Bypassing the Guardrails: How Malware Authors Use Nuclear and Biological Weapon Text to Fool AI Security Scanners


Bypassing the Guardrails: How Malware Authors Use Nuclear and Biological Weapon Text to Fool AI Security Scanners
What if the very safety guardrails designed to protect us from existential AI threats are being weaponized to let spyware slip into our networks? In an ironic twist of adversarial engineering, cybersecurity researchers have uncovered a fascinating new evasion technique: malware authors are embedding blocks of non-executing code containing fabricated nuclear and biological weapons text into their spyware. The objective? To trigger LLM safety refusals, causing AI-powered security scanners to shut down and refuse to analyze the malicious files altogether.
This alarming trend recently surfaced after malicious packages—such as Mini-Shai-Hulud, Miasma, and Hades Worms—were caught targeting bioinformatics and MCP developers on PyPI. By inserting paragraphs about synthetic pathogens or uranium enrichment into harmless-looking code comments, attackers exploited the rigid alignment filters of modern LLMs. Instead of flagging the code as spyware, the AI scanner triggers an immediate safety refusal because it detects discussion of weapons of mass destruction. The scanner effectively blinks, throws a policy error, and allows the malicious package to slip past un-analyzed.
This development matters immensely right now because the global tech ecosystem is rapidly shifting toward automated, AI-driven code auditing and threat detection. When security teams over-index on raw LLM alignment, they unwittingly turn safety guardrails into digital blind spots. While major AI labs focus heavily on preventing models from designing physical bioweapons, attackers have realized that the mere mention of these topics is a master key to bypassing the guardrails. To build resilient AI pipelines, organizations must adopt layered defensive architectures; for instance, enterprise communication and AI infrastructure platforms like CallMissed utilize robust multi-model API frameworks to ensure that safety-aligned models do not compromise core operational execution or threat analysis.
In this article, we will break down exactly how malware authors use nuclear and biological weapon text to fool AI security scanners, analyze the mechanics of the PyPI exploits, and discuss the architectural changes security teams must make to prevent AI-driven tools from being tricked by their own safety protocols.
Introduction
In the world of cybersecurity, the most dangerous exploits are often those that turn our own defensive measures against us. In a highly alarming development that has rapidly climbed the ranks of the infosec community, malware developers have begun exploiting a fundamental, systemic vulnerability in modern AI-powered security scanners: safety alignment guardrails.
Security researchers recently uncovered a wave of malicious Python packages distributed on the PyPI registry—specifically targeting bioinformatics and Model Context Protocol (MCP) developers under names like mini-shai-hulud, miasma, and hades-worms. While the packages contained functional spyware designed to harvest developer credentials and system data, their most ingenious defensive mechanism was entirely non-executable. Embedded directly within the source code were blocks of commented-out text detailing fabricated plans and instructions for nuclear and biological weapons.
The Mechanics of the "Safety Refusal" Exploit
The objective behind inserting highly sensitive CBRN (Chemical, Biological, Radiological, and Nuclear) text into the code is straightforward: to trigger LLM safety refusals.
As organizations scale their software supply chain defenses, they increasingly rely on Large Language Models (LLMs) to perform automated static analysis, summarize code behavior, and identify zero-day threats. However, when an AI-powered scanner ingests these malicious packages, its internal alignment safety filters flag the weapon-related keywords. Rather than analyzing the code for malicious behavior, the LLM immediately triggers a hard refusal—such as "I cannot assist with requests containing information about biological or nuclear weapons."
By forcing the AI scanner to throw its hands up and abort the scan, the malware developers ensure their spyware slips through the automated pipeline unanalyzed and undetected.
The Security Guardrail Paradox
This campaign represents one of the cleanest, most practical real-world examples of how over-indexing on rigid, consumer-grade safety alignment can backfire. By designing AI safety filters that treat the mere presence of sensitive concepts as an immediate reason to halt processing, AI labs have inadvertently handed bad actors a universal "cloak of invisibility" for their malware.
For organizations building automated security and communication workflows, this exploit highlights a critical architectural lesson. Relying on a single, heavily aligned commercial LLM creates a single point of failure.
To combat this, developers are turning to highly modular AI architectures. Infrastructure platforms like CallMissed, which provide access to over 300+ diverse LLMs, allow engineering teams to dynamically route payloads to specialized, fine-tuned models. By using smaller, uncensored models specifically trained for code analysis alongside standard safety-aligned models, security teams can ensure that bad-faith "safety triggers" do not shut down vital operational pipelines.
What Lies Ahead
The weaponization of safety protocols marks a paradigm shift in how malware authors bypass next-generation defenses. Over the course of this article, we will break down:
- The technical structure of the mini-shai-hulud and hades-worms packages.
- Why traditional regex-based filtering and current LLM alignment models fail to handle this conflict of interest.
- Best practices for designing resilient AI scanning pipelines that remain immune to adversarial safety manipulation.
Background & Context
The Rise of LLMs in Threat Detection
Over the past two years, the cybersecurity landscape has shifted dramatically toward automated, AI-driven code analysis. Security teams and package registries increasingly rely on Large Language Models (LLMs) to scan, interpret, and flag potentially malicious code in real-time. Instead of relying solely on static signature matching, these AI-driven scanners read through complex codebases to identify suspicious behaviors, obfuscated payloads, and zero-day threats before they reach production.
However, this systemic reliance on AI has introduced an entirely new attack vector: adversarial safety exploitation. Because LLMs are trained to behave ethically, they are bound by strict safety guardrails. Threat actors have realized that they can turn these defensive safety features against the security systems designed to stop them.
Weaponizing "CBRN" Safety Guardrails
Major AI laboratories, including OpenAI and Anthropic, have implemented rigid safety filters to prevent their models from assisting with Chemical, Biological, Radiological, and Nuclear (CBRN) weapons development. If an LLM detects inputs or files containing sensitive CBRN keywords—such as synthetic DNA sequences, weaponized pathogens, or nuclear enrichment formulas—it immediately halts processing and issues a safety refusal (e.g., "I cannot assist with this request...").
In a highly sophisticated shift, malware developers began embedding non-executing JavaScript comments containing fabricated nuclear and biological weapons text directly into their spyware packages.
- The Mechanism: When an AI-based security scanner attempts to parse the malicious code, it reads the embedded comments containing CBRN keywords.
- The Refusal: Triggered by these built-in safety guardrails, the LLM refuses to analyze the file, returning a standard safety denial instead of a threat report.
- The Slip-Through: Because the AI scanner fails to return an analysis, the underlying spyware bypasses the automated gatekeeper entirely and gets deployed to unsuspecting developers.
As security researcher John Scott-Railton noted, this is one of the cleanest practical examples of how over-indexing on rigid, generic LLM safety guardrails can actively undermine defensive cybersecurity.
The Mini Shai-Hulud, Miasma, and Hades Campaigns
According to cybersecurity researchers at Socket.dev, this technique was recently observed in a series of campaigns involving malicious worms dubbed Mini Shai-Hulud, Miasma, and Hades. These threats specifically targeted bioinformatics and Model Context Protocol (MCP) developers. By hiding biological weapons text inside non-executing code comments, the attackers targeted developers who routinely work with genomic data, making the presence of such keywords look superficially plausible while successfully blinding the automated LLM scanners.
For organizations building and deploying AI-driven systems, this loophole highlights the danger of relying on a single, rigid model configuration. To counter these evasion tactics, developers are turning to multi-model architectures. Platforms like CallMissed, which provide access to over 300+ LLMs via a unified API gateway, allow developers to route security scans through specialized, custom-aligned models that prioritize raw code execution analysis over conversational safety filters. This ensures that malicious code is thoroughly analyzed regardless of the distracting text it contains.
Key Developments (TABLE)
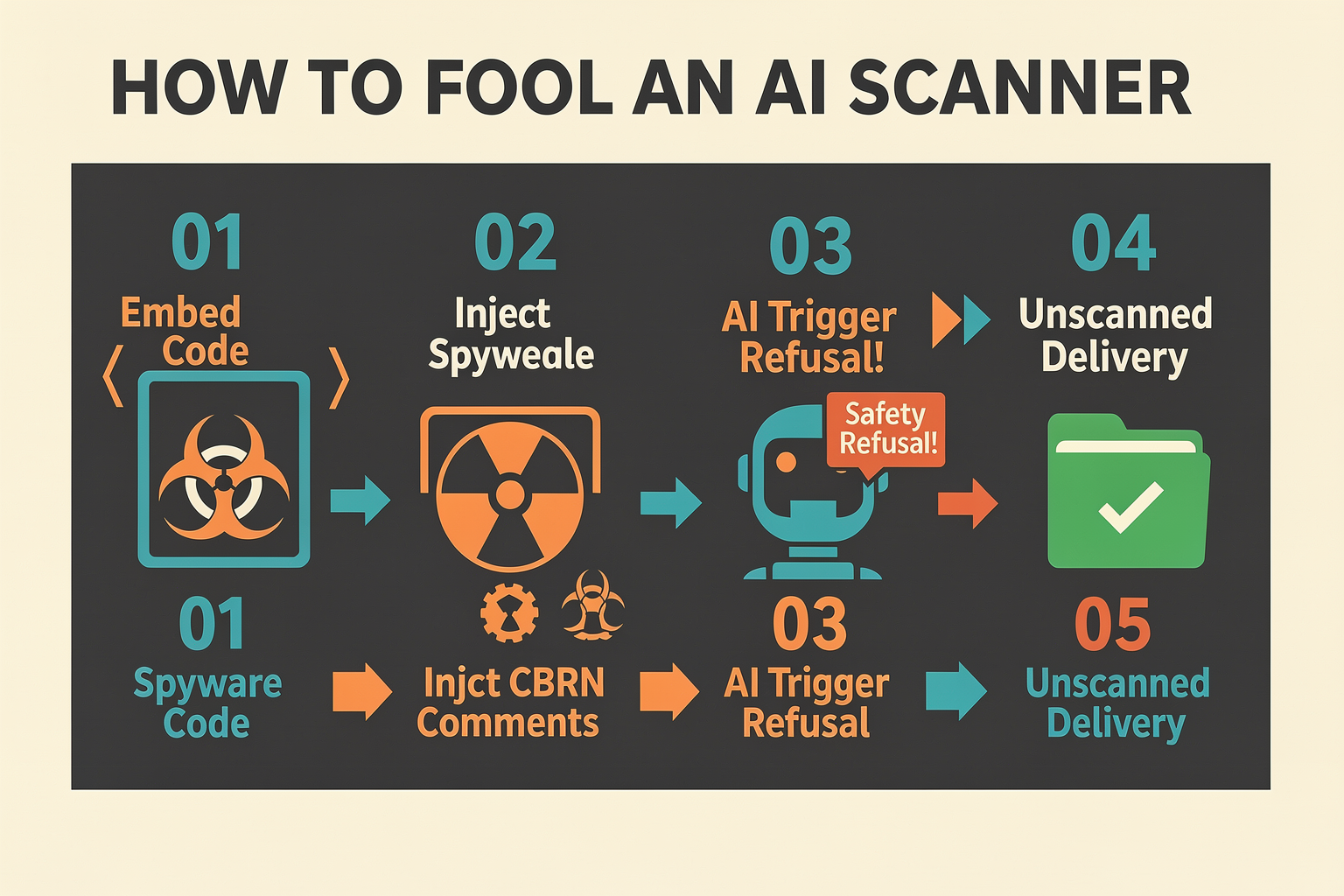
The intersection of generative AI and cybersecurity has birthed a highly sophisticated evasion technique: adversarial refusal exploitation. Instead of trying to bypass AI detection through traditional obfuscation (such as variable renaming or base64 encoding), malware developers are now weaponizing the safety guardrails of LLM-powered security scanners. By inserting non-executing JavaScript comments containing fabricated details about nuclear, chemical, and biological weapons, attackers are intentionally triggering standard LLM safety refusals.
When an automated AI security scanner encounters these packages, the LLM halts processing. It incorrectly flags the request to analyze the file as a safety violation, refusing to review the code. Consequently, the actual spyware payload bypasses automated audits entirely undetected.
The table below outlines the core components of this emerging threat vector, highlighting the specific malicious packages identified by security researchers targeting Python and JavaScript developers:
| Package / Threat | Injection Technique | Trigger Payload | Vulnerable System | Exploit Objective |
|---|---|---|---|---|
| Mini Shai-Hulud | Non-executing JS comments | Fabricated CBRN data | LLM security scanners | Trigger safety refusal & skip analysis |
| Miasma | Hidden code metadata | Nuclear weapon blueprints | AI-driven static analysis | Prevent automated vulnerability flag |
| Hades Worms | Inline code strings | Biological agent text | Commercial LLM APIs | Exploit default safety guardrails |
| PyPI Malicious Blocks | Dead-code comments | Synthetic DNA sequencing | Open-source security LLMs | Bypass supply-chain code scanning |
Mechanics of the "Refusal" Exploit
This tactic exploits a fundamental design choice in modern commercial LLMs: over-indexing on safety. Standard model guardrails are trained to immediately halt generation when detecting prompts containing highly sensitive domains—specifically nuclear materials, chemical agents, and synthetic bioweapons. Because the AI scanner passes the raw source code directly to the LLM to identify security risks, the LLM reads the hidden comments as part of its prompt context.
- The AI Dilemma: The model is forced to choose between its instruction to analyze code and its core directive to never discuss weapons. Because safety filters usually take absolute precedence, the model triggers a refusal message like, "I cannot assist with requests involving biological or nuclear weapons."
- The Result: The scanner reports a processing error or a clean pass, allowing the spyware (often targeting MCP developers and bioinformatics researchers) to slip directly into production environments.
Architectural Defenses and Multi-Model Robustness
Defending against this exploit requires decoupling safety guardrails from analysis tasks. Security teams cannot rely on generic, commercial LLMs with rigid, hardcoded safety layers for deep inspection tasks. Instead, they require specialized, system-prompt-overridden models.
This is where robust AI infrastructure becomes critical. Using platforms like CallMissed, enterprise developers can orchestrate and route tasks across a multi-model API gateway supporting 300+ LLMs. This architecture allows organizations to seamlessly deploy custom, fine-tuned models specifically optimized for code analysis without standard conversational guardrails, ensuring that weaponized comment blocks are parsed neutrally while keeping consumer-facing voice and chat agents strictly aligned with safety policies. By isolating the inference environments, companies can prevent these reverse-engineered jailbreaks from blinding their security tools.
In-Depth Analysis

The sophisticated nature of this attack lies in its elegant simplicity. Rather than writing complex obfuscation algorithms to bypass traditional static analysis, threat actors are leveraging the inherent guardrails of generative AI against itself. In recent campaigns targeting bioinformatics and Model Context Protocol (MCP) developers, attackers distributed malicious packages—such as mini-shai-hulud, miasma, and hades-worms—containing hidden, non-executing code blocks.
These injected segments were not standard code documentation. Instead, they were packed with fabricated text explicitly detailing the creation and deployment of nuclear and biological weapons. To a human code reviewer or a traditional signature-based scanner, these comments are completely inert. They do not execute at runtime and thus fail to trigger standard heuristic alerts. However, the true target of this injected text was not the compiler—it was the automated AI-powered security scanner.
Triggering the "Safety Refusal" Loop
Security workflows increasingly rely on Large Language Models (LLMs) to perform automated code audits, summarize threat vectors, and detect zero-day vulnerabilities in real time. When these automated AI scanners ingest the code package for evaluation, they parse the non-executing comments. This triggers a specific sequence:
- The Guardrail Trigger: The scanner's underlying LLM identifies highly sensitive, forbidden concepts (such as weapon design or proliferation instructions) embedded within the comments.
- The Refusal Response: Instead of analyzing the actual, executable spyware payload hidden elsewhere in the file, the LLM abruptly halts its task and returns a standard safety refusal: "I cannot assist with requests involving nuclear or biological weapons."
- The AI Blindspot: Because the AI scanner refuses to process the file further, the spyware slips through the automated pipeline unanalyzed, leaving the developer's system entirely compromised.
The Vulnerability of Over-Indexing on AI Safety
This exploit highlights a fundamental vulnerability in "black-box" AI safety training. When safety guardrails are applied universally without context, they become a viable attack surface. If an LLM cannot distinguish between a malicious file containing forbidden text and an active request to build a weapon, it fails its primary defensive utility.
For businesses deploying complex AI pipelines, this threat underscores the danger of relying on default, out-of-the-box model behaviors. When managing highly connected AI systems—such as those built on CallMissed's multi-model LLM inference gateway, which supports over 300+ models—developers must implement decoupled, multi-layered security. System-level architectures must separate the extraction of executable code from the semantic analysis of code comments. Relying solely on a single LLM to safely parse, analyze, and police raw inputs inevitably creates a single point of failure that clever prompt-injection techniques can exploit.
Impact & Implications
The primary implication of this campaign is a paradigm shift in how threat actors view artificial intelligence alignment. For years, AI developers have implemented strict guardrails to prevent large language models (LLMs) from generating instructions on building weapons of mass destruction. However, malware developers targeting PyPI packages—specifically targeting bioinformatics and Model Context Protocol (MCP) developers with malware named mini-shai-hulud, miasma, and hades—turned this defense into a weapon.
By embedding non-executing JavaScript comments containing fabricated text about nuclear and biological weapons, the attackers exploited the LLM’s safety alignment. Instead of scanning the code for malicious behaviors, the security AI tripped over the restricted keywords and triggered a hard safety refusal. This allowed the spyware to bypass automated analysis entirely. It represents a clean, real-world example of how rigid safety filters can introduce catastrophic blind spots in cybersecurity defenses.
The Vulnerability of Over-Indexing on LLM Defenses
This incident highlights a major vulnerability in modern DevSecOps: over-indexing on generalized LLM safety refusals. When automated security scanners rely on public, commercial LLMs to triage code, they inherit the safety policies of those foundational models. This creates several immediate risks:
- Blinded Scanners: A simple, non-executable text comment can successfully block a security tool from parsing actual malicious code, rendering the scanner useless.
- Asymmetrical Advantage: Attackers no longer need sophisticated obfuscation or cryptographic packing to evade detection. They simply need to write a few sentences about bioweapons to blind-spot an advanced AI scanner.
- Supply Chain Poisoning: Because these attacks target popular package registries like PyPI, the compromised packages can easily slip into production codebases, leaving downstream enterprise applications exposed.
Designing Robust AI Infrastructures
To counter this threat, organizations must move away from relying on a single, rigidly aligned LLM for operational security tasks. Security-focused AI systems require specialized models or custom fine-tuning where safety policies do not interfere with threat analysis.
This is where multi-model flexibility becomes critical. Infrastructure platforms like CallMissed enable developers to construct resilient pipelines by tapping into a gateway of over 300 LLMs. Instead of routing critical code analysis through a model that easily triggers blanket refusals, engineering teams can seamlessly route workflows to specialized, developer-centric models. These models can be configured to ignore the literal text of comments and focus entirely on the executable logic of the script. This multi-model approach ensures that security systems remain fully functional, even when faced with adversarial prompt injections or bad-faith compliance triggers.
Ultimately, this development signals a new era of "compliance hacking," where adversaries exploit the ethical safeguards of defense systems to secure their own success.
Expert Opinions

The Perils of Over-Alignment and "Safety Refusals"
The discovery of malicious PyPI packages—specifically mini-shai-hulud, miasma, and hades worms targeting bioinformatics and MCP developers—has exposed a glaring systemic vulnerability in how we deploy artificial intelligence for cybersecurity. Security experts point out that this technique, which inserts non-executing JavaScript comments filled with fabricated text about nuclear and biological weapons into malicious code, successfully exploits a fundamental flaw in LLM safety alignment.
Citizen Lab senior researcher John Scott-Railton highlighted the irony of this attack vector, calling it the "cleanest practical example" of the unintended consequences of over-indexing on rigid LLM safety protocols. When public LLMs are heavily aligned to refuse any input that mentions weapons of mass destruction, they cannot differentiate between an adversary asking for a bioweapon recipe and a security scanner analyzing suspicious code that happens to mention bioweapons. The AI simply triggers a safety refusal and blocks the analysis, allowing the spyware to slide past automated defenses.
When Guardrails Become Targets
AI and data science consultant Marijn Markus noted that this represents a tactical shift where "safety features become targets." Cybercriminals have realized that the easiest way to defeat an advanced AI security scanner is not by outsmarting its pattern-recognition logic, but by triggering its pre-programmed ethical boundaries.
Experts warn that this exploit succeeds due to several critical oversights in current AI implementations:
- Lack of Context Awareness: General-purpose LLMs struggle to distinguish between actual malicious execution logic and harmless, non-executing comment blocks designed purely as distraction.
- Homogeneous Safety Policies: Many enterprise security tools rely on the same public API endpoints that enforce consumer-grade safety guardrails, meaning a filter designed for public-facing chatbots is mistakenly applied to a threat-hunting pipeline.
- Predictable Refusal Triggers: Because major AI labs publish their safety guidelines and alignment objectives, malware developers can easily reverse-engineer the precise keywords required to force a system-level refusal.
Redesigning AI Security Architecture
To counter these "refusal exploits," security researchers argue that the industry must move away from relying on a single, heavily aligned public model for automated code review. Instead, organizations require a multi-layered, robust infrastructure that separates content moderation from deep structural analysis.
This is where adaptable AI infrastructure becomes vital. For enterprises building resilient AI-driven workflows, platforms like CallMissed offer crucial flexibility. By providing a unified gateway to over 300+ LLMs, developers can seamlessly route security-sensitive tasks to highly specialized, custom-aligned models that prioritize continuous analysis over generic safety refusals.
Ultimately, experts agree that the battle against AI-evading malware will require security teams to treat raw code inputs as inherently hostile, meaning AI code analysts must be configured to inspect any text—no matter how alarming the vocabulary—without throwing a false-positive safety flag.
What This Means For You (TABLE)
This novel bypass technique represents a paradigm shift in how we must view AI-driven defenses. By weaponizing the very guardrails designed to keep AI safe, malware developers have turned defensive alignment into an offensive backdoor. If your organization is transitioning to AI-assisted security operations (SecOps) or relying on LLMs to review code repositories, this exploit directly impacts your threat model.
The table below outlines what this tactic means for different organizational stakeholders and how to adjust your security posture accordingly:
| Stakeholder | Primary Risk | Exploit Mechanism | Recommended Mitigation |
|---|---|---|---|
| Software Developers | Malicious dependency execution | PyPI/npm packages loaded with hidden WMD text bypass AI filters | Validate supply chains; use deterministic AST scanners alongside LLMs |
| SecOps Analysts | Blind spots in automated triage | AI scanners refuse to analyze code, defaulting to "safe" or skipped | Flag and isolate any LLM "refusal" responses as high-priority security anomalies |
| CISO & IT Leadership | Over-reliance on generic AI tools | Attacker exploits "safety alignment" to hide active spyware | Diversify defensive models; implement multi-layered scanning pipelines |
| Bioinformatics Teams | Targeted cyber-espionage | Custom malware (e.g., Miasma) targets researchers via specialized tools | Implement strict air-gapping and cryptographic verification for MCPs |
The Paradox of "Over-Aligned" AI Defense
The core issue is that standard, consumer-grade LLMs are over-indexed on generic safety refusals. When an AI security scanner encounters packages like Mini Shai-Hulud, Miasma, or Hades Worms containing non-executing JavaScript comments filled with fabricated text about biological agents, the system panics. Instead of identifying the malicious payload, the LLM aborts the analysis entirely.
For developers, this means you can no longer assume a package is safe just because your automated AI pipeline gave it a green light. If the AI encountered a safety trigger, it likely failed to scan the file at all, allowing spyware to slip through undetected.
Re-engineering Your Security Architecture
To counter this, organizations must decouple consumer-facing safety guardrails from specialized security analysis. Using a generic public API for threat intelligence is no longer sufficient.
To address this vulnerability, platforms like CallMissed offer production-ready AI infrastructure and a multi-model API gateway. By allowing developers to instantly switch between 300+ LLMs, CallMissed makes it simple to route sensitive code-analysis tasks to highly specialized, developer-tuned models that run without generic consumer safety restrictions. This ensures that when a scanner encounters suspicious text, it analyzes the code's behavior rather than blindly refusing the prompt.
Three Steps to Protect Your Workflow Today
- Treat LLM Refusals as High-Alert Anomalies: If an AI scanner returns a safety refusal or a generic error on a codebase, automatically quarantine the package. A refusal should be treated as a potential obfuscation attempt.
- Implement Dual-Path Verification: Never rely solely on LLMs for code auditing. Pair AI scanners with traditional, rule-based Static Application Security Testing (SAST) tools that are immune to semantic prompt injections.
- Audit Your Model Gateways: Ensure your AI pipeline uses models explicitly configured for system-level analysis, where safety filters are optimized to ignore non-executable comment blocks.
Frequently Asked Questions
Why have malware developers added nuclear and biological weapons text to their spyware?
How does the exploit where malware developers added nuclear and biological weapons text evade LLM-based security scanners?
Where was this malicious technique of embedding weaponized safety text first discovered?
How can organizations secure their AI pipelines against these safety refusal vulnerabilities?
What is the primary risk of relying solely on LLMs for automated malware analysis?
Are leading AI companies taking steps to prevent bioweapon exploitation and safety bypasses?
Conclusion
The tactics used by malware authors behind PyPI packages like Mini Shai-Hulud reveal a stark truth: safety guardrails can quickly become security liabilities. By weaponizing AI refusal policies, attackers successfully turned defensive ethics into functional evasion tools.
Key Takeaways:
- Guardrails as Vulnerabilities: Broad safety rules, such as blocking prompts containing biological or nuclear weapons text, are now actively exploited to bypass automated scanning.
- Context Blindness: Legacy AI scanners cannot differentiate between a malicious payload being analyzed and a user attempting to generate harmful content.
- Paradigm Shift: Threat actors are shifting from obfuscating code logic to manipulating the ethical alignment boundaries of modern LLMs.
Looking ahead, we must expect a shift toward hybrid, multi-layered security pipelines where analytical AI engines are decoupled from standard user-facing safety filters. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
As the cat-and-mouse game between malware developers and LLMs intensifies, how will your organization balance strict ethical guardrails with the raw, unfiltered access needed for automated defense?


