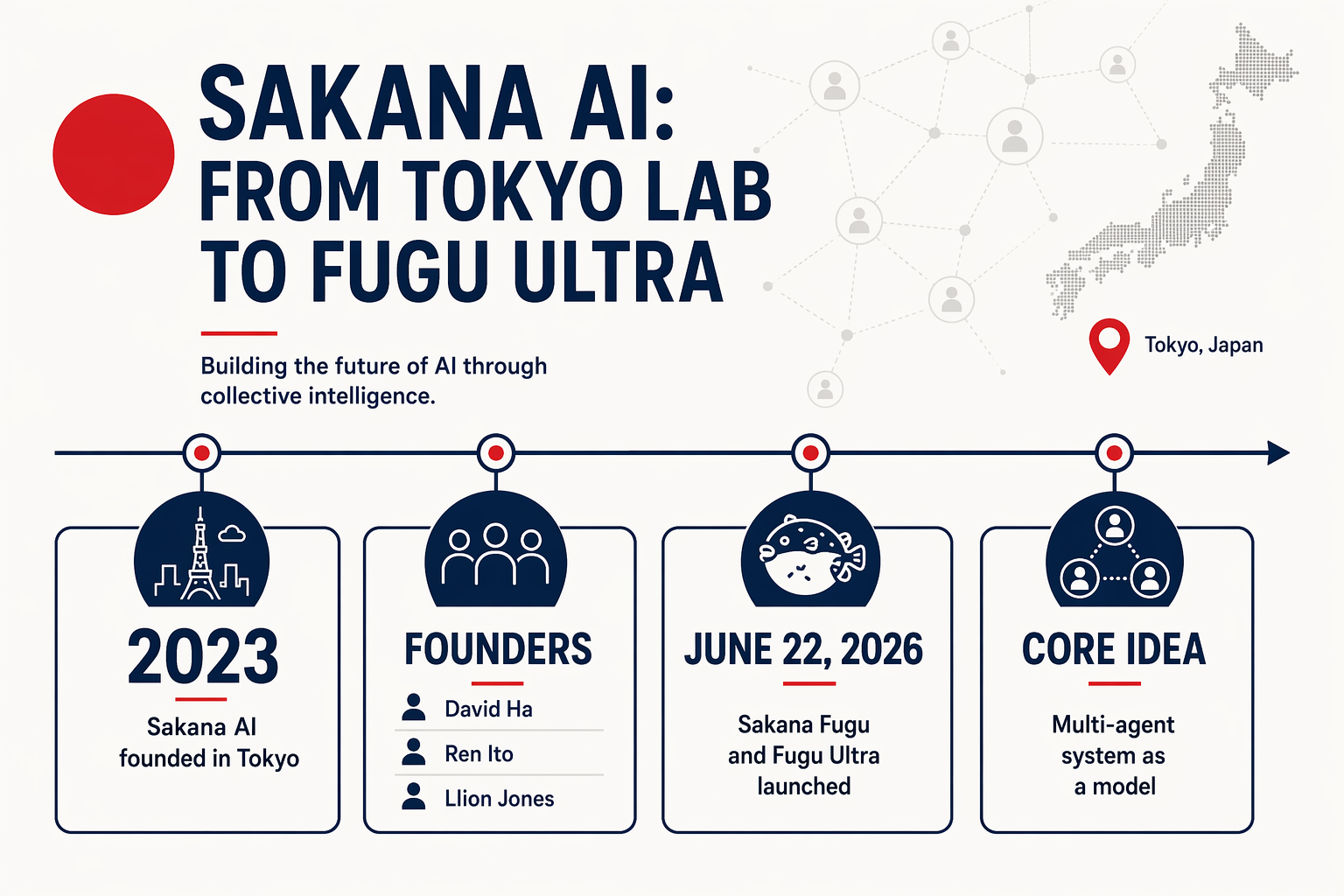
Fugu Ultra Explained: Sakana AI’s Multi-Agent Model API From Japan

What if Japan’s most talked-about new AI “model” is not really a model at all—but a coordinated team of models working behind one API call? That is the...
Fugu Ultra Explained: Sakana AI’s Multi-Agent Model API From Japan
What if Japan’s most talked-about new AI “model” is not really a model at all—but a coordinated team of models working behind one API call? That is the core idea behind Fugu Ultra, Sakana AI’s newly launched system from Tokyo, and it may signal a major shift in how frontier AI performance is built, packaged, and sold.
On June 22, 2026, Sakana AI introduced Sakana Fugu and Fugu Ultra as OpenAI-compatible model APIs. But unlike the familiar race to train ever-larger monolithic foundation models, Sakana describes Fugu as a “multi-agent system as a model”: a single endpoint that dynamically orchestrates multiple specialized AI agents and publicly accessible frontier models behind the scenes. In plain terms, developers call it like a model, but the intelligence comes from routing, coordination, debate, verification, and task decomposition across agents.
That matters right now because AI labs and enterprises are hitting a practical question: is the next jump in capability going to come only from bigger models, or from smarter systems around models? Sakana’s answer is the latter. According to Sakana’s own materials, Fugu Ultra prioritizes answer quality on complex, multi-step reasoning, coordinating more expert agents when accuracy and depth matter most, while standard Fugu is positioned for faster everyday workloads. Third-party coverage, including NDTV and BuildFastWithAI, reports vendor-claimed benchmark strength against leading frontier systems on coding, science, reasoning, and code review tasks—claims that are compelling, but should still be treated as Sakana-reported unless independently verified.
The pricing also makes the launch concrete for developers: listings such as Requesty place Fugu Ultra at around $5 per million input tokens and $30 per million output tokens, putting it in the premium reasoning API category. Its OpenAI-compatible interface could reduce migration friction for teams already using OpenAI-style SDKs and clients.
In this Fugu Ultra explained guide, we’ll unpack what Sakana AI actually launched, how multi-agent orchestration differs from a traditional foundation model, why Japan’s approach is strategically important, what the benchmark claims do—and don’t—prove, and how this model-as-system pattern could reshape AI infrastructure. Platforms like CallMissed, which already expose multi-model LLM access through production APIs, reflect the same broader move toward orchestration-first AI.
Introduction: Japan’s New AI Contender Is Not One Giant Model

The headline is misleading—in an important way
Japan’s newest AI contender, Fugu Ultra, is being discussed online as if Sakana AI has released a single giant frontier model. But that framing misses the more interesting point: Fugu Ultra is not positioned as one monolithic foundation model. Sakana AI describes it as a “multi-agent system as a model”—a model-like API endpoint that coordinates multiple AI agents and models behind the scenes.
Launched by Tokyo-based Sakana AI on June 22, 2026, Sakana Fugu and Fugu Ultra are presented as OpenAI-compatible model APIs. That means developers can interact with them using familiar OpenAI-style clients, but the backend logic is fundamentally different from calling one standalone large language model.
Instead of asking, “How big is this model?” the better question is: How well does the system route, combine, verify, and coordinate intelligence?
One API call, many agents behind it
Sakana’s core idea is simple but strategically significant: developers should not need to manually choose which model or agent is best for every subtask. The system can do that dynamically.
According to Sakana’s own Fugu materials, the platform coordinates expert agents depending on the workload. Fugu Ultra is the higher-quality version, designed for complex, multi-step reasoning, while standard Fugu is aimed at faster, everyday tasks. In practice, that suggests a split between:
- Fugu: lower-latency, general-purpose workloads
- Fugu Ultra: deeper reasoning, code review, technical problem-solving, and multi-step analysis
- Single endpoint access: developers call it like a normal model API
- Agent orchestration: the system may route work across specialized agents and publicly accessible frontier models
That “model-as-system” design is increasingly relevant as AI teams look beyond raw parameter scaling. The next performance jump may come not only from training bigger models, but from building smarter infrastructure around them: routing layers, verifier agents, planning agents, tool-using agents, and multi-model coordination.
This is also why platforms such as CallMissed, which provide production LLM inference across 300+ models, reflect the same broader industry shift. Businesses increasingly want one reliable interface that can abstract away model choice, routing, and deployment complexity.
Why Fugu Ultra matters now
The timing is important. By mid-2026, frontier AI competition is no longer just about who owns the largest training cluster. It is also about who can package intelligence into developer-friendly infrastructure.
Sakana’s launch makes three claims especially noteworthy:
- Architecture shift: Fugu Ultra is framed as a coordinated multi-agent system, not a single model.
- Developer accessibility: the API is OpenAI-compatible, reducing migration friction for teams already using OpenAI-style SDKs.
- Premium reasoning positioning: pricing sources such as Requesty list Fugu Ultra at about $5 per million input tokens and $30 per million output tokens, placing it in the premium reasoning API category.
Third-party coverage has amplified the launch. NDTV reported Sakana’s claim that Fugu Ultra performed on par with systems such as Anthropic Fable 5 and Mythos Preview on engineering, science, and reasoning benchmarks. BuildFastWithAI similarly described Fugu Ultra as a multi-agent orchestration model launched on June 22, 2026, with reported strength across coding, reasoning, science, and code review.
Those benchmark claims are compelling—but they should be read carefully. Unless independently reproduced, they remain vendor-reported performance claims, not settled proof that Fugu Ultra broadly outperforms every frontier competitor.
The real story: orchestration becomes the product
Fugu Ultra’s significance is not just that Japan has another AI system in the global race. It is that Sakana AI is packaging orchestration itself as the product.
If this approach works at scale, the frontier AI market could start shifting from “which single model is smartest?” to “which system best coordinates multiple forms of intelligence?” That is a very different race—and Fugu Ultra is one of the clearest signs yet that it has begun.
Background & Context: Who Sakana AI Is and Why Fugu Matters
Sakana AI: Tokyo’s systems-first AI lab
Sakana AI is not trying to look like a conventional frontier-model lab. Based in Tokyo, the company has built its identity around alternative approaches to AI development: combining models, evolving systems, and using coordination rather than only brute-force scale. That makes Fugu Ultra less of a surprise if viewed through Sakana’s broader philosophy.
The name “Sakana” means fish in Japanese, and “Fugu” continues that aquatic theme. But the branding is also useful shorthand: Fugu is not being presented as one massive neural network with a single set of weights. Sakana’s own description frames it as a “multi-agent system as a model”—a system exposed through a familiar model API, but powered by orchestration underneath.
That distinction matters because most AI competition since 2022 has centered on model size, training compute, and benchmark rankings. Sakana is instead asking a more infrastructure-oriented question: can a lab deliver frontier-like performance by coordinating existing expert models and agents more intelligently?
Why Japan’s role is strategically important
Fugu Ultra also lands in a larger national and regional context. Japan has world-class robotics, manufacturing, gaming, telecom, and enterprise software markets, but the global foundation-model race has been dominated by U.S. and Chinese players. A Tokyo startup positioning itself against leading frontier systems is therefore significant—not just technologically, but strategically.
The June 22, 2026 launch of Sakana Fugu and Fugu Ultra gives Japan a different kind of AI story. Instead of “Japan trained the biggest model,” the message is closer to:
- Japan can compete through architecture, not only raw compute.
- Frontier capability can be packaged as orchestration, not just model weights.
- Developers can access the system through OpenAI-compatible APIs, lowering switching friction.
- High-quality reasoning can be assembled dynamically, using multiple agents and publicly accessible frontier models.
That last point is especially important. Requesty’s listing says Fugu Ultra is built on a pool of publicly accessible frontier models rather than running as a single model, and that it coordinates several models behind the scenes. In other words, Sakana is turning the AI supply chain itself into part of the product.
Why Fugu matters beyond benchmarks
The early attention around Fugu Ultra has focused on benchmark claims. NDTV reported that Sakana said Fugu Ultra performed on par with Anthropic Fable 5 and Mythos Preview on key engineering, science, and reasoning tasks. BuildFastWithAI similarly described the system as a multi-agent orchestration model launched on June 22, 2026, aimed at matching leading frontier systems.
Those claims are notable, but the deeper story is the delivery model. Fugu matters because it suggests a new commercial pattern for AI infrastructure:
- Expose one endpoint that looks like a normal model API.
- Route the task internally to different agents or models.
- Use coordination for hard problems, especially multi-step reasoning.
- Optimize for quality or speed depending on the variant—Fugu Ultra for depth, standard Fugu for faster everyday workloads.
This is close to where enterprise AI is already heading. Businesses rarely want to manually choose a different model for every task; they want reliability, cost control, and strong outputs through simple interfaces. Platforms such as CallMissed reflect the same infrastructure shift by giving developers access to 300+ LLMs through production APIs, making model choice and routing an implementation detail rather than an end-user burden.
The key context: Fugu is a packaging innovation
Fugu Ultra’s importance is not only whether it tops a benchmark leaderboard. It is that Sakana is packaging coordination, routing, and agent collaboration as if they were a single model. If that pattern works, the next frontier may be less about who owns the largest model and more about who builds the smartest system around many models.
Key Developments (TABLE)
The launch at a glance
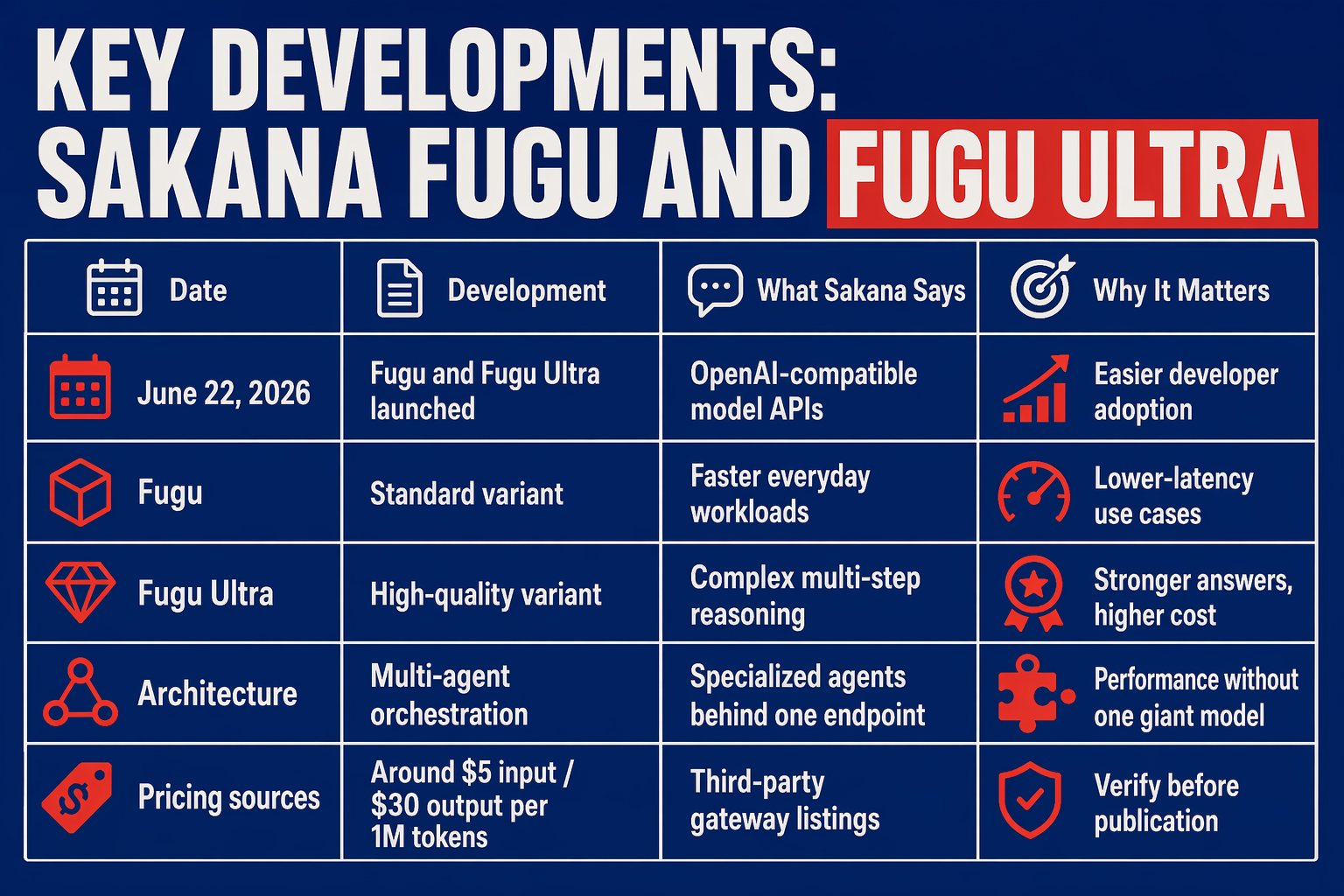
Sakana AI’s June 2026 announcement is best understood as an infrastructure move, not just a model release. The company packaged agent coordination, routing, and verification behind a familiar API shape—so developers interact with Fugu Ultra like a normal model, even though the backend behaves more like a distributed reasoning system.
| Development | What Sakana Announced | Why It Matters | Source/Status |
|---|---|---|---|
| Launch date | Sakana Fugu and Fugu Ultra launched on June 22, 2026 | Establishes Japan’s most visible 2026 entry into frontier-style AI APIs | Sakana AI / BuildFastWithAI |
| API format | Both are offered as OpenAI-compatible model APIs | Teams using OpenAI-style SDKs may migrate or test with less integration work | Sakana AI |
| System design | Fugu is described as a “multi-agent system as a model” | The “model” is actually orchestration across agents/models behind one endpoint | Sakana AI |
| Fugu vs Fugu Ultra | Standard Fugu targets faster everyday workloads; Fugu Ultra prioritizes answer quality | Creates a practical tradeoff between latency/cost and deeper reasoning | Sakana AI |
| Benchmark claims | Reported strength on coding, science, reasoning, and code review tasks | Suggests orchestration can compete with larger monolithic systems, though claims need independent validation | NDTV / BuildFastWithAI |
| Pricing signal | Fugu Ultra listed around $5 per million input tokens and $30 per million output tokens | Places it in the premium reasoning API category rather than commodity chat pricing | Requesty |
What is actually new here
The important shift is that Sakana is selling coordination as capability. Instead of asking developers to assemble their own router, evaluator, tool-using agents, and fallback logic, Fugu Ultra compresses that stack into a single model-like API call.
That has three practical implications:
- Model selection becomes invisible: The user does not manually choose which expert model or agent handles each step.
- Reasoning can be decomposed: Complex requests can be split across specialized agents for planning, solving, checking, or code review.
- Quality can scale through orchestration: Performance gains may come from better routing and verification—not only from training a bigger base model.
This mirrors a broader trend in AI infrastructure. Platforms like CallMissed, for example, already expose access to 300+ LLMs through production APIs, reflecting the same industry movement toward abstraction layers where developers care less about one model name and more about reliable task completion.
The benchmark claims need careful reading
Third-party coverage has been bold. NDTV reported that Sakana said Fugu Ultra performed on par with Anthropic Fable 5 and Mythos Preview on key engineering, science, and reasoning tasks. BuildFastWithAI similarly framed the launch as a system that can match leading frontier models through orchestration.
But the key phrase is vendor-reported. Until independent benchmark suites reproduce the results, the safer interpretation is:
- Fugu Ultra appears designed for high-complexity reasoning workloads.
- Sakana is claiming competitive performance against frontier systems.
- The architectural claim—multi-agent orchestration behind one API—is more strategically important than any single benchmark score.
In other words, the launch is not just “Japan built a better chatbot.” It is evidence that frontier AI competition may increasingly happen at the system layer: routing, agent collaboration, verification, and API packaging.
In-Depth Analysis: How a “Model” Becomes an Orchestrated Team of Agents
From one forward pass to many coordinated decisions
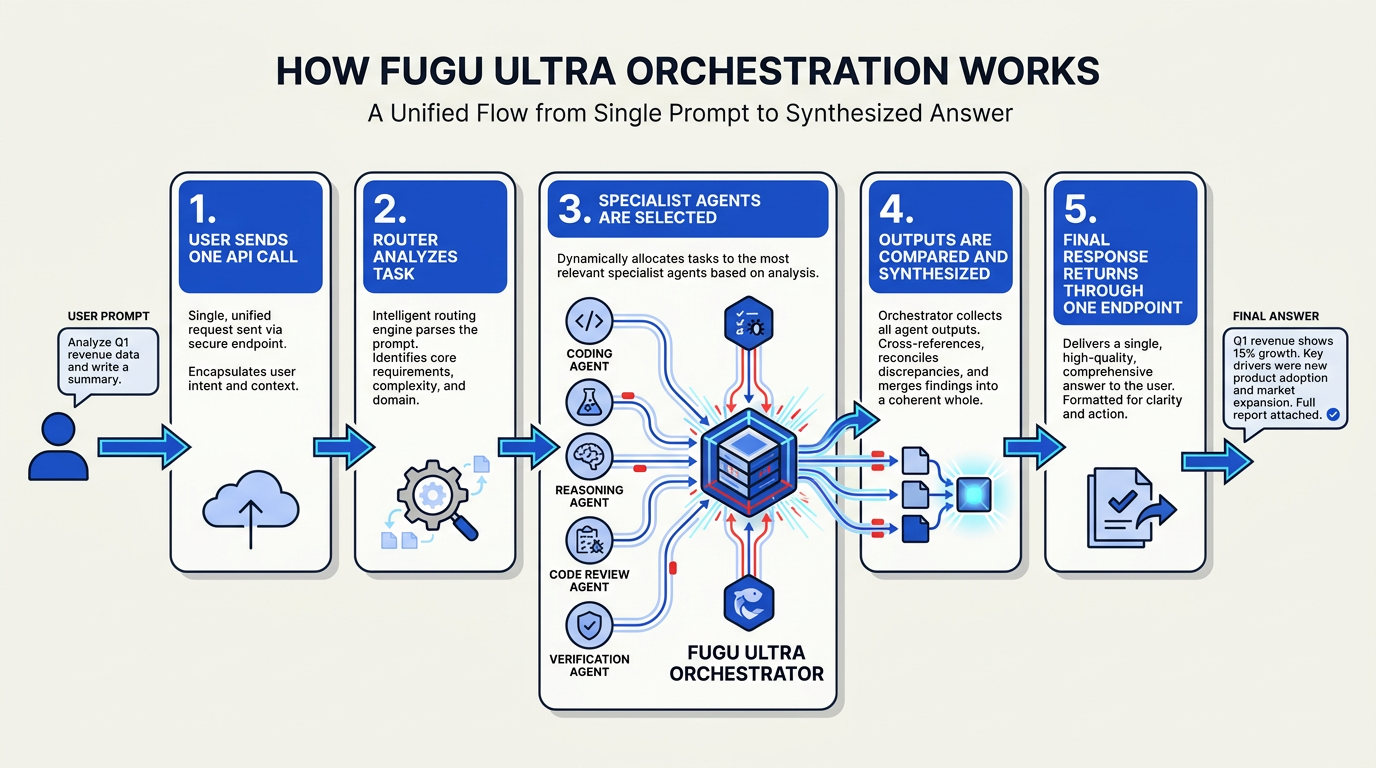
A traditional foundation model is usually experienced as a single system: prompt in, tokens out. Even if the underlying infrastructure is distributed across GPUs, the developer is mostly interacting with one trained model checkpoint. Fugu Ultra changes that abstraction. Sakana AI’s own framing—“multi-agent system as a model”—suggests the endpoint behaves like a model API while internally acting more like an AI operations room.
Instead of asking one model to solve everything, Fugu Ultra can break a request into subtasks, route those subtasks to different agents or publicly accessible frontier models, compare outputs, and synthesize a final answer. Requesty’s model listing describes Fugu Ultra as being “built on a pool of publicly accessible frontier models, rather than running as a single model” and coordinating several models behind the scenes. That is the key architectural distinction.
In practice, a complex prompt might trigger a workflow like this:
- Planner agent interprets the user’s goal and decomposes the task.
- Specialist agents handle coding, math, research, critique, or language-specific reasoning.
- Verifier agents check outputs for consistency, errors, or missing assumptions.
- Aggregator agent merges the strongest results into one response.
- Final response layer returns the answer through an OpenAI-compatible API.
To the developer, this still looks like a normal chat completion call. Internally, it may be closer to a managed committee of models.
Why orchestration can improve difficult reasoning
The reason this matters is that many frontier AI failures are not caused by a lack of raw language ability. They come from weak planning, unverified intermediate steps, hallucinated assumptions, or poor task decomposition. A multi-agent architecture directly targets those failure modes.
Sakana’s Fugu page says Fugu Ultra prioritizes answer quality on complex, multi-step reasoning, coordinating more expert agents “when accuracy and depth matter most,” while accepting higher cost and latency. That trade-off is important: orchestration is not magic efficiency. It spends more inference to improve reliability.
This explains why Fugu Ultra is positioned differently from standard Fugu:
- Standard Fugu: faster, everyday workloads where latency and cost matter more.
- Fugu Ultra: harder reasoning, coding, science, and review tasks where additional agent coordination may pay off.
- Single endpoint design: developers do not need to manually build routing, voting, or verification logic.
- OpenAI-compatible API: teams using OpenAI-style clients can potentially test it with less integration friction.
Third-party coverage from NDTV and BuildFastWithAI reports Sakana’s claims that Fugu Ultra performs on par with or ahead of leading frontier systems on certain engineering, science, reasoning, and code review benchmarks. But those should be read carefully: until independent benchmarkers reproduce the results, they remain vendor-reported performance claims, not settled evidence.
The API hides system complexity
The most commercially significant move may not be the benchmark story—it is the packaging. Multi-agent systems are not new. Developers have been building agentic workflows with routers, evaluators, tool calls, and model ensembles for years. What Sakana is doing is wrapping that complexity inside something developers already understand: a model name in an API call.
That has three implications:
- Procurement becomes simpler: buyers can evaluate “Fugu Ultra” like a model, even if it is actually a system.
- Developer experience improves: teams avoid maintaining their own orchestration stack.
- Model competition changes: the winner may be the best coordinator, not only the largest checkpoint.
This mirrors a broader infrastructure trend. Platforms such as CallMissed already expose production APIs for 300+ LLMs, voice agents, WhatsApp bots, speech-to-text across 22 Indian languages, and text-to-speech—reflecting the same shift from “choose one model” to “orchestrate the right intelligence for the job.”
The hidden trade-offs
Fugu Ultra’s architecture also raises practical questions. If several agents and models contribute to an answer, users will want clarity on:
- Latency: more coordination usually means slower responses.
- Cost: listed pricing of about $5 per million input tokens and $30 per million output tokens places Fugu Ultra in a premium reasoning tier.
- Traceability: enterprises may ask which models contributed to which outputs.
- Reliability: agent debate can improve answers, but poor orchestration can also amplify errors.
- Data governance: routing across multiple models requires strong controls over privacy, logging, and compliance.
So the real innovation is not simply that Sakana connected multiple models. It is that Fugu Ultra turns orchestration itself into the product. The “model” is the interface; the intelligence is the coordinated system behind it.
Benchmark Claims: Strong Results, but Attribute Them Carefully
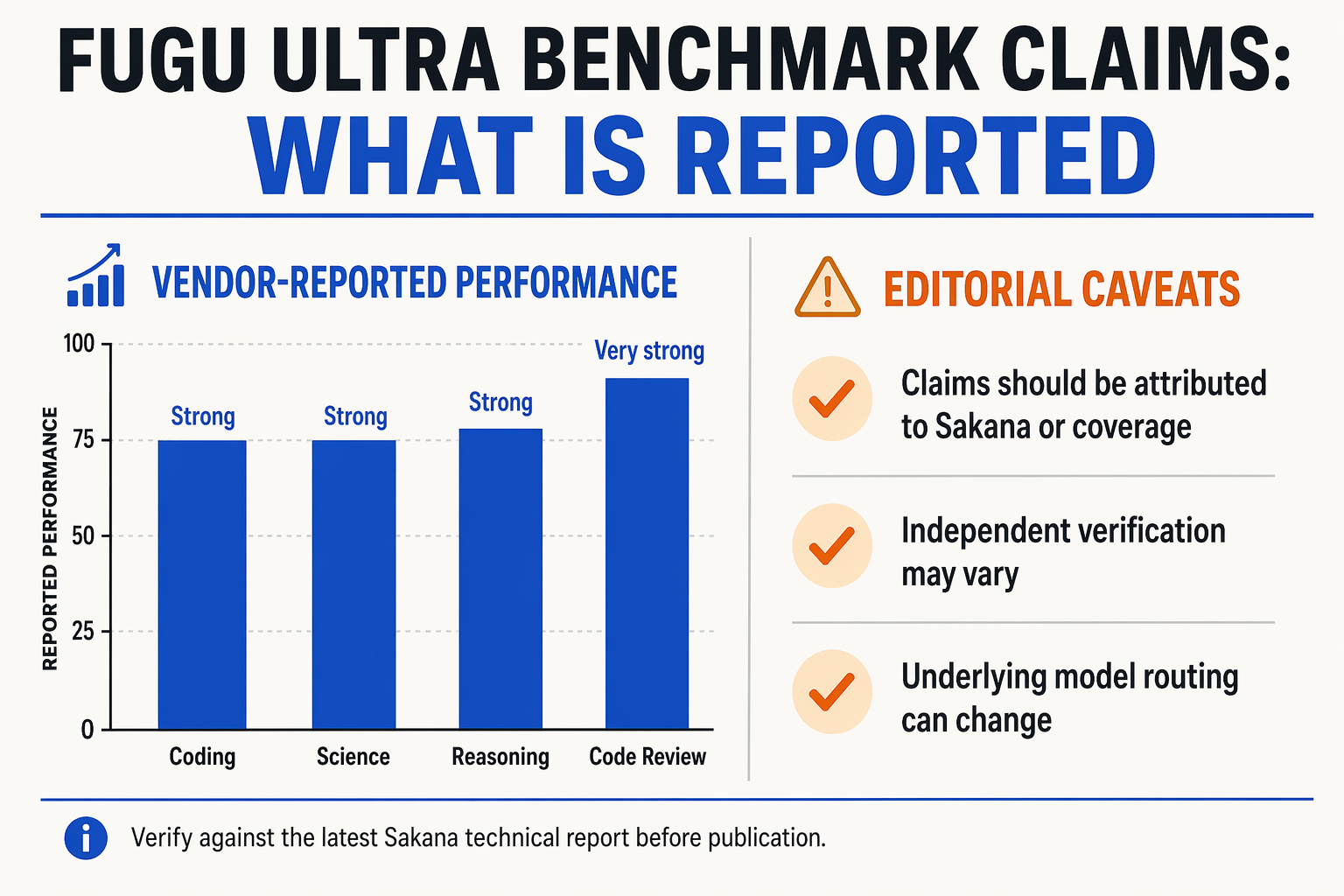
Read the numbers as system benchmarks, not model weights
The most important caveat around Fugu Ultra benchmark claims is simple: if Fugu Ultra is a coordinated multi-agent system, then its scores should not be interpreted the same way as scores from a single foundation model. Sakana’s own framing says Fugu is a “multi-agent system as a model”, and its official page says Fugu Ultra prioritizes answer quality on complex, multi-step reasoning, coordinating more expert agents “when accuracy and depth matter most.”
That means a benchmark result may reflect several layers working together:
- Model selection: routing a task to one or more suitable frontier models
- Agent specialization: assigning subproblems to coding, reasoning, verification, or critique agents
- Deliberation: having agents compare, refine, or challenge intermediate answers
- Post-processing: selecting the best final response from multiple candidates
- Tooling and prompts: using orchestration logic that improves reliability without changing base model weights
So when coverage says Fugu Ultra “matches” or “outperforms” other systems, the fair interpretation is not “Japan trained one model stronger than everyone else.” It is closer to: Sakana claims its orchestration layer can produce frontier-level outputs through coordinated inference.
What Sakana and third-party coverage claim
The reported results are still notable. Sakana launched Sakana Fugu and Fugu Ultra on June 22, 2026, and positioned both as OpenAI-compatible model APIs. Third-party coverage quickly focused on benchmark comparisons:
- NDTV reported that Sakana said Fugu Ultra performed on par with Anthropic Fable 5 and Mythos Preview on “key engineering, science, and reasoning” tasks.
- BuildFastWithAI described Fugu Ultra as a multi-agent orchestration model that matches Fable 5 and Mythos, while emphasizing that it dynamically routes work rather than behaving like one giant model.
- Sakana’s own product positioning distinguishes standard Fugu from Fugu Ultra: the former is aimed at faster everyday tasks, while Ultra spends more compute and coordination on difficult reasoning.
Those claims matter because benchmarks in coding, science, reasoning, and code review are exactly where agentic workflows can shine. A coding task, for example, can be decomposed into planning, implementation, test generation, bug review, and final explanation. A single-pass model may fail one of those steps; a multi-agent system can assign checks and counterchecks.
Why attribution gets tricky
Benchmark attribution becomes harder when the “model” is really a production system. If Fugu Ultra uses a pool of publicly accessible frontier models, as Requesty’s listing describes, then performance is partly dependent on external model behavior, availability, routing strategy, and prompt architecture. That does not make the result invalid—but it changes what is being measured.
A careful benchmark read should ask:
- Was the evaluation independently reproduced, or is it vendor-reported?
- Which underlying models were used during the run?
- How many agent calls were made per task, and what was the total inference cost?
- Were latency and token usage included, or only final-answer accuracy?
- Can the same result be reproduced consistently across repeated runs?
This is especially important because Fugu Ultra’s listed price—about $5 per million input tokens and $30 per million output tokens on Requesty—places it in a premium reasoning API category. Higher-quality orchestration may be worth that cost, but benchmark accuracy alone does not tell the full deployment story.
The right takeaway
The strongest conclusion is not that Fugu Ultra has “beaten” every frontier model. The more defensible takeaway is that orchestration itself is becoming a competitive AI capability. If Sakana’s reported benchmark performance holds up under independent testing, it would validate a broader shift: enterprises may gain frontier-like results not only by accessing bigger models, but by using smarter systems that route, verify, and coordinate models more effectively.
Impact & Implications: Why This Is Architectural and Geopolitical

The architectural shift: capability moves from weights to workflow
The biggest implication of Fugu Ultra is that it changes where “frontier performance” is assumed to come from. In the classic model race, labs compete by training larger foundation models with more parameters, more compute, and more proprietary data. Sakana AI’s framing suggests another path: performance can emerge from system architecture—routing, decomposition, agent specialization, verification loops, and model selection.
That is why the phrase “multi-agent system as a model” matters. Fugu Ultra is packaged as an OpenAI-compatible model API, launched on June 22, 2026, but its behavior is closer to an orchestration layer than a single neural network. According to Sakana’s own description, Fugu Ultra prioritizes answer quality on complex, multi-step reasoning, coordinating more expert agents when accuracy and depth matter most. Requesty’s listing similarly describes Fugu Ultra as being built on “a pool of publicly accessible frontier models” rather than one standalone model.
This has practical consequences for AI engineering:
- Model choice becomes dynamic: the system can route subtasks to different models depending on the prompt.
- Reasoning can be decomposed: coding, verification, planning, and critique can be handled by separate agents.
- Reliability can improve through redundancy: multiple agents can cross-check outputs before a final answer is returned.
- API simplicity hides backend complexity: developers call one endpoint, while orchestration happens invisibly behind it.
That last point is crucial. Fugu Ultra’s architecture says the next competitive layer may not be “who owns the biggest model,” but who can coordinate the best available intelligence most effectively.
Why this matters for enterprises
For companies, the lesson is not simply “use Fugu Ultra.” The broader lesson is that AI infrastructure is moving toward composition. Enterprises increasingly want systems that can combine fast models, reasoning models, domain-specific tools, retrieval pipelines, speech systems, and governance controls without forcing developers to rebuild everything for each provider.
That is why OpenAI compatibility is strategically important. If a team already uses OpenAI-style SDKs, a compatible endpoint can reduce switching costs. Pricing also places Fugu Ultra in the premium reasoning category: Requesty lists it at around $5 per million input tokens and $30 per million output tokens. That means it is likely better suited for high-value workloads—engineering review, scientific analysis, complex planning—than cheap bulk generation.
This mirrors a broader platform trend. For example, infrastructure providers such as CallMissed already expose multi-model LLM access through production APIs, alongside voice agents, WhatsApp automation, speech-to-text, and text-to-speech. The common pattern is clear: businesses do not just need one model; they need an adaptable communication and reasoning stack that can route tasks to the right capability.
The geopolitical implication: Japan is competing differently
Fugu Ultra also matters because it reframes Japan’s role in the global AI race. The dominant AI narrative has been shaped by U.S. hyperscalers, Chinese foundation-model labs, and massive GPU clusters. Sakana AI’s approach suggests a different national strategy: instead of only trying to outspend frontier labs on training runs, Japan can compete through algorithmic coordination, agent design, and efficient use of existing frontier models.
This is geopolitically significant for three reasons:
- It lowers the symbolic barrier to entry
If competitive capability can be assembled through orchestration, more countries and startups can participate without owning the world’s largest compute cluster.
- It creates strategic dependency questions
If Fugu Ultra relies partly on publicly accessible frontier models, its performance may depend on access terms, pricing, latency, and policy decisions from external model providers.
- It shifts the export-control debate
BuildFastWithAI characterized Fugu as an orchestration model that “routes around export controls.” That framing may be provocative, but it highlights a real policy challenge: restrictions aimed at chips or model weights may not fully address systems that combine accessible models through intelligent routing.
Benchmarks are now system benchmarks
The reported benchmark claims—NDTV says Sakana stated Fugu Ultra performed on par with Anthropic Fable 5 and Mythos Preview on key engineering, science, and reasoning tasks—should still be treated as vendor-reported until independently replicated. But even if the numbers are debated, the benchmark category itself has changed.
Fugu Ultra is not just testing a model. It is testing an AI operating pattern: many agents, one endpoint, optimized for high-quality answers. If that pattern holds up, the future of frontier AI may look less like a single supermodel—and more like a well-managed team.
Expert Opinions: The Promise and Trade-Offs of Multi-Agent APIs

Why many AI engineers find the architecture compelling
The strongest expert argument for Fugu Ultra is that frontier capability may increasingly come from systems design, not just model scale. Sakana AI’s own framing—“multi-agent system as a model”—captures a view that has been gaining traction among AI infrastructure teams: a single large model is powerful, but a coordinated workflow of specialized models can be more reliable on complex tasks.
That is especially relevant for workloads where one-shot generation is not enough:
- Software engineering: planning, writing, testing, reviewing, and debugging code
- Scientific reasoning: decomposing hypotheses, checking assumptions, and comparing evidence
- Enterprise analysis: routing subtasks to domain-specific agents, then synthesizing an auditable answer
- Customer operations: combining speech, language, retrieval, and workflow automation in real time
Sakana’s claim that Fugu Ultra prioritizes answer quality on complex, multi-step reasoning by coordinating more expert agents fits this pattern. Instead of asking one model to “think harder,” the system can assign roles: one agent drafts, another critiques, another verifies, and another rewrites. That resembles how high-performing human teams work.
This is why the OpenAI-compatible API detail matters. If developers can access this orchestration through a familiar model endpoint, the architectural complexity is hidden behind a standard interface. The same trend is visible across AI infrastructure: platforms like CallMissed expose multiple LLMs, speech APIs, and voice-agent capabilities through production-ready interfaces so teams can build systems without manually stitching every component together.
The benchmark optimism comes with caveats
The optimistic reading is that Fugu Ultra could validate a new path for countries and companies that do not own the biggest proprietary base models. Third-party coverage, including NDTV and BuildFastWithAI, reports Sakana’s benchmark claims that Fugu Ultra performs on par with or ahead of leading frontier systems on coding, science, reasoning, and code review tasks. Requesty also describes Fugu Ultra as being built on “a pool of publicly accessible frontier models” rather than a single model.
But experts would be careful about over-interpreting that. The benchmark results currently should be treated as vendor-reported claims, not settled independent evidence. Multi-agent systems can perform extremely well on selected tasks, but their real-world value depends on:
- Benchmark transparency — Were prompts, evaluation rubrics, and model settings disclosed?
- Repeatability — Does the system produce consistent results across runs?
- Latency — How long does deeper coordination take?
- Cost efficiency — Does better accuracy justify premium pricing?
- Failure handling — What happens when agents disagree or reinforce the same mistake?
The pricing illustrates the trade-off. Listings such as Requesty place Fugu Ultra at about $5 per million input tokens and $30 per million output tokens, which positions it closer to premium reasoning APIs than commodity chat models. For high-value engineering or research workflows, that may be acceptable. For high-volume customer support or lightweight summarization, standard Fugu or cheaper models may be more practical.
The trade-off: intelligence versus controllability
The key concern with multi-agent APIs is not whether they can be powerful. It is whether they can be controlled, observed, and governed.
A monolithic model is already difficult to debug. A multi-agent system adds more moving parts: routing logic, agent prompts, model selection, intermediate outputs, consensus steps, and tool calls. That creates new operational questions:
- Which agent produced the wrong assumption?
- Did the router choose the right model?
- Was the final answer based on verified evidence or agent agreement?
- Can enterprises inspect intermediate reasoning traces?
- How are data privacy and model-provider boundaries handled?
For regulated industries, these questions matter as much as raw benchmark scores. The promise of Fugu Ultra is that orchestration can make AI more capable. The trade-off is that orchestration can also make AI systems more opaque unless vendors provide strong observability, audit logs, and reliability guarantees.
The expert consensus: promising, but not magic
The most balanced view is that Fugu Ultra is not a replacement for foundation models; it is a new way to package and amplify them. If Sakana’s approach proves reliable beyond vendor benchmarks, it could become a template for the next generation of AI APIs: model-like from the outside, system-like on the inside.
That shift is strategically important. It suggests the future may not belong only to whoever trains the largest model, but also to whoever builds the best coordination layer around many models.
What This Means For You (TABLE)
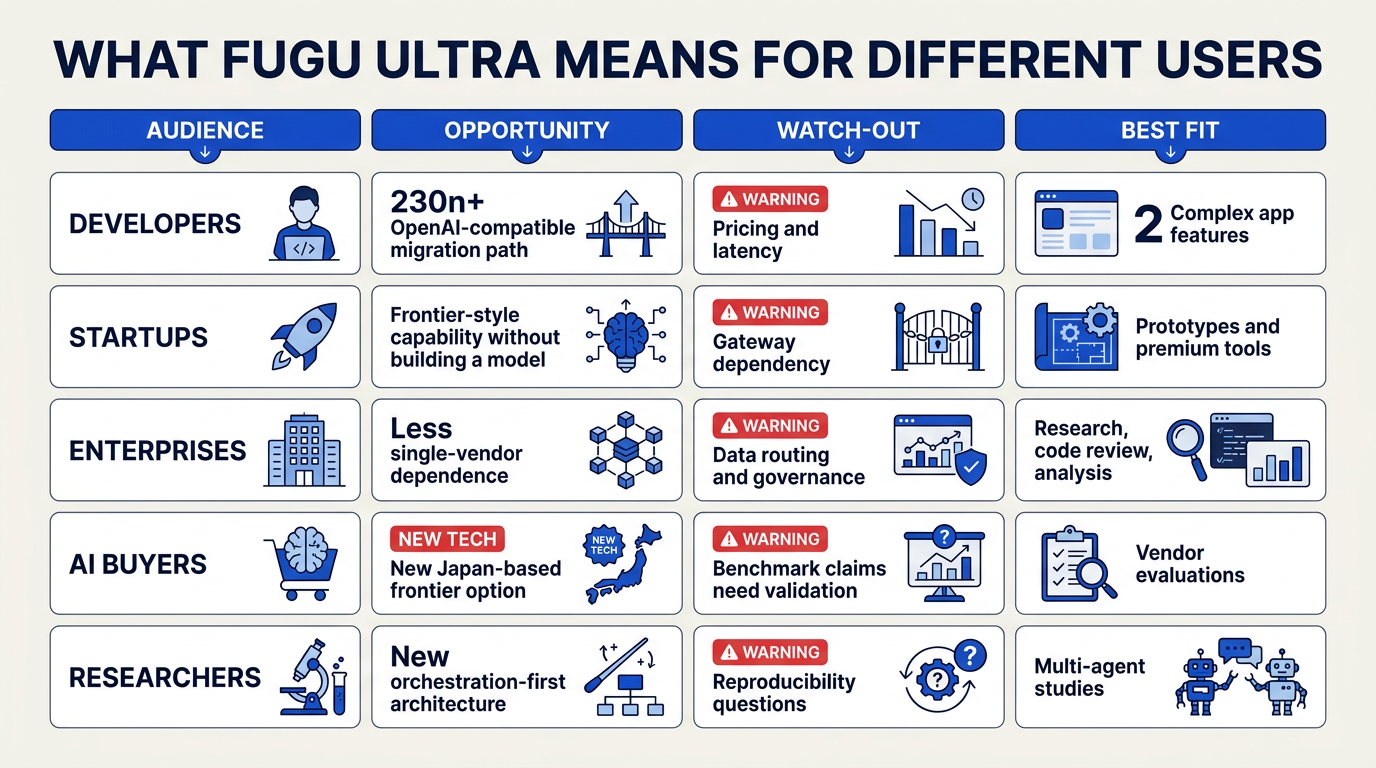
The practical takeaway: “model choice” is becoming “system design”
Fugu Ultra’s launch on June 22, 2026 changes the buying question. Instead of asking only, “Which single LLM is smartest?”, teams now need to ask: Which API gives us the best orchestration layer for the task? Sakana AI’s own positioning—“multi-agent system as a model”—suggests that frontier performance may increasingly come from routing, verification, and specialist-agent collaboration rather than raw model scale alone.
| If you are… | What Fugu Ultra signals | Practical implication | Watch-outs |
|---|---|---|---|
| Developer | OpenAI-compatible APIs can hide complex agent workflows behind one endpoint | You may be able to test orchestration systems without rewriting your app stack | Compatibility does not guarantee identical latency, behavior, or cost |
| Startup founder | High-quality reasoning can be packaged as an API, not built from scratch | Use premium reasoning only for hard tasks; route simple tasks to cheaper/faster models | Fugu Ultra pricing is listed by Requesty at about $5/M input tokens and $30/M output tokens |
| Enterprise AI lead | Multi-agent systems may improve complex workflows like code review, analytics, and compliance checks | Evaluate orchestration quality, observability, audit logs, and fallback behavior | Benchmark claims reported by NDTV and BuildFastWithAI are still vendor-reported unless independently verified |
| AI infrastructure team | The “model” endpoint may actually call multiple frontier models and agents | Your monitoring should track latency, cost per task, model provenance, and failure modes | More agents can mean more moving parts and harder debugging |
| Product manager | Standard Fugu targets faster everyday workloads; Fugu Ultra prioritizes complex multi-step reasoning | Create task tiers: fast responses for routine work, deep reasoning for high-value tasks | Users may not tolerate premium latency for simple requests |
| India/global business | Multilingual, multi-model orchestration is becoming normal AI infrastructure | Platforms like CallMissed already reflect this trend with voice agents, WhatsApp bots, 300+ LLM access, and STT for 22 Indian languages | Match orchestration to real customer channels, not just benchmark scores |
How to evaluate systems like Fugu Ultra
Treat Fugu Ultra less like a single model replacement and more like a reasoning service. That means your evaluation should go beyond leaderboard-style scores.
A sensible test plan:
- Start with your hardest tasks
Use complex prompts involving multi-step reasoning, code review, financial analysis, legal summarization, or scientific interpretation—not generic chatbot questions.
- Measure cost per successful outcome
A premium API can be worth it if it reduces human review time. But with published pricing around $30 per million output tokens, verbose reasoning can become expensive quickly.
- Compare against simpler routing
Test whether a cheaper model plus your own retrieval, tools, or verification pipeline performs nearly as well.
- Track latency and reliability
Sakana says Fugu Ultra coordinates more expert agents when accuracy and depth matter. That may improve quality, but it can also introduce slower responses than standard Fugu-style everyday workloads.
- Demand transparency where possible
Because Fugu Ultra is built around orchestration, teams should ask what can be logged: intermediate reasoning traces, tool calls, model routing decisions, failure recovery, and data-handling guarantees.
The bigger lesson
The important shift is not simply that Japan has another AI competitor. It is that Sakana AI is making orchestration itself productized. For users, this means the next wave of AI applications may be less about picking one “best” model and more about combining models, agents, tools, and verification loops intelligently.
For builders, the message is clear: design your AI stack so it can switch models, route tasks, and add specialist agents over time. Whether you use Sakana’s Fugu APIs, a multi-model gateway, or infrastructure from platforms such as CallMissed, flexibility is becoming a core advantage.
Frequently Asked Questions
What is Fugu Ultra by Sakana AI?
Is Fugu Ultra really a model or a multi-agent system?
How is Sakana Fugu different from Fugu Ultra?
Did Fugu Ultra beat Claude or other frontier AI models?
How much does Fugu Ultra cost for developers?
Why does Fugu Ultra matter for AI infrastructure and businesses?
Conclusion
Fugu Ultra’s real significance is not that Japan has simply produced another frontier model. It is that Sakana AI is packaging orchestration itself as the product: one OpenAI-compatible API call that can coordinate multiple agents, models, and reasoning steps behind the scenes.
Key takeaways:
- Fugu Ultra is a system, not just a model: Sakana describes it as a “multi-agent system as a model,” built to route and coordinate expert agents through one endpoint.
- Quality comes from coordination: the Ultra variant prioritizes complex, multi-step reasoning, while standard Fugu targets faster everyday workloads.
- The benchmark claims are promising but early: reports say Fugu Ultra matches or beats leading systems on coding, science, reasoning, and code review tasks, but these remain vendor-reported until independently verified.
- Developer adoption could be smoother: OpenAI-compatible APIs and listed pricing around $5/M input tokens and $30/M output tokens make it easier to compare with premium reasoning APIs.
What to watch next is whether enterprises begin buying AI systems rather than individual models. To explore how AI communication is evolving in that direction, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
The bigger question: will the next frontier AI race be won by the biggest model, or by the smartest team of models?
Related Posts

Anticipating Claude 5 Sonnet: What to Expect from Anthropic’s Next-Gen Mid-Tier Powerhouse

Claude Sonnet 5 vs. GLM-5.2: The Ultimate Agentic Coding Showdown (Closed vs. Open-Weight)

Claude Sonnet 5 vs GPT-5.6: What We Can—and Can’t—Compare Right Now
Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.