GPT-5.6 Sol Ultra vs Sol, Terra, Luna, Claude & Gemini: Verified Comparison

Compare verified pricing, availability, strengths, and caveats across GPT-5.6, Claude, GPT-5.5, and Gemini models before choosing.
GPT-5.6 Sol Ultra vs Sol, Terra, Luna, Claude & Gemini: Verified Comparison
Could a model called “Sol Ultra” really be scoring 91.9% while its official product family is still being pieced together from previews, snippets, and safety evaluations? That tension is exactly why this GPT-5.6 Sol Ultra vs Sol, Terra, Luna, Claude & Gemini comparison matters right now: the frontier-model market is moving faster than procurement teams, developers, and AI leaders can verify what is actually available.
On June 26, 2026, OpenAI reportedly previewed the GPT-5.6 series with Sol as the flagship and Terra and Luna as lower-cost options, with listed pricing in public snippets of $5 input / $30 output per 1M tokens for Sol, $2.50 / $15 for Terra, and $1 / $6 for Luna. A third-party write-up claims “Sol Ultra” reaches 91.9% on an unspecified benchmark, but that figure needs to be treated as lower-confidence until OpenAI or the benchmark owner documents the exact test, setup, and scoring method.
The comparison is not just about leaderboard drama. Buyers are trying to decide whether to route workloads to premium reasoning models, cheaper high-throughput models, or specialized agents for coding, spreadsheets, customer support, research, and multilingual workflows. Anthropic’s Claude Fable 5 and Claude Mythos 5 appear in announcement coverage, with snippets saying Fable 5 beat Claude Opus 4.8 on an everyday spreadsheet suite while using fewer turns and finishing runs 25% faster; multiple secondary sources also report Fable 5 and Mythos 5 at $10 input / $50 output per 1M tokens. Meanwhile, Claude Sonnet 5 and Gemini 3.1 Pro Preview belong in the discussion, but preview status means claims should be separated from production guarantees.
This guide takes an evidence-first approach: what is confirmed, what is reported, what is speculative, and what matters for real-world deployment. We will compare the models by availability, use case, pricing, reported benchmark strength, and confidence level, while avoiding false precision where source coverage is thin. The METR predeployment evaluation of GPT-5.6 Sol is especially important: its reported conclusion that Sol does not meet the Critical capability threshold for fully automated AI R&D adds needed context to the hype. For teams building on top of these systems, platforms like CallMissed reflect the broader shift toward model-agnostic infrastructure, letting developers route voice, chat, and LLM workloads across many models without rebuilding the stack. The goal is to help you choose a model based on verifiable capability and risk—not viral claims that may change before GA or official release notes.
Introduction: Why This Comparison Needs a Verification-First Approach

The AI model race is moving faster than the evidence
The hard part about comparing GPT-5.6 Sol Ultra, Sol, Terra, Luna, GPT-5.5, Claude Mythos 5, Claude Fable 5, Claude Sonnet 5, Claude Opus 4.8, and Gemini 3.1 Pro Preview is not that there are too many models. It is that the public evidence is uneven.
Some claims are attached to primary or semi-primary sources, such as OpenAI’s preview coverage for GPT-5.6 Sol and METR’s predeployment evaluation. Others come from snippets, secondary summaries, Reddit discussions, YouTube commentary, or third-party benchmark claims. That matters because buyers do not purchase “hype”; they purchase reliability, latency, cost predictability, safety posture, and integration fit.
As of June 30, 2026, the most defensible approach is not to declare a single winner. It is to separate:
- Confirmed or strongly sourced information
- Reported but not fully documented claims
- Preview-only claims that may change before general availability
- Speculative claims that should not drive production decisions
What appears verifiable so far
OpenAI’s GPT-5.6 family appears to be structured around three named models: Sol, Terra, and Luna. Public search snippets describe Sol as the flagship model, with stronger capabilities in coding, science, cybersecurity, long-horizon planning, and agentic workflows. Terra and Luna are positioned as lower-cost alternatives.
The currently reported GPT-5.6 pricing from public snippets is:
- GPT-5.6 Sol: $5 input / $30 output per 1M tokens
- GPT-5.6 Terra: $2.50 input / $15 output per 1M tokens
- GPT-5.6 Luna: $1 input / $6 output per 1M tokens
That pricing suggests OpenAI is segmenting the family by workload economics: Sol for premium reasoning and higher-stakes tasks, Terra for balanced capability and cost, and Luna for high-volume or budget-sensitive applications.
The more controversial claim is “Sol Ultra” reaching 91.9% on an unspecified benchmark, reported by a third-party source. Until OpenAI or the benchmark owner publishes the benchmark name, test setup, scoring method, and comparison cohort, that number should be treated as low-confidence.
Why safety evaluations matter as much as benchmarks
Benchmarks can show capability, but they do not always show deployment risk. That is why METR’s evaluation is central to this comparison. METR reportedly concluded that GPT-5.6 Sol does not meet its Critical capability threshold for fully automated AI R&D and would not, in their view, enable fully automated AI R&D. This does not mean Sol is weak; it means the model should be assessed with nuance rather than treated as an uncontrollable breakthrough based on viral claims.
Anthropic’s models require the same discipline. Search snippets indicate Claude Fable 5 beat Claude Opus 4.8 on an everyday spreadsheet suite while using fewer turns and completing runs 25% faster. Multiple secondary sources also report Claude Fable 5 and Claude Mythos 5 pricing at $10 input / $50 output per 1M tokens. Useful data—but still data that should be checked against official Anthropic documentation before procurement.
The buyer’s question is not “which model is smartest?”
For real teams, the better questions are:
- Is the model generally available, preview-only, or unclear?
- What workload is it actually optimized for—coding, support, research, agents, spreadsheets, multilingual voice, or reasoning?
- Are pricing and rate limits documented?
- Are benchmark claims reproducible?
- Can the model be swapped out if better evidence emerges next month?
That last point is why model-agnostic infrastructure is becoming important. Platforms like CallMissed, which provide access to 300+ LLMs alongside voice agents, WhatsApp chatbots, Speech-to-Text for 22 Indian languages, and Text-to-Speech APIs, reflect where the market is heading: businesses want flexibility while the frontier-model landscape remains unstable.
This comparison will therefore rank evidence before excitement. Where data is strong, we will say so. Where it is thin, preview-only, or unverifiable, we will mark it clearly.
Overview of Options: Model Families, Status, and Likely Use Cases
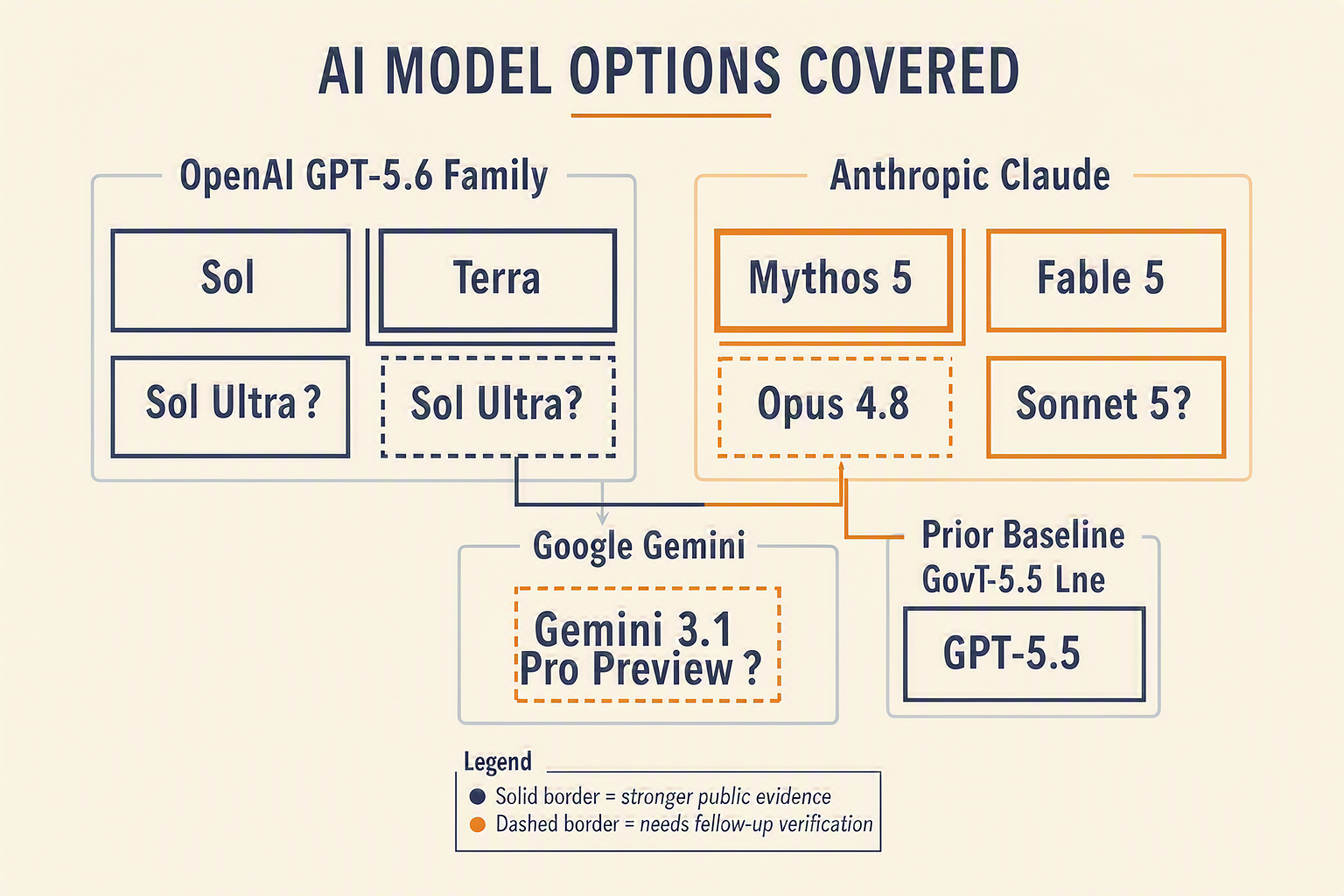
A practical map of the model landscape
For buyers, the first question is not “which model is smartest?” but which option is actually available, at what price, and for what workload. Based on the public snippets and evaluation coverage available as of June 30, 2026, the models fall into four broad buckets: OpenAI’s GPT-5.6 family, legacy/previous-generation GPT-5.5, Anthropic’s Claude 5 family and Opus 4.8, and Google’s Gemini 3.1 Pro Preview.
1. OpenAI GPT-5.6: Sol, Terra, and Luna
OpenAI’s GPT-5.6 lineup appears to include Sol, Terra, and Luna, with Sol positioned as the flagship. OpenAI’s preview page describes GPT-5.6 Sol as a “next-generation model” with stronger capabilities in coding, science, cybersecurity, and broader agentic workflows. The OpenAI community announcement snippet adds that Sol advances long-horizon planning and reliability.
Reported pricing from public snippets is:
- GPT-5.6 Sol: $5 input / $30 output per 1M tokens
- GPT-5.6 Terra: $2.50 input / $15 output per 1M tokens
- GPT-5.6 Luna: $1 input / $6 output per 1M tokens
Likely positioning:
- Sol — premium reasoning, coding, scientific analysis, cybersecurity, complex agents.
- Terra — mid-tier production workloads where GPT-5.5-like capability at lower cost matters.
- Luna — high-volume summarization, routing, extraction, support automation, and lightweight assistants.
A third-party source claims “Sol Ultra” scores 91.9% on an unspecified benchmark, but this remains a low-confidence data point until the benchmark name, test conditions, and official validation are published. Treat “Sol Ultra” as a reported variant or configuration, not yet a procurement-ready SKU.
2. GPT-5.5: the baseline many teams will compare against
GPT-5.5 remains important because many buyers will evaluate GPT-5.6 not in isolation, but against existing cost, latency, and reliability baselines. The DataCamp snippet frames Terra as similar to GPT-5.5 but cheaper, which makes Terra especially relevant for teams seeking migration savings without jumping to Sol-level pricing.
Likely GPT-5.5 use cases include:
- Stable production chat and workflow automation
- Code assistance where frontier-level reasoning is not required
- Knowledge-base Q&A
- Internal copilots
- Batch summarization and classification
The key buyer question is whether Terra or Luna can replace GPT-5.5 workloads while reducing token spend.
3. Anthropic Claude: Mythos 5, Fable 5, Sonnet 5, and Opus 4.8
Anthropic’s newer names — Claude Mythos 5 and Claude Fable 5 — appear in announcement coverage, but public details remain thinner than for established Claude releases. The strongest specific snippet concerns Claude Fable 5, which reportedly beat Claude Opus 4.8 on an everyday spreadsheet suite while using fewer turns and completing runs 25% faster.
Reported secondary-source pricing for Claude Fable 5 and Claude Mythos 5 is $10 input / $50 output per 1M tokens, placing them above the reported GPT-5.6 Sol price.
Likely positioning:
- Claude Fable 5: spreadsheet-heavy business workflows, office automation, structured reasoning.
- Claude Mythos 5: premium reasoning and complex agentic tasks, pending clearer evidence.
- Claude Sonnet 5: likely balanced performance/cost tier, but preview or limited information should be verified.
- Claude Opus 4.8: high-end prior-generation benchmark for comparing newer Claude gains.
4. Gemini 3.1 Pro Preview: promising, but preview means caution
Gemini 3.1 Pro Preview belongs in the shortlist for multimodal, reasoning, and Google ecosystem workloads, but the word Preview matters. Preview models can change pricing, rate limits, latency, safety behavior, and output quality before general availability.
Best-fit use cases may include:
- Google Cloud-native AI applications
- Multimodal research and analysis
- Workspace-style productivity flows
- Evaluation against GPT-5.6 Sol and Claude 5 for enterprise reasoning
What this means for deployment teams
The safest approach is to avoid single-model lock-in. Platforms such as CallMissed reflect this shift by giving teams access to 300+ LLMs, voice agents, WhatsApp chatbots, and speech APIs, so production workloads can be routed by cost, latency, language, and task complexity rather than brand preference alone. For now, the winning strategy is not choosing one model forever — it is building an evaluation layer that can adapt as Sol, Terra, Luna, Claude, and Gemini claims become verifiable.
Feature Comparison (TABLE)

Side-by-side feature matrix: what is verifiable vs reported
The cleanest way to compare these models is not to rank them outright, but to separate primary-source evidence, secondary reporting, and preview-only claims. The table below uses the strongest public signals available from the current source set, including OpenAI’s June 26, 2026 GPT-5.6 preview snippets, METR’s predeployment evaluation, and secondary coverage of Anthropic and Gemini models.
| Model / Family | Availability & Evidence | Likely Best Fit | Reported Price / Benchmark | Confidence Level |
|---|---|---|---|---|
| GPT-5.6 Sol | OpenAI previewed Sol on June 26, 2026 as the GPT-5.6 flagship; METR published a predeployment evaluation the same day. | Premium coding, scientific reasoning, cybersecurity, long-horizon planning, agentic workflows. | Snippets list $5 input / $30 output per 1M tokens. METR said it does not meet the “Critical capability threshold” for fully automated AI R&D. | High for existence, positioning, METR context; medium for full production behavior. |
| GPT-5.6 Sol Ultra | Mentioned in third-party coverage, not clearly confirmed in the provided primary OpenAI snippet. | Possible higher-performance Sol tier, but use case remains unclear until OpenAI documents it. | Third-party source claims 91.9% on an unspecified benchmark. No benchmark name or methodology provided. | Low-to-medium; treat as unverified until primary documentation appears. |
| GPT-5.6 Terra | Appears in OpenAI community announcement snippets as part of Sol/Terra/Luna family; DataCamp describes it as similar to GPT-5.5 but cheaper. | Balanced production workloads: reasoning, support automation, coding assistance where Sol cost is hard to justify. | Listed at $2.50 input / $15 output per 1M tokens; described as 2x cheaper than GPT-5.5 in secondary coverage. | Medium-high for price/positioning; needs formal release notes for limits and benchmarks. |
| GPT-5.6 Luna | Appears in GPT-5.6 family snippets as the lowest-cost option; Reddit discussion highlights price as the major improvement. | High-volume chat, routing, summarization, classification, and cost-sensitive agent tasks. | Listed at $1 input / $6 output per 1M tokens, the lowest OpenAI price in this set. | Medium-high for pricing; lower for capability claims. |
| GPT-5.5 | Used as a comparison baseline in secondary coverage, especially against Terra. | Existing production baseline for teams not ready to move to preview GPT-5.6 models. | Terra is reported as “similar to GPT‑5.5 but cheaper,” and 2x cheaper according to DataCamp’s summary. | Medium; useful as a baseline, but current official specs are not detailed in this source set. |
| Claude Mythos 5 / Fable 5 / Sonnet 5 / Opus 4.8 | Anthropic announcement coverage references Mythos 5 and Fable 5; Fable is compared against Opus 4.8. Sonnet 5 has thinner snippet evidence here. | Spreadsheet automation, enterprise analysis, writing, coding, and multi-step tool workflows. | Fable 5 reportedly beat Claude Opus 4.8 on an everyday spreadsheet suite, using fewer turns and finishing 25% faster. Fable/Mythos pricing reported at $10 input / $50 output per 1M tokens. | Medium for Fable/Mythos reported claims; lower for Sonnet 5 details in this context. |
| Gemini 3.1 Pro Preview | Included because buyers are evaluating it alongside GPT-5.6 and Claude, but source coverage here is preview-oriented and thin. | Multimodal research, coding, long-context analysis, and Google ecosystem workloads—pending verified specs. | No reliable price or benchmark figure is provided in the supplied context. | Low-to-medium until Google publishes comparable production documentation. |
What the table says in practical terms
A few patterns stand out:
- Sol is the most evidence-backed GPT-5.6 model in this set because it has both OpenAI preview coverage and an external METR safety evaluation.
- Luna may matter more commercially than Sol Ultra if the listed $1 / $6 per 1M tokens pricing holds, because high-volume AI systems often optimize for cost-per-task rather than peak benchmark scores.
- Sol Ultra’s 91.9% claim is not procurement-grade evidence yet. Without the benchmark name, task mix, sampling settings, and comparison baseline, the number is more of a signal to monitor than a buying criterion.
- Claude Fable 5 has one of the most concrete workload claims: beating Opus 4.8 on spreadsheet tasks while finishing 25% faster. That is more actionable than a vague “better reasoning” claim.
- Gemini 3.1 Pro Preview and Claude Sonnet 5 should stay in the watchlist category until pricing, availability, context limits, and benchmark methodology are clearer.
For teams deploying real applications, this uncertainty is exactly why model-agnostic infrastructure matters. Platforms such as CallMissed, which support routing across 300+ LLMs alongside voice agents, WhatsApp bots, speech-to-text, and text-to-speech APIs, help businesses test Sol, Claude, Gemini, or cheaper alternatives without rebuilding the entire communication stack each time the leaderboard changes.
Performance Analysis: Benchmarks, METR Findings, and Reliability Signals
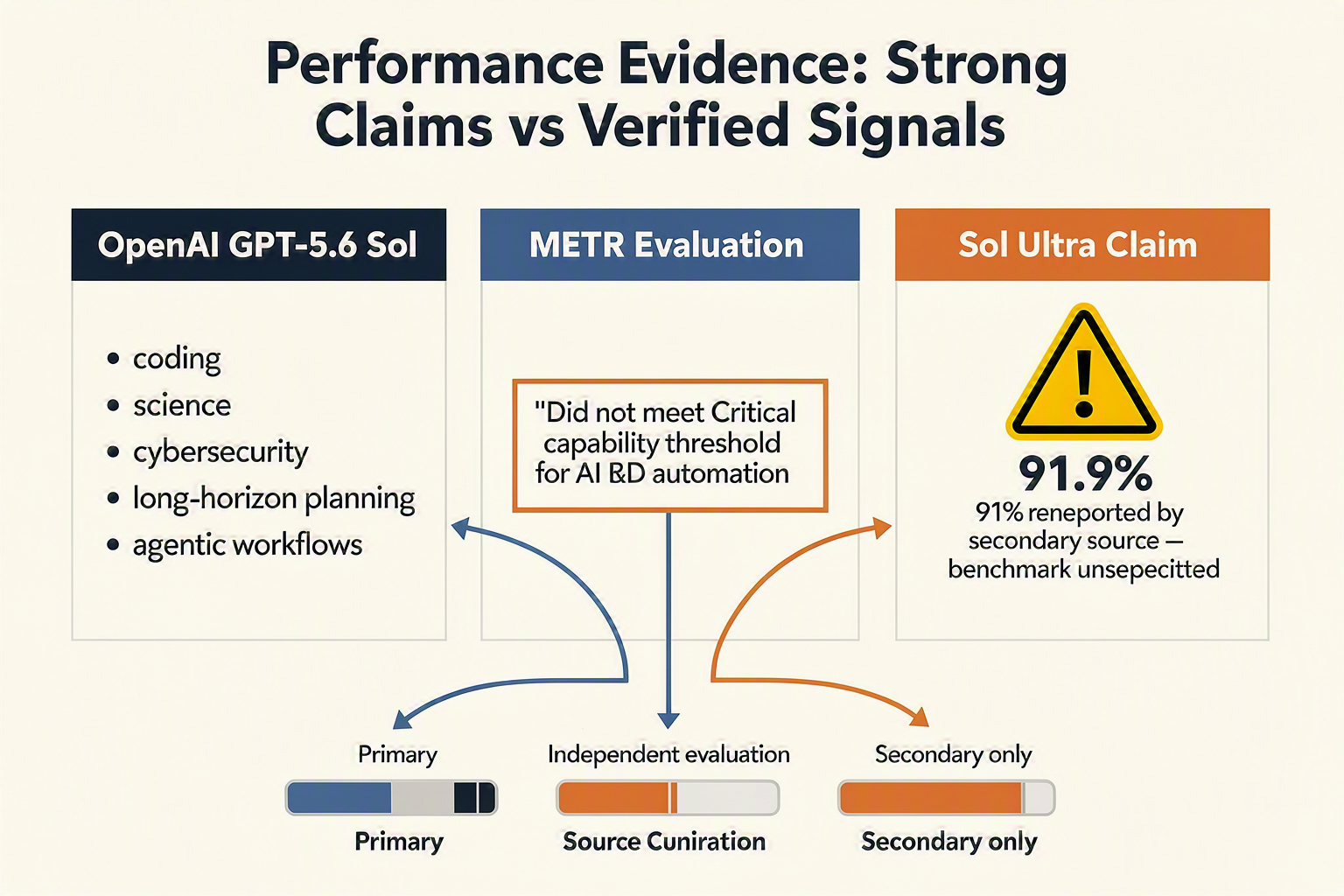
What the benchmark claims actually tell us
The strongest public performance claim in the GPT-5.6 discussion is also the least well-specified: a third-party source says “Sol Ultra” hits 91.9% on an unspecified benchmark. That number may be meaningful, but without the benchmark name, prompt protocol, sampling settings, tool access, pass criteria, and whether the score is averaged across runs, it should not be treated like an audited leaderboard result.
By contrast, the more verifiable GPT-5.6 positioning is qualitative: OpenAI’s preview page describes GPT-5.6 Sol as a next-generation model with stronger capabilities in coding, science, cybersecurity, and “agentic workflows.” The OpenAI community announcement similarly frames the GPT-5.6 family around Sol, Terra, and Luna, with Sol as the flagship and Terra/Luna as cheaper options. That supports a practical interpretation:
- Sol is the premium reasoning and agentic-workflow candidate.
- Terra appears designed for GPT-5.5-class or near-frontier workloads at lower cost.
- Luna is likely the high-volume option where price matters more than peak reasoning.
- Sol Ultra, if real as a distinct tier or benchmark configuration, remains insufficiently documented.
METR’s finding is a reality check, not a dismissal
The most important reliability signal is METR’s June 26, 2026 predeployment evaluation of GPT-5.6 Sol. METR reportedly concluded: “we do not believe GPT-5.6 Sol would enable fully automated AI R&D,” and that it does not meet the “Critical capability threshold” for AI R&D automation.
That matters for two reasons. First, it pushes back against overclaims that a new flagship model is already capable of fully autonomous research engineering. Second, it gives buyers a more mature lens: high benchmark scores do not automatically translate into safe, reliable long-horizon autonomy.
For enterprise deployments, the takeaway is not “Sol is weak.” It is that frontier performance still needs guardrails:
- Human review for code, security, finance, and medical workflows
- Sandboxed tool use for agents that can write files, call APIs, or execute code
- Evaluation on internal tasks, not just public benchmarks
- Regression testing before switching production traffic from GPT-5.5, Claude, or Gemini models
This is where model-routing infrastructure becomes practical. Platforms like CallMissed, which provide access to 300+ LLMs through a multi-model API layer, help teams test frontier models against real customer conversations, voice-agent tasks, and support workflows before committing to one provider.
Claude and Gemini: useful signals, thinner public evidence
Anthropic’s reported Claude Fable 5 signal is more concrete than many preview claims: snippets say it beat Claude Opus 4.8 on an everyday spreadsheet suite, used fewer turns, and completed runs 25% faster. That is a meaningful productivity benchmark because spreadsheets combine instruction-following, arithmetic, tabular reasoning, and iterative correction—skills that matter in finance, operations, and analyst workflows.
However, the same caution applies: we need the full benchmark design before concluding Fable 5 is generally stronger than Opus 4.8. A spreadsheet suite does not necessarily predict performance on deep coding, scientific reasoning, multilingual support, or adversarial robustness.
For Claude Mythos 5, Claude Sonnet 5, and Gemini 3.1 Pro Preview, public information is even less complete in the supplied context. Their inclusion in a buyer’s shortlist is reasonable, but ranking them against GPT-5.6 Sol or Claude Fable 5 would be premature unless official evals, pricing, and availability are confirmed.
Reliability signals buyers should prioritize
Instead of asking “which model won,” ask which model has the strongest evidence for your workload:
- Benchmark transparency: Is the test named and reproducible?
- Safety evaluation: Has a third party such as METR reviewed autonomy risks?
- Latency and completion rate: Does the model finish multi-step tasks reliably?
- Cost-performance ratio: Do Terra or Luna deliver enough quality at $2.50/$15 or $1/$6 per 1M tokens versus Sol at $5/$30?
- Production maturity: Is the model generally available, preview-only, or reported through secondary coverage?
The clearest conclusion so far: GPT-5.6 Sol has the strongest documented safety context via METR, while “Sol Ultra” has the loudest but least verifiable score claim. That distinction is exactly what buyers should preserve when evaluating this generation.
Detailed Comparison (TABLE)
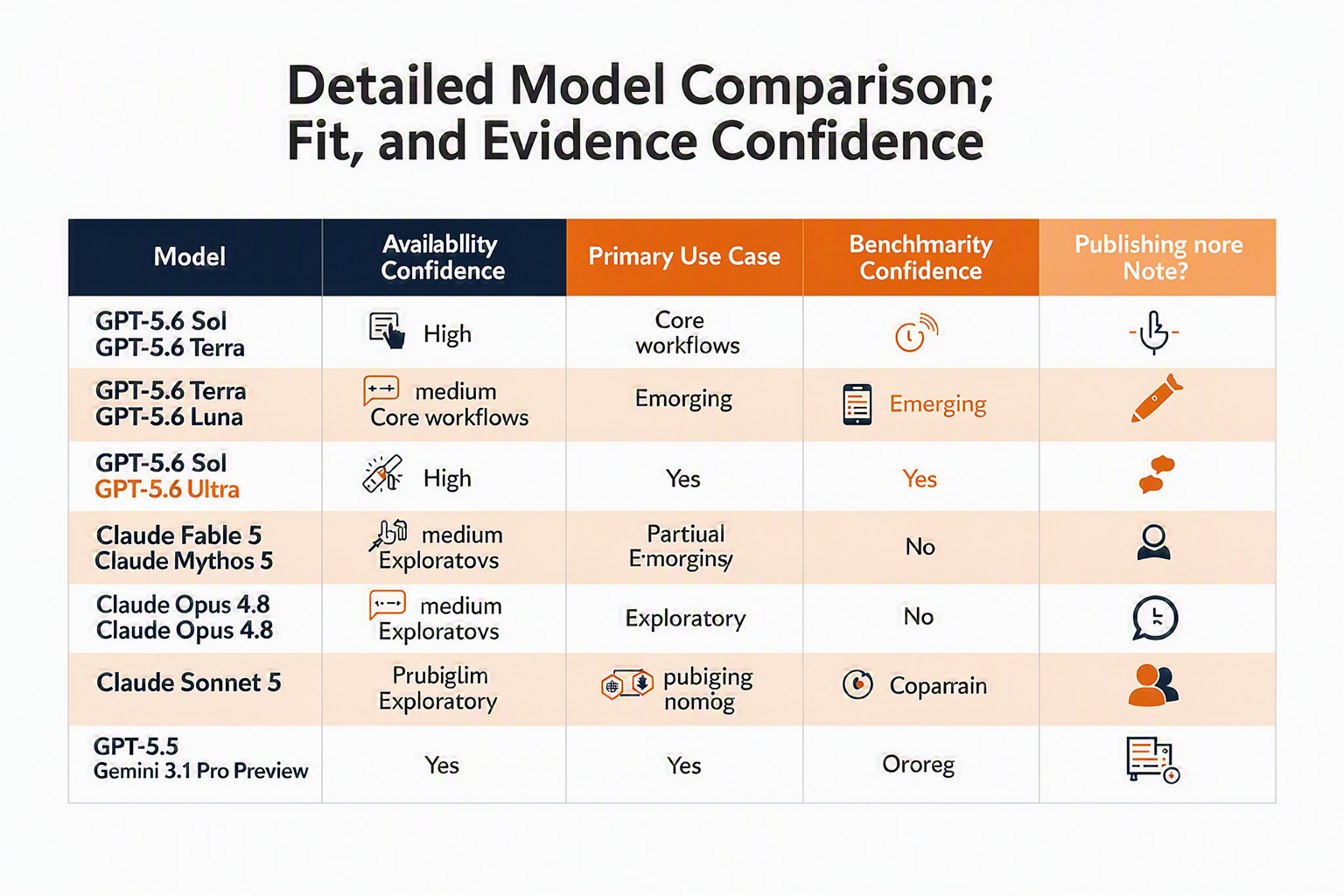
Comparison matrix: what is known vs what is still provisional
The safest way to compare these models is not to crown a winner, but to separate verified positioning, reported pricing, benchmark evidence, and deployment confidence. The table below groups closely related models where public evidence is thin, so buyers do not over-interpret preview-era claims.
| Model / Family | Public status & evidence | Reported pricing per 1M tokens | Strongest reported use case | Confidence level |
|---|---|---|---|---|
| GPT-5.6 Sol / “Sol Ultra” | OpenAI previewed GPT-5.6 Sol on June 26, 2026 as the flagship model. Third-party coverage claims “Sol Ultra” hits 91.9% on an unspecified benchmark. METR published a predeployment evaluation. | Sol: $5 input / $30 output | Coding, science, cybersecurity, long-horizon planning, agentic workflows | Medium for Sol; low for “Sol Ultra” until benchmark details are documented |
| GPT-5.6 Terra | Appears in OpenAI/community snippets as part of the GPT-5.6 family and positioned below Sol. DataCamp describes Terra as “similar to GPT‑5.5 but cheaper.” | $2.50 input / $15 output | Cost-sensitive reasoning, general business automation, GPT-5.5 replacement testing | Medium, but needs full release notes and eval cards |
| GPT-5.6 Luna | Listed as the lowest-cost GPT-5.6 option; public snippets position it for efficiency rather than maximum reasoning depth. | $1 input / $6 output | High-volume chat, routing, summarization, lightweight agents | Medium-low, because capability data is still sparse |
| GPT-5.5 | Prior-generation baseline used for price/performance comparison; Terra is reportedly positioned as similar but cheaper. | Not specified in provided snippets | Stable baseline, regression testing, production fallback | Medium, assuming existing enterprise access and known behavior |
| Claude Mythos 5 / Fable 5 / Sonnet 5 / Opus 4.8 | Anthropic snippets mention Claude Fable 5 and Claude Mythos 5. Fable 5 reportedly beat Claude Opus 4.8 on an everyday spreadsheet suite, used fewer turns, and finished runs 25% faster. Sonnet 5 appears in comparison requests, but public details here are thinner. | Fable/Mythos: $10 input / $50 output reported by secondary sources | Spreadsheet workflows, structured reasoning, enterprise assistants, multi-turn task execution | Medium for Fable/Mythos claims; low for Sonnet 5 specifics |
| Gemini 3.1 Pro Preview | Preview-status model included for forward-looking comparison, but production guarantees and stable benchmark details are not established in the supplied context. | Not verified in provided snippets | Multimodal reasoning, Google ecosystem workflows, preview experimentation | Low-medium until GA documentation is available |
What the table implies for buyers
A few practical patterns stand out:
- Sol is the premium GPT-5.6 candidate, but the strongest safety-relevant evidence is not a leaderboard score. METR’s evaluation reportedly says it does “not believe GPT-5.6 Sol would enable fully automated AI R&D” and does not meet the Critical capability threshold for AI R&D automation. That is useful context for governance teams evaluating agentic risk.
- Terra and Luna are the commercial wildcards. If the listed prices hold—$2.50/$15 for Terra and $1/$6 for Luna—they could matter more operationally than Sol for high-volume workloads.
- The “Sol Ultra 91.9%” claim should not drive procurement yet. Without the benchmark name, test conditions, sample size, and evaluator, it is a signal to monitor rather than a verified buying criterion.
- Claude Fable 5 is the most concrete Anthropic comparison point in the available snippets because it includes a relative performance claim: beating Opus 4.8 on spreadsheets while completing runs 25% faster.
- Preview models should be sandboxed first. Gemini 3.1 Pro Preview and unclear Sonnet 5 details belong in evaluation pipelines, not critical-path production, until pricing, SLAs, and release notes are stable.
For teams operating across multiple models, this is where model-agnostic infrastructure becomes important. Platforms like CallMissed let developers route LLM, voice, WhatsApp, speech-to-text, and text-to-speech workloads across providers, making it easier to test Sol, Claude, Gemini, or lower-cost alternatives without rebuilding the application layer every time the frontier shifts.
Pricing & Value (TABLE)

Cost signals are clearer for GPT-5.6 than for most rivals
The most useful pricing data currently comes from the reported OpenAI GPT-5.6 family snippets. They list Sol at $5 input / $30 output per 1M tokens, Terra at $2.50 / $15, and Luna at $1 / $6. That creates a clean value ladder: Terra is 50% cheaper than Sol, while Luna is 80% cheaper on input and 80% cheaper on output versus Sol.
For Anthropic, multiple secondary sources report Claude Fable 5 and Claude Mythos 5 at $10 input / $50 output per 1M tokens. That makes them materially more expensive than GPT-5.6 Sol on raw token pricing, though Fable’s reported spreadsheet result—beating Claude Opus 4.8, using fewer turns, and finishing 25% faster—could offset cost in workflows where fewer retries matter.
| Model / Group | Reported price per 1M tokens | Simple 1M in + 1M out cost | Value read | Confidence |
|---|---|---|---|---|
| GPT-5.6 Sol / Sol Ultra | $5 input / $30 output for Sol; Ultra pricing not separately verified | $35 for Sol | Premium OpenAI tier; best fit for coding, science, cybersecurity, and agentic workflows if Sol claims hold | Medium for Sol; low for “Ultra” |
| GPT-5.6 Terra | $2.50 input / $15 output | $17.50 | Strong middle option; roughly half Sol’s cost and reportedly similar to GPT-5.5 positioning | Medium |
| GPT-5.6 Luna | $1 input / $6 output | $7 | Lowest-cost GPT-5.6 option; attractive for scale, classification, support, and high-volume chat | Medium |
| Claude Fable 5 / Mythos 5 | Reported $10 input / $50 output | $60 | Expensive on tokens, but Fable’s reported 25% faster spreadsheet runs may improve task-level economics | Medium-low |
| Claude Sonnet 5 / Opus 4.8 | Not reliably confirmed in supplied context | Not comparable | Use only with current vendor price sheet; Opus 4.8 is mainly a reference point for Fable’s reported win | Low from current evidence |
| GPT-5.5 / Gemini 3.1 Pro Preview | Not reliably confirmed in supplied context | Not comparable | Keep as baseline or preview candidate, not as the default value pick without live pricing | Low |
Token price is not the same as task cost
A model with a higher per-token price can still be cheaper per completed task if it uses fewer turns, needs less prompt scaffolding, or avoids manual review. That is why the Fable 5 claim matters: the snippet says it beat Claude Opus 4.8 on an everyday spreadsheet suite while completing runs 25% faster and using fewer turns. If verified, that could reduce total cost for spreadsheet agents even at $60 per 1M input + 1M output.
Still, for output-heavy applications, price differences compound quickly:
- Luna vs Sol: $6 output vs $30 output means Luna is 5× cheaper for generated text.
- Terra vs Sol: $15 output vs $30 output means Terra cuts generation spend by 50%.
- Fable/Mythos vs Sol: $50 output vs $30 output means Anthropic’s reported tier is about 67% more expensive on output.
Practical value takeaway
For most buyers, the initial routing logic should be simple:
- Use Luna for high-volume, lower-risk workloads.
- Use Terra when quality matters but Sol-level reasoning is not required.
- Reserve Sol for difficult coding, research, planning, and security tasks.
- Treat Sol Ultra’s 91.9% benchmark claim as interesting but not procurement-grade until benchmark details are public.
- Test Claude Fable/Mythos where spreadsheet, business reasoning, or turn-efficiency could outweigh raw token cost.
This is also where model-agnostic infrastructure becomes valuable. Platforms like CallMissed let teams route workloads across 300+ LLMs, so a business can send routine WhatsApp or voice-agent tasks to cheaper models while reserving premium models for escalation, analysis, or complex reasoning.
Pros and Cons (TABLE)

How to read the trade-offs without over-ranking the models
At this stage, the safest way to compare GPT-5.6 Sol Ultra, Sol, Terra, Luna, GPT-5.5, Claude Mythos/Fable/Sonnet/Opus, and Gemini 3.1 Pro Preview is to separate usable procurement signals from leaderboard noise. The strongest signals are pricing snippets, preview status, named safety evaluations, and specific workload claims such as Fable 5’s reported spreadsheet gains. The weakest signals are unverified benchmark numbers—especially the 91.9% “Sol Ultra” claim, which lacks a clearly cited benchmark, test setup, or primary-source confirmation in the available context.
| Model / Family | Pros | Cons / Risks | Best-Fit Use Case | Evidence Confidence |
|---|---|---|---|---|
| GPT-5.6 Sol | Flagship GPT-5.6 model; OpenAI preview describes stronger coding, science, cybersecurity, long-horizon planning, and agentic workflows. Listed pricing: $5 input / $30 output per 1M tokens. | Still framed as a preview; buyers should validate latency, rate limits, safety behavior, and tool-use reliability before production migration. | Premium reasoning, complex coding, technical research, agentic workflows. | Medium-high: OpenAI and METR sources exist, but production details may evolve. |
| GPT-5.6 “Sol Ultra” | Reported by a third-party source as reaching 91.9% on an unspecified benchmark, implying possible top-tier performance. | Lowest verification quality: no clear primary benchmark documentation, no setup details, and unclear whether “Ultra” is an official SKU or external label. | Experimental evaluation only; not ideal for procurement decisions yet. | Low until OpenAI or the benchmark owner confirms the claim. |
| GPT-5.6 Terra | Positioned as a lower-cost GPT-5.6 option; listed at $2.50 input / $15 output per 1M tokens, roughly half Sol’s token price. Secondary coverage says Terra is similar to GPT-5.5 but cheaper. | May trade off peak reasoning depth versus Sol; limited verified benchmark detail in public snippets. | Scaled business apps, customer support automation, document workflows, moderate reasoning. | Medium: pricing and positioning are visible, but capability detail is thinner. |
| GPT-5.6 Luna | Lowest-cost GPT-5.6 option at $1 input / $6 output per 1M tokens; attractive for high-volume tasks. | Likely weaker than Sol/Terra on hard reasoning; public evidence is mostly pricing and positioning rather than deep evaluation. | Summarization, routing, classification, lightweight chat, bulk content operations. | Medium-low: useful cost signal, limited benchmark evidence. |
| Claude Fable 5 / Mythos 5 | Fable 5 is reported to beat Claude Opus 4.8 on an everyday spreadsheet suite, using fewer turns and finishing runs 25% faster. Reported pricing for Fable/Mythos: $10 input / $50 output per 1M tokens. | Higher reported price than GPT-5.6 Sol; public details are still snippet-heavy and need confirmation from full Anthropic documentation. | Spreadsheet agents, structured office workflows, high-quality reasoning where cost is secondary. | Medium: specific performance claim exists, but full test methodology matters. |
| Claude Sonnet 5 / Opus 4.8 / Gemini 3.1 Pro Preview / GPT-5.5 | Useful comparison anchors: Opus 4.8 is referenced as the model Fable 5 reportedly beat; GPT-5.5 helps benchmark Terra’s value; Gemini 3.1 Pro Preview remains relevant for multimodal and Google-stack evaluation. | Mixed availability and preview labels make direct ranking risky; pricing and benchmark parity are not consistently documented in the provided context. | Baseline testing, vendor diversification, fallback routing, ecosystem-specific deployments. | Variable: depends heavily on official release notes and enterprise availability. |
Practical pros and cons for buyers
The main advantage of the GPT-5.6 family is price segmentation. OpenAI’s listed structure—Sol at $5/$30, Terra at $2.50/$15, and Luna at $1/$6 per 1M tokens—makes it easier to route workloads by cost and difficulty instead of forcing every task through a flagship model.
The main caution is verification. METR’s predeployment evaluation reportedly concluded that GPT-5.6 Sol does not meet the Critical capability threshold for fully automated AI R&D, which is an important counterweight to claims that the model has crossed into autonomous research dominance.
For production teams, the best strategy is not “pick one winner.” It is:
- Benchmark your own tasks across 3–5 candidate models.
- Route by workload tier: Sol or Claude for hard reasoning, Terra/Luna for scale.
- Treat preview models as unstable until API terms, pricing, and safety behavior are final.
- Use model-agnostic infrastructure where possible. Platforms like CallMissed already support multi-model LLM inference, voice agents, WhatsApp chatbots, STT, and TTS APIs—useful when teams need to switch providers without rebuilding customer-facing workflows.
Frequently Asked Questions
Is GPT-5.6 Sol Ultra vs Sol a real OpenAI product comparison?
What is the verified GPT-5.6 Sol, Terra, and Luna pricing?
How does GPT-5.6 Sol Ultra vs Sol compare with Claude Mythos 5 and Claude Fable 5?
Is GPT-5.6 Sol safer or more capable than GPT-5.5?
Should developers choose GPT-5.6 Luna, Terra, Sol, Claude, or Gemini 3.1 Pro Preview?
Is Gemini 3.1 Pro Preview production-ready compared with GPT-5.6 Sol Ultra vs Sol?
Conclusion
The clearest conclusion is that this is not a simple “which model wins?” race yet. It is a verification problem. GPT-5.6 Sol may be the most important model to watch, but claims around Sol Ultra’s 91.9% score remain lower-confidence until benchmark details are published.
- GPT-5.6 Sol, Terra, and Luna appear positioned as a tiered family: flagship capability at $5/$30 per 1M tokens for Sol, cheaper throughput via Terra at $2.50/$15, and lowest-cost access via Luna at $1/$6.
- METR’s predeployment evaluation adds useful restraint: GPT-5.6 Sol reportedly did not meet the Critical capability threshold for fully automated AI R&D.
- Claude Fable 5 and Mythos 5 look highly competitive, especially with Fable reportedly beating Claude Opus 4.8 on spreadsheet tasks while finishing 25% faster, though pricing and release details still need confirmation.
- Gemini 3.1 Pro Preview, Claude Sonnet 5, and preview-only models should be treated as promising but not fully procurement-ready without stable availability, pricing, and documented benchmarks.
What to watch next: official release notes, reproducible benchmark cards, latency data, context limits, tool-use reliability, and enterprise safety documentation. To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. The real question is: will your stack be ready to switch models as the evidence changes?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.