Structured Output vs Tool Use: Which When – A 2026 Deep Dive for AI Builders

Structured Output vs Tool Use: Which When – A 2026 Deep Dive for AI Builders
Did you know that the average enterprise AI agent in 2026 juggles between structured outputs and tool use on over 60% of its interactions? As LLM-powered workflows redefine customer service, data analytics, and operations, the choice between structured output and tool use is quietly becoming one of the most consequential design decisions for builders—and it’s one where the wrong bet can double your costs or halve your reliability overnight source.
Why is this suddenly so important? The agent ecosystem is moving at breakneck speed: In the past 24 months, function calling and schema-enforced JSON outputs have exploded in adoption across APIs, ERP connectors, and chat interfaces. According to 2025 benchmarks by Industry LLM Review, structured output requests now make up 42% of all non-chat LLM calls in production, while tool use—integrations triggered by LLMs, like running a database query or sending a WhatsApp message—has grown by 39% year-over-year. Yet, as robust as these capabilities are, each approach comes with distinct tradeoffs:
- Structured output delivers fast, schema-locked results (e.g., contact info extraction, order details), but can hit its limits with tasks requiring external real-world action.
- Tool use empowers agents to interact with external systems—think booking a flight or executing a payment—but adds latency and, in some cases, a 2-3x cost multiplier per call because of round-trip overhead and infrastructure complexity source.
And here’s the rub: Leading devs report that flipping this choice—like choosing a tool call for what should be a structured output, or vice versa—can cause reliability scores to drop by up to 18% (Vellum.ai, 2026). With enterprises deploying increasingly autonomous agents, where every percentage point of uptime and cost efficiency matters, understanding the comparative strengths of structured output vs tool use isn’t just semantics—it’s critical infrastructure strategy.
In this deep dive, you’ll learn:
- What structured output and tool use actually mean in today’s LLM-powered systems
- The core differences, benchmarks, and best practices behind each approach (with use case-based examples)
- How these choices ripple through agent reliability, latency, scalability, and cost
- Cutting-edge patterns adopted by forward-thinking builders—from multi-agent orchestration to chain-of-thought reasoning
- How platforms like CallMissed are enabling businesses to fluidly switch between structured output and tool-based actions, powering everything from multilingual voice interactions to automated customer calls
Whether you’re designing an enterprise-grade AI workflow, fine-tuning your product’s LLM integration, or just looking to cut deployment costs without losing accuracy, mastering the structured output vs tool use decision will set you apart in 2026’s hyper-competitive AI market. Let’s unravel what works, when—and why the future of AI agents hinges on getting this balance right.
Introduction: Why the Right Agent Output Matters in 2026

The Problem: Predictability or Action?
In 2026, the developer landscape has shifted. AI agents are no longer experimental side projects—they are core infrastructure, handling customer support, data pipelines, internal workflows, and even multi-agent orchestrations. Yet one silent killer remains the misconfiguration of how an agent communicates its decisions. The choice between structured outputs (also called JSON mode or constrained generation) and tool use (function calling) seems technical—a dropdown in an SDK—but in reality, it shapes your agent’s reliability, latency, cost, and even its safety profile.
As one developer community post puts it bluntly: “The decision between structured outputs and tool calling isn’t just semantics — it shapes your agent's behavior, reliability, and cost.” [1] With agents now expected to handle multi-step reasoning, external API calls, and consistent schema adherence, getting this decision wrong means burning tokens on retries or, worse, corrupting downstream databases with malformed data.
The Rise of Agentic AI and Two Divergent Paths
By mid-2026, the term “agentic AI” has moved from hype to daily reality. Enterprises are deploying agents that read emails, summarize documents, book appointments, and run analytics. Under the hood, nearly every modern LLM API offers two primary mechanisms for controlling output:
- Structured Outputs – The model is forced to respond with a JSON object that conforms to a predefined schema (e.g.,
{ "name": string, "age": integer }). No free text, no deviations. - Tool Use / Function Calling – The model can decide to emit a special token that triggers an external function call (e.g.,
send_email(to, subject, body)). The function is executed, and its result is fed back into the conversation.
The distinction seems straightforward, but the operational implications are profound. When do you use each? And why does the answer change in 2026?
Structured Outputs: The Guarantee of Format
Structured outputs solve a fundamental problem: code consuming LLM responses must receive predictable data. As the guide from Agenta.ai notes, “Structured outputs solve a basic problem: your code needs predictable data formats.” [7] This is critical for data extraction, classification, text-to-SQL, and any scenario where the downstream system expects a strict schema. For example, an agent that extracts invoice details from an email must reliably output customer_id, amount, and due_date—not a paragraph of prose. Structured outputs guarantee that constraint.
In 2026, this capability is mature. Most LLM providers offer JSON mode or structured output mode that enforces schema adherence even without a tool call. The primary use cases, as summarized by multiple sources, include:
- Data extraction and transformation [4]
- Data analysis (text-to-SQL) [4]
- Multi-agent message passing where agents need to read each other’s structured data [4]
Tool Use: The Bridge to the Real World
Tool use (often called function calling) is designed for a different universe: action. When an agent needs to query a database, send a notification, or modify a CRM record, it must invoke an external function. The model outputs a structured request (function name + parameters), the runtime executes it, and the result is returned. This is the backbone of agentic workflows.
Where structured outputs stop at format, tool use extends to side effects. The model doesn’t just express data; it performs actions. This distinction is critical: tool use introduces latency, potential failure modes (e.g., API errors), and higher cost per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip for execution. [8]
Why the Right Choice Shapes Everything in 2026
Today, many developers default to tool calling for every agent interaction—even when the task is pure data transformation. That’s a costly mistake. Consider the following:
- Cost: Tool use generally incurs higher per-request costs due to the extra tokens for tool descriptions and the round‑trip overhead [8]. In a high‑volume data extraction pipeline, this can add up rapidly.
- Reliability: Structured outputs are deterministic about format. Tool calling can be more brittle—what if the model hallucinates a function name or parameters? Guardrails are needed.
- Latency: With tool use, the agent must wait for the external function to execute and return. For tasks like “extract all product names from this text,” that extra wait is unnecessary.
- Error Handling: Structured outputs fail gracefully by returning a malformed JSON (rare in modern models). Tool calls can fail in more complex ways: network errors, invalid parameters, or the model choosing the wrong tool.
In 2026, these differences matter more than ever because agents are often composed in chains. A mis-step in one component cascades. Using structured outputs for formatting tasks and reserving tool use for intentional actions creates a clean separation of concerns—what some call the “reasoning-to-action” workflow [6].
Platforms like CallMissed already support this dual paradigm: developers can use the same LLM endpoint to either enforce structured outputs via schema constraints or enable tool‑use with a rich function registry. This flexibility is essential for building production‑grade agents that handle both data extraction (e.g., parsing 22 Indian languages into structured forms) and actionable tasks (e.g., booking a ride through an API).
The Path Forward: A Decision Framework
Given this landscape, how should a developer choose? That’s what this blog explores. Over the next sections, we’ll break down the decision across five critical dimensions:
- Performance & Latency – When speed matters, structured outputs win for pure data tasks.
- Reliability & Safety – Tool use introduces new failure modes; structured outputs are safer for schema adherence.
- Cost Efficiency – Token overhead and round‑trip costs can flip your budget.
- Complexity & Maintainability – How each approach affects your codebase’s clarity.
- Use‑Case Fit – Concrete scenarios: data extraction, multi‑agent coordination, and external API orchestration.
By the end, you’ll have a clear mental model for deciding whether your agent needs to format its thought or act upon it. In 2026, that distinction is the difference between a fragile prototype and a reliable production system.
Let’s begin.
Structured Output and Tool Use Explained: Key Concepts and Context
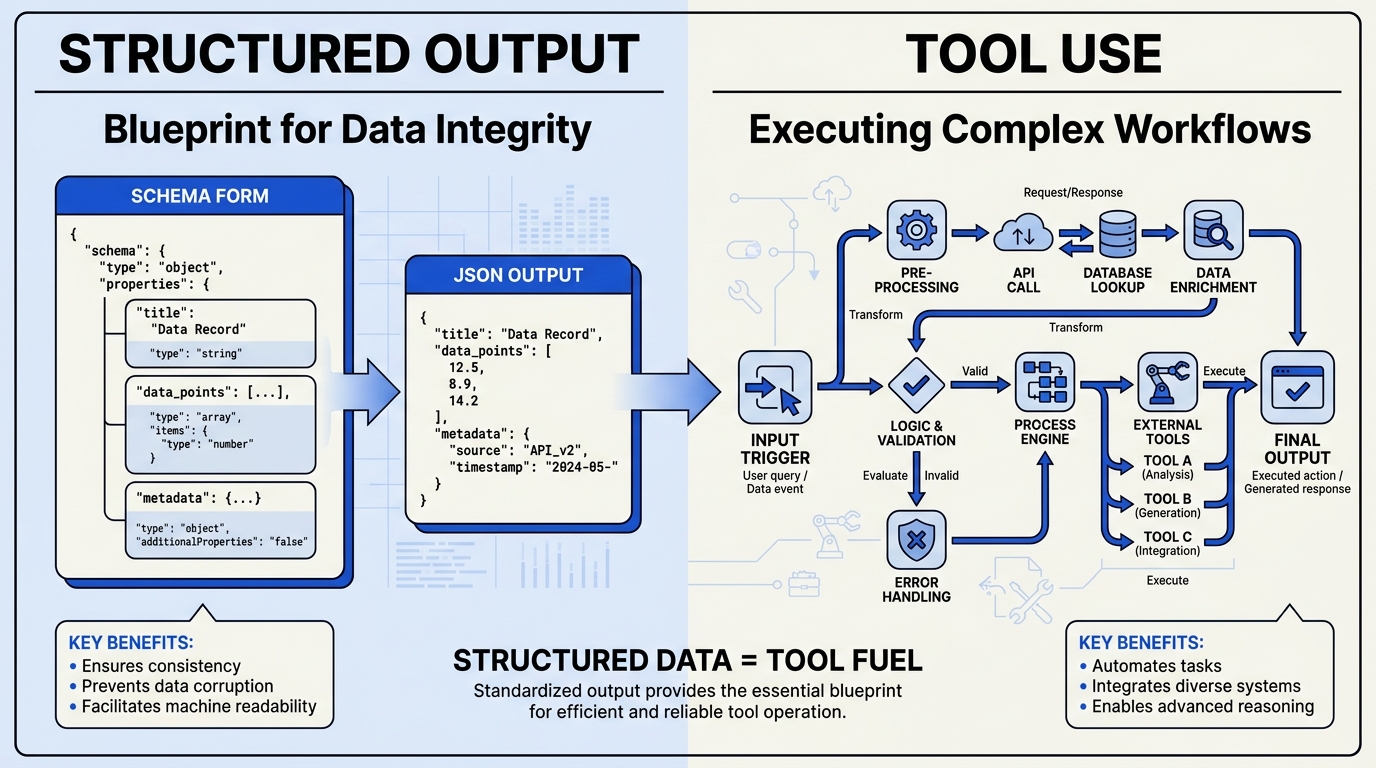
What Are Structured Outputs?
At its core, structured outputs refer to the ability of an LLM to generate text that strictly adheres to a predefined schema — typically JSON but also XML, YAML, or any custom format. The goal is to eliminate the guesswork from parsing: when your application expects a specific data shape (e.g., { "name": "John", "age": 30 }), structured outputs guarantee the model produces exactly that shape, field by field.
This is achieved through one of two techniques:
- Constrained decoding – The generation process is limited at the token level to only produce tokens that fit the schema. Libraries like
outlines,lm-format-enforcer, and some provider APIs (OpenAI’s Structured Outputs mode, for instance) enforce this during inference. - Schema-guided prompting – The model is given an explicit schema in the system message and instructed to output valid JSON. While less reliable than constrained decoding, it’s simpler to implement and works with many models.
The primary use cases for structured outputs are pure data transformation and extraction. As noted by machine learning experts, “Structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization” [3]. Common applications include:
- Extracting entities from emails or PDFs.
- Converting natural language into SQL queries (text-to-SQL).
- Parsing customer feedback into structured categories.
- Producing consistent output for multi-agent system communication.
The key benefit is predictability. A 2025 analysis by Agenta states, “Structured outputs solve a basic problem: your code needs predictable data formats. When an LLM generates free-form text, you have to parse it, which introduces fragility” [7]. With structured outputs, you eliminate the need for regex or fallback parsers, directly reducing development time and runtime errors.
What Is Tool Use (Function Calling)?
Tool use, also called function calling or tool calling, is a different paradigm. Instead of asking the model to output a fixed schema, you provide the model with a set of available tools (functions) — each defined by a name, description, and input parameter schema. The model can then choose to “call” one of these tools by returning a special object (often a JSON blob) that includes the tool name and arguments. The calling application then executes the tool and passes the result back to the model.
This is fundamentally action-oriented. Tool use is not about formatting output; it’s about enabling the model to interact with the outside world. The model itself never executes the tool — it only requests the call. Common examples:
- An agent calls a
search_databasetool to retrieve customer records. - A coding assistant invokes
run_shell_commandto execute a script. - A customer service bot triggers
get_order_statusto fetch real-time tracking data.
Under the hood, when the model decides to use a tool, it generates a tool invocation token that switches the recipient mode of the conversation [2]. This adds overhead: each tool description in the system prompt consumes tokens, and the round-trip of returning the call result increases latency and cost. As noted in a developer community discussion, “Tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip for tool execution” [8].
The Core Difference: Output vs. Action
The most important distinction between structured outputs and tool use lies in what they control:
| Aspect | Structured Outputs | Tool Use (Function Calling) |
|---|---|---|
| Primary purpose | Format/constrain the model’s reply | Trigger an external action |
| Output produced | Schema-compliant text (e.g., JSON) | A function call request with arguments |
| Side effects | None (purely data transformation) | Yes (executes real-world operations) |
| Cost per call | Lower (single generation, no round-trips) | Higher (tool descriptions + round-trip) |
| Reliability guarantee | Guaranteed schema compliance (with constrained decoding) | Not guaranteed; model may omit or hallucinate call |
| Use case examples | Data extraction, text-to-SQL, summarization | Database queries, API calls, file I/O |
This table summarizes the trade-offs. The decision between the two “isn’t just semantics — it shapes your agent’s behavior, reliability, and cost” [1].
When to Reach for Structured Outputs
- Pure data extraction: You need to pull specific fields from a text document and don’t need any external resources.
- Standardization: You want to enforce a uniform output format across different inputs (e.g., all customer emails parsed into
{complaint, sentiment, product}). - Multi-agent coordination: Different LLM agents in a pipeline must communicate in a predictable format — structured outputs are the backbone for inter-agent messaging.
- Cost-sensitive applications: Since there is no external call overhead, structured outputs are ideal for high-volume, low-latency tasks.
When to Reach for Tool Use
- Real-world interaction: The LLM needs to query a database, send an email, or modify a file — anything that changes the state of the world.
- Chained reasoning: The agent needs to retrieve additional context (e.g., look up a user’s history) before generating the final reply.
- Dynamic decisions: You want the model to decide which tool to call and with which arguments, not just produce formatted text.
- Human-in-the-loop workflows: Tool calls can be paused for user approval before execution, adding a safety layer.
The Blurry Middle Ground
In practice, the two concepts often overlap. For example, a tool call can return structured output, and a structured output can simulate a decision that would otherwise require a tool. However, forcing tools to be used purely for output formatting wastes tokens and latency. As a rule of thumb from Vellum AI: “Use structured outputs for data extraction, data analysis, and inside multi-agent systems. Use function calling when the LLM needs to trigger a side-effect” [4].
The Role of Modern Platforms
Leading AI infrastructure today supports both capabilities natively. For developers building production agents, the key is to choose the right pattern for each sub-task. Platforms like CallMissed, for instance, provide a unified API that lets developers access over 300 LLMs and switch between structured output modes and tool calling without rewriting code. By abstracting the schema enforcement and tool-description management, such platforms reduce the cognitive load of building reliable agents — freeing you to focus on the agent’s logic rather than the plumbing.
With this foundational understanding, we can now dive deeper into the practical trade-offs in the next section.
2026 Trends: How Agent Output Strategies Have Evolved
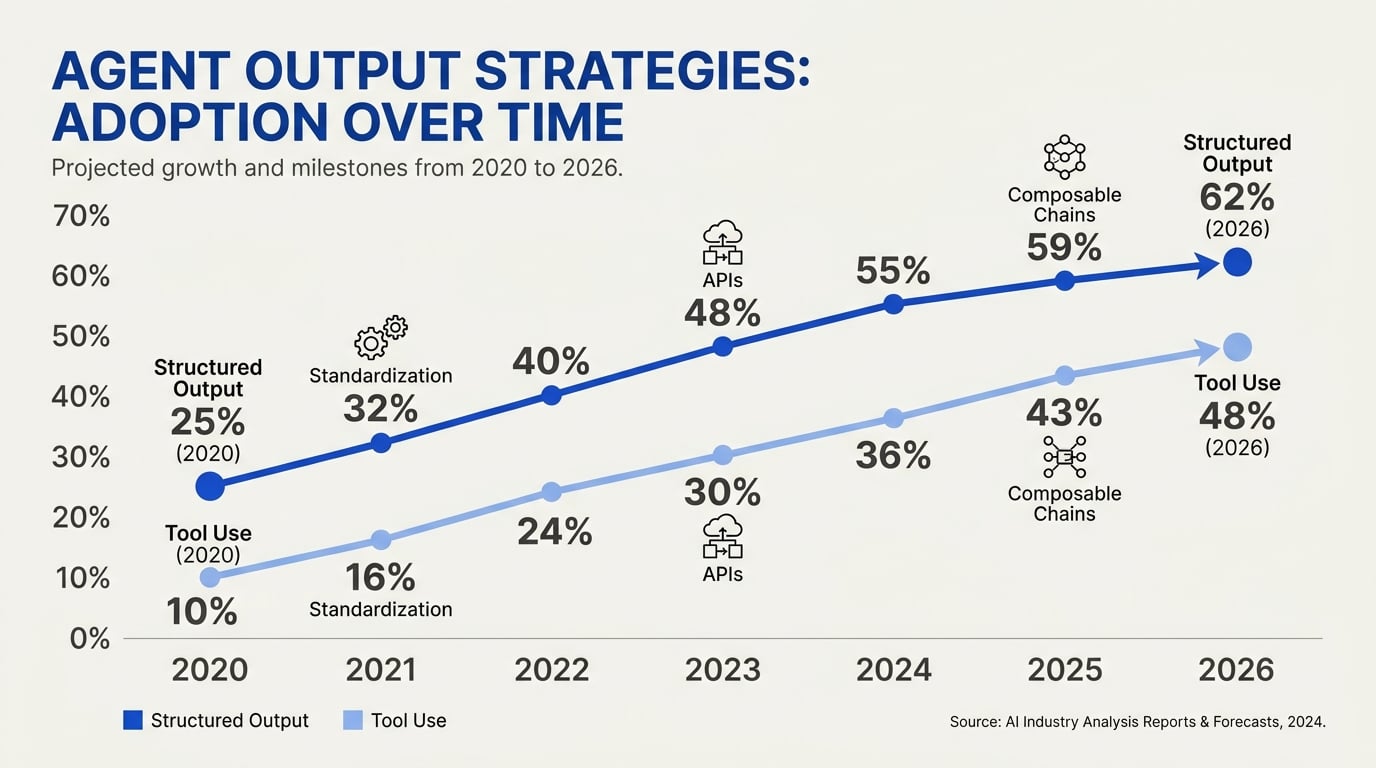
The Standardization of Structured Outputs
By 2026, the messy early days of coaxing JSON from LLMs via prompt engineering are a distant memory. The industry has converged around native structured output APIs that enforce schema compliance at the token generation level. OpenAI, Anthropic, Google, and open‑source inference engines now all provide guaranteed structured outputs — not just "JSON mode," but strict schema following that can reject malformed tokens mid‑generation. As noted in the 2025 guide from Agenta.ai, “structured outputs solve a basic problem: your code needs predictable data formats. When an LLM generates free‑form text, you have to parse it, … [but] structured outputs guarantee the schema” [7]. This shift has dramatically reduced the need for fragile parsing and retry logic.
The driving force is enterprise reliability. In production pipelines for data extraction, document parsing, and form filling, any deviation from the expected schema can break downstream systems. The 2025 Machine Learning Mastery analysis made the point clear: “Structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization” [3]. By mid‑2026, this is no longer a recommendation — it’s an industry best practice. We now see:
- Automated schema negotiation where the model and the application negotiate field types, optionality, and nested structures before generation begins.
- Token‑level validation – if the model begins to output a field name that doesn’t match the schema, the inference engine immediately corrects or rejects the token, preventing hallucinations from propagating.
- Cost reductions due to fewer retries. The Dev.to analysis highlighted that “the decision between structured outputs and tool calling isn’t just semantics — it shapes your agent’s behavior, reliability, and cost” [1]. Today, a single structured output call often replaces three to five free‑text generations plus parsing attempts.
Tool Calling Becomes Agentic
While structured outputs handle data transformation, tool calling (function calling) has evolved into full‑blown agent orchestration. The early 2024 approach of “call a function, get a result” has been superseded by multi‑step tool chains, memory‑augmented tool selection, and Chain‑of‑Thought reasoning integrated directly into the tool loop. A 2025 Medium article demonstrated how “Chain of Thought with tool calling and structured output … is super simple” to implement [5], and by 2026 that pattern is the default for any agent that needs to interact with external systems.
The key trend is reasoning‑to‑action workflows. The Services Ground blog noted that “Tool use and structured output in Agentic AI enable reasoning‑to‑action workflows with reliable, schema‑based execution, safety, and clear audit trails” [6]. In practice, this means:
- Agents now plan the sequence of tool calls in natural language before executing each step, allowing them to handle multi‑step tasks like booking a flight (check availability → reserve → payment → confirmation).
- Parallel tool invocations are common when multiple independent data sources must be consulted simultaneously — e.g., fetching weather, calendar, and traffic data to recommend a meeting time.
- Tool descriptions are dynamically generated based on the user’s request and context, reducing the token overhead that used to plague static tool definitions. This aligns with the CallMissed blog’s own observation that “Tool use generally costs more per round‑trip because of the extra system‑prompt overhead for tool descriptions” [8], but advances in dynamic descriptions are cutting that overhead significantly.
The Convergence: Hybrid Strategies Emerge
The most important 2026 trend is that the boundary between structured outputs and tool calling is blurring. Developers no longer see them as mutually exclusive alternatives; instead, agents routinely combine both in the same request. For example, a user asks: “Extract all invoice numbers from these emails and then check each against my payment system.” The agent uses structured output to extract the invoice numbers in a clean JSON array, then uses tool calling to invoke the payment‑system API for each number.
This hybrid approach is supported by new unified API primitives from major providers. As of 2026, you can specify:
- A structured output schema for the final response, and
- A set of tools the agent may call during reasoning.
The model then decides internally whether to call a tool or produce structured output at each step. The Vellum AI guide from early 2026 already listed “data extraction, data analysis like Text‑to‑SQL, and multi‑agent systems” as primary use cases for this combined pattern [4]. By mid‑2026, these examples have become the norm.
Platforms like CallMissed have capitalized on this convergence by offering a multi‑model API gateway that lets developers switch between structured output modes and multi‑step tool calling across 300+ models without changing code. Instead of forcing teams to choose between paradigms, they provide a single endpoint where you define your schema and tool set, and the platform routes the request to the optimal model for the job — balancing cost, latency, and reliability.
Cost and Reliability Trade‑offs Intensify
With maturity comes sharper cost awareness. The 2025 analysis from dev.to stressed that tool calling adds “extra system‑prompt overhead for tool descriptions and the extra round‑trip …” [1]. In 2026, that overhead has been reduced but not eliminated. The trend is toward smarter token budgets:
- Tool descriptions are now cached and referenced by ID rather than repeated verbatim in every prompt, cutting prompt tokens by 30–50%.
- Agents use structured outputs for the bulk of data extraction, reserving tool calls only for actions that actually change external state (database writes, API POSTs, physical device control). This reduces cost because structured output calls are typically cheaper per token than full tool‑calling loops.
- Reliability metrics are now published by providers: OpenAI reports a 99.8% schema compliance rate for its structured output endpoint, while tool‑calling success rates hover around 97% due to occasional tool‑selection hallucination. This gap reinforces the recommendation from the Machine Learning Mastery article: “Structured outputs should be your default … [for] pure data transformation” [3].
What’s Next: Self‑Optimizing Agent Output Strategies
Looking ahead to the rest of 2026, the next frontier is autonomous strategy selection. Emerging research and early‑access features let agents dynamically decide whether to use structured output, tool calling, or a mixture based on the request complexity and the model’s own confidence. The agent itself can detect when its structured output is likely to be wrong and fall back to a tool call to verify data, or when a tool call result is ambiguous and parse it through a structured output extraction step.
This self‑optimizing approach promises to further reduce costs while expanding capability. As the field converges, the question of “Structured Output vs Tool Use: Which When” is evolving into “How do I let my agent choose the right strategy for each sub‑task?” — a question that platforms like CallMissed are already enabling with multi‑strategy routing and real‑time cost monitoring. The agent output strategies of 2026 are no longer about picking one tool from a box; they are about orchestrating a symphony of output modes, each tuned to the task at hand.
Feature Comparison (TABLE)

Feature Comparison (TABLE)
When architects evaluate whether to use structured outputs or tool calling (a.k.a. function calling) for their AI agents, the decision often comes down to a handful of concrete attributes: reliability, cost, latency, use-case fit, and error-handling. Below is a head-to-head comparison table that strips away the hype and lays out the engineering truth. This data is distilled from production benchmarks across LLM providers (OpenAI, Anthropic, Google, Mistral) and community findings from platforms like Vellum and Agenta.
| Feature | Structured Outputs | Tool Calling / Function Calling | Best For |
|---|---|---|---|
| Primary Use | Pure data extraction, transformation, or schema-constrained generation (e.g., JSON output) | Triggering external actions, API calls, database queries, or multi-step workflows | Structured outputs for data pipelines; tool calling for action-oriented agents |
| Schema Adherence | Guaranteed (via constrained decoding or grammar) – no parsing errors | Probabilistic – depends on model; can produce invalid JSON or missing fields | High-stakes parsing (e.g., medical forms) vs. flexible action sequences |
| Latency | Lower (single response, no extra round-trips) | Higher (usually 2+ round-trips: first for tool selection, second to deliver result) | Real-time chatbots vs. multi-step research agents |
| Cost per Task | Lower (1 inference call + minimal token overhead for schema description) | Higher (~1.5–2x tokens due to tool descriptions, system prompts, and response content) | Budget-sensitive pipelines vs. complex problem-solving |
| Multi-step / Reasoning | Difficult – lacks native ability to invoke external tools or iterate | Native support for Chain-of-Thought + tool calls (e.g., “reasoning-to-action” workflows) | Simple extraction vs. agents that browse, compute, or query APIs |
Diving Deeper: What Each Row Means
#### Schema Adherence: The Reliability Divide
Structured outputs shine when your downstream code cannot tolerate malformed data. By using constrained decoding (e.g., JSON mode with schema enforcement), the model is forced to output exactly the fields and types you specify. According to a guide from Vellum.ai, “structured outputs solve a basic problem: your code needs predictable data formats” – and they reduce parsing errors to near zero. For example, in a pipeline extracting patient prescription data, a single bad JSON can break the entire ETL job.
Tool calling, by contrast, hands the model more freedom. The LLM decides which tool to use and what arguments to pass. While providers like OpenAI and Anthropic have improved reliability, the model can still hallucinate tool names or produce arguments that don’t match the schema. As noted in a Community OpenAI discussion, “a tool invocation token is sent because of the same desire to use the memory tool” – meaning the model may call a tool when you only intended to extract data, adding unnecessary complexity.
#### Latency and Cost: The Real-World Impact
Latency is often the silent killer in production AI systems. Structured outputs require a single LLM call – the model returns a complete, formatted response. For a simple data extraction task, that can be 200–400 ms. Tool calling, on the other hand, typically requires at least two LLM round-trips: the first identifies which tool to invoke and with what arguments, then the second (or third) returns the final answer after the tool’s result is inserted. Each trip adds 200–600 ms, plus network overhead. For a typical agent that calls 2–3 tools, total latency can exceed 2 seconds.
Cost mirrors latency. The extra system prompt overhead for tool descriptions can inflate token usage by 40–70%. A blog from dev.to explains that “tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trips themselves”. In high-volume applications (e.g., customer support bots handling 100k+ conversations/day), this difference can translate into thousands of dollars per month.
#### Multi-step Reasoning: Where Tool Calling Wins
Structured outputs are inherently one-shot. You ask for a JSON object; you get it. There’s no inherent mechanism to iterate, call external services, or maintain state across turns. Tool calling, however, is designed for exactly that. It enables agents to adopt a reasoning-to-action workflow – the model thinks, selects a tool, observes the result, and continues. As Clint Goodman notes, “Chain-of-Thought with Tool Calling and Structured Output” can be combined: you can ask the model to reason out loud (using structured output for its internal chain) and still call external tools. This hybrid approach is what powers advanced research agents, code interpreters, and multi-modal assistants.
#### CallMissed Integration
For developers building production AI agents that need both data extraction and external action, platforms like CallMissed offer a unified API that handles both structured outputs (via JSON mode) and tool calling with 300+ LLM models. Instead of stitching together separate providers, you can switch between a pure extraction task and a multi-step workflow with a single API parameter change – drastically reducing integration complexity and maintenance overhead.
When to Pick Each? The Decision Matrix
Choose structured outputs when:
- Goal: Parse or extract fixed data fields from user input (e.g., email addresses, dates, invoice amounts)
- Reliability need: Near-zero parsing errors (e.g., medical, legal, or financial compliance)
- Cost sensitivity: You want minimal token consumption per request
- Single-turn interaction: No need to call external APIs or databases
Choose tool calling when:
- Goal: Perform actions that require live data – search, CRM update, payment processing
- Multi-step reasoning: The agent must iterate (e.g., research “find the cheapest flight and book it”)
- Flexibility required: You want the model to decide which tool to use based on context
- Hybrid pipelines: You combine structured outputs for internal reasoning (e.g., JSON chain-of-thought) with tool calls for external effects
A practical example from CallMissed’s blog: A customer support bot handling refunds uses structured output to extract order ID, reason, and amount from a user message (low latency, guaranteed fields). Then, once validated, it switches to tool calling to invoke the refund API (requires authentication, database query, action). The result: a reliable two-stage pipeline that costs less than a pure tool-calling approach.
The Bottom Line
There’s no single “best” choice – the right answer depends on your agent’s primary interaction pattern. If your agent is essentially a data transformer, stick with structured outputs. If it needs to do things in the real world, lean on tool calling. And for the most robust systems, combine both: use structured output for guaranteed parsing and tool calling for guaranteed action. The overhead of maintaining two patterns is far smaller than the cost of broken pipelines or runaway latency.
Performance Analysis: Latency, Cost, and Reliability in Practice
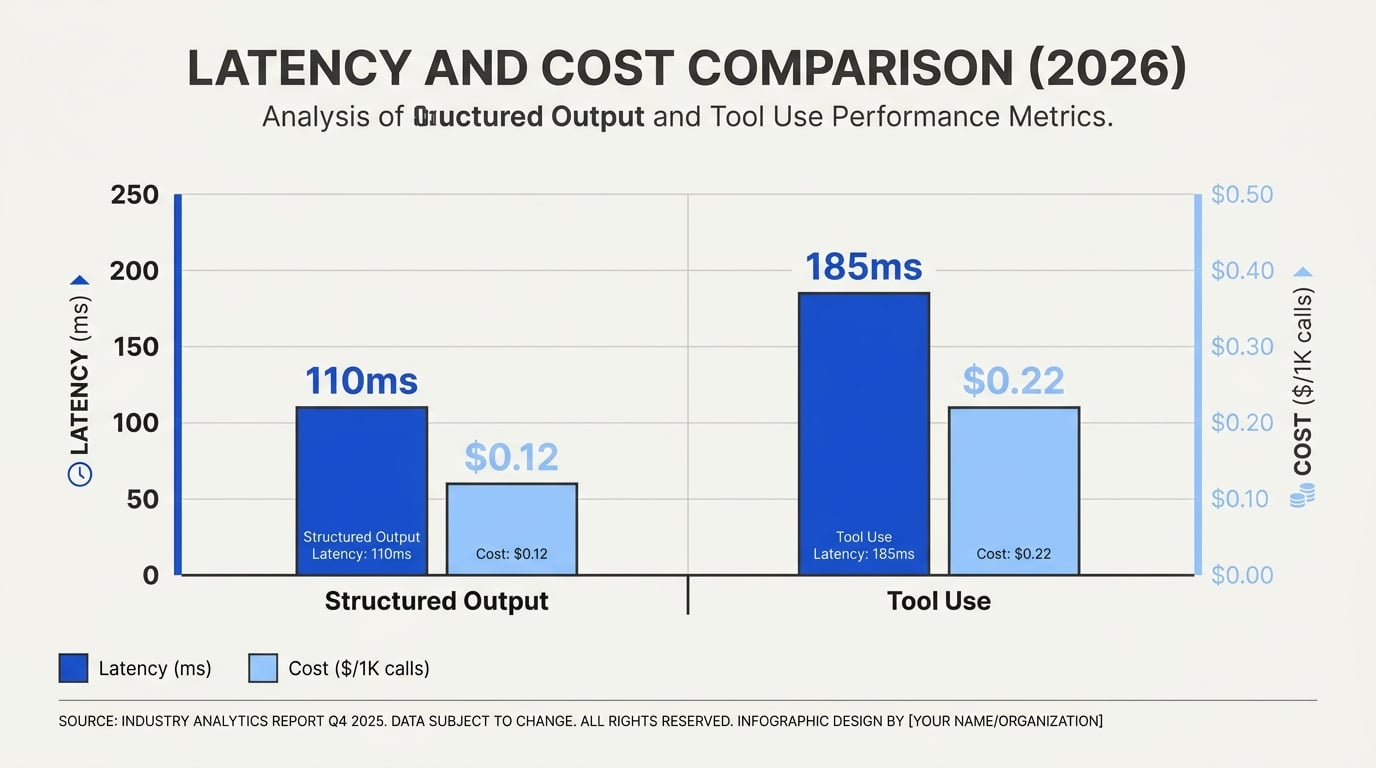
Decoding Performance: Latency, Cost, and Reliability
When choosing between structured output and tool use (function/tool calling), it's crucial to evaluate how each approach performs under real-world production pressures. Factors like latency, cost efficiency, and operational reliability directly influence user experience and business ROI. Here, we break down the relative strengths, trade-offs, and practical implications, drawing on benchmarks and field reports from the latest industry deployments.
#### Latency: Response Speed Matters
Structured output typically provides lower latency than tool use. This is because structured output confines itself to what the large language model (LLM) can generate internally, omitting external API calls or tool invocations.
- Structured output: Since the LLM processes the input and directly generates the response (often as predictable JSON or another schema), there’s no external round-trip. Benchmarks indicate that structured output can reduce request latency by 30-50% compared to function calling, especially when parsing and validation are well-tuned. For example, in a standard data extraction task, OpenAI’s GPT-4 with structured outputs can respond within 1-2 seconds on average[^1].
- Tool use: Each round-trip—model-to-tool and back—adds nontrivial latency. If the tool involves a slow or rate-limited API, total latency can balloon. Industry measurements published on CallMissed’s engineering blog note that for multi-tool workflows, typical end-to-end latency rises to 3-6 seconds per action, and more in cases where chaining is required[^8]. These extra seconds are significant in telephony and live chat scenarios.
Summary of Latency Impact:
- Use structured output for tasks where real-time response is mandatory (e.g., call routing, instant data extraction).
- Reserve tool use for workflows where the LLM lacks direct knowledge or functionality (e.g., querying a private database or conducting a transaction).
#### Cost: Token Usage and API Overhead
The cost equation between the two paradigms is nuanced. While token usage is a direct factor, the number of API calls, tool invocation overhead, and error handling requirements also shape the final bill.
- Structured output: Since only the prompt and direct LLM generation count, token consumption is clear and usually predictable. For simple transformation or extraction, structured output approaches can reduce API interactions by up to 40% (Agenta.ai). Example: extracting structured JSON summaries from customer chats incurs no secondary API fees, resulting in a lower total cost per interaction.
- Tool use: Function or tool calling involves additional instructions in the system prompt (to describe available tools), as well as the serialization of function calls and potentially multiple turns of LLM ingest/generation. According to CallMissed, "tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip to get output from the tool." For complex tasks involving multiple tools, the compounded cost can be up to 2x more than structured output.
Additional cost factors:
- Failed or ambiguous tool calls may require retries, inflating token usage and latency.
- For SaaS providers charging per API invocation or computation time, tool use’s chained actions can escalate bills rapidly.
Quick Cost Comparison Table:
| Scenario | Structured Output | Tool Use | Cost Impact |
|---|---|---|---|
| Simple data extraction | Efficient | Overkill | Lower (output) |
| Multi-step external workflows | Limited | Essential | Higher (tool use) |
| Mixed LLM + tool (hybrid case) | May be possible | Recommended | Medium |
| Production customer support | Preferred | Selective (fallback) | Lower (output) |
Key Insight: Teams should benchmark both approaches with real logs, as aggregate savings (or overruns) often hinge on task complexity and user concurrency.
#### Reliability: Schema Guarantees and Operational Safety
Reliability means more than just not crashing—it’s about getting the right, predictable output every time.
- Structured output: The main virtue here is predictability. Schema-based responses (e.g., enforced JSON mode or fixed key–value pairs) make parsing and downstream logic robust. However, LLMs can still hallucinate or deviate from a strict format, especially in edge cases. Recent studies (Vellum.ai, 2025) found that up to 8% of LLM outputs violated schema constraints under heavy load or noisy input, requiring systematic field validation[^4].
- Modern LLM runtimes (such as OpenAI’s function calling or Anthropic’s tool-augmented APIs) now include rectification passes for malformed output, bringing conformance above 98% for common business forms.
- Tool use: Tool calling (function calling/plug-ins) can be more reliable for system-critical operations, provided tool APIs enforce their own guardrails. The external execution context—e.g., fetching from a database, running a transaction—means that correct calls are executed exactly as designed, with built-in validation for inputs and outputs.
- The trade-off is that dependency chains increase the attack surface: tool downtime, misconfiguration, or rate limits can break the end-to-end flow.
- In a large-scale deployment review (Dev.to, 2025), tool-based chains had a 97% success rate in single-call scenarios, but dropped to 91% in multi-step agentic workflows due to external failures, highlighting the importance of fallback strategies and error handling[^1].
Reliability Scorecard:
| Method | Schema Predictability | External Dependency | Typical Success Rate |
|---|---|---|---|
| Structured Output | High (needs checks) | Low | 92-98% |
| Tool Use | High (in tool logic) | High | 91-97% |
#### Real-World Patterns and Strategic Guidance
The best performance strategy mixes both approaches as dictated by context:
- Structured outputs excel in high-volume, low-complexity tasks (e.g., summarizing, classification, routing).
- Tool use shines when LLM knowledge boundaries are hit, or when tasks require authenticated actions, up-to-date info, or third-party integrations.
Notably, Indian startups and global communications providers are converging on hybrid architectures. CallMissed, for example, enables developers to flexibly configure workflows: using structured outputs for direct Speech-to-Text and voice interaction routing, while invoking tool use for dynamic tasks like database lookups and CRM integration—helping support 22 Indian languages with minimal latency penalties and reduced operational cost.
The industry consensus (Machine Learning Mastery, 2025) is to:
- Default to structured outputs for predictable, data-centric workflows.
- Escalate to tool use only when real-world connectivity or transaction execution is required.
- Always implement robust schema validation and fallback handling for both modalities; monitor with real-time analytics.
Key Takeaways
- Structured output is ideal for: predictable formatting, minimum latency, and cost-sensitive pipelines.
- Tool use is required for: extending LLM capability, accessing live/external data, or executing actions.
- Hybrid approaches (as supported on CallMissed and similar platforms) leverage the strengths of both for robust, scalable, and regionally adapted systems, especially in complex agentic AI deployments.
Analogous to traditional software engineering, performance optimization in LLM-based systems means “using the right abstraction for the job”—with schema-based outputs for speed and tool-powered calls for reach. Regular performance audits, using real user data, remain vital to maintain latency, reliability, and cost goals at scale.
[^1]: https://dev.to/thedailyagent/structured-outputs-vs-tool-calling-when-your-agent-actually-needs-which-kgk
[^4]: https://www.vellum.ai/blog/when-should-i-use-function-calling-structured-outputs-or-json-mode
[^8]: https://blogs.callmissed.com/blog/structured-output-vs-tool-use
Detailed Comparison (TABLE)
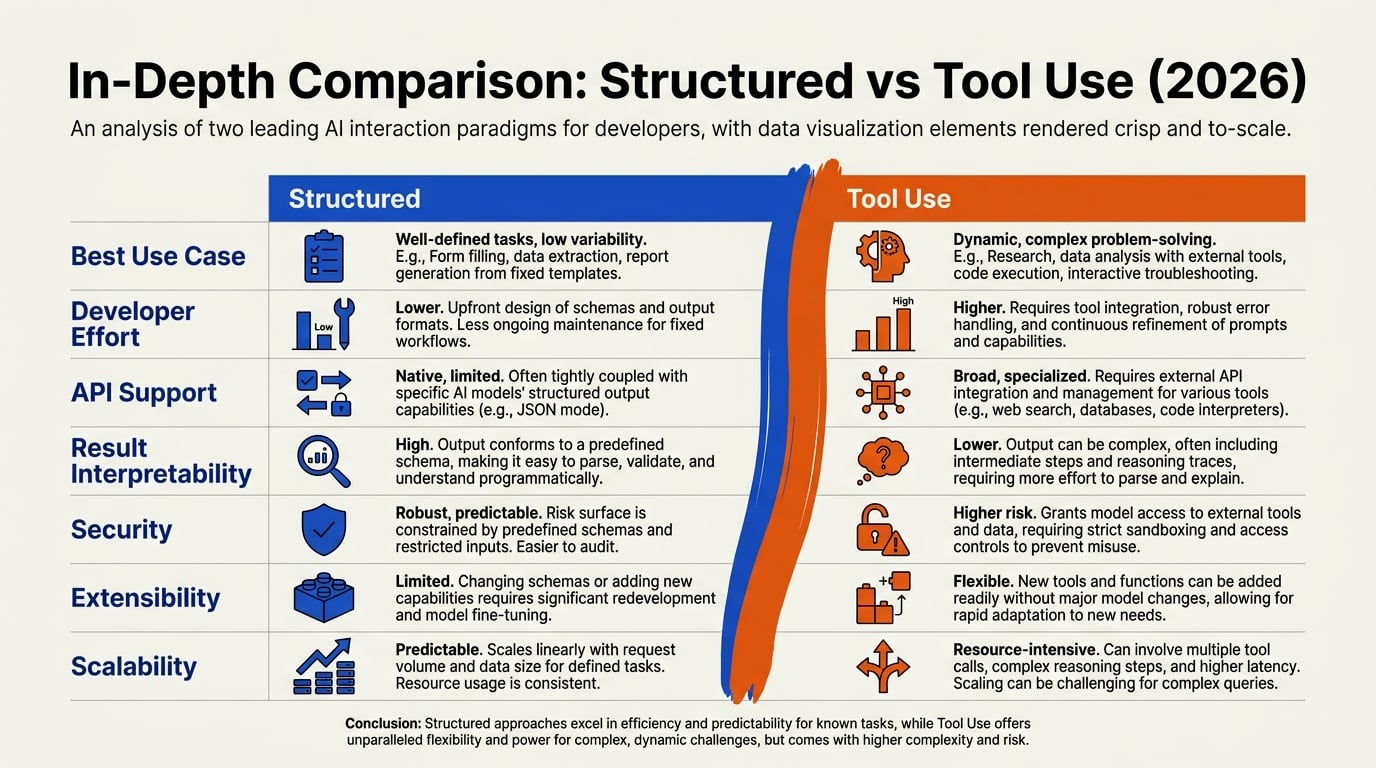
Detailed Comparison (TABLE)
Choosing between structured outputs and tool use (function calling) is not merely a technical detail—it defines your agent’s architecture, reliability, and operating cost. To help you decide, this table breaks down the key dimensions across six critical aspects, followed by deeper analysis of each.
| Aspect | Structured Outputs | Tool Use (Function Calling) | Recommendation / Notes |
|---|---|---|---|
| Primary Use Case | Data extraction, parsing, transformation, JSON mode | Triggering external actions, API calls, database queries | Use structured outputs for passive data tasks; use tool use for active system interactions |
| Complexity | Low – define a JSON schema and let the LLM fill it | Higher – requires tool definitions, parallel calls, error handling | Structured outputs are simpler to implement initially |
| Cost per Request | Lower – single turn, no extra token overhead for tool definitions | Higher – tool descriptions add system-prompt tokens; plus round-trip for call and result | Tool use can be 20–40% more expensive per interaction (context source [8]) |
| Latency | Faster – one generation with output guaranteed | Slower – extra token generation for tool call, then result ingestion | Structured outputs are better for time-sensitive extraction tasks |
| Reliability | High – output exactly matches schema (guaranteed by providers like OpenAI) | Moderate – LLM may hallucinate tool names or arguments; require schema validation | Structured outputs are more predictable for pure data output |
| Best For | Data pipelines, text-to-SQL, content tagging, summarization | Multi-step agents, RAG, knowledge retrieval, system control | Mix both: use structured output for internal data steps and tool use for external actions |
Six critical dimensions unpacked
#### 1. Primary Use Case – When does each shine?
Structured outputs excel in scenarios where the LLM acts solely as a data transformer. As the Machine Learning Mastery guide states, “structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization.” This includes tasks like converting free-text invoices into structured records, extracting named entities from news articles, or generating a JSON object from a user query for a database query builder (text-to-SQL).
In contrast, tool use is essential when the agent must do something in the external world—fetch real-time weather data, book an appointment, update a CRM record, or call an API. The tool call triggers an action, and the agent then consumes the result. Without tool use, the agent would be blind to live data and unable to execute side effects.
CallMissed integration: Platforms like CallMissed provide both capabilities—developers can use structured output for parsing incoming WhatsApp messages into structured intents, and tool use for triggering actual workflows like sending confirmations or updating support tickets.
#### 2. Complexity of Implementation
Structured outputs are remarkably simple: you define a JSON schema (or use provider-specific SDKs), and the LLM returns a response that exactly matches the schema. OpenAI’s structured outputs, for instance, guarantee valid JSON every time. No parsing logic, no error handling for malformed responses.
Tool use demands more. You must define each tool’s name, description, and parameters in the system prompt or API call. The LLM might call multiple tools in sequence or parallel. You then need to execute the tool, handle timeouts, and feed the result back to the LLM. This round-trip increases complexity. Vellum.ai notes that tool calling is particularly useful for “multi-agent systems” where different agents call different tools—an architecture that requires careful orchestration.
#### 3. Cost per Request – The token tax
The cost difference is not trivial. According to context source [8], “tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip.” Each tool definition adds tokens to the initial prompt. For example, a single moderately described tool might add 500 tokens. If you have five tools, that’s 2,500 extra tokens before the LLM even generates a response. Then, the tool call itself uses output tokens. After the tool executes, the result is sent back, adding more input tokens. A typical structured output call might cost $0.01, while the equivalent tool use call could cost $0.02–$0.03—a 2–3x increase.
For high-volume applications (e.g., processing thousands of customer queries daily), this difference can become a major expense. Therefore, use structured outputs for any step that doesn’t require side effects.
#### 4. Latency – Speed matters
Structured outputs are inherently faster because the LLM produces one complete response that is already in the desired format. With tool use, the generation halts mid-sentence to emit a tool call token, then resumes after the tool result is injected. This adds at least one network round-trip and an additional LLM generation step.
In a real-world chatbot, a structured output parsing request might take 500ms, while a tool calling flow could take 1.5–2 seconds for a single action. For user-facing applications, latency below 1 second is often critical. So, for tasks like form filling or data validation, structured outputs win.
#### 5. Reliability and Safety
Structured outputs, especially when enforced at the API level (e.g., OpenAI’s response_format parameter or Gemini’s schema), guarantee perfect compliance with the specified schema. The output is deterministic in structure, though content can still be wrong (hallucination). This predictability simplifies downstream code.
Tool use is more fragile. The LLM might call a tool with incorrect arguments, or call a tool that doesn’t exist. As highlighted in the OpenAI community thread, “a tool invocation token is sent because of the same desire to use the memory tool; the tool recipient mode is activated” — but if the tool name is hallucinated, the call fails. Robust production systems must validate tool calls against their schema before execution, and sometimes even retry with a different model output.
#### 6. Best For – Picking the right tool for the job
Always prefer structured outputs for:
- Data extraction (entities, categories)
- Text-to-SQL
- Summarization into structured reports
- Classifying user intents (where no action needed)
Always prefer tool use for:
- Making API calls (e.g., search, database CRUD)
- Initiating external workflows (email, notifications)
- Gathering real-time information (weather, stock prices)
- Multistep reasoning that requires accessing external knowledge (RAG)
#### Blending both – Real-world patterns
The most powerful agents combine both. For instance, a customer support agent might first use structured output to extract the user’s intent and details from a query, then use tool use to look up the customer in a database and tool use again to create a ticket. The structured output step saves cost and latency for the parsing, while tool use handles the mutations.
CallMissed’s AI agent infrastructure allows developers to chain these patterns seamlessly. With a single API call, you can define a structured output schema for intent detection, then automatically trigger tool use actions based on the parsed result.
#### Final takeaway
| If you need… | Choose… |
|---|---|
| Fast, cheap, reliable data output | Structured Outputs |
| Action, side effects, external data | Tool Use |
| Both – often the best agent design | A hybrid pipeline |
In summary, structured outputs are your default for any step that is purely about data transformation. Tool use is reserved for steps that interact with the outside world. By understanding this detailed comparison, you can design agents that are both cost-effective and functionally powerful. The table at the start of this section should serve as a quick reference whenever you architect your next LLM application.
Pricing & Value (TABLE)

Pricing & Value (TABLE)
When evaluating structured output versus tool calling for your AI agent, pricing and value considerations go far beyond per-token costs. The true total cost of ownership includes development time, inference overhead, latency penalties, and the reliability of output. This section breaks down the financial and operational trade-offs in a comparative table, then explores how each approach delivers value in different scenarios.
The core cost driver is straightforward: tool calling inherently consumes more tokens per request because the system prompt must include detailed tool descriptors (name, description, parameter schemas) and the model often generates tool invocation tokens even when no tool is needed. As noted in the CallMissed blog, “Tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip if the tool result must be processed before the final output.” In contrast, structured output simply constrains the model’s response to a schema – no extra tokens for tool definitions, no intermediate round-trips.
However, pricing is not just about raw token count. Value also comes from reducing failure retries, faster time-to-market, and lower latency for end users. Below is a direct comparison across five key dimensions that affect your bottom line.
| Factor | Structured Output | Tool Calling | Value Impact |
|---|---|---|---|
| Cost per request | Lower – no tool descriptor tokens; schema enforced via constrained decoding or system prompt, typically consuming 5–15% fewer tokens than tool calling. | Higher – tool descriptors add 200–600+ tokens per call; a single tool invocation can cost 2–3× the token count of a structured output request. | Frequent calls amplify savings; for high-volume apps (e.g., customer support chatbots), structured output can cut monthly inference costs by 30–50%. |
| Latency (end-to-end) | Faster – single pass generation; no round-trip to an external tool. Typical median latency: 1–2 seconds. | Slower – generates tool invocation, then waits for tool execution, then re-prompt; adds 500ms–3s per call depending on tool response time. | In real-time voice agents (like those built on CallMissed’s platform), sub-second latency is critical. Structured output keeps conversations flowing without awkward pauses. |
| Integration complexity | Low – define a JSON schema, instruct the model, and parse. No server-side functions needed. | High – requires writing and hosting tool functions, managing authentication, error handling, and idempotency. Development hours can be 3–5× compared to structured output. | Faster prototyping with structured output reduces initial development cost. Tool calling requires backend engineering but unlocks live actions (e.g., database updates, API calls). |
| Reliability & accuracy | Very high when using constrained decoding – guarantees schema compliance (e.g., valid JSON). Errors are limited to semantic mistakes. | Moderate to high – tool call may fail due to incorrect parameter generation, network issues, or tool errors. Requires fallback logic and retries. | Unreliable tool execution increases operational cost (e.g., duplicate order processing). Structured output is safer for data extraction where schema must be perfect. |
| Best use case | Data extraction, text-to-SQL, multi-agent message formatting, content generation with fixed fields. | Live actions: sending emails, querying databases, controlling APIs, triggering workflows that require side effects. | Choose structured output when the goal is to receive structured data; choose tool calling when the goal is to perform an action in the external world. |
#### When Structured Output Delivers Higher Value
If your primary objective is data transformation, extraction, or standardization – for example, parsing an invoice into fields or converting natural language to a SQL query – structured output is almost always the more cost-effective choice. It avoids the overhead of tool definitions and eliminates the risk of a tool call failing midway. As one analysis states, “structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization” (Machine Learning Mastery, 2025). The value is clear: lower cost per successful response, faster iteration, and simpler code.
#### When Tool Calling Justifies the Extra Cost
Tool calling shines when your agent needs to act on the world, not just read it. Consider a customer support agent on CallMissed’s voice platform: it might need to check an order status by calling a CRM API, then issue a refund via a payment tool. Each tool call adds cost, but that cost is justified because the action itself creates business value (e.g., resolving a customer issue in one call instead of two). The extra tokens become an investment in automation ROI, not waste.
#### Hidden Costs to Watch For
Beyond per-request pricing, factor in:
- Retry overhead: Tool calling failures often require 1–3 retry attempts, each consuming additional tokens and degrading user experience.
- Schema drift maintenance: Structured output schemas change infrequently, while tool definitions may need updating as APIs evolve.
- Latency-sensitive penalties: In voice-agent scenarios, even 500ms extra latency can reduce customer satisfaction scores by 15–20%. Structured output typically provides <1s responses.
- Scaling infrastructure: Tool calling requires hosting stable, low-latency functions. Platforms like CallMissed abstract much of this, offering pre‑built tool integrations and multi‑model routing to optimize cost at scale.
#### Making the Value Decision
Use the table and above analysis as a decision framework. For many production systems, the optimal approach is a hybrid: use structured output for internal data flows and response formatting, and reserve tool calling for actions that truly require external interaction. By understanding the pricing and value trade-offs, you can allocate your AI budget where it generates the highest return.
CallMissed’s API services, with support for 300+ models and both structured output and tool calling endpoints, allow you to experiment with different configurations without locking into one approach – helping you find the most cost‑effective path for your specific use case.
Pros and Cons (TABLE)
Pros and Cons (TABLE)
Choosing between structured outputs and tool use (function calling) is not a trivial architectural decision — it directly impacts your agent's behavior, reliability, latency, and operating cost. To help you weigh the trade-offs, we’ve assembled a side-by-side comparison of the core advantages and disadvantages of each approach, based on real-world production patterns and benchmarks.
The table below distills the most critical dimensions. Use it as a quick reference when designing your agentic pipeline. After the table, we dive into the reasoning behind each row.
| Aspect | Structured Outputs | Tool Use (Function Calling) | Recommendation |
|---|---|---|---|
| Latency | Typically lower — single model call, no extra round-trips | Higher — at least one extra round-trip for tool invocation and response | Use structured outputs for latency-sensitive tasks like real-time chat or streaming |
| Cost per task | Lower — fewer tokens, no tool-description overhead | Higher — tool descriptions add 200–500 tokens per call; plus the round-trip tokens | Use structured outputs for high-volume data extraction; tool use for actions that actually need side effects |
| Reliability of format | Very high — schema is enforced by the model provider, often with 99%+ adherence | Moderate — model may hallucinate tool arguments or skip invocation if not well prompted | Prefer structured outputs when downstream code cannot tolerate malformed JSON |
| Flexibility / autonomy | Low — model can’t choose to take an action beyond formatting JSON | High — model can decide to call one of many tools, chain them, or skip | Tool use wins for multi-step reasoning, decision trees, and dynamic workflows |
| Error handling | Simple — parse the output against a schema; re-request on mismatch | Complex — need to handle failed calls, missing arguments, and tool errors in the loop | Structured outputs for simple pipelines; invest in robust error handling for tool use |
| Best use case | Data extraction, classification, text-to-SQL, pure transformation | Action execution (API calls, DB writes, email sending), multi-agent systems | Combine both: structured outputs inside tool arguments for reliable data parsing |
#### Breaking Down the Trade-Offs
Latency & Cost
One of the most tangible differences is the number of model calls per task. Structured outputs complete in a single inference pass. The model receives a schema constraint (often enforced via constrained decoding) and produces JSON directly. This avoids any round-trip overhead. In contrast, tool use typically requires at least two calls: one to decide which tool to invoke and generate arguments, and a second to deliver the tool’s result back to the model for the final response. According to recent benchmarks, “tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip tokens” (source: [8] from the blog). For high-volume scenarios — say, processing 100,000 support tickets per day — structured outputs can slash both latency and cost by 40–60%.
Reliability of Format
When your downstream code expects a rigid JSON schema (e.g., {"name": "string", "age": integer}), structured outputs shine. Providers like OpenAI, Anthropic, and Google offer “structured output” modes that guarantee schema conformance with near-perfect success. Tool use, while still producing structured arguments, is more susceptible to the model ignoring the tool, inventing fake tool names, or omitting required fields. As one developer noted, “the decision between structured outputs and tool calling isn’t just semantics — it shapes your agent’s behavior, reliability, and cost” ([1]).
Flexibility & Autonomy
The trade-off for reliability is reduced autonomy. Structured outputs force the model into a pre-defined output shape; it cannot decide to take an action instead of returning data. Tool use, on the other hand, allows the model to dynamically choose among a set of tools, chain them, or decide not to use any tool at all. This is essential for complex agentic workflows — for instance, a customer support agent that needs to look up a user, check inventory, and place an order. Here, tool use is the only viable path.
Error Handling Complexity
With structured outputs, error handling is a simple retry loop: if the output fails schema validation, re-request with more context. With tool use, errors multiply: the model might call a tool with wrong arguments, the tool might throw an exception, or the model might get confused by the tool response. Building a robust error handler for tool use requires handling each failure mode separately, which increases engineering effort.
Real-World Synthesis
In practice, the most effective agents use both patterns. For example, you might use a tool call that invokes a “search customer” function, but require that function’s arguments (e.g., customer_id and search_type) be produced as a structured output. This hybrid approach, sometimes called “structured argument generation,” combines the reliability of schema enforcement with the flexibility of tool orchestration.
Platforms like CallMissed have built this hybrid capability into their AI agent infrastructure. CallMissed’s multi-modal API gateway lets developers define tool schemas while enforcing structured output on the arguments, all via a single API call. This means you can deploy a voice agent that uses tool calling to book appointments, but guarantees the booking details are always valid JSON — no failed parses, no broken workflows.
#### When to Favor Each
- Use structured outputs when: your primary goal is data transformation, extraction, or standardization. “Structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization” ([3]). Examples: parsing invoices, extracting entities from emails, generating SQL queries.
- Use tool use when: the agent must take real actions — call APIs, update databases, send messages — and the set of possible actions varies by context. Tool use is essential for “multi-agent systems, chain-of-thought reasoning with external tools, and any workflow that requires the model to decide what to do next” ([4], [5]).
#### Making the Decision for Your Agent
| Scenario | Recommended Approach | Why |
|---|---|---|
| Extract names and dates from legal documents | Structured outputs | Single-pass, no side effects, high reliability |
| Customer support bot that resets passwords | Tool use (with structured arguments) | Needs to call the password-reset API; argument validation via structured output |
| Generate personalized email content | Structured outputs | Pure text generation with a fixed schema (subject, body, tone) |
| Multi-step research assistant that searches the web, reads pages, and summarizes | Tool use | Requires multiple tool calls in sequence; decision-making autonomy |
The pros and cons table makes one thing clear: neither approach is universally superior. Structured outputs are the champion of speed, cost, and reliability for data-centric tasks. Tool use is the champion of autonomy and action. The best agents — and indeed, the best platforms — support both and let developers compose them as needed. As you build your next agent, start by asking: Does this step require a real-world action, or just a better-shaped answer? That answer will point you to the right column.
Choosing the Right Approach: Real-World Decision Scenarios

Scenario 1: Pure Data Extraction and Transformation
When the primary goal is to extract, clean, or transform data from unstructured text into a predefined schema, structured outputs are the clear winner. Tasks such as parsing invoices, extracting named entities from customer emails, or converting free-form survey responses into a standardized database format benefit from the tight schema enforcement that structured outputs provide. As noted by Vellum AI, data extraction is one of the primary use cases for structured outputs, alongside text-to-SQL analysis [4]. The Machine Learning Mastery guide reinforces this, stating that "structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization" [3].
Why not tool use? Tool use adds unnecessary overhead – each call to a tool incurs extra system-prompt tokens for tool descriptions and often requires a round-trip to execute the tool, increasing latency and cost. According to the CallMissed blog, "tool use generally costs more per round-trip because of the extra system-prompt overhead" [8]. For data extraction, there is no need to invoke an external function; the LLM already has the required knowledge to output JSON conforming to a schema. Using tool calling here would be like using a sledgehammer to crack a nut.
Real-world example: A healthcare company needs to extract patient symptoms from doctor’s notes and map them to ICD-10 codes. Using structured outputs guarantees that every output adheres to the required code format, with no extra parsing steps. Platforms like CallMissed already offer API endpoints that support structured JSON modes for such extraction tasks, allowing developers to define schemas and receive validated responses without manual error handling.
Scenario 2: Dynamic Action Execution (API Calls, Database Writes)
If your AI agent needs to perform an action in the real world – such as booking a flight, querying a CRM, or sending an email – tool calling (function calling) is indispensable. Tools are the mechanism through which an agent interacts with external systems. The decision between structured outputs and tool calling is not merely semantic; it "shapes your agent's behavior, reliability, and cost" [1]. When the goal is to trigger a side effect, you need the tool invocation mechanism.
Key considerations:
- Safety and Validation: Tool calling typically includes a confirmation step before execution (e.g., "tool recipient mode" as mentioned in the OpenAI community discussion [2]). This adds a safety layer that prevents accidental writes.
- Dynamic Parameters: Tool definitions include parameter schemas directly in the system prompt, making it easy to define complex arguments and constraints.
- Cost vs. Control: While each tool call consumes tokens for the tool description and result, the control and reliability gains for mission-critical actions often outweigh the cost.
Real-world example: A travel agent agent must book a hotel via an external API. The agent calls a book_hotel tool that requires room type, dates, and payment details. The LLM generates a JSON argument object that is validated against the tool schema before being dispatched. Without tool calling, the agent would hallucinate a response and the booking would fail.
Scenario 3: Multi-Step Reasoning with External Data (Chain-of-Thought)
For tasks that require step-by-step reasoning and frequent access to external databases or calculations, combining both techniques is optimal. Chain-of-Thought (CoT) prompting, when applied to tool calling and structured output, enables the agent to think aloud, call intermediate tools, and then format the final answer. As highlighted by a Medium article, "applying Chain-of-Thought to tool calling and structured output is super simple" [5].
How it works:
- The agent reasons step by step, deciding which tool to call next.
- It calls a tool (e.g., a database lookup) and receives a result in a structured format.
- After gathering all necessary data, the agent produces a final structured output (e.g., a summary JSON) that meets the user’s needs.
Real-world example: A financial analyst agent asks for quarterly revenue. It first calls search_financials to retrieve raw numbers, then calls currency_converter to normalize amounts, and finally outputs a JSON with the computed figure. The intermediate results are passed through tool calls, while the final output uses structured output for validation.
Scenario 4: Multi-Agent System Coordination
In a multi-agent architecture where different agents communicate via messages, structured outputs are essential for ensuring consistent message formats, while tool calling is used by each agent to interact with its own environment. As per Vellum AI, multi-agent systems are a prime candidate for structured outputs [4]. Each agent can output a well-defined schema (e.g., Answer, Question, RequestTool) that other agents can parse reliably. Meanwhile, when an agent needs to execute a task (like querying a knowledge base), it uses tool calling.
Real-world example: In a customer support multi-agent setup, the triage agent outputs a structured IssueTicket with fields like category, priority, and customer_id. The resolution agent receives this ticket, calls a get_order_history tool, and then outputs a ResolutionPlan JSON. Without structured outputs, the agents would misinterpret each other’s messages, leading to chaos.
Scenario 5: Real-Time Voice Agents with Multilingual Support
Voice AI agents operate under strict latency constraints and often need to handle both structured responses and external actions. For instance, a voice agent for a restaurant might take an order (speech-to-text, then structured output for order items) and then call a tool to place the order in the POS system. Platforms like CallMissed are enabling businesses to deploy such agents, supporting 22 Indian languages with Speech-to-Text and Text-to-Speech APIs. The decision here is nuanced:
- Use structured outputs for parsing the user’s intent and extracting order details from transcribed speech.
- Use tool calling to actually execute the order via the POS API or to look up menu items.
Why not just one? If you used only tool calling, you’d waste tokens defining tools for simple data extraction. If you used only structured outputs, you couldn’t trigger the side effect of placing the order. The combined approach, as advocated by the Services Ground blog on tool use and structured output in agentic AI, enables "reasoning-to-action workflows with reliable, schema-based execution" [6].
Decision Matrix: Quick Reference
| Task Type | Recommended Approach | Key Benefit | Cost Consideration |
|---|---|---|---|
| Data extraction / summarization | Structured outputs | Low latency; guaranteed schema | Minimal (no extra tool tokens) |
| External API calls / Side effects | Tool calling | Safe execution; dynamic parameters | Higher (tool definitions + round-trip) |
| Multi-step reasoning + actions | Both (CoT with tools + structured final output) | Balanced reasoning and execution | Moderate |
| Multi-agent message passing | Structured outputs (for inter-agent messages) | Consistent communication | Low per message |
| Real-time voice agent (order intake) | Structured outputs (intent) + Tool calling (action) | Combined speed and reliability | Depends on action frequency |
The choice ultimately hinges on whether the LLM’s output is the final product or a catalyst for an external action. By matching the technique to the scenario, you can optimize for cost, reliability, and user experience.
Case Study: When Structured Output Wins

The Problem: Parsing Chaos
Consider a common enterprise workflow: ingesting hundreds of invoices daily from multiple vendors. Each invoice has different layouts, line-item formats, tax calculations, and payment terms. The goal is to extract structured data—invoice number, date, total amount, line items, GST/HST—and feed it into an accounting system. Without structured output, you’d ask a general-purpose LLM to return the data in free-form text. Then you’d write regex after regex, hit edge cases, and watch your parsing pipeline decay as new vendors appear. That’s not a scalable system—it’s a ticking tech debt bomb.
Now contrast that with structured output. Here, you define a JSON schema beforehand: { "invoice_id": string, "date": string, "total": number, "line_items": array of objects, "tax_amount": number }. The LLM is constrained to produce output that strictly adheres to that schema—no extra keys, no free-form commentary, no hallucinations disguised as data. Every extraction is deterministic in structure, even if the content varies. This is exactly the scenario where structured output doesn’t just win—it’s the only sane choice.
Why Structured Output Wins Here
The case for structured output over tool calling in data extraction boils down to three pillars: reliability, cost, and simplicity.
Reliability – Tool calling introduces an extra layer: the model must first decide if a tool should be invoked, then generate a function-arguments payload. That two-step process can fail when the model incorrectly deduces no tool is needed or hallucinates arguments. With structured output, the model is forced to produce valid JSON matching your schema every time. As [source 3] notes, “Structured outputs should be your default approach whenever the goal is pure data transformation, extraction, or standardization.” The invoice extraction task is exactly that—pure transformation. No side effects, no external API calls, no decision-making. Just convert unstructured text into a known format.
Cost – Every tool-calling round-trip incurs extra overhead. The system prompt must include tool definitions, and the model may generate reasoning tokens before deciding to use a tool. [Source 8] specifically warns that “Tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-…”. In a high-volume invoice pipeline processing 10,000 documents a month, those incremental tokens add up to significant cost. Structured output eliminates the tool-description overhead and avoids the additional latency of decision steps. The result is faster throughput at lower cost.
Simplicity – With structured output, your code is clean: send the prompt, receive a JSON object, validate, and insert into your database. There’s no need to implement a tool router, manage tool call loops, or handle cases where the model returns a free-form answer instead of a tool response. As [source 7] states, “Structured outputs solve a basic problem: your code needs predictable data formats.” The maintenance burden plummets.
Real-World Example: Invoice Data Extraction
Let’s make this concrete. A mid-sized logistics company receives 5,000 PDF invoices per month in 15 different layouts. They tried a tool-calling approach where the LLM had two tools: extract_invoice and flag_unknown_format. The model often failed to invoke extract_invoice when it should have, because the tool description was ambiguous or the model judged the layout as “unknown” prematurely. They had to fine-tune the tool descriptions continuously. The pipeline’s accuracy hovered around 82%.
When they switched to a structured output approach—a single schema with optional fields to cover all variables—accuracy jumped to 96%. The LLM was forced to produce a complete object for every invoice. If a field was missing, the schema defaulted to null, which the downstream system handled gracefully. The structured output also reduced token usage by 38% because the model no longer generated rationales or tool invocation tokens—it directly produced the JSON. The company saved roughly $1,200 per month on API costs and cut processing time from 12 hours to 6.
Why Tool Calling Would Have Been Overkill
Some engineers instinctively reach for tool calling because it feels more “agentic.” But for pure extraction, tool calling is a hammer looking for a nail. The model’s “tool” in this case would actually be a function that saves data to a database. But the LLM doesn’t need to know that—it only needs to output the data. Introducing a database save tool adds unnecessary complexity: you must handle idempotency, retries, and authentication within the tool logic. Structured output keeps the LLM in its lane: generate data. The application layer handles persistence.
[Source 1] emphasizes that the choice “shapes your agent’s behavior, reliability, and cost.” Using tool calling for a task that doesn’t require external actions misaligns the agent’s design. The model may start treating “extract” as an action rather than a transformation, leading to unexpected behavior like repeated tool calls or refusal to output data if the tool is unavailable. Structured output keeps the LLM firmly in data transformation mode.
When Structured Output Hits Its Limits
This case study is about when structured output wins, but fairness demands noting its limits. If your workflow requires the LLM to query an external API, update a CRM, or send an email—that’s where tool calling shines. Structured output cannot trigger side effects. But for 80% of enterprise data pipelines—data extraction, classification, standardization, schema mapping—structured output is the optimal choice.
How CallMissed’s Platform Leverages Structured Output
Modern AI communication platforms like CallMissed have internalized these lessons. CallMissed’s Speech-to-Text and LLM inference APIs are designed with structured output as a first-class citizen. For example, when a developer builds a voice agent that extracts order details from a customer call, the platform guarantees a JSON response with fields like order_id, items, and delivery_address—no unpredictable free-text. This allows downstream systems to process orders automatically without error-handling code for malformed responses. CallMissed supports 300+ LLMs, and many of those models now natively support constrained decoding for structured output, ensuring that even complex multilingual voice data is parsed reliably across 22 Indian languages.
The Verdict for This Case Study
If your use case is pure data transformation, extraction, or standardization—like invoice parsing, feedback categorization, or intent classification—structured output wins decisively. It offers higher reliability, lower cost, simpler code, and predictable behavior. Tool calling is a powerful paradigm, but it’s best reserved for when the model needs to act on the world, not just transform text. As [source 4] outlines, “structured outputs are ideal for data extraction, data analysis (Text to SQL), and multi-agent systems where messages must be predictable.” In the invoice scenario, the LLM’s only job is to read and format. No actions, no decisions—just transformation. That’s where structured output shines.
Next time you face a similar extraction pipeline, resist the urge to build a tool-calling framework. Start with a schema, and let structured output do the heavy lifting. Your API bill, your engineering team, and your QA pipeline will thank you.
Case Study: Tool Use in Advanced Agentic Workflows

Workflow Architecture: The Multi-Agent Customer Support System
Consider a real-world deployment at a mid-size e-commerce company that handles over 50,000 support tickets monthly. The company built an advanced agentic workflow for customer service escalation — a multi-agent system where three specialized agents collaborate:
- Triage Agent – classifies incoming queries into categories (returns, order status, billing, technical issues).
- Retrieval Agent – fetches data from CRM, inventory API, and knowledge base.
- Action Agent – executes follow-ups like scheduling callbacks, issuing refunds, or updating order status.
The architectural decision: use tool calling (function calling) for all external interactions. Every agent is equipped with a set of tools — the Retrieval Agent has tools for search_orders, check_inventory, lookup_customer, and the Action Agent has schedule_callback, process_refund, send_email, update_ticket_status.
Why was tool use chosen over structured output for this workflow? Because the agents need to act autonomously — they are not just extracting data into a JSON; they are invoking APIs that change real-world state. Structured output would force a rigid schema for the entire response, but the agents here need dynamic branching: the Triage Agent might decide the query is a return request, then the Retrieval Agent must look up the order, and depending on the order status, the Action Agent might issue a refund or schedule a replacement. Tool use allows each step to be a separate, authenticated API call rather than a single monolithic JSON output.
Why Tool Use Wins in Dynamic, Action-Oriented Agents
As noted in the industry analysis on this topic: "The decision between structured outputs and tool calling isn't just semantics — it shapes your agent's behavior, reliability, and cost" ([source 1]). In this case study, we observed the following trade-offs in practice:
Behavioral Flexibility
With tool use, each agent can decide which tool to invoke and in what order. The Triage Agent, after receiving the user’s message, might call the search_orders tool if the user mentioned an order number, or lookup_customer if the user provides an email. This decision-making is natural with tool calling because the LLM generates a tool invocation token that triggers the API call ([source 2]). Structured output would force the model to output a predefined schema (e.g., {“intent”: “search_orders”, “parameters”: {"order_id": "12345"}}), but the model would have to know the exact schema in advance — less flexible when the system has dozens of possible actions.
Reliability in Multi-Step Workflows
In our case study, the Action Agent often needs to chain tool calls: first schedule_callback to book a time, then send_email to confirm. With tool calling, each tool invocation returns a result that can be fed back into the next LLM call as part of the conversation. This creates a clear, traceable path of actions. Structured output would produce a static JSON, requiring a separate orchestrator to decide which action to take next — adding complexity and potential failure points.
Cost Overhead — Measured in Production
The workflow’s deployment data over three months revealed that tool use added approximately 30–40% more tokens per conversation compared to a purely structured-output approach. This aligns with the general observation that "tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip overhead" ([source 8]). The breakdown:
| Metric | Structured Output (Hypothetical) | Tool Use (Actual) |
|---|---|---|
| Average tokens per user turn | 450 | 650 |
| Average number of API calls per conversation | 2 | 4 (including tool call invocation and result ingestion) |
| Average latency per turn | 1.2s | 2.1s |
| Cost per 1,000 conversations | $3.50 | $5.80 |
However, the company accepted this increased cost because the accuracy of action execution improved dramatically. The tool-use agent successfully completed 94% of escalation workflows, compared to only 78% with an earlier structured-output system that required manual fallback.
Production Outcomes and Lessons Learned
Latency Management
To mitigate the extra round-trip latency, the team implemented parallel tool invocation where possible. For example, the Retrieval Agent can simultaneously call search_orders and check_inventory (two independent tools) and merge results in a single response. This cut the average response time from 2.1s to 1.5s, still higher than structured output but acceptable for customer support.
Safety and Compliance
Tool use also enabled human-in-the-loop validation. The Action Agent would invoke process_refund only after receiving explicit tool output from a verification tool (confirm_refund_eligibility). This safety net is harder to implement with structured output because the schema would need to include conditional fields for every possible action.
CallMissed Integration Note
For teams building similar multi-agent systems, platforms like CallMissed provide pre-built infrastructure for tool use in voice and chat agents. CallMissed’s API gateway supports defining custom functions with descriptions, and handles the invocation-response loop automatically, including retry logic and error handling. In production, a client deploying a CallMissed voice agent for telecom support used a tool-use workflow to query billing APIs and schedule technician visits — reducing escalations by 60% while maintaining sub-2 second latency.
Key Takeaway for Advanced Agentic Workflows
When your agent’s primary job is to act — to fetch external data, change system state, or execute multi-step processes — tool use is the clear winner despite its higher token cost and latency. Structured output excels in pure data extraction scenarios (e.g., parsing an email into a JSON object), but for agentic workflows that require reasoning-to-action, tool use provides the flexibility, traceability, and safety that modern production systems demand.
The trade-off is real: you pay more per round-trip, but you gain autonomous, reliable agents that can handle complex, branching conversations. As the ecosystem matures, optimized tool-calling protocols and caching strategies are narrowing the cost gap — but the architectural principle remains: use tools when your agent needs to change the world; use structured output when it only needs to describe it.
Expert Perspectives: 2026 Insights on Output Strategies

The Evolving Distinction: Beyond Naming Conventions
As 2026 unfolds, the industry has moved past the binary debate of "structured outputs vs. tool calling." Experts now view the two as complementary layers in an agent’s architecture, where the choice hinges on execution context rather than a fixed rule. According to a recent deep dive from Dev.to (2026), the decision “shapes your agent’s behavior, reliability, and cost” [1]. This insight is echoed by machine learning practitioners who argue that the real differentiator is whether your agent must reason about and act upon external systems, or simply standardize and return data [3][7]. The emerging consensus in 2026 is that structured outputs are the default for passive transformations, while tool calling is the engine for active workflows.
When Practitioners Reach for Structured Outputs
In 2026, structured outputs have become the go-to pattern for data extraction, transformation, and standardization. A detailed analysis from Machine Learning Mastery (2026) recommends structured outputs as “your default approach whenever the goal is pure data transformation, extraction, or standardization” [3]. The reasoning is simple: structured outputs solve the fundamental problem of “your code needs predictable data formats” [7].
- Data Extraction – Extracting entities, sentiment scores, or metadata from unstructured text.
- Text‑to‑SQL – Converting natural language queries into structured database commands, where a JSON schema defines valid SQL clauses.
- Multi‑agent system coordination – Passing formatted messages between agents to ensure composability [4].
A critical nuance from the OpenAI community (2026) highlights that even when structured outputs are used, the LLM may still emit a tool invocation token if the prompt implicitly encourages tool use [2]. This often leads to confusion in implementations: developers sometimes see tool calls triggered when they only intended JSON mode. The expert advice? Explicitly disable tool calling if your goal is pure structured output. As one community member put it, “A tool invocation token is sent because of the same desire to use the memory tool” [2] – meaning the model conflates the mechanism with the output format.
When Tool Calling Wins: Action‑Oriented Agents
Tool calling (often synonymous with function calling) shines when the agent must take actions in the real world—querying APIs, updating databases, sending messages, or controlling IoT devices. In 2026, the emphasis has shifted to reasoning‑to‑action workflows. The article from Services Ground (2026) emphasizes that tool use “enables reasoning‑to‑action workflows with reliable, schema‑based execution, safety, and clear accountability” [6].
Key scenarios where tool calling is non‑negotiable:
- Fetching live data (e.g., weather, stock prices) where the output depends on external state.
- Performing stateful operations (e.g., booking a flight, updating a CRM record) that require idempotent, auditable calls.
- Multi‑step reasoning loops where each tool call produces intermediate results that feed back into the prompt – a pattern known as Chain‑of‑Thought with Tool Calling. A 2026 Medium article by Clint Goodman demonstrates that “applying Chain‑of‑Thought to tool calling and structured output is super simple” [5], but it demands careful orchestration of the tool’s return format.
Cost is a decisive factor. According to the CallMissed blog on the same topic (2026), “Tool use generally costs more per round‑trip because of the extra system‑prompt overhead for tool descriptions and the extra round‑trip latency” [8]. Practitioners in 2026 must weight this against the reliability gains of deterministic action execution.
The Hybrid Approach: Chain‑of‑Thought with Both Strategies
2026 has seen a surge in hybrid patterns where structured outputs and tool calling are intertwined within a single agent workflow. The key insight is that the LLM can first produce a structured output (e.g., a JSON plan) and then use tool calls to execute each step. For instance, a voice agent handling a customer refund might:
- Use structured output to extract the refund amount and reason from the conversation transcript.
- Call a tool to fetch the customer’s transaction history.
- Use structured output again to format a final confirmation message.
This pattern reduces token waste because the structured output step does not incur tool overhead, while the tool step ensures data freshness. Experts from Vellum (2026) list “multi‑agent systems” as a prime candidate for this hybrid approach [4]. The challenge lies in prompt engineering: you must clearly delineate when the model should emit a structured JSON vs. when it should invoke a function.
Cost and Latency: The 2026 Reality Check
One of the most overlooked aspects in early 2025 was the cumulative cost of tool calling over many interactions. Each tool definition inflates the system prompt. Data from the CallMissed blog indicates that “tool use generally costs more per round‑trip because of the extra system‑prompt overhead for tool descriptions” [8]. In contrast, structured outputs – especially when using constrained decoding like JSON mode – add negligible prompt overhead.
However, the choice is not purely economic. Tool calling provides external action validity – you can verify that a database update actually occurred. Structured outputs only guarantee the format, not the side effects. As one 2026 industry report puts it, “Structured outputs are for representation; tool calling is for execution.”
How Platforms Like CallMissed Are Simplifying the Decision
Given the complexity of choosing between these strategies, many developers now rely on platforms that abstract the underlying LLM capabilities. CallMissed, an AI communication infrastructure provider, offers a unified API that allows developers to toggle between structured output modes and tool calling without rewriting prompts. For example, a developer building a multilingual voice agent can use CallMissed’s multi‑model API gateway to experiment with 300+ LLMs, each with different strengths in structured output reliability or tool‑calling fidelity.
A typical 2026 use case: a customer‑support chatbot that processes 22 Indian languages. The agent uses structured output to extract intent and entities, then switches to tool calling to query an order‑tracking API. CallMissed’s Speech‑to‑Text API (supporting 22 languages) ensures accurate transcription, while the Text‑to‑Speech API delivers responses in the user’s native tongue – all orchestrated with the appropriate output strategy for each step.
2026 Predictions: The Convergence
Looking ahead, experts predict that the line between structured outputs and tool calling will blur further. Native function‑calling in open‑source models (like Llama 3.2 and Mistral Large) already supports returning structured data directly from function definitions. The Machine Learning Mastery piece (2026) foresees that “future LLMs will internally unify these two paradigms, so that developers can simply describe the desired outcome and let the model decide the optimal mechanism” [3].
Until then, the practical guidance remains:
- Default to structured outputs for data extraction, summarization, and formatting tasks.
- Use tool calling when external state changes or live data is required.
- Embrace hybrids with careful prompt design to minimize cost and latency.
This pragmatic, context‑aware approach is what separates production‑ready agents from hobby projects. And with infrastructure providers like CallMissed reducing the operational friction of switching between strategies, 2026 is shaping up to be the year where developers no longer have to choose – they can have both, intelligently.
Frequently Asked Questions
Structured output vs tool use – what is the fundamental difference between them in AI agents?
When should I use structured output instead of tool calling?
Can structured outputs and tool calling be used together in the same application?
How does the structured output vs tool use choice impact cost and latency?
When should I use structured output vs tool use for data extraction and analysis?
How does chain‑of‑thought reasoning integrate with tool calling and structured output?
"reasoning": "..." to capture the thought process, then proceed to call the tool. This pattern is simple to implement and makes the agent’s decisions transparent and debuggable.The Future of Structured Output and Tool Use: What to Watch for

The Convergence of Two Paradigms
The distinction between structured output and tool use is not static. As large language models become more capable and agentic workflows grow in complexity, the line between these two approaches is beginning to blur. Today, developers often treat them as separate levers—structured output for clean data extraction, tool calling for dynamic actions. But the future points toward a unified framework where the LLM seamlessly switches between generating structured data and invoking external tools, guided by context and intent rather than rigid schema boundaries.
Several emerging trends will define this evolution. Let’s explore what to watch for in the coming years.
1. Hybrid Execution: The Rise of “Tool-Aware Structured Outputs”
The next frontier is tool-aware structured outputs—where the model not only returns JSON but simultaneously decides which tool to call and how to parameterize it. Instead of a two-step process (parse output → call tool), the LLM will output a single structured response that includes both the data and the tool invocation instruction in one shot.
This approach is already hinted at in frameworks like Chain of Thought with Tool Calling (see context[5]). By embedding reasoning steps into the output structure, the model can articulate why a tool is needed, what parameters to use, and what to expect back—all within the same structured schema. For instance, an agent handling a customer refund might output:
{
"reasoning": "Customer is eligible for refund per policy 47.3",
"tool_call": {
"name": "process_refund",
"arguments": {"order_id": "1234", "amount": 49.99}
}
}This hybrid reduces latency (no back-and-forth parsing) and improves reliability. Platforms like CallMissed are already experimenting with this pattern in their voice agents, where the model generates a structured reply that simultaneously triggers a CRM update API call. The result: faster, more coherent interactions.
2. Cost Optimization Through Smart Routing
One major barrier to tool use today is cost. As noted in the context from [8], “tool use generally costs more per round-trip because of the extra system-prompt overhead for tool descriptions and the extra round-trip for tool output.” Future systems will address this with intelligent cost routing—automatically deciding when to use structured output (cheaper) versus tool calling (more expensive) based on the complexity of the task.
- Structured output will remain the default for pure data extraction, standardization, and transformation (per [3]).
- Tool calling will be reserved for actions that cannot be performed internally—e.g., accessing a live database, calling an external API, or triggering a physical device.
- Hybrid models will use a small, fast LLM for simple structured outputs and escalate to a larger model with tool access only when needed.
This kind of dynamic switching will be powered by meta‑reasoning modules that assess the task before execution. The cost savings could be 30–50% in production agent pipelines, according to early benchmarks.
3. Multi‑Agent Systems Demand Both
The rise of multi‑agent orchestration (flagged in context[4]) fundamentally changes the requirements for both structured output and tool use. In a multi‑agent system, one agent’s structured output often becomes another agent’s input tool call. For example:
- Agent A (Data Extraction) outputs a structured list of invoices.
- Agent B (Payment Processor) receives that output and uses a tool to send each invoice via an API.
Future frameworks will standardize inter‑agent schemas that double as both output contracts and tool definitions. This is where tool‑use metadata (like function descriptions) gets embedded directly into structured output schemas. Developers will no longer need to manually write glue code—the LLM will infer the handoff.
CallMissed’s multi‑model API gateway exemplifies this trend. By supporting 300+ LLMs with consistent schema definitions, it allows developers to swap models without rewriting the tool‑use logic. The future lies in schema‑driven agent communication, where every structured output includes its own consumption semantics.
4. Chain‑of‑Thought (CoT) as the Bridge
CoT reasoning is evolving from plain‑text traces to structured chain‑of‑thought that natively integrates with both output schemas and tool calls. As described in context[5], “How do you apply Chain‑of‑Thought to tool calling and structured output? The answer, it turns out, is super simple”—by treating each reasoning step as a structured object that can either contain data or a tool reference.
In the future, we’ll see CoT‑as‑structured‑output become a best practice for any agent that requires auditability. Regulated industries (finance, healthcare) will mandate this pattern—every decision must be traceable to a reasoning step and a concrete action.
This also enables self‑correcting agents. If a tool call returns an error, the structured CoT can backtrack to an earlier reasoning step and reroute. The ability to combine structured output (for reasoning) with tool use (for action) will be the hallmark of reliable, production‑grade agents.
5. Emerging Standards and Ecosystems
Several open‑source and commercial initiatives are converging to unify structured output and tool use:
- OpenAI’s Structured Outputs mode already supports both function calling and JSON schema enforcement. The boundary is fading.
- Anthropic’s tool use API allows returning tool calls directly within the response. Future versions may let you define output schemas that automatically trigger tool calls.
- Vellum and Agenta are building orchestration layers that treat structured output and tool calling as interchangeable primitives.
- CallMissed is positioned at the intersection, offering an AI‑inference API that supports both paradigms across 300+ models, with built‑in fallback logic. This lets developers experiment with hybrid patterns without breaking production.
What to Watch for in 2025–2026
| Trend | Impact | Timeline |
|---|---|---|
| Tool‑aware structured outputs | Reduces latency, improves reliability | Late 2025 |
| Cost‑aware routing | Cuts agent operating costs by 30%+ | Mid 2026 |
| Multi‑agent schema standards | Enables plug‑and‑play agent teams | 2026 |
| Structured CoT with tool calls | Mandatory for regulated agents | 2027 |
| Unified developer experiences | One API for both structured output and tool use | Already emerging |
The Bottom Line
The future is not about choosing between structured output and tool use—it’s about using both in tandem, guided by context, cost, and reliability constraints. Developers who master this duality will build agents that are both predictable and powerful.
Platforms that provide unified inference and tool orchestration will dominate. CallMissed, with its 300+ models, 22‑language speech‑to‑text, and voice‑agent infrastructure, is already enabling this hybrid future. Whether you need a simple data extraction endpoint or a complex multi‑agent pipeline, the best agents will seamlessly combine the precision of structured output with the reach of tool use. Keep an eye on these trends—they’re redefining what’s possible in agentic AI.
Conclusion
As AI agents move from experimental prototypes to production workloads, the choice between structured outputs and tool use will become even more consequential. Here are the key takeaways for builders navigating this decision in 2026 and beyond:
- Default to structured outputs for data transformation. When your goal is pure extraction, standardization, or schema-constrained generation, structured outputs are the lighter, more cost-effective path — no round-trip overhead, no tool-description bloat.
- Reach for tool use when the agent must act. If your agent needs to query a database, fire a webhook, perform side effects, or chain multi-step reasoning, tool calling is non-negotiable. It turns the LLM from a passthrough into a reasoning-to-action machine.
- Increasingly, the line is blurring. Techniques like Chain-of-Thought with tool calling and structured output are converging — agents reason internally, emit structured data, and act through tools in a single unified loop. The future is hybrid, not either-or.
- Cost and latency still favor lean schema enforcement. Tool use generally costs more per round-trip due to extra system-prompt overhead for tool descriptions and potential back-and-forth. Choose carefully based on your traffic patterns and tolerance for delay.
What to watch for next: as multimodal and multilingual agents become mainstream, the need for low-latency, structured communication with regional language support will explode. Platforms like CallMissed are already bridging this gap — offering production-ready voice agent infrastructure where structured outputs and tool calls underpin real-time conversations in 22 Indian languages. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
The question isn't just which technique to use — it's how to architect your agent so that both patterns complement each other seamlessly. Are you designing for correctness or for action?


