Claude Sonnet 5 vs GPT-5.6: What We Can—and Can’t—Compare Right Now

Discover how Claude Sonnet 5 stacks up against OpenAI's GPT-5.6 in coding, reasoning, and agency, and learn how to choose the right model for your stack.
Claude Sonnet 5 vs GPT-5.6: What We Can—and Can’t—Compare Right Now
As OpenAI rolls out its highly anticipated GPT-5.6 and Anthropic counters with Claude Sonnet 5, the frontier AI landscape has transformed from a race of simple chat boxes into an intense battle of complex, agentic reasoning. With both tech giants pushing the absolute limits of LLM capabilities in 2026, developers and enterprise leaders are asking a critical question: which model actually delivers the best performance when put to the test?
The stakes have never been higher. According to recent benchmarks on complex agentic coding, the gap between top-tier models is no longer measured in simple trivia retrieval, but in how effectively they execute multi-step tool calls and self-correct during long-horizon tasks. While early implementations of GPT-5 were noted for taking longer, making more tool calls, and surfacing highly detailed reasoning, Anthropic’s Claude Sonnet series has pushed back hard with its advanced sequential thinking capabilities. This intense rivalry has created a highly fragmented ecosystem where a model’s success depends entirely on how and where it is deployed—whether natively, or through advanced development environments like Cursor, Cline, and Copilot.
Understanding how to compare Claude Sonnet 5 vs GPT-5.6 matters right now because choosing the wrong LLM infrastructure can bottleneck your automated workflows or dramatically inflate API costs. As businesses look to deploy these models into production, multi-model API gateways like CallMissed are becoming essential, allowing developers to seamlessly route queries between GPT-5.6, Claude, and over 300 other LLMs without changing a single line of code.
In this deep dive, we will break down the crucial differences between these two powerhouses. You will learn the core architectural differences in how they handle complex agentic coding, how their pricing structures compare, and why comparing them directly isn't as straightforward as it seems. We will also explore the distinct "personalities" of both models—from GPT-5.6's safe, thorough, and highly communicative reasoning to Sonnet's razor-sharp, sequential execution—to help you decide which model deserves a spot in your production stack.
Introduction: Navigating the Frontier of Claude Sonnet 5 and GPT-5.6

The landscape of frontier artificial intelligence has shifted dramatically. In 2026, we are no longer evaluating LLMs based on their ability to write essays or answer simple trivia. Instead, the industry has entered the era of complex agentic workflows, where models function as autonomous software engineers, data analysts, and system architects. At the absolute peak of this transition stand OpenAI’s newly introduced GPT-5.6 and Anthropic’s powerhouse Claude Sonnet 5.
These two models represent different philosophical approaches to machine intelligence, forcing developers to look beyond standard benchmarks and evaluate how they perform in active production.
The Agentic Shift: Why Simple Benchmarks No Longer Apply
Historically, evaluating LLMs was a matter of looking at standardized benchmarks like MMLU or GSM8k. Today, those metrics are largely saturated. The true test of a frontier model in 2026 lies in long-horizon task execution—specifically, how an AI handles multi-step tool calls, debugs its own code, and self-corrects when a runtime error occurs.
According to developer analyses across specialized coding environments, the differences in how these models execute complex tasks are stark:
- GPT-5.6 (The Thorough Negotiator): OpenAI's model is characterized by a safe, conservative, and highly communicative personality. When integrated into development platforms, GPT-5.6 tends to take longer to respond because it surfaces highly detailed reasoning, makes more sequential tool calls, and actively asks clarifying questions before executing risky code.
- Claude Sonnet 5 (The Sequential Thinker): Anthropic’s model prioritizes rapid, laser-sharp execution. Utilizing its native sequential thinking protocols, Sonnet 5 excels at immediately breaking down a prompt into logical steps and executing them with high precision, making it incredibly popular for rapid, iterative development.
The Integration Paradox: Models vs. Environments
One of the most critical realizations for modern developers is that an LLM is only as good as the interface wrapping it. Recent community feedback on Hacker News highlights a growing integration paradox. For example, developers using Claude Sonnet through basic extensions like GitHub Copilot frequently report execution failures, whereas running the exact same model through advanced, agent-native environments like Cursor, Cline, or Claude Code yields flawless, highly complex multi-file edits.
Because performance depends heavily on the orchestration layer, enterprise teams cannot afford to lock themselves into a single model's ecosystem. This is why infrastructure flexibility has become a primary bottleneck. Platforms like CallMissed address this challenge directly by offering a multi-model API gateway. With access to over 300 LLMs, CallMissed allows developers to dynamically route queries between GPT-5.6 and Claude Sonnet 5, leveraging the unique "personality" and architectural strength of each model depending on the specific micro-task at hand—all without rewriting a single line of integration code.
As we dissect the performance, pricing, and architectural nuances of these two titans, it becomes clear that there is no single "winner." Instead, the goal is to understand their complementary personalities so you can deploy them strategically across your stack.
Background & Context: The State of Generative AI in Mid-2026

The middle of 2026 marks a watershed moment in the evolution of generative artificial intelligence. We have officially transitioned away from the era of static, single-prompt conversational LLMs. Today, the industry is dominated by autonomous, multi-step agentic reasoning engines capable of planning, self-correcting, and executing complex workflows over extended horizons.
In this hyper-competitive landscape, the release of OpenAI’s GPT-5.6 and Anthropic's Claude Sonnet 5 has redrawn the boundaries of what enterprise-grade AI can achieve. However, this is no longer a simple race toward higher academic benchmarks. Instead, both tech giants are optimizing for specialized operational roles, creating a highly nuanced strategic layer where the choice of model dictates the entire architecture of your automation stack.
The Shift from Chatbots to Autonomous Agents
In previous years, AI evaluation focused on static knowledge retrieval or basic code generation. In 2026, the primary metric of success is agentic capability—the capacity of a model to act as an independent agent utilizing external tools, APIs, and sandboxed environments.
The market has adapted rapidly to this shift:
- The Rise of Agentic IDEs: Developers are increasingly bypassing standard chat interfaces, choosing instead to deploy these models directly within advanced environments like Cursor, Cline, Copilot, and Claude Code.
- The Tool-Use Explosion: Models are no longer just writing code snippets; they are diagnosing bugs in massive codebases, executing terminal commands, making sequential tool calls, and verifying their own outputs before finalizing a task.
- Architectural Diversity: Companies are moving away from single-model dependency. Production environments now rely on multi-model routing to balance execution speed, reasoning depth, and API costs.
Two Paradigms: OpenAI’s System-Level Reasoning vs. Anthropic’s Sequential Thinking
The competition between GPT-5.6 and Claude Sonnet 5 highlights two fundamentally different design philosophies.
OpenAI’s GPT-5.6 is engineered to be a cautious, highly communicative powerhouse. Industry reports from Augment Code reveal that GPT-5.6 takes longer to process tasks and initiates a higher volume of tool calls, but it balances this by surfacing exceptionally detailed reasoning chains and actively asking clarifying questions to prevent logical drift.
Conversely, Anthropic’s Claude Sonnet 5 leverages a deeply integrated sequential thinking framework. It is built to execute complex, multi-step actions with razor-sharp precision, making it highly favored in environments that reward rapid, structured execution without the need for constant human intervention.
As businesses rush to integrate these powerful models into their customer-facing and back-office pipelines, managing the underlying infrastructure becomes a critical challenge. Platforms like CallMissed help bridge this gap, offering a unified API gateway that allows enterprises to instantly route tasks between GPT-5.6, Claude Sonnet 5, and over 300 other LLMs. This ensures that developers can leverage the distinct "personalities" of both frontier models—using Sonnet's sequential execution for high-speed workflows while routing complex, ambiguous reasoning tasks to GPT-5.6—all without rewriting their core codebase.
Key Developments: GPT-5.6 vs. Anthropic's Claude Ecosystem (TABLE)

To truly understand how OpenAI’s GPT-5.6 and Anthropic’s Claude Sonnet 5 stack up in 2026, we have to look past simple chat benchmarks and analyze how they handle complex, multi-step agentic workflows. As developers deploy these systems into production, the differences in their core architectures, behavioral personalities, and integration ecosystems become highly pronounced.
While GPT-5.6 is engineered for deep reasoning, extensive tool calling, and extreme safety boundaries, Claude Sonnet 5 is built with a hyper-focus on rapid, sequential execution and razor-sharp code generation. These distinct engineering paths mean that the "best" model depends heavily on the specific deployment environment—whether you are running them inside a specialized IDE like Cursor or routing them through a unified communication stack.
The table below breaks down the technical and behavioral differences between OpenAI’s GPT-5.6 and Anthropic’s Claude Sonnet 5 ecosystem, highlighting how they approach execution, reasoning, and tool integration in real-world scenarios.
| Feature / Dimension | OpenAI GPT-5.6 | Anthropic Claude Sonnet 5 |
|---|---|---|
| Reasoning Style | Play-it-safe, thorough, and communicative; prone to deep verbalization and explaining its reasoning pathways. | Highly focused, sequential, and direct; optimized for swift, step-by-step logical execution. |
| Tool Execution | Highly communicative; takes longer to run but executes more tool calls and frequently asks clarifying questions. | Fast, direct tool execution with native sequential thinking features to minimize API round-trips. |
| Coding Workflow | Strong at architectural planning, refactoring large codebases, and edge-case handling with verbose comments. | Industry-favorite for rapid terminal execution and inline edits inside agents like Cursor, Cline, and Claude Code. |
| Ecosystem Strength | Deeply integrated into Microsoft/Copilot environments; benefits from OpenAI's vast enterprise-grade developer APIs. | Heavily favored in autonomous agent environments and independent developer tools due to raw speed and accuracy. |
| API Infrastructure | Frequently integrated via multi-model gateways to manage latency, API rate limits, and failover routing. | Often paired with unified APIs to switch between LLM providers depending on real-time task complexity. |
Architectural Philosophies: Safety vs. Speed
These differences highlight a fundamental split in how both research labs view agentic AI. OpenAI has trained GPT-5.6 to act as a highly collaborative partner. When faced with an ambiguous coding task or a complex database migration, GPT-5.6 defaults to safety and precision—deliberately pausing to surface its reasoning, making a higher volume of tool calls to verify state, and prompting developers with clarifying questions.
Conversely, Anthropic has optimized the Claude Sonnet 5 ecosystem to get the job done with minimal friction. Its sequential thinking capabilities allow it to execute code changes and terminal commands in a structured, rapid-fire succession. It is less verbose, highly direct, and incredibly efficient, making it the preferred engine for developers running autonomous agents in terminal environments.
For businesses looking to leverage the best of both worlds, relying on a single model ecosystem is no longer practical. To optimize cost, latency, and agent accuracy, modern tech stacks are adopting multi-model infrastructures. Platforms like CallMissed allow developers to dynamically route tasks—sending verbose, safety-critical customer interaction pipelines to GPT-5.6, while routing swift, sequential processing tasks to Claude Sonnet 5. This ensures that you are utilizing the optimal model personality for the right business task without being locked into a single ecosystem.
In-Depth Analysis: Agentic Coding, Reasoning, and Sequential Thinking
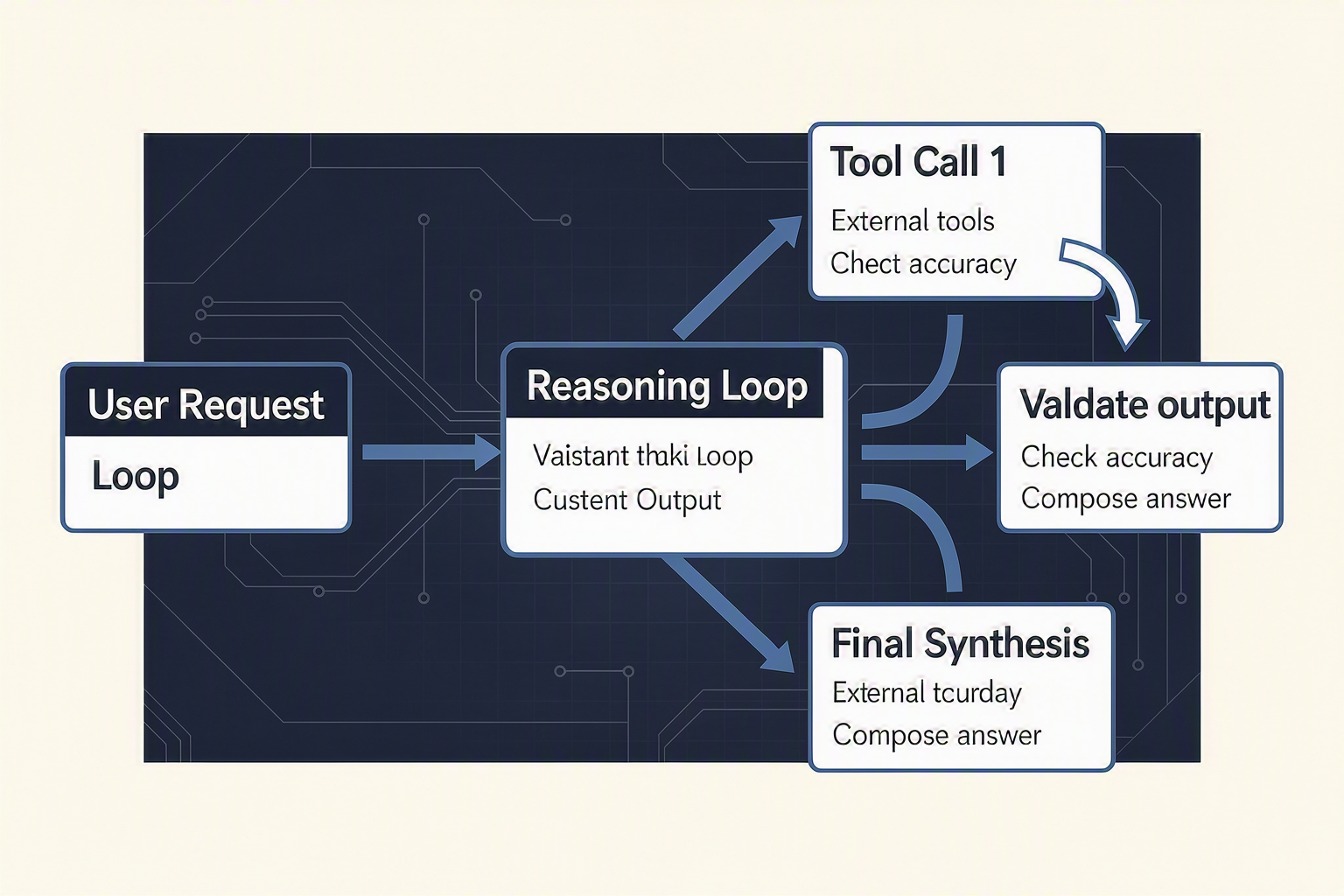
Architectural Philosophies: Conservative Precision vs. Sequential Execution
When evaluated under heavy development workloads, the differences in how GPT-5.6 and Claude Sonnet 5 process complex instructions reveal two distinct engineering philosophies. GPT-5.6 approaches problems with a methodical, conservative, and highly communicative disposition. Real-world evaluations from Augment Code highlight that GPT-5.6 typically takes longer and makes more tool calls, but it offsets this latency by surfacing deeply detailed reasoning and actively asking clarifying questions when it encounters ambiguous parameters. This "play it safe" approach prevents catastrophic silent failures in production, making it ideal for highly regulated environments.
In contrast, Claude Sonnet 5 shines through its specialized sequential thinking capabilities. Rather than pausing to ask for human clarification, Sonnet is designed to self-correct on the fly, systematically breaking down complex, multi-step engineering tasks into a linear execution chain. Engineering teams note that while GPT-5.6 can sometimes be stubborn and over-cautious, Sonnet 5 aggressively executes code generation with razor-sharp speed and remarkable logical fluidity.
The Environment Factor: Why Context Engines Matter
One of the most critical insights from 2026 deployments is that model performance is heavily dictated by the execution environment. As highlighted by discussions on Hacker News, running Claude Sonnet 5 through standard integrations like GitHub Copilot often yields significantly worse results compared to running the exact same model through highly optimized developer environments like Cursor, Cline, or Claude Code.
This performance gap exists because agentic coding is not just about the raw LLM; it is about how the surrounding system orchestrates state management and tool calls:
- Standard Copilots: Often fail to leverage Sonnet’s deeper sequential thinking, treating it as a traditional auto-complete or single-turn chat engine.
- Agentic IDEs (Cursor/Cline): Allow the model to autonomously read files, execute terminal commands, and run self-correction loops, unlocking the true potential of Sonnet's coding capabilities.
Optimizing Production Workflows with Dynamic Routing
Because both models excel at entirely different phases of the software development lifecycle, relying on a single LLM provider can lead to either massive latency overheads or logical bottlenecks. For instance, an enterprise workflow might require GPT-5.6's thorough reasoning to map out the system architecture and handle ambiguous API specifications, but switch to Claude Sonnet 5 to rapidly generate the boilerplate code and run debugging loops.
This is where advanced infrastructure platforms like CallMissed become indispensable. By leveraging CallMissed's multi-model API gateway, development teams can dynamically route developer queries across more than 300 LLMs. This architecture allows companies to seamlessly leverage the distinct, complementary personalities of GPT-5.6 and Claude Sonnet 5 within their custom agentic pipelines—without the engineering overhead of managing multiple API integrations or refactoring codebase logic.
Impact & Implications: Why the 'Model Picker' and Tool Calls Matter

The evolution of GPT-5.6 and Claude Sonnet 5 has fundamentally changed how developers interact with large language models. We are no longer in an era where a single model is crowned the undisputed champion for every task. Instead, the rise of the "Model Picker" in advanced development environments like Cursor, Cline, and Augment Code highlights a shift toward dynamic, context-specific routing.
By analyzing how these models execute tool calls and handle sequential logic, we can understand why having the right model for the right task is critical for maintaining high-performing, cost-effective agentic workflows.
The Mechanics of Tool Calls: Detailed Reasoning vs. Sequential Thinking
The way a model interacts with external APIs, files, and databases determines its success in real-world deployments. GPT-5.6 and Claude Sonnet 5 approach tool execution with two distinct philosophical frameworks:
- GPT-5.6’s Multi-Step Exploration: Real-world testing reveals that GPT-5.6 takes longer to process complex prompts and makes more tool calls on average. However, it compensates by surfacing highly detailed reasoning and showing a greater willingness to ask clarifying questions before executing destructive or irreversible actions. This makes it incredibly reliable for complex debugging where missing context could break production code.
- Sonnet 5’s Sequential Execution: Claude Sonnet 5 leverages refined sequential thinking capabilities. It is designed to think step-by-step in a highly linear, structured manner. This structured approach allows Sonnet 5 to execute complex tool paths rapidly and cleanly, making it the preferred choice for writing code from scratch and handling predictable, multi-step API integrations.
The Ecosystem Factor: Same Model, Different Results
A critical finding from developer communities on Hacker News is that an LLM's performance is heavily gatekept by the IDE or platform wrapper hosting it. For example, developers note that using Sonnet through GitHub Copilot often yields different—and sometimes inferior—results compared to running the exact same model through more agentic-native environments like Cursor, Cline, or Claude Code.
Because these environments structure system prompts, manage context windows, and parse tool calls differently, a model is only as good as the orchestration layer built around it.
Why Dynamic Routing and "Model Pickers" Are the Future
Because GPT-5.6 excels at thorough troubleshooting and interactive clarification, while Claude Sonnet 5 dominates in rapid, sequential code generation, developers are moving away from static API integrations. The industry is rapidly adopting dynamic model pickers to route queries based on the specific complexity of the task at hand.
For enterprises building conversational AI and automated workflows, implementing this orchestration layer from scratch can be a massive engineering bottleneck. This is where platforms like CallMissed become invaluable. By offering a unified infrastructure with access to over 300 LLMs, CallMissed allows developers to dynamically route tasks to the optimal model—whether that means sending a highly complex, multi-lingual customer query to a specialized regional model, or leveraging top-tier frontier models like GPT-5.6 and Claude for advanced decision-making—all without rewriting core application code.
Expert Opinions: What Leading AI Researchers Say About the Matchup

As the rivalry between Anthropic and OpenAI reaches a fever pitch in mid-2026, leading AI researchers and industry practitioners are looking past synthetic benchmarks to evaluate how GPT-5.6 and Claude Sonnet 5 perform in high-stakes production. The consensus among experts reveals a fascinating dichotomy: these systems are no longer just larger language models, but fundamentally different agentic operating systems.
The Philosophical Divide: "Safe & Detailed" vs. "Razor-Sharp Execution"
AI researchers analyzing model telemetry highlight a distinct split in behavioral design. According to hands-on evaluations compiled by Augment Code, the underlying architectures prioritize different cognitive pathways:
- GPT-5.6's Methodical Reasoning: Researchers note that GPT-5.6 is structurally designed to "play it safe." In complex tasks, it takes longer and executes a higher volume of tool calls, but it surfaces exceptionally detailed reasoning. It is also significantly more likely to pause and ask clarifying questions to resolve ambiguity rather than making assumptions.
- Claude Sonnet 5's Sequential Thinking: Conversely, Anthropic's flagship thrives on raw execution speed and sequential logic. Practitioners on developer forums highlight that Sonnet 5 approaches problems with a highly focused, step-by-step mathematical precision. It is built to actively resolve complex engineering challenges autonomously, often completing multi-step refactoring in fewer turn-taking cycles than its OpenAI counterpart.
The Integration Paradox: Why the UI Environment Alters the Winner
A major talking point among AI infrastructure researchers is that a model is only as good as the developer environment hosting it. On Hacker News, experts point out a glaring "integration paradox" where the exact same model yields wildly different results depending on the orchestration layer:
- Orchestrator Depth: Utilizing Claude Sonnet 5 through basic extensions like GitHub Copilot frequently results in failure on complex agentic coding tasks.
- Advanced Environments: The same model excels dramatically when paired with deep-context, agentic IDEs like Cursor, Cline, or Anthropic’s native Claude Code.
This discrepancy exists because advanced environments allow Sonnet’s sequential reasoning to directly manipulate files and self-correct via terminal loops. Consequently, researchers warn enterprise architects that evaluating GPT-5.6 or Claude Sonnet 5 in a vacuum is a mistake; performance is deeply tied to the system prompts, tool schemas, and UI integrations surrounding them.
Strategic Implementation and Multi-Model Architectures
Because both models occupy roughly the same strategic tier, leading research suggests that the future of enterprise AI does not belong to a single winner. Instead, forward-thinking organizations are building dynamic routing infrastructures. For instance, an agentic system might route highly ambiguous, customer-facing tasks to GPT-5.6 to leverage its conservative, communicative safety checks, while shifting complex back-end codebase refactoring to Claude Sonnet 5.
Deploying this multi-model approach in production can easily introduce massive architectural overhead. This is where advanced AI communication infrastructure becomes invaluable. Platforms like CallMissed allow developers to seamlessly orchestrate these frontier models, offering a unified API gateway to route tasks dynamically between GPT-5.6, Sonnet 5, and over 300 other LLMs. By leveraging such infrastructure, businesses can capture the specialized strengths of both giants without getting locked into a single ecosystem.
What This Means For You: Enterprise and Developer Action Plan (TABLE)
Choosing Your Frontier AI Strategy
Navigating the transition to agentic AI requires more than just choosing the most powerful model; it demands a strategic alignment of model "personalities" to your specific operational needs. As of mid-2026, GPT-5.6 and Claude Sonnet 5 represent distinct philosophical approaches to automation, complex reasoning, and multi-step execution.
To help your organization move from experimentation to production, we have mapped out a concrete action plan based on current developer benchmarks, ecosystem integrations, and behavior patterns.
| Goal / Use Case | Recommended Model | Core Action & Implementation Plan | Expected Performance & Behavior |
|---|---|---|---|
| Complex System Architecture & Debugging | GPT-5.6 | Deploy for tasks requiring deep code audits, complex API integrations, and safe system refactoring. | Takes longer, makes more tool calls, but surfaces highly detailed reasoning and asks clarifying questions. |
| Rapid Iteration & Linear Scripting | Claude Sonnet 5 | Integrate into developer environments (like Cursor or Cline) to build features and write sequential code blocks rapidly. | Highly efficient, utilizes advanced sequential thinking, and executes direct code modifications with fewer steps. |
| High-Volume Customer Engagement | Hybrid / Multi-Model | Route initial interactions through tailored voice or text agents, escalating edge cases to the appropriate frontier LLM. | Maximizes cost efficiency and speed while maintaining human-like precision for complex customer queries. |
| Cost-Sensitive Scaled Workflows | Dynamic Routing | Use an abstraction layer or gateway to dynamically switch models based on prompt complexity and token budget. | Optimizes operational costs, ensuring high-reasoning tasks use premium LLMs while routine tasks go to lightweight models. |
Key Takeaways for Tech Leaders and Developers
To maximize the ROI of these frontier models in 2026, engineering teams should focus on three primary implementation guidelines:
- Avoid Single-Model Lock-in: The rapid release cycles of OpenAI and Anthropic mean the "best" model changes quarterly. Building your application with a rigid, single-model SDK creates technical debt. Solutions like CallMissed’s multi-model API gateway allow you to instantly switch between 300+ LLMs, ensuring you can route tasks to GPT-5.6 or Claude Sonnet 5 with zero codebase friction.
- Audit Your Developer Environments: Real-world testing shows that a model's effectiveness is heavily tied to its UI wrapper. For instance, developers report that running Sonnet through older IDE extensions often fails to utilize its sequential thinking capabilities, whereas running it through modern agents like Cursor or Cline unlocks its true potential. Optimize your IDE and agentic toolstacks accordingly.
- Design for Divergent Reasoning Styles: Don't write generic prompts. Customize your agent instructions to leverage GPT-5.6's conservative, highly communicative, safety-oriented behavior for mission-critical logic, while utilizing Claude Sonnet 5's aggressive, direct, and logical execution for rapid feature building.
By deploying these models based on their unique execution profiles—and integrating them via agile infrastructure like CallMissed—enterprises can build resilient, highly adaptable agentic systems capable of handling the most demanding workflows of 2026.
Frequently Asked Questions
When comparing Claude Sonnet 5 vs GPT-5.6, which model is better for complex agentic coding?
How does the reasoning methodology differ between Claude Sonnet 5 and GPT-5.6?
Why do developers experience different performance when deploying Claude Sonnet 5 vs GPT-5.6 in IDEs like Copilot, Cursor, or Cline?
What are the differences in tool calling and API behavior between these two frontier LLMs?
How can enterprises easily test and deploy Claude Sonnet 5 vs GPT-5.6 in production?
Which model is more cost-effective for automated, long-horizon workflows?
Conclusion
Choosing between GPT-5.6 and Claude Sonnet 5 in 2026 is no longer about finding a single "winner." Instead, it requires matching the unique cognitive personality of each frontier model to your specific development and agentic needs.
- Distinct AI Personalities: GPT-5.6 prioritizes safety and thoroughness, taking longer to output detailed reasoning and ask clarifying questions, whereas Claude Sonnet 5 excels in rapid, razor-sharp sequential thinking.
- Environment Matters: A model's real-world coding performance is highly dependent on its execution environment, varying drastically between integrations like Copilot, Cline, and Cursor.
- Infrastructure Strategy: Complex, multi-step agentic workflows can quickly inflate API costs or create bottlenecks if you rely on a single, rigid LLM provider.
Looking ahead, the next battlefield will be how seamlessly these models self-correct during long-horizon, autonomous tasks. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. Which model's reasoning style will you choose to anchor your agentic stack?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.