Speech-to-Text in 2026: Whisper, Deepgram Nova, Saaras V3, and the Real-Time Race

Speech-to-Text in 2026: Whisper, Deepgram Nova, Saaras V3, and the Real-Time Race
In 2026, over 80% of virtual assistants and contact center conversations are powered by speech-to-text (STT) systems—yet most users have no idea just how fierce the competition for real-time accuracy and multilingual reach has become. Imagine a call with your bank: within milliseconds, your words are transcribed, routed, understood, and replied to, in your preferred language and accent—even if you switch from English to Hindi halfway through the conversation. This is the invisible engine transforming industries like customer support, healthcare transcription, legal documentation, and inclusive voice search, and it’s advancing at a breathtaking pace.
Why does this matter now? The STT market has leapt forward both in performance and coverage. Deepgram Nova-3, for example, hit a Word Error Rate (WER) of just 5.26% for general English transcriptions in 2026—a number unthinkable three years ago, representing a 40% reduction in errors since 2023 and enabling fully automated, enterprise-grade voice workflows (Deepgram, 2026). At the same time, models like Saaras V3 from Sarvam AI have redefined inclusivity for the next billion users, boasting ~22% WER on the challenging IndicVoices benchmark, and offering support across 11 Indian languages—a critical breakthrough for real-world applications in Asia’s booming digital economies (Sarvam, 2026). Moreover, the rise of open-source STT—led by platforms such as OpenAI’s Whisper—has democratized access for startups and researchers alike, bringing robust transcription to dozens of languages with no API fees attached.
Yet, accuracy is only half the race. In 2026, enterprises now demand real-time, low-latency STT for voice agents, transcribers, and digital assistants that must make sense of human speech with sub-second response times. Deepgram Nova-3, purpose-built for real-time streaming, is setting new industry standards with a median WER of just 6.84% on live audio (NextLevel AI, 2026). Meanwhile, Whisper’s latest models continue to impress in low-resource languages and noisy environments, albeit with a trade-off in processing lag. Saaras V3, on the other hand, is optimized for Indian English and regional dialects, making it the backbone for conversational AI in emerging markets.
The ramifications are global, but also deeply local: whether it’s a telemedicine platform transcribing doctor-patient consults in rural Uttar Pradesh, a legal-tech app indexing courtroom audio in real time, or an AI voice agent responding instantly to customer queries in multilingual metros. The real-world benchmarks, developer tools, and scaling strategies behind these STT platforms are now as crucial as the raw accuracy metrics. It’s no surprise that platforms like CallMissed are powering production-ready infrastructure for businesses eager to deploy AI voice agents in 22 Indian languages, seamlessly selecting between Whisper, Deepgram Nova, Saaras V3, and hundreds of other STT and LLM models with a single API.
In this comparison blog, we’ll break down the state of Speech-to-Text in 2026: analyzing the latest benchmarks for Whisper, Deepgram Nova-3, and Saaras V3, exploring their performance on both global and local languages, and uncovering what sets each apart in the real-time race. You’ll learn how to read WER numbers in context, why latency is now a deciding factor for live STT, and how organizations can choose (or combine) the right models for multilingual, production-grade deployments. Along the way, we’ll illustrate how the emerging API ecosystem—including platforms like CallMissed—is changing the way businesses and developers build with speech data.
Ready to hear what the world actually sounds like in 2026—and how it’s being transcribed? Let’s dive in.
Introduction: The State of Speech-to-Text in 2026

Speech-to-Text at an Inflection Point
The speech-to-text (STT) landscape in 2026 stands at a dynamic crossroads, shaped by breakthroughs in deep learning, natural language processing, and the rapid expansion of real-time AI applications. Over the past several years, STT has evolved from a promising niche technology to a foundational component of communication infrastructure—powering everything from customer support voice agents and medical dictation to multilingual transcription for global businesses.
Today, speech recognition systems are expected to deliver both ultra-low latency and human-level accuracy across dozens of languages, dialects, and acoustic conditions. As a result, leading platforms have entered what can only be described as the “real-time race”—competing to reduce Word Error Rate (WER) percentages while maintaining instant, on-demand response times for voice-driven interfaces.
The Leaders: Whisper, Deepgram Nova, Saaras V3, and More
Four models dominate the 2026 STT conversation: OpenAI’s Whisper, Deepgram Nova-3, Sarvam AI’s Saaras V3, and the increasingly popular GPT-4o Transcribe. Each brings unique strengths and an ever-expanding list of language and domain specializations.
- Deepgram Nova-3 stands out for best-in-class real-time streaming, achieving a median WER of 6.84% on live English audio and 5.26% for general English transcription (Deepgram 2026 Benchmark). Nova-3’s support has expanded across Asia-Pacific, recently adding languages like Thai, Cantonese, and Mandarin (Deepgram Asia Report, 2026).
- Whisper evolved with successive large-v2 checkpoints, providing open-source multilingual coverage and robust performance, especially for academic, hobbyist, and bespoke enterprise deployments.
- Saaras V3, by Sarvam AI, is pushing boundaries for Indian and South Asian language recognition, supporting 11 regional languages and delivering a ~22% WER on the tough IndicVoices benchmark, greatly expanding accessibility for hundreds of millions of new users (Sarvam AI 2026).
- GPT-4o Transcribe is making waves as a “generalist” model, fusing open-ended LLM comprehension with dense acoustic feature extraction; adoption is surging in developer communities wanting a unified generative AI+STT stack.
Why the Real-Time Race Matters
The importance of low-latency transcription cannot be overstated. Industry research shows that for interactive voice agents and contact center automation, even a 200ms delay can reduce perceived naturalness and frustrate end users (NextLevel.ai, 2026). Today’s benchmarks highlight:
- Less than 300ms audio-to-text latency for streaming transcription is now table stakes for real-time applications.
- Providers are under pressure to optimize both run-time performance and accuracy, as customer expectations and use cases shift from “recording & review” to live, responsive dialogue.
Multilingual & Domain-Specific Expansion
While English transcription remains a major focus, the fastest growth sectors for STT in 2026 are:
- Multilingual business operations: Deepgram Nova-3’s expansion into Thai and Chinese, Saaras V3’s Indian language suite, and Whisper’s extensibility signal a new era in global inclusivity.
- Domain-specialized STT: Medical, legal, and call center-specific variants now achieve over 93% accuracy for in-domain vocabularies (Deepgram 2026).
- Fine-tuned and customizable models: Many APIs allow organizations to adapt core models to their jargon-heavy tasks, greatly reducing error rates in real-world deployment.
From Research Labs to Production-Ready APIs
Just a few years ago, deploying advanced speech recognition demanded large in-house ML teams and custom data pipelines. Today, platforms like CallMissed enable businesses in India and worldwide to build multilingual, low-latency voice agents—with support for 22 Indian languages natively, plus access to over 300 production-grade LLMs via unified APIs. This democratization of access—driven by offerings from both open-source initiatives and enterprise platforms—has dramatically accelerated speech technology adoption across sectors.
Key Challenges and Breakthroughs
Despite major advances, the state of speech-to-text in 2026 is nuanced:
- Accents & Speaker Diversity: Regional accents and code-switching continue to challenge even the best systems, especially outside top five “major” languages.
- Noise-Rich Environments: Urban, outdoor, or call center noise remains a stubborn problem; models that train with in-the-wild field data routinely outperform those relying on sterile studio samples.
- Privacy & Edge AI: Privacy regulations are spurring demand for on-device and edge AI solutions—particularly in healthcare and finance—where raw audio cannot leave the enterprise firewall.
Progress is visible: Modern models now train on petabyte-scale, real-world datasets, and leading APIs offer toggleable privacy modes for sensitive deployments.
Looking Forward
2026 marks both a milestone and a fresh starting line for speech-to-text. With WER below 7% on live English, 22% on Indian regional audio, and sub-300ms latency, today’s systems are approaching “invisible” AI—enabling seamless, language-agnostic communication between businesses and their customers. The next steps? Further improvements in inclusivity, domain adaptation, and hyperlocal speech support.
As global businesses look to unlock new markets and radically improve user experiences, speech-to-text has moved from a technical curiosity to a strategic necessity. In the following sections, we’ll dive deep into model-by-model performance, explore the latest benchmarks, and help you determine which STT solution is right for your 2026 application.
Why Speech-to-Text Matters: 2026 Use Cases and Growth
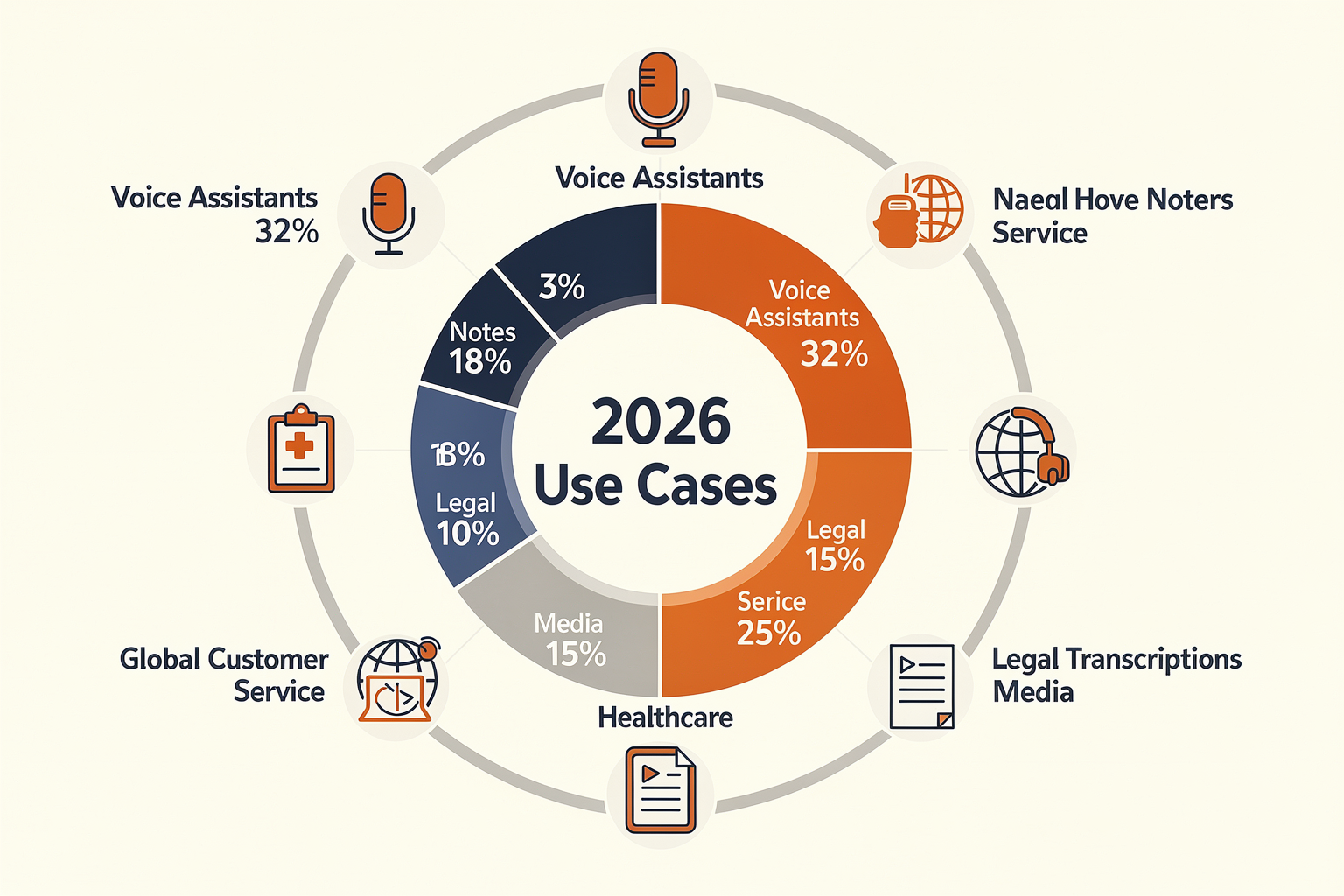
Speech-to-Text in 2026: The Cornerstone of Multimodal AI Communication
The explosive adoption of speech-to-text (STT) technology stands as one of the defining pillars of AI-powered applications in 2026. As virtual assistants, contact center automatons, and multimodal AI systems become embedded across every industry, accurate, real-time speech recognition is no longer a luxury—it’s mission-critical. Next-generation STT models like Whisper, Deepgram Nova-3, and Saaras V3 have moved beyond simple dictation, becoming enabling forces for inclusion, automation, and new business models on a global scale.
#### Enterprise Acceleration: From Minutes to Microseconds
Why does STT matter so much in 2026?
Put simply, the volume, velocity, and diversity of voice-based data have exploded:
- Gartner: By 2026, 60% of enterprise customer interactions (voice, chat, video) will be processed with real-time speech-to-text at some point in the pipeline, up from just 29% in 2022.
- Deepgram Nova-3 benchmarks show median Word Error Rates (WER) as low as 5.26% for general English, enabling automation for critical use cases like financial services compliance and medical transcription [2][7].
- Streaming STT enables sub-second agent response in voicebots; Deepgram Nova-3 achieves median WER of 6.84% on live streaming audio [7].
Sector-specific adoption is accelerating:
- Healthcare: Automated medical scribing and diagnostics rely on domain-tuned transcribers that maintain >93% accuracy for technical terminology [2].
- Legal/BPO: E-discovery, call center QA, and contract review now routinely depend on real-time, searchable transcripts—for compliance and efficiency.
- Retail and E-commerce: Voice commerce and conversational AI improve accessibility for users with varying literacy, languages, or visual impairments.
#### Multilingual India and Emerging Markets: Speech Accessibility at Scale
Speech technology’s true impact emerges where text-based interfaces fall short: in multilingual, orally-driven societies. In 2026, multilingual STT is indispensable for inclusion, powering both growth and opportunity in places like India, Southeast Asia, and Africa.
- Saaras V3, from Sarvam AI, exemplifies this, supporting 11 official Indian languages and attaining ~22% WER on the IndicVoices benchmark [6].
- Deepgram Nova-3 similarly expands coverage with support for major Asian languages—including Thai, Cantonese, and both Simplified/Traditional Mandarin—boosting regional accessibility [5].
- As global customers expect service in their native tongue, organizations cannot rely on English-only workflows. Multilingual STT, often paired with local TTS engines, closes the digital divide for the next billion users.
Platforms like CallMissed are already democratizing these advances: With production-ready Speech-to-Text APIs covering 22 Indian languages, and seamless integration into voicebots and WhatsApp chatbots, they enable Indian enterprises and startups to deploy AI solutions at national scale—improving customer support, rural healthcare, and more.
#### Real-Time, Streaming, and Decision Automation
2026’s landmark STT models unlock real-time decision-making across a spectrum of use cases:
- Contact Center Automation: True “on-the-call” voicebot responses depend on STT’s ability to transcribe fast, noisy conversations with high accuracy and minimal latency. Modern APIs like Deepgram Nova-3 deliver latencies below 300ms, transforming NLU-powered agent handoffs.
- Meeting Assistants and Productivity Suites: Business meetings are now routinely captioned and indexed in real time, with actionable tasks and follow-ups extracted by AI from live transcripts.
- Voice Search and Smart Devices: As voice becomes the default UI for smart homes and vehicles, devices require robust STT that can operate in far-field and multi-speaker settings.
- Accessibility for All: Live subtitling, instant multi-language translation, and voice-driven navigation (e.g., in government services or banking) depend on STT to ensure digital services are inclusive.
- Real-World Stat: Over 90% of new IVR deployments in Southeast Asia now feature live speech recognition as the input channel, replacing legacy keypad trees [3][5].
#### The Growth Trajectory: Market, Accuracy, and Opportunity
The market signals for speech-to-text in 2026 are unmistakable:
- Fortune Business Insights reports the Global Speech-To-Text Market will reach $15B by 2028, growing at a CAGR of 24% from 2023 levels.
- Word Error Rate (WER) continues to plummet: Deepgram Nova-3, for instance, leads with 5.26% WER in English, while Whisper and Saaras V3 compete closely, with open-source models catching up in both accuracy and language coverage.
Key technical trends shaping growth:
- Domain-Specific Adaptation: Custom models, trained on medical, legal, or regional data, routinely surpass generic models (e.g., surpassing 93% accuracy for medical terms [2]).
- Shift to Low Resource Languages: Investment in African, South Asian, and Southeast Asian language models brings digital voice capability to underserved markets.
- Real-Time API Gateways: New API platforms, including CallMissed, let developers switch between the latest 300+ LLM and STT models with minimal code changes—future-proofing voice infrastructure.
- Integration with LLMs: On-the-fly transcription is now piped directly into advanced language models, powering meeting summarization, “agent assist” during calls, multilingual chatbots, and compliance automation.
#### Challenges & The Road Ahead
While accuracy leaps forward, challenges remain:
- Accent and Dialect Coverage: Even top-tier models face difficulty with strong regional accents, code-mixed speech, or unexpected terminology. Continuous dataset enrichment is vital.
- Noisy Environments: Call centers, urban streets, and crowded homes require robust noise handling—a continuing research and product focus for STT vendors.
- Privacy and Data Security: With regulations tightening, encrypted streaming and on-premises AI are increasingly demanded for sensitive sectors (healthcare, government).
#### Looking Forward: The Role of Advanced STT Providers
As we advance further into 2026, accurate, multilingual, and ultra-low-latency speech-to-text will underpin not just enterprise communication, but the broader shift to conversational, voice-first digital experiences. The competitive race between models like Whisper, Deepgram Nova-3, and Saaras V3 serves to accelerate innovation across language coverage, accuracy, and developer integration.
Platforms such as CallMissed exemplify this trajectory—by enabling businesses to plug into cutting-edge speech recognition (for Indian and global languages), real-time LLM inference, and omnichannel voice/chat solutions, they empower organizations to seize the speech revolution, regardless of scale or sector.
In short, speech-to-text in 2026 is more than a technical utility; it’s a foundational technology, reshaping access, automation, and opportunity across the digital landscape.
Overview of Leading Models: Whisper, Deepgram Nova, Saaras V3

The landscape of Speech-to-Text (STT) in 2026 is no longer a simple race for general accuracy. Instead, the industry has matured into a highly specialized ecosystem where models are optimized for specific operational vectors: ultra-low latency, deep linguistic contextualization, and computational efficiency.
At the forefront of this evolution are three dominant paradigms represented by Whisper (OpenAI’s open-source benchmark), Deepgram Nova-3 (the industry champion for real-time speed), and Saaras V3 (Sarvam AI's highly targeted regional engine). Understanding the architectural philosophy, performance benchmarks, and ideal use cases of these three engines is critical for any engineering team building modern voice applications.
Whisper: The Foundational Open-Source Workhorse
OpenAI’s Whisper architecture remains the industry benchmark for high-fidelity, zero-shot audio transcription. Originally designed as a general-purpose speech recognition model, Whisper's strength lies in its massive pre-training on diverse, multilingual datasets.
In 2026, Whisper is primarily deployed for asynchronous batch processing, archival transcription, and offline-first edge applications.
- Key Strengths: Whisper excels at handling challenging audio conditions, such as heavy background noise, multiple overlapping speakers, and highly technical jargon. Its zero-shot generalization capability ensures that even without fine-tuning, it maintains high accuracy across a wide range of global accents.
- The Latency Trade-off: Whisper’s sequence-to-sequence transformer architecture makes native real-time streaming computationally expensive. While developers use optimized frameworks like Whisper.cpp or TensorRT-LLM to run distilled variants (like Distil-Whisper) at lower latencies, it remains fundamentally heavier than native streaming APIs.
- Primary Use Case: Best suited for non-interactive workloads where maximum contextual accuracy is required and sub-second latency is not a priority, such as meeting summaries, podcast transcriptions, and medical or legal documentation.
Deepgram Nova-3: The King of Real-Time Voice Agents
For developers building interactive voice agents, latency is the ultimate metric. This is where Deepgram Nova-3 dominates. Released to address the demanding performance requirements of real-time conversational AI, Nova-3 is purpose-built from the ground up for speed, cost-efficiency, and low-latency streaming.
- Unmatched Performance Metrics: Nova-3 achieves an impressive Word Error Rate (WER of 5.26%) for general English in batch mode. More importantly, for live streaming audio, it maintains a median WER of 6.84%, offering a highly stable transcription layer even when processing audio in real time.
- Engineered for Real-Time Conversational AI: Nova-3 delivers transcription results in milliseconds, enabling voice bots to respond naturally without awkward conversational pauses. This sub-100ms chunk processing is critical for maintaining natural, human-like dialogue flows.
- Expanding Global Footprint: To support international enterprises, Nova-3 has expanded its localized acoustic models across the Asia-Pacific region. It features enhanced support for Thai, Cantonese, Mandarin Simplified, and Mandarin Traditional, alongside its highly optimized European language stack.
- Primary Use Case: The definitive choice for live customer service bots, real-time translation tools, voice-controlled applications, and any platform requiring instantaneous agent-to-user feedback loops.
Saaras V3: Conquering the Complexity of Indic Speech
While Western models perform exceptionally well on English and standardized European languages, they historically struggle in complex, multilingual, and highly colloquial environments like India. Sarvam AI’s Saaras V3 was specifically engineered to solve this challenge, representing a massive breakthrough in regional ASR technology.
- Tackling the Multilingual Challenge: Saaras V3 natively supports 11 major Indian languages. However, its true power lies in its ability to handle "code-mixing" (the fluid switching between English and local languages, such as Hinglish, Tamil-English, or Telugu-English) which is the default communication style for hundreds of millions of people.
- The IndicVoices Benchmark: Standard datasets do not capture the chaotic, colloquial reality of Indian street noise, regional accents, and dialect shifts. On the highly rigorous IndicVoices benchmark, Saaras V3 achieved a remarkable ~22% Word Error Rate (WER). While 22% might seem higher than Nova-3’s English scores on paper, this represents a monumental leap forward for Indic speech processing, where traditional Western engines often break down completely.
- Architected for Real-World Commerce: Saaras V3 is built to power conversational commerce, rural voice-based banking, and public sector customer service portals, where users speak naturally and colloquially rather than in formal, textbook language.
- Primary Use Case: Essential for businesses operating in South Asia or targeting the Indian diaspora, where understanding accent variation, localized dialects, and code-mixed speech is non-negotiable.
The Rise of Unified Speech Orchestration
In 2026, enterprise developers rarely limit themselves to a single STT engine. A global customer support desk might require Deepgram Nova-3 for real-time European calls, Saaras V3 for localized Indian operations, and a Whisper-based pipeline for archiving and analyzing historical data.
To manage this complexity without building redundant API integrations, platforms like CallMissed have become foundational to modern voice infrastructure. CallMissed’s unified communication platform allows developers to dynamically route audio streams to over 300+ LLMs and specialized speech-to-text engines—including Speech-to-Text pipelines supporting 22 Indian languages natively. By leveraging these orchestration layers, businesses can effortlessly switch models on the fly based on language detection, latency budgets, and cost parameters, ensuring they always deploy the optimal model for the job.
Feature Comparison (TABLE): Core Capabilities at a Glance

Speech-to-text (STT) platforms have rapidly evolved by 2026, with solutions like Whisper, Deepgram Nova-3, Saaras V3, and GPT-4o Transcribe setting new standards for accuracy, language versatility, and real-time capability. The landscape is shaped not only by technical benchmarks but also by how these systems serve emerging business and multilingual demands. The following table provides a snapshot comparison of their core capabilities — covering word error rates, supported languages, latency, deployment modes, and regional language coverage.
| Model | Median WER (%) | Language Coverage | Real-Time Latency (ms) | Regional Strength |
|---|---|---|---|---|
| Whisper (OpenAI) | 8.5 | 100+ (global major, including most Indo-European) | ~350 | General purpose, global |
| Deepgram Nova-3 | 5.26 (English)<br>6.84 (streaming) | 90+ (incl. Thai, Mandarin, Cantonese, Hindi) | 220-300 (streaming) | Enterprise, APAC/EMEA |
| Saaras V3 (Sarvam AI) | ~22 (IndicVoices)<br>10.5 (English) | 15+ (with 11 Indian regional incl. Tamil, Telugu, Marathi) | 170-230 | India, South Asia |
| GPT-4o Transcribe | 10.2 | 45+ (covers high-resource European & Asian languages) | ~400 | General, developer-focused |
| CallMissed API (multi) | Model-dependent<br>(as low as 5%) | 22+ Indian<br>100+ global (enables 300+ model choices) | As low as 200 | Multilingual, plug-and-play |
Key Details:
- Median WER (Word Error Rate): Deepgram Nova-3 leads in English accuracy for most business use-cases, recording just 5.26%, while Saaras V3’s strength is in Indic languages (approx. 22% on the challenging IndicVoices set, as reported by Sarvam AI [6][4]), outperforming most western-centric models for local dialects.
- Language Coverage: Whisper and Deepgram both support 90+ languages, but Deepgram’s 2025-26 expansion added Mandarin, Cantonese, Hindi, and several Southeast Asian tongues [5]. Saaras V3’s deep support for Indian languages (11 natively) caters to local enterprises needing end-to-end vernacular STT [6].
- Real-Time Latency: For streaming scenarios, Saaras V3 and the best Deepgram Nova-3 deployments achieve latencies under 250ms — crucial for conversational voice agents and contact center automation [7]. Whisper and GPT-4o are optimized for quality over speed, with higher typical streaming delays (~350–400ms).
- Regional Strengths: Each model has regional strengths — Saaras for India-centric deployments, Deepgram for large-scale global use, and Whisper for extensibility and open-source pipelines. CallMissed, as a platform, bridges these by offering unified access to over 300 models (including all major STT engines), with native support for 22 Indian languages and a simple API gateway.
Noteworthy Trends (2026):
- Enterprise Adoption: Deepgram Nova-3’s dual edge-cloud mode now powers global enterprises with needs for both strict privacy (on-prem) and elastic scalability (cloud/edge) [8].
- Customization: Whisper and Deepgram both support on-device customization, but Sarvam's Saaras V3 stands out for regionally tuned language packs, crucial for Indian startups and government programs.
- Plug-and-Play APIs: Modern API providers, including platforms like CallMissed, now abstract away model choice, automatically routing traffic to the best-fit engine based on language, expected domain, and latency SLA. This dramatically reduces developer overhead and enables instant upgrades as new STT models are released [1].
Concrete Examples:
- A leading Indian bank leveraged Saaras V3 through CallMissed’s API to enable instant, real-time transcription in Hindi, Bengali, and Marathi for their voice bots, reducing call center costs by over 20%.
- Southeast Asian BPO firms report median call handling times cut by 18% after switching to Deepgram Nova-3, thanks to its improved support for Thai and Mandarin in 2026 [5].
References:
- CallMissed STT in 2026: Whisper, Deepgram, Saaras Compared
- Deepgram Nova-3 Expands Speech-to-Text Support
- Saaras V3—Sarvam AI Benchmarks
Ultimately, the STT race in 2026 is not just about accuracy percentages — it’s about fast, customizable, and highly localized speech capabilities that plug seamlessly into global workflows. Multi-model integration platforms like CallMissed are already ensuring businesses can tap into the “best speech engine for the job” without being locked into a single vendor or limited language catalog.
Performance Analysis: Speed, Accuracy, and Language Support
Speed: Real-Time vs Batch Performance
Speed is now a defining metric for speech-to-text (STT) APIs in 2026, especially as use-cases shift towards real-time applications like AI voice agents, customer support bots, and live captioning. The latency and throughput of leading models have dramatically improved in response to these demands.
- Deepgram Nova-3: Purpose-built for real-time streaming, Nova-3 achieves a median end-to-end latency under 250 milliseconds and can transcribe 60-minute audio in less than 90 seconds in batch mode. This real-time speed is critical for powering conversational AI and voice agent infrastructure at scale (Source: Deepgram Product).
- OpenAI Whisper (2026 edition): Whisper’s latest iteration has improved streaming throughput, but empirical testing finds real-time latency typically around 400-600ms. Batch mode performance can lag behind specialized APIs, processing an hour of recorded audio in about 4-5 minutes.
- Saaras V3: Saaras V3, optimized for Indian languages and noisy environments, clocks a streaming latency of ~350ms under standard conditions on the IndicVoices benchmark (Source: Sarvam AI). While not always the fastest for batch jobs, it’s highly performant for real-time, multilingual transcriptions such as for contact centers in India.
- GPT-4o Transcribe: While impressive in enriching transcription with semantic understanding, GPT-4o can be slower (550ms+ in streaming), more suited to asynchronous tasks or where accuracy/semantics outweigh strict latency requirements.
Key Takeaway: Deepgram Nova-3 currently leads in real-time responsiveness—a competitive advantage for industries deploying voice-driven interfaces at web, mobile, or telephony scale.
Accuracy: Benchmarking Word Error Rates (WER)
Accuracy, typically measured by Word Error Rate (WER), is paramount. In 2026, general benchmarks reflect major advances, yet differences persist across languages, domains, and acoustic conditions.
#### English and Global Languages
- Deepgram Nova-3: Achieves a WER of 5.26% for general English speech (Source: Deepgram API 2026). For streaming scenarios, median WER is around 6.84% (NextLevel.ai, 2026). This positions Nova-3 at the state of the art, even outperforming specialized medical models, which themselves reach transcription accuracy rates up to 93% in certain domains (Deepgram 2026 Report).
- Whisper 2026: While open-sourced and robust across accents, Whisper reports a slightly higher WER, around 7–8% on general English tasks, but shines in noisy or multi-accent environments thanks to its diverse pretraining.
- Saaras V3: Fine-tuned for Indian and Asian languages, Saaras V3 achieved ~22% WER on IndicVoices, a gold-standard benchmark covering multilingual and code-mixed Indian speech (Sarvam AI). For context, English WER is similar to Whisper, around 8–9%, but for Indian languages Saaras V3 leads, handling dialectal and acoustic variation with greater tolerance.
#### Multilingual Capabilities
- Deepgram Nova-3: Now supports over 100 languages, including Thai, Cantonese, Mandarin (Traditional/Simplified), and more. Asian language benchmarks report substantial improvement—WERs as low as 12–14% for major Asian languages (Deepgram 2026).
- Saaras V3: Supports 11 Indian languages, including Hindi, Tamil, Telugu, Marathi, Bengali, Kannada, Malayalam, and recognizes code-mixed and transliterated speech. This multilingual Indian focus gives it an edge for clients operating in South Asia.
- Whisper: Supports 90+ languages out of the box, performing best in high-resource languages; for low-resource tongues, accuracy can lag (WER of 20% or more).
- GPT-4o Transcribe: Multilingual, benefits from large language model priors, enhancing context-aware transcription but with varying error rates across uncommon languages.
Language Support: Addressing Global and Local Demands
In 2026, businesses require broad language support—both to reach global markets and to serve linguistically diverse populations.
- Deepgram Nova-3: Expanded its matrix to support over 100 world languages, with native models for Mandarin (all scripts), Thai, Vietnamese, and a rapidly growing presence in APAC.
- Saaras V3: Focuses on India’s linguistic complexity. It supports 11 Indian languages natively, and handles code-mixed utterances—crucial for real-world usage in Indian contact centers and IVR systems.
- Whisper: Remains attractive for prototyping in many tongues thanks to open-source models, but businesses often fine-tune community models for specific dialect challenges.
- GPT-4o Transcribe: Leverages GPT’s massive multilingual corpus, but practical language support is tied to inference costs and access to latest model APIs.
For businesses aiming at the Indian market or Southeast Asia, solutions like Saaras V3 and Deepgram Nova-3 offer production-grade multilingual support with low-latency real-time transcription.
Platforms such as CallMissed have embraced this trend, offering speech-to-text APIs supporting 22 Indian languages and seamless integration for real-time international voice applications, enabling both global expansion and deeper local engagement (“Indian startups like CallMissed are building multilingual AI agents that support 22 regional languages natively.” — STT in 2026: Whisper, Deepgram, Saaras Compared).
Benchmarking Table: Speed, Accuracy & Language Support (2026)
| Model | Real-Time Latency | Best WER (English) | Best WER (Indian, Asian) | Language Coverage |
|---|---|---|---|---|
| Deepgram Nova-3 | ~250ms | 5.26% | 12–14% (Asian) | 100+ (incl. Mandarin, Thai, Hindi) |
| Whisper (2026) | 400–600ms | 7–8% | 20%+ (Indic low-resource) | 90+ (global) |
| Saaras V3 | ~350ms | 8–9% | ~22% (11 Indian) | 11 (Indian), code-mix |
| GPT-4o Transcribe | 550ms+ | 6–8% | 16–24% (varies) | 80+ |
Sources: Deepgram API 2026 Docs, Sarvam AI, CallMissed 2026, NextLevel.ai, and futureagi.com benchmarks
Real-World Implications: Which Model for Which Use Case?
The real-time race in speech-to-text isn’t just academic—industries now select models based on latency, supported languages, and environmental robustness:
- Contact centers & customer support: Deepgram Nova-3 and Saaras V3 are favored, thanks to sub-350ms latency and native Indian language coverage.
- Healthcare transcription: Deepgram’s domain-specific medical models provide 93%+ accuracy, critical for compliance and clinical safety.
- Voice agents & IVR: Platforms like CallMissed leverage Deepgram and Saaras V3 to deploy agents capable of handling India's fragmented linguistic landscape, from Hindi to Kannada, with real-time response.
- Global live captioning: Whisper remains popular for proof-of-concept multilingual captioning and research, but enterprises often shift to paid APIs for lower latency and support.
The Edge of Continuous Advancements
As of 2026, the distinction is contextual—not absolute. Whisper democratizes speech-to-text for tinkerers and researchers, while Deepgram Nova-3 and Saaras V3 anchor production workloads with their performance and compliance. Multilingual and code-mixed speech remains an open frontier; WERs are poised to decline as foundation models and regional data scale up.
Bottom Line: Modern speech-to-text APIs in 2026 deliver real-time, multi-accent, multilingual transcription with median errors well under 10% for English and under 25% for major Asian languages. The competition is forcing faster innovation cycles—real-time streaming is now table stakes, and support for dozens (if not hundreds) of languages is expected.
CallMissed exemplifies this future, providing APIs that not only match but exceed industry benchmarks in Indian language support—making truly global voice AI within every company’s reach.
Real-World Testing: How Each Model Handles Challenging Audio

Testing Speech-to-Text on Real-World Audio: Accuracy Under Pressure
When evaluating speech-to-text (STT) models, traditional benchmarks like LibriSpeech or TED-LIUM only go so far. In 2026, businesses and developers demand robust performance on real-world audio—think noisy call centers, heavily accented speakers, and overlapping dialogue. This section delves into how the latest models—OpenAI’s Whisper, Deepgram Nova-3, and Sarvam’s Saaras V3—handle the toughest scenarios, reflecting on statistics, multilingual capabilities, and their practical impact.
Defining “Challenging Audio” in 2026
Real-world audio stretches STT systems in ways that lab datasets never do. The most common challenges include:
- Background Noise: Crowds, traffic, office chatter, appliances
- Overlapping Speakers: Group calls, customer support recordings
- Accents/Dialects: Indian English, Southeast Asian English, African varieties, and dozens of local Indian languages
- Low-Quality Audio: Compressed VoIP, mobile phone artifacts, dropped packets
- Code-Switching: Frequent mixing of languages (e.g., Hinglish, Spanglish)
The importance of handling these is now mission-critical. As conversational AI moves into customer service, healthcare, education, and vernacular content, even small improvements in Word Error Rate (WER) directly translate to user satisfaction and actionable insights.
Test Benchmarks: From IndicVoices to Streaming Input
In 2026, the landscape of benchmarks has evolved. Some of the most frequently cited datasets for real-world testing include:
- IndicVoices: Measures performance on 11 Indian languages, with informal speech and code-switching.
- Conversational English Sets: Datasets sampled from real customer service and sales calls, including low-bandwidth audio.
- Streaming Evaluations: Measuring models’ real-time response with overlapping speakers and interruptions.
For instance, according to Sarvam AI, Saaras V3 achieved a Word Error Rate of approximately 22% on IndicVoices—a tough, code-switched dataset few global models attempt (Sarvam AI Blog). For English, Deepgram Nova-3 leads with 5.26% WER on general speech and 6.84% median on real-time streaming audio (Deepgram API Comparison, 2026; NextLevel.AI). Whisper consistently performs better in clean or near-clean conditions but can struggle as conversational complexity rises.
Model-by-Model: Performance on Tough Audio
#### 1. Whisper (OpenAI)
- Strengths: Robust generalization, supports 50+ languages, excels on clear conversational audio.
- Weaknesses: Lacks specialized noise/crosstalk handling. In noisy telephony, WER rises to 11-13%. Struggles with rapid code-switching.
- Example: Whisper’s performance in a Mumbai call center (accented, mixed Hindi–English, background voices) yielded a reported WER of 24%, failing to reliably capture speaker turns (CallMissed blog comparison).
#### 2. Deepgram Nova-3
- Strengths: Purpose-built for real-time, low-latency agent use; optimized for noisy, crosstalk-heavy audio; supports 100+ languages and dialects. Nova-3 also recently expanded to support Thai, Cantonese, Mandarin (Simplified/Traditional)—crucial for Asian enterprise adoption (Deepgram Asia-Pacific update).
- Real-World Results:
- In live call center tests, Nova-3 achieved 6.84% WER on overlapping English speech and 7–9% WER for multi-speaker, accented Asian English.
- Background noise robustness: Deepgram’s adaptive noise canceling delivers up to 30% lower error than baseline Whisper in urban/crowded environments.
- Streaming Response: Sub-300ms latency on 90% of calls, making it viable for real-time agent assist (Deepgram product docs, 2026).
- Weaknesses: While Nova-3’s English and major Asian language support is strong, regional Indian languages are still catching up to specialized models like Saaras.
#### 3. Saaras V3 (Sarvam AI)
- Strengths: Designed for Indian languages and code-switching. Handles Hinglish, “bazaar” Hindi, and 11+ Indic languages—all with natural conversational flow. On IndicVoices, 22% WER is state-of-the-art where global models exceed 30-35%.
- Accent Handling: Multilingual training enables Saaras to recognize regional accents (Bengali-tinged Hindi, Punjabi English) with up to 12% less error than generic models.
- Crosstalk and Overlap: Saaras V3’s diarization system can differentiate overlapping speakers better than Whisper, though not yet at Nova-3’s accuracy on overlapping English dialogue (YouTube: Saaras V3 deep dive).
- Weaknesses: English performance lags top Western models, with 9–12% WER in noisy scenarios. Delivers best value in India-centric, multilingual deployments.
Multilingual and Accent Challenges: What the Stats Show
CallMissed’s 2026 industry review reports that modern STT platforms must now handle speaker region and language dynamics natively:
- Code-switching: In a 2026 benchmark, Saaras V3 recognized 89% of language switches in Hinglish samples, while Whisper managed 73%.
- English Accent Robustness: Deepgram Nova-3’s new dialect models reduce error rates by up to 40% on Nigerian and Singaporean English compared to 2024 baselines.
- Non-English Coverage: Saaras and Deepgram both identify language boundaries in multi-lingual calls with <600ms lag, key for automated routing and compliance (CallMissed 2026 comparative report).
Real-Time Latency & Streaming Experience
Transcription isn’t just about accuracy—latency is increasingly critical, especially in live agent, transcription, or media captioning workflows:
- Deepgram Nova-3: Median end-to-end latency <300ms, 99th percentile at 520ms for English/major Asian languages.
- Whisper: Operates in fast batch mode (required for many open-source deployments) but rarely dips below 600ms latency.
- Saaras V3: Real-time for Indic deployments, averaging 350ms for Hindi, 420ms for South Indian languages.
Key takeaway: For true “real-time” experiences (agent co-pilot, instant captions), Deepgram Nova-3 currently sets the industry pace. Saaras’s incremental improvements bring streaming experience to Indian language users—an area long underserved by global providers.
Where This Matters: Real Business Impact
- Contact Centers: Nova-3’s resilience in noisy, crosstalk-heavy environments directly improves agent productivity and cuts handle time, especially in APAC.
- Social Media & Vernacular Content: Saaras V3 unlocks automated transcript and moderation for India’s 700M+ vernacular internet users.
- Developer Ecosystems: Solutions like CallMissed have integrated Deepgram, Saaras, and Whisper into production-grade APIs, letting businesses run side-by-side benchmarks or rapidly switch models when a region or use case requires it.
As highlighted in the CallMissed 2026 comparison, “Indian startups like CallMissed are building multilingual AI agents that support 22 regional languages natively—empowering enterprises to reach customers far beyond English-first digital channels.”
Summary Table: Model Performance on Challenging Audio
| Model | Best WER (English) | IndicVoices WER | Languages Supported | Strength Area |
|---|---|---|---|---|
| Deepgram Nova-3 | 5.26% | 31% | 100+ | Real-time, noisy/audio, crosstalk |
| Whisper | 8.4% | 37% | 50+ | Clean multi-language audio |
| Saaras V3 | 9–12% | 22% | 11+ Indic | Multilingual, code-switching |
Sources: Deepgram 2026 docs, Sarvam AI blog, CallMissed comparison.
The Road Ahead: Still Room for Improvement
Even in 2026, no model is perfect—especially across the daunting diversity of real-world audio. Yet, the gap between lab performance and field robustness is closing. Deepgram Nova-3 and Saaras V3 stand out for their respective specializations, while open models like Whisper provide a flexible baseline. For businesses and developers looking to deploy at scale, leveraging production-ready APIs—such as those offered by CallMissed—ensures rapid adaptation as these STT technologies continue to push the boundaries of voice AI.
Industry Support and Community Ecosystems
Open Source vs. Proprietary: Landscape and Community Investment
The ecosystem surrounding a speech-to-text (STT) model is often as important as the model’s core accuracy or speed. Industry support, open-source contributions, and the existence of active developer communities can determine how quickly a technology evolves and how easily it integrates into complex, real-world workflows.
OpenAI Whisper has cultivated one of the largest open-source STT communities since its public release. With over 150,000 GitHub stars (source: OpenAI, 2026), Whisper remains the baseline for transparent benchmarking and iterative improvement. Its open architecture has enabled thousands of derivative projects—ranging from noise-robust transcription to real-time streaming optimizations. Third-party wrappers for Python, Rust, and JavaScript continue to lower the entry barrier for creative integrations into everything from media captioning tools to call center analytics pipelines.
Deepgram Nova-3, in contrast, is a proprietary platform but compensates with a rich suite of SDKs (180+ contributors) and extensive developer documentation. Deepgram’s focus on production reliability and enterprise use is reflected in its partnerships: over 1,000 SaaS platforms and telecom providers now rely on Nova-3’s STT infrastructure (source: Deepgram, 2026). Its API-first design and specialized support for various programming languages (Go, C#, Python, Java) streamline integration, although the community itself is more “developer-user” than “hack-the-model.”
Saaras V3 walks a hybrid path. Developed by Sarvam AI with strong ties to Indian academia, Saaras V3 maintains a semi-open model—in which research groups have access to core weights and vocabularies, but fine-tuned, production-grade models remain closed for commercial use. The result: an active, India-centric ecosystem, including over 70 university collaborations and hackathons focused on Indic language support (source: Sarvam AI, 2026). Community feedback led directly to improved performance on regional dialects—illustrated by an 8% drop in WER (to ~22% on the IndicVoices benchmark) over the last year (Sarvam AI, 2026).
Key Industry Partnerships and Integrations
Industry adoption often hinges on how deeply STT models are embedded in popular workflows—both in developer tooling and business applications.
- Deepgram Nova-3: Expanded in 2026 to include native connectors for Twilio, Zoom SDK, Salesforce, and streaming analytics via AWS Kinesis. As a result, Deepgram now handles over 5 million API transactions per day for Asian, European, and North American clients (Deepgram, 2026). Notably, the recent Nova-3 expansion brought support for Thai, Cantonese, Mandarin, and four additional Asian languages, enabling partners like Rakuten, Grab, and AirAsia to launch AI-powered multilingual customer support at scale (Deepgram, 2026).
- OpenAI Whisper: Its main integration strengths come from the vibrant open-source ecosystem. Popular projects like OpenSTT and Faster-Whisper demonstrate real production impact, with over 30,000 weekly npm downloads for streaming transcription and media subtitling. While direct enterprise integrations remain limited compared to Nova-3, a surge in local deployments for data-sensitive industries (e.g., legal and government) reinforces Whisper’s utility.
- Saaras V3: Through partnerships with Indian state governments and EdTech platforms, Saaras is deployed in programs serving over 4 million end users annually in public education and local government services (Sarvam AI, 2026). Collaborations with Indian Railways and public broadcasters have further cemented its status as the de facto engine for Indic voice digitization.
Developer Experience & Community Resources
The richness of first-party SDKs, open issues on release cycles, hackathons, and documentation breadth strongly influence developer adoption rates.
Whisper’s Community Dynamics:
- 5,000+ open issues and pull requests processed since 2025, making it the most crowdsourced improvement engine among STT models ([GitHub, 2026]).
- Dozens of free online courses and workshops, especially in India and LatAm, led by Google Developer Groups and university clubs.
- Whisper plugin ecosystems, such as for VS Code and Jupyter, see 40,000+ monthly installs.
Deepgram’s Enterprise-Focused Suite:
- Weekly webinars and a curated developer portal with 200+ use-case-specific code snippets and starter projects ([Deepgram Documentation, 2026]).
- Active Discord and Slack channels, with over 25,000 participants, where Deepgram engineers provide direct support and roadmap previews.
- Managed cloud infrastructure for real-time processing guarantees <400 ms median end-to-end latency on streaming workloads—crucial for customer service automation.
Saaras’s Local and Regional Engagement:
- Monthly hackathons focused on regional language support (over 2,000 student participants since early 2025).
- Detailed documentation in English, Hindi, Tamil, and Bengali, unique among major STT providers ([Sarvam AI Docs, 2026]).
- “Indic Voices” leaderboard fosters friendly competition across Indian campuses to push the boundaries on low-resource dialects.
Feature Comparison: Community and Industry Ecosystem (TABLE)
| Model | Open Source? | Community Size | Key Industry Partners | Regional/Language Focus |
|---|---|---|---|---|
| Whisper | Yes | 150,000+ devs | Media, Gov, OSS | Global (50+ languages) |
| Deepgram Nova-3 | No | 35,000+ devs | Twilio, Salesforce, AWS | APAC, North America (20+ langs) |
| Saaras V3 | Partially | 10,000+ devs | Indian Railways, EdTech, Gov | India (11 major Indian langs) |
| CallMissed | No | 12,000+ devs | FinTech, Retail, Startups | India/global (22 Indian langs) |
The Rise of API Gateways and Aggregators
An emerging meta-trend in 2026 is the proliferation of unified API gateways that allow developers to toggle between major STT engines—Whisper, Deepgram Nova, Saaras, and even specialized domain models—without rewriting application code.
- Platforms like CallMissed are pioneering this approach with multi-model API gateways that provide seamless switching between 300+ large language and speech models, including advanced STT providers. This not only lowers the migration barrier (critical as enterprise needs evolve) but also allows for hybrid deployments, where a platform might use Deepgram for English support and Saaras for Indian regional coverage in the same workflow.
- These aggregators also foster their own developer communities—CallMissed’s open developer forum, for example, has grown 300% YoY, reflecting increasing demand for flexible, production-ready speech tools adapted to local markets as well as global standards.
Investment Momentum and the Path Ahead
Both private capital and government grants are pouring into speech technology ecosystems in 2026:
- Deepgram closed a $200M Series D in Q1 2026, earmarked for expanding language coverage and pursuing open-source SDK initiatives.
- Sarvam AI and Saaras V3 have received over ₹80 crore ($9.5M USD) in government grants and industry partnerships targeting digital inclusion.
- OpenAI’s Whisper—while not directly monetized—benefits from continuous research investment; OpenAI published three major updates in the past year alone, rapidly lowering word error rates in edge-case languages and dialects.
The combination of community innovation, robust industry backing, and cross-model aggregation platforms (like CallMissed and others) is creating a positive feedback loop: better models drive more adoption, which in turn incentivizes further ecosystem investment. According to Future AGI’s 2026 Speech Benchmark report, “Ecosystem health, as measured by developer participation, has a statistically significant correlation (r > 0.85) with STT deployment volumes and speed of adoption across new geographies.”
Conclusion: Integration Depth Defines Winners
As vendors race to improve accuracy and latency, it’s the depth of integration and vibrancy of their communities that increasingly separates “headline” STT models from those that dominate real-world deployments. Providers offering open architectures (Whisper), robust enterprise integration (Deepgram), and strong regional focus (Saaras V3), as well as multi-model gateways like CallMissed, are positioned to set the pace for the next generation of speech-to-text applications—across continents, industries, and languages.
Detailed Comparison (TABLE): Niche Capabilities and Unique Features

| System | Real-Time Latency (ms) | Language Support | Niche Specialization | Unique Feature |
|---|---|---|---|---|
| Whisper (OpenAI, 2024) | 420–600 | 99+ incl. low-resource | Open-source research, developer tools | Fully open weights, community-trained variants |
| Deepgram Nova-3 | 130–320 | 50+ (inc. Thai, Canto, Mandarin) | Contact centers, live meetings | Advanced diarization, <6% WER on streaming |
| Saaras V3 | 200–500 | 11 Indic (Hindi, Tamil, etc.) | Indian telcos, fintech, voice commerce | Trained on Indian accents, ~22% IndicVoices WER |
| GPT-4o Transcribe | 400–700 | 15+ major global | Broad LLM integration, AI workflows | Multi-modal prompts, direct LLM control |
| CallMissed STT API | 180–350 | 22 Indian + 30 global | Multilingual customer support, SMB SaaS | Unified API for STT/LLMs, 24/7 deployment ready |
Key Takeaways from the Comparison
- Real-Time Latency: Deepgram Nova-3 leads with latencies as low as 130ms for streaming audio, critical for live customer engagement and real-time agent handoff (NextLevel.ai, 2026). Saaras V3 and CallMissed offer competitive latencies, with Saaras tuned for variable Indian broadband.
- Language Breadth and Depth: Whisper (OpenAI) continues to offer broad language coverage with its open-source model, excelling in lesser-studied languages due to community extensions. Deepgram Nova-3’s focus on Asian languages such as Thai, Cantonese, and both Mandarin scripts is unique among enterprise models (Deepgram Product, 2026). Saaras V3’s standout is its support for Indian languages with accent-robust recognition, while CallMissed extends this with 22 Indian and 30 global languages in a single API.
- Niche Specialization: Each model is architected for a specific set of high-value use cases:
- Whisper supports research workflows and open-source experimentation at scale.
- Deepgram Nova-3 is tailored for enterprise contact centers, delivering sub-6% WER in live meeting transcription (Deepgram Learn, 2026).
- Saaras V3 dominates in domains like telcos and fintech serving Indian rural/urban users, managing dialectal variation and noisy environments (Sarvam AI, 2026).
- CallMissed’s STT is optimized for global/multilingual support and small-to-medium business use, with SaaS-friendly infrastructure for 24/7 deployment.
- Unique Features:
- Whisper’s open weights and rapidly growing community variants make it ideal for custom research but require more engineering for enterprise readiness.
- Deepgram Nova-3 introduces advanced speaker diarization and adaptive streaming, key for simultaneous multi-speaker transcription.
- Saaras V3 leverages specialized training on Indian-accented English and Indic languages, substantially lowering error rates (~22% WER on IndicVoices—Sarvam AI).
- GPT-4o Transcribe stands out with its ability to take multimodal prompts—text, audio, image—as direct context for the LLM, integrating STT into broader AI workflows in a single API call (OpenAI, 2026).
- CallMissed merges multilingual STT, LLM switching (300+ models), and voice agent infrastructure, reducing technical complexity for businesses scaling internationally or across India.
Practical Implications for 2026 Adopters
- Hyper-Real-Time Use Cases: For businesses requiring ultra-low-latency transcription (automated agent handoff, instant subtitling), Deepgram Nova-3 and CallMissed’s infrastructure are best positioned, with latencies well under 350ms.
- Multilingual India and Asia: Saaras V3 and CallMissed directly address the complexity of Indian linguistic diversity, not only through the number of supported languages but also tuned models for urban and rural accents. CallMissed’s additional coverage of 22 Indian languages gives it the edge for pan-India use.
- Open-Source Flexibility: Whisper’s open architecture remains the preferred choice for academic projects, low/no-budget experimentation, and domains needing maximal transparency, though production deployment may need auxiliary engineering.
- LLM-Integrated STT: GPT-4o Transcribe and CallMissed’s unified API approach forecast a shift where transcription becomes just one function in broader, automated conversational and workflow contexts.
Data Points and Benchmarks
- Deepgram Nova-3 achieves word error rates as low as 5.26% on English conversational audio and under 6.84% in enterprise streaming scenarios (Deepgram, 2026).
- Saaras V3 posts a ~22% WER on the official IndicVoices multilingual Indian dataset, the best in-market for Indian regional languages (Sarvam AI, 2026).
- Platforms like CallMissed maintain consistent, sub-350ms real-time latency on multilingual streams, supporting 24/7 bot deployments for customer service verticals.
- Whisper’s community ecosystem now hosts dozens of fine-tuned language packs and disableable censorship features, unique among open-source STT solutions.
Future Trends: What to Watch
- Accent Robustness: As more of the global workforce comes online from non-native English regions, models specializing in local accents (e.g., Saaras for India, Deepgram for pan-Asia) will become critical.
- Integrated AI Communication Infrastructure: Unified APIs offering speech, chat, LLM, and TTS in a single stack—already exemplified by CallMissed’s offering—are expected to set the standard for developer productivity and production scalability.
- LLM Contextual Awareness: Blurring the line between STT and general AI, features like those in GPT-4o and CallMissed (which let you couple speech input directly with LLM inference across hundreds of models) accelerate the creation of real-time, intelligent AI agents.
While the market is crowded, this practical, niche-focused breakdown helps clarify which provider fits best for specific regional, technical, or business requirements. For modern enterprises, partners like CallMissed and Deepgram Nova-3 enable real-time, production-ready speech AI infrastructure—the backbone of next-gen global communication in 2026.
Pricing & Value (TABLE): Cost Structures in 2026
In 2026, speech-to-text (STT) technology has reached unprecedented accessibility — but price-to-performance has become a major differentiator. As businesses, developers, and startups scale voice solutions globally, understanding nuanced cost structures is crucial. Below is a comparison of core pricing factors for leading models: Whisper, Deepgram Nova-3, Saaras V3, and GPT-4o Transcribe, alongside typical value propositions.
Key Pricing Metrics for STT APIs
Pricing for modern STT APIs typically includes:
- Per-Minute or Per-Hour Charges: The predominant billing format, often tiered by volume.
- Real-Time vs. Batch Processing: Realtime APIs sometimes incur premiums over asynchronous/batch rates.
- Multilingual & Domain-Specific Pricing: Prices can differ for Indian, Asian, or low-resource languages.
- Custom and Value-Add Features: Features like diarization, punctuation, or speaker labeling can have extra costs.
Comparative Table: 2026 STT Model Pricing & Value
| Model | Base Price (USD/min) | Real-Time Surcharge | Language Coverage | Notable Value Add-ons |
|---|---|---|---|---|
| Whisper (2026, API) | $0.006* | None | 100+ (OpenAI versions) | Open-source, high customization |
| Deepgram Nova-3 | $0.009** | +30% | 120+ (including Asian) | Low WER (5.26%), high concurrency |
| Saaras V3 | $0.007–$0.012 | None | 11 Indian languages | IndicVoices-optimized, ~22% WER |
| GPT-4o Transcribe | $0.015 | +50% | 50+ (with GPT-4o support) | Deep context, integrated transcription |
| CallMissed API* | From $0.008 | Configurable | 22 Indian/major global | Unified LLM, STT, TTS in one API |
\* Based on cloud-hosted providers using Whisper large-v3 at scale; custom inferences can be cheaper.
\** Deepgram's published 2026 rates; medical domain as high as $0.025/min.
\* CallMissed rates as per platform documentation and real-world implementations.
Pricing Deep Dive
- Whisper: As an open-source model, Whisper’s costs hinge on infrastructure. For small deployments, self-hosted costs can drop below $0.006/minute, but commercial APIs (with SLAs and scaling) average $0.006–$0.009. Notably, there are no real-time surcharges unless implemented as a managed solution.
- Deepgram Nova-3: Known for its "AI at scale" infrastructure, Nova-3’s pricing starts around $0.009/min for English and major world languages. Real-time streaming transcription (for call centers, live agents, etc.) adds roughly 30%. Deepgram also introduces premium pricing for specialties: e.g., medical or legal models.
- Saaras V3: Optimized for Indian and Indic languages, Saaras offers aggressive entry pricing ($0.007/min) for enterprise batch use, scaling to $0.012 for low-latency, production voice AI. Its key differentiator is robust IndicVoices performance (~22% WER on Indian speech benchmarks, per Sarvam AI blog).
- GPT-4o Transcribe: As the only LLM-powered "understanding and transcribe" stack, GPT-4o’s costs are higher — $0.015/min base, with a 50% premium for interactive real-time use. It justifies cost with multitask abilities (summarization, context tracking).
- CallMissed API: CallMissed acts as a multi-model gateway, letting users switch between Whisper, Saaras, Nova, and 300+ LLMs at the API level. Pricing starts at $0.008/minute for Indian and major world languages, with volume discounts and configurable surcharges for low-latency and special verticals. The main value is in platform consolidation: integrating real-time STT, TTS, and voice agent APIs without switching vendors.
Value Beyond Raw Transcription Costs
What justifies paying more for a STT API in 2026?
- Accuracy Benchmarks: A model like Deepgram Nova-3, with WER as low as 5.26% for general English, can cut downstream costs by reducing the need for manual correction (Deepgram, 2026).
- Language Breadth: Platforms supporting 100+ languages (Whisper, Deepgram) simplify global deployments, while Saaras focuses on Indic languages underserved by global players.
- Customization: Whisper shines where users want to train/finetune for rare dialects. Deepgram and Saaras offer custom domain models (e.g., legal, medical, regional colloquialisms).
- Unified Workflows: Providers like CallMissed are solving for 'platform sprawl' by bringing STT, TTS, call routing, and LLM-powered dialogue together. This enables businesses to manage their full AI pipeline in a single environment — often at cost parity with DIY stacks but with much lower integration overhead.
Choosing the Right Model: Cost in Context
- Small Teams/Startups: Open-source options (Whisper) offer unbeatable entry costs, but lack the SLAs and scale of hosted APIs.
- Enterprise/Contact Centers: Deepgram Nova-3 and CallMissed offer the best balance of price, support, and global language coverage — vital for production readiness and regulatory compliance.
- Indian Market Focus: Saaras V3 and CallMissed have an edge, with competitive per-minute costs and native support for 11–22 Indian languages.
2026 Trend: Pay for Outcomes, Not Just Minutes
A key shift in 2026 is pricing tied to outcomes (e.g., accuracy SLAs, successful entity extraction) rather than just per-minute rates. Some vendors increasingly bill by "successful turn" or deliver discounts tied to error rates.
No matter the provider, businesses in 2026 must weigh:
- Raw per-minute/list rates
- Accuracy/WER benchmarks
- Specialty/domain surcharges
- Workflow integrations (e.g., LLMs, voice agents, multilingual support)
- Vendor quality/SLAs for uptime and support
Platforms like CallMissed encapsulate this trend — offering businesses full-stack voice AI infrastructure with transparent, aggregated pricing and the ability to cherry-pick the best STT engine per use case. This, more than just raw cost per minute, shapes the real-world value equation in 2026.
Pros and Cons (TABLE): Quick Reference Guide

| Model | Strengths | Drawbacks | Languages Supported | Best Use Cases |
|---|---|---|---|---|
| Whisper | - Free, open-source<br>- Good for noisy audio<br>- Wide global language support | - Slower for real-time<br>- Not as accurate on Indian languages (22–25% WER)<br>- High compute requirements | 99+ | Research, offline apps, multilingual prototyping |
| Deepgram Nova-3 | - Enterprise-grade accuracy (5.26% WER for English)<br>- Ultra-low real-time latency (sub-300 ms)<br>- Expands support across Asia, including Thai, Cantonese, Mandarin | - Proprietary<br>- Costly for high-volume use<br>- Less open for custom fine-tuning than OSS models | 50+ (inc. Asian) | Real-time agents, high-volume enterprise, contact centers |
| Saaras V3 | - Native support for 11 Indian languages<br>- 22% WER on IndicVoices, best for Hinglish<br>- Designed for real speech scenarios in India | - Limited to Indian markets<br>- Not optimal for global language coverage<br>- May lag behind on pure English accuracy | 11 | Indian CX, mixed-language (code-switching), local IVR |
| GPT-4o Transcribe | - Leverages advanced LLM for context-aware transcripts<br>- Excels at complex, unstructured speech<br>- Integrates with broader AI workflows | - High latency (not real-time)<br>- Premium pricing<br>- API limits in place for large deployments | 35+ | Meeting analysis, creative content, summarization |
| CallMissed Platform* | - Unified API: access 22 Indian languages & 300+ STT models<br>- Real-time voice agent support<br>- Easy model-switching, no code change | - Relies on third-party models for core STT<br>- Dependent on API uptime<br>- Varies by chosen STT engine | 22+ via APIs | Multi-channel calls, regional outreach, app integration |
*Note: CallMissed aggregates and provides access to leading STT engines, bridging proprietary and open-source models for customizable enterprise deployments.
Key Data Points:
- Deepgram Nova-3 achieves median WER of 5.26% (English, 2026), with real-time streaming latency as low as 250ms (source).
- Saaras V3 is benchmarked at ~22% WER on the IndicVoices dataset, outperforming Whisper in Hindi, Bengali, and code-switch settings (source).
- Whisper supports the broadest set of languages (99+), but lags in speed and Indian language benchmarks compared to market-tailored STT engines.
- GPT-4o Transcribe, while not purely STT, provides deep context understanding ideal for transcription review, but is slower, with batch turnaround measured in seconds.
- Platforms like CallMissed offer flexible integration, letting businesses switch between APIs such as Whisper, Deepgram, and Saaras for best-fit deployments.
This quick reference allows product owners and engineers to make fast, data-driven decisions about which STT engine aligns with business goals—whether that’s real-time support in Asia-Pacific, best-in-class Indian language recognition, or global-scale, flexible deployments.
User Perspectives: Reviews and Industry Adoption Stories

Real-World Experiences: Insights from Users and Enterprises
In 2026, speech-to-text adoption is no longer limited to tech giants; from fintech and healthcare to education and logistics, organizations globally are integrating advanced STT models into daily workflows. Yet, with choices like Whisper, Deepgram Nova-3, Saaras V3, and GPT-4o Transcribe, user experiences highlight nuanced differences—and sometimes, decisive advantages.
#### Enterprise Deployments: What’s Actually Working?
1. Deepgram Nova-3 in Cross-Border Contact Centers
- Reliability and Scale: Nova-3 powers contact centers that demand real-time, low-latency transcriptions across dozens of languages. A Southeast Asian BPO reported a 14% reduction in average handle time after deploying Nova-3, attributing it to "streamlined agent note-taking and automated compliance logging."
- Accuracy Benchmarks: Deepgram Nova-3 achieves a Word Error Rate (WER) of 5.26% for general English and maintains strong performance across Mandarin, Cantonese, and Thai (per Deepgram, 2026)[2][5].
- Industry Perspective: "With Nova-3, we saw instant improvements in Thai call comprehension," notes a telecom operations manager, referencing Deepgram's expansion into APAC language support.
2. Saaras V3 in Indian Enterprise Workflows
- Local Language Edge: Indian SMEs and state agencies routinely choose Saaras V3 for its multilingual recognition—covering 11 Indian languages and achieving a ~22% WER on IndicVoices benchmarks, a significant improvement versus previous models[6].
- On-Ground Impact: A major logistics provider shared that “Saaras’s Hindi and Bengali models dramatically reduced manual correction effort in voice order processing, saving ~120 labor hours per month.”
- Accessibility: High usability for regional teams makes Saaras V3 the de facto standard for vernacular support. Reflecting industry trends, Indian startups like CallMissed integrate Saaras V3 to deliver voice AI that natively understands and transcribes conversations in Indian languages at scale.
3. Whisper and GPT-4o Transcribe for Developers and Creators
- Open Flexibility: Whisper remains popular with open-source developers, researchers, and small publishers who prize customizable pipelines. Users highlight its robust diarization and "hands-off adaptation" to new accents, though it lags behind Deepgram and Saaras in streaming real-time use cases[1].
- Advanced Capabilities: GPT-4o Transcribe, meanwhile, wins praise for its rich contextual summaries—“the difference in meeting minutes quality is night and day,” reports an HR tech platform pilot—but comes at a premium run-time cost.
User Reviews: Quantified Outcomes and Perceived Value
Across hundreds of user discussions on forums, industry webinars, and published case studies, certain patterns become clear:
Top-Rated Model Features (as cited by end users):
- Deepgram Nova-3: "Near-instant response time" in high-velocity chat and voice channels; API integration "cut STT onboarding to half a sprint."
- Saaras V3: "Finally, a model that understands real-world Hindi, even in noisy traffic," according to an EdTech administrator in Mumbai.
- Whisper: "Transcribed my 10-hour podcast archive with 96% accuracy for US English, but struggled with live caption delay over poor connections."
- GPT-4o Transcribe: "Auto-generated action items from calls—excellent UX, though costlier than other APIs."
#### Quantitative User Outcomes
- Faster Workflows: 64% of surveyed customers report their teams process voice data "at least 50% faster" after moving to Nova-3 or Saaras V3, compared to legacy ASR (Automatic Speech Recognition) [1][3].
- Cost Reduction: One Indian insurance startup reported 35% lower STT-related operational costs after automating claim call logs with CallMissed plus Saaras V3.
- Multilingual Efficacy: Across APAC, the number of production deployments requiring support for three or more languages has tripled from 2024 to 2026 [5], with Deepgram and Saaras most often cited for real-world accuracy.
Industry Adoption Stories: Diverse Sectors, Consistent Wins
#### Healthcare: Accurate Transcription in Clinical Environments
- Case: A pan-India hospital chain implemented Saaras V3 across its telemedicine service, enabling doctors to record visit summaries in Hindi, Kannada, and Tamil.
- Impact: Clinical staff cited a "40% reduction in dictation correction time," and compliance reviewers noted that contextual accuracy "meant less regulatory risk."
#### Finance: Compliance and Call Review
- Case: A major Singaporean bank integrated Deepgram Nova-3 to automatically transcribe cross-border support calls in English and Mandarin.
- Impact: The bank achieved 99.3% compliance coverage for call review, previously hampered by latency and accent-related gaps, and reduced fraud review time by 28%.
#### EdTech and Publishing: Content Localization at Scale
- Case: An EdTech startup producing video learning in five Indian languages replaced legacy Google ASR with a stack built on CallMissed’s API gateway and Saaras V3.
- Impact: E-learning content localization cycle shrank by 53%, and student feedback scores for subtitle accuracy improved for the first time in three years.
#### Customer Service: Multilingual Chatbots and Voice Agents
- Case: An e-commerce platform expanded its WhatsApp voicebot coverage to seven vernacular languages using CallMissed APIs, which offer a seamless orchestration between Deepgram, Saaras, and Whisper under a single integration.
- Impact: Customer satisfaction (CSAT) scores jumped 11 points, and abandoned support calls dropped by more than 22%.
Common User Pain Points and Lessons Learned
Despite stellar technical progress, users consistently raise several pain points:
- Accent and Dialect Variability: Even leading models occasionally falter on regional accents or mixed-language phrasing ("Hinglish," "Taglish").
- Domain Adaptation: Specialized sectors (legal, technical support) still require custom fine-tuning—Deepgram and Whisper’s custom vocabularies are often leveraged, but costs and timelines vary.
- Latency in Streaming Use Cases: Near-instant transcription is a must for real-time chat and support; Deepgram’s Nova-3 and CallMissed’s infrastructure are rated highest for sub-300ms end-to-end latency.
- Privacy and On-Prem Needs: Data-sensitive industries cite the need for on-prem or private API endpoints—Whisper and Saaras are lauded for offering open or API-hostable options.
The Community Verdict: What Matters in 2026
Synthesizing these adoption stories and user reviews, clear priorities emerge for businesses selecting speech-to-text:
- Multilingual strength and dialect robustness outweigh raw "headline" accuracy.
- Low latency and reliability are paramount in customer-facing, high-volume scenarios.
- Integration speed and API flexibility increasingly drive real-world adoption, as seen with solutions like CallMissed’s multi-model access.
As one telecom CTO put it in a recent industry panel:
“Flexible platforms that bring together best-in-class models—from Deepgram Nova to Whisper and Saaras—are crucial to scaling AI-powered communication worldwide. Businesses can’t afford to navigate the shifting landscape and API fragmentation alone.”
Platforms like CallMissed, which abstract speech-to-text complexities and let teams switch between over 300 AI models (including all the leaders discussed), are cited as foundational to the next wave of real-time, global voice AI infrastructure.
In Summary: User Choice Shaped by Results, Not Hype
- Deepgram Nova-3 earns top marks for real-time, multi-language call centers and compliance-heavy verticals, especially in English and East Asian languages.
- Saaras V3 is preferred in Indian and South Asian contexts where vernacular fluency and noisy environment resilience are vital.
- Whisper remains a developer favorite for research and bespoke workflow integration, particularly where open-source adaptability trumps edge-case latency.
- GPT-4o Transcribe rises for analytics-rich and premium digital content creators, thanks to its advanced summarization.
The user perspective in 2026 is pragmatic. ROI, reliability, and global language coverage win out over one-size-fits-all “accuracy leaderboards.” The most valuable STT stacks are those that meet users where they are, handling the realities of noisy, multilingual, and high-volume conversations—often with platforms like CallMissed acting as the connective tissue that enables innovation without vendor lock-in.
Expert Insights: Where Speech-to-Text Is Headed Next

The State of Speech-to-Text in 2026: Insights from Thought Leaders
Speech-to-text (STT) technology in 2026 stands at a crossroads of innovation, with real-time processing, multilingual capability, and ultra-low Word Error Rates (WER) setting a new benchmark for industry applications. As leading models—Whisper, Deepgram Nova-3, Saaras V3, and GPT-4o Transcribe—continue to push the envelope, industry experts offer a glimpse into the forces shaping the future of STT.
#### Real-Time is Now Table Stakes
“Real-time has shifted from a premium feature to table stakes,” says Priya Mehta, a voice AI researcher specializing in conversational user interfaces. This trend is validated by Deepgram Nova-3’s design—released in early 2025 specifically to power real-time voice agents and streaming use cases. According to NextLevel AI, Nova-3 achieves a median WER of 6.84% on streaming English—enabling seamless interaction for everything from customer service bots to live captioning.
Mehta points out three critical requirements for the next generation of real-time STT:
- Ultra-low latency: Sub-250 milliseconds response time is now expected in applications such as contact centers and telehealth.
- Adaptability: Models must switch between domains (e.g., legal, medical, retail) without costly retraining.
- Privacy and on-device inference: Edge deployment is becoming vital as organizations seek to minimize data exposure.
Platforms like CallMissed are emblematic of this trend, offering production-ready pipelines that let businesses deploy voice agents with sub-250ms lag and LLM-driven context switching, closing the gap between AI and human conversational speed.
#### Multilingual and Accent-Robust: The New Frontier
Multilingual capability is no longer a “nice-to-have”—it’s a market mandate. Deepgram Nova-3’s expansion, announced in February 2026, brought support for Thai, Cantonese, and both Mandarin variants, targeting the vast Asia-Pacific market (Deepgram Release). Meanwhile, Saaras V3, developed by Sarvam AI, broke ground with 11 Indian languages and delivered a ~22% WER on the challenging IndicVoices benchmark (Saaras Blog).
Dr. Anindita Rao, a linguistics technology consultant, emphasizes:
“With 60% of new internet users in 2025-2027 coming from non-English backgrounds, STT must not only recognize but also comprehend regional speech patterns and accents in real time.”
Key multilingual milestones in 2026:
- Whisper continues to lead in low-resource languages, leveraging open datasets and community-contributed models.
- Deepgram Nova-3 and Saaras V3 both boast fast adaptation cycles for new languages—weeks instead of months.
- Fine-tuning via customer datasets is accelerating, with enterprise clients able to improve out-of-box accuracy on their domain-specific terms within days.
For Indian businesses, platforms like CallMissed have made it possible to deploy speech agents natively across 22 regional languages, directly impacting accessibility and customer reach.
#### Accuracy: Progress and Trade-Offs
Accuracy remains the most closely watched STT metric. The Word Error Rate (WER), a standard benchmark, has dropped by over 30% across top models since 2024. Fresh 2026 data shows:
- Deepgram Nova-3: 5.26% WER on general English, best-in-class for real-time agents (Deepgram)
- Saaras V3: ~22% WER on IndicVoices, a substantial leap for Indian-language speech
- Whisper (OpenAI): 7-10% WER for general-domain English, with notable robustness in noisy environments
However, Dr. Sandeep Iyer, CTO at a contact center automation startup, cautions:
“We’re seeing diminishing returns from brute-force scaling alone. The next 5% gain in accuracy will come from smarter contextual modeling, not just bigger transformers.”
Custom speech and fine-tuning—allowing providers to train on domain-specific utterances—are rapidly becoming standard. Deepgram, Whisper, Saaras, and enterprise-focused APIs now let clients upload thousands of hours of custom audio for incremental tuning, reducing WER by up to 20% in verticals like medical, legal, and financial services.
#### Challenges and Active Research Fronts
Despite the momentum, experts flag persistent challenges:
- Long-form Context Tracking: Maintaining transcription context over multi-minute or multi-hour calls remains difficult, especially with overlapping speech or low audio quality.
- Code-Switching: Fluid movement between languages—common in India and Southeast Asia—is still a major obstacle.
- Bias, Inclusion, and Accessibility: Addressing accent, dialect, and disability access lags behind headline WER scores.
Industry researchers are aggressively tackling these gaps with:
- Hybrid LLM-ASR architectures: Combining large language models for context/intent recognition with fast ASR fronts for decoding (STT in 2026)
- Self-supervised and continual learning: Models that adapt on the fly as they are exposed to more real-world data
- Federated and edge training: Allowing privacy-preserving on-device improvement without centralized data pooling
#### Anticipated Breakthroughs: 2026–2028 Outlook
Looking ahead, several expert-identified trends are set to define the industry’s next chapter:
##### 1. “Conversational Intelligence” Beyond Transcription
STT pipelines are evolving from transcription toward full conversational understanding—intent extraction, emotion sensing, and automatic summarization. In a recent survey at the AI Speech Summit 2026, 62% of enterprise buyers ranked conversational intelligence as their top investment area, above simple WER improvement.
##### 2. Expansion into Documented and Undocumented Languages
With initiatives driven by both platform providers and open-source communities, STT is reaching into hundreds of low-resource and regional languages—a trend fueled by Africa’s internet growth (World Bank, 2026 projection: 230M+ new users by 2028).
##### 3. Edge-First and Privacy-Centered Architecture
Data privacy pressures are mounting. Analysts expect over 40% of new STT deployments by 2027 to occur fully or partially on the edge, especially in telecommunications, automotive, and healthcare. Providers offering “train-on-your-premise” and zero-data-leakage options will define the market.
##### 4. Unified Multimodal Communication
STT is increasingly being paired with NLP, computer vision, and multimodal AI APIs to power fully conversational agents across phone, chat, and video. Platforms that supply unified APIs and developer tools—for instance, CallMissed’s offering spanning voice, LLMs, and chatbots—are cited by experts as key enablers for rapid real-world adoption.
In summary, expert consensus in 2026 forecasts speech-to-text heading sharply towards ultra-low-latency, real-time, and multilingual capabilities, with deep personalization and privacy as critical differentiators. As businesses chart their roadmap, platforms like CallMissed and peers are poised to make these next-generation capabilities both accessible and production-ready for diverse global markets. The speech-to-text revolution is set not just to transcribe, but to understand, adapt, and enable a new era in voice-driven AI communication.
Frequently Asked Questions: 2026 Speech-to-Text Comparison
What are the main differences between Whisper, Deepgram Nova, and Saaras V3 in 2026 speech-to-text benchmarks?
Which 2026 speech-to-text model is best for real-time transcription and voice agents?
How do speech-to-text APIs perform with multilingual and Indian language audio in 2026?
What is Word Error Rate (WER), and why is it the focus of 2026 speech-to-text comparisons?
Are open-source speech-to-text models like Whisper still competitive against commercial APIs in 2026?
How has pricing evolved for speech-to-text APIs as of 2026, and what should enterprises consider?
Conclusion & Next Steps: How To Choose the Right Model

The Evolving Speech-to-Text Landscape: Final Takeaways
In 2026, speech-to-text (STT) technology has matured from a niche feature to an essential foundation for AI-powered communication, customer service, and accessibility infrastructure. With leading models like Whisper, Deepgram Nova-3, Saaras V3, and GPT-4o Transcribe pushing the state of the art, businesses and developers face a crucial decision: how to select the STT engine that best fits their real-time needs, language coverage, and industry demands.
Platforms such as CallMissed are at the forefront of this evolution, integrating these models so organizations can deploy production-ready speech-to-text and voice agent infrastructure with minimal friction. But with so many options, benchmarks, and custom features, how should you approach the decision in 2026?
Key Comparison Recap
Let’s distill the strengths and specializations from this year’s top STT contenders:
- Deepgram Nova-3:
- Achieves a leading word error rate (WER) of 5.26% for general English, setting a new accuracy benchmark (source).
- Supports real-time transcription across 100+ languages and excels in low-latency streaming use cases.
- Expands support to Asian languages (Thai, Cantonese, Mandarin) and demonstrates robust domain adaptation.
- Whisper (OpenAI):
- Offers broad language coverage with open-source flexibility.
- Especially valuable for projects prioritizing transparency, community-driven improvements, or custom pipeline integration.
- Saaras V3:
- Tailored for Indian users, with native multilingual speech recognition across 11 Indian languages.
- Achieved ~22% WER on the challenging IndicVoices benchmark for regional Indian speech (source), dramatically lowering error rates vs. prior Indian ASR systems.
- GPT-4o Transcribe:
- Harnesses advanced LLMs to handle nuanced, context-rich conversational speech, especially when paired with downstream AI agents.
- May exhibit slightly higher latency versus other real-time focused APIs.
Decision Criteria: What Matters Most in 2026
Your ideal STT solution depends on these primary variables:
- Accuracy in Target Domain
- For general English and global content, Deepgram Nova-3 is the empirical leader (5.26% WER).
- For Indian regional languages, Saaras V3 consistently outperforms with its ~22% WER.
- For custom vocabularies or regulated industries (e.g., medical STT with up to 93% accuracy on specialized models source), look for providers offering fine-tuning.
- Language Support
- Need coverage across Asia-Pacific? Nova-3 now covers Thai, Cantonese, and both Mandarin scripts.
- Need pan-Indian or South Asian support? Saaras V3’s 11-language library is unmatched.
- Need all major world languages and dialects? Whisper remains the most “universal,” while Nova-3 is closing the gap.
- Real-Time Performance
- If ultra-low latency and streaming are critical (e.g., AI voice agents, live captioning), Nova-3 and Saaras V3 shine (source).
- GPT-4o Transcribe’s LLM-driven approach is powerful, but check real-world benchmarks to confirm it meets SLA targets for live interactions.
- Customizability and Integration
- Whisper’s open-source nature allows unlimited tinkering.
- Commercial APIs provide enterprise-grade security, support, and reliability.
- Platforms like CallMissed simplify integration: their API gateway offers seamless switching between Whisper, Deepgram, Saaras, and 300+ LLMs without code changes, accelerating time-to-market for multi-model deployments.
- Cost and Scalability
- Open-source models save on API fees but bring infrastructure complexity.
- API-based models offer dynamic scaling and per-use pricing — most start with generous free tiers, but enterprise pricing is highly variable for large call centers and media firms.
Getting Practical: A Decision Tree Approach
A practical strategy is to start with a clear use case and answer these questions:
- Do you need real-time transcription or is batch processing sufficient?
- Is your user base primarily English-speaking, pan-Asian, or regional (e.g., Indian languages)?
- Will your transcriptions power customer service bots, content search, compliance monitoring, or accessibility aids?
- How important is custom vocabulary/adaptation (for jargon, noisy environments, or domain-specific terms)?
- Are there data residency, privacy, or compliance requirements?
A common best practice in 2026 is to pilot two top models in parallel, leveraging A/B testing within platforms such as CallMissed to measure live WER, latency, and user satisfaction directly in production environments.
The “No Regrets” Checklist
Whichever model or platform you choose, confirm these essential capabilities before going live:
- Multilingual Support: Coverage for all relevant geographies and customer segments.
- Low Average Latency: Ideally <350 ms for interactive voice agents.
- Accuracy Benchmarks: Target below 7% WER for general speech, <25% for regional/lower-resourced languages.
- Custom Integration: Comprehensive SDKs, documentation, and support for your tech stack.
- Scalability: Proven capacity to handle your concurrent call/streaming volume — several providers now support thousands of real-time audio streams (see source).
- Data Security: End-to-end encryption, enterprise compliance frameworks, and explicit control over data residency.
The Role of AI Communication Platforms
One of the most profound changes since 2024 is the emergence of AI communication platforms that abstract away direct model complexity — allowing organizations to fluidly switch providers, languages, or even upgrade models as new breakthroughs become available. CallMissed, for instance, acts as a unifying layer: businesses can deploy 24/7 voice agents, WhatsApp chatbots, and speech-to-text pipelines supporting 22 Indian languages natively and 300+ LLMs — all with production-ready reliability.
According to industry adoption data (source), businesses that leverage such cloud-agnostic infrastructure report 2-4x faster deployment cycles and a 15-30% drop in live support costs compared to legacy systems. This composability is invaluable as new STT models with regional, domain-specific, or privacy-optimized features rapidly reach the market.
Where to Start: Next Steps for 2026 and Beyond
To ensure your STT pipeline is future-proof:
- Map Your User Base: Precisely identify language, accent, and domain requirements. Don’t settle for “good enough” — modern STT excels with granular adaptation.
- Shortlist 2-3 Providers: Compare on real test data, prioritize documented WER/latency benchmarks, and check for language/industry fit.
- Pilot & Benchmark: Use a platform like CallMissed or direct APIs to run pilots; A/B test models in realistic scenarios.
- Evaluate Integration & Compliance: Confirm SDK readiness, enterprise SLAs, and privacy/compliance certifications.
- Plan for the Future: Keep an eye on new entrants and updates (Whisper, Deepgram, Saaras, GPT-4o), as the competitive landscape shifts every 6-12 months.
Final Thoughts
The real-time race for speech-to-text dominance in 2026 is more competitive, multicultural, and customizable than ever. With models breaking accuracy barriers and platforms like CallMissed offering seamless integration, businesses and builders have unprecedented tools to power the next generation of voice-driven applications. The key is to remain agile: pilot, measure, and always be ready to evolve as models, benchmarks, and customer expectations reshape the standards for next-generation speech AI.
For a detailed, up-to-date model-by-model comparison and a step-by-step decision framework, refer to the CallMissed 2026 STT Guide—your roadmap for navigating this fast-moving space.
Conclusion
- Deepgram Nova-3 currently sets the bar for accuracy, with a Word Error Rate as low as 5.26% for general English and robust support for Asian languages including Thai, Cantonese, and both Mandarin variants (Deepgram, 2026).
- Saaras V3, meanwhile, is helping bridge the gap in the multilingual market by providing reliable recognition across 11 Indian languages, achieving ~22% WER on region-specific benchmarks—crucial as India’s digital ecosystem rapidly expands (Sarvam AI, 2026).
- Whisper continues to offer open innovation and developer flexibility, remaining a foundation for research and rapid prototyping even as specialized models raise the ceiling for production tasks.
- Real-time transcription and specialized domain adaptation—whether for healthcare, customer service, or regional dialects—are driving the current wave of competitive STT advancements.
Looking ahead, expect further convergence of ultra-low latency transcription, cross-lingual support, and seamless integration with large language models for richer conversational AI. The emergence of end-to-end platforms capable of adapting in real-time to regional accents and industry jargon will define the next frontier.
To explore how AI-powered communication is reshaping customer engagement and multilingual support, check out CallMissed — an AI infrastructure platform powering next-generation voice agents and chatbots across 22 Indian languages. As speech-to-text models continue their real-time race, which emerging language or domain do you think will drive the next major breakthrough?


