Claude Sonnet 5 vs Fable 5: Benchmarks, Pricing, and Best Uses in 2026

Compare Claude Sonnet 5 and Fable 5 on benchmarks, pricing, coding strength, context, and buyer fit for smarter AI decisions.
Claude Sonnet 5 vs Fable 5: Benchmarks, Pricing, and Best Uses in 2026
What if the “smaller” model in your stack could solve more real GitHub issues than the flagship alternative—while costing less to run at scale? That is the core question behind Claude Sonnet 5 vs Fable 5, one of the most important AI model comparisons for developers, product teams, and automation-heavy businesses in 2026.
The timing matters. Third-party benchmark trackers are reporting a sharp jump in coding performance across the Claude ecosystem: MorphLLM lists Fable 5 at 95% on SWE-bench Verified, while NxCode’s coverage of Claude Sonnet 5 “Fennec” cites a reported 80.9% SWE-bench score and claims Sonnet 5 may deliver “Opus 4.5-level performance at 50% of the cost.” That is not a minor spec-sheet difference—it affects which model you choose for autonomous coding agents, customer-support copilots, workflow automation, long-context reasoning, and enterprise knowledge work.
This comparison also lands in a year when context windows, output limits, and inference economics are changing quickly. Anthropic’s own Claude Platform documentation notes that models such as Claude Sonnet 4.6 support up to 300k output tokens on the Message Batches API using the output-300k-2026-03-24 beta header, showing how aggressively frontier labs are expanding what production AI systems can generate in a single run. For businesses, the question is no longer “Which model is smartest?” but “Which model gives the best accuracy, latency, reliability, and cost for my use case?”
In this article, we’ll break down Claude Sonnet 5 vs Fable 5 across the factors that actually matter in deployment: benchmark performance, pricing assumptions, coding ability, reasoning quality, agentic workflows, API fit, and best-use scenarios. We’ll also separate official signals from third-party claims so you can make a practical decision without getting lost in model hype.
For teams building production AI systems, platforms like CallMissed are part of this broader shift, offering access to 300+ LLMs alongside voice agents, WhatsApp chatbots, speech-to-text, and text-to-speech infrastructure—making model choice a real operational decision, not just a leaderboard debate.
Introduction: Why Claude Sonnet 5 vs Fable 5 Matters in 2026

The Model Race Has Moved From “Chat” to “Work”
The reason Claude Sonnet 5 vs Fable 5 matters is that AI models are no longer being evaluated only on conversational quality. In 2026, the decisive question is whether a model can complete economically valuable work: fixing production bugs, operating tools, drafting long technical documents, calling APIs, triaging customer conversations, and reasoning across large repositories or knowledge bases.
That changes the comparison. A model that is “slightly better” on a benchmark can become meaningfully better in production if it reduces:
- Human review time for generated code and customer responses
- Tool-call failures in agentic workflows
- Token spend across high-volume automation
- Latency in real-time use cases like voice agents
- Context loss when handling long documents, repos, or support histories
Anthropic’s own Claude Sonnet 4.6 announcement describes it as an upgrade across coding, computer use, long-reasoning, agent planning, and knowledge work—the exact categories enterprises now care about. That is the backdrop for why Sonnet 5 and Fable 5 are being compared so closely.
Why Benchmarks Are Only Part of the Story
The headline numbers are dramatic, but they need interpretation. MorphLLM reports Fable 5 at 95% on SWE-bench Verified, while NxCode reports Claude Sonnet 5 “Fennec” at 80.9% on SWE-bench and suggests it could offer Opus 4.5-level performance at 50% of the cost. For context, Leanware’s 2026 guide lists Claude Sonnet 4.5 at 77.2% on SWE-bench Verified in standard runs and 82.0% with parallel compute, while Build Fast with AI cites Sonnet 4.6 at 79.6%.
Those figures suggest three important things:
- Coding performance is compressing upward — models that once looked frontier-level are being matched or exceeded within months.
- Cost-performance is becoming the real battleground — a cheaper model with near-frontier accuracy may beat a stronger model in day-to-day deployment.
- Independent verification matters — official docs, third-party benchmark trackers, and leaked or semi-public claims should not be treated equally.
In other words, the winner is not automatically the model with the biggest number. The winner is the model that delivers the best mix of accuracy, reliability, latency, price, context handling, and integration fit for your workload.
The Practical Stakes for Product Teams
For developers and AI product leaders, this comparison affects architecture decisions now. Choosing between Claude Sonnet 5 and Fable 5 may determine whether you build:
- A coding agent that can autonomously resolve GitHub issues
- A customer-support copilot that reasons across policies and tickets
- A sales or operations assistant that can use tools safely
- A long-document workflow for contracts, audits, or compliance
- A multilingual communication agent for voice, chat, or WhatsApp
This is where model flexibility becomes operationally important. Platforms such as CallMissed, which provide access to 300+ LLMs along with voice agents, WhatsApp chatbots, speech-to-text for 22 Indian languages, and text-to-speech APIs, reflect the direction the market is moving: businesses do not want to bet everything on one model. They want the ability to route tasks to the best model for the job.
The Core Question for 2026
So the Claude Sonnet 5 vs Fable 5 debate is not just about Anthropic’s roadmap or leaderboard rankings. It is about a broader shift in AI deployment: from experimenting with impressive models to building cost-efficient, measurable, production-grade AI systems.
That is why this comparison matters. If Fable 5’s reported benchmark lead translates into real-world reliability, it could become a preferred model for autonomous coding and complex reasoning. If Claude Sonnet 5 delivers stronger price-performance, lower latency, or better ecosystem support, it may be the more practical enterprise choice. The rest of this article examines exactly where each model appears to win—and where the evidence is still incomplete.
Background & Context: Where Sonnet 5 and Fable 5 Fit in the Claude Lineup
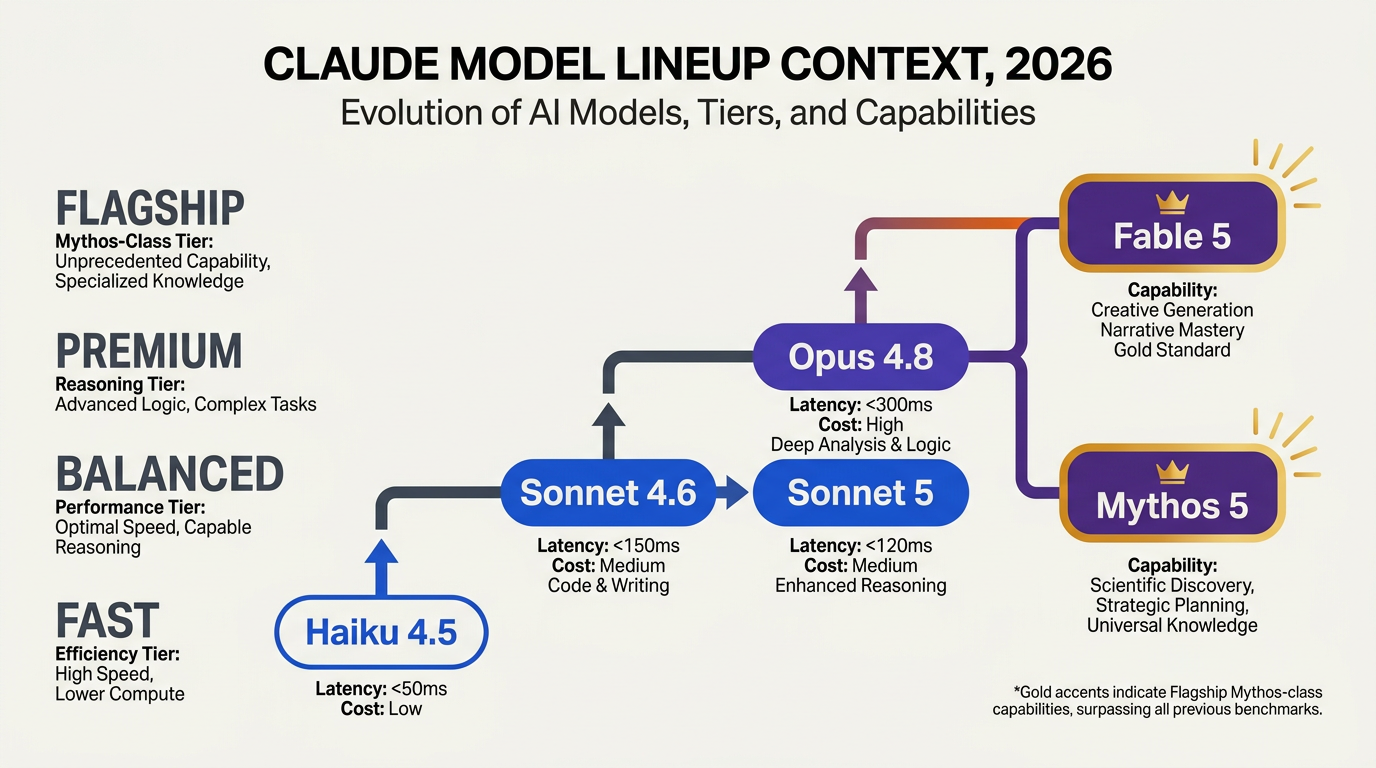
Claude’s Lineup Is Built Around Workload Tiers
To understand Claude Sonnet 5 vs Fable 5, it helps to place both models inside the broader Claude family. Anthropic’s model lineup has historically followed a tiered pattern: faster, cheaper models for high-volume tasks; balanced models for everyday production work; and premium models for the hardest reasoning, coding, and agentic workloads.
By 2026, that structure has become more complex. Anthropic’s official Claude Platform documentation lists advanced models such as Claude Opus 4.8, Opus 4.7, Opus 4.6, and Sonnet 4.6, with support for up to 300k output tokens on the Message Batches API via the output-300k-2026-03-24 beta header. That matters because the Claude ecosystem is no longer just about “chat quality”—it is being optimized for long-running generation, repository-scale coding, enterprise documentation, and agent workflows.
Within that context, Sonnet has traditionally occupied the “best default” position: strong enough for serious reasoning and coding, but economical enough for production-scale use. Anthropic’s own announcement for Claude Sonnet 4.6 described it as a “full upgrade” across coding, computer use, long-reasoning, agent planning, and knowledge work, which signals where the Sonnet branch is headed.
Where Sonnet 5 Fits
Claude Sonnet 5, reportedly developed under the internal codename “Fennec,” appears to continue that balanced-performance lineage. Third-party coverage from WaveSpeed states that Sonnet 5 “officially launched on February 3, 2026,” while NxCode frames it more cautiously as a leak-driven or limited-launch story, claiming that if the reports are accurate, Sonnet 5 could offer “Opus 4.5-level performance at 50% of the cost.”
The most important reported number is NxCode’s cited 80.9% SWE-bench score. That would place Sonnet 5 above earlier Sonnet-generation coding baselines, including published third-party figures for Sonnet 4.5, which Leanware reports at 77.2% on SWE-bench Verified in standard runs and 82.0% with parallel compute.
In practical terms, Sonnet 5 looks positioned as:
- A high-throughput engineering model for coding agents and developer copilots
- A cost-sensitive alternative to Opus-class models
- A strong general-purpose model for reasoning, support automation, and workflow orchestration
- A likely default choice where latency, cost, and accuracy all matter
For platforms that route tasks across many models—such as CallMissed’s multi-model infrastructure with access to 300+ LLMs—this “balanced model” category is especially important because it often becomes the default path for production traffic before escalating harder tasks to more expensive models.
Where Fable 5 Fits
Fable 5 is more unusual because it is not described in the provided context as part of Anthropic’s official public model documentation. Its strongest signal comes from MorphLLM’s 2026 Claude benchmark tracker, which reports Fable 5 at 95% on SWE-bench Verified—a strikingly high number compared with NxCode’s reported 80.9% for Sonnet 5 and MorphLLM’s own listing of Opus 4.8 at 88.6%.
That suggests Fable 5 may be positioned less like a general default model and more like a specialized high-performance coding model, especially for real-world GitHub issue resolution. If the MorphLLM benchmark is accurate and comparable, Fable 5 would sit near the top of the Claude coding stack, potentially outperforming even premium Opus-class models on SWE-bench Verified.
The Key Context: Official Signals vs Benchmark Signals
The important distinction is evidence quality:
- Official Anthropic sources confirm capabilities around Sonnet 4.6 and long-output support for current Claude models.
- Third-party sources provide most of the available Sonnet 5 and Fable 5 claims.
- Benchmark scores are not the same as production fit—latency, tool use, pricing, context handling, and reliability still matter.
So the lineup context is this: Sonnet 5 appears to be the pragmatic production workhorse, while Fable 5 appears to be the benchmark-leading coding specialist. The rest of this comparison is about whether that benchmark advantage translates into better real-world deployments.
Key Developments (TABLE)

What Changed Since the Sonnet 4.x Era
The Claude Sonnet 5 vs Fable 5 debate is being shaped less by marketing language and more by a cluster of 2026 developments: coding benchmarks, long-output infrastructure, agentic reliability, and cost-per-task. The key point is that not every signal has the same confidence level. Anthropic’s own documentation confirms major platform capabilities for current Claude models, while Sonnet 5 and Fable 5 performance numbers are largely coming from third-party benchmark trackers and model-analysis sites.
| Development | Source / Timing | Claude Sonnet 5 Signal | Fable 5 Signal | Why It Matters |
|---|---|---|---|---|
| SWE-bench Verified jump | NxCode / MorphLLM, 2026 | 80.9% reported SWE-bench score for Sonnet 5 “Fennec” | 95% reported SWE-bench Verified | Measures ability to solve real GitHub issues, a stronger proxy for coding agents than generic chat benchmarks |
| Cost-performance positioning | NxCode, 2026 | Claimed “Opus 4.5-level performance at 50% of the cost” | Not framed as cost-first in provided data | Important for teams running thousands of agent tasks, code reviews, or support automations daily |
| Long-output infrastructure | Anthropic Claude Platform Docs, 2026 | Sonnet 4.6 supports up to 300k output tokens via Message Batches API beta header output-300k-2026-03-24 | No equivalent official context-window detail in provided data | Shows the Claude platform is optimizing for large-scale generation, migration scripts, reports, and multi-file outputs |
| Prior Sonnet baseline | Leanware / Build Fast with AI, 2026 | Sonnet 4.5 scored 77.2% SWE-bench Verified, or 82.0% with parallel compute; Sonnet 4.6 cited at 79.6% | Fable 5 appears significantly higher in third-party tracking | Helps separate incremental Sonnet progress from Fable’s reported leap |
| Launch / availability claims | WaveSpeed AI, 2026 | Sonnet 5 “Fennec” described as launched on February 3, 2026 | Benchmark visibility via MorphLLM | Availability affects whether teams can test, fine-tune workflows, and deploy through API gateways |
| Agentic workflow relevance | Anthropic Sonnet 4.6 announcement, 2026 | Sonnet line positioned around coding, computer use, long-reasoning, agent planning, and knowledge work | Fable 5 benchmark suggests stronger coding issue resolution | The winning model may differ by task: repository repair, tool use, customer ops, or long-form reasoning |
How to Read These Signals
The most important development is the gap between reported coding performance and official platform maturity. Fable 5’s 95% SWE-bench Verified number from MorphLLM is the headline-grabber because SWE-bench Verified tests real-world software engineering tasks rather than isolated programming puzzles. If that figure holds under independent replication, Fable 5 would be positioned as a serious choice for autonomous code repair and repository-level development agents.
Sonnet 5, however, has a different kind of appeal: ecosystem continuity. NxCode’s reported 80.9% SWE-bench score is lower than Fable 5’s claimed number, but the same source frames Sonnet 5 as potentially delivering “Opus 4.5-level performance at 50% of the cost.” For production buyers, that matters because the cheapest model is not always the best model—the best model is the one that reaches acceptable accuracy with predictable latency, tool behavior, and operating cost.
Practical Takeaway for Buyers
For engineering teams, these developments suggest a two-track evaluation:
- Use Fable 5 where maximum coding benchmark performance is the priority.
- Use Claude Sonnet 5 where cost-performance, Claude ecosystem compatibility, and general agent behavior matter more.
- Validate both on your own repositories, not just public benchmarks.
- Track official Anthropic documentation separately from third-party claims.
This is also where infrastructure choice becomes strategic. Platforms like CallMissed, which provide access to 300+ LLMs through production APIs, make it easier to benchmark Sonnet-class and Fable-class models side by side before committing to one model for customer support, coding automation, or multilingual AI workflows.
Claude Sonnet 5: Strengths, Limits, and Ideal Workloads

Where Sonnet 5 Appears Strongest
Claude Sonnet 5—reportedly developed under the internal codename “Fennec”—is best understood as the likely “workhorse” model in the Claude 5 family: powerful enough for serious reasoning and coding, but positioned for lower operating cost than the top-tier model. WaveSpeed’s 2026 coverage says Sonnet 5 launched on February 3, 2026, while NxCode reports that, “if the leaks are accurate,” it may deliver Opus 4.5-level performance at 50% of the cost with an 80.9% SWE-bench score.
That makes Sonnet 5 especially compelling for teams that need high-quality automation but cannot justify flagship-model pricing on every request.
Its strongest fit is likely across four workload categories:
- Everyday software engineering
- Bug fixing
- Unit test generation
- Pull request review
- Refactoring medium-sized codebases
- Explaining unfamiliar repositories
- Agentic task execution
- Multi-step tool use
- Browser or computer-control workflows
- Internal operations automation
- API-driven business processes
- Knowledge work
- Policy summarization
- Research synthesis
- Technical documentation
- Contract and compliance review
- Customer-facing AI assistants
- Support copilots
- Sales enablement bots
- Voice-agent reasoning layers
- WhatsApp and chat automation
This aligns with Anthropic’s broader Sonnet positioning. Its official Claude Sonnet 4.6 announcement described the model as a “full upgrade” across coding, computer use, long-reasoning, agent planning, and knowledge work. Sonnet 5 appears to extend that trajectory rather than redefine it.
Why Sonnet 5 May Be the Practical Default
The biggest advantage of Sonnet 5 is not that it beats Fable 5 outright. Based on current third-party data, it probably does not: MorphLLM lists Fable 5 at 95% on SWE-bench Verified, significantly above NxCode’s reported 80.9% for Sonnet 5.
But production AI is rarely about picking the absolute strongest model for every task. It is about finding the best trade-off between accuracy, latency, cost, and reliability. If Sonnet 5 really approaches higher-tier performance at roughly half the cost, it becomes attractive for high-volume workloads where millions of tokens are processed daily.
That includes:
- Tier-1 support automation, where most queries are repetitive but still require reasoning
- Internal coding copilots, where speed and cost matter more than solving the hardest benchmark cases
- Document-heavy workflows, where summarization and extraction volume is high
- Voice and messaging agents, where response time and consistency matter as much as raw intelligence
Platforms like CallMissed, which provide access to 300+ LLMs alongside voice agents, WhatsApp chatbots, STT, and TTS APIs, make this kind of routing practical: Sonnet-class models can handle the majority of requests, while more expensive frontier models can be reserved for escalation paths.
Key Limits to Watch
Sonnet 5’s main limitation is benchmark headroom. An 80.9% SWE-bench result is strong, but it leaves a meaningful gap versus Fable 5’s reported 95%. For autonomous coding agents operating on complex production repositories, that gap can translate into more failed patches, more human review, and slower resolution cycles.
Teams should also be cautious because several Sonnet 5 details come from third-party reports rather than primary Anthropic documentation. By contrast, Anthropic’s platform docs explicitly confirm capabilities such as 300k output tokens for models including Claude Sonnet 4.6 via the output-300k-2026-03-24 beta header on the Message Batches API. Until equivalent official documentation is available for Sonnet 5, treat claims about exact limits, pricing, and benchmark scores as provisional.
Ideal Sonnet 5 Workloads
Sonnet 5 is likely the better choice when you need:
- Strong coding ability without flagship cost
- Reliable reasoning for business workflows
- Fast iteration in developer tools
- High-volume customer or internal automation
- Balanced performance across code, text, and tool use
In short, Sonnet 5 looks like the model you deploy broadly. Fable 5 may be the specialist you call when the task is unusually complex, failure is expensive, or benchmark-leading coding accuracy is worth the premium.
Claude Fable 5: Mythos-Class Performance, Cost, and Use Cases
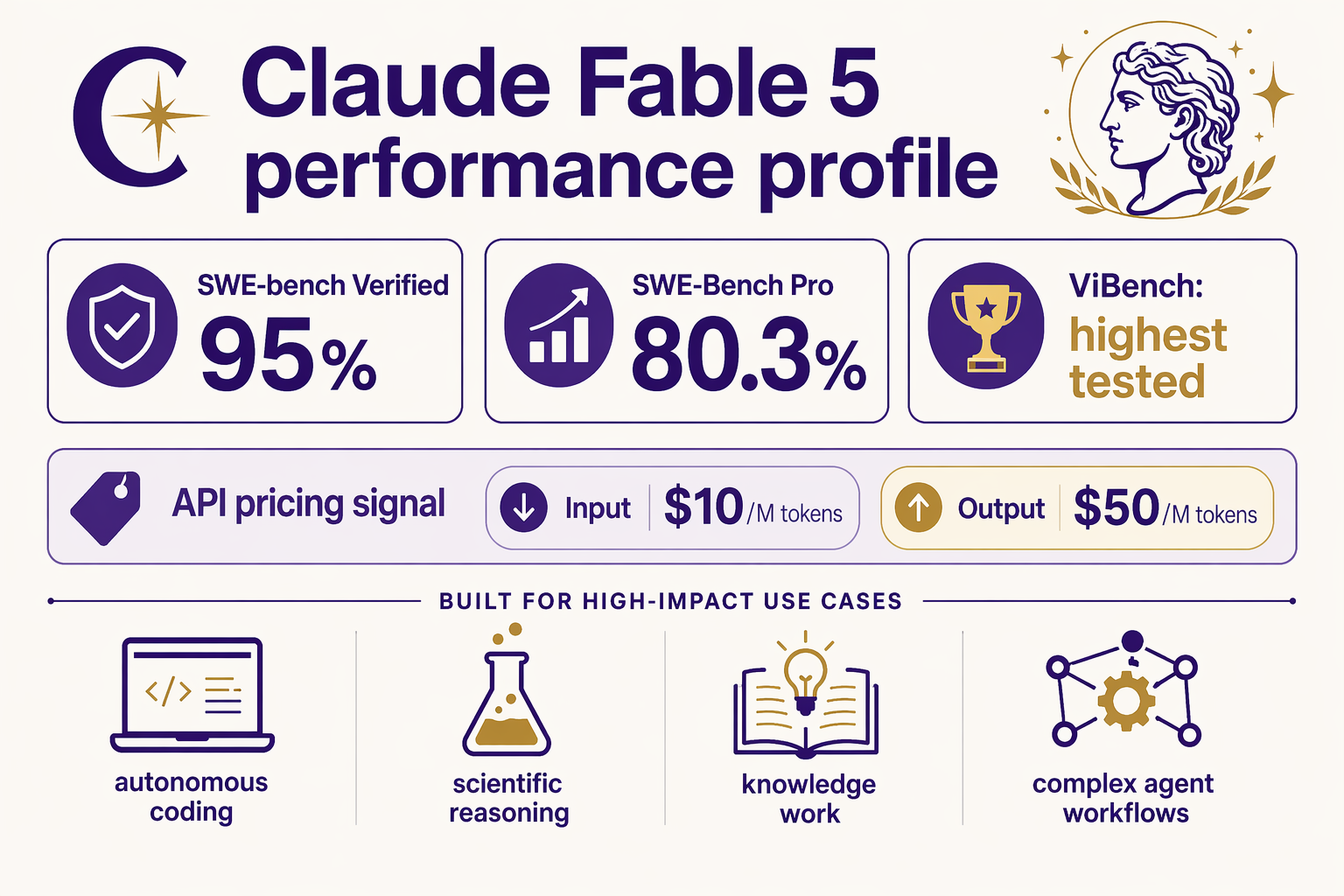
What “Mythos-Class” Means for Fable 5
If Sonnet 5 is positioned as the practical high-throughput workhorse, Fable 5 appears to be the specialist model aimed at maximum task completion—especially in software engineering. The biggest data point so far comes from MorphLLM’s 2026 Claude benchmark tracker, which lists Fable 5 at 95% on SWE-bench Verified. That is an unusually high score for a benchmark built around resolving real GitHub issues, not just answering coding trivia.
To put that in perspective, the same benchmark ecosystem reports:
- Claude Sonnet 4.5: 77.2% on SWE-bench Verified in standard runs, according to Leanware
- Claude Sonnet 4.5 with parallel compute: 82.0%
- Claude Sonnet 5 “Fennec”: reportedly 80.9%, according to NxCode’s coverage
- Claude Opus 4.8: 88.6%, according to MorphLLM
- Claude Fable 5: 95%, according to MorphLLM
That makes Fable 5 interesting because it does not merely edge out Sonnet-class models—it reportedly exceeds even Opus 4.8 on this coding-focused benchmark. However, this should be read carefully: MorphLLM is a third-party source, not an official Anthropic announcement. Until Anthropic publishes full model cards, pricing, and evaluation methodology, Fable 5’s 95% score should be treated as a strong signal rather than a final procurement-grade fact.
Performance Profile: Where Fable 5 Likely Wins
Based on the available benchmark pattern, Fable 5 looks best suited for tasks where correctness matters more than raw throughput. In practice, that means it may be the stronger choice for:
- Autonomous software engineering agents
A 95% SWE-bench Verified score suggests exceptional ability to inspect repositories, understand failing tests, modify code, and produce working patches.
- Complex debugging and refactoring
Teams dealing with legacy systems, multi-file changes, or dependency-heavy codebases may benefit from Fable 5’s apparent depth.
- High-stakes technical reasoning
Architecture reviews, migration plans, security-sensitive changes, and infrastructure automation are areas where a few percentage points of reliability can materially reduce review burden.
- Long-horizon agent workflows
Anthropic’s own Sonnet 4.6 announcement emphasized upgrades in “coding, computer use, long-reasoning, agent planning, knowledge work.” Fable 5 appears to push further into that same direction, especially for coding-heavy work.
Cost: Powerful, But Probably Not the Default for Every Task
The cost question is where Fable 5 becomes less obvious. NxCode claims Sonnet 5 may deliver “Opus 4.5-level performance at 50% of the cost,” positioning Sonnet 5 as a value-optimized model. Fable 5, by contrast, looks like a premium accuracy model: you use it when the cost of a wrong answer is higher than the cost of extra inference.
A practical deployment pattern would be:
- Use Sonnet 5 for routine coding, support automation, summarization, and agent loops
- Escalate to Fable 5 for failed test repairs, complex pull requests, and critical reasoning
- Reserve even larger or slower models only when Fable 5 cannot resolve the task
This routing strategy matters for platforms such as CallMissed, where businesses may combine multiple LLMs across voice agents, WhatsApp chatbots, and workflow automations. With access to 300+ models, teams can route everyday tasks to cheaper models while reserving Fable-class reasoning for difficult escalations.
Best Use Cases for Fable 5
Fable 5 is likely strongest when used selectively, not universally. The best-fit scenarios include:
- AI coding agents that must fix real bugs end-to-end
- Enterprise engineering copilots for large repositories
- Automated QA and test repair workflows
- DevOps runbook generation and incident analysis
- Technical documentation from complex codebases
- Security review assistance where precision is critical
The takeaway: Fable 5 looks like the accuracy-first option in the Claude Sonnet 5 vs Fable 5 comparison. If the 95% SWE-bench Verified figure holds up under broader testing, it may become the model teams choose when they need the highest probability of completing difficult engineering work correctly.
In-Depth Analysis: Benchmarks, Pricing, Context, and Agentic Coding

Benchmarks: Treat Fable 5’s Lead as Powerful but Still “Source-Sensitive”
The headline number is hard to ignore: MorphLLM reports Fable 5 at 95% on SWE-bench Verified, while NxCode cites Claude Sonnet 5 “Fennec” at 80.9% on SWE-bench. If both figures hold under comparable test conditions, Fable 5 would have a major advantage for repository-level bug fixing and autonomous coding tasks.
But benchmark interpretation matters. SWE-bench Verified measures whether a model can resolve real GitHub issues, yet scores can vary based on scaffolding, tool access, retry strategy, and parallel compute. We already saw this pattern with earlier Claude models: Leanware reported Claude Sonnet 4.5 at 77.2% in standard SWE-bench runs and 82.0% with parallel compute, showing that orchestration can move results by several points.
So the practical takeaway is:
- Fable 5 appears stronger for raw coding benchmark performance.
- Claude Sonnet 5 may still be more attractive if its latency, reliability, or price profile is better.
- Teams should test both on internal repos, not just public leaderboards.
Pricing: The “50% Cost” Claim Could Be the Real Differentiator
NxCode’s most important claim is not only that Sonnet 5 reaches 80.9% SWE-bench, but that it may deliver “Opus 4.5-level performance at 50% of the cost.” If accurate, that changes the buying decision. A model that is 10–15 benchmark points behind can still win in production if it cuts inference spend meaningfully.
For high-volume engineering agents, the cost equation includes:
- Input tokens from large codebases, logs, tickets, and docs
- Output tokens from patches, explanations, tests, and review comments
- Retry loops when an agent fails or produces incomplete code
- Tool-call overhead for search, terminal execution, browser use, and CI validation
This is where model routing becomes important. Platforms such as CallMissed, which provide access to 300+ LLMs through production infrastructure, reflect a broader industry pattern: teams increasingly route simple tasks to cheaper models and reserve premium models for hard reasoning, coding, or escalation paths.
Context and Output: Long-Running Agents Need More Than a Big Window
Context length is becoming a deployment feature, not a marketing bullet. Anthropic’s Claude Platform documentation states that Claude Opus 4.8, Opus 4.7, Opus 4.6, and Sonnet 4.6 support up to 300k output tokens on the Message Batches API using the output-300k-2026-03-24 beta header. That matters because agentic coding often requires long outputs: multi-file diffs, test suites, migration plans, documentation, and rollback instructions.
For Claude Sonnet 5 vs Fable 5, the question is not just “How much can the model read?” but:
- Can it keep architectural constraints consistent across many files?
- Can it produce complete patches without truncation?
- Can it summarize prior attempts and continue after tool failures?
- Can it avoid drifting from the original issue after 20+ steps?
A larger output ceiling is especially useful for batch workflows: codebase modernization, API migration, compliance documentation, and large customer-support knowledge updates.
Agentic Coding: Fable 5 Looks Like the Specialist, Sonnet 5 Like the Scaler
For autonomous coding agents, Fable 5’s reported 95% SWE-bench Verified score suggests it may be the better specialist for difficult GitHub issue resolution. If your product depends on fewer failed patches, fewer human corrections, and stronger test-aware reasoning, Fable 5 deserves priority testing.
Claude Sonnet 5, however, may be the better default agent model if NxCode’s “50% of the cost” claim translates into real API economics. Many agentic workflows are not single hard problems; they are thousands of medium-difficulty tasks—triage, refactoring, documentation, code review, dependency updates, and test generation. In those cases, throughput and cost-per-success matter as much as peak benchmark accuracy.
The most realistic architecture is not choosing one forever. It is a tiered system:
- Use Sonnet 5 for high-volume coding assistance and routine automation.
- Escalate hard failures to Fable 5 where benchmark strength matters most.
- Track success rate, retry count, latency, and human-review time internally.
That is the operational lens that turns model comparison from hype into engineering strategy.
Impact & Implications for Developers, Teams, and AI Budgets

Developer Impact: Model Choice Becomes an Engineering Architecture Decision
For developers, Claude Sonnet 5 vs Fable 5 is less about brand preference and more about where each model fits inside the software delivery pipeline. If MorphLLM’s reported 95% SWE-bench Verified score for Fable 5 holds up under broader validation, it suggests Fable 5 may be better suited for high-autonomy coding tasks: resolving GitHub issues, refactoring modules, writing tests, and handling multi-step repository changes with fewer human corrections.
Sonnet 5, meanwhile, appears positioned as the more cost-balanced generalist. NxCode reports an 80.9% SWE-bench score and says Sonnet 5 could deliver “Opus 4.5-level performance at 50% of the cost.” That matters for teams that run AI across many lower-risk tasks: code review summaries, documentation updates, support macros, analytics queries, and workflow automation.
The practical implication: developers should stop thinking in terms of one “best” model and start designing model routing layers:
- Use a stronger model for complex bug-fixing and architecture reasoning.
- Use a lower-cost model for repetitive, high-volume work.
- Route failed or uncertain outputs to a second model for verification.
- Track acceptance rate, latency, and cost per completed task—not just benchmark scores.
Team Workflows: AI Agents Will Need Governance, Not Just Prompts
The stronger these models become, the more they affect team structure. A model capable of solving real software issues changes how engineering managers assign work. Instead of asking, “Can AI write this function?” teams will ask, “Which parts of our backlog can safely be attempted by an agent before a human review?”
That creates new operating requirements:
- Code ownership rules for AI-generated pull requests
- Evaluation suites based on internal repositories, not just public benchmarks
- Human approval gates for production-impacting changes
- Prompt and tool-call observability for debugging failed agent runs
- Security policies around secrets, logs, and customer data
This is especially important because some of the most-cited 2026 numbers are still coming from third-party sources. MorphLLM lists Fable 5 at 95% SWE-bench Verified, while NxCode’s Sonnet 5 reporting includes conditional language such as “if the leaks are accurate.” Teams should treat these as strong directional signals, not as substitutes for internal testing.
Budget Impact: Cost per Successful Outcome Beats Cost per Token
AI budgeting is moving beyond simple token pricing. A cheaper model is not cheaper if it needs three retries, produces failing code, or requires senior engineers to spend 40 minutes reviewing every output. Likewise, a premium model can be cost-effective if it completes a task in one pass.
For finance and engineering leaders, the key metric should be cost per accepted result:
- Cost per merged pull request
- Cost per resolved support ticket
- Cost per generated report approved by a human
- Cost per completed workflow without escalation
- Cost per thousand successful tool calls
This is where Sonnet 5 could be compelling if the reported “50% of the cost” positioning proves accurate. It may become the default model for broad team deployment, while Fable 5 is reserved for expensive failure domains where higher accuracy justifies higher inference spend.
Implications for AI Infrastructure
The bigger lesson is that model diversity is becoming mandatory. Anthropic’s own platform documentation already shows how quickly capabilities are expanding, noting that models such as Claude Sonnet 4.6 can support up to 300k output tokens on the Message Batches API with the output-300k-2026-03-24 beta header. As context windows, output limits, and benchmark scores keep shifting, hard-coding one model into your product stack creates technical debt.
Platforms like CallMissed, which provide access to 300+ LLMs alongside voice agents, WhatsApp chatbots, speech-to-text for 22 Indian languages, and text-to-speech APIs, reflect where enterprise AI infrastructure is heading: flexible routing, multilingual deployment, and production monitoring across multiple model families.
The winning teams in 2026 will not simply pick Sonnet 5 or Fable 5. They will build systems that can test both, route intelligently, and optimize continuously for quality, latency, and budget.
Expert Opinions: What Analysts, Builders, and Reviewers Are Watching

Analysts Are Treating the Benchmarks as Signals, Not Final Verdicts
The expert consensus around Claude Sonnet 5 vs Fable 5 is cautiously optimistic: both models appear to represent a major step forward, but reviewers are watching how benchmark claims translate into real production reliability.
The headline numbers are hard to ignore. MorphLLM reports Fable 5 at 95% on SWE-bench Verified, while NxCode’s coverage of Claude Sonnet 5 “Fennec” cites a reported 80.9% SWE-bench score and says Sonnet 5 could deliver “Opus 4.5-level performance at 50% of the cost.” For analysts, that creates a clear split:
- Fable 5 looks like the model to watch for maximum coding accuracy.
- Claude Sonnet 5 looks like the model to watch for cost-adjusted performance.
- The real winner may depend less on raw benchmark score and more on latency, tool use, context handling, and failure recovery.
This is why many reviewers are avoiding simplistic “best model” conclusions. A 95% SWE-bench Verified result is extraordinary, but enterprises still need to know whether that advantage persists across private repositories, unfamiliar frameworks, legacy codebases, and long-running agent workflows.
Builders Are Focused on Agentic Reliability
Developers and AI infrastructure teams are paying special attention to how these models behave inside multi-step coding agents. Anthropic’s own positioning around Claude Sonnet 4.6 emphasized upgrades across coding, computer use, long-reasoning, agent planning, and knowledge work, according to its model announcement. That matters because Sonnet 5 is being evaluated as the next step in that trajectory.
Builders are watching four practical behaviors:
- Does the model recover from failed tool calls?
Autonomous coding agents often fail not because the model cannot reason, but because it misuses tools, misreads logs, or gets stuck after a failed test.
- Can it preserve intent over long tasks?
Claude Platform documentation notes that models such as Sonnet 4.6 support up to 300k output tokens on the Message Batches API via the output-300k-2026-03-24 beta header. That signals where the industry is heading: longer outputs, larger tasks, and more persistent agents.
- Does it reduce human review burden?
A model that produces fewer subtle bugs can save more money than a cheaper model with higher correction costs.
- Can it work across modalities and channels?
For production teams, coding ability is only one layer. Platforms like CallMissed, which support 300+ LLMs, voice agents, WhatsApp chatbots, speech-to-text in 22 Indian languages, and text-to-speech APIs, reflect the broader demand: models must plug into real customer and developer workflows, not just score well in isolation.
Reviewers Are Watching the Source Quality of Claims
One important expert caution: not all Claude Sonnet 5 and Fable 5 data has the same evidentiary weight. Anthropic’s official documentation currently provides firm details for models including Claude Sonnet 4.6, Opus 4.6, Opus 4.7, and Opus 4.8, including the 300k-output beta capability. By contrast, some Sonnet 5 and Fable 5 figures come from third-party trackers and commentary sites.
That does not make the numbers useless—but it does mean reviewers are separating:
- Official platform documentation from Anthropic
- Third-party benchmark aggregators such as MorphLLM
- Analyst and builder commentary such as NxCode
- Hands-on production evaluations from engineering teams
The most credible evaluations in 2026 will combine all four.
The Emerging Expert Takeaway
The current expert read is nuanced: Fable 5 may be the higher-ceiling coding model, especially if the reported 95% SWE-bench Verified result holds up under independent testing. Claude Sonnet 5 may be the more deployable default if its reported 80.9% SWE-bench performance comes with lower cost, better latency, and stronger integration into existing Claude workflows.
In other words, analysts are not just asking, “Which model is smarter?” They are asking: Which model creates fewer operational surprises once it is connected to tools, repositories, customers, and production systems?
What This Means For You (TABLE)
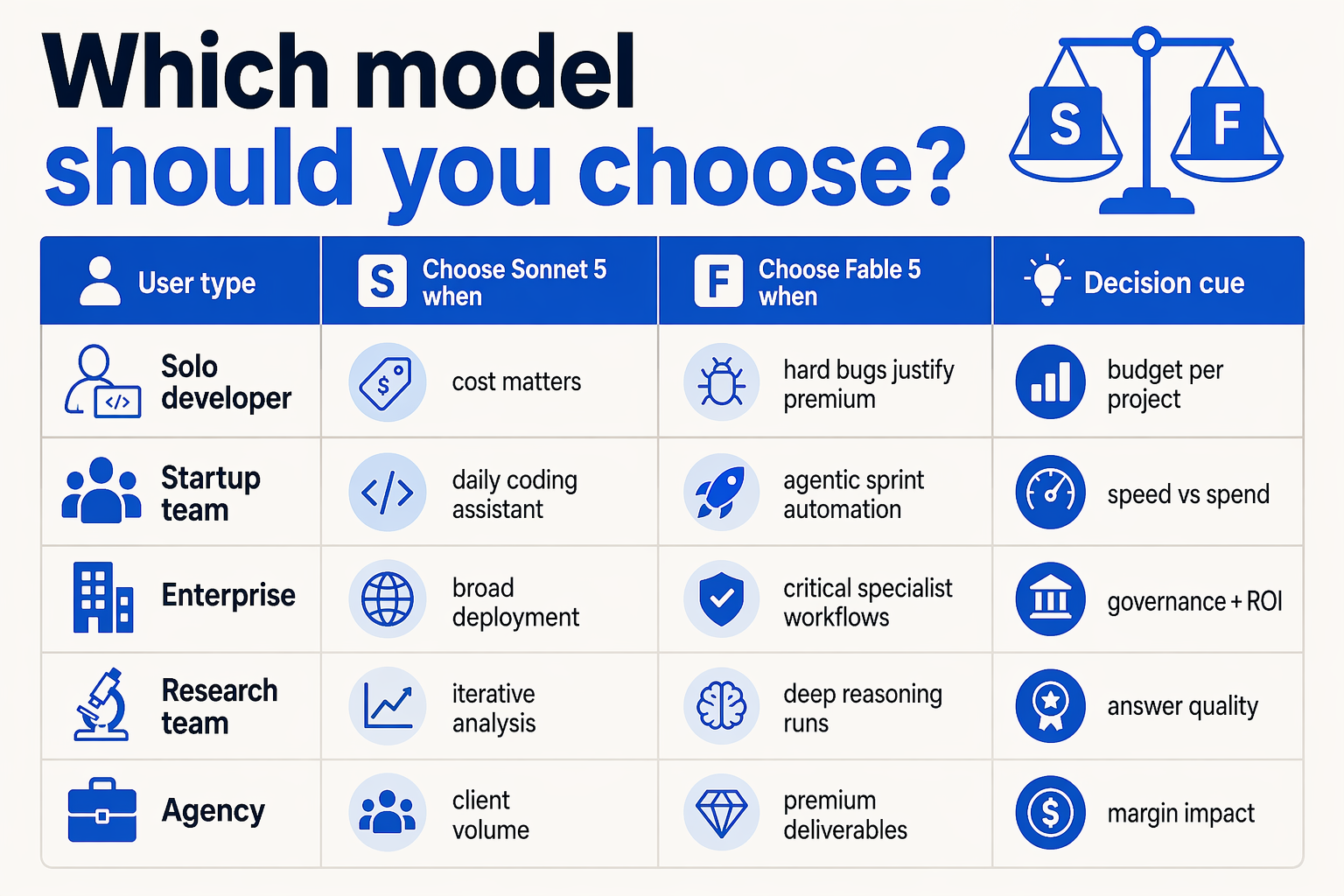
The Practical Decision Is Less About “Best Model” and More About “Best Fit”
For most teams, Claude Sonnet 5 vs Fable 5 should not be treated as a winner-takes-all decision. The better approach is to map each model to workload type, risk tolerance, and operating cost. The key tension is clear: Fable 5 appears stronger on third-party coding benchmarks, while Claude Sonnet 5 may be the safer default if you prioritize ecosystem maturity, cost efficiency, and broader workflow reliability.
The evidence is still uneven. MorphLLM reports Fable 5 at 95% on SWE-bench Verified, an unusually high score for real-world GitHub issue resolution. NxCode, meanwhile, says Claude Sonnet 5 “Fennec” may reach 80.9% on SWE-bench and could deliver “Opus 4.5-level performance at 50% of the cost.” Anthropic’s official documentation also shows the direction of travel: current Claude models such as Sonnet 4.6 support up to 300k output tokens on the Message Batches API via the output-300k-2026-03-24 beta header.
| If You Are... | Prefer Fable 5 When... | Prefer Claude Sonnet 5 When... | Key Data Point |
|---|---|---|---|
| Engineering team | You need maximum autonomous coding accuracy on complex GitHub issues | You need strong coding plus predictable cost and ecosystem support | MorphLLM reports 95% SWE-bench Verified for Fable 5; NxCode cites 80.9% SWE-bench for Sonnet 5 |
| Startup founder | Your product depends on agentic code generation as a core feature | You need a balanced model for coding, support, research, and automation | NxCode claims Sonnet 5 may offer “Opus 4.5-level performance at 50% of the cost” |
| Enterprise AI lead | You can validate benchmark claims internally before rollout | You need safer procurement, governance, and model-routing flexibility | Anthropic docs show Claude’s production focus with 300k output-token batch support in Sonnet 4.6 |
| Customer-support operator | You are building deep technical support agents for developer-heavy users | You need reliable summarization, tool use, CRM updates, and multilingual workflows | Platforms like CallMissed combine voice agents, WhatsApp bots, STT, TTS, and 300+ LLMs |
| AI platform team | You want a specialist model for high-value code repair tasks | You want a general-purpose default model across many internal apps | Use model routing: benchmark both on your own tickets, docs, and API traces |
How to Apply This in Your Stack
A practical rollout should look like this:
- Start with your actual workload, not public benchmarks. SWE-bench is useful, but your failures may come from messy documentation, private APIs, tool-call formatting, or latency constraints.
- Run both models on the same task set: 50–100 real issues, support tickets, workflow automations, or code review tasks.
- Measure total cost per successful outcome, not just token price. A cheaper model that needs three retries may cost more than a stronger model that finishes once.
- Use routing instead of locking in. Send high-complexity code tasks to Fable 5 if it proves superior; keep Claude Sonnet 5 for broader reasoning, documentation, and multi-step business workflows.
Bottom Line
If the reported numbers hold up, Fable 5 is the aggressive choice for coding-heavy teams. Its reported 95% SWE-bench Verified score makes it hard to ignore for autonomous software engineering. But Claude Sonnet 5 is likely the more flexible default for teams that need a strong all-rounder across coding, research, agents, and operational automation.
For production teams, the winning strategy is not choosing one model forever. It is building an architecture that can switch models as benchmarks, prices, and latency change. That is why multi-model infrastructure matters: solutions like CallMissed’s API gateway for 300+ LLMs let businesses test, route, and replace models without rewriting the entire application layer.
Frequently Asked Questions

What is the main difference in Claude Sonnet 5 vs Fable 5?
Is Fable 5 better than Claude Sonnet 5 for coding tasks?
Has Claude Sonnet 5 officially launched in 2026?
output-300k-2026-03-24 beta header, so teams should verify Sonnet 5 availability directly in their API console.Which is cheaper in Claude Sonnet 5 vs Fable 5 for production use?
Should enterprises choose Claude Sonnet 5 or Fable 5 for AI agents?
How should developers benchmark Claude Sonnet 5 vs Fable 5 before switching models?
Conclusion
The Claude Sonnet 5 vs Fable 5 decision in 2026 is less about picking the “best” model overall and more about matching model economics to real workloads.
- Fable 5 appears strongest for coding-heavy agents, with MorphLLM reporting 95% on SWE-bench Verified, making it compelling for autonomous bug fixing and repository-level workflows.
- Claude Sonnet 5 remains a practical high-performance choice, with NxCode citing a reported 80.9% SWE-bench score and potential “Opus 4.5-level performance at 50% of the cost.”
- Pricing and deployment fit matter as much as benchmarks: latency, context needs, output limits, tool reliability, and review costs can outweigh leaderboard differences.
- The Claude ecosystem is moving fast, with Anthropic documentation already showing expanded generation capabilities such as 300k output tokens via the Message Batches API beta header for supported models.
Looking ahead, watch for official benchmark disclosures, stable API pricing, and real-world agent reliability data—not just headline scores. For teams building production AI workflows, platforms like CallMissed offer a way to explore this shift across 300+ LLMs, voice agents, and multilingual chatbots.
So the real question is: will your next AI stack optimize for peak intelligence, or for dependable work completed at scale?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.