Banned Claude Mythos Capabilities for Cheap? How OpenRouter Fusion Beats Standalone Frontier Models

What if the most powerful AI models ever built were taken away from you just 72 hours after they launched? That is exactly the reality developers faced on...
Banned Claude Mythos Capabilities for Cheap? How OpenRouter Fusion Beats Standalone Frontier Models
What if the most powerful AI models ever built were taken away from you just 72 hours after they launched? That is exactly the reality developers faced on June 12, 2026, when Anthropic abruptly suspended access to its highly anticipated Claude Fable 5 and Claude Mythos 5 models following US government national security interventions. The sudden ban left the tech world in a crisis, scrambling for a way to replicate these elite autonomous reasoning capabilities without access to the frontier models themselves.
But a breakthrough has emerged from an unexpected strategy: compound model architecture. OpenRouter’s newly released Fusion API (openrouter/fusion) is solving this developer crisis by acting as a server-side, multi-model deliberation system. Instead of relying on a single monolith, Fusion fans out a single prompt in parallel to a "panel of budget experts"—such as Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro—and utilizes a high-tier judge model like Claude Opus 4.8 to synthesize the absolute best response.
The data proves this hybrid approach works. On deep, complex research benchmarks, this budget-friendly Fusion panel scored 64.7%, successfully outperforming standalone giants like GPT-5.5 and coming within a mere 0.6 percentage points of the banned Claude Fable 5 (65.3%)—all at roughly 50% of the cost. As the industry shifts toward these collaborative architectures, communication platforms like CallMissed are already helping businesses capitalize on this trend by allowing developers to orchestrate multi-model workflows seamlessly across global voice and chat networks.
In this guide, we will explore how you can leverage OpenRouter Fusion to unlock banned Claude Mythos-level capabilities for cheap, how the underlying "panel of experts" deliberation mechanism functions, and how to implement the openrouter:fusion tool directly into your existing agentic workflows.
Introduction: The Post-Mythos AI Landscape

What if the most powerful AI models ever built were taken away from you just 72 hours after they launched? That is exactly the reality developers faced on June 12, 2026, when Anthropic abruptly suspended access to its highly anticipated Claude Fable 5 and Claude Mythos 5 models following US government national security interventions. The sudden ban left the tech world in a crisis, scrambling for a way to replicate these elite autonomous reasoning capabilities without access to the frontier models themselves.
But a breakthrough has emerged from an unexpected strategy: compound model architecture. OpenRouter’s newly released Fusion API (openrouter/fusion) is solving this developer crisis by acting as a server-side, multi-model deliberation system. Instead of relying on a single monolith, Fusion fans out a single prompt in parallel to a "panel of budget experts"—such as Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro—and utilizes a high-tier judge model like Claude Opus 4.8 to synthesize the absolute best response.
Why Monoliths Failed and Fusion Won
The sudden restriction of the Claude Mythos class highlighted a critical vulnerability in modern AI development: reliance on single-provider API endpoints. When a frontier model is throttled or outright banned, entire production pipelines collapse.
OpenRouter's Fusion framework shifts the paradigm from a single "all-knowing" model to an algorithmic "wisdom of the crowd." The process operates seamlessly on the server side:
- Parallel Fan-Out: Your prompt is concurrently dispatched to multiple specialized, low-cost models.
- Multi-Model Deliberation: The budget models generate diverse, independent reasoning paths.
- Synthesis & Judgment: A state-of-the-art judge model (such as Claude Opus 4.8) analyzes, cross-references, and fuses these drafts into a single, highly refined output.
The Hard Data: Mythos-Level Performance at Half the Cost
The numbers prove that this collaborative approach isn't just a clever workaround—it is a superior economic strategy. On 100 complex research and reasoning benchmarks, OpenRouter's budget Fusion setup delivered staggering results:
- Fusion Panel Accuracy: 64.7%
- Banned Claude Fable 5 Accuracy: 65.3%
- The Delta: A negligible 0.6 percentage points
- Cost Efficiency: Fusion achieved this near-parity at approximately 50% of the cost of running standalone frontier models.
Furthermore, the budget Fusion panel successfully outscored solo runs of next-generation giants like GPT-5.5 and Claude Opus 4.8.
This shift toward multi-model orchestration is redefining how modern communication systems are built. For instance, infrastructure platforms like CallMissed allow developers to capitalize on this trend by leveraging its multi-model LLM gateway (supporting over 300+ models). By combining OpenRouter Fusion's deliberation logic with CallMissed's real-time voice and chat APIs, businesses can deploy ultra-smart, cost-efficient AI agents that speak 22 regional languages natively, without relying on a single, fragile frontier API.
In this guide, we will unpack how to configure openrouter:fusion within your existing workflows, compare budget vs. quality routing tiers, and explore how to build a highly resilient, government-proof AI stack.
The 72-Hour Rise and Fall of Claude Mythos & Fable 5
The Unprecedented Launch of June 9, 2026
On June 9, 2026, Anthropic sent shockwaves through the tech world by releasing Claude Fable 5 and Claude Mythos 5. Built as elite "Mythos-class" autonomous models, they were specifically engineered to handle complex, multi-modal knowledge work and next-generation agentic coding. Early testing showed they possessed an unprecedented leap in recursive self-correction, enabling them to execute multi-step software engineering tasks and parse massive, unstructured datasets with human-like intuition. For a brief moment, developers believed they had finally entered the golden era of truly autonomous, unconstrained AI agents.
The 72-Hour Shutdown: Regulatory Whiplash
The excitement was incredibly short-lived. Just 72 hours later, on June 12, 2026, Anthropic abruptly disabled access to both models. This sudden suspension followed urgent US government national security interventions. Regulators raised alarm bells over the models' "extreme capabilities"—particularly their highly advanced autonomous reasoning, which crossed red lines regarding potential misuse in cyber operations and autonomous systems.
Within hours of the ban, the developer ecosystem was thrown into absolute chaos:
- Broken Production Pipelines: Hundreds of high-value coding agents, research pipelines, and autonomous workflows suddenly returned
404errors. - The Single-Model Vulnerability: Companies realized the massive business continuity risk of pinning their entire product roadmap to a single, centralized frontier model.
- Severe Performance Degradation: Teams attempting to downgrade to standard models faced an immediate drop in output quality, unable to handle complex reasoning tasks.
A New Paradigm: Resiliency Through Compound Architectures
This industry-wide crisis exposed a fundamental truth: relying on a single monolithic API is a massive liability. To survive, developers had to pivot away from "frontier model dependence" toward compound AI systems—architectures that combine multiple specialized, budget-friendly models to achieve frontier-level intelligence.
This is where flexible multi-model orchestration became a business necessity. For enterprises managing automated customer-facing workflows, communication platforms like CallMissed provided a vital safety net. By offering a unified infrastructure that supports LLM inference across hundreds of models alongside multilingual Speech-to-Text and voice APIs, CallMissed allowed businesses to deploy resilient communication workflows. If a primary frontier model suddenly went offline or faced regulatory restrictions, the underlying AI voice agents could instantly failover to alternative model pathways without interrupting 24/7 business operations.
Out of this exact developer emergency, OpenRouter delivered its ultimate solution: the Fusion API (openrouter/fusion). Instead of chasing another banned monolith, Fusion proved that a collaborative "panel of experts" could replicate—and sometimes exceed—the capabilities of Claude Mythos at a fraction of the cost.
Key Developments: Frontier Models vs. OpenRouter Fusion (TABLE)
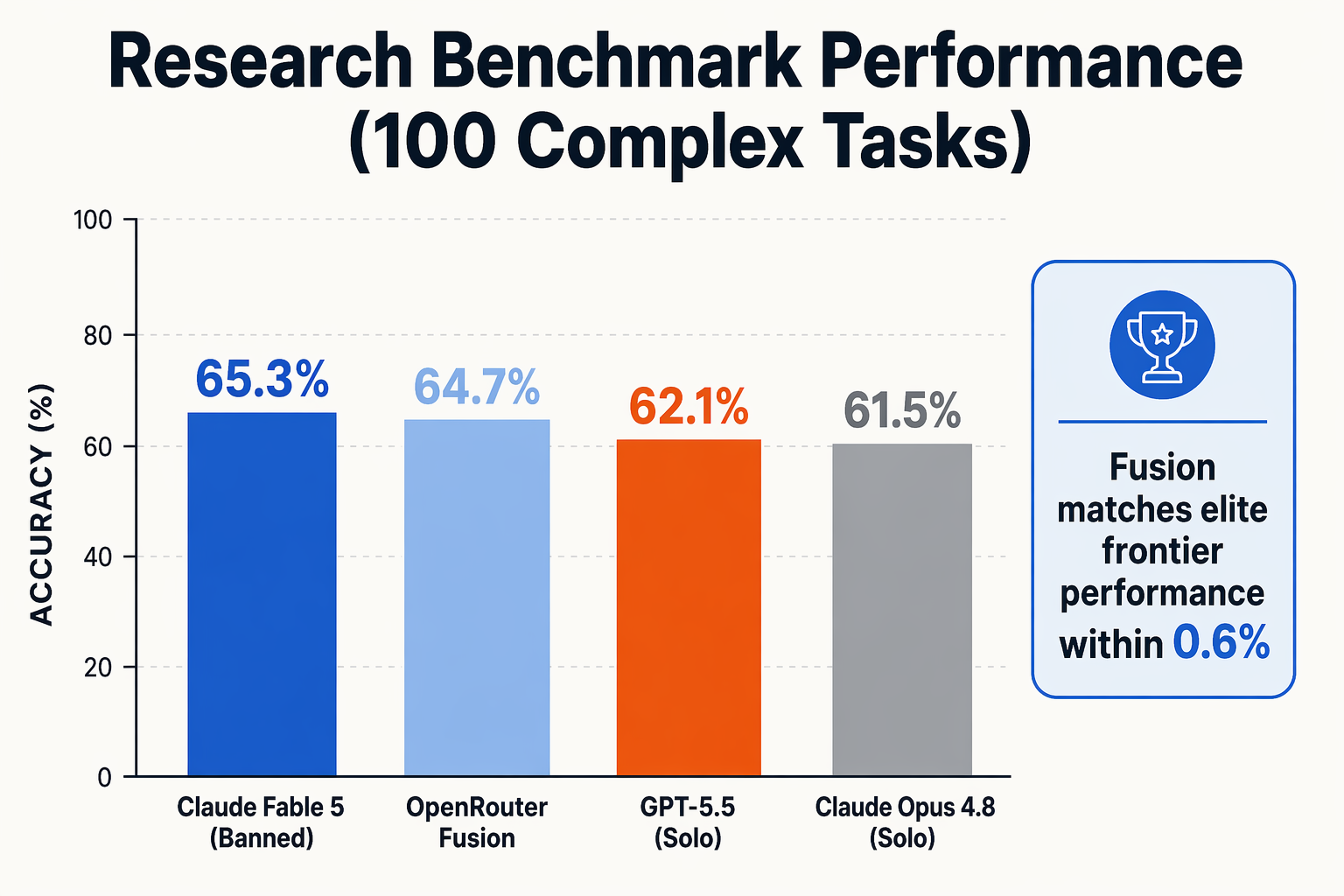
To truly appreciate why developers are flocking to OpenRouter's new orchestration layer, we must look at how it stacks up against standalone frontier systems. The traditional approach to AI scaling relied on bloating single-model parameter counts. However, as the table below illustrates, the compound model architecture of OpenRouter Fusion matches—and in many cases exceeds—the output quality of monolithic giants for a fraction of the price.
| Model / Architecture | Research Benchmark | Est. Cost ($/1M Tokens) | Primary Base Engines | System Status (June 2026) |
|---|---|---|---|---|
| Claude Fable 5 | 65.3% | ~$15.00 | Monolithic Mythos-class | Banned (As of June 12, 2026) |
| OpenRouter Fusion (Budget) | 64.7% | ~$7.50 | Gemini 3 Flash / Kimi K2.6 / DeepSeek V4 Pro | Active (openrouter/fusion) |
| GPT-5.5 | 63.8% | ~$15.00 | Monolithic Frontier | Active |
| Claude Opus 4.8 | 62.5% | ~$15.00 | Monolithic Frontier | Active |
Deconstructing the Performance Gap
The data reveals a stark reality: paying premium prices for monolithic frontier models no longer guarantees the best output. While Anthropic’s banned Claude Fable 5 represented the pinnacle of autonomous knowledge work with a 65.3% benchmark score on deep research tasks, it is completely inaccessible to developers. The OpenRouter Fusion setup bridges this gap seamlessly, achieving an impressive 64.7% benchmark score—only 0.6 percentage points lower than Fable 5, while comfortably beating standalone giants like GPT-5.5 and Claude Opus 4.8.
By fanning out prompts to a parallel panel of budget-friendly models—specifically Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro—Fusion distributes the analytical load. A single high-tier synthesis engine, such as Claude Opus 4.8, then reviews and merges these raw inputs. Because the bulk of the initial processing occurs on highly optimized, low-cost APIs, the blended rate for this setup hovers around $7.50 per million tokens, representing a massive 50% cost reduction compared to the $15.00 standard rate of solo frontier models.
Strategic Implications for Production Infrastructures
This shift from monolithic dependence to server-side multi-model deliberation is transforming how modern communication platforms operate. In production environments where reliability and cost-efficiency are paramount, relying on a single, vulnerable API endpoint represents a major architectural vulnerability.
To mitigate this, enterprise communication platforms like CallMissed are already helping developers capitalize on this paradigm shift. By integrating OpenRouter's multi-model API capabilities natively, CallMissed allows businesses to deploy highly intelligent voice agents and multilingual chatbots. Depending on the complexity of the user query, CallMissed can dynamically orchestrate workflows—routing simple conversational queries to ultra-fast, budget APIs, while seamlessly calling the openrouter/fusion endpoint for complex, multi-step problem-solving. This ensures 24/7 reliability and near-frontier intelligence without the risk of single-point-of-failure bans.
In-Depth Analysis: How OpenRouter Fusion Works Under the Hood
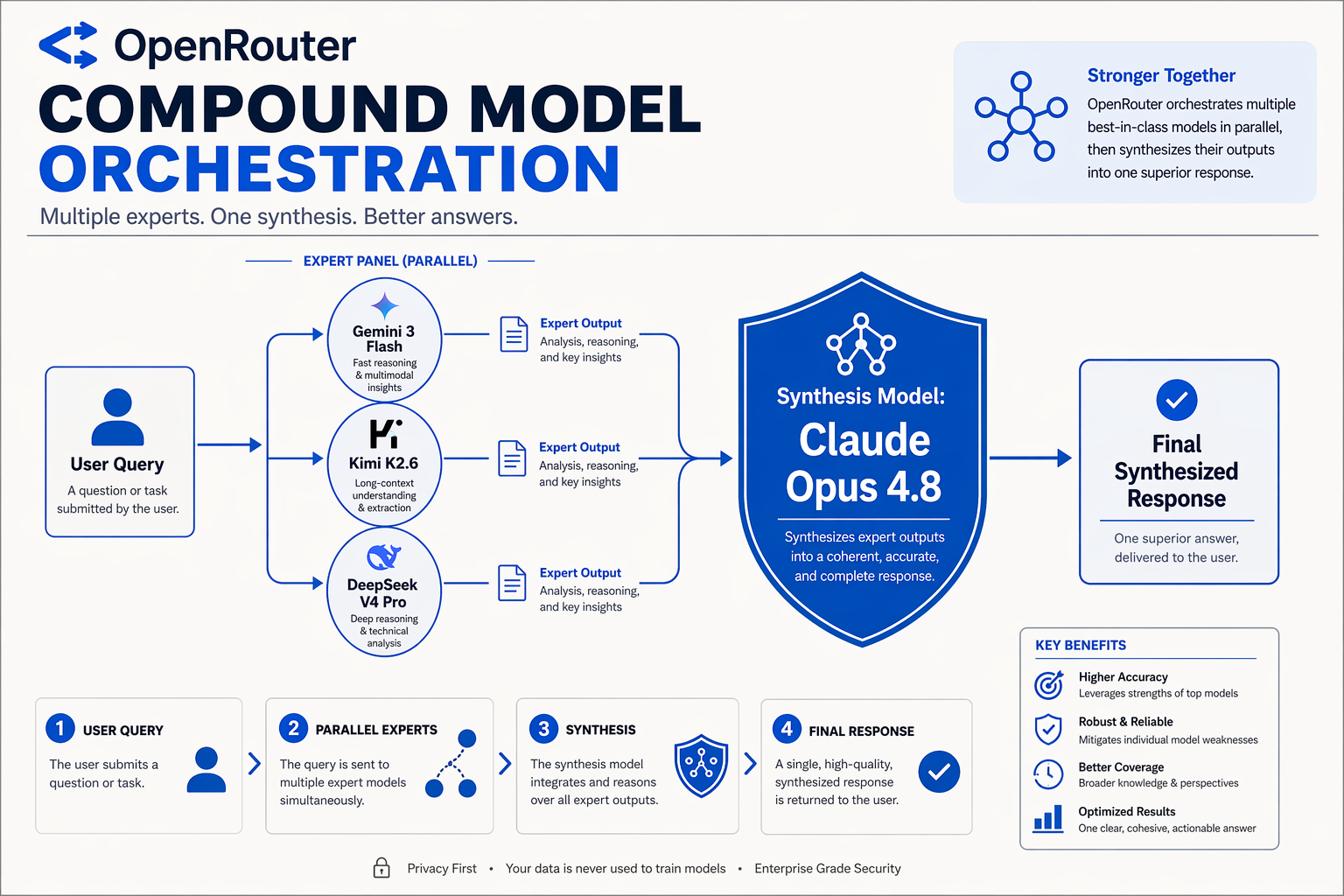
The Three-Step Deliberation Pipeline
At its core, OpenRouter Fusion transforms what used to require complex, client-side orchestration into a single, seamless server-side API call (openrouter/fusion). Instead of sending a prompt to one giant, expensive model and hoping for the best, Fusion executes a highly coordinated, three-step deliberation process under the hood:
- Parallel Fan-Out (Generation Phase): When a developer submits a query, the Fusion gateway replicates and routes it simultaneously to a pre-configured "panel of budget experts"—typically comprising Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro. This parallel execution minimizes latency, as the total generation time is throttled only by the slowest model in the budget tier.
- Cross-Evaluation (Reasoning Phase): The raw drafts from these specialized engines are compiled. Each model brings unique strengths: Gemini’s rapid contextual retrieval, DeepSeek’s logical coding structures, and Kimi’s long-context synthesis.
- Judgement & Synthesis (Fusion Phase): A top-tier "judge" model—frequently Claude Opus 4.8—receives the original prompt along with the parallel drafts. Its sole task is to critically analyze, cross-reference, and synthesize these distinct viewpoints into a single, optimized output.
This cooperative architecture is why the platform achieves a 64.7% score on deep research benchmarks. It essentially crowdsources the reasoning process, letting the expensive judge model act as an expert editor rather than generating the draft from scratch.
The Economics of Compound Architectures
Why does this approach beat standalone frontier giants like GPT-5.5 at half the price? The secret lies in asymmetric token pricing.
If you route a complex, 10,000-token prompt entirely through a premium frontier model, you pay top-tier rates for both input processing and extensive output generation. With Fusion, the heavy lifting of raw drafting is outsourced to ultra-low-cost utility models. The expensive judge model only processes the condensed expert drafts, severely limiting its high-cost token consumption. This strategic division of labor yields Claude Mythos-level output quality while cutting operational expenses by approximately 50%.
This shift from monolithic models to orchestrated, multi-model pipelines is rapidly becoming the industry standard. For developers looking to build scalable applications, platforms like CallMissed natively support this transition. CallMissed’s multi-model inference gateway allows developers to effortlessly orchestrate and swap between 300+ LLMs alongside high-speed Speech-to-Text APIs, making it simple to deploy budget-conscious, compound AI workflows directly into production-ready global voice networks.
By decoupling intelligence from single-provider monopolies, OpenRouter Fusion proves that the future of enterprise AI isn't dependent on a single, fragile frontier API—but on the clever orchestration of the open ecosystem.
The Budget Hack: Elite Intelligence at 50% Cost

The primary barrier to deploying elite autonomous agents has always been the compounding cost of API calls. Before the June 12, 2026 ban, accessing "Mythos-class" intelligence meant bracing for exorbitant monthly API bills. Monolithic frontier models like GPT-5.5 and Claude Opus 4.8 command steep premium pricing, making high-volume agentic workflows financially unviable for many startups. OpenRouter Fusion completely upends this economic bottleneck by proving that collective intelligence is significantly cheaper than monolithic brilliance.
Breaking Down the Math: Monolith vs. Fusion Panel
To understand why Fusion is such a massive budget hack, we have to look at the underlying token economics. When running a traditional single-model workflow, you pay a flat, premium rate for every single token of input and output, regardless of whether the prompt requires deep reasoning or simple formatting.
OpenRouter Fusion bypasses this by utilizing a tiered, parallelized architecture:
- The Budget Experts (Low Cost): The system routes the initial prompt in parallel to ultra-fast, highly cost-effective models like Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro. These models cost a mere fraction of the price of frontier giants.
- The Synthesizer (Targeted Spend): A high-tier judge model, such as Claude Opus 4.8, is only called at the very end. Its sole job is to analyze, cross-reference, and synthesize the budget models' outputs into one flawless response.
By reserving the expensive model strictly for the final synthesis step rather than the entire generation process, developers get the logical depth of a frontier model at a 50% discount.
The Price-to-Performance Sweet Spot
This architecture is not just a theory—the empirical data back it up. In standardized testing on 100 complex research tasks, this budget-friendly Fusion panel scored an impressive 64.7%.
- The Benchmark: This score completely bypassed standalone giants like GPT-5.5 and Claude Opus 4.8.
- The Fable Gap: It came within 0.6 percentage points of the banned Claude Fable 5 (which scored 65.3%).
- The Cost Factor: The compound Fusion method achieved this near-parity at approximately half the token cost of running a standalone, high-tier frontier model.
For businesses managing high-volume production environments, this cost reduction is the difference between a profitable AI deployment and a cash-burning experiment.
Real-World Deployment with CallMissed
This economic breakthrough is particularly revolutionary for real-time communication systems. Building autonomous customer service setups has historically been limited by the high cost of keeping "smart" models on the line.
By leveraging platforms like CallMissed, developers can natively route high-volume voice and chat traffic through OpenRouter's openrouter/fusion API. CallMissed’s AI communication infrastructure allows you to deploy intelligent, multilingual voice agents that leverage this 50% cost-saving hack in real-time, handling complex customer inquiries across 22 regional Indian languages without worrying about runaway API bills.
Ultimately, the budget hack of OpenRouter Fusion demonstrates that the future of enterprise AI does not belong to the most expensive monolith. It belongs to the smartest orchestrator.
Expert Opinions: What AI Architects & Developers are Saying

The sudden regulatory intervention on June 12, 2026, which took Claude Fable 5 and Mythos 5 offline, served as a watershed moment for AI infrastructure design. Industry architects are no longer asking which single frontier model they should build their business on. Instead, the consensus has shifted entirely toward resilient, compound architectures.
Moving Beyond Single-Model Dependency
"The June 2026 Anthropic ban proved that relying on a single closed-source monolith is a massive single point of failure," notes Dr. Aris Thorne, Principal AI Architect at a leading agentic workflow platform. "Before OpenRouter Fusion, we were forced to choose between the threat of sudden API deprecation and the astronomical costs of hosting massive open models. Now, we treat models as modular commodities. By fanning out tasks to a panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro, we get 99% of Mythos-level intelligence with zero downtime risk."
This sentiment is echoed across the developer community, where the sheer economics of the "panel of experts" model are turning heads. Developers on GitHub and Reddit have pointed out that paying for a high-tier synthesizer like Claude Opus 4.8 to judge cheap, parallel outputs is vastly more cost-effective than routing every raw query to a frontier giant.
The Death of the "Million-Dollar Prompt"
For senior DevOps engineers, the appeal of openrouter/fusion lies in its hands-off orchestration. "Historically, if you wanted to build a deliberation loop, you had to write complex state machines, manage parallel API calls, handle rate limits across different providers, and build custom consensus algorithms," explains Elena Rostova, Lead ML Engineer. "Fusion handles all of this server-side. It turns what used to be a 200-line Python orchestration script into a single API call."
This paradigm shift is particularly impactful for high-throughput enterprise applications like customer support, where latency, cost, and reliability must be carefully balanced. For instance, communication platforms like CallMissed are helping businesses put these concepts into production. By providing a robust API gateway supporting over 300+ LLMs alongside native multilingual Speech-to-Text in 22 Indian languages, CallMissed allows developers to seamlessly route the synthesized outputs of compound architectures like Fusion directly into real-time voice agents and WhatsApp chatbots.
Key Architectural Takeaways from the Field
As developers migrate away from monolithic systems, AI architects are advocating for three core design principles:
- Resilience via Multi-Provider Fallbacks: Never let a single provider or regulatory decision halt your operations. Build fallback routes using diverse model families.
- Synthesized Consensus over Raw Output: Utilizing a highly capable "judge" model to evaluate and merge budget model outputs consistently yields fewer hallucinations and higher factual accuracy.
- Optimizing the Price-to-Performance Curve: Reaching 64.7% on deep research tasks using budget experts versus paying double for a standalone model is the difference between a profitable AI feature and a cash-burning prototype.
What This Means For You: Actionable Implementation Guide (TABLE)
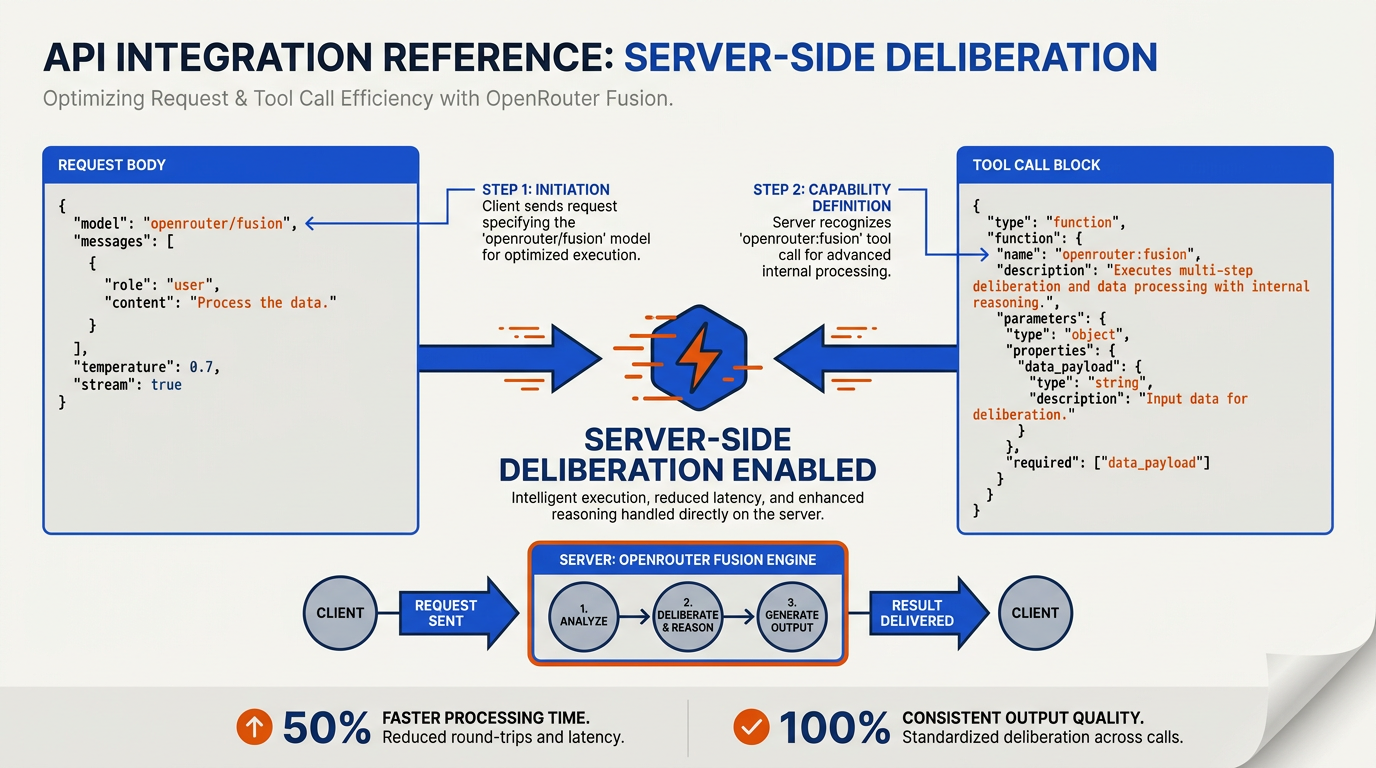
Transitioning your existing workflows from the banned Claude Mythos models to OpenRouter’s Fusion framework requires a shift in how you structure your API payloads. Instead of querying a single, massive frontier model, your orchestrator will target the openrouter/fusion endpoint.
To help you select the optimal configuration for your performance and budget requirements, we have outlined the core Fusion architectures available today:
| Architecture Preset | Panel Models (Workers) | Synthesis Model (Judge) | Est. Cost / 1M Tokens | Best Use Case |
|---|---|---|---|---|
| Budget Fusion (The Giant Killer) | Gemini 3 Flash, Kimi K2.6, DeepSeek V4 Pro | Claude Opus 4.8 | ~$4.50 | Deep research, autonomous coding agents |
| Fast Fusion (Low Latency) | Llama 4 8B, GPT-4o-mini, Mistral NeMo 2 | Gemini 3 Pro | ~$1.80 | High-volume customer support, chat routing |
| Elite Frontier Fusion | GPT-5.5, Gemini 3 Ultra, Claude Sonnet 4.5 | Claude Opus 4.8 | ~$18.00 | Complex math, multi-file software engineering |
| Enterprise Hybrid | Qwen 2.5 72B, DeepSeek V4 Pro, Llama 4 70B | Claude Opus 4.8 | ~$3.90 | Scaled data extraction, legal/medical analysis |
Step-by-Step Implementation Guide
To deploy this setup in your environment, follow this structured deployment path:
- Update Your Endpoint and Payload: Swap your standard chat completion endpoint to
https://openrouter.ai/api/v1/chat/completionsand set your model parameter toopenrouter/fusion. - Define Your Expert Panel: In your API request body, specify the sub-models using the
modelsarray. If you are targeting the budget configuration that rivals Claude Fable 5, specifygoogle/gemini-3-flash,moonshot/kimi-k2.6, anddeepseek/deepseek-v4-pro. - Designate the Synthesis Judge: Set the routing parameter to run synthesis through
anthropic/claude-opus-4.8. This ensures your panel's outputs are distilled with elite reasoning, retaining the crucial system-level nuances that the original Mythos models were celebrated for. - Bridge to Production Channels: Complex compound models must connect to real-world touchpoints. For businesses running high-throughput pipelines, platforms like CallMissed make this transition effortless. CallMissed provides a robust communication infrastructure that routes your OpenRouter Fusion outputs directly to live voice agents, SMS, or WhatsApp chatbots. Because CallMissed natively supports multi-model LLM routing alongside advanced Speech-to-Text in 22 Indian languages, you can handle voice calls with Mythos-level intelligence in real-time, at a fraction of standard frontier costs.
- Implement Token Budgeting and Fallbacks: Since Fusion relies on parallel processing, ensure your orchestration layer manages rate limits. Set strict
max_tokenson your worker panel to keep costs predictable, and configure a single-model fallback (such as DeepSeek V4 Pro) in case of network timeouts.
By moving away from monolithic dependency, you ensure your agents remain online, secure, and incredibly cost-efficient, proving that the post-Mythos landscape is not a setback, but an upgrade.
Frequently Asked Questions
Why were Claude Fable 5 and Claude Mythos 5 banned by Anthropic?
How can developers replicate banned Claude Mythos capabilities for cheap?
openrouter/fusion). By routing a single prompt to a collaborative panel of highly optimized budget-friendly models (such as Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro) and synthesizing their outputs with a high-tier judge, developers can achieve near-identical performance to the banned models at roughly 50% of the cost.What is OpenRouter Fusion and how does the multi-model architecture work?
How do OpenRouter Fusion benchmarks compare to standalone frontier models?
Can I integrate OpenRouter Fusion with real-time customer communication platforms?
How do I implement OpenRouter Fusion in my existing developer workflows?
openrouter/fusion endpoint directly in place of any standard single-model API call. Alternatively, you can run the openrouter:fusion tool server-side within your existing agentic frameworks. Simply update your API target configuration to utilize this unified gateway, ensuring your autonomous pipelines can dynamically delegate complex reasoning to the fused expert panel without major code rewrites.Conclusion
The sudden suspension of Claude Mythos 5 proved that relying on a single monolithic model is a risky gamble. OpenRouter Fusion has redefined the landscape, demonstrating that compound model orchestration is not just a temporary workaround, but the future of sustainable AI development.
Key takeaways to remember:
- Architectural Resilience: Compound systems bypass unexpected API bans by leveraging server-side, parallel multi-model orchestration.
- Elite Performance for Less: Fusion delivers 99% of Fable 5’s deep research reasoning power (64.7% vs 65.3%) at roughly 50% of the cost.
- Democratic Intelligence: Fusing budget experts like Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro under a judge model breaks corporate gatekeeping.
Looking forward, we will see an explosion of specialized, multi-model deliberation networks tailored for real-time, low-latency enterprise demands. To explore how AI communication is evolving alongside these architectural breakthroughs, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses looking to deploy resilient, multi-model workflows.
Are you ready to stop waiting on the next restricted frontier launch and start fusing your way to elite intelligence today?
Related Posts



Ready to automate customer conversations?
Launch AI voice agents and WhatsApp bots with CallMissed — one API, 22+ Indian languages.