Claude Sonnet 5 vs. GPT-5.6: What We Actually Know So Far

Separate verified Claude Sonnet 5 facts from reported GPT-5.6 claims, with practical guidance for coding, agents, cost, and rollout.
Claude Sonnet 5 vs. GPT-5.6: What We Actually Know So Far
What if the biggest AI model matchup of 2026 is half-confirmed, half-rumor—and still important enough to influence your next architecture decision?
That is the reality behind Claude Sonnet 5 vs. GPT-5.6 right now. On one side, Claude Sonnet 5 appears to have a clear official trail: Anthropic’s June 23, 2026 newsroom listing and a dedicated page titled “Introducing Claude Sonnet 5” position it as a frontier model for coding, agents, and professional work at scale. The most concrete detail is pricing: Anthropic’s snippet lists an introductory rate of $2 per million input tokens and $10 per million output tokens, which gives engineering and product teams something tangible to model against budgets.
On the other side, GPT-5.6 is generating intense attention—but the available evidence is more complicated. Current search results surface mostly third-party articles, benchmark breakdowns, YouTube AI news commentary, and comparison posts, rather than a clearly identified official OpenAI announcement in the research available so far. Some third-party snippets claim GPT-5.6 variants such as “Sol” and “Sol Ultra” perform strongly on Terminal-Bench 2.1, with reported scores like 88.8% and 91.9%. Those numbers may be meaningful, but until they are tied to an official release note, reproducible benchmark setup, or independent validation, they should be treated as reported claims—not settled facts.
This matters because teams are no longer comparing models for curiosity. They are choosing infrastructure for agentic coding, customer support automation, internal copilots, voice AI, retrieval systems, and production workflows where small differences in latency, reliability, tool use, and token pricing can become large operational costs. Platforms like CallMissed, which provide voice agents, WhatsApp chatbots, speech APIs, and access to 300+ LLMs, reflect the broader shift: businesses increasingly need flexible AI infrastructure that can adapt as model leadership changes.
In this article, we will separate what is verified from what is still speculative. We will look at Claude Sonnet 5’s announced positioning and pricing, examine the reported GPT-5.6 benchmark claims, and explain how teams should evaluate both models for coding, agents, cost, reliability, and production deployment—without getting swept up in benchmark hype before the evidence is complete.
Introduction: The Credibility-First Verdict

The short answer: compare evidence, not hype
The most honest verdict right now is this: Claude Sonnet 5 is the more verifiable product; GPT-5.6 is the more uncertain comparison target. That does not mean GPT-5.6 is weak, fake, or irrelevant. It means the public evidence trail is uneven.
For Claude Sonnet 5, the available record points to an official Anthropic launch path: a June 23, 2026 newsroom listing and a dedicated page titled “Introducing Claude Sonnet 5.” Anthropic’s own snippet describes Sonnet 5 as delivering “frontier performance across coding, agents, and professional work at scale.” Just as important, it includes concrete pricing: $2 per million input tokens and $10 per million output tokens as an introductory rate.
For GPT-5.6, the picture is different. Current search results are dominated by third-party articles, YouTube commentary, benchmark posts, and comparison pages, not a clearly identified official OpenAI release found in the research so far. Some sources report GPT-5.6 variants such as “Sol” and “Sol Ultra” scoring 88.8% and 91.9% on Terminal-Bench 2.1, but those figures should be treated as reported benchmark claims until tied to an official OpenAI source, reproducible methodology, or independent validation.
Why this distinction matters in 2026
AI model comparisons used to be mostly about leaderboard bragging rights. In 2026, they affect real infrastructure decisions:
- Which model should power coding agents?
- Which API is stable enough for production workflows?
- Which provider gives predictable cost at scale?
- Which model handles long-running tool use without drifting?
- Which ecosystem supports fallbacks when one model underperforms?
That last point is increasingly important. Businesses are no longer betting everything on a single model. Platforms like CallMissed, for example, reflect this broader shift by giving teams access to 300+ LLMs, alongside voice agents, WhatsApp chatbots, Speech-to-Text for 22 Indian languages, and Text-to-Speech APIs. In a market where model leadership can change within weeks, flexible routing and multi-model architecture are becoming safer than one-model dependency.
The credibility-first framework
This article evaluates Claude Sonnet 5 and GPT-5.6 using three evidence tiers:
- Official facts
These include provider announcements, pricing pages, API documentation, and release notes. Claude Sonnet 5 currently has stronger support in this category because Anthropic’s materials list both positioning and pricing.
- Reported claims
These include benchmark numbers from third-party posts. GPT-5.6’s reported Terminal-Bench 2.1 scores of 88.8% and 91.9% fall here unless confirmed by OpenAI or independently reproduced.
- Practical production signals
These include latency, uptime, tool reliability, context handling, cost predictability, and integration maturity—often more important than a single benchmark score.
The verdict before the deep dive
If you need to make a procurement or architecture decision today, Claude Sonnet 5 is easier to evaluate because its public evidence is more concrete. If you are tracking frontier coding performance, GPT-5.6 deserves attention, but the current claims need verification before they should drive high-stakes production planning.
So the right question is not simply, “Which model wins?” It is: Which claims are verified, which are still speculative, and which model fits your actual workload? That is the lens we will use throughout this comparison.
Background & Context: Why This Comparison Is Noisy in June 2026
The market is moving faster than the evidence
The comparison is noisy because the AI ecosystem in June 2026 is no longer waiting for clean, official release cycles before forming opinions. Benchmarks, YouTube roundups, Medium posts, developer newsletters, and model leaderboard screenshots now shape perception within hours—sometimes before the underlying model card, API documentation, or reproducible test setup is public.
As of June 30, 2026, the evidence base is uneven:
- Claude Sonnet 5 has an official-looking Anthropic trail
Anthropic’s own search snippet describes Sonnet 5 as delivering “frontier performance across coding, agents, and professional work at scale.” It also lists concrete introductory pricing: $2 per million input tokens and $10 per million output tokens.
- GPT-5.6 is mostly visible through secondary coverage
The current search results surface third-party pages such as Medium, ExplainX, Rewarx, Mental Momentum, and YouTube commentary. The key gap: no official OpenAI GPT-5.6 announcement was found in the searches completed before handoff.
- Benchmark claims are circulating faster than verification
Third-party snippets claim GPT-5.6 variants such as “Sol” and “Sol Ultra” score 88.8% and 91.9% on Terminal-Bench 2.1. Those numbers may prove important, but without a directly verifiable OpenAI source, they should be treated as reported benchmark claims, not settled model facts.
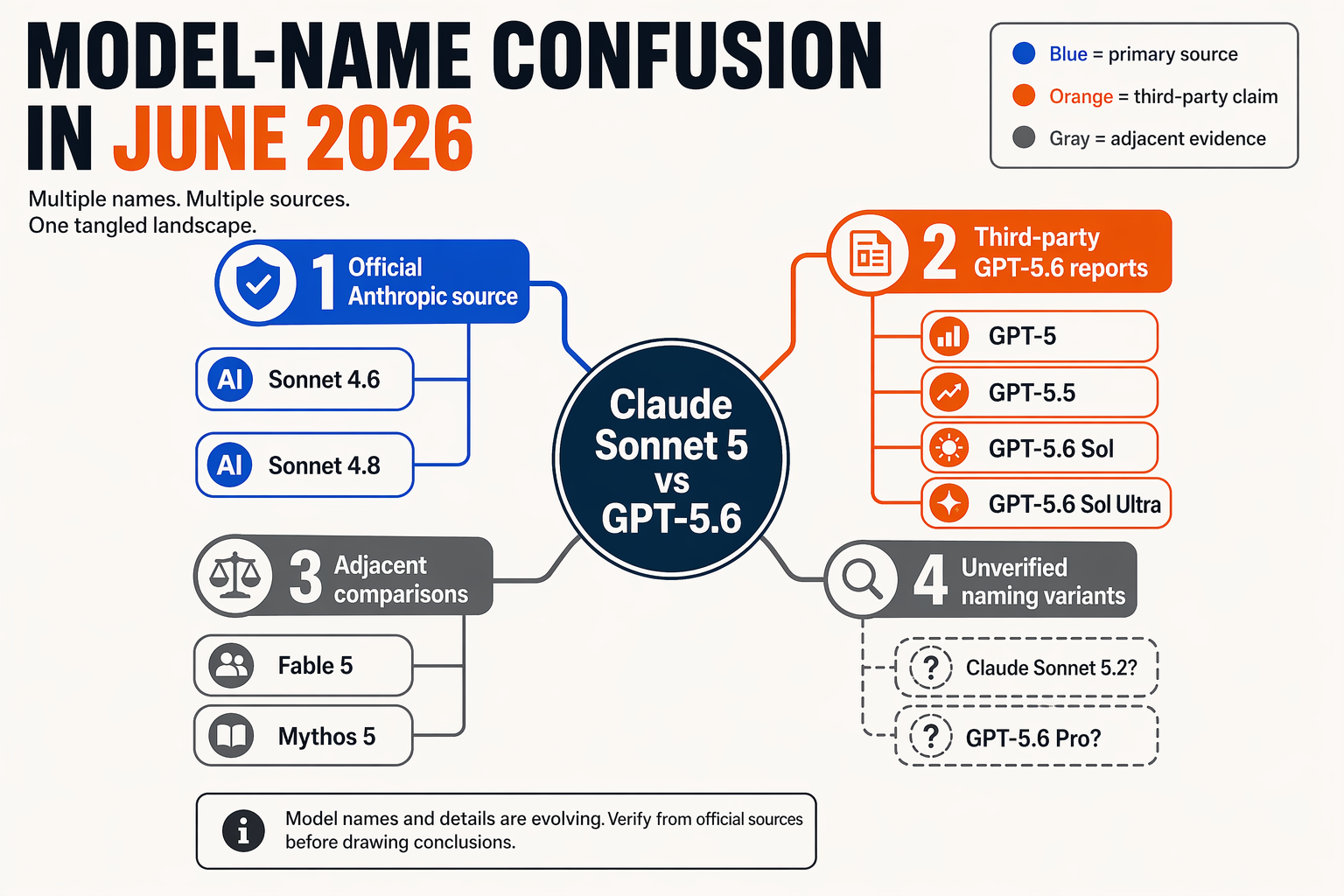
Naming confusion makes the comparison harder
Another reason this matchup is messy: the public web is mixing multiple model names and generations. Search results mention Claude Sonnet 4.6, Claude Sonnet 4.8, Claude Fable 5, Claude Mythos 5, GPT-5, GPT-5.5, and GPT-5.6 in overlapping comparison posts.
For example:
- SitePoint compares Claude Sonnet 4.6 vs. GPT-5, saying Sonnet 4.6 edged ahead in refactoring and debugging, while GPT-5 led in documentation and boilerplate-heavy code generation.
- BuildFastWithAI compares Claude Sonnet 4.6 vs. GPT-5.5 vs. Gemini 3.1 Pro, claiming GPT-5.5 dominates Terminal-Bench while Gemini wins on price and science reasoning.
- Medium and ExplainX snippets discuss GPT-5.6 Sol Ultra and Terminal-Bench 2.1 scores, but in a third-party context.
- Rewarx claims GPT-5.6 has lower pay-as-you-go token costs, while volume discounts bring Claude Sonnet 5 nearly level—again, useful but not equivalent to official pricing documentation.
That creates a practical problem: teams may think they are comparing Claude Sonnet 5 vs. GPT-5.6, while some available data actually refers to adjacent models or unofficial variant names.
Why production teams should care
For model enthusiasts, this uncertainty is annoying. For engineering teams, it is operational risk. A benchmark lead on one test does not automatically translate into better outcomes for:
- Agentic coding workflows
- Customer support automation
- Voice agents
- RAG pipelines
- Tool use and function calling
- Latency-sensitive chat or WhatsApp bots
- High-volume token economics
This is why many companies are moving toward model-flexible infrastructure rather than betting everything on one frontier release. Platforms like CallMissed reflect that shift by giving teams access to 300+ LLMs, voice agents, WhatsApp chatbots, and speech APIs, so applications can route tasks across models as pricing, reliability, and performance change.
The right takeaway is not “ignore GPT-5.6” or “assume Claude Sonnet 5 wins.” It is simpler: separate official evidence from market noise before making architecture decisions.
What’s Officially Confirmed So Far (TABLE)

The verified record is asymmetric
At this stage, the Claude Sonnet 5 vs. GPT-5.6 comparison is not a clean model-to-model spec sheet. It is a comparison between one model with an apparent official vendor trail and another model whose public profile is still mostly shaped by third-party reporting.
The most important distinction: Claude Sonnet 5 has identifiable Anthropic-facing evidence, including a June 23, 2026 newsroom listing and a dedicated page titled “Introducing Claude Sonnet 5.” The available Anthropic snippet also gives concrete commercial detail: $2 per million input tokens and $10 per million output tokens as introductory pricing.
For GPT-5.6, the searches completed for this article did not surface a clearly identifiable official OpenAI announcement. Instead, the current evidence comes from comparison posts, AI news commentary, YouTube coverage, and benchmark-focused articles. That does not invalidate the claims—but it changes how seriously teams should operationalize them.
| Category | Claude Sonnet 5 | GPT-5.6 | Confidence Level |
|---|---|---|---|
| Official announcement trail | Anthropic newsroom listing dated June 23, 2026 and page titled “Introducing Claude Sonnet 5” | No official OpenAI GPT-5.6 announcement found in the completed research | High for Claude; low/unclear for GPT-5.6 |
| Published pricing | Anthropic snippet lists $2 / 1M input tokens and $10 / 1M output tokens | No official pricing confirmed in the available research | High for Claude; unconfirmed for GPT-5.6 |
| Positioning | Described as delivering “frontier performance across coding, agents, and professional work at scale” | Third-party coverage frames it as a strong coding/agent model | High for Claude positioning; medium-low for GPT claims |
| Benchmarks | No specific verified benchmark score in the provided context for Sonnet 5 | Third-party snippets report Terminal-Bench 2.1 scores such as 88.8% for “Sol” and 91.9% for “Sol Ultra” | Reported, not independently verified |
| Source types available | Vendor-owned Anthropic pages plus surrounding coverage | Medium posts, comparison blogs, YouTube/news commentary, benchmark breakdowns | Mixed; GPT-5.6 evidence is less authoritative |
| Production planning usefulness | Pricing and positioning can inform early cost modeling | Benchmark claims may inform watchlists, not procurement decisions | Claude is more actionable today |
What teams can safely conclude
There are three practical takeaways from the confirmed record:
- Claude Sonnet 5 can be budget-modeled now.
The published introductory pricing—$2 per million input tokens and $10 per million output tokens—lets engineering teams estimate costs for coding copilots, agent workflows, document processing, and customer-facing automation.
- GPT-5.6 benchmark claims should be tracked, not treated as settled.
Reported figures like 88.8% and 91.9% on Terminal-Bench 2.1 are potentially significant, especially for agentic coding. But without an official OpenAI release note, reproducible benchmark setup, or independent validation, they remain reported third-party claims.
- The real comparison is not just “which model wins.”
For production AI, teams need to compare:
- Latency under load
- Tool-use reliability
- Context handling
- Cost per completed task
- Failure recovery in agent loops
- Availability through stable APIs
This is why many businesses are moving toward multi-model infrastructure rather than betting on a single vendor. Platforms such as CallMissed, for example, let teams route across 300+ LLMs while also connecting models to voice agents, WhatsApp chatbots, Speech-to-Text, and Text-to-Speech workflows—useful when model leadership changes faster than production roadmaps.
The credibility-first baseline
So far, the official baseline is simple: Claude Sonnet 5 is confirmed enough to evaluate seriously for production planning; GPT-5.6 is important enough to monitor but not yet confirmed enough to treat as a fully documented release. That distinction will shape the rest of this comparison.
Key Developments: Official Facts vs Reported Claims (TABLE)
What is confirmed, what is only reported
The cleanest way to compare Claude Sonnet 5 vs. GPT-5.6 is not to ask “which model wins?” yet. It is to ask: what evidence category does each claim belong to? For production teams, that distinction matters more than leaderboard screenshots. Pricing, availability, benchmark methodology, model variants, rate limits, and safety behavior all affect real deployments.
Below is a credibility-first snapshot based on the research trail available so far.
| Area | Claude Sonnet 5 | GPT-5.6 | Evidence status |
|---|---|---|---|
| Official announcement | Anthropic has a June 23, 2026 newsroom listing and a dedicated page titled “Introducing Claude Sonnet 5.” | No clearly identified official OpenAI GPT-5.6 announcement was found in the searches completed before handoff. | Claude: official; GPT-5.6: unverified in this research |
| Positioning | Anthropic snippet says Sonnet 5 delivers “frontier performance across coding, agents, and professional work at scale.” | Third-party coverage frames GPT-5.6 as a major frontier-model update, often focused on coding and agent benchmarks. | Claude: official wording; GPT-5.6: reported framing |
| Pricing | Anthropic snippet lists $2 per million input tokens and $10 per million output tokens as introductory pricing. | One comparison result claims GPT-5.6 may be cheaper on pay-as-you-go, while Claude may become close under volume discounts. No official GPT-5.6 pricing source was found here. | Claude: concrete price signal; GPT-5.6: third-party claim |
| Benchmark claims | No specific Sonnet 5 benchmark score is provided in the supplied context, beyond Anthropic’s frontier-performance positioning. | Third-party snippets report GPT-5.6 Sol at 88.8% and Sol Ultra at 91.9% on Terminal-Bench 2.1. | GPT-5.6 scores: reported, not independently verified here |
| Model variants | The context names Claude Sonnet 5 directly. | Third-party posts mention variants such as “Sol” and “Sol Ultra.” | Claude naming: clear; GPT variants: reported |
| Deployment relevance | Strong signal for coding, agents, and professional workflows, plus visible token economics. | Potentially strong for terminal/coding tasks if reported scores hold up, but operational details remain unclear. | Claude: actionable now; GPT-5.6: watch closely |
Why this table matters for architecture decisions
A model can look dominant in a headline and still be risky to build around if the operational facts are missing. The GPT-5.6 reports are interesting because Terminal-Bench 2.1 is relevant to developer automation: if scores like 88.8% for “Sol” and 91.9% for “Sol Ultra” are reproducible, that would be meaningful for agentic coding, shell operations, and autonomous engineering workflows.
But reported benchmark strength is not the same as production readiness. Before standardizing on any model, teams should verify:
- Official release notes: Is the model publicly documented by the vendor?
- Pricing and quotas: Can finance and engineering estimate monthly cost?
- Benchmark reproducibility: Are prompts, harnesses, versions, and settings disclosed?
- Latency and reliability: Does performance hold under real traffic?
- Tool-use behavior: Can the model safely call APIs, execute workflows, and recover from errors?
This is where model-agnostic infrastructure becomes practical. Platforms like CallMissed, which provide access to 300+ LLMs alongside voice agents, WhatsApp chatbots, speech-to-text, and text-to-speech APIs, reflect the direction many teams are taking: avoid hard-coding your business to one model until the evidence is mature.
The current evidence-weighted takeaway
For now, Claude Sonnet 5 has the stronger verified foundation: named product, official Anthropic trail, stated positioning, and concrete introductory pricing of $2/M input tokens and $10/M output tokens. GPT-5.6 may be highly competitive, especially if the reported Terminal-Bench 2.1 scores are confirmed, but the public evidence available here is still dominated by third-party commentary and comparison pages.
In short: treat Claude Sonnet 5 as an announced model you can begin evaluating seriously, and treat GPT-5.6 as a potentially important but still verification-dependent contender.
In-Depth Analysis: Coding, Agents, and Professional Workflows

Coding: treat benchmark claims as starting signals
For developer workflows, the strongest verified statement is Anthropic’s positioning of Claude Sonnet 5 as delivering “frontier performance across coding, agents, and professional work at scale.” That matters because Anthropic is not just claiming general intelligence; it is explicitly targeting production software tasks where models must read large codebases, modify files safely, debug regressions, and follow repository conventions.
The GPT-5.6 story is less settled. Third-party sources report strong coding-agent performance, especially on Terminal-Bench 2.1, with claims that GPT-5.6 “Sol” scores 88.8% and “Sol Ultra” reaches 91.9%. A Medium comparison frames that as a meaningful edge over a Claude-related model score of 88.0, while ExplainX repeats the 88.8% / 91.9% figures. But without an official OpenAI release note or reproducible benchmark card, these numbers should be used as evaluation leads, not procurement evidence.
A practical coding evaluation should include:
- Repository-scale refactoring — Can the model change multiple files without breaking interfaces?
- Debugging accuracy — Does it identify root causes or merely patch symptoms?
- Test generation quality — Are tests meaningful, or just coverage-padding?
- Tool use discipline — Does the model run commands, inspect outputs, and revise plans?
- Cost per completed task — Not just token price, but retries, review time, and failure rates.
Agents: reliability beats one-shot brilliance
Agentic workflows are where the comparison becomes more consequential. A model that performs well in a chat demo may fail when asked to operate over tools, APIs, memory, browser sessions, terminals, CRM systems, or ticketing queues.
Claude Sonnet 5’s official framing around agents gives teams a clearer basis for testing. Anthropic’s published introductory pricing—$2 per million input tokens and $10 per million output tokens—also makes it possible to estimate the economics of long-running agents. That is especially important because agent workloads often consume large input context: logs, tickets, code, documents, tool responses, and customer history.
For GPT-5.6, the reported Terminal-Bench 2.1 numbers are relevant because terminal tasks approximate real agent behavior better than static multiple-choice benchmarks. Still, teams should ask: who ran the benchmark, under what prompts, with what tools, and how many retries?
For production agents, evaluate:
- Task completion rate across 100+ realistic workflows
- Recovery behavior after failed API calls or ambiguous instructions
- Permission handling for destructive actions
- Latency variance, not only average latency
- Auditability of plans, tool calls, and final outputs
Platforms like CallMissed reflect this shift toward model-agnostic deployment: businesses increasingly need voice agents, WhatsApp bots, and workflow automations that can route tasks across multiple LLMs as reliability and cost profiles change.
Professional workflows: the hidden benchmark is consistency
In legal, finance, healthcare operations, sales, support, and enterprise knowledge work, the deciding factor is rarely “which model wins a public benchmark?” It is which model produces reviewable, policy-compliant work repeatedly.
Claude Sonnet 5 currently has an advantage in verifiability: an official Anthropic page, a June 23, 2026 newsroom listing, and clear pricing. GPT-5.6 may prove highly capable, especially if the reported 88.8%–91.9% Terminal-Bench 2.1 performance is validated, but buyers should wait for official documentation before assuming parity or superiority.
The best enterprise test is not a leaderboard. It is a workflow bake-off using your own data, tools, policies, and failure thresholds.
Benchmarks Require Caution: Terminal-Bench Claims and Real-World Testing
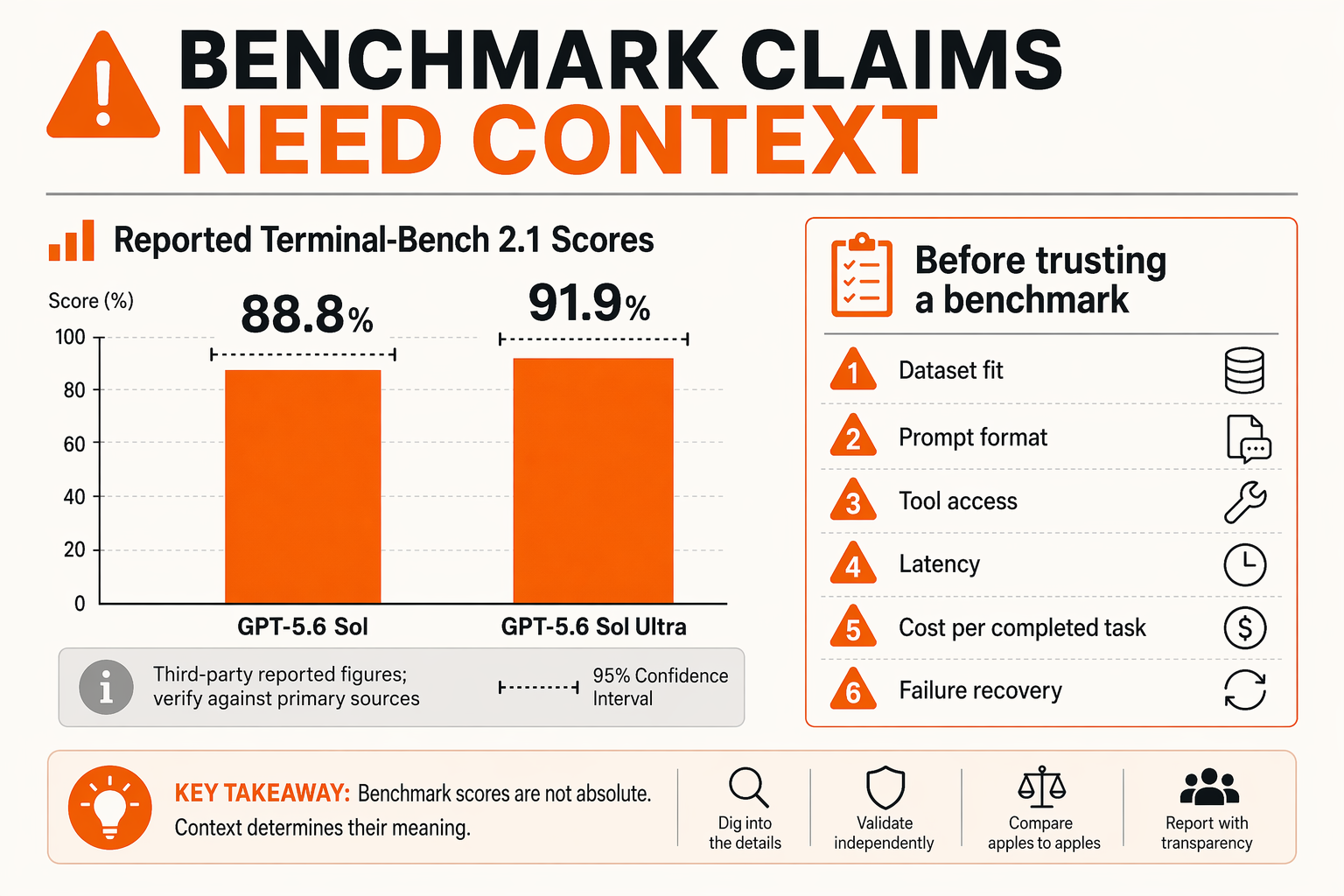
Why Terminal-Bench numbers are useful—but not decisive
The most eye-catching GPT-5.6 claims in current search results revolve around Terminal-Bench 2.1, a benchmark designed to test agentic coding and command-line task execution. Third-party snippets report GPT-5.6 variants such as “Sol” at 88.8% and “Sol Ultra” at 91.9%, while one Medium result frames 91.9 vs. 88.0 as a meaningful edge over a Claude model in coding-oriented tasks.
Those numbers are worth watching. A 3–4 point difference on a difficult benchmark can matter if it reflects repeatable improvements in:
- Multi-step reasoning
- Shell command use
- Debugging under constraints
- Repository navigation
- Tool-calling reliability
- Long-horizon task completion
But the key phrase is if it reflects repeatable improvements. As of the research available here, the GPT-5.6 Terminal-Bench claims appear primarily in third-party comparison posts, AI news commentary, and blog snippets, not in a clearly identified OpenAI release note or reproducible evaluation report. That does not invalidate the numbers—but it does mean teams should treat them as reported claims, not procurement-grade evidence.
The benchmark problem: one score hides many variables
Benchmarks compress messy behavior into a clean percentage. That is useful for quick comparison, but risky for production decisions. A model can score well on Terminal-Bench and still underperform in your workflow if the test conditions differ from reality.
Before relying on any reported score, teams should ask:
- What exact model was tested?
“GPT-5.6,” “Sol,” and “Sol Ultra” may represent different serving tiers, configurations, or access levels.
- Was the benchmark run independently?
Vendor-published and third-party-reported results should be separated from independent, reproducible tests.
- Were tool permissions standardized?
Agentic coding results can change dramatically depending on shell access, retry limits, context window, file visibility, and allowed execution time.
- How many trials were run?
One strong run does not prove reliability. Production agents need consistency across hundreds or thousands of tasks.
- What was the cost per successful task?
A model that solves 5% more tasks but uses 3x the tokens or latency may not be better for business use.
Build a real-world evaluation set
For engineering teams, the better approach is to treat Terminal-Bench as a signal—not the final answer. Create a private benchmark that mirrors your actual workload. For example:
- Coding teams: bug fixes, refactors, test generation, dependency upgrades, CI failure repair
- Support teams: ticket triage, refund workflows, CRM updates, escalation detection
- Voice AI teams: speech-to-text accuracy, interruption handling, latency, fallback behavior
- Agent teams: tool use, memory handling, multi-step task completion, auditability
A good internal test should measure more than accuracy. Track:
- Task success rate
- Median and p95 latency
- Tokens consumed per completed task
- Human intervention rate
- Rollback or correction rate
- Failure mode severity
- Cost per resolved workflow
This is especially important when comparing a more verifiable model like Claude Sonnet 5, which Anthropic positions for “coding, agents, and professional work at scale,” against GPT-5.6 claims that still need stronger official sourcing.
Test models behind an abstraction layer
The practical lesson is not “ignore benchmarks.” It is avoid hard-coding your architecture around benchmark headlines. Model leadership can change quickly, and the best model for coding may not be the best model for voice, retrieval, summarization, or multilingual support.
This is where infrastructure design matters. Platforms such as CallMissed, with access to 300+ LLMs, voice agents, WhatsApp chatbots, speech-to-text for 22 Indian languages, and text-to-speech APIs, reflect a growing pattern: teams want to test and switch models without rebuilding their stack every time a new benchmark appears.
The safest evaluation strategy is simple: use public benchmarks to shortlist models, then run controlled internal tests on your own tasks. Until GPT-5.6 has clearer official documentation and independently reproducible results, Terminal-Bench claims should guide experimentation—not final decisions.
Impact & Implications: Cost, Deployment, Safety, and Vendor Risk
Expert Opinions: How to Read Third-Party Comparisons Without Getting Misled

What This Means For You: Use-Case Decision Matrix (TABLE)

Frequently Asked Questions

Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.