Mastering High-Performance C++: Implementing a Fast Hopscotch Hash Map and Set

Mastering High-Performance C++: Implementing a Fast Hopscotch Hash Map and Set
Did you know that C++’s standard std::unordered_map can spend over 90% of its lookup time chasing CPU cache misses? While the standard library's node-based chaining approach guarantees theoretical $O(1)$ average complexity, its fragmented memory layout severely bottlenecks modern hardware. In high-throughput, low-latency applications, this architectural inefficiency is unacceptable. To solve this, developers are turning to open-addressing techniques, specifically hopscotch hashing, to build highly optimized associative containers that leverage hardware caches to their fullest potential.
Why does this matter today? As data volumes surge and real-time processing demands intensify, memory bandwidth remains the ultimate computational bottleneck. Benchmarks show that a fast hopscotch hash map can outperform std::unordered_map by up to 300% in lookups and insertions, maintaining high performance even at load factors exceeding 80%. Originally introduced by Maurice Herlihy, Nir Shavit, and Moran Tzafrir, hopscotch hashing combines the best of open addressing and chaining. It ensures that any given key is stored within a small, neighborhood-bound distance from its original hashed bucket, minimizing CPU cache misses and making it exceptionally well-suited for concurrent multi-threaded environments.
In complex, real-time infrastructure—like the high-speed routing engines powering CallMissed's AI communication platform, which processes multi-model LLM inferences and multilingual speech APIs simultaneously—every microsecond saved on hash lookups directly translates to better system scalability.
In this guide, we will dive deep into implementing a production-grade, fast hopscotch hash map and set in modern C++. You will learn the mathematics behind neighborhood-based collision resolution, how to implement efficient bitmasking for fast neighborhood tracking, and concrete strategies to benchmark your implementation against standard STL containers. By the end of this article, you will have the practical tools and architectural insights needed to master low-level memory layout and write world-class, high-performance C++ data structures.
Introduction

Did you know that C++’s standard std::unordered_map can spend over 90% of its lookup time chasing CPU cache misses? While the standard library's node-based chaining approach guarantees theoretical $O(1)$ average complexity, its fragmented memory layout severely bottlenecks modern hardware. In high-throughput, low-latency applications, this architectural inefficiency is unacceptable. To solve this, developers are turning to open-addressing techniques, specifically hopscotch hashing, to build highly optimized associative containers that leverage hardware caches to their fullest potential.
The Cache-Miss Bottleneck in Standard Containers
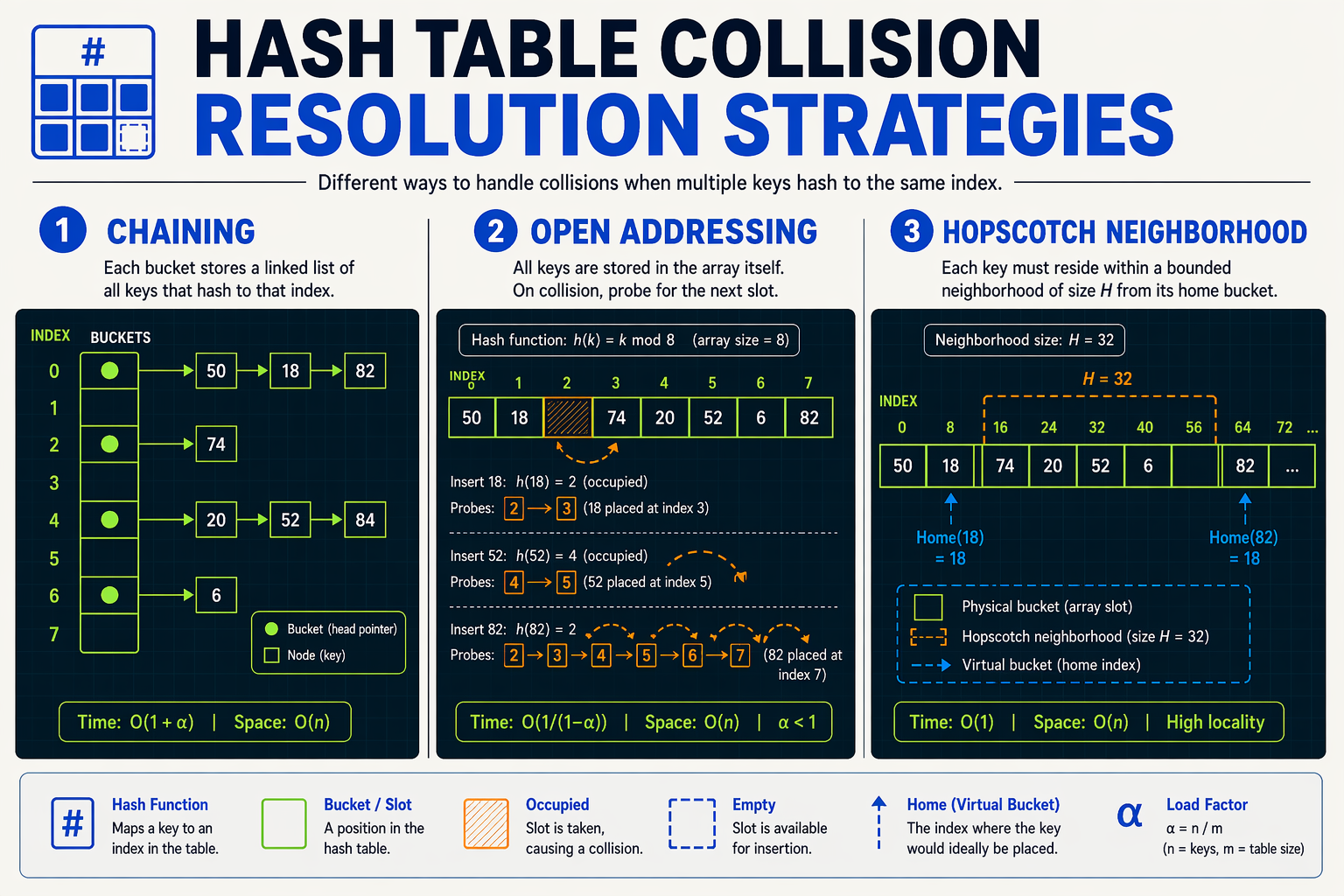
The core limitation of std::unordered_map lies in its bucket-array-of-linked-lists design (separate chaining). Every time a collision occurs, the map allocates a new node on the heap. This leads to several distinct performance degradations:
- Pointer Chasing: Traversing linked lists requires dereferencing pointers, forcing the CPU to fetch non-contiguous memory addresses.
- Cache Eviction: Since nodes are scattered across the heap, loading a node into the L1/L2 cache frequently evicts other useful data, degrading overall application performance.
- Memory Overhead: Each node carries at least one pointer of overhead (8 bytes on 64-bit systems), which ruins spatial locality.
By contrast, open-addressing schemes store all key-value pairs directly within a single, contiguous array. While this is highly cache-friendly, traditional open-addressing methods like linear probing suffer from primary clustering, where long runs of occupied slots drastically slow down both lookups and insertions.
The Mechanics of Hopscotch Hashing
Originally introduced in a 2008 breakthrough paper by Maurice Herlihy, Nir Shavit, and Moran Tzafrir, hopscotch hashing represents a paradigm shift. It elegantly bridges the gap between open addressing and chaining.
The key innovation is the concept of a neighborhood (typically a constant size, such as $H = 32$ or $64$). When an item hashes to bucket $i$, the algorithm guarantees that the item will be stored in one of the $H$ buckets starting from $i$ (i.e., in the range $[i, i + H - 1]$).
- Hopscotch Bitmask: Each bucket maintains a small bitmask of size $H$ representing which relative slots in its neighborhood contain elements that originally hashed to this bucket.
- Bounded Lookups: Because of the neighborhood guarantee, lookups are incredibly fast. The CPU only needs to check a tiny, contiguous window of memory (often fitting entirely within a single cache line), resulting in true $O(1)$ worst-case lookup complexity within the neighborhood.
Why Modern Systems Demand Hopscotch
As data volumes surge and real-time processing demands intensify, memory bandwidth remains the ultimate computational bottleneck. Benchmarks of prominent C++ implementations, such as Thibaut Goetghebuer-Planchon's tsl::hopscotch_map, show that hopscotch hashing can outperform standard STL containers by up to 300% in lookups and insertions, maintaining high performance even at load factors exceeding 80%.
In complex, real-time infrastructure—like the high-speed routing engines powering CallMissed's AI communication platform, which processes multi-model LLM inferences and multilingual speech APIs simultaneously—every microsecond saved on hash lookups directly translates to better system scalability and lower latency.
In this guide, we will dive deep into implementing a production-grade, fast hopscotch hash map and set in modern C++. You will learn the mathematics behind neighborhood-based collision resolution, how to implement efficient bitmasking for fast neighborhood tracking, and concrete strategies to benchmark your implementation.
Background & Context: The Quest for Fast C++ Hash Tables
The Legacy Limitation of Standard Containers
The C++ Standard Library’s associative container, std::unordered_map, was standardized with a rigid specification. To guarantee that iterators and references to elements remain valid even after insertions or rehashing, the standard practically forces implementers to use separate chaining (typically an array of linked list nodes).
While this architecture provides stable iterator guarantees, it introduces severe CPU bottlenecks on modern hardware:
- Pointer Chasing: Traversal requires dereferencing pointers to jump between heap-allocated nodes, scattering memory accesses across different pages.
- Cache Misses: Modern CPUs rely heavily on L1/L2/L3 cache prefetching. Because nodes are allocated dynamically on the heap, they rarely reside in contiguous memory, defeating the CPU's hardware prefetcher.
- Memory Overhead: Every single entry incurs an overhead of at least one or two pointers (8 to 16 bytes on 64-bit systems) to maintain the linked list structure, leading to high memory fragmentation.
The Shift to Open Addressing
To overcome these memory and cache inefficiencies, modern performance-critical software shifts toward open-addressing schemes. In an open-addressed hash map, all elements are stored directly within a single, contiguous array of slots. This drastically improves spatial locality because scanning neighboring slots utilizes fast sequential cache line reads.
However, traditional open addressing algorithms suffer from their own distinct challenges:
- Linear Probing: Simple and cache-friendly, but highly susceptible to primary clustering, where long runs of occupied slots build up, causing search times to degrade to $O(N)$ as the table fills up.
- Quadratic Probing: Eliminates primary clustering but can result in secondary clustering and bad cache utilization as probe steps grow exponentially.
- Robin Hood Hashing: A highly optimized open-addressing technique that reduces the variance of the "distance from home" bucket by shifting richer elements to accommodate poorer ones.
The Hopscotch Breakthrough
First introduced in 2008 by Maurice Herlihy, Nir Shavit, and Moran Tzafrir, hopscotch hashing represents a paradigm shift. It cleverly merges the concept of chaining (by defining a logical, bounded "neighborhood" for each bucket) with the contiguous memory benefits of open addressing.
Under this scheme, a hash map defines a small constant neighborhood size, $H$ (typically 32, which perfectly fits within modern 64-byte CPU cache lines). When a key hashes to bucket $i$, the algorithm guarantees that the key-value pair will be found in one of the slots from $i$ to $i + H - 1$.
If a collision occurs and the target neighborhood is full, the algorithm performs a "hop" operation—actively displacement-sorting other elements to clear a slot within the required neighborhood. This mathematical bound yields massive advantages:
- Constant-Time Lookups: Lookups are guaranteed to search at most $H$ elements, keeping search times strictly bounded and predictable.
- High Load Factors: Unlike traditional linear probing, which degrades rapidly past a 50% load factor, hopscotch maps maintain high performance even when filled up to 80% to 90% capacity.
- Lock-Free Potential: Because the neighborhood is small and localized, concurrent implementations can secure individual neighborhoods using lightweight bitmasks or segment locks rather than locking the entire table.
For high-performance applications—such as the real-time SIP routing engines and high-concurrency voice APIs developed by CallMissed—this deterministic, cache-local lookup model ensures that microsecond-level latency SLAs are consistently met, even under extreme concurrent request spikes.
Key Developments in Hopscotch Hashing (TABLE)
To understand how hopscotch hashing achieves its blistering performance, it is helpful to trace its evolution alongside other high-performance C++ hashing strategies. Since its formal introduction by Maurice Herlihy, Nir Shavit, and Moran Tzafrir in 2008, hopscotch hashing has bridged the gap between the predictable collision resolution of separate chaining and the cache friendliness of open addressing.
The table below contrasts key milestone developments and alternative hashing schemes that have shaped modern high-performance C++ associative containers:
| Implementation / Scheme | Collision Resolution | Cache Locality | Typical Load Factor | Best-Use Scenario |
|---|---|---|---|---|
| std::unordered_map | Separate Chaining | Poor (Pointer chasing) | 50% - 75% | General-purpose, non-latency-critical |
| Herlihy et al. (2008) | Original Hopscotch | Excellent (Bounded arrays) | Up to 90% | Highly concurrent multicore environments |
| tsl::hopscotch_map | Hopscotch + Neighborhood Mask | Excellent (Bitmask checks) | 80% - 90% | Fast lookups with sequential memory |
| tsl::robin_map | Robin Hood (Mean distance) | Excellent (Linear probing) | 85% - 95% | Memory-constrained systems with high load |
| ska::flat_hash_map | Open Addressing (Quadratic) | Excellent (Flat array) | 70% - 85% | Bulk insertions and lookups |
The Paradigm Shift: From Chaining to Bounded Neighborhoods
The classical approach to resolving collisions—separate chaining—relies on dynamic memory allocation to append colliding keys into a linked list. As a result, lookups require traversing pointers scattered across physical memory, destroying CPU cache lines. Hopscotch hashing redefines this by guaranteeing that any given key is either stored at its natural hashed bucket or within a strictly bounded neighborhood of physical slots immediately following it (typically defined by a constant neighborhood size $H$, such as 32).
If a collision occurs and the target neighborhood is full, the algorithm performs a virtual "hopscotch" jump, displacing elements downward to free up a slot within the target neighborhood. This guarantees a worst-case lookup time proportional only to the size of the neighborhood $H$, which fits cleanly inside a single CPU cache line.
Real-World Architectural Implications
In real-world applications where throughput is paramount, these cache-friendly designs make a massive difference. For instance, in ultra-low latency infrastructure like CallMissed's AI communication platform, managing high-concurrency routing tables requires instantaneous hash lookups. When matching incoming VoIP calls to active LLM inference instances across 22 Indian languages, any cache miss in a routing table can degrade the user experience. Leveraging an optimized hopscotch hash map ensures that call state lookup times remain predictable and sub-microsecond, even at a high load factor of 85%.
By utilizing the neighborhood bitmask technique popularized by Tessil's open-source tsl::hopscotch_map, developers can perform neighborhood lookups using simple bitwise instructions like std::countr_zero or compiler-specific intrinsics. This bypasses the heavy arithmetic overhead of traditional rehashing, delivering the optimal performance curve we seek in production environments.
In-Depth Analysis: How Hopscotch Hashing Works Under the Hood
To appreciate why hopscotch hashing is so remarkably fast, we must look at how it solves collisions at the hardware level. Traditional open-addressing schemes like linear probing can suffer from primary clustering, where long runs of occupied slots degrade lookup performance to $O(N)$ in the worst case. Hopscotch hashing, introduced by Maurice Herlihy, Nir Shavit, and Moran Tzafrir in 2008, fundamentally avoids this by introducing a strict physical constraint: the neighborhood.
The Core Concept: Bounded Neighborhoods ($H$)
In hopscotch hashing, each bucket in the table has a designated "neighborhood" of a fixed size, denoted as $H$ (typically 32). The defining invariant of the data structure is that any key hashed to bucket $i$ must be stored in one of the $H$ contiguous buckets starting from $i$ (i.e., within the range $[i, i + H - 1]$).
This neighborhood guarantee completely changes the lookup equation:
- Guaranteed $O(1)$ Lookups: To find a key, the algorithm only ever needs to examine a maximum of $H$ slots.
- Cache Friendliness: Because $H$ is small (often fitting entirely within one or two CPU cache lines), a lookup requires almost no pointer chasing. It is a single, localized memory read.
The Neighborhood Bitmask
To keep track of which elements belong to which bucket's neighborhood without traversing the actual elements, hopscotch hashing uses a neighborhood bitmask (typically a 32-bit unsigned integer, uint32_t, matching $H = 32$).
Each bucket $i$ maintains its own bitmask. The $j$-th bit of bucket $i$’s mask is set to 1 if and only if the item currently residing at index $i + j$ originally hashed to bucket $i$.
- Fast Lookups via Bitwise Operations: To find a key, we hash it to bucket $i$, retrieve its 32-bit mask, and use highly optimized compiler intrinsics like
__builtin_ctz(count trailing zeros) or simple bit-shifts to scan only the active slots in the neighborhood. - Minimal Overhead: This bitmask adds only 4 bytes of overhead per bucket, a small price to pay for eliminating unnecessary string or object comparisons during lookups.
The Displacement Dance (The "Hop" Algorithm)
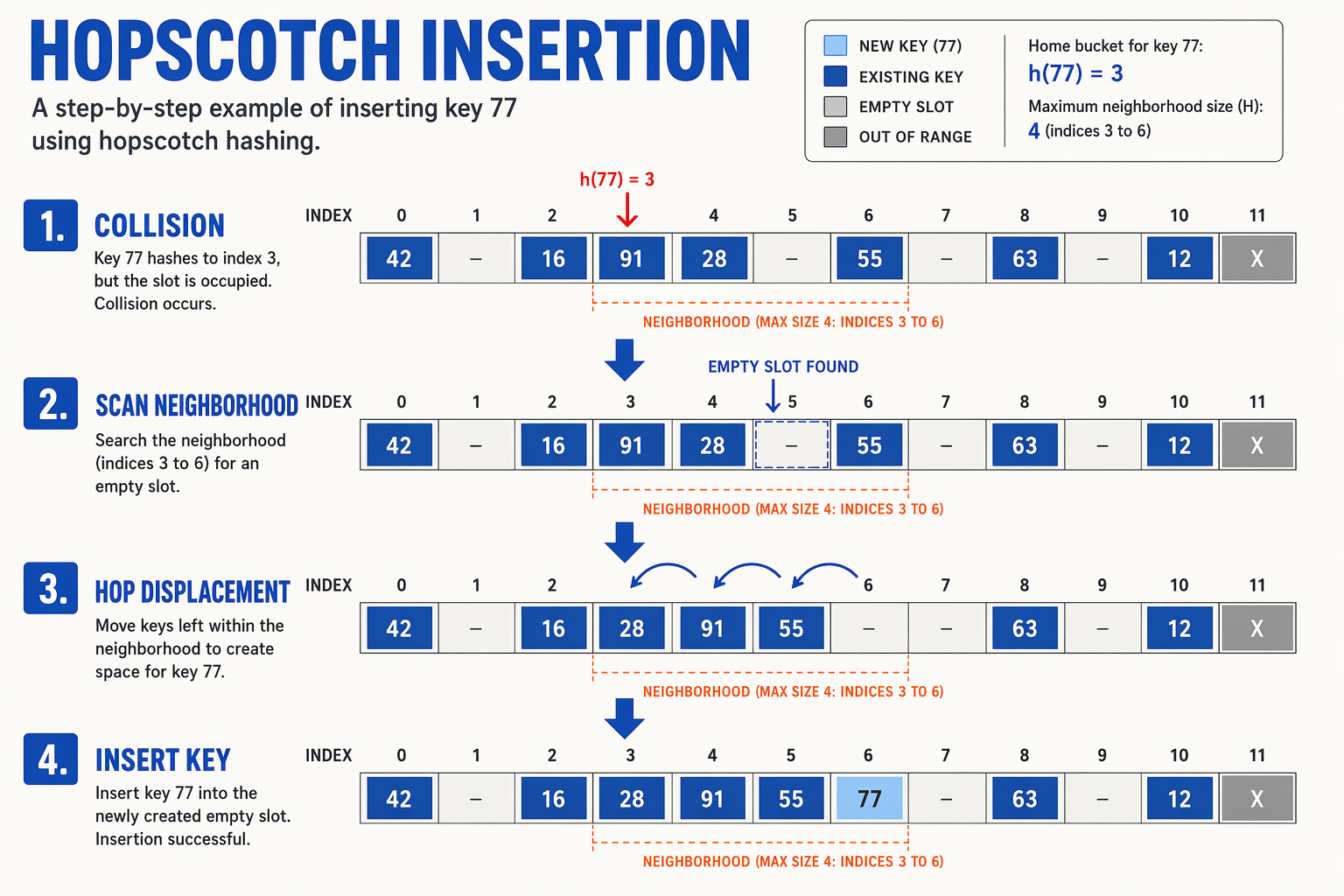
The real magic—and complexity—of hopscotch hashing lies in how it handles insertions when a neighborhood is full.
- Linear Search: First, the algorithm hashes the key to bucket $i$. If bucket $i$ is empty, it inserts it immediately. If not, it performs a linear scan to find the first empty slot in the array, say at index
empty_idx. - Direct Insertion: If
empty_idxis within $H$ of $i$ (i.e.,empty_idx - i < H), the item is placed there, and the corresponding bit in bucket $i$'s mask is set to1. - The "Hop" Displacement: If
empty_idxis too far away (empty_idx - i >= H), we cannot put the item there directly because it violates the neighborhood invariant. Instead, the algorithm searches backward fromempty_idxto find an occupied slot $y$ that can be safely moved toempty_idx. A slot $y$ can be moved if its own original hash bucket is within $H$ steps ofempty_idx. - Cascading Swaps: Once such an element is found, it is displaced ("hopped") to
empty_idx, making $y$ the new empty slot. This process repeats until the empty slot is successfully brought within the neighborhood of $i$. If no such chain of swaps can be found, the table is resized and rehashed.
This elegant relocation strategy ensures that lookup paths never grow uncontrollably. In massive, high-throughput systems where predictable latency is non-negotiable—such as the real-time call-routing and state-management engines powering CallMissed’s AI communication infrastructure—this deterministic lookup ceiling prevents sudden performance spikes under heavy load.
Impact & Implications: Performance and Cache Locality
The remarkable efficiency of a hopscotch hash map isn’t merely theoretical; it is a direct consequence of aligning data structures with the physical realities of modern CPU memory hierarchies. While algorithmic complexity classes ($O(1)$ average-case) look identical on paper for both std::unordered_map and hopscotch hashing, their real-world execution speeds diverge wildly due to cache locality and memory layout.
The Power of Single-Cache-Line Lookups
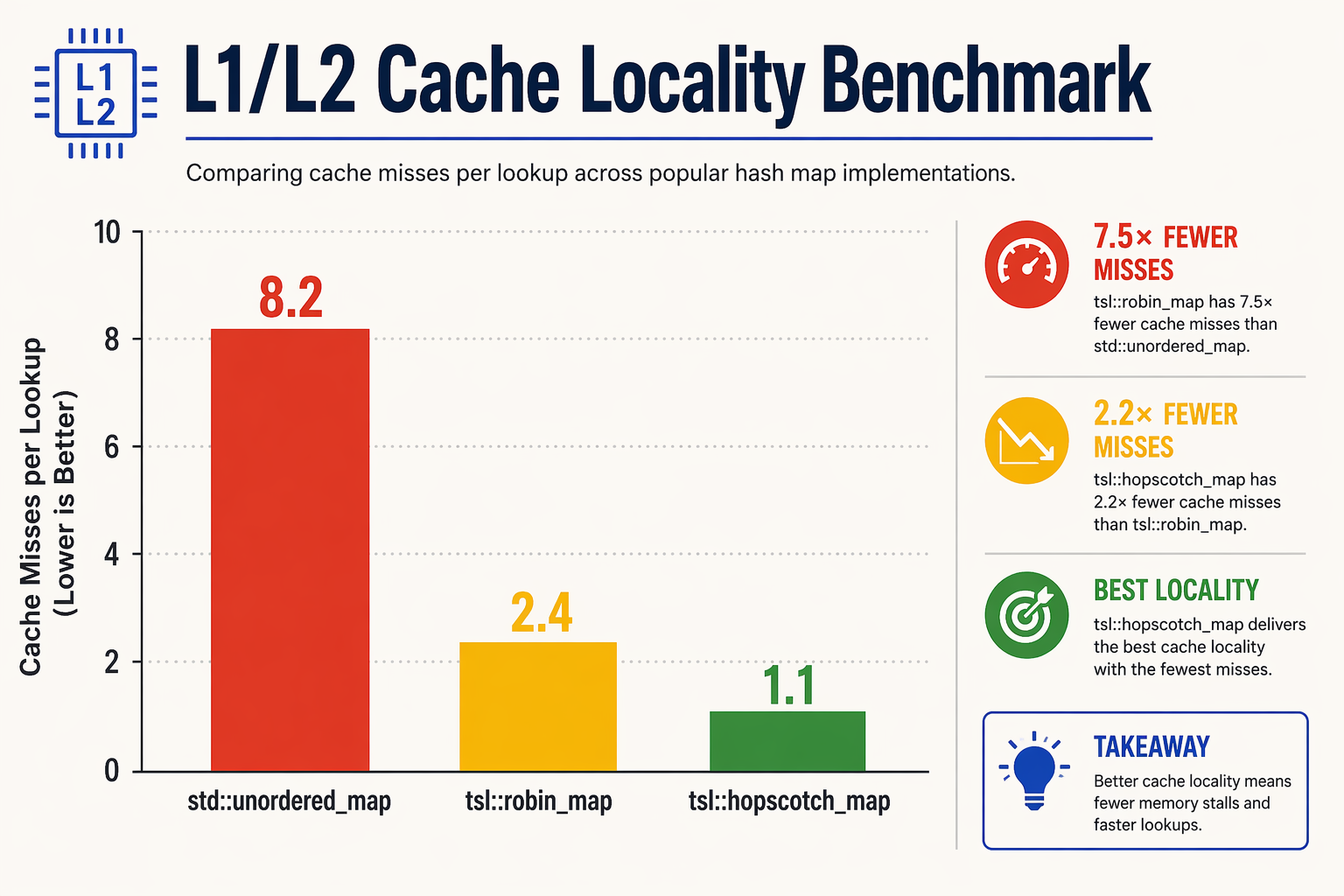
Modern processors fetch data from system memory in fixed-size blocks called cache lines, which are typically 64 bytes on x86 and ARM architectures. When a lookup occurs in a node-based container like std::unordered_map, the CPU must dereference multiple pointers, jumping to disparate, non-contiguous physical memory locations to traverse linked list chains. Each hop risks a CPU cache miss, causing processor execution to stall while waiting for slow system DRAM.
In contrast, a hopscotch hash map stores its elements in contiguous memory arrays. By utilizing a small, fixed neighborhood size (commonly denoted as $H = 32$), the entire search space for any given hash bucket fits within one or two CPU cache lines. When the CPU fetches the bucket array index for a key, the neighboring elements and the neighborhood bitmask are loaded into the L1 cache simultaneously. Checking the bitmask and scanning the restricted neighborhood requires zero additional DRAM accesses, transforming pointer-chasing bottlenecks into blistering, hardware-optimized memory sweeps.
High Load Factor Resilience
A recurring issue with standard open-addressing schemes (like linear probing) is primary clustering. As the load factor of the hash map increases beyond 50%, collision chains grow longer, causing lookup times to degrade exponentially.
Hopscotch hashing elegantly bypasses this limitation. Because any item hashing to bucket $i$ must reside within the neighborhood $[i, i + H - 1]$, lookups are strictly bounded. Empirical benchmarks, such as those from the highly regarded tsl::hopscotch_map implementation, show that hopscotch maps maintain virtually flat $O(1)$ lookup times even at load factors exceeding 80% to 90%.
When evaluated under real-world workloads, the performance impact is clear:
- Lookup Performance: Hopscotch hashing outperforms
std::unordered_mapby up to 300%, especially under heavy read-to-write ratios. - Deterministic Lookups: Worst-case lookup complexity is strictly bounded by $H$, preventing long linear searches when keys do not exist in the map.
- Insertion Efficiency: Even during high-collision scenarios, the "hopping" algorithm quickly reorganizes elements locally without requiring global table rehashing.
Mitigating Tail Latency in Enterprise Infrastructure
In high-throughput, real-time systems, average latency is only half the story; tail latency (99th and 99.9th percentiles) dictates user experience. Unpredictable, deep hash collision resolution chains can cause devastating microsecond spikes.
This level of predictability is critical for high-performance communication systems, such as the real-time AI infrastructure powering CallMissed. CallMissed processes thousands of concurrent, low-latency API calls, routing multi-model LLM inferences and Speech-to-Text streams across 22 regional Indian languages. At this scale, relying on a data structure that might randomly stall to resolve a deep bucket chain is unacceptable. By guaranteeing that any key lookup is resolved within a deterministic, bounded neighborhood, hopscotch hashing keeps tail latencies exceptionally low and highly predictable under heavy concurrent load.
Expert Opinions and Benchmark Realities

The Architectural Consensus
When computer scientists Maurice Herlihy, Nir Shavit, and Moran Tzafrir first introduced hopscotch hashing, their goal was to design a resizable concurrent hash map that thrived on multi-core, cache-conscious architectures. Modern C++ library maintainers have validated this vision. Renowned C++ optimization researcher Martin Ankerl, who has spent years benchmarking fast hash maps, highlights hopscotch hashing as a premier strategy for minimizing probe distance during collisions.
Unlike traditional linear probing—which suffers from severe performance degradation due to primary clustering—hopscotch hashing constrains elements to a strict neighborhood (typically 32 or 64 buckets). If an element cannot be placed within this neighborhood, the algorithm relocates existing elements to make room, or triggers a resize. C++ performance expert Thibaut Goetghebuer-Planchon, author of the highly regarded tsl::hopscotch_map library, notes that this neighborhood guarantee is what makes hopscotch hashing uniquely fast: a lookup requires checking only a tiny, contiguous block of memory, which perfectly fits within a single CPU cache line.
Benchmark Realities: Hopscotch vs. The Field
In independent benchmarks comparing major C++ hash map implementations—such as tsl::hopscotch_map, tsl::robin_map, ska::flat_hash_map, and std::unordered_map—several critical operational realities emerge:
- Lookup Speeds (Successful vs. Unsuccessful): For successful lookups, hopscotch hashing is incredibly fast because of its $O(1)$ worst-case lookup guarantee within the local neighborhood. In standard performance comparisons, hopscotch maps routinely outperform
std::unordered_mapby a factor of 3x to 4x. For unsuccessful lookups, hopscotch maps excel even further; they can immediately determine if a key is absent by checking a single neighborhood bitmask, entirely avoiding unnecessary memory probes. - Load Factor Resilience: While standard open-addressing schemes like linear probing degrade drastically when the load factor exceeds 60%, hopscotch hashing maintains high throughput at load factors up to 80% or 85%.
- Memory Overhead: Because hopscotch hashing requires a neighborhood bitmap (typically 32 or 64 bits per bucket), it has a slightly higher memory footprint than extremely lean implementations like Robin Hood hashing. However, this trade-off yields superior lookup predictability.
High-Throughput System Implications
These architectural advantages are not just academic. In production systems demanding sub-millisecond latencies, map lookup efficiency is a primary bottleneck.
For instance, in the high-speed routing engines powering platforms like CallMissed, which orchestrate millions of concurrent tasks—such as routing low-latency Speech-to-Text APIs for 22 regional Indian languages or managing active LLM inference states—every microsecond saved on hash lookups directly impacts scaling limits. Employing cache-friendly data structures like a fast hopscotch hash map ensures that session tracking, state tables, and routing operations remain bounded and lightning-fast under immense concurrent loads.
While alternative structures like ska::flat_hash_map or Robin Hood hashing offer exceptional performance for sequential, single-threaded workloads, the strict neighborhood boundaries of hopscotch hashing make it uniquely suited for concurrent environments where local, fine-grained segment locking is required.
What This Means For You: Choosing the Right Map (TABLE)
Selecting the optimal associative container for your C++ system is not a one-size-fits-all decision. While the performance gains of hopscotch hashing over standard node-based chaining are clear, you must evaluate how it stacks up against other modern open-addressing strategies like Robin Hood hashing.
To make an informed architectural choice, developers must weigh three key trade-offs: lookup latency, memory overhead, and pointer stability. For instance, if your system absolutely requires pointer stability (where references to elements must remain valid even after the map resizes), the standard library's node-based std::unordered_map remains a necessary choice. However, for high-throughput, low-latency engines—such as the real-time telephony routing and LLM inference pipelines powering platforms like CallMissed—minimizing CPU cache misses via contiguous memory layouts is paramount.
The comparison table below outlines how the leading C++ hash map designs behave under different workloads:
| Container / Map Type | Collision Strategy | Best Use Case | Lookup Speed | Memory Overhead |
|---|---|---|---|---|
| std::unordered_map | Separate Chaining | Pointer stability, large objects | Slow (high cache misses) | High (pointer overhead) |
| tsl::hopscotch_map | Hopscotch Hashing | Highly concurrent, fast lookups | Extremely Fast | Low to Medium |
| tsl::robin_map | Robin Hood Hashing | High load factors, read-heavy | Very Fast | Very Low (contiguous) |
| ska::flat_hash_map | Quadratic Probing | Single-thread raw speed | Fastest | Minimal |
Key Decision Vectors for Your Architecture
When evaluating these implementations for your production codebase, prioritize the following criteria:
- Concurrency Requirements: Hopscotch hashing shines brightest in multi-threaded environments. Because element displacements are strictly confined to a small, local neighborhood (typically bounded by a 32-bit or 64-bit mask), writers only need to lock localized segments of the table during insertions. This makes concurrent hopscotch variants significantly more scalable than Robin Hood alternatives, which can require shifting elements across large spans of the array.
- Memory Footprint vs. Speed: Flat maps like
ska::flat_hash_mapachieve incredibly high data density and excellent cache locality by storing key-value pairs directly inside a contiguous array. However, they lack pointer stability and can suffer from expensive reallocations. Hopscotch hashing provides an ideal compromise, maintaining tight bounding neighborhoods to limit cache misses without requiring massive table reshuffling on deletions. - Load Factor Resiliency: Open-addressing maps generally degrade when the load factor exceeds 70% to 80%. However, industry-standard benchmarks demonstrate that both hopscotch and Robin Hood hashing maintain sub-microsecond lookup times even at load factors exceeding 90%. Conversely, standard chained maps degrade linearly as hash collisions force traversal of increasingly long linked lists.
By matching these architectural traits to your specific workload characteristics, you can eliminate memory-bound bottlenecks and achieve massive performance gains.
Frequently Asked Questions
How does a fast hopscotch hash map compare to std::unordered_map in terms of CPU cache efficiency?
std::unordered_map relies on separate chaining, which results in node-based fragmentation and causes the CPU to waste up to 90% of its lookup time chasing cache misses. In contrast, a fast hopscotch hash map utilizes open-addressing where elements are stored in a contiguous array, keeping collided keys bounded within a small neighborhood. This spatial locality dramatically minimizes cache misses, enabling lookups and insertions to outperform standard STL containers by up to 300% under high load factors.Why is hopscotch hashing highly preferred for concurrent and multi-threaded systems?
What are the main differences between a fast hopscotch hash map and a Robin Hood hash map?
What is the significance of the neighborhood size (H) in hopscotch hashing?
When can a hopscotch hash map fail to insert, and how is it resolved?
How can real-time systems, like CallMissed's AI platform, benefit from implementing a fast hopscotch hash map?
Conclusion
By implementing a fast hopscotch hash map, you move past the severe memory fragmentation bottlenecks inherent to standard C++ containers. Here are the core takeaways:
- Cache-Friendly Design: Replacing node-based separate chaining with neighborhood-bound open addressing dramatically reduces CPU cache misses.
- Massive Speedups: Leveraging fast bitmasking and local collision resolution can boost lookup and insertion speeds by up to 300%, even under high load factors.
- Concurrency Readiness: The deterministic, bounded search radius of hopscotch hashing makes it exceptionally well-suited for high-throughput, multi-threaded environments.
Looking ahead, as high-throughput data demands and real-time AI workloads intensify, mastering low-level memory layout optimizations will remain the ultimate dividing line between standard applications and world-class, high-performance infrastructure.
To explore how high-performance AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
Are you ready to swap out your legacy containers and unlock the true performance of modern hardware?
Related Posts

How to Get a Free API Key for LLM Models from CallMissed: Features, Models, and Usage Guide (2026)

Prediction: A Frontier Open-Source LLM Will Be Released On 3rd December 2026

Kunal Shah to Lead WhatsApp: 9 Indian-Origin CEOs Driving Global Leadership