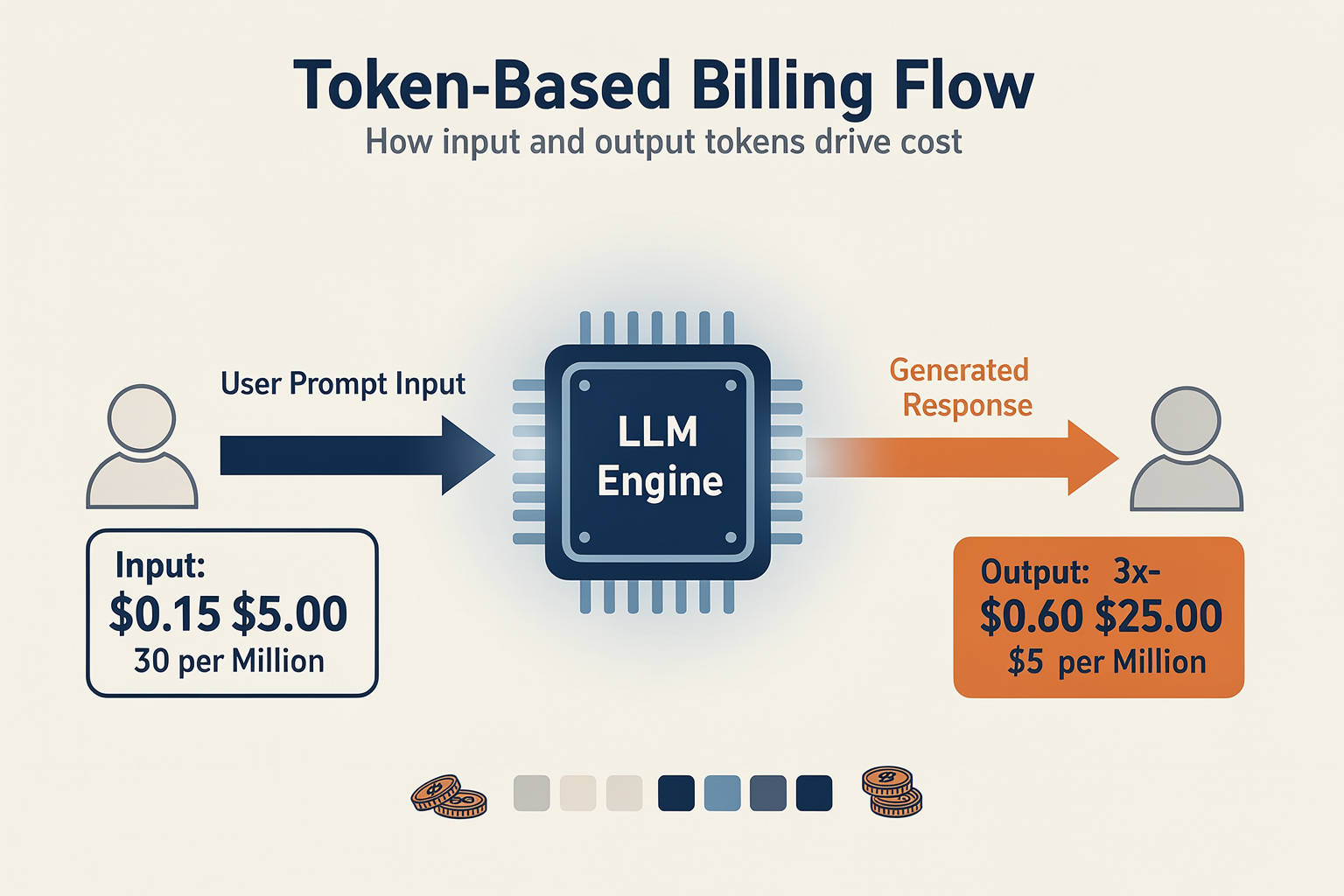
Understanding Per-Token and Usage-Based Pricing
Usage-based pricing—often measured by tokens, API calls, or inference counts—has rapidly become a dominant approach in AI product monetization. In contrast to traditional seat-based models, which charge a flat fee per user regardless of how much they actually use the product, usage-based pricing directly aligns costs with resource consumption. This model is particularly well-suited to AI workloads, where computational expense can vary dramatically depending on the type and volume of requests.
A “token” refers to a discrete unit of text processed by a language model—roughly equivalent to a word or short string of characters. Most large language models (LLMs) process both inputs and outputs in tokens, and vendors typically meter usage (and charge fees) per 1,000 tokens. Common rates as of 2026 range from $0.0001 to $0.10 per 1,000 tokens processed, according to KORIX [1], with variance depending on the model’s sophistication and latency requirements.
This model’s granularity is a compelling advantage:
- It unlocks AI for smaller businesses and teams who want a “pay as you go” approach.
- High-volume, low-complexity use cases can drive down per-unit costs.
- Startups and enterprises alike can better forecast and control budgets, as bills are closely correlated to actual adoption and value delivered.
Why Usage-Based Pricing Thrives in AI
AI workloads are spiky and unpredictable by nature. For instance, a retail business might need 100x more language model inferences during a festival or sale than on a typical day. Per-token billing avoids the inefficiency of paying monthly seat charges for users who rarely interact with the system.
As highlighted by Bessemer Venture Partners’ 2026 AI Monetization Playbook, customers are increasingly demanding value-linked pricing—preferring to pay only for what the AI system actually processes or delivers [6]. Even public sector customers, once locked into massive seat contracts, are shifting: in 2026, small federal agencies faced per-seat AI bills of $300–900K/month, while comparable usage-based models delivered similar utility at a fraction of cost (IBL.ai [4]).
Benefits of Per-Token and Usage-Based Pricing:
- Elasticity: Costs automatically scale up or down with actual use, which is critical in environments facing variable workloads.
- Lower Barriers to Entry: Businesses can experiment or run pilots with minimal upfront expense.
- Transparent ROI: Customers can measure the value delivered against the exact cost of AI resources consumed.
Real-World Numbers: How Per-Token Pricing Works
Let’s break down how these costs play out in practice:
| Service Type | Typical Rate (2026) | Use Case Example | Monthly Cost @ Moderate Volume |
|---|---|---|---|
| LLM Chat (OpenAI/GPT) | $0.001–$0.02/1,000 tokens | Support chatbot, content generation | $300–$2,000 |
| Speech-to-Text | $0.007–$0.04/minute audio | Call transcription (customer service) | $200–$1,000 |
| Vision/Multimodal | $0.03–$0.15/sec video/image | Automated KYC, security analysis | $500–$2,500 |
| Custom AI Inference | $0.0002–$0.05/request | Risk scoring, medical analysis | $500–$2,000 |
Data derived from 2026 vendor listings and industry reports (KORIX [1], IBL.ai [4])
For example, an e-commerce customer support bot running on a per-token model might process two million tokens per month. At $0.002/1,000 tokens, that’s just $4/month for processing, excluding platform or integration fees—a stark contrast to fixed seat-based models.
Challenges With Usage-Based Pricing
While appealing, usage billing carries new challenges for both vendors and customers:
- Bill Shock & Predictability: If usage spikes, so do costs—potentially leading to unexpected bills. Vendors need to provide in-product metering and alerts.
- Complex Value Calculations: Business users may struggle to translate “tokens” or “inferences” into familiar business metrics.
- Vendor Competition: As usage-based pricing becomes more common, vendors must differentiate on reliability, model quality, and ecosystem features, not just raw price.
Usage-Based Models in Practice: CallMissed and the AI Infrastructure Revolution
Platforms like CallMissed are leading the way in enabling seamless, usage-based deployments of advanced AI. By providing multi-channel access (voice agents, WhatsApp bots, and LLM inference endpoints) with transparent per-token usage billing, CallMissed lets businesses of any scale deploy 24/7 AI assistants without committing to large, rigid contracts. Especially in India, where CallMissed natively supports 22 regional languages in its Speech-to-Text offerings, usage-based models bring sophisticated automation within reach of local SMEs who might otherwise be priced out by per-seat contracts.
Key capabilities include:
- API gateway for 300+ models: Developers can experiment, switch, or scale-up models without renegotiating contracts or overprovisioning seats.
- Production-grade metering: Real-time dashboards and alerting prevent runaway spend, answering the “bill shock” concern.
- Transparent value mapping: Usage analytics correlate AI consumption (tokens, minutes, messages) to customer-value metrics like cases resolved or customers engaged.
When Is Per-Token Pricing the Right Choice?
According to the Hamster 2025 Pricing Playbook, usage-based models are most effective when:
- AI interaction frequency varies widely. (For example, knowledge workers using AI as an on-demand copilot.)
- End-user counts are unpredictable or transient. (E.g., B2C chatbot accessed by thousands of customers, not predictable internal seats.)
- Customer wants low initial risk. (SMBs, startups, agencies running proof-of-concepts.)
- AI resource consumption is tightly coupled to delivered value. (A support bot where every token translates to a handled customer query.)
Emerging Trends and The Road Ahead
The shift toward usage and outcome-based pricing will only accelerate as AI technologies mature. According to Data-Mania’s 2026 analysis [5], successful AI vendors now commonly blend models—offering a free-tier or minimum commitment, then escalating fees strictly with usage to maximize adoption and minimize churn.
Key industry predictions:
- Compound annual growth rate (CAGR) for usage-based AI billing exceeds 30% through 2027. (BVP Atlas)
- Over 60% of new AI contracts for enterprises will use some form of usage-based or hybrid pricing by late 2026.
In summary, per-token and usage-aligned pricing delivers on the promise of “only paying for what you use”—radically reducing friction for experimentation, scaling, and real-world deployment. As solutions like CallMissed prove, the model is no longer a niche offering but a foundational layer of modern AI communication infrastructure, reshaping how organizations of all sizes access and value next-gen automation.
Per-Outcome Pricing: The Ultimate Value Realization for AI Agents

The software industry is undergoing a seismic paradigm shift. For over two decades, Software-as-a-Service (SaaS) thrived on the seat-based licensing model—charging a predictable, recurring fee per user, per month. However, as generative AI transitions from passive copilots to fully autonomous agents, this legacy model is breaking down.
When an AI agent can autonomously complete the work of multiple human employees in a fraction of the time, charging per seat actively penalizes the software creator for building a highly efficient product. If a vendor's AI is incredibly fast and accurate, the customer needs fewer human seats, which directly shrinks the vendor's revenue. This fundamental misalignment has paved the way for the ultimate value realization model: per-outcome pricing.
Under this model, buyers stop paying for software as a "tool" and start paying for software as "labor," directly aligning the cost of the technology with the tangible value it delivers.
The Shift from Tools to Labor: How Per-Outcome Pricing Works
In traditional pricing, software is treated as an asset that enables human workers to perform tasks. In an agentic framework, the AI is the worker. Consequently, the pricing unit must shift from the input (the seat or the token) to the output (the successful resolution).
An "outcome" is defined as a discrete, verifiable unit of work that directly moves a business goal forward. Depending on the vertical, these outcomes are typically billed on a per-action basis:
- Customer Support: Paying per successfully resolved customer ticket (per-resolution) rather than per incoming message or active agent seat.
- Lead Generation: Paying per qualified, booked demo rather than per automated outbound email sent.
- Operations & Finance: Paying per reconciled invoice or successfully processed insurance claim.
By billing only for successful completions, vendors eliminate the adoption risk for the buyer. The customer no longer has to worry about paying $150 per seat for a team of employees who might underutilize the tool; they only pay when the AI delivers a verifiable business result.
Comparing the Math: Per-Seat vs. Per-Outcome
To understand why this model is rapidly gaining traction, it is helpful to contrast the unit economics of a typical customer support setup. Consider a mid-sized organization managing 5,000 customer inquiries per month with a team of 20 human agents.
- The Traditional Per-Seat Approach: At an average cost of $100 per seat per month for an AI-enhanced customer service platform, the enterprise pays a flat $2,000 monthly fee. Whether the AI resolves 50 tickets or 4,000 tickets, the price remains fixed. The risk of failure or poor adoption falls entirely on the buyer.
- The Per-Outcome (Per-Resolution) Approach: If the AI platform instead bills at a rate of $1.50 per autonomously resolved ticket, and the AI successfully handles 1,000 resolutions in its first month (a 20% automation rate), the enterprise pays $1,500. If the AI's efficiency increases over time to resolve 3,000 tickets (60% automation), the monthly bill scales to $4,500.
While the nominal cost of the software rises under the per-outcome model, the enterprise’s overall cost per resolution plummet. Instead of hiring more human agents at $25–$40 per hour to scale, the business scales its capacity instantly and variably. The software vendor is rewarded with higher revenue for building a smarter, more autonomous product.
The Operational Challenges of Outcome-Based Models
While per-outcome pricing represents the fairest exchange of value, executing it in the real world is incredibly complex. For software developers and enterprise buyers alike, several friction points must be addressed:
- Defining the Boundaries of "Success": In customer support, what constitutes a "resolved" ticket? If an AI agent answers an inquiry, the customer doesn't reply, and the ticket closes, is that a resolution? What if the customer reopens the ticket 12 hours later? Establish clear, programmatic boundaries (such as a 72-hour window without reopening) to avoid billing disputes.
- Handling False Positives and Negatives: An AI agent might hallucinate an answer and mark a query as resolved when it actually frustrated the customer. Guardrails must be put in place—such as automated sentiment analysis or random human-in-the-loop audits—to verify that billed outcomes meet quality standards.
- The Infrastructure Reliability Tax: To confidently charge per outcome, the developer's underlying tech stack must be exceptionally robust. High latency, system downtime, or poor language comprehension directly translate to failed outcomes and lost revenue.
To successfully execute an outcome-based monetization strategy, AI application developers need a highly reliable, low-latency, and flexible back-end infrastructure. Platforms like CallMissed help bridge this gap. CallMissed provides developers with a production-ready AI communication infrastructure, including voice agents, WhatsApp chatbots, and an LLM gateway supporting 300+ models. By allowing developers to programmatically switch models to optimize accuracy, and providing high-fidelity Speech-to-Text supporting 22 regional Indian languages, CallMissed ensures that communication agents can understand and resolve queries accurately on the first attempt—directly maximizing the volume of billable, successful outcomes.
Is Per-Outcome Pricing Right for Your Product?
Transitioning to an outcome-based model is highly lucrative but requires a strategic match between product capabilities and customer expectations. This model is most effective when:
- The Workflow is Highly Quantifiable: The task must have a binary, easily verifiable ending (e.g., a meeting is on the calendar, a payment has gone through, or a form is filled).
- The AI Operates with High Autonomy: If human employees must constantly step in to correct, edit, or approve the AI's work, the lines between human and machine labor blur, making outcome attribution nearly impossible.
- The Unit Value is High: If the outcome is too small (e.g., correcting a grammatical error), the tracking and transaction costs of billing per outcome will outweigh the revenue. The outcome must carry enough perceived value to justify a distinct price tag.
Ultimately, per-outcome pricing represents the mature phase of the AI revolution. It forces software developers to move away from selling features and instead focus entirely on the reliability, capability, and autonomy of their agents. For companies that can deliver consistent, high-quality results, this pricing model unlocks unmatched margin potential while building unparalleled trust with their enterprise buyers.
The Rise of Hybrid Pricing: Finding the Sweet Spot
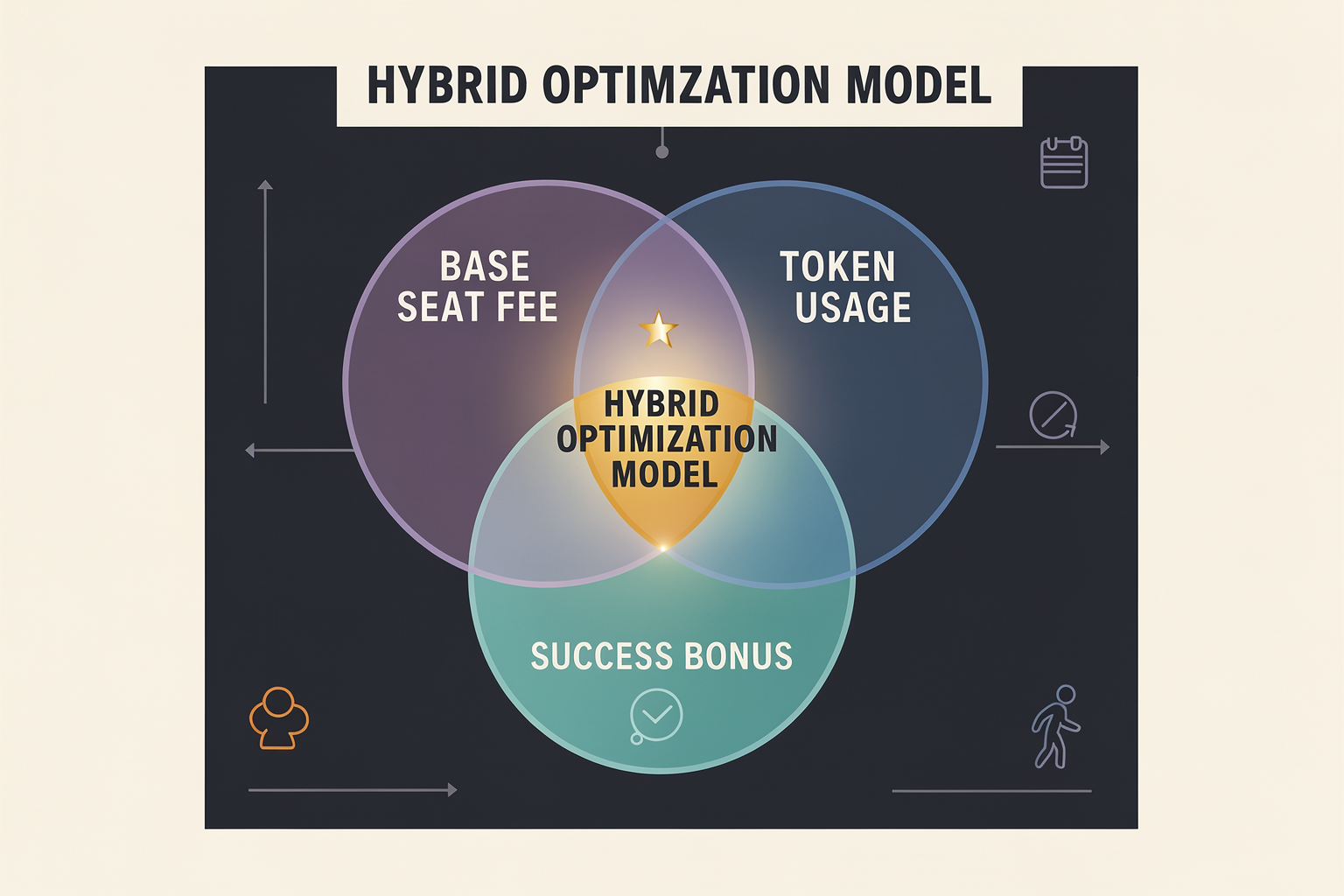
As the AI landscape matures, software vendors and enterprise buyers are reaching a mutual realization: single-dimension pricing models are fundamentally flawed.
Pure per-seat pricing penalizes vendors. When an autonomous AI agent can do the work of five human employees, charging a flat $100/seat/month represents massive revenue leakage for the creator while delivering astronomical, uncaptured ROI to the buyer. On the other end of the spectrum, pure usage-based pricing (such as charging $0.0001 to $0.10 per 1,000 tokens) penalizes the buyer. CFOs hate the unpredictability of token-based billing, where a single runaway recursive loop or an spike in customer queries can cause monthly bills to balloon from $5,000 to $50,000 overnight.
To bridge this gap, the market is rapidly consolidating around hybrid pricing models. By combining the predictable recurring revenue of SaaS with the value-aligned incentives of consumption-based billing, hybrid structures offer the ultimate "sweet spot" for 2026 and beyond.
The Architecture of Hybrid Pricing Blueprints
A successful hybrid pricing strategy does not simply smash seats and tokens together. It carefully matches the pricing mechanism to where the value is actually created. Currently, three dominant hybrid blueprints have emerged across the B2B SaaS and AI agent ecosystems:
#### 1. The "Platform Fee + Consumption" Model
This is the most common transition path for legacy SaaS platforms integrating AI. Customers pay a predictable baseline platform fee (often calculated per-seat or as a flat tenant fee) to access the software infrastructure. This baseline covers basic hosting, UI/UX, customer support, and standard integrations.
On top of this platform fee, customers are billed for actual AI consumption. This is typically metered through:
- Overage charges: Providing a set allocation of tokens or API calls per month, with clear, tiered pricing for any usage beyond the limit.
- Variable utility fees: Charging for secondary actions, such as generating an image, running a complex data analysis, or processing a long-form document.
For example, a marketing platform might charge $80 per seat/month, which includes 500,000 input/output tokens. Any usage beyond that threshold is billed at a transparent rate of $0.02 per additional 1,000 tokens.
#### 2. The "Seat-Licensed Platform + Performance-Based Uplift"
In workflows where AI acts as a direct substitute for labor—such as customer support, sales development, or legal document review—companies are combining low-cost seats with high-value outcome fees.
Under this model, the software provider charges a minimal seat fee (e.g., $15–$30/seat/month) to ensure the buyer's team can log in, audit, and collaborate with the AI. However, the primary monetization engine is triggered by successful actions, such as a resolved support ticket ($0.30 to $1.50+ per resolution) or a qualified booking. This aligns the vendor’s incentives directly with the buyer's operational savings while guaranteeing a baseline recurring revenue stream to cover fixed infrastructure costs.
#### 3. The "Credit-Based abstraction" Model
Directly exposing customers to raw metrics like "tokens," "prompt payloads," or "vector database read/writes" creates friction and confusion. To solve this, vendors are introducing credit-based abstraction systems.
In this hybrid structure, buyers purchase a subscription tier that awards them a set number of "AI Credits" per month (e.g., 10,000 credits for $500/month). Different AI actions consume different amounts of credits.
- Drafting a simple email response might cost 1 credit.
- Generating a highly accurate, multilingual voice response using advanced Speech-to-Text might cost 15 credits.
- Running a deep reasoning agentic workflow might cost 50 credits.
This model gives the vendor complete control over their backend margins. If the cost of underlying LLM inference drops, or if they optimize their prompt engineering, they can adjust the credit cost of specific tasks without needing to rewrite their customer-facing pricing pages.
Balancing Backend Margins with Customer ROI
For AI developers, engineering a hybrid pricing model is as much about managing backend computational costs as it is about customer psychology. When deploying multi-agent systems, a single user prompt can trigger dozens of behind-the-scenes API calls, vector searches, and LLM reasoning steps. Without a hybrid safety net, a fixed-price customer can easily become unprofitable.
Platforms like CallMissed solve this architectural and pricing puzzle by providing a unified, multi-model API gateway with access to over 300+ LLMs. This infrastructure allows developers to build hybrid systems that dynamically route queries. For instance, routine user actions can be handled by smaller, highly cost-effective models, while complex, credit-heavy tasks are routed to frontier reasoning engines. By aligning dynamic backend routing with customer-facing credit tiers, platforms can safeguard their gross margins while delivering predictable bills to their users.
Similarly, when deploying high-throughput, real-time communication systems—such as CallMissed's AI voice agents and Speech-to-Text APIs supporting 22 Indian languages—hybrid pricing is essential. Developers can charge a flat monthly platform subscription for dashboard access and analytics, paired with a pay-as-you-go per-minute fee for multilingual voice interactions, directly matching the infrastructure cost to the customer's scaling volume.
The Benefits of Going Hybrid
| Dimension | Pure Per-Seat | Pure Per-Token | The Hybrid Sweet Spot |
|---|---|---|---|
| For the CFO (Buyer) | Highly predictable, but feels wasteful if seats go unused. | Highly unpredictable; difficult to budget or forecast. | Highly predictable baseline with manageable, value-correlated variable costs. |
| For the Developer (Vendor) | Risk of margin erosion if users run high-volume, complex queries. | Unstable, seasonal revenues; lower valuation multiples from investors. | Stable MRR/ARR base paired with a consumption-based growth engine. |
| Value Alignment | Poor; penalizes the vendor when the AI operates autonomously. | Moderate; tracks raw computation, not actual business outcomes. | Excellent; scales up as the customer extracts tangible utility from the tool. |
How to Transition to a Hybrid Model: A 3-Step Playbook
If you are currently stuck in a rigid per-seat or pure usage model, transitioning to a hybrid structure requires a methodical approach:
- Analyze Your Cost-to-Serve (CTS): Calculate your average token, hosting, and vector database costs per active user. Identify your heavy users ("power users") and determine if their high consumption is eating into the profits generated by low-volume users.
- Define Your Value Metric: Determine what action represents the "aha!" moment for your customer. Is it a generated report, a resolved customer call, or an exported dataset? This value metric should form the basis of your variable usage or credit-based pricing tier.
- Introduce a "Predictability Buffer": When introducing usage or credit-based billing, always include a generous baseline of credits within your subscription tiers. This minimizes transition friction, giving your customers room to explore and adopt the AI features without fearing immediate overage charges.
How Pricing Architectures Shape Enterprise AI Adoption and Budgets
Why Pricing Models Matter: Beyond the Sticker Price
When it comes to enterprise AI deployment, the chosen pricing architecture fundamentally shapes more than just short-term costs—it defines how organizations use, scale, and ultimately trust AI solutions. As highlighted in recent analysis by LinkedIn and Korix (2026), seat-based, token-based, and outcome-based models each drive very different behaviors, incentives, and constraints for enterprise buyers and builders alike [[2]](https://www.linkedin.com/posts/aidigitaluk_choosing-the-right-ai-pricing-model-matters-activity-7421941642309586944-dX-T), [[1]](https://korixinc.com/learning-center/ai-pricing-models-2026).
1. Seat-Based Pricing: Predictability and Guardrails—But at What Cost?
Per-seat pricing—where companies pay a fixed rate (commonly $50-200/seat/month, as of 2026) per user—remains popular for enterprise SaaS and AI platforms [[1]](https://korixinc.com/learning-center/ai-pricing-models-2026). Its key virtues are predictability and easy budgeting. IT and procurement leaders can forecast annual expenditure with confidence, mapping licenses directly to headcount.
Implications for adoption and budgets:
- Lower perceived risk: Fixed costs mean finance teams can run clear ROI calculations, making business cases straightforward.
- Blocked innovation at scale: As AI agents increasingly automate human tasks, seat-based models can artificially cap adoption. For example, if a conversational AI agent replaces five support reps, the customer might still pay for all five seats—a penalty on efficiency [[7]](https://www.builderlab.ai/p/pricing-ai-what-actually-works).
- Underutilization risk: When licenses are tied to individuals rather than outcomes, usage may stagnate, especially if digital agents sit idle for much of the subscription cycle.
Real-world data point: Large government agencies reported per-seat outlays between $300,000-$900,000/month for AI tools in 2026—costs not always justified by utilization, according to IBL.AI [[4]](https://ibl.ai/blog/ai-cost-math-for-small-business-per-seat-vs-usage).
2. Usage-Based Pricing: Flexibility Meets Complexity
Usage-based—or per-token pricing—charges businesses for each API call, token generated, or data processed. Current benchmarks range from $0.0001 to $0.10 per 1,000 tokens [[1]](https://korixinc.com/learning-center/ai-pricing-models-2026).
Adoption and budget impact:
- Democratizes entry: Small teams, pilots, and innovation labs can experiment with cutting-edge AI without committing to large annual costs.
- “Metered” usage shapes habits: Departments watch costs closely, tracking token or API expenditure and optimizing prompts, often leading to more efficient model use.
- Budget unpredictability: As adoption scales, monthly bills can fluctuate widely. A surge in customer interactions, new product launches, or seasonal demand spikes can render spend hard to predict.
Example scenario: For a startup experimenting with multilingual text-to-speech at scale, token-based providers (including those leveraging CallMissed’s Speech-to-Text and LLM APIs) offer transformative flexibility—letting teams iterate on voice AI and only pay for what they use. This model especially benefits organizations deploying AI across multiple touchpoints, such as customer support calls, WhatsApp bots, and email triage systems.
3. Outcome-Based Pricing: Aligning Spend with Business Value
The outcome-based (or per-resolution/per-action) model flips the script: customers pay when AI solutions deliver specific, measurable results—be it solved support tickets, successful sales conversions, or verified fraud detections.
- Typical pricing: $0.30 to $3 per resolved event, depending on complexity and industry vertical [[1]](https://korixinc.com/learning-center/ai-pricing-models-2026), [[8]](https://agentmelt.com/blog/ai-agent-pricing-models-compared/).
- Perfect fit for ROI-driven leaders: Spend is directly correlated with value received. If your AI agent closes 5,000 tickets at $1.50 each, your monthly cost is $7,500, regardless of user count.
- Limits financial risk: Enterprises can scale AI adoption with confidence—knowing they only pay for actual, delivered impact.
Trade-off: Vendors must rigorously define, monitor, and agree on what counts as a “successful” outcome. This can increase commercial complexity, but tight alignment between buyer and seller often outweighs the transactional overhead [[6]](https://www.bvp.com/atlas/the-ai-pricing-and-monetization-playbook).
4. Hidden Frictions: Pricing Choices Shape AI Evangelism
These models also influence internal politics and cross-team collaboration:
- Seat models risk alienating IT, HR, and finance, who may see AI cost as competing with headcount budgets.
- Per-token pricing can shift the burden to technical teams, forcing them to monitor API quotas and optimize prompts in real-time.
- Outcome payments make business stakeholders (sales, support, CX) the primary AI champions, since cost ties directly to their KPIs.
This has real implications: Hamster’s 2025 playbook noted that organizations choosing outcome-based contracts saw 35% higher cross-departmental AI adoption rates, as business leaders were more invested in scaling automation to drive results [[3]](https://tryhamster.com/methods/ai-pricing-playbook).
5. Strategic Implications for the Enterprise C-Suite
Selecting the “right” pricing model becomes a strategic decision, not just a procurement detail. Consider the following questions:
- What’s the expected volume of AI-driven work? High throughputs (thousands of support calls, millions of tokens) often benefit from flexible usage or outcome models.
- Does the business value align with usage or outcomes? For repetitive, commodified tasks, usage pricing suffices. For high-impact, outcome-sensitive roles (e.g., credit approval, medical triage), per-result fees align incentives.
- How mature is your internal AI capability? Mature teams may prefer usage-based pricing for cost control and granular optimization; newer adopters may favor predictability and low operational friction.
6. Building for the Future: Multi-Model and Multi-Language APIs
The future of enterprise AI is modular and deeply integrated. As companies deploy more sophisticated, multilingual, and cross-channel solutions, pricing models must evolve.
Platforms like CallMissed exemplify this evolution: by offering a multi-model API gateway (supporting 300+ LLMs) with both usage-based and outcome-aligned pricing options, they empower enterprises to blend cost predictability with technical flexibility. Features like native support for 22 Indian languages enable AI adoption across diverse markets, often with finely-tuned, granular per-usage fees—ensuring budgets stay tightly mapped to real-world usage and impact.
7. Benchmarks and Budgeting: Concrete Numbers for 2026
Let’s summarize using real benchmarks for 2026, synthesizing multiple sources [[1,4,8]]:
| Model | Typical Cost (2026) | Pros | Cons | Enterprise Adoption Trend |
|---|---|---|---|---|
| Per-Seat | $50-$200/seat/month | Predictable, easy to budget | May penalize automation gains, high up-front cost | Declining for agentic AI |
| Per-Token | $0.0001-$0.10/1,000 tokens | Flexible, pay-as-you-go | Can be unpredictable at scale | Growing in hybrid/innovator orgs |
| Per-Outcome | $0.30-$3/resolution | Cost tied to real value | Complex to define outcomes | Rapidly growing in CX, sales |
| Hybrid/Custom | Varies | Balances flexibility and control | Needs strong governance | Most common in large enterprises |
8. Conclusion: Aligning Pricing Architecture With AI Ambitions
Ultimately, the choice of AI pricing architecture is both a technical and strategic lever. In the age of LLMs, agentic work, and omnichannel customer engagement, getting pricing right is critical to sustained, scalable AI adoption. Enterprises that treat this as a board-level decision—aligning model, integration, and cost structure with their operational goals—are best positioned for success.
As solution providers and platforms like CallMissed show, the leading edge is not just about smarter models, but about smarter models of collaboration, value-sharing, and budget management. The winners will be those who design their AI infrastructure—and their commercial models—for continuous, value-aligned experimentation and growth.
What Industry Leaders and Analysts Say About AI Monetization

As the artificial intelligence landscape matures in 2026, the tech industry is experiencing an unprecedented shift in software economics. For decades, the Software-as-a-Service (SaaS) industry relied on the predictable, user-centric per-seat subscription model. However, venture capitalists, industry analysts, and product leaders now widely agree that generative AI and autonomous agents are breaking this legacy framework.
When software transitions from being a passive tool to an active "doer" of work, charging by human login credentials no longer reflects the value delivered. Industry analysts and pricing strategists are heavily documenting this transition, outlining the benefits, pitfalls, and future of AI monetization.
The Paradigm Shift: Why Seats Are Sinking
A consensus is forming among software pricing experts: charging per seat penalizes AI vendors for making their products highly efficient. If an enterprise AI agent can complete a task in seconds that previously required a team of five people, the customer needs fewer user licenses.
As Pranav Pathak of BuilderLab.ai points out, "When your AI agent does the work of five people, charging per seat penalizes you for the exact outcome your product delivers." If software companies cling exclusively to per-seat models, they face a shrinking revenue base even as their software delivers exponential productivity gains.
Furthermore, market data reveals a stark disconnect in scale:
- Traditional Per-Seat Pricing: Typically hovers between $50 and $200 per seat, per month for premium AI assistant software.
- The Reality of AI Labor: If an agency or enterprise utilizes automated agents to handle thousands of complex processes, charging a flat seat fee means the vendor absorbs massive, unpredictable LLM inference costs while the customer receives disproportionate economic value.
To survive, software companies are forced to realign their pricing structures with the raw utility or direct business value their AI provides.
The Rise of Outcome-Based Economics
According to the monetization playbook published by Bessemer Venture Partners (BVP), the industry is aggressively shifting toward workflow- or outcome-based pricing. In this model, customers are billed only when the AI successfully completes a specific, measurable task.
This model aligns incentives perfectly between the buyer and the vendor. Prominent use cases include:
- Customer Support: Transitioning from seat-based helpdesk software to per-resolution or per-ticket models (typically priced between $0.30 and $1.50+ per resolved issue).
- Marketing & Sales: Paying per qualified lead generated or per campaign successfully executed, rather than paying for the seat of the marketer configuring the tool.
Analysis from AgentMelt compares these cost structures to illustrate the financial realities for enterprise buyers:
- The Per-Seat Approach: 20 support seats billed at $100/seat results in a flat, predictable cost of $2,000/month, regardless of customer inquiry volume.
- The Per-Resolution Approach: If those same 20 seats are replaced or augmented by an AI agent resolving 5,000 customer tickets at $1.50 per resolution, the monthly bill scales to $7,500/month.
While the outcome-based model costs more in high-volume scenarios, analysts point out that the business has avoided the massive overhead of hiring, training, and managing additional human support representatives. The software vendor is rewarded for delivering actual work, not just hosting a digital workspace.
Token-Based Granularity vs. Enterprise Predictability
On the opposite end of the spectrum is usage-based pricing, specifically per-token billing (often ranging from $0.0001 to $0.10 per 1,000 tokens depending on the complexity of the underlying LLM).
While developers prefer token-based pricing because it maps directly to raw hosting and inference costs, financial analysts warn that it creates severe budget volatility for enterprise buyers. IBL’s analysis of public sector and small business AI costs highlights the friction: a federal or state agency trying to budget for the fiscal year cannot easily predict token consumption. Confronted with the choice between predictable $300,000-to-$900,000 per-seat enterprise software agreements or highly fluctuating, variable token bills, risk-averse CFOs often default back to legacy models simply for financial predictability.
Furthermore, as LLM providers continuously cut token costs through optimized model architectures, vendors whose pricing is tied strictly to raw token consumption face a race to the bottom.
Hybrid Pricing: The Emerging 2026 Consensus
To balance vendor profitability, infrastructure costs, and customer demand for predictability, industry leaders are converging on hybrid monetization models. Data-Mania’s research on modern AI pricing frameworks highlights that the most successful SaaS platforms in 2026 combine elements of multiple models:
- A Flat Subscription Base: A low per-seat or platform access fee to guarantee predictable recurring revenue for the vendor.
- Usage-Based Credits: Pre-allocated tokens, API calls, or "credits" bundled into the base subscription.
- Outcome-Based Overages: Additional charges applied only when the AI completes tasks beyond the base tier (e.g., automated invoice processing, successful booking conversions).
This hybrid approach mitigates the risk of high-volume users driving up the vendor's inference costs while still offering a low barrier to entry for smaller teams.
Navigating the Infrastructure Cost Puzzle
For businesses building and deploying these AI solutions, matching user pricing to backend infrastructure costs remains an ongoing challenge. Dynamic resource allocation, model latency, and regional language support all impact the underlying cost of goods sold (COGS).
This is where advanced communication and LLM tooling becomes essential. Platforms like CallMissed address these pricing-architectural frictions directly. By offering a unified multi-model API gateway with access to over 300+ LLMs, CallMissed allows developers to dynamically route prompts to the most cost-efficient models based on complexity. This optimization helps businesses keep their raw token costs predictable. Additionally, for enterprises deploying high-volume, automated customer engagement systems, CallMissed's infrastructure provides production-ready speech-to-text (supporting 22 Indian languages natively) and voice agent APIs. This allows companies to confidently transition to value-driven, outcome-based pricing models without worrying about unpredictable spikes in underlying compute costs.
Ultimately, the consensus among 2026 industry leaders is clear: those who continue to sell AI solely on a "per-user" basis will find their margins squeezed or their growth stunted. The future of software monetization lies in selling the output, not the license.
Decision Matrix: Selecting the Right Model for Your Product (TABLE)
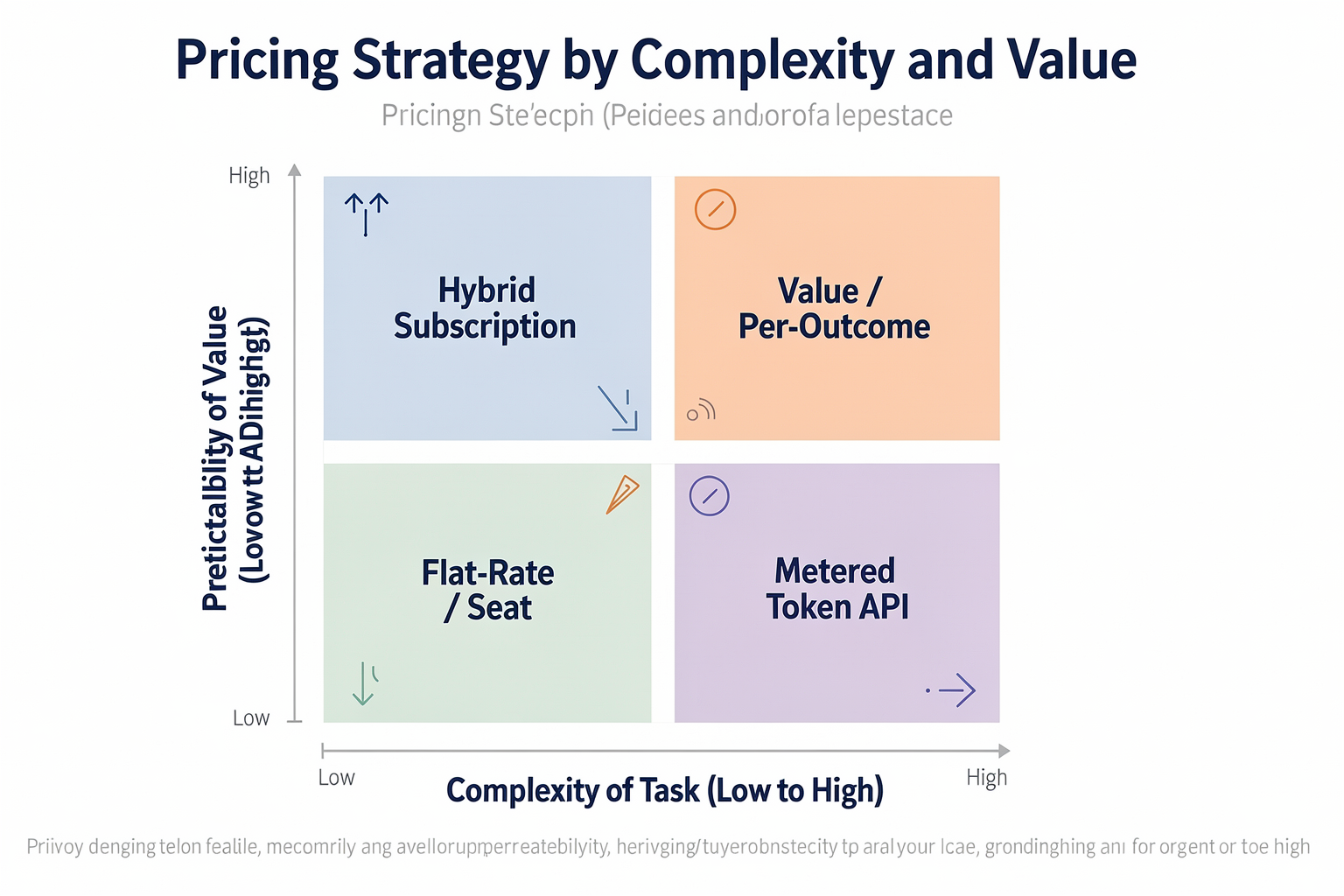
Selecting the wrong pricing strategy for an AI product does more than just hurt your bottom line; it can completely stall customer adoption. If your product does the work of five human agents and you charge a flat per-seat rate, you are actively penalizing your own revenue growth. Conversely, if you charge strictly by the token to non-technical business buyers, you risk alienating them with unpredictable, fluctuating monthly bills.
To help product managers, founders, and finance teams navigate this landscape, the decision matrix below breaks down the core options, their unit economics, and where they fit best in today’s market.
The AI Pricing Decision Matrix
| Pricing Model | Standard Market Rates | Cost Predictability | Margin Risk | Ideal For |
|---|---|---|---|---|
| Per-Seat (SaaS Hybrid) | $50 to $200 / seat / month | High (Fixed recurring revenue) | High (Heavy users can consume massive tokens) | Copilots, design assistants, and workflow-heavy SaaS tools |
| Per-Token (Usage-Based) | $0.0001 to $0.10 / 1,000 tokens | Low (Highly variable monthly invoices) | Low (Directly correlates with raw LLM compute costs) | Developer APIs, bulk data processing, and raw background infrastructure |
| Per-Outcome / Resolution | $0.30 to $1.50 / successful resolution | Medium (Tied directly to business volume) | Medium-High (Requires highly optimized routing) | Customer support agents, automated scheduling, and outbound voice workflows |
| Credit-Based (Hybrid) | Tiered flat-rate packages (e.g., $29 for 1,000 credits) | Medium-High (Upfront commit with overage protections) | Low (Margins are pre-calculated per credit category) | Image/video generation, automated report building, and ad-hoc tools |
Key Considerations When Selecting Your Pricing Strategy
To translate this matrix into a concrete pricing strategy, product leaders must balance customer friction against underlying API COGS (Cost of Goods Sold).
#### 1. Assessing Your Customer’s Budgetary Persona
Enterprise buyers and developers look at AI costs through entirely different lenses.
- The Enterprise Buyer: Large corporations, government agencies, and highly regulated entities demand budget predictability above all else. Imposing a pure, raw consumption model on these groups can lead to massive friction. For example, large scale government or enterprise deployments forced into poorly scoped contracts can easily run into unexpected bills of $300,000 to $900,000 per month due to runaway background processes or FOIA-related scraping workflows. For these buyers, a per-seat hybrid model with soft usage caps is usually the safest path to initial procurement.
- The Developer and Technical Buyer: Conversely, developers want to pay exactly for what they consume. Attempting to charge software engineers a flat per-seat fee for an API tool will result in low adoption. They prefer per-token or pay-per-API-call models where they can optimize their code to reduce costs directly.
#### 2. Managing Margin Risk and Unit Economics
If you opt for a flat per-seat model, you bear 100% of the risk associated with heavy users. A user paying $50 per month who consistently inputs massive PDFs into an advanced reasoning model like GPT-4o or Claude 3.5 Sonnet can easily cost you $150 in underlying token fees, turning a high-margin software business into a loss-making service.
To mitigate this risk, modern AI platforms are increasingly shifting toward hybrid credit models or using highly efficient, specialized infrastructure. For instance, platforms like CallMissed help developers mitigate the margin risk of hybrid pricing by offering a unified API gateway to over 300+ LLMs. This allows companies to dynamically route less complex queries to cheaper, open-source models (costing pennies per million tokens) while reserving expensive frontier models only for complex tasks, preserving high margins under flat-rate pricing structures.
#### 3. Navigating the Transition to Per-Outcome Models
Per-outcome pricing (such as charging $1.00 per successfully resolved customer support ticket) is the holy grail of value alignment. When your AI agent resolves 5,000 customer inquiries a month, a standard per-seat model would yield almost nothing, whereas a per-resolution model yields a healthy $5,000.
However, charging per-resolution requires bulletproof infrastructure. If an AI voice agent drops calls, misunderstands accents, or fails to authenticate users, the "outcome" is lost, and so is your revenue. For businesses deploying transactional voice and text systems, building on top of production-ready communication pipelines is essential.
Leveraging specialized communication infrastructure—such as CallMissed’s ultra-low latency Speech-to-Text (supporting 22 Indian languages natively) and advanced Text-to-Speech APIs—enables customer support startups to deliver flawless, localized conversational experiences. This architectural reliability is what makes companies built on infrastructure like CallMissed highly resilient: they can scale voice agents globally, confidently charge on a per-resolution basis, and maintain a highly predictable, profitable margin structure.
Frequently Asked Questions about AI Pricing Models
Q: What are the main differences between the primary AI pricing models like per-seat, per-token, and outcome-based?
A: Choosing between the primary AI pricing models requires understanding how value is captured and delivered across different architectures. Traditional SaaS models rely on seat-based pricing, whereas modern AI applications charge based on raw computational consumption (per-token) or tangible business results (per-outcome).
To help you compare, here is a detailed breakdown of how these models function in the enterprise landscape:
- Per-Seat Pricing: Customers pay a predictable flat rate per user, typically ranging from $50 to $200 per seat per month. While this offers excellent budget predictability for buyers, it fails to scale with actual AI usage and penalizes the vendor when highly efficient AI agents do the work of multiple human employees.
- Per-Token (Usage-Based) Pricing: Users pay strictly for the volume of data processed, with industry rates hovering between $0.0001 and $0.10 per 1,000 tokens. This model aligns vendor costs directly with underlying LLM API expenditures, making it highly equitable but difficult for enterprise finance teams to predict and budget.
- Outcome-Based (Per-Resolution) Pricing: Customers are charged only when the AI successfully completes a specific business workflow, such as resolving a support ticket, which usually costs between $0.30 and $1.50 per successful outcome. This shifts the risk entirely to the vendor and maximizes customer trust, though it requires sophisticated tracking infrastructure to verify "successful" outcomes.
Q: How does per-token pricing work in usage-based AI pricing models, and what are the typical industry rates?
A: In usage-based AI pricing models, per-token pricing bills customers based on the exact volume of text, code, or media processed by the underlying Large Language Model. A token is a subunit of text, with 1,000 tokens roughly equating to 750 English words, spanning both the input prompt and the generated output.
When analyzing per-token models, developers and enterprises must navigate several variable factors:
- Input vs. Output Asymmetry: Output tokens are computationally more expensive to generate than input tokens to process, meaning output rates are often 3x to 4x higher than input rates.
- Model Tiering: Rates vary drastically from lightweight, fast models (charging as low as $0.0001 per 1,000 tokens) to massive frontier models or fine-tuned reasoning models (costing up to $0.10 per 1,000 tokens).
- Context Window Costs: Long-context inputs exponentially increase the token count, meaning a single document retrieval step can quickly spike transaction costs if not carefully managed.
To help organizations navigate these complex cost structures, communication infrastructure platforms like CallMissed offer unified multi-model API gateways. This allows developers to seamlessly switch between 300+ LLMs without changing a single line of code, ensuring they can dynamically route tasks to the most cost-effective token tier based on the complexity of each incoming prompt.
Q: When should a B2B SaaS company transition from traditional seat-based pricing to outcome-based AI pricing models?
A: A SaaS company should transition to outcome-based AI pricing models when their software evolves from being a "copilot" (which increases human speed) to an "agent" (which autonomously completes entire workflows). When your AI product does the work of five human team members, charging a traditional per-seat fee actively penalizes your business for the massive efficiency and value your software delivers.
Consider the following strategic indicators that it is time to pivot your pricing strategy:
- High Disintermediation of Human Labor: If your software allows a single administrator to manage tasks that previously required a ten-person department, seat-based metrics will severely undervalue your product.
- Clear, Measurable Output Metrics: If your AI produces distinct, easily verifiable outcomes—such as generating a qualified sales lead, successfully processing a medical insurance claim, or filing a legal compliance document—you can easily tie your pricing directly to that value.
- Strong Unit Economics: Ensure your margin remains healthy; for instance, if it costs you $0.05 in compute tokens to generate an outcome, charging a value-based rate of $1.50 per outcome guarantees an exceptional gross margin while providing immense ROI to the buyer.
Q: What is per-resolution pricing, and how does it compare to traditional per-ticket support costs?
A: Per-resolution pricing is a specialized form of outcome-based pricing where a customer is only billed when an AI agent successfully resolves a customer query without human intervention. This contrasts sharply with traditional customer service pricing models, which charge either a flat subscription per human seat or a variable fee per ticket opened, regardless of whether the customer's problem was actually solved.
The differences in cost structures and incentives between these models are substantial:
- The Cost Comparison: Traditional human helpdesk software or outsourced customer support typically costs between $15 and $45 per hour per agent, or a set flat rate per ticket. In contrast, autonomous AI resolutions generally cost between $0.30 and $1.50 per resolution, representing an immediate cost reduction of up to 90% for the enterprise.
- Alignment of Incentives: Under traditional per-ticket models, vendors have little incentive to reduce ticket volumes. Under per-resolution AI models, the vendor is incentivized to make the AI as intelligent, fast, and helpful as possible, because they do not get paid if the customer has to be escalated to a human agent.
- Risk Mitigation: If an AI agent attempts to resolve 5,000 customer inquiries but only successfully closes 3,000 of them, the buyer is only billed for the 3,000 completed resolutions, protecting their budget from failed automation attempts.
Q: How can enterprises manage and predict their monthly expenditures when deploying voice and chat AI agents?
A: Enterprises can manage and predict their AI operational costs by implementing hybrid billing systems, setting strict rate limits, and utilizing consolidated, multi-tenant infrastructure platforms. Without these guardrails, unstructured usage-based pricing can lead to extreme budget volatility, as seen in government and enterprise agencies where unmonitored seat-based bills or unbounded API consumption have resulted in unexpected monthly invoices ranging from $300,000 to $900,000.
To keep infrastructure expenditures predictable while scaling customer engagement, enterprises should adopt the following tactical measures:
- Leverage Native Multilingual Infrastructure: Running separate pipelines for translation and transcription dramatically inflates token and API costs. Platforms like CallMissed resolve this by offering production-ready Speech-to-Text APIs supporting 22 Indian languages natively, cutting down the computational steps required to deploy voice agents globally.
- Implement Hard Budget Caps and Throttling: Set maximum daily or monthly token spend limits at the API key level to prevent run-away recursive loops in autonomous agents.
- Utilize Task-Specific Model Routing: Route simple customer intents (like FAQ retrieval) to lightweight, hyper-affordable open-source models, and reserve premium, high-cost LLMs exclusively for complex reasoning and transactional workflows.
Q: Is there a hybrid model that successfully combines seat-based, token-based, and outcome-based pricing?
A: Yes, many leading AI-native companies deploy a hybrid model—often referred to as a "credit-system" or "capped usage" model—to balance the vendor's need for predictable recurring revenue with the buyer's demand for value-aligned pricing. This multi-layered pricing architecture allows organizations to monetize different aspects of their platform based on how their clients extract value.
A typical enterprise hybrid pricing structure operates using the following three tiers:
- The Platform Subscription Fee (Base Seats): A predictable monthly charge (e.g., $50 per administrator per month) that covers hosting, security compliance, platform maintenance, and access to the basic dashboard interface.
- The Pre-Allocated Credit Allowance: Each base subscription seat includes a set number of free monthly tokens or resolutions (e.g., 500 free customer interactions per month) to encourage early adoption and daily usage.
- The Pay-As-You-Go Overage Rate: Once the pre-allocated credit threshold is crossed, the billing engine automatically switches to a usage-based tier, charging a micro-fee per additional token consumed or a flat $1.00 per extra successful outcome, ensuring the vendor's margins are protected during peak traffic seasons.
Conclusion
As we navigate the shifting dynamics of AI commercialization in 2026, the transition from legacy SaaS pricing to value-aligned models is rapidly accelerating. To stay competitive, organizations must adapt to a few critical market realities:
- The Decline of Pure Per-Seat Pricing: Charging per user license actively penalizes software creators when AI agents perform the work of multiple people. This conflict of interest is driving a massive industry shift away from flat, headcount-based monetization.
- Tokens as Backend Infrastructure: While raw usage-based billing ($0.0001 to $0.10 per 1,000 tokens) is critical for developers managing API costs, it is proving too volatile and abstract for mainstream corporate buyers who demand budget predictability.
- The Rise of Hybrid, Value-Driven Models: The market is consolidating around hybrid frameworks that combine a low baseline subscription fee with outcome-based triggers, such as charging directly per successful customer resolution or automated ticket closure.
Looking ahead, the next major trend to watch is the normalization of dynamic, real-time pricing engines where AI agents negotiate micro-transactions based on task complexity and resource consumption. This transition ensures that enterprises only pay for tangible, high-quality outcomes rather than idle, underutilized software seats.
To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. As autonomous agents become the default workforce for enterprise operations, how will your organization restructure its technology budgets to pay for productivity instead of seats?


