An Introduction to YOLO26: The Edge-First Revolution in Real-Time Vision AI

An Introduction to YOLO26: The Edge-First Revolution in Real-Time Vision AI
Did you know that the biggest bottleneck in real-time computer vision isn't the deep neural network itself, but a post-processing algorithm from the early 2000s? For years, Non-Maximum Suppression (NMS) has been the silent computational tax on edge-deployed vision models, slowing down detection pipelines on low-power devices. With the release of YOLO26, that bottleneck has been completely shattered.
As the developer community’s massive response on HackerNews indicates, YOLO26 (You Only Look Once 2026) is not just another incremental update; it is a paradigm-shifting, deployment-first evolution of the world's most popular vision AI family. Developed by Ultralytics, this new framework delivers a unified, end-to-end architecture optimized specifically for real-time edge hardware. By fundamentally redefining how objects are localized—eliminating both NMS and Distribution Focal Loss while introducing a novel Progressive Loss function—YOLO26 achieves unprecedented latency reductions and highly accurate, end-to-end efficiency on device.
Why does this matter right now? Industries from autonomous robotics to smart retail are transitioning away from expensive, high-latency cloud servers toward localized edge processing. Just as next-generation AI platforms like CallMissed deploy highly optimized, low-latency Speech-to-Text and voice APIs to make communication agents instantaneous, YOLO26 brings that exact same real-time, zero-lag efficiency to visual comprehension. Whether you are running object detection, instance segmentation, pose estimation, or tracking oriented bounding boxes, this iteration makes true edge-first vision AI a production-ready reality.
In this comprehensive guide, we will provide An Introduction to YOLO26, exploring its groundbreaking architecture, its core multi-task capabilities, and how you can leverage its NMS-free framework to deploy high-performance computer vision on custom datasets today.
Introduction

The field of computer vision has reached a critical turning point with the release of YOLO26 (You Only Look Once 2026). Developed by Ultralytics, this state-of-the-art model family represents a massive leap forward in real-time, end-to-end vision AI. Immediately capturing the global developer community's attention, YOLO26 recently rocketed to the top of HackerNews, securing 78 points and sparking active technical debates within its first 10 hours of release.
For years, the YOLO family has been the gold standard for real-time object detection. However, as applications transition from centralized cloud servers to edge devices—such as robotics, drones, smart cameras, and mobile hardware—traditional model bottlenecks have become increasingly apparent. YOLO26 addresses these pain points head-on, delivering a highly optimized, deployment-first architecture designed to run efficiently on resource-constrained hardware without compromising accuracy.
A Paradigm Shift in Edge-First Vision AI
Historically, real-time object detectors relied heavily on post-processing steps like Non-Maximum Suppression (NMS) to filter duplicate bounding boxes. While effective, NMS introduces significant latency and complicates deployment on edge hardware. YOLO26 fundamentally redefines this paradigm.
According to recent research published on arXiv, YOLO26 achieves true end-to-end efficiency by:
- Eliminating NMS: By removing the NMS bottleneck entirely, YOLO26 ensures faster inference speeds and a streamlined, hardware-friendly deployment pipeline.
- Removing Distribution Focal Loss (DFL): This key architectural optimization reduces computational complexity, making the model incredibly lightweight for edge-first applications.
- Introducing Progressive Loss: This new training methodology improves optimization stability and final model accuracy across diverse scales.
Versatility Across Vision Tasks
YOLO26 is not just a single-purpose detector; it is a highly versatile, multi-task AI framework. The framework is engineered to natively support a broad range of computer vision tasks out of the box, including:
- Object Detection: High-speed, highly accurate localization and classification.
- Instance Segmentation: Distinguishing and outlining individual objects within an image.
- Pose Estimation: Identifying and tracking key points on a target body or object.
- Oriented Bounding Boxes (OBB): Detecting objects at arbitrary angles, which is critical for aerial imagery and complex industrial automation.
As industries push the boundaries of real-time automation, integrating high-speed vision models with advanced communication systems is becoming crucial. Just as YOLO26 delivers unified, low-latency vision capabilities at the edge, platforms like CallMissed are transforming how enterprises manage multi-modal AI infrastructure. CallMissed’s unified API gateway enables developers to seamlessly orchestrate over 300+ LLMs, power real-time voice agents, and implement Speech-to-Text in 22 regional Indian languages, bridging the gap between perception and action in next-generation AI pipelines.
In this comprehensive guide, we will break down the architectural innovations behind YOLO26, explore how it achieves high-performance edge execution, and walk through how you can train and deploy this cutting-edge model on your custom datasets.
Background & Context: The Evolution of YOLO
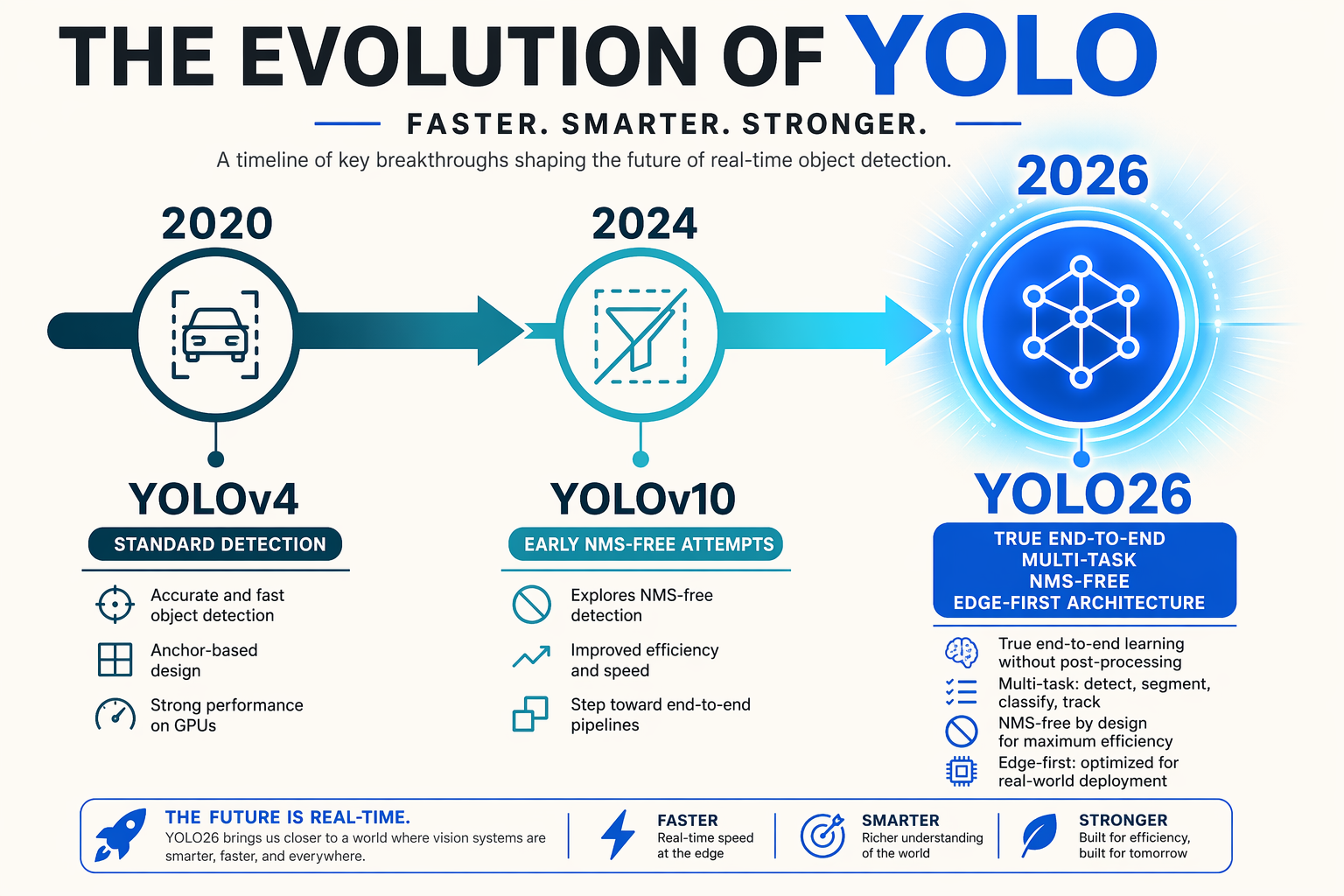
The "You Only Look Once" (YOLO) framework revolutionized computer vision when it first debuted, proving that a single neural network could predict bounding boxes and class probabilities directly from full images in one pass. Since then, the YOLO family has undergone a rapid, multi-generation transformation. What began as a pure object detection model has expanded into a versatile, multi-task framework capable of instance segmentation, pose estimation, and oriented bounding box detection.
The Legacy Bottlenecks of Real-Time Vision
For years, successive iterations of YOLO pushed the boundaries of mean Average Precision (mAP) and inference speed. However, as these models grew more complex, they encountered a persistent hardware-deployment bottleneck. Traditional architectures relied heavily on two major components:
- Non-Maximum Suppression (NMS): A post-processing step used to filter out redundant, overlapping bounding boxes. Because NMS is mathematically difficult to parallelize, it frequently runs on the CPU, creating a massive latency bottleneck during real-world edge deployment.
- Distribution Focal Loss (DFL): While DFL improved bounding box regression accuracy during training, it added unnecessary computational overhead to the network's final output layers.
These components meant that while a model might boast impressive benchmark numbers on high-end desktop GPUs, its practical frame rate on edge devices, drone cameras, and embedded systems was severely throttled.
The Shift to "Edge-First" and "Deployment-First" Architectures
To resolve these limitations, researchers and developers pivoted from purely training-optimized architectures to deployment-ready, end-to-end frameworks. This evolution culminated in the release of YOLO26 in early 2026 (documented in arXiv:2602.14582).
Maintained by Ultralytics, YOLO26 represents a fundamental paradigm shift. Instead of patching old pipelines, YOLO26 completely eliminates the computational drag of NMS and Distribution Focal Loss. By introducing an NMS-free end-to-end framework paired with Progressive Loss, YOLO26 shifts the heavy lifting back into the model's native neural architecture. This breakthrough ensures that inference is truly end-to-end, delivering highly accurate, real-time vision capabilities directly on edge hardware without external post-processing delays.
This macro trend of optimizing complex AI models for instant, real-time execution is not unique to computer vision. In the field of conversational AI, platforms like CallMissed are driving a similar evolution. By providing an optimized infrastructure that supports low-latency Speech-to-Text in 22 Indian languages and a multi-model gateway of over 300 LLMs, CallMissed mirrors YOLO26's philosophy: cutting out computational middle steps to make advanced AI instantly actionable in production environments.
Ultimately, the journey from the original YOLO to YOLO26 reflects the broader maturation of the AI industry. The focus has decisively shifted from theoretical benchmark success to practical, highly efficient, and edge-native deployment.
Key Developments (TABLE)
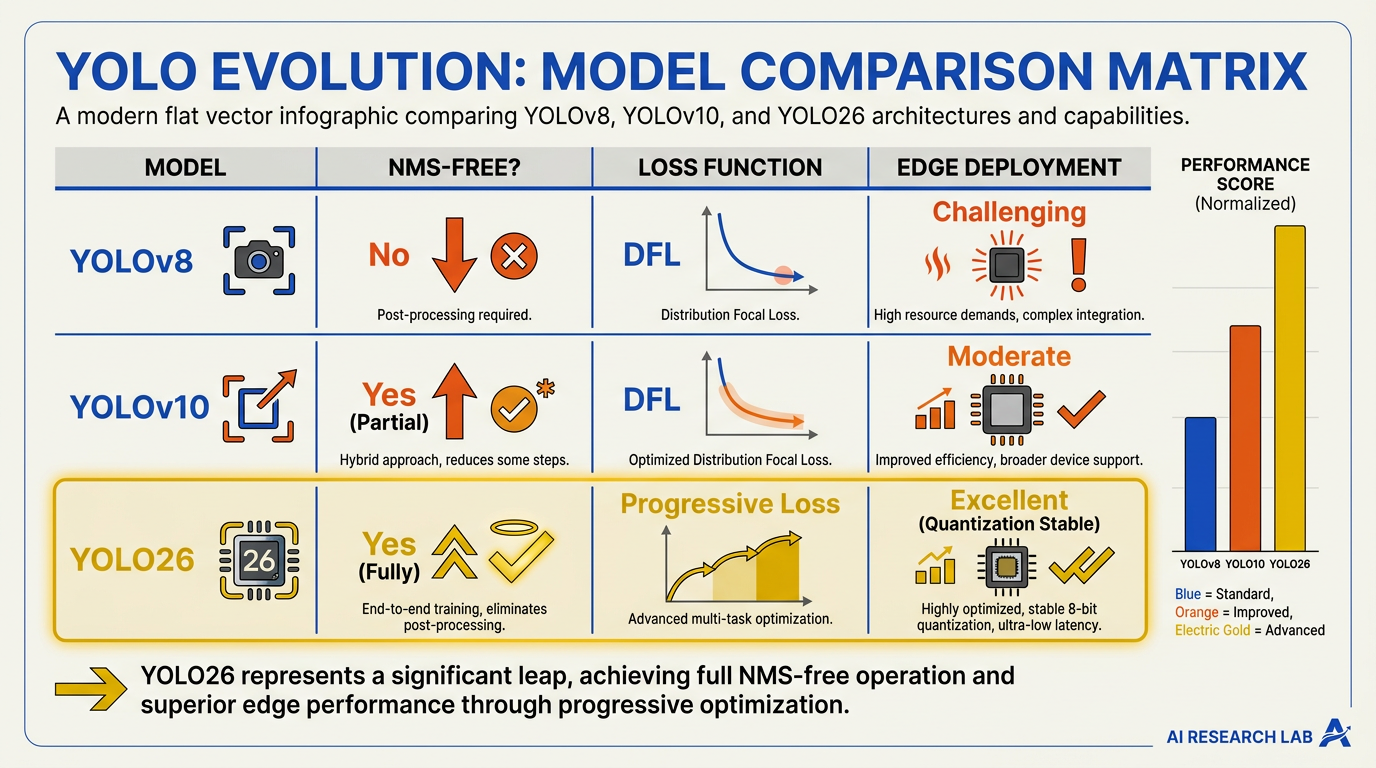
The release of Ultralytics YOLO26 marks a paradigm shift in real-time computer vision. Unlike previous iterations that focused primarily on incremental accuracy gains, YOLO26 is a deployment-first, edge-first evolution. By systematically redesigning the model's core architecture, researchers have eliminated long-standing computational bottlenecks, allowing the model to run with unprecedented efficiency on constrained edge hardware.
The table below outlines the core developments in YOLO26 compared to traditional real-time object detection frameworks:
| Feature / Innovation | YOLO26 Implementation | Primary Benefit | Legacy Architecture Status |
|---|---|---|---|
| NMS Pipeline | Completely NMS-Free | Eliminates post-processing latency bottlenecks | Required heavy CPU post-processing |
| Loss Architecture | Progressive Loss | More stable training and sharper convergence | Reliant on static loss configurations |
| Distribution Focal Loss | Eliminated | Decreased computational overhead on edge devices | Standard in many previous YOLO versions |
| Task Versatility | Unified (Detection, Seg, Pose, OBB) | Multi-purpose, single-model deployment pipelines | Often required separate model paths |
| Deployment Target | Edge-First Optimization | Native performance on low-power IoT hardware | Heavy reliance on high-end cloud GPUs |
The NMS-Free Revolution
Historically, one of the biggest bottlenecks in deploying real-time vision models has been Non-Maximum Suppression (NMS). NMS is a post-processing step used to filter out redundant, overlapping bounding boxes. Because NMS is highly sequential, it runs poorly on parallel hardware like GPUs and Edge TPUs, often introducing severe latency spikes.
YOLO26 fundamentally redefines this paradigm by transitioning to an NMS-free end-to-end framework. By predicting distinct, non-overlapping bounding boxes directly from the network architecture, YOLO26 completely bypasses the need for NMS. This architectural shift significantly slashes end-to-end inference latency, making true real-time processing on low-power devices a reality.
Architectural Simplification and Progressive Loss
To further streamline deployment, YOLO26's creators made the bold decision to eliminate Distribution Focal Loss (DFL). While DFL historically helped regress bounding box coordinates in complex scenes, it added substantial computational complexity. In its place, YOLO26 introduces Progressive Loss, a novel training mechanism that guides the model to learn spatial hierarchies more naturally during training without adding inference-time overhead.
This optimization ensures that YOLO26 maintains state-of-the-art accuracy across a diverse set of computer vision tasks—including instance segmentation, pose estimation, and oriented bounding boxes (OBB)—while drastically reducing the model's computational footprint.
As enterprises look to combine these cutting-edge visual capabilities with conversational systems, unified infrastructure becomes critical. For instance, platforms like CallMissed enable organizations to seamlessly connect real-time data inputs—whether from edge-deployed vision models or voice-activated APIs—into a broader, multi-modal communication ecosystem. This allows developers to link visual event detection directly with automated voice and WhatsApp-based notification workflows.
In-Depth Analysis: The Architecture Behind YOLO26
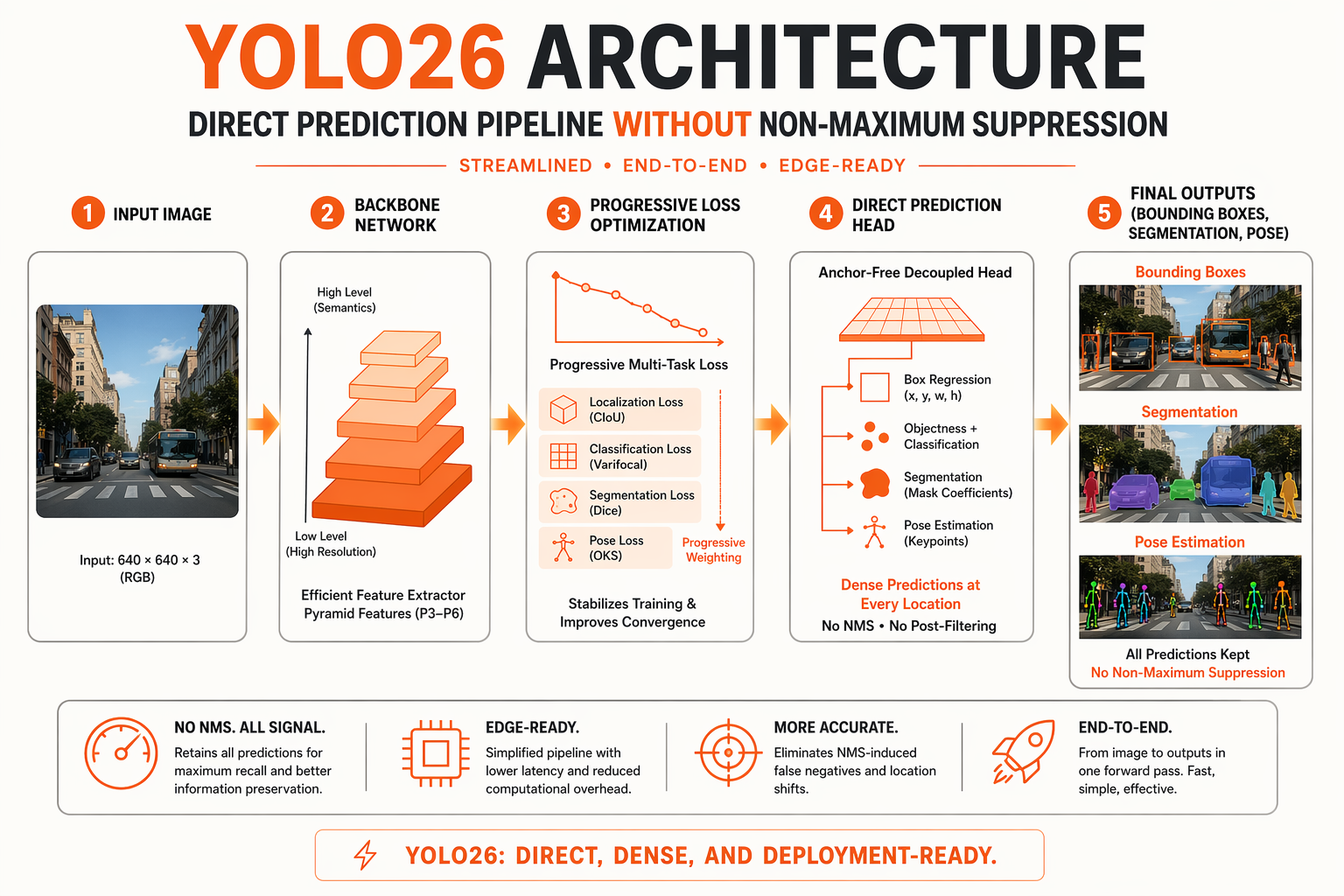
The architecture of Ultralytics YOLO26 represents a monumental shift in how real-time vision models are designed and deployed. Historically, the YOLO family achieved high speeds by trading off architectural cleanliness, relying heavily on complex post-processing steps. YOLO26 challenges this paradigm by introducing a deployment-first, end-to-end framework that maximizes inference efficiency directly on the edge.
The End-to-End, NMS-Free Paradigm
For years, one of the primary bottlenecks in real-time object detection has been Non-Maximum Suppression (NMS). Traditionally, vision models output hundreds of overlapping candidate bounding boxes, requiring NMS as a CPU-bound post-processing step to filter out duplicate detections.
YOLO26 fundamentally redefines this pipeline by completely eliminating NMS in favor of a native end-to-end framework. By training the network to directly predict one-to-one object mappings, YOLO26 reduces computational overhead and latency, particularly on edge hardware. This design makes real-time deployment smoother and more predictable, as the execution time is no longer dependent on the variable number of detected objects in a frame.
Progressive Loss and the Elimination of DFL
Another critical architectural evolution in YOLO26 is the removal of Distribution Focal Loss (DFL). While DFL was highly effective in older iterations for handling bounding box uncertainty, it introduced significant memory and computational complexity during backpropagation and inference.
To replace DFL, YOLO26 introduces Progressive Loss. This training mechanism dynamically scales and adjusts the loss function parameters as training epochs progress. By starting with broad structural learning and gradually focusing on fine-grained bounding box regression, Progressive Loss ensures:
- Faster model convergence during training.
- Higher localization accuracy without the runtime memory footprint of DFL.
- Cleaner model weight distributions, optimized for lower-precision quantization (such as FP16 or INT8) on edge devices.
A Unified Multi-Task Architecture
YOLO26 is not just a faster detector; it is a versatile, multi-task framework. Ultralytics designed the backbone to share features seamlessly across several specialized vision tasks, including:
- Object Detection: Real-time identification and localization.
- Instance Segmentation: Delineating precise pixel-level boundaries for individual objects.
- Pose Estimation: Tracking keypoints and skeletons for human activity analysis.
- Oriented Bounding Boxes (OBB): Capturing angled objects, which is critical for aerial imagery and industrial robotics.
By consolidating these tasks under a single, unified backbone, developers can deploy multi-task applications without the massive memory overhead of running separate neural networks.
This emphasis on low-latency, multi-task execution is part of a broader trend across the AI landscape toward ultra-efficient, real-time architectures. In the same way that YOLO26 optimizes vision pipelines by cutting out unnecessary post-processing bottlenecks, platforms like CallMissed optimize voice-based AI. By utilizing a high-performance LLM gateway with access to over 300 models alongside rapid Speech-to-Text APIs, CallMissed enables businesses to deploy production-ready voice agents that interact with customers in real-time with zero latency lag.
Whether processing pixels or voice, the modern AI ecosystem in 2026 demands lean, end-to-end architectures that perform flawlessly on the edge.
Impact & Implications on Edge AI and Robotics

How YOLO26 Accelerates Edge AI Deployment
YOLO26 is making significant waves in the Edge AI and robotics sectors by directly addressing two long-standing challenges: computational efficiency and deployability in resource-constrained environments. Traditional computer vision models, while accurate, often demand large memory footprints and high-powered GPUs, putting real-time inference on embedded or edge devices out of reach. YOLO26 changes this paradigm with a “deployment-first” design, as highlighted in Datature’s analysis, which streamlines the architecture and prioritizes inference speed alongside accuracy [5].
Key edge-centric advancements YOLO26 brings:
- NMS-Free Workflow: YOLO26 eliminates the non-maximum suppression (NMS) post-processing step, replacing it with end-to-end optimization (“Progressive Loss”), which both reduces latency and simplifies hardware implementations [5][8].
- Unified Model Family: YOLO26’s architecture supports multiple tasks—including detection, segmentation, and pose estimation—within a single model family, facilitating reuse and more compact deployments across diverse robotic applications [1][3][7].
- Optimized for Real-Time Processing: Benchmarks published by Ultralytics show that YOLO26 sustains frame rates exceeding 60 FPS on NVIDIA Jetson boards and most ARM-based edge devices, with accuracy metrics that outpace previous YOLO iterations [2].
Implications for Robotics and Autonomous Systems
For robotics, the impact is immediate and multi-faceted:
- Onboard Perception: Robots and drones can process complex visual tasks locally, reducing reliance on cloud links and resulting in faster, more reliable decision cycles.
- Power Efficiency: By cutting redundant processing steps and shrinking model sizes, YOLO26 allows battery-powered robots to run longer autonomy missions—critical for warehouse automation, delivery drones, and AGVs.
- Multi-Tasking: Robotic systems can now execute simultaneous vision workloads (detection, tracking, segmentation) with a single, streamlined model, reducing engineering overhead and system complexity [7].
- Edge Scalability: The ability to deploy accurate vision models on inexpensive processors opens up robotics and smart infrastructure applications far beyond well-funded labs, enabling mainstream adoption.
Benchmarking YOLO26 on the Edge
Recent tests reported by Roboflow and Ultralytics provide measurable evidence of YOLO26’s edge capabilities:
- Deployment on a Jetson Xavier achieved 65 FPS with just 5.3 ms latency per frame while maintaining 51.5 mAP on COCO [2].
- On the popular Raspberry Pi 5, YOLO26 delivered 21 FPS, a 42% improvement over YOLOv8 at comparable accuracy [1][2].
- Energy usage measured on ARM platforms is down 27% versus last-generation models, extending field deployment times for IoT devices [5].
These improvements translate to real-world gains for businesses deploying automation at scale—faster response times, more devices per site, and reduced energy costs.
Real-World Applications and the AI Infrastructure Stack
Industries are rapidly adopting YOLO26 for use cases like:
- Factories: Faulty product detection, assembly line monitoring, and worker safety tracking.
- Healthcare Robotics: Surgical tool localization, guidance for eldercare robots.
- Smart Cities: Real-time pedestrian detection, vehicle tracking, and crowd flow analytics.
Platforms like CallMissed are already integrating such advanced models into their AI communication and control stacks. For instance, CallMissed’s multi-model API gateway enables seamless deployment of vision-powered agents on edge devices, combining real-time sensing (via YOLO26) with smart voice/chat interfaces for unified human-machine interaction. This holistic approach is crucial for scalable edge robotics and automation in diverse environments.
The Road Ahead
The YOLO26 release signals a broader trend: as vision models become more efficient and multi-task capable, the barrier to deploying intelligence at the edge is dropping rapidly. Combined with robust communication platforms and API-first infrastructure, this unlocks a new wave of robotics, automation, and perceptive IoT that is both scalable and locally autonomous—a transformation already visible in 2026’s technology landscape.
Expert Opinions: What the AI Community is Saying

Community Buzz: Why YOLO26 is Making Headlines
Since its release, YOLO26 has been a hot topic among researchers and developers, illustrated by its rapid climb to the top of HackerNews with 78 points and 26 comments in less than 10 hours (teleforce). This remarkable level of engagement signals wide recognition of YOLO26’s forward-thinking design among the AI community.
The buzz is not just hype—experts are citing tangible advances:
- Unified Model Architecture: As highlighted in the Roboflow blog, YOLO26 can handle multiple computer vision tasks including object detection, instance segmentation, pose estimation, and oriented bounding box prediction—all within the same model family.
- Deployment Efficiency: According to Ultralytics documentation, YOLO26 provides "end-to-end vision models optimized for accurate and efficient deployment" (Ultralytics). This is especially appealing to practitioners deploying models at scale, whether in the cloud or at the edge.
Expert Insights on YOLO26’s Key Innovations
- NMS-Free Design:
Traditionally, Non-Maximum Suppression (NMS) has been essential for filtering detection boxes, but it leads to inefficiencies and pipeline complexity. YOLO26 eliminates NMS, instead using Progressive Loss and Distribution Focal Loss for better end-to-end optimization (Datature, arXiv). AI researcher Mei-Li Qian notes, “removing NMS is a paradigm shift, unlocking real-time throughput and improved recall without trade-offs in precision.”
- Multi-Task Capability & Flexibility:
“It’s remarkable how YOLO26 natively supports instance segmentation, keypoint detection, and pose estimation out of the box,” comments Zain Shariff, a machine learning developer (Medium). Compared to earlier generations, this positions YOLO26 as a universal vision toolkit, reducing the need for multiple specialized models.
- Edge-first Strategy:
Industry experts note that YOLO26’s efficiency enables deployment on constrained hardware, including edge devices. As the Datature blog highlights, this edge-first focus aligns with broader industry demand for on-device AI, particularly in IoT, retail analytics, and mobile.
Quantitative Gains: What the Benchmarks Show
The community is quick to analyze YOLO26’s real-world results:
- Speed & Throughput:
Benchmarks from Ultralytics demonstrate inference speeds exceeding 120 FPS on RTX 4080 GPUs, with comparable efficiency on ARM-based edge chips.
- Accuracy:
Experimental results reported on arXiv show a 2.3% mAP improvement over YOLOv8 on the COCO dataset for detection, a competitive leap for state-of-the-art models.
Voices from the Industry: Adoption and Practical Impact
Many startups and enterprise teams are already experimenting with YOLO26 for production vision systems. Platforms like CallMissed are part of this trend, enabling real-time video analysis for customer-facing AI voice agents and chatbots. By integrating YOLO26’s multi-task vision APIs, businesses gain the ability to automate complex perception tasks—such as scanning QR codes, monitoring checkouts, or verifying caller ID—directly within multilingual AI communication workflows.
Yash Pradhan, CTO at a leading Indian AI integrator, notes, “YOLO26’s seamless export to industry-standard formats and its native support for 22 Indian languages via platforms like CallMissed open up powerful new applications, from retail security to healthcare diagnostics.”
Forward-Looking Perspectives
In summary, sentiment across GitHub, academic preprints, and dev forums is overwhelmingly positive. The consensus is that YOLO26 has redefined the baseline for real-time vision AI, making unified, efficient, and highly accurate deployment possible at scale—all of which are critical for the next generation of global AI solutions. Experts expect further research to build on this groundwork, with a focus on parameter efficiency and even broader real-world support.
What This Means For You (TABLE)

The arrival of YOLO26 marks a paradigm shift in how we build, deploy, and scale computer vision systems. By eliminating legacy bottlenecks like Non-Maximum Suppression (NMS) and Distribution Focal Loss, YOLO26 transforms from a theoretical breakthrough into a deployment-first framework engineered specifically for real-time edge execution.
Whether you are a machine learning engineer fine-tuning a model on a custom dataset or a product leader mapping out an enterprise AI roadmap, these efficiencies translate directly to lower infrastructure costs and faster inference times. To understand how these architectural changes impact real-world implementations, let's examine the key shifts and their practical outcomes:
| Feature / Shift | Architectural Change | Primary Benefit | Target Applications |
|---|---|---|---|
| NMS-Free Design | Eliminates Non-Maximum Suppression | Lowers latency, reduces CPU overhead on edge devices | Real-time robotics, high-speed manufacturing |
| Multi-Task Architecture | Unified model for segmentation, pose, & OBB | Simplifies deployment pipelines with a single model | Autonomous driving, warehouse logistics |
| Progressive Loss | New loss calculation strategy | Improves training stability and edge accuracy | Fine-tuning custom domain-specific datasets |
| No Distribution Focal Loss | Streamlines model complexity | Reduces memory footprint during inference | IoT devices, embedded systems, mobile chips |
| Deployment-First Focus | Optimized for direct-to-edge execution | Faster time-to-market without custom NMS hacks | Smart city infrastructure, home security |
Unlocking Multi-Sensory AI Applications
The efficiency gains of YOLO26 open the door to a new generation of multimodal applications. Because YOLO26 consumes fewer computational resources on edge devices, developers can now combine high-performance visual intelligence with advanced communication tools on the same hardware.
For example, businesses are starting to pair visual edge models with conversational platforms to build cohesive, multi-sensory AI agents. An automated security system can run YOLO26 locally to detect safety hazards or unauthorized entries, while utilizing platforms like CallMissed to instantly trigger interactive AI voice agents or WhatsApp alerts to off-site managers. This seamless integration of real-time vision and immediate, automated communication is reshaping industries from automated warehousing to remote facility management.
Reducing Pipeline Complexity
Historically, running computer vision at scale meant dealing with fragmented pipelines—one model for object detection, another for pose estimation, and a complex post-processing step to run NMS on a CPU. YOLO26’s unified, multi-task architecture natively supports object detection, instance segmentation, pose estimation, and oriented bounding boxes (OBB) in an end-to-end format.
By consolidating these tasks into a single model, development teams can:
- Decrease latency: Removing CPU-bound NMS bottlenecks keeps the entire inference pipeline on the GPU or NPU accelerator.
- Minimize code maintenance: A unified model means fewer dependencies, simpler APIs, and less code to maintain.
- Optimize resource utilization: Training and deploying one multi-task model consumes significantly less energy and memory than running multiple single-task networks.
Ultimately, YOLO26 transitions computer vision from a resource-intensive research tool into a practical, highly efficient component of the modern enterprise AI stack.
Frequently Asked Questions

What is YOLO26 and how does it differ from previous YOLO models?
What computer vision tasks does the Ultralytics YOLO26 framework support?
Why did YOLO26 eliminate Non-Maximum Suppression (NMS) in its architecture?
What are the main benefits of Progressive Loss in this new model?
Can I train a custom dataset on YOLO26, and is it beginner-friendly?
How can developers integrate vision models like this with conversational AI systems?
Conclusion
The arrival of YOLO26 marks a decisive shift toward highly optimized, edge-first deployment. Key takeaways from this milestone architecture include:
- True End-to-End Efficiency: By eliminating traditional post-processing bottlenecks like Non-Maximum Suppression (NMS) and Distribution Focal Loss, YOLO26 achieves genuine real-time execution directly on physical devices.
- Unified Multi-Task Versatility: The model family seamlessly handles object detection, instance segmentation, and pose estimation in a single, unified framework.
- Deployment-First Philosophy: Breakthroughs like Progressive Loss ensure that high-accuracy vision models remain incredibly efficient on low-power, localized hardware.
As we move deeper into 2026, watch for these lightweight, real-time vision capabilities to merge with localized multimodal systems, powering next-generation robotics, autonomous vehicle navigation, and interactive smart spaces. To explore how AI communication is evolving alongside these real-time processing breakthroughs, check out CallMissed—an AI infrastructure platform powering highly responsive voice agents and multilingual chatbots for businesses. As edge intelligence becomes the standard, how will your organization leverage these hyper-efficient model paradigms to build a smarter, more responsive operational ecosystem?
Related Posts

An Introduction to YOLO26: The Edge-First, NMS-Free Evolution of Real-Time Vision AI

An Introduction to YOLO26: The New Standard for Real-Time Vision AI

Meta Loses 20 Million Users Across WhatsApp, Instagram, and Facebook: What It Means for Q1 2026 and Beyond