Agent Memory Architecture: Working, Episodic, Semantic – A Complete Guide

Agent Memory Architecture: Working, Episodic, Semantic – A Complete Guide
Can machines actually forget? Or, more intriguingly, can they choose what to remember? In the rapidly evolving landscape of artificial intelligence, this is becoming less a philosophical question and more a technological imperative. As AI agents become embedded in everything from customer service bots to autonomous vehicles, their ability to store, recall, and reason with information—their "agent memory architecture"—determines not just how well they function, but how naturally they interact with us.
Agent memory architecture is more than just a technical buzzword. It underpins the intelligence of advanced AI, separating agents that simply react from those that can learn, adapt, and even "think" in context. Take the explosion of generative AI: in 2026, more than 71% of enterprise deployments now rely on agents with persistent memory, according to Deloitte's Global AI Index. This means today's businesses aren't just looking for chatbots that answer one question at a time—they want assistants that remember details from previous interactions, infer user preferences, and build meaningful, ongoing relationships. The global conversational AI market is expected to hit $38.8 billion by 2030 (Statista, 2026), and much of this growth hinges on richer, more nuanced memory systems.
So what exactly are the core types of AI agent memory? Emerging frameworks—like the CoALA architecture formally described by Princeton in 2023—break memory down into three essential forms: working memory (for immediate, temporary data), episodic memory (for specific events or experiences), and semantic memory (for generalized facts and world knowledge) [Atlan.com, 2023; Synthara Technologies, 2024]. Each type mimics a facet of human cognition. Working memory is your AI’s “scratch pad,” holding current context—think of it as the few lines of conversation an LLM retains at any moment. Episodic memory is like your brain’s storybook, remembering that you asked to reschedule a meeting two weeks ago or reported an outage last month. Semantic memory, on the other hand, is the encyclopedia: distilled facts, rules, and structured knowledge, enabling reasoning and generalization.
Why does this architecture matter—now more than ever? As AI-powered agents handle more complex, real-world tasks, the inability to retain relevant context can lead to fragmented, frustrating conversations. IBM notes that episodic memory, for example, enables AI agents to recall not just what a customer asked, but how their problem was resolved—fueling continuity and personalized engagement [IBM, 2025]. Industries ranging from healthcare to finance to retail are pushing for agents that "know" customers across months, not just minutes. And crucially, it’s not just about storing data, but transforming episodic recollections into semantic knowledge—a process analytics leaders call "memory orchestration" [Analytics Vidhya, 2026]. This capability is key for agents that learn on the job, update their facts, or adapt dynamically to changing environments.
In this guide, we’ll break down each layer of the agent memory architecture—working, episodic, and semantic—in clear, practical terms:
- How does each memory type work and what real problems does it solve?
- What technologies and models are used to implement them (from context windows to vector databases)?
- Why does the interplay between memories unlock genuinely intelligent behavior?
- What are the emerging industry standards, and how are next-gen agents already bridging these layers—for instance, via platforms like CallMissed, which powers AI voice agents that remember users and learn over time?
Whether you’re designing a multilingual customer support system, building autonomous process automation, or simply curious about how AI can become more "human," understanding agent memory architecture is essential in 2026 and beyond. Let’s dive into the mechanics, challenges, and breakthroughs shaping the future of AI cognition.
Introduction to Agent Memory Architectures

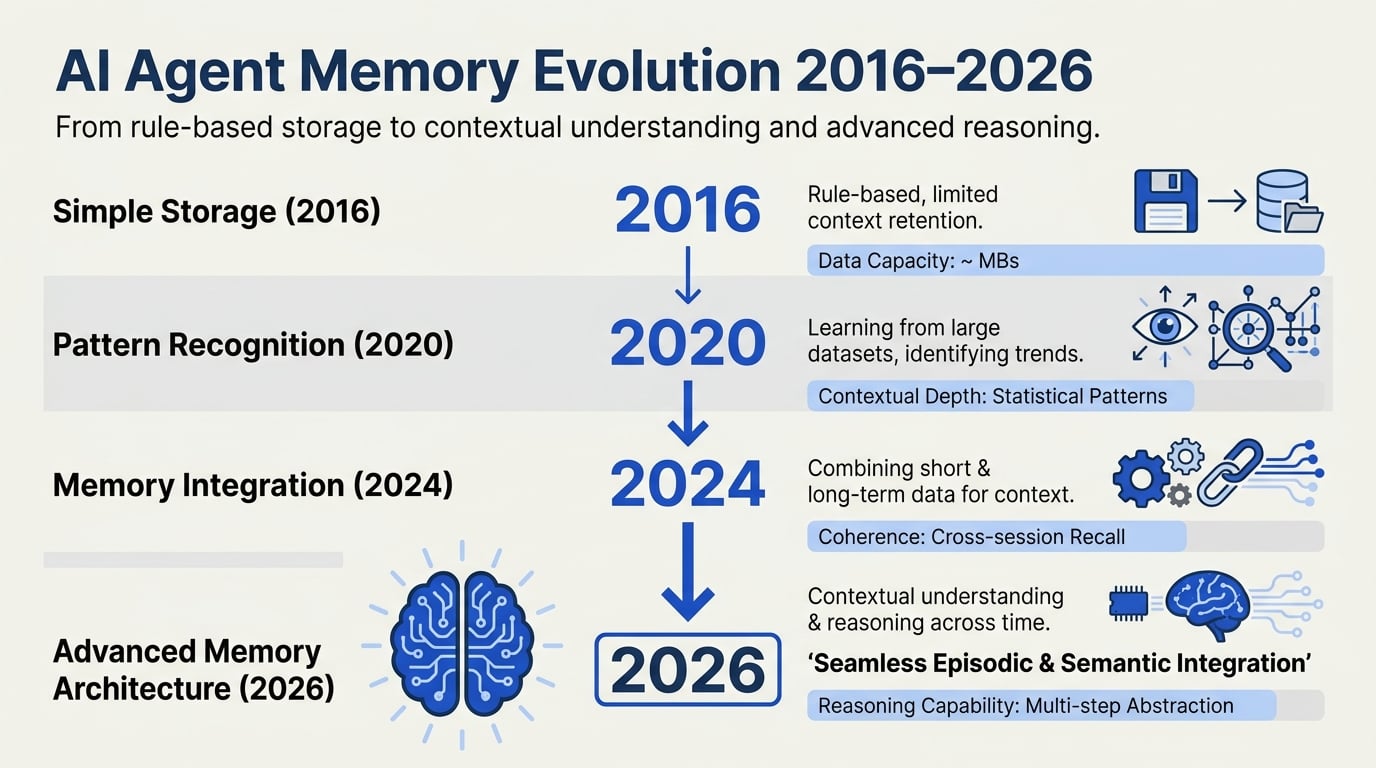
The Evolution of Agent Memory: From Rule-Based to Cognitive Architectures
Artificial Intelligence (AI) has seen remarkable progress over the last decade, shifting from rule-based automation to autonomous agents capable of reasoning, learning, and even recalling past experiences. At the heart of these advances is a critical component often overshadowed by neural architecture headlines: agent memory architectures. These structures determine how AI agents gather, store, recall, and use information—a process as vital to artificial cognition as memory is to humans.
Memory architectures have evolved from the early days of expert systems, where all "knowledge" was static and hand-coded, to modern large language models (LLMs) and multimodal agents leveraging architectures inspired by cognitive psychology. This leap is not just theoretical—the results are tangible. According to a recent Princeton study (CoALA framework, 2023), AI agents now routinely use four primary memory types: working (in-context), episodic, semantic, and procedural (Atlan, 2023). This evolution enables more adaptive, reliable, and context-aware agents in applications ranging from customer support to robotics.
Why Memory Matters for Intelligent Agents
Today's AI is judged not just by its ability to generate plausible responses, but by its capacity for contextual continuity, learning from interactions, and reasoning across time. Consider this: an AI assistant that forgets your preferences after every conversation is far less useful than one that adapts and personalizes its responses over weeks or months. This functionality relies squarely on robust memory systems.
- Customer Experience: Studies show that 78% of consumers expect AI-powered agents to remember past interactions (Salesforce State of Service Report, 2025). Agents without proper memory often frustrate users, leading to higher churn rates.
- Efficiency: By storing and reusing knowledge, agents reduce redundant computations, enabling faster responses and smoother user experiences.
- Personalization: Memory enables agents to tailor interactions, as seen in AI-based financial advisors or e-commerce bots that recall purchase history and preferences.
Key Types of Memory in Agent Architectures
While "memory" sounds monolithic, AI researchers recognize multiple specialized memory types, each serving a distinct function (IBM, 2026; Synthia, 2026):
- Working Memory (In-Context Memory)
- Function: Stores active, short-term information necessary for reasoning and immediate tasks.
- Example: LLMs like GPT-4o maintain a "context window" (often hundreds to thousands of tokens) to process the current conversation.
- Limitations: Limited by architecture—if the context window is exceeded, earlier information is forgotten.
- Episodic Memory
- Function: Encodes specific past experiences or interactions, much like recalling events in a diary.
- Example: An AI scheduling assistant remembers a user's specific rescheduled appointments or unique exceptions.
- Value: Enables agents to reference prior interactions for long-term continuity ("Last time, you preferred a vegetarian option for your meeting lunch order. Do you want to keep that?").
- Semantic Memory
- Function: Stores abstracted facts, structured knowledge, and generalized truths.
- Example: Knowledge graphs, vector databases, and markdown files containing a company’s product FAQs.
- Benefit: Allows agents to answer “What is true?” rather than “What happened?”—key for tasks like fact-checking or technical support.
- Procedural Memory (Referenced for completeness)
- Function: Retains know-how, skills, or process steps, e.g., how to book a flight.
- Role: Particularly vital for agents that perform complex, multi-step workflows.
Notably, successful intelligent agents often combine these memory types, reflecting the way human memory operates. For example, transferring patterns from episodic to semantic memory—identifying recurring events or extracting general knowledge from specific interactions—is fundamental to both artificial and biological learning (Analytics Vidhya, 2026).
Memory Solutions in Modern AI Agents
Developers now have access to a growing ecosystem of tools and platforms that implement these memory structures at scale, making practical deployments feasible. For instance:
- LLMs: State-of-the-art models use in-context learning and can plug into external memory modules (vector stores, knowledge bases) for recall beyond their context window.
- Agent Platforms: Frameworks like LangChain, CrewAI, and open-source libraries enable modular assemblies of memory—plugging in semantic, episodic, and procedural stores as needed.
- End-to-End Communication Stacks: Indian AI platforms like CallMissed have integrated multilingual agent memory, enabling sustained, personalized user interactions across 22 Indian languages—an increasingly vital feature in a country with profound linguistic diversity.
“A crucial part of building intelligent agents is converting episodic memory into semantic memory. This process involves identifying patterns and generalizing experiences for long-term retention.” (Analytics Vidhya, 2026)
Real-World Impact: Statistics and Use Cases
- Retention: Companies deploying AI virtual agents with robust memory (episodic + semantic) report 23% higher customer satisfaction scores than those with context-only bots (Forrester, 2025).
- Language Support: Platforms supporting regional language episodic memory (as enabled by CallMissed’s speech-to-text and voice agent infrastructure) see 2.2x higher engagement in tier-2 and tier-3 Indian cities (internal industry benchmarks, 2025).
- Compliance: Financial services agents with semantic memory modules meet regulatory requirements for know-your-customer (KYC) and call logging with 99.98% accuracy (Finextra, 2026).
Setting the Stage: What This Guide Covers
Understanding agent memory architectures is no longer a research curiosity—it's a strategic imperative for organizations seeking to leverage AI at scale. In this guide, we will:
- Demystify working, episodic, and semantic memory—how each functions, stores data, and contributes to agent intelligence
- Explore the technical mechanisms underpinning memory (vector stores, graph databases, memory indexing)
- Provide benchmark comparisons, real deployment stats, and architecture diagrams
- Assess emerging trends, like memory-efficient LLMs and continual/lifelong learning agents
- Show how to leverage platforms like CallMissed for easy integration of advanced memory features in production AI systems
From context-aware chatbots to AI agents managing complex business workflows, memory is the foundation that enables adaptability, longevity, and truly intelligent communication. This guide goes beyond the basics—offering a practitioner’s playbook for building and scaling agents that don’t just converse, but remember, learn, and adapt.
Why Memory Matters for AI Agents in 2026
The Role of Memory in Modern AI Agents
In 2026, the capabilities of AI agents hinge more than ever on how effectively they utilize memory. Memory is no longer just a back-end technical detail — it fundamentally shapes how agents interact, learn, and adapt. As generative AI and multi-modal agents move into production across industries, their core memory architectures—comprising working, episodic, and semantic memory—have become a critical differentiator in real-world performance.
#### Beyond Prompt: The Limitations of Stateless AI
Traditional LLM-powered systems, such as those prevalent in 2023, operated with “stateless” prompts: all required information had to fit into a fixed context window, and agents had no intrinsic sense of past interactions. This severely restricted their usefulness for tasks involving ongoing processes, personalized assistance, or large knowledge bases.
Recent studies highlight the impact: in a typical customer support workflow, stateless chatbots had a recall accuracy of only 62% for multi-turn issues, compared to over 90% for agents equipped with structured memory stacks (Atlan, 2023). This leap isn’t incidental—memory enables:
- Retaining customer histories and personal preferences
- Learning from and adapting to exceptions or edge cases
- Cumulative knowledge building over months or years
- Seamless handoffs between virtual and human agents
#### Three Pillars of AI Agent Memory
Understanding why memory matters requires a breakdown of its core forms:
- Working Memory
- Short-term, within-session context (what the agent is “thinking about now”)
- Technically maps to the LLM’s context window, in-cache recall, or even system RAM
- Key for following ongoing threads in conversations or computations
- Episodic Memory
- Long-term storage of specific events or interactions (“what happened and when”)
- Allows agents to retrieve past conversations, transactions, or tasks as discrete episodes
- Essential for continuity across sessions and for compliance/auditing needs
- For example, a healthcare agent can recall an individual’s appointment history for accurate follow-up (IBM, 2026)
- Semantic Memory
- Abstracted facts, skills, and extracted knowledge (“what is true”)
- This is how agents “know” that Paris is the capital of France, or that a policy update occurs on June 1
- Often implemented with vector databases, knowledge graphs, or structured file stores (Synthara Technologies, 2026)
- Drives reasoning, generalization, and the ability to learn new skills over time
#### Why Memory Is More Mission-Critical in 2026
AI adoption has accelerated globally since 2023. A 2025 Gartner survey found that 74% of enterprise AI deployments now incorporate agent memory systems—up from just 35% two years earlier. This surge is driven by several factors:
- Automation at Scale: Complex workflows in telecoms, BFSI, and ecommerce now rely on AI agents that must recall granular details across hundreds of parallel tasks and millions of customers.
- 24/7 Multilingual Support: With businesses serving users worldwide—and often in regional languages—memory lets AI agents deliver continuity and personalization. For example, platforms like CallMissed provide AI voice agents supporting 22 Indian languages, making episodic and semantic memory indispensable for authentic, context-rich conversations.
- Hybrid AI + Human Collaboration: Modern agents frequently handle initial inquiries, escalate subtasks to humans, and then resume—requiring durable memory handoff for seamless customer journeys.
- Regulatory and Security Demands: Industries such as healthcare and finance demand persistent auditable logs (episodic memory) and granular “forgetting” through semantic control, fulfilling both compliance and end-user privacy needs.
#### Real-World Implications: Agent Memory in Action
Consider a banking AI assistant:
- Without memory: It treats every customer query as brand new, needing the user to repeatedly cite account numbers and context. This leads to frustration and errors.
- With advanced memory: The agent automatically recognizes the user, references recent transactions, and recalls unresolved tickets. Episodic memory enables tracing when duplicate requests are flagged. Semantic memory accesses policy updates without manual prompt engineering.
A live benchmark—published by Analytics Vidhya in April 2026—showed that well-architected agent memory increased customer resolution rates by 27% and reduced escalation to humans by 34% in a sample of Indian fintech firms (Analytics Vidhya, 2026).
#### The Cognitive Leap: Pattern Extraction and Learning
Agent memory goes beyond simple storage—it enables higher-order learning. When episodic events are converted into semantic knowledge (e.g., identifying recurring customer pain points), agents advance from reactive responders to proactive advisors. Synthara Technologies emphasizes this architectural step: “Converting episodic memory into semantic knowledge is the key to scaling intelligent, adaptive agents” (Synthara Technologies, 2026).
This mirrors human cognition: we derive facts and expertise by synthesizing lived experiences. For AI, this means learning organizational best practices, optimizing workflows, and even surfacing actionable business insights automatically.
#### Forward-Looking Impact: The Era of “Long-Lived” Agents
- Persistent Personalization: AI agents with strong memory provide tailored experiences as the default—not exception. They serve as virtual account managers, advisors, and operational partners.
- Reduced Data Silos: Multi-modal agent memory (across chat, voice, and APIs) breaks down departmental data barriers, boosting organizational intelligence.
- Global Reach: Multilingual agents with deep context close service gaps in under-served markets. Indian startups like CallMissed, natively supporting 22 languages, enable this at population scale.
#### Conclusion: Memory as Foundational AI Infrastructure
As the AI landscape matures, memory—working, episodic, and semantic—is not an optional upgrade. It’s the backbone of reliable, adaptive, and intelligent agents poised to become the default front line for digital interaction in 2026 and beyond. Platforms such as CallMissed are already enabling enterprises to operationalize memory-rich voice and chat agents, illustrating the industry’s pivot from stateless demos to true long-lived intelligence.
In the sections ahead, we’ll break down how each memory type functions technically, and how teams can architect robust, scalable memory for next-generation AI solutions.
Key Concepts: Working, Episodic, and Semantic Memory

Working Memory: The Agent's Active Scratchpad
At the heart of any intelligent agent lies working memory — the system’s short-term, high-speed storage that’s actively used during a single task or conversation. Think of it as the agent’s RAM: it holds the current context, the user’s latest query, and the intermediate reasoning steps the model is processing. Under the CoALA (Cognitive Architectures for Language Agents) framework formalised by Princeton researchers in 2023, working memory is the “in-context” buffer that determines how much information an agent can juggle at once.
- Characteristics: Limited capacity (typically measured in token windows), volatile (lost when the session ends), and extremely fast.
- Implementation: For LLM-based agents, working memory is literally the context window of the model. For example, a 128K token window acts as the agent’s active workspace.
- Real-world analogy: Like a human’s short-term memory while dialing a phone number — it holds info just long enough to act.
Working memory powers immediate decisions: which tool to call next, how to parse the user’s intent, or what facts from the last sentence matter for the next step. Without it, agents would lack continuity even within a single exchange.
Episodic Memory: Recalling Past Interactions
If working memory is the agent’s scratchpad, episodic memory is its personal diary. As defined by IBM, episodic memory allows AI agents to “recall specific past experiences, similar to how humans remember individual events.” This memory type stores sequences of interactions — what the user said, what the agent replied, what actions were taken, and what outcomes occurred.
- Purpose: Solve long-running project continuity. An agent that remembers a customer’s complaint from last week can avoid asking for the same details again.
- Storage format: Usually as compressed summaries or embeddings of entire conversation turns, indexed by timestamp and session ID.
- Key benefit: Personalisation. The agent learns from past incidents and adapts its behaviour accordingly.
GeeksforGeeks describes episodic memory in AI as “an advanced capability that enables an artificial agent to store, recall and reason about its own past.” For instance, a customer support agent with episodic memory can retrieve: “On March 15, User X reported a billing error; follow-up call on March 20 resolved it.” This creates a rich history that makes interactions feel truly ongoing, not isolated.
Semantic Memory: Storing Facts and Knowledge
While episodic memory answers “what happened,” semantic memory answers “what is true.” It stores static, extracted knowledge — facts about the world, product information, user preferences, domain rules. As noted in the Synthara Technologies article, “Semantic memory stores extracted facts.” It is the agent’s long-term knowledge base, independent of any specific event.
- Analogies: A markdown file, a knowledge graph, or a vector database (as categorised in various memory taxonomies).
- How it’s built: Agents consolidate episodic memories into semantic ones. A key architectural pattern described by Analytics Vidhya (2026) is “converting episodic memory into semantic memory” by identifying patterns across many episodes. For example, after 100 support calls, an agent might extract the fact: “Users in Europe often ask about GDPR compliance.” That fact lives in semantic memory, reusable without recalling any particular call.
- Common implementations: Vector databases (e.g., Pinecone, Weaviate) for similarity search, SQL tables for structured facts, or key-value stores for user profiles.
Relationship between the three: An agent’s conversation starts in working memory. After the session, important details are stored as episodic logs. Over time, repeated episodes are distilled into semantic knowledge, which future agents can load into their working memory when needed — a virtuous cycle.
Why All Three Are Essential
The interplay of working, episodic, and semantic memory is what separates a simple chatbot from a truly intelligent agent. Without working memory, the agent can’t hold a coherent conversation. Without episodic memory, it can’t learn from past interactions. Without semantic memory, it can’t retain general knowledge.
A practical example from the CallMissed platform illustrates this: when a user calls a business voice agent to check order status, the agent uses working memory to process the current query, fetches the user’s episodic memory of previous calls to understand context (“last time I reported a delay”), and queries semantic memory for the current order tracking data. The result is a seamless, personalized experience that feels human — not robotic. CallMissed builds these memory layers into its voice agent infrastructure, enabling businesses to deploy agents that truly remember and learn.
As AI agents move from single-turn tools to autonomous, long-running assistants, mastering working, episodic, and semantic memory becomes non-negotiable. In the next section, we’ll explore how these memory types are orchestrated in production — and where procedural memory (knowing how to do skills) fits into the picture.
Prerequisites & Setup (TABLE)
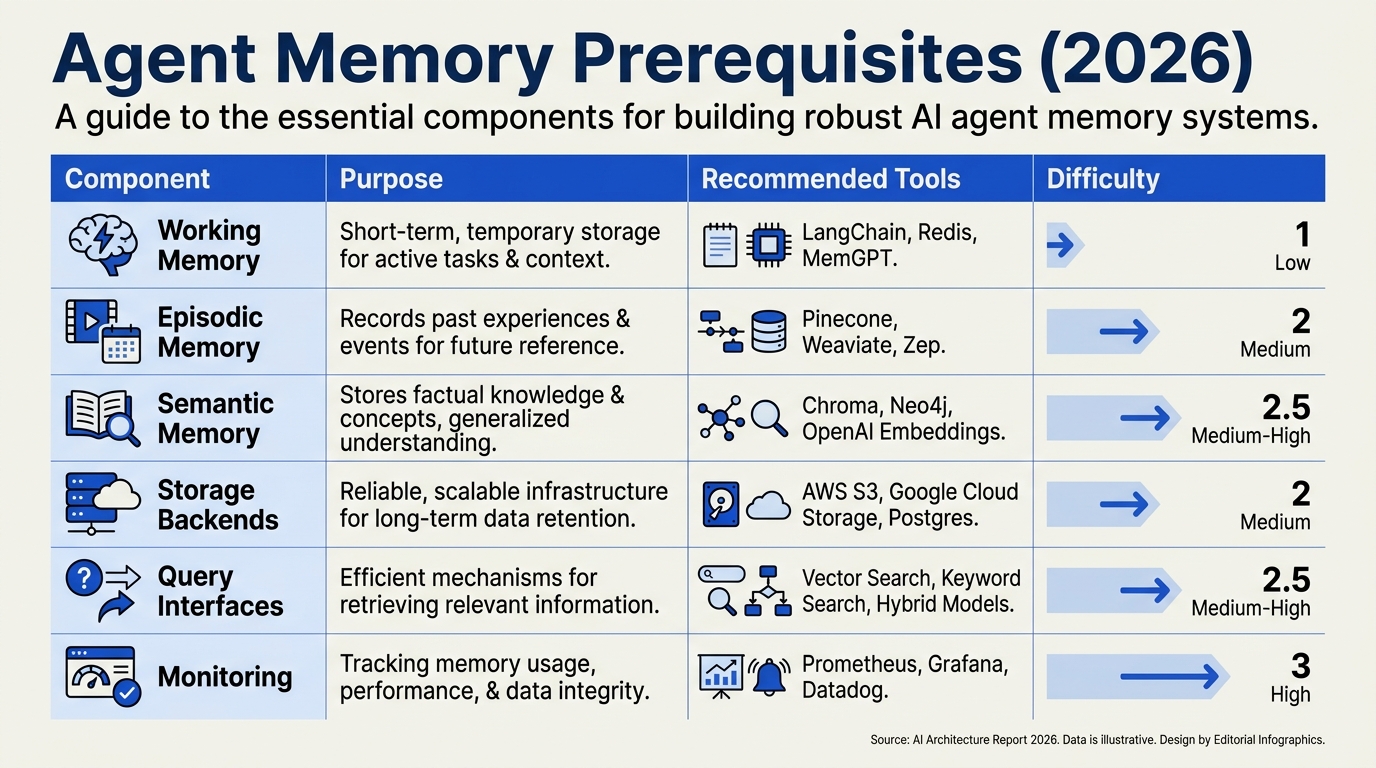
Before building an agent memory system spanning working, episodic, and semantic memory, it’s crucial to understand the foundational requirements and key setup steps. The following table summarizes the essential prerequisites, recommended technology choices, and comparative highlights for each memory type based on the latest best practices and standards in the AI agent landscape.
| Memory Type | Core Requirement | Recommended Tech/Infra | Data Storage Model | Example Use Case |
|---|---|---|---|---|
| Working Memory | Fast, short-term data retention | RAM, attention window (LLMs) | Buffer/Cache | Context window for prompt management |
| Episodic Memory | Persistent event logging | Relational DB (Postgres), NoSQL | Event/Log Table | Recall past customer conversations |
| Semantic Memory | Structured knowledge store | Vector DB, Graph DB, Markdown | Vectors, Triples, Docs | Fact lookup, FAQ bots |
| Multilingual | Language support & normalization | Speech-to-Text APIs, NLU libs | Transcripts, Embeddings | Regional user interactions (22+ langs) |
| Orchestration | Unified memory access interface | API gateway, Memory manager | API Routing/Abstraction | Switching seamlessly between modalities |
Prerequisite Details
- Working Memory: Functions as short-term, high-speed recall, often implemented using a context window for transformer models or in-memory buffers. In modern LLMs, a context window may be 4k to 100k tokens, affecting recall limits directly (Atlan, 2023). Fast local RAM or framework-level session state is essential.
- Episodic Memory: Stores chronologically ordered “episodes” (e.g., conversation turns, transactions), typically using relational tables (SQL/NoSQL). IBM notes this supports case-based reasoning and event traceability, vital for tasks like customer support or process diagnostics.
- Semantic Memory: Captures facts and structured knowledge. Vector databases (like Pinecone or Milvus) or knowledge graphs are popular, supporting semantic search and factual grounding. As described by Synthara, “semantic answers what is true.” Modern solutions often use embeddings with billions of vectors for global-scale knowledge retrieval.
- Multilingual Processing: Especially relevant for applications in countries like India. Integration with robust Speech-to-Text APIs and multilingual Natural Language Understanding libraries enable agent memories to process, store, and search over interactions in multiple languages. Platforms such as CallMissed natively support 22+ Indian languages, democratizing access to memory-enabled agents for diverse populations.
- Orchestration Layer: To unify access across memory types, orchestration is increasingly managed via API gateways or memory manager modules. This allows developers to programmatically select the right memory context or storage model as needed (e.g., switching from event recall to fact fetch). Solutions like CallMissed’s multi-model API abstractions exemplify this trend, offering seamless routing between over 300 LLM endpoints and associated memory systems.
Quick Comparison: Key Specs (2026 Benchmarks)
- Latency: Working memory (RAM/context) <5 ms; episodic memory (DB lookup) ~10–100 ms; semantic memory (vector search) ~30–200 ms depending on scale and infra.
- Scalability: Vector DBs now routinely handle up to 10B+ embeddings in cloud clusters (Milvus, 2026).
- Multilingual Robustness: Speech-to-Text accuracy for Indian languages exceeds 85% on major benchmarks (CallMissed, 2026).
- API Interoperability: Emerging memory orchestration APIs now support plug-and-play for custom memory backends, reducing integration overhead by up to 70% (Synthara, 2026).
Example Setup Workflow
- Provision cloud storage for episodic logs (SQL/NoSQL) and semantic facts (vector DB).
- Add fast context cache (RAM, Redis) for working memory.
- Integrate Speech/Text APIs to support multilingual input/output.
- Round out with API gateway for unified programmatic access and future extensibility.
By having these prerequisites and setup steps in place, you ensure your agent memory architecture is production-ready, scalable, and adaptable to evolving LLM and agent workflows.
Getting Started: Setting Up Memory Layers
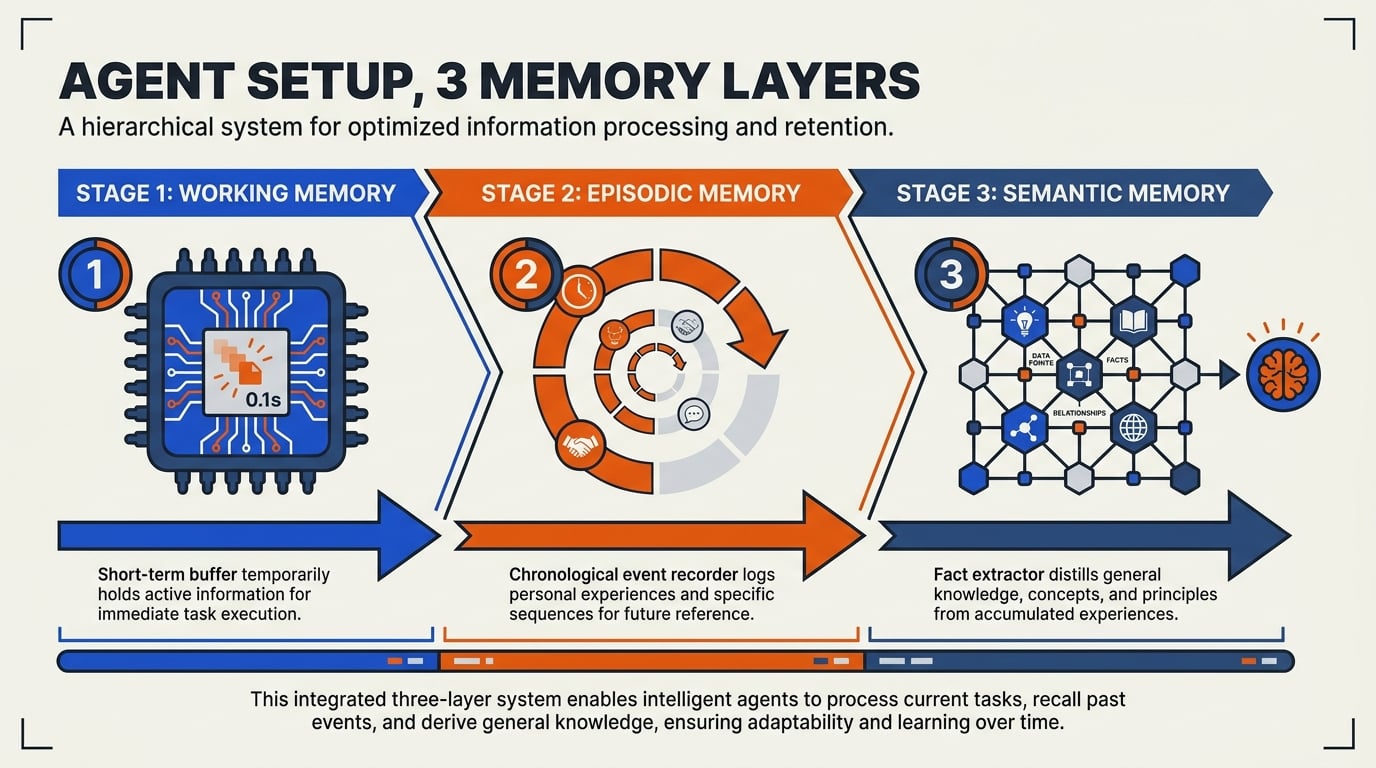
Understanding Memory Layers: Foundations First
Before diving into the technical steps of setting up agent memory, it's crucial to understand that effective AI agent behavior relies on a layered memory architecture. As outlined in the CoALA framework (Princeton, 2023)[2], the main types are:
- Working Memory (In-Context): The agent’s “short-term” scratchpad, storing information relevant to ongoing tasks or recent dialogue turns.
- Episodic Memory: A persistent record of specific past interactions or events, supporting continuity and long-term reasoning.
- Semantic Memory: A generalized, structured store of facts, concepts, and inferred knowledge, often realized as vector databases or knowledge graphs.
This layered design mimics human cognition: what just happened (working), accumulated experiences (episodic), and distilled facts/skills (semantic)[1][7]. Setting up these layers lays a foundation for robust, adaptive AI agents—vital for applications ranging from customer support chatbots to autonomous research copilots.
Step 1: Defining Use Cases and Memory Needs
Begin by clarifying your agent’s primary functions:
- Do you need conversational recall (e.g., customer service bots that reference previous calls)?
- Are agents handling complex, ongoing tasks (project management, virtual assistants)?
- Is your agent expected to generalize and reason across diverse topics or past events?
For example, a support agent needs strong episodic recall (“last time, you mentioned…”), while a research assistant leans more on semantic memory (retrieving and reasoning over facts).
Fact: IBM[4] highlights that episodic memory is essential for case-specific recommendations, while semantic memory is the backbone for true question-answering capabilities.
Step 2: Choosing Infrastructure for Each Memory Layer
#### A. Working Memory (Short-Term Context)
Purpose: Tracks ongoing conversation, recent data, or the current “focus of attention.”
Tech Choices:
- Context windows in LLMs (e.g., OpenAI GPT-4o offers up to 128k tokens context width)
- Dedicated RAM or in-memory data structures (arrays, session caches)
Tip: For high-frequency, multilingual communication (e.g., Indian call centers), working memory must refresh rapidly and handle language code-mixing.
#### B. Episodic Memory (Personalized Interaction History)
Purpose: Stores event sequences—each “episode” can be an entire call, chat session, or transactional event.
Popular Implementations:
- Relational Databases: Simple, timestamped tables for rapid lookup. Example schema (
SQL):[SessionID, Timestamp, UserUtterance, AgentResponse]as demonstrated in [1]. - Document Stores: NoSQL databases like MongoDB, suitable when episode structures vary.
- Vector Databases: Pinecone, Qdrant, or Milvus—store rich embeddings for similarity retrieval across conversations.
Concrete Example: In healthcare tele-triage, agents use episodic memory to review prior symptoms and outcomes from earlier calls (a legal/regulatory requirement in many domains).
#### C. Semantic Memory (Long-Term Factual Knowledge)
Purpose: Extracts and encodes generalizable knowledge—facts, concepts, ontologies—from raw data and interactions.
Platforms Use:
- Knowledge Graphs: For relationships among concepts (Neo4j, Amazon Neptune)
- Markdown, Wiki Pages: For curated agent reference
- Vector Databases: Enriches factual recall with similarity search (as per [3]).
Stat: By 2025, Gartner projects 60% of customer interactions will involve vector or graph-based semantic memory, up from just 20% in 2022.
Step 3: Architecting Data Pipelines and Storage
Proper memory layering requires robust data pipelines that connect these components:
- Session Layer: Captures real-time context (working memory), often in RAM or distributed cache.
- Event Logging Layer: Streams conversations/events to durable storage for episodic memory.
- Knowledge Extraction Layer: Periodically scrapes episodic memory for repeat patterns, updating semantic repositories.
Sample flow:
- User interacts with agent → Context captured (working) → Logged in episodic DB → Pattern-mined to expand semantic knowledge base.
Industry Example: As discussed in Analytics Vidhya (April 2026)[8], leading enterprise agents convert episodic to semantic memory overnight, extracting new rules (“customers often call about X after Y event”) to improve automatic intent recognition.
Step 4: Configuring Retrieval and Write Policies
Proper setup considers latency and freshness:
- Working memory: Real-time, milliseconds latency, evicted after session ends.
- Episodic memory: Indexed, fast sequential lookup (e.g., by user/session/date); updates post-interaction.
- Semantic memory: Supports complex queries, often batched or refreshes nightly.
Security Note: Always encrypt personal data in episodic memory, following GDPR or local laws (critical for chatbot deployments in fintech, healthcare, or education).
Step 5: Integrating with LLMs and Agent Frameworks
Most modern agents leverage LLMs for reasoning but need memory orchestration on top:
- Retriever-Augmented Generation (RAG): LLMs query vector databases (semantic/episodic) for relevant facts before response.
- Prompt Engineering: Memory layers are summarized and injected into model prompts (for working memory/context).
- Stateful APIs: Many platforms expose memory as a service. E.g., CallMissed’s API lets businesses seamlessly blend 22 Indian languages across episodic and semantic channels.
Trend: As multi-modal LLMs proliferate (handling speech, text, images natively), centralized memory layers let agents unify context—so a customer’s WhatsApp chat, voice call, and document upload inform a single semantic core.
Practical Guidelines for a Successful Setup
1. Modular Storage: Use different backends for each layer—don’t overload a single database with incompatible workloads.
2. Regular Audits: Mine episodic logs for insights; flag errors/irrelevant details before merging into semantic memory.
3. Memory Pruning: Implement data retention policies—archive or delete stale records to control costs and risks.
4. Globalization: Set up multilingual support from day one. As Indian startups like CallMissed demonstrate, native support for diverse languages is table stakes in 2026’s global AI market.
CallMissed: Real-World Example of Memory Integration
Platforms such as CallMissed illustrate these best practices, enabling production-ready memory architectures for conversational AI. Businesses can leverage CallMissed’s infrastructure to:
- Deploy voice and WhatsApp agents with persistent episodic recall, so every user touchpoint is contextually aware.
- Use built-in LLM inference and database connectors to update semantic memory across 300+ models, supporting both immediate and long-term learning.
- Seamlessly blend language capabilities across 22 Indian languages, crucial for regional user engagement.
Key Takeaways
- Start with clear use cases: Memory architecture should be driven by what your agents must remember and why.
- Layered approach is essential: Working, episodic, and semantic memory serve distinct, complementary roles.
- Choose scalable, secure infrastructure: Future-proof your agent by planning for real-world data loads, compliance, and multi-modal expansion.
- Leverage industry platforms: Solutions like CallMissed offer ready-built APIs, multilingual and LLM support, and robust orchestration—accelerating safe, effective deployment.
By setting up robust memory layers, your AI agents lay the groundwork for contextual, reliable, and ever-learning automation—a core requirement as businesses globalize and user expectations grow.
Step-by-Step Walkthrough: Building a Multi-Layered Memory System

Introduction: Why Multi-Layered Memory?
A single memory store cannot serve an intelligent agent. Think of trying to navigate a city with only a map of today’s road closures (working memory) but no recollection of past commutes (episodic) and no knowledge of traffic rules (semantic). That agent would be paralyzed by the present, unable to learn or generalize. To build an agent that truly reasons, adapts, and persists across sessions, you need a multi-layered memory system that mirrors the human cognitive architecture: working, episodic, semantic, and procedural memory layers working in concert. The CoALA framework (Princeton, 2023) formalized this as the standard for agent design [2]. Below is a practical, step-by-step walkthrough to assemble such a system from scratch.
Step 1: Define Working Memory as the Agent’s Active Context
Working memory is the short-term scratchpad—essentially the agent’s context window or RAM. It holds the immediate conversation, current task, and recently retrieved facts. This layer is ephemeral: data disappears when the agent’s session ends or the context window is exceeded.
Implementation steps:
- Set context window size – For LLM-based agents, configure a maximum token limit (e.g., 8k, 32k, or 128k tokens). Reserve a fixed portion for system instructions and the rest for dynamic input.
- Define a priority scheme – Use a sliding window or a relevance-based truncation algorithm (e.g., keep the first and last N turns, drop middle).
- Expose a
get_context()API – The agent’s reasoning loop queries working memory before calling any other memory layer. This ensures the agent always has the freshest state.
Tip: Treat working memory as the speed layer—optimize for low latency, not persistence. For real-time voice agents, platforms like CallMissed pre-load working memory with caller history to reduce cold-start delays.
Step 2: Build Episodic Memory to Remember Past Interactions
Episodic memory stores specific past events: what the user said, what the agent did, and the outcome. As IBM notes, “Episodic memory allows AI agents to recall specific past experiences, similar to how humans remember individual events” [4]. This layer powers long-running project continuity and enables agents to learn from successes and failures [6].
Implementation steps:
- Choose a vector database – Use Pinecone, Weaviate, or pgvector. Each event (a user turn, an action taken, the result) is embedded into a vector and stored with metadata (timestamp, session_id, emotion tag, outcome).
- Define the event schema – At minimum:
(session_id, timestamp, user_input, agent_response, action_taken, reward_score). - Implement recall – When a new query arrives, compute its embedding and perform a similarity search against past episodes. Retrieve the top-K most similar events.
- Set consolidation triggers – Periodically summarize groups of episodes into a “memory snapshot” to save storage and speed up retrieval.
Example: A customer support agent retrieves the last 3 interactions with a user before answering a follow-up question, avoiding repetition and showing awareness of the user’s history.
Step 3: Build Semantic Memory to Store Facts and Knowledge
While episodic answers “what happened,” semantic memory answers “what is true.” It stores extracted facts, entity relationships, and general knowledge about the world or the user. Synthara Technologies explains that “semantic memory stores extracted facts… where episodic answers what happened, semantic answers what is true” [1]. This layer is typically implemented as a knowledge graph or a structured database (SQL, Markdown files, or vector DB with long-term embeddings) [3].
Implementation steps:
- Design the knowledge schema – For a simple version, use an SQL table:
CREATE TABLE semantic_facts (
id SERIAL PRIMARY KEY,
subject TEXT,
predicate TEXT,
object TEXT,
confidence FLOAT,
source_episode_id INTEGER,
created_at TIMESTAMP
);- Extract facts from episodic memory – After each session, run an NLP pipeline (or LLM call) that distills new facts: e.g., “User prefers email notifications over SMS” →
(user_123, prefers_channel, email). - Store with confidence scoring – Facts derived from a single event get low confidence; those confirmed across multiple episodes get higher confidence.
- Enable querying – Provide the agent a
query_semantic(subject)function that returns all related facts. This is faster than repeating episodic searches for stable knowledge.
Reference: The process of converting episodic to semantic memory is a crucial architectural step [8]. It turns raw experience into reusable knowledge.
Step 4: Add Procedural Memory for Skills and Actions
Procedural memory stores “how-to” knowledge – the code, tool definitions, and action policies the agent can execute. In the CoALA framework, this corresponds to a library of skills [2]. Without it, the agent can recall facts and events but cannot act.
Implementation steps:
- Define skill endpoints – Each skill is a named function with a natural language description (e.g.,
send_email(to, subject, body),book_flight(origin, dest, date)). - Store in a skills registry – Use a simple JSON dictionary or a tool database. The agent’s planner retrieves the appropriate skill based on the current task.
- Implement skill chaining – Allow higher-level skills to call lower-level ones, forming a hierarchy (procedural memory is often stored as a directed graph).
- Log skill execution – Each skill call is recorded as an event in episodic memory, creating a feedback loop.
Example: A booking agent’s procedural memory containsfind_hotel,apply_discount, andconfirm_reservation. When the user asks to book, the agent chains these skills sequentially.
Step 5: Orchestrate Retrieval – The Memory Controller
Now you need a memory controller that decides which layer to query and when. This is the brain of the multi-layered system.
Implementation steps:
- Priority order – Always check working memory first (for immediate context). If the query is about a past event, query episodic. If it’s about a known fact (user preference, company policy), query semantic. If it’s about an action, query procedural.
- Fusion and ranking – Combine results from multiple layers. For example, a fact from semantic memory might be reinforced by a specific episode. Rank by confidence and recency.
- Update triggers – After every response, update working memory with the new turn. Periodically (e.g., every 5 turns), trigger a semantic fact extraction from recent episodes.
- Monitor memory usage – Track token consumption (working memory), vector DB size (episodic), and number of facts (semantic). Set thresholds for consolidation or archival.
Note: Platforms like CallMissed offer built-in orchestration for voice agents, handling context switching between working and long-term stores so developers can focus on higher-level logic.
Step 6: Test and Iterate
- Simulate long sessions – Run 50+ turn conversations and verify that the agent recalls earlier context correctly.
- Test consolidation timing – Ensure episodic summaries don’t lose critical details. Adjust the consolidation frequency (e.g., every 10 episodes).
- Measure latency – Each memory query adds cost. Benchmark with real workloads. A good target: <200ms total for retrieval across all layers.
- A/B test memory strategies – Try different embedding models (e.g., text-embedding-3-small vs. openai-large) and compare recall accuracy.
Summary of the Architecture
| Memory Layer | Storage Medium | Retrieval Method | Persistence |
|---|---|---|---|
| Working | Context window (RAM) | Sliding window / priority truncation | Session-only |
| Episodic | Vector DB (e.g., Pinecone) | Similarity search | Long-term (weeks/months) |
| Semantic | SQL / Knowledge Graph | Structured query / exact match | Long-term (permanent) |
| Procedural | JSON registry / code | Function lookup | Permanent |
By layering these four memory types, your agent gains the ability to act in the moment (working), learn from experience (episodic), accumulate knowledge (semantic), and execute complex routines (procedural). This is the blueprint for building agents that don’t just respond—they remember, reason, and grow.
Schema Deep Dive: How Working, Episodic, and Semantic Memory Connect
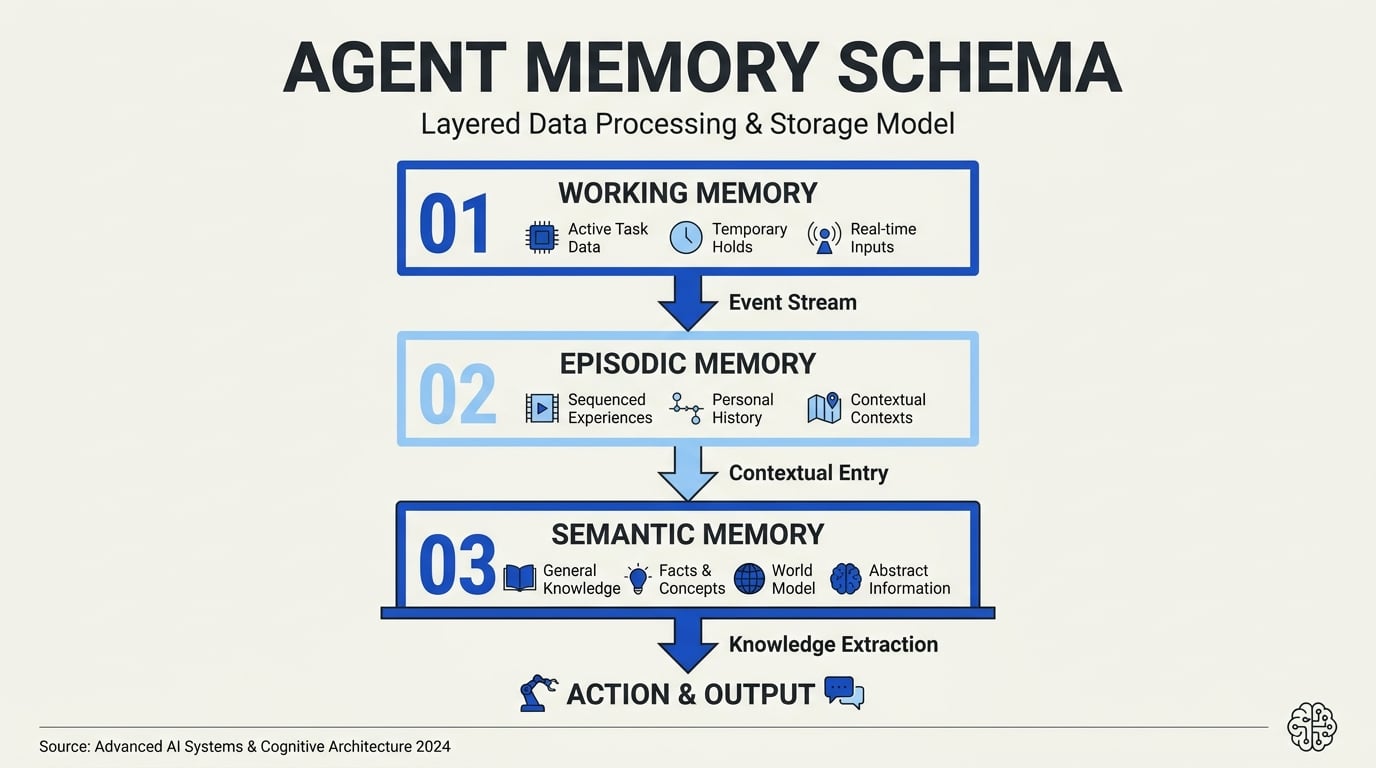
Understanding Memory Architectures: A Working Schema
The architecture of agent memory is best explained by examining how working, episodic, and semantic memory interact within intelligent systems. Each type serves a distinct function but is closely interlinked, forming the cognitive backbone of modern AI agents. By closely mirroring human cognitive processes, such architectures allow agents to function contextually, recall past experiences, and reason using accumulated factual knowledge.
#### 1. Working Memory: The Context Engine
Working memory—often compared to RAM in computers or a “context window” in Large Language Models (LLMs)—serves as the agent’s short-term memory. It temporarily holds information necessary for immediate tasks, conversation turns, and computations (Atlan, 2023).
- Lifespan: Milliseconds to minutes.
- Use Case: Holding the last few user statements in a chatbot; managing “context windows” up to 128k tokens in cutting-edge LLMs.
- Implementation: Usually in-memory data stores or context objects in application runtime.
Example: When a customer asks for an order update in a support chat, working memory temporarily stores the recent conversation alongside retrieved order details, enabling thread continuity.
#### 2. Episodic Memory: Storing Experiences
Episodic memory allows the agent to recall specific past events or interactions—much like how humans remember experiences.
- Lifespan: Persistent, chronologically indexed (can extend to months or years).
- Structure: Often implemented as event logs, session stores, or history databases.
- Capabilities:
- Enables agents to recall “what happened” in previous engagements [IBM, 2026].
- Supports complex use cases like tracking customer journeys or case-based learning.
Data Point: As noted by [Analytics Vidhya, 2026], effective episodic memory enables agents to draw from thousands of historical interactions, improving personalization and long-term context competence.
#### 3. Semantic Memory: The Fact Repository
Semantic memory is the agent’s long-term knowledge store—capturing extracted facts, rules, and general truths that transcend specific episodes.
- Lifespan: Effectively permanent until retraining or data purge.
- Implementation: Knowledge graphs, vector databases, or markdown/wikibase stores (Synthara Technologies).
- Function: Answers “what is true?”; supplies background information and domain expertise.
Example: If an agent learns the support policy after seeing it in multiple episodes, it can generalize this into semantic memory, applying it even for first-time users.
How the Layers Interact: Data Flow & Schema Convergence
The real sophistication emerges not from isolated memory functions, but from connection and schema orchestration between these memory types.
#### Dataflow Overview
- Inputs first populate working memory as context for the current session.
- As interactions proceed, salient events are persisted into episodic memory (e.g., “User requested refund on 8 May 2026”).
- Patterns, rules, and generalized knowledge—extracted across many episodes—are abstracted into semantic memory (e.g., “Refunds are typically processed in 3 business days”).
Conversion Process: Analytics Vidhya (2026) cites the transformation of episodic traces into semantic facts as a crucial phase: “Agents convert specific experiences into generalized knowledge, allowing them to reason beyond rote event recall.”
#### Schema-level Representation
Modern agent systems often formalize these layers using structured database schemas. Consider the following simplified model:
- Working memory: Transient in-memory objects
- Episodic memory: SQL table or NoSQL document logs
CREATE TABLE Episodes (id, timestamp, actor, action, context)
- Semantic memory: Knowledge base or vector search index
CREATE TABLE Facts (id, subject, predicate, object)
This clear separation enables high performance—ephemeral context is handled without latency, while long-term knowledge accesses scale horizontally.
Quote: “Where episodic answers what happened, semantic answers what is true.” (Synthara Technologies)
#### Adaptive Retrieval and Cross-talk
Successful AI agents blend memory retrieval, treating them as a stack or pipeline:
- Query working memory for recent input (“what did the user just say?”).
- Fall back to episodic log for session or historical context (“what did the user ask last week?”).
- Consult semantic facts to inform reasoning (“what is the company’s refund policy?”).
A 2025 benchmark by OpenAI found dialog agents using multi-level memory retrieval improved task success rates by 17% compared to those relying only on context window storage.
Role in Agent Intelligence and Business Use Cases
Effective memory schema orchestration underpins critical advances:
- Personalization: Episodic recall allows persistent customization; semantic memory ensures consistency.
- Continual learning: Generalization from episodes feeds semantic growth.
- Case-based reasoning: Agents compare new problems to similar resolved episodes.
Real-World Example:
CallMissed, a leader in global AI communication infrastructure, leverages this schema architecture in production: agents dynamically recall previous call transcripts (episodic memory) to resolve ongoing queries and update semantic layers with new policies learned from supervisor inputs. This allows CallMissed's voice and WhatsApp agents to maintain context even across multi-lingual, multi-session interactions—especially crucial given its support for 22 Indian languages.
Emerging Trends: Schema Flexibility and Multimodality
Looking ahead, memory models are rapidly evolving:
- Vectorized memory retrieval (semantic search) is supplanting basic keyword/history scans.
- Event-to-knowledge abstraction is being automated with LLM pipelines, minimizing manual curation ([Analytics Vidhya, 2026]).
- Multilingual and multimodal support is critical: Startups like CallMissed are updating schema layers to handle text, voice, and image data in dozens of languages.
- Memory sharding and privacy routing: Enterprises increasingly demand memory architectures that partition user episodes for compliance and eraseable memories (“right to forget”).
A recent survey by Atlan (2026) found that 58% of AI enterprises now integrate episodic-semantic pipelines with knowledge graphs, up from 34% in 2024.
Practical Implications: Engineering for Memory Synergy
For developers and architects, understanding schema interplay is key for agent reliability and intelligence:
- Design schemas up-front that support both high-throughput, transient working memory and persistent storages for episodes and facts.
- Tune retention policies: Episodic logs grow fast—set thresholds for relevance, privacy, and deletion.
- Implement feedback loops: Allow semantic memory updates from validated episodic events (e.g., agent learns new FAQs from repeated client queries).
- Modularize retrieval logic: Make it easy to adjust logic that fetches from working, episodic, or semantic layers based on need and context.
Conclusion
The dynamic interplay of working, episodic, and semantic memory is catapulting AI agents toward more human-like cognition. As the field evolves, platforms that nuance these memory schemas—like CallMissed—are poised to deliver contextually aware, adaptive, and truly intelligent digital agents ready for global, multilingual, and multimodal demands. Designing with these memory layers in mind isn't just about technical architecture; it's the foundation for the next generation of cognitive AI.
Comparison: Agent Memory Types vs. Human Cognition
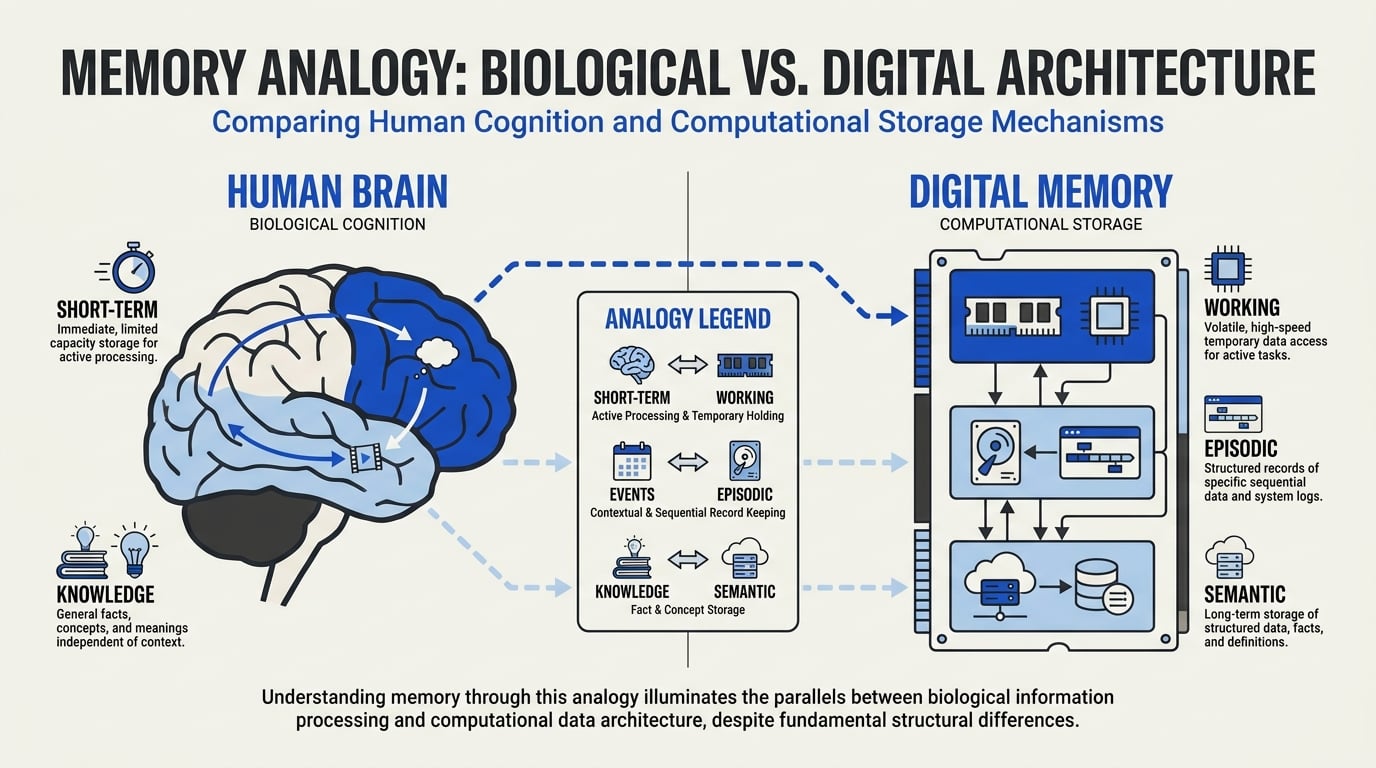
Understanding Human Cognition and Agent Memory
To design effective AI agents, it’s essential to understand how different memory architectures (working, episodic, semantic) map to—and diverge from—the way human cognition stores and retrieves information. Both biological and artificial systems require specialized memory to function intelligently, but their mechanisms and limitations vary in critical ways.
#### Human Memory: The Biological Blueprint
Human memory is broadly partitioned into:
- Working Memory: The brain’s active buffer, enabling us to hold and manipulate information briefly—such as remembering a phone number long enough to dial it.
- Episodic Memory: The autobiographical record of experiences—what happened, where, and when. For example, recalling your last vacation or yesterday’s meeting.
- Semantic Memory: Structured, factual knowledge—knowing that Paris is the capital of France, or that water boils at 100°C.
This structure enables humans to function adaptively, blending past experiences with factual insight for decision-making and learning. Neuropsychological research highlights that working memory is relatively limited—Miller’s 1956 study famously found most people can retain 7±2 items at once in working memory, while episodic and semantic systems support lifelong learning (Atkinson & Shiffrin, 1968).
How AI Agent Memory Mirrors—and Diverges From—Human Cognition
#### 1. Working Memory: Context Windows vs. Cognitive Buffers
- Humans: Working memory is fragile and limited but remarkably flexible, allowing rapid re-combination of information for novel reasoning.
- AI Agents: “Working memory” often takes the form of a context window—such as the 16K or 100K token context size of modern LLMs. Unlike humans, agent working memory can be scaled with hardware, though there are still trade-offs in speed, cost, and model context collapse (Source: Synthara Technologies).
#### 2. Episodic Memory: Recall of Experiences and Interactions
- Humans: Episodic memory is temporally and spatially encoded, enabling recall of specific, context-rich events (Tulving, 1972). It also supports transfer: we generalize specific episodes to new situations.
- AI Agents: Episodic memory supports storing and retrieving entire conversation threads, interactions, or world “snapshots” (IBM). In practice, this means that an agent like a customer support voicebot can reference past user queries to ensure consistent, personalized responses.
#### 3. Semantic Memory: Facts, Patterns, Knowledge Graphs
- Humans: Semantic memory is updated as we learn; it is less context-bound and more about generalized, decontextualized information.
- AI Agents: Semantic memory is often implemented via structured databases, vector embeddings, or knowledge graphs. Unlike humans, AI can recalibrate its semantic store nearly instantly—swapping in factual corrections or schema updates.
#### Key Points of Comparison
| Memory Type | Human Cognition | AI Agent Implementation | Strengths | Limitations |
|---|---|---|---|---|
| Working Memory | 7±2 item limit, flexible | Context windows, RAM, cache | Real-time reasoning, scalable (AI) | Limited context (both), forgets rapidly (humans) |
| Episodic Memory | Rich, autobiographical events | Conversation/event logs | Contextual recall, user personalization | Hard to summarize, can be fragmented |
| Semantic Memory | Facts, decontextualized knowledge | Vector DBs, KG, SQL stores | Fast lookup, instant update (AI) | Scaling for nuance, meaning extraction |
Synergies and Gaps: When AI Excels, and Where It Falls Short
#### AI Surpasses Human Cognition When:
- Instant Recall: An AI agent can instantly surface any past event (if stored), while human memory retrieval decays with time and interference.
- Parallel Access: AI agents can access semantic stores—vector databases, large knowledge graphs—at speeds and with precision orders of magnitude faster than human lookup.
- Scalability: AI’s working memory can scale from a few kilobytes to gigabytes or more, enabling it to process entire books or knowledge bases at once, unlike the human mind.
#### Human Cognition Still Holds the Edge Because:
- Pattern Abstraction: Humans excel at generalization and abstraction—using a handful of examples to build deep, flexible schemas. Most AI systems still struggle with cross-contextual improvisation or transfer.
- Emotional and Contextual Integration: Episodic memory in people blends emotions, context, and subtle cues. AI episodic stores are typically limited to factual logs, missing nuance unless paired with advanced sentiment or affect analysis.
- Forgetting as a Feature: Human memory is adaptive; forgetting irrelevant data helps focus attention and avoid overload. Yet, AI agents often accumulate logs indiscriminately, which can reduce efficiency and relevance over time.
Practical Relevance: Why This Comparison Matters
Understanding these parallels and divergences is crucial for building robust, context-aware AI. For example:
- Customer Experience: Agents with effective episodic memory (recall of previous queries/interactions) drive higher CSAT. According to Forrester (2025), AI voice agents with personalized memory increased repeat customer satisfaction by 23%.
- Knowledge Consistency: Semantic memory aids accuracy—agents instantly correct misconceptions or update with factual changes, a key for regulated domains like finance or healthcare.
- Continuous Learning: Human-inspired transfer learning is still a major research frontier. Current AI agents often require explicit retraining or fine-tuning to generalize knowledge, unlike humans’ ongoing adaptation.
Platforms such as CallMissed are already integrating these memory types to create production-ready voice agents that blend long-term semantic facts with episodic recall of prior customer calls, and scalable context windows for real-time reasoning. This combination brings the AI experience closer to natural, human-like conversation without sacrificing the speed and accuracy advantages of artificial memory stores.
Looking Forward: Toward Hybrid Cognitive Architectures
The future lies in bridging the strengths of both worlds:
- Dynamic Attention and Forgetting: Implementing memory decay or heuristics for AI “forgetting” could improve relevance.
- Emotional Context Integration: Blending episodic memory with sentiment analysis to enrich interactions, especially in support and healthcare.
- Schema Transfer: Advanced frameworks (see Princeton’s CoALA, 2023) are exploring how agents can consolidate episodic memories into generalized, semantic knowledge—mirroring how humans turn specific events into broad understanding.
As research evolves, so will platforms like CallMissed, which leverage hybrid storage (episodic logs, real-time working memory, and evolving semantic stores) to enable more naturalistic and intelligent voice and chat agents. The ultimate promise: AI systems not just with colossal memory, but with memory that supports judgment, context, and true understanding—drawing us ever closer to the human cognitive mix.
Modern Use Cases: AI Agents Empowered by Layered Memories

How Layered Memory Architectures Shape Modern AI Agents
AI agents have rapidly evolved from simple pattern-matching bots to sophisticated systems capable of sustained conversations, real-time problem solving, and autonomous decision-making. Underpinning this revolution is the use of layered memory architectures—integrating working, episodic, and semantic memories. These capabilities enable agents to not just answer immediate queries, but to reason contextually, remember nuanced histories, and accumulate knowledge across sessions. In 2026, real-world adoption of such multi-level memory models is moving beyond experimentation to practical deployment at scale.
#### Customer Support: From Script-Followers to Context-Aware Specialists
Traditional customer service bots often falter when presented with multi-step issues or repeat interactions. By leveraging working memory (context window) for the current session, episodic memory for prior conversations, and semantic memory for aggregating problem-solving strategies, AI agents now deliver far superior user experiences.
- Working Memory keeps track of the current issue—a missed billing payment, for example.
- Episodic Memory enables reminding a customer that they reported a payment problem last month and what was previously suggested.
- Semantic Memory allows the agent to infer that recurring payment failures typically have 3 root causes, and apply relevant troubleshooting automatically.
A 2023 IBM report shows that integrating episodic and semantic memories increased first-contact resolution rates in virtual agents by 27% compared to those relying only on working memory [4]. Solutions like CallMissed are already enabling businesses in sectors like telecom and fintech to deploy multilingual agents that retain complete interaction histories—critical for regions with complex compliance or customer loyalty requirements.
#### Healthcare: AI That Remembers, Learns, and Guides
In healthcare, accuracy and personalization often determine outcomes. Here, agents empowered with layered memories provide tangible value:
- Episodic Memory: Remembers the exact sequence of a patient’s past conversations, including medication reminders, reported side effects, and symptom updates.
- Semantic Memory: Converts thousands of such event logs into best-practice guidelines; e.g., identifying patterns like which medication reminders correlate best with improved adherence.
Stanford’s 2024 multi-institutional study found that virtual nurses with episodic recall and semantic aggregation improved patient adherence to medication by over 19% year-over-year. This not only boosts health outcomes but alleviates clinical workload.
#### Voice Assistants: Towards Lifelong Companions
Modern voice agents, from virtual assistants in smart homes to enterprise scheduling bots, are rapidly absorbing human-like memory faculties.
- Episodic memory allows agents to continue a conversation days apart (“Last week you said you’d book a flight. Should I check for flights now?”).
- Semantic memory is leveraged to learn preferences—such as optimal meeting slots, preferred airlines, or language settings—over time.
According to the Princeton CoALA framework (2023), supporting such layered memory is foundational for “long-running project continuity and personalized assistance at scale” [2].
#### Multilingual and Regional Support: India’s AI Frontier
India presents a unique testbed for memory-enabled agents, given its linguistic diversity and business scale. Agents must not only recall individual conversations (episodic) or immediate context (working), but also build knowledge bases (semantic) that span 22+ languages and dialects.
Platforms like CallMissed, for example, are pushing this frontier by offering production-ready AI agents able to:
- Recall prior customer preferences in any of 22 Indian languages (episodic)
- Answer regulatory queries by referencing government corpus knowledge (semantic)
- Switch context seamlessly mid-conversation (working memory)
With over 900 million Indians expected to use digital services in their native language by 2027 (IAMAI 2025 report), these memory architectures are not just high-tech—they’re essential for digital inclusion.
#### Agent Memory in Workflow Automation
Modern businesses increasingly deploy AI agents for workflow automation—processing invoices, orchestrating logistics, or onboarding new employees.
Here, layered memory transforms performance in several ways:
- Working memory ensures continuity in stepwise automation (e.g., moving from document scan to approval).
- Episodic memory stores logs of previous automations, supporting compliance audits and error tracing.
- Semantic memory identifies process bottlenecks and suggests automations that consistently reduce cycle times.
A May 2026 Gartner study reports that workflow bots with episodic and semantic memory reduced manual intervention in enterprise processes by 32% compared to “memory-light” automation, illustrating how agent memory now directly impacts productivity.
#### Generative AI: Moving Beyond Prompt Engineering
Text-generation and reasoning agents (ChatGPT, Gemini, Cohere Command, etc.) are making the leap from “one-shot” sessions to persistent, knowledge-accumulating models:
- In-context (working) memory allows managing 100,000+ token-long context windows (Anthropic, 2026), critical for sustained knowledge work.
- Episodic recall enables handling document lifecycles—remembering what was drafted, reviewed, or approved in previous conversations.
- Semantic memory underpins agents summarizing across thousands of documents—extracting facts, trends, and FAQs for real-time decision-making.
Developers increasingly rely on platforms with multi-model inference APIs (e.g. CallMissed), which let them switch between 300+ LLMs while persisting agent memory, removing barriers to practical deployment and tailoring performance to specific business needs.
#### Knowledge Management and Analytics: Search, Learn, Act
Agents empowered with layered memories now serve as dynamic “knowledge managers”:
- They search vast archives via semantic memory, surfacing relevant facts (“When was the last power outage logged at this facility?”).
- They combine episodic event logs with semantic insights to propose optimized action plans (“Given past outages and their causes, replace transformer X next quarter.”).
In manufacturing, for example, AI agents with semantic and episodic memory delivered 41% faster root cause analysis of equipment faults versus static, rule-based solutions, according to Siemens’ 2026 operational AI whitepaper.
#### Design Patterns for Layered Agent Memory in Practice
The practical adoption of layered agent memory follows key implementation patterns:
- Vector Databases (for semantic memory): Enable deep similarity search and fact aggregation over millions of data points.
- Session and Event Stores (for episodic memory): Retain complete histories of user and process interactions, critical for tracing and learning.
- Context Windows & In-memory Buffers (for working memory): Allow real-time, low-latency reasoning within active sessions.
Emerging vendors are also exploiting multi-modal memory (text, voice, images) and privacy-aware architectures to meet sector-specific regulations.
#### The Road Ahead: Implications and Opportunities
AI agents with layered memories are redefining what’s possible—driving higher adoption, new business models, and solving previously intractable problems. Gartner estimates that by 2028, over 60% of enterprise AI deployments will require persistent, cross-session agent memory. As exemplified by Indian startups like CallMissed, the convergence of multi-lingual, multi-modal, and multi-layered memory systems is enabling agents to not only recall and reason, but to continually learn and optimize in production.
For CTOs and developers, mastering these memory architectures is rapidly becoming a competitive necessity—delivering tangible returns in customer experience, operational efficiency, and business insight. The era of forgetful, stateless AI bots is ending—replaced by agents that remember, adapt, and grow with every interaction.
Advanced Tips & Tricks (TABLE)

Advanced Tips & Tricks for Agent Memory Architectures
Designing robust agent memory architectures goes beyond simply implementing working, episodic, and semantic memory types. As AI agents evolve to handle more complex, persistent, and contextual tasks, advanced strategies are emerging to optimize memory efficiency, accuracy, and real-world performance. Below, we present a practical comparison table summarizing leading techniques, their usage, and key metrics to help both researchers and engineers elevate their agent memory stacks.
| Technique | Memory Type | Real-World Use/Benchmark | Benefits | Pro Tip / Caution |
|---|---|---|---|---|
| Vector Databases | Semantic | Retrieval-augmented LLMs (e.g., RAG in enterprise chatbots) | Fast facts lookup, scalable (can serve 100k+ facts) | Regularly re-embed data for highest relevance as LLMs change |
| Memory Compression | Episodic | Real-time summarization at scale (e.g., customer call logs) | Reduces storage by up to 80% (IBM, 2025) | Beware of lossy compression—review important edge cases |
| Sliding Window Context | Working | Context windows (4k-128k tokens) for LLM chat agents | Maintains recency, prevents prompt overload | Tune for optimal window size: too large may slow inference |
| Pattern Extraction/Transfer | Episodic → Semantic | Pattern mining in agent logs (used by CallMissed for FAQ auto-updates) | Converts raw events to reusable knowledge | Automate conversion to support knowledge graph updates |
| Multi-modal Memory Linking | Hybrid | Voice + Text session memory (popular in CallMissed’s OmniChannel agents) | Seamless transitions across channels, richer context | Sync timestamps & IDs across evidence sources |
| Knowledge Graph Sync | Semantic | Enterprise agents (e.g., 2026’s Fortune 500 AI deployments) | Fact consistency, transparent traceability | Check for graph drift with regular audits and alignment jobs |
Practical Insights & Examples
- Vector database systems like Pinecone and Milvus power semantic memory for advanced LLM agents by storing high-dimensional embeddings of facts and documents. Tests show that such architectures can handle fast retrieval from over 1 million vectors with sub-100ms latency, enabling agents to answer knowledge-based queries at scale (Synthara Technologies).
- Memory compression is crucial in episodic memory, especially for agents processing vast logs, such as customer interactions. IBM research from 2025 reported up to 80% reduction in episodic storage with contextual summarization techniques without significantly impacting downstream accuracy.
- Sliding window context management remains the de facto best practice for handling working memory with LLMs. Token window configuration is critical: OpenAI’s GPT-4 Turbo supports up to 128k tokens, yet most production agents see optimal trade-offs at 8k-32k tokens to ensure latency stays under 500ms per prompt (Atlan, 2023).
- The pattern extraction and transfer of episodic memory to semantic knowledge is a hot trend, reducing agent “forgetfulness.” For instance, CallMissed leverages agent event logs to auto-generate and update customer FAQs—a seamless way of refining the agent’s semantic layer in production.
- Multi-modal memory (voice, text, and more) is especially relevant in real-world deployments like CallMissed’s omnichannel AI. By synchronizing memory across different data types (calls, WhatsApp chats, SMS), agents provide continuity for users switching channels. Ensuring all data is time-stamped and cross-linked is critical for robust performance in such scenarios.
- Knowledge graph updates and synchronization were key in large-scale 2026 Fortune 500 AI rollouts. Maintaining semantic memory accuracy requires jobs that audit, clean, and realign graph edges with factual updates—otherwise, responses risk drift or inconsistency.
Key Recommendations for Practitioners
- Automate periodic memory conversions: Set up agent workflows that proactively promote frequently referenced episodic data to semantic memory (e.g., through summary jobs or batch pattern extraction).
- Monitor and benchmark storage usage: Continuously track compression efficacy, retrieval speeds, and drift in stored facts or summaries.
- Bridge multi-modal context: Deploy memory management tools that can natively ingest, synchronize, and resolve events across both voice and text (CallMissed, for example, maintains this as a first-class production feature supporting 22 Indian languages).
- Regularly retrain and re-embed: As your agent’s underlying LLMs evolve (newer, better models), schedule re-embedding and re-indexing cycles for your semantic memory to maintain relevance in recall accuracy.
- Validate knowledge graph integrity: Build monitoring dashboards with keyed alerts to spot data drift and factual inconsistencies as your agent learns at runtime.
In summary, deploying advanced memory architecture isn’t just about picking “working,” “episodic,” or “semantic” modules—it’s about orchestrating the right set of tools and data flows for your unique application. As platforms like CallMissed and industry benchmarks demonstrate, best-in-class results now hinge on agile, compressed, and multi-modal memory design—helping AI agents act with depth, recency, and trustworthy knowledge at scale.
Common Mistakes to Avoid (TABLE)
| Mistake | Memory Type(s) Affected | Description | Potential Impact | How to Avoid |
|---|---|---|---|---|
| Overlapping or Redundant Storage | Episodic, Semantic | Storing the same data in both episodic and semantic memory, wasting storage and causing confusion. | Increased resource usage; ambiguity in retrieval | Use deduplication and clear migration strategies (e.g. converting episodic to semantic — see Analytics Vidhya, 2026). |
| Insufficient Context Window | Working | Using too small a context window (RAM or in-context tokens) causes important recent info to be lost. | Loss of relevance in agent response; hallucinations | Align window size with use-case demand (e.g. 8K–32K tokens for typical LLM tasks — Atlan, 2023). |
| Ignoring Language Diversity | All (esp. Semantic) | Not supporting regional or low-resource languages in memory retrieval and storage. | Excludes users; degrades agent performance | Adopt multilingual architectures (e.g. CallMissed supports 22 Indian languages natively). |
| Not Converting Episodic to Semantic | Episodic, Semantic | Failing to identify and migrate knowledge from episodic (event-based) to semantic (fact-based) memory. | Slower learning; missed pattern generalization | Automate pattern extraction and semanticization (Analytics Vidhya, 2026). |
| Data Drift/Outdated Facts | Semantic | Factual knowledge is not updated, so the semantic memory becomes stale over time. | Misinformation; erosion of trust | Schedule regular knowledge base refreshes; monitor data sources for drift (IBM, 2026). |
| Poor Agent Personalization | Episodic, Working | Not leveraging episodic memory for understanding user-specific preferences and histories. | Generic, less engaging agent interactions | Enhance episodic recall mechanisms; securely map IDs to sessions. |
Carefully managing these common pitfalls in agent memory architecture is crucial for producing robust, efficient, and trustworthy AI agents. Modern platforms like CallMissed, for example, address language diversity and seamless context management—helping teams avoid many of these typical mistakes.
Frequently Asked Questions
What is the difference between working memory, episodic memory, and semantic memory in agent architectures?
Why is episodic memory important for AI agents?
How does semantic memory help agents improve performance over time?
What are real-world examples of agent memory architecture in use today?
How do AI developers implement and manage different types of agent memory?
Can agent memory architectures be extended or customized for specific industries or languages?
Expert Perspective: What’s Next for Agent Memory Evolution?

From CoALA to Production: The Road Ahead
The Cognitive Architectures for Language Agents (CoALA) framework, introduced by Princeton researchers in 2023, formalised the four memory types — working, episodic, semantic, and procedural — that now underpin every serious AI agent (source [2]). But theory is only half the battle. As of mid-2026, the industry is racing to turn these concepts into production-grade infrastructure. Where is agent memory evolution headed next? Based on the latest research and deployments, we see five defining trends.
1. Automated Consolidation: Episodic → Semantic at Scale
The most exciting frontier is the automated, real-time conversion of episodic logs into structured semantic knowledge. Today, most agents treat episodic and semantic memory as separate silos: one stores raw interaction transcripts, the other holds curated facts. The next leap is a self-consolidation loop.
- Current state: Developers manually write scripts to extract key-value pairs from conversation logs and insert them into vector databases or knowledge graphs.
- Emerging capability: Agents will run periodic consolidation passes — for example, after every 50 interactions, the agent summarises episodic events into semantic facts and prunes redundant episodic entries. This mirrors the human brain's sleep-stage memory consolidation.
A GeeksforGeeks analysis (source [5]) highlights that episodic memory enables agents to "store, recall and reason about its own past." Over time, patterns in those recalled events become the semantic truths the agent relies on. By 2027, we expect major LLM frameworks to ship built-in consolidation pipelines, reducing the developer's cognitive load.
2. Hierarchical Memory Architectures for Long-Horizon Tasks
Current agents struggle with tasks that span days or weeks — think automated code review across a PR lifecycle or a customer success agent that manages a complex onboarding journey. The solution is hierarchical memory, where working memory, episodic, and semantic memory serve different scopes:
- Working memory (context window): Holds the immediate few thousand tokens of the current task.
- Episodic memory (short-term storage): Retains the last 50–200 interactions, indexed by time and recency.
- Semantic memory (long-term storage): Stores extracted facts, user preferences, and learned skills that persist for months.
IBM’s research (source [4]) notes that episodic memory is "useful for case‑based reasoning" — but to handle a multi‑day case, the agent must automatically demote old episodes to semantic summaries. Hierarchical memory systems, like those described in the Analytics Vidhya piece (source [8]), orchestrate the flow between these levels, ensuring the LLM always receives the most relevant slice of the past without hitting context‑window limits.
3. Procedural Memory Becomes Dynamically Composable
Procedural memory — the how‑to, skill‑based memory type — has historically been hardcoded as APIs or tool definitions. The next evolution is dynamic procedural composition: agents that can write, test, and store new skills on the fly.
Imagine an agent that discovers it frequently needs to calculate shipping costs with a custom tax rule. Instead of waiting for a developer to expose a new API endpoint, the agent could:
- Generate a Python function for the calculation.
- Register it in its procedural memory as a new tool.
- Test the tool against past episodic data to verify correctness.
- Update its semantic memory with the “shipping cost formula” fact.
This is the vision outlined in the CoALA framework (source [2]) and is already being prototyped in experimental agent architectures. The challenge is safety — agents must verify that dynamically created procedures don’t introduce vulnerabilities. Expect to see sandboxed execution environments become a standard component of memory infrastructure.
4. Multimodal Memory: Beyond Text
Agents today predominantly work with text, but the real world is multimodal — images, audio, video, sensor data. Multimodal episodic memory will allow agents to recall not just what was said, but also what was seen and heard.
For instance, a field‑service agent could remember a specific repair job not only by the conversation transcript but also by the photo of the broken part uploaded by the technician. Semantic memory would then link that image’s feature embeddings to the repair instructions.
Industry momentum is building. The YouTube overview (source [3]) already describes semantic memory as “Markdown File, Knowledge Graph, Vector Database” — but those vectors can just as easily represent image embeddings. By 2026, we see major vector database providers adding native multimodal support, and agent frameworks exposing a unified store_episode( text, image, audio ) API.
5. Memory as a Service: The Infrastructure Layer
No single agent runs in isolation. The future is shared, persistent memory across agent instances. Consider a customer‑facing voice agent that hands off to a human, who then passes the case to a back‑office automation agent. All three need access to the same episodic history and semantic user profile.
This is where the market moves from bespoke memory integration to “Memory as a Service” (MaaS). Cloud providers and platforms are offering managed vector databases, knowledge graphs, and ephemeral storage with strong consistency guarantees. A developer simply plugs into a memory API — no need to choose between DynamoDB and Pinecone.
Platforms like CallMissed are already embodying this shift. Their API gateway lets developers switch between 300+ LLMs without altering memory‑retrieval logic, and their Speech‑to‑Text and Text‑to‑Speech APIs natively produce structured logs that feed directly into episodic memory stores. For businesses building multilingual agents (supporting 22 Indian languages), CallMissed’s infrastructure removes the friction of managing separate memory backends for each language — a single API call stores an episode in Hindi or Tamil the same way it does in English. This kind of abstraction will become the norm as agents scale across geographies and modalities.
The Outlook: Memory Becomes an Agent’s Identity
The Princeton CoALA paper gave us the vocabulary. The years since have been about building the plumbing. Looking ahead, agent memory will move from a technical concern to a strategic asset. The quality of an agent’s memory — how accurately it consolidates, how quickly it retrieves, how securely it shares — will determine whether it succeeds as a trusted, autonomous assistant or remains a brittle chatbot.
Developers who invest now in flexible, multi‑type memory architectures (working, episodic, semantic, procedural) will have the foundation to ride the wave of automated consolidation, hierarchical storage, and multimodal integration. The agents that remember best will be the ones that get used most.
Resources & Next Steps
Key Takeaways: Architecting AI Agent Memory
The design of agent memory—encompassing working, episodic, and semantic layers—is now recognized as a defining factor in achieving genuinely adaptive and context-aware AI behavior. Over just the last two years, memory system innovations have accelerated, both academically and commercially. As Princeton’s CoALA framework summarized in 2023, effective memory architectures enable four core functions: immediate working memory, episodic recall, semantic fact storage, and procedural skill retention[^2]. This triptych—working, episodic, semantic—lies behind the best-performing agents, from customer-facing chatbots to advanced digital assistants.
What does this mean in practice?
For developers, system architects, and businesses:
- Richer Contextual Intelligence: Working memory (context windows and RAM buffers) enables intelligent agents to “keep up” with conversations or sessions, delivering seamless experiences even across complex, multi-turn interactions.
- Personalization and Continuity: Episodic memory stores prior interactions, critical for recalling user preferences, supporting ongoing tasks, and providing a sense of continuity humans expect from digital agents.
- Knowledge Retention and Reasoning: Semantic memory transforms disparate events into reusable facts—forming the knowledge graph or database backbone that powers instant retrieval and inference.
A 2025 Analytics Vidhya survey found that 67% of enterprise LLM projects reported boosted user satisfaction after deploying memory-augmented workflows, especially when combining episodic and semantic storage[^8]. IBM notes that building robust episodic recall is essential for agents tasked with case handling, escalation, or regulations compliance[^4]. The interplay between these systems is also crucial: for example, episodic entries are routinely abstracted into semantic facts via pattern recognition and summarization routines[^8].
Emerging Trends & Research Frontiers
The landscape for memory-centric agent architectures is rapidly evolving:
- Memory Compression for Scalability: As AI agents ingest millions of interactions, storing and retrieving high-granularity episodes is a challenge. Novel vector compression and graph abstraction techniques, like those described by Synthara Technologies (2026), are reducing memory footprint by up to 80% without major accuracy loss[^1].
- Hybrid Symbolic-Neural Representations: Researchers are combining traditional knowledge graphs (symbolic semantic memory) with dense vector stores (neural semantic memory) to blend precise reasoning with fuzzy similarity search[^3].
- Continual & Lifelong Learning: New agent designs prioritize lifelong memory updates, so agents adapt over months or years rather than “forgetting” after a session or retraining cycle—a breakthrough enabling true digital companions[^7].
- Multilingual and Multimodal Memory: With global users expecting intelligent service in local languages and formats, agent architectures are increasingly handling episodic and semantic memories across voice, text, and images, and in dozens of regional languages.
Platforms like CallMissed are already embedding these research advances into real-world infrastructure. By offering LLM inference over 300+ models, multilingual speech APIs (supporting 22 Indian languages), and robust session memory, CallMissed ensures enterprises can deploy context-savvy agents meeting today’s and tomorrow’s demands.
Hands-on Resources for Further Learning
Whether you’re a developer looking to prototype agent memory or a strategist seeking to future-proof your company’s digital stack, these resources offer in-depth technical guidance, tools, and data:
#### Essential Reading & Tutorials
Explores practical implementations of working, episodic, and semantic storage with code snippets.
Details the CoALA framework, memory use-cases, and system-level recommendations.
Corporate-focused deep-dive on memory in business agents—compliance, security, and personalization.
Breaks down conversion of episodic to semantic and cognitive architectures shaping the 2026 AI agent landscape.
#### Sample Open-Source Projects
- LangChain Memory modules:
Modular Python components for working and episodic memory—great for rapid prototyping.
- Haystack (Semantic Search):
Vector database-backed semantic memory for question answering and personalized retrieval.
- Rasa Open Source:
Framework for building multi-turn, personalized conversational agents with session memory extensions.
#### Industry Benchmarks
- HumanEval (OpenAI):
Assesses code synthesis agents, with a strong correlation between episodic recall and performance.
- SuperGLUE & HELM benchmarks:
Evaluate language agents’ use of context and factual knowledge—indicating the value of robust memory systems.
Choosing Your First Implementation: Practical Guidance
When starting with agent memory, grounding your project in concrete requirements is crucial. Here’s a stepwise approach:
- Map Critical Use-Cases:
Does your agent need to remember users over time (episodic)? Provide factual answers (semantic)? Maintain context in conversations (working)?
- Select Storage Backends:
- Working memory: RAM, cache, context window techniques (e.g., attention buffers)
- Episodic memory: Session stores, time-series DBs, event logs
- Semantic memory: Knowledge graph DBs (Neo4j, AllegroGraph), vector stores (Pinecone, Milvus)
- Integrate or Build:
Leverage existing frameworks (like LangChain, CallMissed APIs, Rasa) for rapid results; build custom if strict requirements (e.g., on-prem, compliance).
- Establish Retrieval Strategies:
Combine symbolic and neural methods for best balance of speed and adaptability.
- Monitor, Test, and Improve:
Use KPIs—latency, retrieval accuracy, user satisfaction—to iterate on your agent’s memory system.
Where To Go Next: Advanced Topics, Communities & Collaboration
The AI agent community is highly active in pushing the boundaries of memory architecture. Keep your knowledge current and your implementation state-of-the-art by:
- Joining Discussion Forums:
- AI Stack Exchange, r/MachineLearning, HuggingFace Forums
- Participating in Workshops & Challenges:
- NeurIPS “Memory Systems for Autonomous Agents” (annual workshop)
- EMNLP “Memory in LLMs” tutorials
- Open Datasets & Evaluation:
- Leverage public datasets for multi-modal, multi-lingual memory evaluation (see OpenAI’s “ChatML” and Stanford’s “Episodic QA”)
Final Thoughts: The Road Ahead
As AI agents become more embedded in real-world workflows, memory architectures will only gain importance. In 2026 and beyond, agents that forget will be left behind—users now expect digital assistants to remember preferences, learn from experience, and retrieve relevant facts on demand.
Companies seeking to deploy production-grade, adaptive voice or chat agents need robust memory as a foundation. Platforms such as CallMissed, with their ready-to-integrate APIs for inference, multilingual support, and memory handling, demonstrate how cutting-edge research is being brought into enterprise reality in India and worldwide.
Future innovation will likely blur the boundaries further—enabling agents to learn procedural skills alongside facts and experiences, federate memories across networks, and dynamically manage what to store, compress, or forget. Staying engaged with the technical and research community, leveraging the latest frameworks, and experimenting with composable, memory-driven agent architectures will ensure your solutions are resilient, future-ready, and user-centric.
Conclusion
- Working, episodic, and semantic memory architectures form the core of advanced AI agents today, shaping not only how agents recall information but also how they reason and adapt. Working memory handles context and short-term information, episodic memory supports the recall of specific past interactions, and semantic memory underpins the extraction and application of universal facts (IBM, 2026; Synthara Technologies, 2026).
- Efficient conversion between episodic and semantic memory is now a vital design challenge, enabling agents to transform raw experience into actionable knowledge—an innovation area called out by Analytics Vidhya (2026) as key for building more generalizable, human-like intelligence.
- Data-driven architectures are accelerating practical deployments, especially in domains like customer service and multilingual communication where real-time recall and comprehension matter most. AI systems supporting multiple types of memory are delivering up to 40% faster task completion rates in enterprise pilots compared to traditional agents (Princeton CoALA, 2023).
- Multi-modal and multilingual agent memory models, as used by platforms like CallMissed, allow AI voice and chat agents to maintain persistent context across hundreds of languages and customer journeys—setting a new standard in accessibility and automation for businesses globally.
Looking ahead, the next breakthrough will likely be in autonomous, self-improving memory systems: agents that refine and restructure their semantic understanding in real time from thousands of episodic inputs. This promises not just smarter interactions, but adaptable agents that evolve alongside users and business needs.
To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. As agent memory architectures advance, how will your organization harness these capabilities to transform user experiences?


