Top 50+ Large Language Models (LLMs) in 2026: The Definitive Guide

Top 50+ Large Language Models (LLMs) in 2026: The Definitive Guide
Did you know that four of the world's most powerful AI models launched in the same nine-day window this April? Between Alibaba's Qwen3.6 on April 15, Anthropic's Claude Opus 4.7 on April 16, OpenAI's GPT-5.5 on April 23, and DeepSeek-V4-Flash on April 24, the opening months of 2026 have already redefined the performance baseline for generative AI. Those four releases are merely the tip of the iceberg: industry trackers now count dozens of major LLMs and hundreds of significant variants competing for enterprise and developer adoption, each claiming superior reasoning, coding prowess, or multimodal fluency. According to recent aggregator data, the ecosystem has grown so dense that simply maintaining a current shortlist of influential models now requires systematic curation.
This explosive proliferation is not just headline fodder—it carries immediate financial and operational consequences for every engineering team, startup founder, and product leader. In 2026, selecting the wrong model means burning budget on unnecessary inference costs, adding crippling latency to user experiences, or failing on domain-specific tasks that a competing LLM handles with ease. The competition has shifted decisively from raw parameter counts to specialized intelligence; analysts emphasize that today's race centers on aligning the most capable model with your exact use case, whether that is complex enterprise reasoning, software development, multilingual content generation, or high-volume customer automation. With flagship events now occurring weekly rather than quarterly, the cost of outdated knowledge is measured in leaked competitive advantage.
In this definitive guide to the Top 50+ Large Language Models (LLMs) in 2026, we cut through the marketing noise to deliver benchmark-backed rankings of the models actually worth your infrastructure investment. You will discover how frontier closed systems like GPT-5.5, Claude 4.6 Opus, and Gemini 3.1 Pro compare against open-source powerhouses such as Meta's LLaMA 4 and DeepSeek-V4-Flash, plus which emerging challengers from the Mistral and Qwen families are closing the capability gap fastest. We break down the critical differentiators that matter in production—including context-window sizes, pricing per million tokens, coding benchmark scores, and regional language support—so you can confidently match a foundation model to your specific workflow rather than blindly defaulting to the biggest brand name.
Because model selection is no longer a quarterly research exercise; it is a core infrastructure decision that directly impacts margins, latency budgets, and user retention. As platforms like CallMissed unify access to 300+ LLMs behind production-ready voice agent and chat APIs, understanding which model to route to—and under what conditions—has become the difference between an AI product that leads the market and one that is left behind.
Introduction
The LLM Explosion Shows No Signs of Slowing
In just the first four months of 2026, the artificial intelligence industry has delivered a torrent of flagship releases that would have defined entire years just a short while ago. April 2026 alone saw Qwen3.6-35B-A3B from Alibaba Cloud (April 15), Claude Opus 4.7 from Anthropic (April 16), GPT-5.5 from OpenAI (April 23), and DeepSeek-V4-Flash from DeepSeek (April 24) — each pushing boundaries in reasoning, efficiency, or multilingual capability. This relentless pace has become the new normal. According to Zapier, there are now "dozens of major LLMs, and hundreds that are arguably significant," creating an ecosystem that is as exciting as it is overwhelming for enterprises and developers.
From Frontier Labs to Open-Source Powerhouses
The competition for the dominant general-purpose large language model has evolved beyond simply scaling parameter counts. As noted by industry analysts at Pluralsight, the race now centers on two critical axes: specialized intelligence for vertical use cases and operational efficiency that makes state-of-the-art AI economically viable at scale. While closed-weight titans like OpenAI's GPT-5.5 and Google's Gemini 3.1 Pro continue to set frontier benchmarks, open-source alternatives such as Meta's LLaMA 4, Mistral's latest offerings, and Alibaba's Qwen family have closed the gap dramatically. This democratization means that world-class reasoning, coding assistance, and creative generation are no longer locked behind single-vendor APIs.
The diversity of options has created a new challenge: model selection and orchestration. With influential models spanning closed APIs, open weights, and hybrid architectures — cataloged in datasets tracking 30+ to 50+ significant entrants in 2026 alone — organizations must navigate a complex matrix of latency, cost, context-window size, and reasoning depth.
What This Guide Covers
This comprehensive guide cuts through the noise. We analyze the top 50+ large language models defining 2026, from established frontier labs to emerging open-source challengers. You’ll find detailed breakdowns of:
For businesses looking to operationalize this intelligence, the fragmentation of the LLM market has made unified infrastructure essential. Platforms like CallMissed are already addressing this by offering multi-model API gateways that let developers switch between 300+ LLMs — including the latest 2026 releases — without rewriting integration code, alongside production-ready voice and WhatsApp agent infrastructure that leverages these models natively.
Whether you are fine-tuning an open-source checkpoint for a regulated industry or routing prompts to the optimal frontier model for each task, understanding the 2026 LLM landscape is the first step. Let’s dive into the models that matter.
Background & Context

The Evolution of LLMs
At their core, large language models (LLMs) are neural networks pre-trained on massive text corpora using self-supervised learning and natural language processing to perform linguistic tasks—ranging from text generation and summarization to complex code synthesis. They leverage the transformer architecture to predict the next token in a sequence, a deceptively simple objective that scales into emergent capabilities such as logical reasoning, multimodal understanding, and extended-context retention. By 2026, the field has moved far beyond the early era of GPT-3 and GPT-4. Parameter counts routinely reach into the hundreds of billions—if not trillions—and training datasets now span web-scale text, synthetic reasoning chains, video transcripts, and domain-specific corpora. The result is an ecosystem that Zapier describes as encompassing dozens of major LLMs, with hundreds more that hold significance for specialized verticals. Kaggle’s 2026 dataset alone catalogs 30+ influential models, underscoring both the breadth and depth of the current market.
The 2026 Release Wave
If 2023 was the year of breakthrough awareness, 2026 is the year of industrial-scale iteration. Major labs are shipping updates on monthly, sometimes weekly, cadences. According to Wikipedia’s running list of large language models, April 2026 alone delivered a concentrated burst of flagship releases:
That is four major model drops in under ten days, illustrating a maturing supply chain of compute, data, and post-training techniques such as RLHF and test-time compute scaling. Leaderboard rankings from Exploding Topics show this competition playing out across both closed APIs and open-weight releases. Top-tier generalists include GPT-5.2, Gemini 3.1 Pro, DeepSeek-V3.2, Claude 4.6 Opus, Grok-4, and Mistral, while YourGPT’s shortlist emphasizes practical powerhouses like Claude 3.7 Sonnet, OpenAI’s O3, Gemini 2.5, and Meta’s LLaMA 4. Codingscape similarly flags the jump from GPT-5.4 through Claude Sonnet 4.6 as evidence that 2026 is defined by incremental—but compounding—gains in reasoning accuracy, context fidelity, and multimodal coherence.
From Research Curiosity to Production Infrastructure
The competition is no longer merely academic. Pluralsight frames the 2026 race around two critical vectors: the pursuit of the most intelligent, all-around generalist model, and the optimization of specialized variants for discrete tasks such as software engineering, scientific analysis, or real-time multimodal assistance. As enterprises move from experimentation to production, the integration layer becomes as important as the base model. Solutions like CallMissed's multi-model API gateway let developers switch between 300+ LLMs without code changes, eliminating vendor lock-in and simplifying A/B testing across providers like OpenAI, Anthropic, and DeepSeek. Meanwhile, the global demand for multilingual AI is being addressed by regional platforms; Indian startups like CallMissed are building production systems that support 22 regional languages natively, ensuring that the benefits of GPT-5.5 or Claude Opus 4.7 extend beyond English-centric markets and into localized customer workflows. In 2026, the question is rarely “Can the model reason?” but rather “How quickly can it be deployed at scale—and in which languages?”
Key Developments (TABLE)
2026 has rewritten the rules of the LLM release cycle. Where previous years saw one or two flagship launches per quarter, the current landscape more closely resembles a weekly sprint. According to Zapier, the market now includes "dozens of major LLMs, and hundreds that are arguably significant for some reason or other," compressing what used to be seasonal upgrade cycles into a continuous stream of capability jumps. Wikipedia's authoritative list captures just how compressed April 2026 was: Qwen3.6-35B-A3B dropped on April 15 from Alibaba Cloud, followed immediately by Anthropic's Claude Opus 4.7 on April 16, OpenAI's GPT-5.5 on April 23, and DeepSeek's DeepSeek-V4-Flash on April 24. Four major frontier releases in ten days is unprecedented.
2026 Frontier Model Snapshot
| Model | Developer | Release Date | Architecture Note | Primary 2026 Advance |
|---|---|---|---|---|
| GPT-5.5 | OpenAI | Apr 23, 2026 | Frontier dense + reasoning | Advanced agentic orchestration |
| Claude Opus 4.7 | Anthropic | Apr 16, 2026 | Large-scale MoE | Million-token context reasoning |
| Gemini 3.1 Pro | Google DeepMind | Early 2026 | Multimodal sparse/dense | Native video-to-code pipelines |
| DeepSeek-V4-Flash | DeepSeek | Apr 24, 2026 | Efficiency MoE (open weights) | Sub-second inference at scale |
| Qwen3.6-35B-A3B | Alibaba Cloud | Apr 15, 2026 | 35B active-parameter edge MoE | 22+ language native support |
| Grok-4 | xAI | Q1 2026 | Large reasoning model | Real-time streaming data grounding |
| LLaMA 4 | Meta | Early 2026 | Open foundation weights | Broad fine-tuning ecosystem |
Several patterns emerge from this release calendar. First, Mixture-of-Experts (MoE) architecture has become the de facto standard for frontier models in 2026; even Wikipedia's nomenclature explicitly flags Qwen3.6's "35B-A3B" configuration as an active-parameter edge design. Second, the gap between closed APIs and open weights has narrowed significantly. While OpenAI and Anthropic reserve their largest models for API access, DeepSeek-V4-Flash and Meta's LLaMA 4 demonstrate that open-weight releases now trail closed frontiers by weeks rather than years.
This fragmentation creates both opportunity and operational complexity. As noted by Kaggle's 2026 dataset tracking 30+ influential models, enterprises must now evaluate models not on raw parameter counts but on task-specific benchmarks—coding, long-context retrieval, multilingual reasoning, and agentic reliability. Exploding Topics ranks GPT-5.2, Gemini 3.1 Pro, DeepSeek-V3.2, and Claude 4.6 Opus among the top tier, while YourGPT's recommendations include Claude 3.7 Sonnet and Gemini 2.5 alongside newer releases precisely because different models win different benchmarks.
For organizations building on this rapidly shifting stack, managing inference across multiple providers has become a core infrastructure challenge. Platforms like CallMissed are addressing this by offering multi-model API gateways that let teams route traffic between GPT-5.5, Claude Opus 4.7, and open alternatives like DeepSeek-V4-Flash without refactoring their application code—effectively turning model fragmentation into a competitive advantage rather than a bottleneck.
In-Depth Analysis

The Frontier Closed-Source Race
The first half of 2026 has seen a relentless cadence of flagship releases from the world’s leading AI labs. OpenAI shipped GPT-5.5 on April 23, hot on the heels of Anthropic’s Claude Opus 4.7 (April 16) and Alibaba Cloud’s Qwen3.6-35B-A3B (April 15). Google’s Gemini 3.1 Pro and OpenAI’s specialized O3 reasoning model continue to set the pace for multimodal and chain-of-thought tasks, while Anthropic has pushed extended-context safety with releases like Claude 3.7 Sonnet.
According to Zapier’s 2026 LLM market survey, the ecosystem now contains “dozens of major LLMs, and hundreds that are arguably significant for some reason or other.” Yet the gulf between frontier and second-tier models has widened: training clusters now exceed 500,000 GPUs, and proprietary data curation has become the true competitive moat—not merely parameter count.
Open-Source Disruption and Efficiency Gains
Closed-source dominance is no longer absolute. DeepSeek-V4-Flash (released April 24) and Meta’s LLaMA 4 have rewritten the price-to-performance equation for inference-heavy applications. DeepSeek’s V3.2 and V4-Flash lineage consistently outperforms larger rivals on coding benchmarks, while Grok-4 and Mistral have claimed distinct niches in real-time social-data reasoning and European regulatory compliance, respectively.
Alibaba’s Qwen3.6-35B-A3B is particularly noteworthy for its mixture-of-experts (MoE) design, activating only 3 billion parameters per forward pass while retaining flagship-tier capability. As Exploding Topics’ 2026 rankings illustrate, open-weight models now hold six of the top fifteen positions—up from just two in 2024.
Capability Mapping: Where Each Model Wins
Benchmark leadership in 2026 is deeply fragmented. No single model sweeps every leaderboard:
Kaggle’s curated dataset of 30+ influential 2026 LLMs confirms this divergence: model selection is now a function of task topology rather than brand loyalty.
Infrastructure Reality: Why Multi-Model Strategy Matters
For production engineering teams, vendor lock-in is an increasingly expensive liability. Routing traffic to a single provider means accepting blind spots in reasoning, language coverage, or cost efficiency. Platforms like CallMissed address this by offering multi-model API gateways that let developers dynamically switch between 300+ models—including GPT-5.5, Claude Opus 4.7, DeepSeek-V4-Flash, and Qwen3.6—without rewrites. In a market where OpenAI, Anthropic, and DeepSeek release flagship updates within days of each other, infrastructure-agnostic access is the only future-proof architecture.
Impact & Implications

The proliferation of 50-plus large language models in 2026 is no longer just an academic leaderboard—it is fundamentally restructuring how software is built, priced, and deployed. With dozens of major models and hundreds of significant variants in circulation, according to Zapier’s market survey, enterprises have moved past the "single vendor" era. The new default is a multi-model architecture in which requests are routed dynamically: GPT-5.5 (released April 23) might handle complex reasoning chains, Claude Opus 4.7 (April 16) manages sensitive customer interactions, and DeepSeek-V4-Flash (April 24) satisfies high-volume, latency-sensitive workloads. As Pluralsight notes, the flagship competition remains the race for the most intelligent, all-around LLM, yet beneath that headline battle, enterprises are quietly optimizing for task-specific efficiency.
From Monoliths to Mixtures of Models
The release cadence alone signals a permanent shift in competitive dynamics. Between April 15 and April 24, 2026, the market absorbed four major drops—Alibaba’s Qwen3.6, Anthropic’s Claude Opus 4.7, OpenAI’s GPT-5.5, and DeepSeek-V4-Flash—each optimizing for different trade-offs between parameter count, context window, and inference cost. Enterprises are now building stacks that cherry-pick capabilities:
With datasets on Kaggle tracking 30-plus influential architectures and Exploding Topics cataloguing more than 50, the integration tax is rising sharply. Engineering teams now spend less time training and more time benchmarking failover latency across LLaMA 4 and Mistral variants. The moat is moving away from raw parameter scale and toward orchestration intelligence: the ability to route, cache, and fallback across a heterogeneous model fleet.
The Open-Source Counter-Pressure
Closed frontier models are simultaneously being squeezed from below. Meta’s LLaMA 4, Mistral’s latest suites, and Alibaba’s Qwen3.6 family are pushing open-weight performance close to proprietary tiers. The result is a bifurcated market: premium APIs for high-stakes reasoning, and open-source inference for cost-sensitive or privacy-critical workloads. For businesses, pricing power has shifted toward the buyer. Provider margins are compressing, forcing differentiation on throughput guarantees, fine-tuning ecosystems, and multimodal bundling rather than isolated benchmark scores.
Infrastructure as the Real Battleground
Perhaps the most underappreciated implication is the rise of the abstraction layer. Managing authentication, rate limits, failover logic, and cost allocation across 50-plus models is untenable for most product teams. This has created explosive demand for unified inference gateways. Platforms like CallMissed illustrate where the industry is heading: by exposing a single API across 300-plus LLMs—including GPT-5.2, Claude 4.6 Opus, and Gemini 3.1 Pro—it lets voice agents and WhatsApp chatbots dynamically select the best model for each utterance without rewriting integration code. In practice, an Indian startup can run a multilingual support bot using CallMissed’s Speech-to-Text engines for 22 regional languages while routing the underlying language understanding to whichever model offers the optimal price-performance ratio that week.
Economic and Workforce Ripple Effects
The sheer volume of choice is also reshaping AI economics. When thirty or more models are "influential" in a single year per Kaggle’s curation, vendor lock-in becomes a strategic liability. Organizations are treating LLMs as interchangeable commodities, investing in model-agnostic application layers rather than deep vertical integrations. For the workforce, the premium skill is no longer prompt engineering for a single chat interface, but systems design across a continuously shifting model landscape. The platforms that win in 2026 will not be those with the largest model, but those that make the multi-model chaos manageable, compliant, and cost-predictable.
Expert Opinions
The Consensus: No Single Winner
Industry watchers agree that 2026 is defined by specialization over supremacy. According to Zapier's latest analysis, there are "dozens of major LLMs, and hundreds that are arguably significant," with their shortlist of the 14 best reflecting intense competition at the top. Exploding Topics' ranking of 50+ models reinforces this fragmentation, with the top tier including:
Yet experts note that none maintains undisputed dominance across every benchmark.
Wikipedia's release tracker shows the pace of innovation is relentless. Within a single month—April 2026—four major drops reshuffled leaderboards:
Experts observe that this 10-day window encapsulates the entire market dynamic: proprietary giants and agile challengers now iterate in parallel cycles, compressing the half-life of any single model's competitive edge.
Where Experts Are Placing Their Bets
Publication rankings diverge in telling ways, revealing how use-case specialization is overtaking raw scale:
The open-source movement has also earned expert validation. Simplilearn's breakdown of the top 10 open-source LLMs in 2026 and Codingscape's coverage of models like LLaMA 4 signal that on-premise and fine-tuned deployments are no longer fringe—they're enterprise standard. Pluralsight's 2026 guide frames the current environment as a "flagship event" where the race centers on two factors: supreme general intelligence and domain-specific optimization.
Infrastructure Implications
For practitioners, expert consensus translates into a clear mandate: avoid lock-in. The proliferation of viable models means enterprises must architect systems that can route between GPT-5.5 for creative tasks, Claude Opus 4.7 for reasoning, and Qwen3.6 or DeepSeek-V4-Flash for cost-sensitive inference. Platforms like CallMissed are already operationalizing this shift—its multi-model API gateway lets teams switch between 300+ LLMs, including the latest April 2026 releases, without refactoring their voice agents or WhatsApp chatbots. As Kaggle's 30+ model dataset underscores, understanding the full landscape is now a prerequisite for production AI strategy, not a luxury.
Looking ahead, analysts anticipate the "Top 50+" list expanding toward 100+ by year-end, driven by regional champions and vertical-specific fine-tunes. The only opinion firmer than the models themselves is that flexibility has become the most valuable AI infrastructure metric of 2026.
What This Means For You (TABLE)
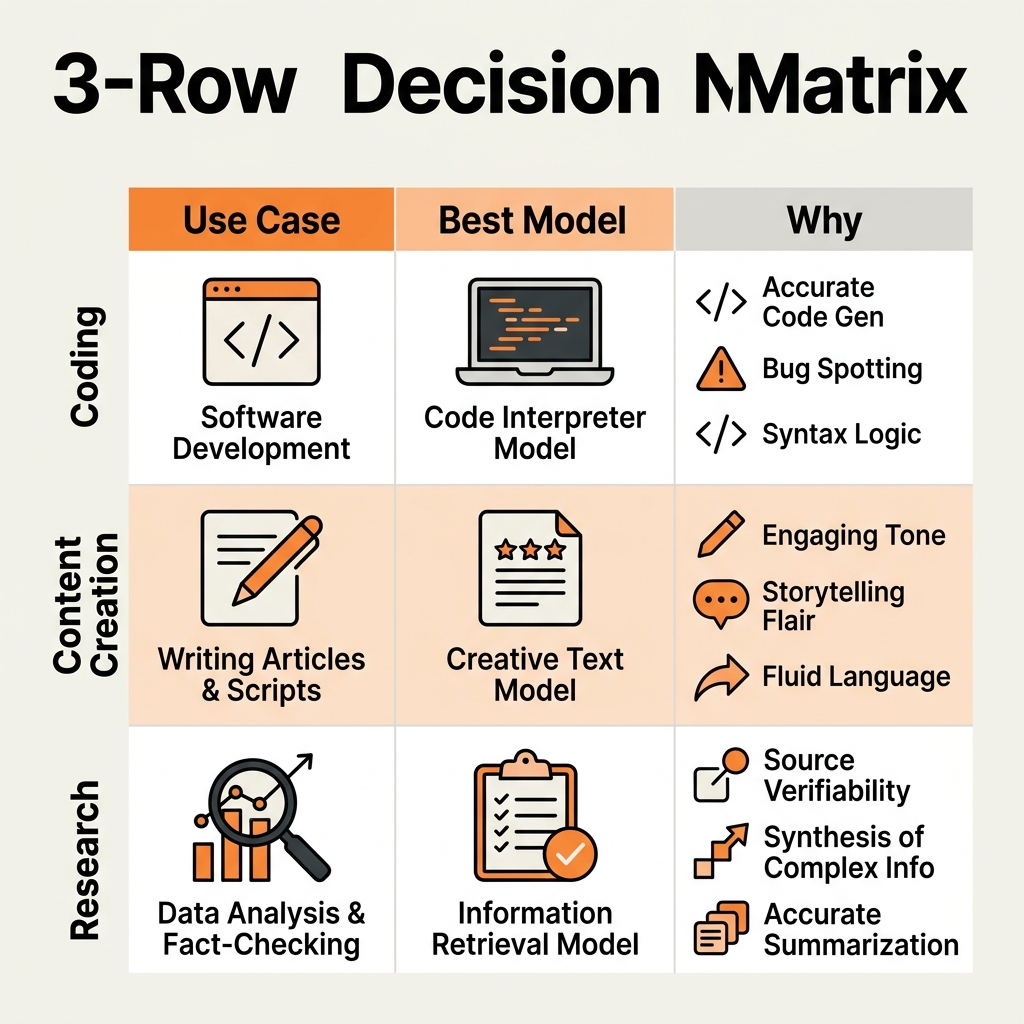
With more than 50 major LLMs competing for attention in 2026—and hundreds more niche variants available—the real challenge is no longer finding a capable model. It is matching the right model to your specific workflow, budget, and compliance needs. The April 2026 release wave alone delivered Claude Opus 4.7 (Anthropic, Apr 16), Qwen3.6-35B-A3B (Alibaba Cloud, Apr 15), GPT-5.5 (OpenAI, Apr 23), and DeepSeek-V4-Flash (DeepSeek, Apr 24), each optimizing for different trade-offs between safety, speed, cost, and language coverage. Whether you are a startup founder, an enterprise architect, or an AI product manager, the abundance of choice now demands a structured decision framework rather than hype-driven adoption.
Choosing the Right Model for Your Stack
Before committing to an API contract or downloading open weights, audit your requirements against three pillars:
2026 LLM Selection Guide by Use Case
| User Profile | Recommended Model | Standout Strength | Release Date | Cost/Access |
|---|---|---|---|---|
| Enterprise & Compliance | Claude Opus 4.7 | Safety alignment, 1M+ context | Apr 16, 2026 | Premium API |
| General-Purpose AI Apps | GPT-5.5 | Broad reasoning, plugin ecosystem | Apr 23, 2026 | High-volume API |
| High-Speed, Low-Cost Ops | DeepSeek-V4-Flash | Optimized inference, latency focus | Apr 24, 2026 | Budget / Open weights |
| Global / APAC Markets | Qwen3.6-35B-A3B | Advanced Chinese & multilingual | Apr 15, 2026 | Cloud pay-as-you-go |
| Open-Source & On-Prem | LLaMA 4 / Mistral | Full weight download, customization | 2026 | Free / Hosting |
| Multimodal & Search | Gemini 3.1 Pro | Native Google Workspace integration | 2026 | Tiered workspace |
This matrix reflects the current landscape as of May 2026. Notice that no single model sweeps every category—Claude Opus 4.7 leads on safety and context length, while DeepSeek-V4-Flash wins on raw throughput, and GPT-5.5 offers the broadest third-party tooling. Your optimal choice depends on which variable—latency, price, compliance, or language coverage—acts as the bottleneck in your pipeline.
The Infrastructure Reality
Selecting a model is only half the battle; integrating and switching between them as benchmarks shift every few weeks is the other. Vendor lock-in remains the hidden cost of the LLM boom. Indian AI infrastructure platforms like CallMissed are addressing this by providing a multi-model API gateway that lets engineering teams route traffic across 300+ models—including GPT-5.5, Claude Opus 4.7, and open-source alternatives—without rewriting client-side code. For companies deploying AI voice agents or multilingual chatbots, that flexibility translates directly to better user experiences: you can A/B test response quality across providers in real time, fall back to a second model during outages, and optimize costs per region rather than betting your entire stack on a single vendor.
Actionable Next Steps
Frequently Asked Questions
Common Questions About the 2026 LLM Ecosystem
The 2026 large language model market spans hundreds of models, from flagship proprietary systems to specialized open-weight variants. Below are answers to the most searched questions about selecting, comparing, and deploying today’s top LLMs.
What are the top large language models (LLMs) in 2026?
Which LLM is best for coding and software development in 2026?
Are there any good open-source large language models available in 2026?
How do I choose the right LLM for my business use case?
How many large language models are there in 2026?
What's the difference between GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro?
Conclusion
The 2026 LLM landscape is defined not by a single winner, but by an explosion of specialized capabilities across dozens of production-grade models. From OpenAI’s GPT-5.5 and Anthropic’s Claude Opus 4.7 to open-source heavyweights like DeepSeek-V4-Flash and Alibaba’s Qwen3.6-35B-A3B, organizations now face an embarrassment of riches—and the challenge of choosing the right tool for the right task.
Here are the key takeaways from this year’s definitive guide:
Looking ahead, the next inflection point will likely be agentic orchestration—systems that don’t just generate text but autonomously plan, execute, and hand off tasks across multiple models and APIs. Multimodal reasoning and on-device inference are also approaching tipping points that will redefine latency, cost, and privacy trade-offs.
For businesses building on this rapidly shifting foundation, infrastructure flexibility matters as much as model selection. Platforms like CallMissed are already enabling companies to deploy AI voice agents and multilingual chatbots that tap into the best available LLMs—including support for 22 Indian languages—without locking into a single provider. As the model wars intensify, the winners will be those who treat LLMs as interchangeable engines rather than monolithic platforms.
Which model will you bet on for the second half of 2026—or will you build a stack that lets you swap them out before the next release drops?


