GPT-5.5 vs. Claude Opus vs. Gemini 3.5 vs. Llama 4: The Enterprise LLM Buyer’s Guide for 2026

Compare 2026's top enterprise LLMs—GPT-5.5, Claude Opus 4.7/Fable 5, Gemini 3.5, and Llama 4—across reasoning, cost, and context to find your ideal fit.
GPT-5.5 vs. Claude Opus vs. Gemini 3.5 vs. Llama 4: The Enterprise LLM Buyer’s Guide for 2026
Did you know that in 2026, the average enterprise now deploys four or more distinct large language models across its production workflows, rather than relying on a single "winner-take-all" provider? The era of treating LLM selection as a simple race to the top of a leaderboard is officially over. Today, CTOs and enterprise architects are realizing that the true ROI of artificial intelligence lies not in raw parameter counts, but in mapping specific business workloads—such as agentic reasoning, long-context ingestion, and code generation—to the specialized strengths of frontier architectures.
With the mid-2026 release of powerhouse models like GPT-5.5, Claude Opus 4.7 (alongside early previews of Fable 5), Gemini 3.5, and Llama 4, the decision-making framework has fundamentally shifted. It is no longer a question of which model is universally "the best," but rather: Which model is the most cost-effective and architecturally sound for my specific task?
Navigating this hyper-specialized landscape requires cutting through aggressive vendor marketing to look at how these engines perform under real-world pressure. In this comprehensive guide, we will break down the exact workloads where each model excels:
- GPT-5.5 remains the industry leader for complex multi-step reasoning, advanced agentic planning, and highly interactive general-purpose tasks—albeit at a premium price point.
- Claude Opus continues to hold its ground as the gold standard for software engineering, precise coding syntax, and complex technical drafting.
- Gemini 3.5 dominates the long-context and multimodal arena, effortlessly processing native video files and massive, million-token codebases with ultra-low latency.
- Llama 4 represents the ultimate breakthrough in open-weights technology, giving enterprises complete data privacy, fine-tuning freedom, and massive cost savings for self-hosted deployments.
To make implementation seamless, multi-model infrastructure platforms like CallMissed now allow enterprise developers to easily switch between 300+ LLMs via a single API, ensuring you can deploy the perfect model for every micro-service without rewriting your codebase.
Whether you are building autonomous customer support systems, automated code-refactoring pipelines, or analyzing massive regulatory documents, this Enterprise LLM Buyer’s Guide for 2026 will provide you with the objective, data-driven framework needed to optimize your AI stack for performance, privacy, and budget.
Introduction: Navigating the Multi-LLM Era in 2026

The enterprise AI landscape has undergone a tectonic shift. In 2026, the question is no longer, "Which LLM is the absolute best?" Instead, CIOs and enterprise architects are asking, "Which model is the most cost-effective and architecturally optimized for this specific micro-service?"
According to recent industry data, the average enterprise now deploys four or more distinct large language models across production workflows, moving away from "winner-take-all" single-provider strategies. The era of selecting a model based solely on generalized leaderboard rankings has been replaced by a pragmatic, workload-first selection framework.
The Specialization of Frontier LLMs
The mid-2026 release of powerhouse models like GPT-5.5, Claude Opus 4.7 (with early previews of Fable 5), Gemini 3.5, and Llama 4 has established distinct operational niches for each provider. Rather than competing head-to-head on every metric, these foundation models have diverged into specialized domains:
- GPT-5.5 (OpenAI): The undisputed leader for complex multi-step reasoning, advanced agentic planning, and highly interactive general-purpose tasks. While it carries a premium price point, its ability to navigate ambiguous, multi-layered business logic remains unmatched.
- Claude Opus 4.7 / Fable 5 (Anthropic): The gold standard for software engineering, precise coding syntax, and complex technical drafting. Claude consistently dominates coding benchmarks like SWE-bench, making it the preferred engine for automated refactoring and CI/CD pipelines.
- Gemini 3.1 Pro / 3.5 (Google): The absolute ruler of the long-context and multimodal arena. With its massive native context window, Gemini effortlessly processes multi-hour video files, entire audio archives, and million-token codebases with ultra-low latency and highly competitive pricing.
- Llama 4 (Meta): The breakthrough in open-weights technology. For enterprises requiring complete data privacy, custom fine-tuning capabilities, and zero-egress data boundaries, Llama 4 offers near-frontier performance at a fraction of the cost of proprietary APIs when self-hosted.
Engineering the Multi-LLM Architecture
Operating a highly specialized, multi-model infrastructure presents significant integration challenges. Swapping models across different business departments—such as using Claude for dev tools, Gemini for document analysis, and GPT-5.5 for customer-facing agents—historically required maintaining fragmented API integrations and disparate SDKs.
This is where advanced orchestration layers become critical. Platforms like CallMissed resolve this friction by offering a unified API gateway that connects developers to over 300+ LLMs. This allows enterprise engineering teams to hot-swap models, benchmark latency, and run fallback protocols dynamically without rewriting their core codebase.
As we dive into this buyer's guide, we will move past the marketing noise to analyze the hard performance data, cost-per-token metrics, and deployment trade-offs of these four frontier giants to help you architect a high-yield AI strategy.
Background & Context: The Specialization of Frontier Models
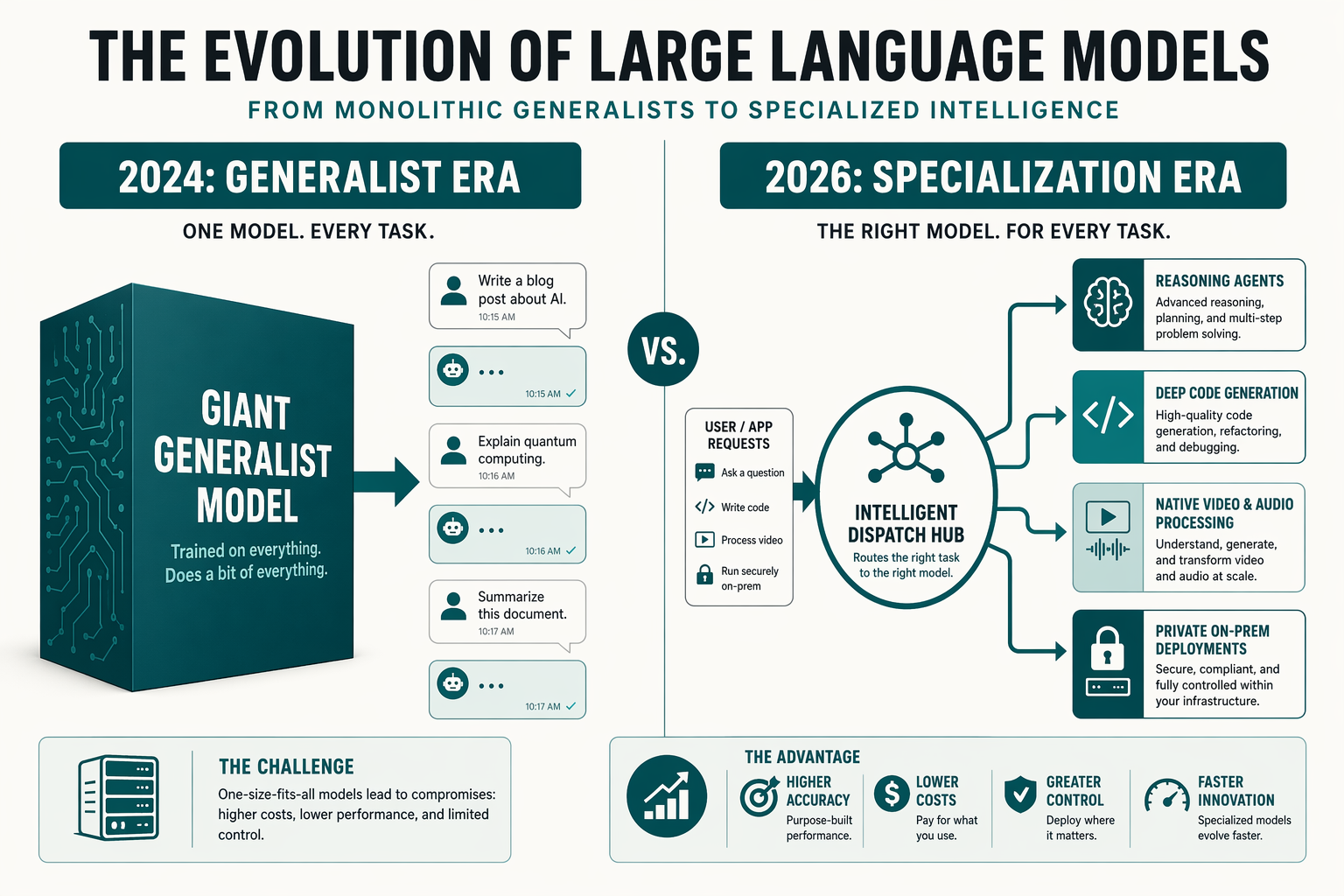
The transition from monolithic AI adoption to highly specialized, multi-model architectures represents the defining shift in enterprise IT strategy. In earlier phases of generative AI deployment, organizations routinely fell into the trap of the "vendor lock-in" cycle—attempting to force a single commercial model to handle every corporate workload. By mid-2026, empirical data from the field has rendered this approach obsolete.
Modern enterprise workloads demand distinct structural capabilities that no single frontier model can optimize simultaneously. To maximize ROI and minimize API latency, enterprise architects are now mapping four primary workload characteristics—reasoning depth, syntactical precision, context window ingestion, and data sovereignty—to the corresponding strengths of the market's leading engines.
The Specialist Breakdown: Mapping 2026's Frontier Engines
To build a resilient, cost-effective AI infrastructure, organizations must evaluate models based on their architectural specialization rather than generic leaderboard averages:
- OpenAI GPT-5.5 (Agentic Planning & Multi-Step Reasoning): OpenAI’s latest flagship remains the premier choice for complex, autonomous workflows. GPT-5.5 excels in environments requiring advanced agentic planning, chain-of-thought logic, and highly interactive, non-linear task execution. For enterprises deploying multi-agent systems that negotiate, cross-reference databases, and execute APIs autonomously, GPT-5.5 serves as the central orchestrator, despite its premium pricing tier.
- Anthropic Claude Opus 4.7 / Fable 5 Preview (Software Engineering & Technical Drafting): Anthropic has solidified its position as the gold standard for deterministic technical execution. Claude Opus 4.7 dominates coding benchmarks (consistently leading on platforms like the SWE-bench) and complex technical writing. It is the preferred engine for automated code refactoring, legacy migration, and drafting highly structured legal or regulatory documentation.
- Google Gemini 3.5 & 3.1 Pro (Long-Context & Multimodal Ingestion): Google leads the industry in native multimodal processing and context window capacity. Capable of effortlessly ingesting million-token codebases or native video files, Gemini 3.5 allows enterprises to perform real-time, low-latency analysis on massive datasets without needing complex chunking or retrieval-augmented generation (RAG) pipelines.
- Meta Llama 4 (Data Sovereignty & Cost-Efficient Customization): As the premier open-weights family of 2026, Llama 4 offers enterprises complete deployment freedom. For highly regulated industries like healthcare or defense, Llama 4 allows companies to host models entirely on-premises or within private clouds, ensuring strict data privacy and allowing for deep, task-specific fine-tuning at a fraction of the cost of proprietary APIs.
Navigating the Multi-Model Infrastructure
Managing this level of specialization requires robust orchestration. Implementing individual API integrations for each specialist model creates massive technical debt.
This is where advanced communication and LLM routing platforms become essential. For instance, CallMissed’s multi-model API gateway enables developers to seamlessly switch between 300+ LLMs—including GPT-5.5, Claude, Gemini, and Llama 4—without rewriting core application code. This infrastructure allows a business to route a high-stakes customer support call to a low-latency voice agent powered by CallMissed's specialized Speech-to-Text APIs, while simultaneously running deep analytical workflows on the backend using the optimal frontier reasoning model. By decoupling the application layer from the underlying LLM, enterprises can dynamically balance cost, speed, and accuracy in real-time.
Key Developments: Side-by-Side Model Profiles (TABLE)

To help enterprise architects and decision-makers cut through vendor marketing, we have compiled a side-by-side technical profile of the mid-2026 frontier models. This comparison evaluates each LLM across five critical enterprise pillars: primary workload specialization, context window capacity, pricing structure, deployment flexibility, and industry benchmark performance (based on compiled data from Epoch AI and Scale AI).
Side-by-Side Enterprise LLM Profiles (Mid-2026)
| Model & Provider | Primary Specialization | Context Window | Estimated Pricing (per 1M Tokens) | Key Strengths & Deployments |
|---|---|---|---|---|
| GPT-5.5 <br>(OpenAI) | Multi-step agentic planning, complex reasoning, general-purpose orchestration | 128k tokens (high-density retrieval) | Input: $10.00 <br>Output: $30.00 | Best-in-class for autonomous workflows and complex reasoning; hosted via OpenAI API or Azure. |
| Claude Opus 4.7 <br>(Anthropic) | Advanced software engineering, precise technical drafting, compliance analysis | 200k tokens | Input: $15.00 <br>Output: $75.00 | Coding gold standard (79.6%+ on coding benchmarks); hosted via Anthropic Console or AWS Bedrock. |
| Gemini 3.5 <br>(Google) | Native multimodal analysis, massive codebase ingestion, video processing | 2.0M tokens | Input: $1.25 <br>Output: $3.75 | Unmatched long-context retrieval and ultra-low latency native video analysis; hosted via Google Cloud Vertex AI. |
| Llama 4 <br>(Meta / Open-Weights) | Enterprise fine-tuning, high-volume pipeline automation, secure on-premise tasks | 128k tokens | Infrastructure costs only (Self-hosted) | Maximum data privacy and zero API marginal cost; deployed on-premise, on VPC, or via cloud hyper-scalers. |
Architectural Strengths: Where to Allocate Your Workloads
Evaluating these models side-by-side reveals that the 2026 AI stack is highly specialized:
- For Multi-Agent Automation: GPT-5.5 remains the undisputed orchestrator. Its advanced agentic planning capabilities allow it to break down highly complex, non-linear business problems into executable sub-tasks, making it the ideal brain for complex corporate workflows.
- For Software Development Pipelines: Claude Opus 4.7 (and early previews of Fable 5) dominates codebase refactoring and precise technical writing. For enterprises maintaining legacy systems or automating CI/CD pipelines, its code-generation precision dramatically reduces debugging cycles.
- For Heavy Document and Video Analytics: Gemini 3.5 represents a massive leap in multi-modal capabilities. With its 2-million-token window, enterprises can ingest entire regulatory books, hours of video footage, or millions of lines of code without needing complex Retrieval-Augmented Generation (RAG) chunking.
- For High-Volume, Private Data Processing: Llama 4 offers the ultimate defense against rising API costs. For industries handling highly sensitive data—like healthcare or finance—deploying Llama 4 within a private VPC ensures complete data residency compliance while driving down inference costs to near-zero marginal rates.
Deploying and managing this diverse, multi-model architecture can be operationally complex. This is where unified API gateways like CallMissed become invaluable. Instead of maintaining separate integrations, authentication protocols, and SDKs for OpenAI, Anthropic, Google, and Meta, CallMissed provides developers with a single, highly optimized endpoint. Through a unified gateway, enterprises can instantly route requests to over 300+ LLMs, dynamically switching between models based on real-time cost, latency, or specific workload requirements without rewriting a single line of application code.
In-Depth Analysis: Evaluating the Four Giants Across Key Workloads
To build a highly optimized, cost-effective AI stack in 2026, enterprise architects must look beyond generic leaderboards. Real-world ROI comes from matching the distinct architectural strengths of these four frontier giants to the specific workloads they were engineered to master.
1. Complex Multi-Step Reasoning & Agentic Workflows: GPT-5.5
When it comes to executing multi-hour autonomous workflows, navigating ambiguous instructions, or performing complex strategic planning, OpenAI’s GPT-5.5 remains the undisputed market leader. According to benchmark data from Scale AI and Epoch AI, GPT-5.5 excels at maintaining state and logic over hundreds of sequential agentic steps.
- Best Enterprise Workload: Autonomous customer operations, supply chain logistics simulation, and multi-agent financial auditing.
- The Blueprint: While it carries a premium price point, GPT-5.5's advanced reasoning reduces the "hallucination loop" in autonomous agents, making it the safest choice for high-stakes decision-making pipelines.
2. Software Engineering & Technical Drafting: Claude Opus 4.7 / Fable 5
Anthropic has systematically captured the developer mindshare. Claude Opus 4.7 (and the early preview builds of Fable 5) represent the absolute gold standard for technical execution. It leads major coding benchmarks—such as SWE-bench—by wide margins, displaying a granular understanding of legacy system dependencies, refactoring logic, and precise syntax.
- Best Enterprise Workload: Automated codebase migration, continuous integration/continuous deployment (CI/CD) code reviews, and drafting complex legal or regulatory compliance documents.
- The Blueprint: If your goal is to accelerate software development lifecycle (SDLC) pipelines or generate mathematically precise technical documentation, Claude is the industry's default engine.
3. Massive Codebase Ingestion & Multimodal Analysis: Gemini 3.5
Google’s Gemini 3.5 (including Gemini 3.1 Pro) dominates the long-context and multimodal arena. Leveraging a native million-plus token context window, Gemini can ingest hours of high-definition video, entire audio archives, or massive enterprise repositories in a single prompt with near-zero degradation in retrieval accuracy.
- Best Enterprise Workload: Native video/audio analysis, auditing massive multi-million-token legal contracts, and querying entire corporate knowledge bases.
- The Blueprint: Gemini operates at ultra-low latency, making it the most viable engine for processing multimodal sensory data and colossal text corpora without requiring complex retrieval-augmented generation (RAG) chunking strategies.
4. Self-Hosted Privacy & Custom Fine-Tuning: Llama 4
For organizations operating under strict regulatory frameworks (such as healthcare, defense, or sovereign banking), Meta’s Llama 4 represents the pinnacle of open-weights technology. It offers a level of deployment freedom and data custody that closed-source APIs simply cannot match.
- Best Enterprise Workload: Highly secure on-premise deployments, domain-specific proprietary fine-tuning, and high-throughput, low-latency internal microservices.
- The Blueprint: By hosting Llama 4 within your private cloud, you eliminate data-outflow risks and slashing operational API costs to the bare minimum of your hardware depreciation.
Navigating the Multi-Model Orchestration Challenge
Deploying a hybrid architecture—such as routing coding tasks to Claude, agentic planning to GPT-5.5, and long-context video files to Gemini—can introduce significant integration overhead.
To solve this, modern enterprises rely on unified communication infrastructure. Platforms like CallMissed streamline this orchestration, offering a single API gateway that connects developers to over 300+ LLMs alongside production-ready voice agent infrastructure, Speech-to-Text in 22 regional Indian languages, and ultra-low-latency Text-to-Speech APIs. This ensures your multi-model routing remains seamless, reliable, and completely future-proof.
Impact & Implications: Shifting from Vendor Lock-In to Orchestration

The staggering diversity of the 2026 model landscape highlights a fundamental truth: the era of single-provider dependency is officially dead. Early in the generative AI boom, enterprises routinely signed exclusive agreements with a single cloud or model vendor. In 2026, that strategy is a fast track to architectural stagnation, inflated operational costs, and severe vendor lock-in.
As enterprises move from experimental pilots to production-grade agentic workflows, the focus has shifted from single-model procurement to dynamic multi-model orchestration.
The Multi-Model Routing Paradigm
Rather than forcing every corporate task through a single, expensive frontier model, forward-thinking engineering teams are implementing intelligent orchestration layers. By utilizing a "router" architecture, incoming queries are analyzed in real-time and automatically sent to the most cost-effective model suited for that specific task:
- Dynamic Tiering: A customer inquiry regarding a billing discrepancy is first routed to a lightweight, highly efficient model like Gemini 3.5 Flash for initial triage and sentiment analysis.
- Intelligent Escalation: If the system detects a highly complex, multi-step financial dispute requiring deep logical reasoning, the orchestrator seamlessly escalates the query to GPT-5.5 or Claude Opus 4.7.
- Locally Hosted Fallbacks: For highly sensitive, regulated data handling, the orchestrator routes the transaction to an on-premises Llama 4 deployment, ensuring absolute data privacy.
This orchestration approach dramatically lowers overall inference costs—often by up to 60%—while maintaining the high-quality output of frontier models for complex reasoning.
Abstracting the Integration Layer
The primary bottleneck to achieving this level of agility has historically been the integration cost. Rewriting proprietary prompt chains, parser systems, and API schemas to accommodate different model endpoints can paralyze an engineering team.
This is where advanced communication and LLM infrastructure platforms become critical. Solutions like CallMissed’s multi-model API gateway allow enterprise developers to instantly switch between 300+ LLMs without rewriting their underlying code. Whether you need to swap an expensive proprietary model for a fine-tuned, open-weights Llama 4 engine, or dynamically routing a voice agent's backend to match a user's regional dialect across CallMissed's 22 supported Indian languages, abstraction layers ensure your AI stack remains modular, future-proof, and resilient to vendor price fluctuations.
Navigating the Open vs. Closed Divide
As you build your orchestration strategy, the architectural decision-making matrix comes down to a clear division of labor:
- Proprietary Frontier APIs (GPT-5.5, Claude Opus 4.7, Gemini 3.5): Best reserved for highly dynamic, unpredictable, or reasoning-heavy workloads where absolute bleeding-edge performance is required. These are accessed via cloud APIs, prioritizing rapid deployment and zero infrastructure maintenance.
- Self-Hosted Open-Weights (Llama 4): Best utilized for highly repetitive, specialized tasks where data privacy is paramount, or where custom fine-tuning on proprietary internal datasets yields a distinct competitive advantage.
By building an architecture centered on orchestration rather than single-vendor lock-in, enterprises can insulate themselves from the rapid depreciation of individual models. In 2026, the ultimate competitive advantage belongs not to the organization with the largest AI budget, but to the one with the most agile, multi-model infrastructure.
Expert Opinions: Industry Consensus on 2026 LLM Deployments

As enterprises move past the pilot phase and into full-scale production in 2026, a clear industry consensus has emerged among CIOs, enterprise architects, and AI researchers. The consensus is simple: monolithic AI architectures are obsolete. According to research from leading benchmarks like LMCouncil.ai and enterprise evaluations by Ideas2IT, the strategy for 2026 centers on workload-specific routing, cost-performance optimization, and strict data governance.
Industry experts emphasize that selecting an LLM is no longer a "winner-take-all" race, but a strategic mapping exercise.
The Architect’s Blueprint: Matching Workloads to Models
Based on deployment data and expert surveys from the first half of 2026, enterprise leaders have aligned on specific operational roles for each frontier model:
- GPT-5.5 for Agentic Orchestration: Industry analysts widely agree that OpenAI’s GPT-5.5 remains the premier choice for complex, multi-step agentic workflows. When an enterprise application requires an AI to independently navigate databases, call APIs, self-correct, and execute long-horizon planning, GPT-5.5 is the consensus favorite despite its premium pricing.
- Claude Opus 4.7 & Fable 5 for Deterministic Engineering: For software development lifecycle (SDLC) automation, precise technical drafting, and rigorous code synthesis, Anthropic remains the undisputed gold standard. Experts point to Claude's dominant performance on coding benchmarks like Sweatbench and HumanEval as proof of its superior syntax handling and logical consistency.
- Gemini 3.5 for Ingestion and Multimodality: Google’s massive 1-million-plus token context windows and native multimodal processing make Gemini the default selection for high-volume document analysis, video intelligence, and deep codebase ingestion.
- Llama 4 for Privacy and Cost Control: For high-throughput, repetitive tasks where data sovereignty is non-negotiable—such as financial transaction auditing or healthcare record analysis—Meta’s open-weights Llama 4 is the industry-recommended foundation for on-premise or private-cloud hosting.
The Rise of the Hybrid Infrastructure
"The most successful enterprise AI implementations we see in 2026 do not rely on a single API key," notes one prominent system integrator. Instead, companies are building dynamic routing layers that send simple customer inquiries to low-cost models, coding tasks to Claude, and complex logical reasoning loops to GPT-5.5.
Implementing this multi-model architecture can introduce significant integration friction if developers have to manage distinct SDKs and security protocols for every vendor. To solve this, forward-looking enterprises are relying on unified communication backbones. Platforms like CallMissed streamline this exact complexity, offering a multi-model API gateway that allows developers to seamlessly route tasks across 300+ LLMs.
By decoupling the application layer from individual model providers, enterprises can dynamically swap out an underlying model—for instance, switching an automated voice response agent from a proprietary API to a fine-tuned, self-hosted Llama 4 instance—without rewriting a single line of application code. In 2026, this architectural flexibility is not just a cost-saving measure; it is a core competitive advantage.
What This Means For You: Enterprise Workload Mapping (TABLE)
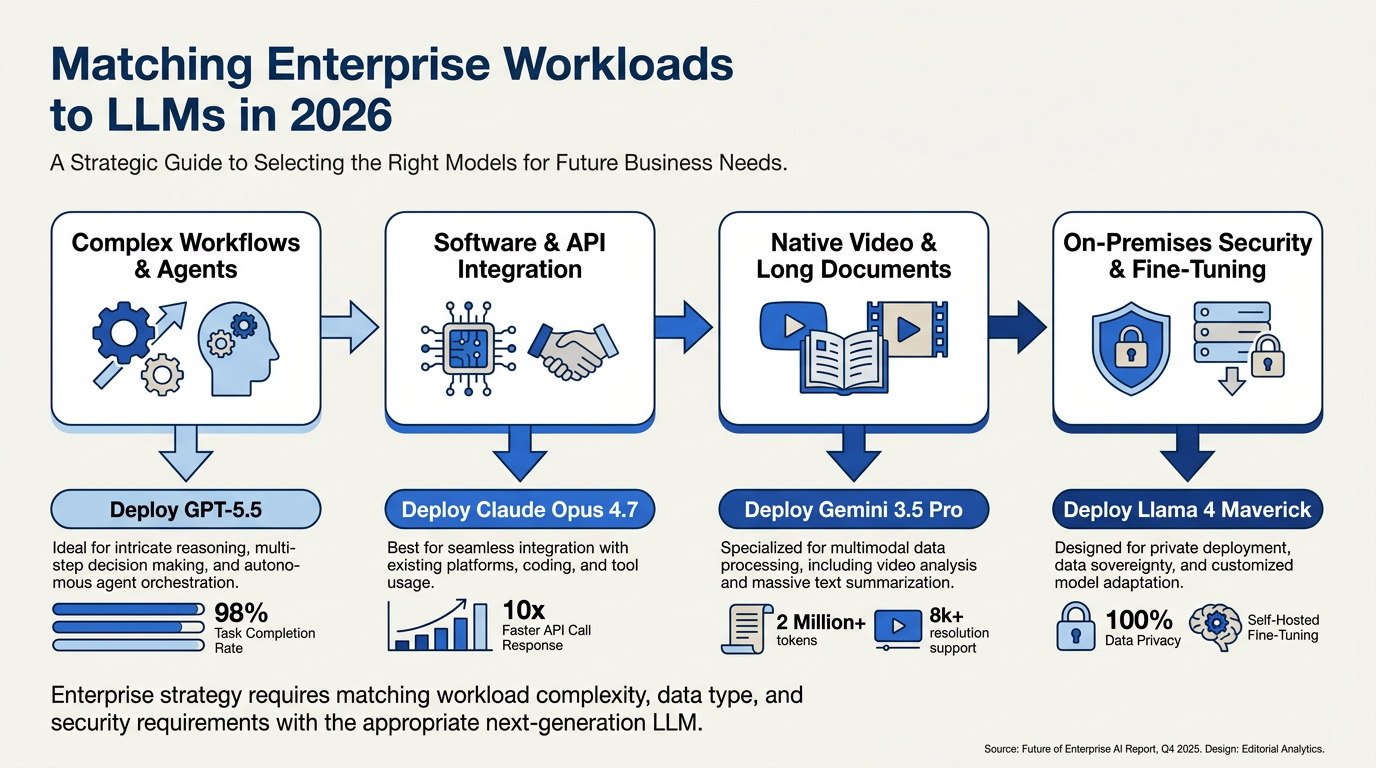
To successfully transition from a single-model architecture to a highly optimized, multi-model infrastructure in 2026, enterprise architects must look past synthetic benchmarks and evaluate how each frontier engine performs under real-world operational constraints. Selecting the wrong model for a production pipeline can lead to runaway API costs, sluggish response times, or critical reasoning failures.
For instance, routing a straightforward transactional task to a premium engine like GPT-5.5 results in unnecessary expenditures, while using a lightweight model for complex codebase refactoring leads to broken deployments. Conversely, choosing the wrong deployment architecture can expose sensitive proprietary data to third-party APIs.
To help you design an efficient, high-performance AI stack, we have mapped the core enterprise workloads of 2026 to their most optimal model pairings. This framework balances execution capability, speed, context window depth, and overall cost-efficiency.
The 2026 Enterprise Workload Mapping Matrix
| Workload Type | Primary Objective | Best-Fit Model | Key Advantage | Latency & Cost Profile |
|---|---|---|---|---|
| Agentic Workflows | Multi-step planning, tool use, & autonomous negotiation | GPT-5.5 | Industry-leading tool calling, planning logic, & state tracking | High latency; premium pricing |
| Software Engineering | Complex code generation, refactoring, & tech drafting | Claude Opus 4.7 / Fable 5 | Unrivaled syntax precision & architectural consistency | Moderate latency; high cost |
| Document Ingestion | Analyzing massive regulatory files & multi-hour video | Gemini 3.5 | Native multimodal parsing with up to 2M+ token context | Ultra-low latency; mid-tier cost |
| High-Volume Support | Customer service routing & basic transactional APIs | Llama 4 | Complete data privacy, zero API toll, & high throughput | Low latency; highly cost-effective |
| Omnichannel Comms | Real-time voice agents & multilingual chatbots | CallMissed Multilingual API | Native support for 22 regional Indian languages & 300+ LLMs | Real-time response; optimized cost |
Designing Your Routing Strategy
When implementing this routing matrix within your enterprise architecture, consider these three core deployment rules for 2026:
- Implement Dynamic Cascading: Start your pipeline with a highly efficient, open-weights model like Llama 4 for initial triage and basic processing. Only escalate the request to a high-reasoning model like GPT-5.5 or Claude Opus 4.7 when the system detects a complex reasoning gap or multi-step execution requirement.
- Decouple by Data Sensitivity: Keep highly regulated compliance tasks, proprietary IP ingestion, and internal HR workloads entirely on-premise or in your private cloud using fine-tuned Llama 4 models. Route external-facing, non-sensitive creative content and complex public-facing support inquiries through hosted API endpoints.
- Unify Your Infrastructure: Avoid vendor lock-in by utilizing an abstract API layer. Platforms like CallMissed allow developers to dynamically route workloads across 300+ LLMs, integrate high-speed speech-to-text for 22 Indian languages, and deploy automated voice agents through a single unified gateway, drastically reducing integration overhead.
Frequently Asked Questions
Which model in the 2026 Enterprise LLM Buyer’s Guide is best for autonomous agentic workflows?
How do I choose between Claude Opus 4.7 and GPT-5.5 for software engineering tasks?
What makes Gemini 3.5 the preferred choice for long-context and multimodal workloads in 2026?
Is Llama 4 a viable alternative to proprietary models for enterprise deployments?
How can enterprises avoid vendor lock-in when navigating the 2026 Enterprise LLM Buyer’s Guide?
What are the primary cost considerations when deploying frontier LLMs in 2026?
Conclusion
Selecting the right model is no longer about finding a single, all-powerful LLM. Success in 2026 relies on matching your specific enterprise workloads to the specialized strengths of the market's leading architectures:
- GPT-5.5 remains the benchmark for complex, multi-step agentic planning and reasoning tasks where precision is paramount.
- Claude Opus 4.7 stands as the unmatched gold standard for software engineering, technical drafting, and precise code generation.
- Gemini 3.5 leads the pack in multimodal processing, easily digesting vast codebases and native video with ultra-low latency.
- Llama 4 provides the ultimate open-weights alternative, offering unmatched data privacy, control, and cost-efficiency for self-hosted architectures.
As the industry progresses, watch for the rise of hyper-specialized micro-models and real-time agentic orchestration that dynamically routes queries to the most cost-effective engine. To easily explore how next-generation AI infrastructure is evolving, check out CallMissed—an AI communication platform powering production-ready voice agents and multilingual chatbots for modern businesses. How will your organization orchestrate its multi-model stack to maintain a competitive edge this year?
Related Posts

Never Lose a Lead Again: Why "Call Missed" is Your Biggest Revenue Leak (and How to Fix It with CallMissed.com)

Banned Claude Mythos Capabilities for Cheap? How OpenRouter Fusion Beats Standalone Frontier Models

Anthropic Introduces Claude Sonnet 5 & Claude Science: The Dawn of Agentic AI
Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.