Claude Sonnet 5 vs Fable 5: Why There Is No Verifiable Comparison Yet

We cut through the hype to explain why a direct Claude Sonnet 5 vs Fable 5 comparison is impossible today, detailing benchmarks, current models, and what's next.
Claude Sonnet 5 vs Fable 5: Why There Is No Verifiable Comparison Yet
Did you know that Anthropic’s newly released Claude Fable 5 has already shattered industry benchmarks, scoring an unprecedented 95% on SWE-bench Verified and 80.3% on SWE-bench Pro? As developers and tech leaders scramble to integrate this powerhouse—which Anthropic's own legal teams note "materially different" in its ability to out-redline previous models—a massive debate has ignited across Reddit and the developer community. While early adopters are already hooked on Fable 5's elite agentic coding and reasoning capabilities, a highly vocal segment of developers is asking: Am I the only one more excited for Sonnet 5?
This question has triggered a wave of speculative performance comparisons. However, the reality of the situation is stark: there is currently no verifiable comparison between Claude Sonnet 5 vs Fable 5.
This topic matters immensely right now because enterprise AI strategy hinges on balancing cost, speed, and raw cognitive power. While Fable 5 and its creative sibling, Mythos 5, have officially entered the wild as heavy-duty, highly secure "Covered Models," Sonnet 5 remains on the horizon. Until Sonnet 5 is officially released with verified benchmark data, any head-to-head performance claims are purely theoretical. For businesses and developers building production-grade AI systems, navigating this hype cycle without concrete data is a massive financial and operational risk.
In this article, we will cut through the noise to explain why a verifiable Claude Sonnet 5 vs Fable 5 comparison is currently impossible. We will analyze Fable 5's verified architectural leaps, examine the historical role of the "Sonnet" tier as a cost-efficient developer workhorse, and explore how next-generation communication infrastructure platforms like CallMissed allow developers to dynamically route queries between these frontier models as soon as they become available. Finally, we will provide a framework for deciding whether to integrate Fable 5 today or wait for the mid-tier breakthrough of Sonnet 5.
Introduction

The AI landscape in 2026 has been set ablaze by Anthropic’s release of Claude Fable 5 and Claude Mythos 5. As developers and enterprise architects rush to dissect these new releases, Fable 5 has already established a staggering benchmark, achieving an unprecedented 95% on SWE-bench Verified and 80.3% on SWE-bench Pro. To put this in perspective, Anthropic's own legal teams noted during blind reviews that Fable 5's contract redlines "matched or beat" their current models every single time, signaling a massive leap in agentic reasoning, code synthesis, and security analysis.
Yet, beneath the roaring hype of this frontier release, a quieter, highly strategic debate has taken over developer communities. While Fable 5 represents the absolute peak of agentic coding, a vocal contingent of engineers is asking: Am I the only one more excited for Sonnet 5 than Fable 5? Historically, the "Sonnet" tier has been the ecosystem's dependable workhorse—balancing blazing-fast inference speeds with cost-effective, high-tier intelligence. The prospect of what Sonnet 5 might deliver has many engineers hesitating before rewriting their entire production pipelines for Fable 5.
The Hype vs. The Reality of Claude Sonnet 5
This hesitation has birthed a wave of speculative performance comparisons. However, enterprise leaders must face a stark technical truth: there is currently no verifiable comparison between Claude Sonnet 5 and Fable 5.
While we have concrete, audited data for Anthropic's active 2026 lineup—including Fable 5, Opus 4.8 (88.6% on SWE-bench Verified), and Sonnet 4.6—Sonnet 5 remains unreleased. Any chart, benchmark, or blog post claiming to show a head-to-head matchup between Sonnet 5 and Fable 5 is entirely theoretical. Navigating this landscape requires separating proven, production-grade performance from speculative roadmap projections. For businesses, making long-term infrastructure decisions based on unreleased models poses severe operational and financial risks.
Why This Comparison Gap Matters Today
Choosing between these model tiers isn't just about raw intelligence; it involves complex trade-offs in architecture, security, and integration:
- Data Governance & Retention: Unlike older standard API endpoints, both Fable 5 and Mythos 5 are designated as "Covered Models." They carry a strict 30-day data retention policy and are currently unavailable under zero-data-retention agreements.
- Cost vs. Capability: Fable 5's unmatched agentic performance comes with higher latency and compute costs compared to what a mid-tier Sonnet 5 is expected to demand.
- Infrastructure Agility: Modern software architectures cannot afford to lock themselves into a single model. Forward-thinking companies are leveraging multi-model API gateways, such as CallMissed, which allows developers to dynamically route queries across over 300+ LLMs. Platforms like CallMissed ensure that whether you are deploying Fable 5 for heavy-duty agentic coding today, or waiting to integrate Sonnet 5 tomorrow, your infrastructure remains completely decoupled from provider lock-in.
In this article, we will unpack the verifiable architectural leaps of Fable 5, analyze why the "Sonnet" tier remains the developer sweet spot, and show you how to build a resilient AI infrastructure that adapts to Anthropic’s rapidly evolving ecosystem.
Background & Context
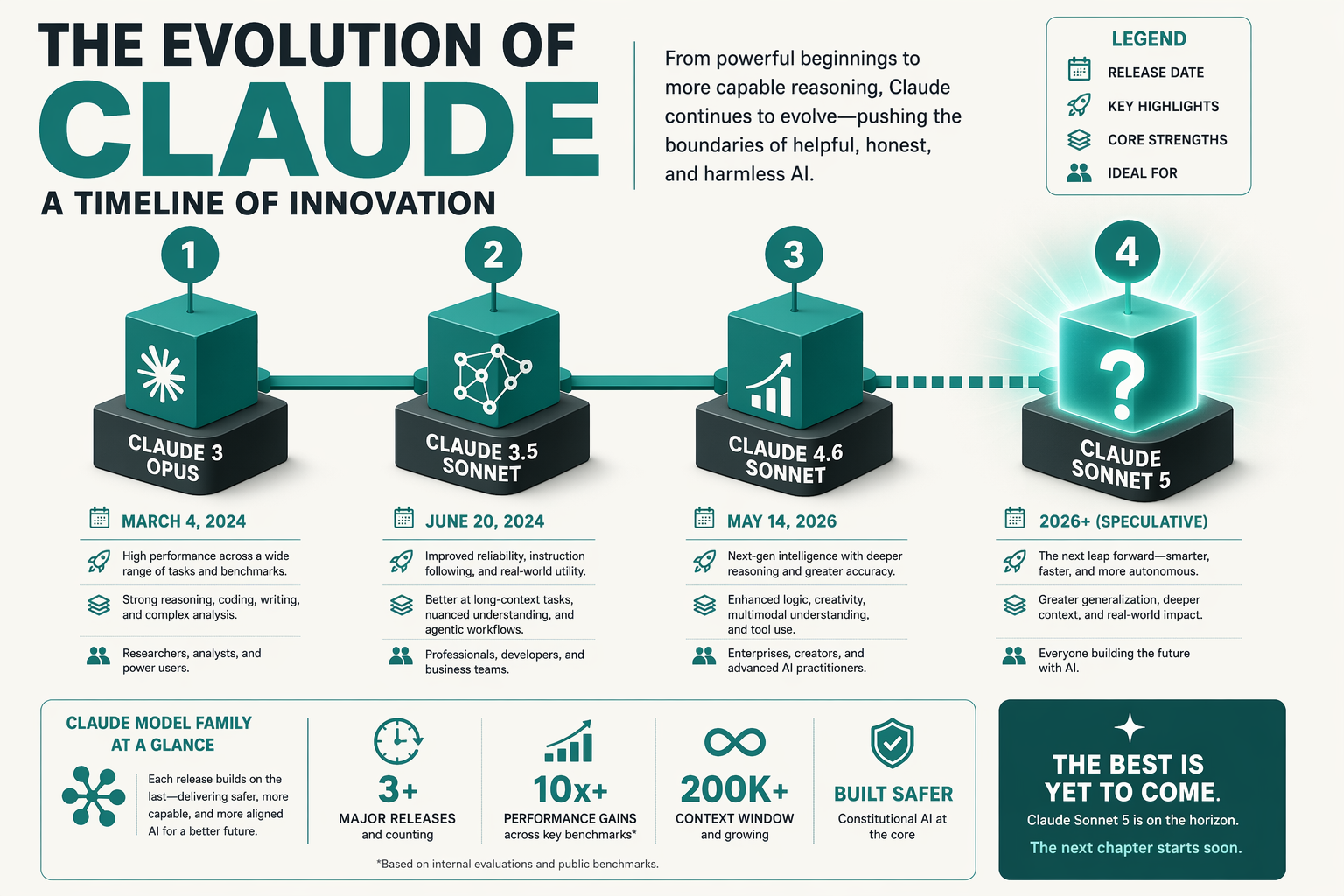
To understand why the debate between Claude Sonnet 5 and Claude Fable 5 is raging despite one model not yet existing, we must look at how Anthropic has structured its model ecosystem in 2026. Anthropic’s release of Claude Fable 5 and its creative counterpart, Claude Mythos 5, represents a massive architectural and operational pivot.
The Reality of the Fable 5 Era
Unlike prior generations, where new model tiers were rolled out incrementally under standard developer agreements, Fable 5 and Mythos 5 have been designated as "Covered Models." This classification introduces specific compliance and data handling guidelines that enterprises must navigate:
- 30-Day Data Retention: Both Fable 5 and Mythos 5 carry a mandatory 30-day data retention policy.
- No Zero Data Retention (ZDR): Neither model is currently available under zero-data-retention terms, forcing enterprise security teams to carefully evaluate where and how they route proprietary codebases and sensitive customer data.
- Heavy-Duty Cognitive Load: Fable 5's massive leap to a 95% SWE-bench Verified and 80.3% SWE-bench Pro score means it operates less like a fast chatbot and more like an elite agentic system.
While Fable 5 excels at catching subtle logic edge cases, naming inconsistencies, and security flaws, this extreme reasoning capability comes with a higher latency and cost footprint than everyday software engineering tasks typically require.
Why the Developer Community Craves Sonnet 5
Historically, the "Sonnet" tier (such as Sonnet 4.6) has served as the undisputed workhorse for modern engineering teams. It was the dependable, cost-efficient, and incredibly fast daily driver that handled routine coding, translation, and system orchestration without breaking the bank.
The current excitement on Reddit and developer forums around a speculative Sonnet 5 stems from a desire to combine the architectural breakthroughs of the 5-series with the lightning-fast execution and lower cost of a mid-tier model. For many production environments, a highly optimized Sonnet 5 would be far more practical for high-volume customer interactions and API orchestration than a heavyweight agentic model like Fable 5.
Navigating the Multi-Model Landscape
This ongoing transition highlights a major operational hurdle for businesses: as the performance and compliance gap between heavyweight frontier models and agile mid-tier models widens, hardcoding a single LLM into your tech stack is a recipe for technical debt.
To navigate these shifts, forward-thinking engineering teams rely on unified communication and AI infrastructure. For instance, platforms like CallMissed provide a robust multi-model API gateway supporting over 300+ LLMs. This architecture allows developers to dynamically route tasks—sending complex, high-stakes code audits or legal redlines to Claude Fable 5 while automatically shifting high-volume conversational tasks and database queries to Sonnet models the moment they become available, all without rewriting a single line of backend application code.
Ultimately, understanding this background reveals why comparing Sonnet 5 and Fable 5 today is premature. The models are designed to serve entirely different purposes within the enterprise software lifecycle, and until Anthropic releases official benchmark data for Sonnet 5, any head-to-head comparison remains purely theoretical.
Key Developments (TABLE)
The landscape of Anthropic’s model offerings has shifted dramatically. To understand where the unreleased Claude Sonnet 5 might eventually sit in the hierarchy, it is essential to map out the current performance tiers and operational constraints of Anthropic's existing lineup.
To help developers and enterprise architects navigate this transition, the table below compiles the verified metrics and technical specifications of the current model family alongside the projected expectations for Sonnet 5.
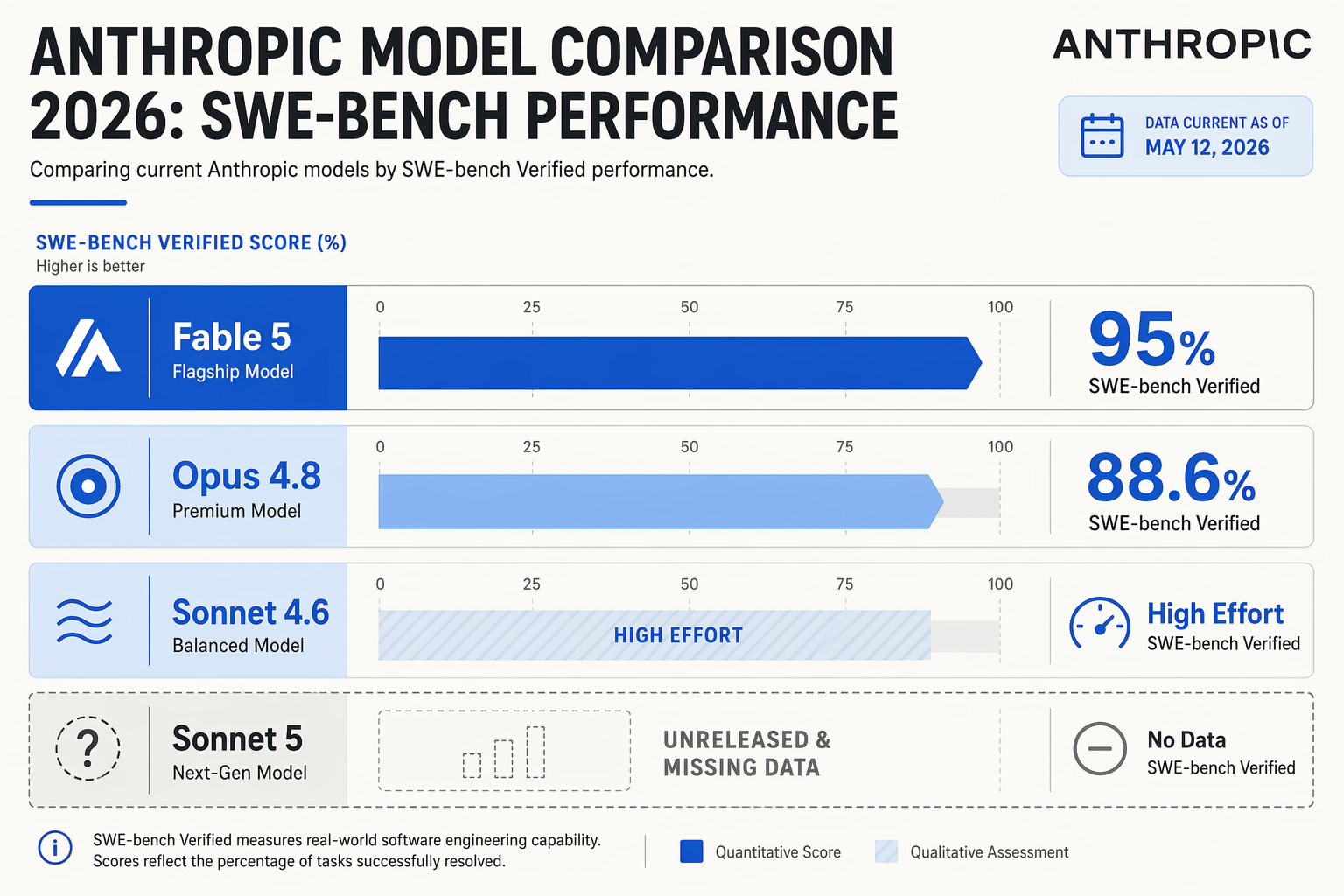
| Model Name | SWE-bench Verified | SWE-bench Pro | Data Retention Policy | Status (as of mid-2026) |
|---|---|---|---|---|
| Claude Fable 5 | 95.0% | 80.3% | 30-Day (Covered Model) | Released & Active |
| Claude Mythos 5 | Not Disclosed | Not Disclosed | 30-Day (Covered Model) | Released & Active |
| Claude Opus 4.8 | 88.6% | 69.2% | Zero-Data Option | Active |
| Claude Sonnet 4.6 | Legacy Baseline | Legacy Baseline | Zero-Data Option | Active |
| Claude Sonnet 5 | TBD (Unreleased) | TBD (Unreleased) | TBD (Unreleased) | Highly Anticipated |
Core Structural Shifts
The table highlights several critical shifts that explain why the developer community is experiencing mixed emotions about Fable 5 and looking ahead to Sonnet 5:
- The "Covered Models" Constraint: Unlike older models such as Sonnet 4.6 or Opus 4.8, both Claude Fable 5 and the creative-focused Claude Mythos 5 carry a mandatory 30-day data retention policy. They are designated as "Covered Models" and are currently not eligible for zero-data retention. For highly regulated industries like fintech and healthcare, this policy represents a significant compliance hurdle, regardless of Fable 5's elite coding scores.
- The Performance Gap: Fable 5 represents a monumental leap over Opus 4.8, claiming an unprecedented 95% score on SWE-bench Verified compared to Opus's 88.6%. On the more grueling SWE-bench Pro, which tests deep multi-file agentic coding, Fable 5 hits 80.3% while Opus 4.8 trails at 69.2%.
- The Sonnet 5 Void: As shown, there are absolutely no verified benchmarks for Claude Sonnet 5. This total lack of data makes any direct head-to-head performance claims pure speculation.
Managing Model Transitions Dynamically
Because frontier models introduce entirely new variables in pricing, data retention, and performance, sticking to a single LLM provider is no longer a viable long-term strategy for agile engineering teams.
This is where multi-model infrastructure becomes essential. Platforms like CallMissed offer a unified, production-ready gateway that allows developers to seamlessly switch between 300+ LLMs—including the latest Anthropic models. By utilizing CallMissed's dynamic routing, enterprise teams can instantly leverage the raw reasoning power of Fable 5 for complex system architecture tasks, while maintaining the flexibility to route simpler tasks to zero-retention, low-latency models. This ensures that when Sonnet 5 eventually launches, organizations can deploy and benchmark it instantly without operational downtime.
In-Depth Analysis

To understand why a head-to-head comparison between Claude Fable 5 and the unreleased Claude Sonnet 5 is currently impossible, we must look closely at Fable 5's unique architectural classification and the distinct role the "Sonnet" tier plays in a developer’s stack.
The Enterprise Compliance Divide: Covered Models vs. Standard APIs
One of the most critical, yet frequently overlooked, differences between Fable 5 and previous Claude models lies in data governance. According to Anthropic's official model documentation, both Claude Fable 5 and Claude Mythos 5 are designated as Covered Models.
- 30-Day Data Retention: Both Fable 5 and Mythos 5 carry a mandatory 30-day data retention policy.
- No Zero-Data Retention: Unlike previous mid-tier models, they are strictly unavailable under zero-data retention terms.
For enterprise architects in highly regulated sectors—such as healthcare, finance, or defense—this compliance detail is a massive bottleneck. While Fable 5 offers unmatched reasoning, many organizations cannot legally feed proprietary data into a model that caches inputs for 30 days. This is precisely why the developer community is eagerly anticipating Sonnet 5. Historically, Anthropic's Sonnet and Haiku tiers have offered flexible zero-data retention options, making them the preferred daily drivers for corporate application development.
The Agentic Performance Gap: Fable 5's True Benchmarks
Comparing a speculative model to a live powerhouse requires looking at the actual, verified baselines we have today. Fable 5’s current dominance is reflected in its specialized coding and reasoning scores:
- SWE-bench Verified: Fable 5 achieves a historic 95%, dwarfing Claude Opus 4.8's score of 88.6%.
- SWE-bench Pro: Fable 5 scores 80.3%, compared to Opus 4.8’s 69.2%.
Because Sonnet 5 does not yet have an official API model ID, performance benchmarks, or pricing, any claim that Sonnet 5 "beats" or "rivals" Fable 5 is pure speculation. Developers are currently forced to use Fable 5 for high-complexity agentic coding, while relying on Claude Sonnet 4.6 or older models for cost-efficient, high-throughput tasks.
Mitigating Model Risk with Dynamic Infrastructure
Navigating this transition period requires a flexible architecture. Enterprises cannot afford to hardcode their infrastructure around Fable 5, only to rewrite their entire codebase when Sonnet 5 eventually launches.
This is where advanced communication and AI infrastructure becomes vital. Platforms like CallMissed solve this issue by offering a unified LLM inference gateway that supports over 300+ models. By integrating CallMissed, developers can build production-ready voice agents and chatbots that leverage Fable 5 for highly complex, multi-turn reasoning tasks today, while dynamically routing simpler, high-volume customer queries to more cost-effective models. Once Sonnet 5 is officially released, teams can transition their workloads instantly via CallMissed's API without changing a single line of underlying application code—ensuring they remain agile as the frontier model landscape shifts.
Impact & Implications

Compliance and Security Under the "Covered Model" Umbrella
The arrival of Claude Fable 5 and Mythos 5 has introduced a critical compliance shift that enterprise IT departments must navigate immediately. Both of these frontier models have been designated by Anthropic as Covered Models. Crucially, they carry a mandatory 30-day data retention policy and are currently not available under zero data retention (ZDR) agreements.
For highly regulated sectors—such as healthcare, fintech, and defense—this 30-day retention window introduces significant data privacy considerations. Organizations that had previously optimized their pipelines for zero-retention API endpoints must now re-evaluate their data governance frameworks before exposing sensitive customer data or proprietary codebases to Fable 5’s reasoning engine, despite its superior performance.
The Economic Reality of "Max Mode" AI
While Fable 5’s technical achievements are staggering—scoring 95% on SWE-bench Verified and 80.3% on SWE-bench Pro—running a frontier-class model for everyday software development tasks is an expensive proposition. Historically, the "Sonnet" tier served as the ultimate developer workhorse, offering a perfect equilibrium of speed, intelligence, and cost-efficiency.
The lack of a verifiable Sonnet 5 means developers are currently caught in a dilemma:
- The Over-Provisioning Trap: Forcing simple API integrations or repetitive boilerplate generation through Fable 5. This "max mode" approach leads to unnecessarily high API token bills.
- The Capability Gap: Sticking to older models like Sonnet 4.6, which, while highly reliable, lack the agentic prowess to catch the subtle naming inconsistencies, logic edge cases, and security vulnerabilities that Fable 5 effortlessly flags.
This tension explains why the developer community remains highly eager for Sonnet 5. Until a mid-tier alternative is released, building highly complex AI agents remains a costly, premium endeavor.
Future-Proofing with Multi-Model Architecture
To mitigate these compliance risks and rising token costs, engineering teams are shifting away from single-model dependency. Instead of hardcoding Fable 5 into their applications, architecture leaders are building dynamic routing systems.
For example, platforms like CallMissed enable developers to construct robust communication infrastructures by dynamically routing tasks across a multi-model gateway supporting over 300 LLMs. By leveraging this framework, an enterprise can:
- Route high-stakes tasks, such as real-time legal contract redlining or complex code debugging, to Fable 5.
- Direct routine conversational inquiries, data formatting, and standard customer interactions to faster, more economical models.
- Seamlessly hot-swap the model routing configuration to integrate Sonnet 5 the moment its API goes live, with zero downtime or code rewrites.
By adopting this hybrid architecture, businesses do not have to choose between Fable 5's unmatched agentic power and the cost efficiency they anticipate from Sonnet 5—they can strategically leverage both.
Expert Opinions
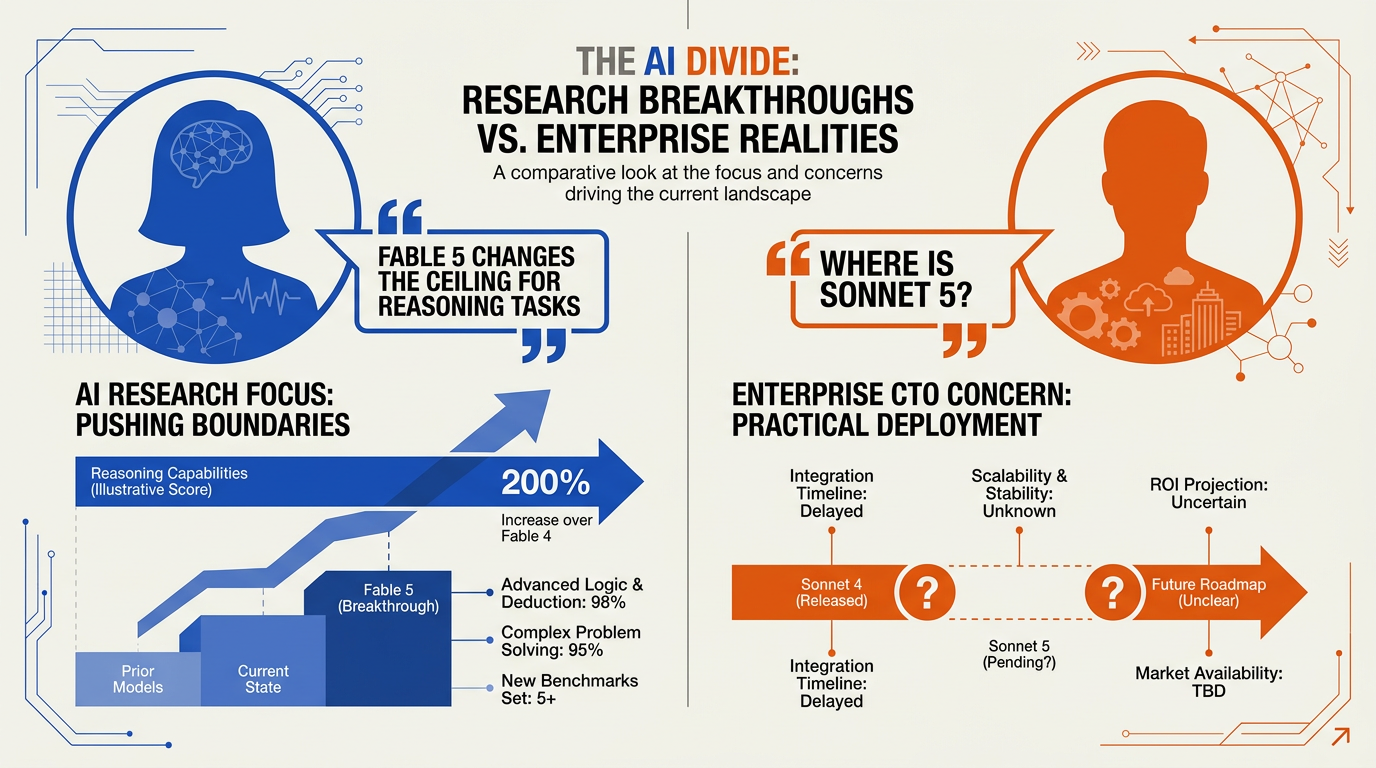
The "Materially Different" Legal and Security Verdict
Industry experts and enterprise legal teams are focusing heavily on the operational guardrails of Anthropic’s new releases. According to Anthropic’s internal blind reviews, legal experts noted that Claude Fable 5 feels "materially different" from its predecessors, with legal teams reporting that Fable 5's contract redlines "matched or beat" their current models in every single test.
However, enterprise security architects urge caution regarding data governance. Because both Claude Fable 5 and Claude Mythos 5 are designated as "Covered Models," they carry a mandatory 30-day data retention policy and are currently unavailable under zero data retention agreements. For highly regulated industries like finance and healthcare, this means Fable 5's unmatched reasoning must be carefully balanced against strict corporate data-handling compliance.
The Developer Community’s Practical Dilemma
Within the developer community, the reception of Fable 5's incredible benchmarks—specifically its 95% on SWE-bench Verified and 80.3% on SWE-bench Pro—is met with a mix of awe and practical skepticism. Leading technical analysts note that integrating Fable 5 is "no longer as easy as switching to the latest model, going on max mode, and calling it a day." Deep dives comparing Fable 5's system prompt to older models like Opus reveal a highly complex, agent-centric architecture that requires precise prompt engineering to avoid runaway token consumption.
This underlying complexity is precisely why a growing cohort of developers on Reddit are expressing that they are far more eager for Sonnet 5 than Fable 5. For years, the Sonnet tier has been celebrated as the ultimate "dependable workhorse"—quick, sharp, and highly cost-efficient for daily workflows. Developers argue that while Fable 5 is an incredible frontier model for massive, multi-step agentic coding tasks, Sonnet 5 will likely be the more practical daily driver for standard API calls and rapid prototyping. Until Sonnet 5 is released, however, comparing the two remains speculative.
Architectural Routing and the CallMissed Advantage
Faced with this uncertainty, AI infrastructure experts recommend building model-agnostic systems. Rather than hardcoding applications to Fable 5 and risking vendor lock-in or high API bills, enterprises are building dynamic routing layers that can pivot as the model landscape shifts.
This is where platforms like CallMissed become invaluable. By utilizing CallMissed’s LLM inference gateway, which supports over 300+ models alongside advanced Speech-to-Text and Text-to-Speech APIs, developers can deploy Fable 5 for heavy-duty reasoning tasks today. When Sonnet 5 eventually launches, teams can dynamically route high-volume, low-latency tasks to the new mid-tier model with zero downtime, optimizing both performance and cost on the fly without rewriting a single line of core integration code.
What This Means For You (TABLE)
The current market dynamics force technical leaders to make a critical choice: adopt the ultra-powerful yet computationally expensive Claude Fable 5 today, or optimize current architectures while waiting for the release of Claude Sonnet 5. Because Sonnet 5's release remains on the horizon without verified benchmark data, committing your entire production workflow to Fable 5 might lead to unnecessary overhead once a highly efficient mid-tier model becomes available.
To help you navigate this transition, the table below highlights the performance, compliance, and functional differences across the Claude lineup in 2026, comparing current models against what we anticipate for Sonnet 5 based on historical tier patterns.
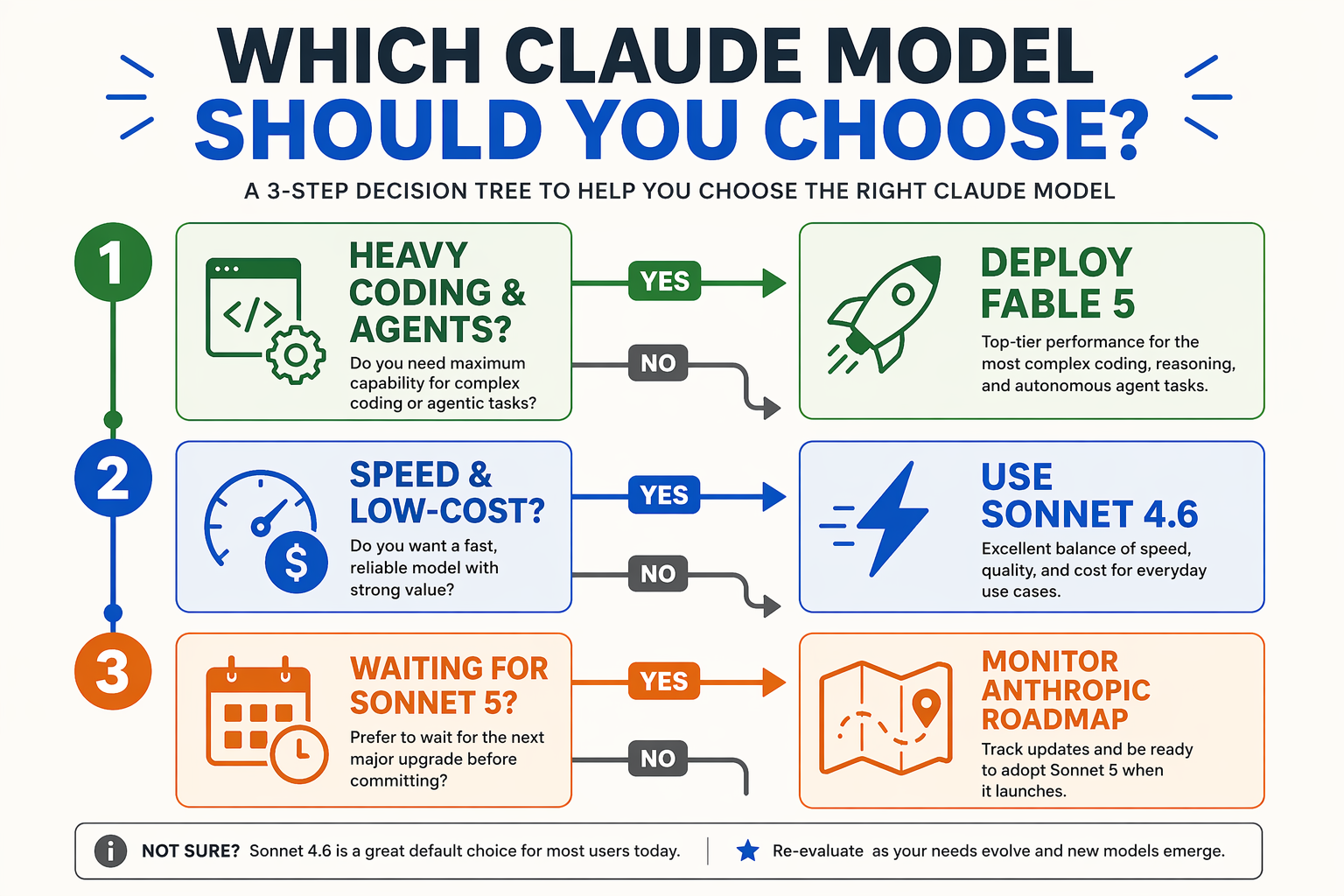
| Model Name | SWE-bench Verified Score | SWE-bench Pro Score | Data Retention Status | Core Production Use Case |
|---|---|---|---|---|
| Claude Fable 5 | 95.0% | 80.3% | 30-Day Retention (Covered Model) | Elite agentic coding, security redlining, complex legal analysis |
| Claude Mythos 5 | N/A (Creative Focus) | N/A | 30-Day Retention (Covered Model) | Nuanced narrative generation, high-end copywriting |
| Claude Opus 4.8 | 88.6% | 69.2% | Zero Data Retention available | Legacy heavy-reasoning tasks requiring strict compliance |
| Claude Sonnet 4.6 | Benchmark baseline | Benchmark baseline | Zero Data Retention available | High-throughput API pipelines, general-purpose daily coding |
| Claude Sonnet 5 | TBD (Unreleased) | TBD (Unreleased) | TBD | Future high-performance, cost-effective enterprise agents |
Strategic Takeaways for Enterprise Architecture
- Do Not Pause Agentic Roadmap for Sonnet 5: If your product requires state-of-the-art agentic reasoning today, waiting for Sonnet 5 is a missed opportunity. Fable 5's 95% score on SWE-bench Verified is a massive milestone that is ready for production. Deploy it immediately for your most complex coding, logic, and reasoning tasks.
- Prepare for Strict Compliance Guardrails: Both Fable 5 and Mythos 5 are designated "Covered Models" and carry a mandatory 30-day data retention policy. If your application handles sensitive PII or medical data that requires absolute Zero Data Retention (ZDR), you must rely on Claude Opus 4.8 or Sonnet 4.6 until Sonnet 5's compliance terms are officially announced.
- Build with Multi-Model Agility: Relying on a single model tier is an architectural vulnerability. To prevent model lock-in, forward-thinking enterprise teams are decoupling their core application logic from specific LLM APIs.
Using platforms like CallMissed allows developers to implement dynamic routing. You can seamlessly route highly complex, multi-step agentic tasks to Fable 5, use cost-effective models for high-volume customer inquiries, and plug in Claude Sonnet 5 the second it launches without rewriting a single line of code in your communication or voice agent infrastructure. This approach ensures your business remains agile, leveraging Fable for raw cognitive power today and Sonnet 5 for cost-effective scale tomorrow.
Frequently Asked Questions

Is there any official benchmark data available for Claude Sonnet 5 vs Fable 5?
Why are developers debating Claude Sonnet 5 vs Fable 5 when only one model has been released?
What are the main benchmark achievements of Claude Fable 5?
How do the data retention policies differ in a potential Claude Sonnet 5 vs Fable 5 comparison?
Can I use Claude Fable 5 for production-grade customer support or voice agents today?
What is Claude Mythos 5 and how does it relate to Fable 5?
Conclusion
As the AI landscape in 2026 continues its rapid evolution, navigating the transition between frontier releases requires a data-driven approach rather than reliance on speculative hype. To recap the key takeaways of this model landscape:
- No Verifiable Comparison Yet: While Claude Fable 5 has established concrete, record-breaking benchmarks like scoring 95% on SWE-bench Verified, Claude Sonnet 5 remains unreleased, making any direct head-to-head performance claims purely theoretical.
- Strategic Trade-Offs: The heavy-duty agentic capabilities and strict data policies of Fable 5 serve as a powerful solution for complex enterprise workflows, yet developers still eagerly await the "Sonnet" tier as a cost-efficient, everyday workhorse.
- Architectural Agility is Key: Rather than locking into a single model, forward-thinking businesses must design flexible infrastructures that can dynamically route tasks to the most efficient LLM as new options emerge.
Looking forward, the true test for enterprises will be how quickly they can integrate Sonnet 5 once Anthropic officially releases its verified benchmarks. To explore how modern AI communication is evolving and prepare your business for the next wave of model upgrades, check out CallMissed—an AI communication infrastructure platform powering intelligent voice agents, multilingual chatbots, and multi-model LLM integration.
Are you building your enterprise workflows to be model-agnostic, or will your infrastructure leave you locked out when the next breakthrough model drops?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.