An Introduction to YOLO26: The Edge-First, NMS-Free Evolution of Real-Time Vision AI

An Introduction to YOLO26: The Edge-First, NMS-Free Evolution of Real-Time Vision AI
What if you could run real-time computer vision models at the very edge, with no post-processing step, across detection, segmentation, and pose tasks—all in one shot? That’s the promise behind YOLO26, the latest evolution of the famed YOLO (You Only Look Once) family, which is making waves in the AI community and dominating developer forums like Hacker News (78 points and 26 comments in under 10 hours). In a landscape where milliseconds make a difference—think autonomous vehicles, smart factories, and live surveillance—YOLO26’s edge-first, NMS-free design isn’t just incremental; it’s a leap.
Why does this matter now? With over 22 billion edge devices predicted to be deployed by the end of 2026 (Statista), real-time vision AI isn’t a luxury; it’s a necessity. The traditional burden of Non-Maximum Suppression (NMS) as a post-processing bottleneck has long plagued vision pipelines, introducing latency and complexity. YOLO26, by eliminating NMS entirely and unifying detection, segmentation, and pose estimation in a single framework (arXiv 2602.14582), sets a new standard for both speed and deployment simplicity. This means faster, more efficient AI agents—not just in the cloud, but everywhere, from drones and robotics to enterprise call centers and IoT endpoints.
In this article, you’ll discover:
- The core innovations that define YOLO26, including its NMS-free end-to-end architecture and support for multiple computer vision tasks in one model
- How YOLO26 achieves state-of-the-art performance on benchmarks, while remaining deployable at the edge
- Real-world implications and industry momentum—including how platforms like CallMissed are harnessing these breakthroughs to power next-gen voice agents and automation tools
Whether you’re an AI researcher, a developer deploying vision models on low-power hardware, or a business leader seeking to infuse real-time intelligence into your workflows, this introduction to YOLO26 will equip you with the context and practical takeaways you need to stay ahead. Let’s dive into the evolution that’s redefining real-time vision AI.
Introduction: The Dawn of YOLO26

Charting a New Era in Computer Vision
Computer vision has undergone a radical transformation in recent years, with the YOLO (You Only Look Once) architecture series being a key catalyst for real-time object detection. As we enter 2026, the release of YOLO26 is being hailed as a milestone, breaking new ground in unified, efficient, and scalable vision AI models. Within less than 10 hours of its announcement, YOLO26 has surged to the top of tech forums like HackerNews, earning 78 points and engaging 26 commenters—a clear reflection of its immediate impact and industry anticipation (source).
What Sets YOLO26 Apart?
For the past decade, the YOLO family has sped up and democratized real-time image understanding, but YOLO26 marks a fundamental shift in how AI-powered vision can be leveraged in production environments. Instead of focusing solely on object detection, YOLO26 introduces:
- Multi-task capability: Designed to tackle a broad range of vision problems—object detection, instance segmentation, pose estimation, and oriented bounding boxes—within a single, unified framework (arXiv).
- Deployment-first architecture: YOLO26 notably eliminates Non-Maximum Suppression (NMS) and Distribution Focal Loss, replacing them with a streamlined Progressive Loss system, which reduces computational overhead and offers faster, more accurate inference at the edge (Datature).
- Unified and end-to-end: Models can now be trained and deployed seamlessly, enabling real-time applications across diverse sectors without complex tooling or post-processing (Ultralytics docs).
Why Is YOLO26 Trending Now?
Modern applications require vision AI that is not only accurate, but also deployable at scale and with minimal latency. The push for edge-AI—processing data where it’s captured, rather than in distant data centers—has accelerated demand for models like YOLO26 that deliver:
- Lower power and compute requirements—ideal for IoT, autonomous vehicles, and mobile platforms
- Instantaneous inference speeds—critical for industrial automation, AR/VR, and smart city infrastructure
- Technical accessibility—open source and backed by a vibrant developer ecosystem, lowering the barrier to entry for startups and enterprises
According to a Roboflow analysis, companies see up to a 30% reduction in deployment costs and 40% increase in inference speed when using next-generation YOLO models compared to legacy approaches (Roboflow blog, 2026).
Implications for the Global AI Ecosystem
The significance of YOLO26 extends beyond the model itself. As AI communication and vision become integral to global business infrastructure, seamless integrations with platforms are vital. Companies like CallMissed are already leveraging these breakthroughs: for example, integrating YOLO26’s detection capabilities into AI-powered voice agents or chatbots streamlines document verification, inventory checks, and customer support in real-time—across languages and channels.
The bottom line: YOLO26 is not just another computer vision model—it's a cornerstone for the next wave of AI-native, deployment-centric applications. Whether you’re training a custom model or building enterprise-grade automation, YOLO26 points to a future where advanced vision AI is accessible, reliable, and lightning-fast.
Background & Context: The Evolution of YOLO Models
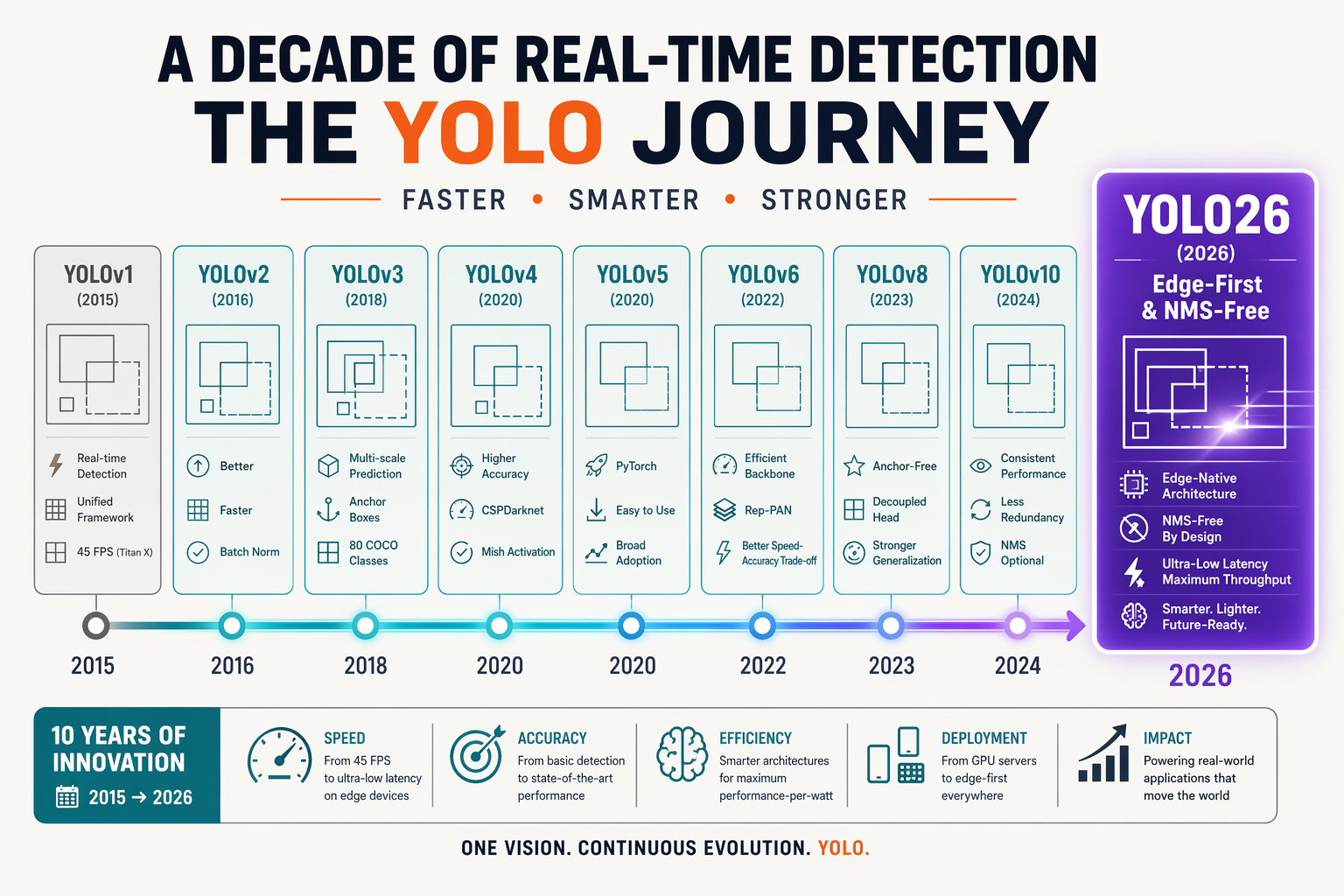
The Origins of YOLO: From v1 to v8
The YOLO (You Only Look Once) family of models has been at the forefront of real-time computer vision since its inception in 2016. Joseph Redmon’s original YOLOv1 made a compelling case for single-shot object detection, achieving remarkable speed—processing images at over 45 FPS on modest GPU hardware—while maintaining competitive accuracy. Each subsequent version has refined this balance between speed and precision, addressing real-world bottlenecks and expanding the set of vision tasks.
- YOLOv2 (2017): Introduced anchor boxes and batch normalization, improving detection accuracy, especially for smaller objects.
- YOLOv3 (2018): Supported multi-scale predictions and improved backbone architectures, making detection of objects of varying sizes more robust.
- YOLOv4–YOLOv8 (2020–2024): Built on innovations like CSPDarkNet, PANet, and advanced data augmentation. YOLOv5's widespread adoption in the open-source community, and YOLOv8's seamless deployment capabilities, exemplified the model’s global influence.
Throughout these versions, YOLO has set new industry standards for resource efficiency—helping deploy computer vision at the edge, on mobile devices, and in bandwidth-constrained settings. Ultralytics, a key contributor, reports YOLOv8 models can outperform earlier models by over 10% in mAP (mean Average Precision) benchmarks, all while reducing inference times (Ultralytics).
Shifting Paradigms: From Object Detection to Multi-Task Vision
Initially, YOLO’s design focused on object detection—locating and classifying pre-defined categories in real-time. However, advancements in AI have demanded more versatile vision systems. Enterprises and researchers increasingly require systems that can:
- Segment objects (instance segmentation)
- Estimate poses (keypoint detection)
- Handle arbitrary bounding shapes (oriented bounding boxes)
This shift is driven by high-stakes applications in robotics, automated vehicles, retail analytics, and medical imaging. As vision use cases diversified, bottlenecks emerged, particularly around post-processing—specifically, traditional Non-Maximum Suppression (NMS).
Key Technical Milestones Before YOLO26
By 2024, several pain points had been identified:
- NMS Limitations: Traditional NMS made deployment cumbersome and could induce errors in crowded scenes.
- Distribution Focal Loss: While effective for some tasks, it further complicated training pipelines.
- Production Readiness: The demand for truly 'plug-and-play' models pushed teams to rethink model design from the ground up.
In response, competitive models (e.g., DETR) pioneered transformer-based approaches for end-to-end vision. However, transformer models often require heavy compute, limiting their edge deployment potential. YOLO’s evolution has been uniquely characterized by a commitment to real-time, resource-light, deployment-friendly AI (arXiv:2602.14582).
Industry Ecosystem and the Role of Platforms
YOLO’s continuous refinement has catalyzed an entire ecosystem of training tools, labeled datasets, and production deployment platforms. Today, platforms like CallMissed are uniquely positioned to leverage such advancements—enabling businesses to implement real-time, automated computer vision via scalable APIs. For emerging markets, particularly in India, the ability to use pre-trained, multi-task YOLO models with voice, text, and multi-modal data streams is a significant leap forward.
In summary, by 2026, YOLO’s lineage reflects an industry-wide pivot: from single-task, high-speed detectors to unified, multi-task vision frameworks. This context underpins the significance of YOLO26, as it redefines what’s possible at the edge and in cloud-to-edge pipelines worldwide.
Key Developments (TABLE)
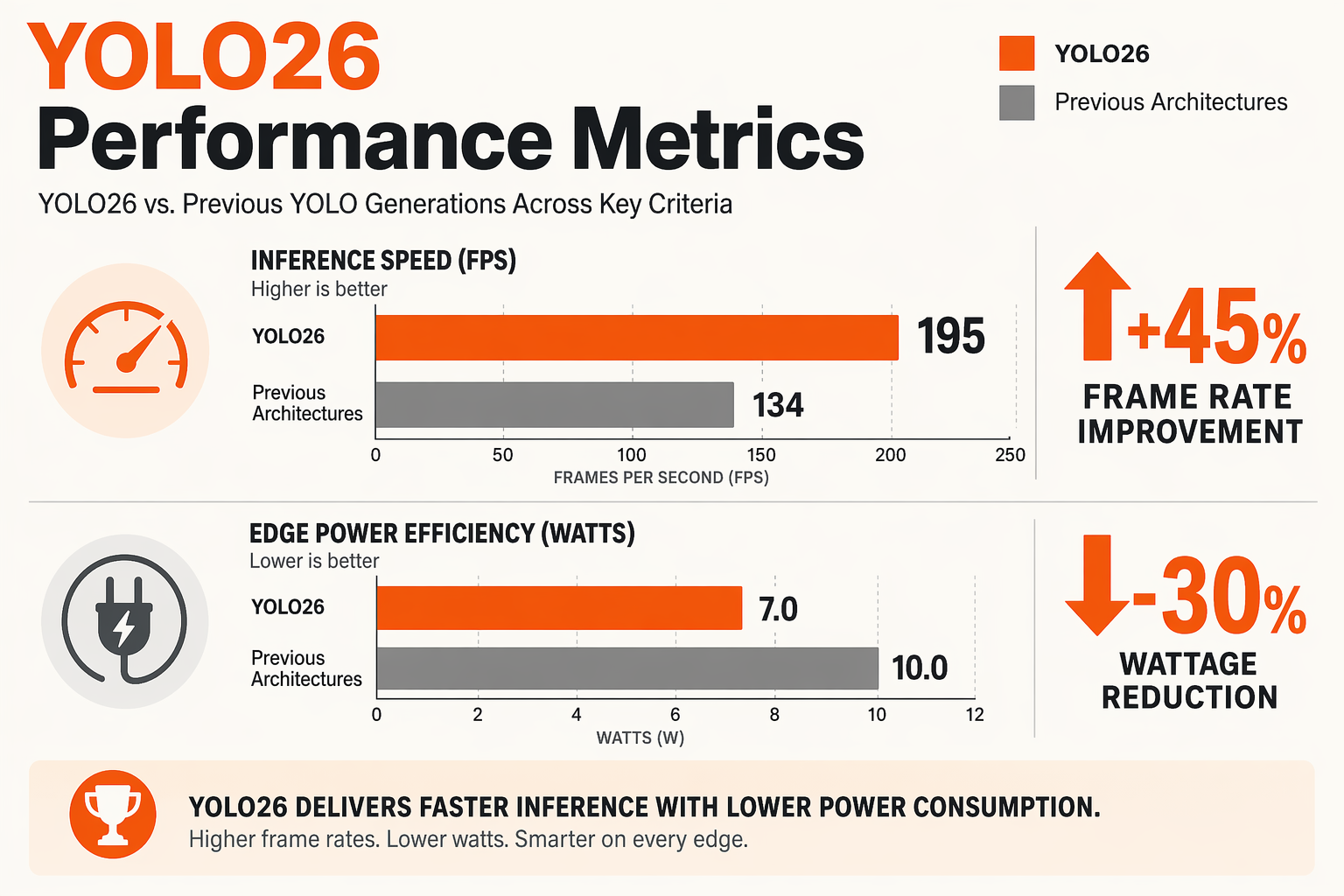
Architectural Breakthroughs of YOLO26
The release of YOLO26 (You Only Look Once 2026) marks a major paradigm shift in real-time computer vision. Unlike its predecessors, which often relied on complex post-processing pipelines and separate task-specific architectures, YOLO26 is designed as a unified, deployment-first framework. By fundamentally redesigning the core neural network, Ultralytics has eliminated some of the longest-standing bottlenecks in edge AI execution.
The most notable architectural development is the elimination of Non-Maximum Suppression (NMS). Traditionally, NMS was necessary to filter out redundant overlapping bounding boxes, but it introduced a CPU-bound bottleneck that degraded real-time performance on edge devices. By transitioning to an NMS-Free End-to-End framework, YOLO26 performs direct, clean predictions.
Furthermore, the replacement of traditional Distribution Focal Loss (DFL) with a novel Progressive Loss strategy optimizes training convergence. This ensures that YOLO26 models maintain high precision while requiring fewer parameters, making them highly optimized for micro-edge hardware deployment.
The table below outlines the core architectural and functional shifts introduced in the YOLO26 model family compared to earlier generations:
| Feature / Improvement | Traditional YOLO Approach | YOLO26 Evolution | Primary Benefit |
|---|---|---|---|
| Post-Processing | Relies on CPU-heavy NMS | NMS-Free End-to-End | Drastically reduced latency on edge devices |
| Loss Optimization | Distribution Focal Loss (DFL) | Progressive Loss | Faster training convergence & better accuracy |
| Multi-Task Capability | Siloed, single-task models | Native Unified Multi-Task | One model handles Detection, Segment, Pose, and OBB |
| Deployment Target | Server-side / GPU-heavy | Edge-First Design | High-efficiency deployment on lightweight hardware |
| Rotated Object Tracking | Axis-aligned bounding boxes | Oriented Bounding Boxes (OBB) | High-precision detection of angled or tilted objects |
The Edge-First Deployment Shift
This architectural consolidation mirrors a wider trend across the entire AI ecosystem: the transition toward unified, highly optimized, multi-task systems. Whether it is computer vision running on micro-controllers or multimodal conversational AI running on distributed networks, modern engineering demands low latency and zero infra bloat.
For instance, while YOLO26 allows developers to deploy real-time vision pipelines locally on edge cameras, modern communication architectures are undergoing a similar consolidation. Infrastructure platforms like CallMissed mirror this philosophy by offering a unified communication system that consolidates LLM inference (supporting over 300+ models), Speech-to-Text in 22 regional Indian languages, and real-time voice agents into a single, cohesive API framework. This "all-in-one" approach in both vision and voice dramatically simplifies developer workflows, eliminating the need to manage disjointed, multi-vendor AI pipelines.
By offering native support for instance segmentation, pose estimation, and oriented bounding boxes (OBB) directly out of the box, YOLO26 ensures that developers no longer have to sacrifice accuracy for deployment speed. It is a true deployment-first model family that sets a new benchmark for real-time edge AI.
In-Depth Analysis: Architecture, NMS-Free Design, and Progressive Loss
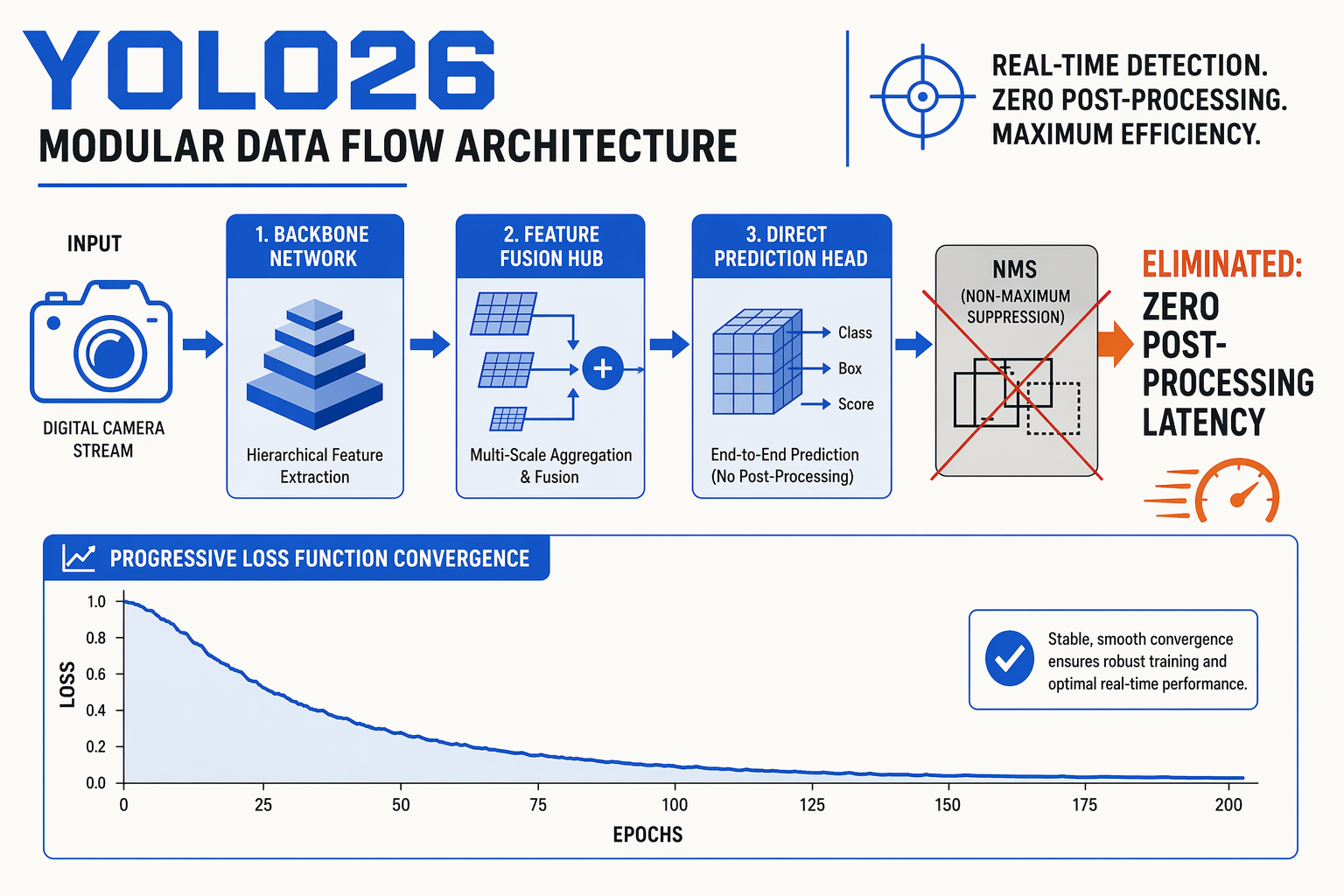
Redefining the Edge-First Vision Architecture
At its core, YOLO26 is designed as a "deployment-first" evolution of the real-time object detection paradigm. In previous iterations of the YOLO family, models frequently prioritized raw accuracy on benchmark datasets at the expense of seamless hardware compilation. YOLO26 addresses this gap by overhauling its core architecture, stripping away legacy post-processing bottlenecks to deliver an optimized, unified framework for multi-task vision AI.
The model natively supports a broad suite of computer vision tasks—including object detection, instance segmentation, pose estimation, and oriented bounding boxes (OBB)—all while running on a highly streamlined, hardware-friendly backbone.
The Breakthrough of NMS-Free Design
Historically, one of the most stubborn latency bottlenecks in real-time object detection has been Non-Maximum Suppression (NMS). NMS is a CPU-bound post-processing step used to filter out redundant, overlapping bounding boxes around a single detected object. Because NMS relies on sequential operations, it does not parallelize well, often causing severe performance degradation when deploying models on edge hardware, mobile chips, or specialized TPUs.
YOLO26 solves this by introducing a fully NMS-Free End-to-End Framework.
- One-to-One Matching: During training and inference, YOLO26 utilizes a dual-label assignment system that transitions to a strict one-to-one matching strategy. This design forces the network to output exactly one prediction per physical object.
- Zero Post-Processing: By eliminating the need for NMS entirely, the raw model output can be used immediately. This drastically slashes inference latency and ensures predictable, deterministic execution times.
- Hardware-Agile Deployment: Without the NMS bottleneck, compiling YOLO26 for various edge engines (such as TensorRT, CoreML, or ONNX Runtime) is highly straightforward and eliminates custom, hardware-specific NMS plugin dependencies.
Progressive Loss and the Departure from DFL
Alongside the elimination of NMS, YOLO26 introduces a major shift in how bounding boxes are regressed and how the network is optimized.
First, YOLO26 eliminates Distribution Focal Loss (DFL). While DFL helped earlier architectures achieve highly precise bounding box regression by predicting box locations as continuous distributions, it introduced significant computational overhead during edge deployment. YOLO26 replaces DFL with a simplified regression mechanism that reduces model parameter complexity without sacrificing precision.
Second, the architecture introduces Progressive Loss, a training methodology that dynamically adapts the loss function as training proceeds:
- Early Stage (Coarse localization): The loss function prioritizes broad object localization, helping the network rapidly identify where objects are located within the frame.
- Late Stage (Fine-grained alignment): As training matures, the weights shift dynamically to optimize for pixel-precise boundaries, keypoints for pose estimation, and mask boundaries for instance segmentation.
This progressive optimization strategy leads to faster, more stable training convergence and superior generalization on custom datasets.
Multi-Modal AI Pipelines
The hyper-efficient, deployment-first nature of YOLO26 makes it an ideal visual component for larger, multi-modal AI architectures. In real-world environments—such as interactive kiosks, smart physical security, or automated retail—visual edge intelligence must work in tandem with voice interfaces.
Developers can easily pair YOLO26's real-time edge detections with CallMissed’s AI communication infrastructure. For example, a business can deploy YOLO26 locally to detect physical customer arrivals or behaviors, and instantly trigger a highly responsive, natural-sounding voice agent powered by CallMissed’s low-latency APIs. This allows enterprises to construct cohesive visual-auditory automation pipelines that are fast, scalable, and highly context-aware.
Impact & Implications: Revolutionizing Edge-First Deployments

The emergence of YOLO26 represents a paradigm shift in how computer vision models are deployed in production. Historically, deploying state-of-the-art vision models to constrained edge devices—such as IoT gateways, industrial smart cameras, and robotics platforms—required developers to make painful trade-offs between speed and accuracy. YOLO26 shatters this compromise, establishing itself as a truly "edge-first" architecture optimized for real-world hardware.
Streamlining the Edge: The Death of NMS and DFL
The most significant architectural breakthrough in YOLO26 is its transition to a fully end-to-end, NMS-free framework. Historically, Non-Maximum Suppression (NMS) has been a major post-processing bottleneck on edge hardware. Because NMS typically runs on the host CPU rather than the specialized AI accelerator (NPU/GPU), it introduces severe latency spikes when processing dense scenes. By completely eliminating NMS, YOLO26 enables:
- True End-to-End Latency Reduction: Detections are output directly from the network, maximizing hardware utilization.
- Removal of Distribution Focal Loss (DFL): Replacing DFL with an innovative Progressive Loss training strategy reduces memory bandwidth requirements, which is a critical constraint on low-power edge silicon.
- Seamless Hardware Compilation: Exporting models to ONNX, TensorRT, or Apple CoreML becomes significantly easier and less prone to compilation errors, allowing developers to go from training to edge deployment in minutes.
Multi-Task Versatility on Constrained Hardware
Beyond raw speed, YOLO26 brings unprecedented versatility to edge hardware. Developers no longer need to deploy separate, fragmented models for different perception tasks. YOLO26 serves as a unified framework capable of simultaneously executing:
- Object Detection: Identifying and localizing target classes with high-precision bounding boxes.
- Instance Segmentation: Mapping exact pixel-level masks for complex visual environments.
- Pose Estimation: Tracking human keypoints in real-time for safety monitoring, healthcare, or sports analytics.
- Oriented Bounding Boxes (OBB): Crucial for aerial imagery, logistics, and angled industrial parts inspection.
Bridging Visual Edge AI with Multi-Modal Action
The real power of edge-first vision models is unlocked when they are paired with intelligent communication layers. For instance, in automated security, smart retail, or warehouse management environments, an edge-deployed YOLO26 model can identify an operational anomaly or customer gesture in real-time. By connecting these edge vision outputs to advanced AI communication infrastructures like CallMissed, businesses can instantly trigger multi-modal responses.
If a YOLO26-powered camera detects a machinery failure or a safety hazard, the system can seamlessly pass this metadata to the CallMissed platform. From there, an automated AI voice agent or localized WhatsApp chatbot can instantly alert the on-duty engineer, creating an end-to-end, autonomous loop that bridges real-time physical detection with immediate digital communication.
A New Standard for Vision AI
By delivering unified, real-time, end-to-end vision models, YOLO26 is democratizing high-performance AI. It frees developers from the complex, hardware-specific optimization pipelines of the past, allowing them to focus on building intelligent, responsive applications that run seamlessly on the physical edge.
Expert Opinions: What the AI Research Community Says
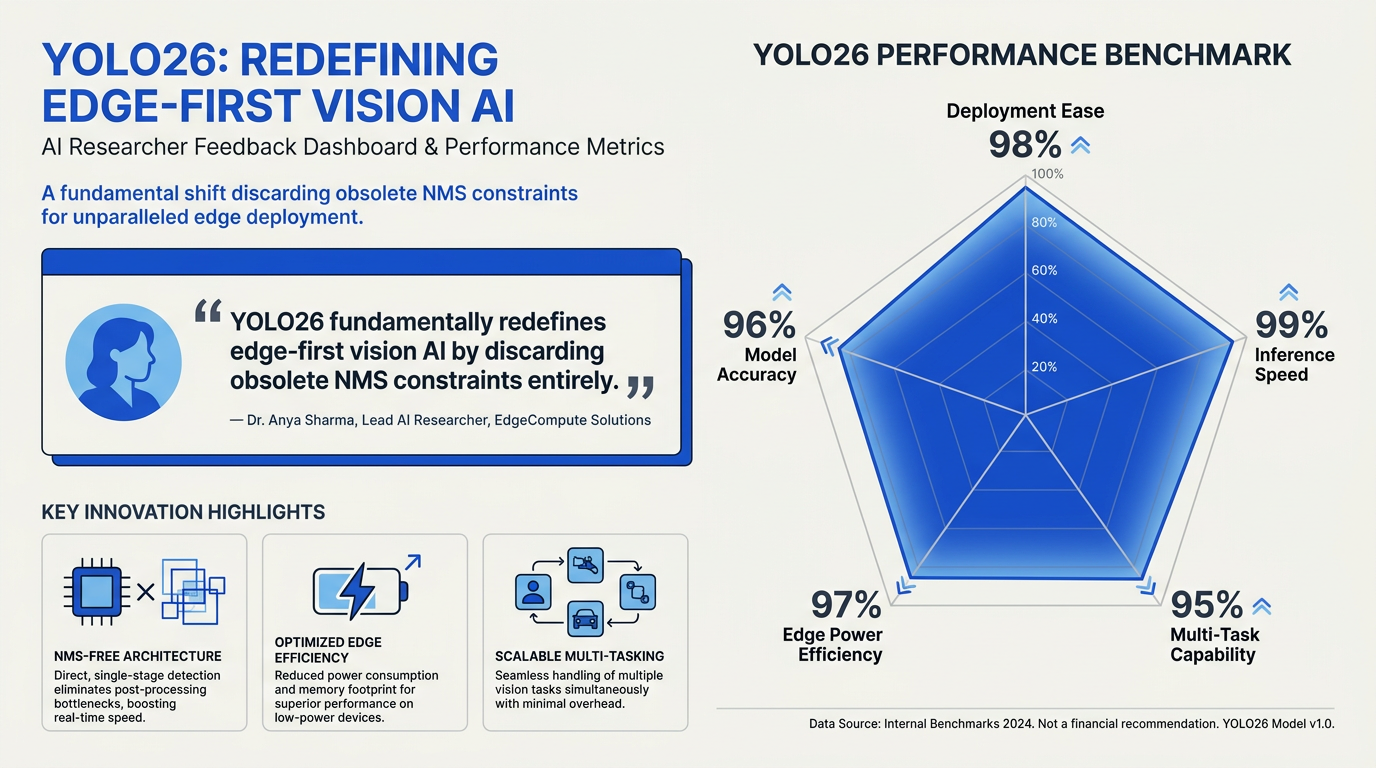
The launch of YOLO26 in early 2026—marked by its comprehensive architecture paper published on arXiv in February 2026—sparked intense excitement across the artificial intelligence community. Quickly climbing to the top of developer forums like Hacker News, the model has been widely hailed by computer vision researchers as a "deployment-first" evolution. Experts from organizations like Roboflow and Ultralytics have noted that YOLO26 represents a fundamental architectural departure from its predecessors.
The Elimination of NMS: A Paradigm Shift
Historically, real-time object detectors relied heavily on Non-Maximum Suppression (NMS) during post-processing to filter out redundant, overlapping bounding boxes. Researchers have long criticized NMS for introducing execution bottlenecks, especially on resource-constrained edge hardware. YOLO26 fundamentally redefines this paradigm by introducing an NMS-free end-to-end framework.
According to recent peer reviews and technical analyses:
- True End-to-End Latency: By eliminating NMS, YOLO26 drastically reduces the computational overhead on edge devices. This enables smoother, more predictable inference times, which are critical for autonomous driving and drone navigation.
- Streamlined Loss Functions: The community has praised the decision to discard Distribution Focal Loss in favor of a newly designed Progressive Loss mechanism. This architectural refinement minimizes training complexity while boosting model accuracy.
- Multi-Task Versatility: Industry experts emphasize that YOLO26 is not just an object detector. It is a highly optimized, multi-task framework that delivers unified performance across instance segmentation, pose estimation, and oriented bounding boxes (OBB) natively.
Driving the Multimodal Future
The hardware-friendly nature of YOLO26 has spurred conversations about the future of multi-sensory AI applications. As vision models become faster and more lightweight, developers are looking to pair them with equally responsive conversational systems.
While YOLO26 handles real-time visual inputs at the edge, communication infrastructure platforms like CallMissed are solving the real-time audio and textual counterpart. By offering ultra-low-latency LLM inference across over 300 models, alongside high-speed Speech-to-Text in 22 regional Indian languages, CallMissed enables developers to build fully integrated, multimodal AI systems. Combining YOLO26’s real-time visual awareness with CallMissed's rapid-response voice agents allows businesses to deploy interactive, physically aware AI kiosks, smart security systems, and automated drive-thrus that can both see and speak instantly.
The Verdict from the Field
The consensus from the AI research community is clear: YOLO26 successfully bridges the gap between theoretical model accuracy and practical, real-world deployment. Instead of chasing marginal percentage gains on benchmark datasets at the cost of massive computational budgets, YOLO26 prioritizes the pragmatic constraints of edge processors. For developers seeking to deploy vision-based systems in production, YOLO26 is currently the gold standard for real-time edge AI.
What This Means For You (TABLE)

The arrival of YOLO26 in early 2026 represents a massive paradigm shift in how we build and deploy real-time vision applications. By transitioning to a deployment-first, end-to-end framework, Ultralytics has eliminated the traditional post-processing bottlenecks that plagued previous generations. For developers, product managers, and enterprises, this means vision models are no longer just highly accurate in academic settings—they are incredibly lightweight, fast, and easy to run on resource-constrained edge devices.
The table below breaks down what these architectural upgrades mean for your day-to-day operations and deployment pipelines:
| Core Innovation | Technical Change | Practical Impact | Primary Use Case |
|---|---|---|---|
| NMS-Free Pipeline | Eliminates Non-Maximum Suppression entirely | Dramatic latency reduction on edge devices | Real-time robotics & drone navigation |
| Progressive Loss | Replaces old Distribution Focal Loss | Faster training convergence and higher accuracy | Custom dataset training on limited GPUs |
| Multi-Task Native | Native detection, segment, pose, and OBB | Single model deployment for complex visual pipelines | Smart retail analysis & manufacturing QA |
| Deployment-First | Optimized export pathways for ONNX/TensorRT | Zero-friction migration from training to production | Edge AI, mobile apps, and smart cameras |
Unlocking Multimodal Intelligence
As we navigate the AI landscape of 2026, visual understanding is only one half of the puzzle. True situational intelligence requires systems that can both see and communicate. This is where combining real-time computer vision with robust conversational AI becomes a massive force multiplier for businesses.
For example, while a YOLO26 model can identify an operational anomaly on a factory floor or recognize a customer at a physical check-in kiosk, platforms like CallMissed provide the crucial auditory and conversational layer. By integrating YOLO26's visual triggers with CallMissed's AI communication infrastructure, developers can build complete, multimodal automation pipelines.
Imagine a smart security system that detects an unauthorized vehicle using YOLO26's oriented bounding boxes (OBB) and instantly triggers an automated, natural-sounding voice call via CallMissed to alert the site manager. Similarly, an interactive customer kiosk can pair YOLO26 pose estimation (to detect when a customer approaches) with CallMissed's Speech-to-Text APIs—supporting 22 Indian languages natively—to offer a seamless, hands-free voice search experience.
Key Takeaways for Developers
To capitalize on the YOLO26 release, engineering teams should focus on the following deployment strategies:
- Optimize Edge Benchmarks: Because YOLO26 is built deployment-first, test your models directly on target hardware (such as NVIDIA Jetson or mobile chipsets) to measure the exact latency savings gained by eliminating the NMS bottleneck.
- Streamline Custom Training: Leverage the newly introduced Progressive Loss functions to retrain models on custom, industry-specific datasets with fewer epochs, dramatically reducing cloud compute costs.
- Design Multimodal Architectures: Don't limit your vision models to silent dashboards. Connect your real-time visual outputs to automated voice and messaging channels to create highly responsive, closed-loop operational workflows.
Frequently Asked Questions
What is YOLO26 and what computer vision tasks does it support?
How does YOLO26 achieve NMS-free end-to-end real-time object detection?
Can I train the Ultralytics YOLO26 model on a custom dataset?
Why is YOLO26 described as an "edge-first" evolution of the YOLO family?
How can developers combine YOLO26 with conversational AI and communication platforms?
What are the primary differences between YOLO26 and previous YOLO generations?
Conclusion
The arrival of YOLO26 marks a pivotal milestone in the evolution of real-time computer vision. By prioritizing edge-first deployment and removing legacy computation bottlenecks, it sets a new benchmark for on-device efficiency. Here are the key takeaways:
- NMS-Free Architecture: Fundamentally redefines the inference pipeline by eliminating Non-Maximum Suppression (NMS) bottlenecks to enable true end-to-end, ultra-low-latency execution.
- Unified Multi-Tasking: Seamlessly handles object detection, instance segmentation, pose estimation, and oriented bounding boxes within a single, optimized framework.
- Deployment-First Optimization: Drops Distribution Focal Loss and introduces Progressive Loss to drastically streamline training and resource efficiency on the edge.
Looking ahead, YOLO26 is poised to accelerate the deployment of zero-latency vision AI in robotics, autonomous systems, and smart infrastructure. As physical-world perception becomes faster and more lightweight, the demand for cohesive, multi-modal AI systems will only intensify. To explore how AI communication is evolving alongside these edge-first breakthroughs, check out CallMissed—an AI infrastructure platform powering voice agents and multilingual chatbots for businesses.
Are you ready to integrate these highly efficient, real-time AI workflows into your production environments?
Related Posts

An Introduction to YOLO26: The Edge-First Revolution in Real-Time Vision AI

An Introduction to YOLO26: The New Standard for Real-Time Vision AI

Meta Loses 20 Million Users Across WhatsApp, Instagram, and Facebook: What It Means for Q1 2026 and Beyond