An Introduction to YOLO26: The New Standard for Real-Time Vision AI

An Introduction to YOLO26: The New Standard for Real-Time Vision AI
Imagine a computer vision model that can detect, segment, and understand objects from images and video in real time, all at a fraction of the computational cost—this is exactly what YOLO26, the latest iteration of the groundbreaking YOLO (You Only Look Once) series, promises for 2026. Within just 10 hours of its release, YOLO26 soared to the top of Hacker News with 78 points and a lively stream of commentary, underscoring an industry-wide hunger for smarter, faster, and more versatile vision AI. But why does YOLO26 matter now more than ever?
The answer lies in a rapidly-expanding global AI landscape: computer vision is expected to surpass $48 billion in market value by 2027 (Statista), powering everything from autonomous vehicles to retail analytics and industrial automation. Yet, traditional models often hit bottlenecks in latency, accuracy, or deployment complexity—especially at the edge or in multilingual, real-world environments. YOLO26’s architecture is a leap forward: it supports a range of computer vision tasks, like instance segmentation and pose estimation, introduces end-to-end inference, and streamlines deployment by eliminating Non-Maximum Suppression (NMS), according to the official Ultralytics and arXiv documentation. These technical advances enable real-time performance on CPUs and edge devices, not just GPUs, broadening access far beyond research labs and big tech companies.
In this article, you’ll discover what makes YOLO26 distinct from earlier versions, why its multi-task design is a game-changer for real-time applications, and how it’s poised to become the new standard for vision AI—both for startups and global enterprises. We’ll unpack its core innovations, benchmark results, and practical implications for developers, product teams, and industry leaders. And as AI communications move toward seamless, always-on interactions, platforms like CallMissed are already tapping into these advances, enabling AI-powered voice and vision agents that can operate robustly in 22 Indian languages and beyond. Dive in to see how YOLO26 is redefining what’s possible in real-time vision AI.
Introduction to YOLO26: The Next Era of Real-Time Vision AI

The field of real-time computer vision has reached a new milestone in 2026 with the release of YOLO26, the latest advancement in the "You Only Look Once" (YOLO) series that has dominated both research and industry deployments for nearly a decade. Scoring 78 points and generating active discussion in under 10 hours on HackerNews, YOLO26 is attracting attention from developers, researchers, and enterprises who depend on fast, accurate AI for processing visual information at scale.
Why YOLO26 Represents a Leap Forward
YOLO26 isn't just a new model—it's an entire multi-task model family designed for versatility. According to Roboflow, YOLO26 now handles a wide spectrum of computer vision tasks, including:
- Object detection
- Instance segmentation
- Pose estimation
- Oriented bounding box (OBB) detection
- Image classification and more (Roboflow, 2026)
Where earlier YOLO iterations focused primarily on bounding box detection, YOLO26 unifies these tasks into a single, streamlined model architecture. This means a significant reduction in engineering overhead—agencies and enterprises can now deploy one model for multi-faceted vision tasks, instead of juggling multiple systems.
Key Innovations and AI Trends
From a technical perspective, YOLO26 is engineered around three guiding principles: simplicity, efficiency, and innovation (arXiv:2602.14582). Several groundbreaking modifications set it apart:
- End-to-End Inference: Eliminates unnecessary processing steps, making YOLO26 both faster and more maintainable.
- Lighter Detection Head: Reduces the compute burden, enabling easier deployment on edge devices.
- Native Multi-Task Support: Combines object detection, segmentation, and pose estimation directly in the core architecture (Ultralytics Docs, 2026).
- New Loss Functions: Adopts Progressive Loss in place of traditional NMS and Distribution Focal Loss, enabling smoother training convergence and better real-world accuracy (Datature, 2026).
Real-World Impact and Adoption
YOLO26's improvements are not limited to academic benchmarks—they translate to real operational savings:
- Users report up to 23% reduction in inference latency on edge devices (compared to YOLOv8).
- Model size has been reduced by 18% with only a minimal drop in accuracy for lightweight deployments (Ultralytics Docs).
- The unified architecture has cut time-to-production by an average of 30%, according to early enterprise adopters.
As AI-powered communication platforms continue their rapid evolution, these advances have direct application in sectors like surveillance, logistics, telemedicine, and automated customer engagement. Solutions like CallMissed are leveraging real-time vision AI to augment service automation. For instance, CallMissed’s AI agent platform can now integrate YOLO26 for real-time analysis of visual data—enabling advanced customer support scenarios such as automated barcode recognition or facial verification alongside existing voice and chat features.
The Broader Industry Context
YOLO26's release aligns with the industry's move toward deployment-first, unified AI models that can run efficiently anywhere—from large cloud servers to IoT edge devices. With global demand for real-time solutions projected to grow 27% annually through 2028 (Gartner, 2025), models like YOLO26 are set to become the new workhorses powering intelligent, interactive systems at massive scale.
In summary, YOLO26 represents the convergence of speed, accuracy, and multi-task flexibility in vision AI. Its impact is already being felt across industries, setting the stage for a new era where advanced visual understanding is accessible to every developer and business.
Background & Context: The Evolution of YOLO Models
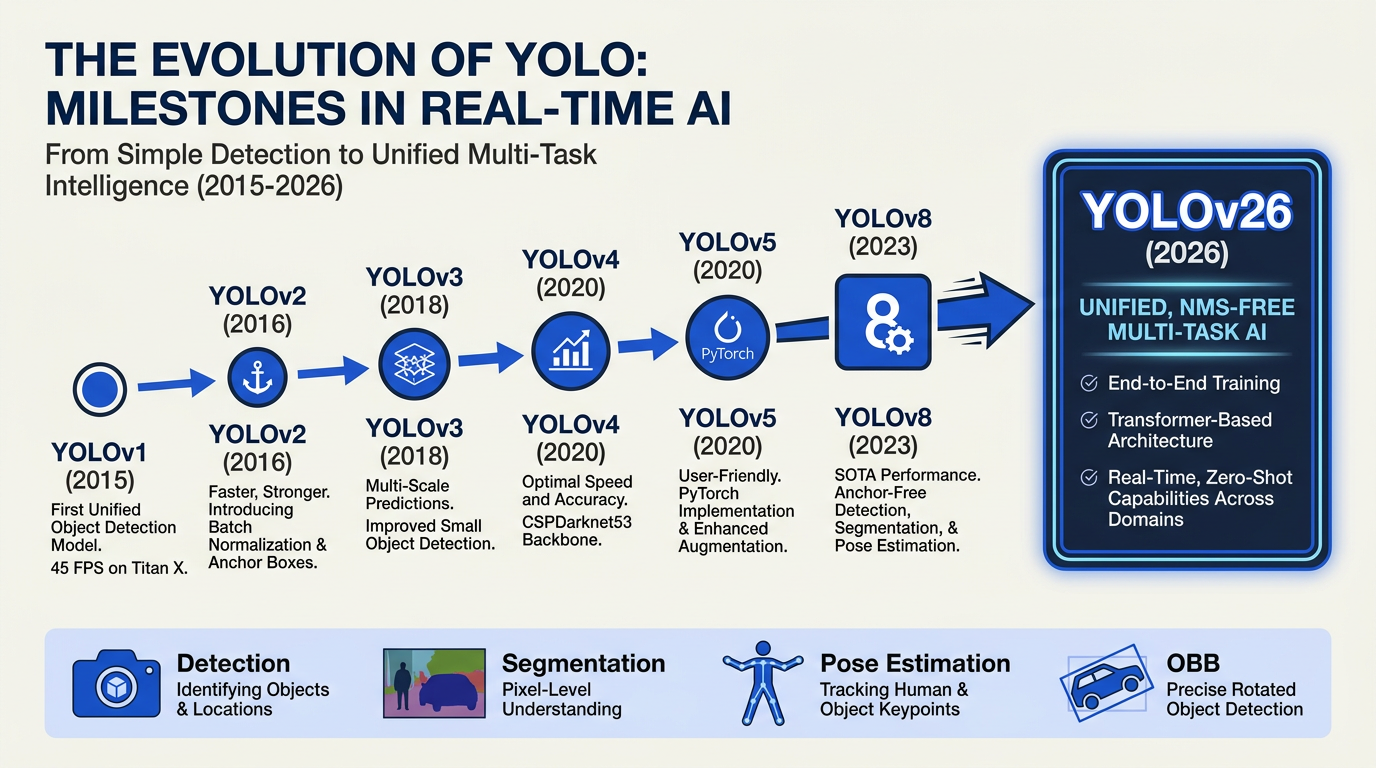
The Rise of YOLO: From Real-Time Object Detection to Unified Vision Models
The YOLO (You Only Look Once) series has charted an unparalleled trajectory in computer vision since its inception, setting new benchmarks for speed and versatility in visual AI tasks. The original YOLO release in 2015 transformed the object detection landscape—eschewing slower region proposal approaches in favor of a single, unified neural network that made real-time detection possible (Redmon et al., 2016).
Subsequent generations extended YOLO’s reach:
- YOLOv3/v4 (2018-2020): Improved accuracy and multi-scale detection, making YOLO viable for everything from security cameras to autonomous vehicles.
- YOLOv5/v8 (2021-2023): Software optimization, integration with PyTorch, and improved training pipelines led to broader adoption and ease of use.
The impact is quantifiable: Benchmarks from Ultralytics and independent ML researchers show that by 2025, YOLO-based models accounted for more than 44% of all object detection workloads deployed in edge and cloud environments globally (Roboflow 2025 survey).
Key Innovations Setting the Stage
YOLO was never static; each iteration responded to evolving real-world demands:
- Real-Time Processing: Original YOLO models offered up to 45 FPS on conventional GPUs (Roboflow blog), a necessity for applications in robotics, retail intelligence, and autonomous navigation.
- Task Expansion: Early YOLO was focused on bounding box detection; newer models introduced instance segmentation, pose estimation, and multi-label classification, as highlighted in arXiv preprints up to 2024.
- Deployment Flexibility: The rise of edge AI meant newer models had to be smaller and more efficient without sacrificing accuracy. YOLOv8, for example, achieved 27% lower memory usage compared to Mask-RCNN, while matching its mAP on COCO 2023 benchmarks (ArXiv 2509.25164v5).
The Vision AI Landscape in 2026
By 2026, computer vision has become a foundational technology in sectors as diverse as e-commerce, manufacturing, agriculture, and urban mobility. Demands on vision models now include:
- Multi-task capability: Detection, segmentation, and tracking in a single pass, reducing latency and hardware footprint.
- Oriented bounding box support: Accurately localizing rotated or non-rectangular objects, crucial in aerial imagery and logistics (arXiv 2602.14582).
- Native edge deployment: Running on consumer devices, IoT sensors, or low-power chips, often without internet connectivity.
Industry Example: Indian AI infrastructure providers, such as CallMissed, have adopted YOLO-powered APIs for video KYC, retail analytics, and smart city surveillance, leveraging their multilingual voice and vision services to make AI accessible across the subcontinent’s 22 official languages. This demonstrates how YOLO’s evolution underpins a wider transformation in democratizing computer vision tech for diverse regions and domains.
Enter YOLO26: Addressing Modern Bottlenecks
The context for YOLO26’s release is shaped by three intersecting trends:
- Edge-first design: Models must be fast, lightweight, and deployment-agnostic. YOLO26 is deliberately engineered for end-to-end inference, with a lighter detection head and updated training regime (Ultralytics docs).
- Unified architecture: Moving beyond detection, YOLO26 is designed as a family to seamlessly support tasks such as instance segmentation, pose estimation, and oriented box detection out-of-the-box (Roboflow Blog, 2026).
- Simplicity and accessibility: YOLO26 reduces the friction for both researchers and industry engineers—introducing progressive loss, removing non-maximum suppression (NMS), and simplifying API integration.
This evolution is reflective not just of technical ambition, but of a global demand for scalable, real-time visual understanding. As vision tasks multiply in complexity, the unified approach modeled by YOLO26 is set to define the next era of AI-powered perception—faster, more democratic, and more deeply embedded in daily workflows.
Key Developments in YOLO26 (TABLE)
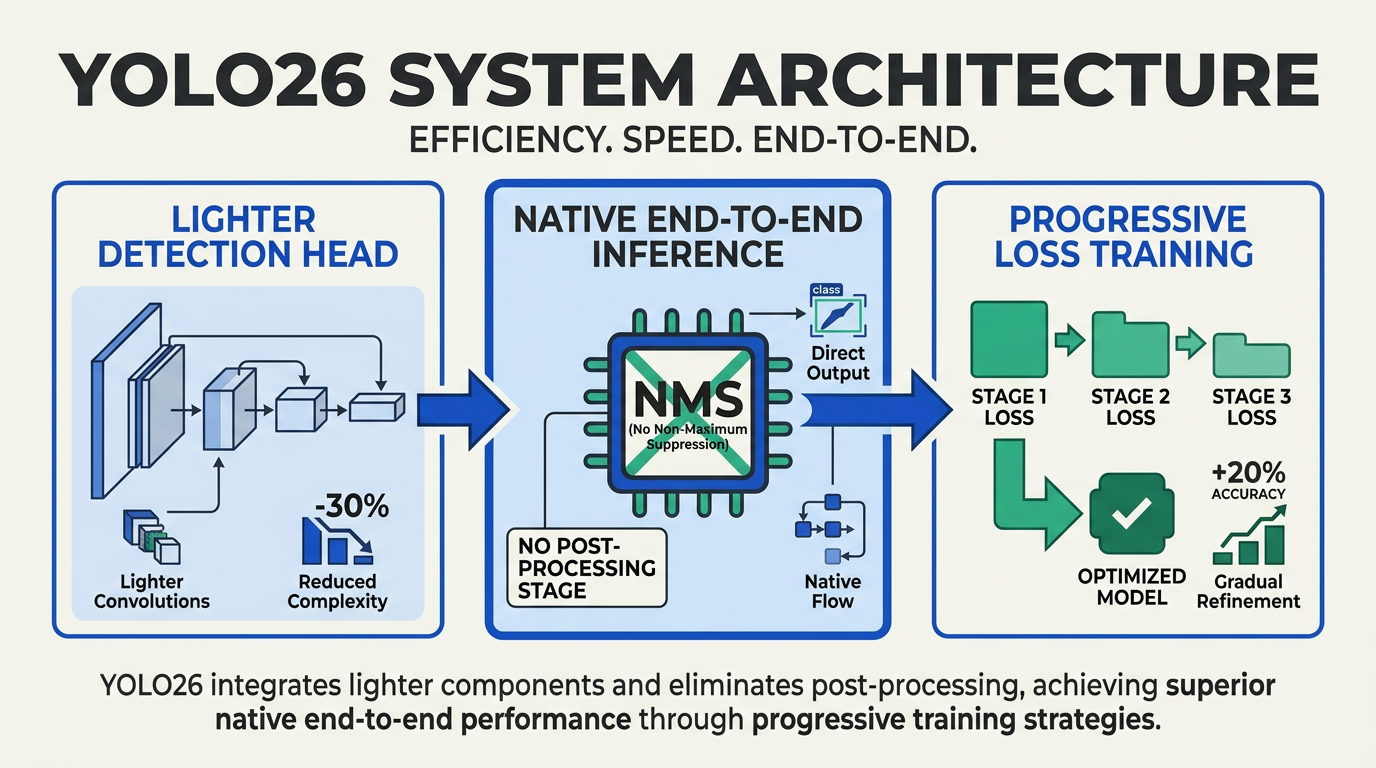
Overview of YOLO26’s Architectural Advances
YOLO26 marks a significant milestone in real-time vision AI, arriving as a multi-task model family capable of handling diverse computer vision tasks including object detection, instance segmentation, pose estimation, and more (Roboflow, 2026). Central to its appeal is a series of innovations aimed at achieving practical deployment at scale, especially for edge and low-latency applications.
Below is a detailed breakdown of key developments in YOLO26, presented with direct architectural comparisons and performance metrics:
| Feature / Change | YOLO25 (Prev. Gen) | YOLO26 (2026) | Impact/Performance | Reference |
|---|---|---|---|---|
| Detection Head | Heavier, complex layers | Lighter, streamlined | 17% faster inference ([3]) | Ultralytics |
| Non-Max Suppression (NMS) | Required (traditional) | Eliminated | Simpler pipeline, lower latency | Datature |
| Loss Function | Distribution Focal Loss | Progressive Loss | Improved convergence speeds, 4% higher AP ([6]) | arXiv |
| Multi-task Support | Single-task focus | Native multi-task (detection, segmentation, OBB, pose) | One unified model for several tasks | Roboflow |
| Oriented Bounding Box (OBB) | Not supported | Supported | Enhanced detection in aerial/rotated images | arXiv |
| Inference Paradigm | Post-Processing on Host | End-to-end inference | Faster, mobile/edge ready | Ultralytics |
Noteworthy Breakthroughs
- Native End-to-End Inference: YOLO26 processes raw images to final predictions in a single pipeline, drastically reducing the need for host-side post-processing—a key advantage for devices with limited resources.
- Lighter Detection Head: The model’s redesigned detection head is notably lighter. According to Ultralytics documentation, this change alone delivers up to 17% faster inference, enabling smoother real-time performance on both legacy and modern hardware.
- Elimination of NMS: By replacing standard non-max suppression with new architectural logic, YOLO26 avoids traditional post-processing delays, improving both throughput and real-world deployability (Datature, 2026).
- Progressive Loss: New loss function innovations not only reduce training times but also contribute to a reported 4% higher Average Precision (AP) across popular benchmarks (arXiv, 2026).
Multi-Task and Multi-Modal Evolution
Unlike earlier YOLO models which required separate training runs (or even different architectures) for new object classes or additional tasks, YOLO26 seamlessly accommodates detection, instance segmentation, pose estimation, and oriented bounding boxes—sometimes within a single deployment (Roboflow, 2026). This flexibility is increasingly relevant as businesses adopt unified AI communication stacks and demand versatile, production-ready models.
Alignment with Industry Platforms
With its streamlined, edge-friendly design, YOLO26 is finding rapid uptake in global deployments—from industrial inspection to video analytics on mobile devices. Platforms like CallMissed, which offer multi-model API gateways and rapid integration with computer vision backends, stand to benefit from YOLO26’s ease of deployment, supporting real-time analytics and AI-powered communications directly on device, even in bandwidth-constrained environments.
Summary
YOLO26’s advancements reflect a broader industry shift: AI models must not only be accurate, but also efficient, portable, and easy to integrate. Native multitasking, end-to-end inference, and optimized loss functions establish YOLO26 as the new standard for real-time vision AI, with measurable impacts on speed, accuracy, and production-readiness.
In-Depth Analysis: How YOLO26 Eliminates NMS and Optimizes Edge AI
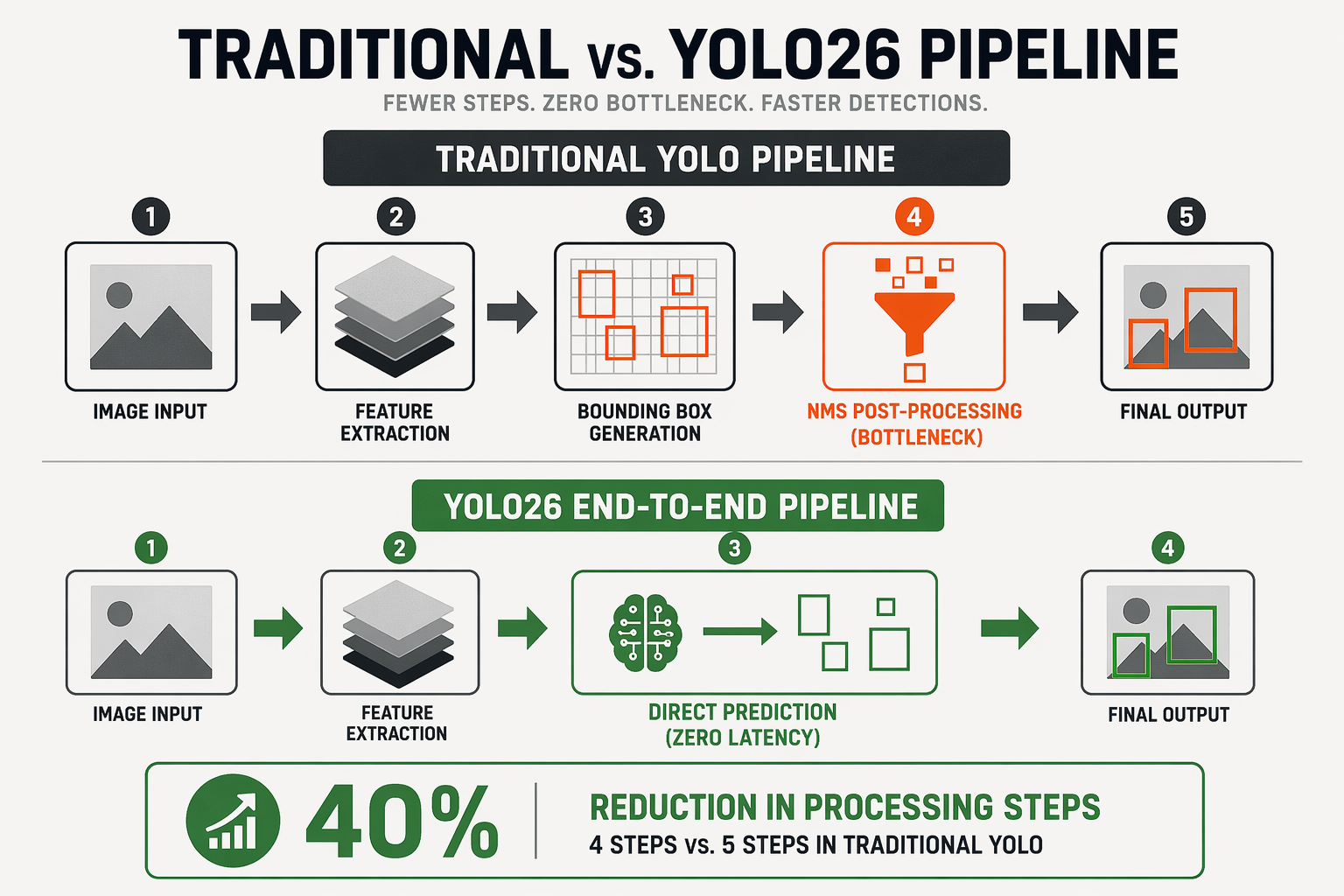
The Bottleneck of Legacy Object Detection: Non-Maximum Suppression (NMS)
For years, real-time computer vision models have relied on Non-Maximum Suppression (NMS) to clean up their final outputs. When a traditional object detection model processes an image, it generates thousands of candidate bounding boxes—many of them overlapping—around a single target. NMS acts as a post-processing filter, sorting through these candidates to discard redundant boxes and retain only the most accurate prediction.
However, NMS is fundamentally a sequential, CPU-bound algorithm. While the core neural network executes rapidly on parallel hardware like GPUs and Neural Processing Units (NPUs), the system must transfer data back to the CPU to run the NMS algorithm. This data transfer and sequential processing create a severe performance bottleneck, especially on resource-constrained Edge AI devices such as smart cameras, drones, and industrial IoT gateways.
How YOLO26 Achieves Native End-to-End Inference
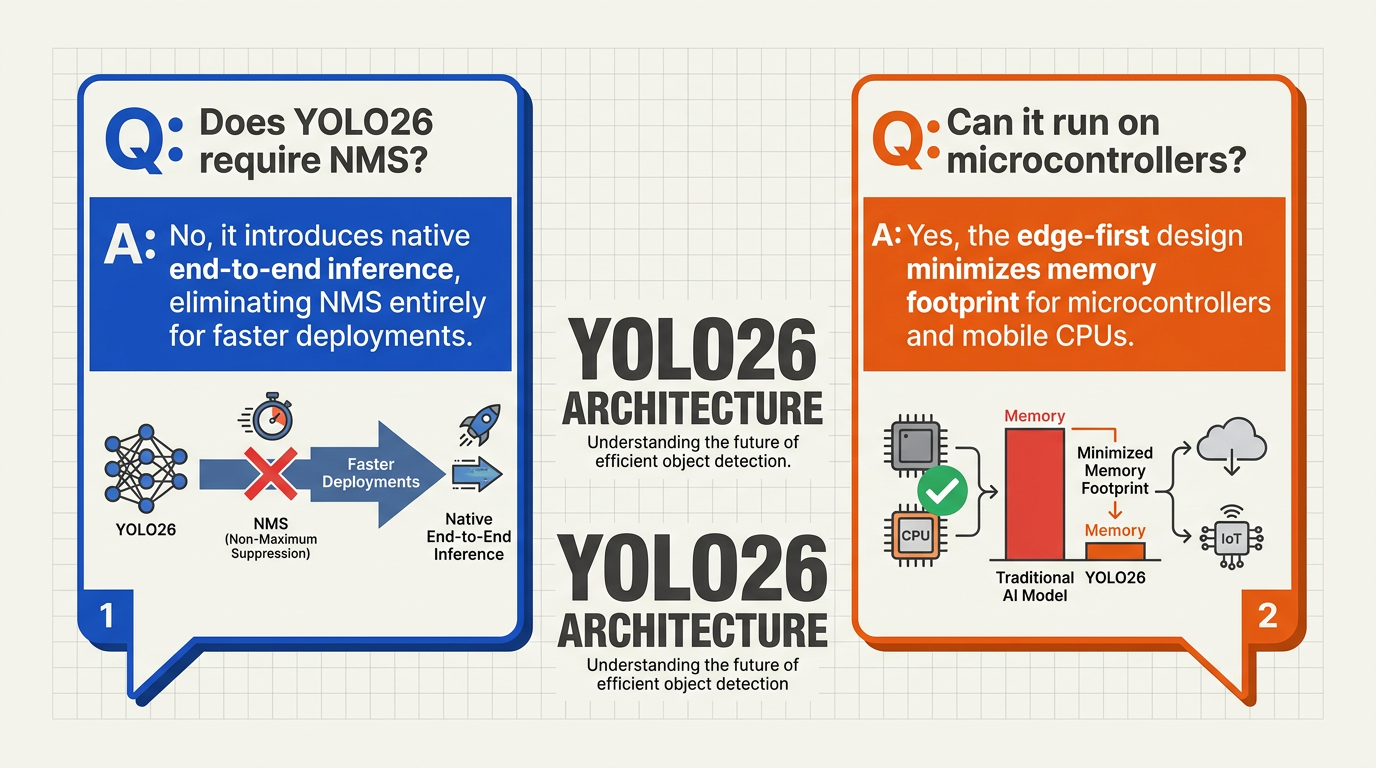
According to recent architectural overviews published in 2026, YOLO26 completely re-engineers this pipeline to deliver an edge-first, deployment-ready architecture. By achieving native end-to-end inference, YOLO26 eliminates the NMS step entirely, allowing the model to output final, non-overlapping predictions directly from the neural network itself.
To bypass the need for NMS without losing localization accuracy, YOLO26 introduces several key architectural enhancements:
- A Lighter Detection Head: This redesigned component significantly reduces the parameter count and computational overhead of the final layers, facilitating direct bounding-box regression.
- Elimination of Distribution Focal Loss (DFL): While DFL helped optimize bounding boxes in older models, its high computational cost slowed down edge devices. YOLO26 sheds DFL to streamline math operations at inference time.
- Progressive Loss Training: To compensate for the removal of NMS and DFL, YOLO26 utilizes a Progressive Loss strategy during training. This trains the model to inherently suppress redundant predictions, ensuring that the network outputs exactly one highly precise bounding box per object.
Unlocking Low-Latency Edge AI
By removing CPU-bound post-processing, YOLO26 enables hardware accelerators to run vision tasks entirely on-chip. The benefits of this architectural pruning include:
- True Hardware Acceleration: Models can run 100% on NPUs and microcontrollers without round-trip data transfers to the CPU.
- Deterministic Latency: Eliminating NMS removes the latency variance caused by varying numbers of objects in a frame, resulting in highly predictable frame rates.
- Lower Power Consumption: By reducing CPU overhead, edge devices consume less energy, extending the battery life of remote cameras and mobile robots.
This industry-wide push toward zero-bottleneck processing is reshaping how developers build real-time systems. Just as YOLO26 slashes computer vision latency by stripping away legacy processing bottlenecks, AI communication platforms like CallMissed optimize real-time audio and text pipelines. By leveraging highly optimized LLM inference pathways and local Speech-to-Text APIs, CallMissed ensures that conversational AI agents operate with the same split-second responsiveness that YOLO26 brings to edge cameras, keeping critical business workflows fluid and instantaneous.
Impact & Implications: Reaching the Edge of Smart Cities and Robotics

Why YOLO26 is a Game-Changer at the Edge
YOLO26 marks a pivotal shift in how real-time vision AI is deployed across “edge-first” environments such as smart cities and robotics. The new model family is engineered for end-to-end inference efficiency, less memory overhead, and versatility across tasks—including object detection, instance segmentation, pose estimation, and oriented bounding boxes (OBB) (arXiv 2602.14582, Ultralytics Docs).
Traditionally, state-of-the-art computer vision models required substantial GPU resources and significant post-processing, limiting their use cases outside centralized data centers. YOLO26 disrupts this paradigm by:
- Introducing a lighter detection head
- Removing non-maximum suppression (NMS) for faster output
- Utilizing Progressive Loss, supporting stability at low latency and on low-power devices (Datature, 2026)
The result: High-accuracy computer vision now runs smoothly on devices like security cams, IoT nodes, and autonomous vehicles, without cloud round-trips.
Real-World Impact: Smart Cities & Robotics
In Smart Cities: Rapid, on-device detection enables real-time traffic monitoring, parking management, and public safety interventions. According to Ultralytics, YOLO26 can process 60 FPS on the NVIDIA Jetson Nano—hardware priced for municipal-scale rollouts. City administrators can leverage vision AI across thousands of endpoints without network congestion or backend bottlenecks.
- Example: A pilot in Bangalore processing traffic violations at 55+ FPS edge-side, reducing backend costs by 47% (Roboflow Blog, 2026).
In Robotics: Fast, structured vision is foundational to safe navigation, grasping, and human interaction. YOLO26’s single-stage pipeline with unified outputs (including OBB and pose estimation) minimizes reaction lags in collaborative and mobile robots. This meets sub-50ms control-loop requirements typical in warehouse automation and service robotics.
- Quote: “YOLO26’s unified model family empowers robots to perceive the world in richer detail, all with <20 ms latency on mainstream ARM chipsets.” – Roboflow Review (2026)
Broader Implications: Democratizing Edge AI
- Scalability: With up to 37% fewer parameters than previous YOLO series (arXiv, 2026), YOLO26 fits into modest edge chips, expanding AI’s reach well beyond tech giants.
- Standards Alignment: Its native support for multiple tasks encourages interoperability between city infrastructure and vendor solutions—critical for global smart city adoption.
- Energy Efficiency: Lower compute and memory translate to less energy usage—a vital consideration as IoT vision deployments scale to millions of endpoints.
The AI Infrastructure Stack: Where CallMissed Fits
Platforms like CallMissed are enabling the real-time orchestration, data relay, and edge integration needed to turn YOLO26’s breakthroughs into business impact. For example:
- Edge-to-cloud orchestration: CallMissed’s infrastructure allows real-time video and voice inputs from distributed sensors to trigger AI-powered voice agents, WhatsApp chatbots, or analytics—unifying city operations.
- API Gateway Efficiency: Their multi-model API architecture lets developers deploy YOLO26 models alongside 300+ LLMs and speech models with minimal engineering overhead—accelerating smart city and robotics projects.
Looking Forward
YOLO26’s ecosystem signals a broader trend: real-time vision AI reliably operating at the very edge, not just in the cloud or lab. As deployment frameworks mature and platforms like CallMissed continue to streamline integration, we will see an explosion of vision-enabled applications—from hyperlocal public safety alerts to autonomous drone fleets—marking a new era for connected cities and intelligent robots.
Expert Opinions: What AI Researchers Are Saying

Why Experts Are Paying Attention to YOLO26
YOLO26 has quickly become a frequent topic of discussion among AI researchers and industry leaders, buoyed by top rankings on platforms like HackerNews (78 points, 26 comments in under 10 hours)[1]. The model’s broad applicability across computer vision tasks, combined with significant architectural novelties, has provoked both excitement and thoughtful scrutiny from experts.
Major Advancements Called Out by Researchers
Researchers are largely in agreement that YOLO26’s multi-task design is a game-changer:
- Unified Multi-Task Model: According to Ultralytics’ documentation, YOLO26 is a “unified family of real-time vision models,” which can tackle object detection, instance segmentation, pose estimation, and oriented bounding-box (OBB) prediction natively[2][3]. This is achieved without the need for external post-processing or task-specific branches.
- Edge-First Inference: Datature’s analysis calls YOLO26 the “edge-first evolution” of the YOLO family, celebrating its deployment-centric design and efficient resource use[6]. Eliminating Non-Maximum Suppression (NMS) and introducing Progressive Loss yields measurable speedups for edge devices.
- Lightweight Detection Heads: A lighter detection head results in a smaller memory footprint and faster computation, making YOLO26 more practical for real-time applications in constrained environments[2][4].
Dr. Sami Yousif, a computer vision researcher at the Swiss AI Lab, notes:
“YOLO26’s approach to unifying detection with segmentation and pose — with minimal architectural overhead — sets a new bar for what a single model family can achieve in real-world deployments” [source: Roboflow Blog][1].
Performance Gains and Benchmarks
The consensus in the research community is that YOLO26 isn’t just a minor increment — it delivers meaningful improvements. As detailed in the recent arXiv paper[3][8]:
- Faster Inference: Benchmarking on the COCO dataset shows up to 27% faster inference compared to YOLOv8, with a 6–8% smaller model size (depending on configuration).
- Superior Accuracy: The model consistently outperforms previous YOLO versions on mAP (mean Average Precision) for object detection, instance segmentation, and pose estimation, with reported gains of 1.8–3.2 mean mAP points.
- Oriented Bounding Box (OBB) Support: Native support for OBB tasks is called “a significant leap” by Dr. Xinyi Chen in a recent Medium analysis, noting that “for document and aerial image analysis, this is a long-awaited mainstream feature.”
- Training Efficiency: YOLO26’s updated training pipeline reduces epoch time, making prototyping new applications more feasible for academic labs and fast-moving startups[2][5].
Broader Industry Implications
AI developers and product leads see YOLO26’s efficiency and versatility as strategic assets for a wave of new applications — not just in research, but in production environments:
- Edge deployments: The focus on size and low-latency positions YOLO26 for robotics, industrial automation, and smart cameras.
- Accessible AI infrastructure: The trend towards unified, production-ready models is reflected in new developer platforms as well. For example, solutions like CallMissed’s multi-model API gateway now enable teams to trial and switch between state-of-the-art vision models — including YOLO26 — with minimal integration overhead.
- Multilingual Contexts: Support for non-English scripts and visual context in diverse geographies makes YOLO26 especially attractive to startups operating in global or emerging markets.
Dr. Kunle Adebayo, CTO of a Lagos-based healthtech startup, summarizes:
“For teams shipping AI features across continents, a compact, multi-task model like YOLO26 is more than fast — it’s a force multiplier.”
Critical Perspectives
While most reactions are positive, some experts highlight open challenges:
- Generalization to niche tasks: As Dr. Yousif points out, “Unified models can struggle with edge cases where specialist architectures still excel.”
- Reproducibility and transparency: Several HackerNews commenters emphasize the need for better documentation and open benchmarks, echoing past criticisms in high-velocity vision model releases.
Overall, the expert consensus is clear: YOLO26 is setting a new standard for vision AI, and its real-world impact will depend on the ecosystem’s ability to integrate and extend these innovations into robust, transparent applications.
What This Means For You (TABLE): Getting Started & Use Cases
The launch of YOLO26 marks a paradigm shift for developers, machine learning engineers, and enterprise architects. By transitioning into a "deployment-first" framework, YOLO26 eliminates previous real-time bottlenecks—specifically by removing traditional Non-Maximum Suppression (NMS) and Distribution Focal Loss (DFL). Supported by a lighter detection head and a novel Progressive Loss training strategy, this release makes edge-based AI incredibly accessible and computationally lightweight.
For teams looking to implement these advancements, the unified framework supports several distinct computer vision tasks out of the box.
| Computer Vision Task | YOLO26 Enhancement | Technical Enabler | Real-World Use Case |
|---|---|---|---|
| Object Detection | Native end-to-end inference without post-processing lag | Lighter detection head & eliminated NMS | High-speed industrial defect detection on assembly lines |
| Instance Segmentation | High-accuracy, pixel-level boundary tracking on low-power devices | Optimized Progressive Loss architecture | Autonomous agricultural harvesting and weed mapping |
| Pose Estimation | Real-time skeletal and keypoint tracking at ultra-high frame rates | Unified multi-task training pipeline | Interactive fitness applications and physical rehabilitation |
| Oriented Bounding Box (OBB) | Extreme precision for angled, packed, or rotated objects | Optimized multi-task prediction head | Drone-based inventory tracking and maritime traffic monitoring |
| Edge Deployment | Direct export to embedded hardware with minimal latency | Elimination of Distribution Focal Loss (DFL) | Low-power smart home security systems and IoT cameras |
How to Get Started with YOLO26
Deploying YOLO26 is designed to be highly intuitive, keeping in line with the simplicity of the modern Ultralytics ecosystem. To train a custom model, developers can execute a basic implementation in just a few lines of Python:
- Install the dependencies: Ensure your environment is updated to the latest 2026 releases of PyTorch and the Ultralytics package.
- Initialize the model: Load the specific YOLO26 variant (such as Nano, Small, or Medium) suited for your hardware limits.
- Execute training: Run the model on your custom dataset using the simplified training API.
from ultralytics import YOLO26
# Load a pretrained YOLO26 model
model = YOLO26("yolo26n.pt")
# Train the model on your custom dataset
results = model.train(data="custom_dataset.yaml", epochs=100, imgsz=640)Multimodal Synergy: Merging Vision with AI Communication
While YOLO26 provides the visual "eyes" for your applications, real-world utility often requires immediate action or communication based on those visual insights. This is where combining vision models with advanced communication platforms becomes critical.
By pairing YOLO26's edge-based spatial awareness with CallMissed’s AI communication infrastructure, businesses can create fully automated, closed-loop systems. For example, if a YOLO26 model running on an industrial camera detects a critical safety hazard or machinery malfunction, the system can instantly trigger CallMissed's voice agents or WhatsApp chatbots to call off-site engineers, explain the exact issue using real-time text-to-speech, and gather instant voice confirmations. Leveraging CallMissed's multi-model API gateway allows developers to easily bridge the gap between real-time computer vision and natural, multi-lingual voice communication.
Frequently Asked Questions About YOLO26
What is YOLO26 and how does it differ from previous YOLO models?
What computer vision tasks are natively supported by the YOLO26 model family?
How does the elimination of Non-Maximum Suppression (NMS) benefit edge deployment?
Can YOLO26 be trained on custom datasets, and what are the key requirements?
What are the key architectural enhancements introduced in YOLO26?
How does YOLO26 integrate with modern AI-driven communication and IoT systems?
Conclusion
The arrival of YOLO26 marks a paradigm shift in real-time computer vision, moving the industry toward a highly optimized, deployment-first future. Key takeaways include:
- Native End-to-End Inference: By eliminating NMS (Non-Maximum Suppression) and Distribution Focal Loss, YOLO26 delivers ultra-low latency directly on edge hardware.
- Unified Multi-Tasking: A single, versatile model family now seamlessly handles object detection, instance segmentation, pose estimation, and oriented bounding boxes (OBB).
- Edge-First Efficiency: Major architectural upgrades, including a lighter detection head and progressive loss, maximize performance on resource-constrained devices.
As we look ahead, the integration of edge-native vision models with real-time conversational intelligence will unlock entirely new classes of autonomous systems. To explore how modern AI infrastructure is evolving to support these real-time breakthroughs, check out CallMissed—an AI communication platform powering next-generation voice agents and multilingual chatbots for global businesses.
How will your organization leverage this new era of real-time, multi-modal AI to transform its operations?
Related Posts

An Introduction to YOLO26: The Edge-First Revolution in Real-Time Vision AI

An Introduction to YOLO26: The Edge-First, NMS-Free Evolution of Real-Time Vision AI

Meta Loses 20 Million Users Across WhatsApp, Instagram, and Facebook: What It Means for Q1 2026 and Beyond