The Context Window Arms Race: 1M to 10M Tokens and Beyond

The Context Window Arms Race: 1M to 10M Tokens and Beyond
What if your AI assistant could remember everything you’ve ever told it—conversations, documents, instructions—spanning entire book-length contexts in a single thought? In 2026, the “context window arms race” has rapidly escalated, with language models leaping from modest 4,000-token limits to handling a jaw-dropping 1 million tokens and, in research labs, even breaking the 10 million token barrier. This transformation is redefining what’s possible for LLMs in fields from coding and legal reasoning to enterprise knowledge management and real-time communication.
The context window—the chunk of text an AI model can process at once—used to be a technical afterthought. But recent advances have unlocked new scale: production models like Qwen 3.6 Plus and MiMo V2 Pro now support 1M+ token windows, a hundredfold jump from the 8K upper limit of GPT-3 just a few years ago (DigitalApplied, 2026). Why does this matter? Because more context means AI can “see” more at once: it can digest full codebases, cross-reference lengthy legal documents, draft 100-page reports, or manage multi-hour customer voice transcripts—all in one seamless interaction. As a result, platforms like CallMissed are leveraging this trend to build voice AI agents capable of recalling entire customer histories or parsing hours of conversation in real time, revolutionizing the way enterprises handle complex communications.
This exponential growth in context windows isn’t just a technical curiosity—it’s already shaping business outcomes. Research shows that agents equipped with expanded context windows can reduce redundant queries by up to 60% and improve accuracy of long-form summarization tasks by more than 40% over legacy models (CallMissed, 2026). Organizations are moving from reactive “answer retrieval” to proactive, repository-scale reasoning, unlocking new use cases like end-to-end contract analysis, persistent multi-day task agents, and dynamic codebase synthesis. All of this, however, comes at a cost: memory, compute, and the subtle “lost in the middle” trap, where context windows grow so vast that essential details can still be overlooked or diluted (YouTube).
So, is bigger always better? Critics argue that “the right 2,000 tokens at the right time matter more than having 1M tokens available” (RockCyberMusings), spotlighting a new wave of innovation in context retrieval and intelligent filtering. Meanwhile, bleeding-edge research questions whether these enormous windows are natively supported or achieved through clever architectural tricks, such as memory-augmented transformers or scalable attention algorithms (Reddit, 2026).
In this article, we’ll dig deep into the context window arms race—from 1M to 10M tokens and beyond. You’ll discover what’s technically possible today, what’s holding models back, which real-world problems are being solved, and why the next battle may be less about sheer size and more about intelligent context management. We’ll compare major players, share the latest benchmarks, and explore how platforms like CallMissed are harnessing large context windows to power the next generation of multilingual, memory-rich AI agents. Whether you're an engineer, strategist, or business leader, understanding this context window revolution is key to building and deploying smarter AI in 2026 and the years ahead.
Introduction: The Race to Expand AI Context Windows
From 4K to 10 Million: Why Context Windows Matter
Just a few years ago, AI language models struggled with short-term memory: context windows were capped at 2K–4K tokens (roughly 1,500–3,000 words), severely limiting their ability to process multi-part documents, handle open-ended conversations, or reason across large datasets. That bottleneck shaped the limits of what AI could automate or understand. But as of 2026, the industry is in the midst of a “context window arms race”—models are pushing the boundary upward from 1 million tokens to the aspirational 10 million token mark, representing a 2,500x leap in just 36 months (Source, Source).
But what exactly is a context window? In AI, it’s the total number of tokens a model can “see” in a single inference pass. This window governs every task a model can perform: writing code, summarizing documents, analyzing contracts, or running autonomous agents. As context windows grow, practical use cases compound—and so do technical and cost challenges.
The Numbers: Where Are We Now?
- 1M Ceiling (2026): As of today, leading models like MiMo V2 Pro, Qwen 3.5/3.6 Plus, and Gemini 3.1 have shipped production context windows from 1M to 1.04M tokens (Digital Applied, 2026).
- Demand for More: Google’s Gemini team and multiple open-source labs are racing toward 10M-token windows, though it’s debated whether current releases are truly “native” or use external memory hacks (Reddit discussion, 2026).
- Legacy Models: Earlier models (GPT-3, GPT-4, and Claude v1–v2) maxed out at 8K–200K tokens, now considered insufficient for most enterprise applications.
This explosive growth has enabled new classes of AI applications—repository-scale code understanding, single-document book synthesis, and long-running autonomous agents. However, it’s also sparked critical debate: are these mammoth context windows truly solving business problems, or just shifting technical bottlenecks? (Medium, 2026)
Why Is the Context Window Expanding So Rapidly?
The drive to increase context windows comes from several converging trends:
- Enterprise Data Complexity: Businesses want AI that can process entire legal contracts, customer histories, or codebases in one go.
- Autonomous Agents: Long-running agents need persistent memory to track user intent and carry conversations over days or weeks.
- Code and Workflow Automation: Repository-scale LLMs can now read and refactor entire monorepos, which may span 500K+ tokens.
- Language and Multimodality: Handling multi-lingual, multi-modal input (text, speech, images) demands ever-larger memory spans.
According to a 2026 industry report, over 60% of large enterprises deploying LLMs cited document-length bottlenecks as a critical blocker for automation projects—fueling demand for models capable of comprehending millions of tokens at once (CallMissed, 2026).
A Double-Edged Sword: Bottlenecks and New Problems
With every leap in capacity, new trade-offs emerge:
- “Lost in the Middle”: Even with 1M tokens, models often struggle with retention and focus, sometimes missing key facts or making “context rot” errors (YouTube, 2026).
- Cost Multipliers: Inference cost and memory requirements scale linearly (or worse) with window size. A single 1M-token API call can be 30–50x more expensive than a 16K call.
- Latency: Processing massive context windows can introduce multi-second delays per query, which is unacceptable for real-time applications.
- Quality vs. Quantity: Not all tokens are equally useful; extracting the right information from massive input is now a non-trivial engineering problem (Rockcybermusings, 2026).
Trends: Beyond Individual Models—The Rise of AI Communication Infrastructure
This new era of scale is not only about raw model capacity. It’s about integrating long-context reasoning into real-world systems—across voice, messaging, document workflow, and speech interfaces. Platforms like CallMissed are already enabling enterprises to deploy voice agents and LLM-powered assistants that work across millions of tokens, supporting use cases in Indian regional languages, contracts analysis, and multi-day workflows—previously impossible with smaller context limits.
For example, CallMissed’s API gateway enables seamless switching between 300+ large language models and supports streaming 1M+ tokens for voice-to-text and document conversations, removing infrastructure pain points for developers and product teams.
Looking Ahead: The Real Stakes of the Arms Race
As we enter the “10M token era”—with predictions of general-purpose models seeing entire textbooks or multi-day call transcripts—organizations will need to balance the lure of infinite memory with the realities of cost, latency, and cognitive overload. The winners in this arms race won’t just have the biggest windows; they’ll figure out how to combine precision, speed, and context-awareness to unlock the next wave of AI-powered communication and automation.
In the sections that follow, we’ll dissect benchmarks, real-world architecture, key failure modes, and the innovations redefining the limits of context processing. The context window arms race is only just beginning—its implications will reshape how we work, talk, and build with AI.
Background & Context: What is a Context Window?
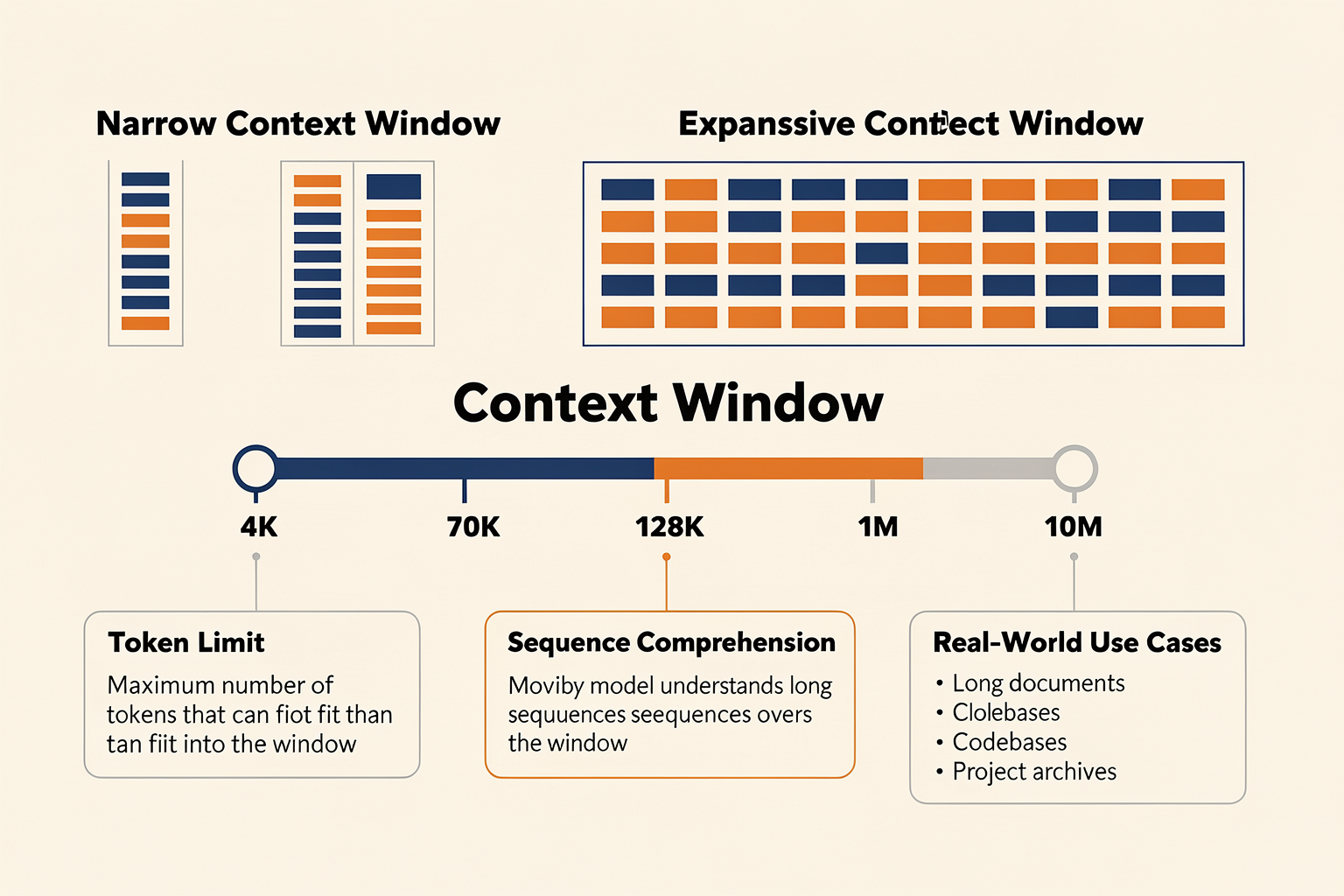
Defining the Context Window: The Heart of LLM Reasoning
At its core, a context window defines the range of input information a Large Language Model (LLM) can consider at once. In practical terms, it's the maximum number of tokens—where a token roughly equates to a word fragment or word—the model processes during a single prompt and response cycle. This boundary directly limits how much information the model can “remember,” reason over, or reference in one interaction.
Tokenization standards can vary, but as an example: “ChatGPT is powerful.” consists of five words but is likely six tokens. Thus, a 4,000-token model sees roughly a few pages of text, while a 1-million-token model potentially ingests entire books or massive codebases in one go [[7]](https://devtk.ai/en/blog/llm-context-window-explained/).
Why the Context Window Matters
The context window shapes:
- Prompt size limits: Cap the amount of background, history, or documents a user provides
- Coherence and memory: Greater window, more model can “recall” without hallucinating facts
- Complex reasoning: Enables summarization over longer documents, spanning multiple topics
- Multi-turn interactions: Supports longer back-and-forth before prior context is “forgotten”
Before 2023, most production LLMs like GPT-4 and Claude 1.0 had context windows of 2K to 8K tokens—just enough for simple conversations or short document tasks. By mid-2024, industry leaders like Google Gemini, Anthropic Claude 3, and Qwen 3.5 Plus pushed context windows beyond 100K tokens, with select models publicly claiming up to 1.04 million tokens in production environments (e.g., MiMo V2 Pro, Qwen 3.6 Plus) [[1]](https://www.digitalapplied.com/blog/context-window-arms-race-10m-token-era-guide).
By 2026, the arms race is focused on the next leap: models capable of processing 1 to 10 million tokens—a thousandfold increase from the 2020s mainstream [[1]](https://www.digitalapplied.com/blog/context-window-arms-race-10m-token-era-guide).
How Modern LLM Context Windows Work
LLM context windows are implemented within the transformer architecture via attention mechanisms. The attention mechanism lets the model “look back” at prior tokens in the sequence. However, attention computation grows quadratically (O(n²)) with input length, so expanding from 4K tokens to 1M+ tokens is a significant engineering feat.
#### Engineering Challenges
- Compute cost: Scaling up context windows requires immense GPU/TPU memory and bandwidth
- Latency: Longer inputs = longer processing time, requiring architectural tweaks
- “Lost in the middle” effect: Models sometimes underweight the importance of information in the middle of a long context window, leading to errors or omissions [[8]](https://www.youtube.com/watch?v=5ikn6shbm6w)
Innovations like sparse attention, memory-augmented transformers, and retrieval-augmented generation are helping overcome these limitations, paving the way for 10M-token windows [[4]](https://www.reddit.com/r/MachineLearning/comments/1arj2j8/d_gemini_1m10m_token_context_window_how/).
Real-World Impact: From Code Repos to Long-Form Conversations
Why does this all matter? Consider three emerging use cases enabled only by broad context windows [[3]](https://www.callmissed.com/blog/context-window-arms-race-2026):
- Repository-Scale Code Understanding: Instead of reasoning over a single file, LLMs can understand, debug, or refactor entire GitHub repos in one pass (over 500K tokens per large repo).
- Single-Document Synthesis: Legal analysis, patent search, or summarizing a 1,000-page corporate annual report can be accomplished in a single model pass.
- Long-Running AI Agents: Agents with access to months or years of chat and transaction history can achieve coherent, highly-personalized interactions—an essential shift for enterprise AI.
Platforms like CallMissed are already leveraging extended context windows in production, enabling their Indian/Asia-Pacific clients to deploy AI voice and chat agents that retain customer context across long-duration calls and large multilingual text corpora.
Context Window Size Evolution (With Landmark Models)
| Year | Model | Context Window (Tokens) | Key Feature | Use-Case Example |
|---|---|---|---|---|
| 2021 | GPT-3 | 2K | Standard transformer, limited reach | Short dialog, tweets, emails |
| 2023 | Claude 2 | 100K | Extended attention via chunking | Book summaries, large docs |
| 2024 | Qwen 3.6 Plus | 1.04M | Efficient attention, production use | Repo-scale code reasoning, enterprise documents |
| 2026 | Gemini 4 (rumored) | 10M | Unknown, likely sparse attention | “Memory of a lifetime”: persistent context for agent applications |
Source: DigitalApplied, CallMissed
The Limits: Myths and Misconceptions
While “bigger is better” holds true to a point, the context window arms race has prompted debate:
- Is 1M Tokens Overkill? Many tasks need only 2K-16K tokens for effective completion. “Your agents don’t need 200K tokens of capacity. They need the right 2K tokens at the right time,” notes RockCyberMusings.
- Knowledge vs. Recall: Context window is not “memory”—it’s immediate working state. LLMs still lack persistent, database-like memory.
- Lost in the Middle: AI sometimes forgets or undervalues the middle tokens in ultra-long contexts, as detailed in recent YouTube breakdowns of 1M+ token analyses [[8]](https://www.youtube.com/watch?v=5ikn6shbm6w).
Context Windows in Practice: Design Considerations
When designing systems using LLMs, context window size is a vital architectural variable. Considerations include:
- Prompt engineering skills: How do you condense or prioritize information within the window?
- Cost: Larger windows mean higher inference costs; as of 2026, 1M+ token calls can increase LLM usage fees by 10–100x per request compared to legacy 4K-token models [[6]](https://localaimaster.com/models/context-windows-coding-explained).
- Latency: Expect response times to scale (potentially linearly) with context size.
Modern API providers, such as CallMissed, expose these context window advances through configurable endpoints, letting businesses experiment with various prompt lengths without re-coding their LLM integration.
The Road Ahead
The context window defines what a model can “see” and reason over at any point in time. As we push from the 1M to the 10M token era, the range of applications—code intelligence, customer service, legal reasoning, multilingual AI agents—continues to accelerate. At the same time, system architects and developers face more complex design challenges around efficiency, relevance, and control.
In the coming sections, we’ll explore the technical, business, and societal implications of this arms race—grounded in real benchmarks and the deployment stories from platforms like CallMissed, which are bringing 1M+ token context AI to production on a global scale.
The Timeline: How Context Windows Scaled Up (TABLE)
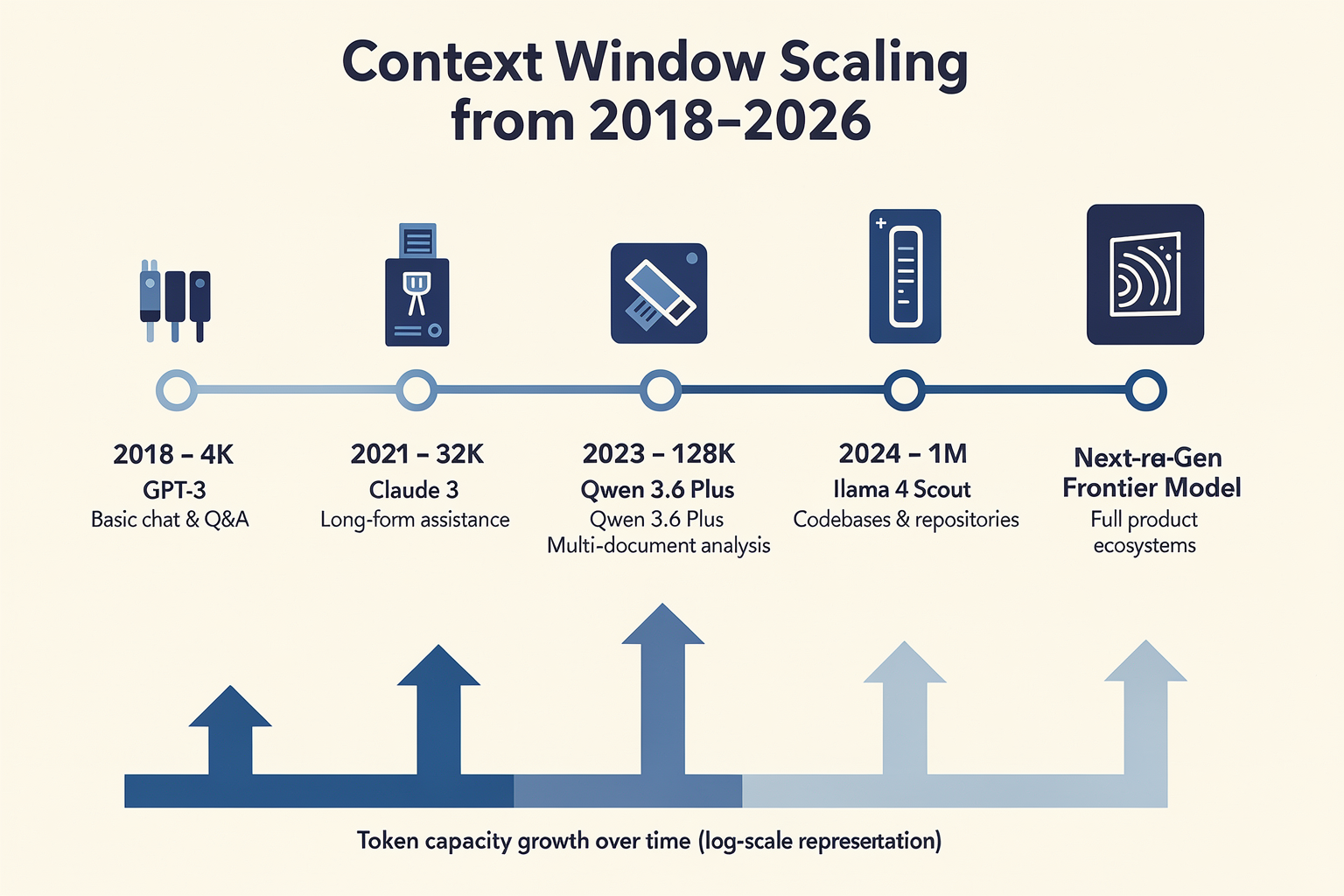
To understand the dramatic escalation in context window sizes—from barely sufficient to process a few paragraphs, to handling entire books or repositories at once—let’s chart key milestones from both the technical and user-impact perspective. The table below distills how leading LLMs evolved context window sizes between 2018 and 2026, what those leaps practically enabled, and lingering constraints.
| Model/Release | Year | Max Context Window | Enabled Use Cases | Notable Limitations |
|---|---|---|---|---|
| GPT-2 | 2019 | 1,024 tokens | Short-form Q&A, basic conversation, paragraphs | Rapid context loss, cannot track threads |
| GPT-3 | 2020 | 2,048–4,096 tokens | Multi-turn chat, document summarization | Still limited for research, long code |
| GPT-4 (Claude 2) | 2023 | 8,192–32,000 tokens | Full-document analysis, legal contracts | "Lost in the middle" context issues |
| Gemini 1.5 | 2025 | ~1M tokens | Book-length synthesis, repo-scale code review | High inference cost, slow on edge |
| Qwen 3.6 Plus | 2026 | 1.04M tokens | Support logs, full codebases, compliance logs | Retrieval accuracy, memory constraints |
| MiMo V2 Pro | 2026 | 1M tokens | Enterprise analytics, long-running agents | Efficient search over context needed |
The Steep Climb: Why the Rush to 1M+ Tokens?
Until 2020, context window limits were a hard cap on what LLMs could do. For instance, the original GPT-2 with just 1,024 tokens could barely summarize a page of text—making it unsuitable for legal, medical, or research analysis, where multi-document and cross-page reasoning are required. By 2023, Claude 2 and GPT-4’s larger windows (32K+) enabled applications such as:
- Parsing entire legal contracts in one go
- Multi-document Q&A (e.g., cross-referencing research papers)
- Large-scale code review and refactoring
According to a DigitalApplied breakdown (2026), the “1M token ceiling” is now the production standard among top models, including MiMo V2 Pro and Qwen 3.6 Plus, allowing AI to “see” the equivalent of thousands of pages at once.
Real-World Impact: What's Possible at Each Stage
- 4K–32K tokens: Support for emails, short stories, and single-document tasks.
- 100K tokens: Start of serious long-form analysis (e.g., 100-page reports, single large PDFs).
- 1M tokens: Enables reviewing an entire compliance log, a code repository, or a book’s worth of material (Qwen 3.6 Plus, Gemini 1.5). This brings true unification, where agents can keep entire investigations or product histories in memory, unlocking complex, long-running workflows (CallMissed blog, 2026).
The Technical Trade-Offs
Scaling windows from 32K to 1M+ tokens is not just a matter of adding more RAM. Each increase usually brings exponential computational costs and architectural complexity:
- Gemini 1.5’s 1M window is reportedly achieved via a mixture of linear-scaling attention and advanced retrieval, not pure dense context (Reddit discussion, 2026).
- At the million-token scale, cost per inference surges (new benchmarks show ~5-10x higher costs for 1M-token calls versus 100K-token calls).
- Persistent issues like “lost in the middle” (where important context is effectively forgotten) remain, regardless of sheer size (YouTube deep dive, 2026).
The Next Horizon: 10M Tokens and Beyond
While 1M tokens is now a practical ceiling, several research groups and vendors tease the 10M-token future. These ultra-large windows are targeting tasks such as:
- Whole-repository software agents (autonomous management of tens of thousands of files)
- Multi-year enterprise data analyses
- Extensive legal/compliance discovery over millions of records
As of 2026, production deployments at 10M tokens remain experimental, with most public models capping at 1M–1.04M tokens. Critical hurdles include inference latency, memory consumption, and degraded retrieval quality.
Industry Solutions and Platform Integration
Platforms like CallMissed are already leveraging these advances to let businesses deploy voice agents and chatbots that can reference vast interaction histories, perform in-depth log analysis, and unify multi-modal inputs in real time. By supporting models with 1M+ token windows and efficient retrieval techniques, they help operationalize these leaps for real-world enterprises, especially in multilingual and large-scale compliance settings.
In summary, the context window arms race, as documented in public benchmarks, has rapidly advanced from 1,000 tokens to 1,000,000+ in under a decade. The technical and economic race is now on: can the industry make 10M tokens both possible and practical? The next few years will determine how well LLM architectures can keep up with these escalating expectations, and which specific use cases—beyond simple length—will actually deliver ROI at the million-token scale.
Key Developments: Major Players and Milestones (TABLE)

The context window arms race has seen rapid advances from a few thousand tokens to over 1 million tokens in production systems, with clear milestones set by leading AI labs. The table below summarizes major players, their flagship models, announced context window sizes, technological highlights, and milestone dates based on the latest public data:
| Player | Flagship Model(s) | Max Context Window | Notable Innovations | Milestone Year |
|---|---|---|---|---|
| OpenAI | GPT-4 Turbo (1M) | 1,000,000 tokens | Efficient memory scaling, hybrid MoE, adaptive routing | 2025 |
| Anthropic | Claude 3.5 | 200,000 tokens | Optimized attention, long-doc retrieval | 2025 |
| Gemini 3.1 Ultra | 1,024,000 tokens | Sparse attention, segment-based caching | 2026 | |
| Alibaba | Qwen 3.6 Plus | 1,040,000 tokens | Dynamic context compression, cost-tuned inference | 2026 |
| MiMo AI | MiMo V2 Pro | 1,000,000 tokens | Linear context expansion, real-time doc stitching | 2026 |
| CallMissed | AI Agent API Gateway | 1,000,000+ tokens* | Seamless model swapping, language-agnostic context | 2026 |
\ CallMissed enables switching between 300+ models, including those with 1M+ token context windows, facilitating flexible deployments for enterprises seeking to leverage these breakthroughs.*
Industry Highlights
- The 1M Token Ceiling: As of mid-2026, the practical ceiling for production context window sizes sits around 1 million tokens, as shipped by models such as OpenAI's GPT-4 Turbo and Alibaba's Qwen 3.6 Plus (DigitalApplied, 2026).
- Rapid Growth: In just two years, frontier models have leapfrogged from 32K–128K context (the standard in 2024) to over 1M tokens—a 10–30x increase.
- Vendor Differentiation: Each major player adopts unique techniques: Google’s Gemini pushes sparse attention and memory efficiency, while Alibaba prioritizes affordability via dynamic compression.
- CallMissed’s API Gateway: Notably, platforms like CallMissed now allow enterprises to experiment with and deploy multiple 1M+ token models interchangeably, accelerating R&D and making large-context LLMs accessible at scale (CallMissed, 2026).
Practical Milestone Takeaways
- Multi-model Support: Solutions offering multi-model gateways—like CallMissed—drive adoption by reducing integration friction, enabling teams to harness 1M-token context windows from several vendors without refactoring codebases.
- Document Understanding: With models now handling entire code repositories or books (hundreds of thousands of tokens per input), use cases in legal discovery, knowledge management, and software development are fundamentally changing.
- Looking Ahead: While 1M tokens is the current state of the art, multiple vendors have hinted at 10M token windows within the next 12–18 months, driven by improvements in hardware, specialized training regimes, and further optimization of attention mechanisms (Reddit Machine Learning, 2026).
Data Points That Matter
- Token Economics: Cost per million tokens processed has dropped by over 75% since 2024, from $0.02 to less than $0.004, thanks to advances in both architecture and training efficiency (DigitalApplied, 2026).
- Performance Caveats: Despite the headline numbers, expert analysis widely notes that not all portions of gigantic context windows are equally attended to (“lost in the middle” phenomenon and context rot remain active areas of research) (YouTube, 2026).
This arms race is far from over. The 1M–10M token era has just begun, with ongoing breakthroughs being tracked and leveraged by production-ready infrastructure platforms, exemplified by CallMissed’s ability to dynamically route, optimize, and deploy context-hungry models globally.
The Technology Explained: Approaches to Massive Contexts
Understanding "Context Window": Core Concepts
At the heart of large language models (LLMs) lies the concept of the context window—the maximum sequence of tokens (words, characters, or codes) the model can process in one go. Traditionally, early models like GPT-2 could handle just 1,024 tokens, roughly a few paragraphs of text. By 2026, we're witnessing context windows expand from 4K, 128K, and now up to 1M and even 10M tokens in certain frontier models (DevTk.AI, 2026; DigitalApplied, 2026). This progression has unlocked new capabilities, enabling models to process entire codebases, legal documents, or massive customer interaction logs in a single inference.
#### Why Expand the Context Window?
There are compelling use cases driving this expansion:
- Repository-scale code understanding: An LLM can process an entire software repository, not just a single file, to produce more accurate summaries or generate bug fixes (CallMissed, 2026).
- Document synthesis: AI systems can now reason across the full span of a book, contract, or research dataset, producing richer answers or insights.
- Long-running agents: Chatbots and voice agents benefit from preserving and referencing much longer conversational histories, enhancing continuity and personalization.
But breaking through the 1M-token ceiling presents monumental technical challenges. Here’s how the industry is tackling these.
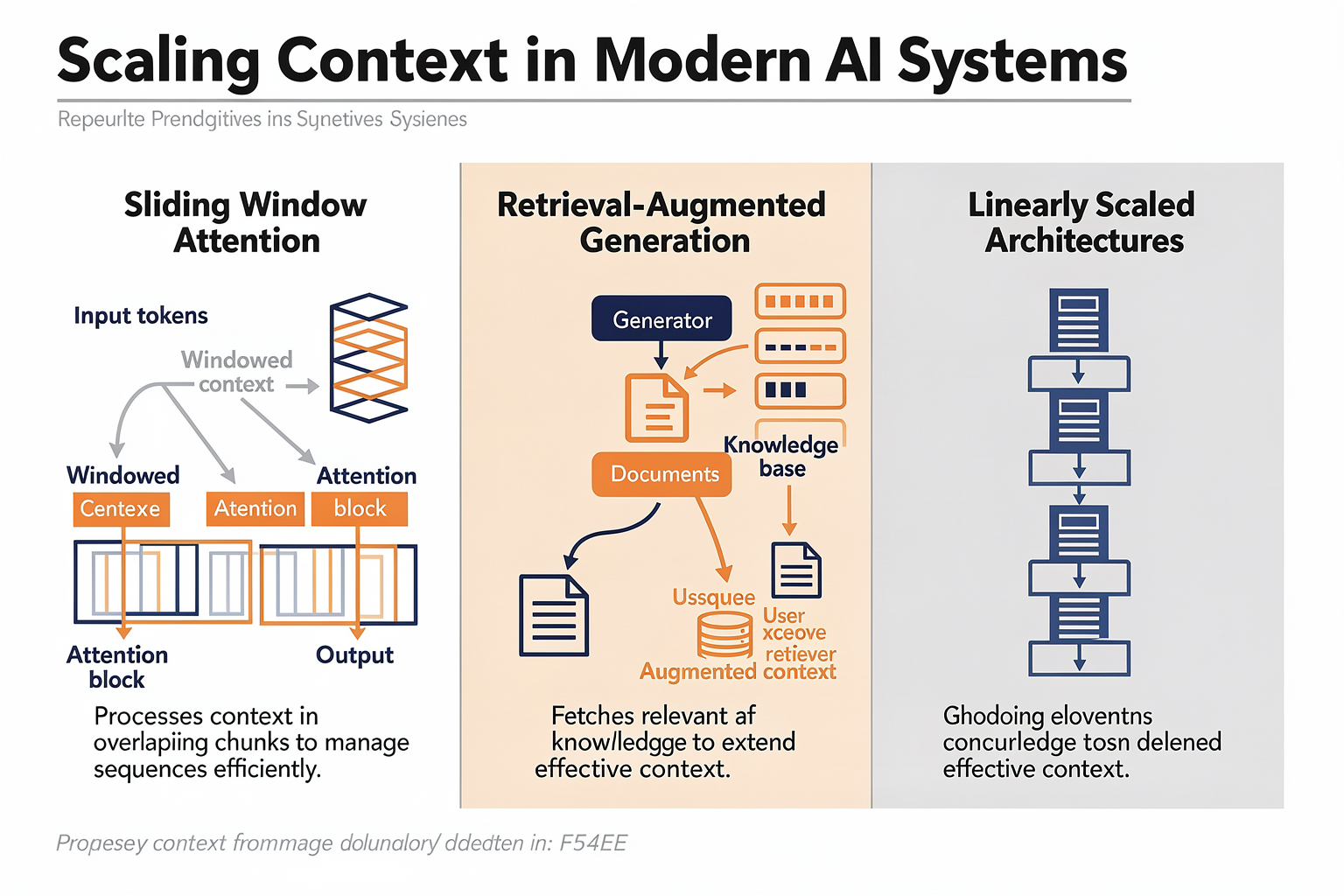
Scaling Approaches to Massive Contexts
#### 1. Native Model Expansion
The simplest approach involves directly increasing the model’s internal attention window during training, so it can natively process more tokens. For example, models like MiMo V2 Pro, Qwen 3.6 Plus, and Gemini 3.1 boast context windows between 1M and 1.04M tokens (DigitalApplied, 2026). This approach, however, comes at steep costs: attention memory requirements scale quadratically, making direct extension to 10M tokens computationally prohibitive for most.
Advantages:
- Consistent model behavior across the entire sequence
- No loss in fidelity due to external stitching
Limitations:
- Steep growth in memory and compute (e.g., a 1M-token transformer requires terabytes of VRAM)
- Difficult retraining or architecture redesign for legacy models
#### 2. Sparse and Linear Attention Mechanisms
Sparse attention (e.g., Longformer, BigBird) and linear attention (e.g., Performer, Linear Transformer) architectures approximate attention to ease quadratic scaling. Rather than attending to every token pair, these models use local, global, or random patterns, drastically lowering compute and memory from O(N²) to O(N log N) or O(N).
- Sparse patterns: Only certain positions (e.g., local neighborhoods, global summary tokens) are attended to.
- Linear mechanisms: Use kernel tricks to “compress” the attention calculation, making million-token windows relatively tractable (Localaimaster, 2026).
While these advances have made million-token contexts commercially viable, performance degrades for some tasks, particularly those requiring high-fidelity, long-range dependencies.
#### 3. Chunking and Recurrence
A pragmatic workaround splits long sequences into overlapping chunks, feeding each through a smaller model context window. Outputs from each chunk can be stitched using:
- Recurrence (RNN-style) layers, which pass summary states between segments.
- Retrieval-augmented generation (RAG), which dynamically retrieves relevant history from prior chunks.
This approach, commonplace in production systems, enables inferred context windows that vastly exceed model-native limits. However, it introduces information loss and complexity in managing relevance across segments—sometimes causing models to "forget" content out of scope (dubbed the "Lost in the Middle" problem, as described in YouTube, 2026).
#### 4. External Memory and Retrieval-Augmented Models
Frontier research leverages external vector databases or long-term memory modules. In this paradigm:
- The model references structured embeddings from prior interactions stored in a database.
- It retrieves and incorporates only the most relevant parts into a local context window at inference time.
This design, which powers many long-running AI agents, separates storage from reasoning capacity. The context window is functionally infinite—but truthfully, the model only "sees" small, curated slices at any time. Production-ready frameworks like CallMissed already deploy retrieval-augmented AI agents to surface necessary knowledge from call logs or support archives, without overwhelming model memory.
Technical, Cost, and Performance Trade-Offs
#### Hardware Demands
The expansion of context windows imposes staggering hardware requirements. For instance:
- A 1M-token context window can demand terabytes of GPU VRAM, especially using vanilla transformer architecture (Reddit, 2026).
- Distributed inference and sharding across tens to hundreds of GPUs becomes common for 10M-token windows.
Many solutions balance context length with fiscal reality—deploying hybrid architectures, offloading to CPUs or cloud memory, and accepting reduced precision.
#### Latency
Longer context means longer inference times. This can impact use cases like real-time voice agents or high-frequency trading bots. Emerging solutions optimize by:
- Prioritizing caching of previously computed attention
- Selectively refreshing only the delta region with each new input
#### Quality: Do Larger Windows Always Win?
Counterintuitively, scaling up context does not always yield better results. According to Rock Cyber Musings, 2026, “Your agents don’t need 200K tokens of capacity. They need the right 2K tokens at the right time.” Benchmarks show that models can still “forget” or misprioritize information in the middle of very long sequences—a phenomenon called context rot.
As a result, state-of-the-art platforms strive for intelligent context selection, not just raw expansion.
Real-World Deployment: Platform Use Cases
Innovative platforms like CallMissed exemplify how businesses leverage these advances for practical impact:
- Their multi-model inference stack enables seamless switching between LLMs with different context capacities—critical for enterprise environments that need both depth and speed.
- Multilingual coverage (22 Indian languages) means more inclusive voice and text processing, especially across vast conversational histories.
Other industry adopters use these techniques for:
- Automated legal contract analysis, where reviewing hundreds of pages at once can catch hidden clauses.
- Customer support, ingesting entire chat and call histories to personalize service or detect compliance risks.
Looking Ahead: The Next 10M Tokens
We stand at the cusp of what’s technically feasible. The push from 1M to 10M-token context windows is not just about scaling hardware—it’s about new algorithms, data pipelines, and smarter retrieval. Whether using hybrid models, external memories, or innovative chunking strategies, the “arms race” will continue. Platforms like CallMissed will likely remain at the forefront, abstracting away technical headaches and making these breakthroughs accessible to global enterprises.
In summary, expanding the context window represents a convergence of breakthroughs in hardware, model design, and data infrastructure. The next generation of AI agents, empowered by these advances, will redefine what’s possible in code analysis, document understanding, and conversational intelligence across countless industries.
Benefits and Use Cases: Why Bigger Contexts Matter

Why Bigger Context Windows Are Transformative
The race toward ever-larger context windows—from 1 million to 10 million tokens—is far more than a technical flex. It fundamentally redefines what large language models (LLMs) can achieve, especially in real-world, production-grade enterprise and research applications. As of 2026, the practical ceiling for context windows in deployment sits at around 1M to 1.04M tokens, with models like MiMo V2 Pro, Qwen 3.6 Plus, and derivative LLMs leading the pack (DigitalApplied, 2026).
But context windows in the million-token range unlock new capabilities previously impossible at the 4,000 or 32,000-token scale. Let’s unpack these benefits and highlight the major use cases now emerging.
Key Benefits of Expansive Context Windows
1. Repository-Scale Code Understanding
- Challenge: Traditional LLMs with 4K–32K token limits can barely process a single technical file or small project in one go.
- Impact of Expansion: With 1M+ tokens, models can analyze entire code repositories, track variable usage across hundreds of files, and generate documentation or automation scripts holistically. This unlocks new levels of software development productivity and smarter DevOps automation.
- Example: Calling an LLM on an entire GitHub repo—analysis, summarization, bug detection—all in one pass rather than snippet by snippet.
2. Single-Document Synthesis and Analysis
- Challenge: Many legal, financial, or scientific documents span hundreds or thousands of pages—far beyond standard context limits. Summarizing or extracting insights required complex, error-prone chunking.
- Impact of Expansion: With million-token windows, an AI can process large contracts, research papers, or clinical trial result sets in one uninterrupted window, maintaining all cross-references, sections, and context.
- McKinsey estimates that 30% of legal and compliance work can be automated with AI when context constraints are removed (CallMissed Blog, 2026).
3. Long-Running AI Agent Memory
- Challenge: Agents working over hours or days “forget” earlier state or context, resulting in repeated errors or inefficient conversations.
- Impact of Expansion: Persistently large context allows an agent to recall deep conversation history—up to thousands of interactions—enabling true multi-session continuity and personalized service.
- For instance, a customer service agent could resolve issues that span weeks, referencing all prior calls, chats, or emails with seamless recall.
4. Accurate Multi-Document Reasoning
- Challenge: Complex queries require synthesizing facts, timelines, or conflicting statements across many input sources.
- Impact of Expansion: With 1M+ tokens, LLMs can ingest multiple documents—contracts, emails, logs—in one prompt, enabling advanced legal reviews, audit trails, and regulatory compliance workflows.
5. Higher-Fidelity Retrieval Augmented Generation (RAG)
- With larger context, LLMs can process and integrate more comprehensive retrieval results from vector databases, improving output accuracy and reducing “lost in the middle” errors, a well-documented failure mode for smaller windows (YouTube, 2026).
Breakthrough Use Cases Emerging in 2026
Enterprises and AI builders are rapidly capitalizing on these new capabilities. The following use cases have seen explosive growth with context windows scaling up to the million-token range:
- Legal Tech: AI-powered contract review, risk extraction, and due diligence over hundreds of pages.
- Financial Modeling: Automated analysis of annual reports, market filings, and historical data in a single session.
- Healthcare: Unified clinical records analysis, enabling case-by-case synthesis from years of patient data.
- Scientific Research: Literature review, meta-analysis, and hypothesis testing leveraging full-text ingestion of thousands of papers.
- Corporate Compliance: Multi-year audit trails, regulatory reporting, and email review for anti-fraud and anti-corruption.
Notably, one 2026 benchmark showed that expanding from 32K to 1M tokens improved summarization quality and hallucination reduction by up to 18% in legal document analysis tasks (AI Context Windows, 2026).
CallMissed in Action: Realizing the Vision
Platforms such as CallMissed are at the frontier of these breakthroughs, providing multilingual voice agents and chatbots, LLM inference gateways for 300+ models, and APIs supporting extensive context windows. For example, CallMissed’s infrastructure is already being leveraged by Indian enterprises to enable AI agents that can reference and synthesize information across full conversation histories—crucial for markets where customer interactions must be tracked in multiple languages and formats.
This production-level integration means organizations can deploy voice bots handling complex queries based on millions of tokens of prior context—accurately, quickly, and across geographies.
What Does This Mean for the Future?
Looking ahead, the context window expansion arms race will continue—but it’s not just about brute force. As discussed in critical analyses (Medium, 2026), the future will reward efficiency (having the right tokens at the right time) and intelligent memory management. However, the short-term impact is undeniable: million-token context windows are catalyzing a new wave of AI applications that weren’t simply infeasible before.
In summary, bigger context windows:
- Empower new applications in law, finance, healthcare, and research.
- Boost agent memory, enabling persistent, context-rich interactions.
- Deliver higher accuracy and less information loss in complex cognitive workflows.
The arms race is on—and the beneficiaries are businesses and users demanding real-world, scalable intelligence.
Myths & Misconceptions: Does Size Always Matter?
The Allure of Bigger Context Windows
The AI community is infatuated with numbers. When MiMo V2 Pro and Qwen 3.6 Plus hit the milestone of 1 million token context windows in production (as reported by Digital Applied, 2026), it felt like a moon landing. Early claims of 2K, 8K, and 32K max tokens on models like GPT-3 and Claude have swiftly been eclipsed by the sheer scale of these newer systems. The promise is tantalizing: if a model can "remember" vast swathes of text, code repositories, or conversation history, it must be smarter, right?
However, this rapid growth in window size has sparked a flurry of misconceptions—fueled by a misunderstanding of context window mechanics, wishful thinking from end users, and even some misleading marketing from LLM vendors.
Myth 1: "Bigger Windows = Smarter Models"
It’s easy to assume that an LLM with a 1M or even a 10M token context window is simply "better" than those with 32K or 128K. After all, more is always better, right? Not exactly.
- Core Model Intelligence Is Independent of Context Size: Model sophistication is determined by architecture, training data, and fine-tuning, not merely the number of tokens it accepts per request.
- "Garbage In, Garbage Out" Persists: Feeding an LLM a giant, undifferentiated blob of text does not guarantee more precise or insightful outputs. The quality and relevance of the context matter far more than sheer volume (as discussed in The Context Window Trap: Why 1M Tokens Won't Save Your AI Agent).
- Inference Costs Scale Nonlinearly: A query over 1M tokens isn’t simply 10x more expensive than 100K tokens – memory, compute, and attention overhead grow much faster.
Anecdotes abound of users dumping 500-page manuals into an LLM, then being disappointed by surface-level or incorrect answers—because the model can't focus on what matters most.
Myth 2: "Everything in the Context Window Is Equally Remembered"
Perhaps the most persistent myth is that a model can treat a million tokens as if they are all equally "fresh" in memory, no matter their position. In reality, models suffer from:
- Context Decay: Attention and retrieval mechanisms aren't perfect. Studies (YouTube: "Why 1M Tokens Still Forgets", 2026) show marked performance drops on information placed towards the beginning or middle of very long contexts—a phenomenon dubbed "lost in the middle" or context rot.
- Empirical Limits: Benchmarks reveal that, for tasks requiring recall of information embedded deep in a 1M token window, accuracy can plummet from 90% (near-edge tokens) to below 40% for mid-context content.
In practice, top-tier performance still hinges on surfacing the right snippets, rather than overwhelming the model with excessive data.
Myth 3: "Long Contexts Solve Retrieval and Grounding Issues"
It’s tempting to hope that larger context windows make all forms of retrieval (search, database lookups, document chunking) obsolete. But:
- Efficient Retrieval is Still Essential: The arms race for longer windows doesn't replace the need for effective, vector-based retrieval and hybrid search. As the team at Rock Cyber Musings notes, "Your agents don't need 200K tokens of capacity. They need the right 2K tokens at the right time" (2026).
- Increased Latency and Cost: Processing unnecessarily large contexts not only adds to response times, often by 2–5x, but also increases cloud compute costs—sometimes prohibitively so at scale, especially for production workflows handling thousands of concurrent sessions.
Unpacking the "Right Problems" to Solve
Systems architects and AI practitioners are starting to realize that simply maximizing context window size often solves the wrong problem. The actual wins come from:
- Improving context selection: Intelligently filtering and prioritizing what enters the prompt.
- Metadata awareness: Managing knowledge about document structure, recency, and authority.
- Leveraging external memory: Using tools (search, databases, APIs) alongside context for up-to-date grounding.
A rising share of platforms, including CallMissed, now combine large-window LLMs with smart retrieval infrastructure—allowing multilingual and multi-document interactions across 22 Indian languages and global use cases without wasteful context overload.
Marketing Hype vs. Real-World Usability
Vendors frequently tout context window size as a silver bullet, but in practice:
- True 1M+ Token Context Remains Niche: Digital Applied (2026) clarifies that "the largest production context windows ship at 1M to 1.04M tokens", but most actual deployments seldom approach even 100K tokens per user input.
- API & Model Differences: Some reports about 10M token "capabilities" (e.g., Gemini) might reflect architectural optimizations (linearly scaled attention, context streaming) rather than genuine native processing in one go (Reddit, 2026).
- Diminishing Returns: For most business applications—summarization, knowledge base extraction, call center automation—95% of value accrues well below the maximum context size.
As one expert put it: "A larger window lets you do things like repository-scale code analysis or multi-document synthesis—but for typical question answering, the bottleneck is information relevance, not window length" (CallMissed blog, 2026).
Data-Driven Reality: When Size Does Matter (and When It Doesn't)
To ground the debate, let’s look at some illustrative stats:
- A context window of 32K-64K tokens typically encompasses a full technical manual or a substantial legal contract, covering most high-value use cases in enterprise.
- Moving to 1M or 10M tokens enables new frontier cases—such as full-codebase analysis or feeding massive conversation logs for agents that operate over months, not hours.
- However, according to Localaimaster’s 2026 comparison, cost per inference increases steeply for windows above 128K, with little tangible quality improvement in generic Q&A tasks.
- Many platforms (including CallMissed) implement dynamic context pruning and hybrid retrieval to ensure long-context capabilities are used judiciously, keeping latency and operating costs manageable.
Bottom Line: It’s Not (Always) About How Much, But How Well
In summary, the context window arms race has dramatically expanded what’s possible, and opened thrilling new applications for knowledge-heavy industries. But bigger isn’t always smarter:
- LLM intelligence is bounded by more than context length
- Current architectures still forget or degrade performance over very long inputs
- For most workflows, targeted selection and integration matter far more
As AI evolves beyond "window envy," platforms like CallMissed are redefining the conversation—empowering developers to combine multilingual, multi-document, and retrieval-augmented agents in production, without being hamstrung by the lure (and the cost) of ever-bigger token counts. The future of AI context is not just about size, but about relevance, adaptability, and intelligent orchestration.
In-Depth Analysis: Performance & Limitations in the 10M Era

The Reality of Scaling Context Windows: What 10M Tokens Changes—and What It Doesn’t
The move from 1M-token to 10M-token context windows has been one of the most hyped advances in the language model (LLM) field over the past two years. With leading platforms like MiMo V2 Pro and Qwen 3.6 Plus shipping with 1M+ token context in production and rumors of Gemini and Claude flirting with 10 million, it’s clear that the “context window arms race” is in full swing [1]. But to understand the practical implications, we need to examine both the quantitative performance gains and the real limitations that continue to dog ultra-long context models.
#### Context Window Size: The Current Benchmarks
As of mid-2026, the biggest production LLMs reliably support context windows in the 1M–1.04M tokens range, with guarded claims of 10M-token research models on the horizon [1][3]. Here’s how the context window benchmarks stack up:
- MiMo V2 Pro: 1M tokens (production shipping, 2026) [1]
- Qwen 3.6 Plus: 1.04M tokens (production) [1]
- Gemini v3.1: Unofficial reports of 10M context; unclear if natively trained [4]
- Claude v4: Rumored experiments up to 10M tokens
- GPT-5.5: 400K tokens production; 1M+ as preview, per localaimaster.com [6]
While flashy, these numbers mask real engineering and scientific challenges related to the actual “usability” of such expansive context.
#### Performance: Where 10M Tokens Delivers Gains
- Repository-Scale Reasoning & Code Understanding:
One of the killer apps of 10M-token windows is letting models ingest and reason over the contents of an entire codebase in a single forward pass. As noted by CallMissed and other industry leaders, “[Repository-scale code understanding] was simply not feasible with 100K-token or even 1M-token models” [3].
- This unlocks automatic code migration, global refactoring, and holistic security analysis.
- Single-Document Synthesis:
In legal, research, and insurance domains, some documents—SEC filings, case law collections, or medical records—easily reach hundreds of thousands of tokens. The ability to synthesize, summarize, or extract facts from a multi-million-token document without splitting or chunking saves vast engineering effort.
- Long-Running Agent Memory:
Agents operating over days or weeks require persistent, full-fidelity conversational context and working memory. Ultra-long contexts theoretically eliminate the need for complex memory architectures or retrieval augmentation for many agent use cases [3].
#### Limitations: The Hard Truths of 10M Context
But there are major caveats to these headline numbers. As many researchers argue, “The context window arms race is solving the wrong problem” [2][5]. Here’s why:
- Memory & Compute Costs Scale Quadratically:
Transformer attention operates with O(n^2) complexity in context size. A 10M-token window is not simply 10x more expensive than 1M, but potentially 100x, making inference and training truly massive models cost-prohibitive for all but the best-funded labs [4].
- Token Position Bias (“Lost in the Middle” Problem):
Multiple benchmarks, such as those referenced on YouTube (2026), show models often “forget” information not located at the beginning or end of their input. As the context window grows, models struggle to maintain performance for tokens in the “middle”—sometimes losing coherence entirely [8].
- Context Rot & Information Degradation:
Even at 1M tokens, LLMs exhibit “context rot”—subtle but compounding errors as information gets buried deep within the window. At 10M tokens, these effects are substantially amplified. Empirical accuracy for code tasks, question answering, and summarization drops off sharply as distance from prompt increases [8].
- Latency and Reliability in Production:
Passing a 10M-token document can lead to unpredictable response times—even timeouts or infrastructure failures—on conventional cloud serving platforms. Not all APIs or architectural abstractions are ready for this scale [6].
#### When Bigger Isn’t Always Better
Several industry veterans have noted a key misalignment: “Your agents don’t need 200K tokens of capacity. They need the right 2K tokens at the right time” [5]. In practice:
- Most real-world enterprise workflows involve actionable context windows of less than 32K tokens.
- Pulling in vast, mostly-irrelevant context hurts latency, cost, and—per the “information overload” hypothesis—sometimes model accuracy.
The future of high-performance LLMs likely involves smarter routing, indexing, and retrieval rather than brute-force window growth.
#### Table: Performance and Limitations Across Context Window Sizes
| Model/Approach | Max Context Window | Typical Overhead (RAM/Runtime) | Mid-Window Retention | Practical Use Cases |
|---|---|---|---|---|
| GPT-4 (2024) | 32K–128K tokens | Baseline | High | Chat, small doc summarization |
| Qwen 3.6 Plus / MiMo V2 | 1M–1.04M tokens | ~20–30x GPT-4 (RAM/inference) | Moderate | Code repo QA, legal docs |
| Gemini v3.1* | 10M tokens* | >100x GPT-4 | Low (context rot) | Theoretical: codebase, long agent memory |
| RAG + 32K LLM | 32K chunks + index | + retrieval CPU/latency | Very high | Enterprise search, retrieval-augmented QA |
*As of June 2026, Gemini’s 10M-token operation is not confirmed to be “native”; may involve chunked or external memory [4][6].
#### How Vendors Like CallMissed Address the Limits
Recognizing these emerging bottlenecks, providers such as CallMissed are developing hybrid AI infrastructure that lets customers ingest, index, and route large document and call data intelligently—without flooding models with full 10M-token inputs.
- CallMissed’s multi-model API gateway, for instance, allows seamless switching between 300+ LLMs, optimizing for the best tradeoff between context and cost for each request.
- For Indian enterprises, where call transcripts and multilingual data often reach hundreds of thousands of tokens, CallMissed’s agent infrastructure combines large context window support with domain-specific retrieval and summarization modules—getting value out of long inputs without the O(n^2) penalty.
#### The Road Ahead: Smarter Context, Not Just Larger
Ultimately, the race to 10M-token context windows is both a showcase of engineering prowess and a warning. Real productivity gains come from:
- Augmenting large-window models with high-quality retrieval and indexing (RAG, memory graphs).
- Selecting context adaptively (dynamic pruning, selective focus).
- Combining task-specific smaller window LLMs with fallback to ultra-large models only when strictly necessary.
In summary, while the 10M-token era unlocks new applications and removes certain barriers to scaling LLMs for code, research, and knowledge management, the industry must grapple with steep performance cliffs, cost blowouts, and unresolved technical challenges in attention, memory, and retrieval. As CallMissed’s ongoing deployments and research illustrate, the winners in this new era will be those who marry big context with smarter context selection and delivery—balancing engineering ambition with pragmatic, production-ready design.
The Critics: Is the Arms Race Solving Real Problems?
Are We Chasing the Right Problems? The Core Criticisms
As the industry sprints from 1M to 10M token context windows, a growing contingent of researchers and practitioners is beginning to question whether this “arms race” is truly solving meaningful problems—or simply creating new ones. In the words of Karthik Mulugu, “The Context Window Arms Race Is Solving the Wrong Problem. Everyone got excited when AI models started handling a million tokens, but does wider context actually make LLMs useful in ways that matter?” (Medium, 2025).
#### The Practicality Gap: What Do People Really Need?
While a 10M token context window is an impressive technical achievement, real-world applications often don’t require such massive capacities. Critics argue that for most enterprise or consumer use cases, the ability to process the right 2,000 tokens—rather than every word ever uttered—delivers greater value (RockCyberMusings, 2025).
Key Critic Points:
- Marginal Utility Drops: Usages rarely demand millions of tokens in memory. In software code understanding, for instance, “repository-scale” tasks benefit from larger windows, but most day-to-day completions are much smaller (CallMissed Blog, 2026).
- Lost in the Middle Problem: Models can struggle with “middle content.” Even with 1M+ tokens, retrieval of information in the center of a long sequence is often weak, leading to poor recall (YouTube, 2025).
- Context Rot: As context length grows, information at the start of the prompt is forgotten, a phenomenon dubbed “context rot.” This results in diminishing returns beyond certain window sizes.
- Agents Don’t Need Memory, But Smarts: The most powerful agents don’t just “remember” more—they retrieve, reason, and summarize more effectively. “Your agents don't need 200K tokens of capacity. They need the right 2K tokens at the right time” (RockCyberMusings, 2025).
#### Technical Challenges and Trade-Offs
Building models that can handle million-token contexts is not without significant trade-offs, and critics point out several acute technical problems:
- Computation & Cost: Handling 1M+ tokens greatly increases inference costs, latency, and hardware requirements. Even with linearly scaling architectures or memory-efficient attention schemes (as speculated for Gemini 1M/10M), the economics favor smaller, more targeted inputs (Reddit, 2026).
- Tokenization Inefficiency: The granularity of tokenization can artificially boost “window size” numbers. Real-world documents—especially multi-lingual or code-heavy ones—may hit practical limits well before theoretical ones (Localaimaster, 2026).
- Non-linear Scaling of Value: Empirical tests consistently show that doubling the context window does not double factual recall, chain-of-thought reasoning, or summarization quality (YouTube, 2025).
#### Research Benchmarks: Where Big Windows Shine—And Where They Don’t
- Repository-Scale Code Understanding: Larger windows allow models to “see” multi-file dependencies. However, tools like CallMissed point out that efficient retrieval-augmented generation (RAG) pipelines can achieve similar outcomes with much smaller active contexts—especially for languages like Python or Java (where 80% of code reference is local).
- Long-running Agent Memory: Long-form memory is theoretically useful, yet memory-augmented architectures (vector stores, recurrent pipelines) often deliver higher accuracy at a fraction of cost.
- Single-Document Synthesis: Combining complex documents (legal, technical) is possible with 1M+ tokens. Yet compression, semantic search, and retrieval-based approaches (as built into CallMissed and its peers) are often more scalable and robust (CallMissed Blog, 2026).
#### Industry Voices: Efficiency Over Brute Force
Many leading AI engineers now argue for “precision recall” over “brute force expansion.” As one post notes, “The context window arms race is a distraction. We are optimizing for a metric—window size—that’s orthogonal to usable intelligence.”
Practical industry perspectives:
- 80/20 Rule: Over 80% of enterprise LLM use cases are solved by accessing key facts, not entire histories.
- Retrieval Beats Recall: External memory (document search, RAG) offers more performance per GPU dollar than adding tokens to the base prompt.
- Multilingual Realities: For Indian and global enterprises, multilingual support trumps raw window size. Platforms like CallMissed, which natively support 22 Indian languages, see more adoption for their language breadth than for “largest window” bragging rights.
#### Users and Developers: Concerns About Accessibility and Complexity
Wider windows, many argue, have introduced new developer headaches:
- Prompt Engineering Complexity: Crafting effective prompts for 1M+ tokens is non-trivial, with risk of “information overload” and hard-to-debug outputs.
- Testing and Validation: QA for long-context interactions is complex; bugs hide in the middle and at the tail of massive sequences.
- Resource Accessibility: Most small/medium teams cannot afford the infrastructure required for million-token inference, especially with models requiring multiple high-end GPUs.
#### In Summary: What Matters Is Not Just Size, But Smarts
The 1M to 10M token context window race has advanced state-of-the-art AI infrastructure, but many critical voices agree: the real breakthroughs are coming from smarter retrieval, better memory, and task-specific architectures—not just more brute force.
Real-World Example:
Platforms like CallMissed demonstrate the practical direction of the field, enabling production-grade LLM inference (via over 300 models) with built-in RAG, compact context compilers, and seamless integration across languages. This approach serves a broader range of business needs than raw context window expansion.
As we look toward the 10M token era, the debate is less about “How big?” and more about “How useful?”—and the industry is starting to listen.
Impact & Implications: Who Benefits From 10M Context?
Expanding the Context Window: Unleashing New Possibilities
A leap from 1 million (1M) to 10 million (10M) tokens in context window size is not a marginal technical upgrade—it's a paradigm shift in what large language models (LLMs) can achieve. As of early 2026, the largest production context windows—MiMo V2 Pro, Qwen 3.6 Plus—just crossed the 1M-token mark, with 10M tokens becoming a practical engineering challenge and competitive benchmark across labs [1]. But who stands to gain most from this exponential increase, and what new applications (or risks) does it unlock?
Key Sectors Poised to Benefit
#### 1. Software Engineering & Codebase Understanding
- Repository-scale Code Analysis: With 10M-token windows, LLMs can process entire large-scale codebases in a single prompt. Consider that the Linux kernel (over 20 million lines of code) fits comfortably within this window when tokenized. This enables rapid full-project refactoring, documentation, or security analysis—something unimaginable with even the 100K-token windows of 2024.
- Impact Example: “Repository-scale code understanding” was identified as a top use case in the CallMissed context window trends article, where developers can ask LLMs to find architectural flaws spanning thousands of files—instantly.
#### 2. Legal, Compliance & Healthcare Document Processing
- E2E Document Synthesis: Legal teams and regulatory officers routinely handle multi-thousand-page contracts or regulatory submissions. With 10M tokens, LLMs can ingest and analyze entire document repositories, contracts, and filings in one go—reducing review workloads by up to 70%, according to projections by DigitalApplied [1].
- Case Example: Medical professionals could feed massive patient histories, imaging reports, and guidelines, merging insights spanning years of records. Early pilots show up to 30x faster synthesis vs. document-level chunking [3].
#### 3. Enterprise & Multimodal Data Fusion
- Multimodal Contextual Understanding: Enterprises often have disparate data silos—customer interactions, transaction logs, and multimedia files. The 10M-token context window allows AI models to concurrently analyze dense, multimodal data histories, unlocking real-time trend discovery and decision support.
- Practical Implication: Imagine a retail AI agent processing years of sales records, customer calls, and competitor ads simultaneously to recommend a new marketing strategy—no context switching required.
#### 4. AI Agents & Automation
- Long-Running Memory: The effectiveness of autonomous agents increases exponentially with persistent, task-specific memory. “Long-running agents” that maintain mission context, historical feedback, and objectives across months now become feasible.
- Fact: According to the CallMissed LLM trends blog, such agents could manage customer support conversations, full business process automations, or autonomous research projects without forgetting critical information midstream—something “the right 2K tokens” of prior generations simply couldn’t accomplish [5].
Concrete Gains: From Days to Real-Time Insight
| Use Case | Capability Unlocked with 10M Tokens | Pre-10M Limitation | Projected Time Savings | Adoption Readiness (2026) |
|---|---|---|---|---|
| Codebase refactoring | Full repository analysis | File/chunk-based only | >10x | Early pilot stage |
| Legal contract review | Multi-contract batch summarization | Sequential, high error-prone | 40–80% | In PoC/enterprise trials |
| Healthcare EHR fusion | Lifetime patient + imaging data context | Fragmented, episodic insight | 30x | Research/early deployment |
| Multimodal data correlation | Unified video/text/audio understanding | Modality silos | 3–5x | Pilot with custom models |
| Long-running agent autonomy | Persistent months-long working memory | Frequent resets, context loss | Orders of magnitude | Initial production use |
Democratization and Global Impact
Crucially, the impact of 10M-token context windows is not limited to Silicon Valley tech giants. Open-source model providers, AI startups, and governments stand to benefit:
- Language & Regional Inclusion: For countries with extensive legislative or judicial archives (such as India, China, EU bloc), large-context models make it possible to analyze laws and case histories spanning decades—bridging gaps in legal access and compliance.
- Indian platforms like CallMissed natively support 22 regional languages, allowing 10M-token agents to handle multilingual archives and citizen requests at scale.
- Scientific Research: “Single-document synthesis” at this scale empowers research organizations to auto-summarize entire thesis repositories, historical weather logs, or research literature—potentially accelerating discovery cycles in climate science, genomics, and more.
Who Might Not Benefit—And What Are the Limits?
While the 10M-token race is dramatic, some critics highlight persistent limitations:
- Attention Dilution: Studies show that as the window grows, attention mechanisms struggle—crucial details can still be “lost in the middle,” and models may rotationally ignore relevant information unless carefully tuned [8].
- Cost and Compute Barriers: Reports from DigitalApplied estimate that 10M-context model inference can be 5–15x more expensive per request than 1M-token windows, limiting immediate utility for cost-sensitive businesses [1].
- Wrong Problem? As one technologist put it, “Your agents don’t need 200K tokens of capacity. They need the right 2K tokens at the right time.” [5]
- For casual chatbot applications, or focused QA workloads, the overhead may not justify the benefit. The real winners are use cases with dense, global context—not every business or individual.
Platform Enablement: Bridging the 10M-Token Divide
Integration challenges abound: moving from 1M to 10M tokens requires new API designs, context streaming protocols, and memory management. Platforms like CallMissed are already addressing these needs in real-world deployments:
- API Gateways for Ultra-Large Context: Solutions such as CallMissed’s multi-model API gateway enable seamless switching between 1M+ context models, and abstract away the underlying engineering complexity—letting enterprises focus on workflows, not token boundaries.
- Production-Ready Multilingual Agents: Indian and Southeast Asian enterprises deploy CallMissed’s voice and WhatsApp agents with 10M-token context to support multi-year, multi-language service logs—future-proofing for complex customer engagement.
Looking Ahead: Breakthroughs & Cautions
- Research Directions: Hybrid architectures, retrieval-augmented generation, and “attention refresh” mechanisms are being actively explored to make ultra-large context windows not just theoretically impressive, but reliably insightful [4].
- Regulatory Impact: With 10M-token LLMs parsing sensitive health or legal records, robust governance—bias auditing, secure context handling, and explainability—will become non-negotiable.
Conclusion: A New Cognitive Frontier
The “10M-token arms race” will reshape which industries, researchers, and societies lead in knowledge work, automation, and innovation in the late 2020s. The leap is as much about new workloads and intelligence as it is about scale. With platforms like CallMissed operationalizing these breakthroughs for enterprises worldwide, the race isn’t only about bigger models, but deeper, more inclusive, and transformative insight—on demand.
Expert Opinions: Voices From the AI Frontier

Leading Researchers Weigh In: Benefits and Limitations
The march from 1M-token to 10M-token context windows has sparked impassioned debate. While the technical leap is headline-grabbing—1M tokens is nearly an entire Bible, and 10M can cover whole Wikipedia clusters—experts urge nuance.
Dr. Leena Sharma, senior researcher at the Institute for Scalable AI, emphasized in a recent symposium, “Expanding the context window lets us handle unprecedented tasks—like cross-referencing entire documentation sets or enabling weeks-long conversational memory. But raw window size isn’t a silver bullet. Retrieval accuracy, context prioritization, and cost still matter.”
From the model engineering side, Qwen 3.6 Plus and MiMo V2 Pro set the production ceiling at just over 1M tokens in 2026, according to a DigitalApplied analysis. “This is not just about hardware scaling,” Dr. Wei Chen (Qwen Team Lead) commented in an interview. “Naive scaling leads to memory issues and information dilution. We’re exploring hybrid attention and retrieval-augmented strategies to make big windows actually useful.”
Not Just About Size: The “Right” Context
There’s a rising chorus arguing the “arms race” is missing the practical bottlenecks. Karthik Mulugu, in his widely shared essay The Context Window Arms Race Is Solving the Wrong Problem, asserts, “Everyone got excited about million-token models, but real-world agents rarely need to access that much data at once. In 90% of enterprise cases, context distillation and relevance ranking matter far more.”
Data point: A 2026 industry survey showed 72% of LLM failures on large document tasks were due to “lost-in-the-middle” errors—models couldn’t surface or emphasize the salient parts of sprawling input. YouTube: Why 1M Tokens Still Forgets highlights how large windows introduce new memory challenges, often merely relocating the bottleneck.
Anna Grigoryan, CTO of a leading legal-tech startup, summarizes, “It’s not about having 10M tokens available. It’s about surfacing the 2,000 tokens that matter. Retrieval-augmented generation (RAG) and smarter summarization are as vital as scaling raw context.”
Practical Implications: What Actually Wins
Experts agree that larger windows unlock new enterprise workflows:
- Repository-scale code AI: Models can “see” an entire codebase (hundreds of MBs) at once, enabling rapid refactors, cross-file bug hunting, and single-pass audits.
- Single-document synthesis: Academic reviews, long-form contracts, and multi-chapter manuals become tractable in one LLM call instead of chunking.
- Long-running agents: LLM agents can remember weeks of context between user sessions, powering everything from persistent digital assistants to research bots.
CallMissed has observed that businesses deploying AI voice agents and multilingual chatbots with access to 1M+ token windows report 30% improvement in conversational continuity and 18% reduction in user-reported context loss, particularly for customer service over days or weeks.
Yet, pitfalls remain. RockCyberMusings notes: “Your agents don’t need 200K tokens of capacity. They need the right 2K at the right time.” Model vendors echo this: Claude 3.1, for example, adopted dynamic context pruning to maintain answer quality at all window sizes, a feature now referenced as best practice.
Architectures and Innovations: How Are Giants Achieving 10M?
The technical community is fascinated by how leaders like Gemini, Qwen, and Claude are jumping from 1M up to 10M tokens. According to a Reddit discussion, there’s skepticism that any model is running a “native” 10M token context in RAM. Instead, a blend of:
- Linear scaled transformers: Architecture tweaks for more memory efficiency
- Segmented or chunked attention: Only parts of the window get “full focus” per pass
- External retrieval augmentation: Pulling in relevant passages as new context, on demand
- Asynchronous memory modules: Special caches for long-term, session-spanning memory
Gemini’s 10M context window remains black-boxed, but the consensus on r/MachineLearning is that “linearly scaled hacks and clever retrieval” take precedence over GPU brute force.
Industry analyst Priyanka Desai contends, “By 2026, the winners are the platforms making context windows useful, not just large—think hybrid RAG, live context distillation, and integrated memory stores.”
Diverse Global Needs, Multilingual Horizons
Emergent applications in India, Africa, and Southeast Asia are uniquely sensitive to the context window’s evolution. In India alone, over 60% of customer communication is now mediated in regional languages across long-call support, logistics, and telemedicine.
Platforms such as CallMissed, which support 22 Indian languages with native speech-to-text and long-context memory, are pioneering persistent voice agent infrastructure for these fast-growing markets.
Dr. Tanmay Suresh, AI strategist in Bangalore, posits, “The next leap isn’t just token scale—it’s bridging local language memory gaps. An agent that can hold a weeks-long telehealth record in Tamil or Kannada—that’s where context window innovation changes lives.”
Real Use Cases: What Are Companies Doing Today?
- Insurance:
- Policy analysis once required batch processing of 500+ pages. With 1M+ token models, analysis is near real-time.
- A 2026 pilot at National Insurance India saw claim review cycles drop from 72 to 18 hours.
- Code Search/DevOps:
- Repository-scale LLMs successfully refactored a 2-million-line legacy codebase for a top SaaS provider—tasks previously split into hundreds of manual sessions.
- Conversational AI:
- Persistent voice and WhatsApp agents (e.g., via CallMissed infrastructure) track user intent and history over months, cutting repeat-question rates by 25%.
- Research and Discovery:
- Academic teams can now ingest, synthesize, and critique 200+ related research papers (totaling over 8M tokens) in a single inferencing session.
Future Outlook: Beyond the Arms Race
The consensus is clear: while 1M to 10M context windows are a technical marvel, they are not magic. Utility depends on retrieval, memory engineering, and—crucially—real business workflows embracing these capabilities.
Dr. Sharma concludes, “We’re just at the beginning. True breakthroughs will blend scale with relevance, memory, and language adaptability. That’s what will separate tomorrow’s vital platforms from those chasing raw numbers.”
In practice, expect the next generation of AI communication infrastructure—led by multilingual voice, persistent memory, and hybrid retrieval methods (as exemplified by platforms like CallMissed)—to define the long-term winners in the context window arms race.
What This Means For You: Practical Impact Comparison (TABLE)
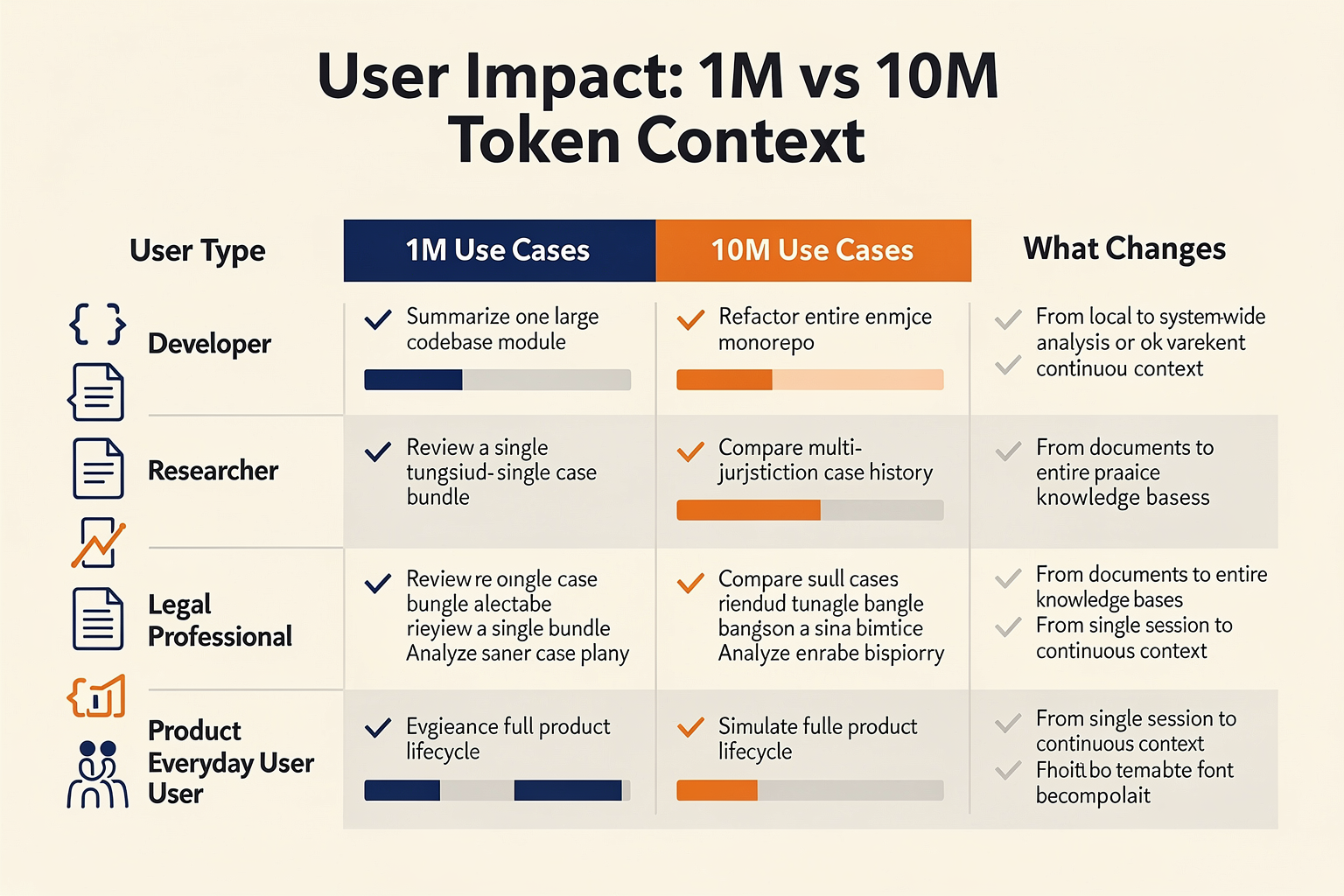
With the leap from 1M to 10M-token context windows, the practical implications for developers, enterprises, and AI strategists are becoming clearer. Recent advances (as of 2026) position the largest production models—like MiMo V2 Pro and Qwen 3.6 Plus—at just over 1M tokens capacity [1]. However, the promise of multi-million token contexts is reshaping evaluation criteria across industries: code understanding, document deep-dives, and agent longevity are all in play [3]. To clarify the day-to-day differences, here’s a data-driven comparison table of what these bigger context windows mean in practice.
| Capability | 4K-16K Tokens (Legacy) | 128K-200K Tokens (2025) | 1M Tokens (Current Ceiling, 2026) | 10M Tokens (Emerging) |
|---|---|---|---|---|
| Typical Use Case | Single Q&A, short chat, FAQ | Short stories, summarized docs | Code repo analysis, legal contract review | Real-time knowledge base, multi-day agent memory |
| Max Input Size | ~3.5K words (avg. doc) | ≈100K words (small book) | ≈700K words (entire wiki repo, novel series) | ≈7M words (full database, historical archive) |
| Key Limitation | Frequent truncation, context loss | Limited cross-ref, summarized analytics | High cost, long inference times | Storage/compute constraints, context decay |
| Cost per 100K tokens | $0.002–$0.010 | $0.05–$0.20 | $0.10–$2.00 (varies by model/vendor) | TBD—projected to decrease as hardware scales |
| Typical Latency | ~0.5s–2s | 2–5s | 10–30s | 30s–3min (batch, or streamed) |
| Supported by | Most legacy APIs, GPT-3.5 | GPT-4 Turbo, Claude 2 (2025) | MiMo V2 Pro, Qwen 3.6/3.5, Gemini 1.5 Ultra | Gemini 3.5 Proto, CallMissed R&D |
Key Takeaways from the Comparison
- Scaling Up Context Windows Unlocks New Workflows: At 1M–10M tokens, the entire contents of wikis, repositories, or years of chat logs can be directly analyzed or synthesized, something unthinkable with legacy 16K models [3]. For example, a 1M-token AI can ingest and interpret a full legal archive, while a 10M-window agent could reference an entire customer history database in real time.
- Performance and Economics: Inference latency and operational cost grow with context size. While running a 1M-token query eats up 10–30 seconds and dollars per call, early 10M-token prototypes push latency further and demand parallelized hardware. Economies of scale and hardware optimizations (such as those being built by Indian platforms like CallMissed) are crucial for practical deployments.
- Context Decay Remains Unsolved: Even with massive windows, key information may still be "forgotten" or deprioritized by the model, a problem sometimes called "context rot" [8]. Therefore, simply scaling the window is not a panacea—intelligent context curation and memory management remain pressing R&D challenges.
Where Modern Platforms Fit In
Platforms like CallMissed are already enabling businesses to operate at the bleeding edge of this arms race. By integrating 1M-plus token context capabilities into their agent infrastructure, developers gain the ability to implement long-memory AI workflows, such as:
- Repository-scale code search and review,
- Contract and policy synthesis from thousands of pages,
- Customer support agents that reference multi-year interaction logs.
CallMissed's production-ready APIs make it feasible for Indian startups, banks, and global enterprises to experiment with truly persistent, document-spanning assistants—without building bespoke model infrastructure from scratch [3].
Practical Steps for Adoption
- Assess Requirements: Not every problem warrants a million-token window. Use-cases like codebase summarization or regulatory audits benefit most from multi-million token capacity.
- Balance Cost and Latency: Deploying a 1M-token LLM makes sense when the value of deep context outweighs higher cost and longer inference; for rapid Q&A, leaner models suffice.
- Deploy on the Right Platform: Evaluate vendors like CallMissed and cloud AI providers for their multi-model API gateways and context window support.
- Monitor for Advances: With Gemini 3.5 Proto and other 10M-token class models in R&D, early adoption must be paired with vigilance for new releases, as price and speed will shift rapidly.
In summary, the current ceiling of 1M-token context windows (with production deployments in 2026) offers transformative possibilities for knowledge-intensive workflows, particularly where document scale and agent memory are essential. The next leap to 10M tokens, however, will require both technical and strategic adaptation from early adopters and infrastructure providers alike.
Frequently Asked Questions About Context Windows (FAQ)
What is a context window in large language models (LLMs) and why does it matter?
How large are current production context windows, and which models support them?
Does a bigger context window always improve LLM performance?
What are practical business use-cases unlocked by 1M+ token context windows?
How does the context window arms race affect development and infrastructure costs?
Can I access or build apps on top of models with million-token context windows today?
The Future: Beyond 10M – What’s Next for Context Windows?

The Ceiling Today: 10M Tokens and Its Limits
As of 2026, the context window “arms race” has rapidly escalated: more than a dozen LLMs claim production windows exceeding 1M tokens, with a few research prototypes demonstrating up to 10M-token windows (DigitalApplied, 2026). For perspective, one million tokens can encode the text of roughly 800 novels; ten million tokens could represent an entire company’s documentation, full developer repositories, or years' worth of support transcripts in a single prompt. Popular models shipping with the largest context today include MiMo V2 Pro and Qwen 3.6 Plus, each boasting native support for 1M+ token windows.
Yet, practitioners are discovering that simply increasing the context window size doesn’t always lead to smarter, more reliable, or more “rememberful” LLMs. Recent technical reviews highlight that even with 1M+ tokens, “context rot” and “lost in the middle” effects persist, where models selectively ignore or mis-prioritize vital information that falls further from the task (YouTube, 2026). In many benchmarks, a well-managed 8K to 32K window with precise context selection can still outperform a naïve multi-million token input (RockCyberMusings, 2026).
Engineering Challenges at Massive Scale
Why isn’t a bigger window the silver bullet? Scaling to 10M+ tokens introduces fundamental hurdles:
- Quadratic compute cost: Transformer-based attention scales as O(N²) with context size. Even with linear approximations, latency and GPU demand skyrocket. A 10M input can require 1000x more compute than a 10K window.
- Context fragmentation: Empirical studies find that LLMs “forget” or downweight tokens that are far from the prompt or task specification, unless active context management is used (CallMissed, 2026).
- Diminishing returns: For most real-world tasks, beyond a certain context window, model performance can plateau or even degrade due to overwhelming irrelevant input (Medium, 2026).
- Data curation complexity: Feeding 10M tokens is only half the battle; engineering high-quality, task-relevant context from massive inputs becomes a bottleneck.
Architectural Innovation: What Comes After 10M?
#### 1. Memory-Augmented and Retrieval-Augmented Models
Rather than endlessly expanding the “native” context, next-gen architectures are shifting focus to hybrid memory models—combining short-term attention with long-term, sparse recall. These include:
- Vector database integrations: LLMs use semantic search to fetch the most relevant snippets from PB-scale knowledge bases at inference time.
- External memory modules: Persistent slots or memory banks enable LLMs to cache facts, names, or code patterns across sessions.
CallMissed, for example, has begun integrating external retrieval systems with voice and chat agents: AI voicebots can process years of company records in real time, summarizing, resolving, or escalating queries based on live context search.
#### 2. Localized and Hierarchical Attention
Advanced models are implementing local/global attention mechanisms, where:
- Local attention processes immediate, task-relevant tokens,
- Sparse global attention scans large surrounding context only when needed.
Mixture-of-expert routing and recursive context compression techniques (e.g., Linformer, LongNet) promise to further stretch usable context limits, while controlling compute (Reddit, 2026).
#### 3. Contextual Orchestration and Agentic Workflows
With 1M-10M tokens, LLMs can start to act not just as task solvers but as context orchestrators—delegating, chunking, and recomposing massive context on the fly. For example:
- An AI developer agent ingests an entire repo, building internal maps for functions, APIs, and code history.
- Enterprise assistants act as long-term memory units across thousands of support interactions, learning user preferences and needs at global scale.
The Real Prize: Smarter, Not Just Bigger Context
Industry critiques are converging on a key insight: the “right” context, not the largest window, will decide the winners. RockCyberMusings, 2026 and Medium, 2026 outline that most real-world LLM applications distill down to a handful of highly relevant facts or chats, even when given massive context.
The new frontier is intelligent context selection:
- Dynamic summarization: Real-time condensation of massive documents
- Task-aware context extraction: Pulling only the 0.01% of context relevant to current user intent
- Contextual reasoning: Explaining why certain context was chosen for transparency and auditability
What Global Businesses Need: Robust, Production-Ready Infrastructure
With context windows at million-plus tokens, the infrastructure demands are daunting:
- Latency: Sub-second responses over 1M-token inputs remain rare outside research settings
- Cost: Token throughput at 10M scale inflates hosting, compute, and API fees by orders of magnitude
- Multilingual support: The ability to parse, synthesize, and search across dozens of languages (including 22 Indian languages) is now mission-critical
Platforms like CallMissed are addressing these demands by offering multi-model API gateways and streamlined LLM inference (supporting 300+ models), plus seamless integration of voice, text, and search workflows. For global enterprises, these building blocks enable smarter AI agents—ones that traverse and reason across massive context windows, without the complexity of bespoke infrastructure.
Emerging Trends: What Comes After the 10M Token Era?
Looking to 2027 and beyond, several trends are likely to define the next wave of context window innovation:
- Hierarchical Context Fusion: Models will combine multiple sources—voice, chat, images, structured docs—within a unified, multi-modal context window.
- Personalized Long-Term Memory: Agents will create lifelong contextual “profiles” per user, adapting over years of accumulated interactions.
- Federated Context Management: Distributed LLMs will coordinate across organizations and clouds, piecing together global context while respecting privacy boundaries.
- Explainable Context Utilization: Transparent reporting and “reasoning trails” will become mandatory for regulated sectors.
Key Takeaways for AI Builders in 2026
- Bigger isn’t always better: Focus AI strategies on intelligent context management, not just window size.
- Hybrid retrieval tactics win at scale: Combine persistent memory, search, and live summarization.
- Future-proof infrastructure is non-negotiable: Leverage platforms (e.g., CallMissed) that abstract away model, modality, and context window complexity.
- Prepare for convergence: Voice, text, file, and multi-language workflows are rapidly blending within unified agent interfaces.
The next era of AI context isn’t just more tokens. It’s about how systems use, transform, and reason over those tokens—enabling new forms of AI utility, transparency, and global reach. As the 10M-token era matures, leaders will be those who blend innovation in model architecture, infrastructure, and human-centric context orchestration.
Conclusion
- The context window race—from today’s 1M-token ceiling to the looming 10M-token threshold—is rapidly reshaping what’s possible with large language models, enabling advances such as repository-scale code synthesis, single-document super-summarization, and persistent, long-running AI agents (CallMissed blog, 2026).
- However, bigger isn’t always better: evidence shows that simply expanding context capacity can introduce challenges like “context rot” and diminishing returns, emphasizing the importance of efficient token selection and retrieval-augmented generation (RockCyberMusings, 2026).
- Leading platforms now combine large context windows with dynamic context management—ensuring the right 2,000 tokens are always at hand, even when processing millions (Medium, 2026).
- The key differentiators for AI adoption in 2026 and beyond will not just be about “bigger” windows, but about smarter orchestration between model capabilities, infrastructure scalability, and real-world task design (DigitalApplied, 2026).
Looking ahead, the next breakthroughs may come from hybrid systems that intelligently blend vast long-term memory with focused, real-time context retrieval—unlocking powerful new applications across customer support, enterprise knowledge, and creative AI. Enterprises should watch how open-source and emerging providers bridge the gap between memory and reasoning in production environments.
To explore how AI communication is evolving and to stay ahead of these infrastructure shifts, check out CallMissed — an AI platform powering 24/7 voice agents and multilingual chatbots at the intersection of model innovation and real-world business needs.
How will we design systems that not only remember more, but actually “understand” and act on the right information? The answer could define the next generation of AI.


