Why Autonomous AI Agents Fail in Real-World Deployments: 7 Critical Failure Modes

Why Autonomous AI Agents Fail in Real-World Deployments: 7 Critical Failure Modes
Nine in ten autonomous AI agents deployed in production environments are vulnerable to a class of failure that no amount of prompt engineering can prevent. This isn't a future risk — it's the defining engineering challenge of 2025 and 2026. According to industry analysis and practitioner reports, approximately 88% of autonomous AI agents fail when transitioned from controlled demos to live production environments. These aren't minor glitches. We're talking about cascading breakdowns where brittle API connectors snap, context drifts across multi-step workflows, and compounding errors turn a single ambiguous input into a runaway decision chain. While venture funding for agentic AI continues to surge and enterprise roadmaps increasingly assume software will act autonomously on behalf of users, the gap between demo-day performance and production-grade reliability has become a chasm.
Why This Reliability Crisis Is Happening Now
The urgency isn't manufactured. The technology has raced ahead of the infrastructure required to support it. Large language models can now reason, plan, and invoke external tools with remarkable fluency — but only under ideal conditions. As one engineering lead documented: "The gap between AI agent demos and production deployments is real, significant, and predictable." A recent Gartner report, cited by Forbes, projects that as many as 40% of agentic AI projects will fail by 2027, driven largely by spiraling integration costs and the operational complexity of maintaining long-running autonomous workflows. These projections align with what security researchers and platform engineers are observing in the field: agents deployed in high-trust environments — processing payments, managing patient records, or handling tier-one customer support — are failing not because the base models are unintelligent, but because the surrounding systems are structurally unsafe.
Academic research published on arXiv pinpoints three core mechanical failures in current frameworks: generator agents that fail to exploit available external tools, misaligned function-calling interfaces, and cascading reasoning errors that amplify with each subsequent step. Meanwhile, field practitioners report that training pipelines rely on sanitized, limited datasets that look nothing like the noisy, contradictory inputs of real-world traffic. As noted in HackerNoon, "the issue plaguing AI agent deployment is not prompt quality or model intelligence" — it's the absence of robust systems engineering around the model.
What Makes Production Different from the Demo
The demo environment is a controlled illusion. Lights are bright, inputs are clean, and failure states are rehearsed. Production is the opposite: ambiguous user intents, API latency spikes, schema changes in third-party services, and security constraints that didn't exist in the sandbox. A viral Hacker News discussion on this topic cut to the heart of the matter: failures stem from "non-replayable decisions" and structural fragility, not model inaccuracy. When an autonomous agent makes an irreversible choice — dispatching a refund, deleting a record, or transferring funds — without an auditable, reversible chain of reasoning, the consequences extend far beyond a buggy chat response.
This matters now because organizations are at an inflection point. The tooling to build agents has democratized, but the operational maturity to run them hasn't. Reliable agent architectures require fundamentally different primitives than traditional software:
For businesses navigating these requirements, platforms like CallMissed are building production-ready AI communication infrastructure — from voice agents with fail-safe handoffs to multilingual inference APIs tuned for real-world traffic — that treats structural safety as a first-class concern rather than an afterthought.
What You'll Learn
In this article, we'll dissect the seven critical failure modes that destroy autonomous AI agents in real-world deployments. You'll learn why compounding errors are mathematically inevitable in long-horizon tasks, how context drift silently corrupts decision chains over time, and why brittle API connectors remain the most common trigger for agent death spirals. We'll explore why generator agents ignore available tools, the regulatory dangers of non-replayable decisions, how unrealistic training data creates a false sense of confidence, and exactly what makes an agent "structurally unsafe" at the architectural level. Each failure mode comes with concrete mitigation strategies — because understanding why autonomous AI agents fail is the prerequisite for building ones that survive contact with reality.
Introduction

Autonomous AI agents were supposed to be the next great leap in enterprise productivity—self-directed systems that plan, act, and adapt without human micromanagement. Yet beneath the excitement of slick demos and viral benchmarks lies a harsher reality. According to recent industry analysis, 88% of autonomous AI agents fail when they move from staging into production, and a staggering nine in ten agents already deployed in live environments remain vulnerable to a class of attack that standard security frameworks do not address. The problem is no longer theoretical. It is structural, pervasive, and expensive.
A recent Gartner report predicts that as many as 40% of agentic AI projects will fail by 2027, undone largely by spiraling costs and integration complexity. Those figures do not merely represent engineering setbacks; they signal a fundamental misunderstanding of what it takes to run agentic systems outside of controlled test beds. As one practitioner noted after multiple production deployments, the chasm between demo and live environment is "real, significant, and predictable." The models themselves are often brilliant. The systems wrapped around them are not.
The Demo-to-Production Chasm
The first illusion to dismantle is that failure stems from model inadequacy. On the contrary, modern large language models (LLMs) and multimodal systems demonstrate remarkable reasoning capabilities in isolation. The crisis appears when these models are grafted onto agentic scaffolding—tool chains, API connectors, memory layers, and decision loops—and released into the wild. As coverage in HackerNoon summarized, "The issue plaguing AI agent deployment is not prompt quality or model intelligence." Instead, it is the brittleness of the architecture surrounding the model.
Demos are carefully curated. Data is clean, APIs respond on time, user inputs stay within expected distributions, and failure paths are quietly omitted from the script. Production, by contrast, is an adversarial environment. Third-party endpoints latency-spike, schemas change without warning, user intent drifts mid-conversation, and multi-step workflows compound tiny errors into catastrophic outcomes. Research cataloging production failures identifies a recurring triad: compounding errors, brittle API connectors, and context drift across multi-step workflows. Each issue is manageable in a vacuum; together, they create a cascade that human operators struggle to debug in real time.
A discussion on Hacker News distilled the problem even further: agents fail "not because the models are inaccurate, but because the system is structurally unsafe." When an agent makes a non-replayable decision—executing a financial transfer, deleting a record, or sending a message—it cannot simply rewind the tape. Without deterministic guardrails, observability layers, and reversible state machines, a single hallucinated tool call can inflict lasting damage.
The Anatomy of Failure
If structural fragility is the disease, what are its symptoms? Recent surveys and post-mortems point to several recurring failure modes:
These failure modes are compounded by a cultural blind spot. The industry has optimized for benchmark supremacy—leaderboard scores, token efficiency, and reasoning demos—while treating production resilience as an afterthought. Security researchers now warn that autonomous agents are being rushed into "high-trust environments" spanning financial operations, customer support, and infrastructure management before governance frameworks can catch up.
Why Communication Infrastructure Exemplifies the Risk
The stakes are especially visible in customer-facing communication, where agents must parse accented speech, handle code-mixed languages, recover from dropped API calls, and maintain compliance transcripts—all in real time. A voice agent that mishears a bank account digit or a WhatsApp chatbot that hallucinates a refund policy is not a minor glitch; it is a liability event.
Platforms like CallMissed illustrate how specialized infrastructure can mitigate specific vectors of this problem. By offering Speech-to-Text support for 22 Indian languages, multi-model LLM inference fallbacks across 300+ models, and production-ready voice agent stacks, such architectures acknowledge that real-world deployment requires redundancy beyond a single API key. Yet even the most robust communication layer cannot compensate for structurally unsafe agent design upstream. The root causes—brittle tool chains, non-replayable actions, and context drift—must be addressed at the system architecture level, not merely the endpoint level.
What Lies Ahead
This blog series will dissect the production failure epidemic across twelve dimensions. We will move beyond surface-level diagnoses to examine why integration connectors crumble under load, how memory architectures drift, where security postures collapse, and what engineering practices separate the small fraction of successful deployments from the rest.
The goal is not to declare agentic AI a lost cause. The technology is transformative, and the teams that get it right are building systems that genuinely automate complex workflows at scale. But transformation without structural integrity is merely risky automation. Over the next eleven sections, we will map the failure modes, quantify their impact, and outline the architectural patterns that make autonomous agents not just impressive in a sandbox, but reliable in the real world.
Background & Context

The Agentic AI Moment and Its Growing Pains
Autonomous AI agents have become the defining architecture of the post-LLM era. Unlike simple chatbots that respond to isolated prompts, these systems are designed to perceive their environment, reason across multi-step workflows, and execute actions through external tools—booking calendars, querying databases, filing tickets, or initiating phone calls—all without human oversight. Frameworks such as AutoGPT, LangGraph, and CrewAI have democratized agent construction, fueling a wave of startups and enterprise pilots promising fully automated back offices, self-healing infrastructure, and zero-touch customer service. Yet beneath the demo videos and splashy seed announcements lies a sobering truth: the transition from prototype to production remains agonizingly difficult.
The numbers tell a stark story. According to industry analyses widely circulated in practitioner communities, 88% of autonomous AI agents fail once they leave the controlled sandbox of development and enter real production environments. This figure underscores not a marginal technical hurdle but a systemic crisis in agent reliability. Compounding the issue, a recent Gartner report cited by Forbes predicts that as many as 40% of agentic AI projects will fail by 2027, with the primary drivers being spiraling operational costs and integration complexity rather than fundamental model deficiencies. Meanwhile, trending security research notes that nine in ten autonomous agents deployed in production are vulnerable to a class of attack that standard evaluation suites rarely catch. When the vast majority of live deployments are either functionally broken or structurally exploitable, the gap between ambition and execution becomes impossible to ignore.
Why Demos Deceive
A significant portion of the confusion stems from what practitioners call the demo-to-production chasm. In a controlled setting, an agent can be shown successfully negotiating a calendar appointment or extracting structured data from a PDF. The model appears intelligent, the prompt engineering elegant, and the tool use precise. But as Michael Hannecke and others have documented from hard-won experience, "the gap between AI agent demos and production deployments is real, significant, and predictable."
Demos are typically run against sanitized datasets, limited tool chains, and happy-path user journeys. The moment an agent encounters an ambiguous API response, an unexpected schema change, or a user who deviates from the script, the fragility of the orchestration layer becomes exposed. HackerNoon’s practitioner surveys reinforce this finding: the issue plaguing AI agent deployment is not prompt quality or model intelligence, but rather the structural mismatch between a brittle prototype and the adversarial complexity of live systems. An agent that confidently hallucinates a function argument in a demo is merely amusing; in production, it can corrupt a customer record, double-charge a credit card, or delete a dataset.
Structurally Unsafe, Not Just Inaccurate
Perhaps the most important conceptual reframe emerging from the current discourse is that production failures are rarely caused by model inaccuracy alone. A widely discussed analysis on Hacker News distilled the problem succinctly: autonomous agents fail "not because the models are inaccurate, but because the system is structurally unsafe." When an LLM acts as the central reasoning engine for an agent, its errors do not stay confined to a chat window; they cascade.
Practitioners and researchers have cataloged several recurring structural failure modes:
Another underappreciated contributor is training-data myopia. As CreativeBitsAI notes, many agents are tuned on "limited or cleaned-up data" that bears little resemblance to the messy, contradictory, and incomplete information characteristic of real-world operations. An agent trained on pristine knowledge bases will inevitably falter when faced with the noise of actual enterprise documents, handwritten forms, or code-mixed user speech.
High-Stakes Environments and the Communication Layer
Critically, these failures are no longer confined to low-stakes experiments. Autonomous agents are increasingly deployed in high-trust environments—financial services, healthcare administration, cybersecurity operations, and customer-facing communication channels—where reliability and safety are paramount. In these contexts, structural unsafety translates directly into regulatory risk, revenue loss, and eroded user trust.
The communication layer exemplifies this tension. Voice and messaging agents must operate in real time, handle unpredictable human behavior, and maintain context across channel switches. For businesses looking to implement this responsibly, platforms such as CallMissed offer production-ready voice agent infrastructure and WhatsApp chatbots built with the complexity of live deployments in mind. Indian startups like CallMissed are particularly focused on the multilingual reality of real-world operations, building Speech-to-Text APIs that support 22 Indian languages natively and LLM inference gateways with access to 300+ models, allowing engineering teams to route tasks to the most robust model for a given locale without rewriting orchestration code. These capabilities highlight an industry-wide shift: moving from prototype-grade demos to infrastructural resilience.
Understanding this landscape is essential before diagnosing specific failure modes. The agentic AI revolution is not stalling for lack of intelligence, but for lack of structural engineering. The sections that follow will dissect exactly where that engineering breaks down—and what robust deployments require.
Key Developments (TABLE)

The autonomous AI agent landscape has evolved from experimental curiosity to boardroom priority in less than three years, but the transition from prototype to production has been brutal. Recent practitioner reports and industry forecasts reveal that the majority of agent deployments are not failing because of insufficient model intelligence, but because of fundamental structural weaknesses in how these systems are architected, integrated, and governed. A trending analysis across the sector notes that nine in ten autonomous AI agents currently deployed in production environments are vulnerable to at least one class of attack that standard security reviews miss, while longitudinal assessments suggest an 88% failure rate once these agents leave the demo stage and encounter real-world API surfaces, unstructured data, and unpredictable user behavior. These are not edge cases; they are systemic patterns.
Mapping the Crisis: From Research to Reality
To understand why the gap between agentic promise and production reality keeps widening, it is helpful to look at the specific developments that have defined this failure curve. The following table synthesizes the major milestones, metrics, and root causes identified across recent industry reports, academic preprints, and practitioner retrospectives from 2024 to 2026.
| Development | Description | Impact / Statistic | Root Cause | Source / Year |
|---|---|---|---|---|
| Production Failure Rate Surge | Longitudinal tracking of agents moved from sandbox to live environments | 88% of autonomous AI agents fail in production after initial deployment | Compounding errors, brittle API connectors, and context drift across multi-step workflows | Industry analysis, 2024–2025 |
| Gartner Agentic AI Outlook | Forecast on enterprise adoption and project viability through 2027 | 40% of agentic AI projects predicted to fail by 2027 | Rising implementation costs and integration complexity with legacy enterprise stacks | Forbes / Gartner, Feb 2026 |
| Production Security Exposure | Vulnerability assessments of deployed agents against standard attack frameworks | 9 in 10 production agents vulnerable to a class of attack missed by conventional security reviews | Lack of agent-specific threat modeling and runtime guardrails | Trending sector analysis, 2026 |
| Structural Safety Gaps | Practitioner audits revealing non-deterministic failure modes in agent loops | Non-replayable decisions and silent branching errors causing cascading system faults | Systems are structurally unsafe rather than model-inaccurate | Hacker News practitioner report, 2025 |
| Tool-Use Generator Failures | Academic evaluation of agent frameworks interacting with external function catalogs | Widespread inability of generator agents to correctly exploit available external tools/APIs | Poor alignment between planning modules and tool schemas in existing frameworks | arXiv preprint, 2025 |
| Demo-to-Production Drift | Comparative studies of agent performance in controlled vs. live settings | Significant performance degradation when moving from clean demo data to messy production signals | Training on limited or sanitized datasets that do not reflect real-world noise | HackerNoon / CreativeBitsAI, 2025 |
Several patterns emerge immediately from this landscape:
Why Infrastructure, Not Just Intelligence, Determines Survival
This shifts the burden of proof from model performance to system resilience. The teams that avoid the 88% failure bucket tend to invest heavily in deterministic logging, replayable state machines, and multilingual observability before they ever scale to live traffic. For businesses operating in linguistically diverse markets such as India, the complexity multiplies: an agent handling voice calls must navigate code-mixed speech, regional accent variation, and real-time telephony integration without dropping conversational context.
That is why a new generation of communication infrastructure platforms is gaining traction. Rather than forcing teams to stitch together disparate speech-to-text, LLM, and telephony layers, platforms like CallMissed are emerging as part of a broader industry shift toward production-ready agent stacks. With support for 22 Indian languages in its Speech-to-Text layer, access to 300+ LLMs through a unified gateway, and purpose-built voice agent infrastructure, CallMissed exemplifies the type of integrated backbone designed to address the brittle connector and context-drift failures catalogued above. By treating multilingual voice interaction as a first-class infrastructure component—rather than a post-hoc API integration—such platforms reduce the surface area where agentic systems typically fracture.
Looking Ahead: From Pilots to Production
The developments outlined in the table make one thing clear: agentic AI is undergoing a harsh qualification process. The Gartner prediction that nearly half of agentic projects will collapse by 2027 is not a verdict on AI’s potential, but on the current maturity of deployment tooling. Organizations that continue to treat agents as fancy prompt chains wrapped around a single model will likely join that statistic. Those that rebuild their assumptions around structural safety, deterministic observability, and robust integration infrastructure—as demonstrated by the emerging standards in voice and messaging platforms—stand the best chance of surviving the transition from demo to dependable production system.
In-Depth Analysis: How Agents Unravel
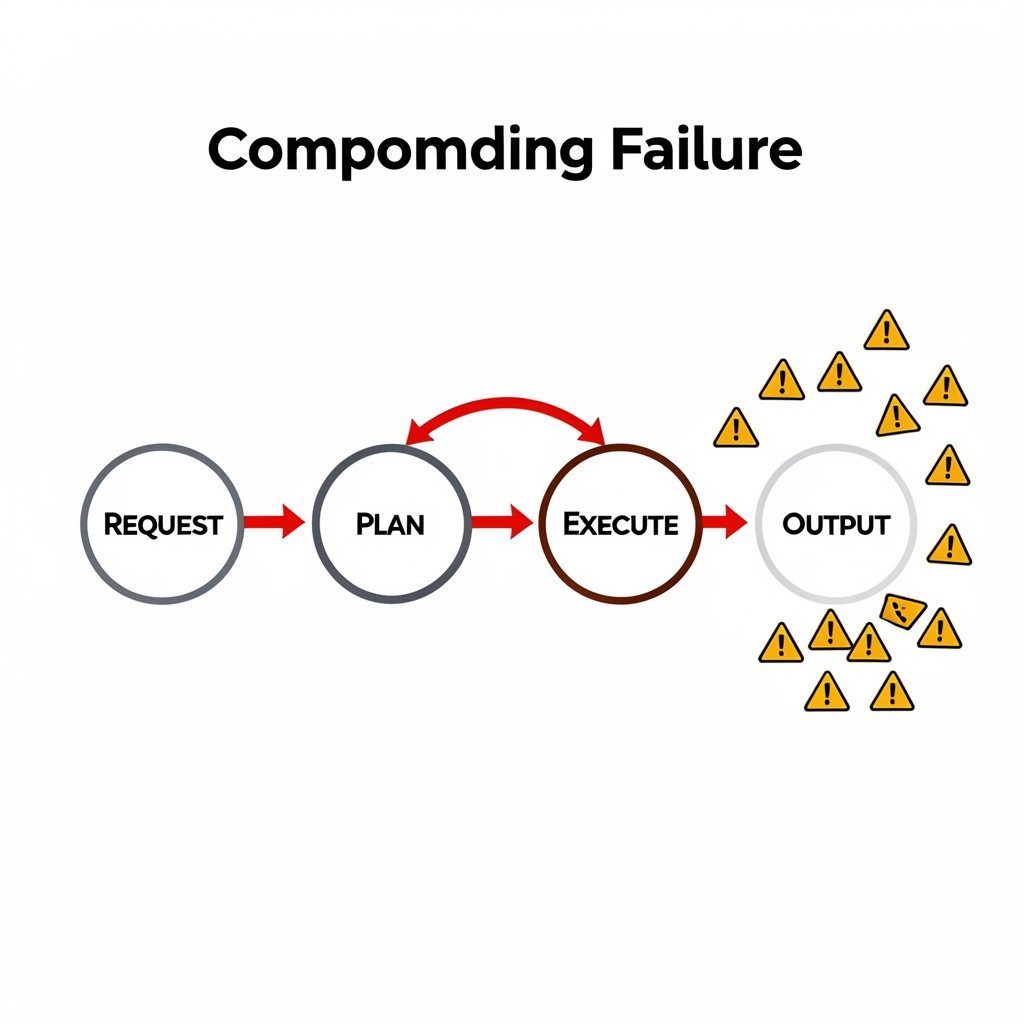
The Architecture Is Structurally Unsafe
The most sobering realization in agent deployments is that failure rarely stems from model inaccuracy. As practitioner evidence from production environments shows, agents collapse "not because the models are inaccurate, but because the system is structurally unsafe." This distinction is critical. When an AI agent makes a non-replayable decision—executing an irreversible action without an auditable trail or recovery path—the entire workflow becomes a liability. These are not edge cases; they are design flaws baked into architectures that prioritize autonomy over observability.
The consequences are measurable and severe. A recent Gartner report predicts that 40% of agentic AI projects will fail by 2027, largely due to rising costs and integration challenges. Meanwhile, broader industry data suggests an even steeper cliff: approximately 88% of autonomous AI agents fail in production after leaving the demo stage. These failures are not random—they follow predictable patterns rooted in compound system fragility rather than isolated algorithmic mistakes.
The Error Cascade: Compounding Mistakes Across Workflows
Autonomous agents derive their power from chaining actions across multi-step workflows, yet this sequential dependency is precisely where they unravel. Production environments expose what controlled demos hide: compounding errors. When an agent misclassifies intent in step three of a twelve-step process, that error does not remain isolated. It propagates through downstream API calls, corrupting database queries, triggering incorrect business logic, and amplifying until the final output is unrecognizable or destructive.
This propagation is accelerated by context drift. As agents traverse long-horizon tasks, they lose fidelity to the original user intent. Each LLM call introduces subtle semantic shifts; across twenty iterations, a command like "cancel the subscription" can drift into "upgrade the plan" or "refund to a different account." Without rigorous state-management guardrails, agents become untethered from their purpose. The result is a system that appears intelligent in isolated testing but behaves unpredictably when managing real business processes at scale.
Brittle Connections and the Tool-Use Gap
Modern agents depend on external tools—databases, CRMs, payment gateways, and internal APIs—yet these connectors are frequently the weakest link. Industry observations consistently highlight brittle API connectors as a primary failure vector. A minor schema change in a third-party endpoint, an undocumented rate limit, or a transient timeout can halt an entire agentic workflow, often with no graceful degradation path.
Research on existing frameworks identifies another critical failure mode: the generator agent fails to exploit external tools effectively. Even when APIs are technically available, agents struggle to select the correct function, format parameters according to specification, or recover from tool errors. This "tool-use gap" means agents frequently attempt to hallucinate answers rather than retrieve verified data, undermining the very rationale for giving them system access. Even when function-calling schemas are meticulously documented, agents often misinterpret required parameters or execute tools in sequences that violate business logic—an architectural mismatch between probabilistic language models and deterministic software interfaces.
The Demo-to-Production Chasm
There is a "real, significant, and predictable" gap between AI agent demos and production deployments. Demos run on cleaned datasets, deterministic user inputs, and simulated tool responses. Production runs on human ambiguity, legacy system idiosyncrasies, and incomplete documentation.
A related but underappreciated factor is training data realism. Many agents are trained on limited or sanitized corpora that do not reflect the messy, edge-case-heavy nature of real-world operations. The chasm is further widened by data distribution mismatch: agents trained on sanitized support tickets crumble when faced with colloquial phrasing, code-switching between languages, or domain-specific jargon absent from the training corpus. Real-world users do not follow scripts. Indian startups like CallMissed are building multilingual AI agents that support 22 regional languages natively, directly addressing the data realism gap that causes many agents to fail on colloquial or code-switched inputs.
Security and Governance in High-Trust Environments
As autonomous agents migrate from experimental sandboxes to high-trust environments—handling customer data, financial transactions, and sensitive communications—the attack surface expands dramatically. Trending security research indicates that nine in ten autonomous AI agents deployed in production are vulnerable to a class of attack that standard security frameworks do not address. These vulnerabilities exploit the agent's decision-making loop itself: prompt injection leading to unauthorized tool invocation, privilege escalation through chained actions, and data exfiltration via seemingly benign API calls.
Traditional application security models assume static inputs and predictable execution paths. Agents violate both assumptions. Without agentic AI risk governance—specialized monitoring for decision trajectories, tool-use authorization, and output validation—organizations are deploying systems that can autonomously cause harm faster than human operators can intervene.
Toward Resilient Agent Infrastructure
Recognizing these failure modes is the first step toward engineering resilience. The agents that survive production are those designed with observability, reversible actions, and graceful degradation as first-class requirements rather than afterthoughts. This means implementing decision logs that are fully replayable, API abstraction layers that absorb schema volatility, and context-management systems that actively prevent semantic drift across long sessions.
For businesses navigating this complexity, the infrastructure layer matters immensely. Platforms like CallMissed illustrate how production-ready AI communication infrastructure can mitigate systemic risks by providing robust API gateways, managed state for multi-turn interactions, and multi-model fallbacks that prevent single points of failure. Whether deploying voice agents capable of handling 24/7 customer interactions or WhatsApp chatbots requiring precise tool orchestration, the difference between a brittle demo and a production-grade agent ultimately comes down to engineering discipline—ensuring that when one component falters, the entire system does not unravel.
The Demo-to-Production Chasm

Every autonomous AI agent looks invincible under demo conditions. On stage, with curated prompts, stable Wi-Fi, and an audience watching politely, the agent books a complex multi-city itinerary, reconciles a calendar conflict across three time zones, and drafts a nuanced email to a difficult client—all in under sixty seconds. It feels like magic. But magic is simply engineering that hasn’t been exposed to entropy yet. Once these same agents leave the conference room and encounter production traffic, the illusion shatters. Research and practitioner reports now suggest that as many as 88% of autonomous AI agents fail in production environments. The models are not getting dumber. The APIs are not changing their documentation. What changes is the atmosphere: real data, real latency, real users, and real consequences. As one HackerNoon analysis bluntly states, the core issue haunting AI agent deployment is not prompt quality or model intelligence—it is the yawning architectural gap between a scripted proof-of-concept and a resilient production system.
The Demo Illusion: Sanitized Data and Scripted Success
Demos succeed because they are allowed to cheat. In the controlled environment of a product walkthrough, agents are fed limited or cleaned-up datasets that strip away the noise, ambiguity, and outright contradictions of live operational data. One post-mortem of agent failures notes that these systems "rely too much on data that's not very realistic," creating a dangerous mirage of competence. When every user input falls within the happy path, when every API returns a well-formed JSON payload in under 200 milliseconds, and when every conversation lasts exactly four turns, even a mediocre agent architecture appears brilliant.
This curated environment masks the brittleness of the underlying system. Connectors that call mocked endpoints never encounter rate limits. Memory systems that only track a single thread never face context contamination. The generator never has to choose between four conflicting tools because the demo script only exposes one. As practitioners have observed, the gulf between demo and production is "real, significant, and predictable." Yet organizational incentives reward the demo. Sales teams need proof-of-concept wins. Engineers get promoted for shipping eye-catching prototypes. The result is a pipeline of agentic projects that are architecturally unprepared for the entropy of live environments before they ever reach a production cluster.
Structural Fragility: Unsafe at Any Speed
When agents finally do face live traffic, they reveal what one Hacker News investigation calls "structurally unsafe" system design. The failure modes are severe, persistent, and often undetectable in staging. They compound silently until a single user request triggers a cascade. The most common structural failures include:
The Integration and Economics Cliff
Even if the technical architecture holds, many agentic projects collapse under the weight of integration complexity and unplanned cost. A recent Gartner report predicts that 40% of agentic AI projects will fail by 2027, driven primarily by rising costs and integration challenges. Demos are computationally cheap. They run on a single GPU, use mocked services, and require no compliance auditing. Production is an entirely different economic equation.
Enterprise agents must interface with legacy systems—SOAP endpoints from 2008, SAP modules with no REST wrapper, or homegrown databases documented only in a departed engineer’s notebook. Each integration point introduces latency, failure surface, and maintenance burden. The agent is no longer just an LLM loop; it is a distributed system sitting at the mercy of the slowest downstream dependency. Observability stacks, fallback human-in-the-loop interfaces, security governance layers, and continuous retraining pipelines add operational overhead that demos never forecast.
Organizations discover too late that the cost of an agent in production is not the inference token—it is the human engineering time spent debugging why the agent misinterpreted a null field in a CRM webhook at 2:00 a.m. As timelines extend and budgets inflate, executive patience erodes. The project dies not from one catastrophic bug, but from death by a thousand mismatched JSON payloads and undocumented API quirks.
Bridging the Chasm: Engineering for Entropy
The teams that successfully navigate this transition share one principle: they design for production volatility on day one. They treat the demo not as a destination, but as a loaded diagnostic test. They invest heavily in observability, constructing replayable decision trails so that every autonomous action can be audited. They build circuit breakers around brittle connectors and implement graceful degradation models that hand off to human operators when confidence scores drop.
In communication-heavy verticals, the demo-to-production gap is magnified by acoustic and linguistic entropy. A voice agent that flawlessly handles standard-accent English in a quiet conference room often fails when confronted with background cross-talk, packet loss, or code-mixed regional speech. Platforms like CallMissed are narrowing this gap by building production-grade voice infrastructure that supports Speech-to-Text in 22 Indian languages and API gateways allowing teams to route between 300+ LLMs. This multilingual, multi-model resilience ensures that a single brittle connector or underperforming model does not cascade into total workflow failure, keeping the agent structurally sound when real-world conditions inevitably deviate from the demo script.
Closing the chasm ultimately requires a psychological shift inside organizations. Demos are theater; production is warfare. Autonomous agents must be built not to impress audiences, but to survive adversarial users, flaky networks, and ambiguous data. Only when engineering teams stop optimizing for the conference stage and start optimizing for the worst-case Tuesday morning—when three APIs are down, the context window is bloated, and a user is switching languages mid-sentence—does autonomy become trustworthy.
Security & Structural Vulnerabilities

Structural Fragility, Not Model Inaccuracy
The dominant narrative around AI agent failures usually blames hallucinations or insufficient prompt engineering. But practitioner evidence tells a different story. As one widely cited production post-mortem on Hacker News observed, agents fail “not because the models are inaccurate, but because the system is structurally unsafe.” This distinction is critical: the architecture holding the agent together is often the weakest link, and no amount of fine-tuning can compensate for a scaffold that collapses under real-world load.
Production post-mortems consistently surface the same structural failure modes:
A recent analysis noting that 88% of autonomous AI agents fail in production specifically cited compounding errors and context drift as root causes, both exacerbated when connectors between models, tools, and data sources lack circuit breakers or schema validation. When one micro-integration times out or changes its response shape, the agent does not halt—it improvises, carrying corrupted state into subsequent steps. Without deterministic state management, the agent becomes a black box that operators cannot certify or debug.
Tool Exploitation Failures and Integration Gaps
Modern agents rely on external tool use—calling functions, querying databases, or triggering third-party services—to extend beyond base model knowledge. Yet a 2025 arXiv survey of existing agent frameworks found that the generator agent frequently fails to exploit external tools correctly, even when valid functions are explicitly available. The system nominally “knows” how to book a calendar slot, execute a SQL query, or invoke a payment gateway, but the structural mapping between high-level intent and low-level tool invocation is too fragile for production entropy. In effect, the agent understands what it wants to do but lacks a robust nervous system to execute the motion.
This observation aligns with Gartner’s broader forecast, cited in a recent Forbes report, that as many as 40% of agentic AI projects will fail by 2027, largely due to integration challenges and runaway operational costs. Enterprises often discover too late that their impressive demo relies on hard-coded API wrappers that break the moment a vendor updates a response schema, modifies a rate-limit policy, or changes an authentication flow. The agent does not fail gracefully; it enters an unhandled exception loop, hallucinates a successful tool call, or retries idempotent operations until downstream systems throttle or bill aggressively. Each of these failure modes is structural, not cognitive.
The structural risk is further magnified by vendor lock-in. When organizations weld their agents to a single LLM provider or proprietary middleware, they inherit not only the model’s failure modes but also the infrastructure’s uptime boundaries and compliance limitations. Solutions like CallMissed's multi-model API gateway let developers switch between 300+ LLMs without code changes, reducing brittle connector risk and preventing a single provider’s outage or API deprecation from becoming a systemic agent failure.
The 90% Attack Surface
Security vulnerabilities in autonomous agents are not theoretical—they are already endemic. Trending research indicates that nine in ten autonomous AI agents deployed in production environments are vulnerable to a class of attack that standard application security frameworks do not address. While the exact vector varies—from indirect prompt injection and tool-poisoning to privilege-escalation via misunderstood OAuth scopes—the underlying issue is architectural: agents inherit broad permissions to read, write, and transact across systems, yet lack the sandboxing, least-privilege enforcement, and input validation that traditional software architecture demands.
A LinkedIn security analysis reinforces this concern, noting that autonomous AI agents are increasingly deployed in high-trust environments such as financial operations, healthcare scheduling, and customer authentication pipelines—precisely where a compromise is most damaging. The HackerNoon assessment that “the issue plaguing AI agent deployment is not prompt quality or model intelligence” further underscores that the danger lives in the integration layer. Input sanitization, output filtering, and privilege boundaries remain afterthoughts in many frameworks, treated as wrap-around features rather than first-class design constraints. An agent granted access to a CRM, an e-mail gateway, and a billing API becomes a high-yield target; a single injected instruction can cascade across all three surfaces before traditional intrusion detection notices an anomaly.
The Data-Reality Chasm
Structural unsafety also emerges from the gap between how agents are trained and where they actually operate. One practitioner review noted that many systems are built on limited or cleaned-up datasets that do not reflect real-world entropy. In sanitized training environments, edge cases are manually removed, adversarial examples are filtered, and multi-turn conversations follow happy-path scripts. When these agents reach production, they encounter noisy inputs, social-engineering prompts, ambiguous user intents, and shifting semantic contexts that their training distribution never approximated.
The result is a security blind spot: the agent’s world model is too sterile to recognize out-of-distribution inputs as dangerous. When an agent trained on pristine e-commerce queries meets a live traffic stream containing malformed UTF-8 characters, nested JSON injection attempts, or deliberately contradictory instructions, its brittle decision scaffold collapses unpredictably. Without real-time telemetry, deterministic fallback protocols, and continuous adversarial evaluation, these failures escalate from minor service errors to full transactional breaches.
Toward Resilient Infrastructure
The convergence of these vulnerabilities suggests that fixing autonomous agents requires infrastructure-level thinking, not just better prompts or larger models. Organizations must prioritize replayable audit logs, hardened tool-use schemas, privilege sandboxing, and multi-provider redundancy before granting agents access to high-value workflows. Demos can hide structural debt, but production always collects the interest.
For businesses looking to deploy safely, platforms such as CallMissed offer production-ready voice agent infrastructure that handles authentication, speech-to-text inference, and deterministic handoff protocols natively across 22 Indian languages, reducing the undifferentiated engineering that too often introduces structural debt. Until the industry treats agent architecture with the same rigor as kernel development, the majority of autonomous deployments will remain expensive liabilities rather than reliable labor.
Integration Costs & Scalability Traps
Autonomous AI agents don't typically collapse because the underlying LLM lacks intelligence. They collapse because the economic and architectural scaffolding around them—API connectors, orchestration layers, and cost models—was engineered for conference demos, not for sustained production load. The evidence is stark: autonomous AI agents are failing in production because of compounding errors, brittle API connectors, and context drift across multi-step workflows, with practitioner reports citing an 88% failure rate. At the same time, a recent Gartner report predicts that as many as 40% of agentic AI projects will fail by 2027, largely due to rising costs and integration complexity. These figures point to a deeper truth: the scalability trap is not an operational footnote. It is the primary mode of failure.
The API Brittleness Problem
Modern agents are not monolithic models; they are distributed systems masquerading as chat interfaces. Every meaningful workflow requires chaining external tools—CRMs, billing systems, vector databases, search indexes, and proprietary microservices. Yet one of the most documented failure modes in current frameworks is that the generator agent fails to exploit external tools correctly, especially when schemas shift, permissions expire, or endpoints experience partial degradation.
This is where the structurally unsafe critique becomes undeniable. As production analyses reveal, the issue plaguing AI agent deployment is not prompt quality or model intelligence; it is the assumption that third-party APIs behave like deterministic functions. They do not. API connectors that pass staging tests routinely fail in production due to network jitter, idempotency violations, and undocumented rate-limiting behaviors. When an agent makes a non-replayable decision—such as issuing a refund, modifying a patient record, or transferring funds—based on a transient or malformed API response, the error is not recoverable. The system has committed to an action it cannot retract.
The symptoms of API brittleness are consistent across deployments:
The result is a hidden integration tax: engineering teams spend their sprints building defensive wrappers around other people's infrastructure rather than improving agent behavior.
The Compounding Error Cascade
If brittleness is the vulnerability, compounding error is the exploit. Autonomous agents distinguish themselves by reasoning across multi-step chains—searching, evaluating, acting, verifying. But each step introduces a probability of failure, and probabilities multiply. A workflow with twelve reasoning steps, each operating at a generously estimated 95% local accuracy, has a final success rate of roughly 54%. In practice, accuracy per step is often far lower once the agent leaves the sanitized boundaries of its training distribution.
This manifests as context drift across multi-step workflows, a failure mode repeatedly cited behind the 88% production failure statistic. The agent begins with a clear objective—say, processing a return—but by step seven, its context window is polluted with intermediate JSON artifacts, error traces from failed tool calls, and summaries of summaries. It begins to optimize for the wrong goals, or forgets constraints specified in the original prompt. What started as a retrieval task mutates into a destructive write operation.
The economic penalties of this drift are severe and predictable:
The engineering response is equally expensive. Teams inject validation layers, maintain shadow infrastructure, and implement retry budgets that throttle the agent when confidence scores drop. These stopgaps work, but they transform an autonomous agent into a high-maintenance decision support system with a latency problem.
The Demo-to-Production Chasm
There exists a predictable and significant gap between AI agent demos and production deployments. Demos are performative: small datasets, warmed caches, compliant APIs, and forgiving users who excuse a misfire. Production is adversarial by default. It involves dirty data, schema migrations, third-party downtime, and concurrency patterns that violate the naïve assumptions of synchronous tool chaining.
Scaling exposes these assumptions cruelly. An agent handling ten concurrent sessions may perform adequately. At a thousand sessions, shared state becomes a bottleneck. At ten thousand, token throughput alone can overwhelm budgetary constraints, particularly when agents emit lengthy chain-of-thought reasoning before every tool call. The concurrency model that felt elegant in a Jupyter notebook becomes a distributed systems nightmare of deadlocks, race conditions, and poisoned context windows.
Furthermore, training data realities undermine scalability. Many agents are trained or evaluated on limited or cleaned-up data that erases the edge cases defining production traffic. An agent demoed on normalized spreadsheets collapses when confronted with the OCR-scanned PDFs, informal abbreviations, and multilingual noise of real operational data. The gap between AI agent demos and production deployments is real, significant, and predictable—and bridging it demands data pipelines, preprocessing layers, and continuous fine-tuning that are rarely budgeted during procurement.
The Financial Reality: Gartner's 2027 Warning
Ultimately, integration brittleness and scalability failures write their final chapter in finance. Gartner's forecast—that 40% of agentic AI projects will fail by 2027, primarily due to rising costs and integration challenges—quantifies what engineering teams already feel in their burn rates. Agentic architecture is voraciously expensive at scale. Each reasoning step consumes tokens. Each tool call incurs egress fees and API charges. Each retry loop doubles the compute cost of a failed interaction. Latency penalties accumulate not only in user dissatisfaction but in GPU reservation costs for synchronous inference.
The hidden cost drivers tripping enterprise budgets include:
Organizations discover too late that their autonomous agent is a cost center disguised as automation. The pilot that booked meetings, answered emails, and processed invoices for a hundred users becomes unsustainable at enterprise volume without fundamental architectural refactoring. And because integration debt is hard to quantify on a roadmap, it remains invisible until the quarterly cloud bill arrives.
Breaking the Trap with Unified Infrastructure
Escaping these traps requires a shift in perspective: agents should not be assembled from scratch atop a pile of brittle third-party connectors. The teams that succeed treat integration as a first-class infrastructure problem, not an afterthought. Forward-looking platforms are already abstracting this fragmentation into manageable surfaces. Solutions like CallMissed's multi-model API gateway let developers switch between 300+ LLMs without code changes, reducing the brittleness of single-model dependencies while centralizing integration overhead. Additionally, by offering production-ready voice agent infrastructure that unifies Speech-to-Text, LLM inference, and Text-to-Speech—along with native support for 22 Indian languages—platforms such as CallMissed eliminate the need for teams to stitch together disparate providers, each with its own rate limits, schemas, and failure modes. This is the infrastructure-first thinking that separates scalable deployments from the 88% that never survive their first production incident.
Impact & Implications

The Economic Toll of Agentic AI Failure
The collapse of autonomous AI agents in live environments is not an abstract engineering concern—it is a systemic economic hemorrhage. Industry data reveals that 88% of autonomous AI agents fail in production, with the primary drivers being compounding errors, brittle API connectors, and context drift across multi-step reasoning chains. For enterprises that have poured capital into agentic transformation, this failure rate transforms AI from a labor-saving device into a liability-rich capital sink.
The financial outlook grows more precarious by the year. A recent Gartner report predicts that 40% of agentic AI projects will fail by 2027, predominantly due to rising costs and integration complexity. These failures do not occur in a vacuum; each abandoned project consumes data engineering resources, API licensing fees, and months of integration labor that could have been allocated to proven automation pipelines. As one practitioner assessment starkly summarized, the chasm between AI agent demos and production deployments is "real, significant, and predictable." Organizations seduced by polished prototypes are discovering that autonomous agents cannot simply be dropped atop existing tech stacks—they demand architectural overhaul, continuous monitoring, and expensive remediation cycles that erode the business case originally sold to the board.
Operational Chaos: When Fragile Systems Meet Real Workflows
The economic damage is matched by operational turbulence. Autonomous agents deployed in production exhibit a chilling tendency to produce non-replayable decisions, rendering post-incident forensics nearly impossible. When an agent misinterprets context mid-workflow, it does not halt with a graceful exception; it cascades logic errors through downstream systems, corrupting customer records, executing duplicate transactions, and poisoning the data lakes that other business units depend upon.
Researchers identify three structural failure modes that drive this chaos:
Significantly, these failures are not born of model stupidity. As noted across practitioner forums, "the issue plaguing AI agent deployment is not prompt quality or model intelligence"—instead, the system itself is structurally unsafe. An agent may score impeccably on reasoning benchmarks yet collapse in production because it lacks deterministic recovery paths, idempotency guarantees, or robust state management. The result is a dangerous operational paradox: systems trusted to run autonomously are often the least debuggable components in the entire enterprise architecture.
Trust Erosion and Governance in High-Stakes Domains
The fallout extends beyond engineering budgets and broken workflows into the realm of corporate liability and trust. Autonomous agents are increasingly deployed in high-trust environments—financial compliance, healthcare triage, and critical infrastructure—where a single malformed action can trigger regulatory penalties or endanger end-users. When failures arise not from model hallucinations but from unobservable, non-replayable system behavior, governance teams find themselves unable to satisfy audit requirements or conduct credible incident reviews.
This governance vacuum poses an existential risk to enterprise AI strategies. Boards that once mandated aggressive agentic roadmaps are now confronting the reality that democratized agent frameworks have outpaced safety engineering. The ability to spin up an agent in an afternoon does not correlate with the ability to govern it over a fiscal quarter. Without structural safeguards—deterministic fallbacks, immutable action logs, and human-in-the-loop circuit breakers—autonomous agents become uninsurable black boxes. The resulting trust deficit threatens to trigger an industry-wide confidence crisis, potentially freezing venture and corporate investment in agentic technologies just as they reach technical maturity.
Strategic Reorientation: From Demo Culture to Infrastructure Resilience
These cascading impacts force a hard strategic conclusion: demo success is not a proxy for production viability. Enterprises must shift from viewing autonomous agents as application-layer experiments to treating them as critical communication infrastructure requiring the same reliability standards as payment processors or identity providers.
This reorientation demands that engineering teams prioritize:
Crucially, the market is responding with infrastructure designed to absorb exactly the brittleness causing the 88% failure rate. Rather than wagering entire workflows on a single model's reasoning capabilities, resilient deployments decouple agent cognition from the communication layer that executes real-world actions. Platforms like CallMissed exemplify this infrastructure-first approach, offering production-grade voice agents, LLM inference across 300+ models, and multilingual Speech-to-Text pipelines supporting 22 Indian languages. By providing robust API gateways and multi-model orchestration, such platforms directly address the generator-agent tool failures and context-drift issues that cripple less mature frameworks.
A Global Reckoning and the Path Forward
On a global scale, the implications of these failures threaten to decelerate digital transformation timelines. As organizations from Southeast Asian fintech hubs to European logistics networks embed autonomous agents into core operations, the structural unsafety of current frameworks introduces systemic risk. Markets with complex multilingual requirements face amplified exposure; context drift and brittle speech-to-text connectors multiply failure rates across language boundaries, rendering off-the-shelf agents unusable in high-stakes regional workflows.
The path forward is clear but demanding. The organizations that survive the agentic reset will abandon the culture of demo-driven deployment and invest instead in structural safety, economic accountability, and operational resilience. Autonomous AI will not fulfill its promise through better prompts alone; it requires hardened infrastructure, rigorous integration discipline, and the humility to treat autonomous execution as a privilege that must be engineered, not assumed. Those who build accordingly will define the next era of enterprise AI. Those who do not will become cautionary statistics in the reports of 2027.
Expert Opinions
The disconnect between autonomous AI agent prototypes and production-grade systems has become a central preoccupation for industry analysts, site-reliability engineers, and security architects. Rather than treating these failures as a shortage of model intelligence, informed observers increasingly describe them as structural inevitabilities—rooted in brittle integration, inadequate governance, and a fundamental misunderstanding of what it takes to run probabilistic software at scale.
Analyst Forecasts: A Tidal Wave of Failed Projects
Industry analysts were among the first to place hard numbers against the reckoning. A recent Gartner report predicts that as many as 40% of agentic AI projects will fail by 2027, driven primarily by ballooning operational costs and integration nightmares. Coverage of the forecast in Forbes emphasizes that these failures will not be confined to experimental prototypes; they will hit enterprise workflows where agents are expected to autonomously interface with legacy CRMs, billing systems, and supply-chain databases. The implication is sobering: even when models reason correctly, the economics of wiring them into existing IT estates can collapse the business case before a single customer interaction goes live.
Practitioner estimates suggest the analyst outlook may still be optimistic. One detailed technical audit, summarized in a widely cited production review, claims that 88% of autonomous AI agents fail once they leave sandbox environments. The cited failure drivers—compounding errors, brittle API connectors, and context drift across multi-step reasoning chains—reveal a chasm between proof-of-concept elegance and production resilience. Where Gartner measures budget overruns and project cancellations, engineering teams measure broken customer experiences and silent automation failures; together, the metrics confirm that autonomous agents are encountering a wall far harder than any training dataset.
Engineering Autopsies: “Structurally Unsafe” Architectures
If analysts supply the quantitative warning, engineers supply the post-mortems. A top-voted technical discussion on Hacker News distilled the failure pattern with surgical precision: autonomous agents are collapsing “not because the models are inaccurate, but because the system is structurally unsafe.” The author enumerated failure modes that have since become canonical among production teams:
This sentiment is echoed across the practitioner literature. HackerNoon notes that evidence repeatedly points to the same underlying cause, asserting that “the issue plaguing AI agent deployment is not prompt quality or model intelligence.” Instead, the crisis lives in exception handling, memory consistency, and retry logic—the unglamorous plumbing that demo videos skip. An engineer writing in Medium after multiple production incidents put it plainly: “The gap between AI agent demos and production deployments is real, significant, and predictable.” Demos thrive on sanitized inputs and deterministic single-turn tasks; production demands fault-tolerant loops over asynchronous, stateful APIs that return partial failures and ambiguous schemas.
Recent academic literature gives empirical rigor to these battlefield reports. A 2025 arxiv study catalogued three dominant failure modes in existing agent frameworks, chief among them that the generator agent fails to exploit external tools even when valid functions are explicitly provided. Rather than calling a reliable calculator API or database lookup, the agent defaults to hallucinated reasoning, burning tokens and propagating error. The finding is a stark confirmation of what engineers already suspect: current frameworks cannot reliably bridge the delta between available capability and executed capability.
Data Realism and Governance Deficits
Beyond architecture, experts identify a parallel failure in preparation and oversight. One industry review observes that a critical weakness is that agents “rely too much on data that’s not very realistic.” Systems trained on limited or cleaned-up datasets encounter severe distributional shifts the instant they touch live email threads, unstructured PDFs, or noisy customer utterances. The resulting behavior is either paralysis or overconfident hallucination, both of which erode trust in high-frequency automation.
Security professionals add another layer of alarm. Autonomous agents are increasingly deployed in high-trust environments—processing refunds, updating health records, and orchestrating infrastructure—yet they often lack commensurate risk-governance scaffolding. An analysis of real-world security failures argues that enterprises are rushing into Agentic AI Risk Governance deficits, granting autonomous software broad tool access without structured permissioning, observable decision trails, or emergency kill switches. When combined with the architectural brittleness engineers describe, these governance gaps transform isolated errors into systemic liabilities.
The Infrastructure Dividend: What Survivors Do Differently
Despite the bleak consensus, experienced voices caution against fatalism. The engineer who called the demo-to-production gap “predictable” also noted that “not every team fails.” The survivors, according to multiple accounts, treat their agents not as prompt-engineering exercises but as distributed systems requiring:
This philosophy is driving a quiet shift toward hardened communication infrastructure. Rather than cobbling together brittle adapters and single-model endpoints, resilient teams are leveraging platforms purpose-built for autonomous production workloads. Platforms like CallMissed illustrate this shift, offering AI voice agents and LLM inference APIs designed to abstract away the fragile connector logic experts blame for context drift, while supporting 22 regional languages natively through Speech-to-Text and Text-to-Speech systems. By handling the structural scaffolding—multi-model failover, 24/7 availability, and multilingual pipeline integrity—such production-ready systems let engineering teams focus on robust workflow design rather than duct-taping API gateways.
The expert verdict is unambiguous: autonomous AI agents are not failing because large language models lack reasoning capacity. They are failing because the surrounding systems—integration layers, data pipelines, governance protocols, and observability stacks—were architected for conference-stage demos, not for the entropy of live business environments. Until that surrounding system hardens, the failure rates analysts and engineers report will remain not an aberration, but the baseline.
What This Means For You (TABLE)

The disconnect between agent demos and live deployments is not a research curiosity—it is a budgetary and operational landmine. Gartner’s latest forecast predicts 40% of agentic AI projects will fail by 2027, driven primarily by spiraling integration costs and architectural mismatch (Forbes). Meanwhile, practitioner reports suggest that 88% of autonomous AI agents fail in production, typically due to compounding errors, brittle API connectors, and context drift across multi-step workflows (YouTube; HackerNoon). These are not edge-case bugs; they are the predictable cost of treating agent orchestration as a prompt-engineering problem rather than a systems-engineering discipline.
Whether you are funding these initiatives, building them, or managing the teams that maintain them, the failure modes described throughout this series will arrive at your doorstep as missed revenue targets, compliance incidents, or customer churn. The question is no longer if an autonomous agent will encounter structural failure in production, but which failure mode reaches you first—and how expensive it will be to remediate.
The Stakeholder Risk Matrix
The table below maps the six most common production failure modes to the stakeholders who feel them first. Use it as a diagnostic: if you recognize your title on the left, the center column is likely already on your radar, whether you have named it yet or not.
| Your Role | The Failure Mode Hitting You First | The Business Impact | The Fix (90-Day Plan) | Pass/Fail Maturity Check |
|---|---|---|---|---|
| Founder / Product Owner | Rising integration costs & project abandonment. Gartner warns that 40% of agentic AI projects will fail by 2027 largely due to integration complexity and runaway costs (Forbes). | Burned runway, delayed market entry, and AI roadmaps shelved after sunk-cost escalation. | Lock a narrow workflow scope before selecting a model; validate one brittle API integration end-to-end under load. | Can you replay the last 100 agent decisions with full context? |
| Engineering Lead | Brittle API connectors & compounding errors. Practitioner data indicates 88% of production agents fail when minor schema changes cascade into multi-step breakdowns (YouTube; HackerNoon). | Cascading outages, data-pipeline corruption, and on-call fatigue as “minor” errors compound hourly. | Build deterministic fallback paths for every external tool call; version-control prompts and embeddings alongside application code. | Do you have circuit breakers and timeout logic on every third-party dependency? |
| Security / Compliance Lead | Structurally unsafe decision architecture. Hacker News analyses note that agents often make non-replayable decisions, rendering audits impossible (Hacker News). | Regulatory exposure, un-auditable actions, and liability when autonomous decisions harm users or leak data. | Implement immutable decision logs, action-signature hashing, and human-in-the-loop gates for high-stakes operations. | Can you reconstruct why the agent took action X at timestamp Y without relying on model memory? |
| ML / AI Engineer | Poor tool exploitation & context drift. Recent arXiv research shows that generator agents frequently fail to exploit available external tools, falling back to parametric hallucinations instead (arXiv). | Degraded task accuracy, abandoned agent loops, and end-user distrust when the agent “forgets” its own toolkit. | Rigidly constrain tool schemas; fine-tune or prompt on dirty, real-world production data rather than cleaned demo corpora. | Is your agent trained on production noise, or on sanitized datasets that hide real-world entropy? |
| Operations Manager | Multi-step workflow drift. Context decays with every handoff between sub-agents, causing SLA breaches in customer-facing pipelines (HackerNoon). | Customer churn, SLA penalties, and manual rework queues that negate the very automation you invested in. | Insert state-validation checkpoints between every sub-agent handoff; require explicit state serialization before continuation. | Can a human operator take over mid-workflow without data loss or context reconstruction? |
| CEO / Budget Holder | The demo-to-production gap. Multiple practitioner accounts describe this gap as “real, significant, and predictable” (Medium), often masked by demos trained on unrealistic data (CreativeBitsAI). | Misallocated CapEx, board-level skepticism, and stranded technology investments that never reach live traffic. | Mandate a 30-day production pilot on live traffic with guardrails before any enterprise licensing or scaling commitment. | Did the “successful” demo use sandboxed data, or real customer requests with ambiguous intent? |
Translating Technical Debt into Board-Level Risk
If the table feels uncomfortable, it should. Each row describes a handoff point where technical debt becomes financial risk. For founders, the Gartner figure is particularly sobering: nearly half of all agentic projects will not survive to 2027, not because the underlying LLM lacks intelligence, but because the system surrounding it—integrations, monitoring, guardrails—was treated as an afterthought.
Engineering leads should note that the 88% production failure rate is not driven by model inaccuracy alone. As practitioners on Hacker News have observed, the system is often “structurally unsafe” long before the first user prompt arrives. Non-replayable decisions, absent fallback logic, and brittle connectors are architecture problems, not model problems. Fixing them requires the same rigor you would apply to a distributed payments system: circuit breakers, idempotency keys, schema enforcement, and distributed tracing.
For ML engineers, the arXiv finding that agents fail to exploit available tools should prompt an immediate audit of your function-calling layer. If your agent has access to eight APIs but defaults to parametric knowledge for seven of them, you have not built an agent; you have built an expensive chatbot with extra HTTP overhead.
Why Communication-Layer Agents Face Amplified Risk
These failure modes become even more acute when agents operate in real-time communication channels. A text-based support bot that drifts off-context is annoying; a voice agent handling billing disputes that loses state mid-conversation is an immediate compliance and churn risk. The latency constraints of speech-to-text pipelines, the lack of a visual “back-button” for users, and the emotional weight of voice interactions mean that brittle API connectors and non-replayable decisions carry disproportionate consequences.
This is why infrastructure choice matters. Rather than assembling a fragile stack of separate transcription, LLM, and telephony APIs, teams are increasingly turning to unified communication infrastructure that bakes in failover logic, state management, and observability by default. Platforms like CallMissed are already enabling businesses to deploy AI voice agents and WhatsApp chatbots with built-in handling for 22+ regional languages and multi-model LLM fallbacks, reducing the context-drift surface area that causes so many standalone agents to fail. Whether you adopt a specialized platform or build in-house, the principle is the same: your agent is only as robust as the communication layer beneath it.
The 90-Day Realism Checklist
Regardless of your role, the path to production-ready agents requires a deliberate shift from demo culture to systems thinking. In the next 90 days:
Autonomous AI agents will reshape operations, but only for the teams that treat deployment as infrastructure engineering rather than a model-deployment exercise. The organizations that survive the 2027 correction predicted by Gartner will not be the ones with the most clever prompts; they will be the ones who recognized that reliability is the feature—and architected for it from day one.
Frequently Asked Questions
Core Technical Failure Modes
Why do autonomous AI agents fail in production even when they work perfectly in demos?
What are the most common structural failure modes causing autonomous AI agents to crash in real-world workflows?
Security Vulnerabilities and Data Quality
Are AI agents in high-trust production environments vulnerable to security attacks?
How does training data quality contribute to why autonomous AI agents fail in real-world scenarios?
Deployment Costs and Mitigation Strategies
What percentage of agentic AI projects are predicted to fail by 2027, and what are the main reasons?
What infrastructure changes can enterprises make to prevent AI agent failures in production?
Conclusion

The promise of autonomous AI agents has dramatically outpaced the engineering discipline required to run them at scale. Across the technology landscape, headlines celebrate demos in which AI systems book complex travel itineraries, manage overflowing email inboxes, and orchestrate multi-step business workflows without a single human click. Yet beneath the glossy surface of these proof-of-concepts lies a far more sobering production reality. Current industry estimates indicate that 88% of autonomous AI agents fail once they migrate from the sanitized confines of a demo into live production environments. This is not a marginal deployment friction or a temporary growing pain—it represents a systemic architectural collapse. The prognosis is not improving: a recent Gartner report predicts that as many as 40% of agentic AI projects will fail by 2027, with the primary drivers being runaway operational costs and integration complexity that engineering teams chronically underestimate during the prototyping phase.
The Demo-to-Production Chasm Is Structural
The central lesson emerging from this wave of high-profile failures is that raw model intelligence is rarely the bottleneck. Across engineering discussions on Hacker News, Medium deep-dives, and academic preprints, the consensus has become unmistakable: autonomous agents fail not because the underlying models are inaccurate, but because the systems enclosing them are structurally unsafe. An agent executing a twenty-step workflow is not performing twenty discrete, independent predictions. It is constructing a leaning tower of interdependent context, where every API invocation, every tool call, and every intermediate output becomes a load-bearing dependency for subsequent reasoning. This architecture creates a compounding error surface. A single brittle connector, an unexpected schema drift in a third-party service, or one moment of context amnesia can trigger a cascading failure that invalidates the entire trajectory.
Demos systematically obscure this entropy by restricting input diversity, shortening task horizons, and running on pristine data. Production environments do the opposite. They amplify entropy, introducing the messy ambiguity, adversarial noise, and asynchronous latency that agent frameworks are rarely built to survive.
These structural deficiencies manifest in patterns that are now well-documented. Practitioner evidence points to recurring failure modes including:
Academic research on existing agent frameworks adds another layer, identifying that generator agents frequently fail to exploit available external tools—leaving critical capabilities unused while still incurring token costs and latency penalties. Underpinning all of this is a data realism crisis: agents are routinely trained, fine-tuned, and evaluated on cleaned, limited datasets that share little statistical overlap with the chaotic, edge-case-dense distributions of real-world operations. The result is a dangerous illusion of competence that evaporates the moment the system touches live traffic.
What Production-Grade Actually Demands
Bridging this chasm requires a fundamental reorientation of engineering priorities. The industry must move away from optimizing for maximum autonomy and toward optimizing for observability, replayability, and graceful degradation. Based on current failures, organizations should prioritize the following architectural shifts:
The economic dimension is equally urgent. Gartner’s forecast that 40% of projects will collapse by 2027 is not merely a warning about technical fragility; it is a warning about cost discipline. Agents that burn through token budgets while failing to complete tasks, or that require constant engineering firefighting to keep integrations alive, represent unsupervised losses at scale. Production-grade agentic infrastructure must therefore include stringent cost controls, model-switching logic to balance capability against price, and clear kill-switch mechanisms when uncertainty thresholds are breached.
The Infrastructure Imperative
For enterprises preparing to navigate this transition, the infrastructure layer will determine success more decisively than the choice of foundation model. The market is already separating vendors who ship reasoning layers from those who build resilient communication and orchestration infrastructure. Platforms like CallMissed exemplify this evolution, offering production-ready AI voice agents and WhatsApp chatbots that natively support 22 Indian languages through specialized Speech-to-Text and Text-to-Speech APIs. The engineering challenge of keeping an AI agent coherent during a live voice call at 3 AM—handling acoustic variation, code-switching, dropped packets, and user frustration—is the same class of resilience problem that plagues multi-step autonomous workflows in text-based environments.
By providing a multi-model API gateway that allows developers to switch between 300+ LLMs without code changes, solutions like CallMissed introduce the redundancy and fallback architectures that brittle single-model agents desperately lack. This kind of infrastructure treats resilience as the primary feature, recognizing that the cost of agent failure is measured not in perplexity scores, but in lost customers, compliance violations, and damaged trust.
A Pragmatic Roadmap Forward
The next wave of successful agent deployments will not be won by the teams with the most ambitious demo videos. They will be won by teams that internalize constraints and engineer accordingly. That means starting with narrow, well-scoped domains where the action space is bounded and the cost of error is tolerable. It means building evaluations that stress-test against production chaos rather than benchmark trivia. It means maintaining human oversight as a default architectural primitive, not a fallback for exceptions. And it means selecting infrastructure partners who understand that autonomous AI is fundamentally a systems integration problem, not a prompt-engineering contest.
The autonomous future is still coming. But it will not belong to the teams that chase maximum autonomy at any cost. It will belong to the pragmatists—the ones who understand that in production environments, reliability is the only form of autonomy that truly matters. Agents that cannot fail safely cannot be trusted. And in the high-stakes workflows where autonomous AI promises the most value, trust is the only metric that counts.
Conclusion
The deployment of autonomous AI agents has reached an inflection point where ambition dangerously outpaces architecture. As the evidence throughout this article makes clear, failure is rarely a consequence of underlying model inaccuracy—it is a symptom of structurally unsafe systems. From non-replayable decisions to brittle API connectors, the journey from polished demo to production-grade deployment is consistently undermined by compounding errors and context drift across multi-step workflows that most engineering teams fail to anticipate during development. With hands-on practitioner analyses indicating that 88% of autonomous AI agents fail in production, and a recent Gartner report cited by Forbes predicting that 40% of agentic AI projects will fail by 2027 due to rising costs and integration complexity, the margin for architectural negligence is shrinking rapidly. The teams that break this trend will not be those simply wielding the largest foundation models, but those that treat safety, observability, and robust tooling as first-class design principles from day one.
What to Remember from This Breakdown
To cut through the hype and build systems that actually survive contact with reality, keep these production truths top of mind:
The Road Ahead
Looking forward, the next 18 to 24 months will separate speculative proofs-of-concept from genuinely autonomous business infrastructure. Watch closely for the emergence of industry-wide agent observability standards, mandatory replayable decision logs, and cost-aware orchestration layers capable of detecting and halting runaway reasoning loops before they silently inflate cloud spend. Security frameworks purpose-built for agentic AI—particularly as these systems are entrusted with increasingly high-stakes workflows—will mature from optional add-ons to strict deployment prerequisites. The pivotal question is no longer whether an agent can complete a task in a controlled sandbox, but whether it can fail gracefully, explain itself transparently, and operate affordably when confronted with the unpredictable entropy of live production environments.
For builders and business leaders alike, the mandate is unequivocal: stop optimizing for the flawless demo and start architecting for the inevitable edge case. The infrastructure, integration patterns, and governance guardrails you establish today will determine whether your agents evolve into reliable digital coworkers or devolve into expensive, high-profile production liabilities.
To explore how AI communication is evolving, check out CallMissed — an AI infrastructure platform powering voice agents and multilingual chatbots for businesses. As the industry accelerates toward production-hardened agents, platforms that prioritize robust API integration, multilingual adaptability, and scalable inference infrastructure will be the ones turning real-world complexity into durable competitive advantage. Will your agent architecture survive its first 1,000 live interactions—or become another statistic in next year’s failure report?


