Claude Sonnet 5 vs GPT-5.6: What We Can—and Can’t—Compare Right Now

Understand which Claude Sonnet 5 and GPT-5.6 claims are verifiable, which are speculative, and how to evaluate them fairly today.
Claude Sonnet 5 vs GPT-5.6: What We Can—and Can’t—Compare Right Now
What if the biggest problem with comparing Claude Sonnet 5 vs GPT-5.6 is not performance—but whether both models can be verified on the same facts yet?
That is the unusual position AI teams find themselves in right now. The market is moving so fast that model names, leaked codenames, benchmark screenshots, and official release notes are often being mixed together before developers have stable API access. In Claude’s case, the confusion is especially visible: NxCode reported that a “Claude Sonnet 5” Fennec leak may have actually corresponded to what launched publicly as Claude Sonnet 4.6 on February 17, 2026, citing 79.6% on SWE-Bench and $3/$15 per million tokens pricing. Meanwhile, other coverage claims “Claude Sonnet 5” reached 82.1% on SWE-Bench, offered a 1M-token context window, and cost half as much as Opus 4.5. That gap matters because a few percentage points on SWE-Bench can influence enterprise coding workflows, agent reliability, and infrastructure budgets.
The same caution applies to GPT-5.6. If you are trying to decide which frontier model should power a production AI agent, coding copilot, customer support workflow, or multimodal assistant, leaderboard numbers alone are not enough. You need to know whether the benchmark is official, whether the model ID is public, what pricing applies, what context limits exist, and whether latency and tool-use behavior hold up under real traffic.
That is why this comparison is less about declaring a winner and more about separating confirmed capability from speculation. In this article, we will look at what can be compared today—benchmarks, pricing signals, coding performance, context windows, and deployment readiness—and what cannot yet be treated as settled. We will also explain why platforms such as CallMissed, which route workloads across 300+ LLMs, are becoming important as businesses avoid locking themselves into one model name before the evidence is clear.
By the end, you will have a practical framework for evaluating Claude Sonnet 5 vs GPT-5.6 without falling for hype, leaked labels, or benchmark cherry-picking.
Introduction

The comparison starts with a verification problem
The most important question in Claude Sonnet 5 vs GPT-5.6 is not “which model is smarter?” It is: are we comparing two publicly verifiable models under the same conditions?
That distinction matters in mid-2026 because frontier AI coverage is increasingly shaped by a messy mix of official release notes, leaked model names, benchmark screenshots, internal codenames, and third-party speculation. For engineering teams, that creates real risk. A model that looks unbeatable in a leaked benchmark may not have a stable API ID, documented pricing, production-grade latency, or the same behavior once deployed inside an agentic workflow.
Claude is a good example. NxCode reported that the widely discussed “Claude Sonnet 5” Fennec leak may actually correspond to what launched publicly as Claude Sonnet 4.6 on February 17, 2026, with 79.6% on SWE-Bench and $3 input / $15 output per million tokens pricing. But another report from WaveSpeed describes Claude Sonnet 5 as having an 82.1% SWE-Bench score, a 1M-token context window, and pricing at half the cost of Opus 4.5. EvoLink also noted that, as of February 2, 2026, Claude Sonnet 5 was not listed in Anthropic’s public model documentation, release notes, or official announcement.
That is not a small discrepancy. In production, the difference between 79.6% and 82.1% on SWE-Bench can affect:
- Code-agent reliability across complex repositories
- Autonomous debugging success rates
- Cost forecasts for high-volume developer tools
- Whether teams choose Sonnet, Opus, GPT, Gemini, or a routed multi-model setup
Why GPT-5.6 is even harder to compare
The same caution applies to GPT-5.6. If the model name is being discussed before consistent public documentation, pricing, API IDs, benchmark methodology, and deployment limits are available, then a direct “winner” comparison becomes premature.
A serious model comparison needs more than headline scores. At minimum, teams should verify:
- Official model identity — Is the model ID public and available through an API?
- Benchmark source — Was the score published by the lab, a third party, or a leak?
- Test conditions — Was SWE-Bench run in the same mode, with the same tools and pass criteria?
- Cost structure — Are input/output token prices confirmed?
- Production behavior — Does the model maintain quality under latency, concurrency, and tool-use pressure?
This is why comparing Claude Sonnet 5 and GPT-5.6 today requires a more careful framework than a simple benchmark table.
What this article will—and won’t—claim
This article will separate confirmed signals from unverified claims. We will compare what can reasonably be discussed now: benchmark reports, pricing signals, context-window claims, coding use cases, and deployment readiness. We will also flag what cannot yet be treated as settled, especially where model naming and release status remain unclear.
For businesses building AI agents, customer support systems, coding assistants, or multilingual workflows, the practical lesson is simple: avoid hard-coding strategy around one hyped model name. Platforms such as CallMissed, which provide access to 300+ LLMs alongside voice agents, WhatsApp chatbots, Speech-to-Text for 22 Indian languages, and Text-to-Speech APIs, reflect where the market is heading: flexible AI infrastructure that can route workloads based on real performance, cost, and availability—not speculation.
The goal is not to crown a winner. It is to understand what can be compared responsibly right now.
Background & Context
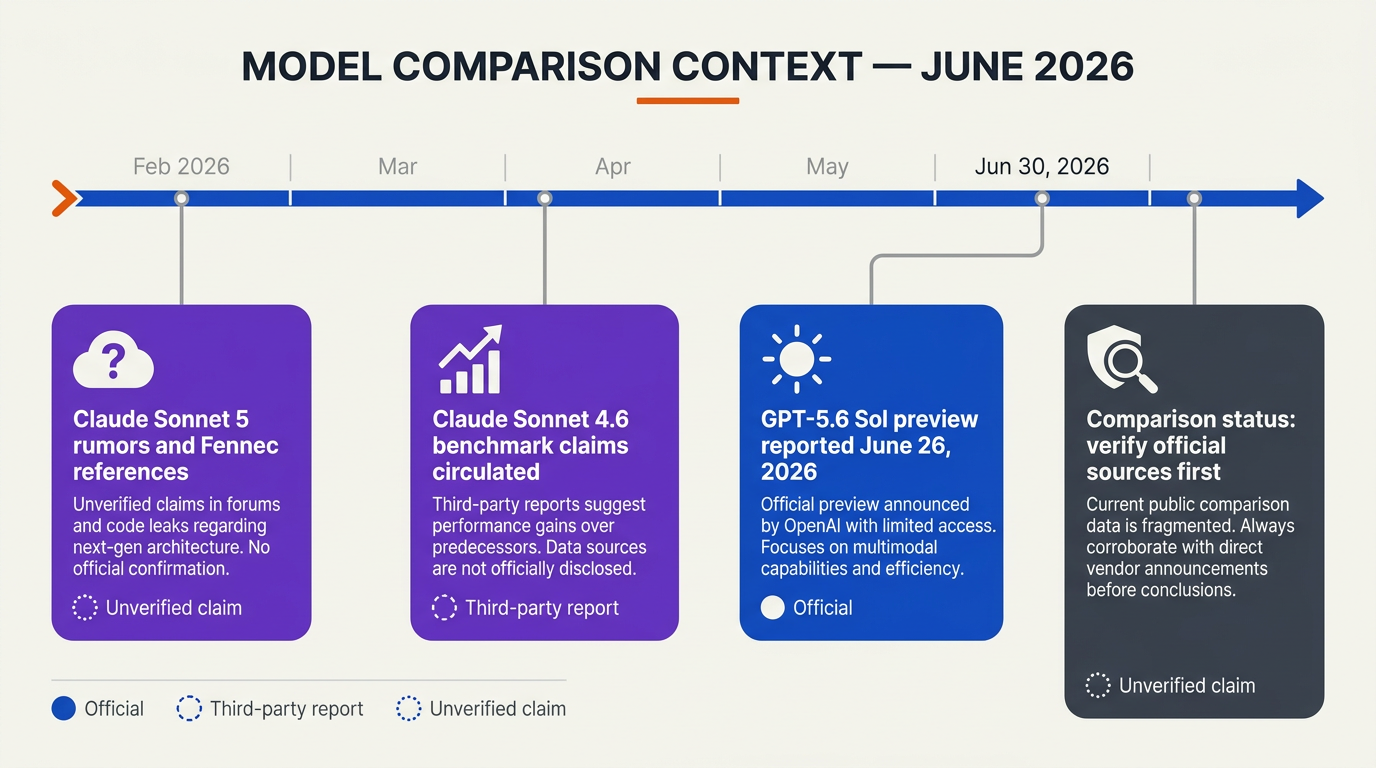
Why this comparison is unusually hard in 2026
The background to Claude Sonnet 5 vs GPT-5.6 is not a normal model-vs-model release cycle. In earlier generations, teams could usually wait for an official model card, API documentation, and a few independent benchmark runs before making procurement decisions. In 2026, the gap between leak, launch, benchmark, and production availability has narrowed—and sometimes collapsed.
Claude’s naming confusion shows the pattern clearly. EvoLink reported that, as of February 2, 2026, “Claude Sonnet 5” was not listed in Anthropic’s public model documentation, release notes, or official announcement materials. Around the same time, social posts referenced an internal February 3, 2026 date string for a model branded Claude Sonnet 5. Then NxCode reported that the “Fennec” leak many people associated with Sonnet 5 may have corresponded to the model that publicly launched as Claude Sonnet 4.6 on February 17, 2026, with 79.6% on SWE-Bench and $3 input / $15 output per million tokens pricing.
That sequence matters because model labels are now part of the product risk.
The Claude side: strong signals, mixed labels
The Claude ecosystem has several benchmark claims circulating at once:
- NxCode: Fennec-like claims map to Claude Sonnet 4.6, not necessarily a confirmed Sonnet 5 release; reported 79.6% SWE-Bench and $3/$15 per million tokens.
- WaveSpeed: Describes Claude Sonnet 5 / Fennec as reaching 82.1% on SWE-Bench, supporting a 1M-token context window, and costing half as much as Opus 4.5.
- Build Fast with AI, April 2026 ranking: Lists Claude Opus 4.6 at 80.8% SWE-bench Verified, Gemini 3.1 Pro at 78.8%, and Claude Sonnet 4.6 at 79.6%.
- MorphLLM: Claims newer Claude-family results such as Fable 5 at 95% SWE-bench Verified and Opus 4.8 at 88.6%, with 69.2% on SWE-bench Pro.
The takeaway is not that one source is automatically wrong. It is that buyers need to separate official release identity from performance claims. A model can be real internally, partially exposed in testing, renamed before launch, or benchmarked under conditions that are not yet reproducible through a public API.
The GPT-5.6 side: the burden of comparability
For GPT-5.6, the same standard should apply. A useful comparison requires more than a model name and a leaderboard screenshot. Teams should ask:
- Is there an official API model ID?
- Are pricing, context length, rate limits, and latency documented?
- Were benchmarks run on the same task version, such as SWE-bench Verified?
- Can independent developers reproduce results outside a private preview?
- Does the model maintain performance in tool-heavy, multi-step agent workflows?
Without those answers, comparing GPT-5.6 against a disputed Claude Sonnet 5 label risks producing a false sense of precision.
Why infrastructure strategy matters
This uncertainty is why many AI teams are shifting from single-model bets to model-routing architectures. Instead of hardcoding one frontier model, they evaluate multiple providers across cost, latency, reasoning, coding, voice, and multilingual performance.
Platforms like CallMissed reflect this trend: its LLM inference layer supports 300+ models, allowing developers to route workloads without rewriting application logic. That becomes especially valuable when model branding moves faster than enterprise validation cycles.
In short, the context behind Claude Sonnet 5 vs GPT-5.6 is not just an AI benchmark race. It is a lesson in how fast-moving model markets require better evidence, better routing, and better deployment discipline.
Key Developments (TABLE)

What has changed—and what is still unverifiable
At this point in the Claude Sonnet 5 vs GPT-5.6 discussion, the useful move is to separate developments into three buckets: officially comparable, reported but unresolved, and not yet comparable. The table below summarizes the key signals that matter for buyers, developers, and AI infrastructure teams.
| Development | Reported data | Source | What it means | Confidence |
|---|---|---|---|---|
| “Claude Sonnet 5 / Fennec” leak may map to Sonnet 4.6 | Feb. 17, 2026 launch, 79.6% SWE-Bench, $3/$15 per million tokens | NxCode | Suggests some “Sonnet 5” discussion may actually refer to a released Sonnet 4.6-class model | Medium-high |
| Alternative Sonnet 5 claims circulate | 82.1% SWE-Bench, 1M-token context, half the cost of Opus 4.5 | WaveSpeed AI | Promising, but needs confirmation against Anthropic docs, model IDs, and API pricing | Medium |
| Broader Claude benchmark stack is moving fast | Fable 5: 95% SWE-Bench Verified, Opus 4.8: 88.6%, 69.2% SWE-Bench Pro | MorphLLM | “Sonnet 5” should not be evaluated in isolation; adjacent Claude models may outperform it on coding | Medium |
| April 2026 model rankings show tight competition | Claude Opus 4.6: 80.8%, Gemini 3.1 Pro: 78.8%, Claude Sonnet 4.6: 79.6% | Build Fast with AI | Small benchmark gaps may not justify migration unless latency, cost, and reliability improve too | Medium |
| Desktop automation claims exceed human baseline | Human expert baseline cited at 72.4% | Dev.to coverage | Useful signal for agentic workflows, but task definition and reproducibility matter | Low-medium |
| GPT-5.6 comparison gap | No matched public data in the provided source set for pricing, context, SWE-Bench, or API model ID | Available context | A direct Claude Sonnet 5 vs GPT-5.6 table would be premature without OpenAI-side verified specs | Low |
The pattern behind the numbers
The most important development is not a single benchmark score—it is the fragmentation of evidence. A model can look decisive if one source cites 82.1% on SWE-Bench, but that becomes less clear when another source connects the same “Fennec” discussion to Claude Sonnet 4.6 at 79.6% with published-looking pricing of $3 input / $15 output per million tokens.
For production teams, that creates two practical rules:
- Do not compare leaked names to official model IDs. A codename, screenshot, or third-party post is not equivalent to a stable API release.
- Do not treat SWE-Bench as the whole product. Coding score, context length, tool reliability, cost per million tokens, and rate limits all affect real deployments.
This is especially relevant for AI agents. A customer support agent, coding copilot, or voice workflow may fail not because the model is “less intelligent,” but because it has inconsistent tool calls, slower response time, weaker long-context retrieval, or higher operating cost under peak traffic.
Why this matters for deployment strategy
Until Claude Sonnet 5 and GPT-5.6 have comparable official model cards, teams should benchmark across multiple candidates rather than commit early. Platforms like CallMissed, which provide access to 300+ LLMs through a multi-model inference layer, are useful in this environment because teams can test routing strategies without rewriting application logic every time a new frontier model appears.
The takeaway: the market is clearly advancing, but the evidence is uneven. Claude-related benchmarks are becoming more specific; GPT-5.6 remains under-specified in this comparison set. That means the right next step is controlled testing—not headline-based model selection.
In-Depth Analysis
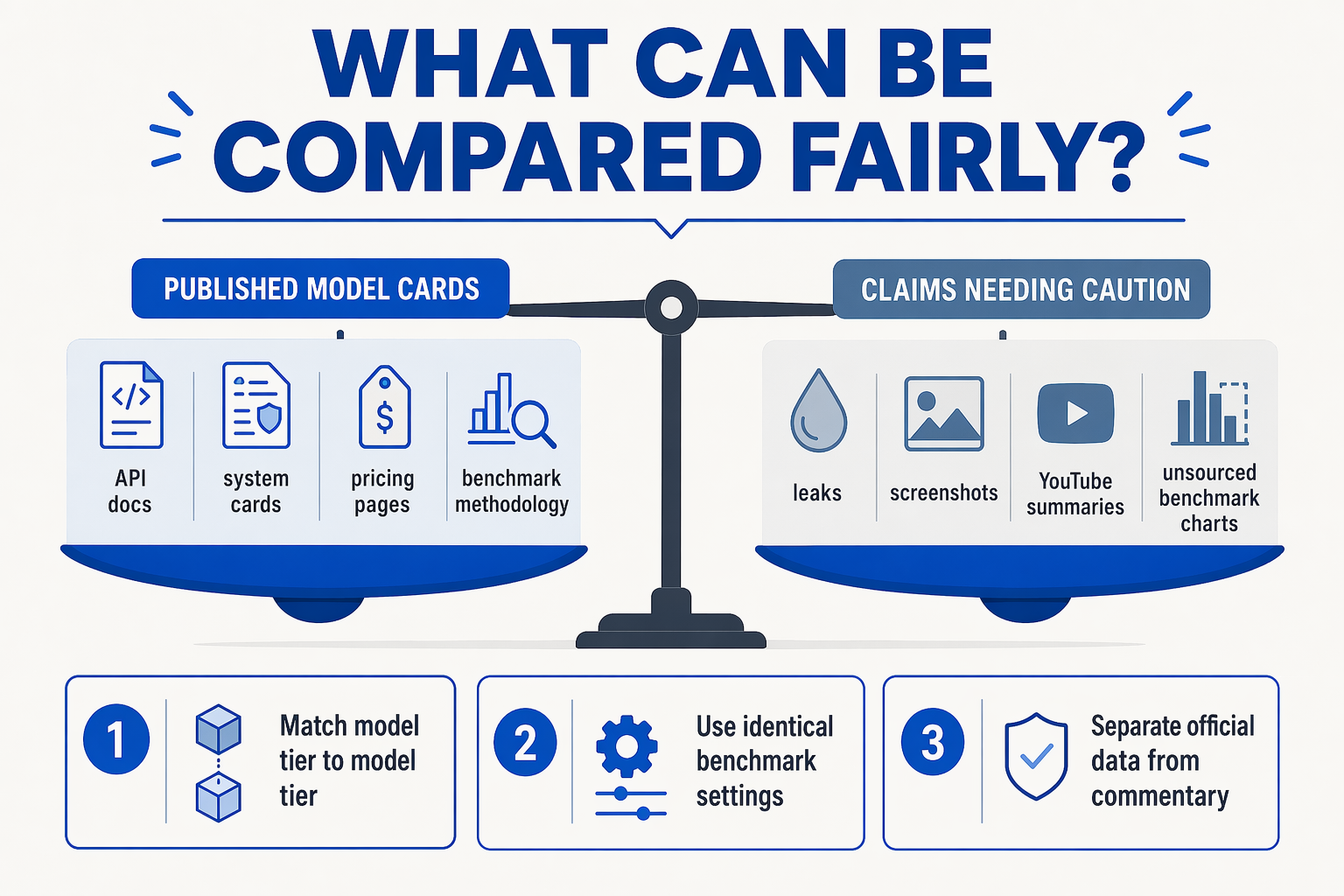
What an apples-to-apples comparison would require
A serious Claude Sonnet 5 vs GPT-5.6 analysis needs more than headline scores. To compare frontier models fairly, teams need the same evidence across five dimensions:
- Official model identity — public model ID, release notes, and API availability
- Benchmark methodology — same benchmark version, same evaluation harness, same pass criteria
- Pricing — input/output token cost, cache pricing, batch discounts, and agent runtime cost
- Context and tool use — not just maximum context, but retrieval quality, tool reliability, and long-session stability
- Production behavior — latency, rate limits, safety refusals, observability, and uptime under real workloads
Right now, Claude has more visible—but still conflicting—signals in the provided public coverage. NxCode says the “Claude Sonnet 5” Fennec leak may have mapped to the model released as Claude Sonnet 4.6 on February 17, 2026, with 79.6% on SWE-Bench and $3/$15 per million tokens pricing. Wavespeed’s coverage, by contrast, describes Claude Sonnet 5 as reaching 82.1% on SWE-Bench, supporting a 1M-token context window, and costing half as much as Opus 4.5.
Those are not small differences. A move from 79.6% to 82.1% on SWE-Bench could represent meaningful gains in autonomous coding reliability. But if one number refers to Sonnet 4.6 and another to a disputed or differently labeled Sonnet 5, the comparison becomes a naming problem before it becomes a performance problem.
The benchmark gap is narrower than the hype suggests
The current Claude-side claims cluster around software engineering benchmarks, especially SWE-Bench. That makes sense: coding agents are one of the clearest commercial use cases for frontier models. But SWE-Bench is only one slice of model quality.
For example, Build Fast with AI’s April 2026 ranking listed Claude Opus 4.6 at 80.8% on SWE-Bench Verified, Gemini 3.1 Pro at 78.8%, and Claude Sonnet 4.6 at 79.6%. That places top models within a relatively tight band. If Sonnet 5’s claimed 82.1% is accurate, it would be ahead—but not by a margin large enough to ignore cost, latency, context handling, and integration maturity.
A practical reading is:
- Below 80% SWE-Bench: strong coding assistance, but still needs human review for complex patches
- Around 80–82%: potentially better agentic coding workflows, but reliability depends on test execution and tool use
- Above 85%: would be a clearer step-change, but requires verified public evidence
This is why a single leaderboard screenshot should not drive procurement decisions.
GPT-5.6 is harder to evaluate without matching public evidence
For GPT-5.6, the key issue is not whether it may be powerful—it is whether teams have enough comparable, public data to evaluate it against the Claude claims above. If a model is available only through limited rollout, private previews, or non-standardized benchmark posts, then developers cannot reliably compare it with a Claude model that has cited SWE-Bench figures, pricing references, and context-window claims.
The right question is not “Which one wins?” but:
- Are both models accessible through stable APIs?
- Are benchmark results independently reproducible?
- Are prices published for input and output tokens?
- Can both run the same coding-agent tasks with the same tools?
- Do they behave consistently across long conversations and retries?
Until those answers are documented, Claude Sonnet 5 vs GPT-5.6 remains a provisional comparison.
The production answer may be multi-model, not model-loyal
In real deployments, the best architecture may not choose one model permanently. A coding workflow might use one model for repository reasoning, another for patch generation, and a cheaper model for test summarization. A customer-support agent might route simple questions to a low-cost model and escalate complex cases to a frontier model.
That is where platforms like CallMissed fit the broader trend: a multi-model API gateway with access to 300+ LLMs lets teams switch models without rewriting the whole application. For businesses evaluating uncertain frontier releases, that flexibility is often more valuable than betting early on a single model name.
The deeper takeaway: compare verified model behavior, not branding. Claude’s reported numbers are promising, but mixed. GPT-5.6 may be competitive, but needs the same level of public evidence. Until then, the winning strategy is disciplined evaluation, reproducible tests, and architecture that can adapt as the facts change.
Impact & Implications

The business impact is uncertainty, not just model quality
The biggest implication of the Claude Sonnet 5 vs GPT-5.6 debate is that AI buyers can no longer treat frontier model names as stable procurement units. In 2026, teams are not simply choosing “Anthropic vs OpenAI”; they are choosing between verified APIs, unclear release labels, leaked benchmarks, pricing claims, and workload-specific behavior.
That matters because even small benchmark differences can change real budgets. NxCode reports that the Fennec-labeled leak may have corresponded to Claude Sonnet 4.6, launched on February 17, 2026, with 79.6% on SWE-Bench and pricing of $3 input / $15 output per million tokens. Other coverage, including WaveSpeed, describes “Claude Sonnet 5” as reaching 82.1% on SWE-Bench, supporting a 1M-token context window, and costing half as much as Opus 4.5. Those are materially different assumptions for an engineering team planning coding agents, repository-scale refactors, or support automation.
Why this changes model evaluation
The practical lesson is simple: frontier AI evaluation has become an infrastructure problem. A leaderboard result is useful, but it is not enough to justify production migration.
Teams should now evaluate models across at least four layers:
- Verification layer
Is the model listed in official documentation, or only in leaks and third-party posts? EvoLink noted that, as of February 2, 2026, Claude Sonnet 5 was not listed in Anthropic’s public model documentation or release notes.
- Benchmark layer
Are scores from the same benchmark variant? Build Fast with AI listed Claude Sonnet 4.6 at 79.6% and Claude Opus 4.6 at 80.8% on SWE-Bench Verified in April 2026 rankings, while other sources cite different Claude-family numbers.
- Economic layer
Does the claimed price apply to public API usage, enterprise contracts, cached tokens, batch inference, or a temporary preview?
- Operational layer
Can the model sustain real workloads with predictable latency, tool calling, retries, observability, and safety controls?
This is where platforms like CallMissed become relevant. Instead of hard-coding a single frontier model assumption, businesses can route workloads across 300+ LLMs, test alternatives in production-like conditions, and shift traffic when pricing, latency, or capability changes.
The implications for AI product teams
For product and engineering leaders, the current Claude-vs-GPT comparison points to three strategic changes:
- Do not build around a model name alone. Build around an abstraction layer that lets you swap models without rewriting your application.
- Separate coding benchmarks from customer-facing performance. A strong SWE-Bench score may not predict how well a model handles multilingual support, voice interactions, or high-volume WhatsApp workflows.
- Track cost per resolved task, not cost per token. A model with higher token pricing may still be cheaper if it completes tasks with fewer retries, better tool use, or shorter outputs.
The broader implication is that AI advantage is shifting from “who picked the best model this month?” to who built the most adaptable AI stack. Until both Claude Sonnet 5 and GPT-5.6 can be verified under the same public conditions, the safest strategy is not loyalty to one label—it is disciplined testing, routing flexibility, and evidence-based deployment.
Expert Opinions

What experts are converging on: verify before ranking
The strongest expert consensus right now is not that Claude Sonnet 5 beats GPT-5.6 or vice versa. It is that serious teams should separate model branding from model evidence before making procurement or architecture decisions.
Developer-focused sources are already treating the Claude side cautiously. NxCode framed the “Claude Sonnet 5” discussion as a leak-resolution problem, saying the Fennec leak “actually launched as Claude Sonnet 4.6 on Feb 17, 2026,” with 79.6% on SWE-Bench and $3/$15 per million tokens pricing. That is a very different claim from coverage such as WaveSpeed, which says “Claude Sonnet 5” reached 82.1% on SWE-Bench, added a 1M-token context window, and cost half as much as Opus 4.5.
Those numbers may all be directionally useful, but experts would not treat them as equivalent unless they share:
- A public model ID
- Official release notes
- Reproducible benchmark methodology
- Stable API access
- Documented input/output pricing
- Known context-window limits
Without those, the comparison becomes less “Claude Sonnet 5 vs GPT-5.6” and more “one verified deployment versus a moving target.”
Benchmark specialists are focused on methodology, not headlines
The SWE-Bench numbers are especially important because they influence how companies evaluate AI coding agents. But experts know that even a 2–3 point gain can be misleading if the benchmark variant, scaffold, retry policy, or tool access differs.
For example, Build Fast with AI’s April 2026 ranking listed Claude Opus 4.6 at 80.8% SWE-bench Verified, Gemini 3.1 Pro at 78.8%, and Claude Sonnet 4.6 at 79.6%. Meanwhile, MorphLLM reported a separate Claude benchmark landscape, including Fable 5 at 95% SWE-bench Verified, Opus 4.8 at 88.6%, and 69.2% on SWE-bench Pro. These figures show why benchmark context matters: “SWE-Bench” is not always a single apples-to-apples measurement.
Expert reviewers generally ask three questions before trusting a score:
- Was it run on SWE-bench Verified, SWE-bench Pro, or another variant?
- Did the model use tools, agents, retries, or hidden scaffolding?
- Can an independent team reproduce the result through a public API?
If the answer to the third question is no, the number should be treated as a signal—not a production decision.
Enterprise AI architects care more about operational evidence
For CIOs and platform teams, expert opinion is shifting from “which model tops the chart?” to which model behaves reliably in production. A coding benchmark does not reveal how a model handles:
- Long-running agent sessions
- Hallucination recovery
- Function-calling reliability
- Multilingual customer conversations
- Latency under peak traffic
- Cost drift from long context usage
This is where model-routing infrastructure becomes strategically important. Platforms like CallMissed, which provide access to 300+ LLMs alongside voice agents, WhatsApp chatbots, Speech-to-Text for 22 Indian languages, and Text-to-Speech APIs, reflect a broader expert recommendation: avoid binding critical workflows to one frontier model label until pricing, latency, and reliability are proven under your own workload.
The practical expert verdict
The expert view can be summarized simply: compare capabilities, not rumors.
Right now, Claude-related claims range from 79.6% SWE-Bench for Sonnet 4.6 in NxCode’s account to 82.1% for a claimed Sonnet 5 in WaveSpeed’s coverage. Other benchmark sources report even higher numbers for different Claude-family models, such as 95% SWE-bench Verified for Fable 5. That spread does not automatically mean one source is wrong; it means buyers need to inspect the exact model, benchmark, and access conditions.
Until Claude Sonnet 5 and GPT-5.6 can both be tested through stable, documented APIs, expert opinion favors a cautious approach: benchmark them internally, monitor official documentation, and design infrastructure flexible enough to switch models when the evidence changes.
What This Means For You (TABLE)

Use the comparison as a buying framework, not a scoreboard
For most teams, the takeaway from Claude Sonnet 5 vs GPT-5.6 is practical: do not migrate production workloads based on a model name until you can verify the API ID, pricing, benchmark source, context window, latency, and availability under your own traffic.
The Claude side already shows why. NxCode reported that the “Claude Sonnet 5” Fennec leak may have corresponded to Claude Sonnet 4.6, launched on February 17, 2026, with 79.6% on SWE-Bench and $3 input / $15 output per million tokens pricing. Meanwhile, WaveSpeed described a separate “Claude Sonnet 5” claim with 82.1% on SWE-Bench, a 1M-token context window, and “half the cost of Opus 4.5.” Those are materially different procurement assumptions.
| If you are… | What to compare now | Useful data point | What remains uncertain | Best next step |
|---|---|---|---|---|
| Engineering leader | Coding reliability, repo-scale edits, tool use | Sonnet 4.6 reported at 79.6% SWE-Bench by NxCode and Build Fast with AI | Whether “Sonnet 5” is official, leaked, or renamed | Run private SWE-style evals on your own repos |
| CFO / FinOps team | Token cost, output-heavy workloads, cache savings | NxCode cites $3/$15 per 1M tokens for Sonnet 4.6 | Whether claimed Sonnet 5 pricing is real | Model cost per resolved ticket/task, not per token alone |
| AI product manager | Context length, latency, multimodal needs | WaveSpeed claims 1M-token context for Sonnet 5 | Public availability and sustained latency | Test long-context accuracy, not just max window size |
| Support / CX operator | Voice, chat, escalation, multilingual accuracy | Desktop automation coverage cited a 72.4% human expert baseline in one report | How GPT-5.6 and Claude behave in live customer flows | Pilot with human fallback and QA sampling |
| Startup CTO | Vendor flexibility and rollout speed | MorphLLM claims newer Claude-family scores up to 95% SWE-bench Verified for “Fable 5” | Whether third-party rankings map to your use case | Use model routing instead of hardcoding one provider |
| Compliance / procurement | Documentation, data controls, auditability | EvoLink said on Feb. 2, 2026 Sonnet 5 was not in Anthropic public docs | Official release status and contractual terms | Require vendor docs before regulated deployment |
The safest architecture is model-agnostic
The lesson is not “ignore frontier models.” It is to design systems so you can adopt them quickly after they are verified. That means:
- Separate orchestration from model choice so prompts, tools, and guardrails are portable.
- Benchmark on real tasks, including failed support calls, messy codebases, and multilingual inputs.
- Track cost per outcome, such as resolved bug, booked appointment, or closed ticket.
- Keep fallback models live in case a new frontier release has rate-limit, latency, or regression issues.
This is where platforms like CallMissed fit into the broader shift. A multi-model API gateway with access to 300+ LLMs lets teams test Claude, GPT, Gemini, and open models without rewriting application logic. For customer-facing AI agents, that flexibility matters more than a temporary leaderboard lead.
Bottom line for decision-makers
If you need to choose today, do not frame the decision as Claude Sonnet 5 vs GPT-5.6 winner-takes-all. Frame it as an evidence pipeline:
- Confirmed model + documented API + reproducible evals = production candidate
- Leaked name + benchmark screenshot + unclear pricing = watchlist
- Strong benchmark + poor latency or tool behavior = limited deployment
- Slightly weaker benchmark + stable cost and reliability = often better for production
In other words, the right move is not to wait forever—but to avoid betting your roadmap on unverified labels.
Frequently Asked Questions

Is Claude Sonnet 5 officially released as of June 30, 2026?
What is the main problem with comparing Claude Sonnet 5 vs GPT-5.6 right now?
Which model is better for coding, Claude Sonnet 5 or GPT-5.6?
Should businesses wait for official benchmarks before adopting either model?
Are SWE-Bench scores enough to compare Claude Sonnet 5 vs GPT-5.6?
What should developers look for before using Claude Sonnet 5 or GPT-5.6 in production?
Conclusion
The real lesson from Claude Sonnet 5 vs GPT-5.6 is that frontier-model comparisons now require more discipline than hype. Until both models have stable public identifiers, official pricing, documented context limits, and reproducible benchmark results, the safest conclusion is not “which one wins,” but what can be trusted.
Key takeaways:
- Model names are not enough. The reported “Claude Sonnet 5” Fennec leak may have mapped to Claude Sonnet 4.6, which NxCode says launched on February 17, 2026 with 79.6% on SWE-Bench and $3/$15 per million tokens pricing.
- Benchmarks need provenance. Claims of 82.1% SWE-Bench, 1M-token context, or lower Opus-level pricing matter only if tied to official releases and repeatable tests.
- GPT-5.6 comparisons remain limited without confirmed API behavior, pricing, latency, and deployment data under the same workloads.
- Production readiness beats leaderboard drama. Coding agents, support bots, and multimodal workflows need reliability, routing, and fallback options.
Going forward, watch for official model IDs, benchmark methodology, tool-use performance, and real-world latency under load. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents, multilingual chatbots, and access to 300+ LLMs for businesses.
So the better question is: are you choosing a model name—or building an AI system resilient enough to outlast the next leaderboard shift?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.