Claude Sonnet 5 vs Opus 4.8: 2026 Model Comparison Guide

Compare Claude Sonnet 5 vs Opus 4.8 on benchmarks, coding, agentic work, pricing, context, and which model to choose in 2026.
Claude Sonnet 5 vs Opus 4.8: 2026 Model Comparison Guide
What if the smartest model choice in 2026 is not the newest one—but the one with the clearest production evidence? That is the real question behind Claude Sonnet 5 vs Opus 4.8, especially as engineering, support, research, and automation teams move from “Which model is more powerful?” to “Which model should we trust with real workflows?”
Right now, Claude Opus 4.8 has the stronger public footprint. Anthropic describes Opus 4.8 as an upgrade to its Opus class with “stronger performance across coding, agentic tasks,” while its platform docs recommend starting with Claude Opus 4.8 for the most complex tasks. Anthropic’s own Opus page goes further, saying the model has “noticeably better judgment” in Claude Code: it “asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound.” For teams building AI agents, that matters more than a marginal benchmark gain—because judgment, self-correction, and refusal to follow flawed plans are what keep autonomous systems useful instead of risky.
At the same time, the Sonnet line remains critical because Sonnet models have traditionally represented the performance-to-cost sweet spot: fast enough for production scale, capable enough for complex reasoning, and economical enough for high-volume workloads. But the key issue in mid-2026 is clarity. Public search context around adjacent releases shows uncertainty even around Sonnet 4.8—one June 17, 2026 report noted it was still pre-release with “no API id, no benchmarks”—while Opus 4.8 is already documented, benchmarked, and positioned as Anthropic’s most capable Opus-tier model. LLM Stats comparisons also show Opus 4.8 outperforming Claude Sonnet 4.6 on 9 benchmarks, while Sonnet 4.6 leads on only 1 benchmark.
This guide cuts through the hype and compares the models the way technical teams actually evaluate them:
- Reasoning and coding performance
- Agentic task reliability
- Speed, cost, and latency trade-offs
- API readiness and production deployment
- Best-fit use cases for startups, enterprises, and developers
Platforms like CallMissed, which route workloads across 300+ LLMs for voice agents, WhatsApp bots, and multilingual AI workflows, reflect where the market is heading: not one “winner” model, but smarter model selection per task.
By the end, you’ll know whether Claude Sonnet 5 is worth waiting for—or whether Claude Opus 4.8 is the safer choice for serious AI systems today.
Introduction: Claude Sonnet 5 vs Opus 4.8 at a Glance

Why this comparison matters in 2026
The debate around Claude Sonnet 5 vs Claude Opus 4.8 is really a debate about two different priorities: future potential versus proven production capability. For AI teams, the best model is not always the newest or most expensive one—it is the model that delivers reliable reasoning, stable APIs, predictable latency, and measurable business value.
As of June 30, 2026, Claude Opus 4.8 has the clearer public record. Anthropic describes it as an upgrade to the Opus family with “stronger performance across coding, agentic tasks”, and its platform documentation recommends starting with Claude Opus 4.8 for the most complex tasks. That positioning matters because Opus is Anthropic’s premium reasoning tier, intended for workloads where accuracy, judgment, and autonomy are more important than raw speed.
Claude Sonnet 5, by contrast, is best understood as the model many teams are watching for: a likely successor in the Sonnet line, which has historically balanced cost, speed, and capability. But comparison becomes difficult when public availability, API identifiers, pricing, and benchmark data are not equally mature. Even related Sonnet-release tracking remains uncertain: a June 17, 2026 report on Claude Sonnet 4.8 noted “no API id, no benchmarks”, while Opus 4.8 was already shipped and benchmarked.
The quick read: Opus 4.8 is the safer current choice
For teams making deployment decisions today, Claude Opus 4.8 has the advantage in evidence. Anthropic’s own Opus page says the model shows “noticeably better judgment” in Claude Code, including the ability to ask the right questions, catch its own mistakes, and push back when a plan is not sound. That is especially important for agentic systems, where the model is not just answering questions—it may be planning tasks, modifying code, triggering tools, or coordinating workflows.
Independent comparison data also favors Opus 4.8 over the latest clearly benchmarked Sonnet-class model in the provided context. According to LLM Stats, Claude Opus 4.8 beats Claude Sonnet 4.6 on 9 benchmarks, while Sonnet 4.6 leads on only 1 benchmark. That does not automatically mean Opus is better for every workload, but it does suggest that for complex reasoning and agentic tasks, Opus 4.8 currently has the stronger case.
At a glance:
- Best for complex reasoning: Claude Opus 4.8
- Best for coding agents: Claude Opus 4.8, based on Anthropic’s Claude Code claims
- Best expected cost-performance tier: Claude Sonnet line
- Best production certainty today: Claude Opus 4.8
- Biggest unknown: Claude Sonnet 5 availability, pricing, and benchmarks
How businesses should frame the decision
The practical question is not “Which model wins?” but “Which model should handle which task?” A startup building an internal coding assistant may choose Opus 4.8 for architecture reviews and bug diagnosis, while using a cheaper Sonnet-class model for summarization, classification, or routine chat. An enterprise support team may reserve Opus 4.8 for escalations and use faster models for high-volume first responses.
This is also where multi-model infrastructure becomes important. Platforms like CallMissed help teams route workloads across 300+ LLMs, voice agents, WhatsApp chatbots, and multilingual speech systems, so businesses are not locked into a single model choice. In practice, the winning architecture is often a model mix: premium reasoning where mistakes are costly, efficient models where scale matters.
So, at a glance, Claude Opus 4.8 is the stronger production-backed option today, while Claude Sonnet 5 remains the model to watch if Anthropic delivers the usual Sonnet promise: near-frontier capability at better speed and cost.
Background & Context: How Anthropic’s Sonnet and Opus Tiers Diverged
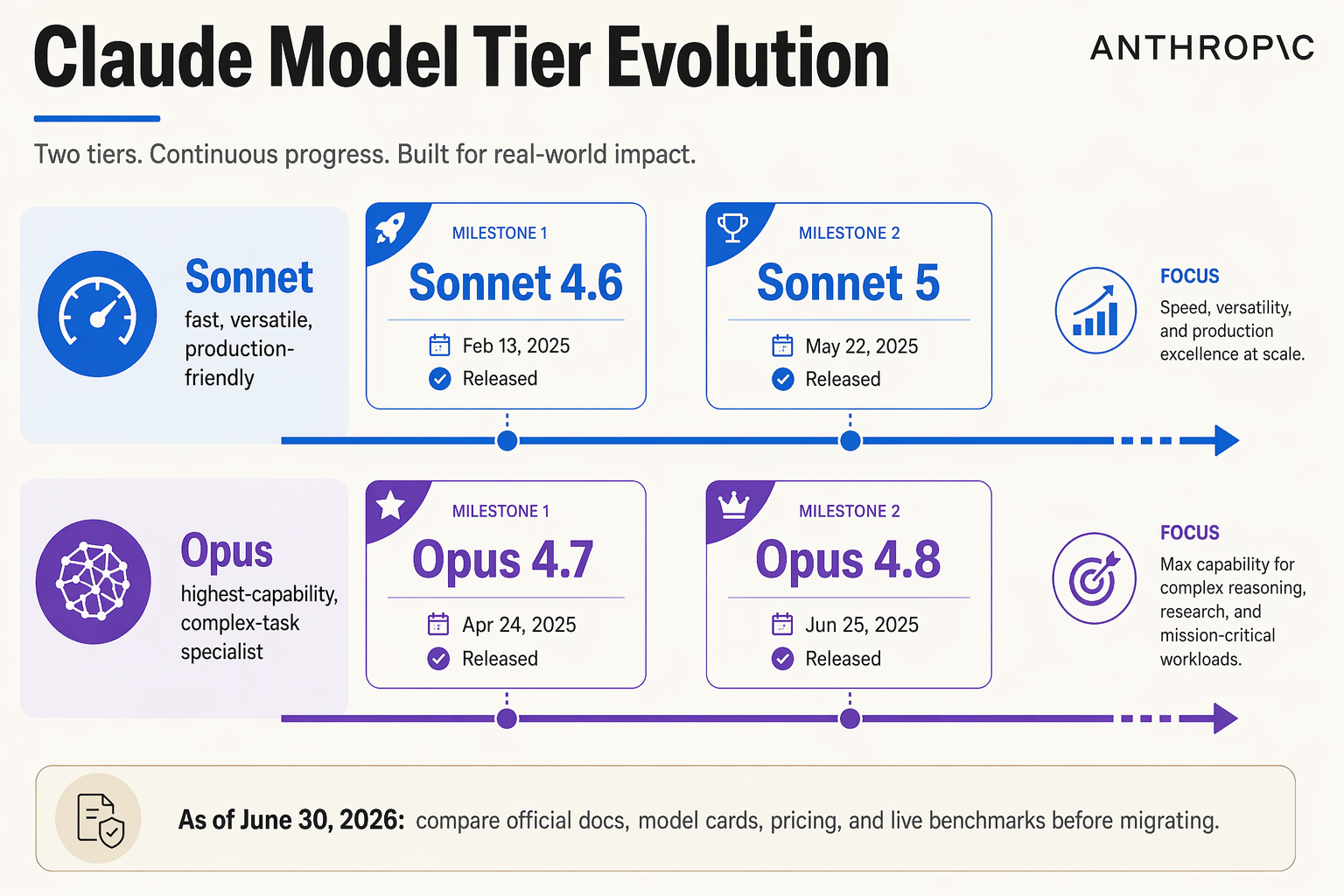
From “one best model” to tiered model strategy
Anthropic’s Claude lineup has increasingly split into two distinct roles: Opus as the frontier reasoning tier and Sonnet as the scalable workhorse tier. That divergence is central to understanding the Claude Sonnet 5 vs Opus 4.8 question. These models are not just sequential upgrades; they represent different product philosophies.
The Opus tier is designed for tasks where failure is expensive: complex coding, deep research, multi-step planning, agent supervision, and high-stakes reasoning. Anthropic’s own model documentation now says that if users are unsure which model to choose, they should “consider starting with Claude Opus 4.8 for the most complex tasks,” calling it the company’s “most capable Opus-tier model.” That positioning matters because it is not just benchmark marketing—it is deployment guidance from the platform provider.
Sonnet, historically, has served a different function. It is the model tier teams choose when they need a blend of:
- Strong reasoning
- Lower latency
- Better cost efficiency
- Higher-volume production viability
- Good enough coding and automation performance
That makes Sonnet models especially attractive for customer support copilots, internal workflow automation, analytics assistants, and AI agents that run thousands or millions of times per month.
Why Opus 4.8 became the “serious agent” model
The key shift with Claude Opus 4.8 is Anthropic’s emphasis on judgment, not just raw intelligence. On its Claude Opus page, Anthropic says Opus 4.8 has “noticeably better judgment” and that in Claude Code it “asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound.”
That language reflects where LLM competition has moved in 2026. Enterprises are no longer only asking whether a model can answer a question. They are asking whether it can:
- Detect flawed instructions before acting
- Maintain context across long workflows
- Debug its own reasoning
- Escalate uncertainty instead of fabricating confidence
- Operate reliably inside autonomous agent loops
This is where Opus 4.8 has a clearer public case today. Anthropic’s launch materials describe it as an upgrade with “stronger performance across coding, agentic tasks,” and third-party comparison data from LLM Stats shows Claude Opus 4.8 beating Claude Sonnet 4.6 on 9 benchmarks, while Sonnet 4.6 leads on only 1 benchmark.
Where Sonnet’s value comes from
Sonnet’s advantage has never been that it always beats Opus on the hardest tests. Its value is that it can be the better operational choice when the workload does not justify Opus-level compute. In production, the best model is often the one that gives 90–95% of the needed capability at meaningfully better speed and cost.
That is why the Sonnet tier remains strategically important for teams building:
- Customer service chatbots
- Voice AI agents
- Sales and support automation
- Document summarization pipelines
- Routine code review assistants
- Internal knowledge-base copilots
For example, platforms like CallMissed use multi-model routing across 300+ LLMs so businesses can reserve premium reasoning models for complex escalations while using faster, more economical models for routine voice, WhatsApp, and support workflows. This mirrors the broader market shift: model choice is becoming workload-specific, not brand-specific.
The uncertainty around Sonnet 5
The complication is that Claude Sonnet 5 is still best treated as a forward-looking comparison point unless Anthropic provides formal release details, API identifiers, pricing, and benchmarks. Even adjacent Sonnet release reporting has shown uncertainty: a June 17, 2026 report on Sonnet 4.8 described it as pre-release, with “no API id, no benchmarks,” while noting that Opus 4.8 had already shipped.
That context creates an important distinction:
- Opus 4.8 is documented, positioned, and benchmarked
- Sonnet 5 is expected to matter, but cannot yet be evaluated with the same confidence
- Sonnet’s likely role is scale efficiency, not necessarily maximum reasoning
- Opus remains the safer default for complex autonomous tasks today
So the background is not simply “Sonnet versus Opus.” It is the story of Anthropic separating its model family into two production lanes: Opus for maximum judgment and complex agents, Sonnet for high-throughput intelligence at scale.
Key Developments (TABLE): Launch Status, Claims, and Official Sources
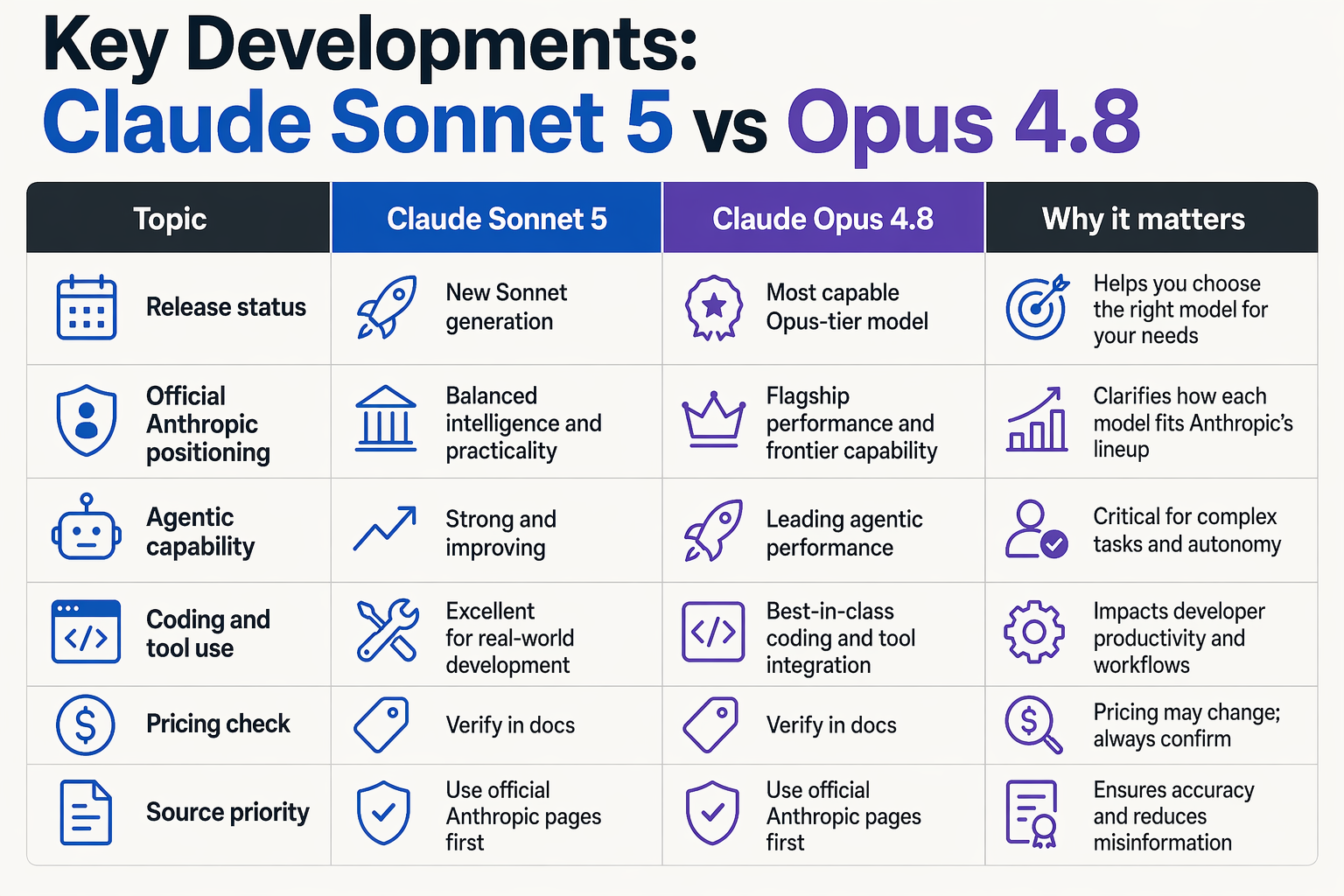
What is officially confirmed right now?
The most important development in this comparison is not a benchmark score—it is source quality. As of June 30, 2026, Claude Opus 4.8 has direct Anthropic documentation, product positioning, and public comparison data. Claude Sonnet 5 does not yet have the same official evidence trail in the provided context, which makes any production recommendation speculative.
| Development | Launch Status | Source / Claim | Evidence Cited | Practical Meaning |
|---|---|---|---|---|
| Claude Opus 4.8 announced | Shipped | Anthropic news post says Opus 4.8 is “an upgrade to our Opus class” | Anthropic: “stronger performance across coding, agentic tasks” | Safe to evaluate for real engineering, agent, and reasoning workloads |
| Opus 4.8 recommended for complex tasks | Available in docs | Claude Platform Docs | “Consider starting with Claude Opus 4.8 for the most complex tasks” | Strong official signal for enterprise-grade use cases |
| Opus 4.8 positioned as top Opus-tier model | Current Anthropic model | Claude Platform Docs | “Anthropic’s most capable Opus-tier model” | Makes Opus 4.8 the reference point for high-end Claude deployments |
| Better agent judgment claimed | Public product claim | Anthropic Claude Opus page | It “asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound” | Relevant for autonomous coding, support escalation, and workflow agents |
| Sonnet 4.8 uncertainty | Pre-release in third-party reporting | Codersera report, June 17, 2026 | “No API id, no benchmarks” | Even adjacent Sonnet releases lack full public validation in the available context |
| Sonnet 5 evidence gap | Not officially confirmed in provided sources | No Anthropic launch/docs source shown | No launch note, model ID, benchmark, or pricing data in context | Treat Sonnet 5 claims as unverified until Anthropic publishes official details |
Why launch status matters more than model naming
Model names can create false certainty. A “Sonnet 5” label sounds newer than “Opus 4.8,” but production teams need answers to operational questions:
- Is there an official API model ID?
- Are there published benchmarks?
- Does the provider document recommended use cases?
- Are pricing, rate limits, and latency characteristics available?
- Has the model been tested in coding, tool use, and agent workflows?
On those criteria, Opus 4.8 is ahead in public evidence. Anthropic has not merely named the model; it has described where it fits, what it improves, and how developers should think about it. The platform docs explicitly recommend starting with Claude Opus 4.8 for the most complex tasks, while the Opus product page emphasizes judgment in Claude Code—self-correction, questioning bad plans, and pushing back when needed.
The benchmark picture is also asymmetric
The strongest comparative signal in the context comes from LLM Stats, which compares Claude Sonnet 4.6 vs Claude Opus 4.8. According to that result, Opus 4.8 leads on 9 benchmarks, while Sonnet 4.6 leads on 1 benchmark, specifically Finance Agent. That does not prove how Sonnet 5 will perform, but it does establish that the latest documented Opus model is already outperforming the available Sonnet baseline across a broad benchmark set.
For platforms routing real workloads—such as CallMissed, where voice agents, WhatsApp bots, STT, TTS, and LLM inference may rely on different models per task—this distinction matters. A model with official docs and benchmark visibility is easier to place into production routing than one defined mostly by expectation.
Bottom line from the sources
The key development is simple: Opus 4.8 is documented; Sonnet 5 is not yet evidenced in the supplied official sources. Until Anthropic publishes a Sonnet 5 launch post, model documentation, benchmarks, or API details, the responsible comparison is between a proven Opus 4.8 and a hypothetical Sonnet 5.
In-Depth Analysis: Performance, Reasoning, Coding, and Agentic Behavior

Performance: proven benchmark lead vs expected efficiency
The strongest measurable advantage today sits with Claude Opus 4.8, not because Sonnet-class models are weak, but because Opus 4.8 has public evidence behind it. Anthropic positions it as an “upgrade to our Opus class” with “stronger performance across coding, agentic tasks”, and its own platform documentation recommends starting with Claude Opus 4.8 for the most complex tasks.
That matters because the Sonnet side of the comparison is still partly speculative. Public context around even Claude Sonnet 4.8 showed uncertainty as recently as June 17, 2026, with one report describing it as pre-release with “no API id, no benchmarks.” If Sonnet 5 follows the traditional Sonnet pattern, it may target a better balance of speed, price, and scale—but until published benchmarks exist, it should be evaluated as a future candidate, not a verified replacement.
The clearest current signal comes from LLM Stats’ comparison of Claude Sonnet 4.6 vs Claude Opus 4.8, where Opus 4.8 leads on 9 benchmarks, while Sonnet 4.6 leads on only 1 benchmark. That does not prove Opus 4.8 will beat Sonnet 5, but it sets a high bar for Sonnet 5 to clear.
Reasoning: Opus 4.8 is built for hard judgment calls
For reasoning-heavy workflows, the key difference is not just answer accuracy—it is judgment under ambiguity. Anthropic says Claude Opus 4.8 has “noticeably better judgment” and, in Claude Code, can “ask the right questions, catch its own mistakes, push back when a plan isn’t sound.”
That behavior is especially important in:
- Architecture planning, where the model must identify missing constraints
- Legal, finance, or compliance review, where overconfident answers create risk
- Multi-step research, where sources and assumptions need to be challenged
- Autonomous workflow execution, where the model must decide when not to act
A hypothetical Sonnet 5 may be more economical for broad reasoning tasks, but for high-stakes decisions, Opus 4.8 currently has the stronger documented case.
Coding: Opus 4.8 looks stronger for complex engineering work
Coding is where the Opus advantage becomes more practical. Anthropic explicitly calls out stronger performance across coding and agentic tasks, while its Opus product page highlights Claude Code behavior such as self-correction and plan validation.
In real engineering environments, that translates into better performance on tasks like:
- Debugging multi-file applications
- Refactoring legacy code safely
- Reviewing pull requests for hidden logic errors
- Generating migration plans
- Working inside tool-using coding agents
Sonnet 5, if released with the expected Sonnet profile, could be attractive for high-volume code generation, test writing, documentation, and simpler automation. But for deep debugging and architecture-level reasoning, Opus 4.8 is the safer default today.
Agentic behavior: reliability matters more than raw intelligence
Agentic AI is where model selection becomes operationally critical. A model running tools, browsing files, calling APIs, or managing workflows must do more than produce fluent text. It needs to know when to pause, ask for clarification, or reject a flawed instruction.
This is why Anthropic’s description of Opus 4.8 is significant. A model that “pushes back when a plan isn’t sound” is better suited to agentic systems than one that blindly completes every request. For AI agents, useful resistance is a feature—not a bug.
Platforms such as CallMissed, which help businesses deploy AI voice agents, WhatsApp chatbots, and multi-model LLM workflows across 300+ models, reflect this shift: production teams increasingly route difficult reasoning or escalation tasks to stronger models, while using faster models for routine interactions.
Bottom line for this category
For performance, reasoning, coding, and agentic reliability, Claude Opus 4.8 currently wins on evidence. Sonnet 5 may eventually become the better scale model, but until Anthropic publishes API details, benchmark results, and deployment guidance, Opus 4.8 remains the more defensible choice for complex production workloads.
Pricing, Context Window, and Deployment Trade-Offs
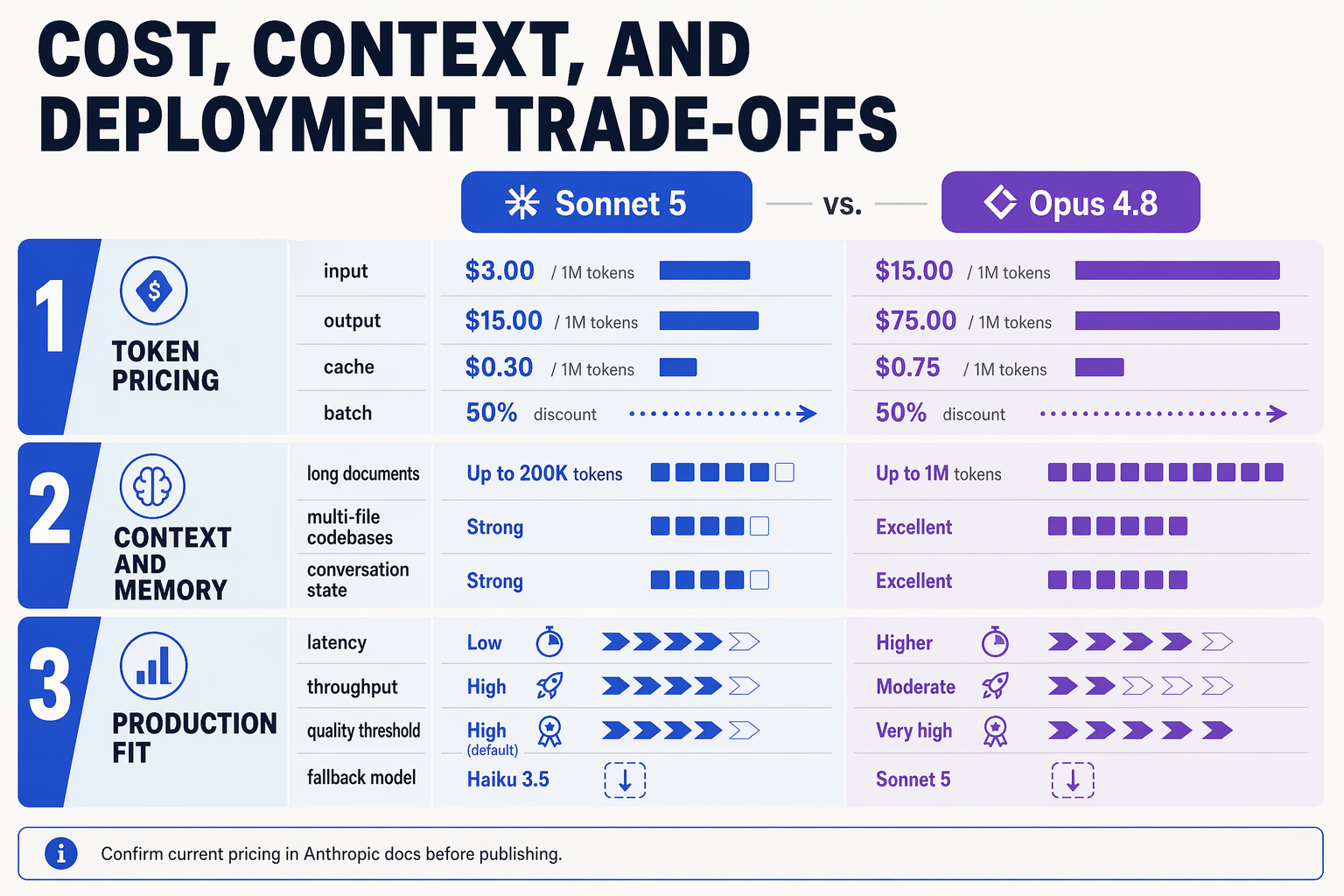
The real cost question: unit price vs workflow cost
For production teams, pricing is not just dollars per token. It is the total cost of completing a workflow successfully: prompt tokens, output tokens, retries, tool calls, latency, human review, and failed-agent recovery.
That is where Claude Opus 4.8 has a clearer current position. Anthropic’s platform docs say that if teams are unsure which model to use, they should “consider starting with Claude Opus 4.8 for the most complex tasks,” calling it Anthropic’s “most capable Opus-tier model.” Anthropic also says Opus 4.8 delivers “stronger performance across coding, agentic tasks,” which matters because complex agent workflows often become expensive when weaker models require repeated retries.
For Claude Sonnet 5, the pricing trade-off is still harder to evaluate publicly. The Sonnet family has historically been the more economical production tier, but as of the current comparison window, the public evidence is stronger for Opus 4.8 than for a finalized Sonnet 5 release profile. The available market signal around nearby Sonnet releases is uncertainty: a June 17, 2026 report noted Claude Sonnet 4.8 was still pre-release with “no API id, no benchmarks,” while Opus 4.8 had already shipped.
Context window: bigger is useful only if the model uses it well
A large context window helps when your application needs to process:
- Long codebases or multi-file pull requests
- Legal, financial, or compliance documents
- Long customer histories across chat, email, and voice transcripts
- Agent memory and tool traces
- Research synthesis across many sources
But context length alone does not guarantee better results. In real deployments, teams should test context utilization: does the model retrieve the right detail from a long prompt, or does it miss key constraints?
This is where Opus 4.8’s positioning is important. Anthropic says the model has “noticeably better judgment” in Claude Code: it “asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound.” That kind of behavior is especially valuable in long-context tasks, where the model must decide which information matters and when to challenge the user’s assumptions.
For Sonnet 5, the key question will be whether it delivers similar judgment at lower latency and lower cost. If it does, it could become the default for high-volume long-context applications. Until then, Opus 4.8 is the safer pick for workflows where missing one clause, bug, or dependency can create real business risk.
Deployment trade-offs: when to use Opus 4.8 vs wait for Sonnet 5
A practical deployment strategy looks like this:
- Use Opus 4.8 for high-stakes reasoning
- Complex coding agents
- Multi-step planning
- Risk review and compliance workflows
- Autonomous agents that need self-correction
- Use Sonnet-class models for scale-sensitive workloads
- Customer support summarization
- Chat routing
- Draft generation
- FAQ automation
- Internal knowledge assistants
- Wait for Sonnet 5 if your priority is cost-performance optimization
- Especially if you can tolerate model uncertainty and run evaluations before migration.
Platforms like CallMissed make this trade-off easier by routing workloads across 300+ LLMs, so businesses can reserve premium models for complex cases while using faster, cheaper models for routine voice-agent and WhatsApp chatbot interactions.
Bottom line for production teams
If your application is experimental, Sonnet 5 may be worth watching. But if you are deploying now, Opus 4.8 has the stronger public deployment case: Anthropic has documented it, positioned it for the “most complex tasks,” and highlighted improvements in coding and agentic reliability. The best architecture is not choosing one model forever—it is building a routing layer that can shift between Opus-level reasoning and Sonnet-level efficiency as pricing, context, and API maturity evolve.
Impact & Implications: What the Matchup Changes for AI Teams

1. Model strategy shifts from “best model” to “best routing”
The biggest implication of the Claude Sonnet 5 vs Opus 4.8 matchup is that AI teams can no longer evaluate models as one-size-fits-all replacements. Anthropic’s own documentation says teams should “consider starting with Claude Opus 4.8 for the most complex tasks,” positioning it as the safer default for high-stakes reasoning, coding, and agentic workflows. But that does not automatically make it the best model for every request.
In production, the winning strategy is increasingly model routing:
- Use Opus 4.8 for complex planning, code review, multi-step agents, and sensitive decisions.
- Use Sonnet-class models where speed, volume, and cost efficiency matter more.
- Add fallback logic when a model shows uncertainty, tool errors, or low-confidence outputs.
- Track quality, latency, cost, and escalation rates per workflow—not just benchmark scores.
This is where platforms like CallMissed fit the broader market direction: teams are moving toward multi-model infrastructure that can route tasks across 300+ LLMs instead of hard-coding one provider or one model into every workflow.
2. Agent reliability becomes a board-level concern
The Opus 4.8 release matters because Anthropic is explicitly emphasizing judgment, not just raw intelligence. Anthropic says Opus 4.8 has “noticeably better judgment” in Claude Code: it “asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound.” That language is important for AI teams building autonomous systems.
For agentic workflows, the risk is not only that a model gives a wrong answer. The bigger risk is that it confidently continues down a bad path—calling tools, modifying code, sending messages, or making decisions without enough verification.
The practical implication: AI teams should measure models on behavior under uncertainty. Useful evaluation questions include:
- Does the model pause and ask clarifying questions?
- Does it identify flawed instructions?
- Does it recover from tool failures?
- Does it explain trade-offs before taking action?
- Does it escalate when confidence is low?
On that front, Opus 4.8 currently has stronger public evidence than Sonnet 5. Anthropic’s launch note says Opus 4.8 improves performance across “coding, agentic tasks,” while public Sonnet 5 evidence remains less concrete as of June 30, 2026.
3. Benchmark evidence changes procurement conversations
For engineering leaders, public benchmark availability affects buying decisions. LLM Stats shows Claude Opus 4.8 outperforming Claude Sonnet 4.6 on 9 benchmarks, while Sonnet 4.6 leads on only 1 benchmark. That does not prove Sonnet 5 will underperform, but it does show why teams should be cautious about betting roadmaps on an unverified future model.
The lesson is simple: procurement should favor measured capability over assumed capability.
AI teams should ask vendors and internal platform teams for:
- Benchmark results on their own datasets
- API stability and versioning details
- Latency distributions, not just average response times
- Cost per completed task
- Failure and escalation rates
- Security and audit logging support
A model that looks expensive per token can still be cheaper per resolved task if it reduces retries, human review, or broken agent runs.
4. The Sonnet 5 question becomes a roadmap decision
The real impact of Sonnet 5 will depend on whether it preserves the traditional Sonnet advantage: strong reasoning at a better cost-latency profile. If Sonnet 5 delivers near-Opus reasoning with lower operating cost, it could become the default for customer support, internal copilots, sales workflows, and high-volume automation.
But until APIs, benchmarks, and production reports are public, teams should avoid delaying critical deployments. The uncertainty around adjacent Sonnet releases is a useful warning: one June 17, 2026 report noted Claude Sonnet 4.8 was still pre-release with “no API id, no benchmarks,” while Opus 4.8 had already shipped and appeared in public comparisons.
5. What AI teams should do next
The matchup changes the playbook in three practical ways:
- Deploy Opus 4.8 where reliability matters most: coding agents, complex reasoning, compliance-heavy workflows, and autonomous task execution.
- Prepare for Sonnet 5 without waiting for it: design abstraction layers so models can be swapped when evidence improves.
- Build evaluation into production: every model decision should be backed by task-level metrics, not launch hype.
For businesses deploying AI voice agents, WhatsApp bots, or multilingual support automation, this means choosing infrastructure that can evolve as the model landscape changes. The future is not Opus versus Sonnet in isolation—it is adaptive AI systems that use the right model for the right job.
Expert Opinions: Where Analysts and Developers Agree or Disagree

Where experts broadly agree
Across analyst write-ups, developer discussions, and Anthropic’s own positioning, there is one clear point of consensus: Claude Opus 4.8 is the safer production choice today. Anthropic’s model docs explicitly recommend starting with Claude Opus 4.8 “for the most complex tasks”, calling it the company’s most capable Opus-tier model. That matters because developers usually do not evaluate frontier models on raw intelligence alone—they evaluate whether the model can be trusted inside repeatable workflows.
Experts tend to agree on three practical points:
- Opus 4.8 has the stronger evidence base.
Anthropic says Opus 4.8 brings “stronger performance across coding, agentic tasks,” and LLM Stats shows it beating Claude Sonnet 4.6 on 9 benchmarks, while Sonnet 4.6 leads on only 1 benchmark.
- Agentic reliability is the differentiator.
Anthropic’s Opus page says Claude Opus 4.8 has “noticeably better judgment” in Claude Code, including the ability to ask the right questions, catch its own mistakes, and push back when a plan isn’t sound. Developers see this as more valuable than a model that simply produces longer or faster answers.
- Public availability beats speculation.
The Sonnet side of the discussion is less settled. A June 17, 2026 report on Claude Sonnet 4.8 noted it was still pre-release, with “no API id, no benchmarks.” That makes analysts cautious about projecting too much onto Claude Sonnet 5 until Anthropic publishes formal specs, pricing, and benchmark data.
Where analysts and developers disagree
The disagreement is not whether Opus 4.8 is strong—it clearly is. The disagreement is whether teams should standardize on it.
Analysts often emphasize capability leadership. From that perspective, Opus 4.8 is the obvious recommendation because it is documented, benchmarked, and officially positioned for complex workloads. If the task involves multi-step coding, financial reasoning, autonomous research, or high-stakes planning, analysts generally favor the model with the clearest public performance record.
Developers, however, often push back with production realities:
- Cost sensitivity: A slightly less capable Sonnet-class model may be better for high-volume workloads if it offers lower inference cost.
- Latency requirements: Customer-facing chat, voice, and support workflows may prioritize response time over maximum reasoning depth.
- Model routing: Many teams no longer want one default model. They want routing logic that sends simple tasks to cheaper models and escalates complex tasks to Opus-class systems.
- API stability: Developers care about rate limits, SDK behavior, versioning, and observability as much as headline benchmarks.
This is why platforms like CallMissed, which provide access to 300+ LLMs for voice agents, WhatsApp bots, and API workflows, reflect a growing developer preference: use the best model for the job, not the most powerful model for every job.
The practical middle ground
The most balanced expert view is that Opus 4.8 should be the benchmark to beat, while Claude Sonnet 5 should be evaluated only after real release data exists. If Sonnet 5 eventually delivers near-Opus reasoning with better speed or economics, it could become the preferred default for production scale. But as of June 30, 2026, the public record favors Opus 4.8.
A sensible evaluation strategy would be:
- Use Opus 4.8 for complex coding, autonomous agents, planning, and review-heavy workflows.
- Use current Sonnet-class models for throughput-oriented tasks where cost and latency dominate.
- Re-test when Claude Sonnet 5 has an official API, pricing, benchmark coverage, and developer feedback.
- Avoid migration decisions based on rumors or pre-release assumptions.
In short, analysts value Opus 4.8 because it is proven; developers remain interested in Sonnet 5 because Sonnet-class models often define the practical performance-per-dollar layer. Both sides are right—but for different deployment priorities.
What This Means For You (TABLE): Best Model by Use Case
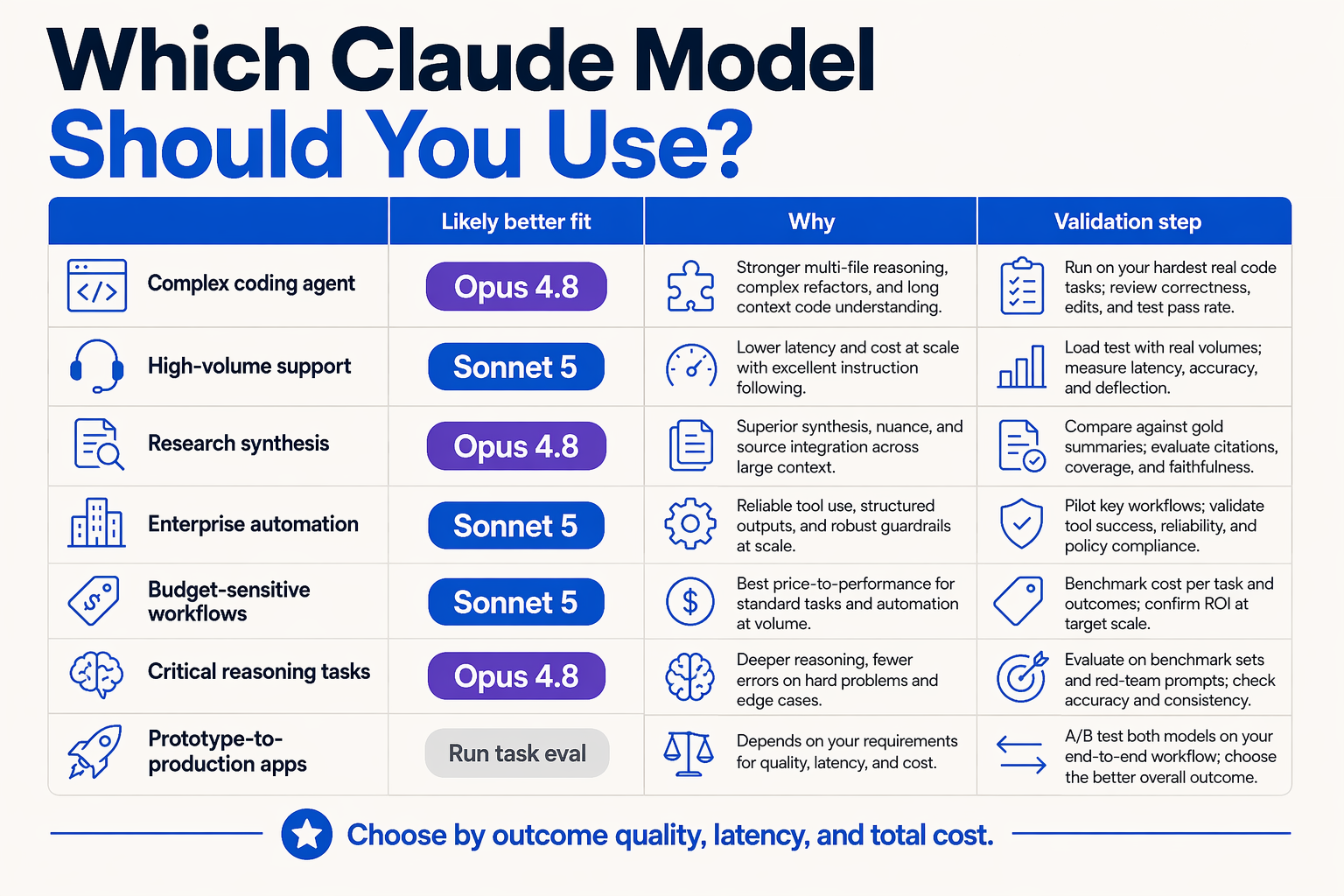
The practical answer: choose by workflow risk, not model hype
For most teams, Claude Opus 4.8 is the safer default for high-stakes work today because it has public documentation, benchmark visibility, and clear positioning from Anthropic. Anthropic’s platform docs explicitly say that if you are unsure which model to use, you should consider starting with Claude Opus 4.8 for the most complex tasks, calling it the company’s “most capable Opus-tier model.”
By contrast, Claude Sonnet 5 should be treated as a future evaluation candidate unless Anthropic has published stable API access, pricing, benchmarks, and production guidance for your environment. The broader Sonnet line remains attractive for cost-sensitive scale, but model selection should be based on operational evidence—not naming assumptions.
| Use Case | Best Choice Today | Why | Risk Level | Practical Recommendation |
|---|---|---|---|---|
| Complex coding agents | Claude Opus 4.8 | Anthropic says Opus 4.8 has “stronger performance across coding, agentic tasks” and “noticeably better judgment” in Claude Code. | High | Use Opus 4.8 for repo-wide refactors, code review, migration planning, and autonomous debugging. |
| Enterprise decision support | Claude Opus 4.8 | Anthropic recommends Opus 4.8 for “the most complex tasks,” making it better suited for reasoning-heavy workflows. | High | Use for legal, finance, compliance, strategy, and multi-step research where mistakes are expensive. |
| High-volume customer support | Sonnet-class model, then escalate to Opus 4.8 | Sonnet models are typically the performance-to-cost tier, while Opus is better for difficult edge cases. | Medium | Route routine tickets to Sonnet when available; escalate angry customers, refunds, or complex cases to Opus. |
| Voice agents and WhatsApp bots | Hybrid routing | Latency and cost matter, but judgment matters during exceptions. | Medium | Use a fast Sonnet-tier model for common intents and Opus 4.8 for fallback reasoning or sensitive flows. |
| AI research and benchmark testing | Claude Opus 4.8 | LLM Stats shows Opus 4.8 beating Claude Sonnet 4.6 on 9 benchmarks, while Sonnet 4.6 leads on only 1 benchmark. | Medium | Benchmark Opus 4.8 as your current frontier Claude baseline before testing Sonnet 5. |
| Experimental Sonnet 5 adoption | Wait and test | Public context around even Sonnet 4.8 showed uncertainty as of June 17, 2026: “no API id, no benchmarks.” | Variable | Do not migrate production workflows until Sonnet 5 has stable docs, evals, pricing, and rollback paths. |
A smart deployment pattern
The best architecture is not “Sonnet 5 or Opus 4.8 forever.” It is model routing by task difficulty:
- Start cheap and fast for simple classification, summarization, FAQ, and form-filling.
- Escalate to Opus 4.8 when the task involves ambiguity, multi-step reasoning, code execution, or business risk.
- Log failures and compare outputs before promoting any new Sonnet model into production.
- Keep rollback paths so a model upgrade does not break your customer or developer experience.
This is especially important for communication-heavy products. Platforms like CallMissed already reflect this direction by allowing teams to route workloads across 300+ LLMs for voice agents, WhatsApp chatbots, speech-to-text, and multilingual customer workflows. In practice, that means a business can use a lower-cost model for routine conversations while reserving Opus-class reasoning for complex escalations.
Bottom line for buyers and builders
If your workflow is mission-critical, agentic, or reasoning-heavy, choose Claude Opus 4.8 today. It has the stronger public case: Anthropic’s own guidance, stronger positioning for coding and agents, and benchmark evidence against Sonnet 4.6.
If your workflow is high-volume and cost-sensitive, Sonnet 5 may become attractive—but only after it has visible API maturity and independent benchmark data. Until then, the winning strategy is clear: deploy Opus 4.8 where correctness matters most, and use Sonnet-class models where speed and scale matter more than deep judgment.
Frequently Asked Questions

What is the main difference in Claude Sonnet 5 vs Opus 4.8 for production teams?
Is Claude Opus 4.8 better than Claude Sonnet 5 for coding and AI agents?
Should I wait for Claude Sonnet 5 or use Claude Opus 4.8 now?
How do Claude Sonnet 5 vs Opus 4.8 compare on benchmarks?
Is Claude Opus 4.8 worth the cost compared with Sonnet models?
What is the best use case for Claude Opus 4.8 in 2026?
Conclusion
The takeaway from Claude Sonnet 5 vs Opus 4.8 is simple: in 2026, model selection should be based on production evidence, not release hype.
- Opus 4.8 is the safer choice today for complex reasoning, coding, and agentic workflows, with Anthropic describing stronger performance across “coding, agentic tasks” and recommending it for the most complex tasks.
- Judgment matters as much as benchmarks: Anthropic says Opus 4.8 “asks the right questions, catches its own mistakes, pushes back when a plan isn’t sound,” which is critical for autonomous systems.
- Sonnet remains the line to watch for cost-efficient, high-volume production use—but Sonnet 5 needs public API details, benchmarks, pricing, and deployment evidence before teams can treat it as a default.
- The best architecture is multi-model, routing premium reasoning to Opus-class models while using faster, cheaper models where latency and scale matter more.
Looking ahead, watch for Sonnet 5’s official release notes, benchmark transparency, API availability, and real-world latency data. That will determine whether it becomes the new production sweet spot—or whether Opus 4.8 remains the trusted choice.
To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents, multilingual chatbots, and model routing for businesses. The real question is: will your AI stack be ready to switch when the evidence changes?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.